Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
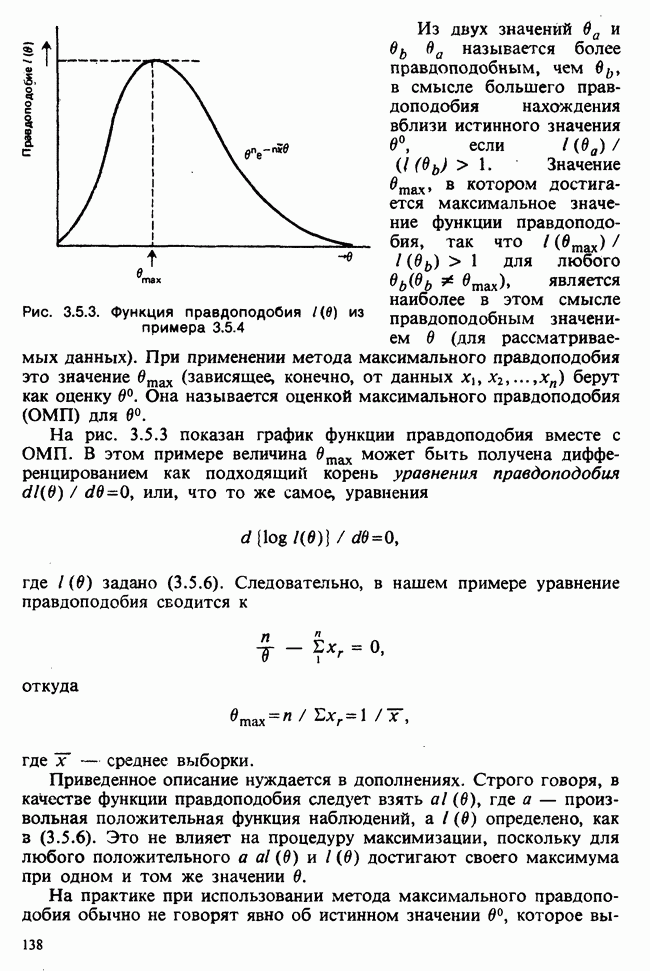
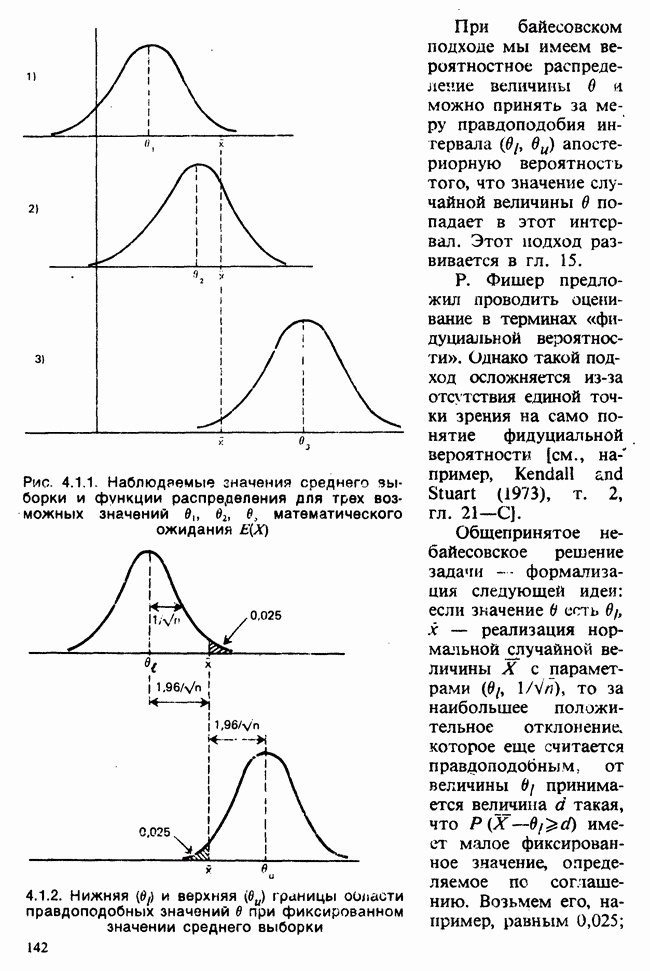
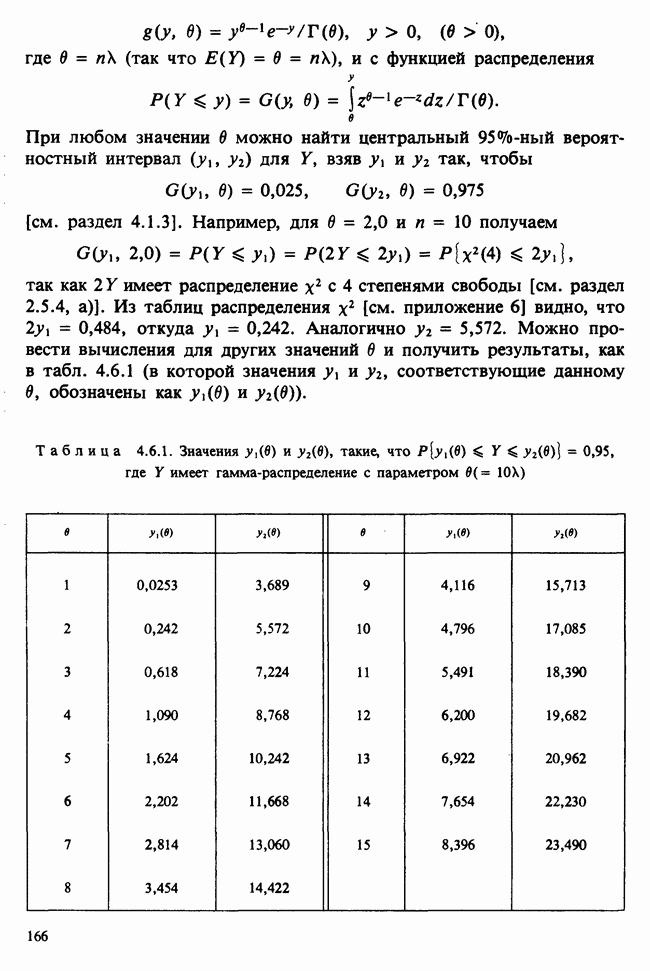
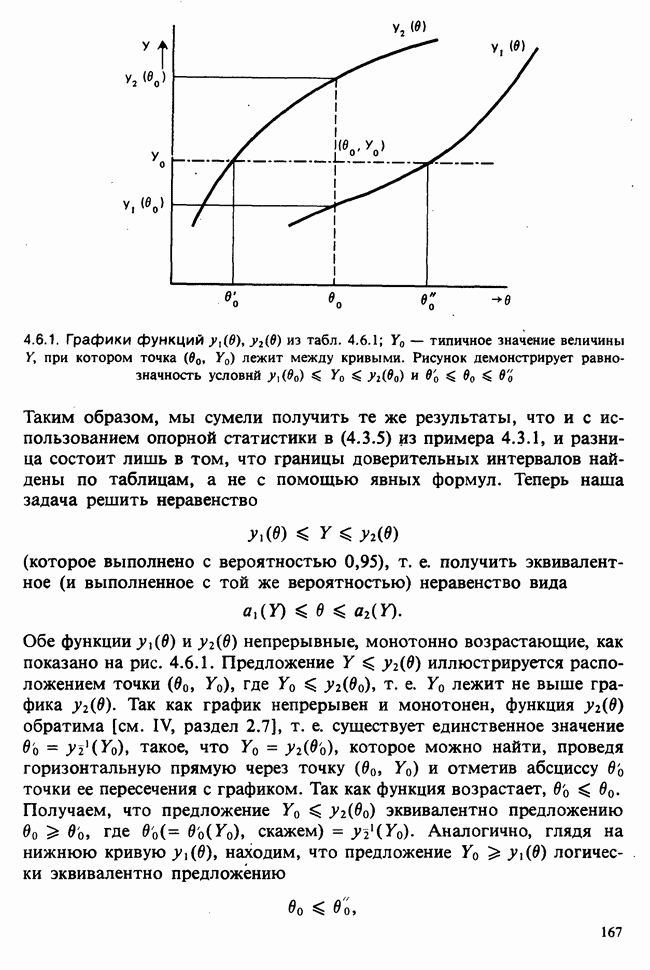
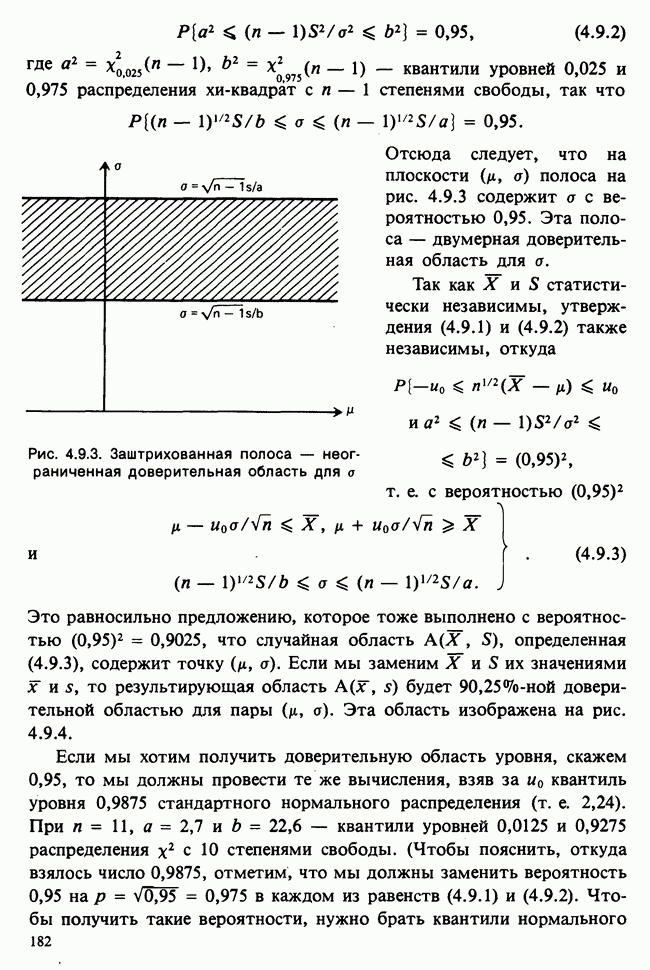
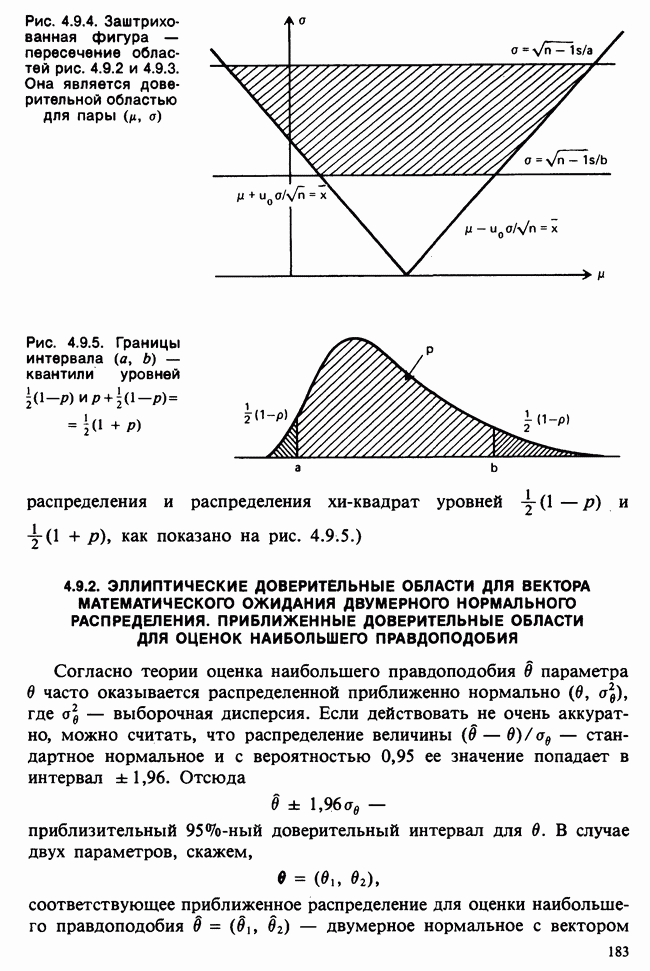
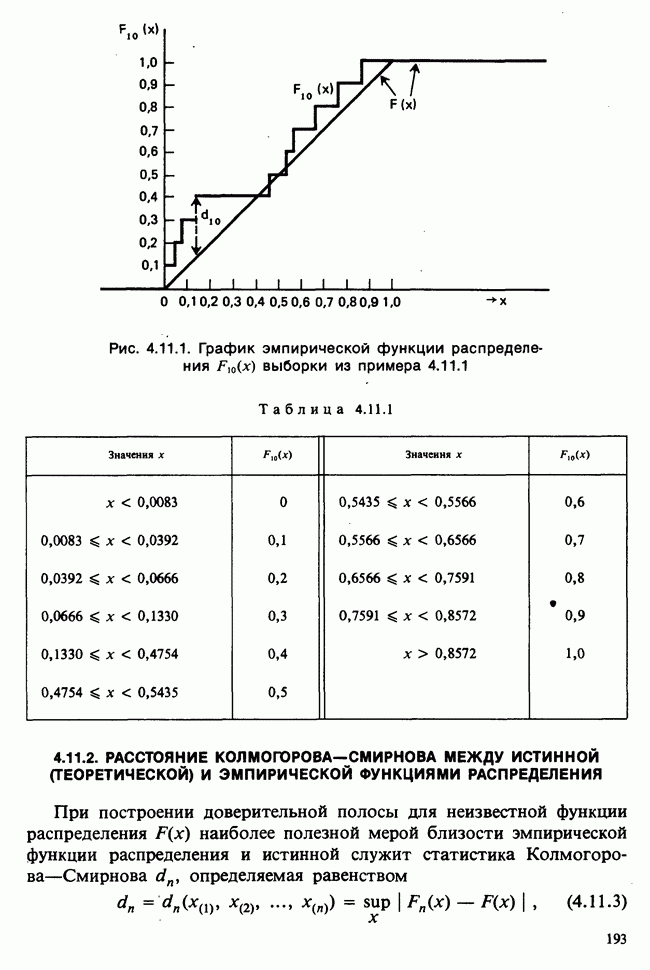
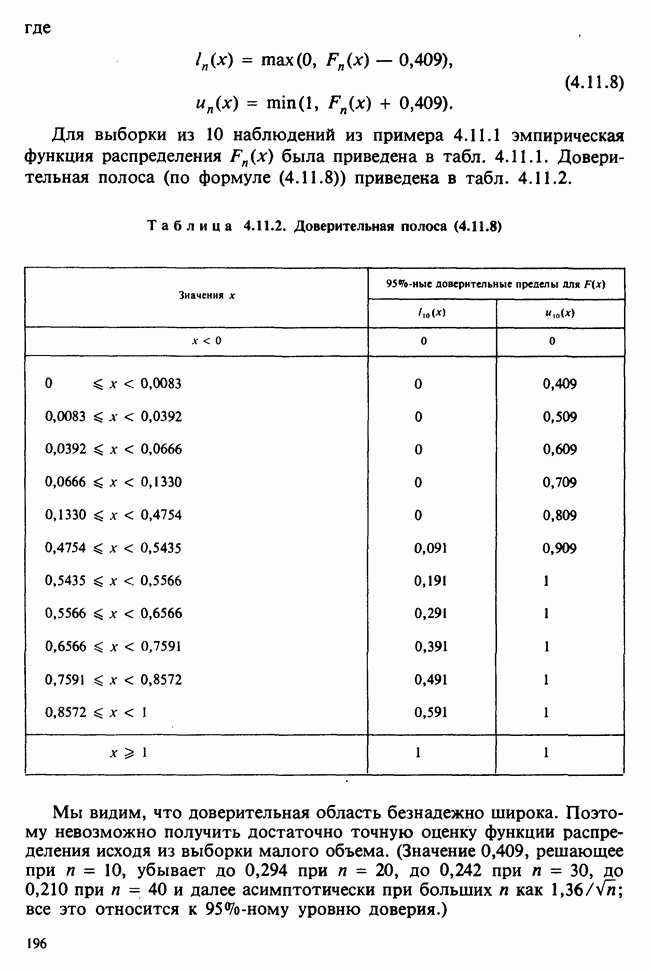
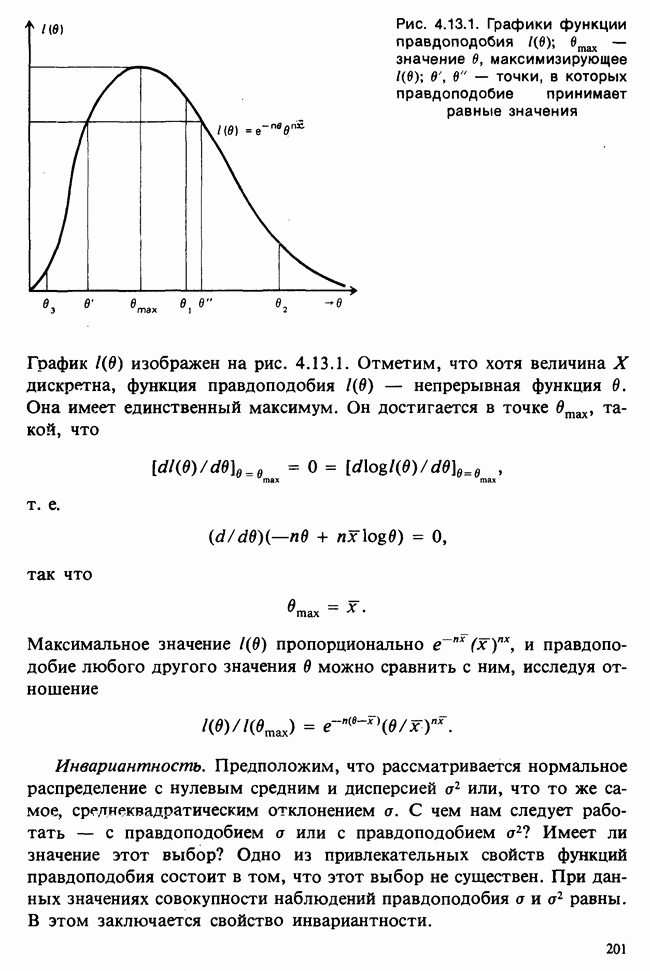
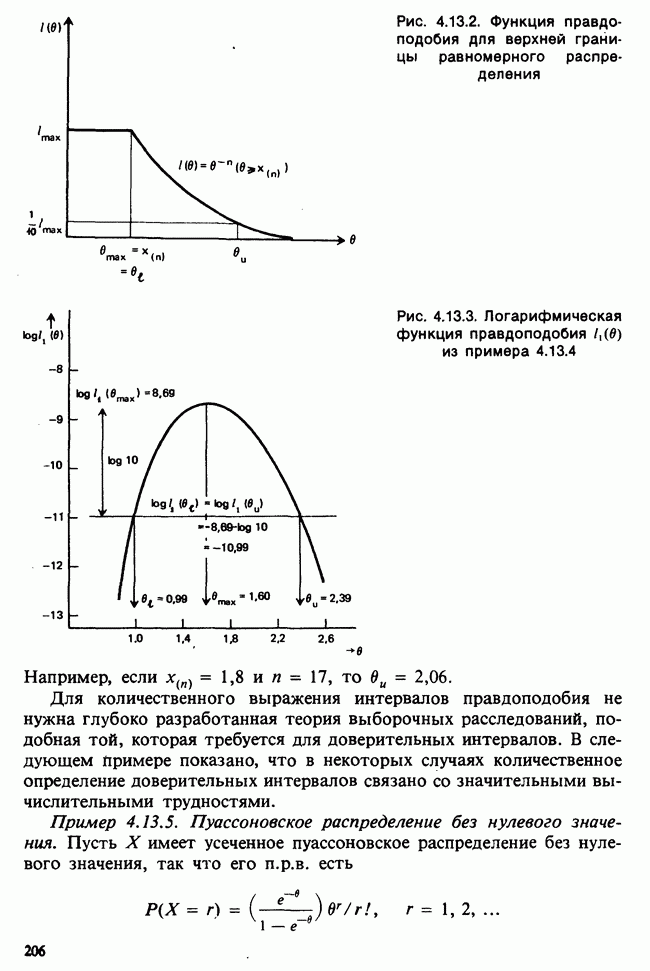
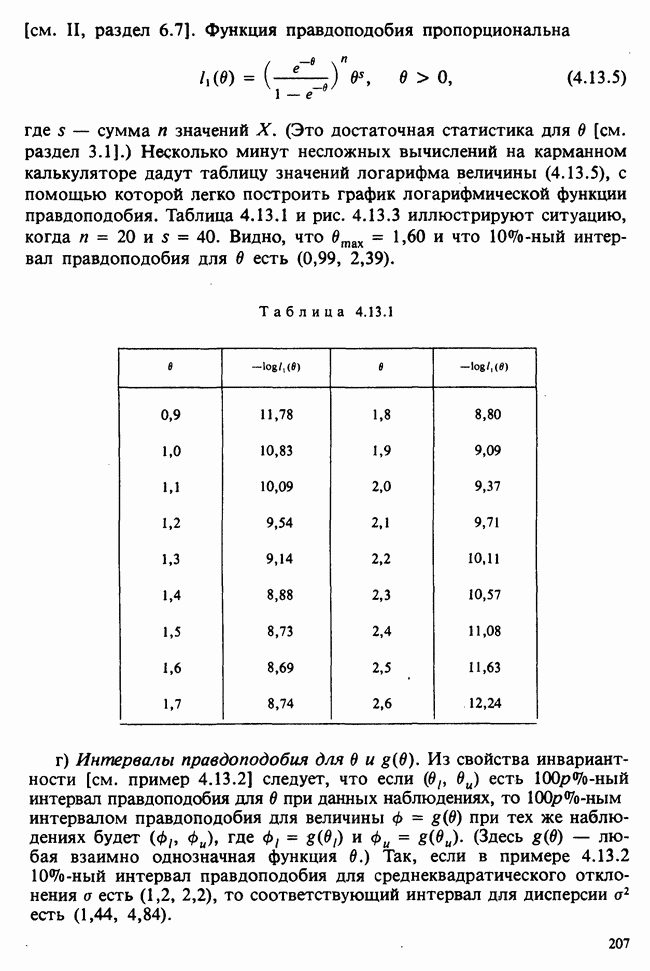
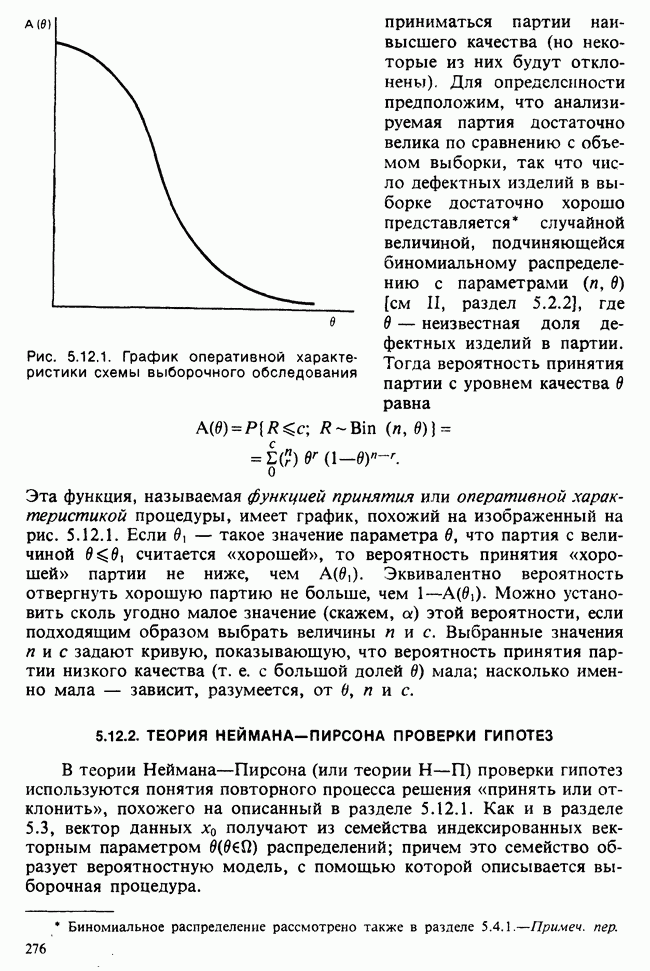
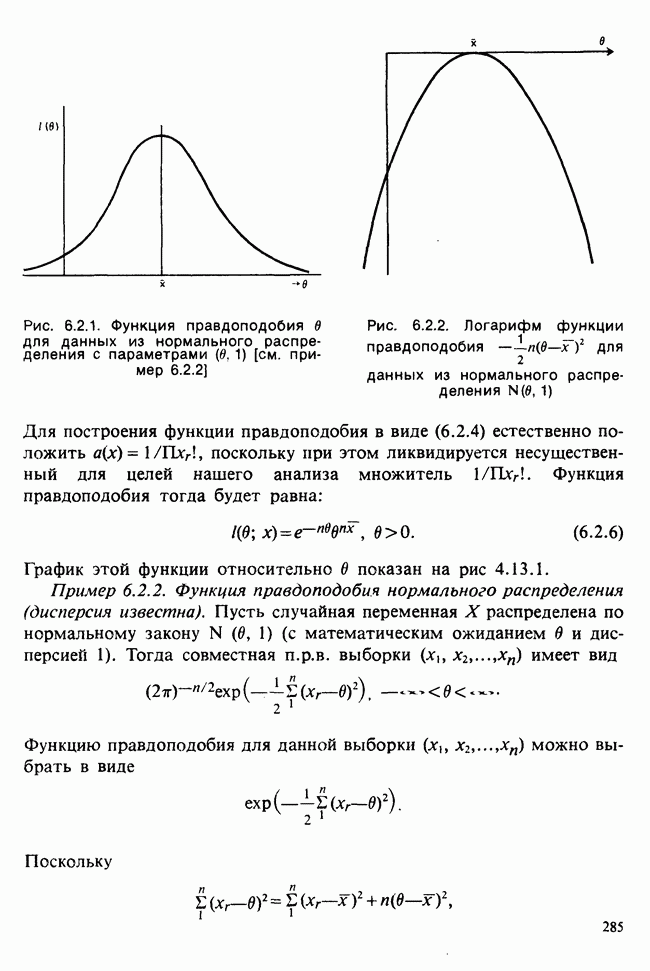
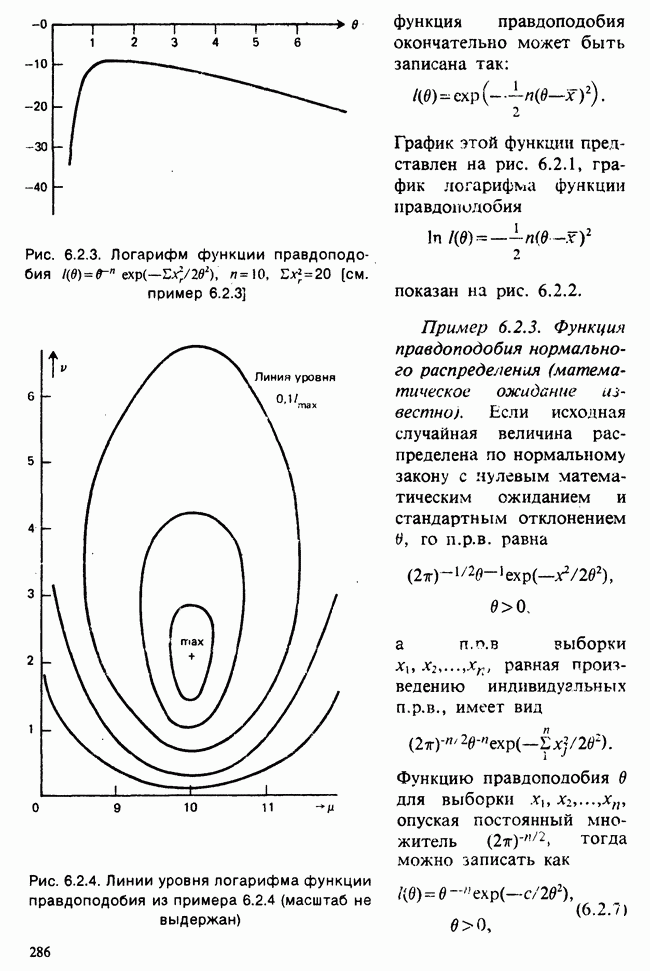
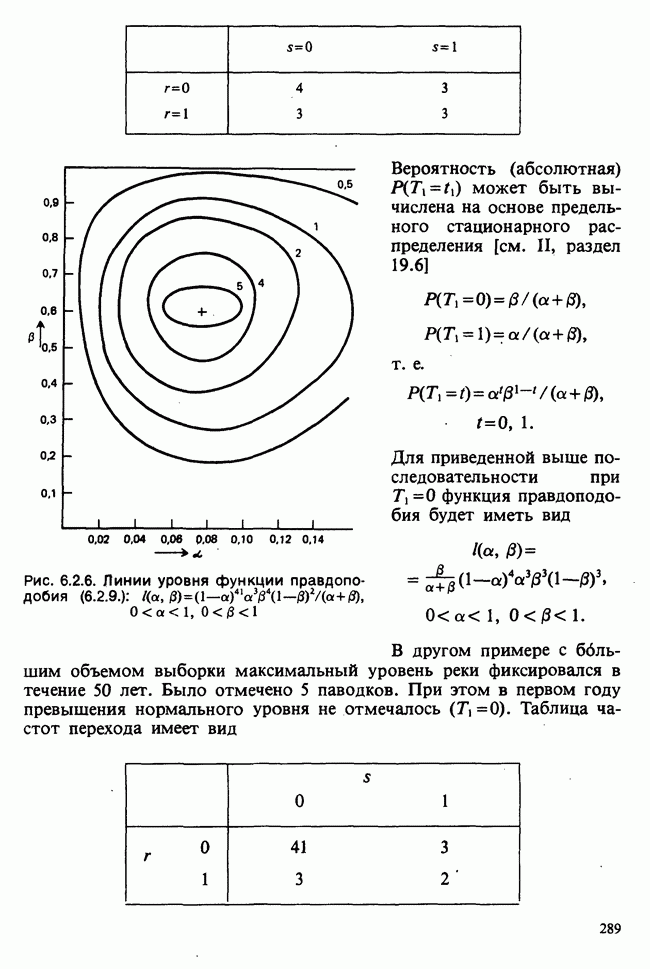
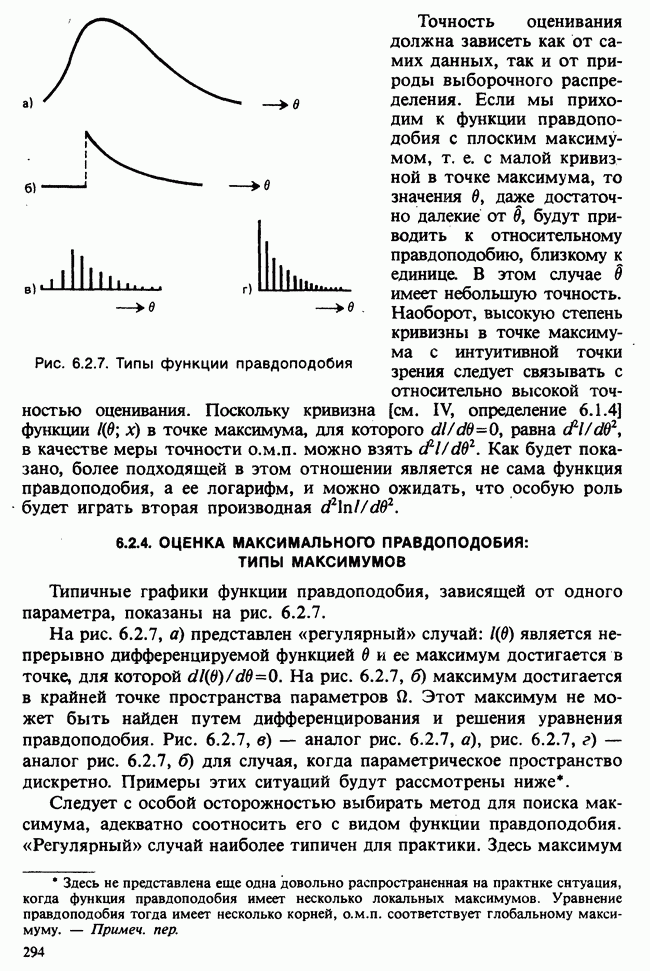
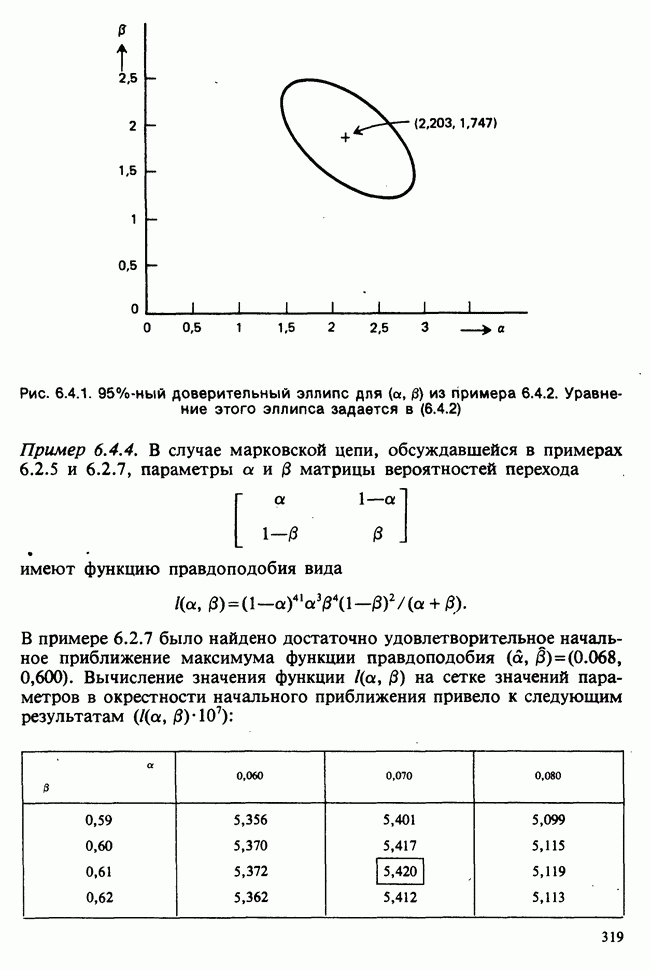
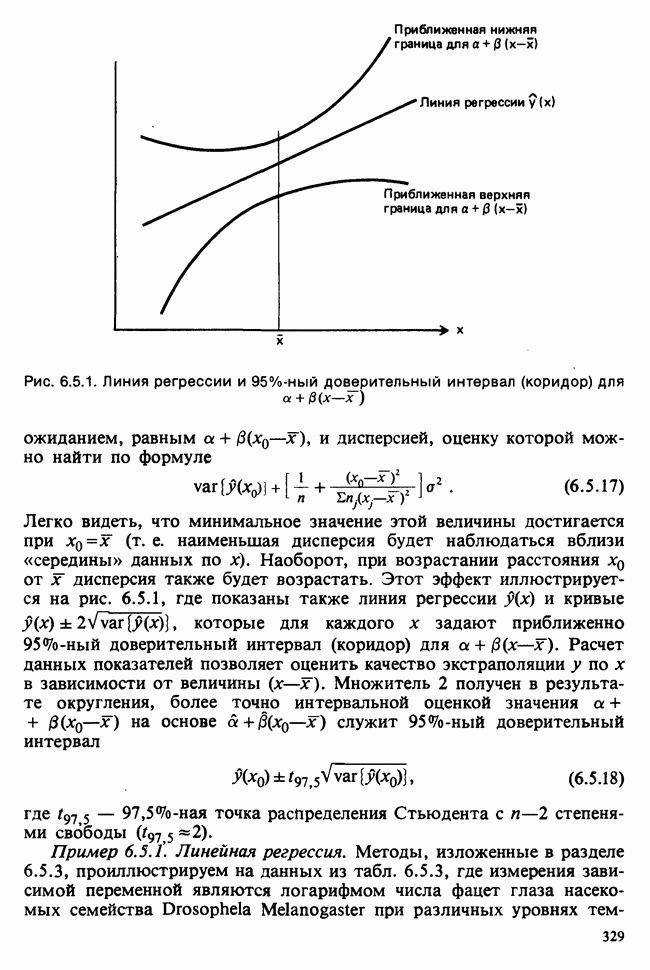
Глава I. ВВЕДЕНИЕ В СТАТИСТИКУ1.1. СМЫСЛ ПОНЯТИЯ «СТАТИСТИКА»В Оксфордском словаре английского языка приведено следующее разъяснение термина «статистика»: собранные и классифицированные числовые данные и сведения. Таким образом, можно говорить о статистике образования, финансовой статистике, статистике промышленности и т. д. В том же словаре дается и другое рячъяпнение этого термина: в более старой трактовке статистика — один из разделов науки об управлении государством, сбор, классификация и обсуждение сведений о состоянии общества и государства. В настоящее время — наука, изучающая методы сбора и обраоотки фактов и данных, относящихся к человеческой деятельности и природным явлениям. Итак, устаревшее определение, если его освободить от связи с государством, окажется не слишком отличающимся от современного то листания. Это «современное» определение удивительно старомодно, поскольку в нем не отражен ключевой аспект — интерпретация данных. Определение, вполне приемлемое для большинства практических работников, можно сфбрмулировать, перефразировав приведенное в Оксфордском словаре: в настоящее время статистика — наука, изучающая методы сбора и интерпретации числовых данных. Здесь интерпретация данных рассматривается как существенный аспект. Трудно дать краткое и в то же время исчерпывающее определение статистики — дисциплины с такой широкой и разнообразной областью приложения. Однако в первом приближении можно сказать, что главная цель статистики — получение осмысленных заключений из несогласованных (подверженных разбросу) данных. Действительно, исключая тривиальные ситуации, реальные данные всегда являются несогласованными, что требует применения статистических методов. Рассогласованность (разброс) между индивидуальными наблюдениями может быть, например, обусловлена ошибкой, как при считывании позиции указателя, когда он расположен между двумя делениями шкалы прибора. Изменчивость может быть также следствием флуктуаций во внешней среде, как, например, в случае мерцания звезд из-за флуктуаций в атмосфере, или следствием неравномерности работы электронного оборудования при передаче сообщений по радио или телеграфу. (В последнем случае для характеристики ситуации используется термин «шум».) Можно еще привести пример обследования части генеральной совокупности, индивидам которой присуща врожденная изменчивость измеряемой характеристики (например, рост двадцатилетних студентов мужского пола). Чаще всего ситуация слишком сложна, чтобы ее можно было изучить на основе полного описания, отражающего все детали. Поэтому обычно применяется некоторая математическая модель явления. Она, по замыслу, должна воспроизводить его существенные черты и исключать те, которые предполагаются несущественными. Такая модель использует законы науки, приложимые к рассматриваемой ситуации, и обычно включает в себя детерминистские и стохастические (случайные) элементы. Последние в свою очередь представлены некоторой вероятностной моделью, необходимой для объяснения математической модели и проверки истинности того, что статистические выводы, строго говоря, применимы. Пример 1.1.1. Молоко и вес детей. Рассмотрим, влияет ли регулярное потребление молока на физическое развитие школьников. Прежде чем попытаться получить ответ, мы должны решить, какое количество молока (полпинты в день?) должно быть взято, за какой период (год?), какого возраста дети ( режимом питания и Это в принципе простой пример, но он иллюстрирует некоторые главные черты статистического вывода. Прежде всего сбор данных должен быть организован так, чтобы выполнялись требования теории вероятностей: обследование должно быть правильно спланировано, и выборочный метод должен соответствовать поставленной цели. Далее характеристики жизни детей, несущественные для исследования, необходимо исключить из рассмотрения. Тогда модель будет основана на упрощающем предположении, что при правильном планировании вариабельность может быть объяснена в терминах выбранного семейства распределений [см. II, гл. 4 и 11]. Выбор такого семейства (нормального в нашем примере) является результатом компромисса между сложностью реальности и простотой, необходимой для получения правильных количественных заключений с наименьшими вычислительными трудностями. Чтобы гарантировать истинность этого выбора, возможно, понадобятся дальнейшие исследования. В рассмотренном примере модель проста: наблюдениями является вес детей, а в качестве исследуемого эффекта взято различие между конечным и исходным весом. В хорошо разработанном эксперименте наблюдения могли бы быть выражены в виде более сложных функций переменных и/или параметров, предлагаемых или необходимых в данной области науки. Некоторые (или все) из этих переменных могли бы рассматриваться как подверженные случайному разбросу, что требует толковать их как случайные переменные. Могли бы быть подобраны подходящие семейства распределений и оценены соответствующие параметры. Затем, как и в вышеприведенном примере, следовала бы процедура, подтверждающая пригодность модели в целом. Например, наблюдениями могло бы быть количество осадков, измеряемых в 20 соседних городах за каждый из 100 последовательных четвертьчасовых интервалов. Модель, основанная на радиометеорологии, могла бы связать осадки в данном месте как функцию времени с зарождением, ростом, распадом облачных масс. В качестве переменных тогда можно было бы использовать темп зарождения облачности (возможно, как двумерный пуассоновский процесс [см. II, раздел 20.1.7]) и параметры, описывающие форму облаков и скорость их роста и распада. Пример 1.1.2. Эксперимент по определению смертельной дозы инсектицида. Другой пример, детально описанный в разделе 6.6, связан с оценкой смертности насекомых в зависимости от дозы применяемого инсектицида. Действие различных доз инсектицида измеряется числом насекомых, погибших после применения соответствующей дозы. При очень низкой дозировке насекомые не погибают, при очень высокой погибают все. В то же время при промежуточных дозах процент погибших насекомых, который подвержен экспериментальному разбросу и зависит от многих факторов, в среднем возрастает с увеличением дозы. Необходимо: а) подобрать правдоподобную параметрическую модель для описания «кривой роста» доли погибших насекомых в зависимости от дозировки; б) оценить параметры этой кривой и проверить, что результирующая кривая действительно является приемлемой моделью; в) получить значение дозировки, при которой погибает 50% насекомых (эта величина будет служить принятой мерой токсичности), вместе с оценкой ее надежности. Приведенный пример показывает, что нам необходимы методы для получения хороших приближенных значений параметров («оценок»), характеризующих член выбранного семейства вероятностных распределений, а также методы для описания точности этих оценок. Оценка точности должна подсказать, являются ли различия в оценках параметров настолько значимыми, чтобы можно было говорить о различиях между действительными (неизвестными) значениями параметров. Она необходима также для того, чтобы проверить, дает ли избранное семейство распределений приемлемую модель для наблюдаемых данных. Таковы наиболее важные черты статистического вывода. Они детально описаны в последующих главах настоящего Справочника наряду с некоторыми другими подходами, основанными на них. Введение в статистический вывод содержится в работе [Barnett (1982), гл. 1].
|
 |
Оглавление
|











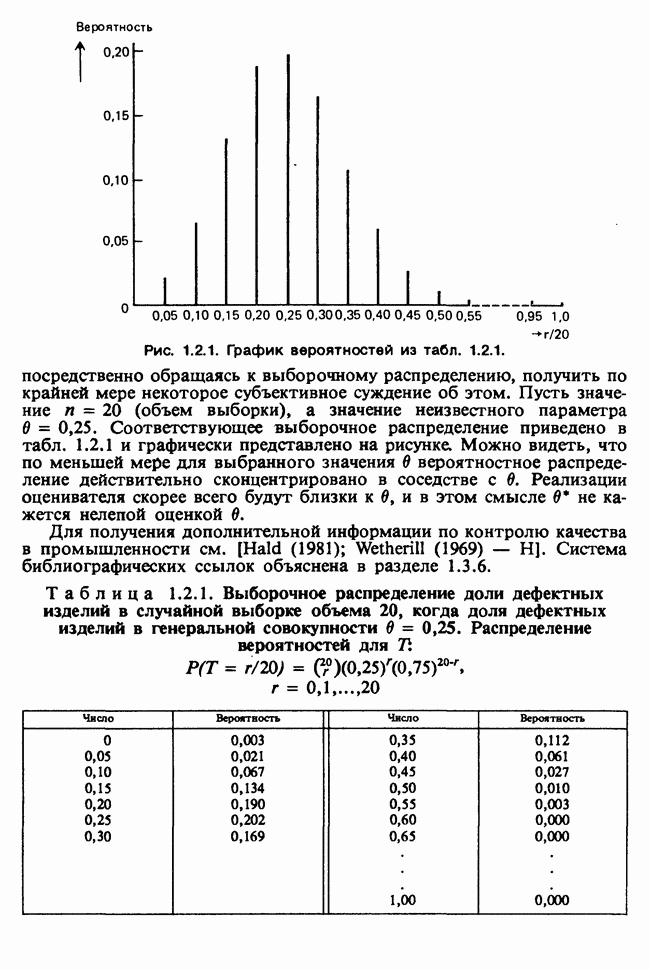

































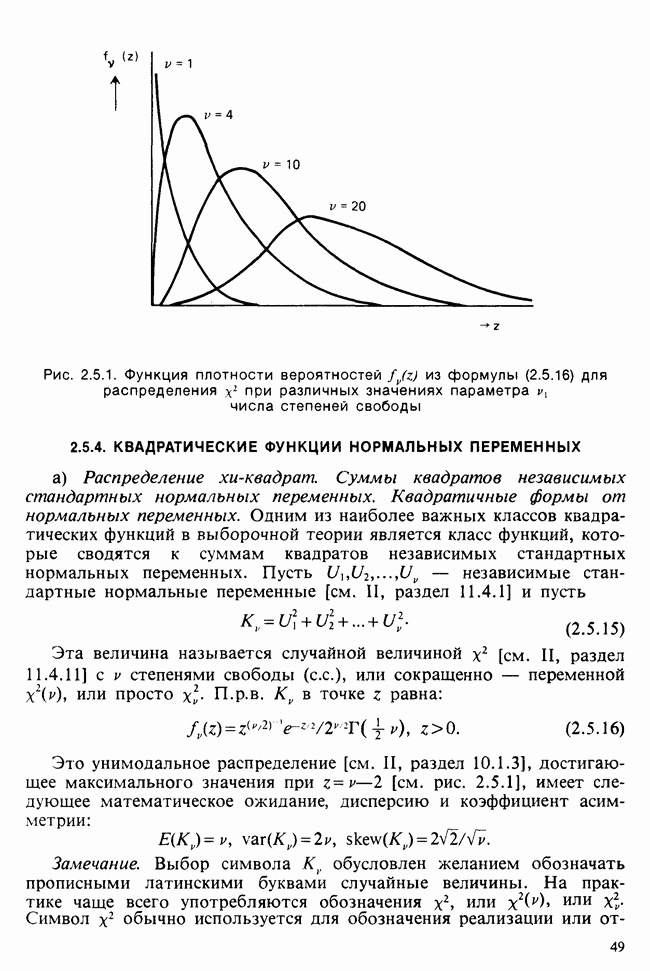











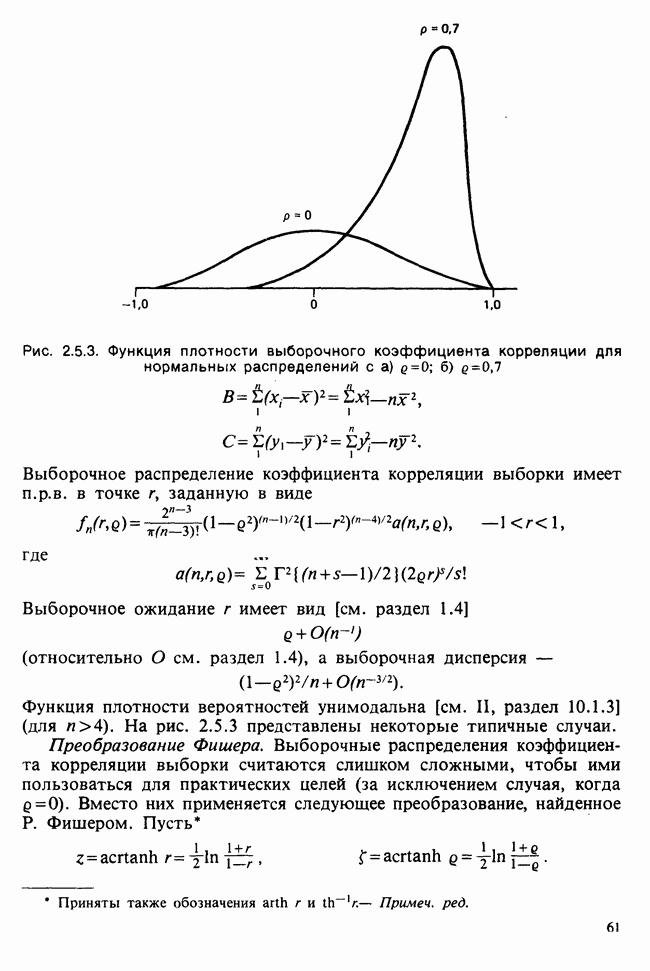












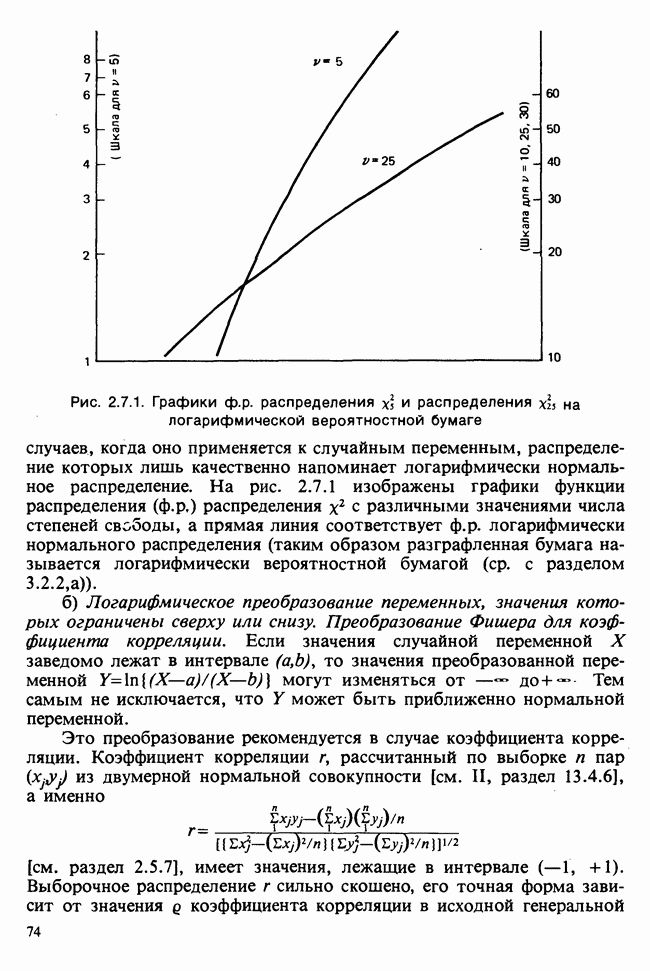
































































































































































































































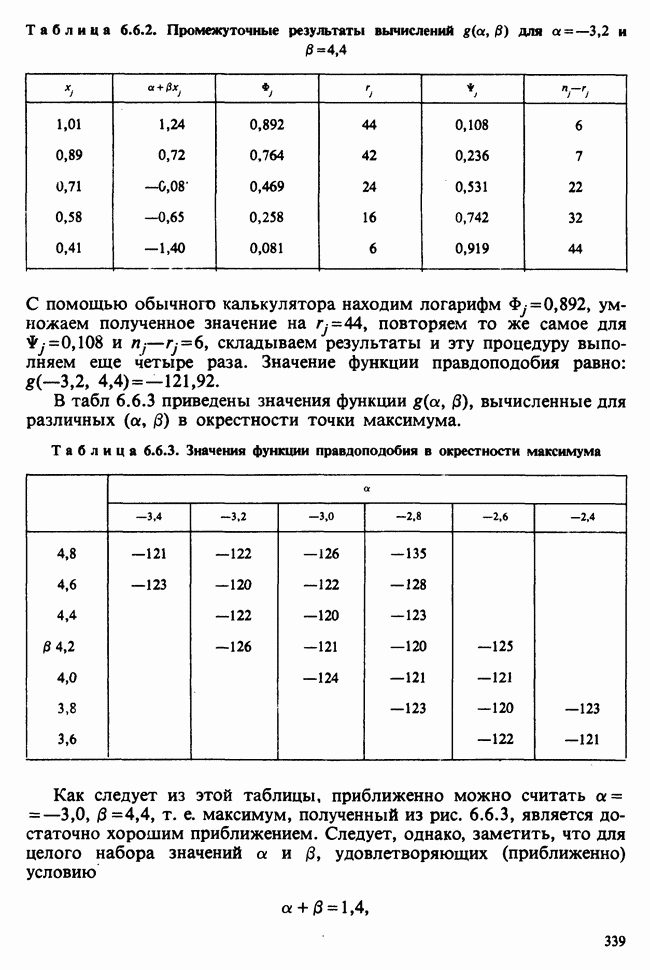


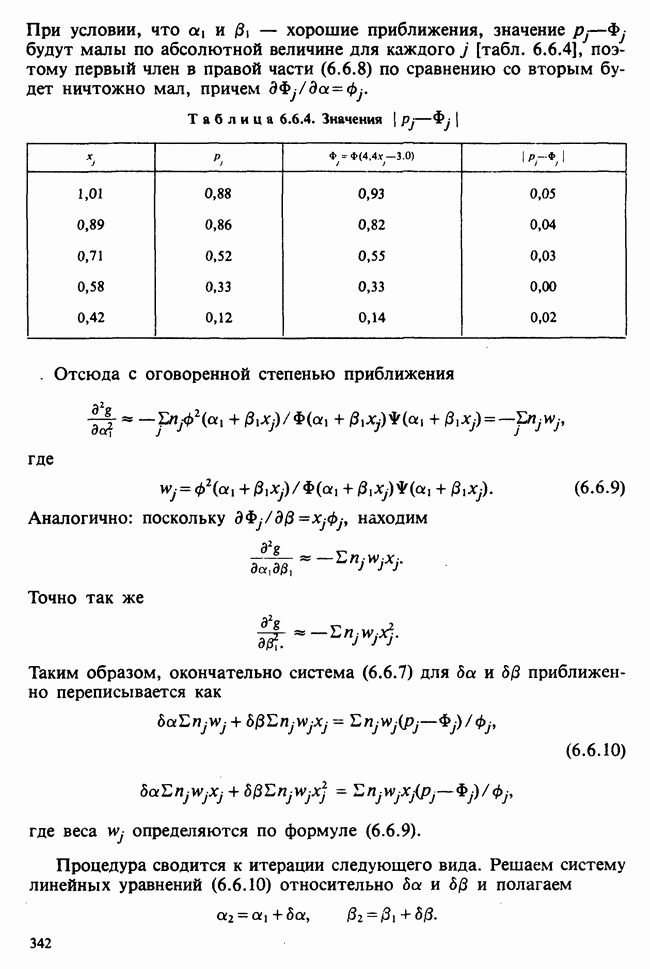

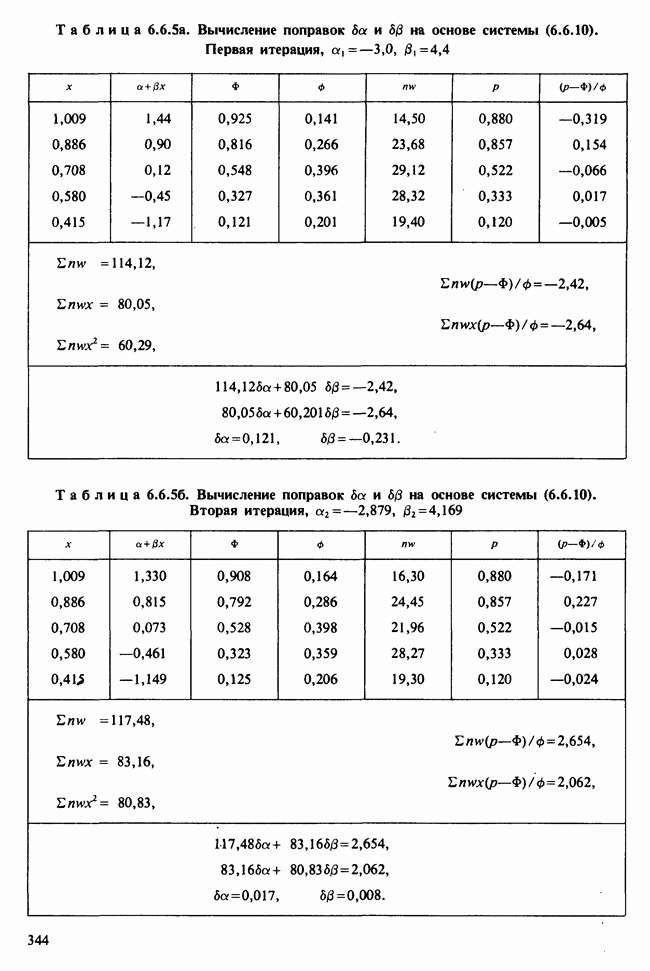

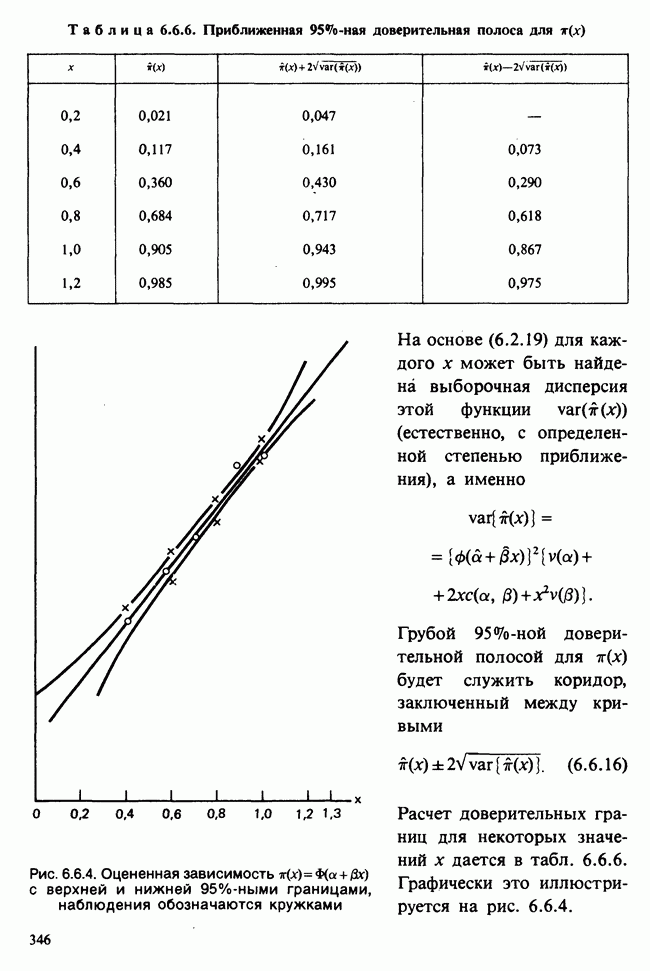









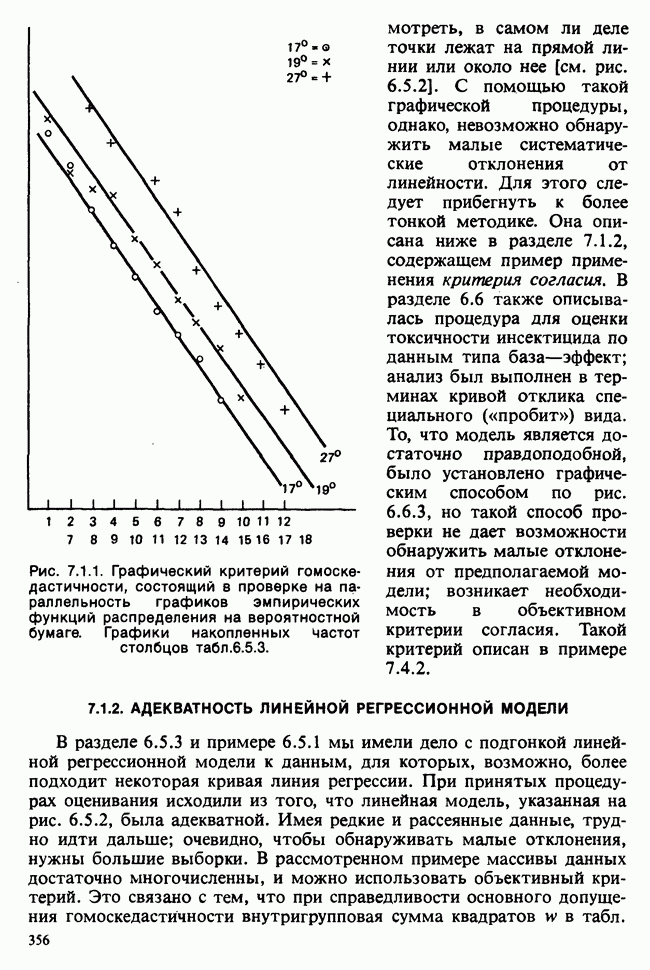
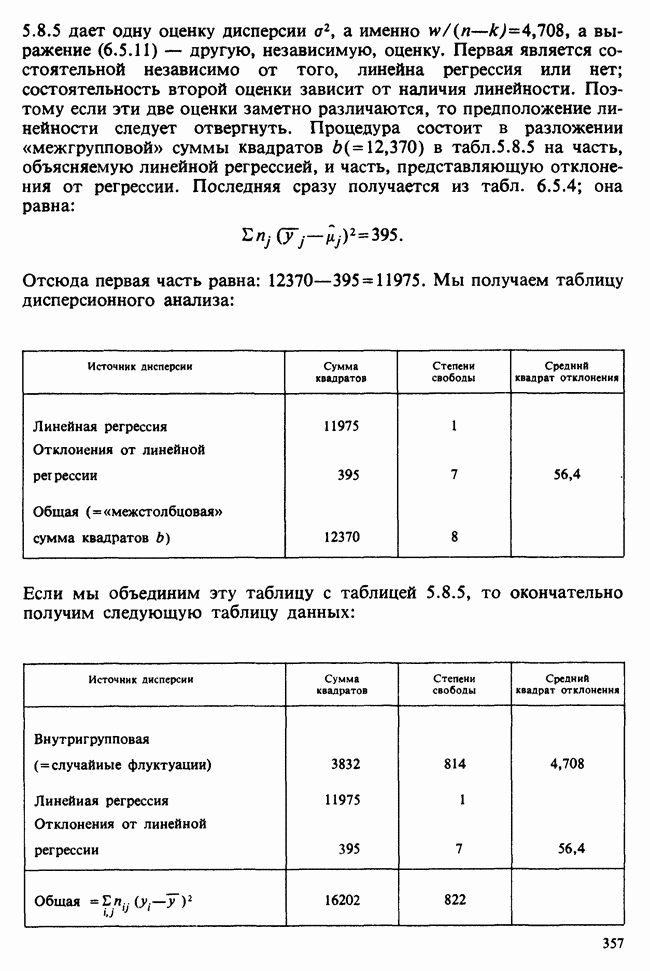

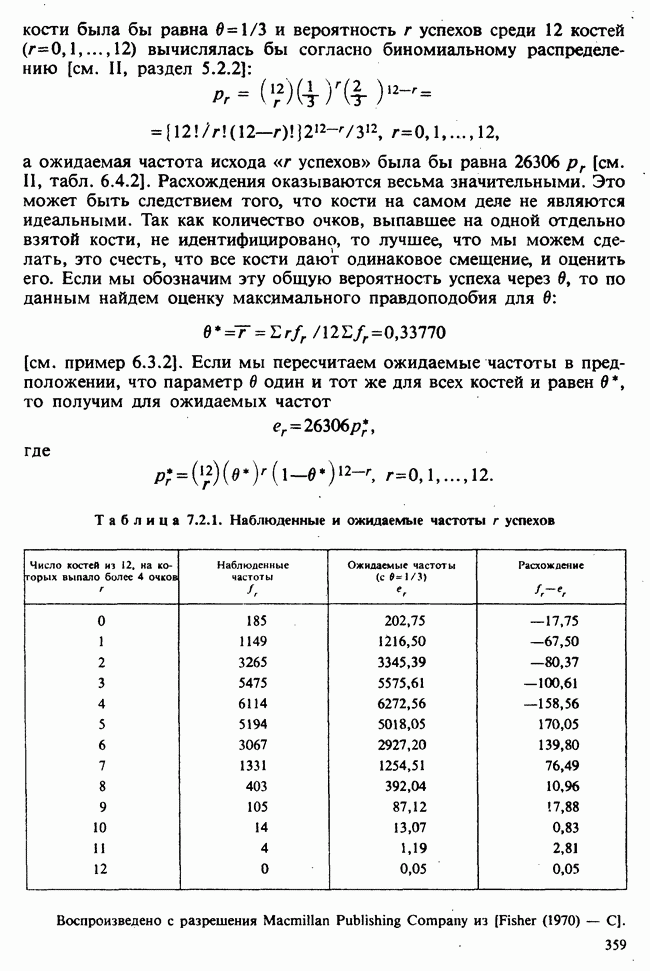
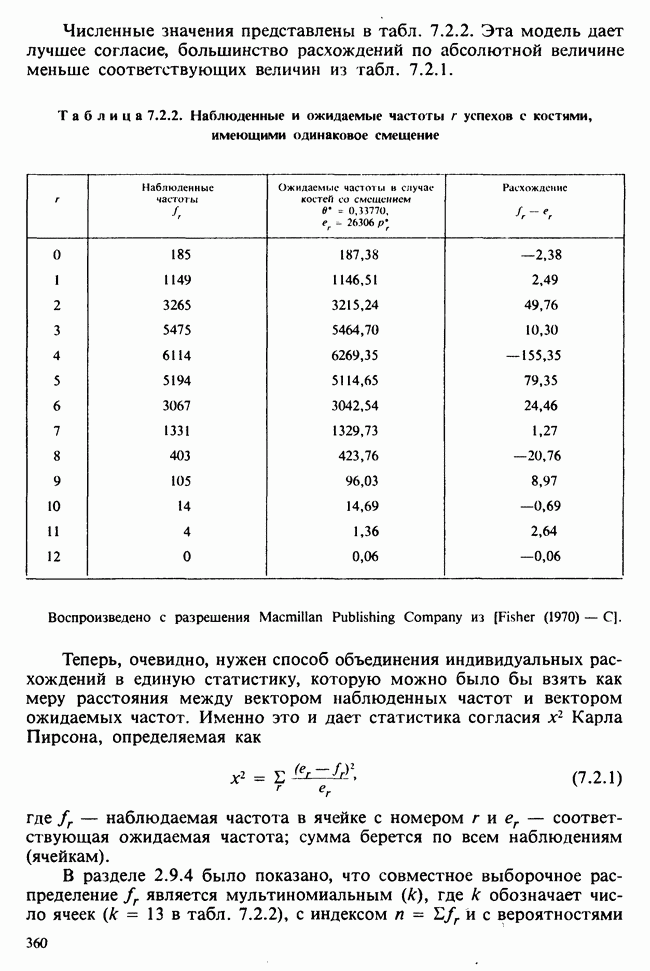






































































































































 — лет?) и какой аспект (или аспекты) их физического развития должен быть измерен (их вес?). Простой метод взвешивания детей до и после периода регулярного потребления молока непригоден, так как при этом невозможно отделить приращение веса, обусловленное потреблением молока, от того, которое произошло независимо от его потребления. Чтобы выявить эти составляющие, необходимо сравнить группу детей, находящихся на молочной диете, с контрольной группой детей с обычным режимом питания (который должен быть определен). Для отнесения детей к группе с молочной диетой и к контрольной группе можно было бы применить какой-либо из методов, предполагающих процедуры рандомизации, что позволило бы рассматривать индивидуальные изменения веса как реализации независимых случайных величин [см. II, определение 4.4.1]. В первом приближении, но с достаточной точностью эти изменения веса могли бы рассматриваться как нормально распределенные [см. II, раздел 11.4] со стандартным отклонением а и с математическим ожиданием для группы детей с обычным
— лет?) и какой аспект (или аспекты) их физического развития должен быть измерен (их вес?). Простой метод взвешивания детей до и после периода регулярного потребления молока непригоден, так как при этом невозможно отделить приращение веса, обусловленное потреблением молока, от того, которое произошло независимо от его потребления. Чтобы выявить эти составляющие, необходимо сравнить группу детей, находящихся на молочной диете, с контрольной группой детей с обычным режимом питания (который должен быть определен). Для отнесения детей к группе с молочной диетой и к контрольной группе можно было бы применить какой-либо из методов, предполагающих процедуры рандомизации, что позволило бы рассматривать индивидуальные изменения веса как реализации независимых случайных величин [см. II, определение 4.4.1]. В первом приближении, но с достаточной точностью эти изменения веса могли бы рассматриваться как нормально распределенные [см. II, раздел 11.4] со стандартным отклонением а и с математическим ожиданием для группы детей с обычным
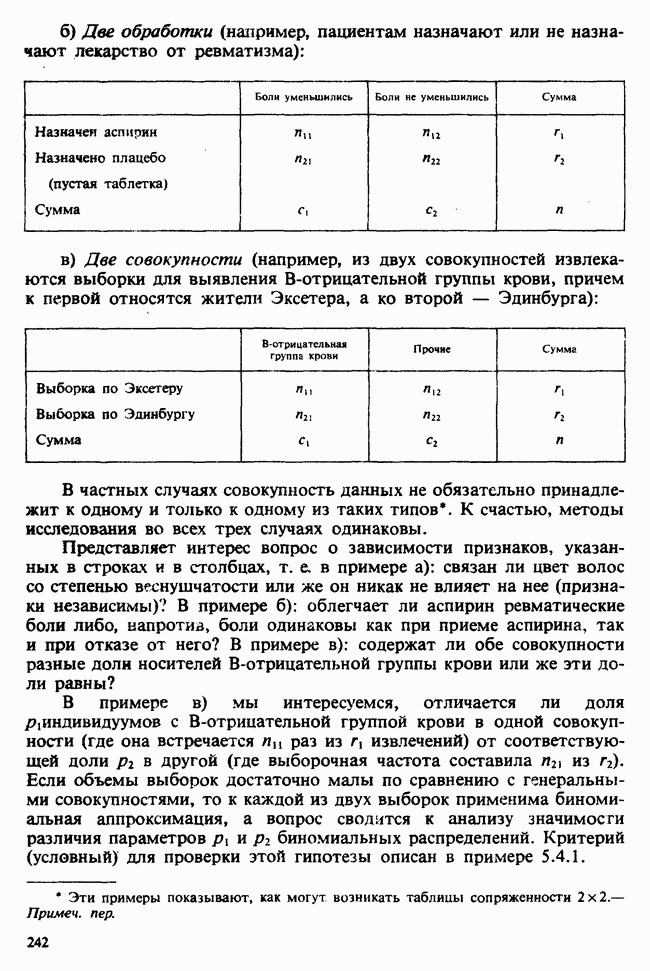
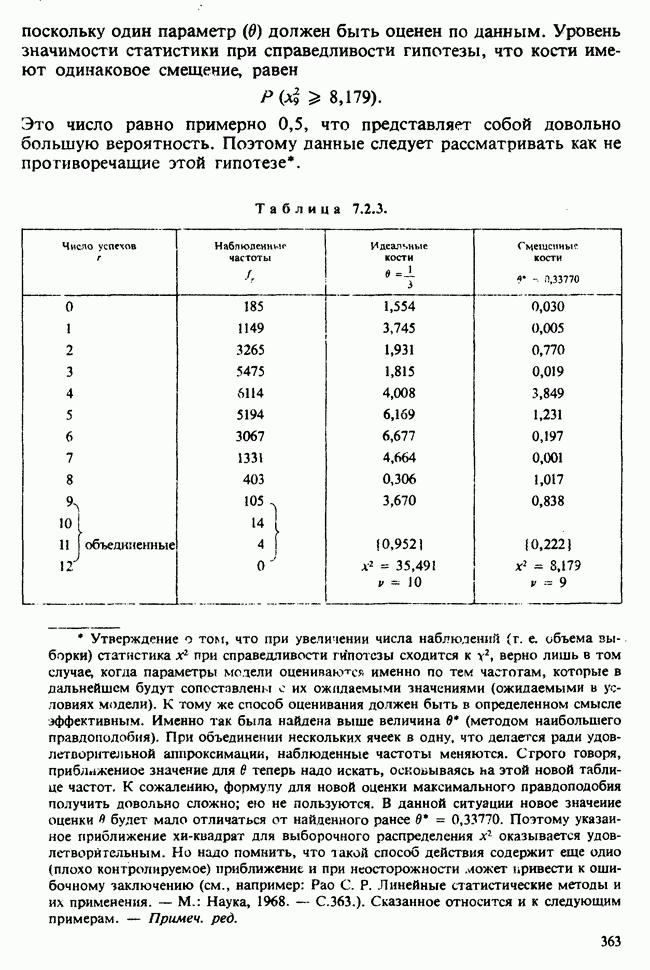
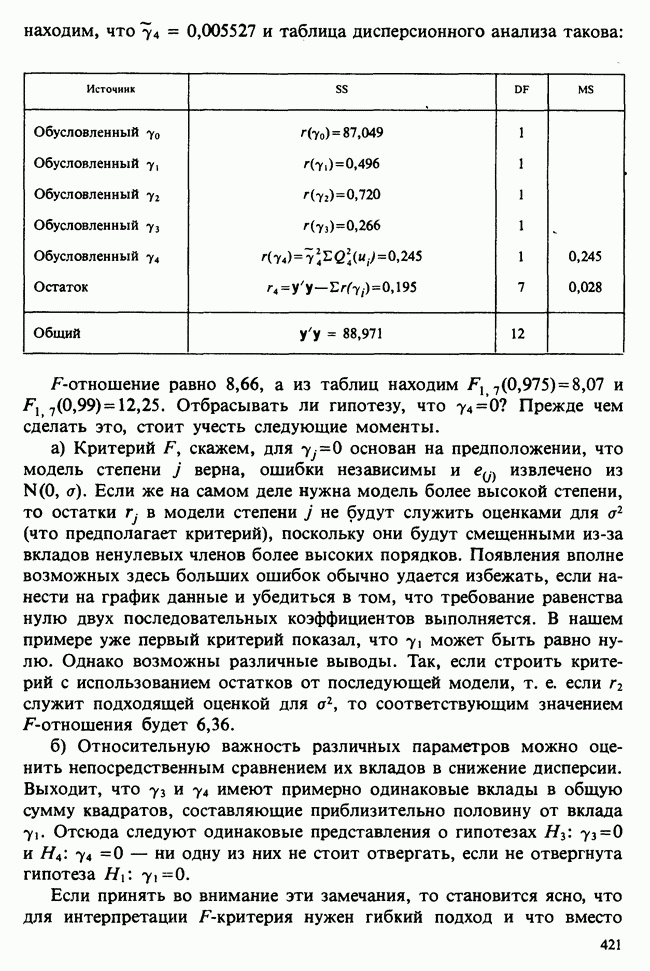
 для группы детей с молочной диетой. Здесь
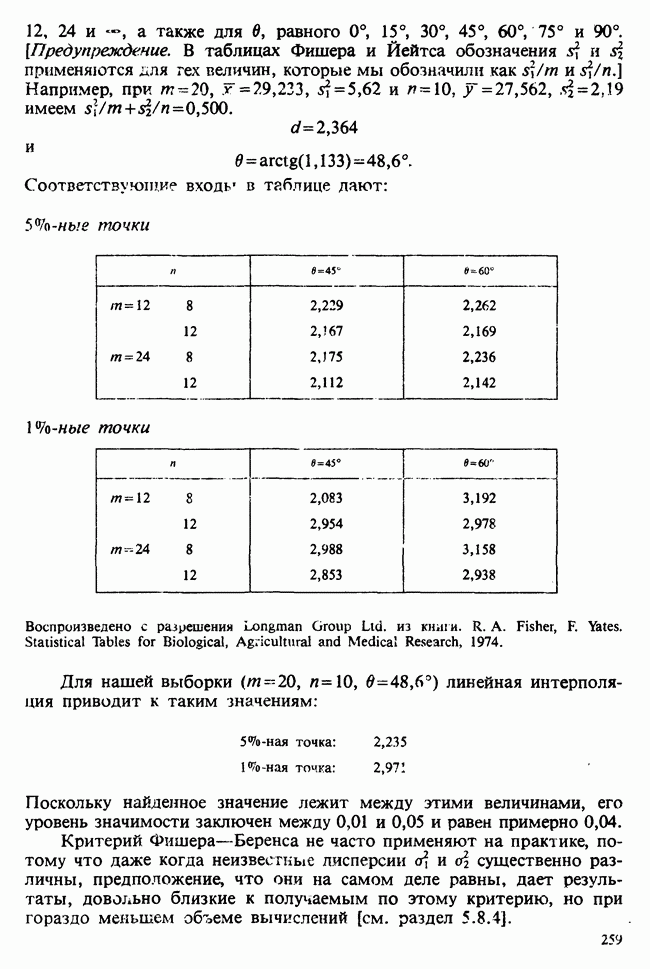
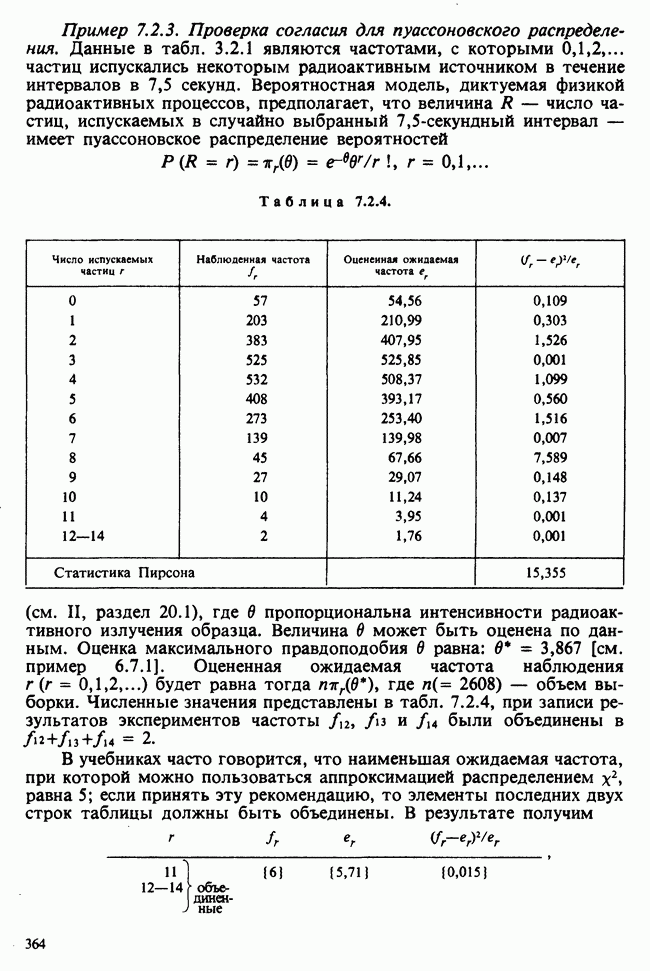
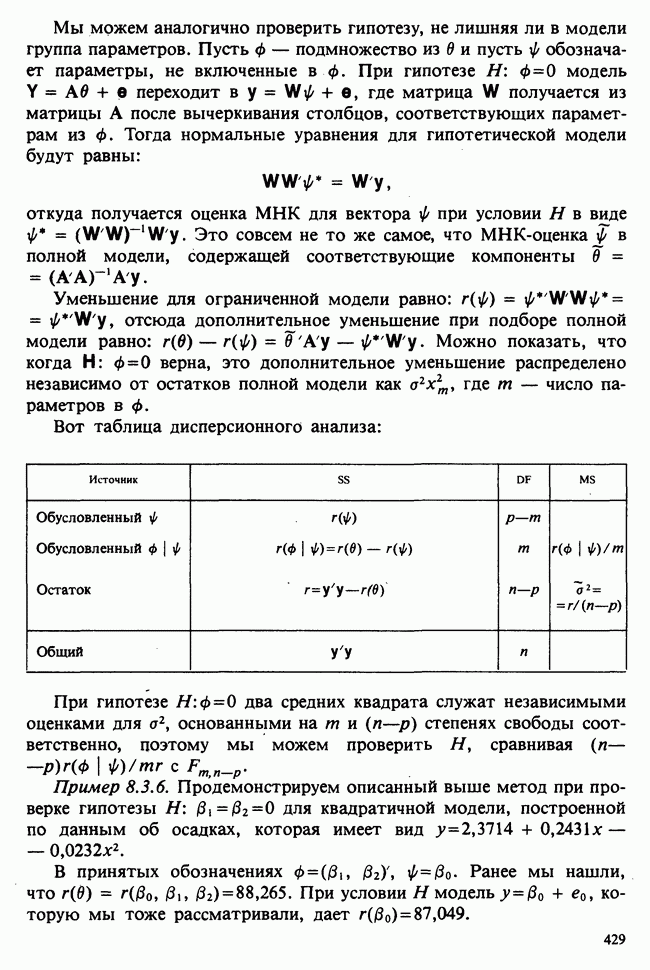
для группы детей с молочной диетой. Здесь  — неизвестные параметры. Подходящие приближения для их значений, называемые «оценками», могли бы быть выведены из данных. Исходный вопрос «Ведет ли увеличенное потребление молока к возрастанию веса?» превращается в следующий: «Является ли различие между оценками
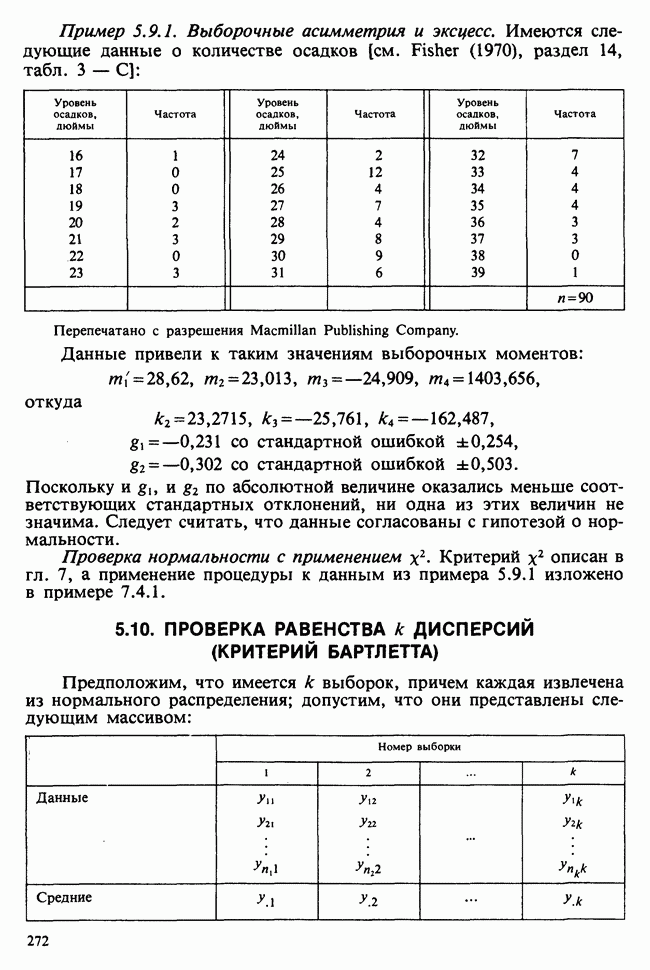
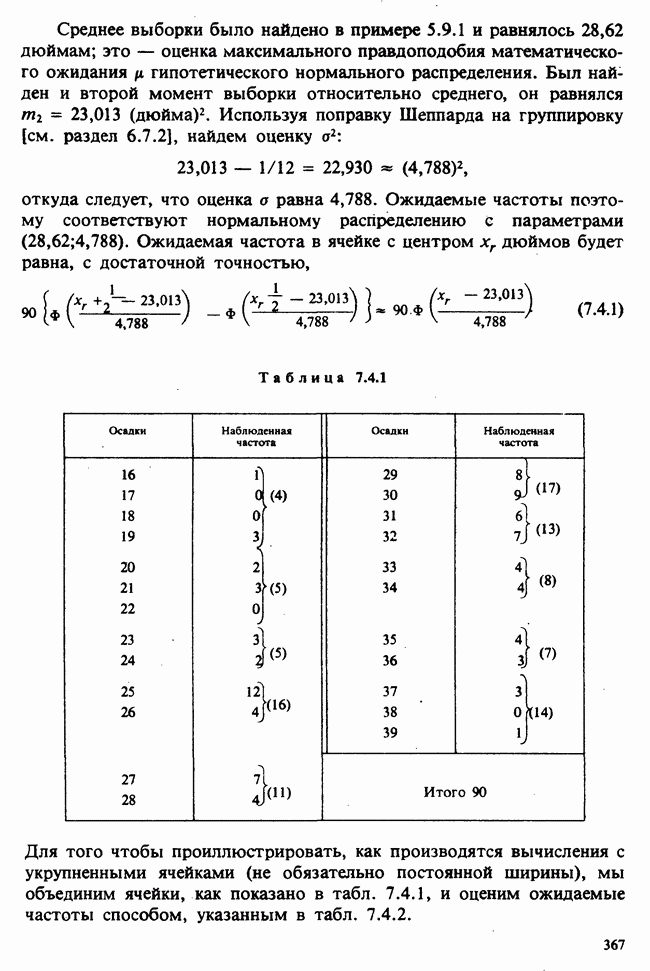
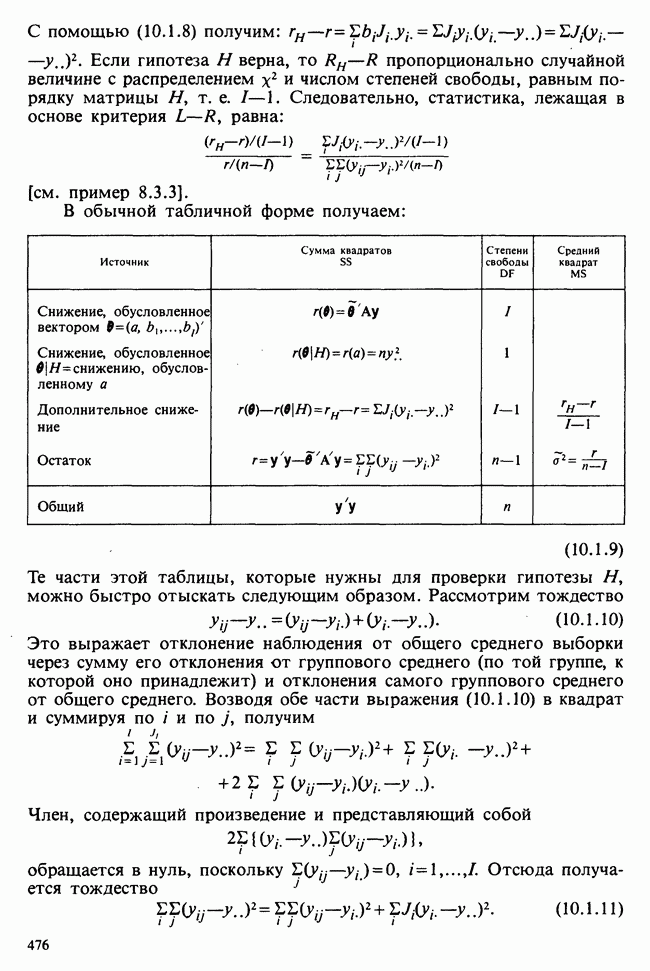
— неизвестные параметры. Подходящие приближения для их значений, называемые «оценками», могли бы быть выведены из данных. Исходный вопрос «Ведет ли увеличенное потребление молока к возрастанию веса?» превращается в следующий: «Является ли различие между оценками  значимым, т. е. достаточно ли оно велико, чтобы позволить нам учесть случайные эффекты и заключить, что
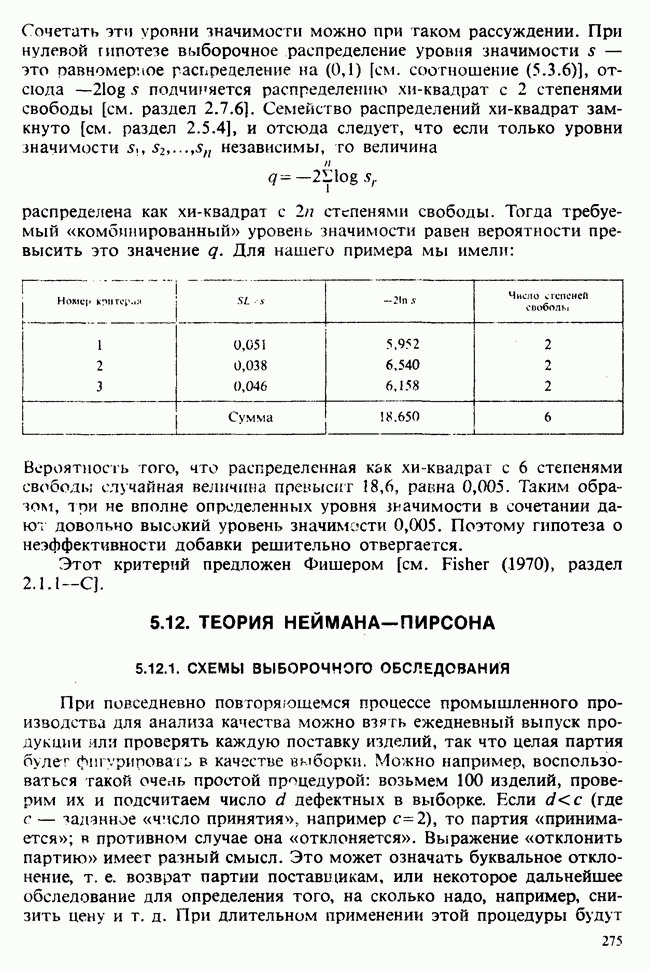
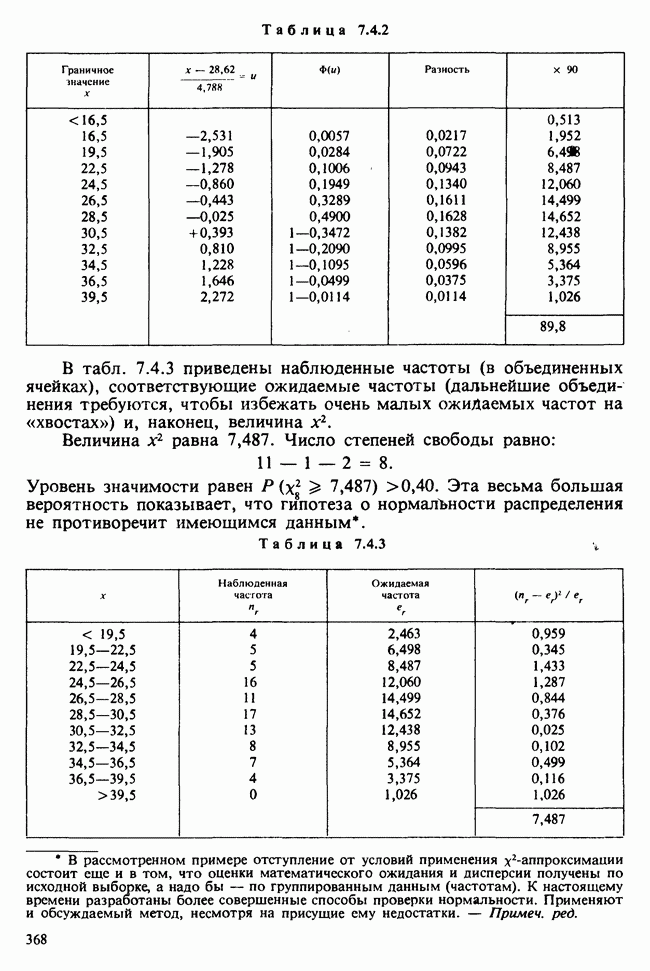
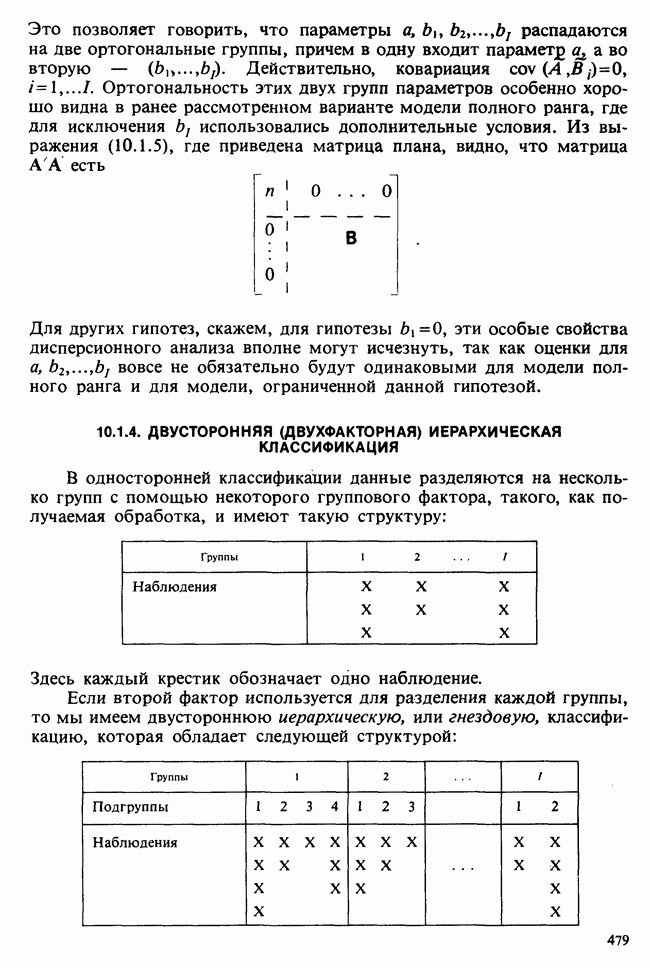
значимым, т. е. достаточно ли оно велико, чтобы позволить нам учесть случайные эффекты и заключить, что  действительно больше, чем
действительно больше, чем  и если это так, то сколь значительно и насколько точно оценено различие?».
и если это так, то сколь значительно и насколько точно оценено различие?».