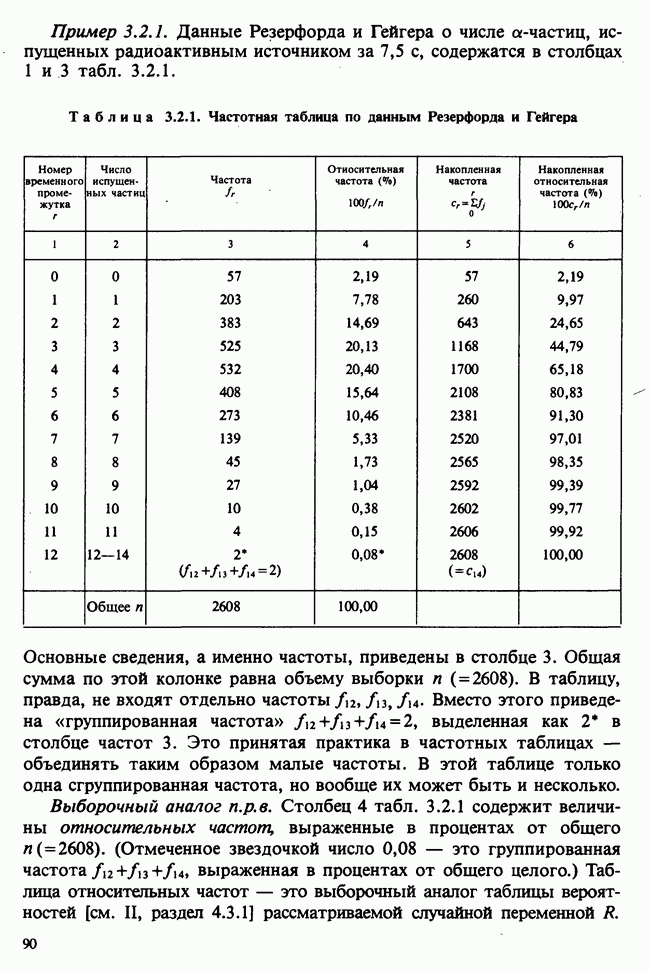
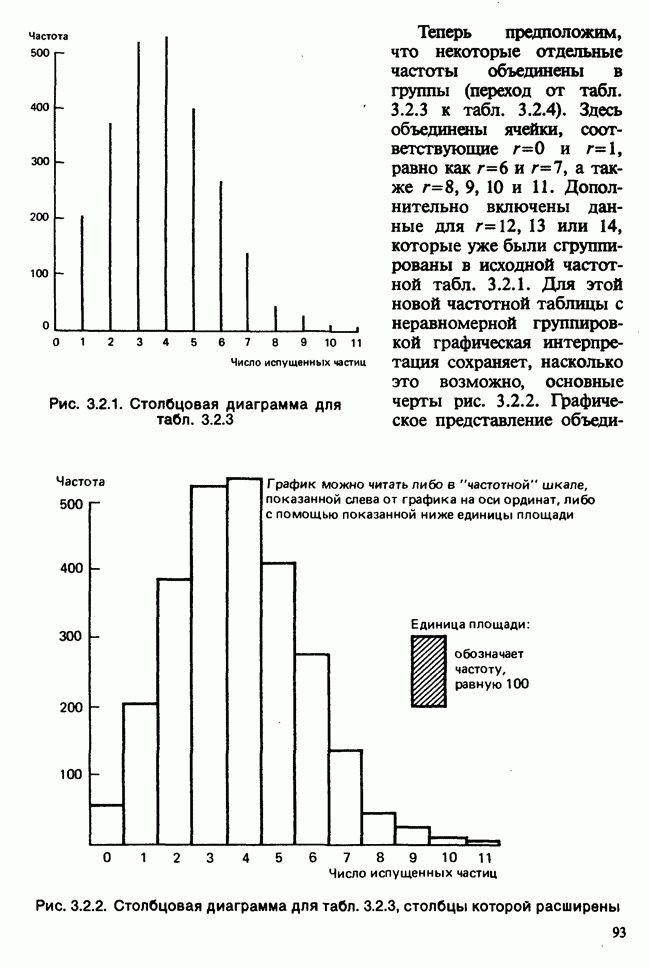
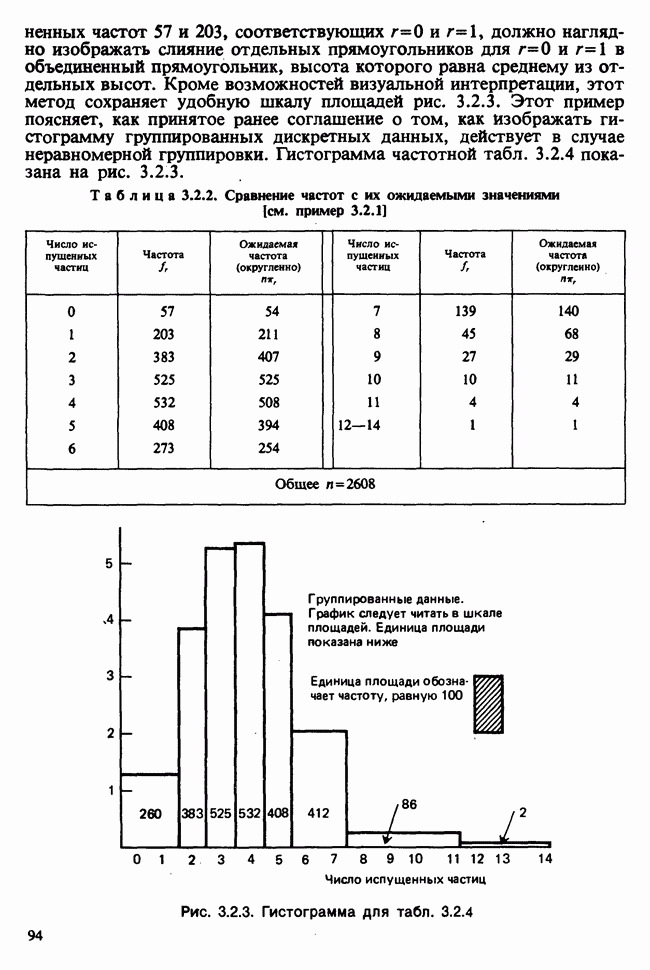
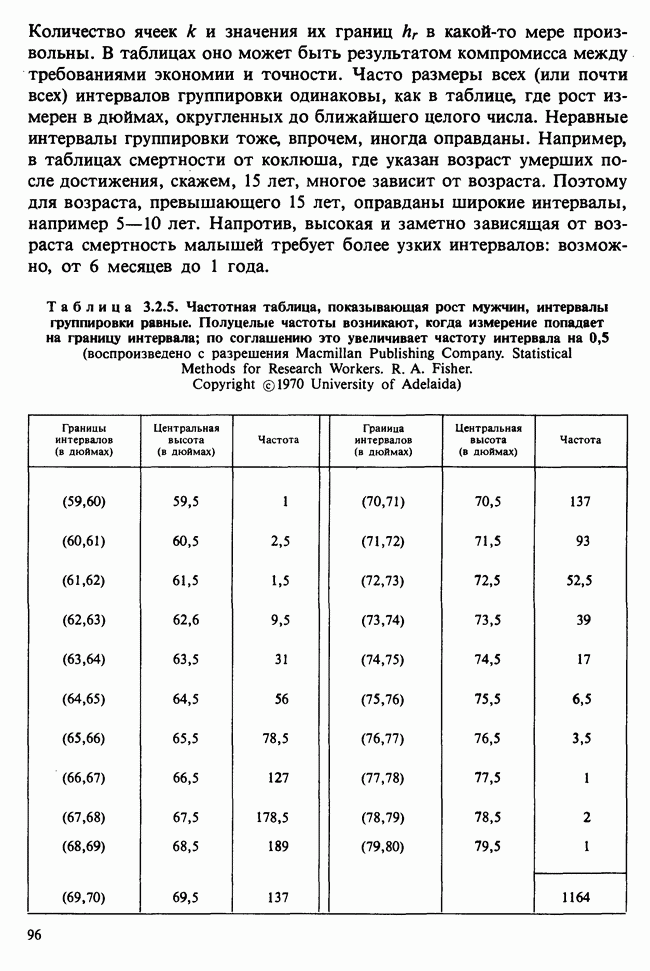
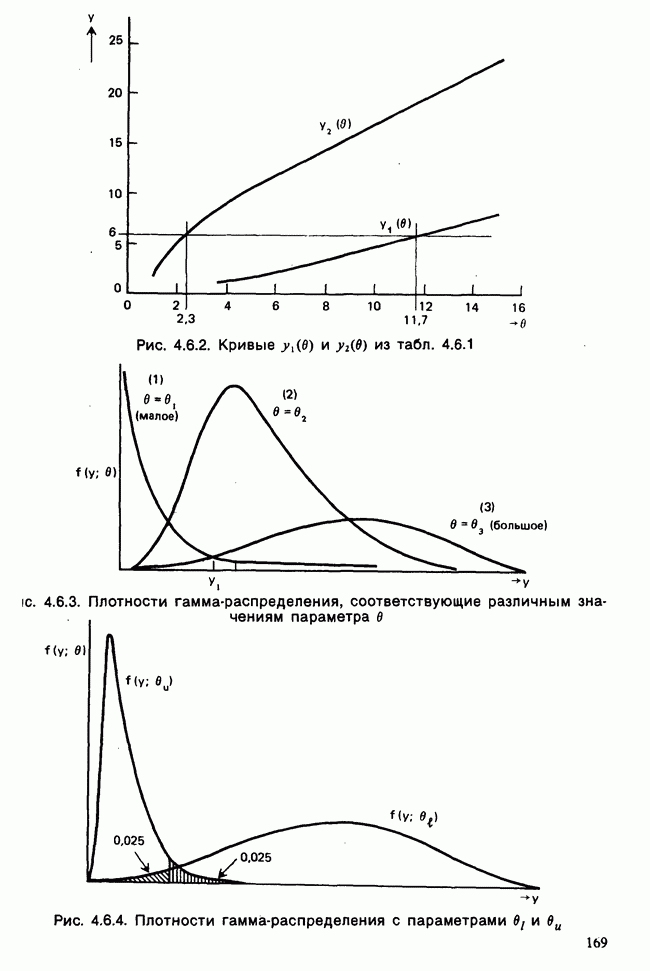
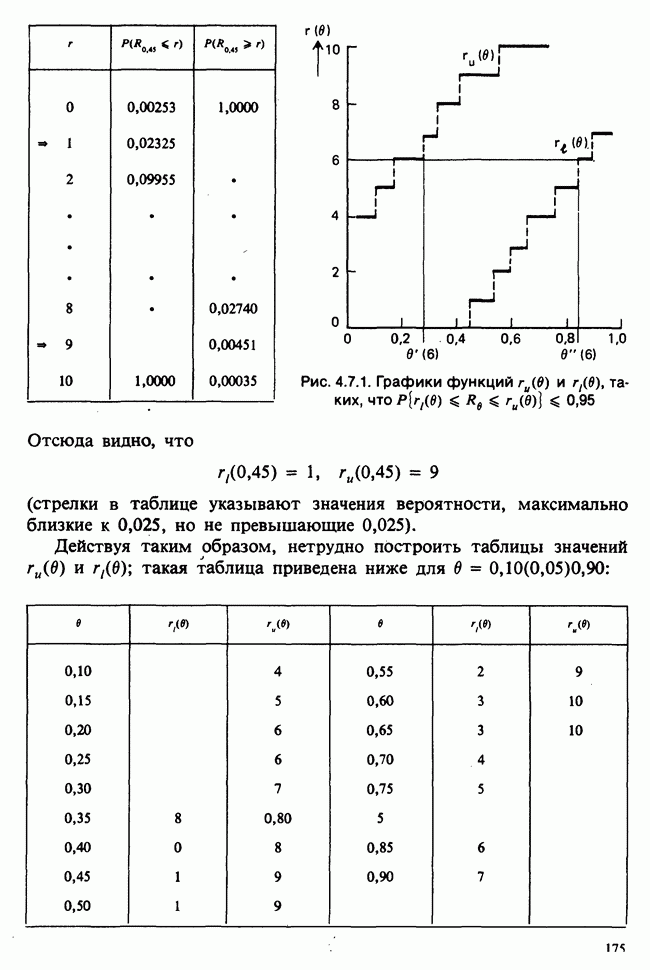
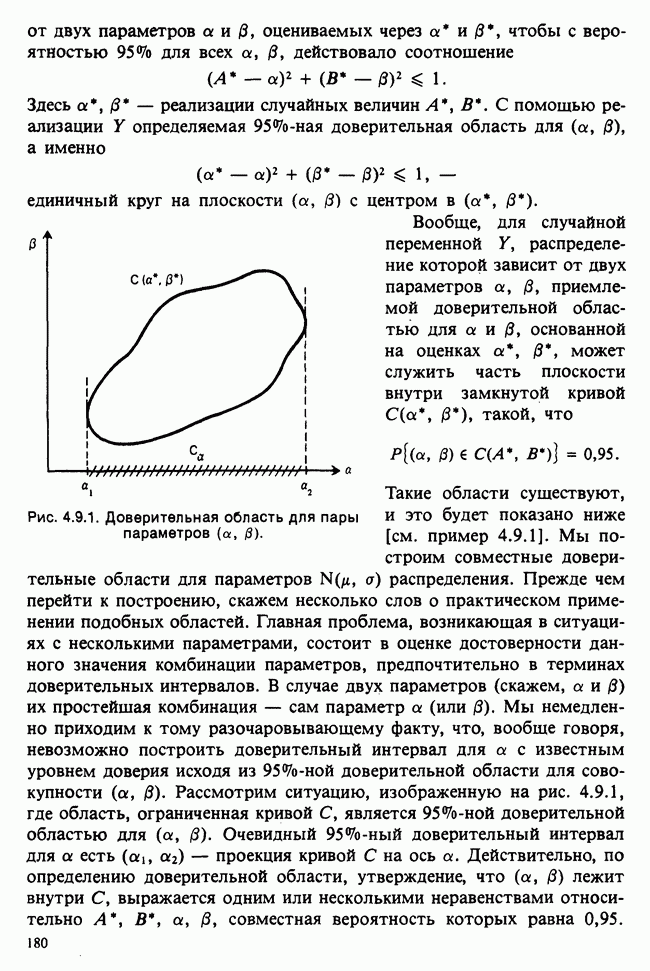
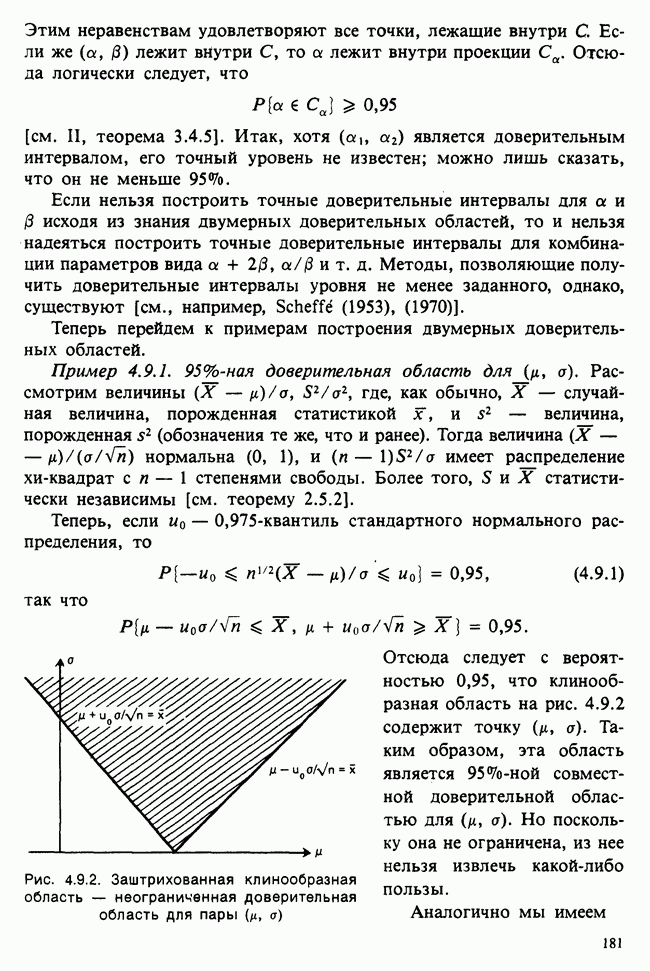
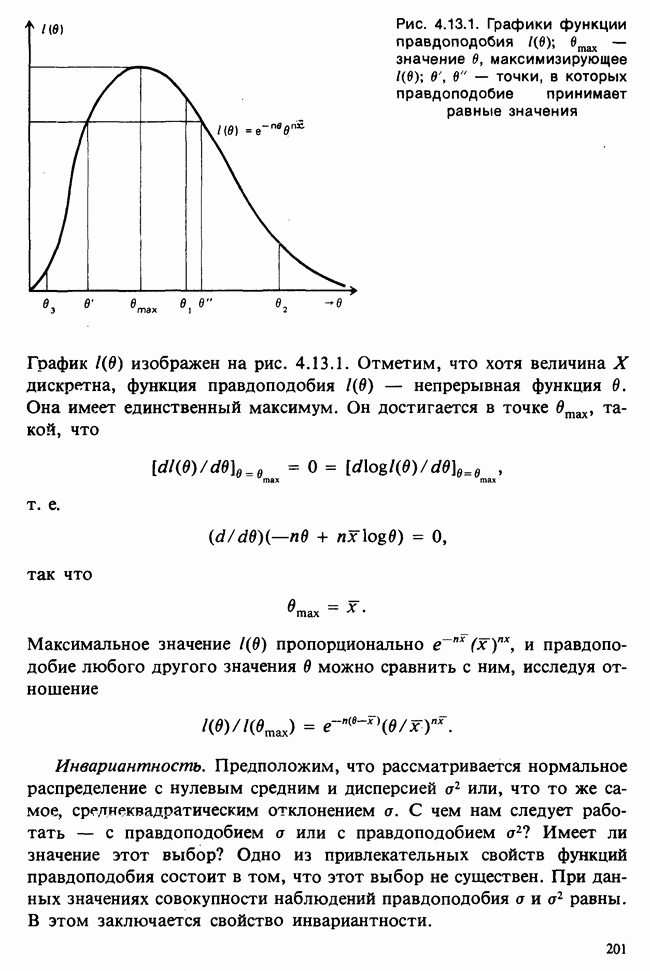
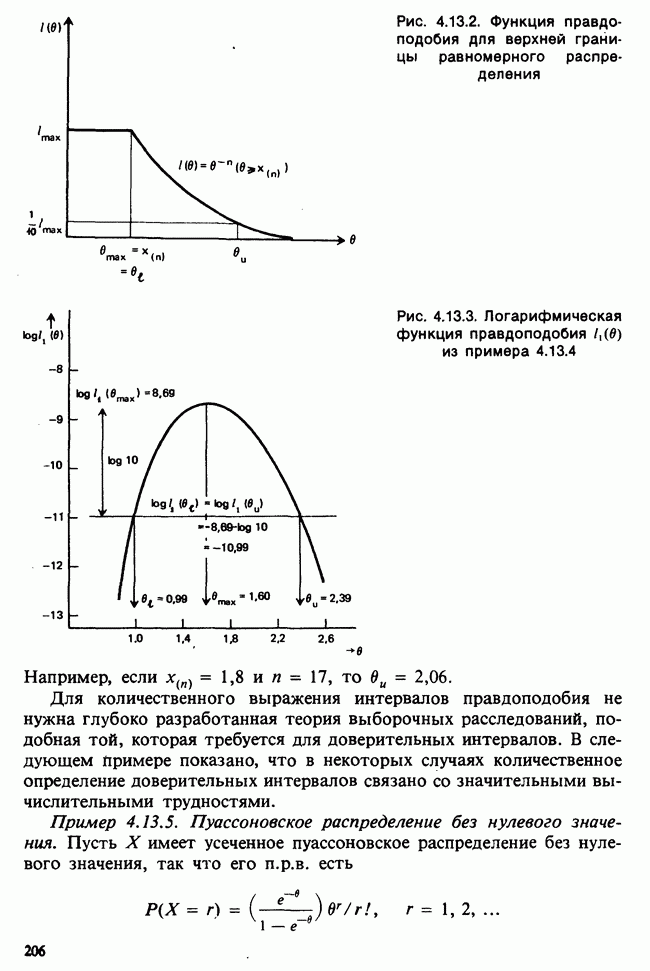
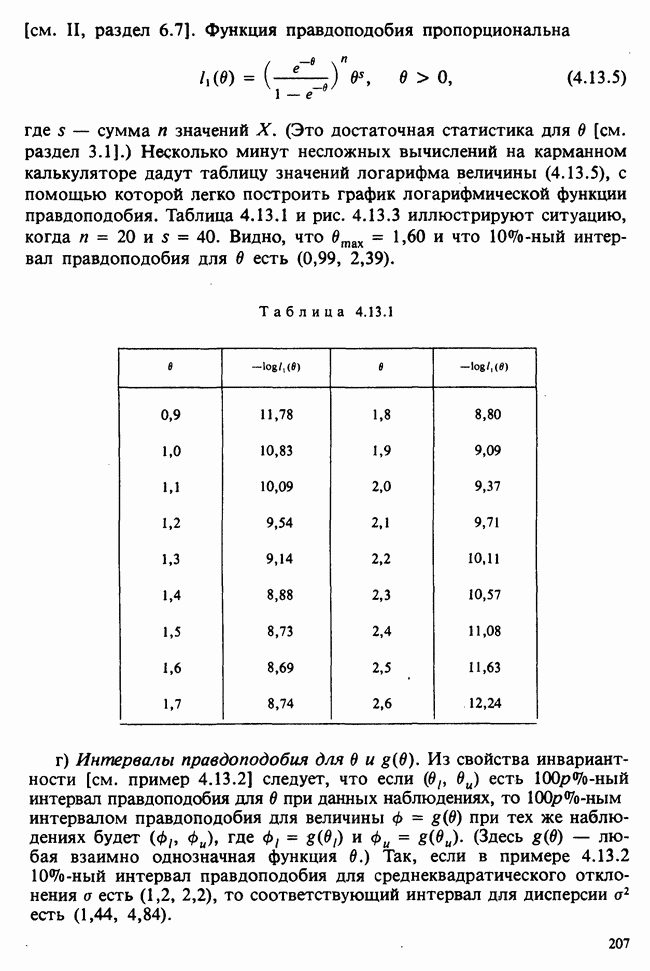
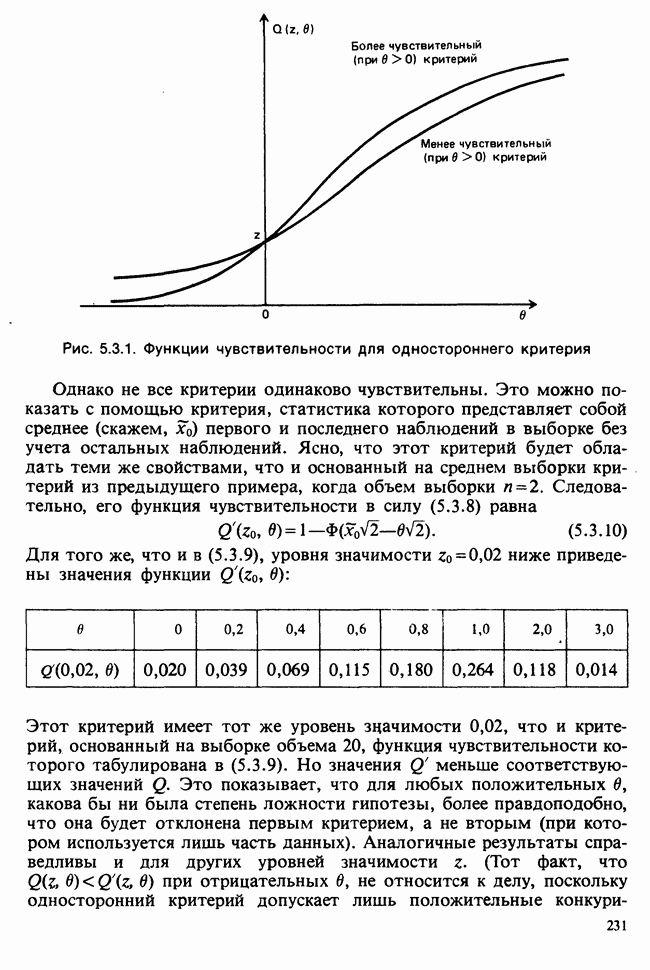
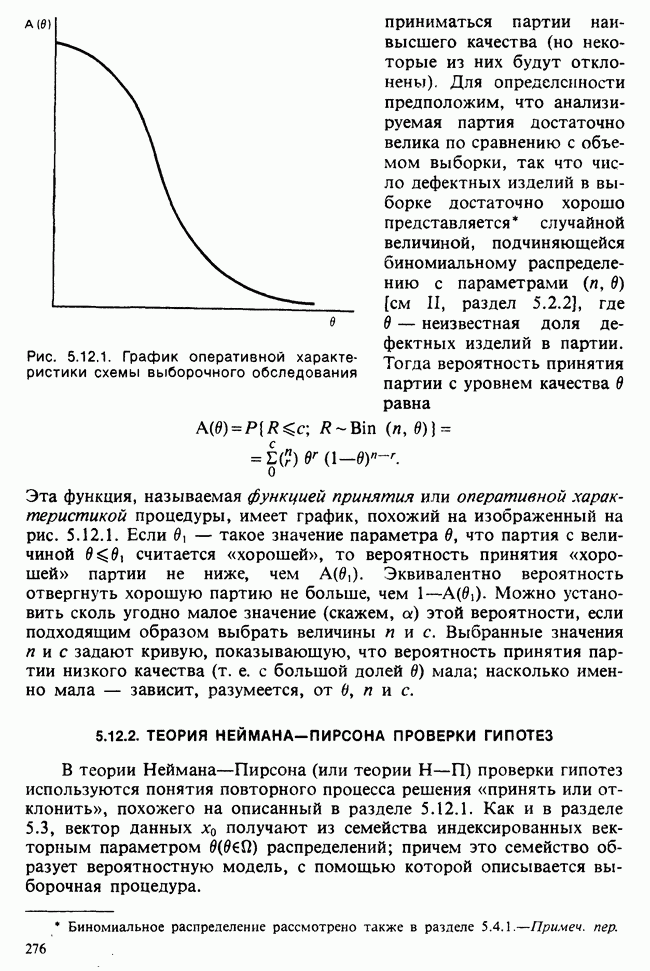
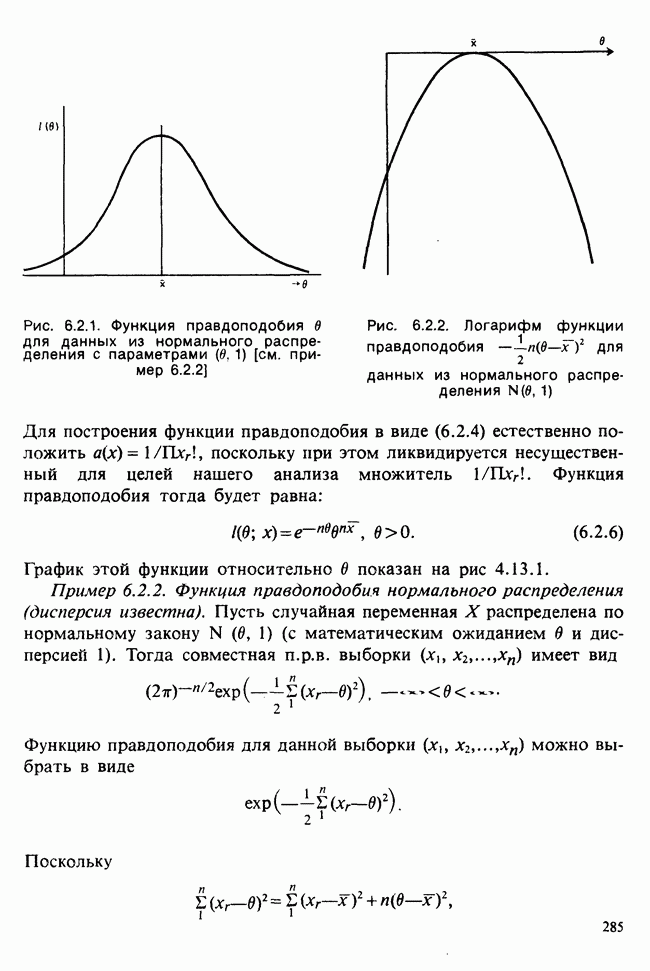
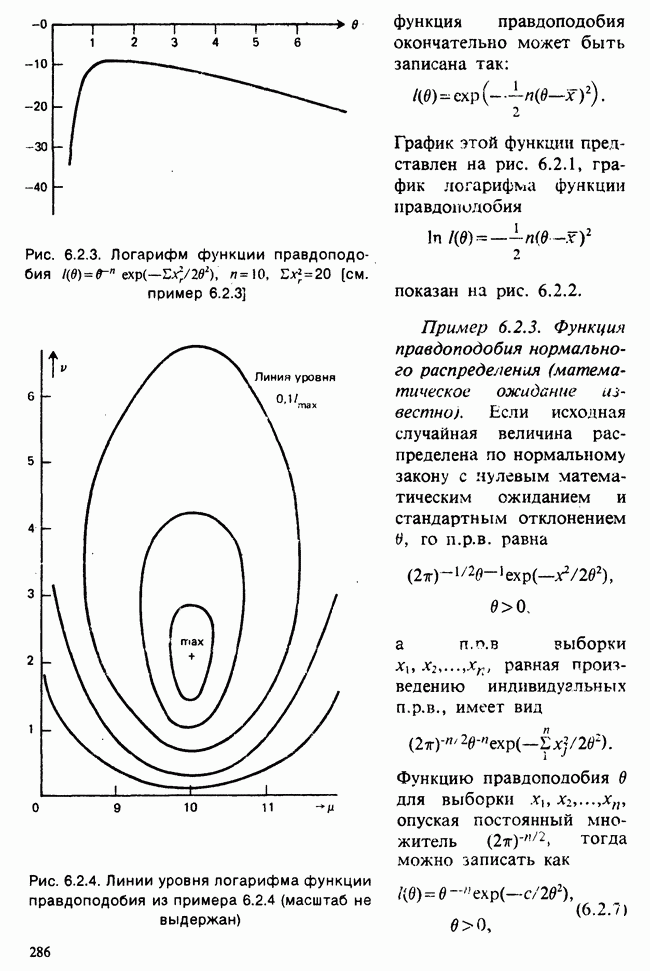
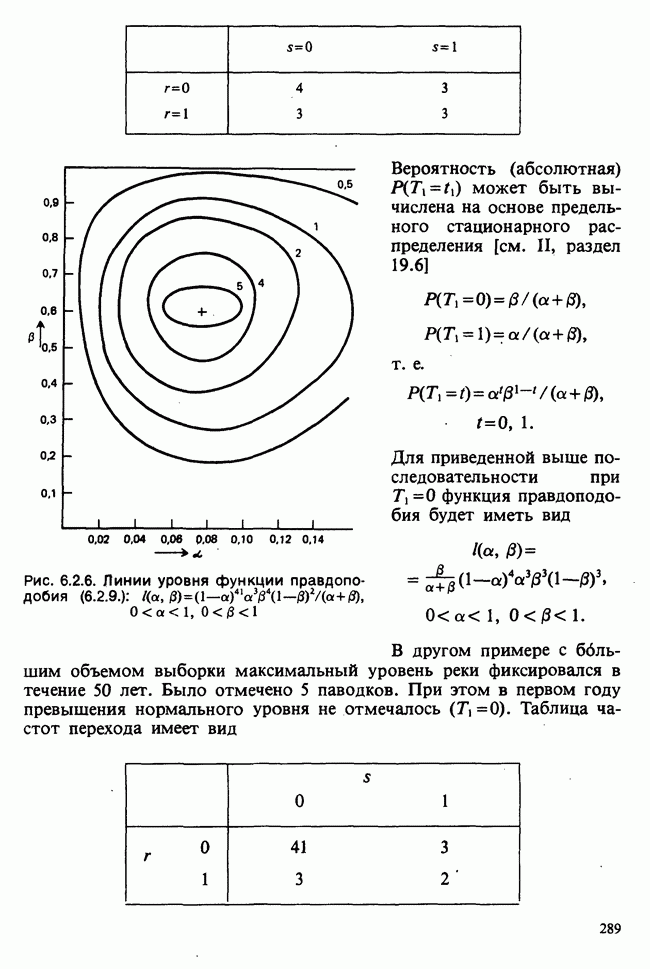
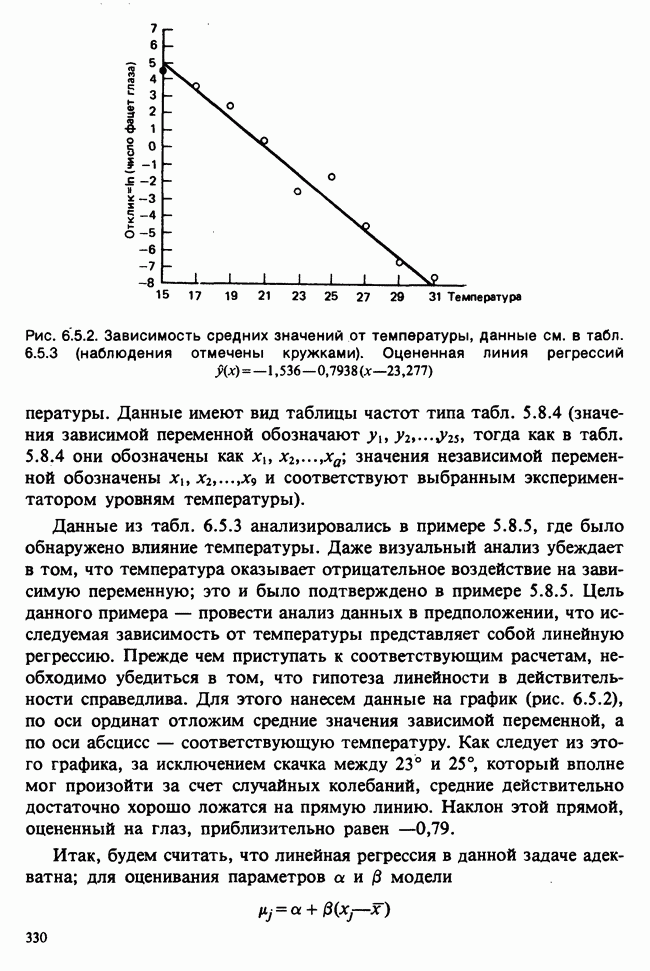
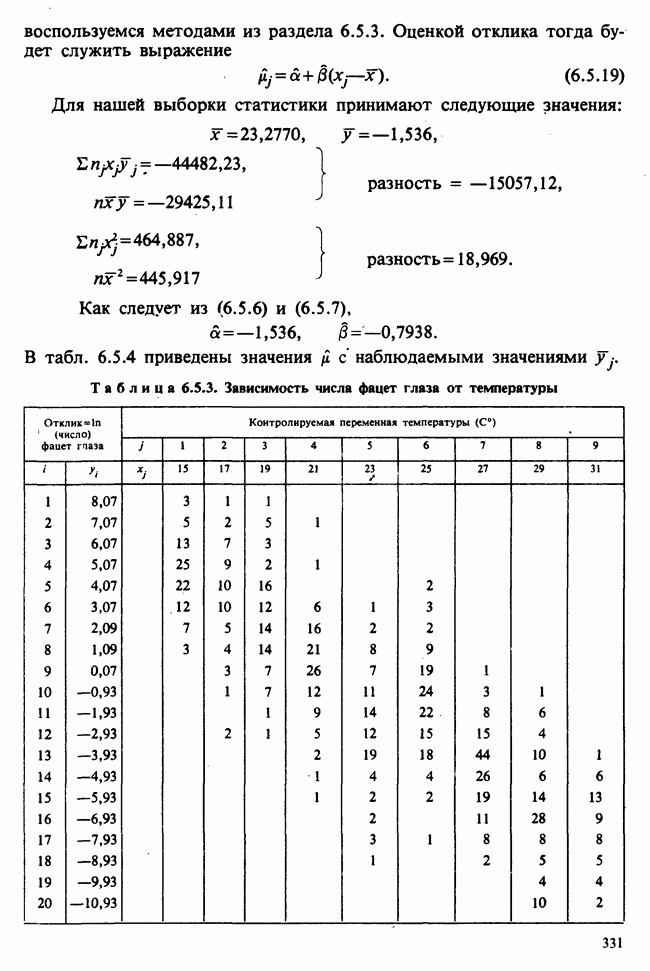
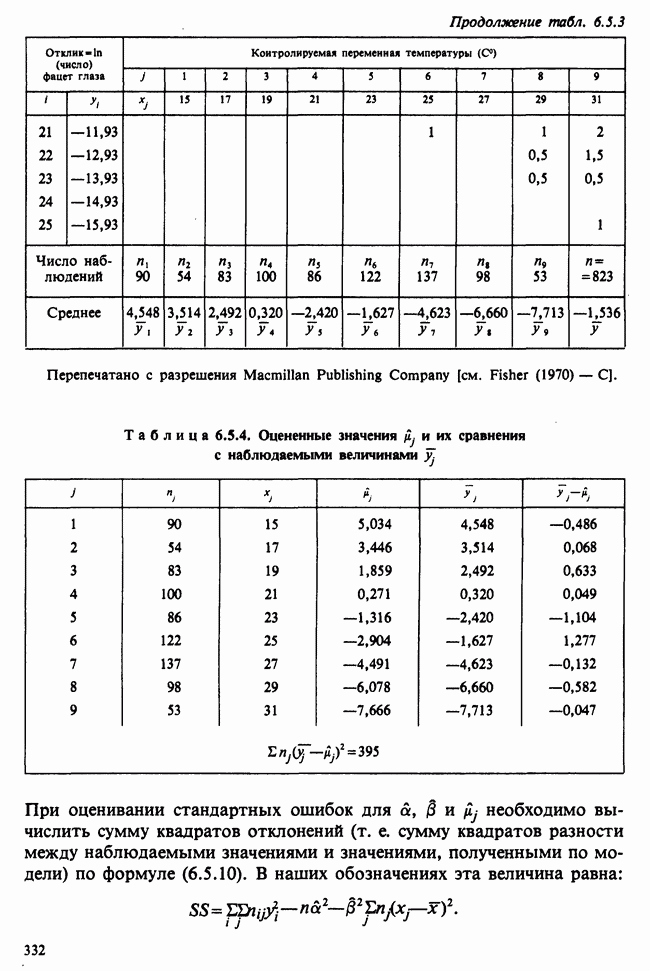
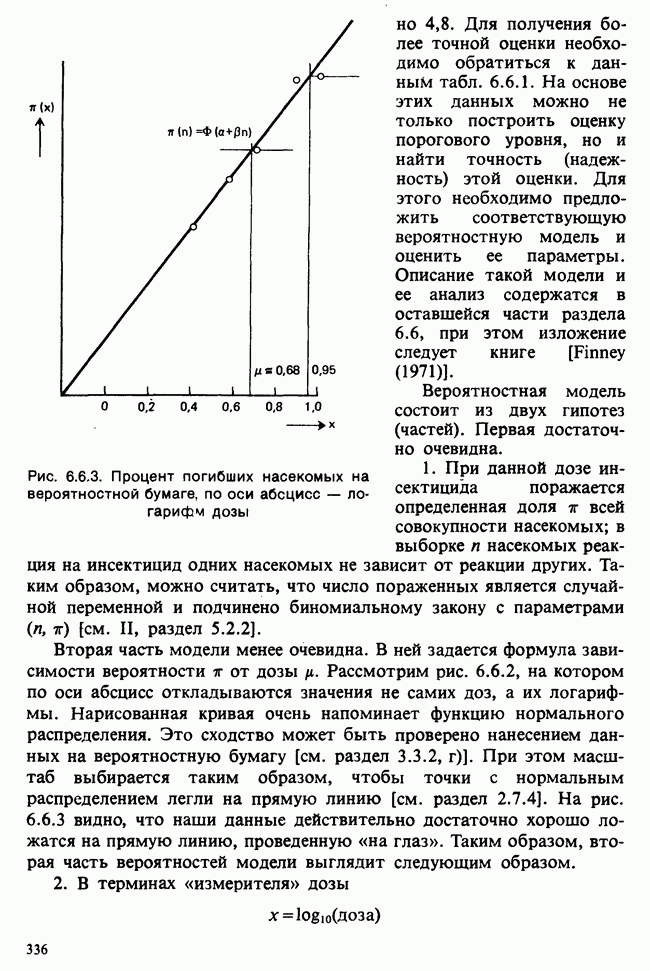
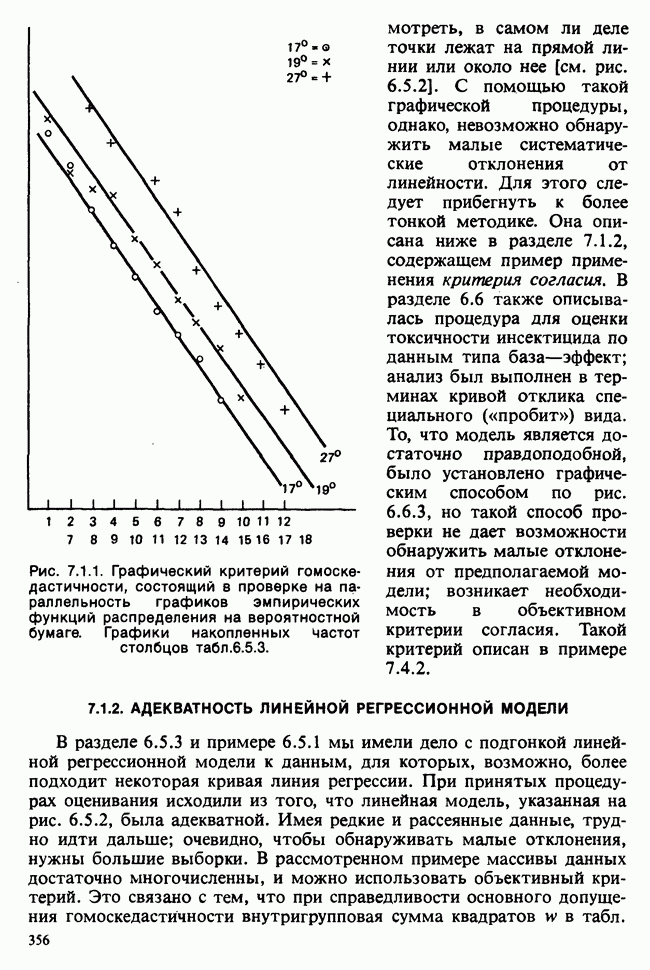
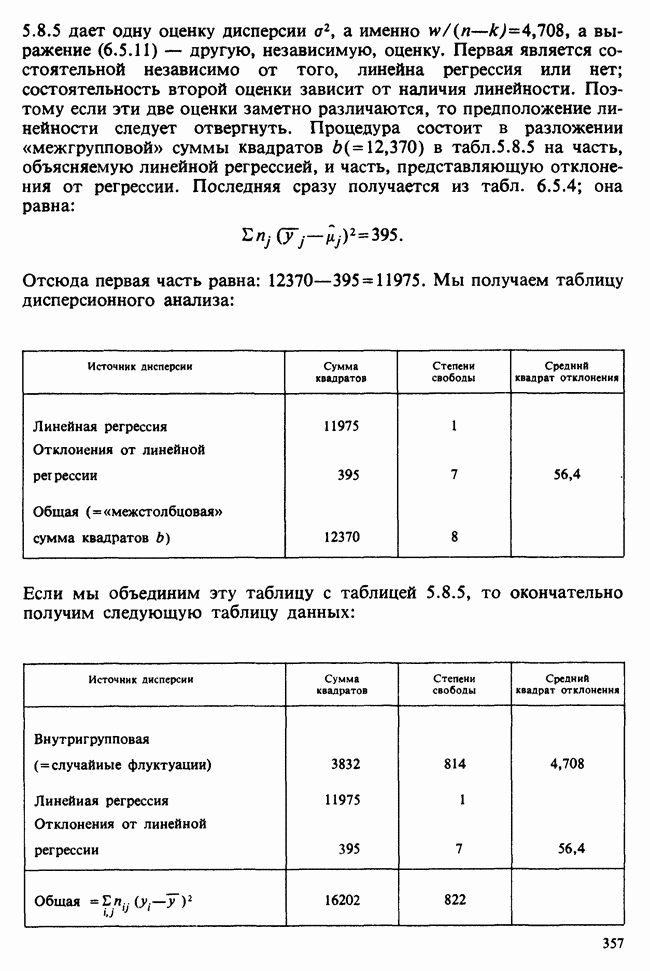
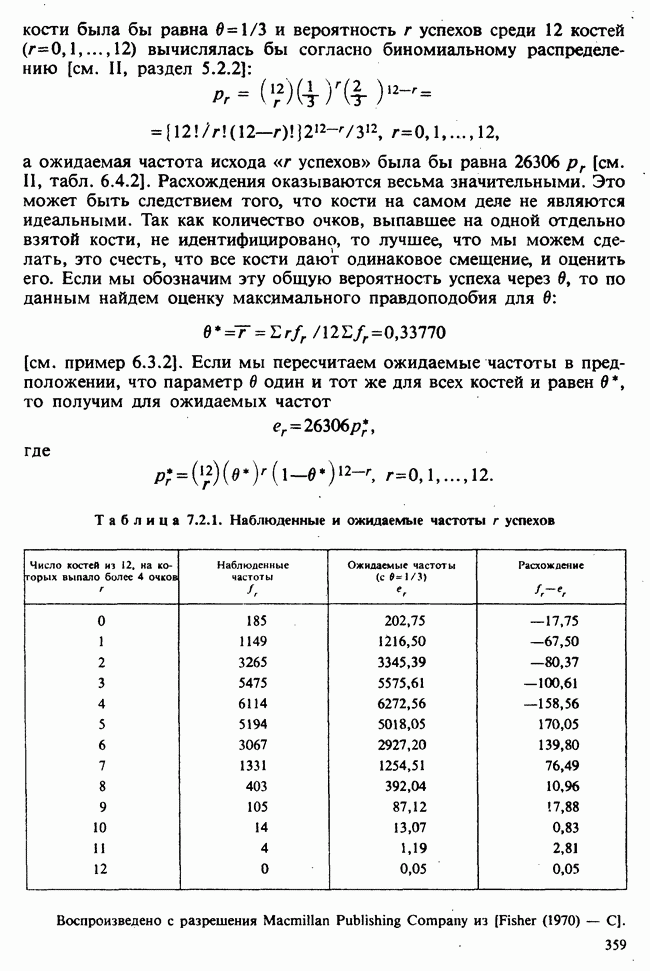
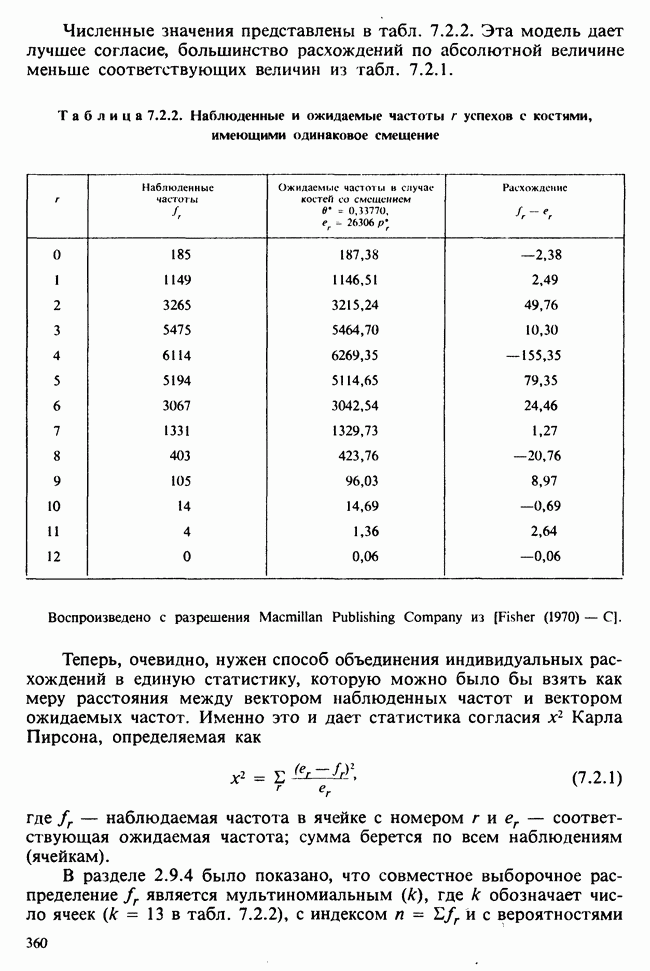
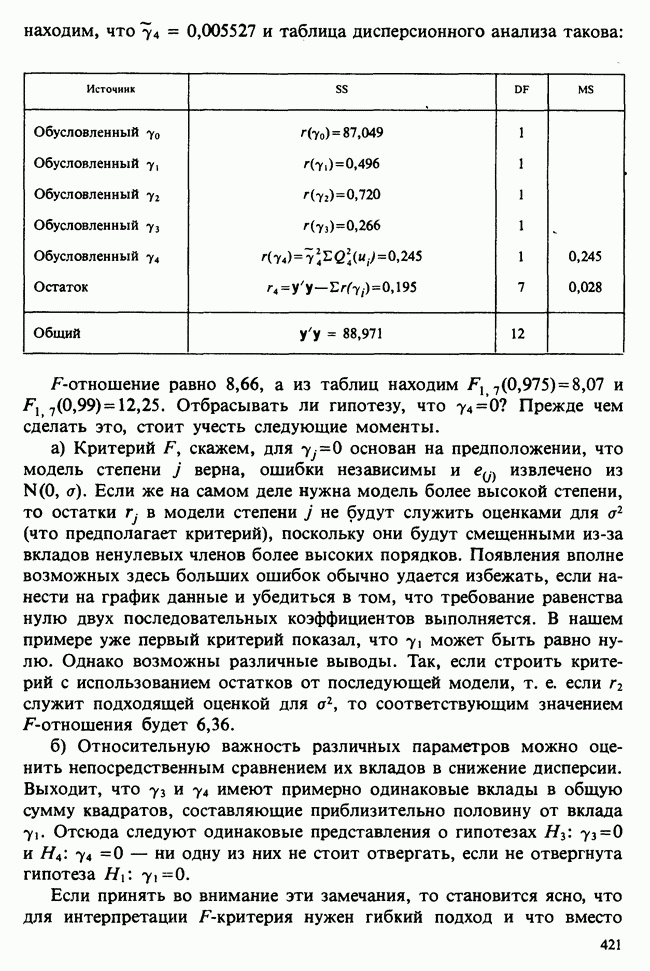
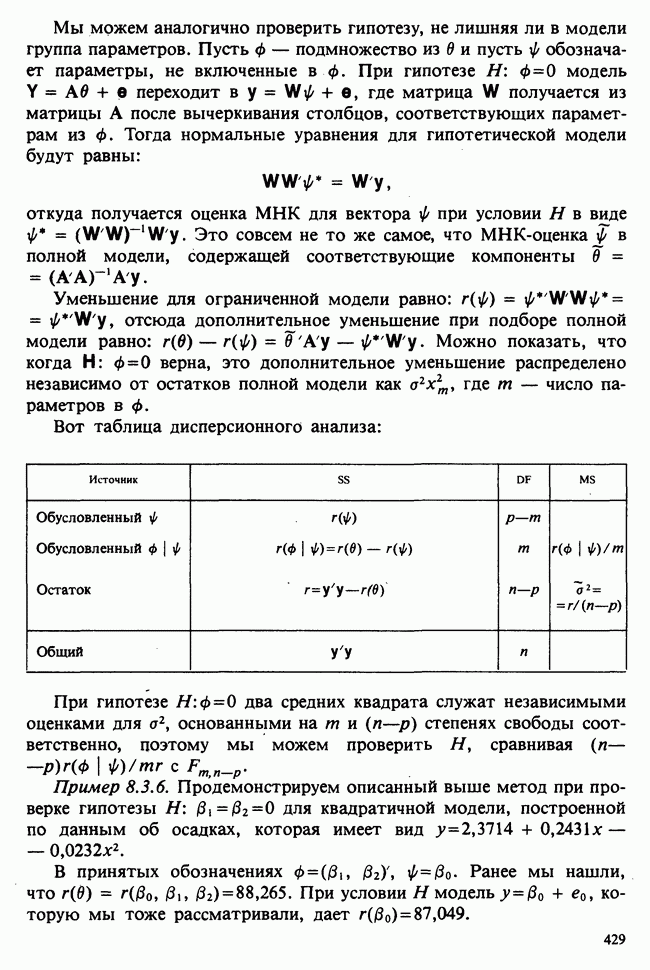
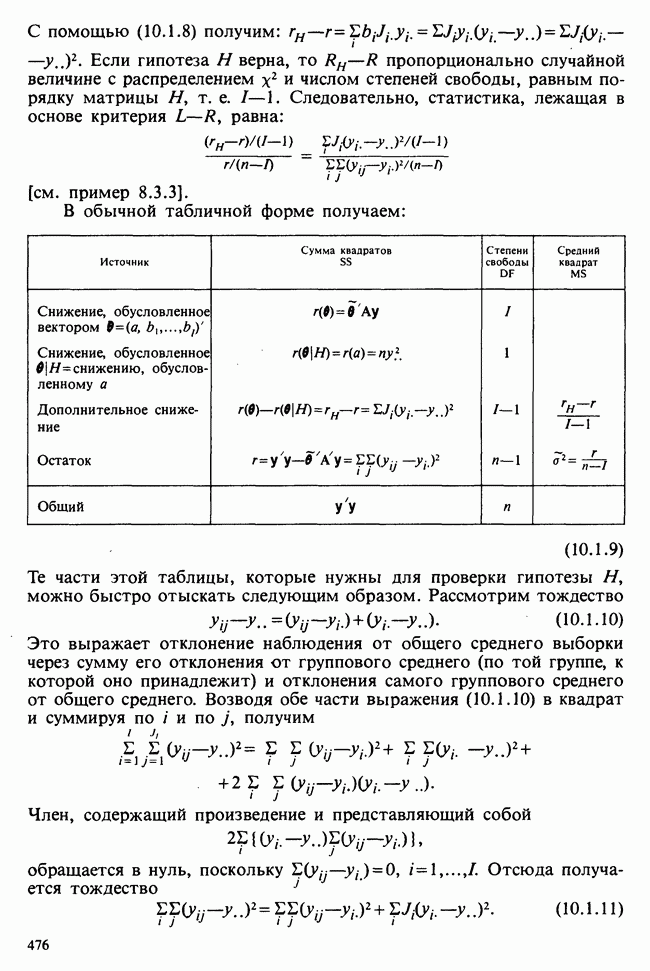
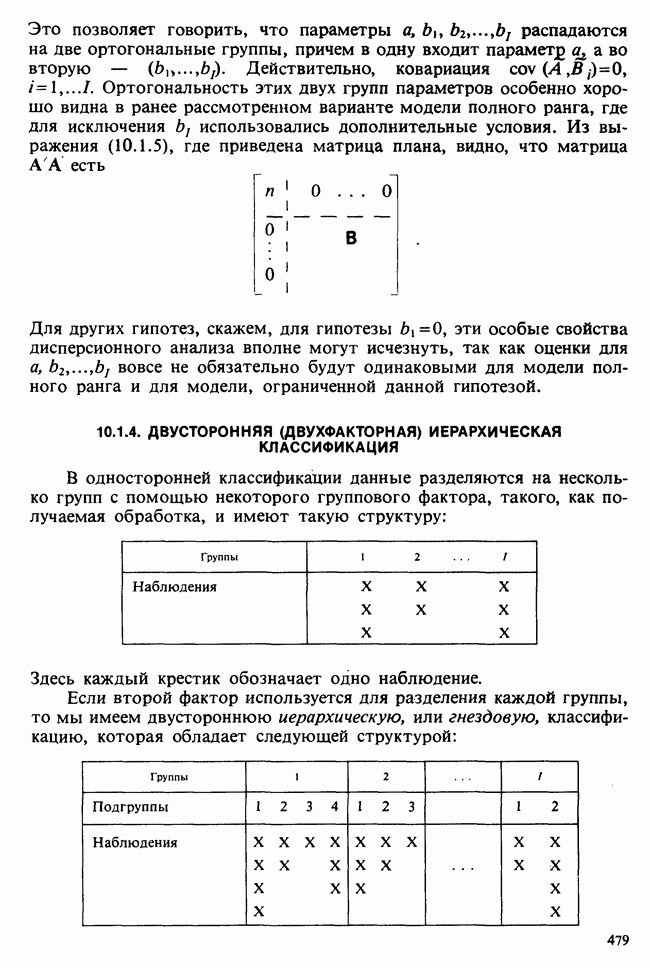
Глава 9. ПЛАНИРОВАНИЕ СРАВНИТЕЛЬНЫХ ЭКСПЕРИМЕНТОВ
9.1. ИСТОРИЧЕСКОЕ ВВЕДЕНИЕ
В естествознании XIX века постановки задач и сложность лабораторных методик обеспечивали снижение ошибки эксперимента до такого уровня, при котором надлежащим образом организованные повторения эксперимента позволяли воспроизводить исходные наблюдения с точностью, достаточной для любых практических целей. В биологии же ситуация была совершенно иной. Фрэнк Йейтс [см. Yates (1937)] писал: «Большинству биологических объектов свойственна вариабельность, и прелесть простоты и воспроизводимости физических или химических экспериментов из-за этого утрачивается. А значит, на передний план начинают выдвигаться статистические проблемы».
Статистические проблемы стали актуальны в связи с трудностями интерпретации невоспроизводимых результатов. Они привели к вопросу о том, как же надо расположить опыты, чтобы минимизировать влияния вариабельности, обусловленной конкретной задачей.
В агробиологии прежде, чем в других науках, началось систематическое изучение такого рода проблем. Особая роль принадлежит агробиологической станции в Ротамстеде (Англия), основанной в 1843 г. Здесь были начаты полевые опыты для оценки влияния удобрений на урожай и, для сравнения урожаев различных сортов зерновых. Занимавшиеся этим ученые должны были не только считаться с большой изменчивостью их материала — в плодородии делянок, качестве семян, количестве осадков и т. п., — но и с тем, что каждый из их опытов требовал для своего завершения приблизительно год.
В этих обстоятельствах не оставалось иного пути, как провести специальные исследования и создать продуманные планы экспериментов, обеспечивающих уменьшение негативных последствий внутренней вариабельности настолько, насколько это возможно, и позволяющих объективно оценивать точность окончательных выводов.
В качестве типичного можно было бы рассматривать эксперимент по сравнению урожаев (скажем, пшеницы), получаемых при
отсутствии удобрений («контроль») и при внесении в почву определенного количества азотных удобрений. Или более реалистично: по множественному сравнению контрольного урожая и урожаев при различных уровнях азотных, фосфорных и калийных удобрений (для каждого вида удобрений в отдельности).
К концу прошлого столетия были разработаны некоторые общие принципы планирования и накоплен большой объем данных. Следующий шаг вперед в интерпретации этих данных и изобретение таких планов, снижающих ошибку, которые можно было усовершенствовать в процессе работы, связаны с деятельностью в Ротамстеде Р. А. Фишера. Он сразу же начал изучать вопрос, как лучше всего приспособить принципы современной статистики к исследовательской работе в агробиологии, что привело его к параллельной и взаимосвязанной с этим разработке собственных принципов теории статистического вывода. Подобные проблемы и методы относились не только к агробиологии; они положили начало новой науке о планировании и анализе сравнительных экспериментов в таких областях, как агробиология, биохимия, материаловедение, инженерная химия и т. д., т. е. там, где высока вариабельность результатов эксперимента. Теперь это отдельная область профессиональной деятельности со своими законами, известная как планирование и анализ экспериментов.
Цель данной главы состоит в том, чтобы кратко описать основные принципы планирования эксперимента, включая рандомизацию, разбиение на блоки, балансировку, взаимодействия, смешивание. Это в основном качественные принципы. Анализ экспериментальных данных включает оценивание методом наименьших квадратов параметров подходящей (часто линейной) модели в соответствии с планом и проверку гипотез (вроде гипотезы относительно равенства некоторого параметра нулю или равенства двух параметров) стандартными методами дисперсионного анализа.
В терминах гл. 8 модели, используемые в большинстве планов, окажутся «вырожденными», т. е. вследствие симметрии они содержат параметров больше, чем модель в состоянии оценить, да еще компенсирующие условия, элиминирующие избыток.
Соответствующая этому случаю модификация теории метода наименьших квадратов приведена в гл. 10.
9.2. ЛЕДИ, ДЕГУСТИРУЮЩАЯ ЧАЙ
Фишер дал знаменитое толкование принципов планирования эксперимента на примере (вероятно, придуманном) спланированного эксперимента для испытания способности некой леди различать, что было
раньше налито в чашку — чай или молоко, после того, как она попробует содержимое чашки с напитком неизвестного ей происхождения. Построенный Фишером план обладал следующими свойствами [см. Fisher (1950)]:
повторяемость (дублирование): это обычно необходимый компонент. Ни один экспериментатор не должен делать каких бы то ни было выводов о верной или ошибочной идентификации порядка смешивания молока и чая по одной единственной чашке;
сбалансированность: наша леди должна попробовать равное число чашек с молоком, добавленным в чай, и с чаем, долитым в молоко, чтобы в ее суждении не возникло смещения;
рандомизация: этот существенный момент в планировании относится к тому, в каком порядке следует представлять чашки на дегустацию. Рандомизация их порядка есть на самом деле необходимое условие для того, чтобы стало возможным применение к анализу результатов статистических принципов;
чувствительность: Р. Фишер отмечал, что пока число чашек не превысит некоторый минимум, никаких разумных выводов сделать нельзя, т. е. эксперимент может оказаться совершенно нечувствительным, если выборка слишком мала. Причем после того, как этот минимум пройден, чувствительность эксперимента растет тем больше, чем больше (в пределах ограничений) число повторений;
однородность: изложенные выше соображения нельзя распространять слишком далеко. Когда число чашек превысит некоторый предел, утверждаемое леди различие в букете, обусловленное тем, что раньше было налито молоко или чай, может маскироваться разностью температур, эффектом настаивания, притуплением вкусовых рецепторов леди и т. п. А это нарушает однородность, что может затруднить анализ или даже сделать его невозможным.
Анализ проводится так. Сначала ясно определяется цель эксперимента, которая заключается в установлении того, способна ли наша леди различать ситуации. Это формулируется в виде нуль-гипотезы, что она на самом деле совершенно не способна различать порядок введения ингредиентов.
Допустим, что ей в случайном порядке предложены  чашек чая:
чашек чая:  — молоко-чай и
— молоко-чай и  — чай-молоко. Если верна нуль-гипотеза, то вероятность того, что она способна правильно идентифицировать
— чай-молоко. Если верна нуль-гипотеза, то вероятность того, что она способна правильно идентифицировать  раз, равна:
раз, равна:

Так, например,

Таким образом, если  (т. е. по две чашки каждого вида), то один шанс из семи определить все совершенно правильно, даже если на самом деле леди ничего не понимает. Это довольно большая вероятность, так что даже абсолютно правильная идентификация всех чашек не может служить аргументом против нуль-гипотезы. (Это как раз случай нулевой чувствительности, о котором говорилось выше.) При
(т. е. по две чашки каждого вида), то один шанс из семи определить все совершенно правильно, даже если на самом деле леди ничего не понимает. Это довольно большая вероятность, так что даже абсолютно правильная идентификация всех чашек не может служить аргументом против нуль-гипотезы. (Это как раз случай нулевой чувствительности, о котором говорилось выше.) При  правильное определение всех четырех чашек, начинавшихся с чая (а значит, и всех четырех чашек, начинавшихся с молока), было бы невероятно, если бы леди не умела их различать. Такое событие имеет всего один шанс из семидесяти.
правильное определение всех четырех чашек, начинавшихся с чая (а значит, и всех четырех чашек, начинавшихся с молока), было бы невероятно, если бы леди не умела их различать. Такое событие имеет всего один шанс из семидесяти.
Однако вполне можно себе представить, что она допустила случайную ошибку. Требовать, чтобы она могла точно классифицировать каждую чашку, было бы слишком строго. Тогда для  с правильным определением трех или более чашек чая из четырех связана вероятность 17/70, близкая к одной четвертой. А это слишком большое значение, чтобы дискредитировать нуль-гипотезу. Следовательно, если мы хотим отвергнуть ее претензии даже в том случае, когда допустима одна ошибка, чашек каждого вида потребуется больше, чем 4. Так, например, при
с правильным определением трех или более чашек чая из четырех связана вероятность 17/70, близкая к одной четвертой. А это слишком большое значение, чтобы дискредитировать нуль-гипотезу. Следовательно, если мы хотим отвергнуть ее претензии даже в том случае, когда допустима одна ошибка, чашек каждого вида потребуется больше, чем 4. Так, например, при  уровень значимости (см. раздел 5.2.2) для результата, когда из
уровень значимости (см. раздел 5.2.2) для результата, когда из  выборов правильно сделаны
выборов правильно сделаны  составит 0,015, и большинство специалистов, по-видимому, его сочтут достаточно малым для дискредитации нуль-гипотезы (см. табл. 5.2.1), а значит, такое событие будет рассматриваться как убедительное подтверждение претензий нашей леди.
составит 0,015, и большинство специалистов, по-видимому, его сочтут достаточно малым для дискредитации нуль-гипотезы (см. табл. 5.2.1), а значит, такое событие будет рассматриваться как убедительное подтверждение претензий нашей леди.