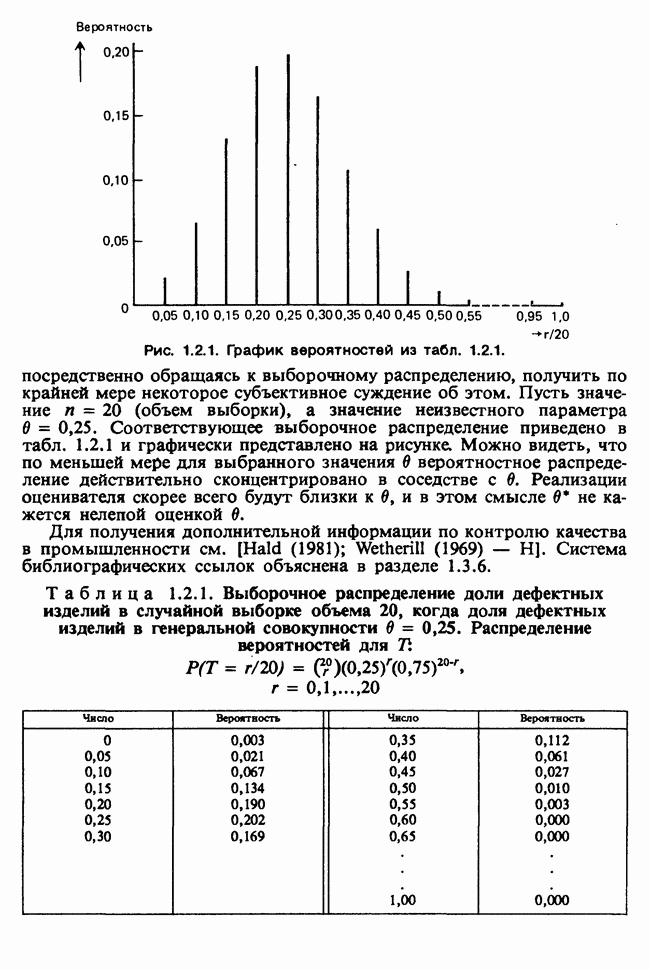
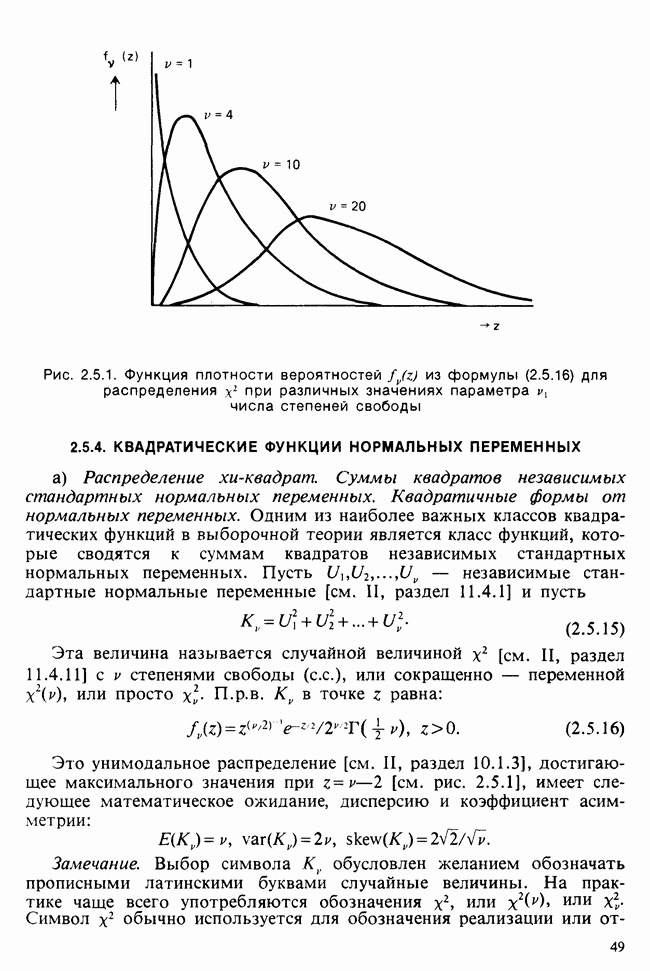
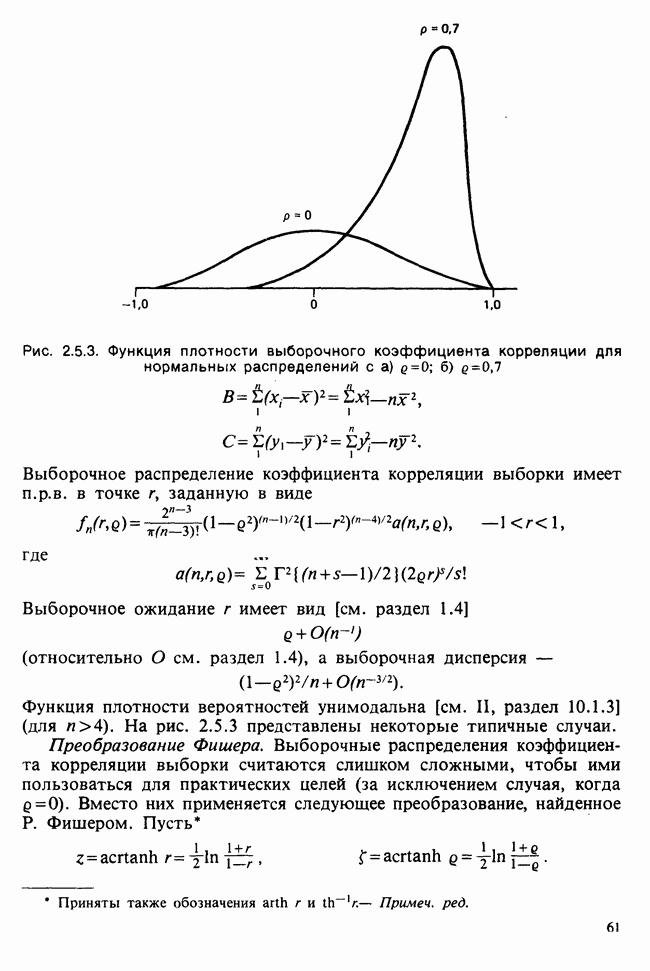
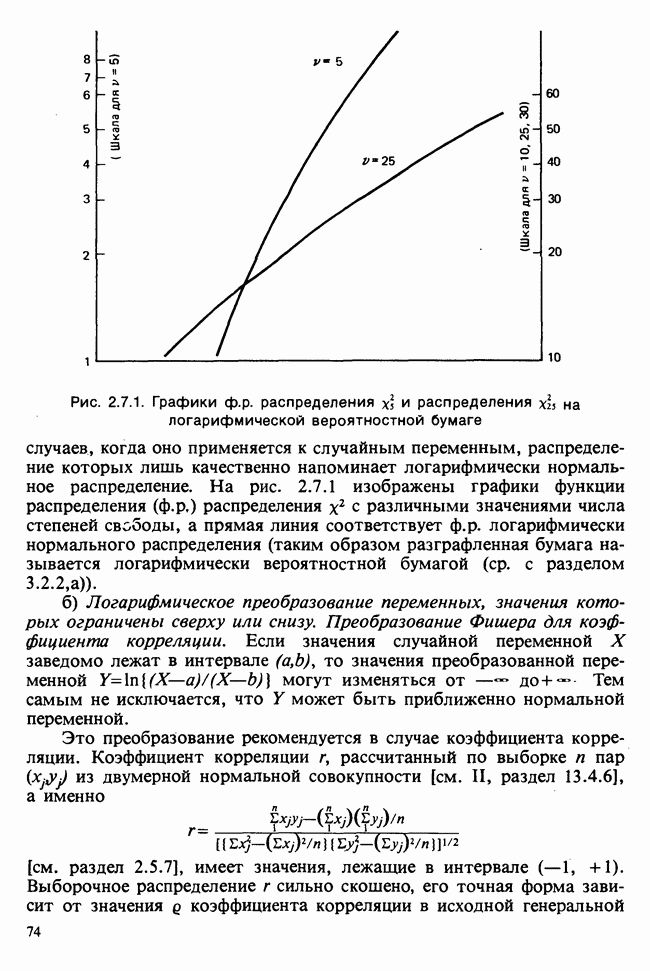
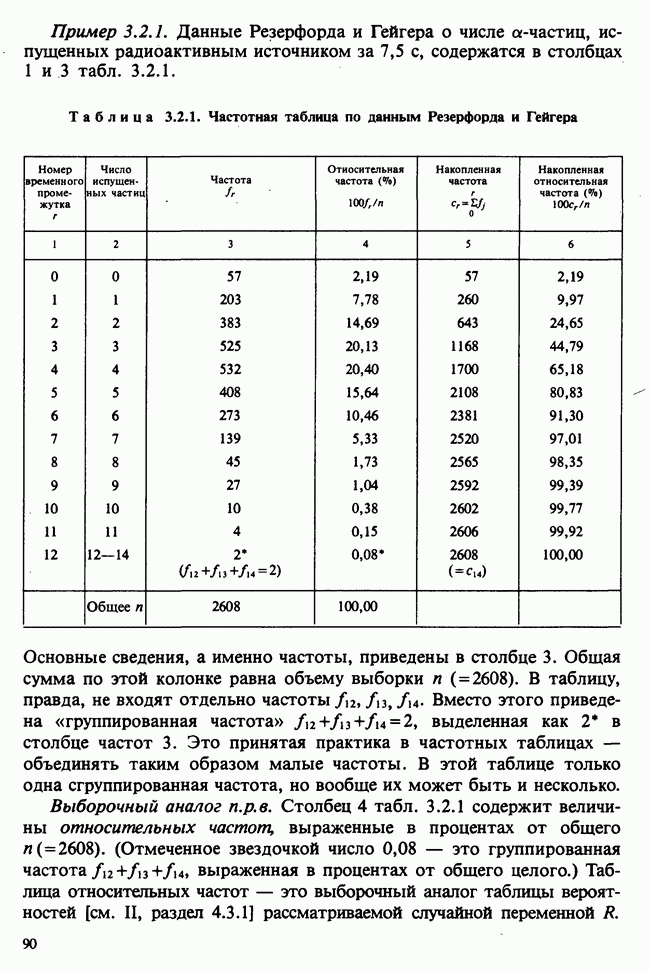
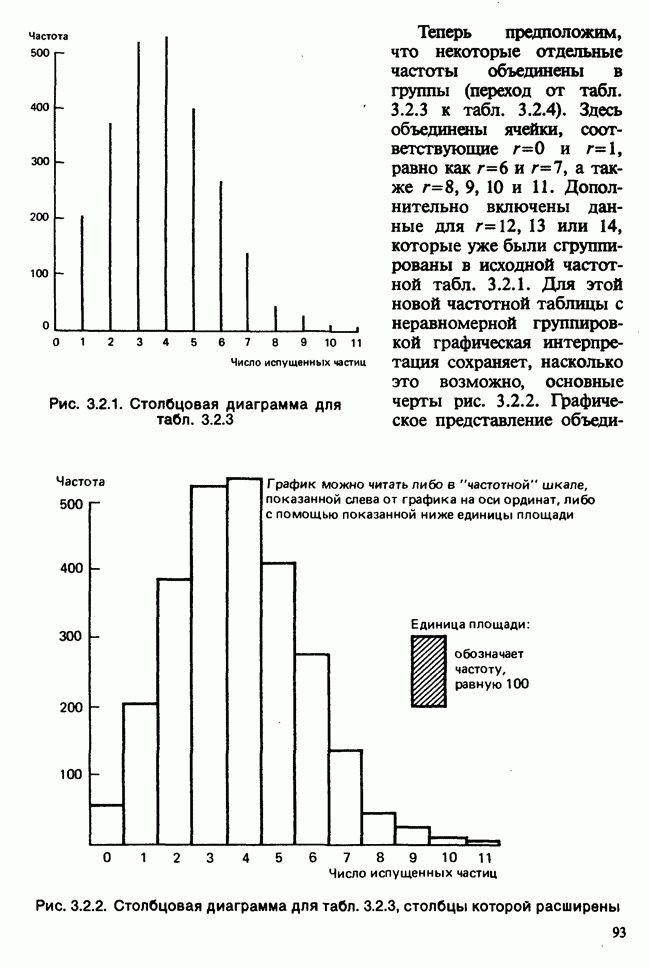
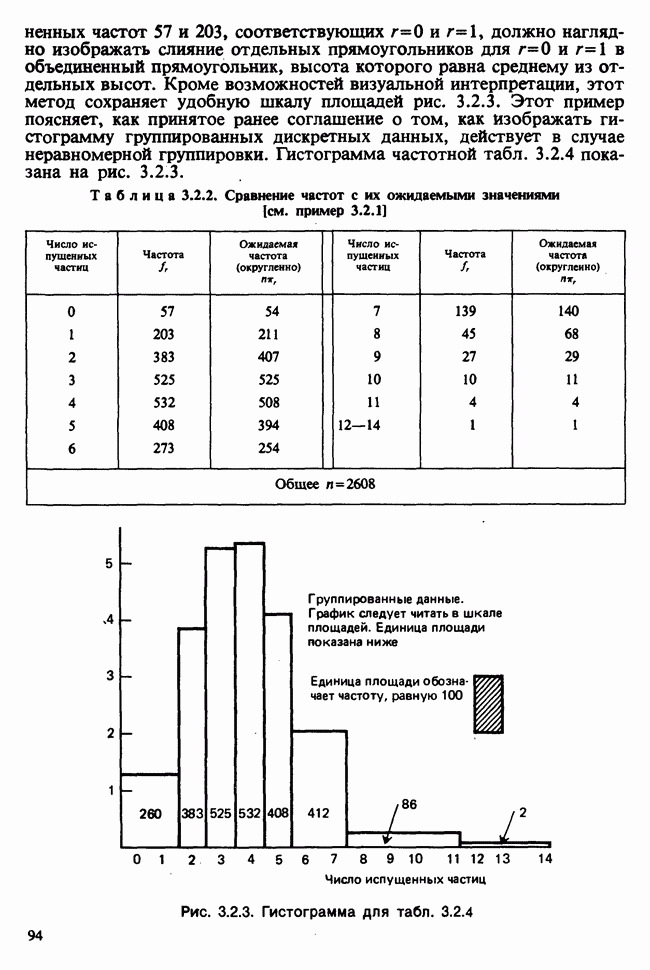
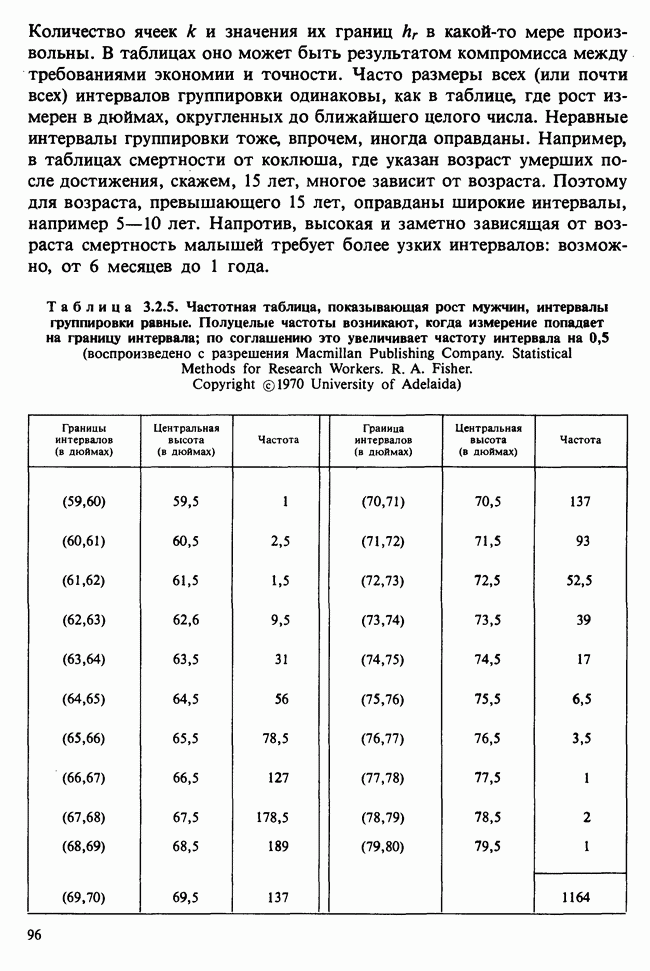
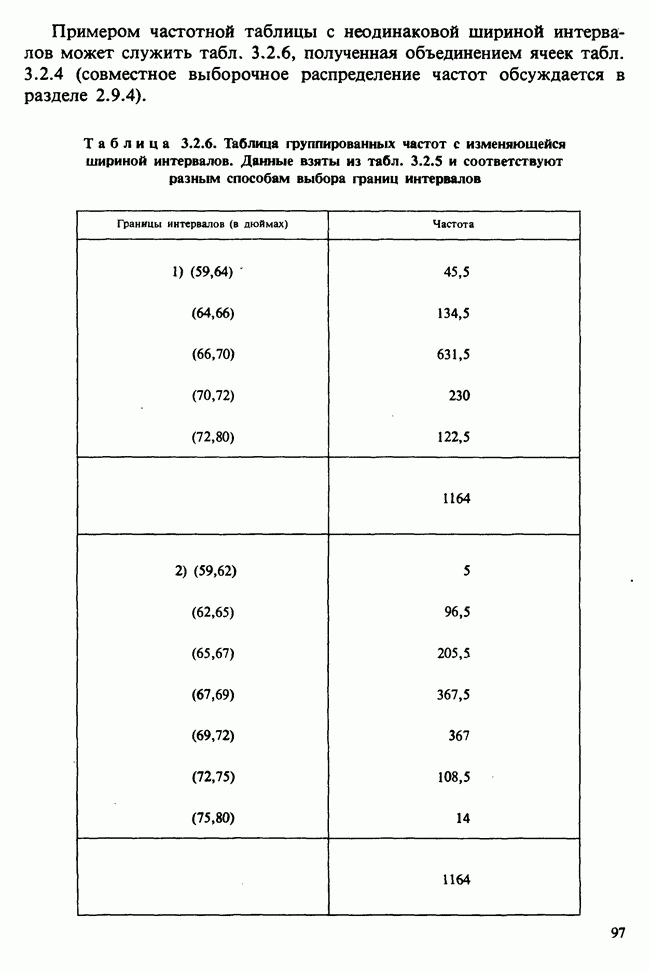
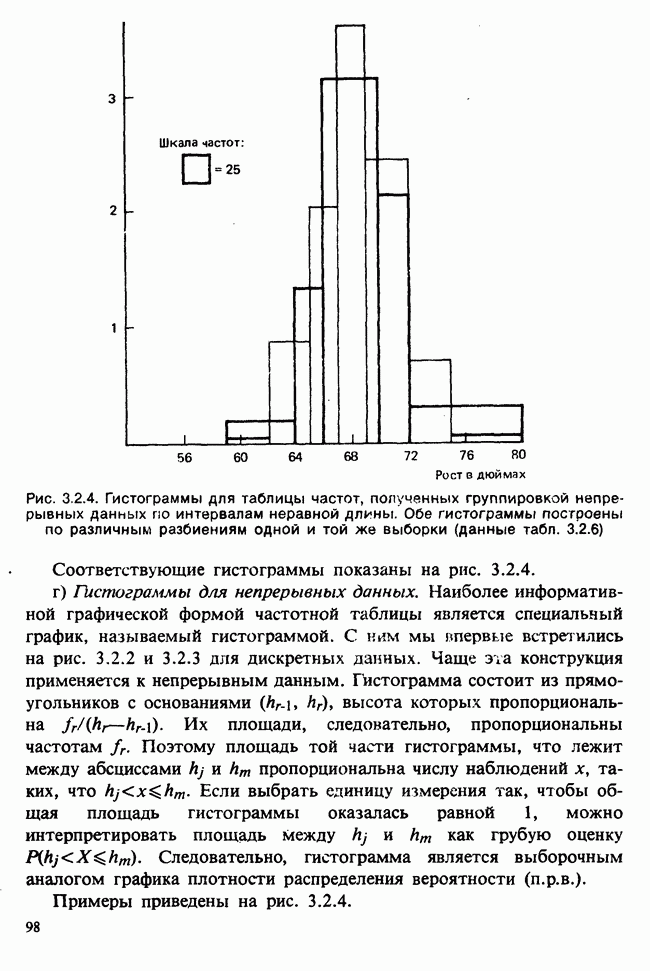
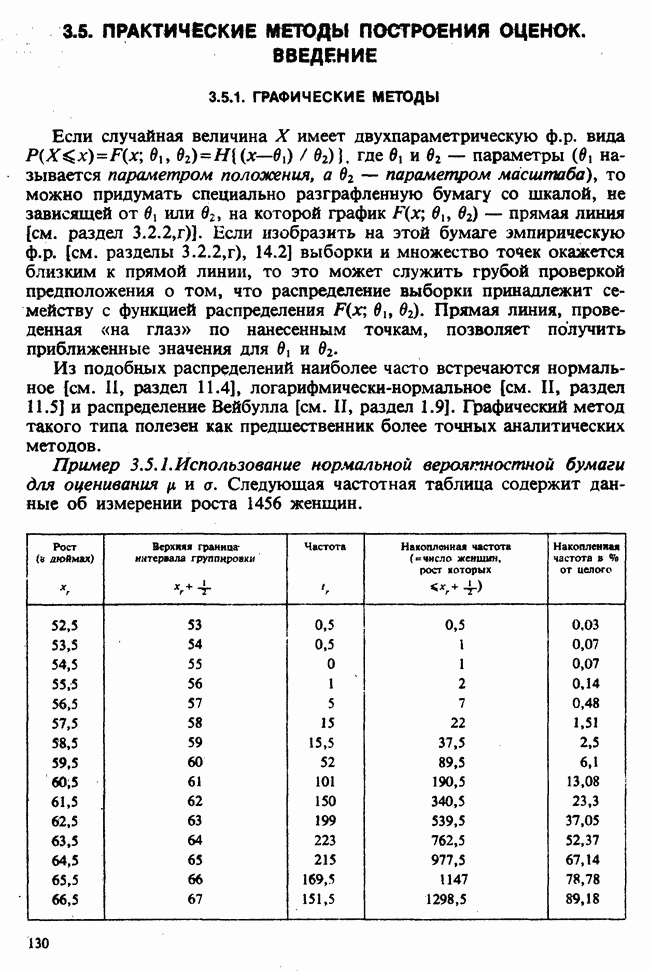
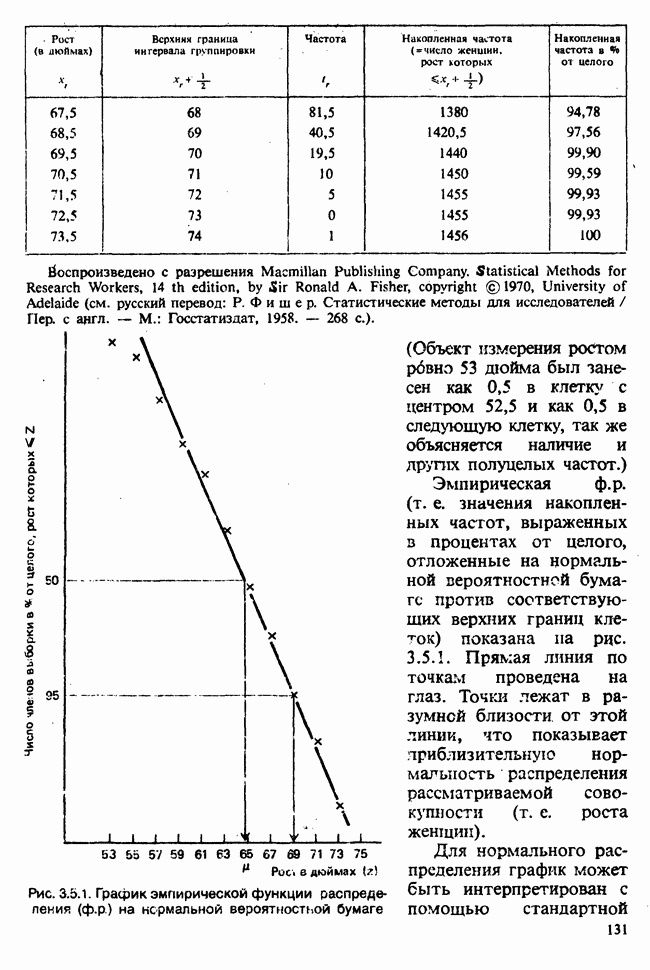
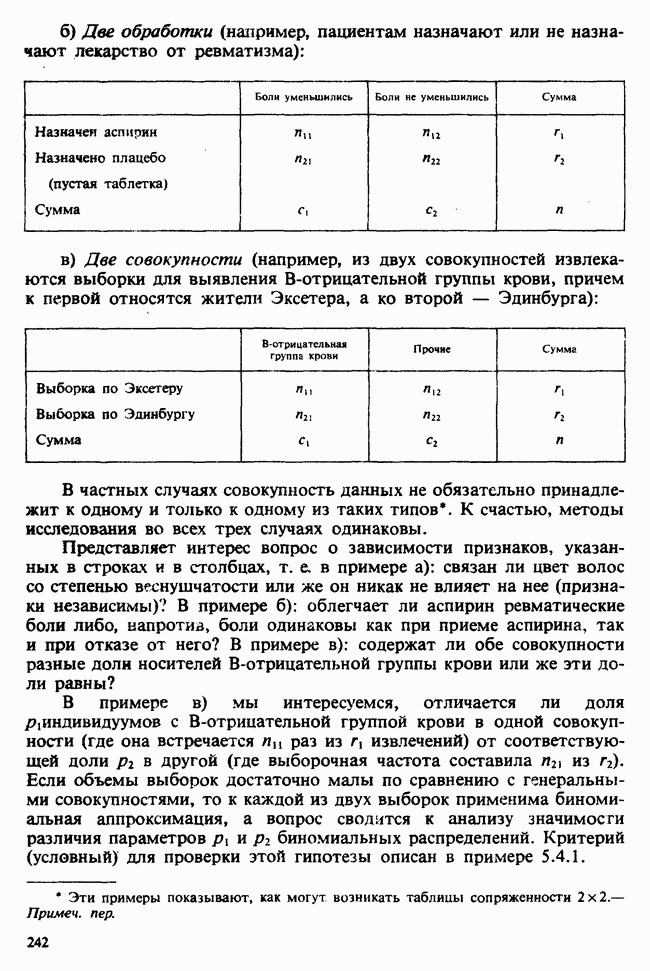
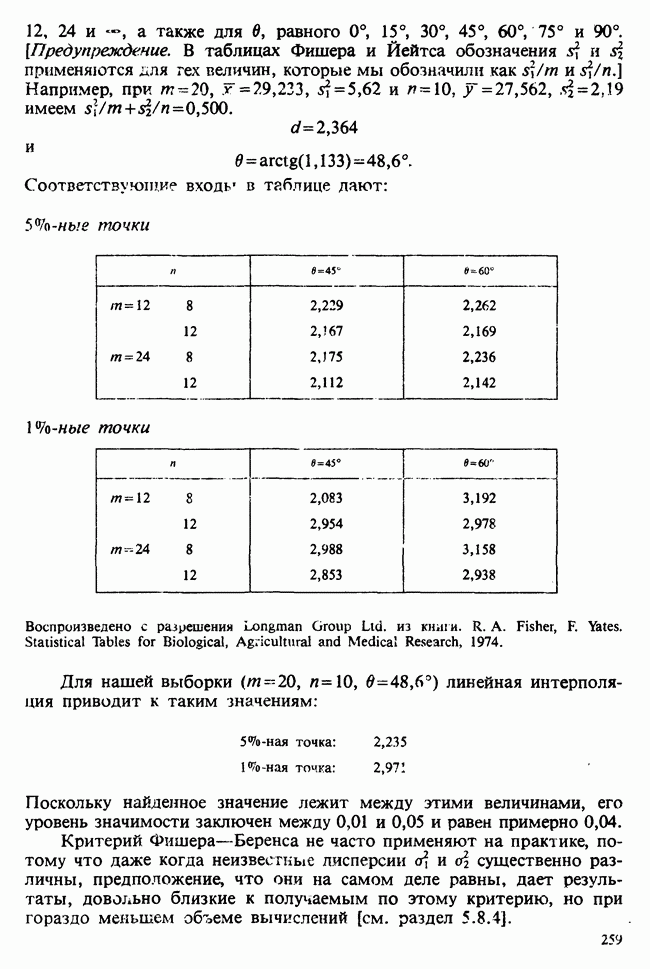
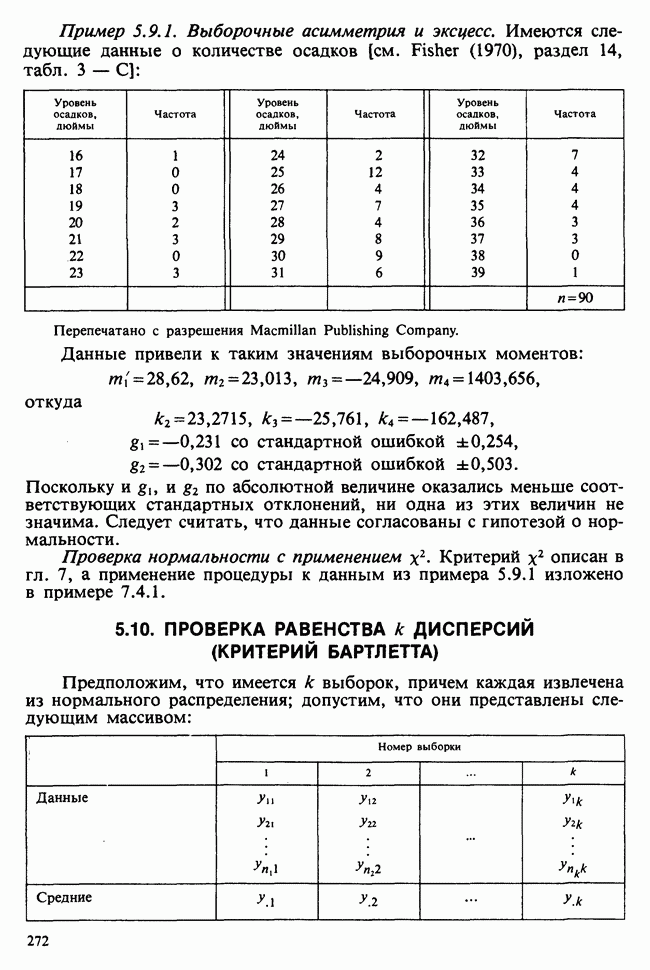
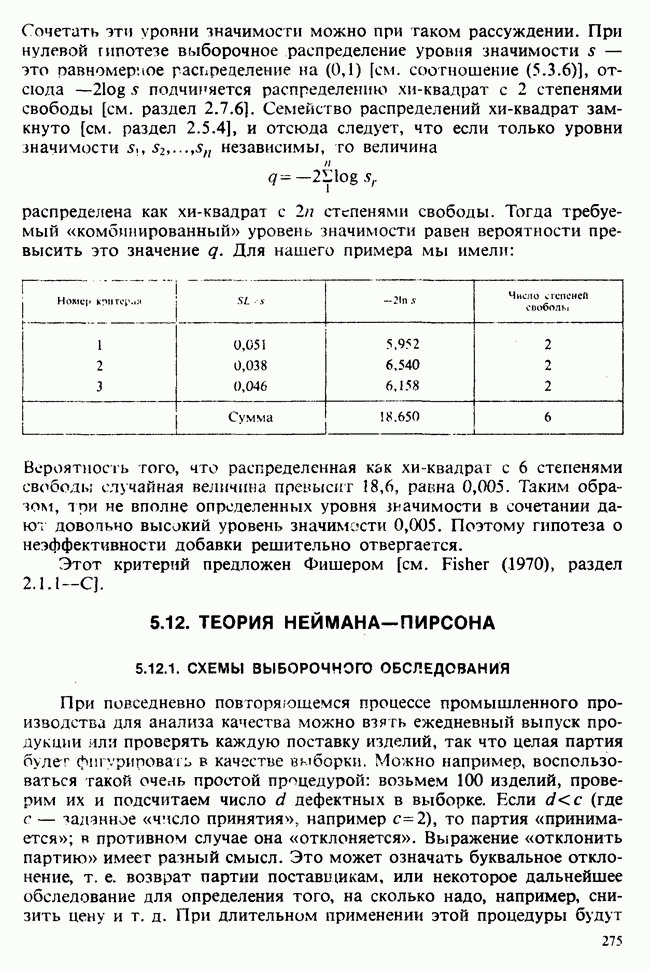
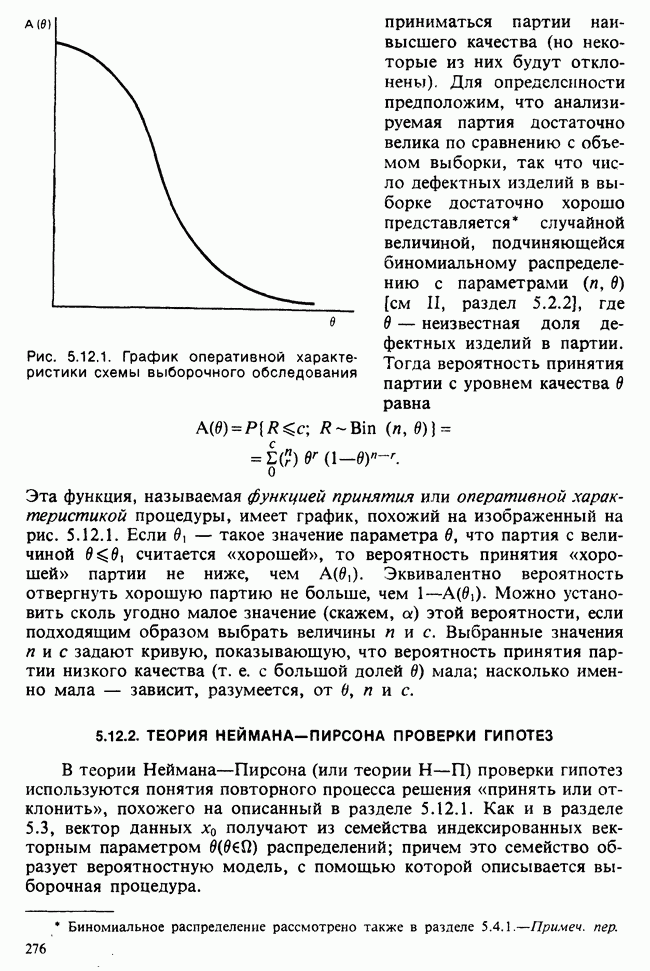
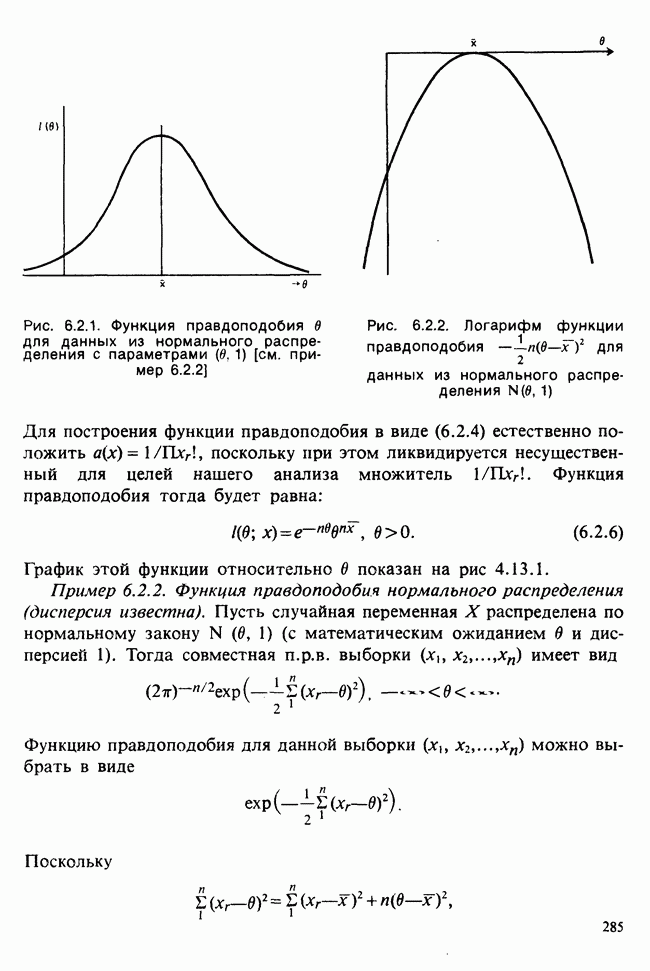
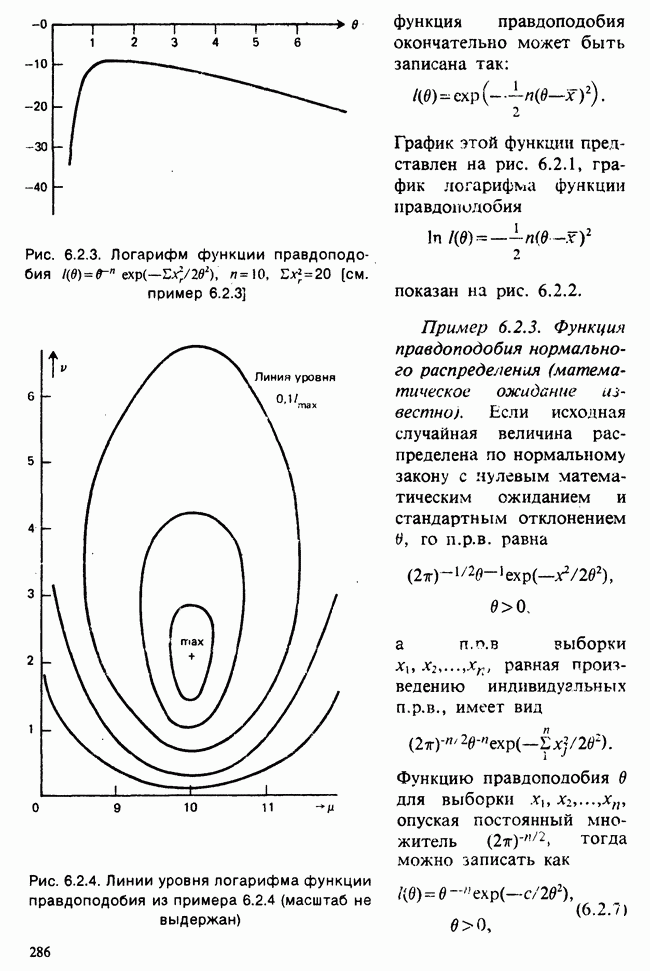
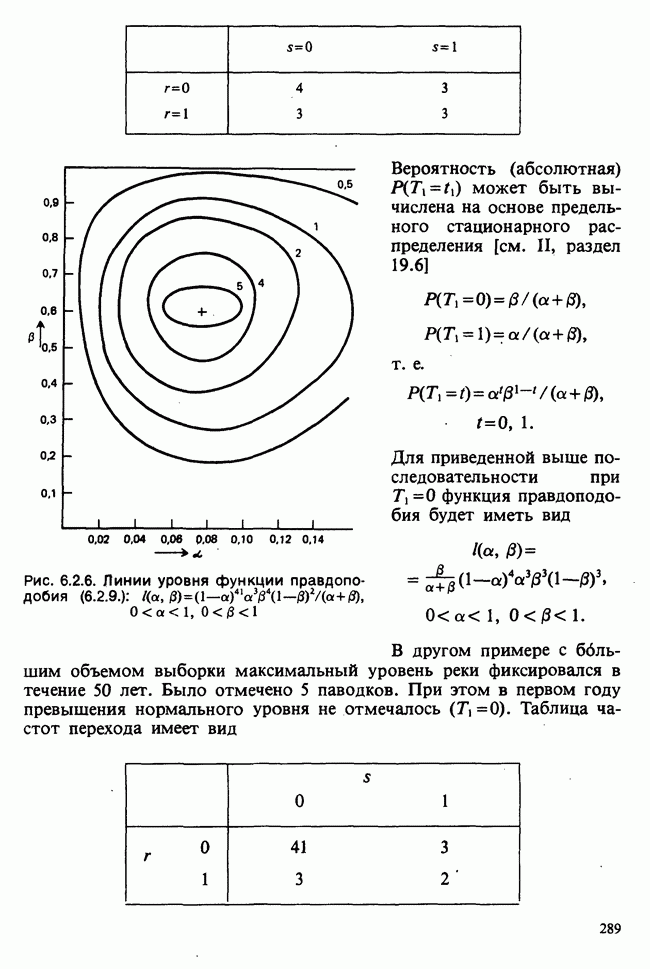
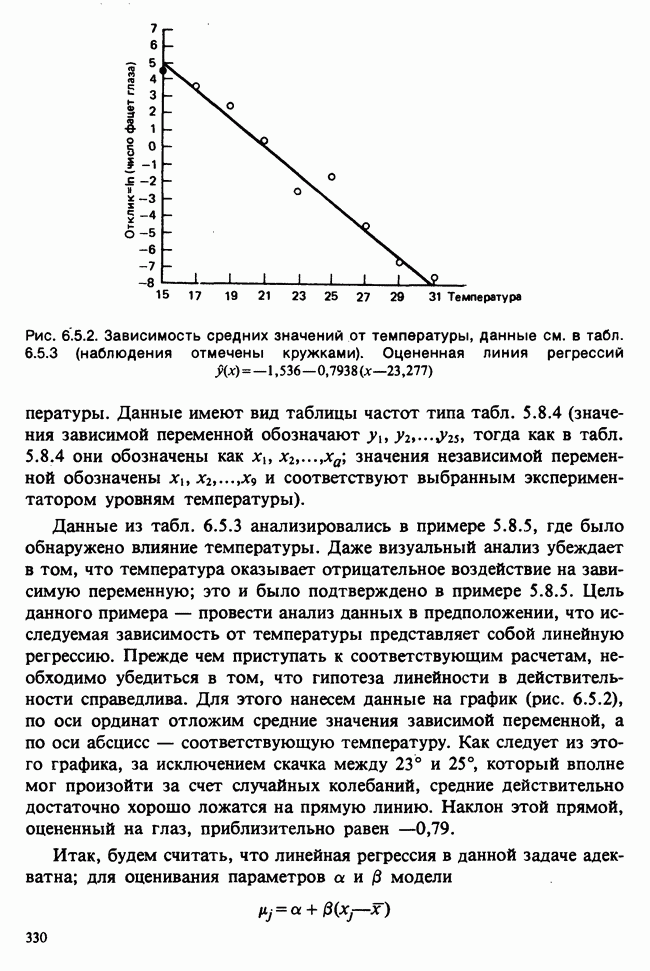
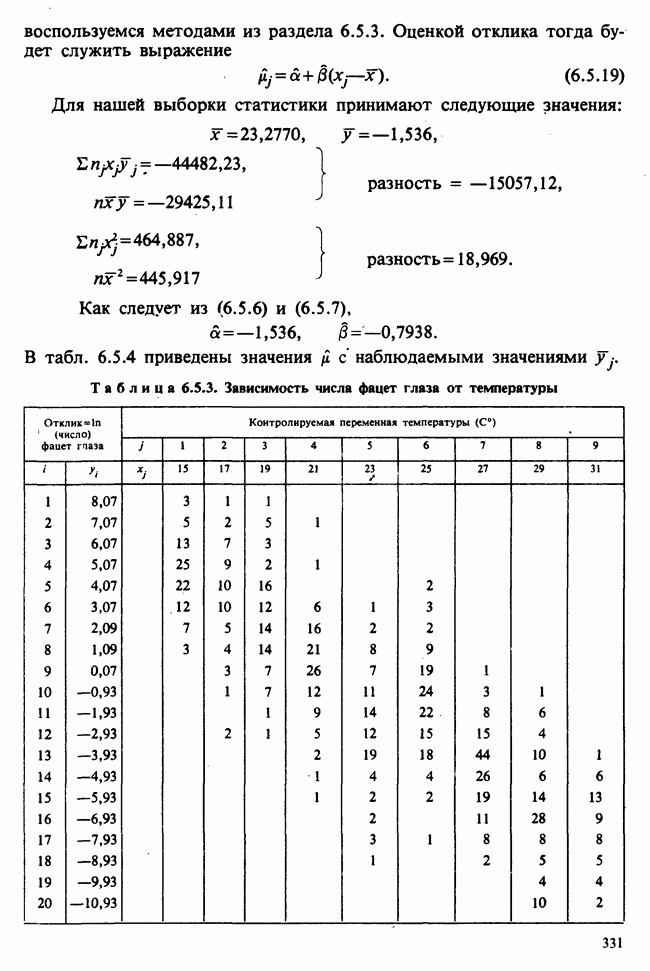
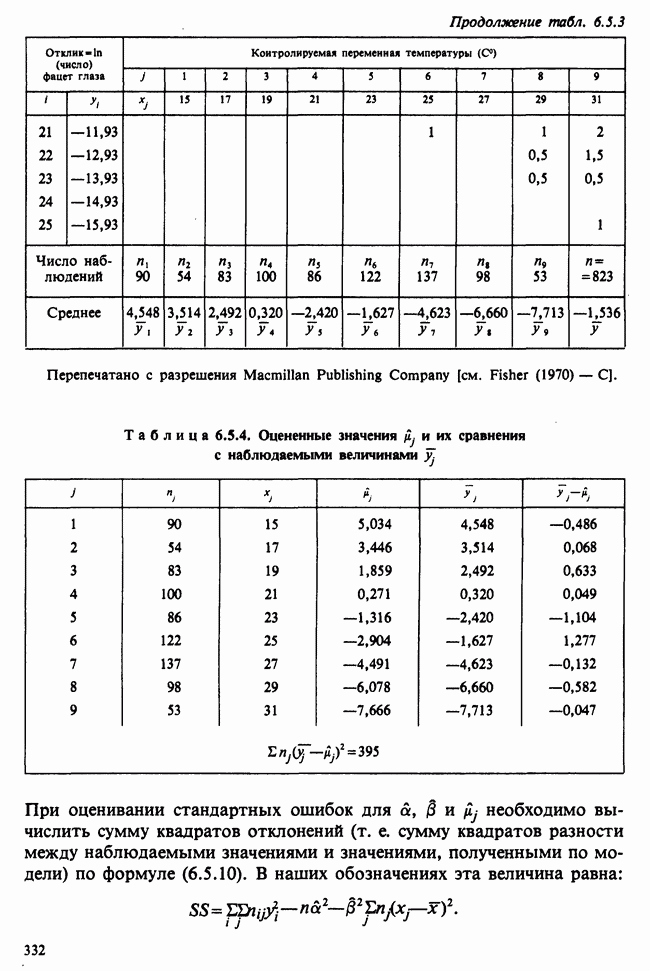
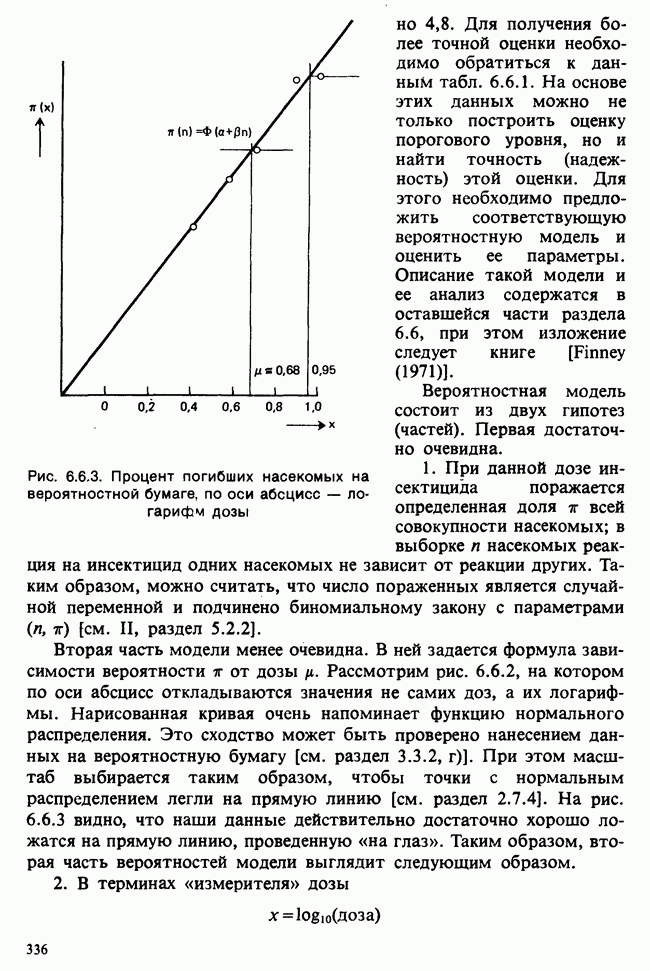
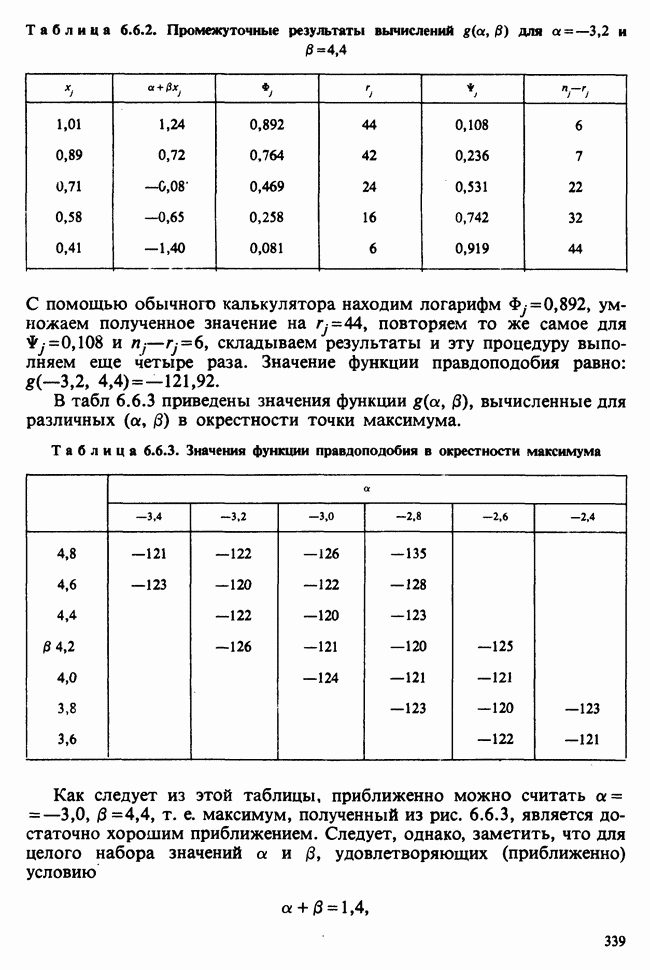
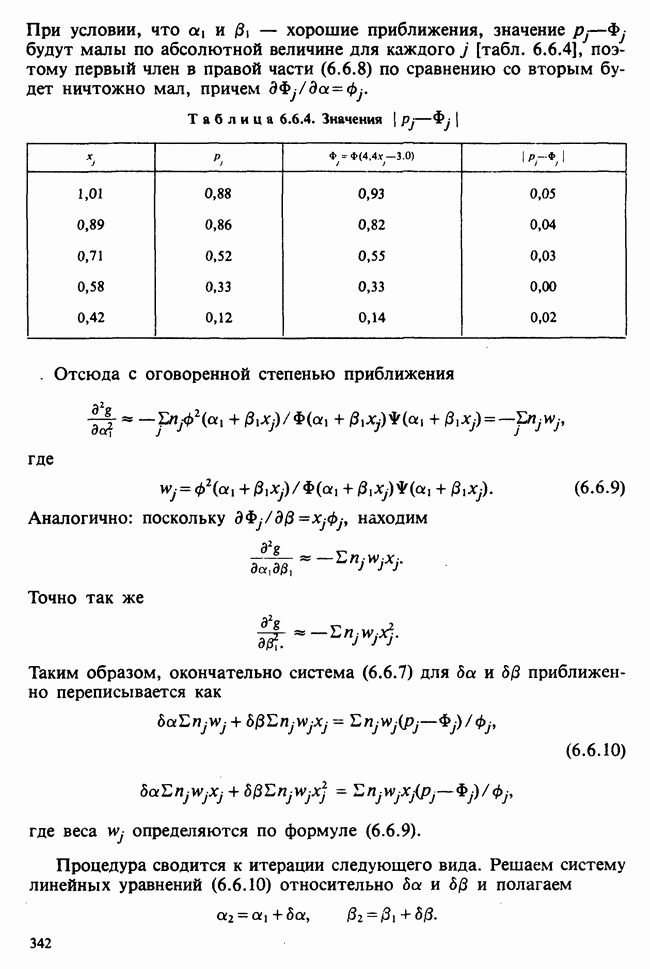
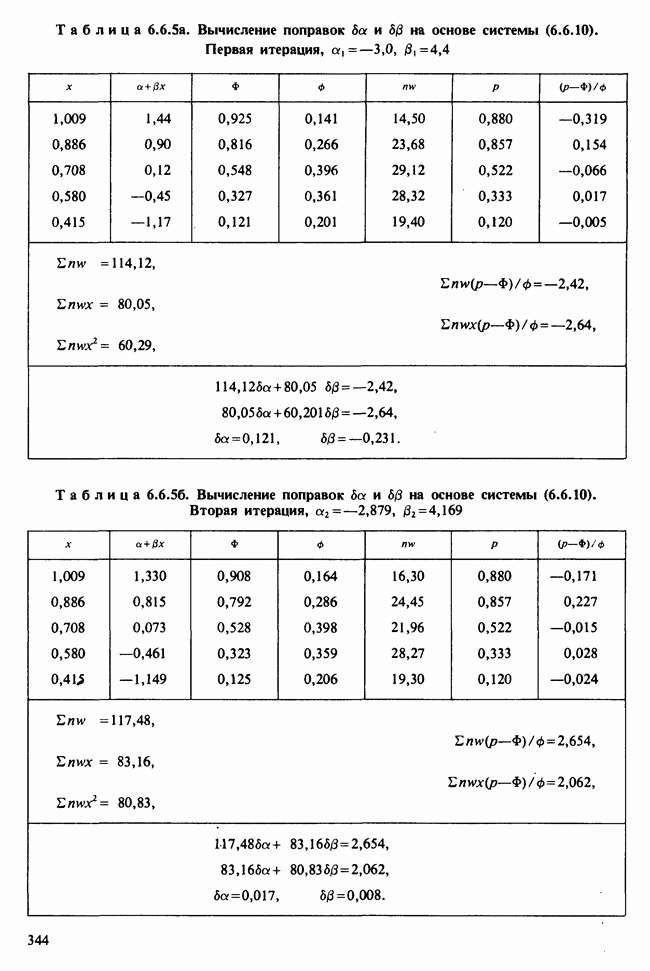
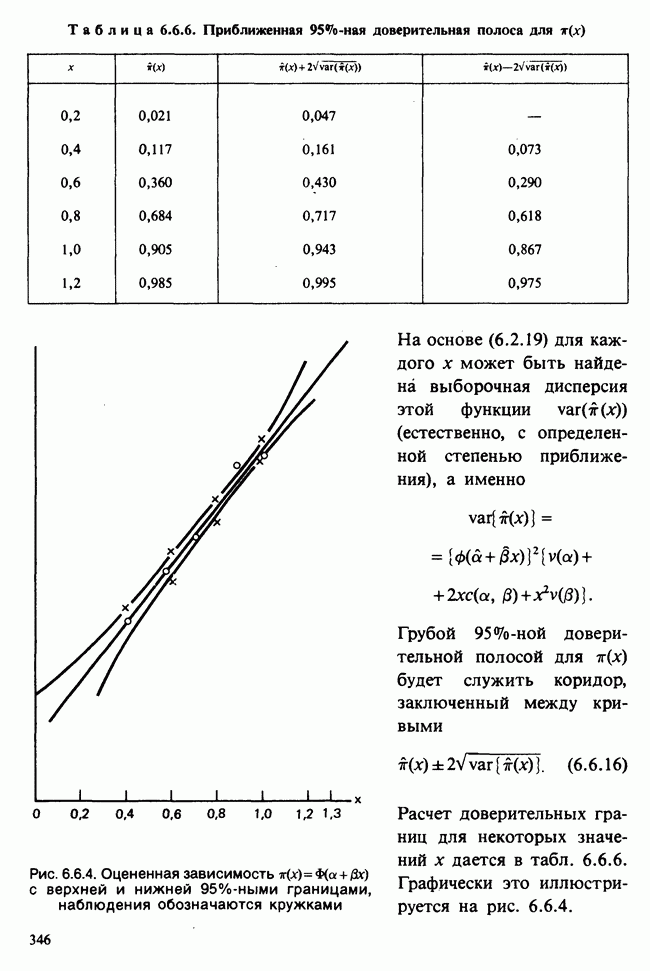
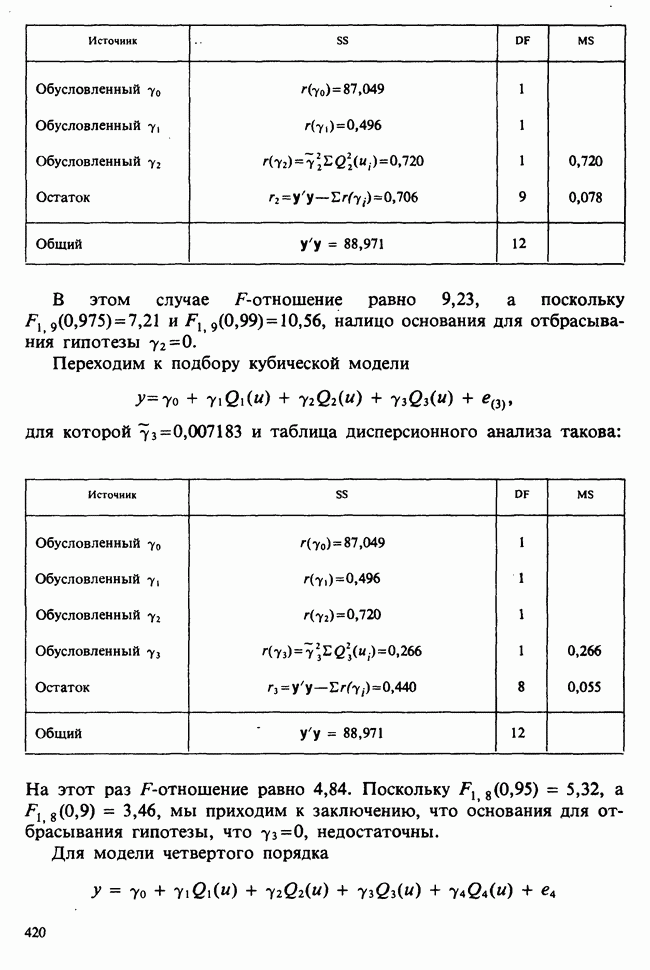
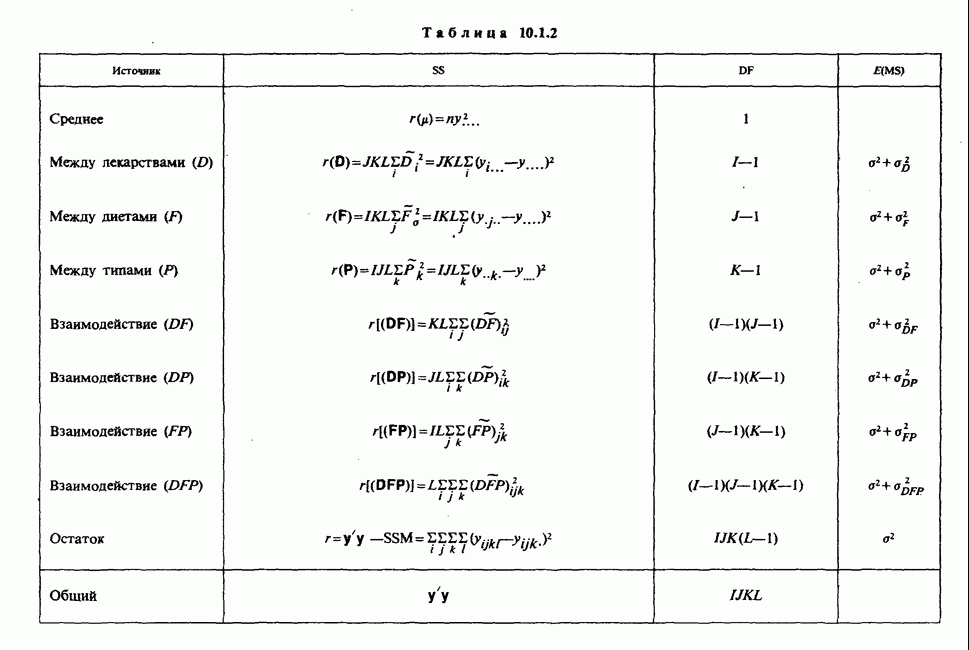
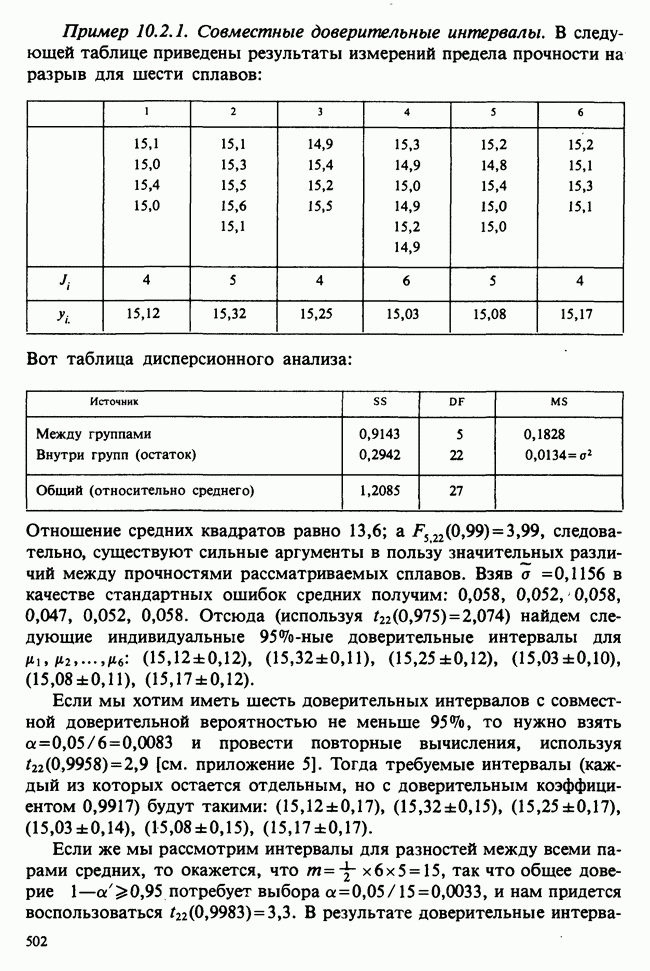
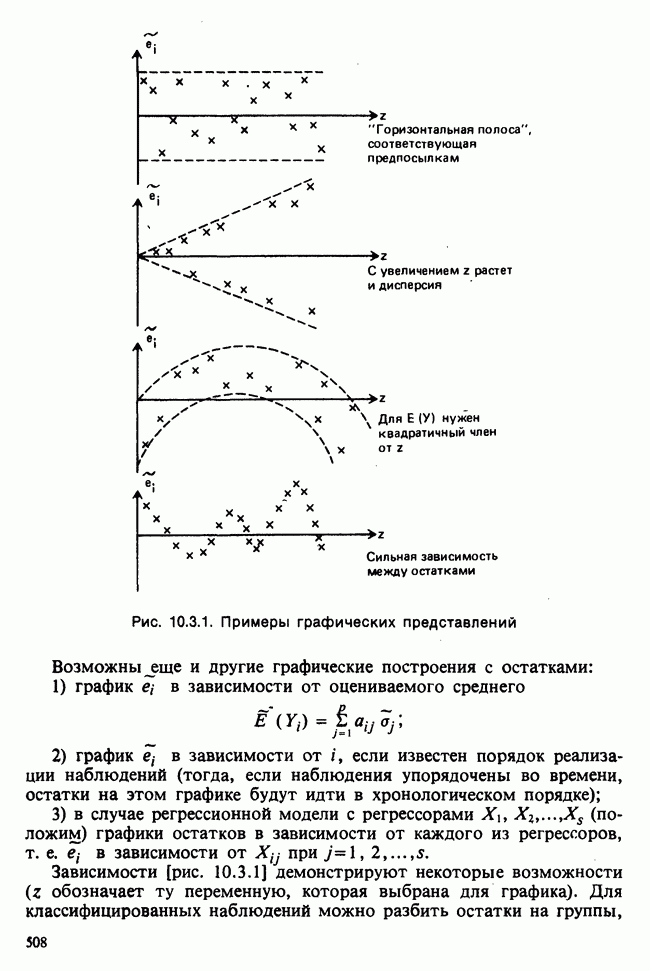
7.4. КРИТЕРИЙ «хи-квадрат» ДЛЯ НЕПРЕРЫВНЫХ РАСПРЕДЕЛЕНИЙ
Принципы, используемые при работе с данными из непрерывного распределения, представленными в виде таблиц частот, идентичны применяемым в дискретном случае. Некоторые дополнительные вычислительные трудности, однако, могут возникнуть при крупных интервалах группирования.
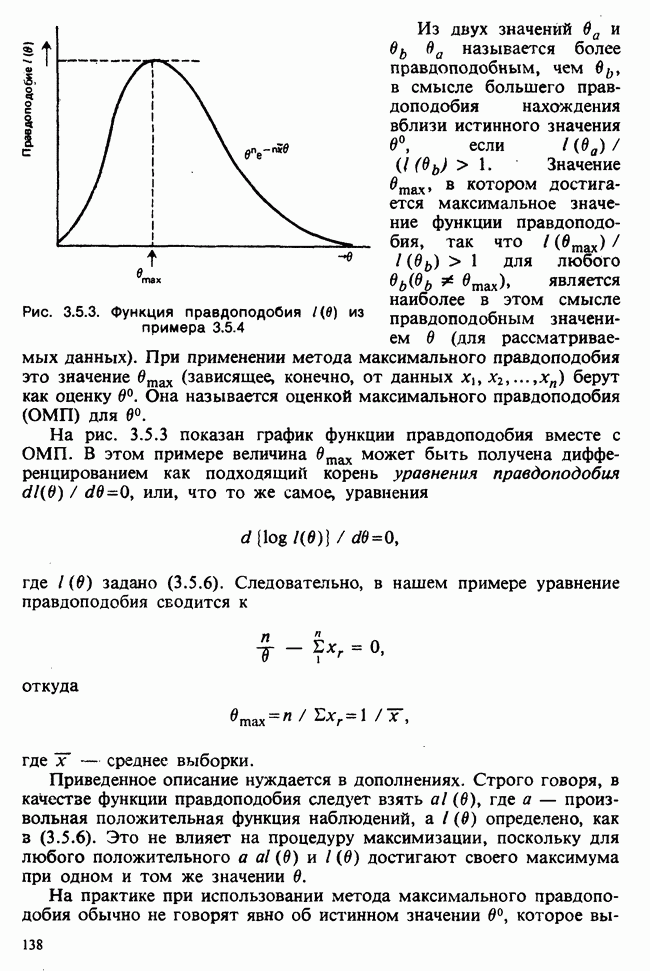
Оценка параметров по таблице частот (округленных) непрерывных данных обсуждалась в разделе 6.7.2. Похожие рассмотрения возникают при вычислении ожидаемых частот. Если данные сгруппированы в ячейки  и проверяемая гипотеза состоит в том, что плотность распределения рассматриваемой случайной величины в точке х равна
и проверяемая гипотеза состоит в том, что плотность распределения рассматриваемой случайной величины в точке х равна  с функцией распределения
с функцией распределения  то ожидаемая частота (при этой гипотезе) в
то ожидаемая частота (при этой гипотезе) в  ячейке оценивается величиной
ячейке оценивается величиной

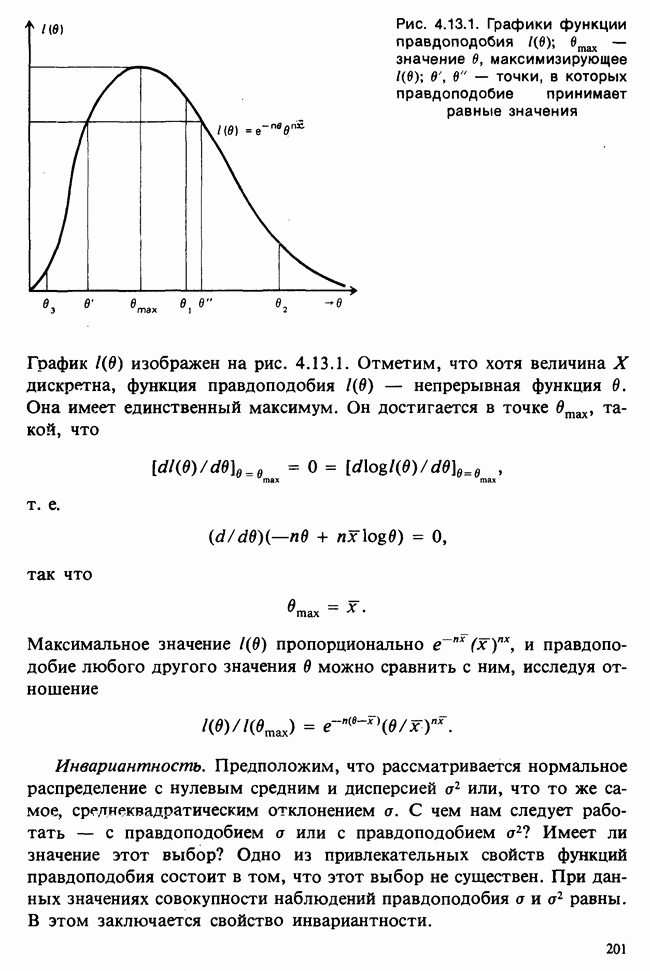
где в — оценка максимального правдоподобия параметра  [см. раздел 6.7.2] и
[см. раздел 6.7.2] и  — объем выборки. Если И. невелико,
— объем выборки. Если И. невелико,  можно заменить это выражение более простой формулой
можно заменить это выражение более простой формулой  .
.
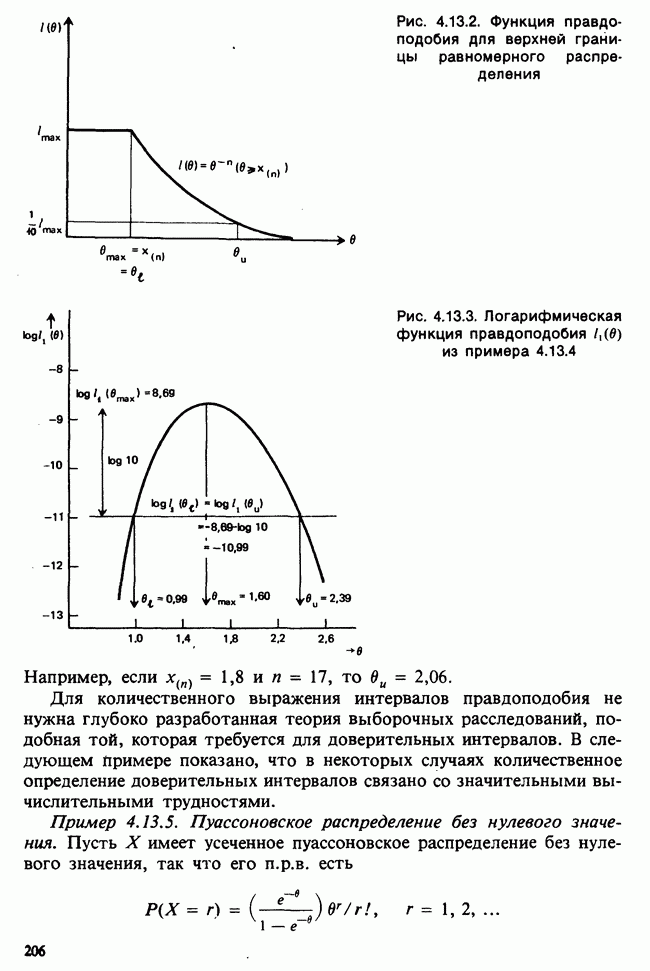
Что касается наименьших допустимых частот, то целесообразно придерживаться рекомендаций К. Кокрена для критериев  с непрерывными данными. А именно объединять ячейки на «хвосте» (на «хвостах») таким образом, чтобы наименьшая ожидаемая частота была не меньше 1. Для максимизации чувствительности критерия размер интервалов группирования следует выбирать достаточно малым, чтобы ожидаемые частоты не превышали 12 в каждой ячейке для выборки объема
с непрерывными данными. А именно объединять ячейки на «хвосте» (на «хвостах») таким образом, чтобы наименьшая ожидаемая частота была не меньше 1. Для максимизации чувствительности критерия размер интервалов группирования следует выбирать достаточно малым, чтобы ожидаемые частоты не превышали 12 в каждой ячейке для выборки объема  — для
— для  и 30 — для
и 30 — для  [см. Cochran 1952), (1954)].
[см. Cochran 1952), (1954)].
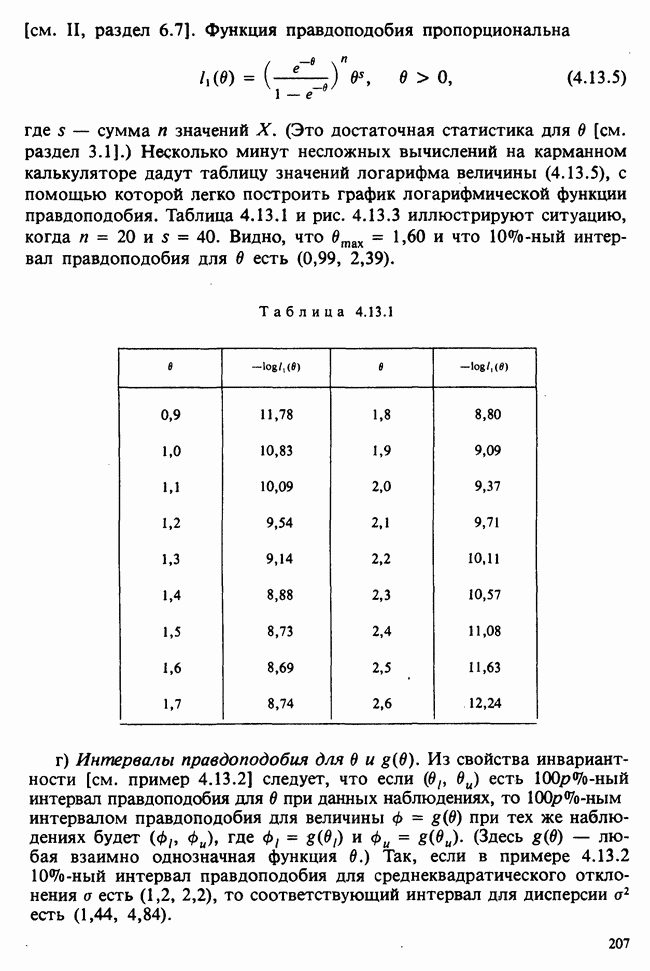
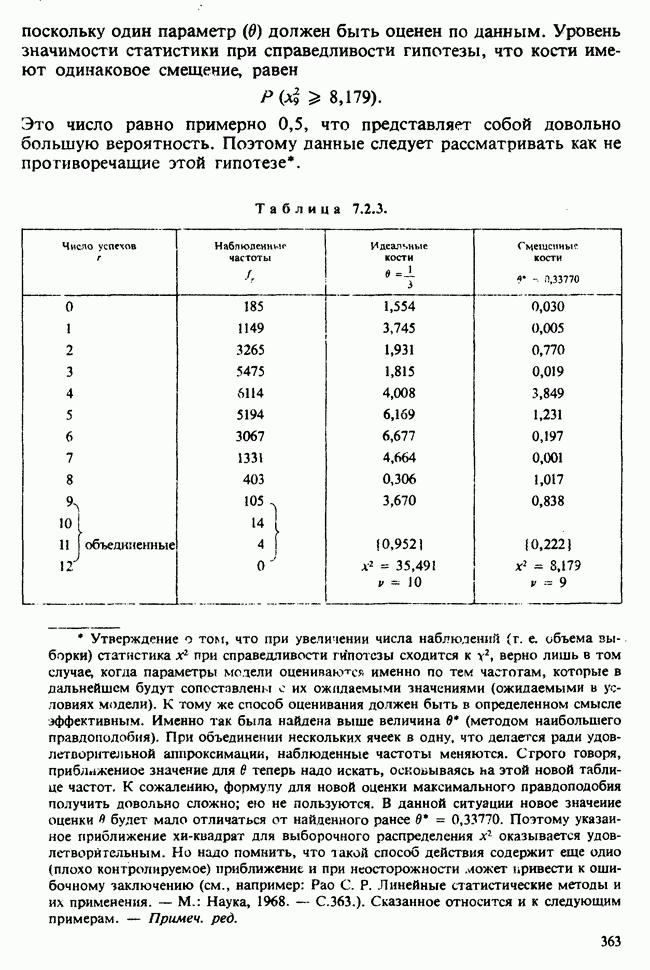
Пример 7.4.1. Критерий  для проверки нормальности. Данные о количестве осадков (воспроизведенные в табл. 7.4.1) обсуждались в примере 5.9.1 и проверялись на асимметрию и эксцесс. Коэффициенты асимметрии и эксцесса этой выборки незначительно отличались от соответствующих величин для нормального распределения. Мы теперь применим к тем же данным критерий
для проверки нормальности. Данные о количестве осадков (воспроизведенные в табл. 7.4.1) обсуждались в примере 5.9.1 и проверялись на асимметрию и эксцесс. Коэффициенты асимметрии и эксцесса этой выборки незначительно отличались от соответствующих величин для нормального распределения. Мы теперь применим к тем же данным критерий  принимая в качестве рабочей гипотезы, что данные имеют нормальное распределение с параметрами
принимая в качестве рабочей гипотезы, что данные имеют нормальное распределение с параметрами 
Среднее выборки было найдено в примере 5.9.1 и равнялось 28,62 дюймам; это — оценка максимального правдоподобия математического ожидания  гипотетического нормального распределения. Был найден и второй момент выборки относительно среднего, он равнялся
гипотетического нормального распределения. Был найден и второй момент выборки относительно среднего, он равнялся  Используя поправку Шеппарда на группировку [см. раздел 6.7.2], найдем оценку
Используя поправку Шеппарда на группировку [см. раздел 6.7.2], найдем оценку  :
:

откуда следует, что оценка о равна 4,788. Ожидаемые частоты поэтому соответствуют нормальному распределению с параметрами  Ожидаемая частота в ячейке с центром
Ожидаемая частота в ячейке с центром  дюймов будет равна, с достаточной точностью,
дюймов будет равна, с достаточной точностью,

Таблица 7.4.1 (см. скан)
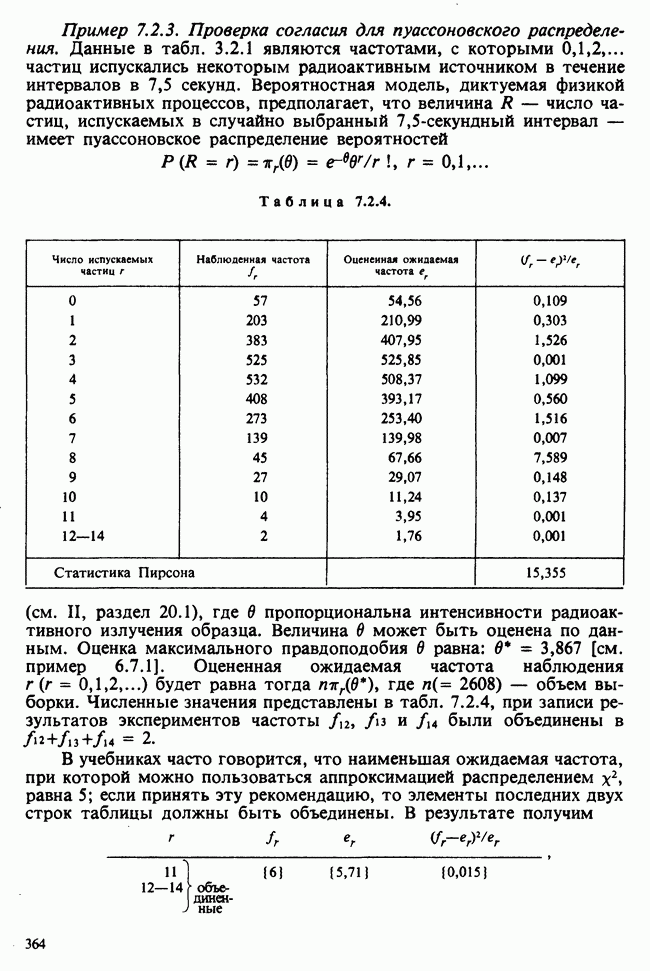
Для того чтобы проиллюстрировать, как производятся вычисления с укрупненными ячейками (не обязательно постоянной ширины), мы объединим ячейки, как показано в табл. 7.4.1, и оценим ожидаемые частоты способом, указанным в табл. 7.4.2.
Таблица 7.4.2 (см. скан)
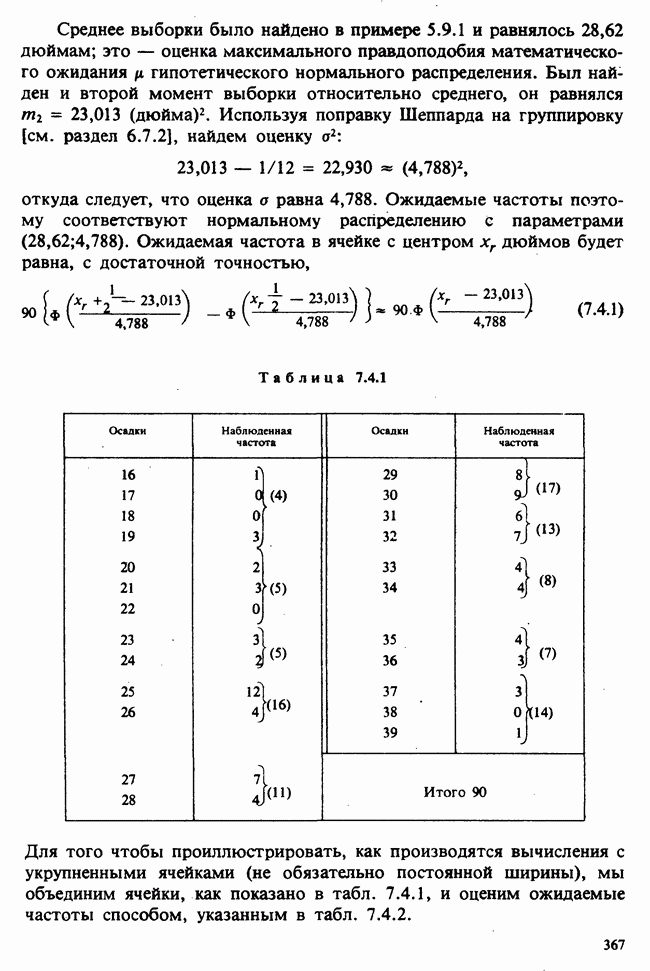
В табл. 7.4.3 приведены наблюденные частоты (в объединенных ячейках), соответствующие ожидаемые частоты (дальнейшие объединения требуются, чтобы избежать очень малых ожидаемых частот на «хвостах») и, наконец, величина 
Величина  равна 7,487. Число степеней свободы равно:
равна 7,487. Число степеней свободы равно:

Уровень значимости равен  Эта весьма большая вероятность показывает, что гипотеза о нормальности распределения не противоречит имеющимся данным.
Эта весьма большая вероятность показывает, что гипотеза о нормальности распределения не противоречит имеющимся данным.
Таблица 7.4.3 (см. скан)
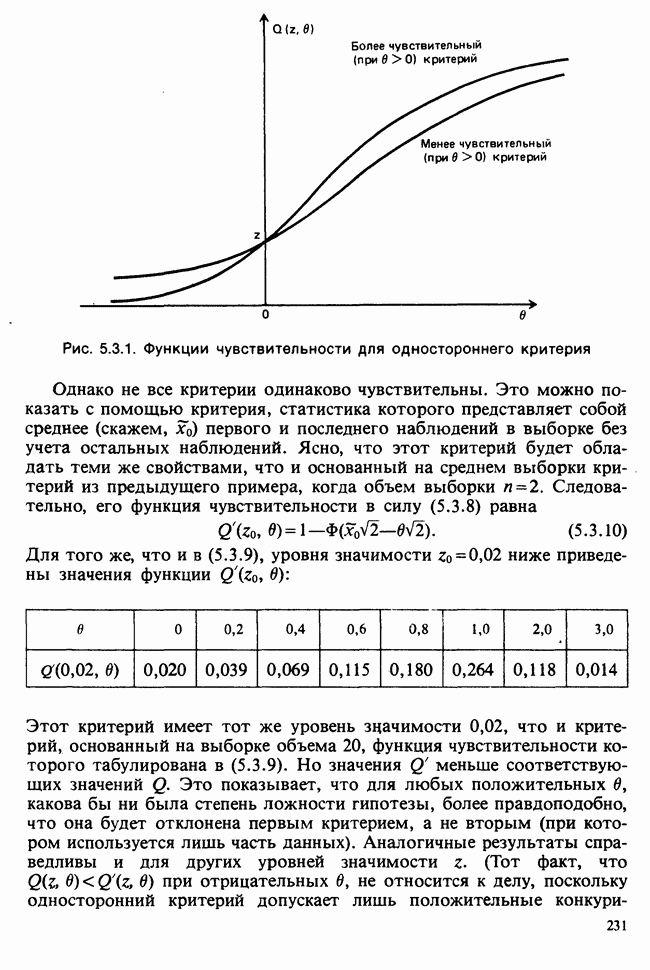
Пример 7.4.2. Критерий  для модели доза — эффект из раздела 6.6. Ранее мы имели дело с оценкой токсичности инсектицида методом, при котором предполагалось, что вероятность
для модели доза — эффект из раздела 6.6. Ранее мы имели дело с оценкой токсичности инсектицида методом, при котором предполагалось, что вероятность  гибели насекомого после обработки дозой инсектицида, измеренной в логарифмах,
гибели насекомого после обработки дозой инсектицида, измеренной в логарифмах,  задается формулой
задается формулой

где Ф означает стандартный нормальный интеграл. Были найдены оценки максимального правдоподобия для 

[см. (6.6.10)]. Число подвергнутых обработке насекомых и погибших при различных дозах инсектицида [см. табл. 6.6.1] вместе с оцененными вероятностями  представлено в следующей таблице:
представлено в следующей таблице:

В каждой строке записано число наблюденных успехов  в биномиальной схеме с параметрами
в биномиальной схеме с параметрами  для которой ожидаемое число успехов равно
для которой ожидаемое число успехов равно  неявно здесь также записано число неудач
неявно здесь также записано число неудач  со средним
со средним 
Вклад такой строки в общую величину пирсоновского  равен:
равен:

его выборочное распределение (приблизительно)  Если бы
Если бы  были известны, т. е. не было бы параметров, которые надо оценивать, то число степеней свободы было бы равно 1 (2 ячейки,
были известны, т. е. не было бы параметров, которые надо оценивать, то число степеней свободы было бы равно 1 (2 ячейки,  параметров;
параметров;  ). Таким образом для всего множества данных
). Таким образом для всего множества данных

выборочное распределение этой величины есть  Пять членов, дающих вклад, а именно
Пять членов, дающих вклад, а именно  составляют в сумме пять степеней свободы. Однако теперь мы должны сделать поправку на то, что два
составляют в сумме пять степеней свободы. Однако теперь мы должны сделать поправку на то, что два
параметра  оценивались, поэтому в итоге число степеней свободы равно трем. Таким образом, уровень значимости данных при гипотезе
оценивались, поэтому в итоге число степеней свободы равно трем. Таким образом, уровень значимости данных при гипотезе

равен:

Эта очень большая величина указывает на то, что Ф-гипотеза совместима с данными.