Пред.
След.
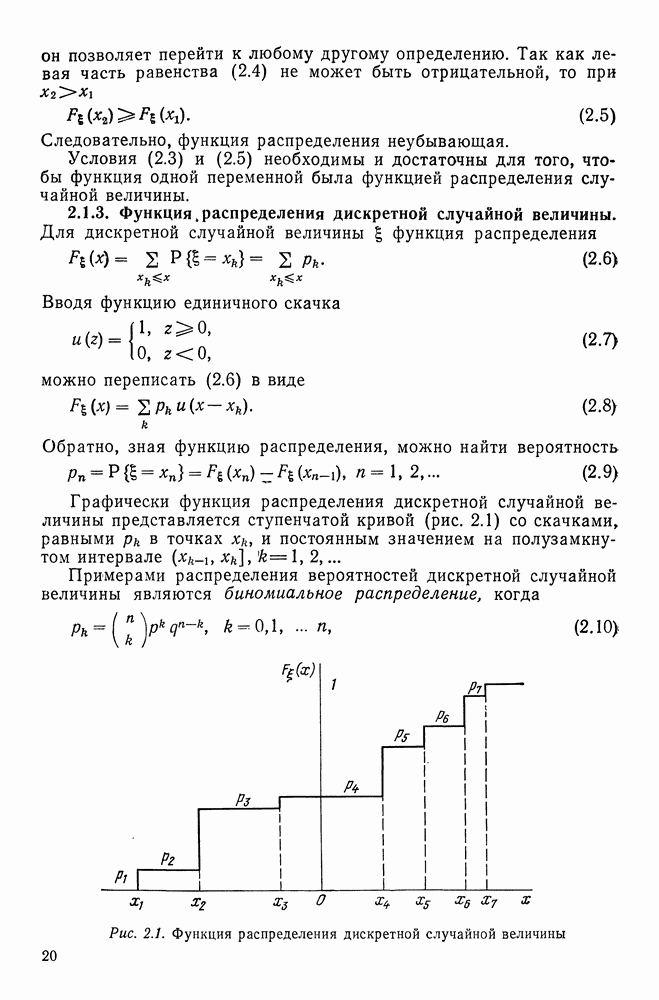
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
22.3. АДАПТИВНЫЕ АЛГОРИТМЫ КЛАССИФИКАЦИИ В УСЛОВИЯХ ПАРАМЕТРИЧЕСКОЙ АПРИОРНОЙ НЕОПРЕДЕЛЕННОСТИ22.3.1. Метод апостериорных вероятностей.Пусть в результате наблюдения получена векторная (информационная) выборка Предполагается, что распределения классов характеризуются плотностями
Используя формулу Байеса, определим апостериорную вероятность принадлежности классу
где
Так как
Алгоритм классификации (22.45) предписывает вычисление величин Функцию
или
так как очевидно, что Второй сомножитель в подынтегральной функции (22.46) определяется согласно (22.42). Заметим, что, когда параметры
и из (22.46) следует
В этом случае алгоритм классификации совпадает с оптимальным байесовским алгоритмом проверки гипотез [см. (20.11)]. 22.3.2. Теорема Бернштейна — Мизеса.Адаптивный алгоритм классификации (22.45) зависит от априорных плотностей распределений параметров [см. (22.42), (22.45), (22.46)]. Проверить возможность использования этого алгоритма без какого-либо определенного предположения об этих априорных плотностях можно с помощью теоремы, установленной С. Н. Бернштейном и Р. Мизесом [71]. Сущность ее состоит в следующем. Пусть
где
Аналогично, когда имеется независимая выборка
где
Упомянутая теорема утверждает, что если априорная плотность Таким образом, при достаточно большом 22.3.3. Адаптивный алгоритм обнаружения случайного сигнала на фоне аддитивной гауссовской помехи.В качестве иллюстрации метода синтеза адаптивного алгоритма классификации в условиях параметрической априорной неопределенности рассмотрим следующую задачу. Имеется реализация Пусть
где
Если известно, что наблюдение
Используя формулу (22.46), находим
Так как интеграл в (22.54) представляет свертку двух плотностей нормального распределения, то непосредственно находим
где Если наблюдение
Из (22.55) и (22.55 а) получаем следующий адаптивный алгоритм обнаружения [см. (22.45)]: принимается решение, что наблюдение
и решение, что наблюдается помеха, в противном случае. После элементарных преобразований алгоритм (22.56) приводится к виду
Здесь в левой части коэффициент Если размер обучающей выборки неограниченно возрастает, то, как следует из (22.51) и (22.52), при
В этом случае квадратический член в левой части (22.57) стремится к нулю, алгоритм классификации становится линейным с перестраиваемым порогом
и не зависит от начального априорного распределения сигнала. Напротив, если
т. e. не зависит от обучающей выборки и полностью определяется априорными данными. Предположим теперь, что наблюдение Пусть
Соотношения (22.60), (22.61) можно представить в рекуррентной форме
Если известно, что наблюдение
Из (22.46) следует
Так как интеграл в (22.65) представляет свертку двух плотностей
где вектор Если наблюдение
Из (22.66) и (22.66 а) получаем следующий адаптивный алгоритм обнаружения: принимается решение, что наблюдаемый вектор
и решение, что наблюдалась помеха, в противном случае. Если размер обучающей выборки
В этом случае алгоритм классификации линейный с перестраиваемым порогом
22.3.4. Адаптивный метод преодоления априорной неопределенности мешающих параметров.Пусть в задаче проверки многоальтернативных гипотез (см. § 13.3) функция правдоподобия, соответствующая
где
Если известны априорные распределения мешающих параметров, то эти параметры можно исключить из (22.70) путем усреднения по этим параметрам, заменив функцию
где В условиях параметрической априорной неопределенности, когда функции
где
в предположении, что существуют указанные производные. Приближение (22.72) допустимо при условии, что априорные плотности распределения мешающих параметров «шире» апостериорных, которые формируются по обучающим выборкам. При этом функция
Для простой функции потерь
где
Представляет интерес и ряд других адаптивных алгоритмов проверки гипотез, рассмотренных в [73].
|
 |
Оглавление
|






















































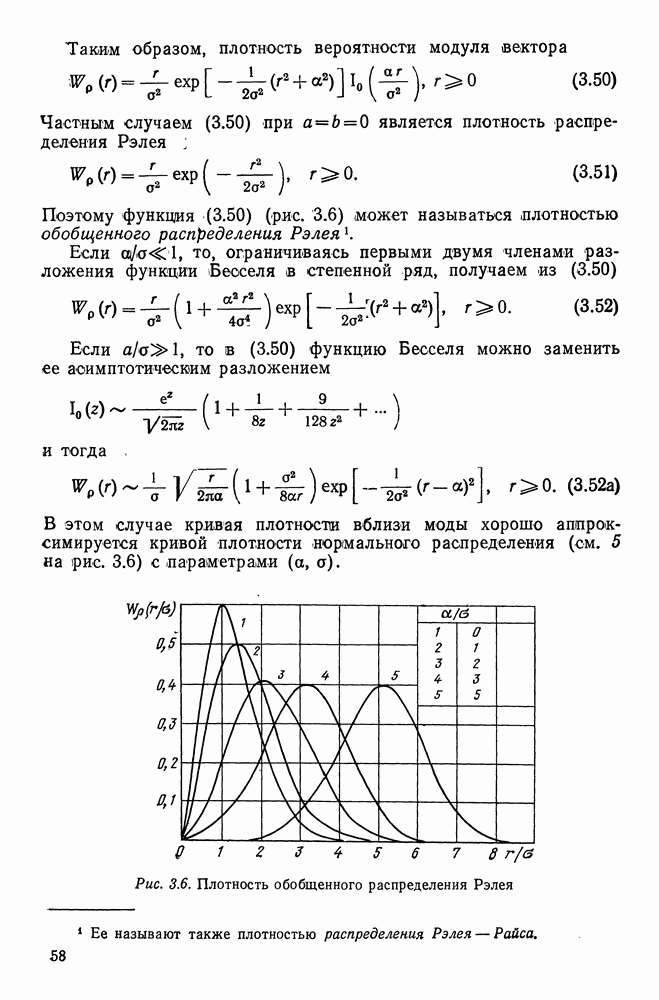



























































































































































































































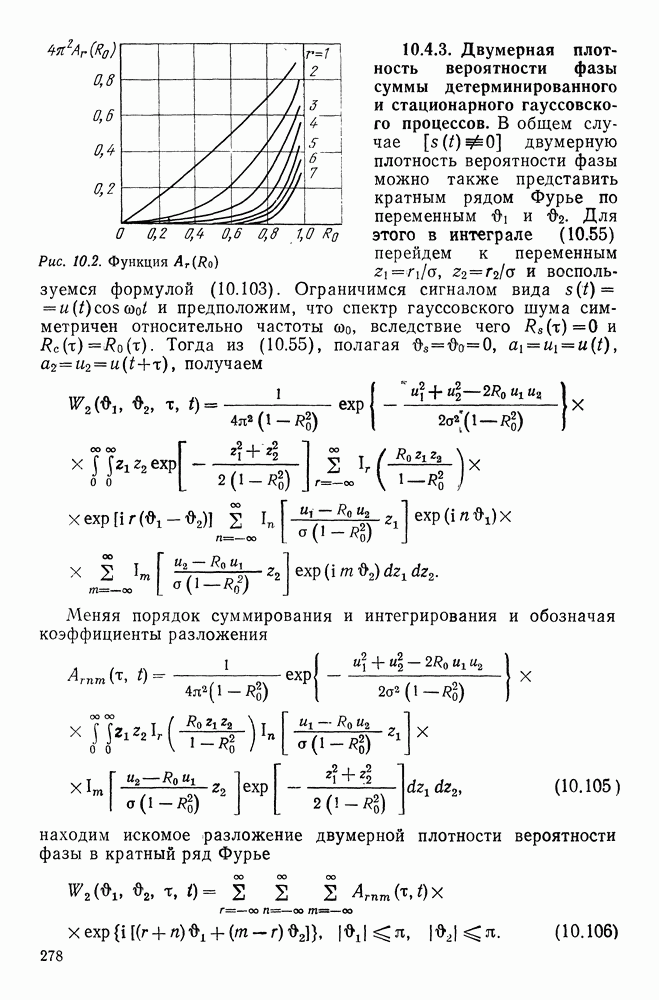











































































































































































































































































































































































 Задача состоит в том, чтобы отнести наблюдение
Задача состоит в том, чтобы отнести наблюдение  к одному из классов
к одному из классов 
 , причем параметры
, причем параметры  представляют независимые случайные векторы с априорными плотностями вероятностей
представляют независимые случайные векторы с априорными плотностями вероятностей  которые отражают первоначальные знания о распределениях этих параметров. Имеется набор обучающих классифицированных выборок
которые отражают первоначальные знания о распределениях этих параметров. Имеется набор обучающих классифицированных выборок  где вектор
где вектор  принадлежит классу
принадлежит классу  Эту обучающую выборку можно использовать для корректировки априорных знаний путем определения апостериорной плотности
Эту обучающую выборку можно использовать для корректировки априорных знаний путем определения апостериорной плотности
 (22.42)
(22.42)
 при данных
при данных 
 (22.43)
(22.43)
 — априорная вероятность принадлежности классу
— априорная вероятность принадлежности классу  . По критерию максимальной апостериорной вероятности относим наблюдение к классу
. По критерию максимальной апостериорной вероятности относим наблюдение к классу  если
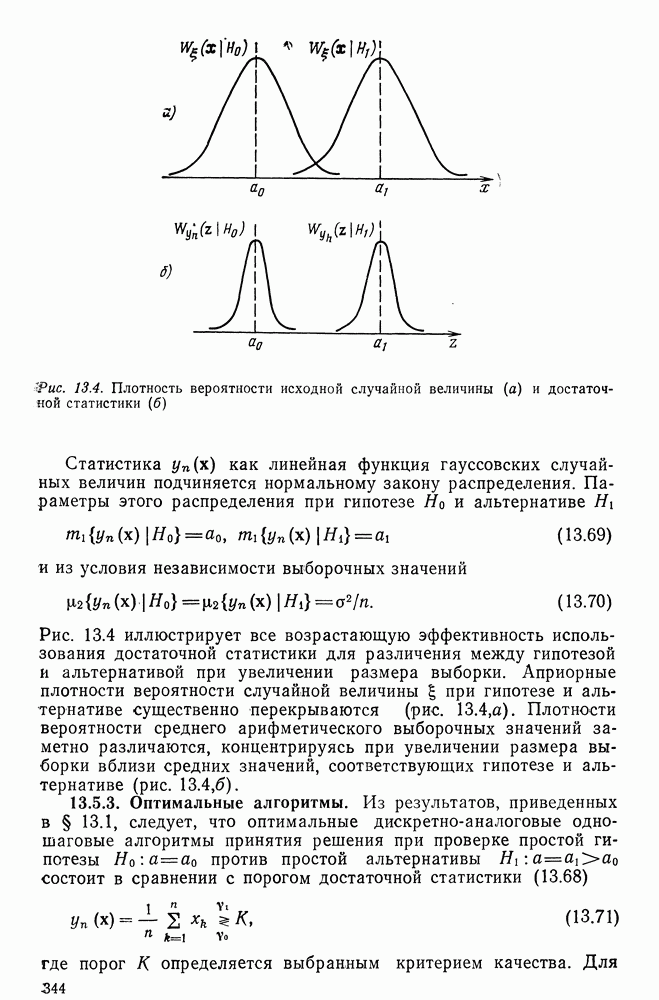
если
 (22.44)
(22.44)
 то из (22.43), (22.44) следует
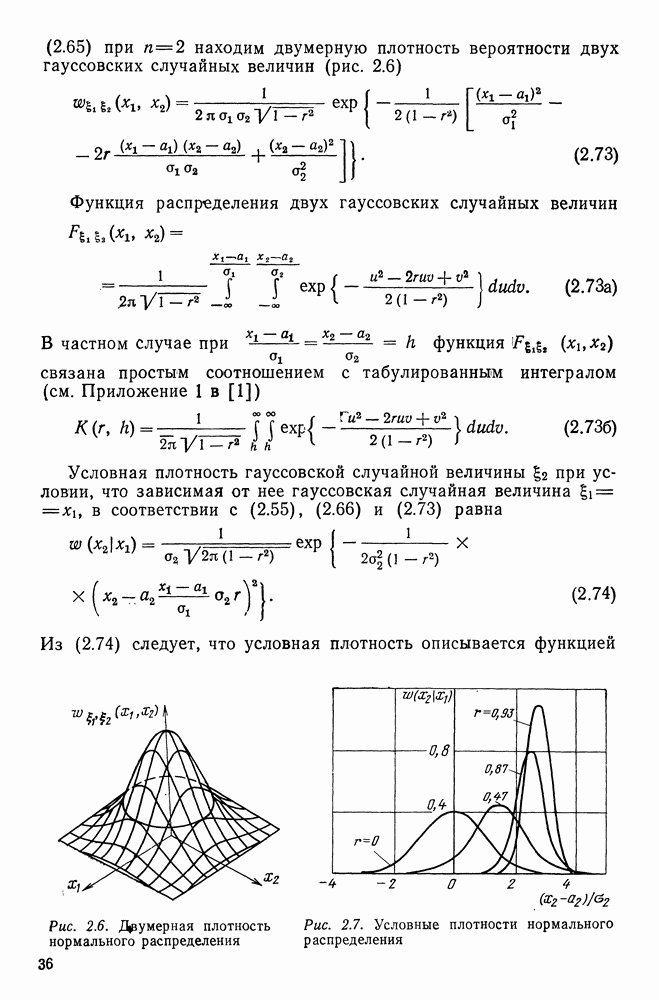
то из (22.43), (22.44) следует
 (22.45)
(22.45)
 и отнесение вектора наблюдения
и отнесение вектора наблюдения  к тому классу
к тому классу  которому соответствует максимальная из указанных величин. Если априорные вероятности
которому соответствует максимальная из указанных величин. Если априорные вероятности  одинаковы,
одинаковы,  классификация при заданном наборе
классификация при заданном наборе  сводится к определению того класса S, для которого наблюдаемая выборка
сводится к определению того класса S, для которого наблюдаемая выборка  максимизирует по индексу
максимизирует по индексу  функцию правдоподобия
функцию правдоподобия  . Последние можно рассматривать как оценки неизвестных плотностей распределений классов при заданном наборе обучающих
. Последние можно рассматривать как оценки неизвестных плотностей распределений классов при заданном наборе обучающих 
 вычисляем, используя формулу полной вероятности
вычисляем, используя формулу полной вероятности

 (22.46)
(22.46)
 , а функция
, а функция  вовсе не зависит от обучающих выборок.
вовсе не зависит от обучающих выборок.
 априори известны и равны
априори известны и равны  их условные плотности представляют дельта-функции
их условные плотности представляют дельта-функции


 — выборочное значение из распределения с неизвестным случайным параметром О. Апостериорное распределение этого пара» метра
— выборочное значение из распределения с неизвестным случайным параметром О. Апостериорное распределение этого пара» метра
 (22.47)
(22.47)
 — априорная плотность вероятности параметра
— априорная плотность вероятности параметра  . Если извлекается следующее выборочное значение
. Если извлекается следующее выборочное значение  независимое от
независимое от  , то
, то  можно использовать в качестве нового априорного распределения для вычисления апостериорного
можно использовать в качестве нового априорного распределения для вычисления апостериорного

 размером
размером  , то
, то
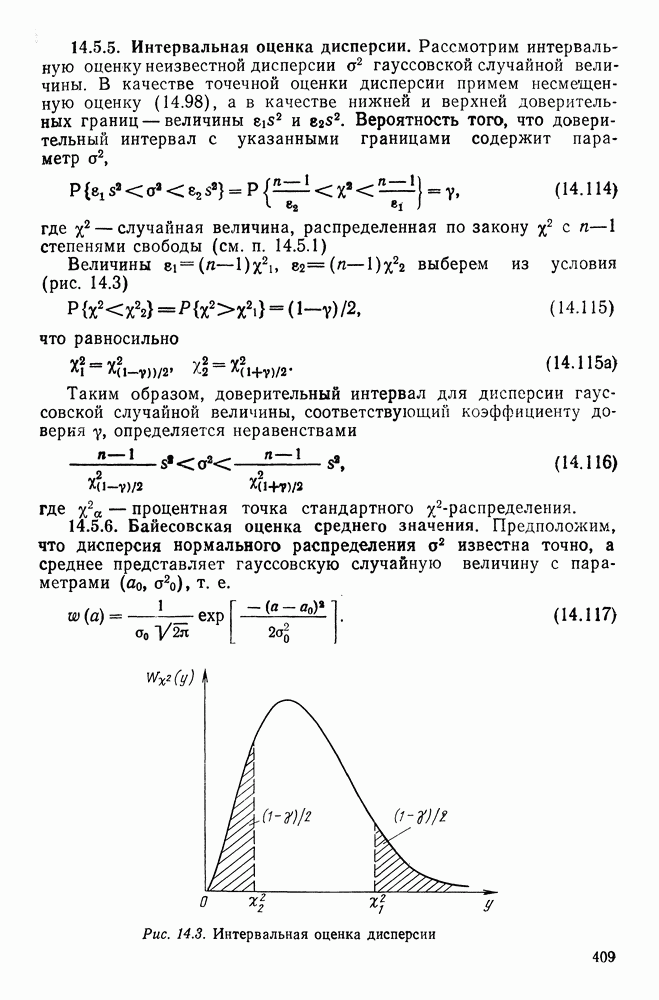
 (22.49)
(22.49)

 параметра
параметра  непрерывна, то по мере возрастания объема выборки апостериорное распределение
непрерывна, то по мере возрастания объема выборки апостериорное распределение  перестает зависеть от априорного распределения.
перестает зависеть от априорного распределения.
 безразлично, какую непрерывную функцию w (О) подставить в формулу (22.49). Эта предельная теорема послужила основой синтеза алгоритма классификации, предложенного Роббинсом [71].
безразлично, какую непрерывную функцию w (О) подставить в формулу (22.49). Эта предельная теорема послужила основой синтеза алгоритма классификации, предложенного Роббинсом [71].
 скалярной случайной величины, которую следует отнести к одному из двух классов:
скалярной случайной величины, которую следует отнести к одному из двух классов:  — помеха, представляющая гауссовскую случайную величину с нулевым средним и дисперсией
— помеха, представляющая гауссовскую случайную величину с нулевым средним и дисперсией  — аддитивная смесь этой помехи и независимого от нее случайного сигнала, среднее значение а которого
— аддитивная смесь этой помехи и независимого от нее случайного сигнала, среднее значение а которого  случайная величина, распределённая по нормальному закону с параметрами
случайная величина, распределённая по нормальному закону с параметрами  Предполагается, что априорные вероятности принадлежности наблюдения классам
Предполагается, что априорные вероятности принадлежности наблюдения классам  одинаковы.
одинаковы.
 — независимая классифицированная выборка аддитивной смеси сигнала с гауссовской помехой. По формул (22.42) находим апостериорную плотность распределения сигнального параметра а [см. (14.119)]
— независимая классифицированная выборка аддитивной смеси сигнала с гауссовской помехой. По формул (22.42) находим апостериорную плотность распределения сигнального параметра а [см. (14.119)]
 (22.50)
(22.50)
 (22.51)
(22.51)
 принадлежит классу
принадлежит классу  , то
, то


 (22.55)
(22.55)
 а величины
а величины  определяются согласна (22.51) и (22.52).
определяются согласна (22.51) и (22.52).
 — помеха, то [см. (22.46 а)]
— помеха, то [см. (22.46 а)]
 (22.55 а)
(22.55 а)
 представляет смесь случайного сигнала с аддитивной гауссовской помехой, если
представляет смесь случайного сигнала с аддитивной гауссовской помехой, если
 (22.56)
(22.56)
 (22.57)
(22.57)
 зависит от обучающей выборки, а коэффициент
зависит от обучающей выборки, а коэффициент  априори заданных дисперсий
априори заданных дисперсий  и размера
и размера  обучающей выборки. Порог в правой части (22.57) зависит и от указанных значений дисперсий, и от обучающей выборки.
обучающей выборки. Порог в правой части (22.57) зависит и от указанных значений дисперсий, и от обучающей выборки.

 (22.58)
(22.58)
 с (22.9)]
с (22.9)]
 (22.59)
(22.59)
 то
то  и алгоритм (22.57) преобразуется к виду
и алгоритм (22.57) преобразуется к виду

 представляет векторную (размером N) случайную величину, которую следует отнести к одному из двух классов:
представляет векторную (размером N) случайную величину, которую следует отнести к одному из двух классов:  — гауссовская помеха с нулевым вектором средних и ковариационной матрицей
— гауссовская помеха с нулевым вектором средних и ковариационной матрицей  — аддитивная смесь помехи и независимого от нее случайного сигнала, вектор средних а которого случайный, подчинен многомерному нормальному распределению с параметрами
— аддитивная смесь помехи и независимого от нее случайного сигнала, вектор средних а которого случайный, подчинен многомерному нормальному распределению с параметрами 
 — классифицированная выборка аддитивной смеси сигнала и гауссовской помехи. По формуле (22.42) с учетом результатов, приведенных в п. 14.5.7 и 14.5.8, находим, что апостериорная плотность сигнального параметра а подчиняется многомерному нормальному распределению с параметрами
— классифицированная выборка аддитивной смеси сигнала и гауссовской помехи. По формуле (22.42) с учетом результатов, приведенных в п. 14.5.7 и 14.5.8, находим, что апостериорная плотность сигнального параметра а подчиняется многомерному нормальному распределению с параметрами
 (22.60)
(22.60)
 (22.62)
(22.62)
 приндалежит классу
приндалежит классу  , то
, то
 (22.64)
(22.64)
 (22.65)
(22.65)
 -мерного нормального распределения, то непосредственна находим
-мерного нормального распределения, то непосредственна находим
 (22.66)
(22.66)
 и матрица
и матрица  определены согласно (22.60), (22.61).
определены согласно (22.60), (22.61).
 — помеха, то
— помеха, то
 (22.66 а )
(22.66 а )
 представляет аддитивную смесь случайного сигнала и гауссовской помехи, если
представляет аддитивную смесь случайного сигнала и гауссовской помехи, если
 (22.67)
(22.67)
 то
то
 (22.68)
(22.68)
 с (22.22) и с (22.59)
с (22.22) и с (22.59)
 (22.69)
(22.69)
 гипотезе, зависит от векторного мешающего параметра
гипотезе, зависит от векторного мешающего параметра  Запишем выражение среднего риска как функции мешающих параметров
Запишем выражение среднего риска как функции мешающих параметров
 (22.70)
(22.70)
 (22.70 а)
(22.70 а)
 — область выборочного пространства X, соответствующая решению
— область выборочного пространства X, соответствующая решению  о принятии гипотезы
о принятии гипотезы  — элементы матрицы потерь,
— элементы матрицы потерь,  — априорная вероятность гипотезы
— априорная вероятность гипотезы 
 функцией
функцией
 (22.71)
(22.71)
 - априорная плотность распределения параметра
- априорная плотность распределения параметра 
 неизвестны, при помощи обучающих выборок можно определить оценки максимального правдоподобия
неизвестны, при помощи обучающих выборок можно определить оценки максимального правдоподобия  мешающих параметров и, как показано в [72], воспользуемся вместо (22.71) приближенным выражением
мешающих параметров и, как показано в [72], воспользуемся вместо (22.71) приближенным выражением

 — размерность вектора
— размерность вектора  — матрица с элементами
— матрица с элементами
 (22.72 а)
(22.72 а)
 существенно слабее зависит от
существенно слабее зависит от  чем остальные множители в правой части (22.72), и поэтому ее, наряду с величиной
чем остальные множители в правой части (22.72), и поэтому ее, наряду с величиной  можно рассматривать как несущественный сомножитель. Тогда адаптивный алгоритм проверки многоальтернативных гипотез определяется минимизацией (путем определения соответствующих решающих функций
можно рассматривать как несущественный сомножитель. Тогда адаптивный алгоритм проверки многоальтернативных гипотез определяется минимизацией (путем определения соответствующих решающих функций  ) величины
) величины
 (22.73)
(22.73)
 (22.74)
(22.74)
 — символ Кронекера, оптимальный адаптивный алгоритм формулируется следующим образом: принимается гипотеза
— символ Кронекера, оптимальный адаптивный алгоритм формулируется следующим образом: принимается гипотеза  если для всех
если для всех 
