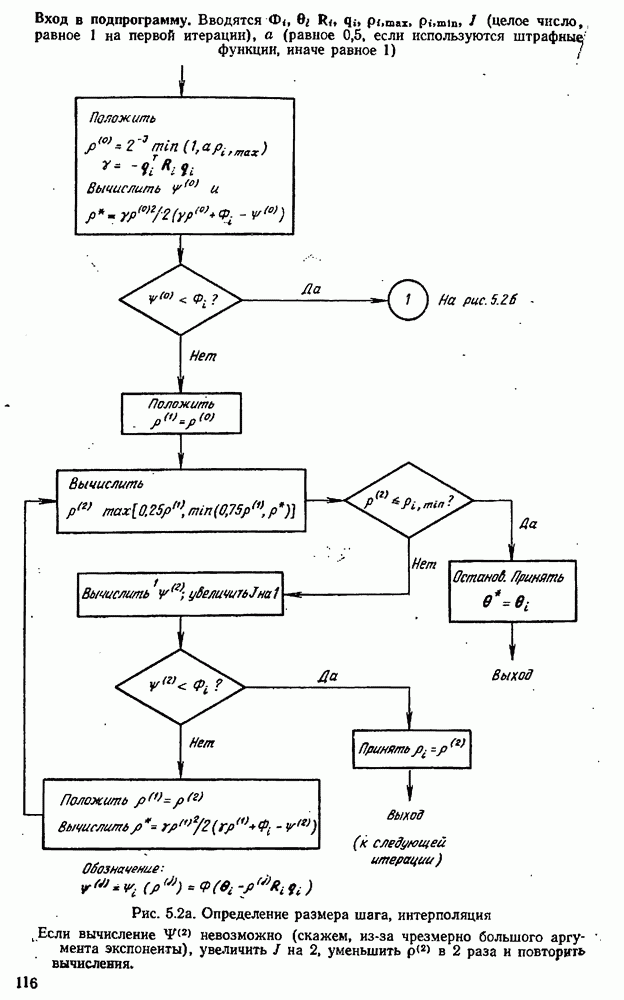
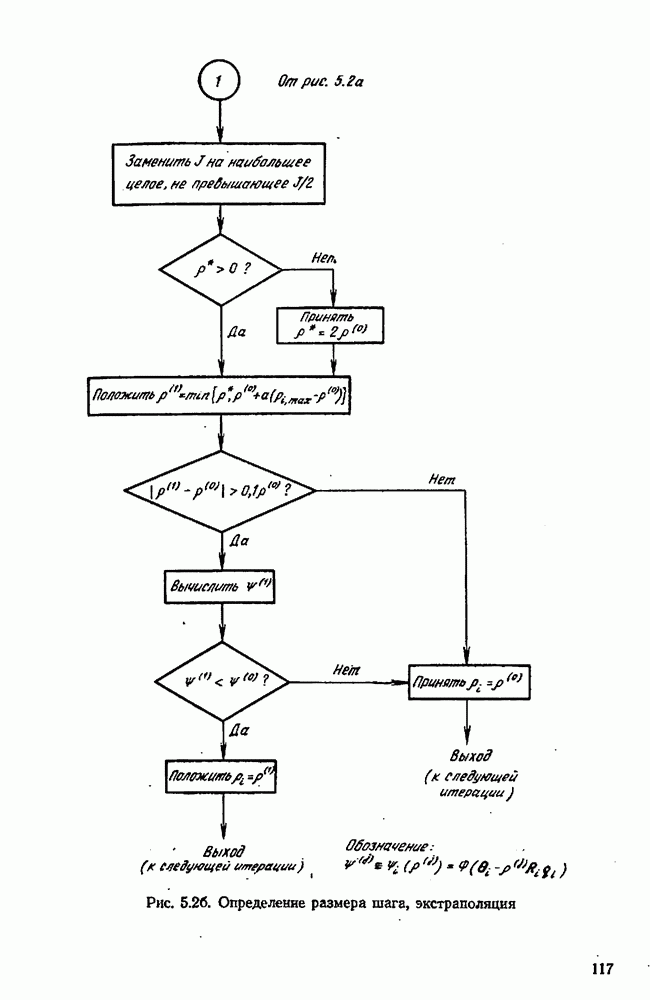
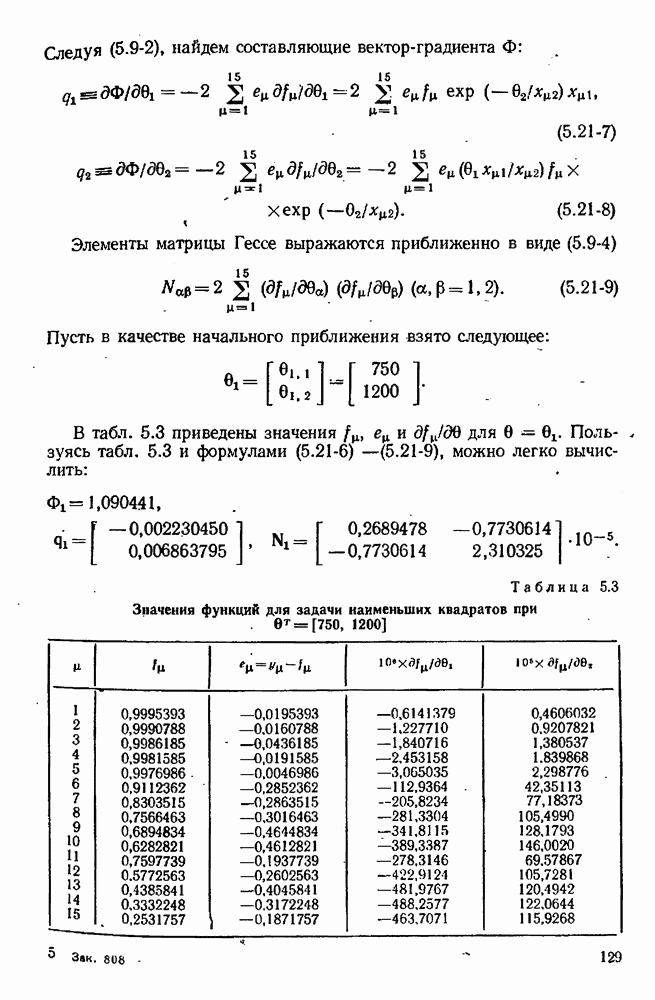
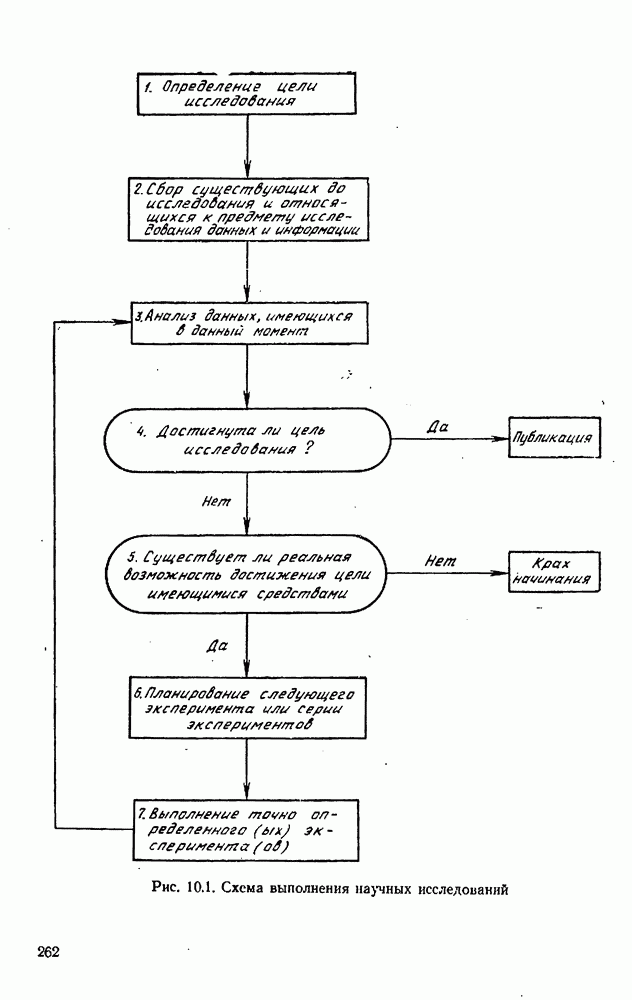
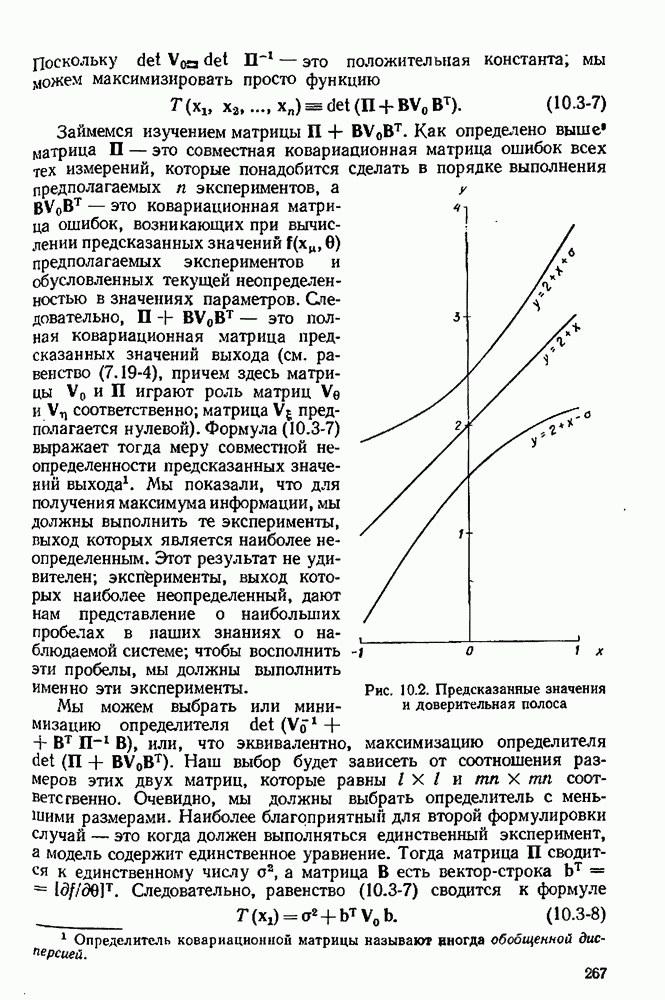
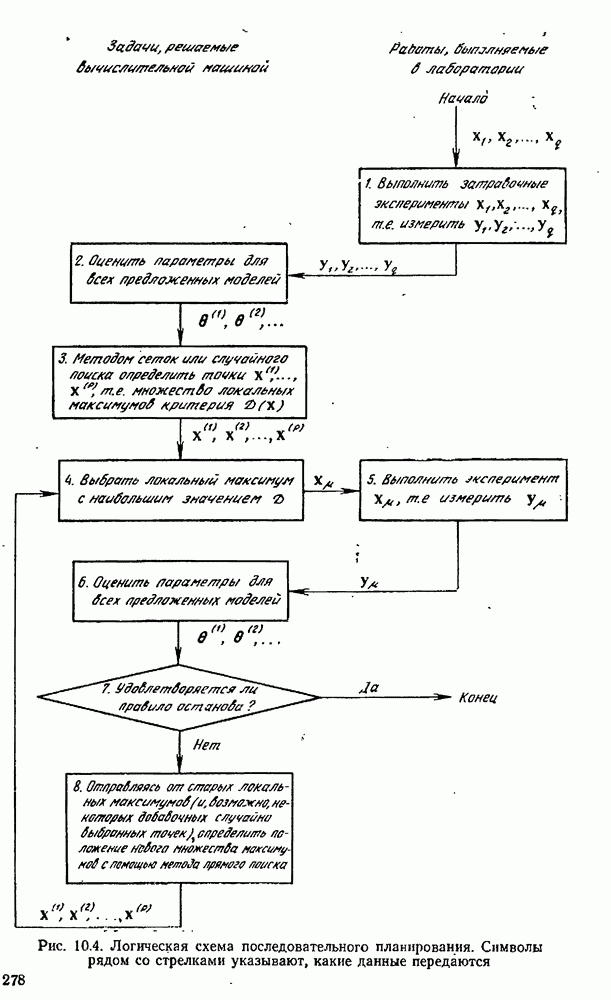
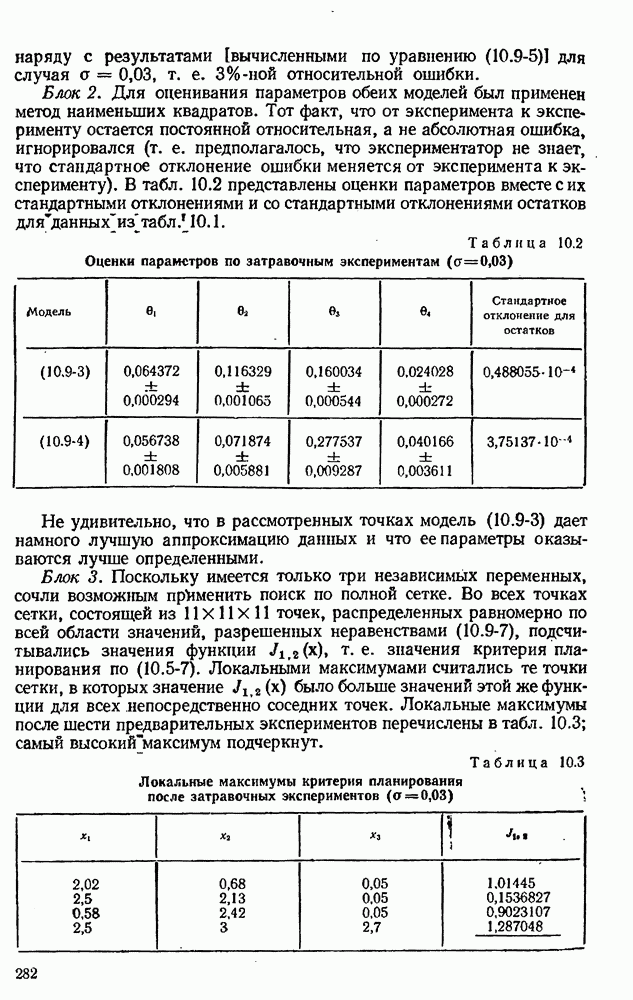
10.5. Критерий планирования для дискриминации моделей
Иногда для одной и той же физической ситуации предполагается несколько альтернативных моделей. Мы хотим провести эксперименты так, чтобы у нас была возможность выбрать «наилучшую» модель, т. е. модель, которая наилучшим образом соответствует данным.
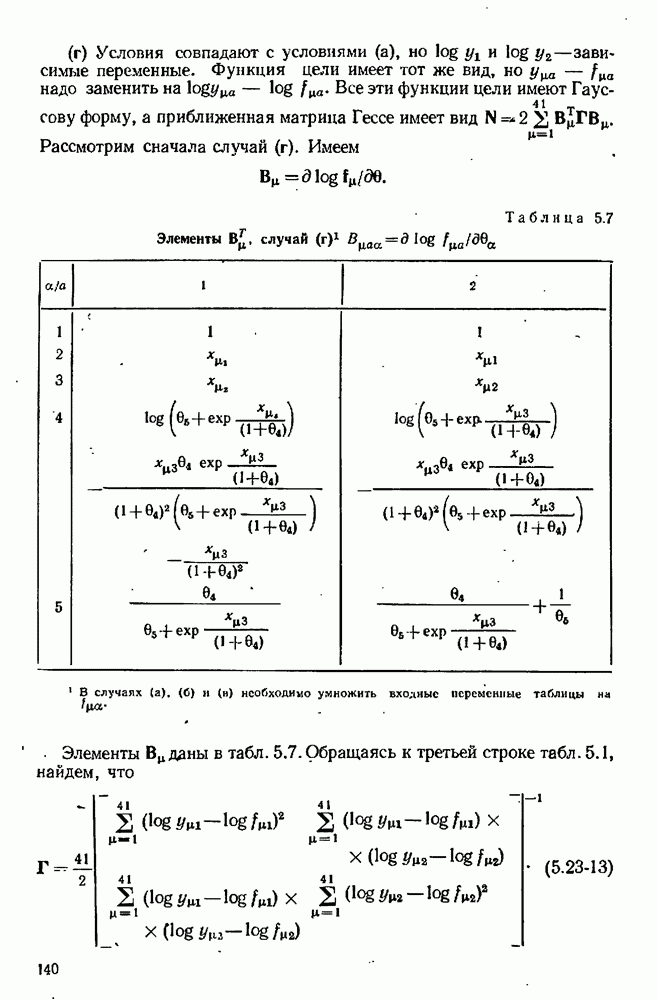
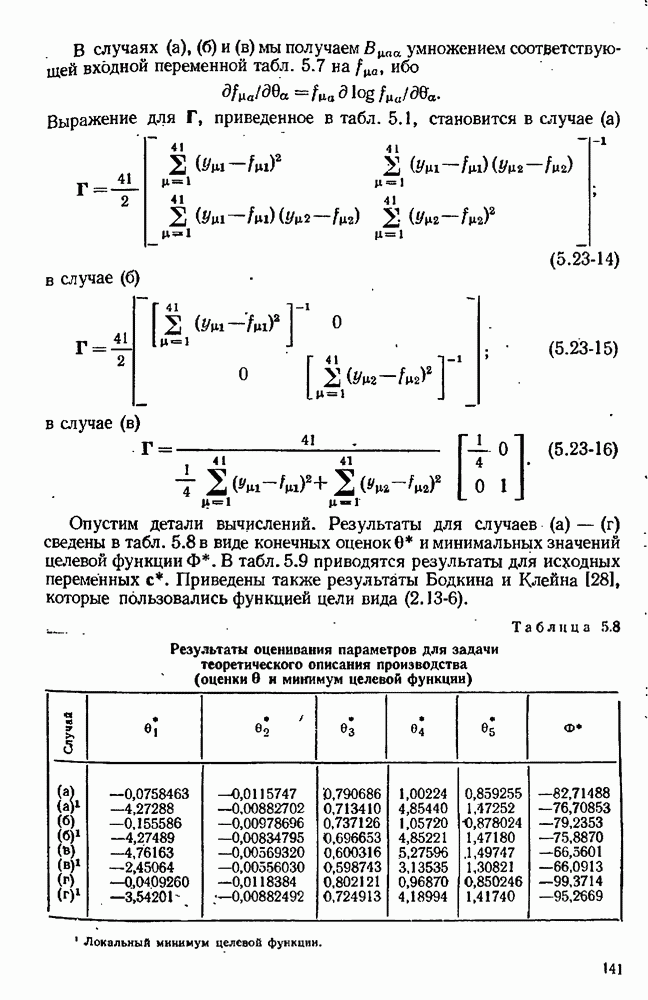
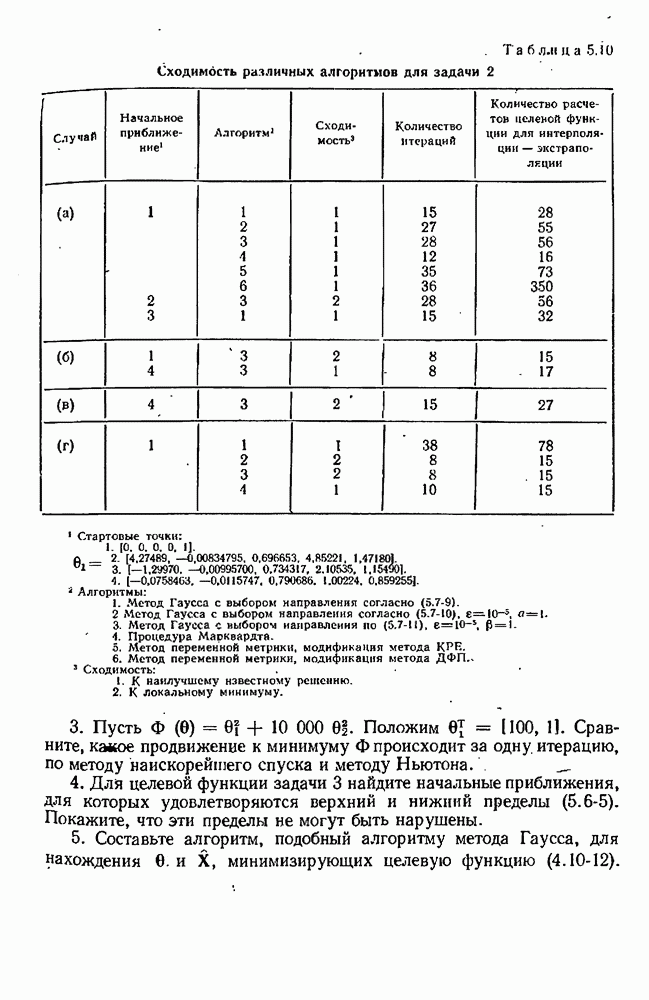
Каждая из наших моделей предназначена для предсказания величины у как функции от х и 0. Что меняется от модели к модели — так это математический вид функции и множество включенных в нее параметров (хотя некоторые из этих параметров, появляющихся в разных моделях, могут иметь одну и ту же физическую интерпретацию). Мы будем отмечать верхним индексом  величины, имеющие отношение к
величины, имеющие отношение к  модели. Уравнение
модели. Уравнение  модели записывается в виде
модели записывается в виде

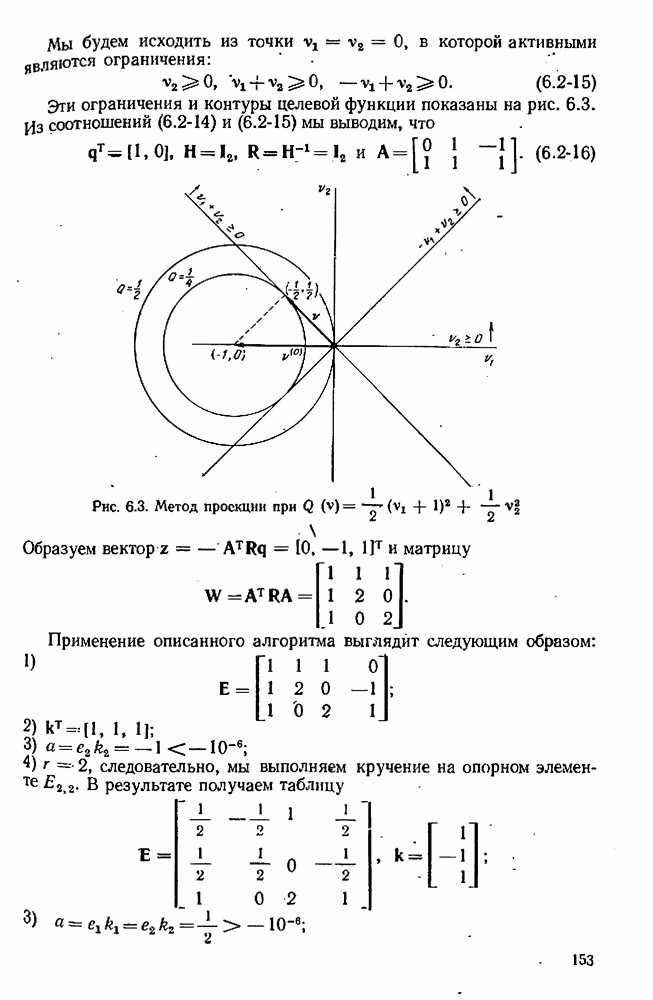
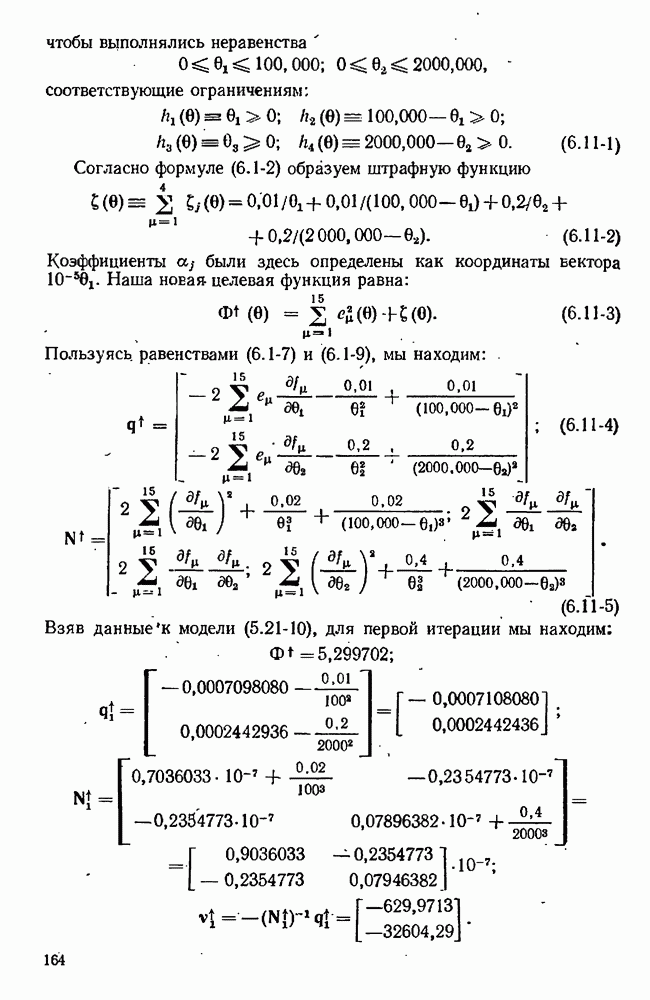
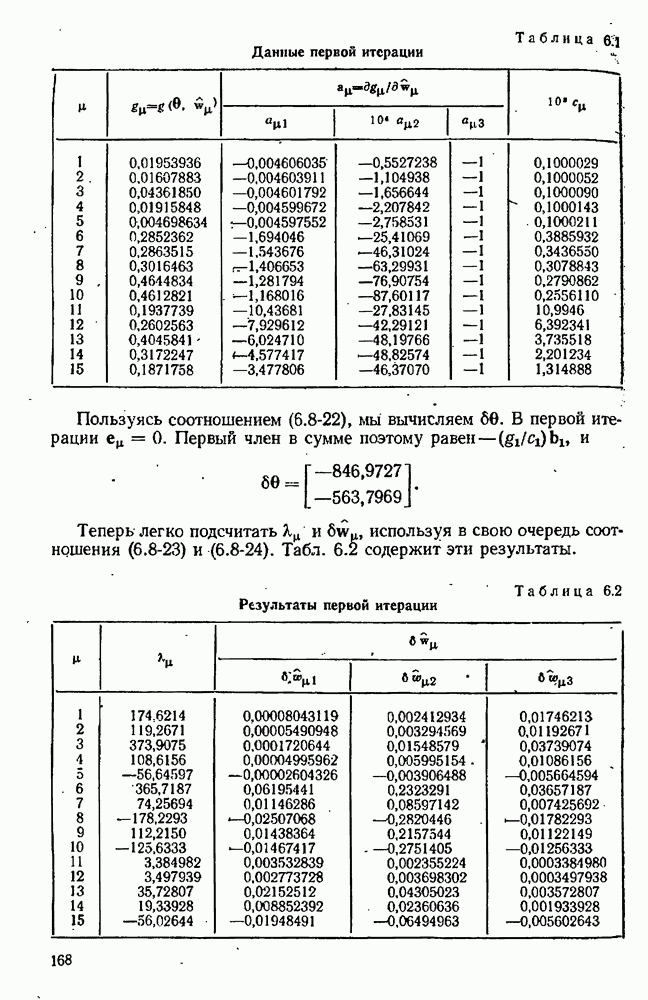
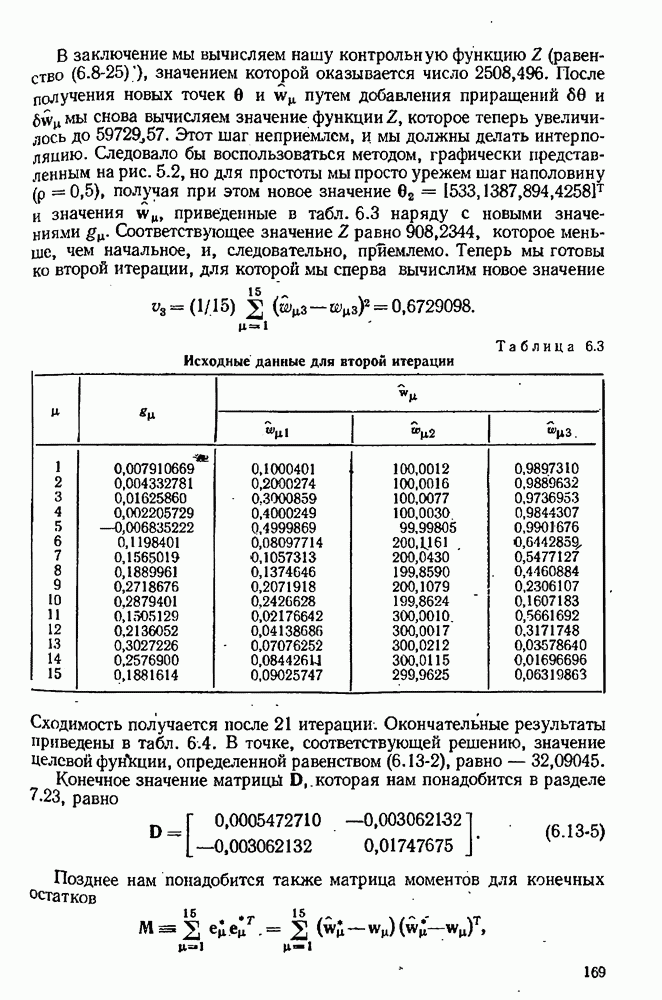
Допустим, что мы уже имеем оценки  для параметров, содержащихся в
для параметров, содержащихся в  модели, и оценки
модели, и оценки  для соответствующих ковариационных матриц. Обычно они получаются после подгонки каждой модели по очереди к данным предварительно выполненных экспериментов. Используя значения параметров
для соответствующих ковариационных матриц. Обычно они получаются после подгонки каждой модели по очереди к данным предварительно выполненных экспериментов. Используя значения параметров  мы можем предсказывать выход
мы можем предсказывать выход  при любом предполагаемом х, считая, что
при любом предполагаемом х, считая, что  модель верна. Это предсказание дается формулой
модель верна. Это предсказание дается формулой

Все еще считая, что  модель верна, мы можем вычислить ковариационную матрицу ошибок предсказания по уравнению
модель верна, мы можем вычислить ковариационную матрицу ошибок предсказания по уравнению  В соответствии с формулой
В соответствии с формулой  эта матрица равна:
эта матрица равна:

где  а матрица V — это ковариационная матрица ошибок измерения величины у (которая тоже может быть функцией от
а матрица V — это ковариационная матрица ошибок измерения величины у (которая тоже может быть функцией от 
Гипотеза, что  модель верна, ведет нас к тому, чтобы рассматривать выход предполагаемого эксперимента х как случайную переменную
модель верна, ведет нас к тому, чтобы рассматривать выход предполагаемого эксперимента х как случайную переменную  с плотностью распределения
с плотностью распределения  и имеющую среднее и ковариационную матрицу, заданные формулами
и имеющую среднее и ковариационную матрицу, заданные формулами  соответственно. Допустим, что в эксперименте фактически был пслучен выход у. Тогда мы можем подсчитать числа
соответственно. Допустим, что в эксперименте фактически был пслучен выход у. Тогда мы можем подсчитать числа  которые являются значениями правдоподобия, связанными с
которые являются значениями правдоподобия, связанными с  гипотезой.
гипотезой.
В данную минуту ограничимся случаем двух альтернативных моделей. Величина

служит мерой того, насколько лучше наблюдения у соответствуют модели 1, когда альтернативой служит модель 2 (эта мера связана с отношением правдоподобия, см. раздел 10.6). Заранее, до проведения эксперимента, мы не знаем значения у, так что мы не в состоянии вычислить величину  но мы можем вычислить ее ожидаемое значение
но мы можем вычислить ее ожидаемое значение
при условии, что модель 1 верна (символом  обозначается математическое ожидание при этом условии):
обозначается математическое ожидание при этом условии):

Если действительно модель 1 верна, то желательно провести некий эксперимент х, который скорее всего подтвердит это, т. е. при котором можно ожидать, что получится большое значение величины  Обратно, если модель 2 верна, то желательно, чтобы наш эксперимент приводил к большому значению соответствующей величины
Обратно, если модель 2 верна, то желательно, чтобы наш эксперимент приводил к большому значению соответствующей величины  Поскольку мы не знаем, какая модель верна, мы образуем сумму этих двух величин:
Поскольку мы не знаем, какая модель верна, мы образуем сумму этих двух величин:

Теперь следует выбрать тот эксперимент, который максимизирует величину  большое значение может получиться только тогда, когда величина
большое значение может получиться только тогда, когда величина  много больше, чем
много больше, чем  или наоборот. В каждом из этих двух случаев наблюдаемый выход будет давать резкое предпочтение одной модели в противовес другой.
или наоборот. В каждом из этих двух случаев наблюдаемый выход будет давать резкое предпочтение одной модели в противовес другой.
Величина 2 называется дивергенцией, или, информацией для дискриминации ([130], [129]). Ее сходство с величиной  очевидно.
очевидно.
Если для обеих моделей предполагаются нормальные распределения ошибок с ковариационными матрицами  и
и  соответственно, то можно показать, что
соответственно, то можно показать, что

где  Зависимость величины
Зависимость величины  от экспериментальных условий х проявляется косвенно по формулам
от экспериментальных условий х проявляется косвенно по формулам  Нередко имеет место важный частный случай, когда противопоставляются однооткликовые модели,
Нередко имеет место важный частный случай, когда противопоставляются однооткликовые модели,  при
при 
Тогда -  и
и

Это равенство было выведено Боксом и Хиллом 132]. Аналогом формул  в этом случае будут соотношения:
в этом случае будут соотношения:

где  стандартное отклонение ошибок измерения и
стандартное отклонение ошибок измерения и 
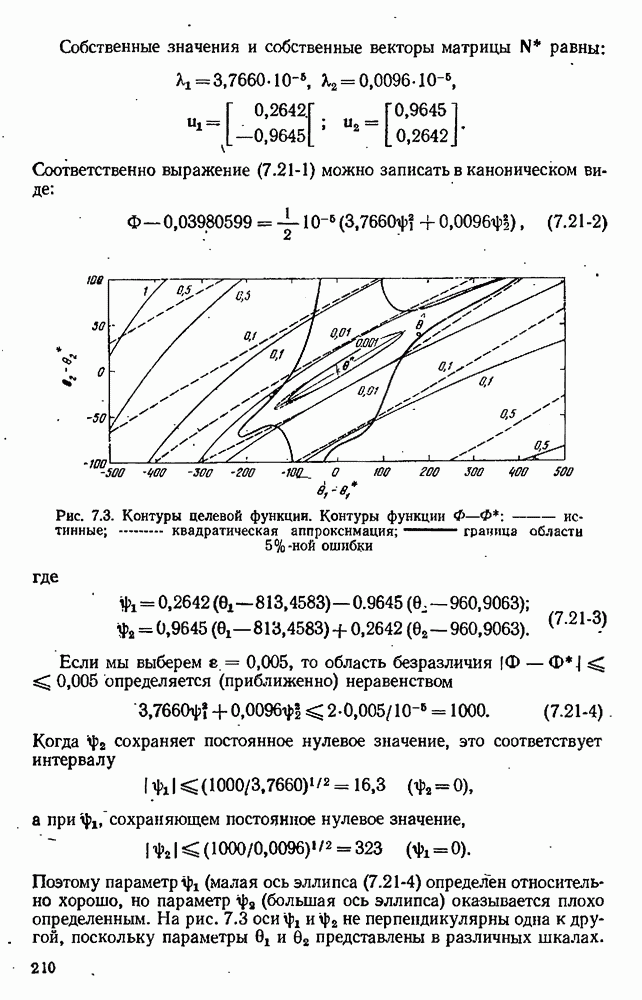
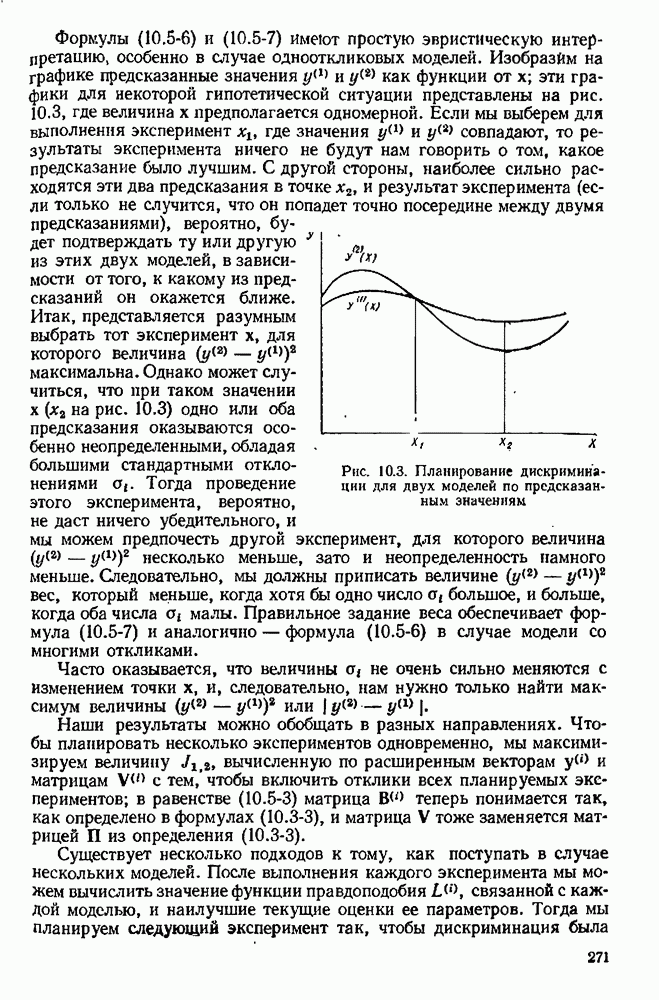
Формулы  имеют простую эвристическую интерпретацию особенно в случае сднооткликовых моделей. Изобразим на графике предсказанные значения у и
имеют простую эвристическую интерпретацию особенно в случае сднооткликовых моделей. Изобразим на графике предсказанные значения у и  как функции от
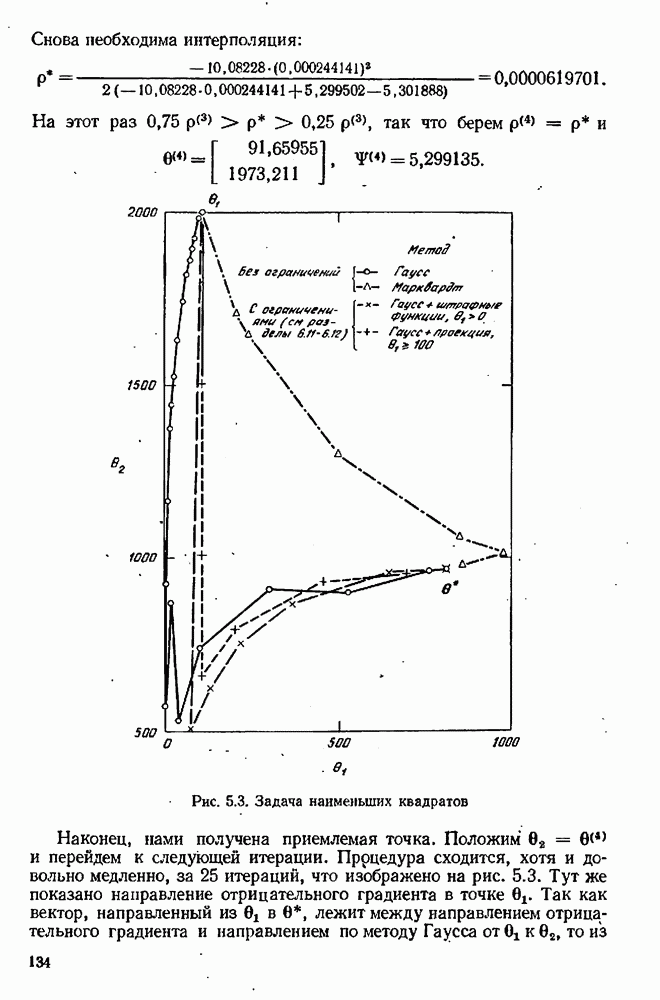
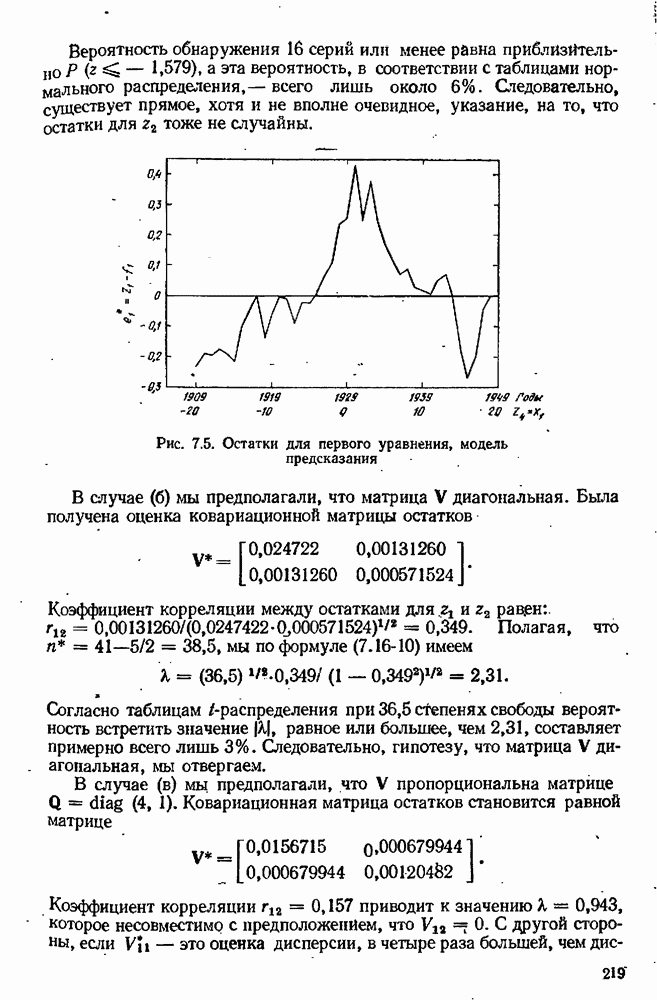
как функции от  эти графики для некоторой гипотетической ситуации представлены на рис. 10.3. где величина х предполагается одномерной. Если мы выберем для выполнения эксперимент
эти графики для некоторой гипотетической ситуации представлены на рис. 10.3. где величина х предполагается одномерной. Если мы выберем для выполнения эксперимент  где значения
где значения  совпадают, то результаты эксперимента ничего не будут нам говорить о том, какое предсказание было лучшим. С другой стороны, наиболее сильно расходятся эти два предсказания в точке
совпадают, то результаты эксперимента ничего не будут нам говорить о том, какое предсказание было лучшим. С другой стороны, наиболее сильно расходятся эти два предсказания в точке  и результат эксперимента (если только не случится, что он попадет точно посередине между двумя предсказаниями), вероятно, будет подтверждать ту или другую из этих двух моделей, в зависимости от того, к какому из предсказаний он окажется ближе.
и результат эксперимента (если только не случится, что он попадет точно посередине между двумя предсказаниями), вероятно, будет подтверждать ту или другую из этих двух моделей, в зависимости от того, к какому из предсказаний он окажется ближе.

Рис. 10.3. Планирование дискриминации для двух моделей по предсказанным значениям
Итак, представляется разумным выбрать тот эксперимент х, для которого величина  максимальна. Однако может случиться, что при таком значении
максимальна. Однако может случиться, что при таком значении  на рис. 10.3) одно или оба предсказания оказываются особенно неопределенными, обладая большими стандартными отклонениями
на рис. 10.3) одно или оба предсказания оказываются особенно неопределенными, обладая большими стандартными отклонениями  Тогда проведение этого эксперимента, вероятно, не даст ничего убедительного, и мы можем предпочесть другой эксперимент, для которого величина
Тогда проведение этого эксперимента, вероятно, не даст ничего убедительного, и мы можем предпочесть другой эксперимент, для которого величина  несколько меньше, зато и неопределенность намного меньше. Следовательно, мы должны приписать величине
несколько меньше, зато и неопределенность намного меньше. Следовательно, мы должны приписать величине  вес, который меньше, когда хотя бы одно число
вес, который меньше, когда хотя бы одно число  большое, и больше, когда оба числа
большое, и больше, когда оба числа  малы. Правильное задание веса обеспечивает формула
малы. Правильное задание веса обеспечивает формула  и аналогично — формула
и аналогично — формула  в случае модели со многими откликами.
в случае модели со многими откликами.
Часто оказывается, что величины  не очень сильно меняются с изменением точки
не очень сильно меняются с изменением точки  следовательно, нам нужно только найти максимум величины
следовательно, нам нужно только найти максимум величины  или
или 
Наши результаты можно обобщать в разных направлениях. Чтобы планировать несколько экспериментов одновременно, мы максимизируем величину  вычисленную по расширенным векторам
вычисленную по расширенным векторам  и матрицам
и матрицам  с тем, чтобы включить отклики всех планируемых экспериментов; в равенстве
с тем, чтобы включить отклики всех планируемых экспериментов; в равенстве  матрица
матрица  теперь понимается так, как определено в формулах
теперь понимается так, как определено в формулах  и матрица V тоже заменяется матрицей
и матрица V тоже заменяется матрицей  из определения
из определения 
Существует несколько подходов к тому, как поступать в случае нескольких моделей. После выполнения каждого эксперимента мы можем вычислить значение функции правдоподобия  связанной с каждой моделью, и наилучшие текущие оценки ее параметров. Тогда мы планируем следующий эксперимент так, чтобы дискриминация была
связанной с каждой моделью, и наилучшие текущие оценки ее параметров. Тогда мы планируем следующий эксперимент так, чтобы дискриминация была
направлена на различение двух моделей с наибольшими зьачениямц функции правдоподобия. Или, следуя Боксу и Хиллу [32], мы можем образовать совместную дивергенцию как линейную комбинацию пар.  дивергенций:
дивергенций:

У нас нет в данный момент никакого опыта, которым можно было бы руководствоваться в том, какой метод следует использовать; но очевидно, что первый метод требует меньше вычислений.
Мы можем преследовать сразу две цели: найти наилучшую среди альтернативных моделей и в то же самое время найти хорошие оценки для параметров этой наилучшей модели. Решение данной проблемы, предложенное Хиллом и др. 1104], состоит в том, чтобы использовать в качестве критерия планирования взвешенную сумму величин  причем последняя величина вычисляется для наилучшей на данном этапе модели. Сначала относительно большой вес придается слагаемому
причем последняя величина вычисляется для наилучшей на данном этапе модели. Сначала относительно большой вес придается слагаемому  но по мере того как одна модель становится все более предпочтительной, относительный вес, приписанный слагаемому
но по мере того как одна модель становится все более предпочтительной, относительный вес, приписанный слагаемому  постепенно увеличивается.
постепенно увеличивается.