ковариационная матрица V определяется формулой 

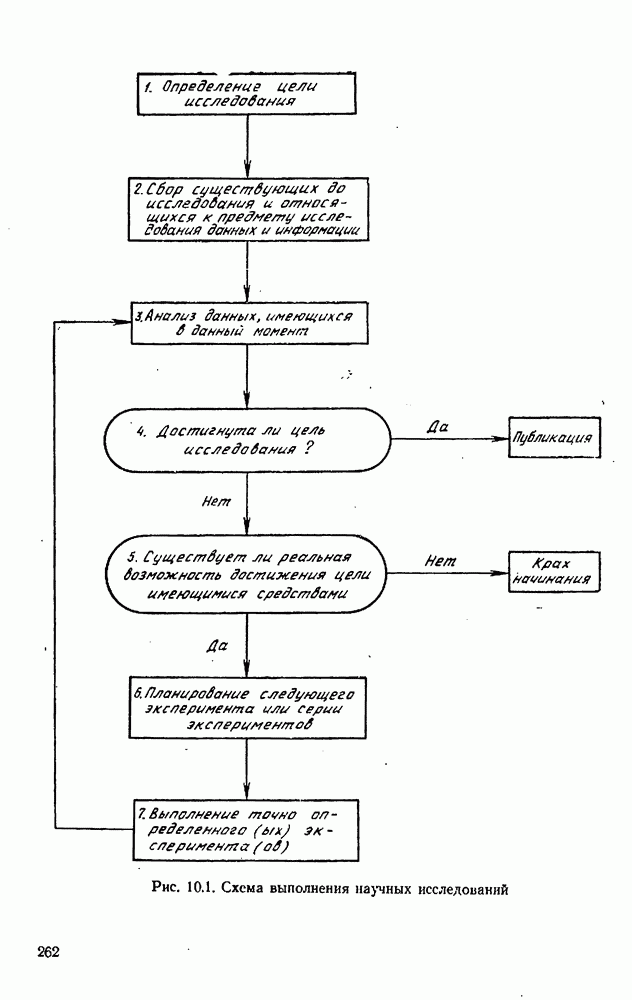
где, как обычно, матрица  вычисляется при
вычисляется при  Поскольку эксперименты на самом то деле не были выполнены, мы не можем сказать, какое значение 0 получится; но, пытаясь вычислить матрицу V, мы можем для того, чтобы оценить величины
Поскольку эксперименты на самом то деле не были выполнены, мы не можем сказать, какое значение 0 получится; но, пытаясь вычислить матрицу V, мы можем для того, чтобы оценить величины  взять точку
взять точку  вместо в.
вместо в.
С помощью равенства  мы, таким образом, будем в состоянии для любого заданного множества предполагаемых экспериментальных условий
мы, таким образом, будем в состоянии для любого заданного множества предполагаемых экспериментальных условий  оценить, какой будет матрица V, после того как предполагаемые эксперименты будут проведены. Сказанное есть не что иное, как утверждение, что оцениваемая матрица V есть функция от
оценить, какой будет матрица V, после того как предполагаемые эксперименты будут проведены. Сказанное есть не что иное, как утверждение, что оцениваемая матрица V есть функция от 
Чтобы максимизировать количество информации, получаемой в экспериментах, нам нужно выбрать точки  таким образом, чтобы минимизировать неопределенность, т. е. так, чтобы величина
таким образом, чтобы минимизировать неопределенность, т. е. так, чтобы величина

была минимальной. Тем самым минимизируется также объем доверительной области для параметров. Понятно, что минимизация  эквивалентна минимизации определителя
эквивалентна минимизации определителя  или максимизации определителя
или максимизации определителя 
Введем снова обозначения:

Матрица  это совместная ковариационная матрица ошибок
это совместная ковариационная матрица ошибок  Тогда равенство
Тогда равенство  принимает вид
принимает вид

и

Напомним теперь (см. формулу (А. 1-33)), что  , так что
, так что

Поскольку  это положительная константа; мы можем максимизировать просто функцию
это положительная константа; мы можем максимизировать просто функцию

Займемся изучением матрицы  Как определено выше матрица
Как определено выше матрица  это совместная ковариационная матрица ошибок всех тех измерений, которые понадобится сделать в порядке выполнения предполагаемых
это совместная ковариационная матрица ошибок всех тех измерений, которые понадобится сделать в порядке выполнения предполагаемых  экспериментов, а
экспериментов, а  это ковариационная матрица ошибок, возникающих при вычислении предсказанных значений
это ковариационная матрица ошибок, возникающих при вычислении предсказанных значений  предполагаемых экспериментов и обусловленных текущей неопределенностью в значениях параметров. Следовательно,
предполагаемых экспериментов и обусловленных текущей неопределенностью в значениях параметров. Следовательно,  это полная ковариационная матрица предсказанных значений выхода (см. равенство
это полная ковариационная матрица предсказанных значений выхода (см. равенство  причем здесь матрицы
причем здесь матрицы  и
и  играют роль матриц
играют роль матриц  и
и  соответственно; матрица
соответственно; матрица  предполагается нулевой). Формула
предполагается нулевой). Формула  выражает тогда меру совместной неопределенности предсказанных значений выхода. Мы показали, что для получения максимума информации, мы должны выполнить те эксперименты, выход которых является наиболее неопределенным. Этот результат не удивителен; эксперименты, выход которых наиболее неопределенный, дают нам представление о наибольших пробелах в наших знаниях о наблюдаемой системе; чтобы восполнить эти пробелы, мы должны выполнить именно эти эксперименты.
выражает тогда меру совместной неопределенности предсказанных значений выхода. Мы показали, что для получения максимума информации, мы должны выполнить те эксперименты, выход которых является наиболее неопределенным. Этот результат не удивителен; эксперименты, выход которых наиболее неопределенный, дают нам представление о наибольших пробелах в наших знаниях о наблюдаемой системе; чтобы восполнить эти пробелы, мы должны выполнить именно эти эксперименты.

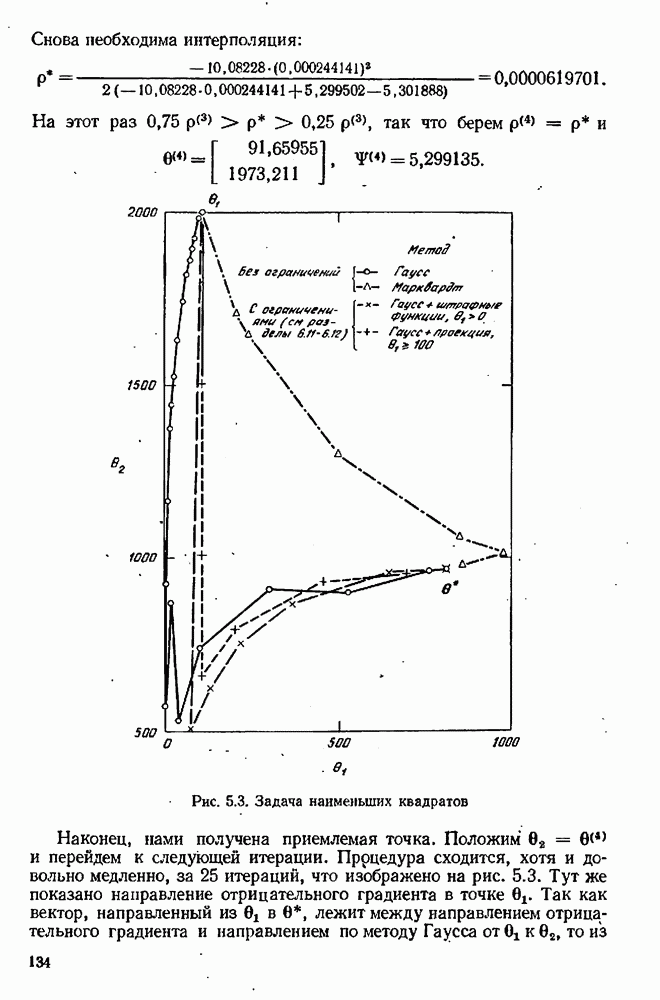
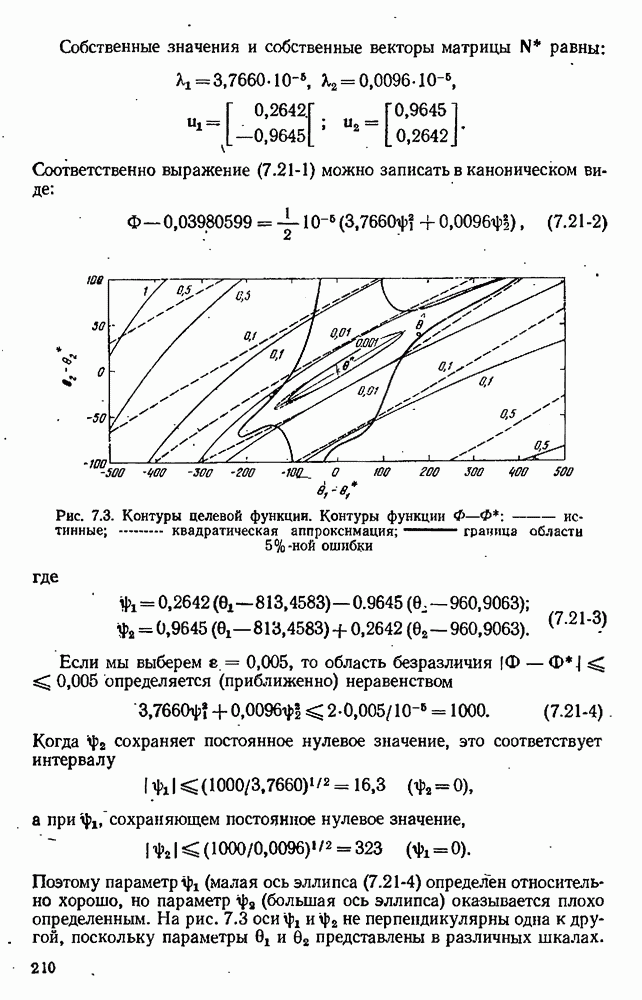
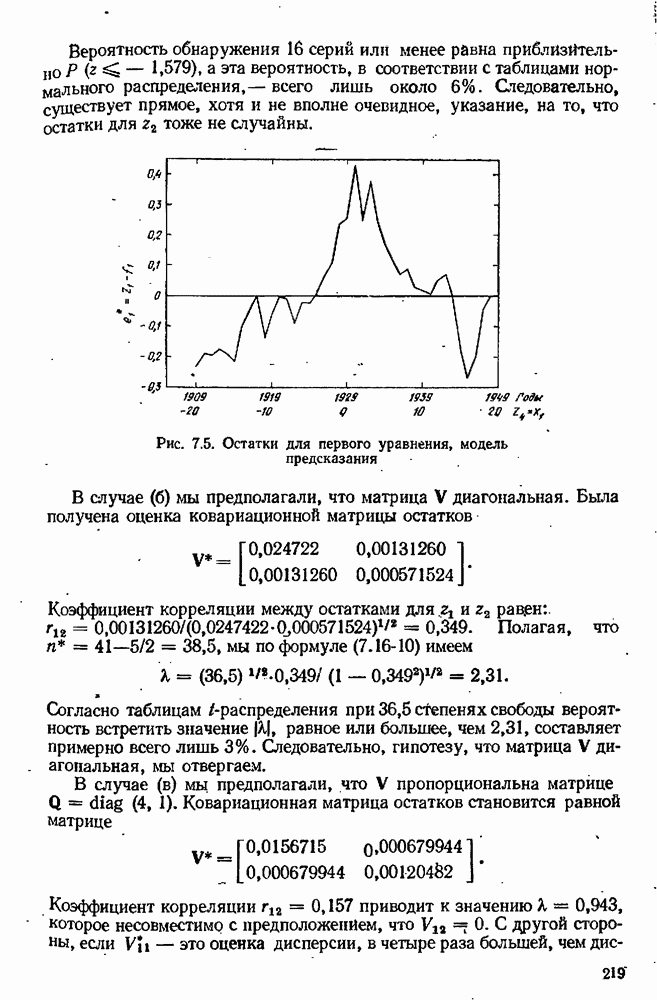
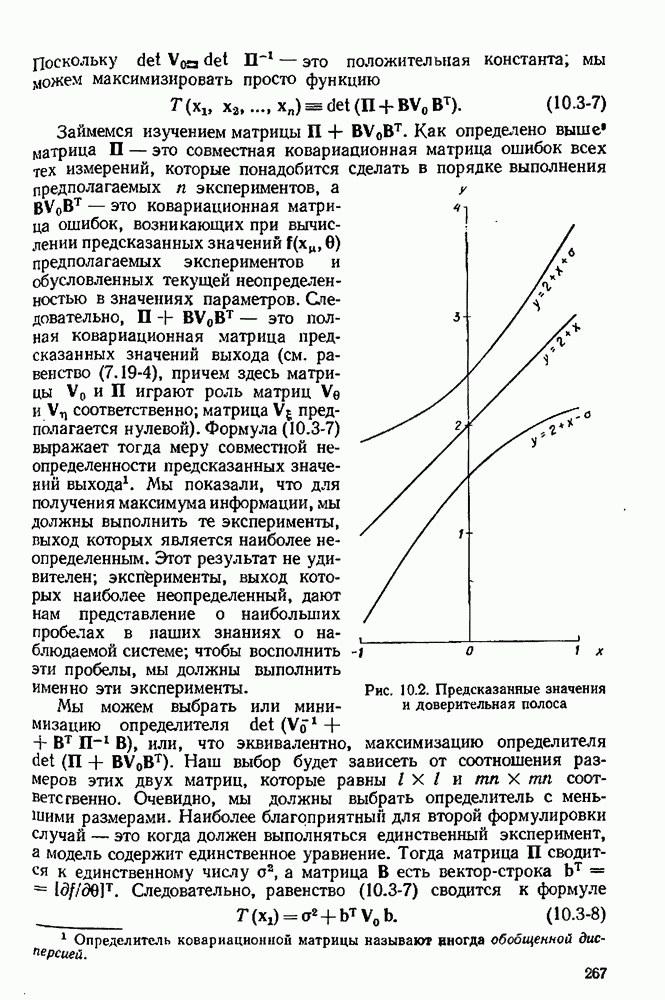
Рис. 10.2, Предсказанные значения и доверительней полоса
Мы можем выбрать или минимизацию определителя 
В), или, что эквивалентно, максимизацию определителя  Наш выбор будет зависеть от соотношения размеров этих двух матриц, которые равны
Наш выбор будет зависеть от соотношения размеров этих двух матриц, которые равны  соответственно. Очевидно, мы должны выбрать определитель с меньшими размерами. Наиболее благоприятный для второй формулировки случай — это когда должен выполняться единственный эксперимент, а модель содержит единственное уравнение. Тогда матрица
соответственно. Очевидно, мы должны выбрать определитель с меньшими размерами. Наиболее благоприятный для второй формулировки случай — это когда должен выполняться единственный эксперимент, а модель содержит единственное уравнение. Тогда матрица  сводится к единственному числу
сводится к единственному числу  а матрица В есть вектор-строка
а матрица В есть вектор-строка  Следовательно, равенство
Следовательно, равенство  сводится к формуле
сводится к формуле

Если дисперсия а постоянна, то нам нужно найти только точку  ко торая максимизирует дисперсию ошибки предсказания
ко торая максимизирует дисперсию ошибки предсказания 
Посмотрим, как выглядят вычисления, связанные со следующим простым примером. Допустим, что модель линейная:

Мы имеем  Пусть
Пусть  ; предположим, что текущими оценками были
; предположим, что текущими оценками были  с ковариационной матрицей
с ковариационной матрицей  . Предсказанный выход у при любом эксперименте х равен
. Предсказанный выход у при любом эксперименте х равен  а дисперсия этого предсказания, в соответствии с формулой
а дисперсия этого предсказания, в соответствии с формулой  равна:
равна:

Чтобы добиться улучшения оценок  мы должны провести эксперимент, максимизирующий величину
мы должны провести эксперимент, максимизирующий величину  т. е. мы должны выбрать число х настолько большое (по абсолютной величине), насколько это практически возможно. Эта ситуация иллюстрируется рис. 10.2, где изображена кривая предсказаний
т. е. мы должны выбрать число х настолько большое (по абсолютной величине), насколько это практически возможно. Эта ситуация иллюстрируется рис. 10.2, где изображена кривая предсказаний  окруженная кривыми, ограничивающими полосу доверия шириной
окруженная кривыми, ограничивающими полосу доверия шириной  Для нашего эксперимента мы выбираем значение х, при котором доверительная полоса широка настолько, насколько это возможно.
Для нашего эксперимента мы выбираем значение х, при котором доверительная полоса широка настолько, насколько это возможно.
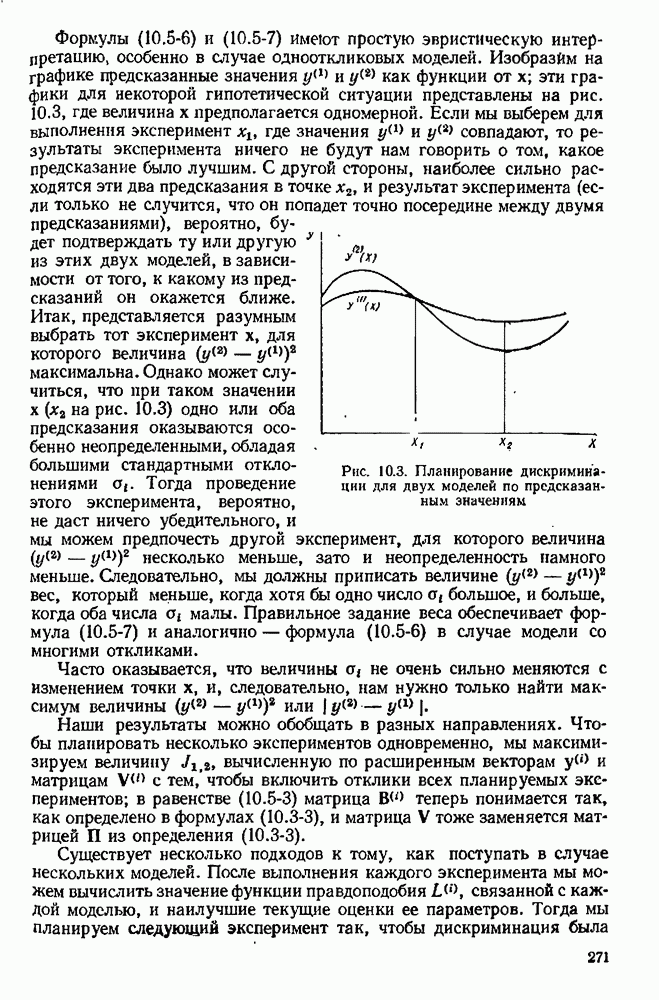
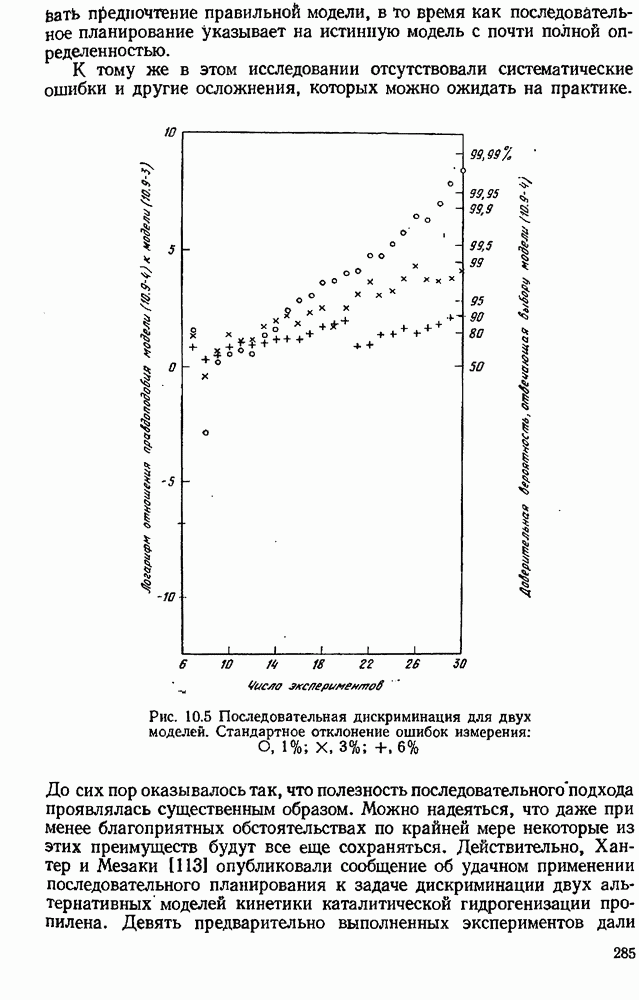
Критерий планирования, обсуждением которого мы здесь занимались, возникал по разным соображениям у Бокса и Лукаса [36] и у Бокса и Хантера [34], с дальнейшей разработкой предлагался Дрейпером и Хантером [60], [61], [62], а также Аткинсоном и Хантером [10]. Применение этого метода с имитационным моделированием на ЭВМ процессов химической кинетики описывалось Китреллом, Хантером и Уотсоном 1123], а детальная разработка для оценки параметров полимеризации сделана Бенкеном [22].

















































































































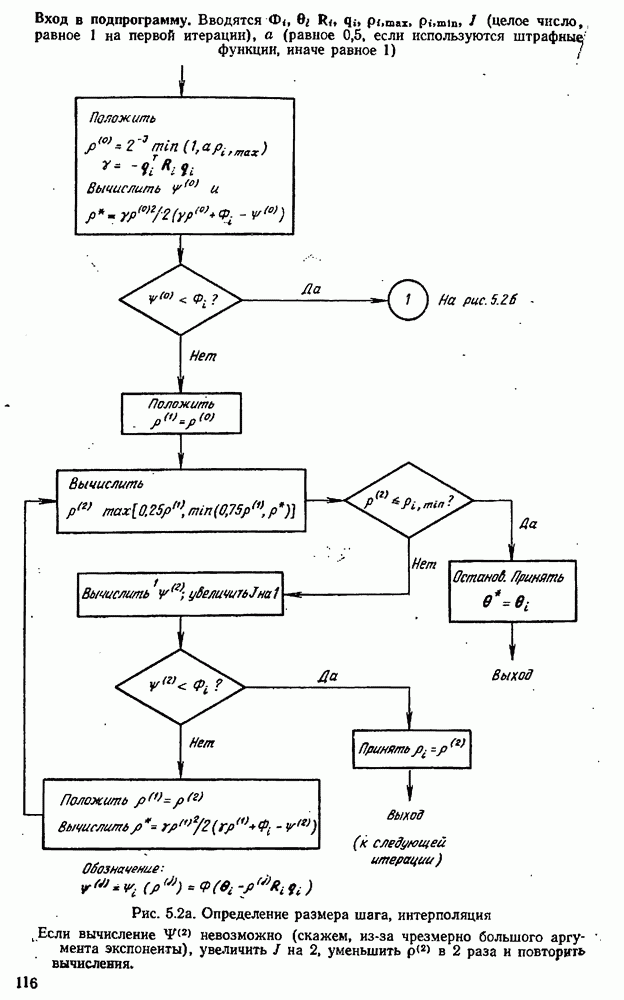
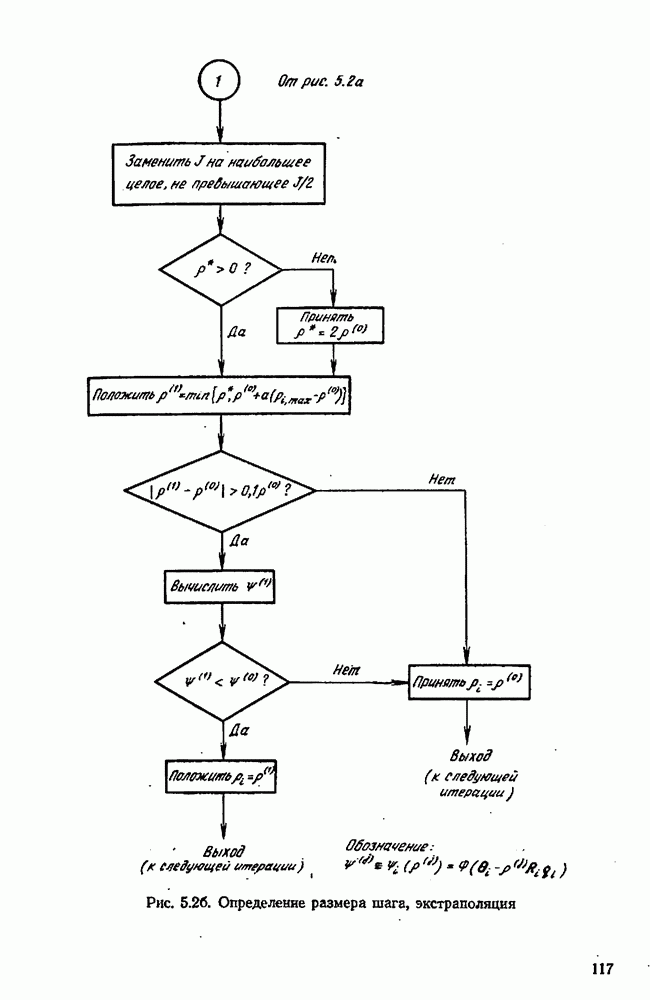










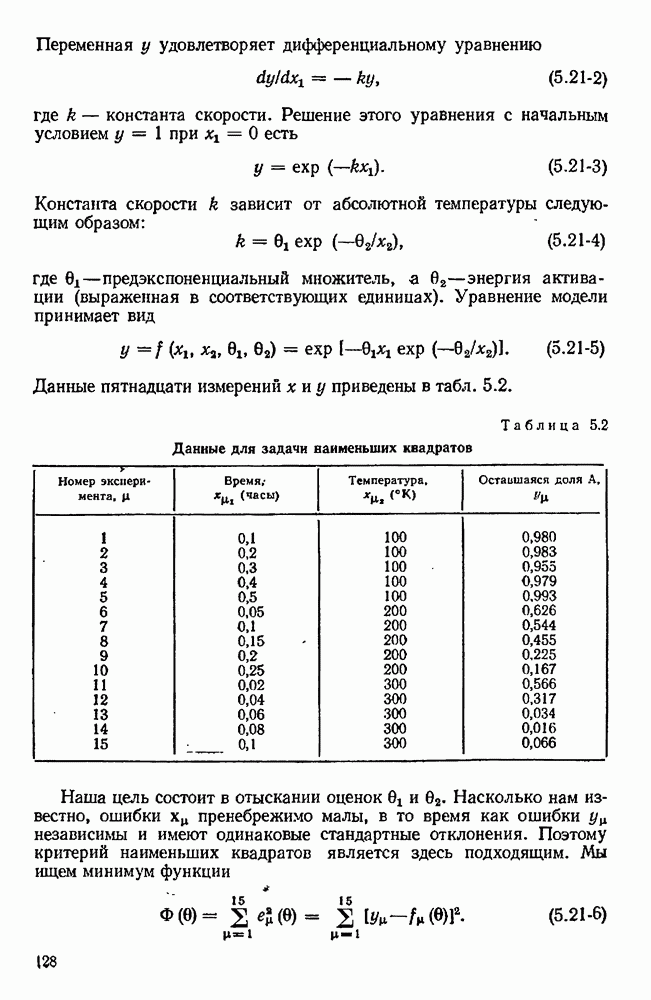
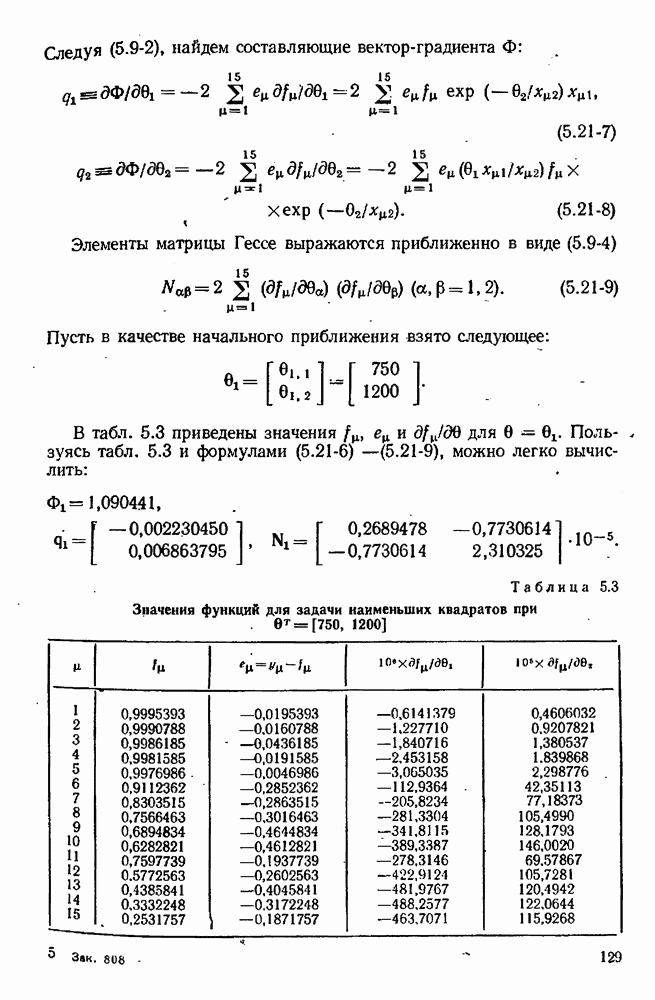









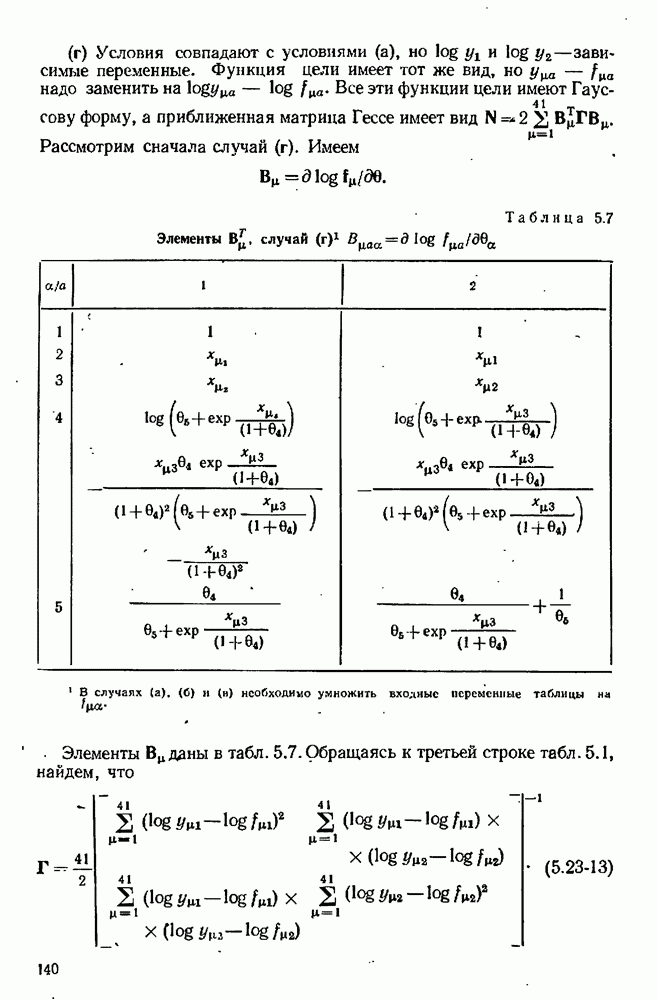
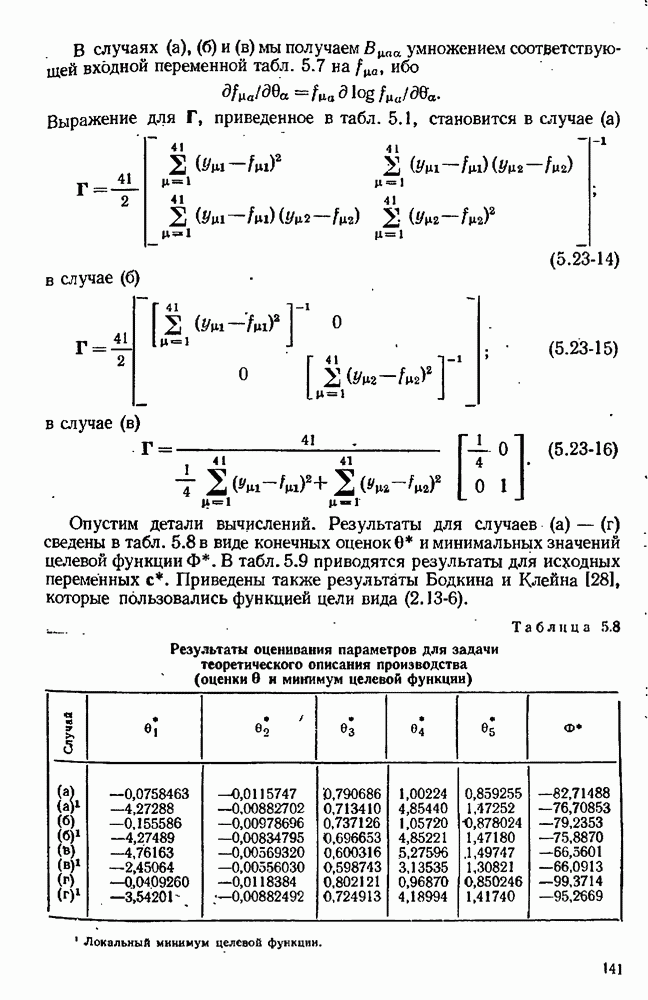

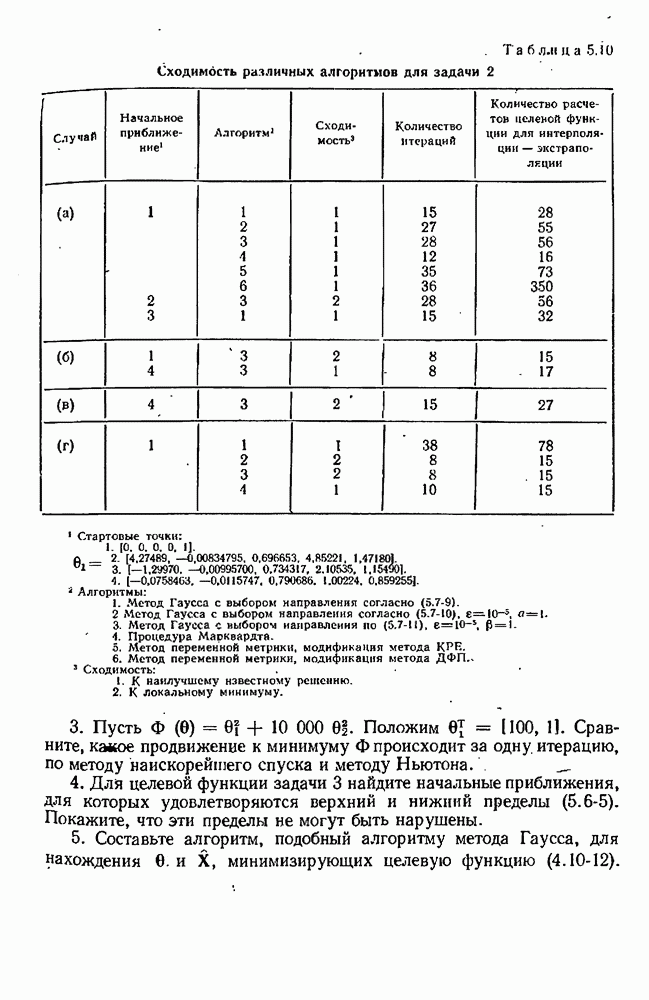























































































































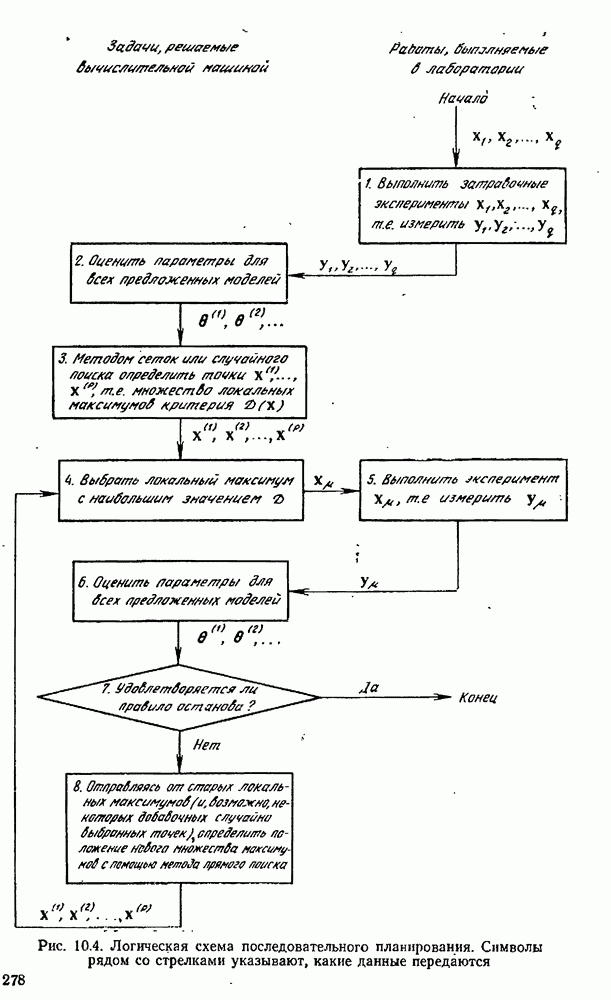

























































 можно свести в итоге к априорному нормальному распределению
можно свести в итоге к априорному нормальному распределению  . Обычно это будет апостериорное (или выборочное) распределение по отношению к уже проведенным экспериментам. Мы намереваемся провести
. Обычно это будет апостериорное (или выборочное) распределение по отношению к уже проведенным экспериментам. Мы намереваемся провести  добавочных экспериментов, в которых будут измеряться величины
добавочных экспериментов, в которых будут измеряться величины  Нашей задачей является определение значений
Нашей задачей является определение значений  при которых должны будут осуществляться эти измерения. Мы допускаем, что ошибки
при которых должны будут осуществляться эти измерения. Мы допускаем, что ошибки  имеют нормальное распределение
имеют нормальное распределение 
 Вектор 0 будет модой апостериорной плотности; апостериорная
Вектор 0 будет модой апостериорной плотности; апостериорная