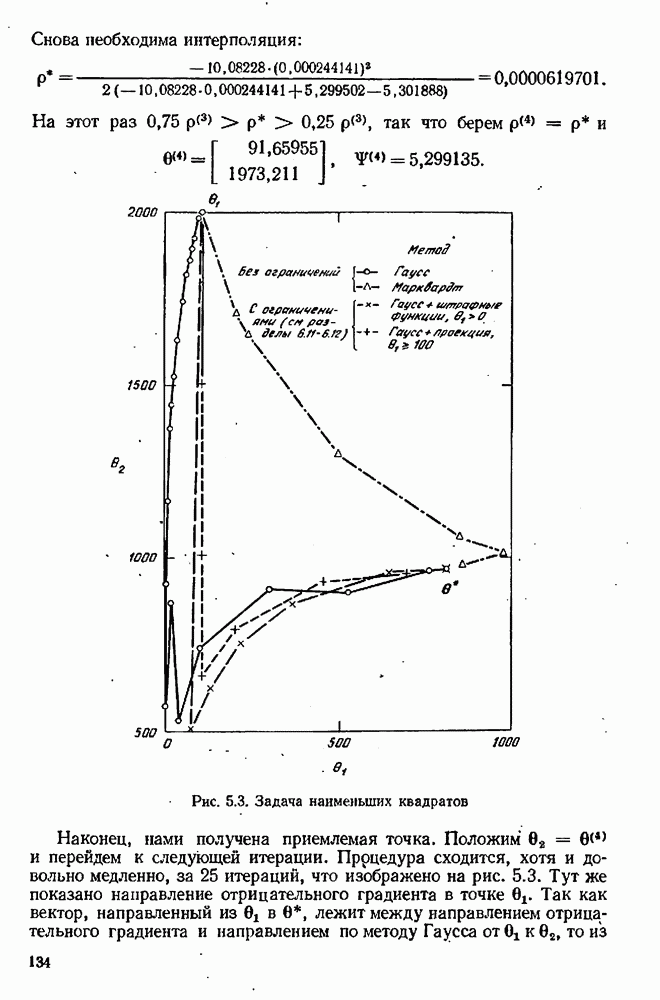
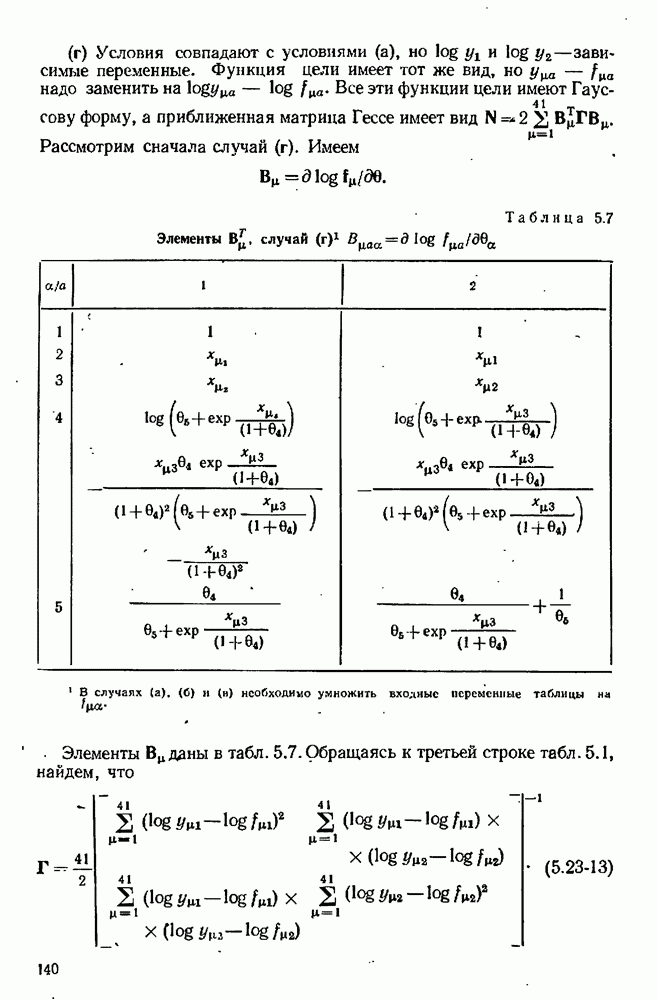
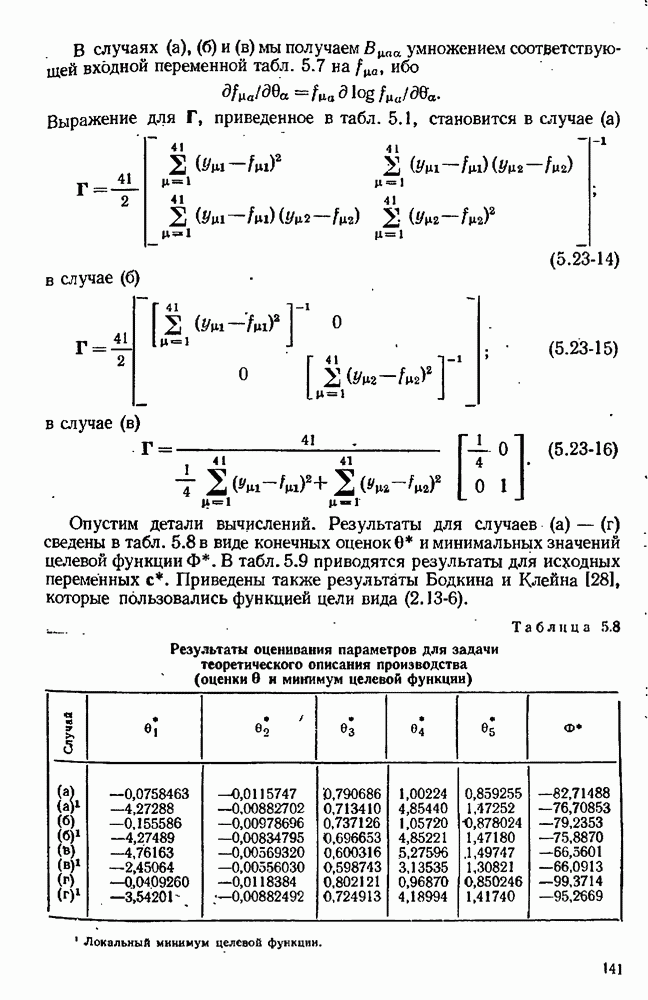
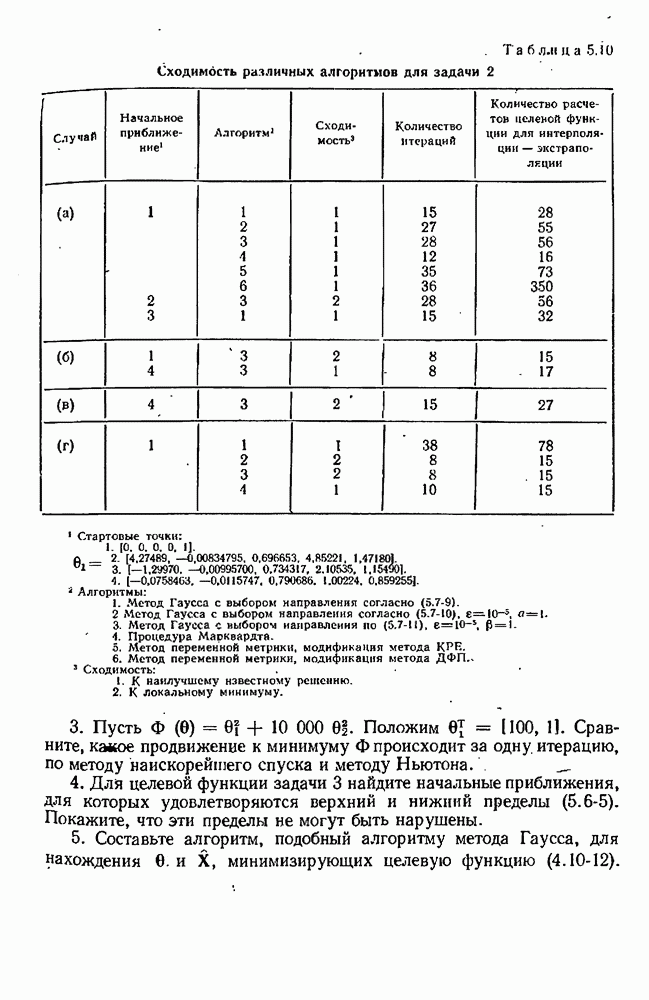
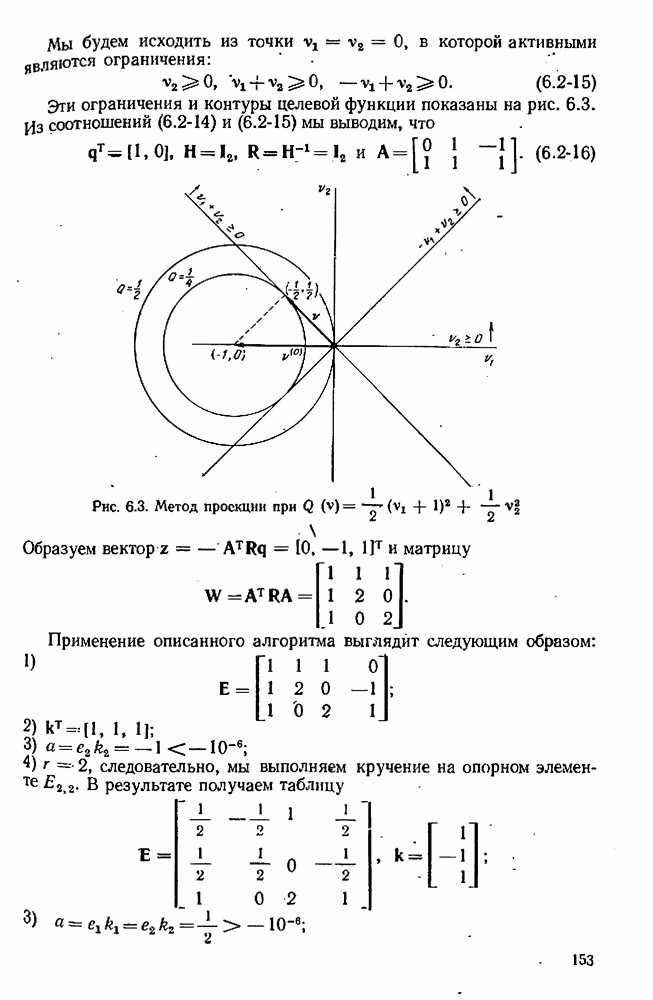
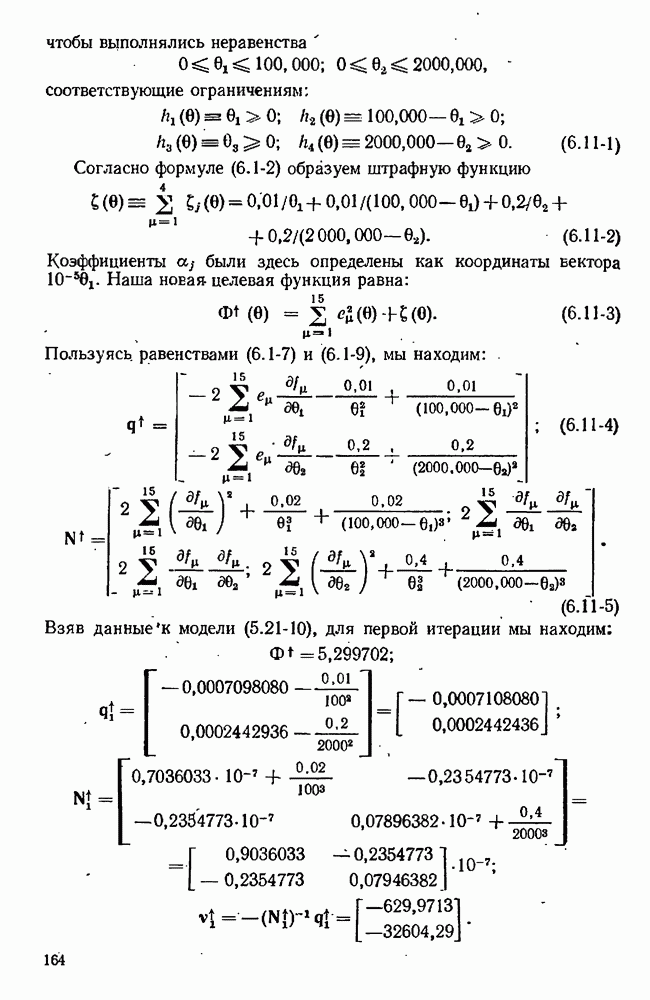
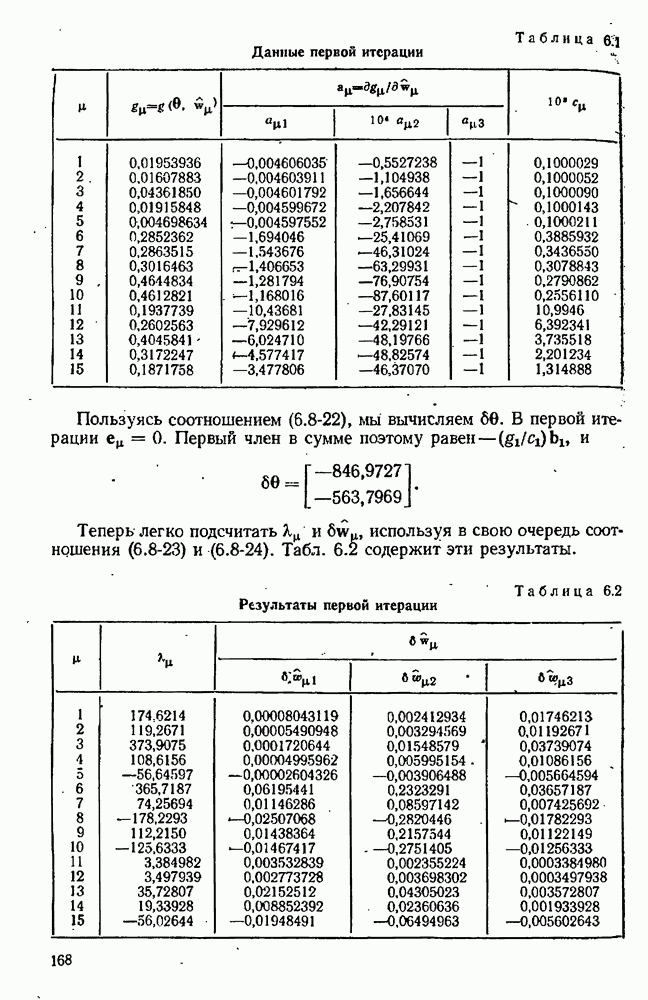
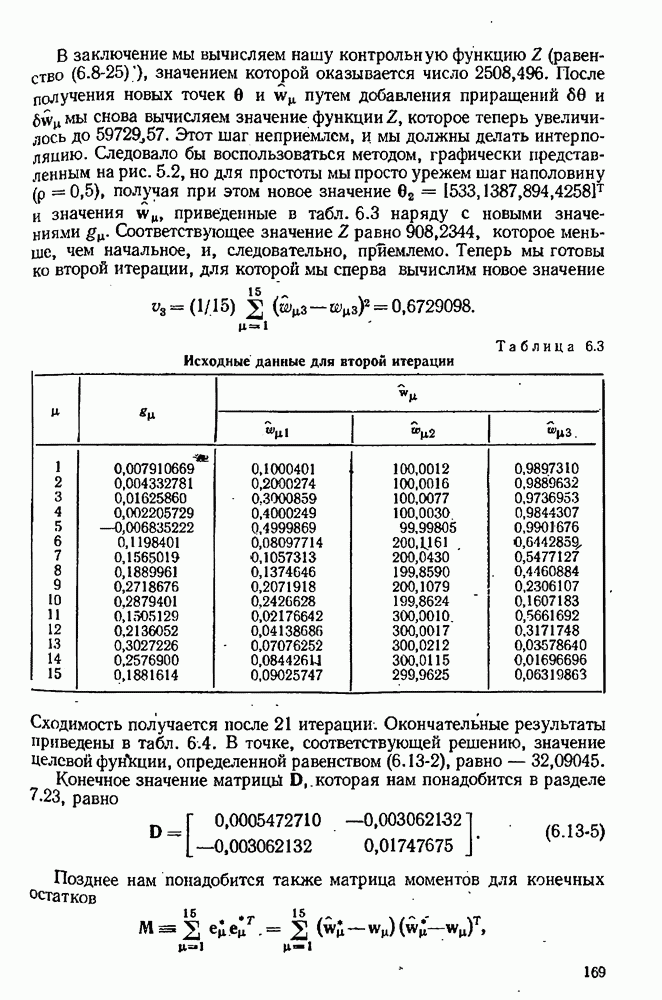
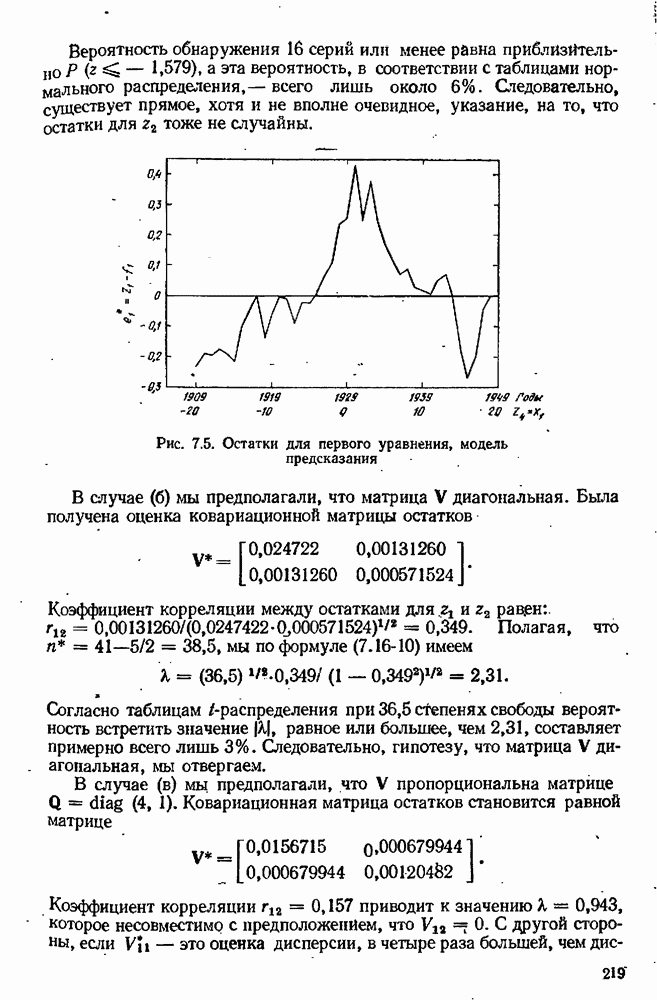
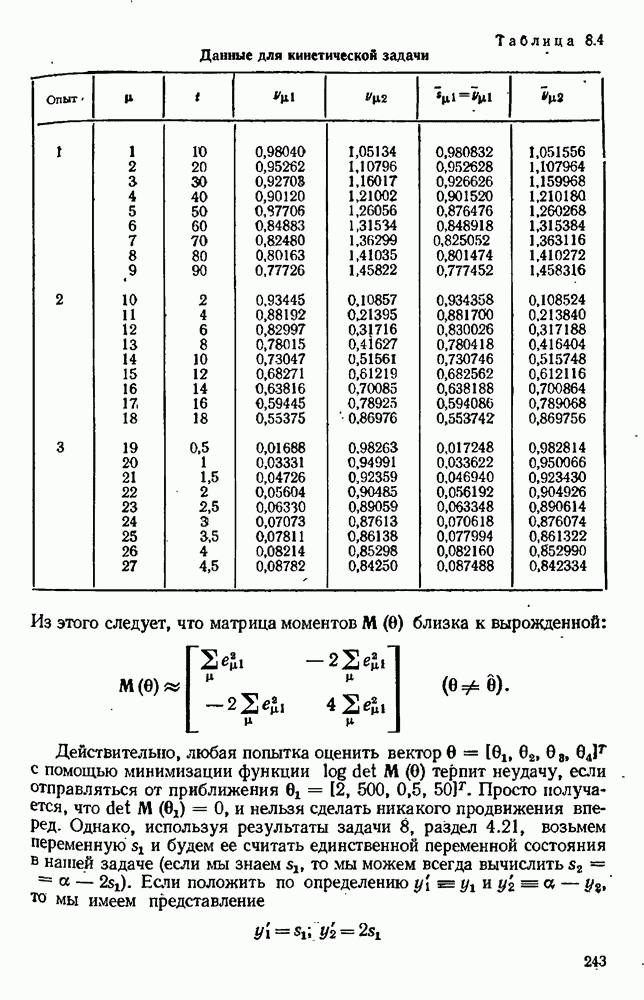
7.15. Адекватность модели
Решающий вопрос, который возникает после того, как были получены оценки, — соответствует ли модель данным? На этот вопрос можно отвечать утвердительно, если остатки для полученной модели могут быть объяснены как ошибки в наблюдениях, С другой стороны, если остатки настолько велики или имеют настолько неслучайный характер, что их нельзя приписать случайности ошибок наблюдения, то мы будем говорить, что модель неадекватна данным. Подчеркнем, что в то время как недостаток соответствия ставит на прочное основание отвержение или по меньшей мере видоизменение модели, хорошее соответствие не доказывает, что модель верна. Хорошее соответствие просто устанавливает тот  что нет никаких причин отвергнуть модель на основе имеющихся данных. На самом деле никакое количество данных не может никогда доказать правильность модели; самое большее, на что мы можем надеяться, это то, что они ее не опровергнут.
что нет никаких причин отвергнуть модель на основе имеющихся данных. На самом деле никакое количество данных не может никогда доказать правильность модели; самое большее, на что мы можем надеяться, это то, что они ее не опровергнут.
Наши оценки наименьших квадратов или максимального правдоподобия обычно основывались на предположении, что ошибки в каждом эксперименте были наблюдениями над случайной величиной со средним  и ковариационной матрицей
и ковариационной матрицей  После оценивания параметров мы имеем множество остатков
После оценивания параметров мы имеем множество остатков  по которым вычисляем центрированную ковариационную матрицу V (смотри, например, равенство
по которым вычисляем центрированную ковариационную матрицу V (смотри, например, равенство  Установить адекватность модели — значит проверить гипотезу, что, с некоторыми оговорками
Установить адекватность модели — значит проверить гипотезу, что, с некоторыми оговорками  остатки образуют выборку из распределения, которое мы постулировали для ошибок, с поправками на смещение, рассмотренное в разделах 7.13, 7.14.
остатки образуют выборку из распределения, которое мы постулировали для ошибок, с поправками на смещение, рассмотренное в разделах 7.13, 7.14.
Чтобы проверить статистическую гипотезу, обычно мы по выборке вычисляем некоторую подходящую статистику Я. Это значение X мы сравниваем с некоторым справочным (табличным) значением  и гипотезу отвергаем, если
и гипотезу отвергаем, если  Поступая так, мы подвергаемся опасности впасть в ошибку на одном из следующих путей:
Поступая так, мы подвергаемся опасности впасть в ошибку на одном из следующих путей:
1) ошибка первого рода: мы отвергаем гипотезу, хотя она верна,
2) ошибка второго рода: мы принимаем гипотезу, хотя она неверна.
В предположении, что модель правильна, можно определить распределение статистики Я и, следовательно, найти число  такое что
такое что

где а — соответствующим образом выбранное малое число; например 0,05 или 0,01. Если мы отвергаем модель, когда  то вероятность совершения ошибки первого рода равна а. Вероятность совершения ошибки второго рода зависит от того, какова на самом деле истинная модель, и мы не будем здесь рассматривать этот вопрос.
то вероятность совершения ошибки первого рода равна а. Вероятность совершения ошибки второго рода зависит от того, какова на самом деле истинная модель, и мы не будем здесь рассматривать этот вопрос.
Статистики, которые мы будем употреблять, имеют силу для широкого класса распределений ошибок. Однако распределения этих статистик известны и табулированы главным образом для случая, когда распределение ошибок нормально. Только в этом случае легко найти критическое значение  связанное с данной вероятностью а. С другой стороны, здесь не делается никакого различия между случаями, когда уравнения модели линейные и нелинейные. Остатки должны быть такими, чтобы их можно было отнести за счет ошибок, независимо от того, по модели какого вида они были вычислены.
связанное с данной вероятностью а. С другой стороны, здесь не делается никакого различия между случаями, когда уравнения модели линейные и нелинейные. Остатки должны быть такими, чтобы их можно было отнести за счет ошибок, независимо от того, по модели какого вида они были вычислены.
Когда распределение X неизвестно и не поддается аналитическому выводу, критическое значение  все еще легко вычислить с помощью метода Монте-Карло. Случайные выборки с надлежащим распределением генерируются на вычислительной машине, для каждой выборки вычисляется статистика
все еще легко вычислить с помощью метода Монте-Карло. Случайные выборки с надлежащим распределением генерируются на вычислительной машине, для каждой выборки вычисляется статистика  , и число
, и число  выбирается так, чтобы статистика
выбирается так, чтобы статистика  превосходила его для доли а от всех выборок.
превосходила его для доли а от всех выборок.
Различные и обычно применяемые статистики  обсуждаются в следующем разделе.
обсуждаются в следующем разделе.