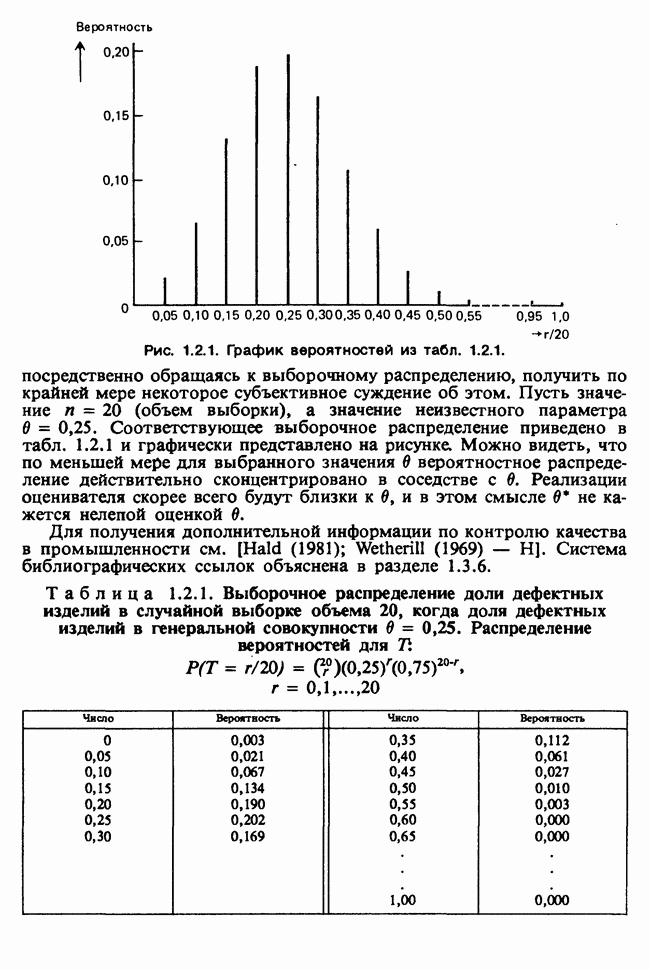
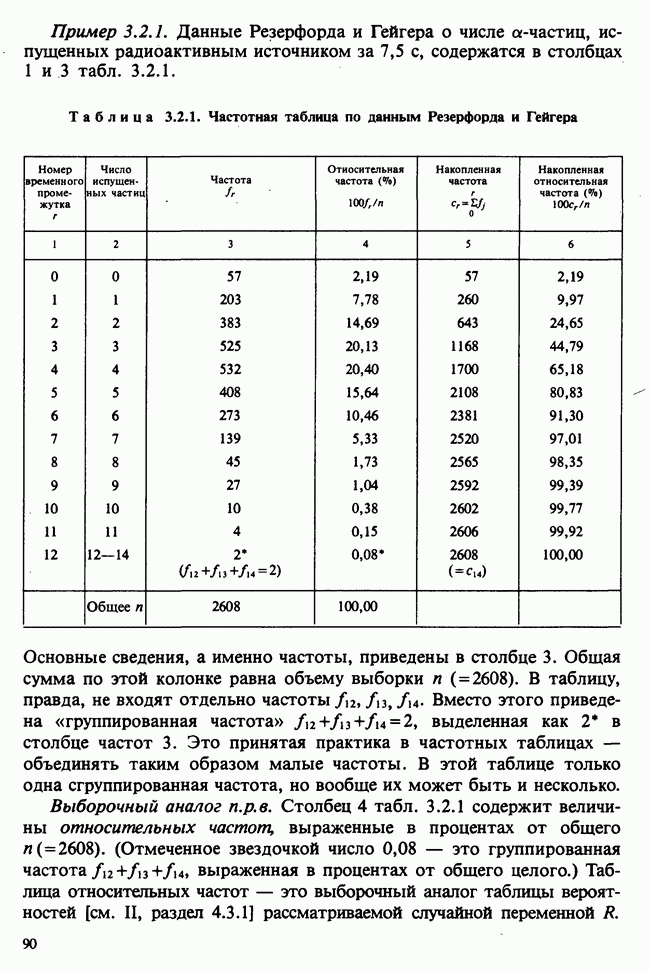
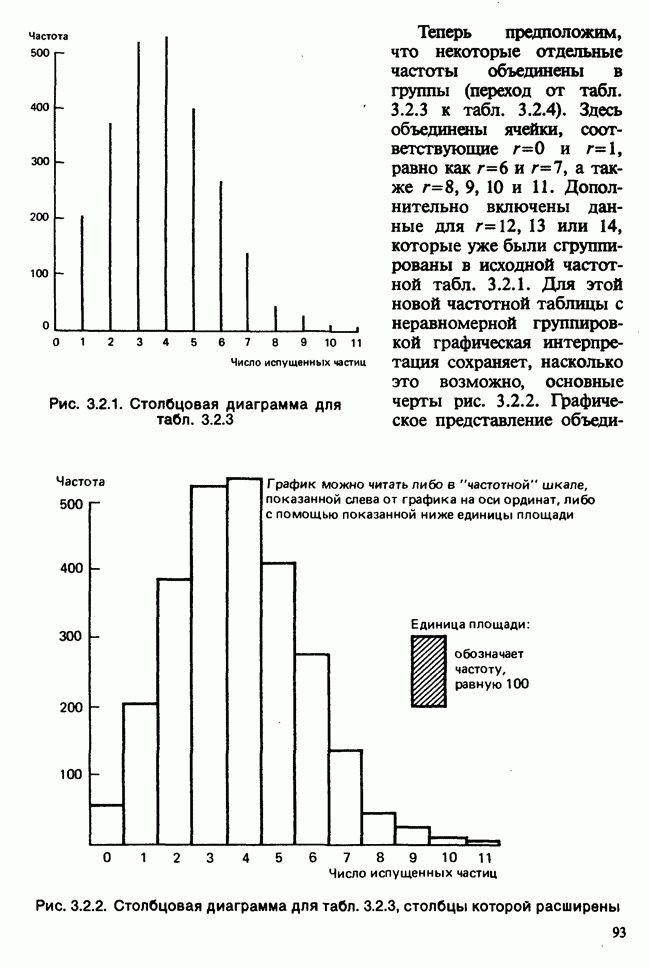
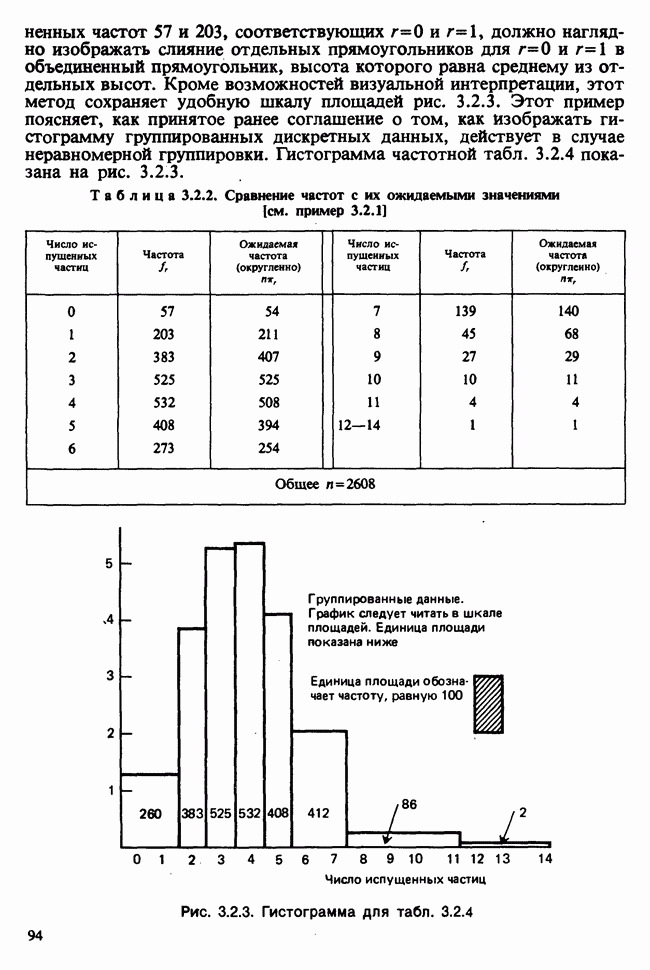
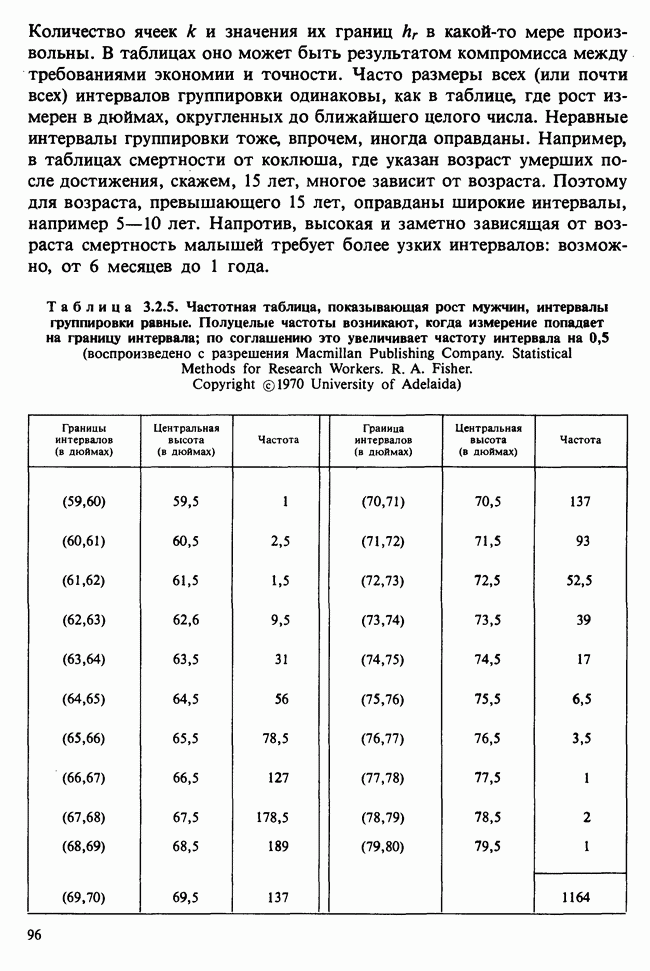
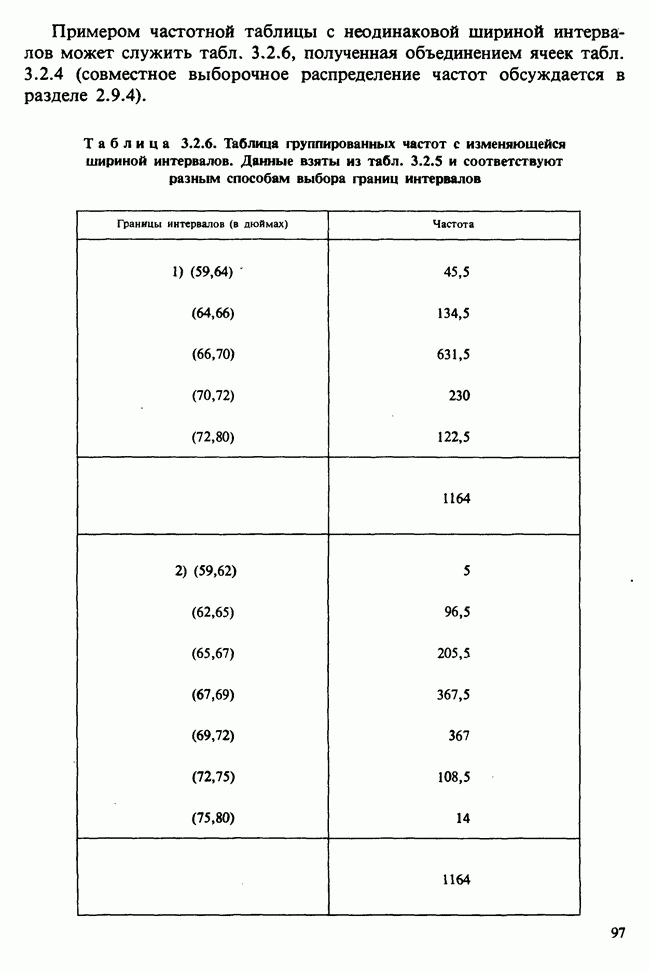
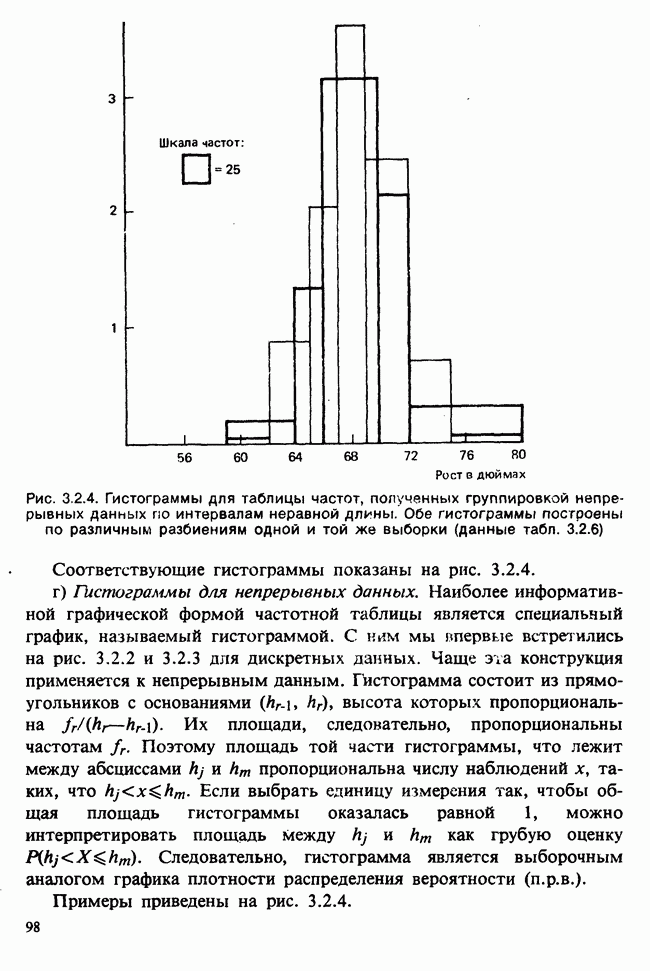
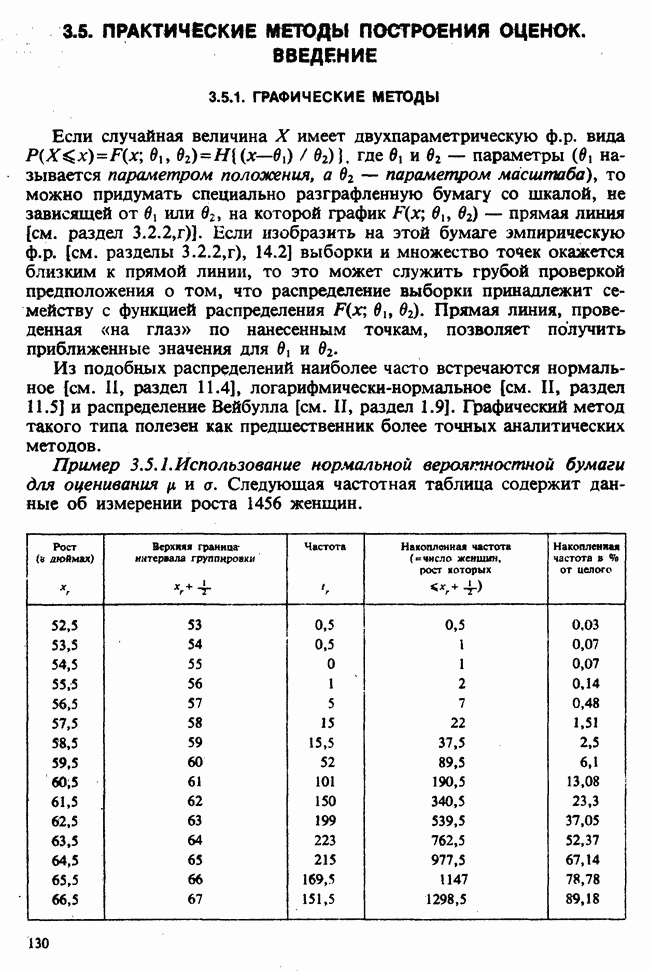
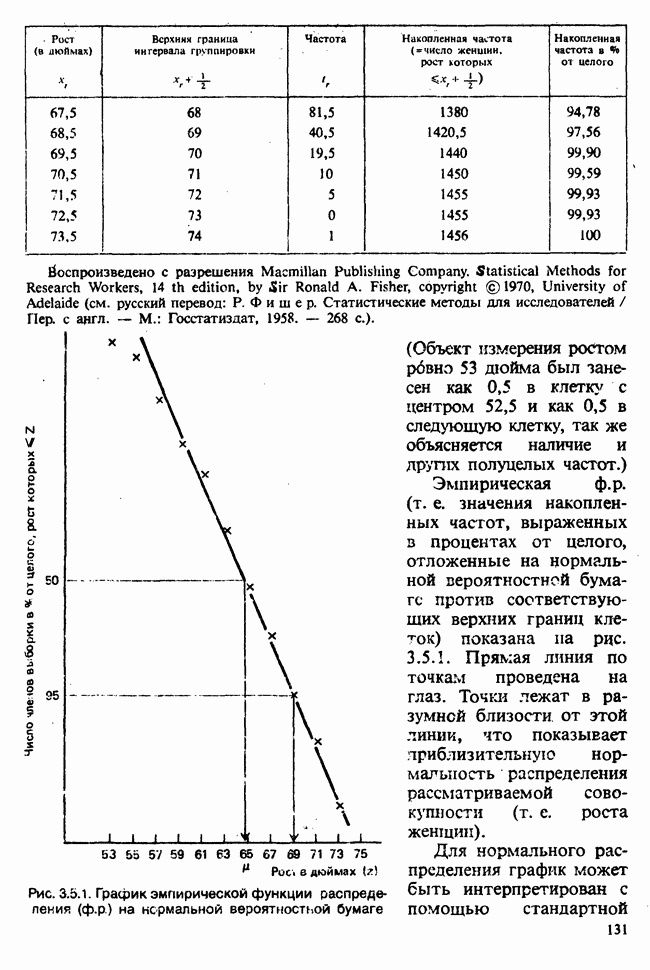
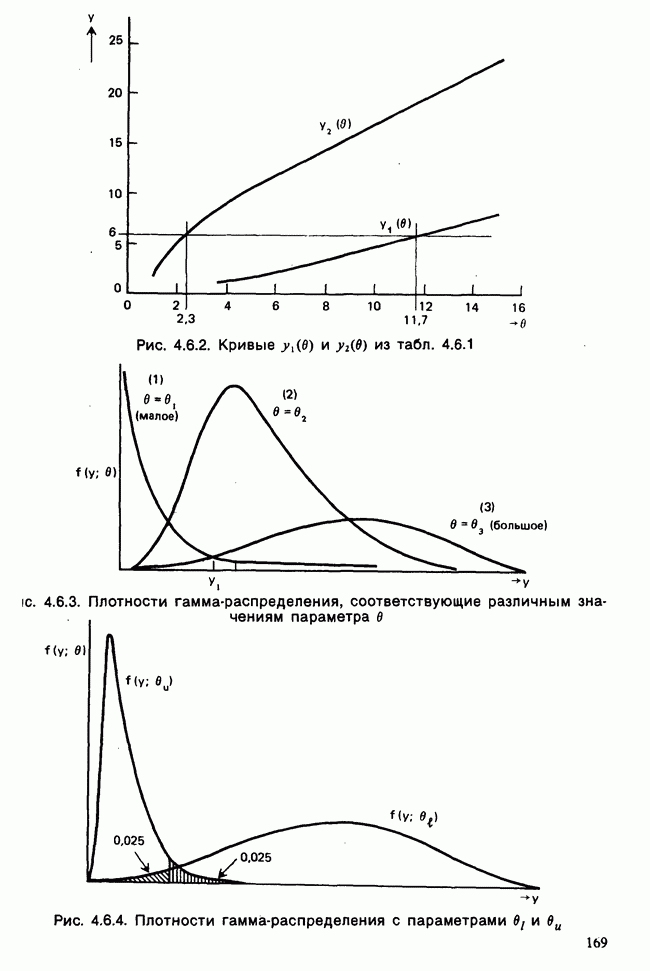
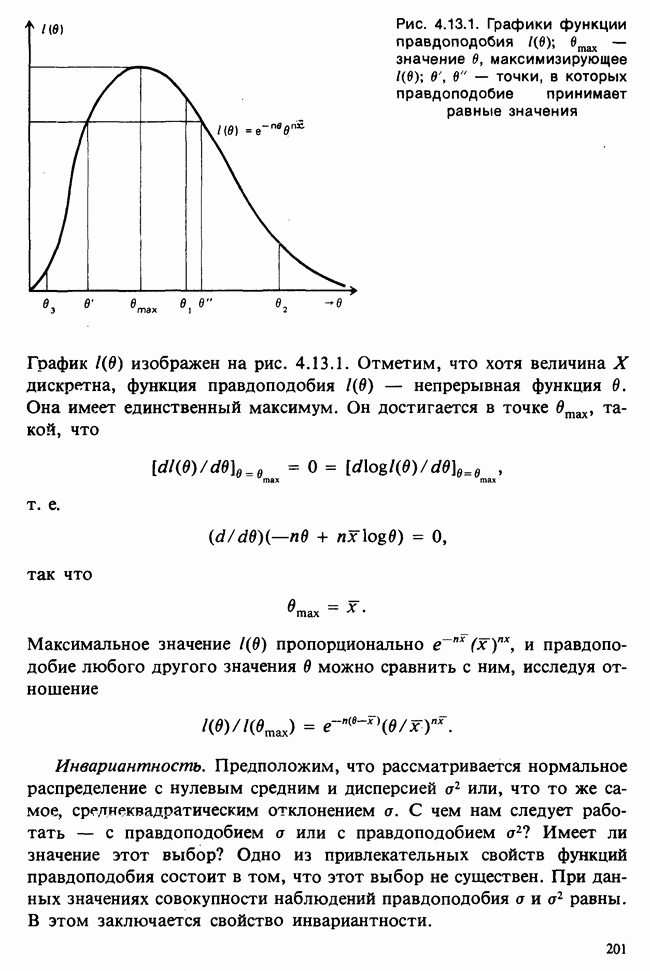
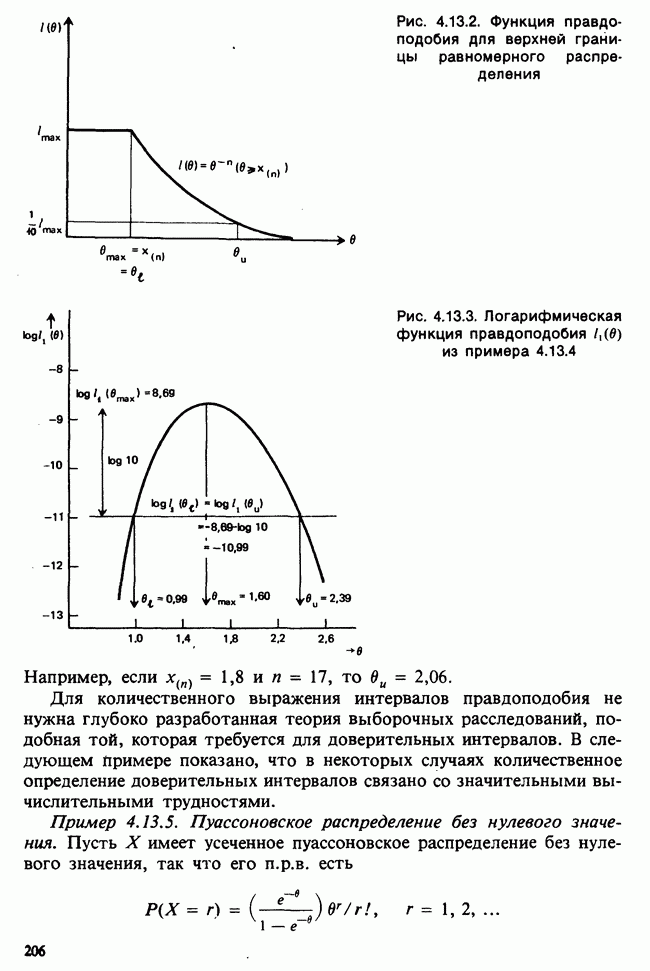
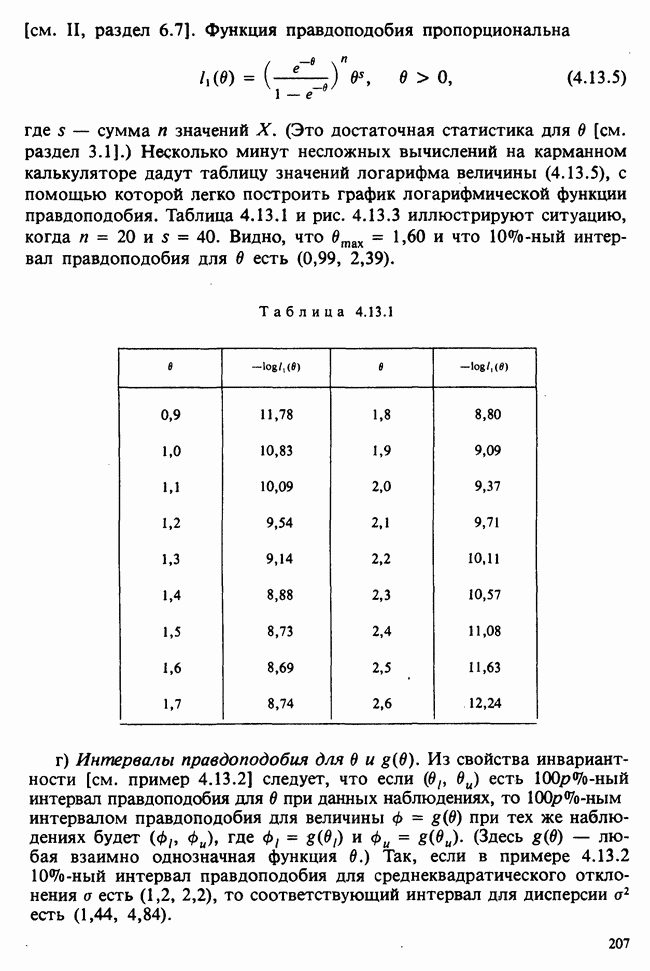
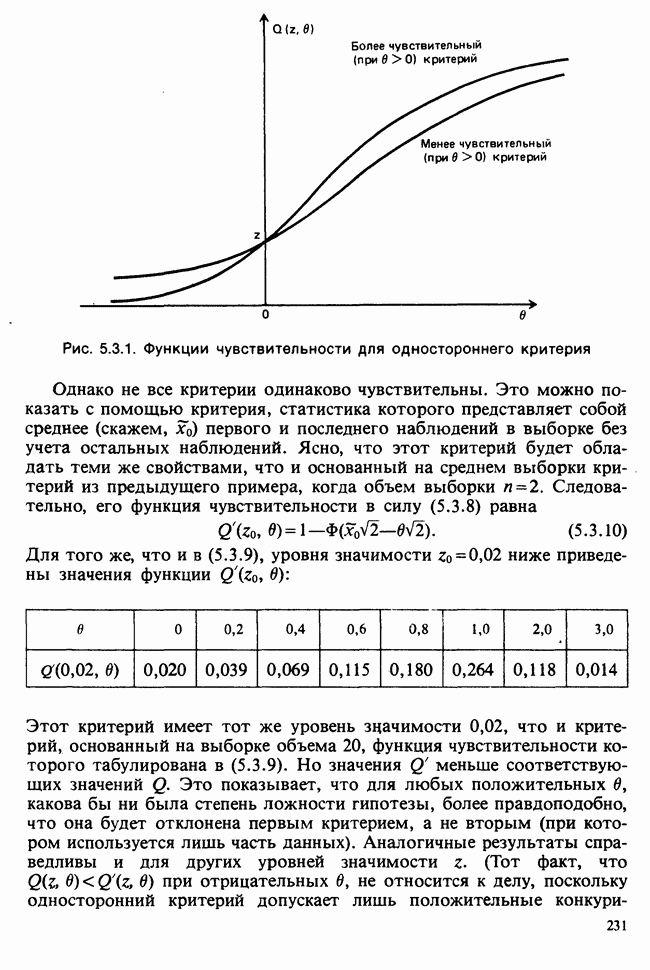
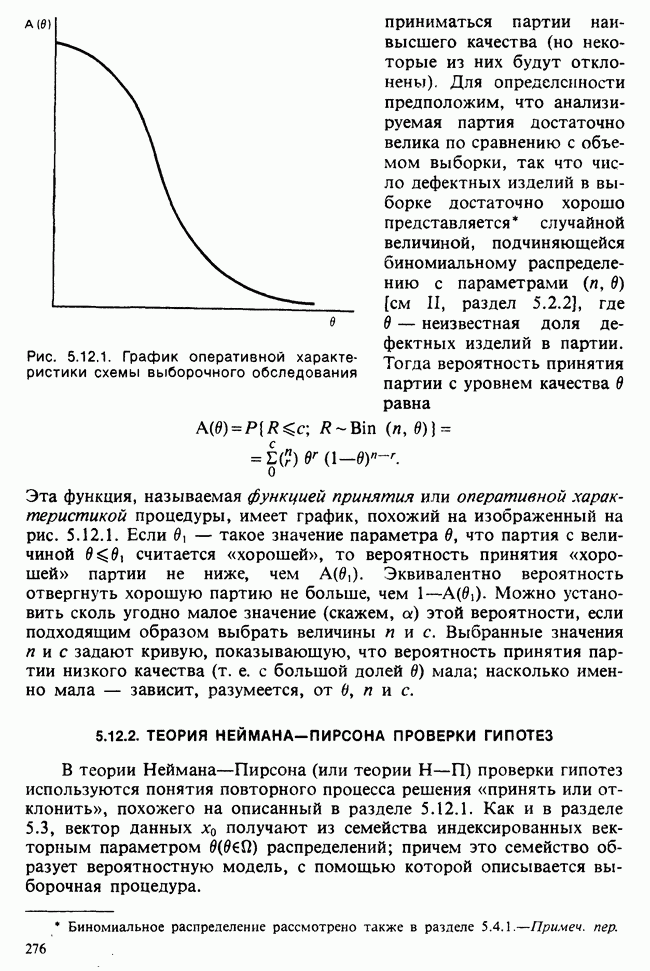
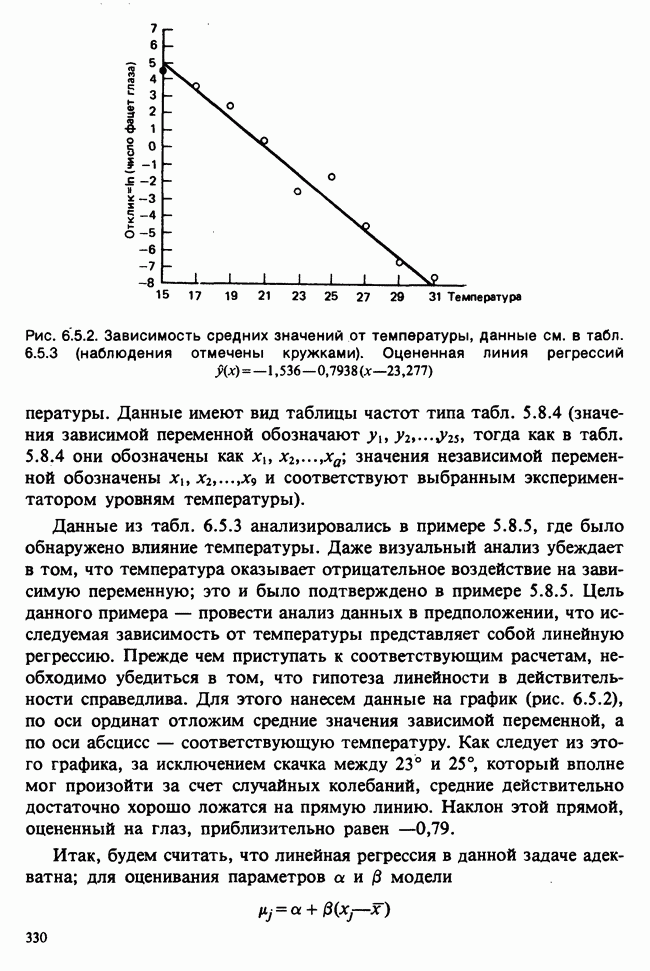
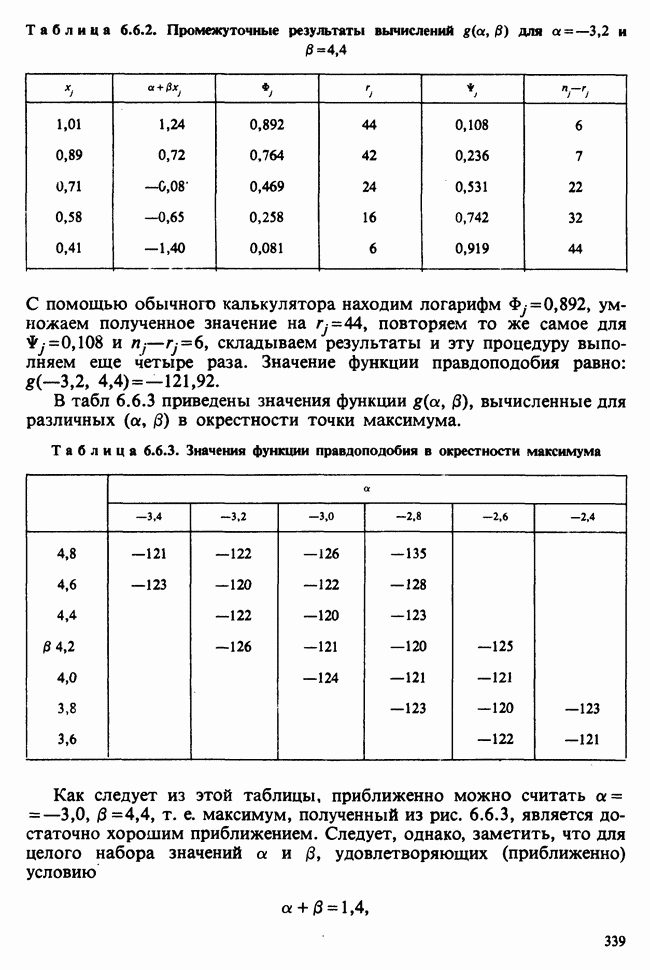
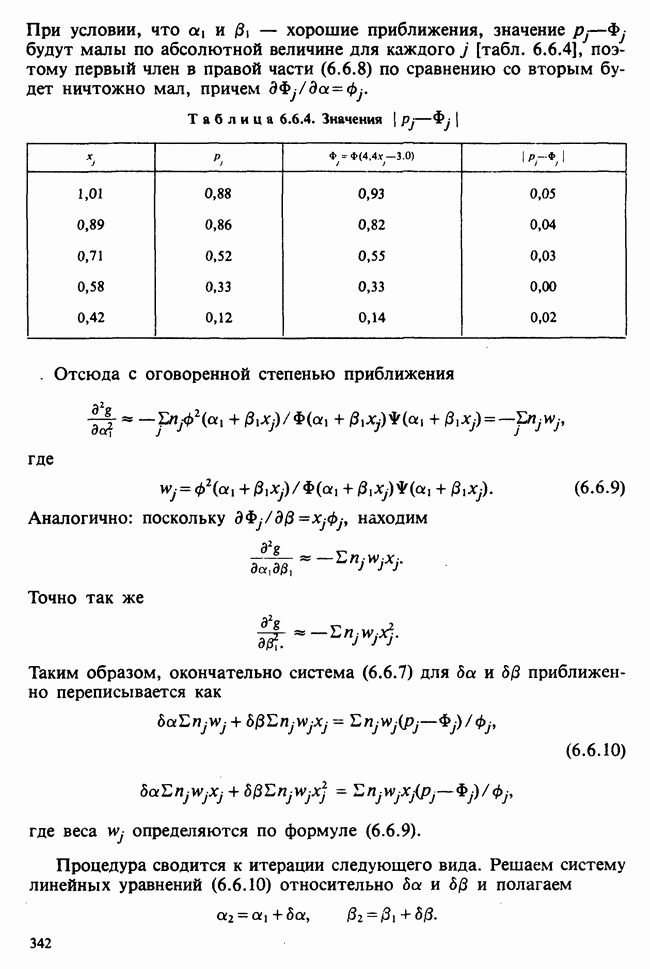
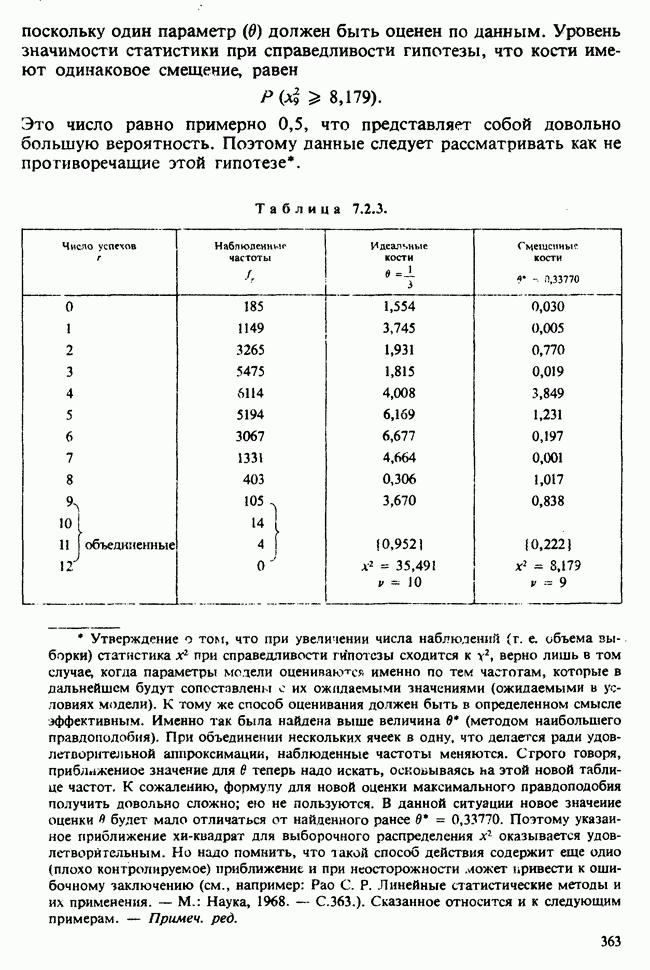
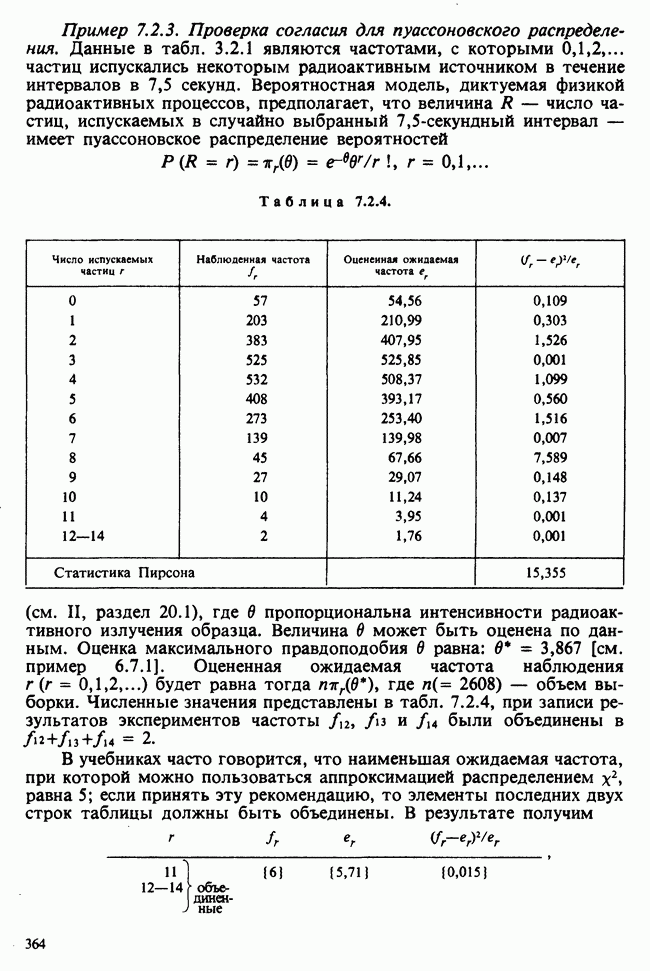
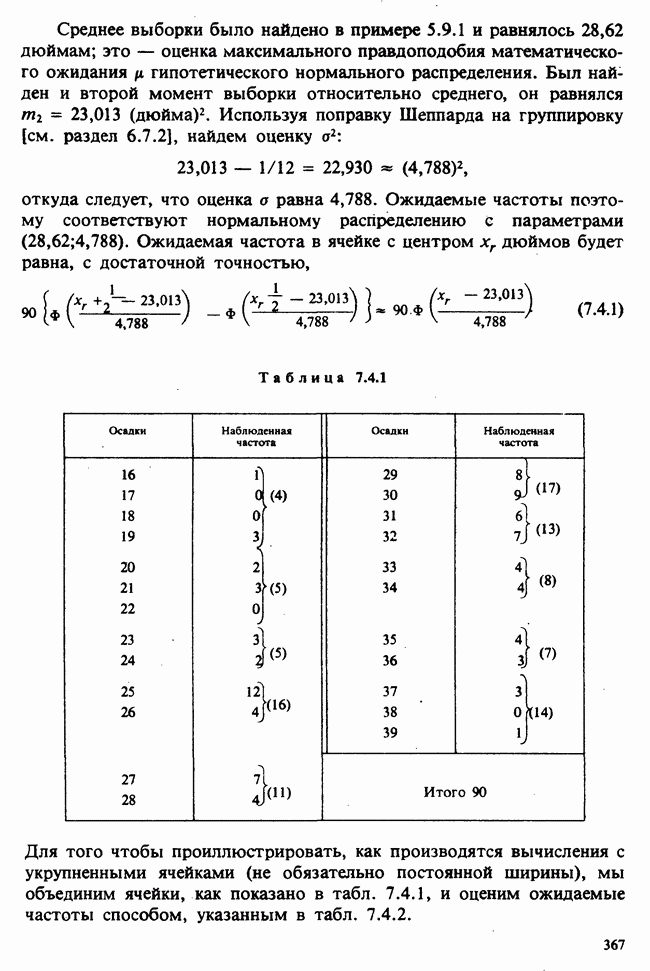
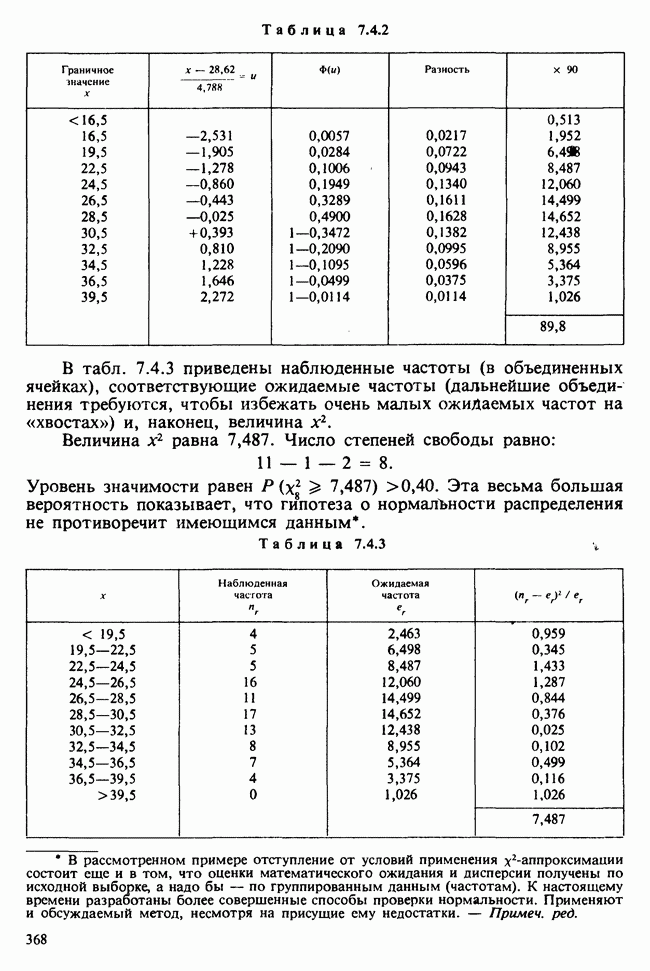
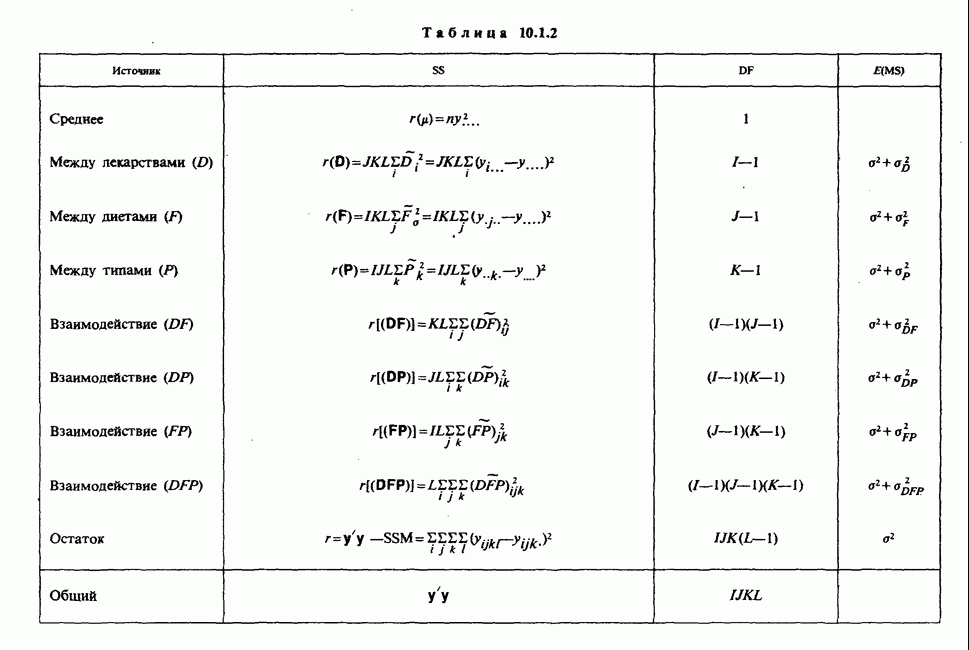
10.1.4. ДВУСТОРОННЯЯ (ДВУХФАКТОРНАЯ) ИЕРАРХИЧЕСКАЯ КЛАССИФИКАЦИЯ
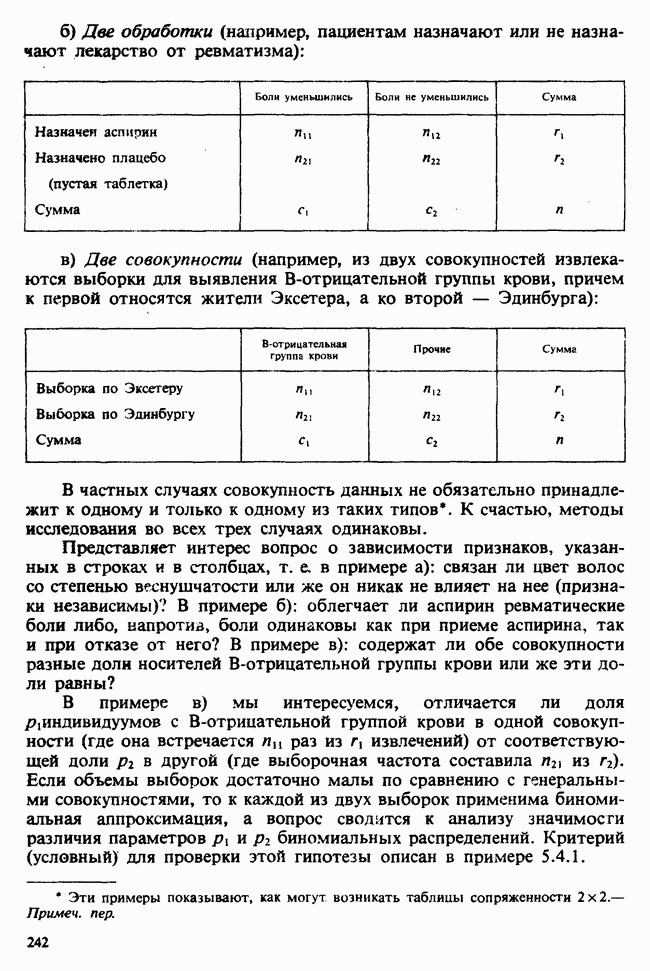
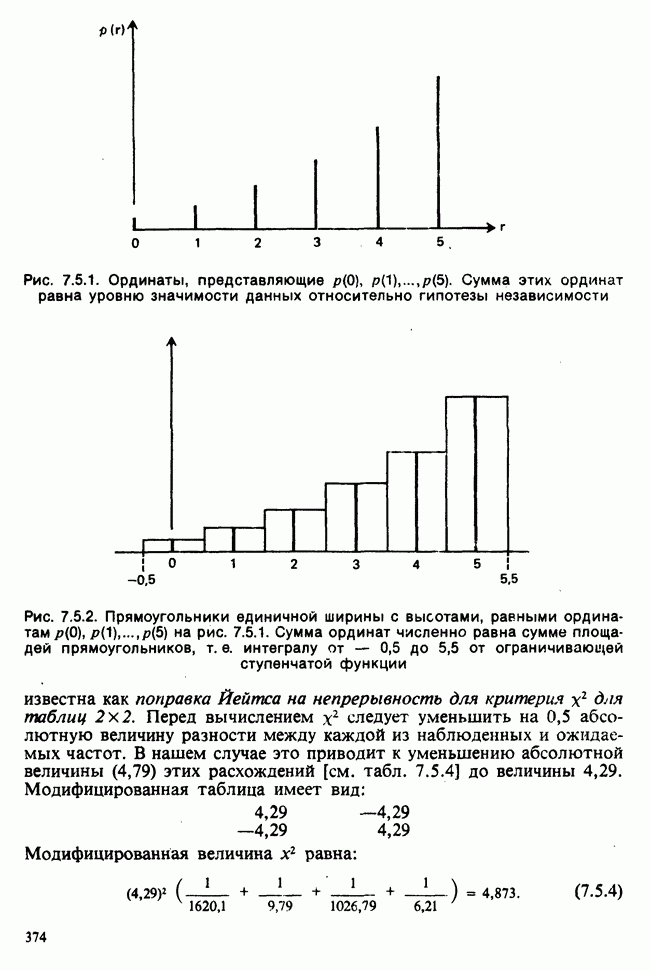
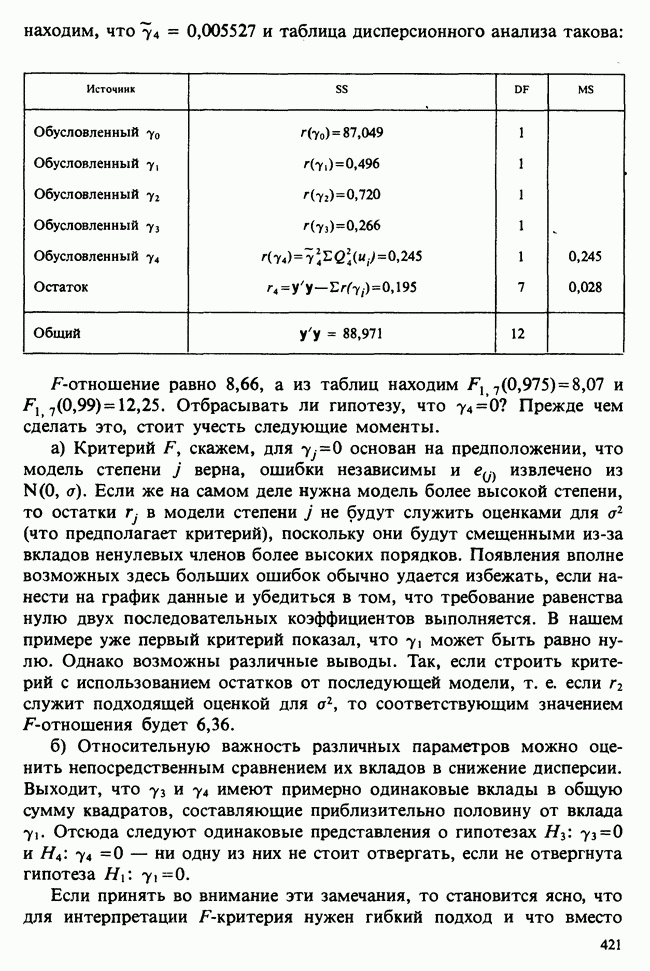
В односторонней классификации данные разделяются на несколько групп с помощью некоторого группового фактора, такого, как получаемая обработка, и имеют такую структуру:

Здесь каждый крестик обозначает одно наблюдение.
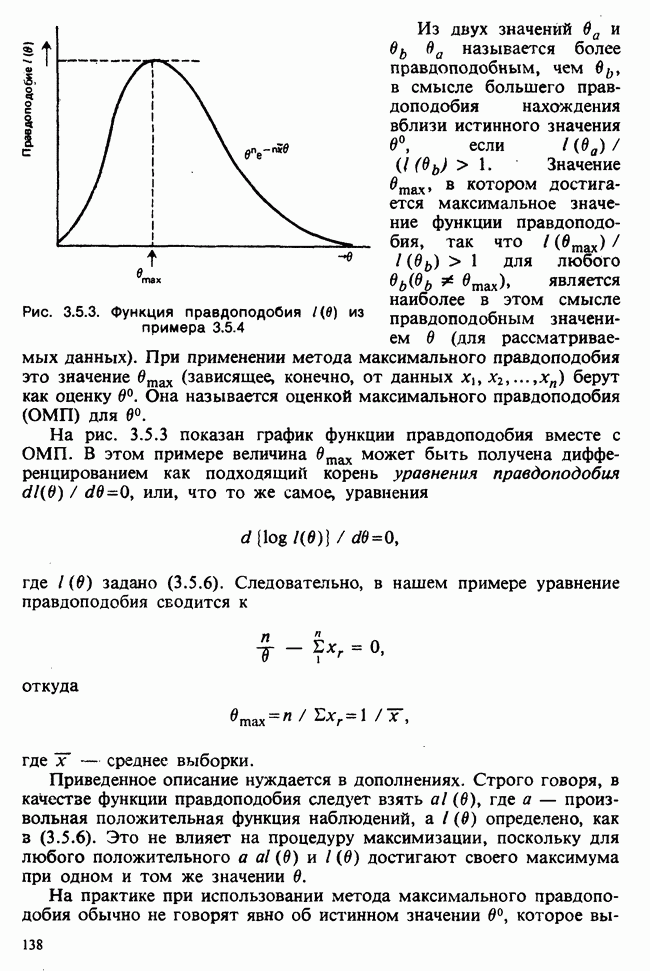
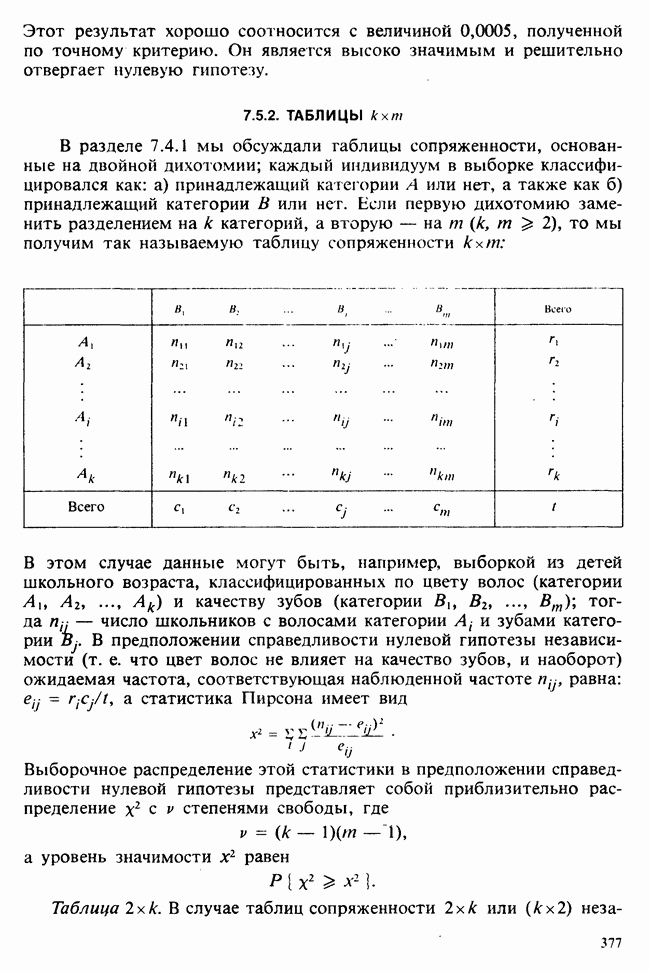
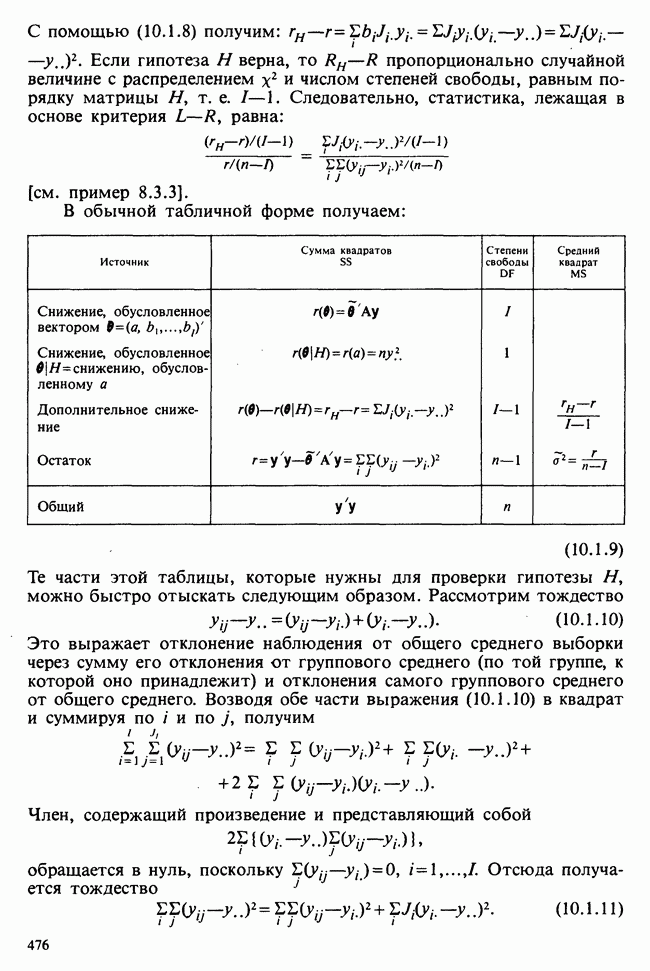
Если второй фактор используется для разделения каждой группы, то мы имеем двустороннюю иерархическую, или гнездовую, классификацию, которая обладает следующей структурой:

Здесь группа 1 разбита на 4 подгруппы, каждая из которых содержит четыре, два, одно и три наблюдения, и т. д. Так, например, данные могут представлять собой результаты измерений загрязнения воздуха в различных городах нескольких стран; страны образуют группы, а города — подгруппы.
Обозначим  наблюдение в
наблюдение в  подгруппе
подгруппе  группы через
группы через  и предположим, что
и предположим, что  группа имеет подгрупп,
группа имеет подгрупп,  из которых содержит
из которых содержит  наблюдений. Так, группа 2 в примере, приведенном выше, имеет
наблюдений. Так, группа 2 в примере, приведенном выше, имеет  подгруппы, а число наблюдений в первой из них равно:
подгруппы, а число наблюдений в первой из них равно: 
Модель полного ранга для этой ситуации такова:

где  — неизвестные параметры, а — независимые наблюдения со средним
— неизвестные параметры, а — независимые наблюдения со средним  . Иначе говоря, наблюдения в
. Иначе говоря, наблюдения в  подгруппе
подгруппе  группы представляют собой случайную выборку из распределения со средним
группы представляют собой случайную выборку из распределения со средним  параметров
параметров  равно, следовательно, числу подгрупп, т. е.
равно, следовательно, числу подгрупп, т. е. 
Такая модель не вполне подходит. Она недостаточно хорошо отражает структуру данных. В ней нет простых параметров, связанных с теми эффектами, которые мы обычно хотим исследовать, а уточнение гипотез, рассмотренных ниже, получается громоздким. Вместо этого будем рассматривать вырожденную модель

где 
Эта новая модель имеет  параметров и оказывается перепараметризованной. Если вместо подставить
параметров и оказывается перепараметризованной. Если вместо подставить  вместо
вместо  , а вместо
, а вместо  то
то  не изменится. Всего есть
не изменится. Всего есть  избыточных параметров.
избыточных параметров.
Мы приходим к этому, используя следующие дополнительные условия на  и на
и на 

где  — число наблюдений в
— число наблюдений в  группе. В результате этих
группе. В результате этих  дополнительных условий получаются единственные МНК-оценки для
дополнительных условий получаются единственные МНК-оценки для  что позволяет нам следующим образом интерпретировать параметры:
что позволяет нам следующим образом интерпретировать параметры:
 — математическое ожидание среднего по всем наблюдениям;
— математическое ожидание среднего по всем наблюдениям;
 — математическое ожидание среднего по наблюдениям в
— математическое ожидание среднего по наблюдениям в  группе;
группе;
следовательно,  — мера эффекта группы
— мера эффекта группы 
 математическое ожидание среднего по наблюдениям в подгруппе
математическое ожидание среднего по наблюдениям в подгруппе  группы
группы  следовательно, — мера эффекта
следовательно, — мера эффекта  подгруппы в
подгруппы в  группе.
группе.
МНК-оценки параметров находят, минимизируя сумму  с учетом указанных выше дополнительных условий, причем параметры при поиске минимума рассматриваются как алгебраические переменные. Как можно предположить, мы найдем, что:
с учетом указанных выше дополнительных условий, причем параметры при поиске минимума рассматриваются как алгебраические переменные. Как можно предположить, мы найдем, что:

 где
где  — среднее в
— среднее в  группе,
группе,  где у — среднее в
где у — среднее в  подгруппе
подгруппе  группы. Остаточная сумма квадратов равна:
группы. Остаточная сумма квадратов равна:

с числом степеней свободы, равным числу наблюдений минус число независимых параметров, т. е.  где
где  — число наблюдений,
— число наблюдений,  — число подгрупп. Представляют интерес, главным образом, две гипотезы:
— число подгрупп. Представляют интерес, главным образом, две гипотезы:
1)  т. е. что между группами вообще нет никакой разницы;
т. е. что между группами вообще нет никакой разницы;
2)  все
все  т. е. что внутри каждой группы нет различий в подгруппах.
т. е. что внутри каждой группы нет различий в подгруппах.
Для проверки этих гипотез нам надо снова оценить параметры с учетом каждой из них и найти соответствующие остаточные суммы квадратов. Детали такого подхода очевидны, и мы их опустим, а основные моменты обсудим. Параметры образуют три ортогональные группы, а именно  содержащие
содержащие  параметров, из которых только (7—1) независимы;
параметров, из которых только (7—1) независимы;  содержащие
содержащие  параметров, из которых только
параметров, из которых только  независимы. Следовательно, оценки значений
независимы. Следовательно, оценки значений  при гипотезе
при гипотезе  и значений
и значений  при гипотезе
при гипотезе  будут теми же, что и для модели полного ранга, а оценка
будут теми же, что и для модели полного ранга, а оценка  равная
равная  сохраняется во всех трех случаях. Величина, на которую
сохраняется во всех трех случаях. Величина, на которую  уменьшается благодаря подгонке значений
уменьшается благодаря подгонке значений  останется той же независимо от того, включены ли в модель значения
останется той же независимо от того, включены ли в модель значения  и наоборот. Таким образом, сумму квадратов, обусловленную подбором полной модели (СКМ), можно представить в виде
и наоборот. Таким образом, сумму квадратов, обусловленную подбором полной модели (СКМ), можно представить в виде

где  — уменьшение, обусловленное подбором
— уменьшение, обусловленное подбором  т. е. увеличение остатков при условии
т. е. увеличение остатков при условии  (так что
(так что  — увеличение остатков при условии
— увеличение остатков при условии  . Такой дисперсионный анализ можно представить в обычной табличной форме:
. Такой дисперсионный анализ можно представить в обычной табличной форме:

где  Для каждой группы число степеней свободы — это число независимо подбираемых параметров. Критерии строятся обычным образом с помощью сравнения каждого среднего квадрата с
Для каждой группы число степеней свободы — это число независимо подбираемых параметров. Критерии строятся обычным образом с помощью сравнения каждого среднего квадрата с  и соотнесения полученного отношения с подходящим значением
и соотнесения полученного отношения с подходящим значением  -распределения.
-распределения.
Непосредственные выражения различных сумм квадратов через наблюдения появляются как естественная составная часть анализа методом наименьших квадратов. Их можно отыскать и скорее с помощью простого приема, который применялся ранее при односторонней классификации. Представим отклонение произвольного наблюдения от общего среднего в виде суммы трех слагаемых:

Если теперь возвести обе части этого равенства в квадрат и просуммировать по  , то получим
, то получим

так как члены, содержащие перекрестные произведения, равны нулю. Члены, стоящие в правой части этого уравнения, не что иное, как  Левую сторону можно представить как
Левую сторону можно представить как

Это с учетом того, что  позволяет при простом переобозначении получить основную формулу
позволяет при простом переобозначении получить основную формулу

Из выражения (10.1.13) можно увидеть, что уменьшение  обусловленное подбором группы параметров, может служить некоторой мерой вариабельности между группами. В соответствии с этим выражением
обусловленное подбором группы параметров, может служить некоторой мерой вариабельности между группами. В соответствии с этим выражением  называется межгрупповой суммой квадратов. Аналогично величина
называется межгрупповой суммой квадратов. Аналогично величина  служит некоторой мерой вариабельности между подгруппами внутри
служит некоторой мерой вариабельности между подгруппами внутри  группы, а величина
группы, а величина  объединяет эти меры по всем группам и называется суммой квадратов между подгруппами внутри групп (МПВГСК). Математические ожидания средних квадратов для этих сумм можно найти с помощью элементарных методов:
объединяет эти меры по всем группам и называется суммой квадратов между подгруппами внутри групп (МПВГСК). Математические ожидания средних квадратов для этих сумм можно найти с помощью элементарных методов:

а значит, снова критерий для сравнения с остатками будет односторонним.