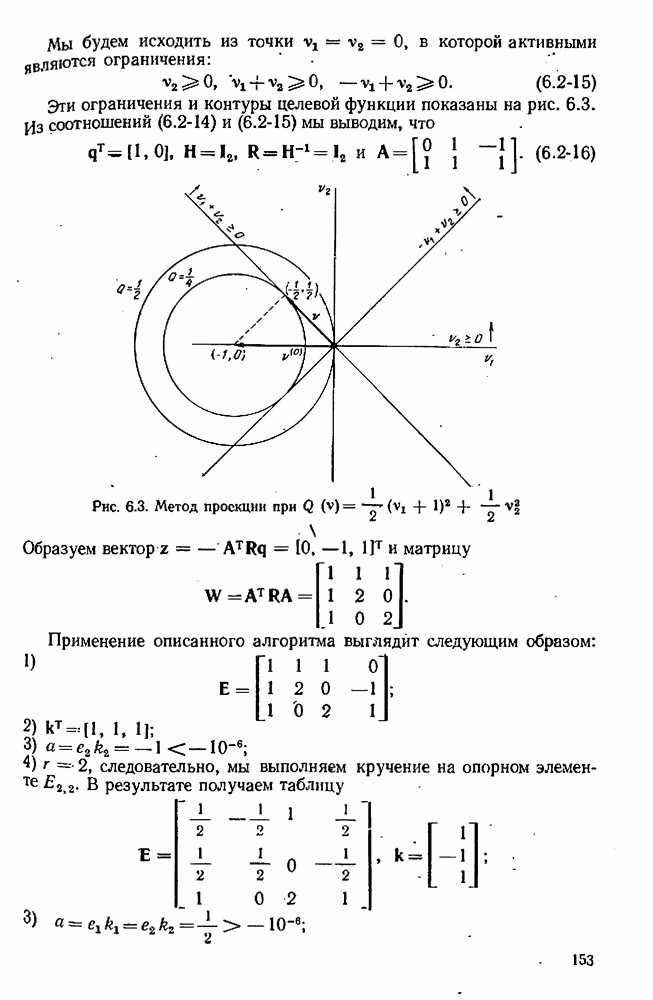
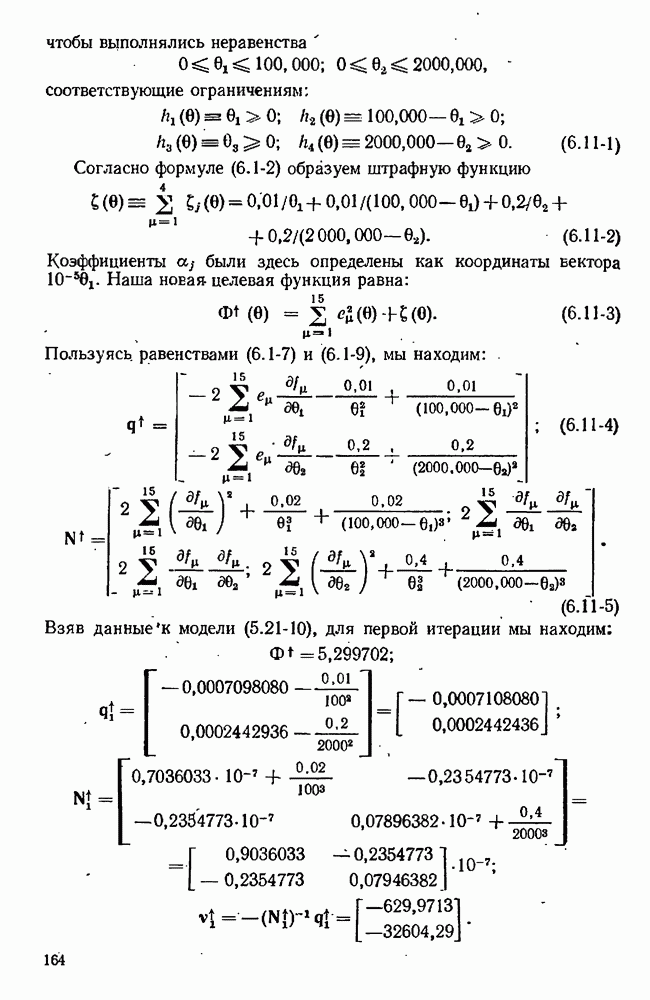
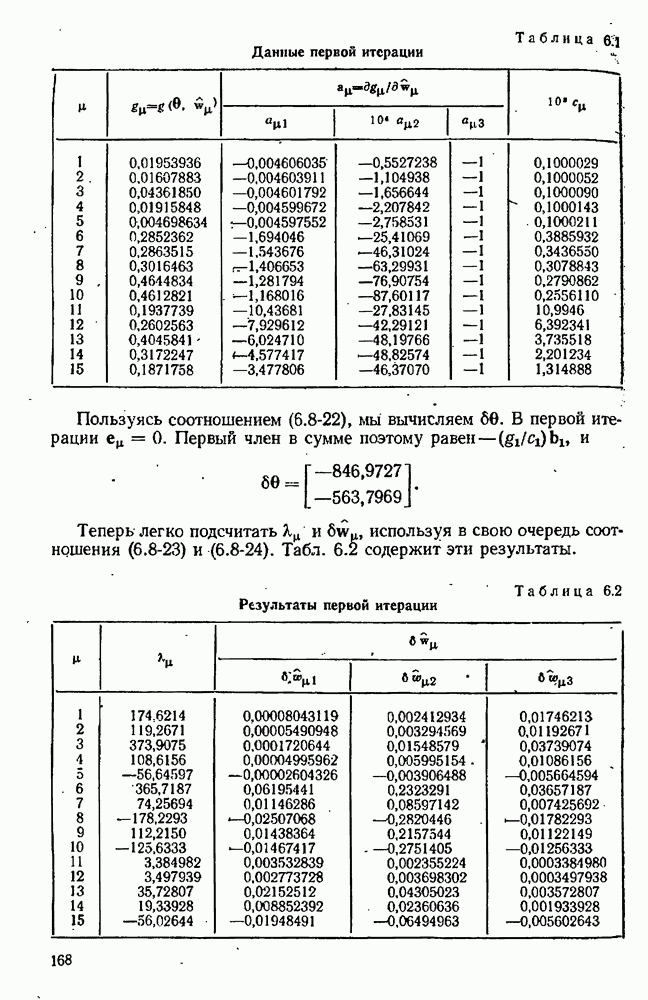
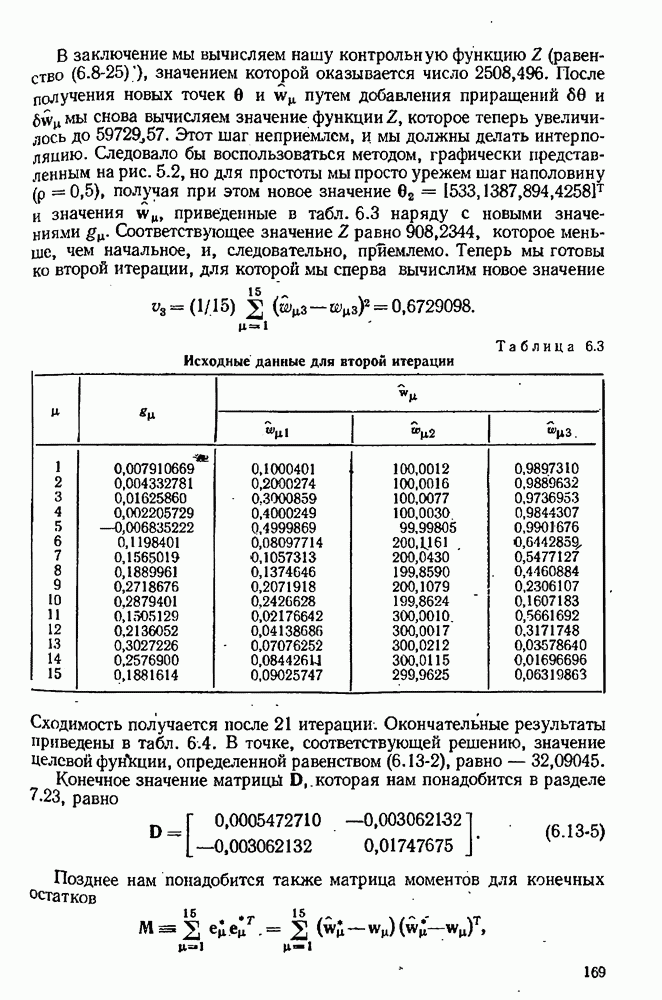
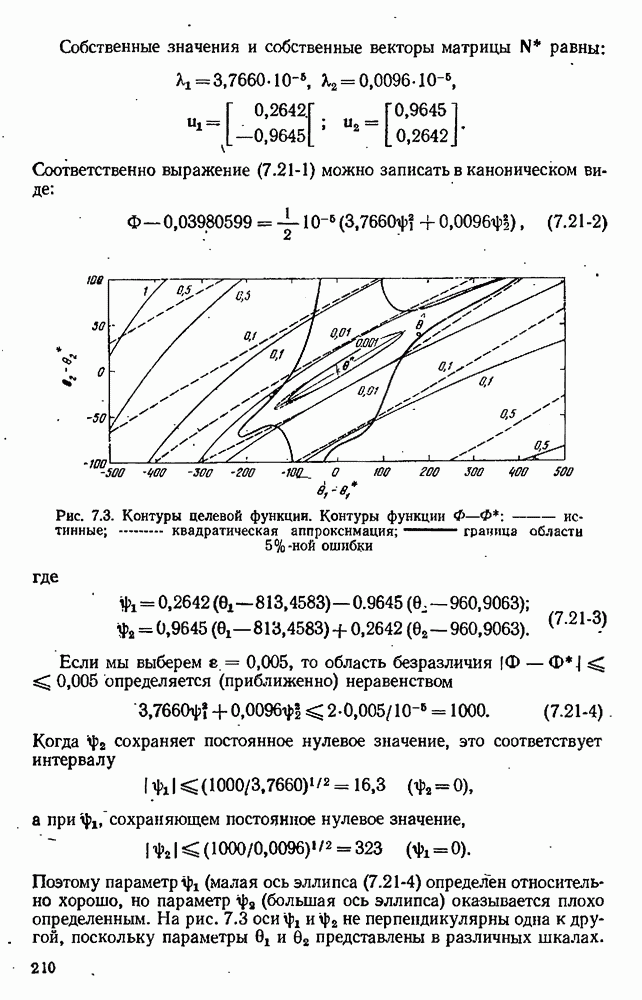
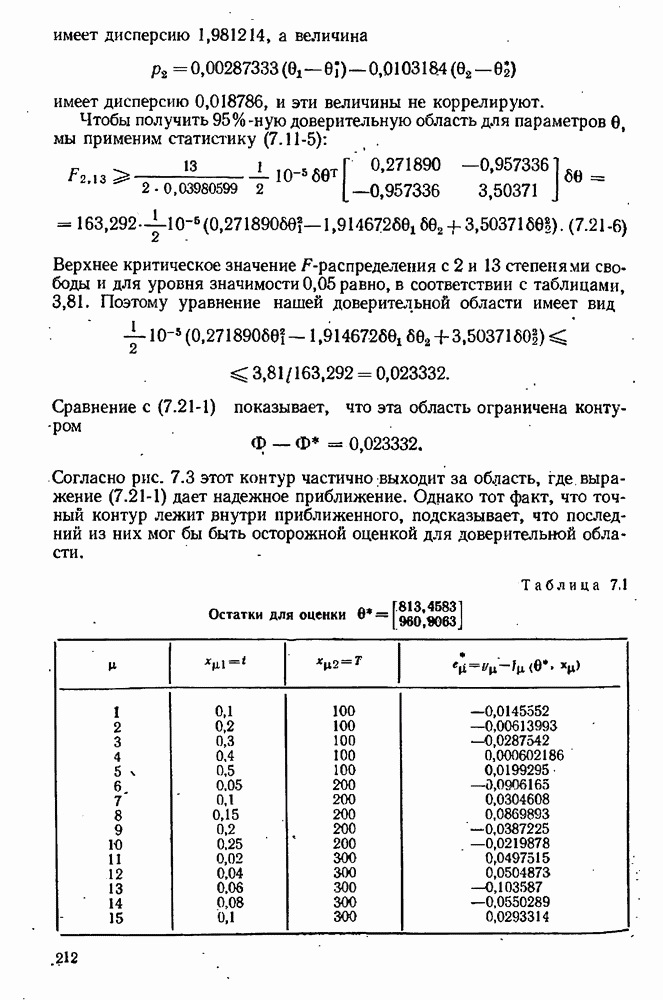
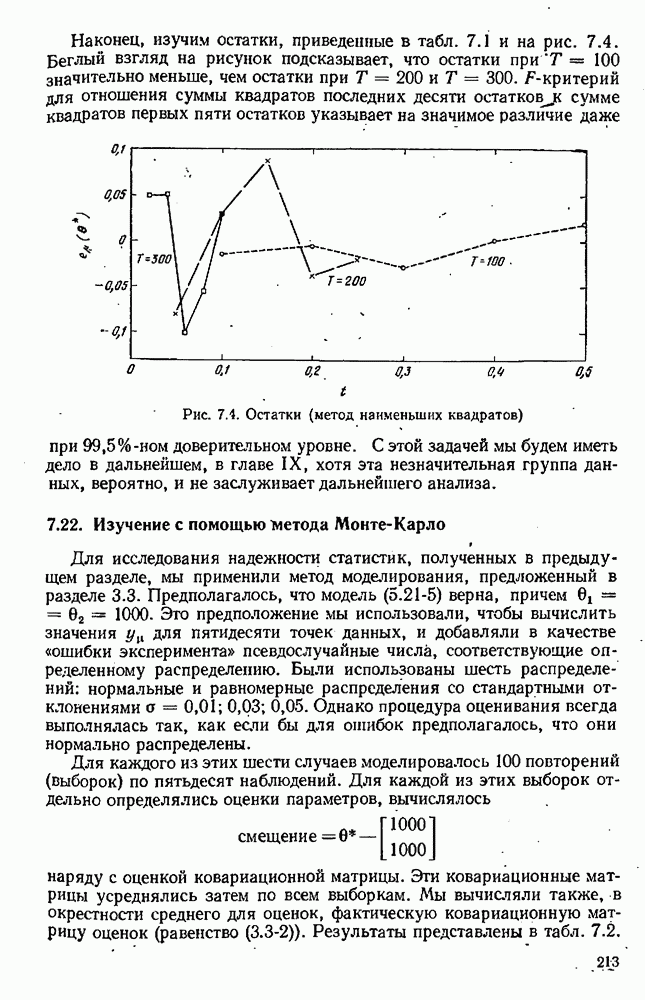
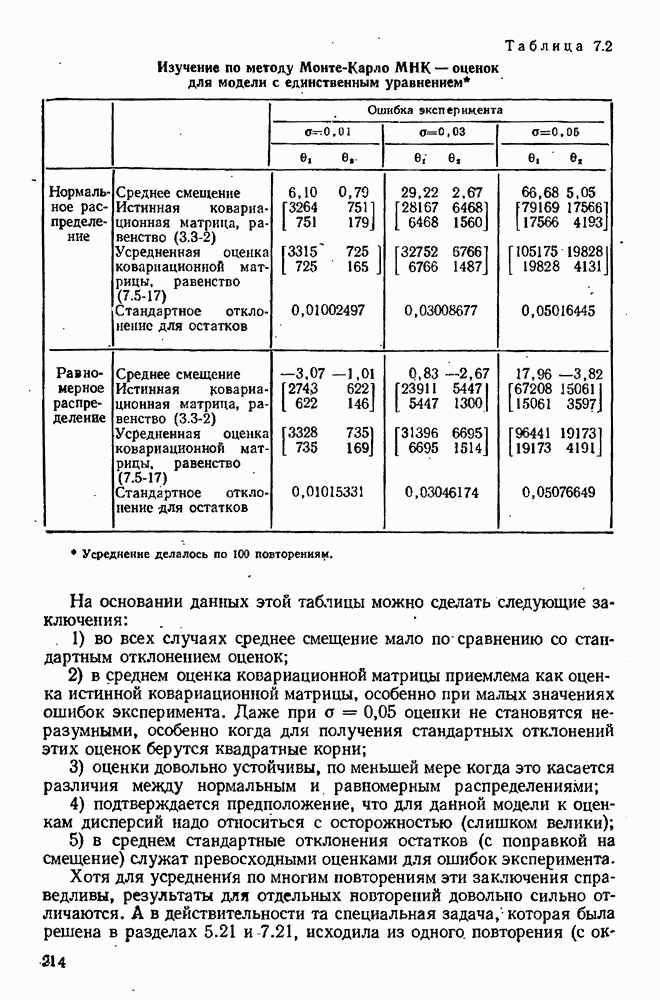
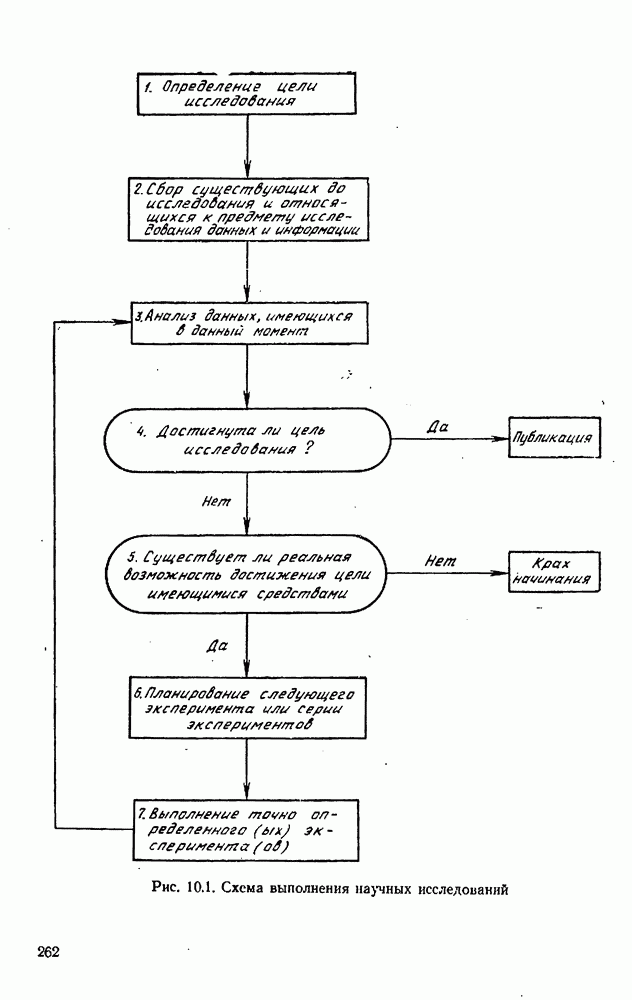
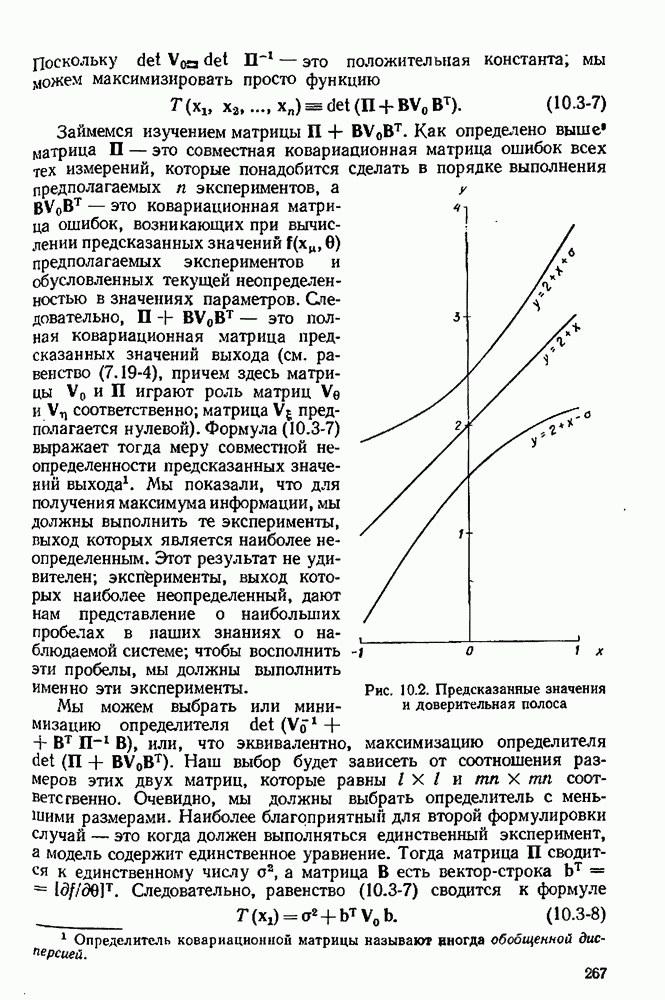
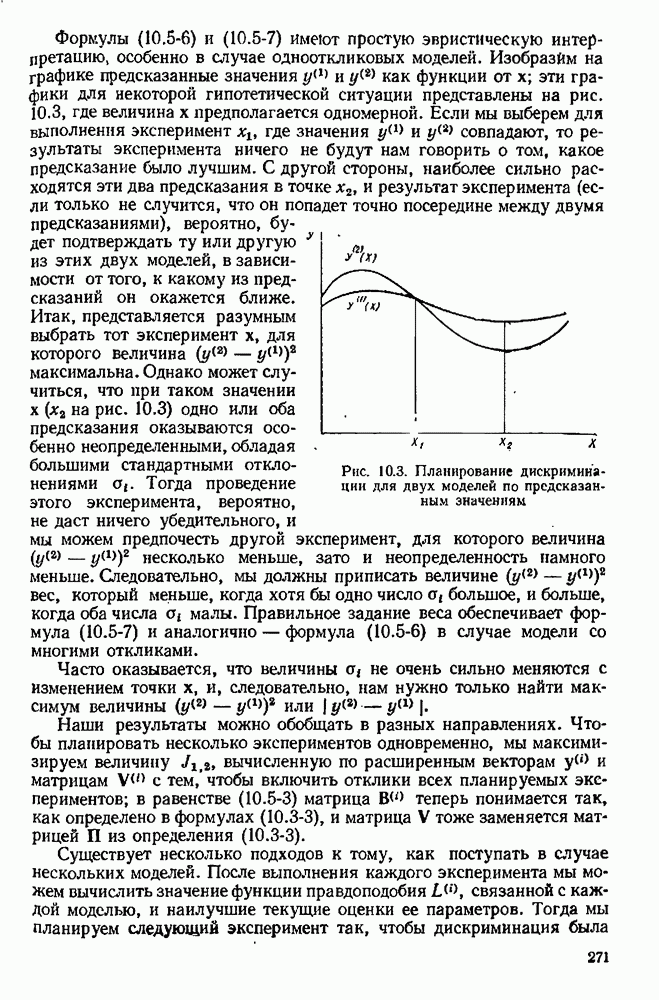
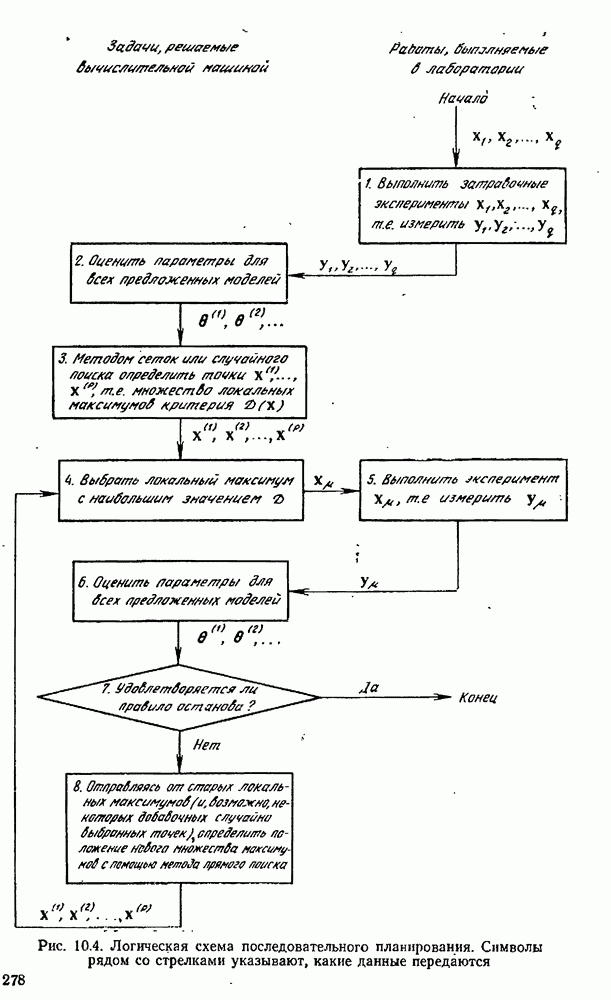
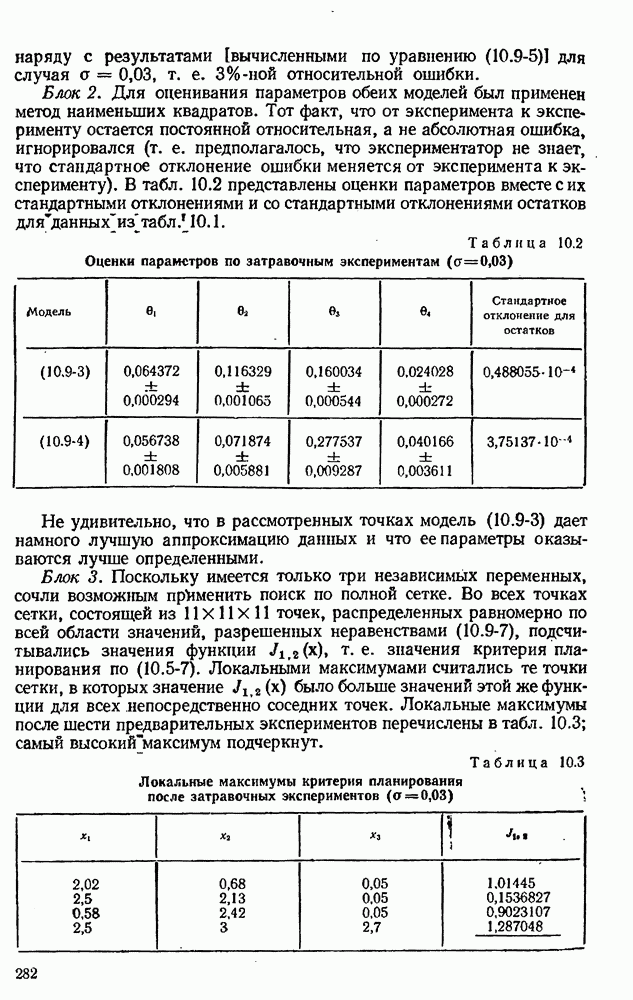
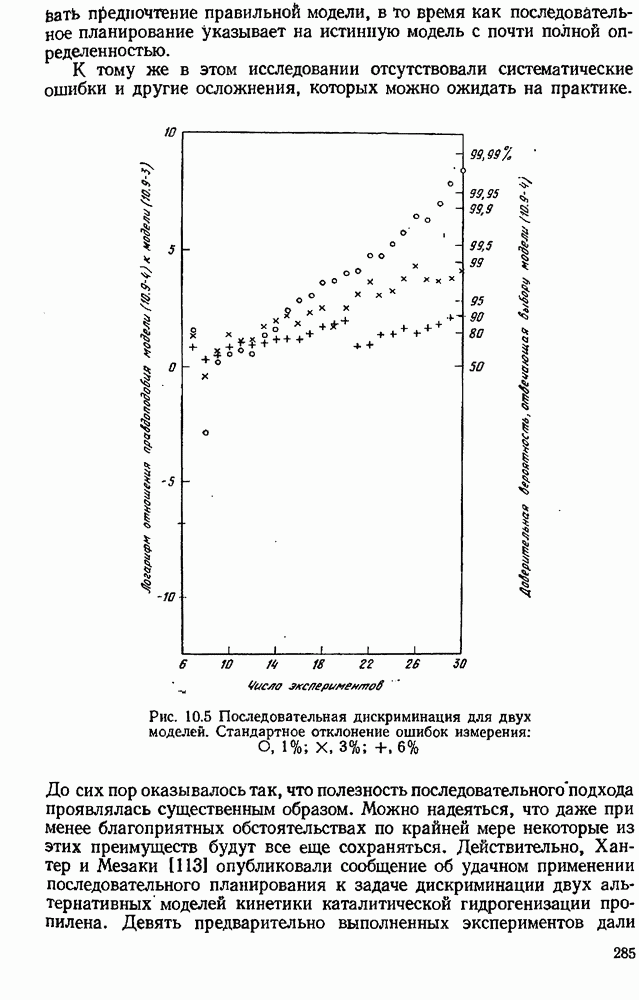
4.4. Множественная линейная регрессия
Если модель линейна, правильный выбор весов в  обеспечивает оптимальные статистические свойства соответствующих оценок. Линейная модель принимает вид
обеспечивает оптимальные статистические свойства соответствующих оценок. Линейная модель принимает вид

где  матрица заданных функций (в задачах подгонки кривых часто используются полиномы и тригонометрические функции). Объединяя уравнения для всех значений
матрица заданных функций (в задачах подгонки кривых часто используются полиномы и тригонометрические функции). Объединяя уравнения для всех значений  получаем в матричной форме
получаем в матричной форме

где

Для определенного набора данных В — это постоянная матрица. Пусть значения  измеряются без ошибок, а каждое наблюдение у,
измеряются без ошибок, а каждое наблюдение у,
является случайной величиной со средним значением и пусть V — ковариационная матрица всех элементов у, т. е.

Если  минимизирует функцию
минимизирует функцию

то 0 должно удовлетворять условию

Это эквивалентно системе нормальных уравнений

Разрешая их относительно 0, найдем, при условии, что матрица  не вырождена,
не вырождена,

Это хорошо известная формула множественной линейной регрессии. Очевидно,  является линейной оценкой, имеющей вид
является линейной оценкой, имеющей вид 
По нашим предположениям,  Следовательно, если
Следовательно, если  постоянны, найдем из
постоянны, найдем из 

Это значит, что 0 есть несмещенная оценка 0. Далее, (4 4-3) эквивалентно следующему:

Легко показать также, что

Следовательно, выражение для ковариационной матрицы выборочного распределения оценки 0 преобразуется в следующее:

Теорема Гаусса-Маркова (доказанная в приложении Д) утверждает, что среди всех линейных несмещенных оценок та, которая выражается  имеет наименьшую дисперсию. Если, кроме того, распределение нормально, оценка будет эффективной. В случае, когда
имеет наименьшую дисперсию. Если, кроме того, распределение нормально, оценка будет эффективной. В случае, когда
ошибки измерений независимы и имеют равные дисперсии  мы получим
мы получим  и
и

это обычная оценка наименьших квадратов без взвешивания. Ковариационная матрица этой оценки имеет вид 
Вычислительные методы решения задач линейной регрессии обсуждаются в разделе 5.11. При решении задач линейной регрессии часто возникает вопрос: какие переменные следует включить в модель и какие исключить из нее? Говоря другими словами, вопрос заключается в том, какие параметры следует опустить (положить их равными нулю) из-за их незначимого вклада в модель. Метод шаговой регрессии (раздел  дает
дает  на этот вопрос.
на этот вопрос.
Перед тем как покончить с обсуждением линейных моделей, Коротко рассмотрим, как изменятся оптимальные свойства регрессионной оценки, если предполагаемая модель неверна.
Во-первых, предположим, что в модели опущены некоторые существенные ее члены. Тогда уже не будет верным равенство  вместо этого имеем
вместо этого имеем

где  фиксированный вектор, связанный с теми членами, которые исключены из уравнения. Если 0 вычисляется по
фиксированный вектор, связанный с теми членами, которые исключены из уравнения. Если 0 вычисляется по  то находим, что
то находим, что

так что 0 уже не будет несмещенной оценкой. Смещение выражается точно в виде

Во-вторых, рассмотрим случай, когда мы ошиблись в выборе матрицы  Пусть истинная ковариационная матрица есть
Пусть истинная ковариационная матрица есть  Тогда ковариационная матрица оценки, определяемой по
Тогда ковариационная матрица оценки, определяемой по  выглядит так:
выглядит так:

Мы хотим оценить, насколько эта оценка уступает по эффективности наилучшей возможной оценке, для которой  Ковариационная матрица последней согласно
Ковариационная матрица последней согласно  есть
есть  Определим относительную неэффективность
Определим относительную неэффективность  оценки, найденной по
оценки, найденной по  как отношение ее обобщенной дисперсии к минимально возможной обобщенной дисперсии, т. е.
как отношение ее обобщенной дисперсии к минимально возможной обобщенной дисперсии, т. е.

Очевидно, что  если
если  Можно показать, что в других случаях
Можно показать, что в других случаях  может принимать значения лишь в интервале, приведенном ниже; его величина определяется матрицей В:
может принимать значения лишь в интервале, приведенном ниже; его величина определяется матрицей В:

где а — число обусловленности, а именно отношение наибольшего собственного числа матрицы  наименьшему. Для примера положим, что используется оценка наименьших квадратов без взвешивания, в то время как фактически дисперсии ошибок меняются от 10 до 100. Тогда
наименьшему. Для примера положим, что используется оценка наименьших квадратов без взвешивания, в то время как фактически дисперсии ошибок меняются от 10 до 100. Тогда  где
где  вектор, компонентами которого являются числа в диапазоне от 10 до 100. Отсюда следует, что
вектор, компонентами которого являются числа в диапазоне от 10 до 100. Отсюда следует, что  Неэффективность оценки 0 может быть порядка
Неэффективность оценки 0 может быть порядка 
В то время как оценка вида  или
или  является наилучшей несмещенной оценкой, возможно построение смещенных оценок с меньшим значением обобщенной дисперсии. Например, в методе гребневой регрессии [106], [107] в
является наилучшей несмещенной оценкой, возможно построение смещенных оценок с меньшим значением обобщенной дисперсии. Например, в методе гребневой регрессии [106], [107] в  подставляется оценка
подставляется оценка

где  это положительный параметр. Можно показать, что ковариационная матрица оценки выражается следующим образом:
это положительный параметр. Можно показать, что ковариационная матрица оценки выражается следующим образом:

и что величина  минимальна, когда
минимальна, когда  удовлетворяет уравнению
удовлетворяет уравнению

Так как 0 неизвестно, оптимальное значение Я нельзя определить априори. Хёрл и Кеннард рекомендовали строить так называемый гребневый след, который представляет собой график зависимости компонент  от
от  при
при  , возрастающем от нуля. Значение
, возрастающем от нуля. Значение  выбирается там, где прекращается быстрое изменение
выбирается там, где прекращается быстрое изменение  Заметим, что при
Заметим, что при  мы имеем обычную оценку наименьших квадратов. Заметим также, что
мы имеем обычную оценку наименьших квадратов. Заметим также, что  не удовлетворяет
не удовлетворяет  Следовательно, оценка наименьших квадратов никогда не будет линейной оценкой с наименьшей обобщенной дисперсией.
Следовательно, оценка наименьших квадратов никогда не будет линейной оценкой с наименьшей обобщенной дисперсией.