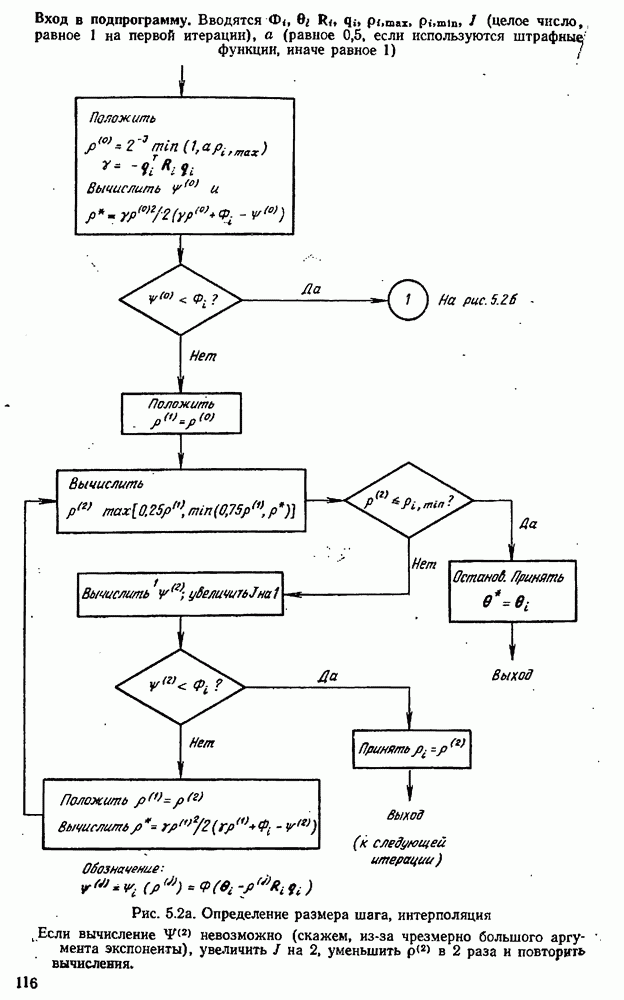
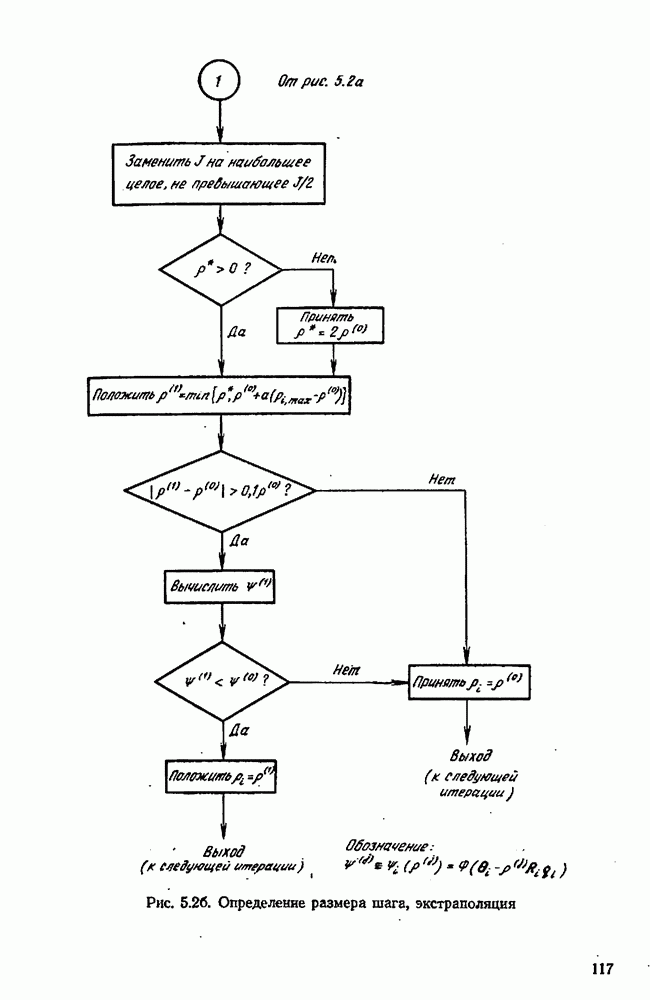
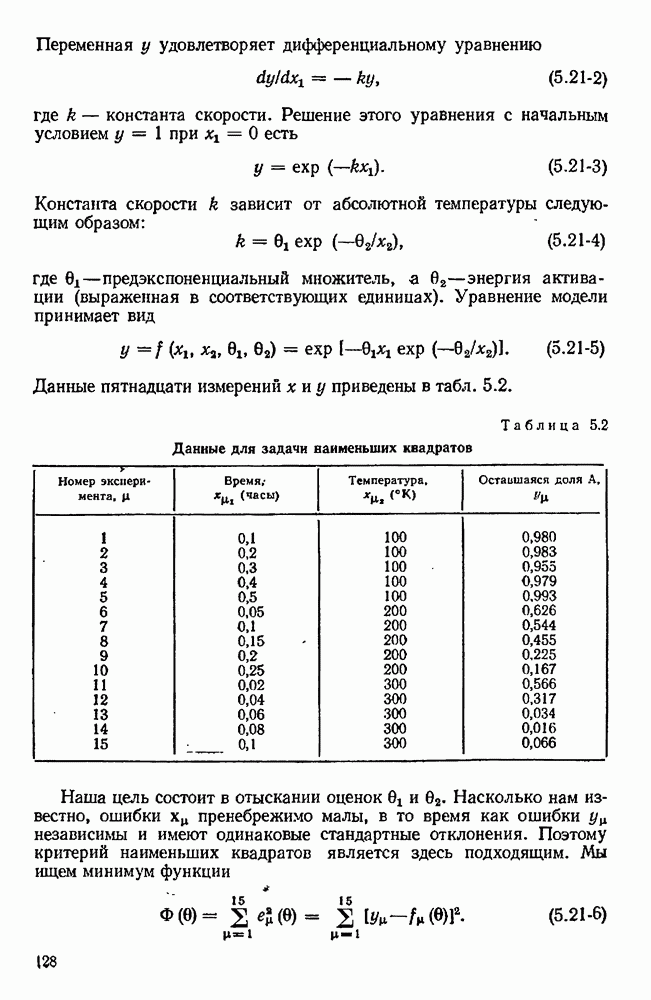
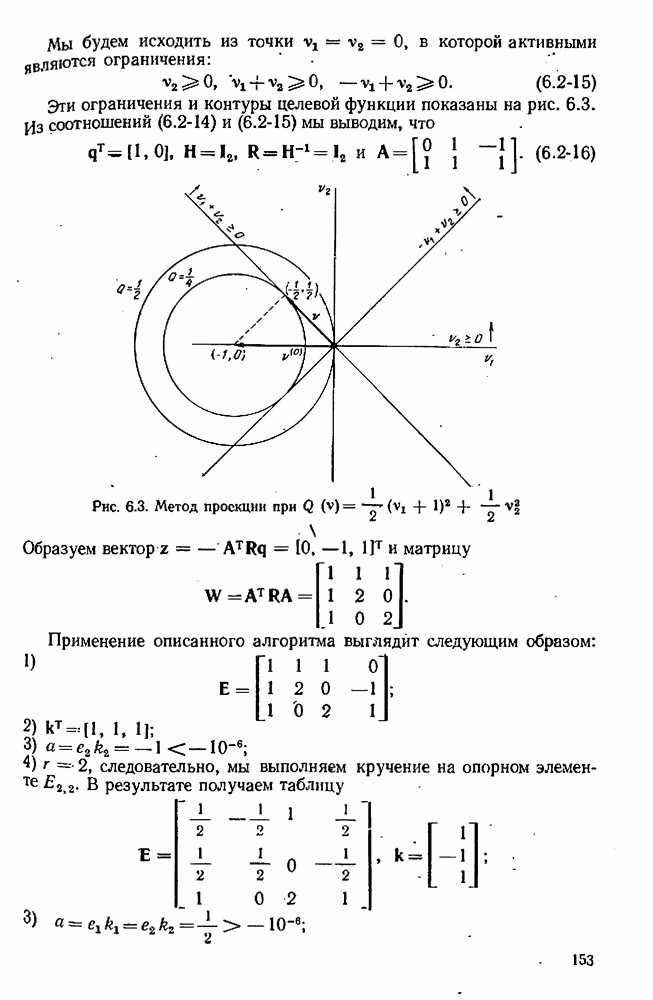
Максимальная суммарная ошибка приближенно составляет:

Она имеет минимум при

Если нас интересует среднеквадратическая ошибка, мы будем минимизировать

так что

Выражения  или
или  можно использовать как основу для оценки размера шагов
можно использовать как основу для оценки размера шагов  требуемых для вычисления разностей. Те же уравнения можно было бы получить, если считать, что оба источника ошибок вносят одинаковые вклады. Максимальная общая ошибка по
требуемых для вычисления разностей. Те же уравнения можно было бы получить, если считать, что оба источника ошибок вносят одинаковые вклады. Максимальная общая ошибка по  оказывается равной
оказывается равной  в то время как среднеквадратическая ошибка по
в то время как среднеквадратическая ошибка по  есть
есть 
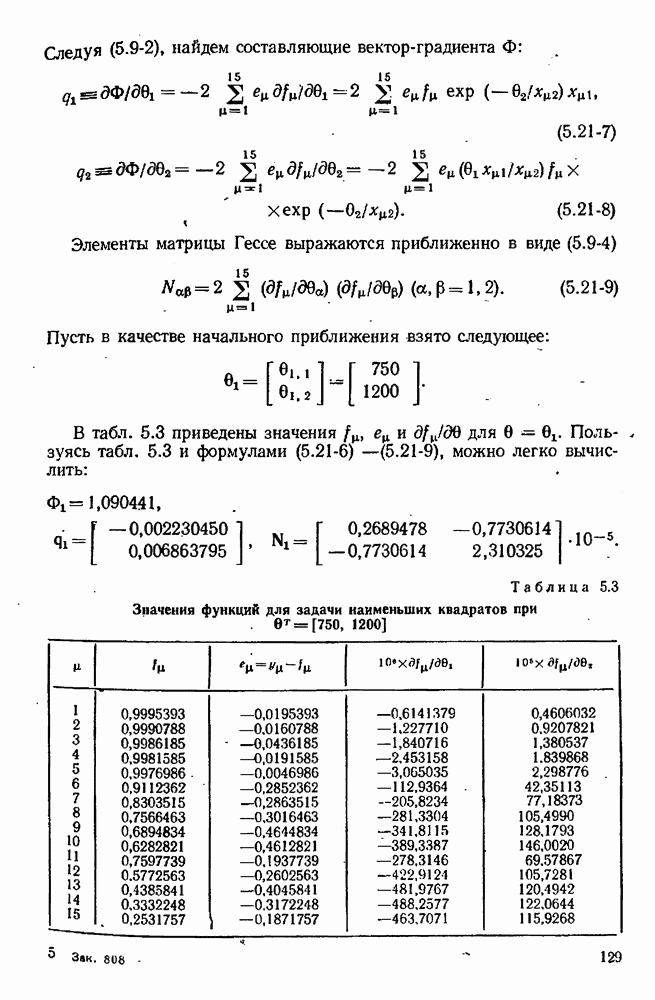
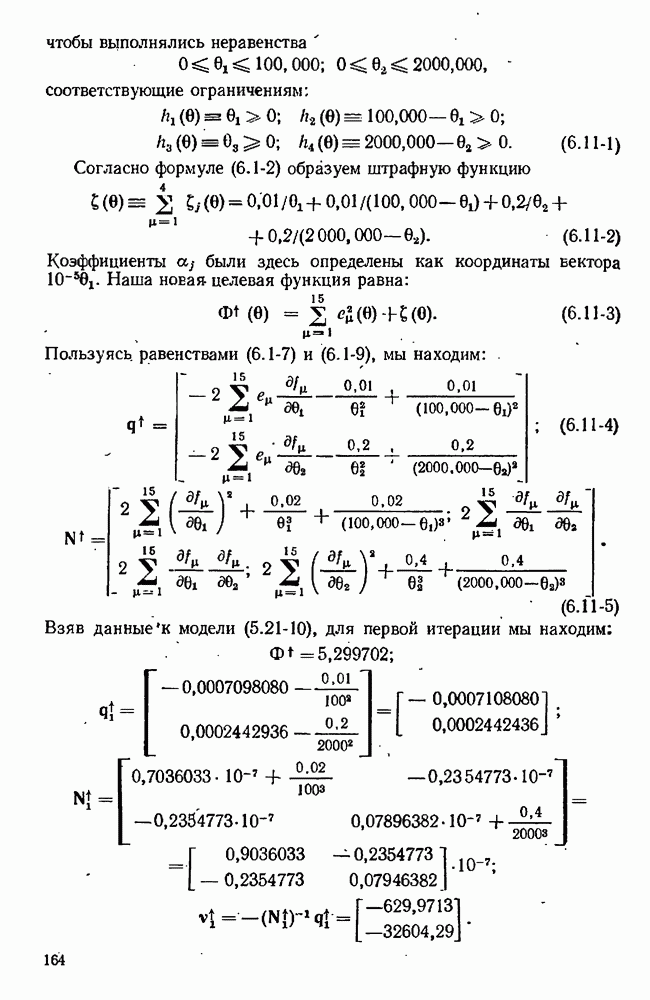
Чтобы применять эти формулы, мы должны знать оценки элементов матрицы Гессе  Эти оценки мы имеем, пользуясь методами Гаусса и переменной метрики. В последнем случае обычно матрица
Эти оценки мы имеем, пользуясь методами Гаусса и переменной метрики. В последнем случае обычно матрица  т. е. она является скорее приближением
т. е. она является скорее приближением  чем аппроксимацией
чем аппроксимацией  Однако, если начать итерационную процедуру с диагональной матрицы
Однако, если начать итерационную процедуру с диагональной матрицы  то легко образовать
то легко образовать  Тогда легко проверяемая формула
Тогда легко проверяемая формула

позволит нам в методе КРЕ вычислять последовательно матрицы  которые являются аппроксимациями
которые являются аппроксимациями  Подобная процедура для метода Дэвидона — Флетчера-Пауэлла приводится Стюартом [182].
Подобная процедура для метода Дэвидона — Флетчера-Пауэлла приводится Стюартом [182].
В методе Гаусса нам необходимо знание производных от уравнений модели скорее, чем от самой функции цели. Если нельзя предложить ничего лучшего, рекомендуем пользоваться  или
или  для выбора
для выбора  . Вместо уравнения
. Вместо уравнения  однако, будем применять подобные соотношения к уравнениям модели для каждого эксперимента в отдельности.
однако, будем применять подобные соотношения к уравнениям модели для каждого эксперимента в отдельности.
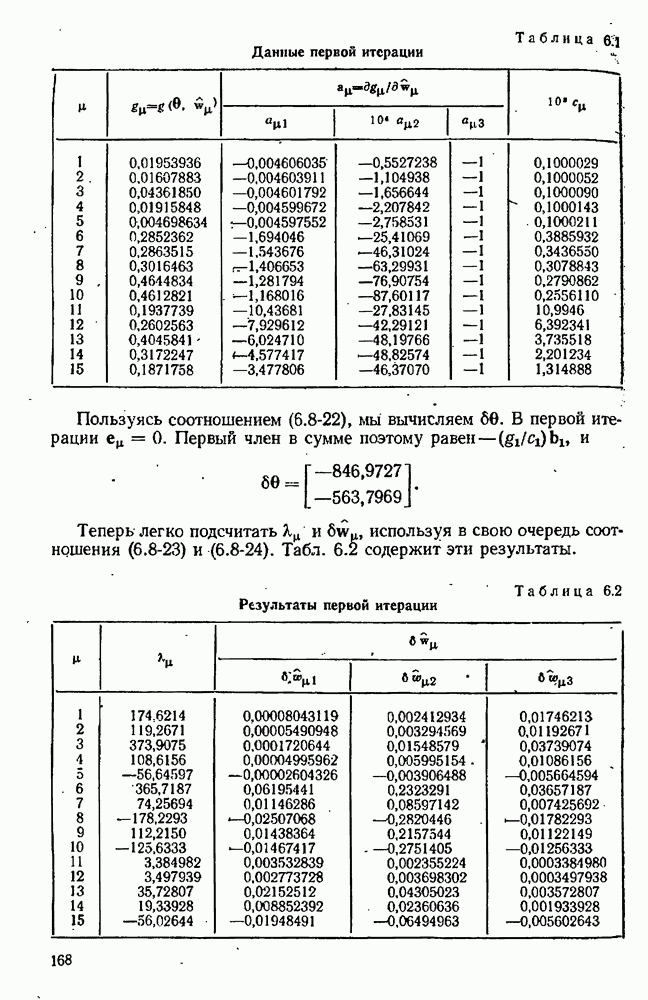
Эти формулы не следует употреблять слепо. Большие ошибки в оценке  могут привести к абсурдным значениями
могут привести к абсурдным значениями  Следует ограничить
Следует ограничить  сверху и снизу, например
сверху и снизу, например  Если вычисления проводятся с двойной точностью, то можно принять меньшую нижнюю границу.
Если вычисления проводятся с двойной точностью, то можно принять меньшую нижнюю границу.
Уравнение  дает самую грубую оценку
дает самую грубую оценку  из всех возможных. Лучшая оценка получается по центральной разностной схеме:
из всех возможных. Лучшая оценка получается по центральной разностной схеме:































































































































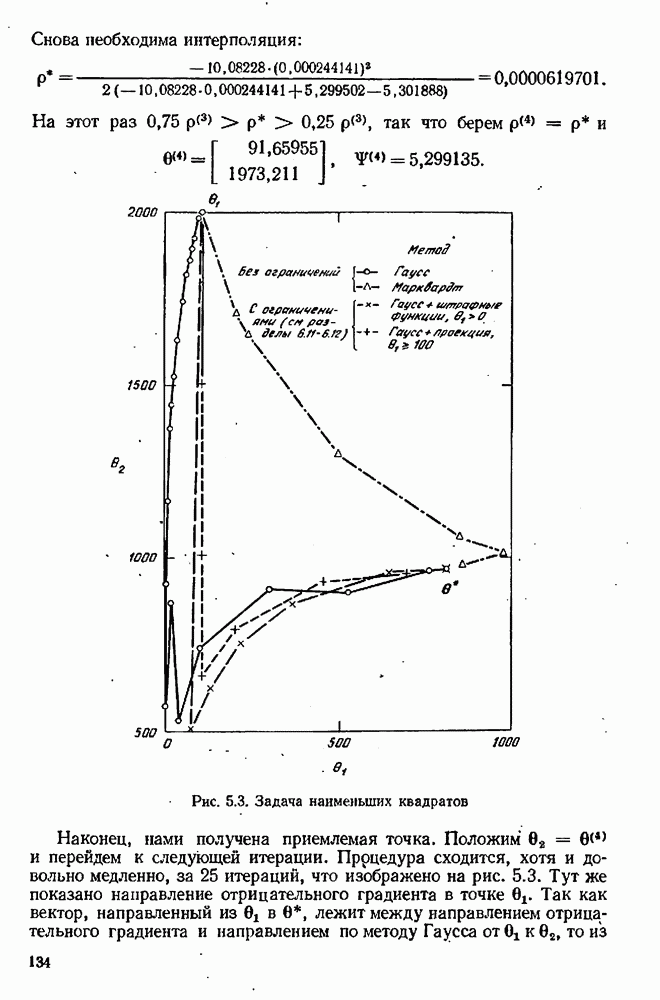





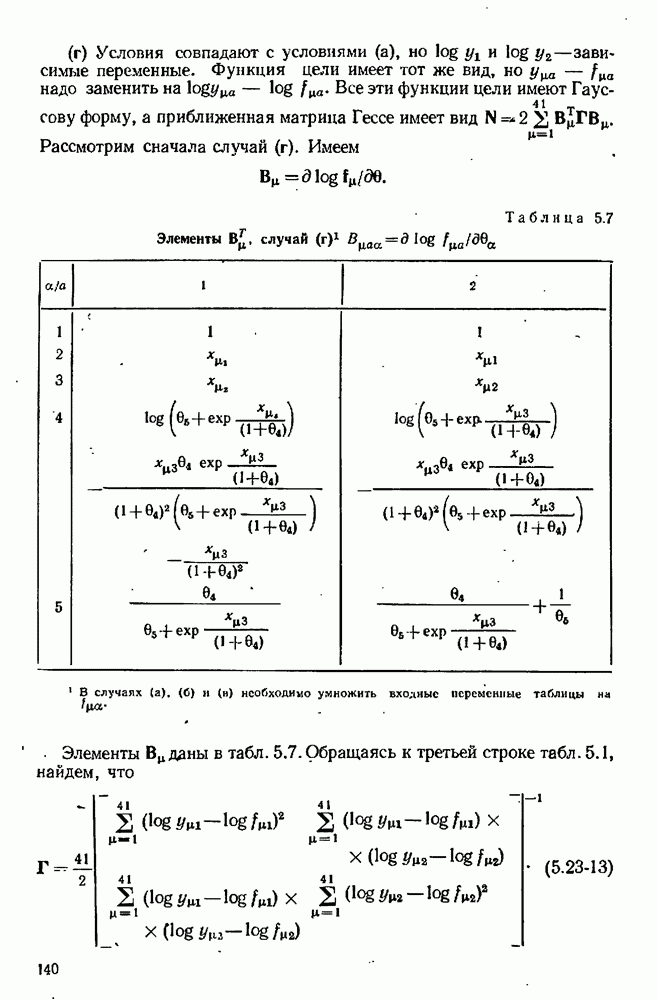
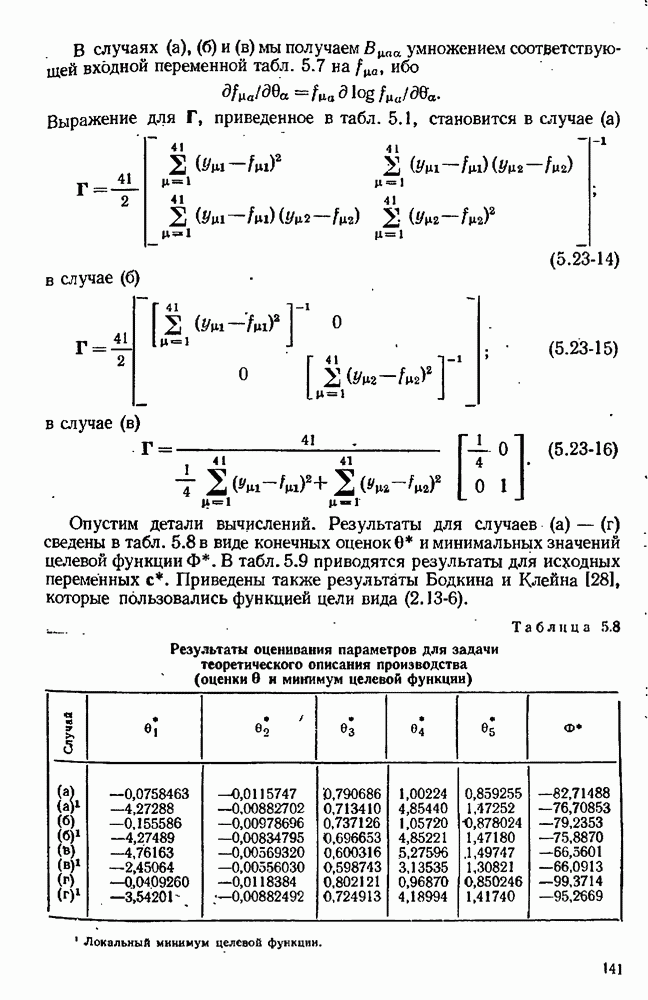

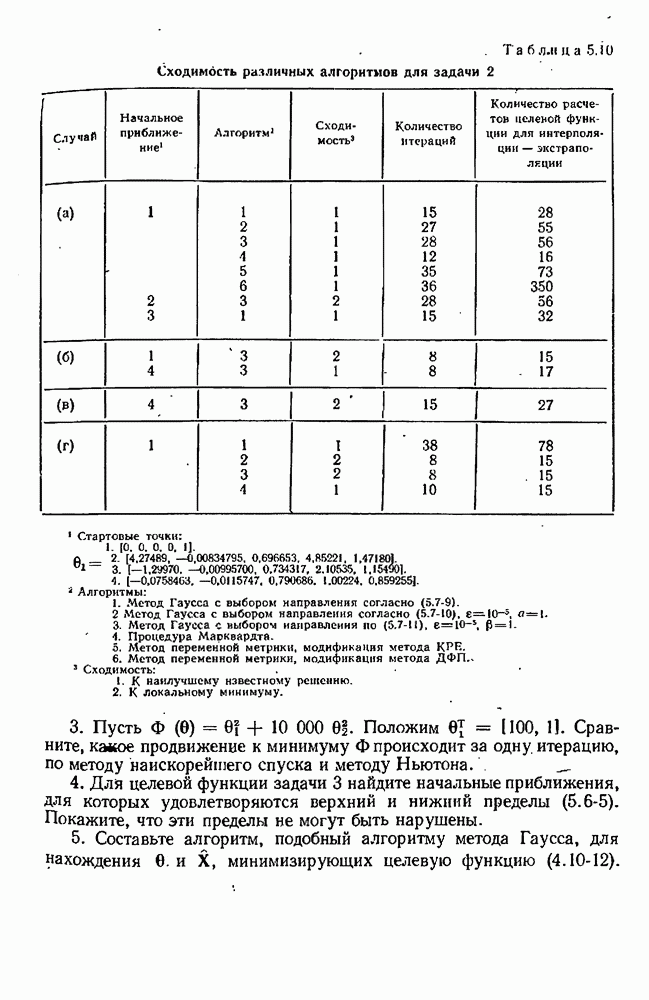






















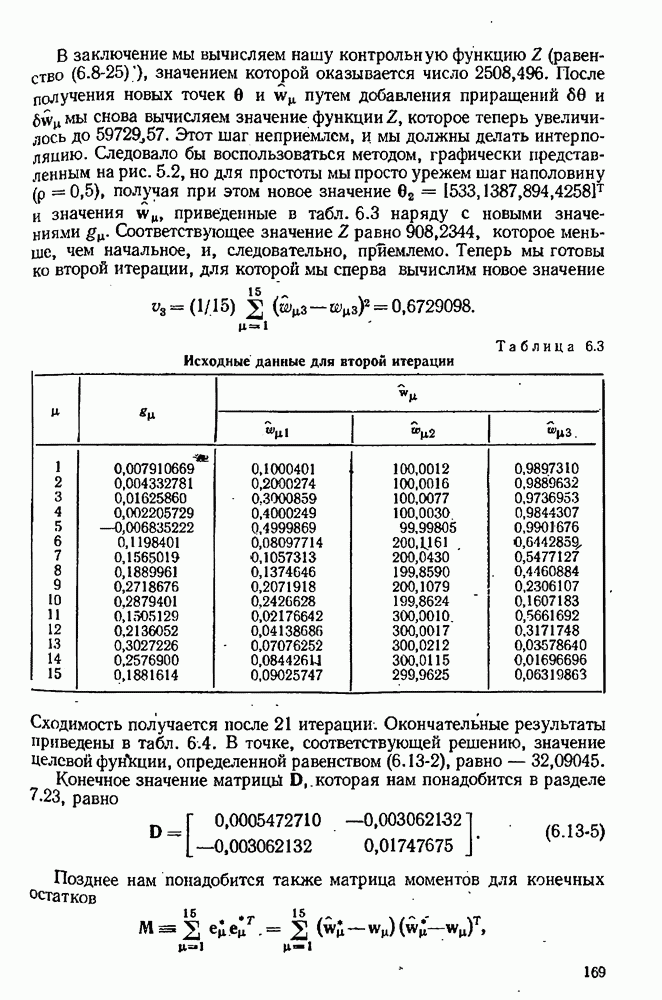








































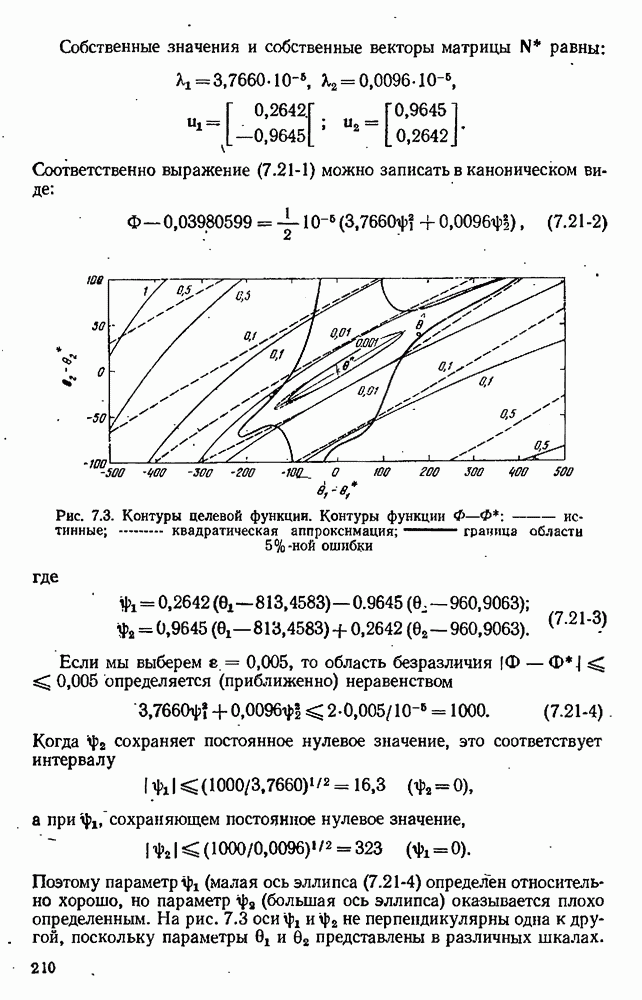



















































































































 обусловлена двумя источниками ошибок: (1) ошибка округления, связанная с разностью двух близких значений
обусловлена двумя источниками ошибок: (1) ошибка округления, связанная с разностью двух близких значений  и (2) ошибка усечения, связанная с неточным характером выражения
и (2) ошибка усечения, связанная с неточным характером выражения  которое соблюдается точно лишь в пределе при
которое соблюдается точно лишь в пределе при 
 . Впредь мы будем писать для сокращения вместо
. Впредь мы будем писать для сокращения вместо  Пусть
Пусть  относительная ошибка вычисления
относительная ошибка вычисления  (в лучшем случае
(в лучшем случае  где
где  число двоичных цифр, с которым ведутся вычисления на компьютере). Абсолютная ошибка
число двоичных цифр, с которым ведутся вычисления на компьютере). Абсолютная ошибка  имеет величину
имеет величину  а ошибка разности
а ошибка разности  может быть порядка
может быть порядка  хотя среднеквадратическая ошибка равна только
хотя среднеквадратическая ошибка равна только  Максимальная ошибка округления в
Максимальная ошибка округления в  поэтому равна:
поэтому равна:


 приближенно равна:
приближенно равна:

 есть
есть  где
где  Шаг при наименьшей максимальной ошибке имеет длину
Шаг при наименьшей максимальной ошибке имеет длину  а сама ошибка имеет величину
а сама ошибка имеет величину  Эти формулы не очень полезны, ибо мы редко знаем
Эти формулы не очень полезны, ибо мы редко знаем  Однако можно с уверенностью сказать, что здесь можно использовать несколько большие значения 60а, чем при односторонней разностной схеме.
Однако можно с уверенностью сказать, что здесь можно использовать несколько большие значения 60а, чем при односторонней разностной схеме.
