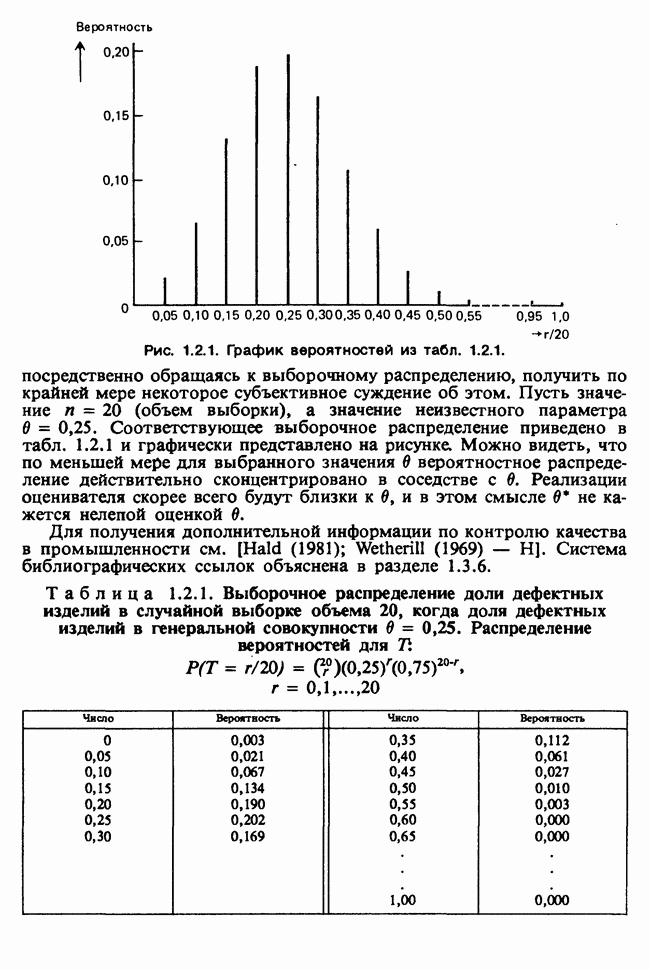
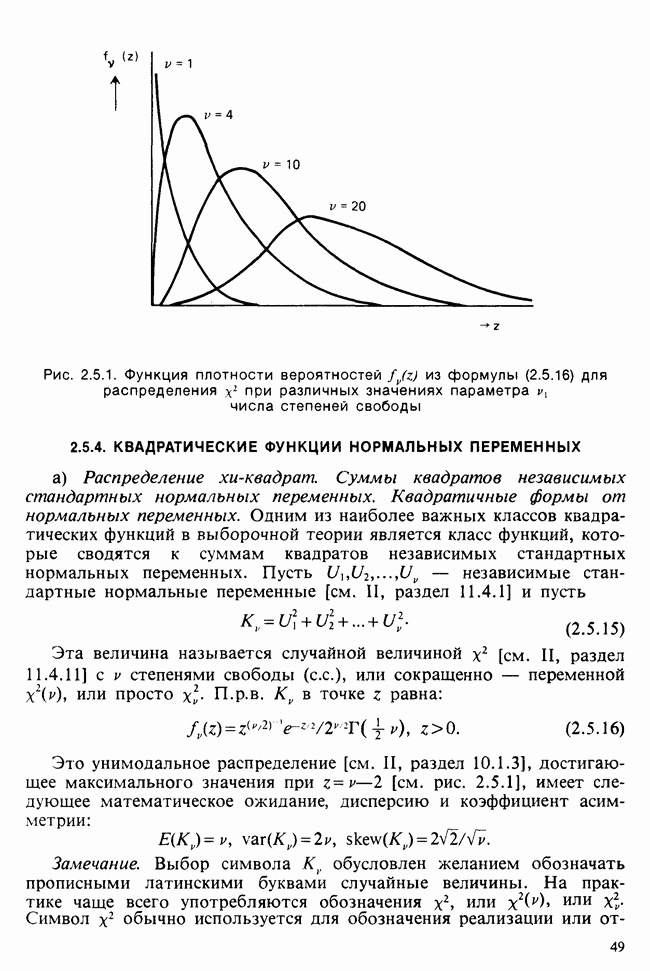
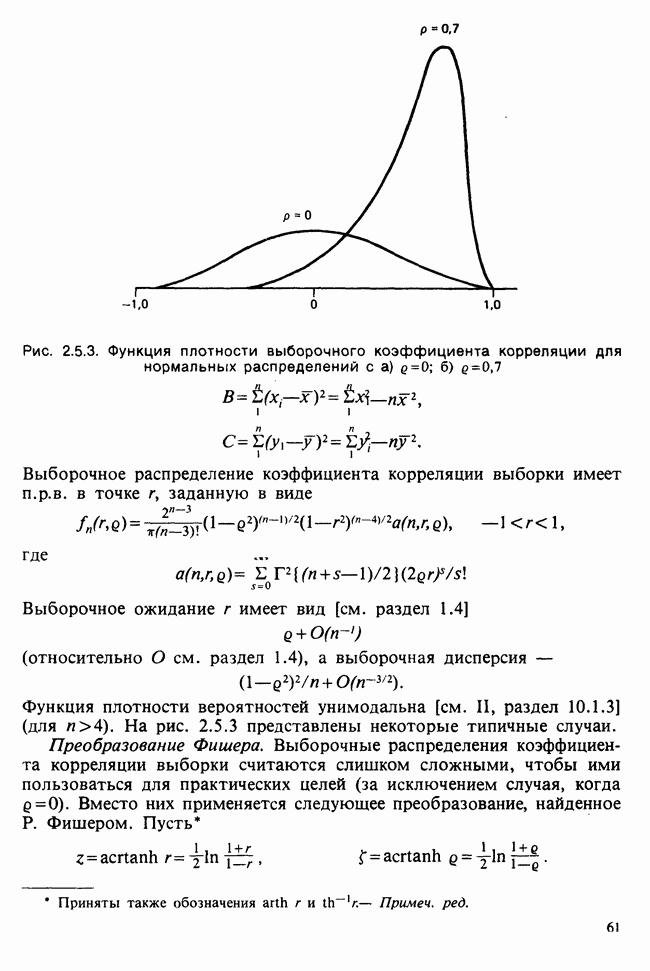
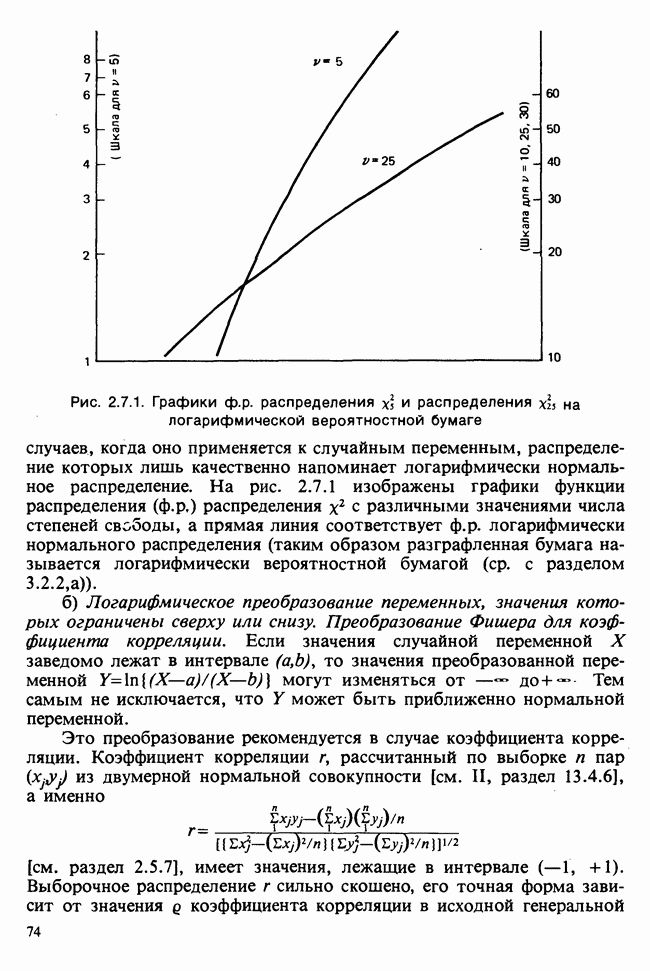
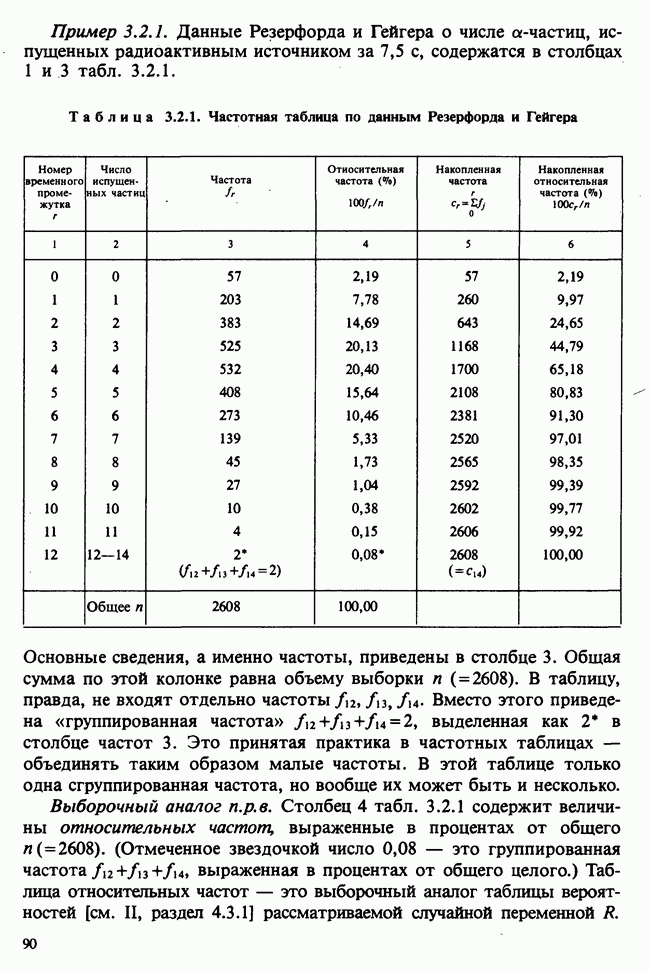
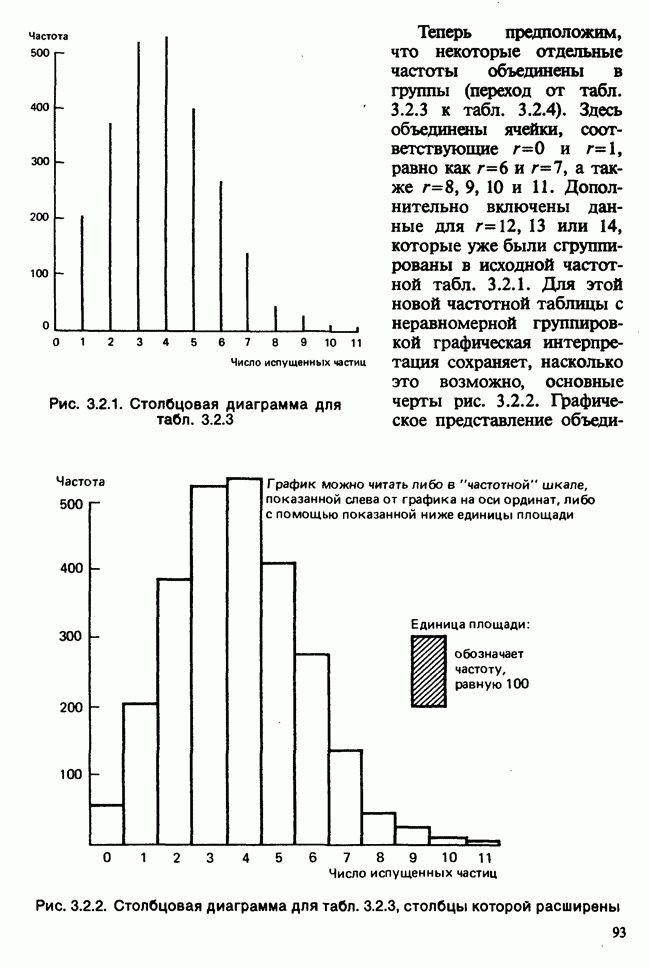
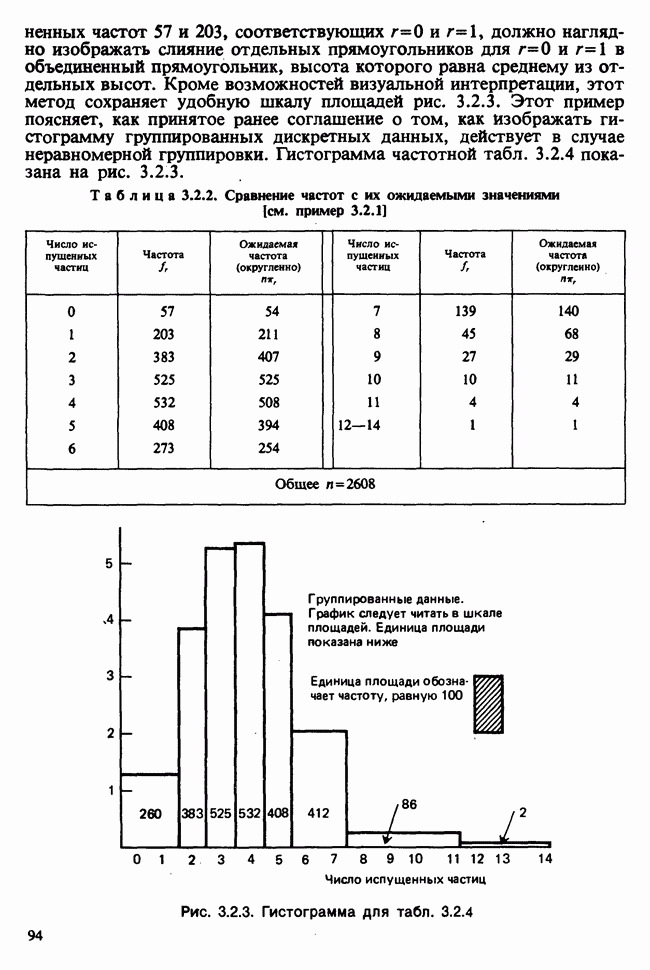
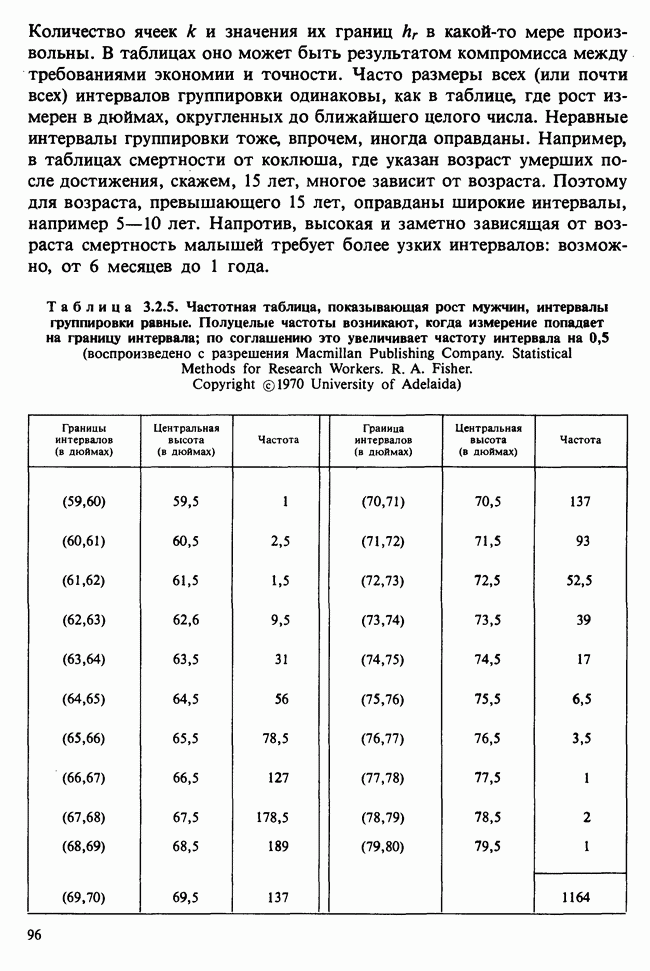
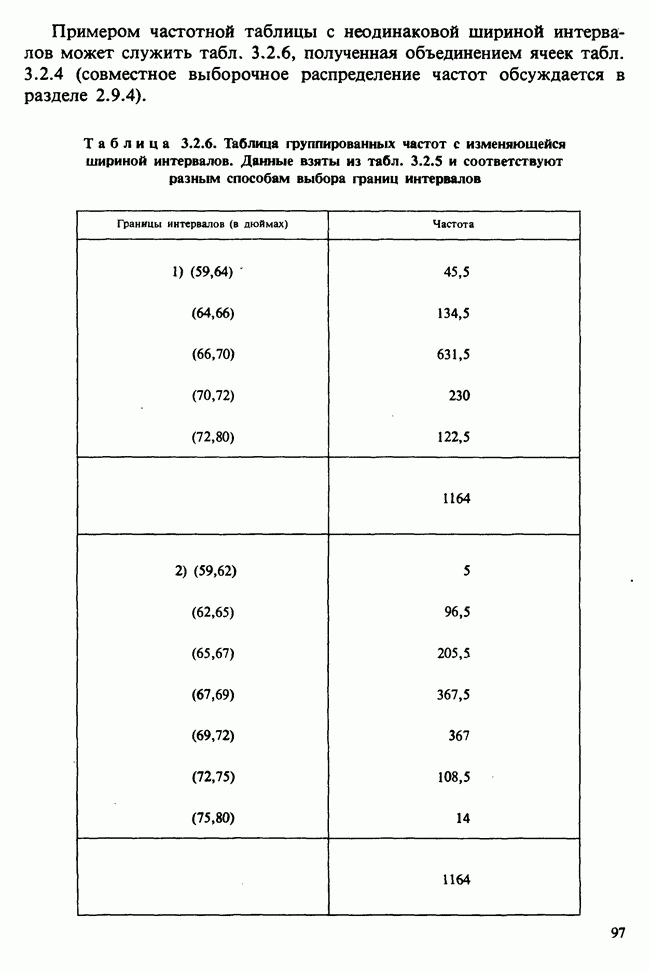
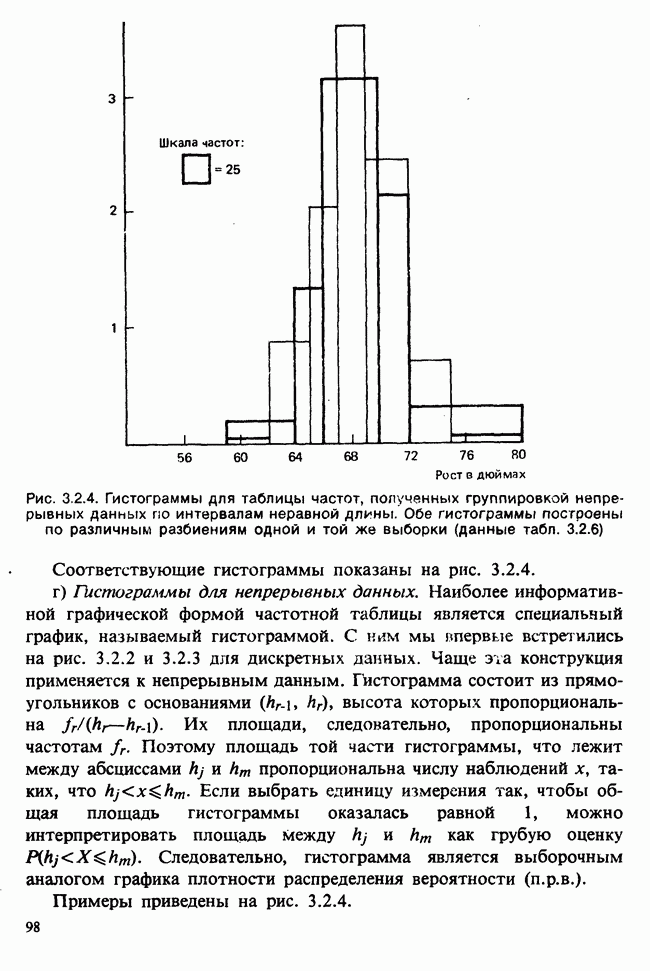
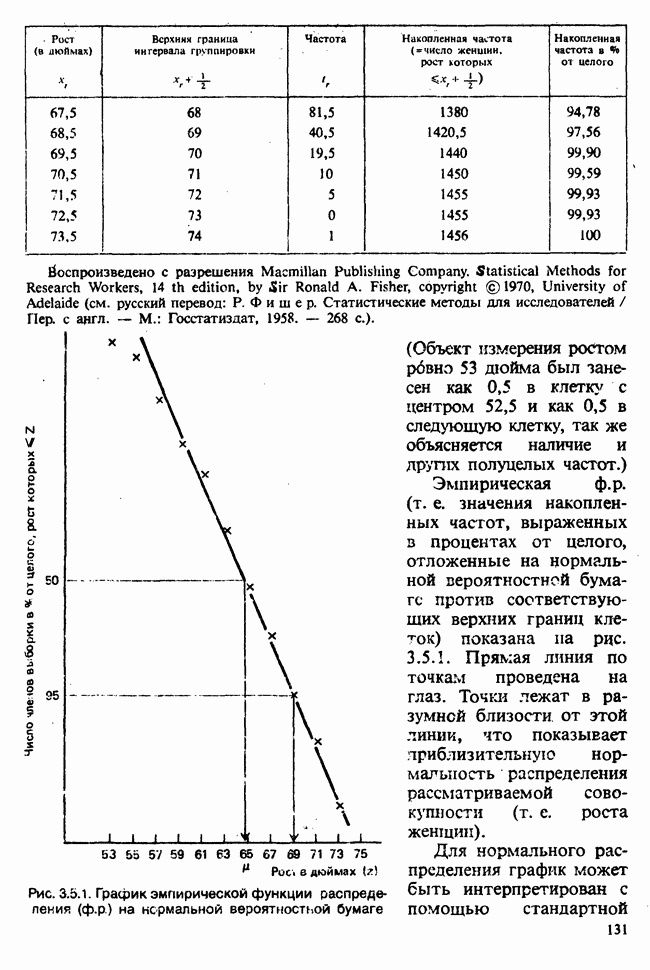
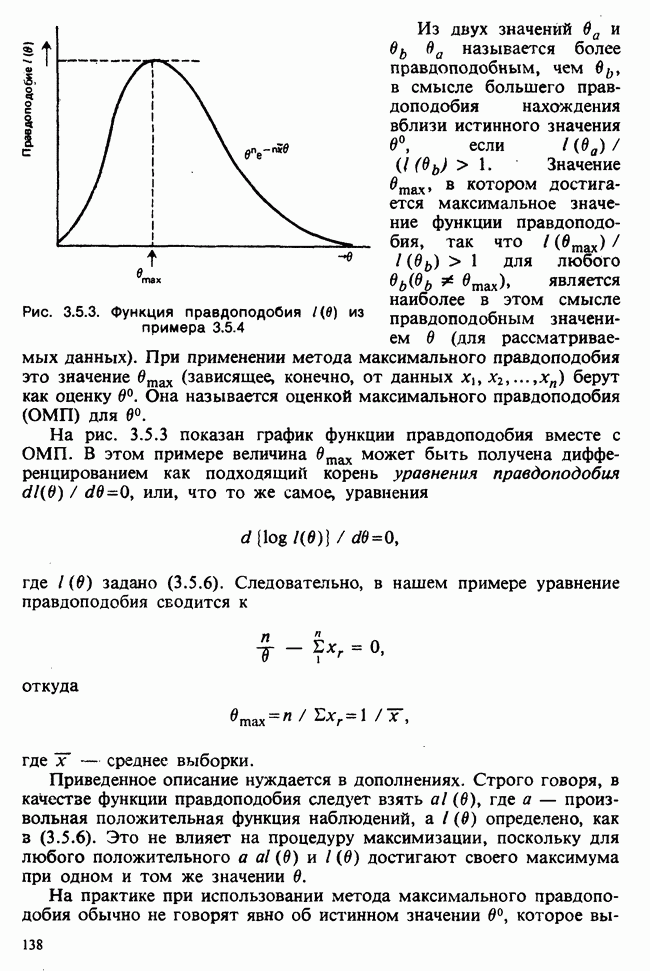
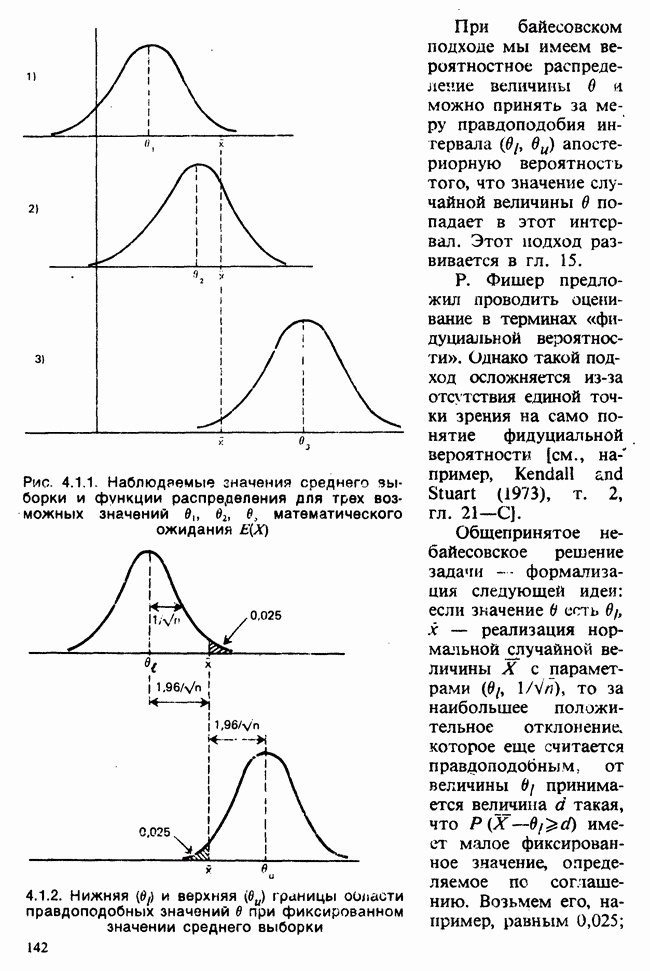
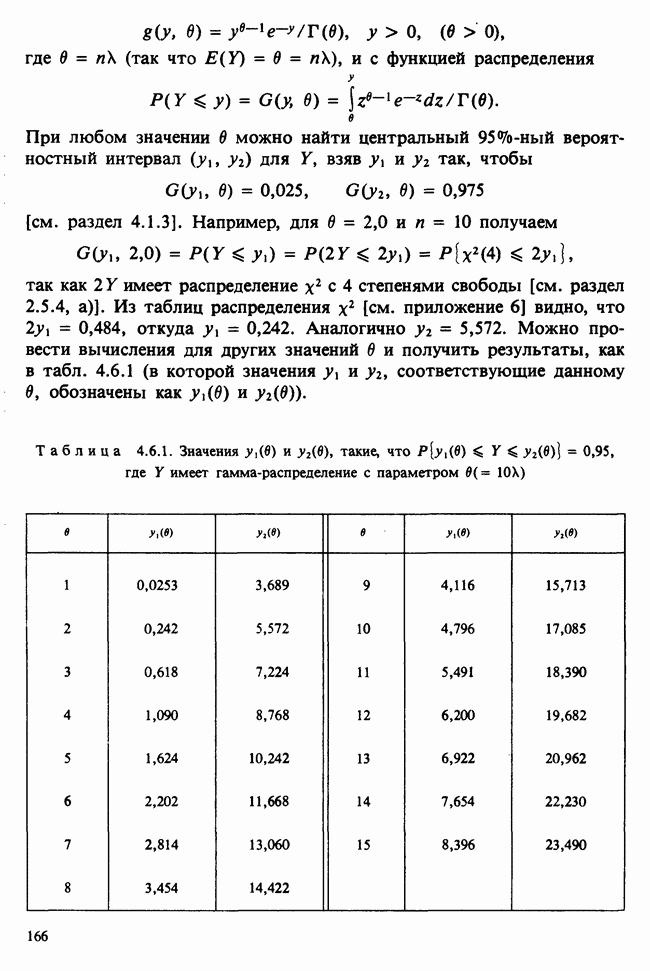
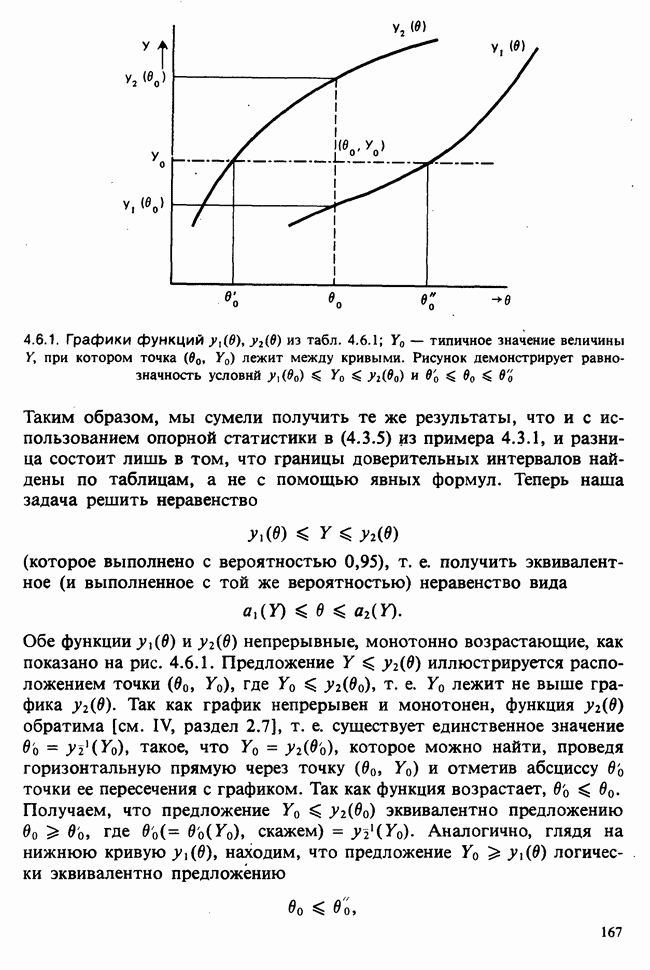
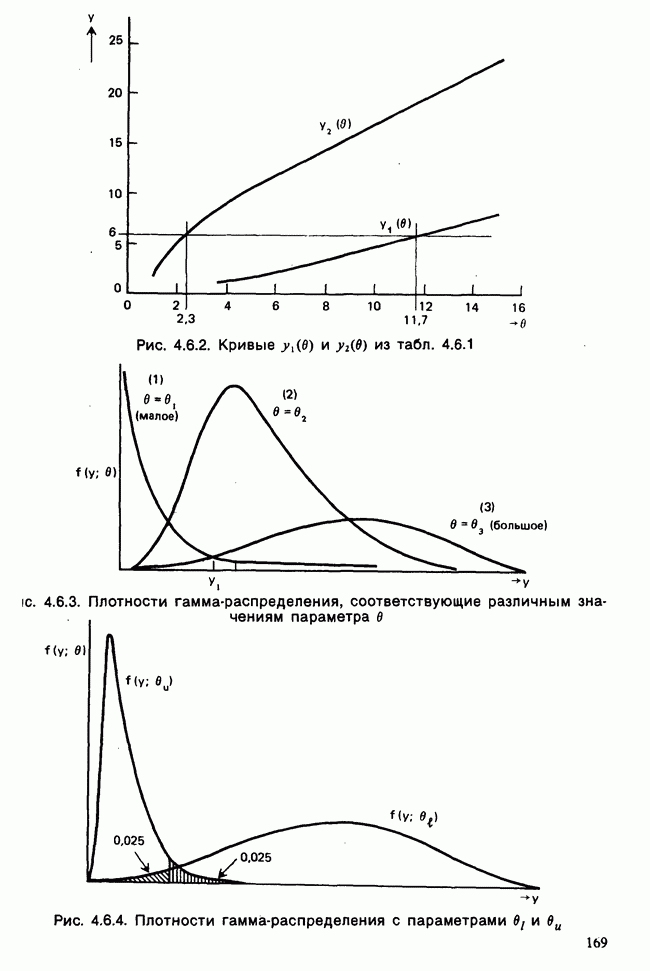
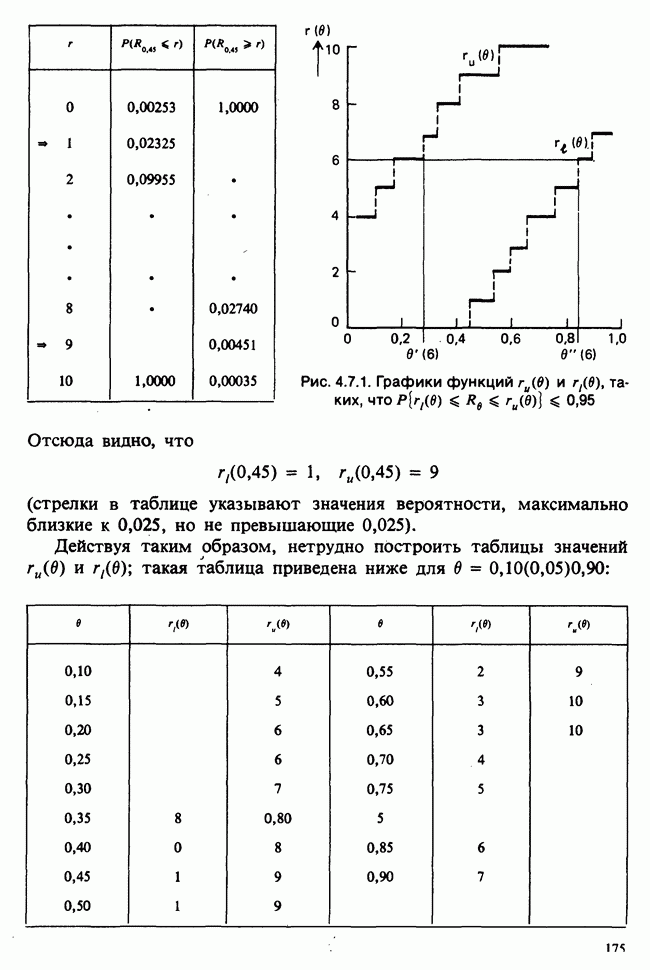
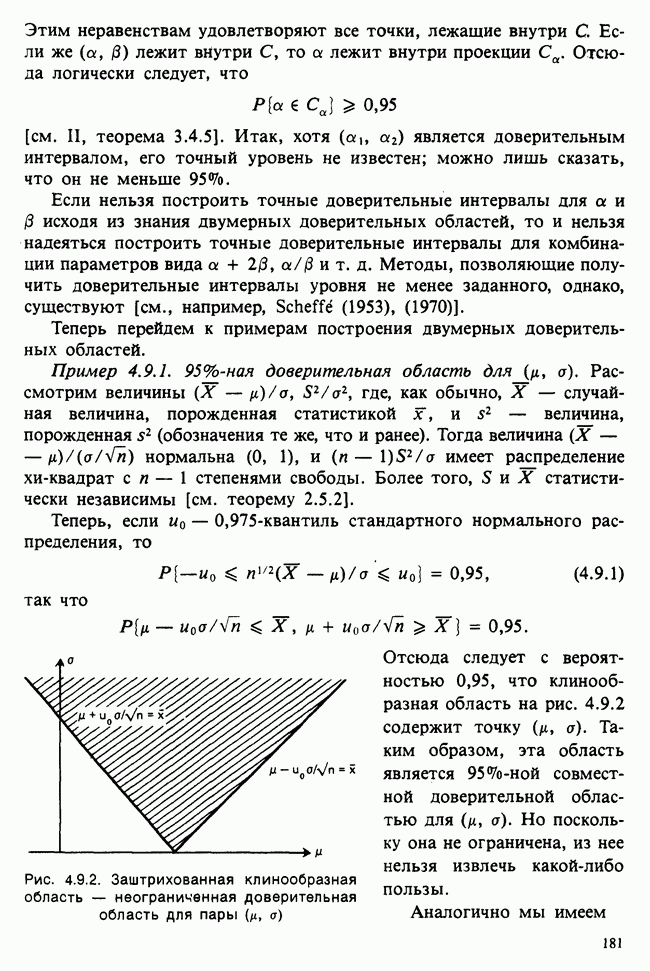
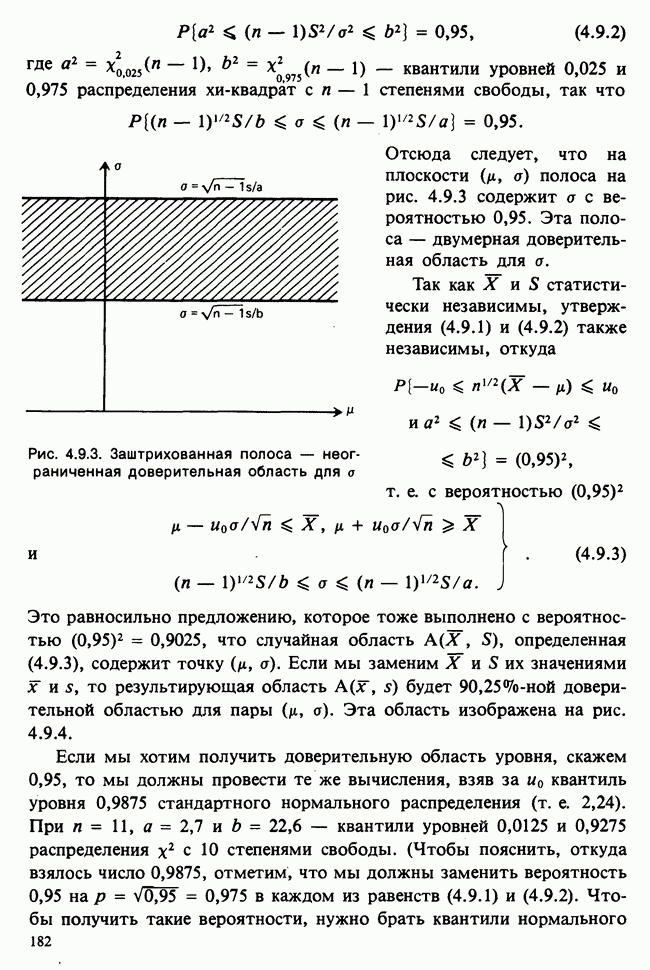
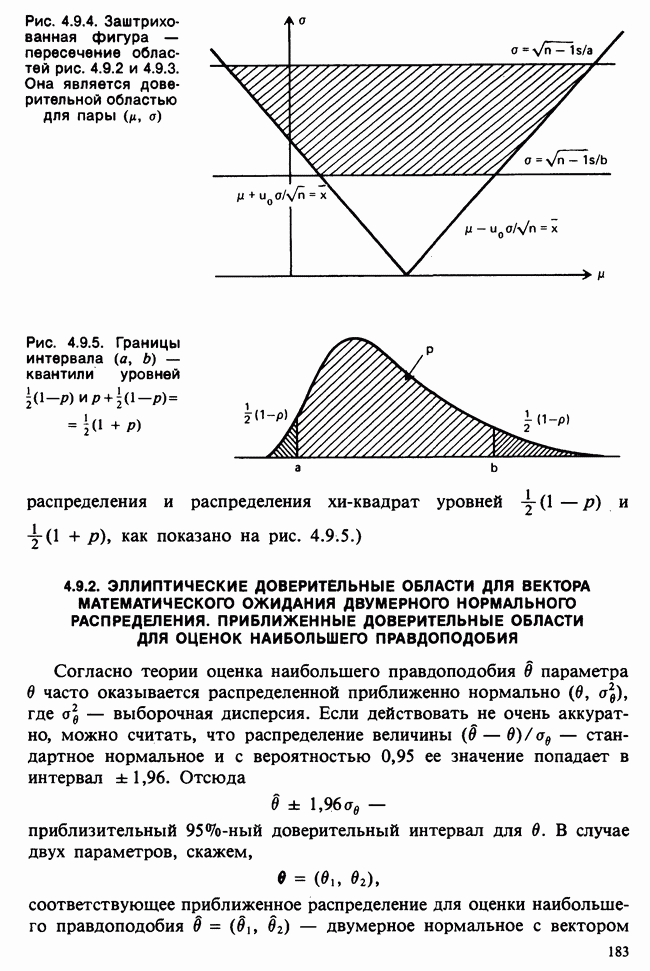
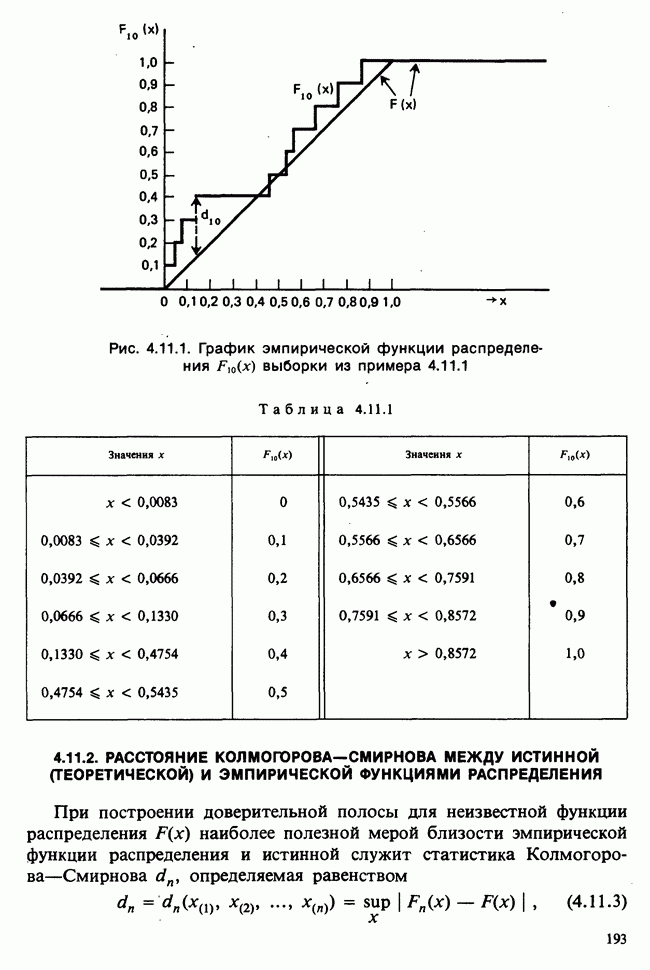
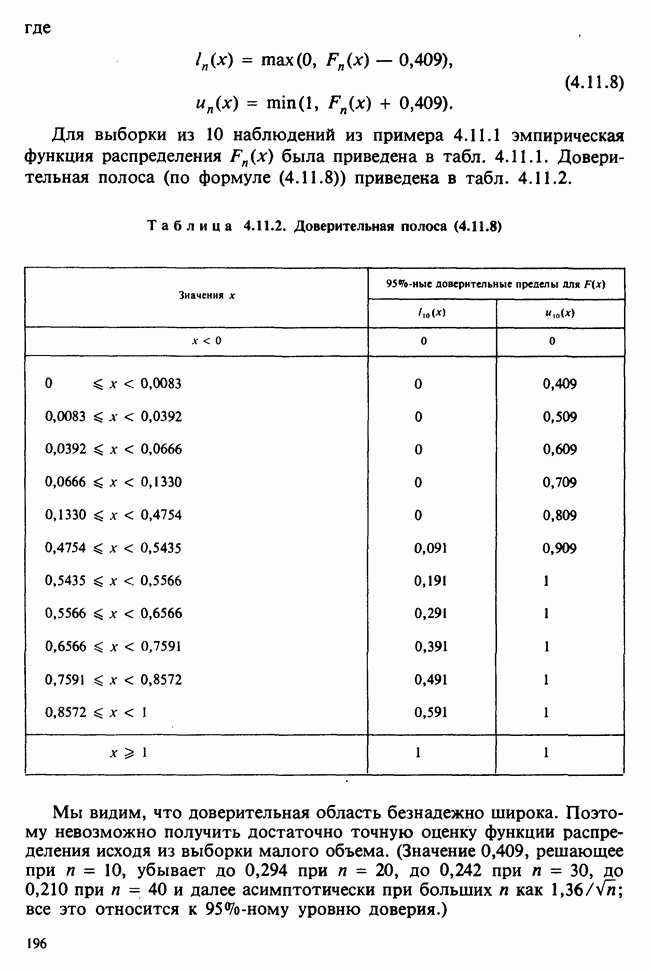
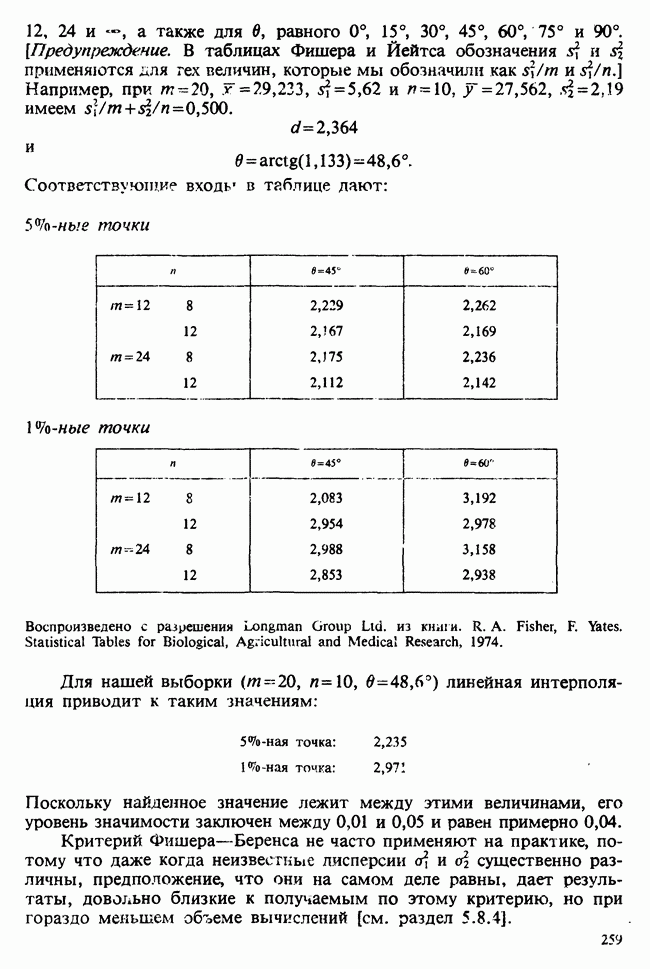
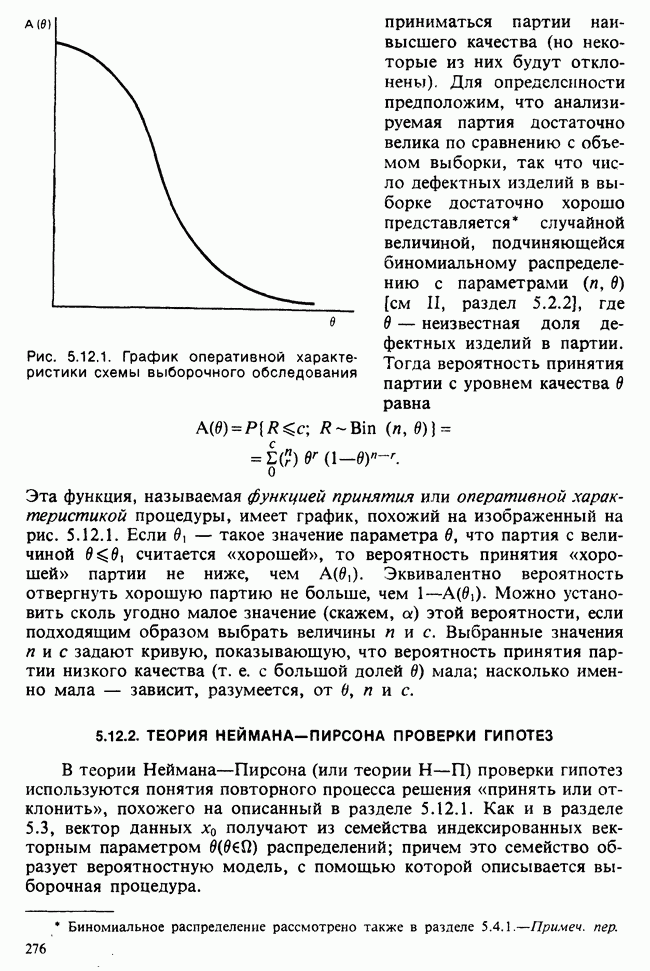
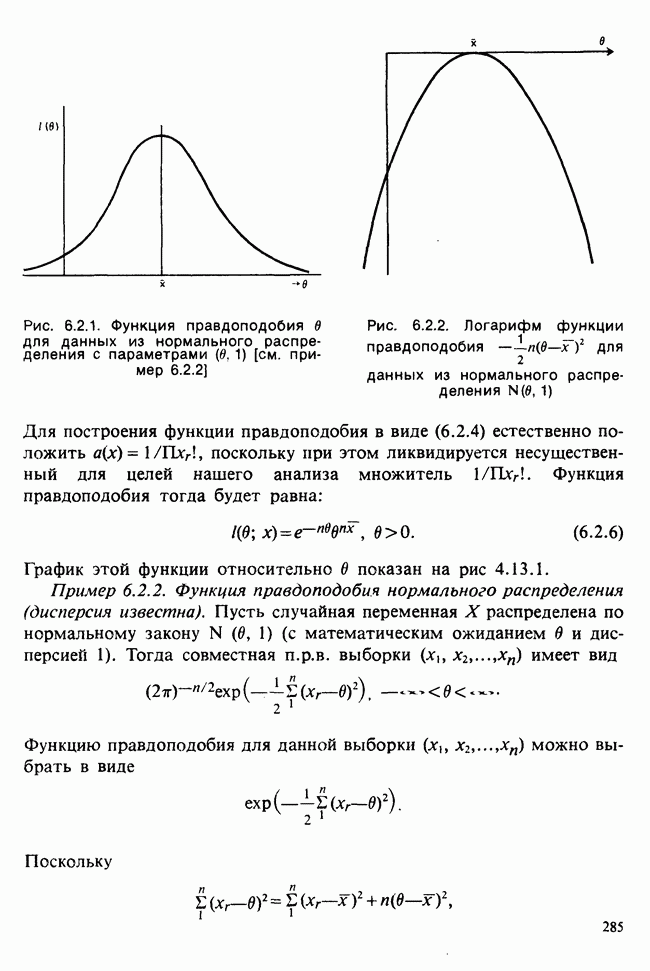
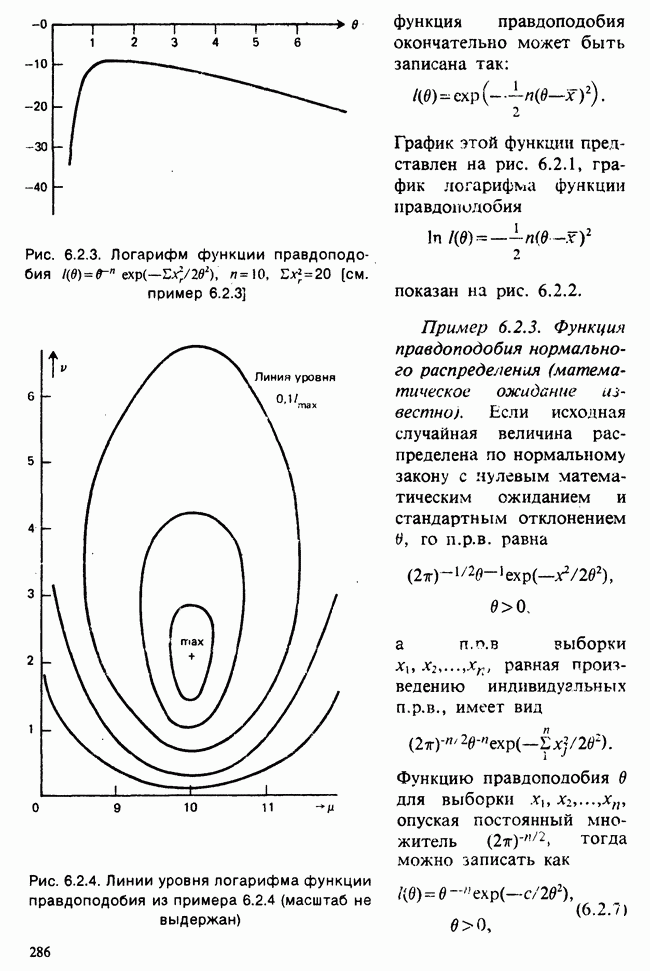
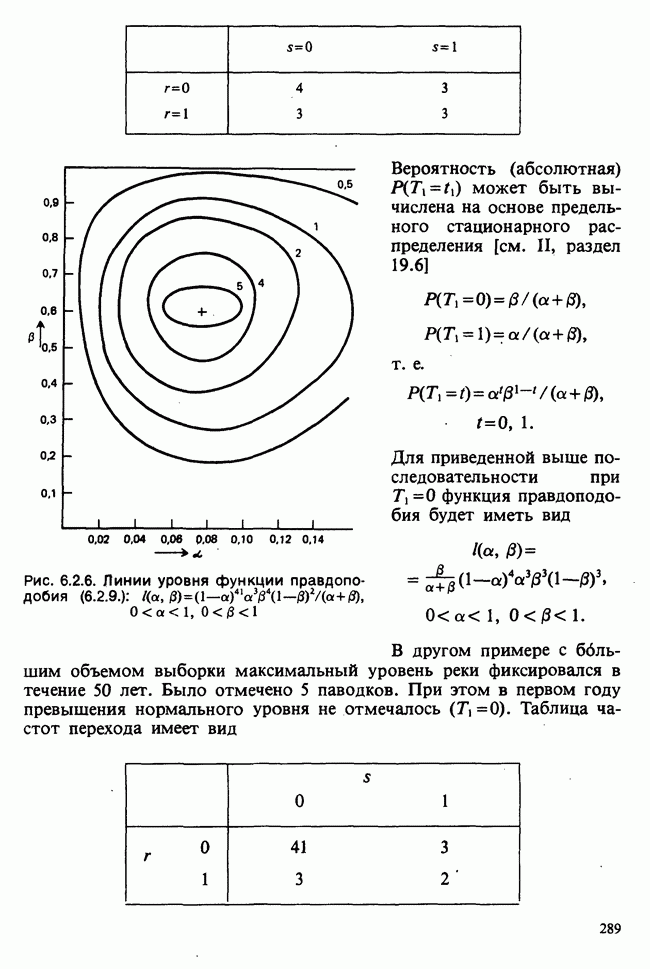
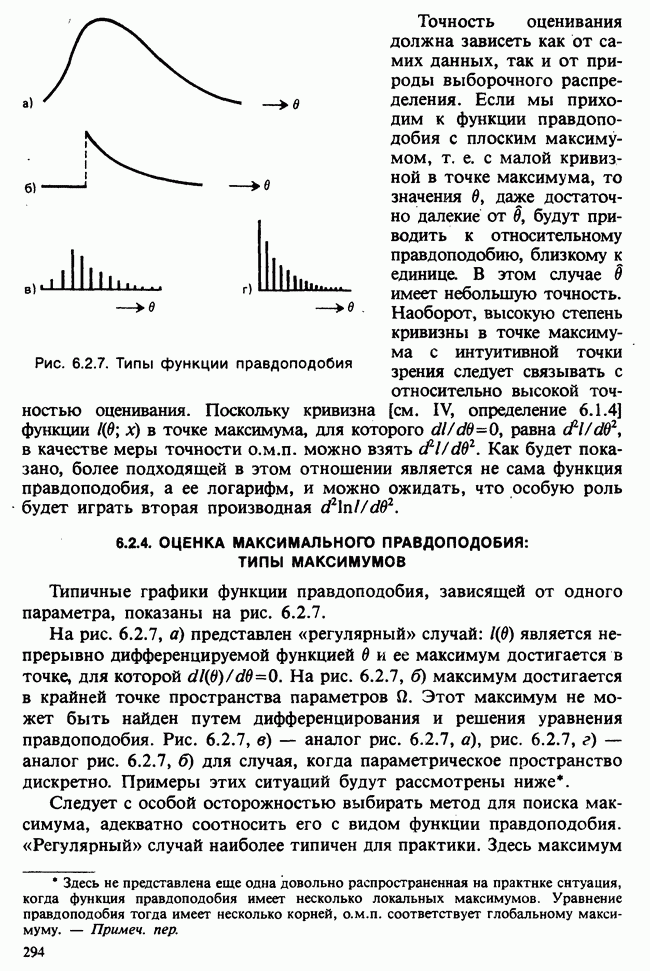
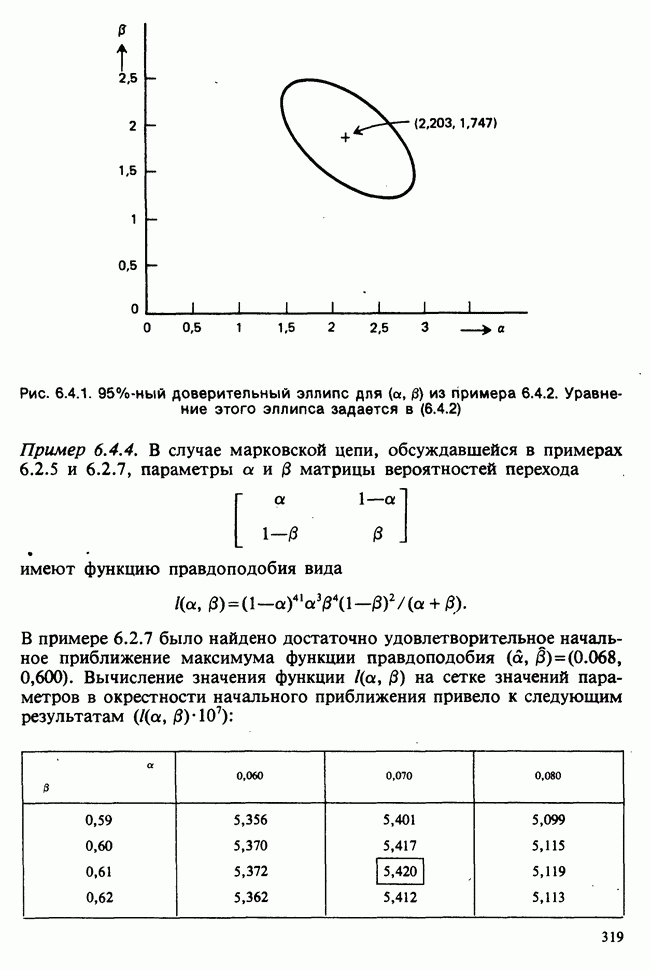
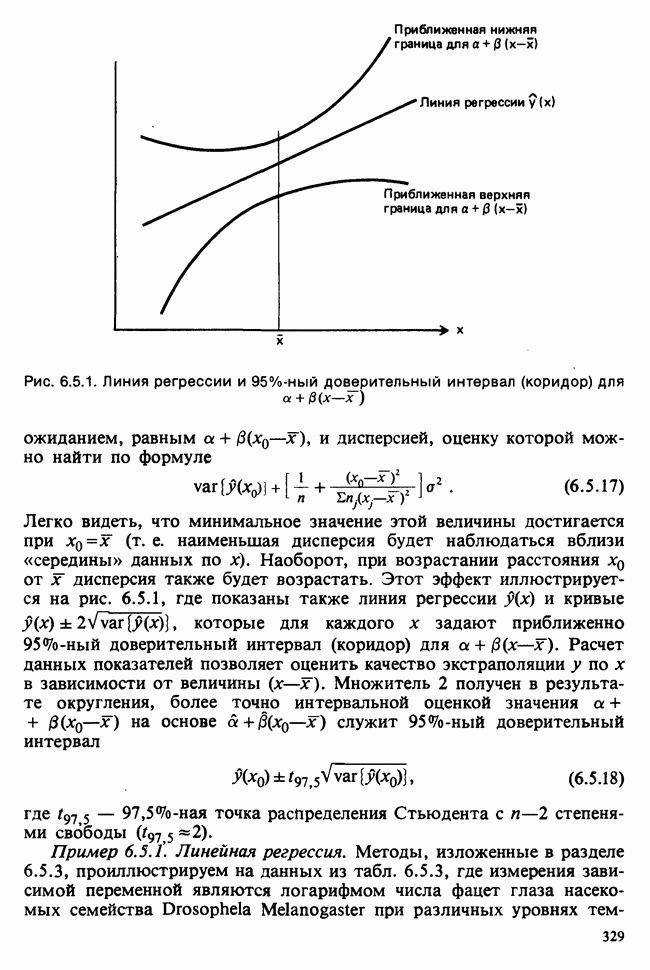
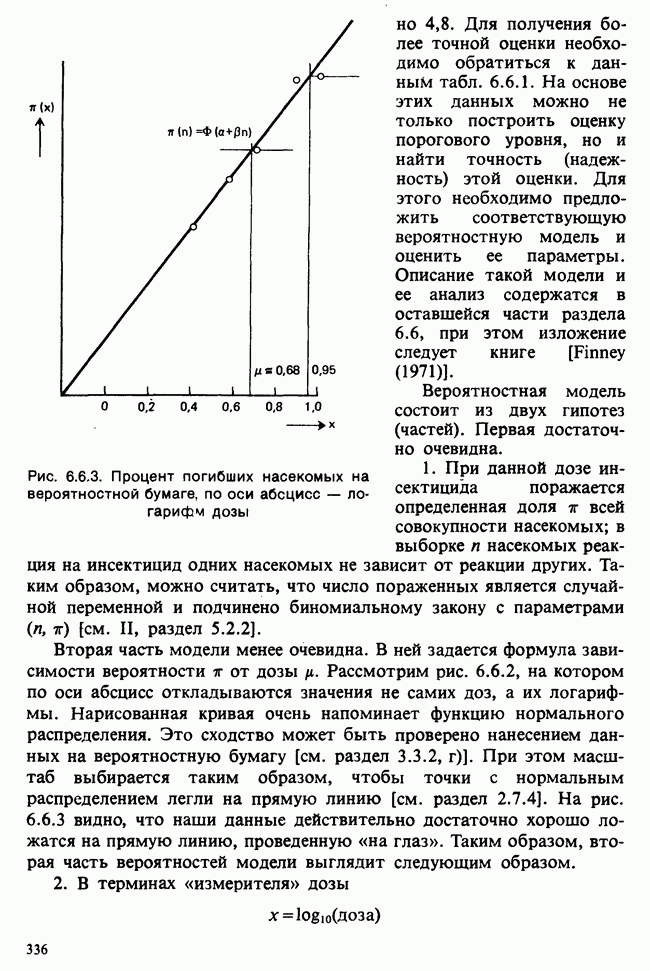
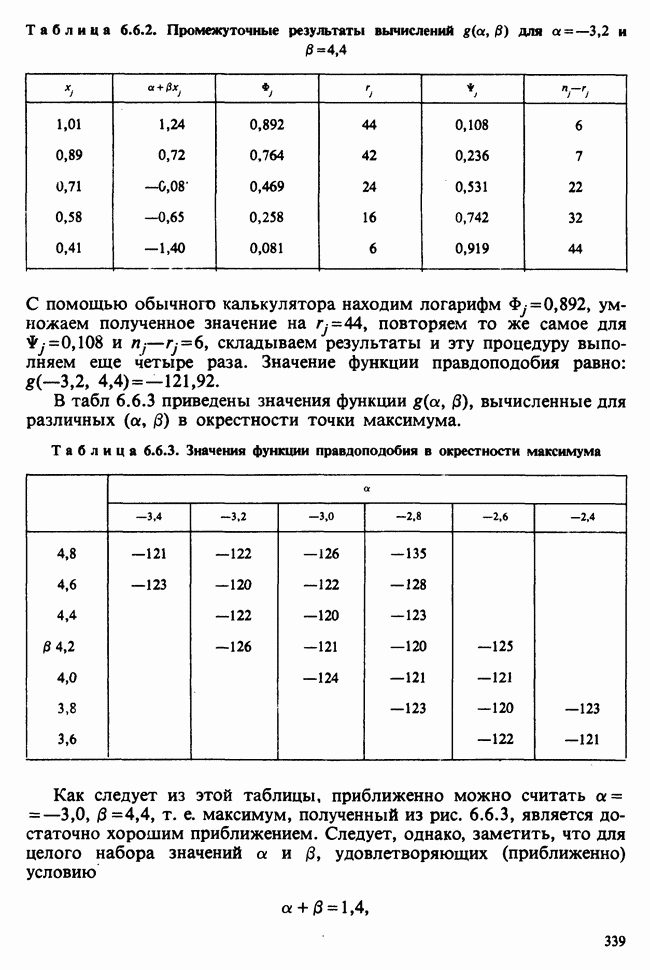
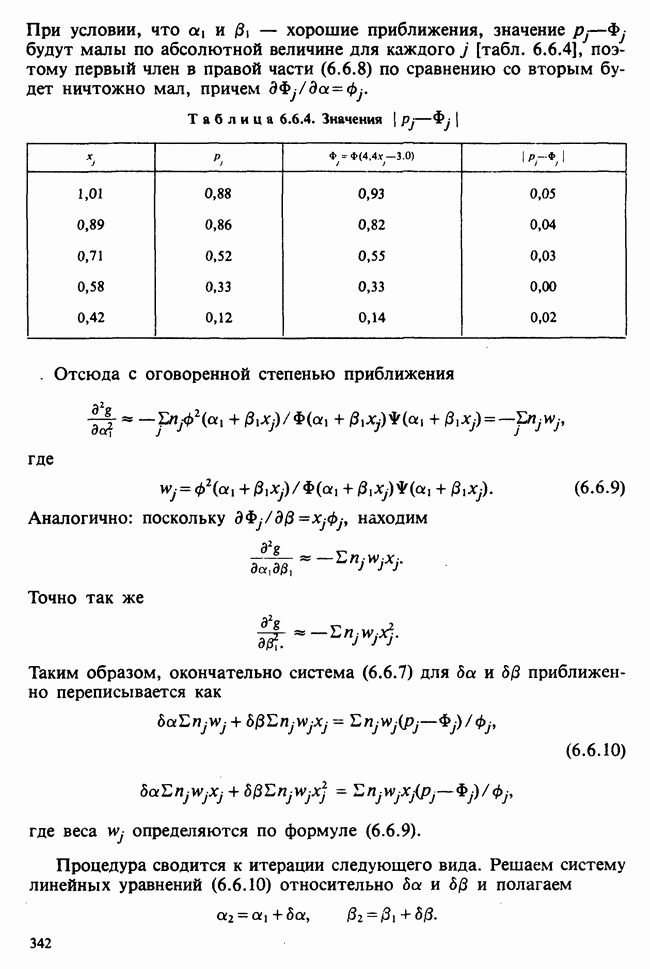
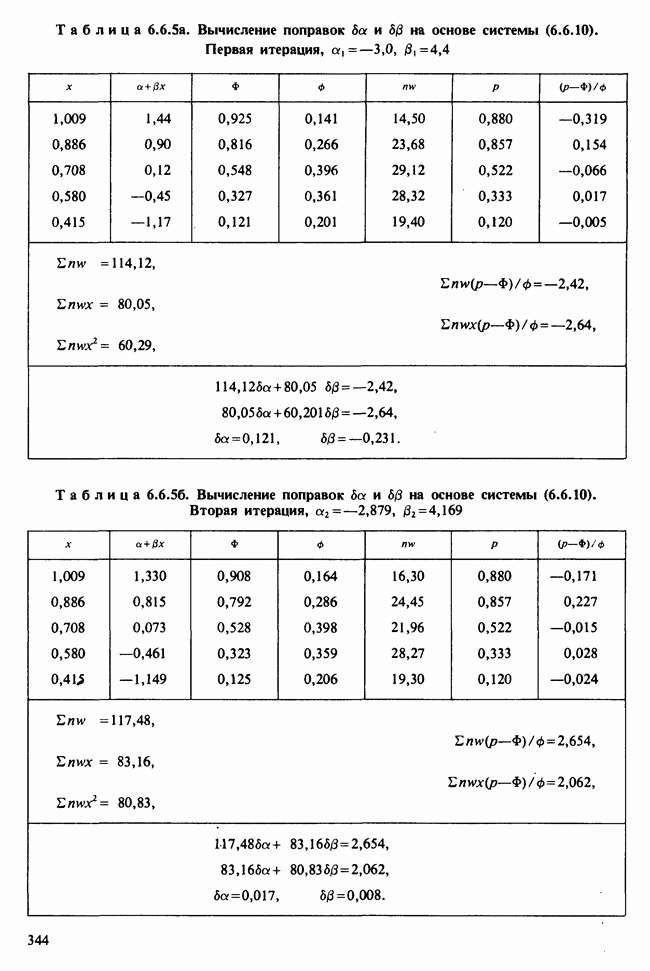
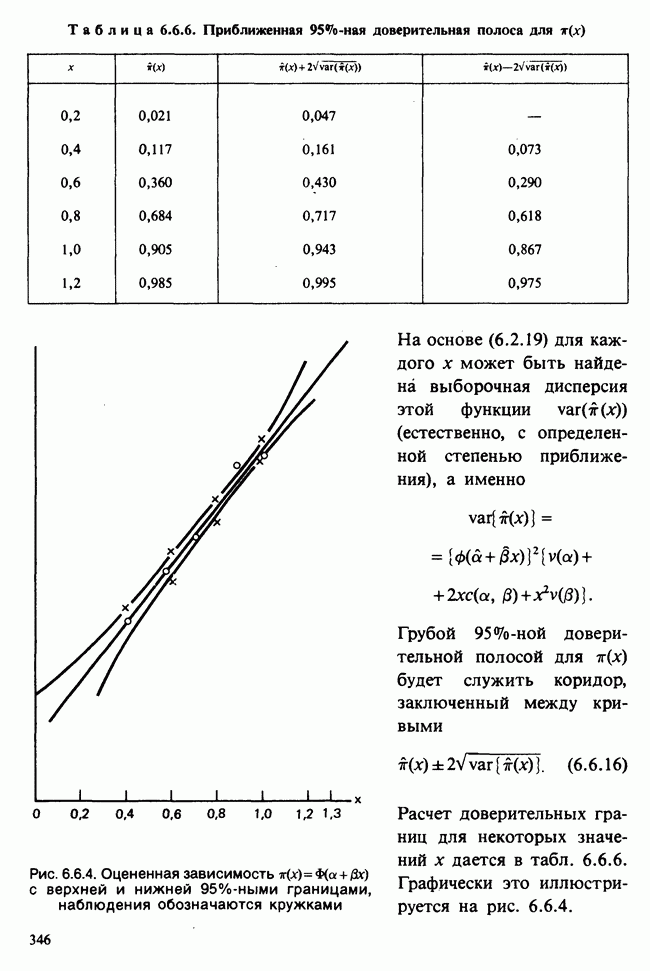
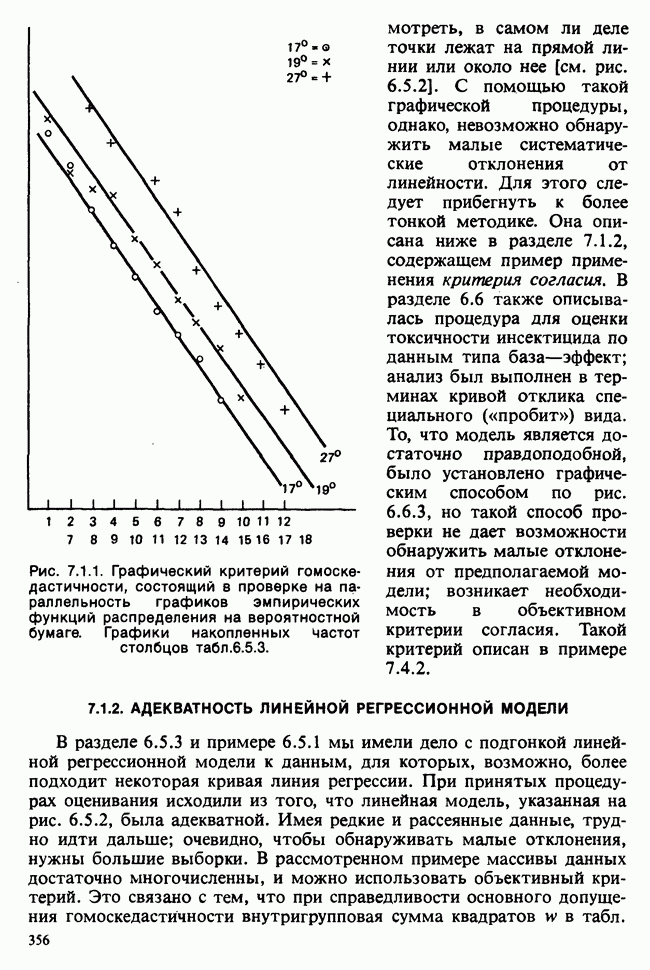
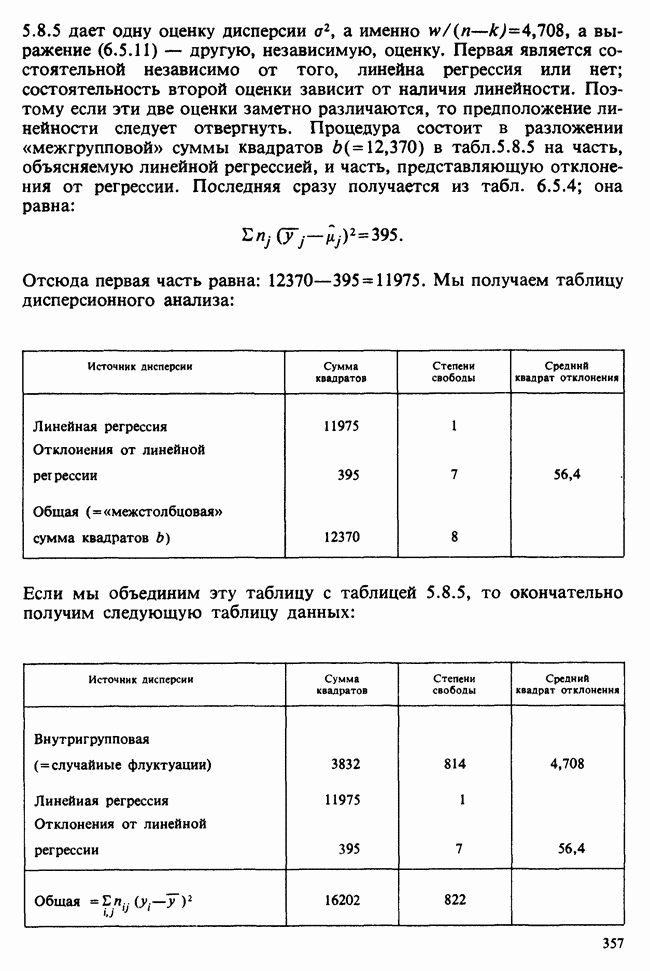
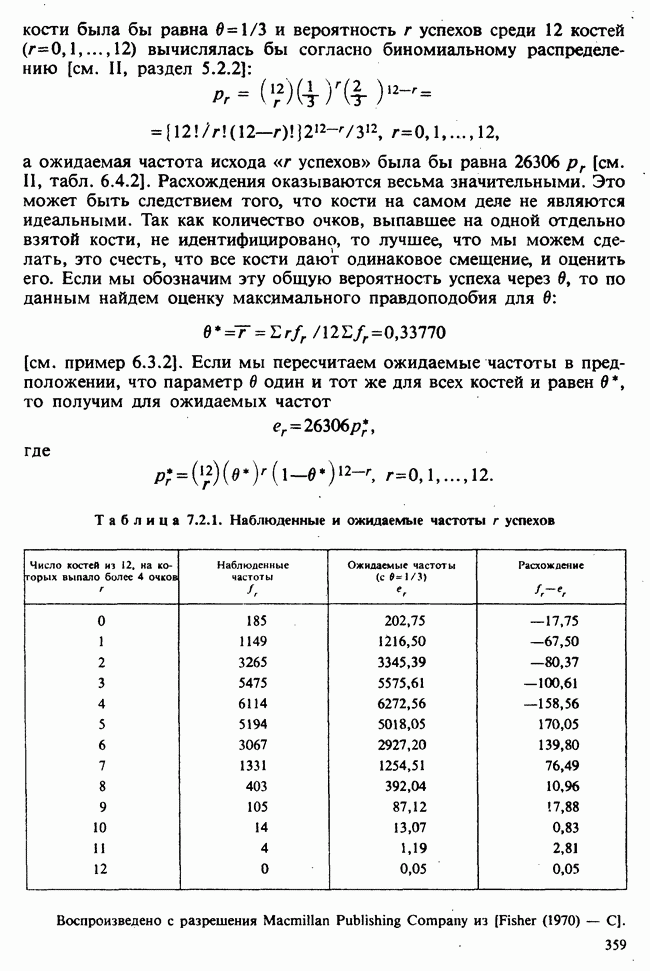
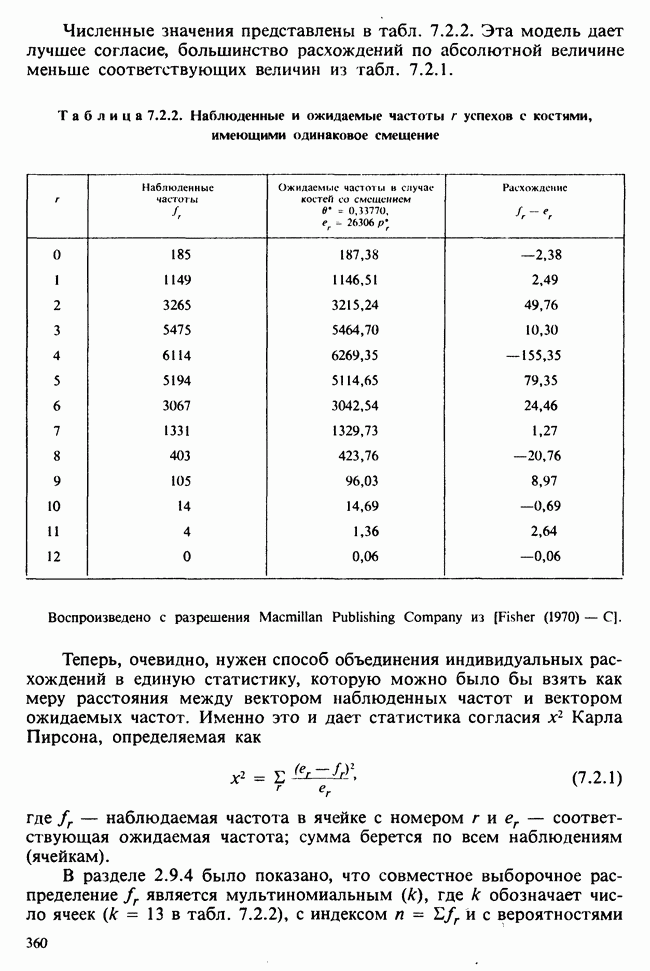
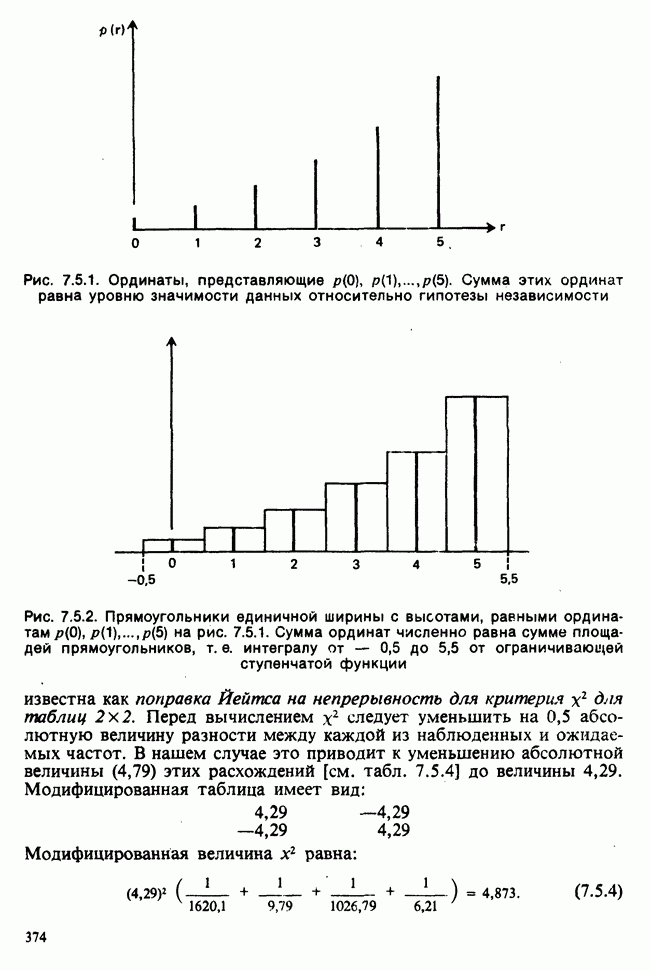
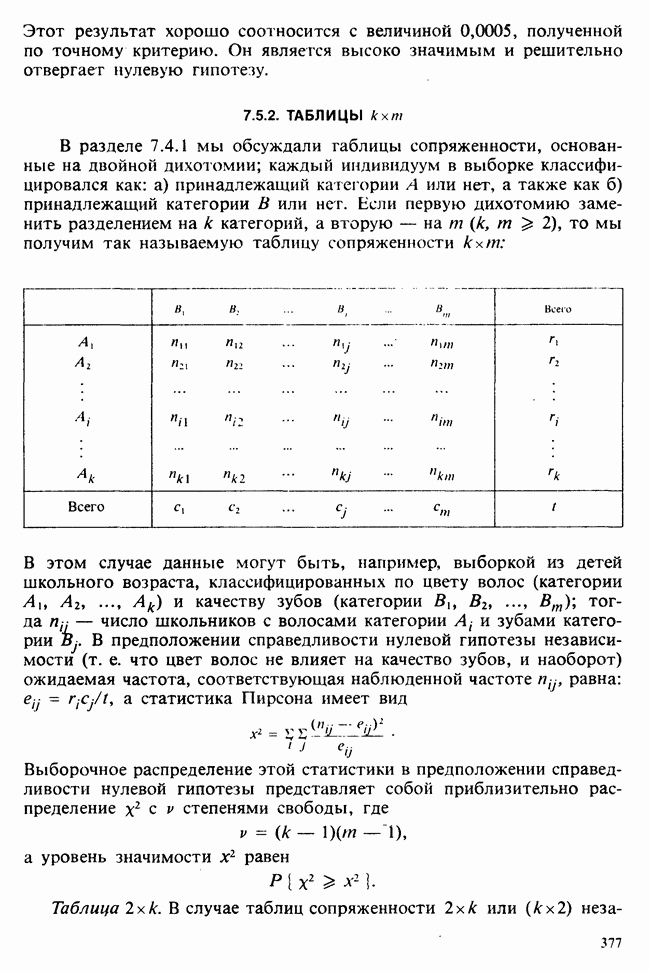
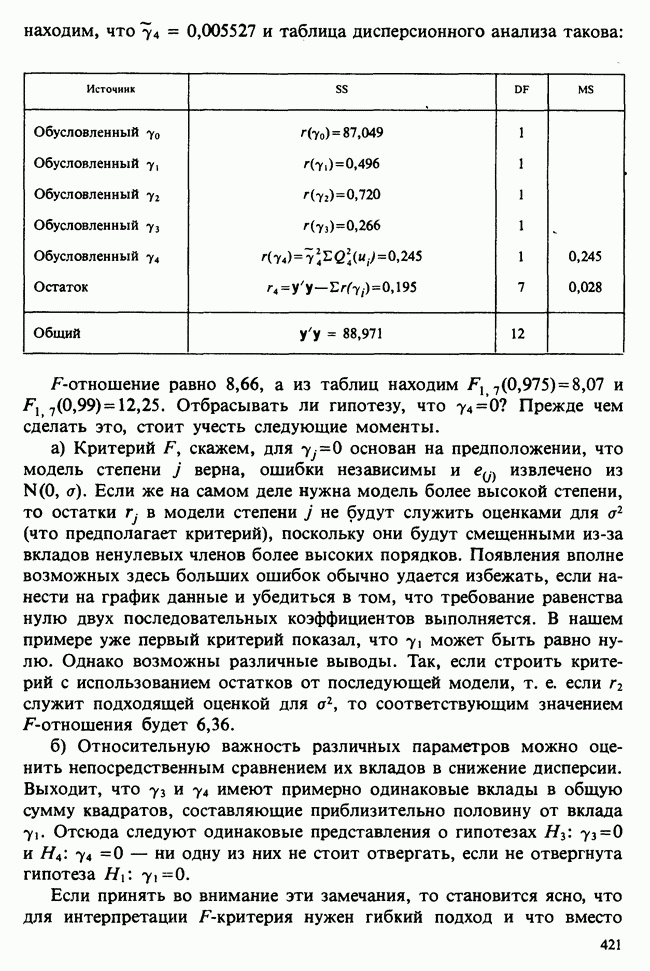
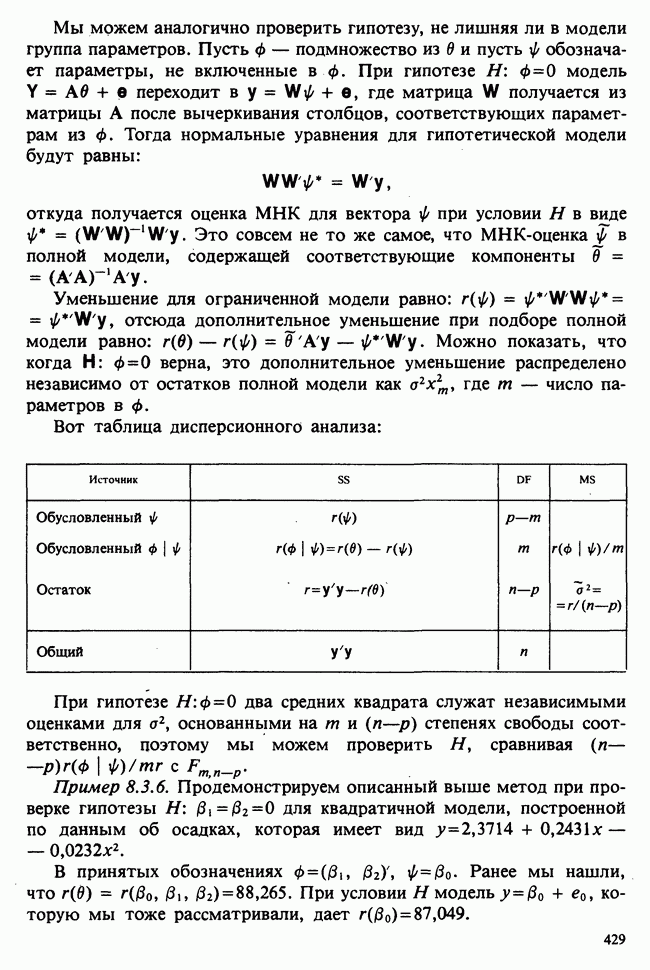
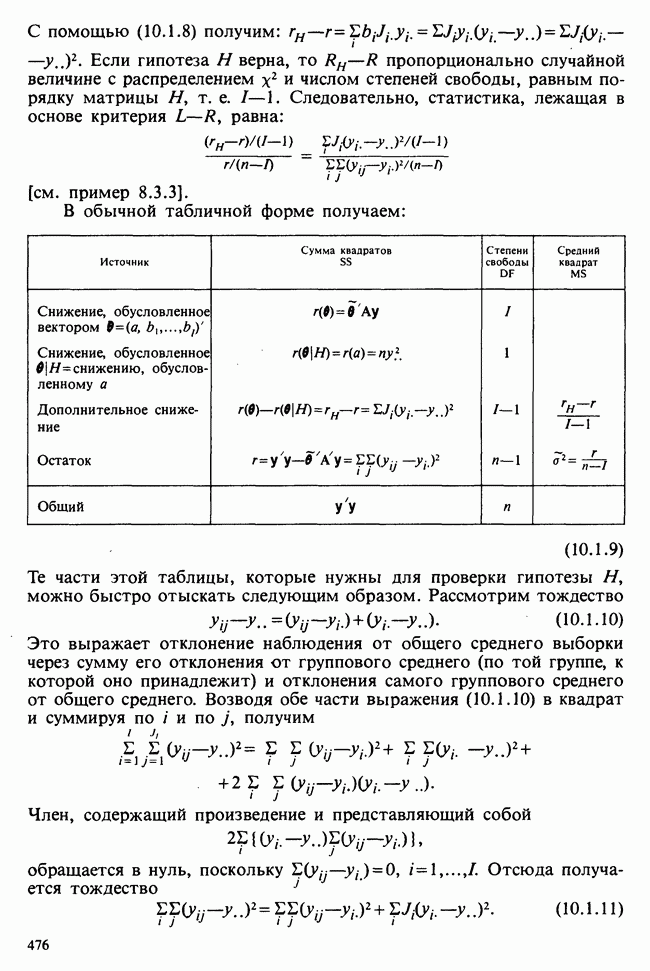
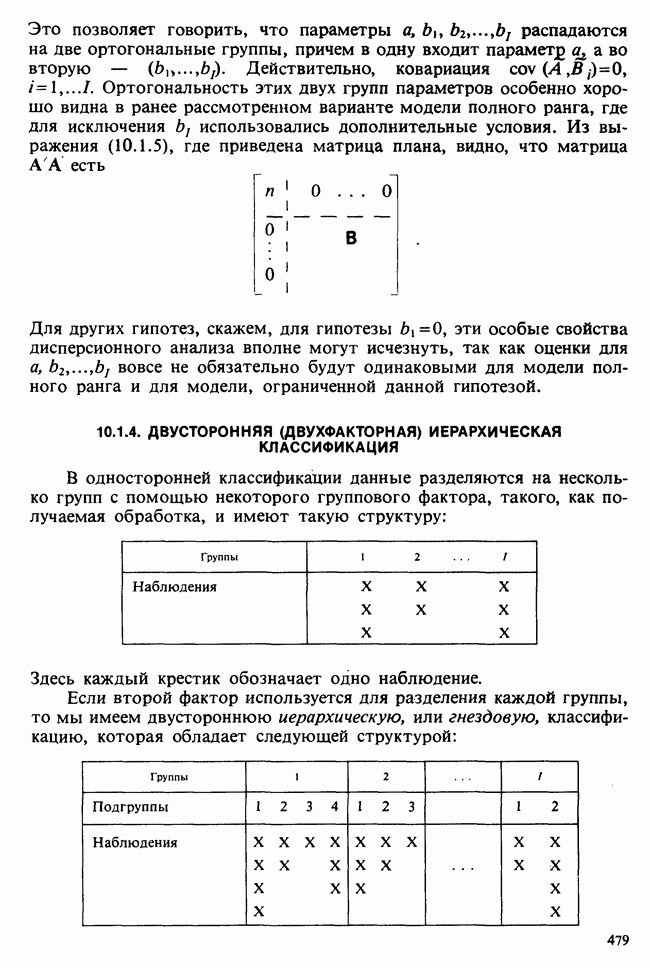
5.8.7 ПРОВЕРКА РАВЕНСТВА НЕКОТОРЫХ СРЕДНИХ. ВВЕДЕНИЕ В ДИСПЕРСИОННЫЙ АНАЛИЗ
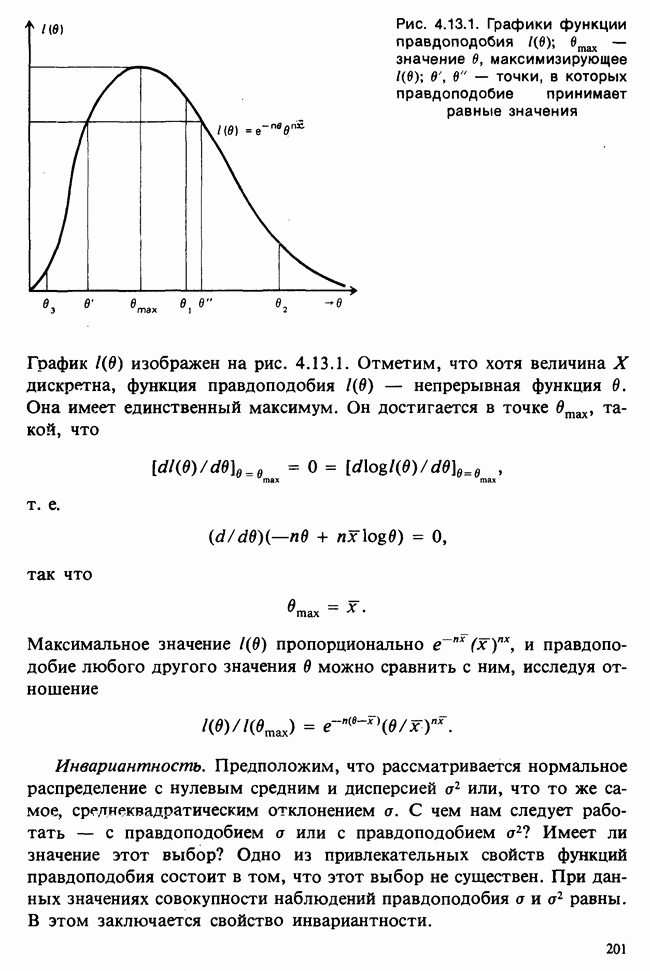
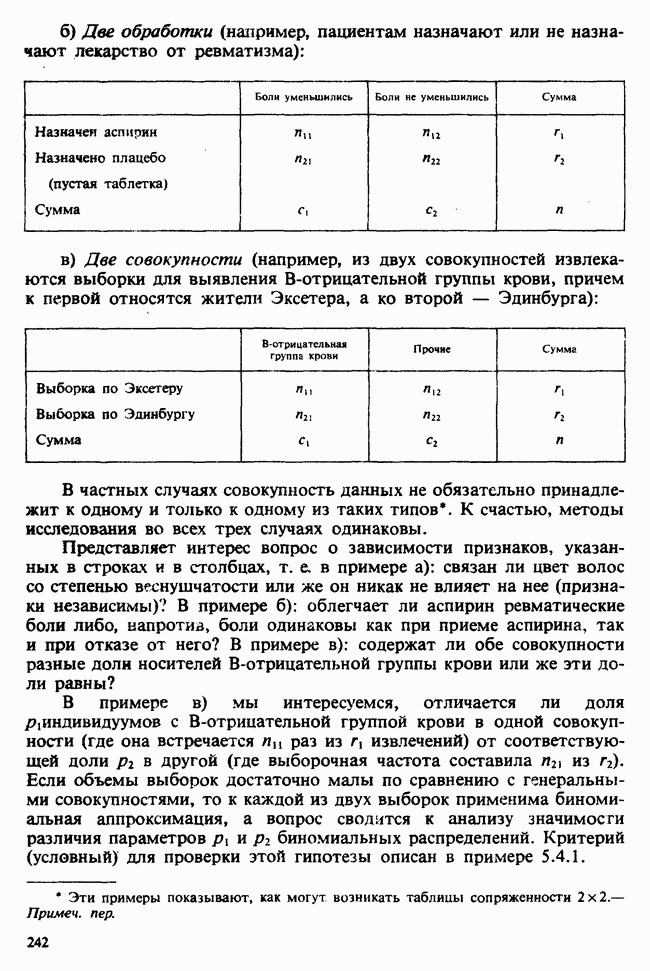
а) Введение. В разделе 5.8.4 обсуждалась проблема оценки значимости различия между средними двух выборок. Соответствующая вероятностная модель исходила из предположения, что обе выборки извлечены из нормальных совокупностей с общей дисперсией, но, возможно, с различными математическими ожиданиями, и проверялось, согласуются ли. данные с нулевой гипотезой о фактическом равенстве этих математических ожиданий. На практике эти две выборки могли бы быть измерениями каких-то сопоставимых величин, полученных в результате различных «обработок», а расхождение между математическими ожиданиями, если оно имеется, можно было бы приписать различию действия (эффекта) обработок. Например, измерения могли бы быть урожаями пшеницы, а две обработки соответствовали бы применению различных удобрений, так что одно из удобрений вносится на том поле, где собирают данные о первой выборке, а другое — на том, откуда поступают данные о второй выборке.
Но как сравнить три и более обработок? Один способ состоит в их попарном сравнении, когда для каждой пары применяются методы, рассмотренные в разделе 5.8.4. Это довольно обременительно и не может нас удовлетворить (не все пары будут независимыми), поэтому предпочтительнее обобщить двухвыборочную процедуру так, чтобы можно было ответить на вопрос: равны ли три (или более) математических ожидания?
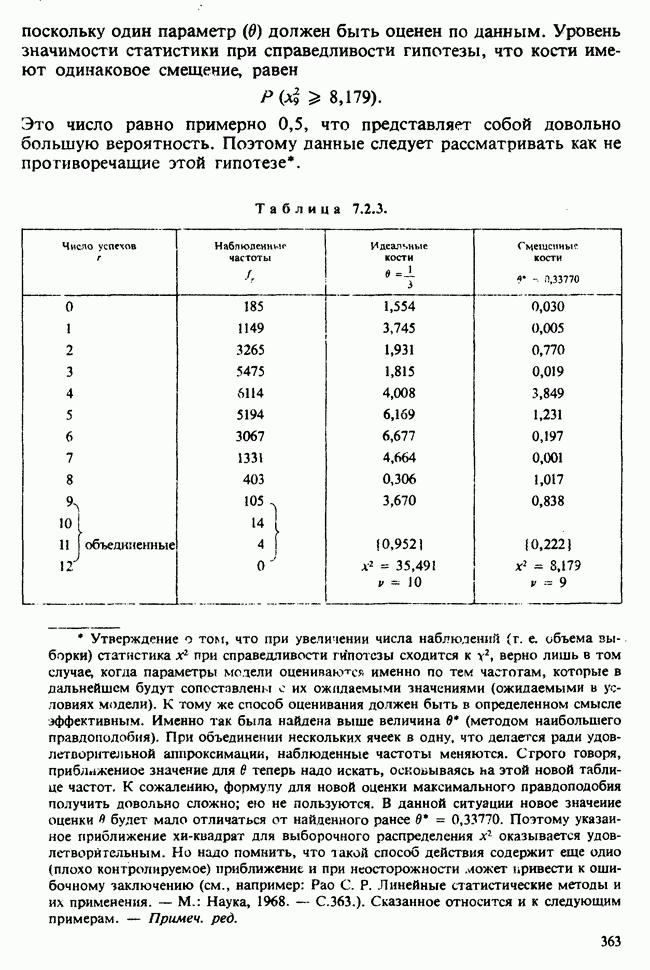
Таблица 5.8.1. Значения  имеющие установленный уровень значимости
имеющие установленный уровень значимости

б) Сравнение двух средних как дисперсионный анализ. На первый взгляд неясно, как обобщить соображения, высказанные в разделе 5.8.4. Чтобы увидеть, какие изменения необходимы для обобщения, рассмотрим альтернативную точку зрения относительно проведенного в разделе 5.8.4 анализа. Сначала в (5.8.8) избавимся от квадратного корня, для чего возведем правую часть в квадрат. Рассмотрим теперь связь между числителем и знаменателем. Для ее выражения применим следующие обозначения:

так что вектор  будет представлять собой объединение двух выборок, т. е. [см. I, раздел 6.6] его можно разделить на такие части
будет представлять собой объединение двух выборок, т. е. [см. I, раздел 6.6] его можно разделить на такие части  Пусть
Пусть

Эта величина называется главным средним. Далее, справедливо алгебраическое тождество

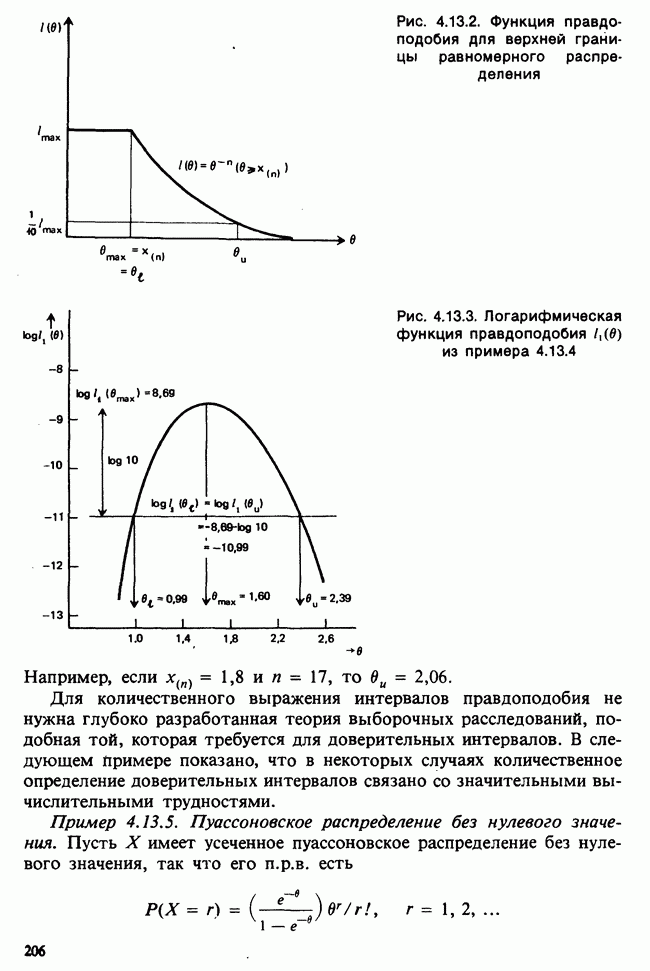
Первый член в правой части называется суммой квадратов  он пропорционален изменчивости элементов первой выборки. (На самом деле он просто, равен увеличенной в
он пропорционален изменчивости элементов первой выборки. (На самом деле он просто, равен увеличенной в  раз выборочной дисперсии.) Второй член справа, равный сумме квадратов
раз выборочной дисперсии.) Второй член справа, равный сумме квадратов  имеет такой же смысл для второй выборки. Сумма
имеет такой же смысл для второй выборки. Сумма  этих двух членов образует меру изменчивости «внутри» выборок и называется внутривыборочной суммой квадратов.
этих двух членов образует меру изменчивости «внутри» выборок и называется внутривыборочной суммой квадратов.
Последний член справа,  понятным образом измеряет различие между выборками и называется межвыборочной суммой квадратов. Наконец, стоящая слева величина называется полной суммой квадратов, она измеряет изменчивость совокупности данных в целом, а в силу тождества понятно, что полная сумма квадратов представляет собой сумму внутривыборочной и межвыборочной компонент.
понятным образом измеряет различие между выборками и называется межвыборочной суммой квадратов. Наконец, стоящая слева величина называется полной суммой квадратов, она измеряет изменчивость совокупности данных в целом, а в силу тождества понятно, что полная сумма квадратов представляет собой сумму внутривыборочной и межвыборочной компонент.
Если две исследуемые выборки на самом деле не отличаются, проявившееся различие, обозначенное  вызвано лишь случайными флуктуациями, которые и породили внутривыборочные изменения, обозначенные
вызвано лишь случайными флуктуациями, которые и породили внутривыборочные изменения, обозначенные  Фактически нетрудно увидеть, что выборочные математические ожидания будут следующими:
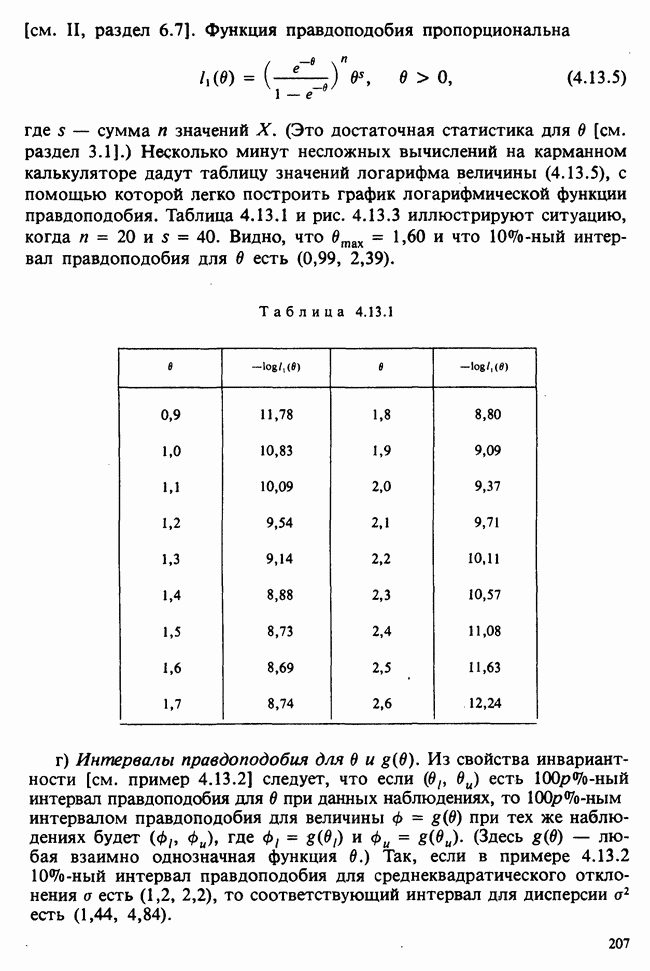
Фактически нетрудно увидеть, что выборочные математические ожидания будут следующими:

где  — общая дисперсия наблюдений.
— общая дисперсия наблюдений.
Однако, когда имеется реальное различие между совокупностями, так что их математические ожидания отличаются на величину  , то выборочное математическое ожидание В увеличивается до
, то выборочное математическое ожидание В увеличивается до

Поскольку величина  неизвестна, нужна подходящая процедура, позволяющая вычислить отношение
неизвестна, нужна подходящая процедура, позволяющая вычислить отношение  или более удобную величину
или более удобную величину  . Тогда при нулевой гипотезе числитель и знаменатель будут иметь одинаковые математические ожидания, но когда воздействия различны, математическое ожидание в числителе будет больше, чем в знаменателе.
. Тогда при нулевой гипотезе числитель и знаменатель будут иметь одинаковые математические ожидания, но когда воздействия различны, математическое ожидание в числителе будет больше, чем в знаменателе.
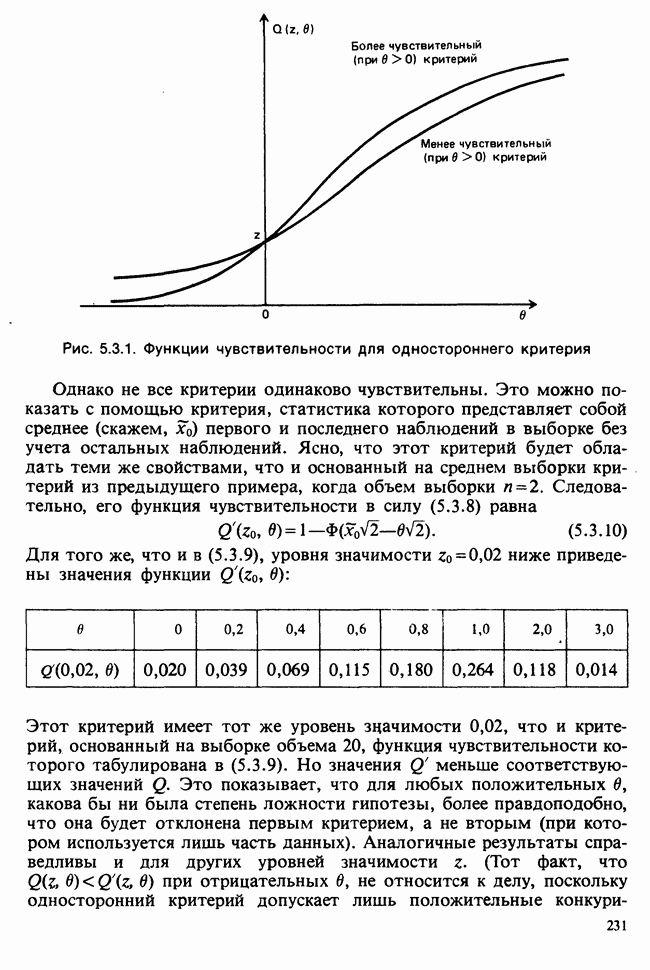
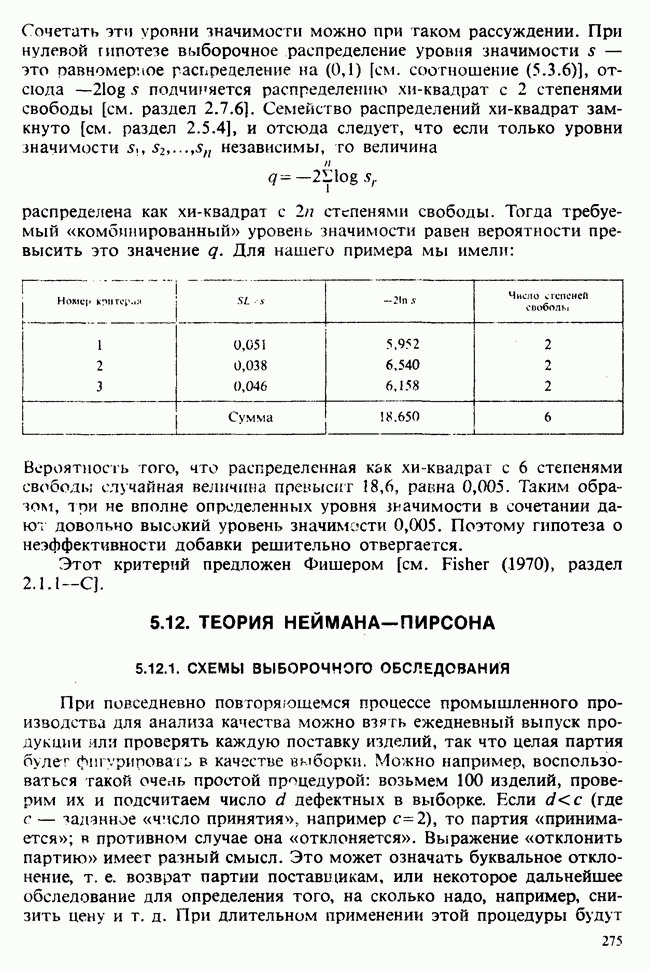
Рассмотрим выборочное распределение величины  При нулевой гипотезе это
При нулевой гипотезе это  -распределение. Уровень значимости данных относительно нулевой гипотезы об отсутствии различий в действии обработок против гипотезы о том, что эффект различия обработок есть, равен
-распределение. Уровень значимости данных относительно нулевой гипотезы об отсутствии различий в действии обработок против гипотезы о том, что эффект различия обработок есть, равен

где  обозначают наблюденные значения величин
обозначают наблюденные значения величин  и
и  которые определены согласно (5.8.15).
которые определены согласно (5.8.15).
Если сопоставить это с (5.8.8), то квадрат величины  в точности равен
в точности равен  причем явно это общее значение равно
причем явно это общее значение равно

Квадратный корень из случайной величины  подчиняется распределению Стьюдента с
подчиняется распределению Стьюдента с  степенями свободы. Тем самым (5.8.16) приводит точно к такому же уровню значимости, что и t-критерий (5.8.8).
степенями свободы. Тем самым (5.8.16) приводит точно к такому же уровню значимости, что и t-критерий (5.8.8).
В чем же смысл проведенного анализа? Этот метод, основанный на тождестве для сумм квадратов (5.5.15), указывает способ обобщения на три или более выборок. Прежде чем продолжить, представим результаты анализа двух выборок в следующей таблице:
(см. скан)
Таблица с подобным представлением арифметических значений входящих в тождество (5.8.15) членов, а также их делителей (т. е. соответствующих значений числа степеней свободы той или иной суммы квадратов) и приведенной в первом столбце интерпретацией называется таблицей дисперсионного анализа.
Мы привели довольно обстоятельные рассуждения не только потому, что они играют основополагающую роль при сравнении трех или более средних, что обсуждается ниже в пункте в), но и потому, что дисперсионный анализ имеет исключительно важное значение в статистических исследованиях [см. гл. 8, 10].
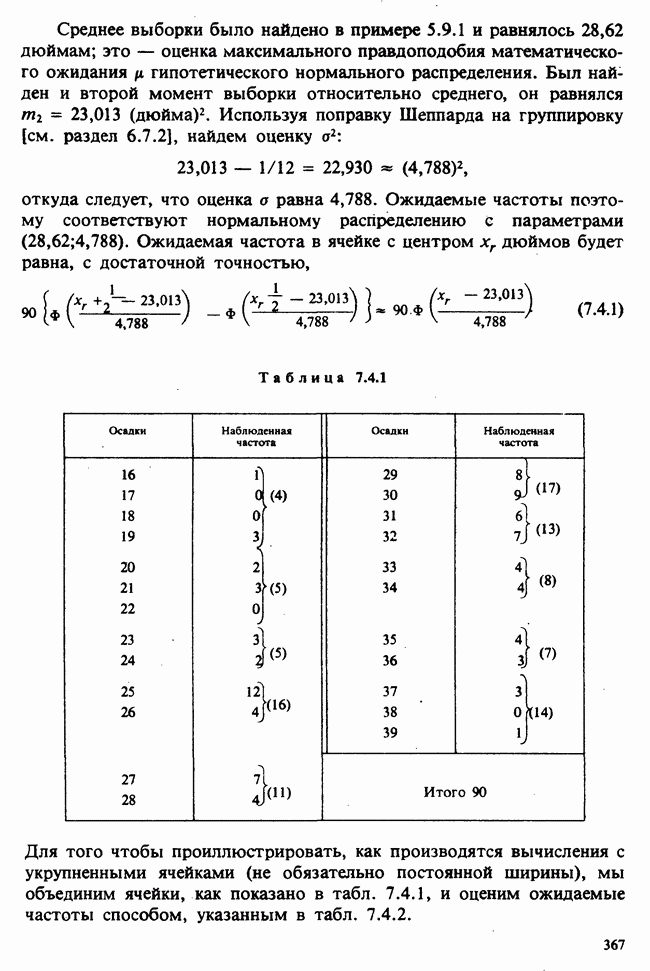
в) Ситуация при к выборках. Предположим теперь, что имеется к выборок, относящихся соответственно к к обработкам и имеющих объемы  как в табл. 5.8.2 (где выборки представлены векторами данных). Тождество для сумм квадратов имеет вид
как в табл. 5.8.2 (где выборки представлены векторами данных). Тождество для сумм квадратов имеет вид

т. е.

Таблица 5.8.2 (см. скан)
Выборочное математическое ожидание  равно
равно  где
где  полный объем наблюдений. Выборочное математическое ожидание
полный объем наблюдений. Выборочное математическое ожидание  равно
равно  если нулевая гипотеза верна (т. е. если на самом деле воздействия к обработок не различаются), но оно будет больше этого значения, если нулевая гипотеза неверна (т. е., по крайней мере, некоторые из обработок приводят к различным эффектам). Итак, подходящей статистикой критерия служит
если нулевая гипотеза верна (т. е. если на самом деле воздействия к обработок не различаются), но оно будет больше этого значения, если нулевая гипотеза неверна (т. е., по крайней мере, некоторые из обработок приводят к различным эффектам). Итак, подходящей статистикой критерия служит  ее большие значения (значимо превышающие единицу) указывают на реальный эффект обработок. Более точно, эта статистика имеет выборочное распределение
ее большие значения (значимо превышающие единицу) указывают на реальный эффект обработок. Более точно, эта статистика имеет выборочное распределение  а уровень значимости относительно нулевой гипотезы об отсутствии эффектов обработок равен
а уровень значимости относительно нулевой гипотезы об отсутствии эффектов обработок равен

Арифметические выкладки удобно представить в виде таблицы дисперсионного анализа [см. табл. 5.8.3].
Таблица 5.8.3. Анализ дисперсий внутри выборок и между ними

Полная сумма квадратов определяется приведенным в таблице выражением. Величина  определяется формулой
определяется формулой

 можно получить, если вычесть
можно получить, если вычесть  из полной суммы квадратов.
из полной суммы квадратов.
На практике вычисления оказываются менее сложными, чем представляется на первый взгляд. Надо вычислить суммы по столбцам  общую сумму
общую сумму  средние по столбцам
средние по столбцам  общее среднее
общее среднее  и сумму квадратов, скажем,
и сумму квадратов, скажем,  всех наблюдений. Тогда
всех наблюдений. Тогда

а

и

Наконец, вычисляется  и с помощью распределения
и с помощью распределения  находится уровень значимости, который равен
находится уровень значимости, который равен

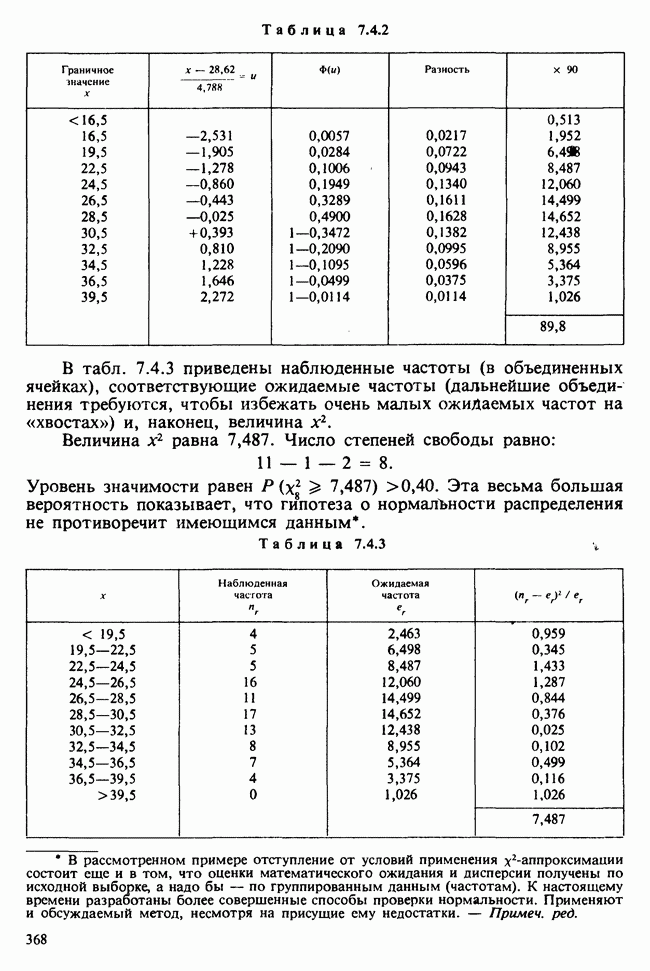
Можно предложить эквивалентное представление данных в виде таблицы частот [см. табл. 5.8.4]. Тогда  указывает частоту отклика х, при применении обработки с номером
указывает частоту отклика х, при применении обработки с номером 
Таблица 5.8.4. (см. скан) Представление к выборок в виде таблицы частот
Здесь  и т. д.,
и т. д.,  При таком подходе тождество для суммы квадратов принимает вид
При таком подходе тождество для суммы квадратов принимает вид

Сумма квадратов всех  наблюдений равна:
наблюдений равна:

суммы С; и средние с, по столбцам, а также полные сумма  и среднее
и среднее  указаны в таблице; статистики
указаны в таблице; статистики  и
и  и уровень значимости (относительно гипотезы об отсутствии эффектов обработок) вычисляются так же, как для приведенной ранее таблицы с векторами данных.
и уровень значимости (относительно гипотезы об отсутствии эффектов обработок) вычисляются так же, как для приведенной ранее таблицы с векторами данных.
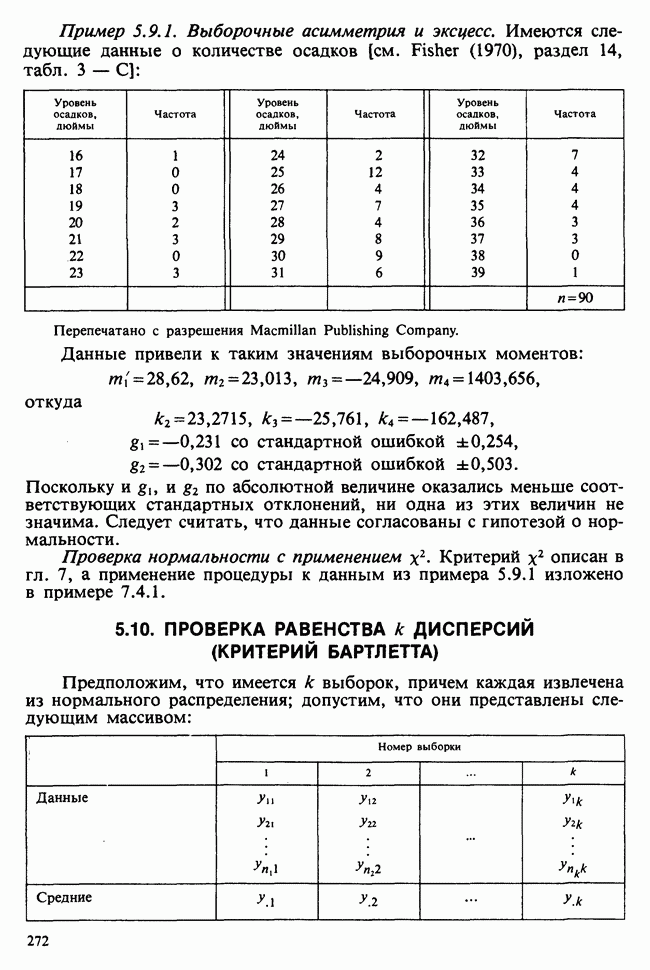
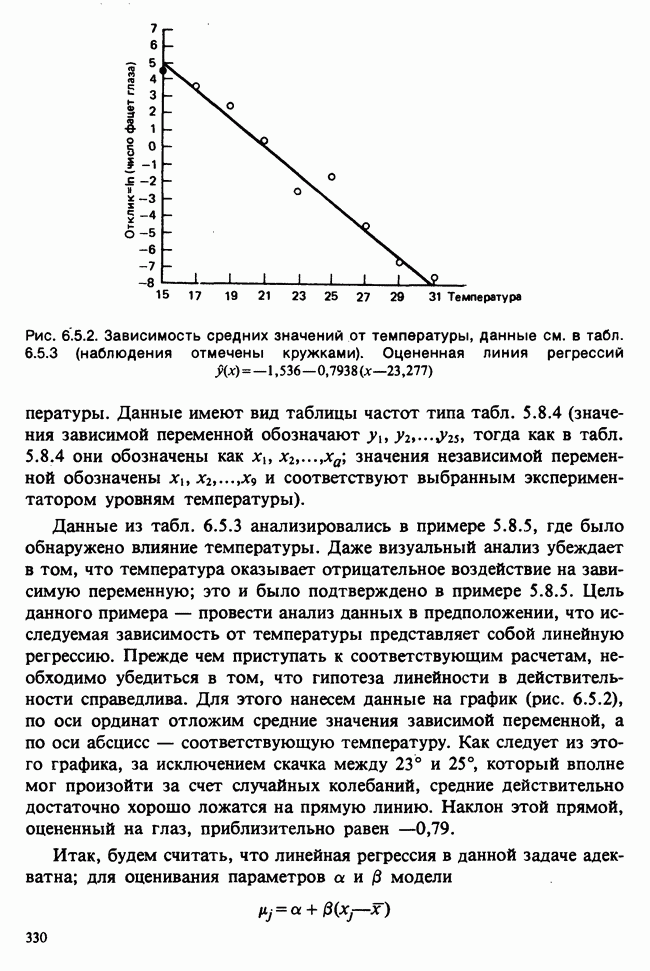
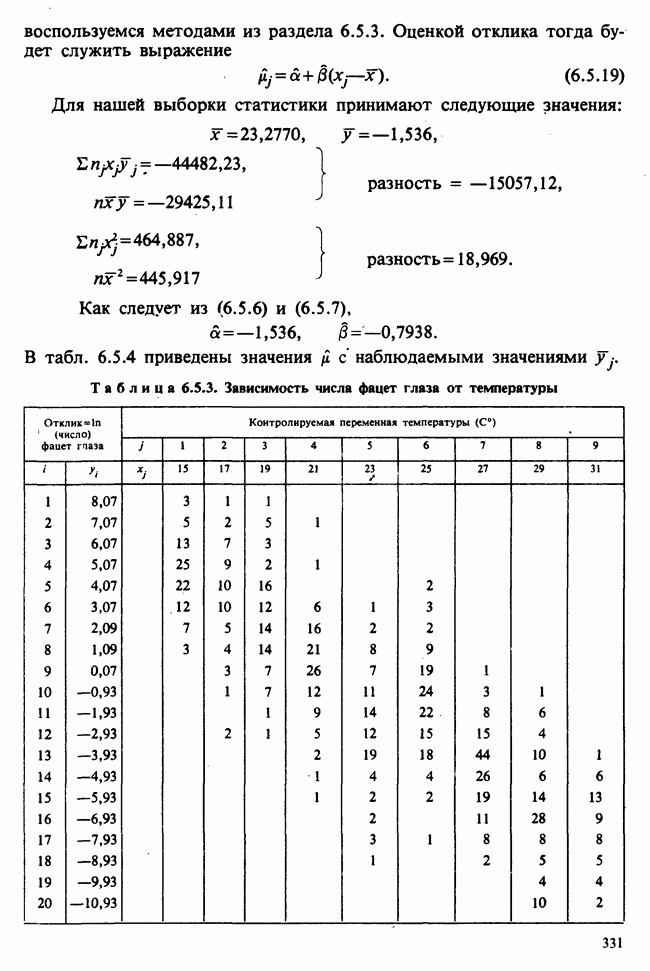
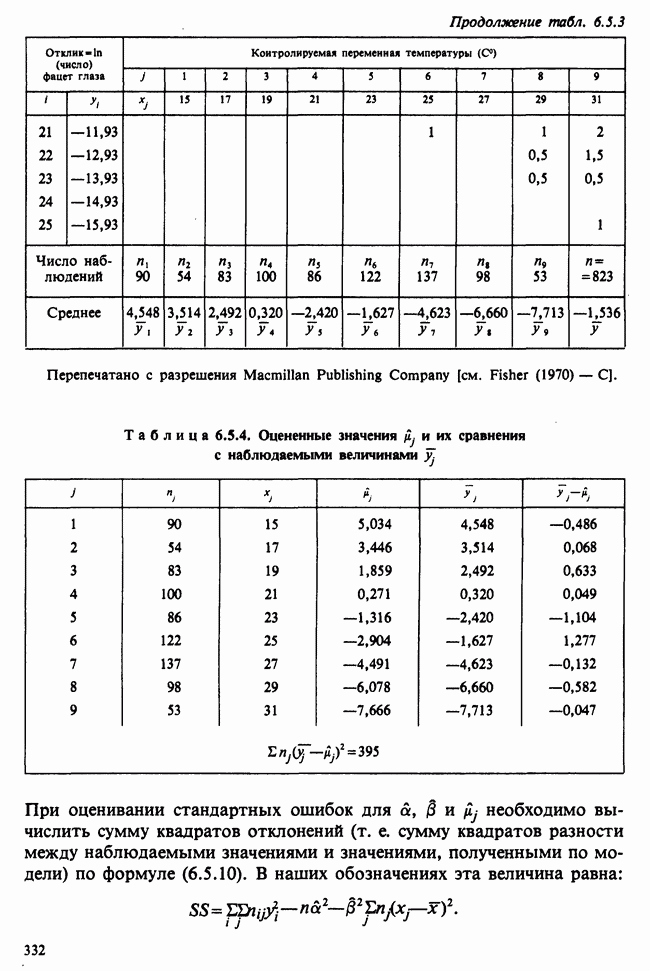
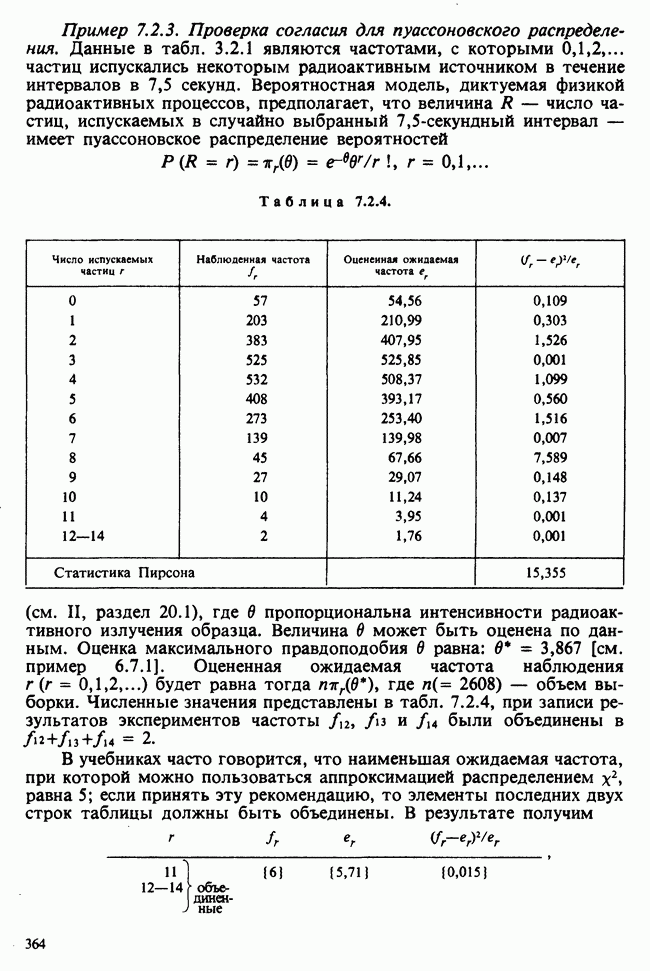
Пример 5.8.5. Проверка эффектов обработок. Совокупности данных можно представить в виде таблицы частот [см., например, табл. 6.5.3]. Здесь «обработки» — температура; имеющая номер  обработка обозначена
обработка обозначена  Отклики, ранее обозначавшиеся как
Отклики, ранее обозначавшиеся как  в этой таблице обозначены
в этой таблице обозначены  Суммы
Суммы  и средние
и средние  по столбцам таковы:
по столбцам таковы:
(см. скан)
(см. скан)
 и
и  равны соответственно
равны соответственно  тогда как величина
тогда как величина  Поэтому таблица дисперсионного анализа будет такой, как табл. 5.8.5.
Поэтому таблица дисперсионного анализа будет такой, как табл. 5.8.5.
Таблица 5.8.5. (см. скан) Таблица дисперсионного анализа
Таким образом, дисперсионное отношение равно 329. Вероятность получить такое или большее значение при  -распределении, конечно, ничтожно мала; тем самым показано, что гипотеза об отсутствии значимых различий между столбцами неразумна (что, коьечно, было очевидно и вначале).
-распределении, конечно, ничтожно мала; тем самым показано, что гипотеза об отсутствии значимых различий между столбцами неразумна (что, коьечно, было очевидно и вначале).