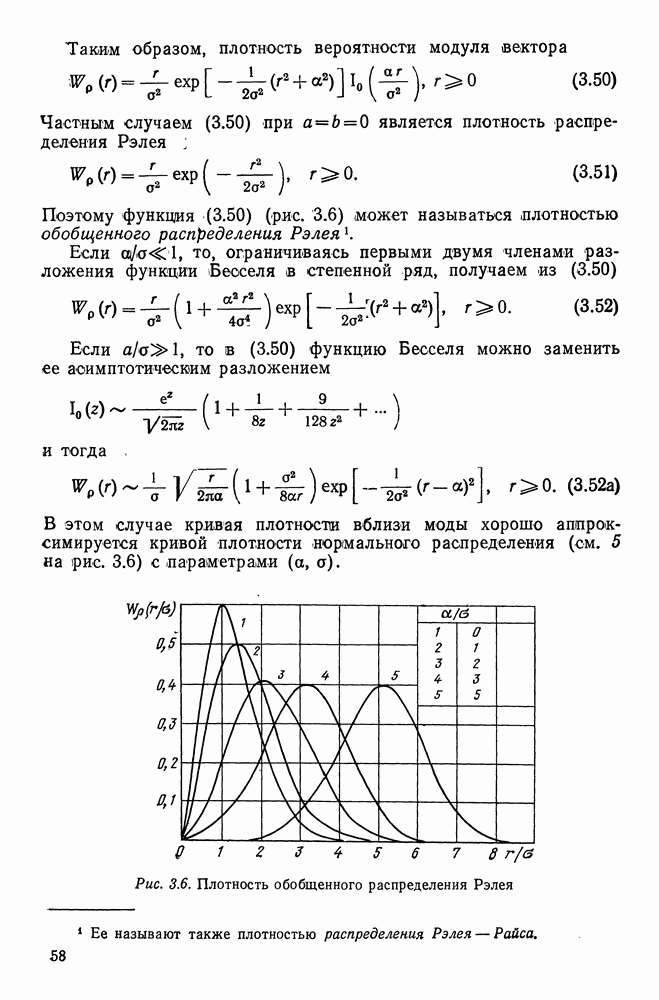
то, как показано в [74], подходящей аппроксимацией функции  является функция
является функция  получаем согласно рекуррентному алгоритму
получаем согласно рекуррентному алгоритму
 (22.78)
(22.78)
где  — числовая последовательность, подчинения условию сходимости
— числовая последовательность, подчинения условию сходимости  к D при
к D при  . Обозначая через
. Обозначая через  коэффициенты разложения (22.76) на
коэффициенты разложения (22.76) на  шаге, получаем из (22.78) следующий рекуррентный алгоритм оценивания этих коэффициентов по обучающей выборке:
шаге, получаем из (22.78) следующий рекуррентный алгоритм оценивания этих коэффициентов по обучающей выборке:
 (22.79)
(22.79)
На первом шаге в качестве нулевого приближения  , можно выбрать произвольные константы.
, можно выбрать произвольные константы.
Зависимые обучающие выборки рассмотрены в [75]. Рекуррентным адаптивным алгоритмом, основанным на использовании классифицирующих статистик, посвящена монография [76] (см. также [79]).
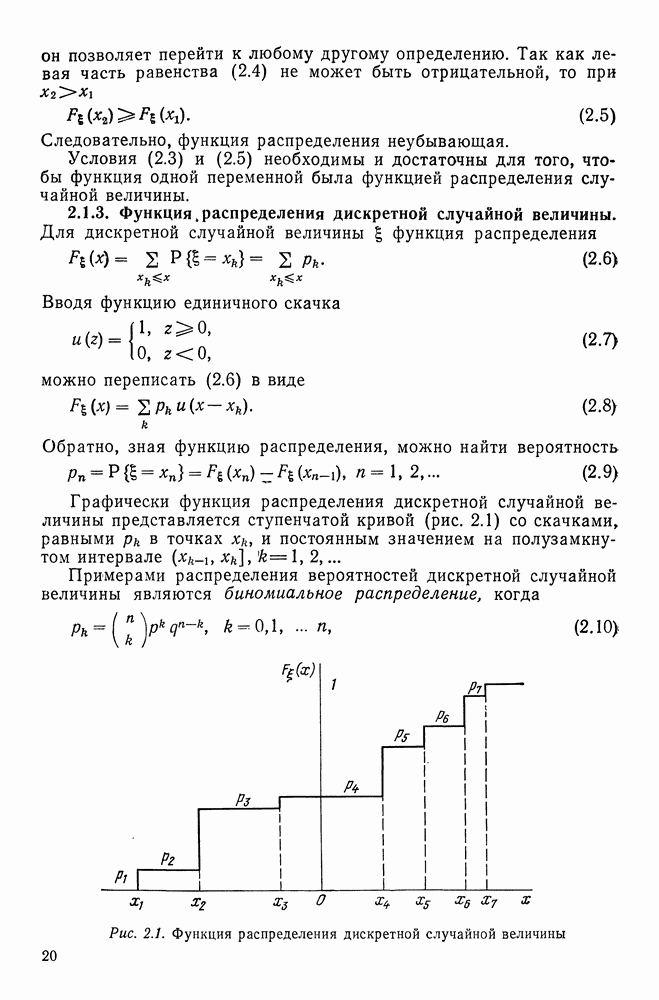
22.4.2. Метод оценки классифицирующей статистики.
Пусть  — последовательность независимых обучающих векторных (
— последовательность независимых обучающих векторных ( -мерных) выборок, принадлежащих
-мерных) выборок, принадлежащих  классу
классу  . Каждый вектор
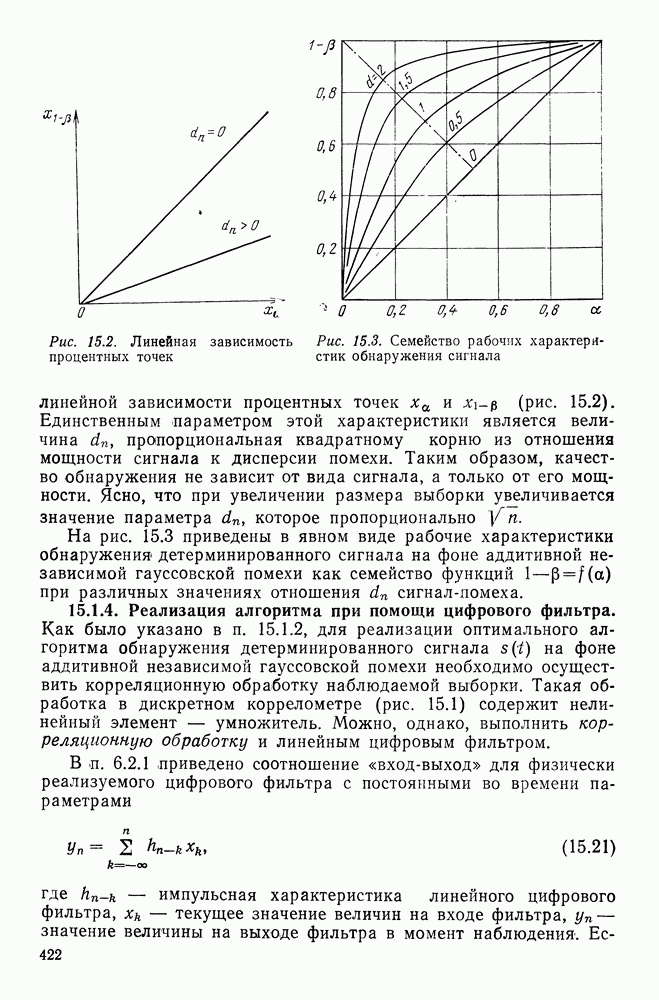
. Каждый вектор  появляется с вероятностью
появляется с вероятностью  если
если  и с вероятностью
и с вероятностью  если
если  . Введем дискретную случайную величину
. Введем дискретную случайную величину  принимающую два значения:
принимающую два значения:
 (22.80)
(22.80)
Ясно, что

Обозначив
 (22.82)
(22.82)
можно объединить обе обучающие последовательности в одну  и использовать эту последовательность для аппроксимации классифицирующей статистики
и использовать эту последовательность для аппроксимации классифицирующей статистики  [см. (22.76)]. Так как
[см. (22.76)]. Так как  можно воспользоваться методами оценки многомерной плотности вероятности. Примем в качестве аппроксимации
можно воспользоваться методами оценки многомерной плотности вероятности. Примем в качестве аппроксимации  ) функцию
) функцию
 (22.83)
(22.83)
где
 (22.83 а)
(22.83 а)
ядро  и константы
и константы  удовлетворяют условиям (14.22а-в) и (14.25 а,б) [см., например, [80]].
удовлетворяют условиям (14.22а-в) и (14.25 а,б) [см., например, [80]].




























































































































































































































































































































































































































































































































































































































































 -мерным вектором
-мерным вектором  Решается задача классификации — принадлежности этого наблюдения одному из двух классов
Решается задача классификации — принадлежности этого наблюдения одному из двух классов  . Если известны плотности
. Если известны плотности  а также априорные вероятности
а также априорные вероятности  принадлежности первому и второму классам, то оптимальной классифицирующей статистикой служит отношение правдоподобия
принадлежности первому и второму классам, то оптимальной классифицирующей статистикой служит отношение правдоподобия  . В условиях непараметрической априорной неопределенности можно попытаться аппроксимировать статистику
. В условиях непараметрической априорной неопределенности можно попытаться аппроксимировать статистику  используя неклассифицированную независимую обучающую выборку
используя неклассифицированную независимую обучающую выборку  из пространства X.
из пространства X.
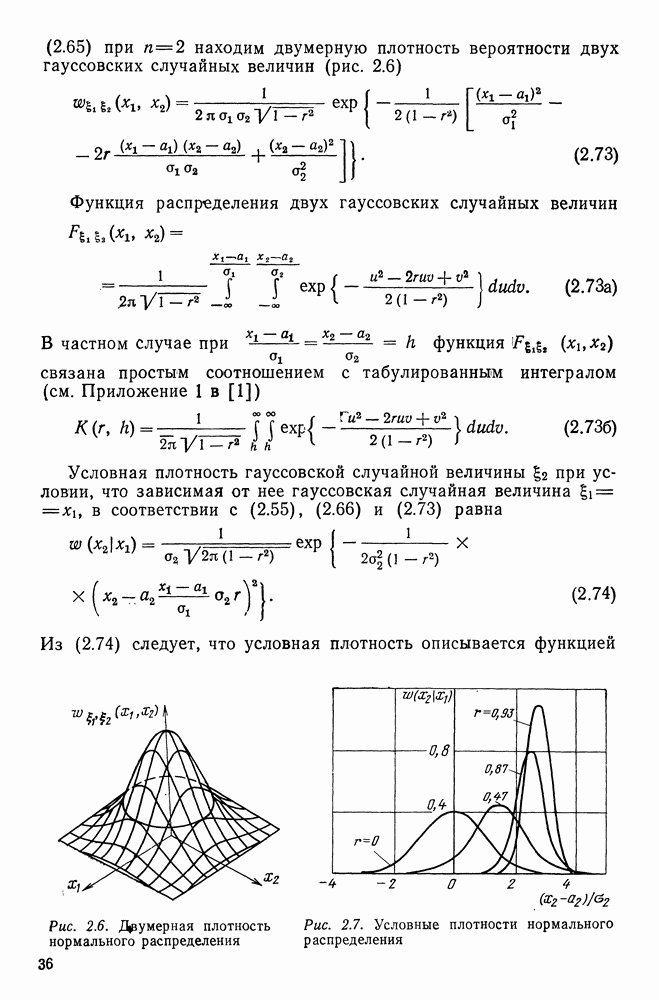
 (22.76)
(22.76)
 (22.77)
(22.77)
 (22.84)
(22.84)
 неограниченно возрастает. При этом оценка вероятности ошибки классификации при использовании классифицирующей статистики
неограниченно возрастает. При этом оценка вероятности ошибки классификации при использовании классифицирующей статистики  сходится к вероятности ошибки классификации, соответствующей оптимальному правилу при полной априорной информации.
сходится к вероятности ошибки классификации, соответствующей оптимальному правилу при полной априорной информации.
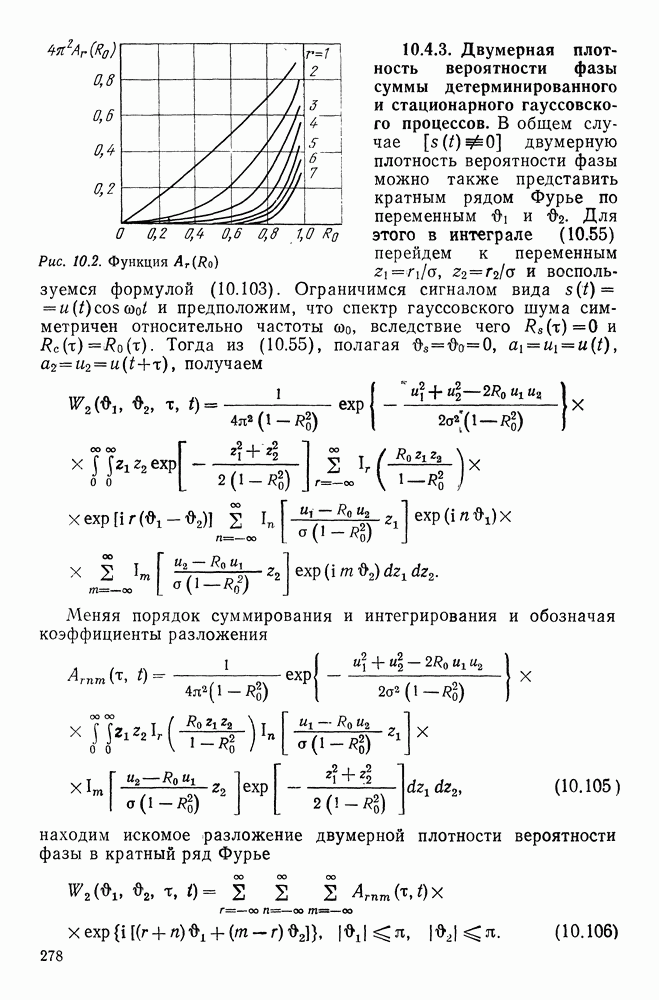
 непрерывна в точке
непрерывна в точке  и последовательность областей
и последовательность областей  с объемами
с объемами  удовлетворяет следующим условиям:
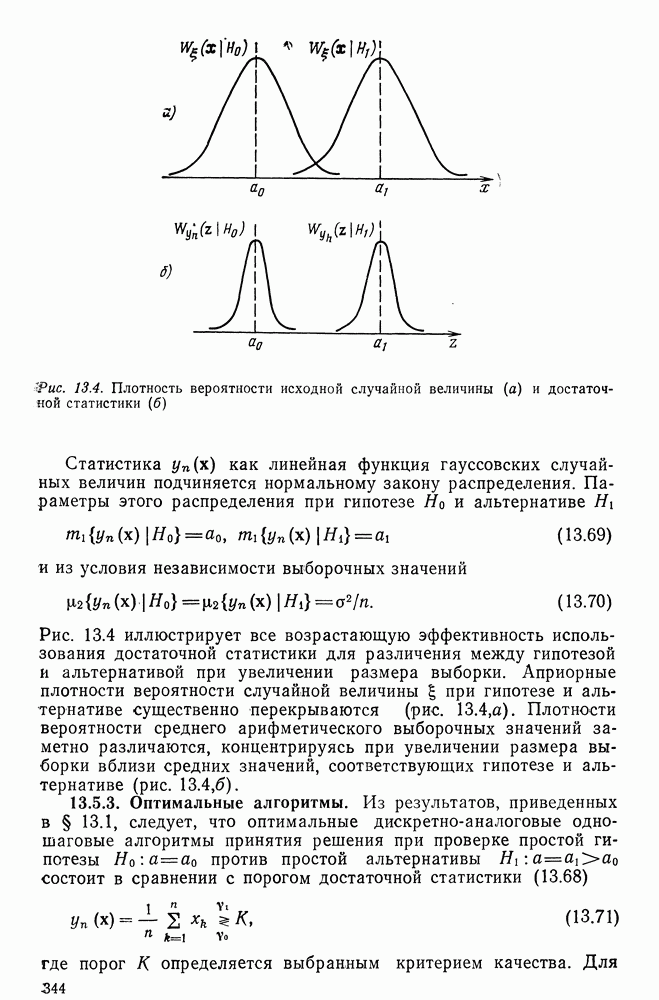
удовлетворяет следующим условиям:


 попадающих в область
попадающих в область  таково, что
таково, что  при
при  и
и

 в точке
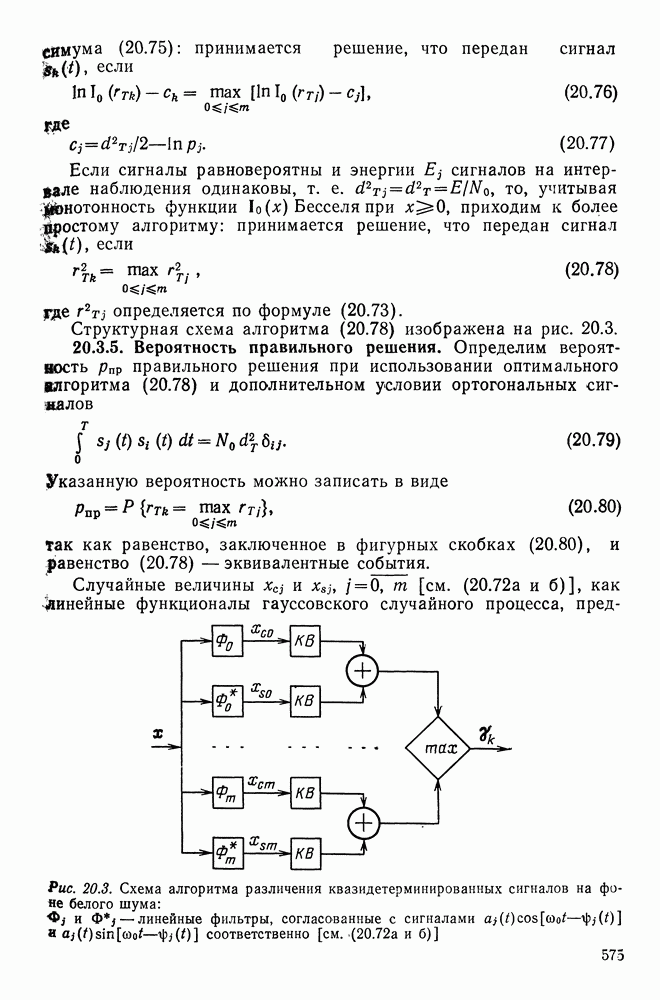
в точке 
 обучающих независимых выборок
обучающих независимых выборок  о каждой из которых известно, к какому из двух распределений принадлежит выборка, и если среди k обучающих выборок, ближайших к наблюдаемой выборке
о каждой из которых известно, к какому из двух распределений принадлежит выборка, и если среди k обучающих выборок, ближайших к наблюдаемой выборке  принадлежит распределению с плотностью
принадлежит распределению с плотностью  — к распределению с плотностью
— к распределению с плотностью  то принимается решение, что наблюдаемая выборка
то принимается решение, что наблюдаемая выборка  относится к классу с плотностью
относится к классу с плотностью  если
если
 (22.85)
(22.85)
 в противном случае. Адаптивное правило (22.85) не требует построения оценок плотностей распределений и является в известном смысле непараметрическим (см., например [78]).
в противном случае. Адаптивное правило (22.85) не требует построения оценок плотностей распределений и является в известном смысле непараметрическим (см., например [78]).
