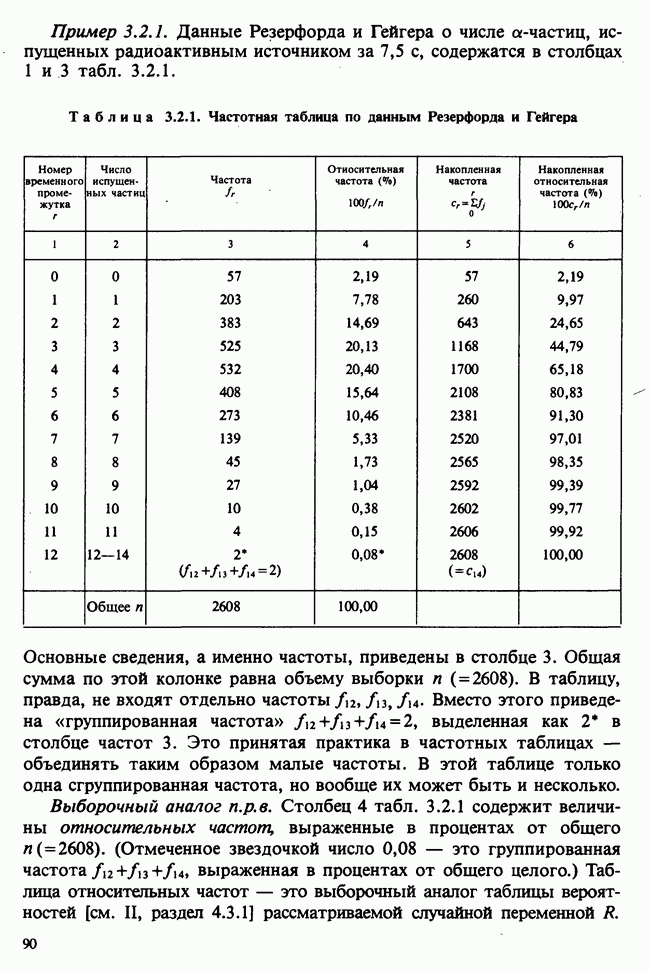
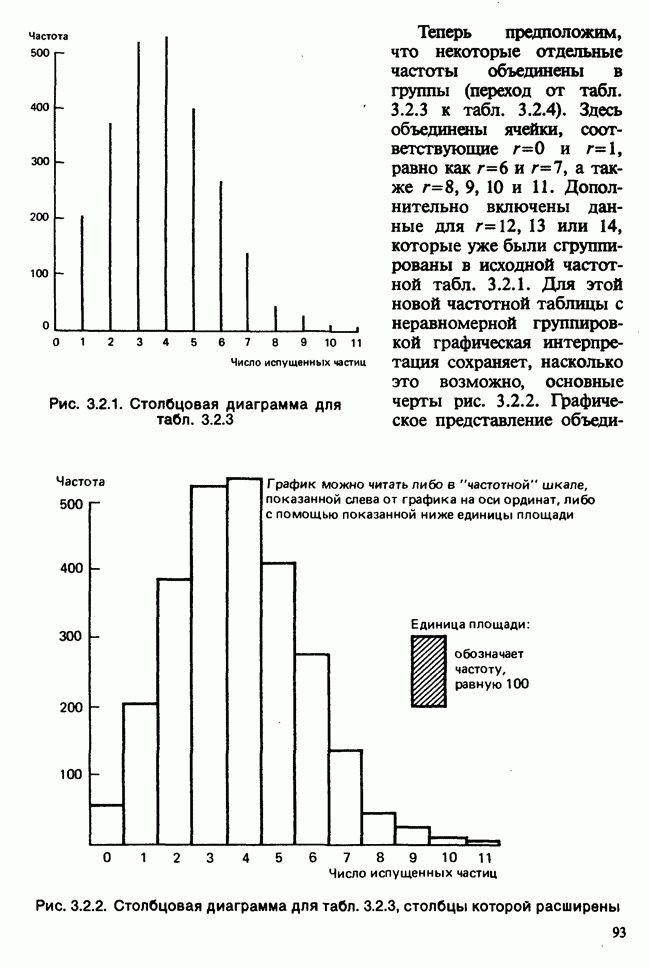
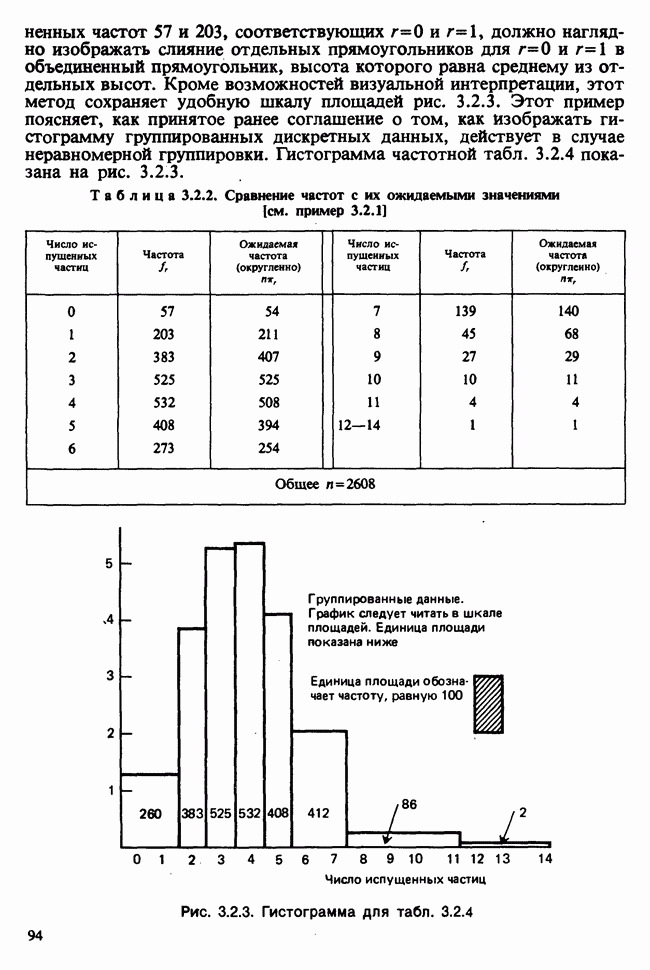
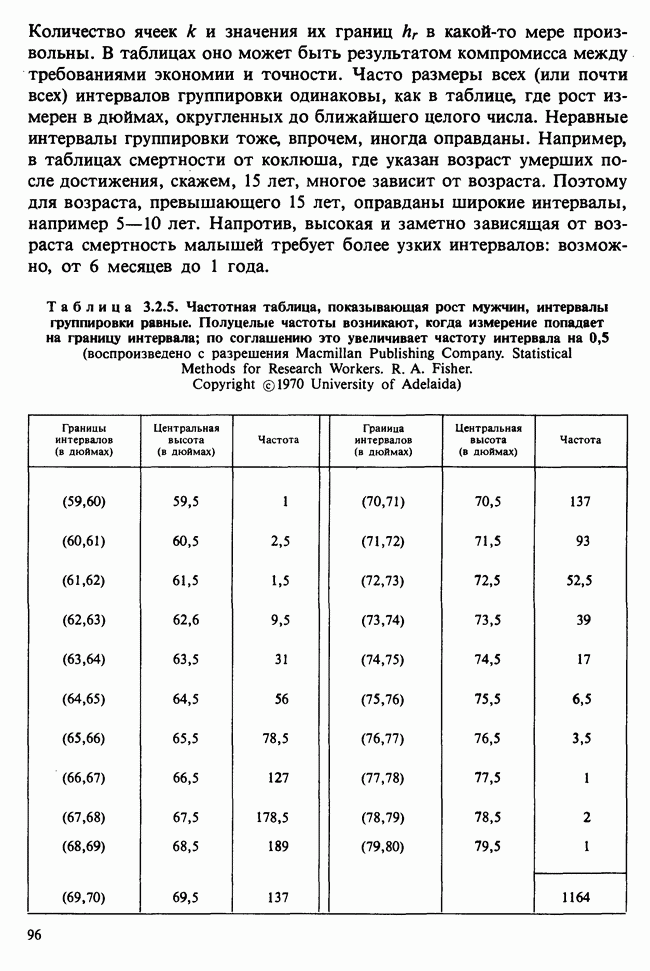
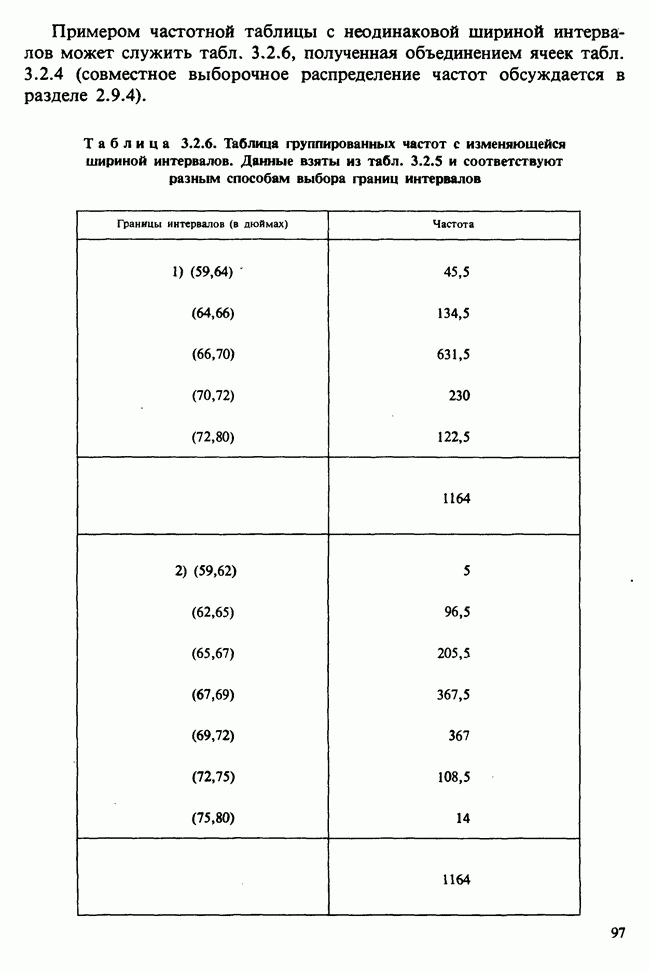
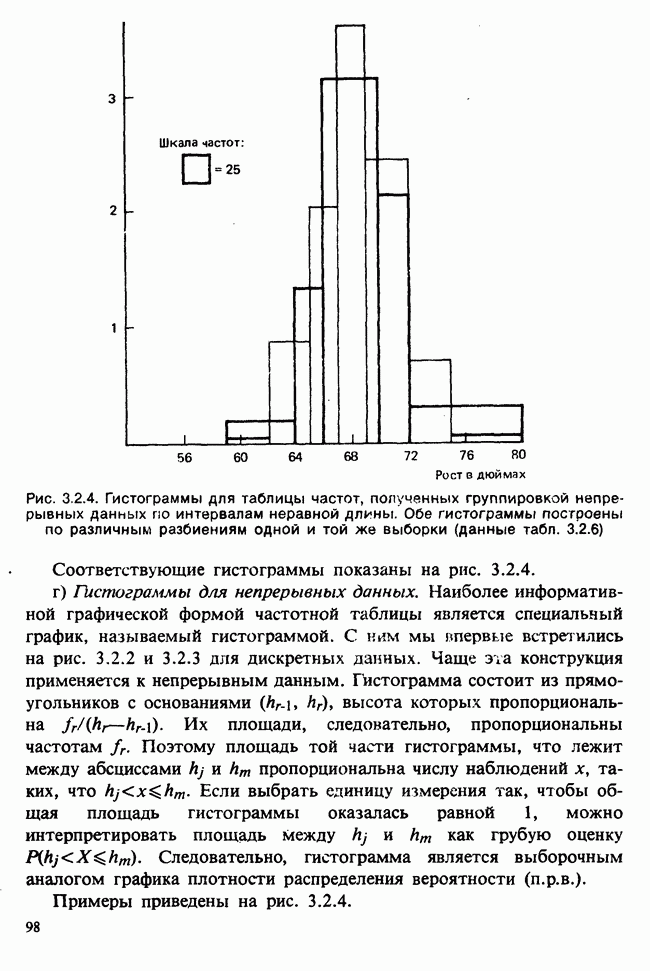
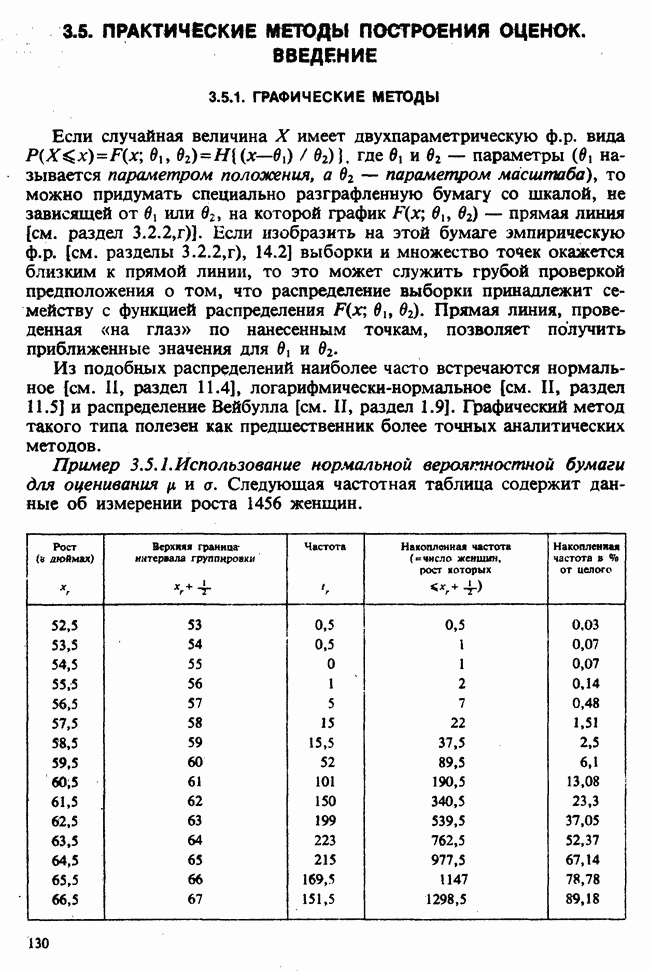
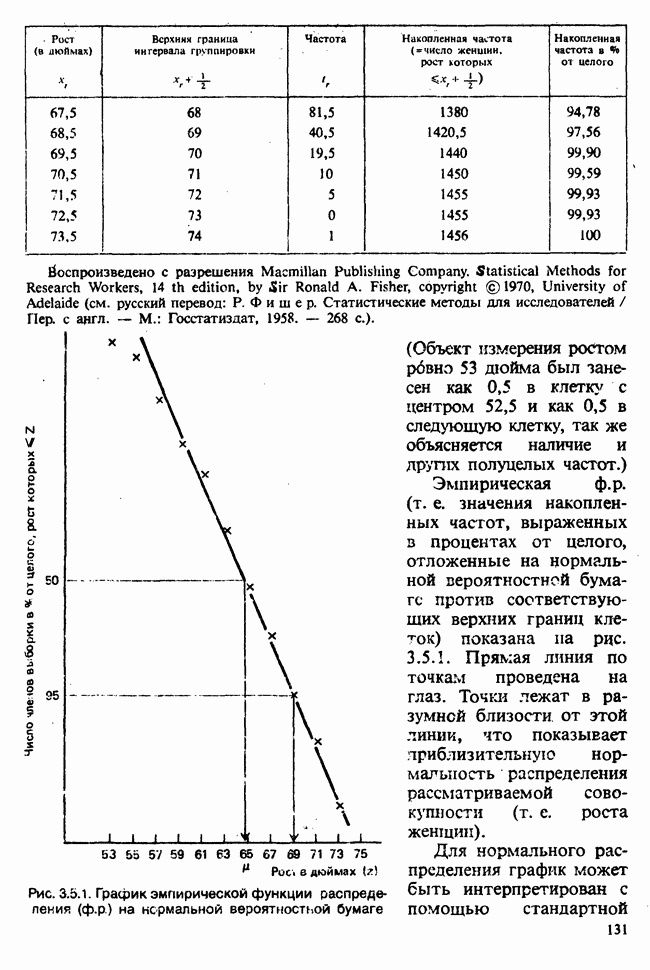
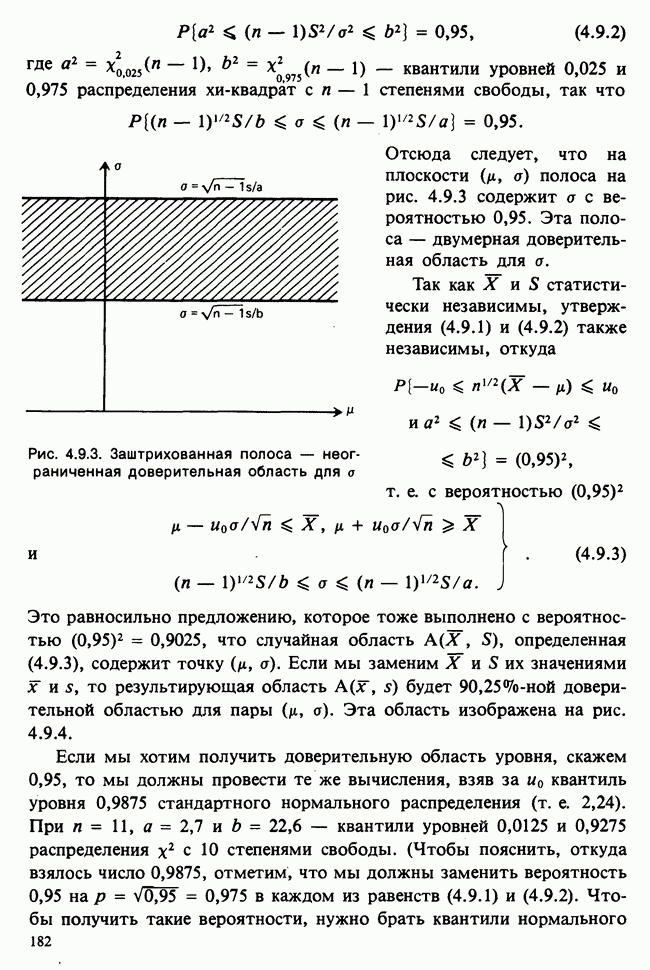
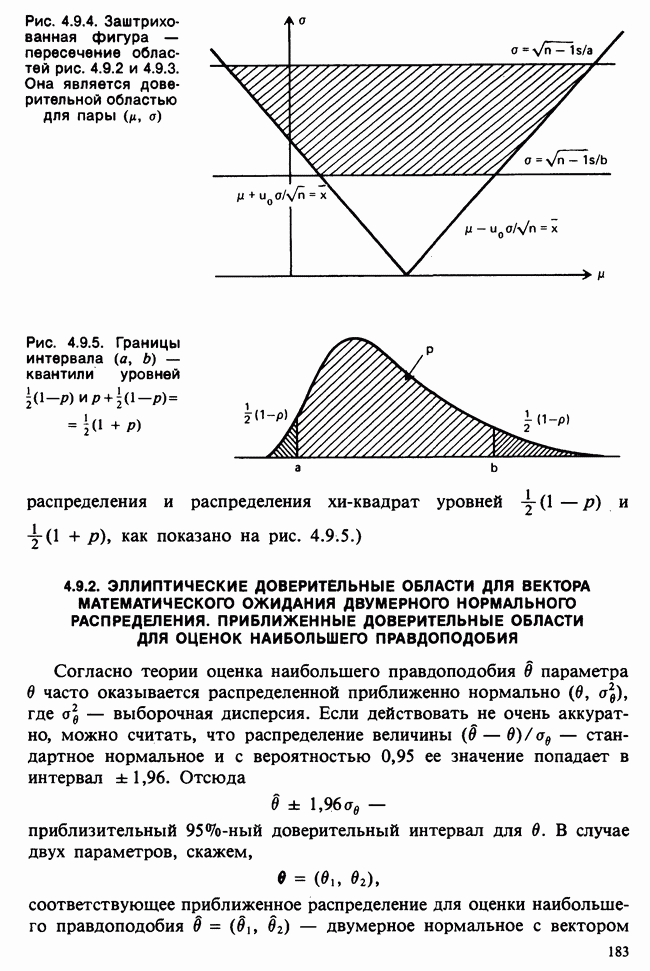
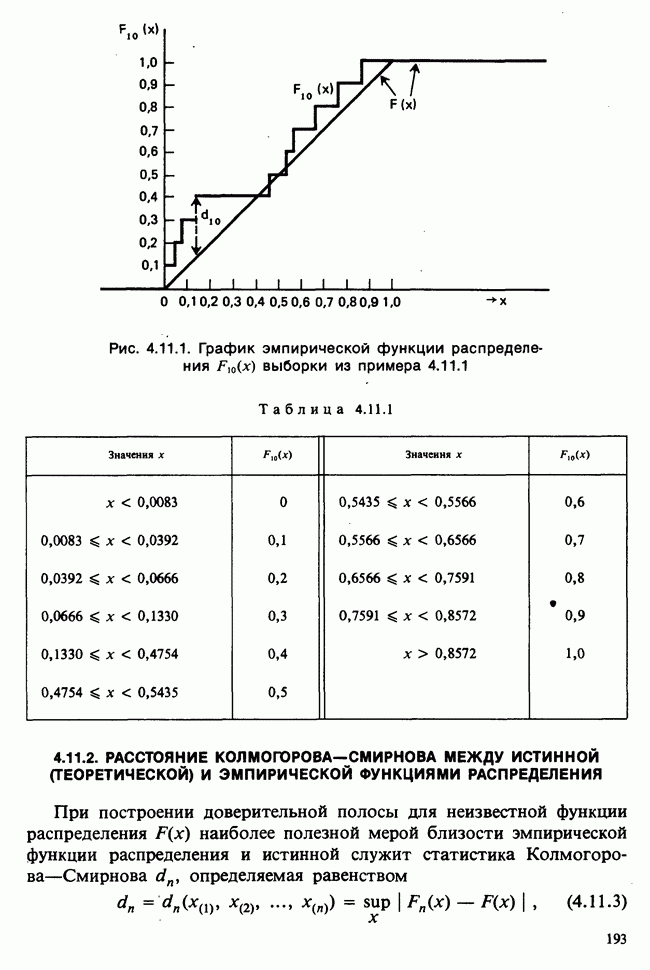
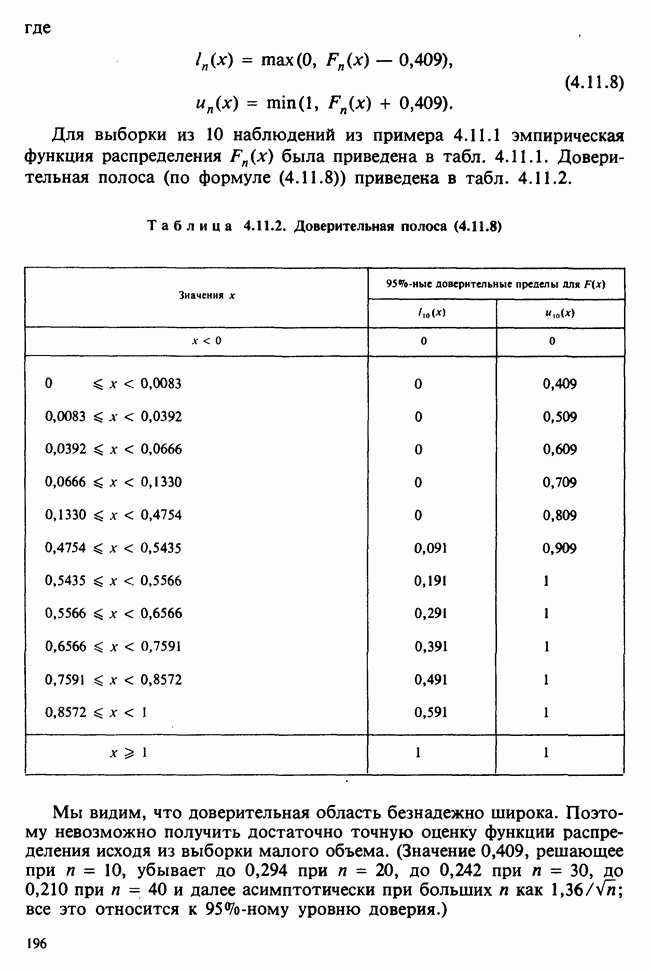
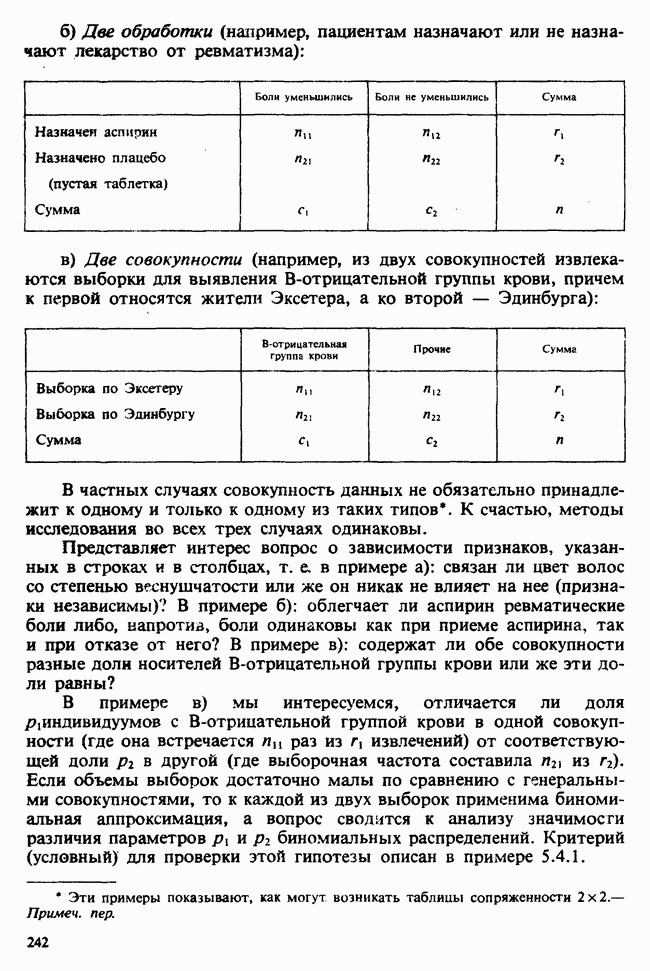
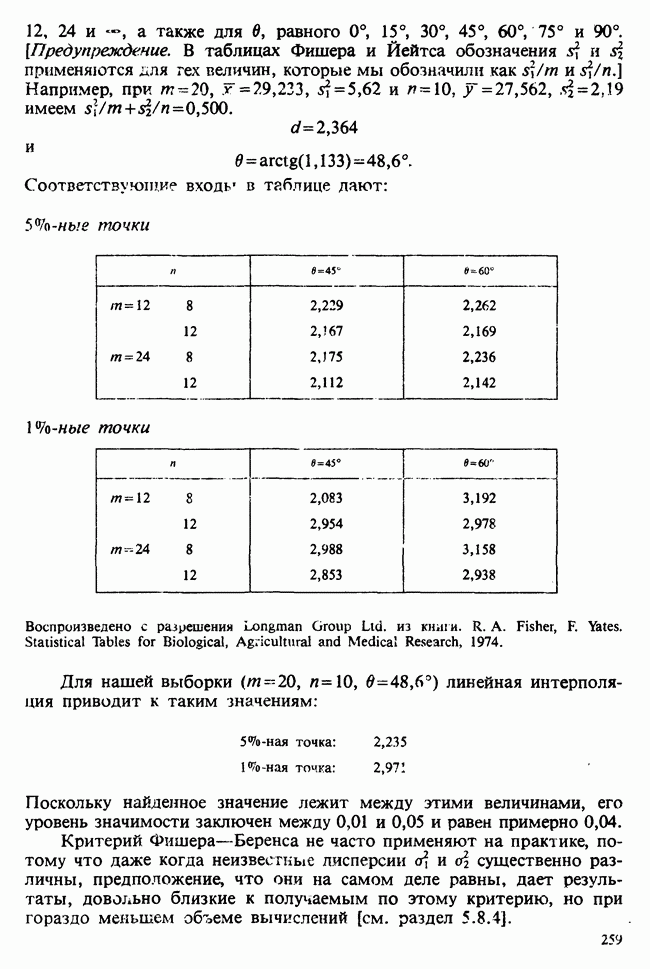
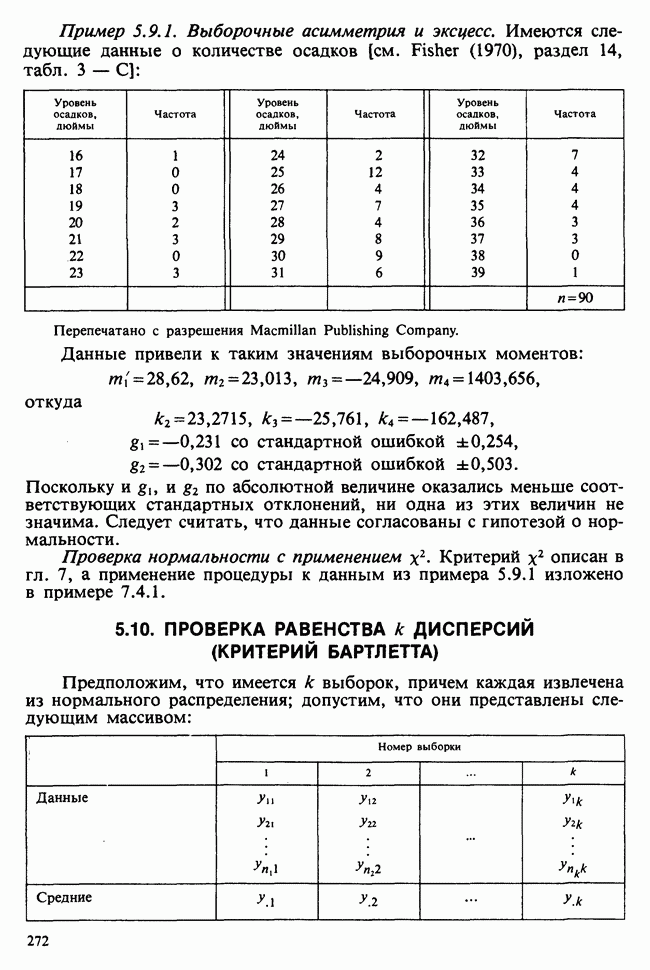
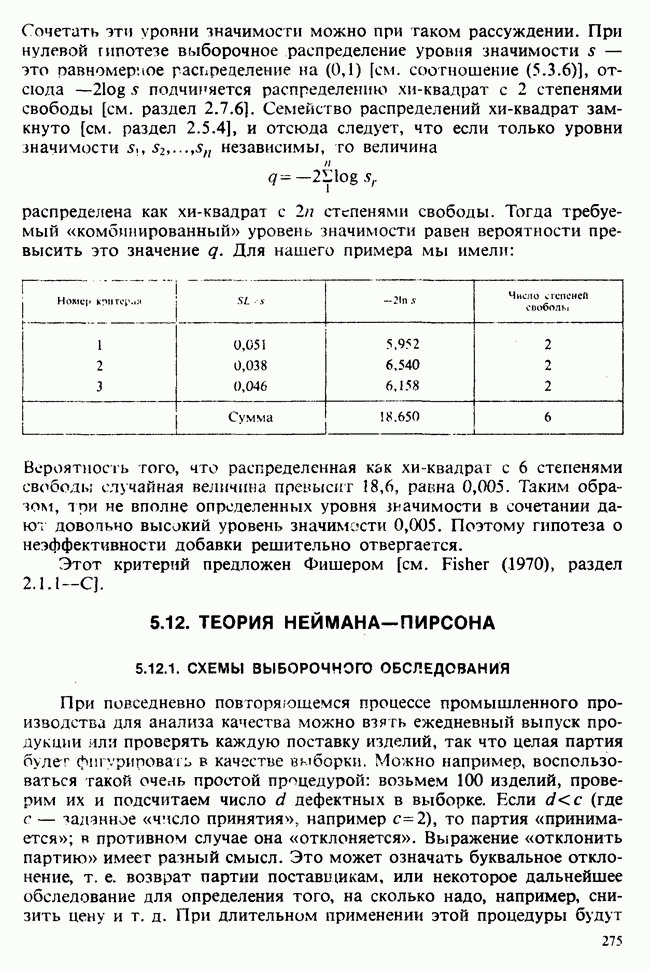
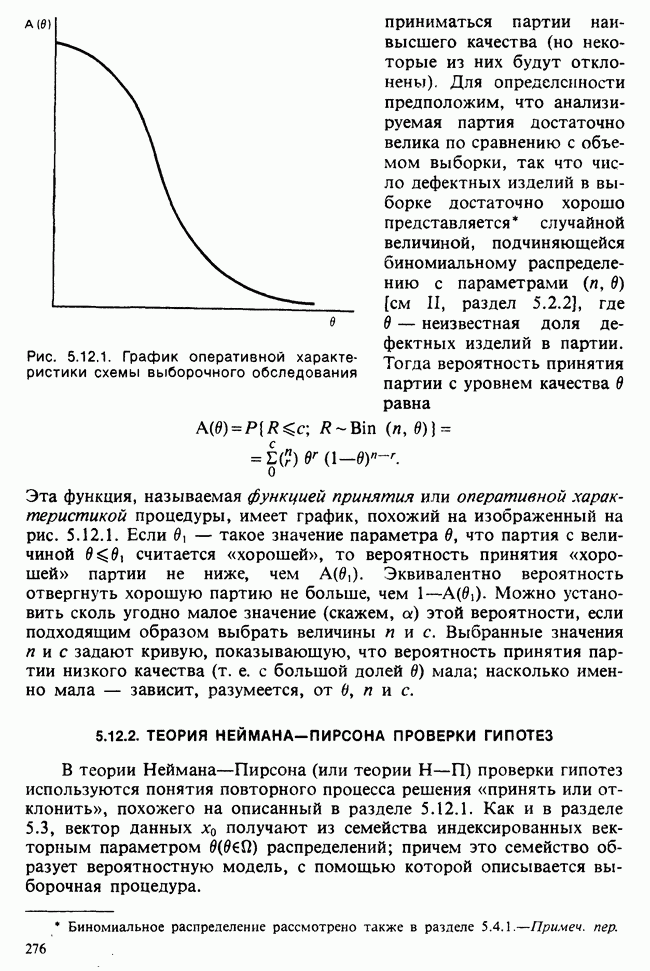
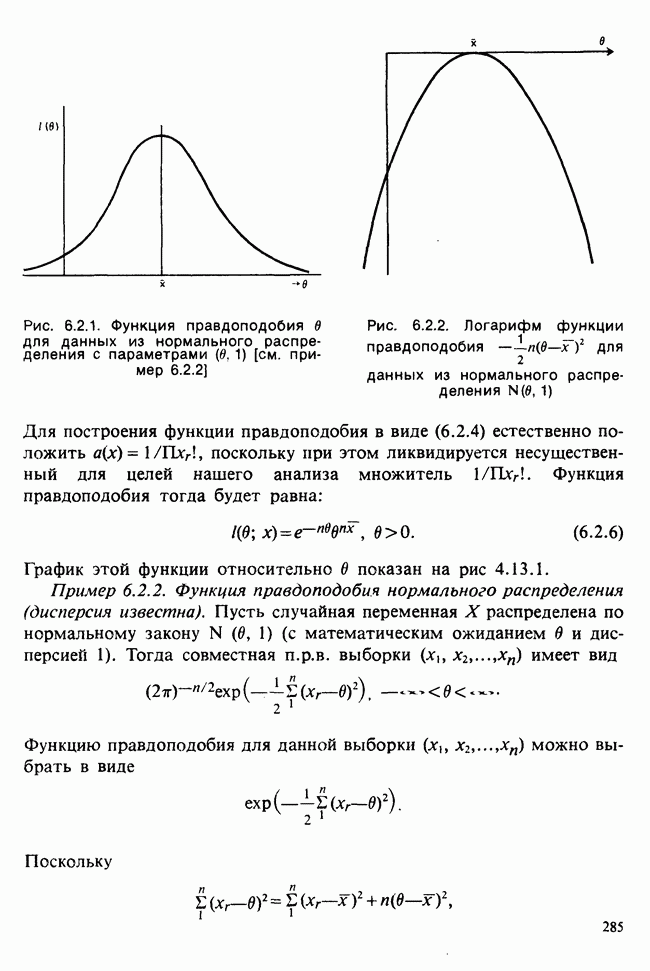
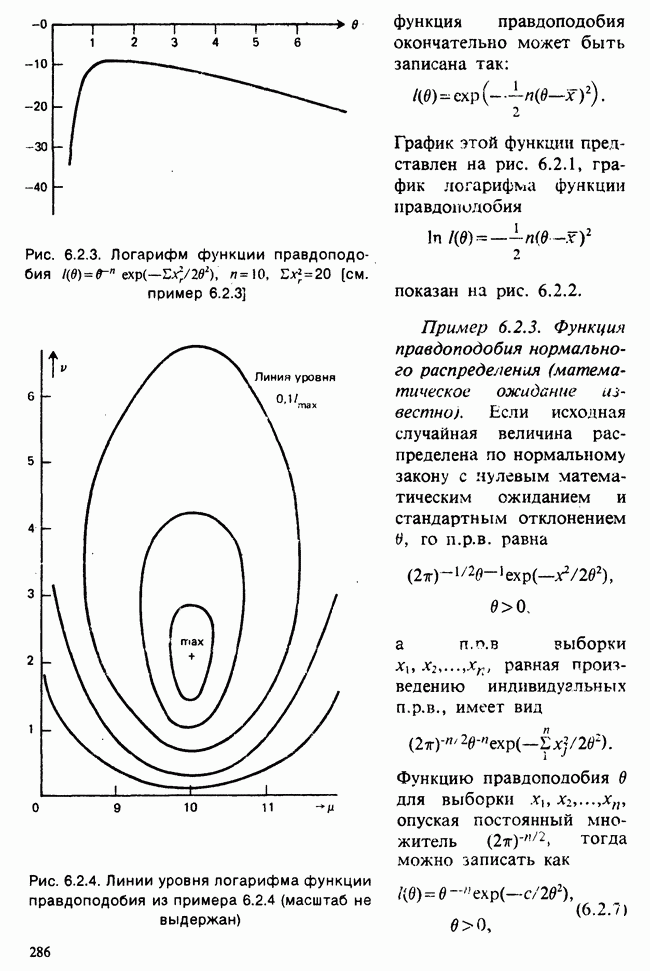
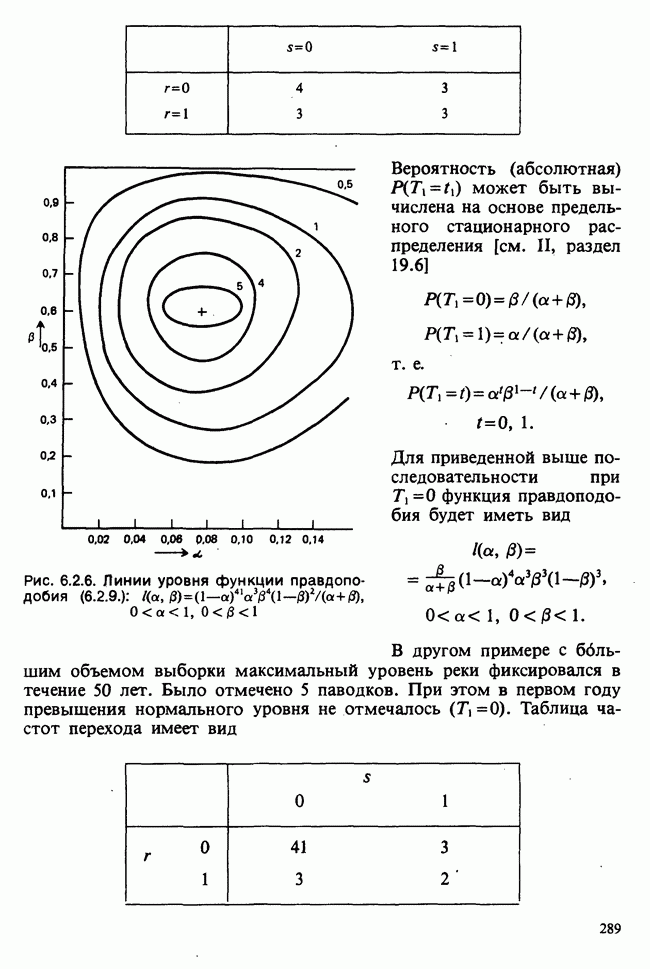
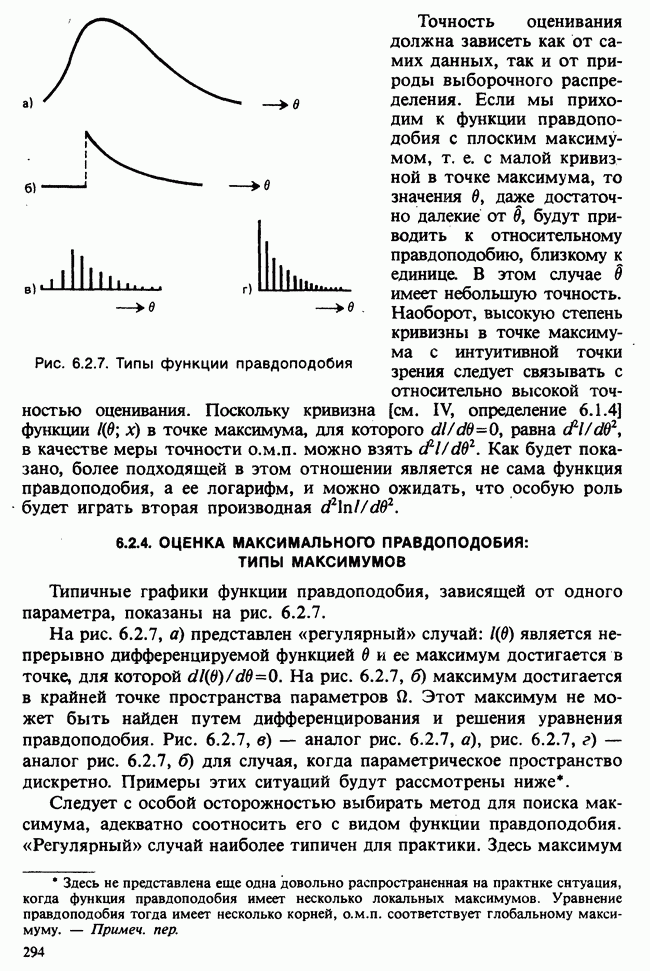
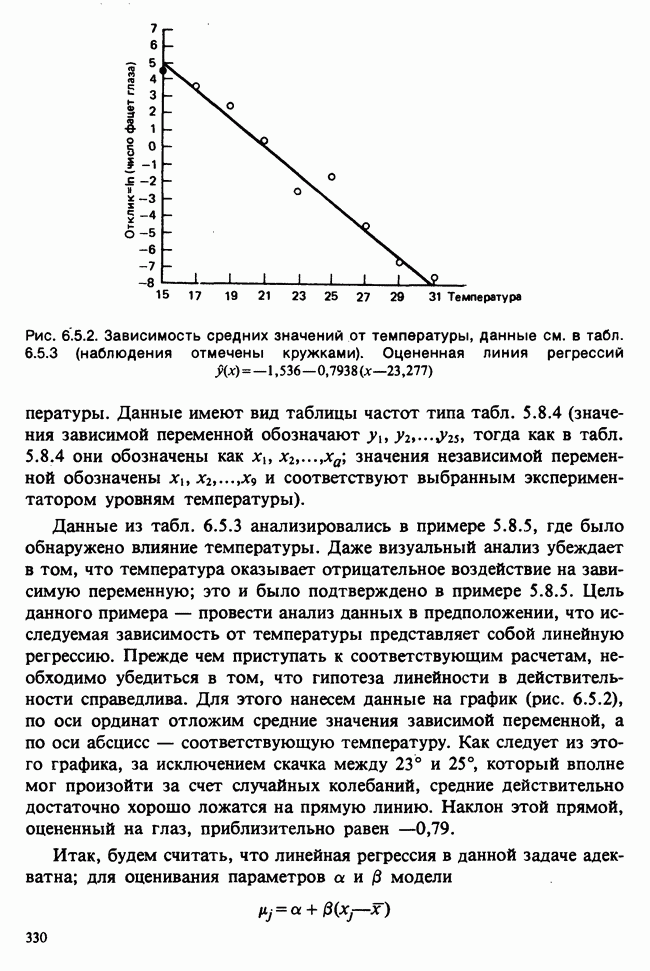
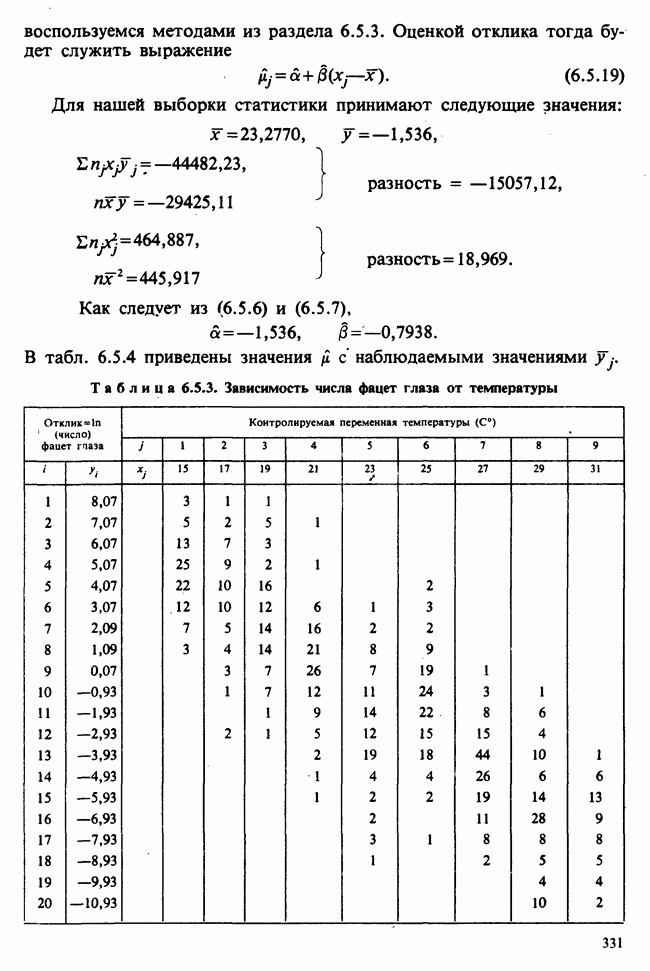
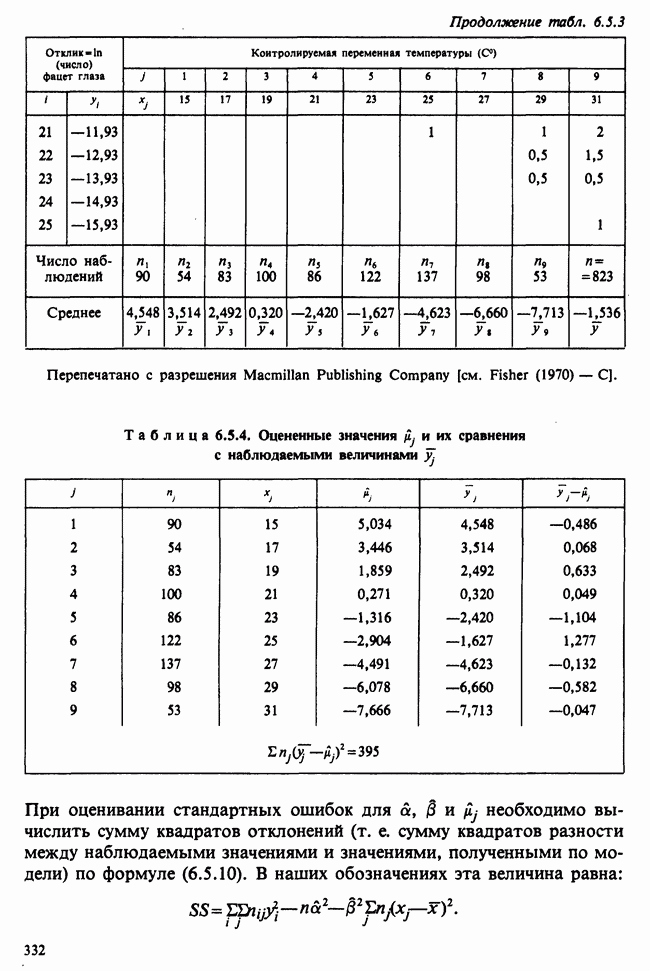
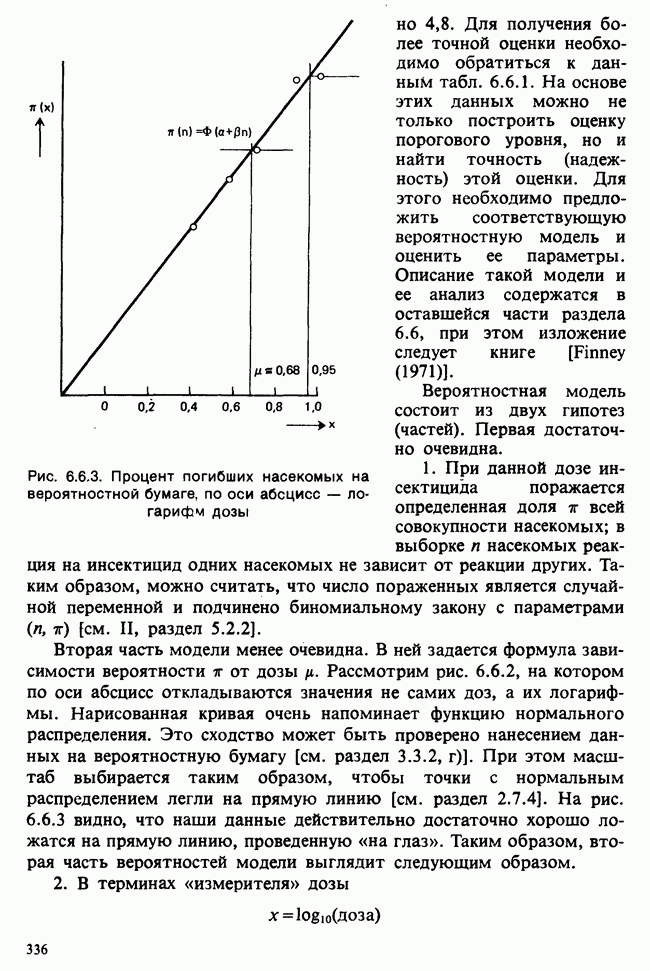
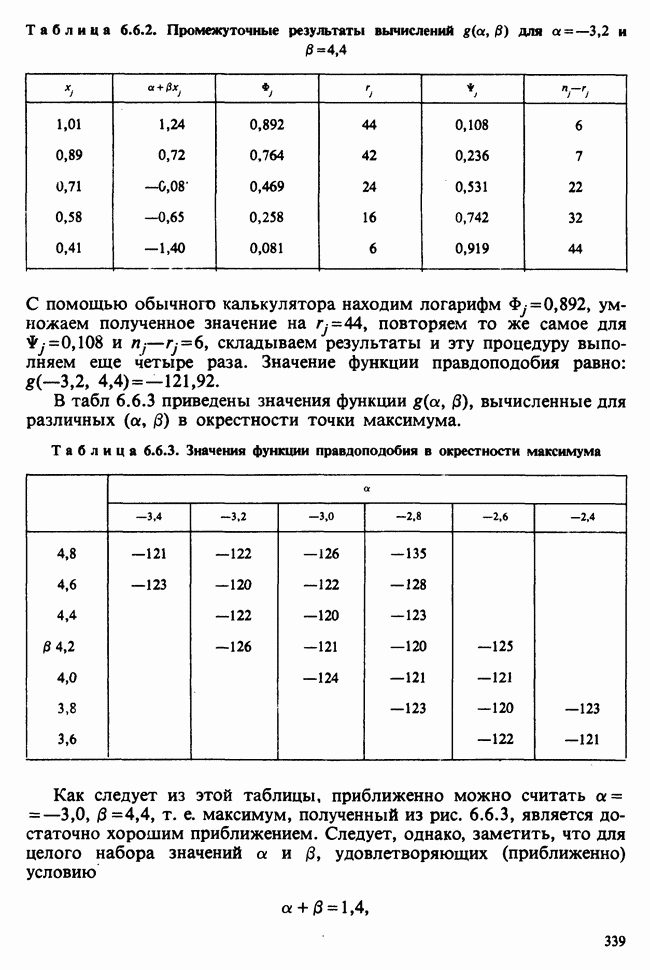
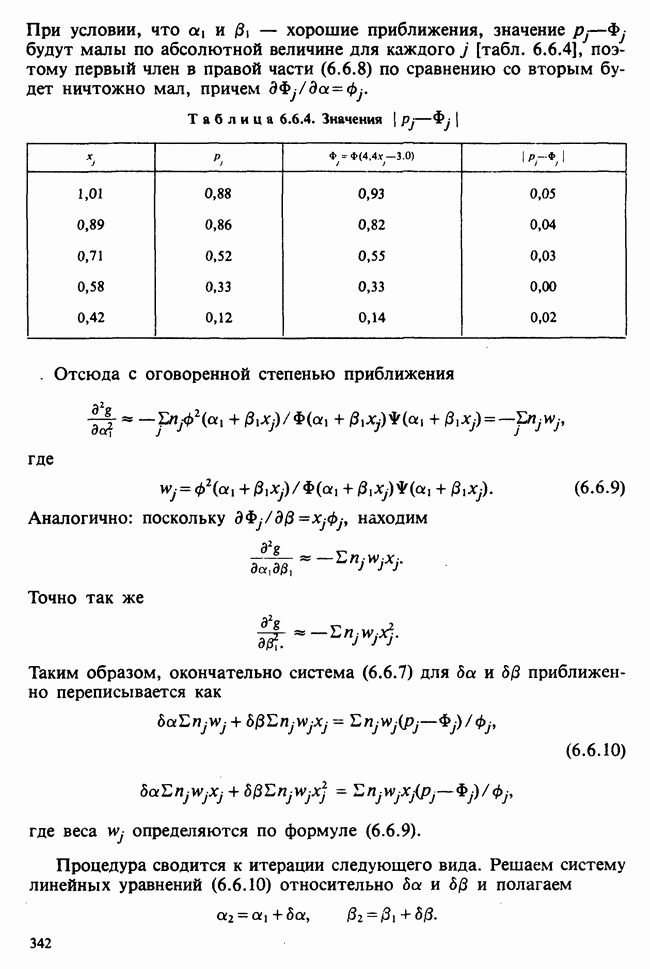
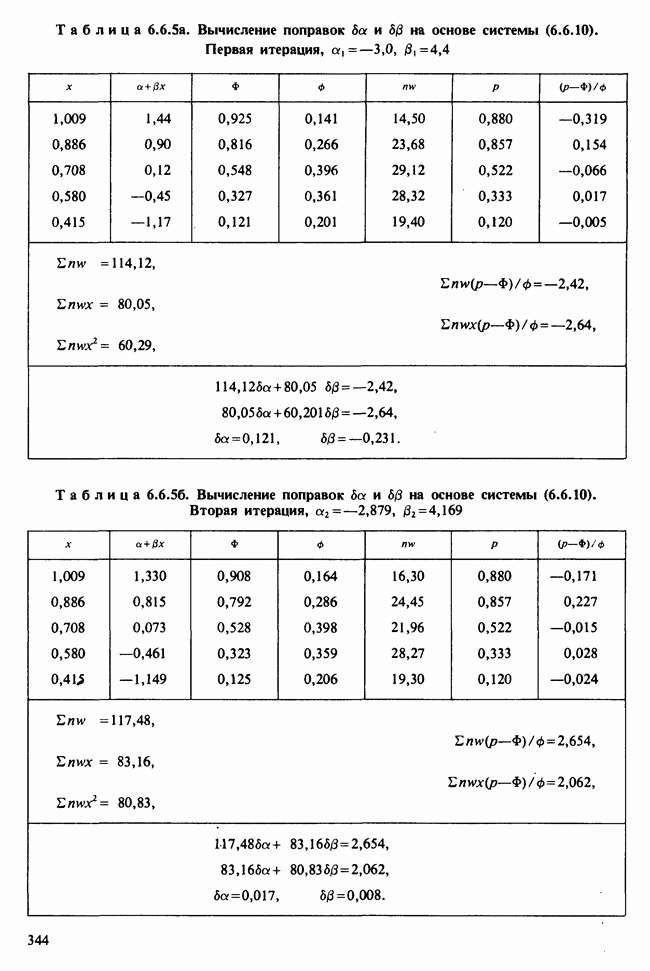
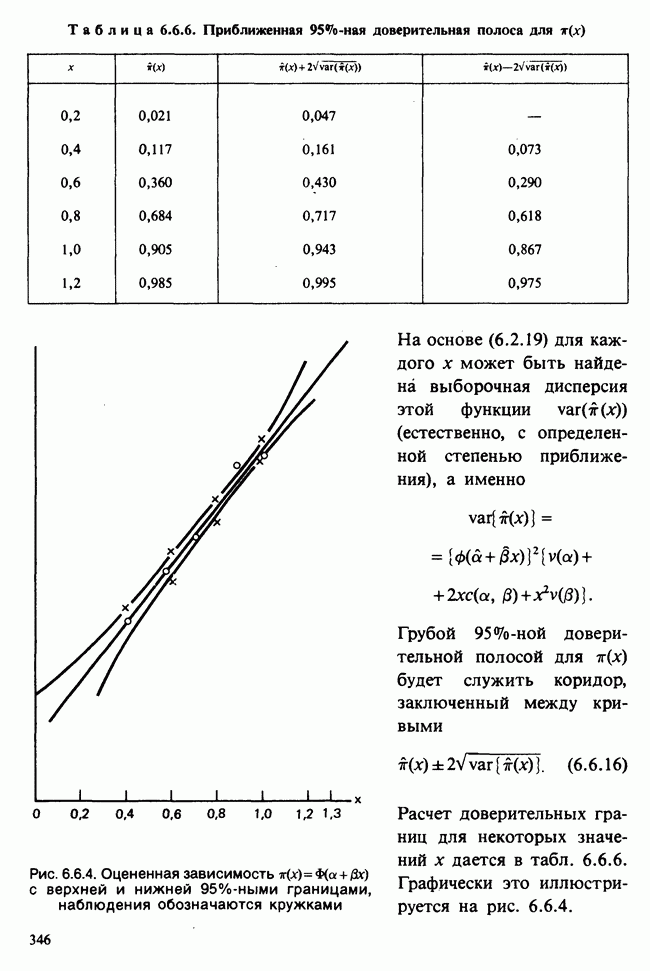
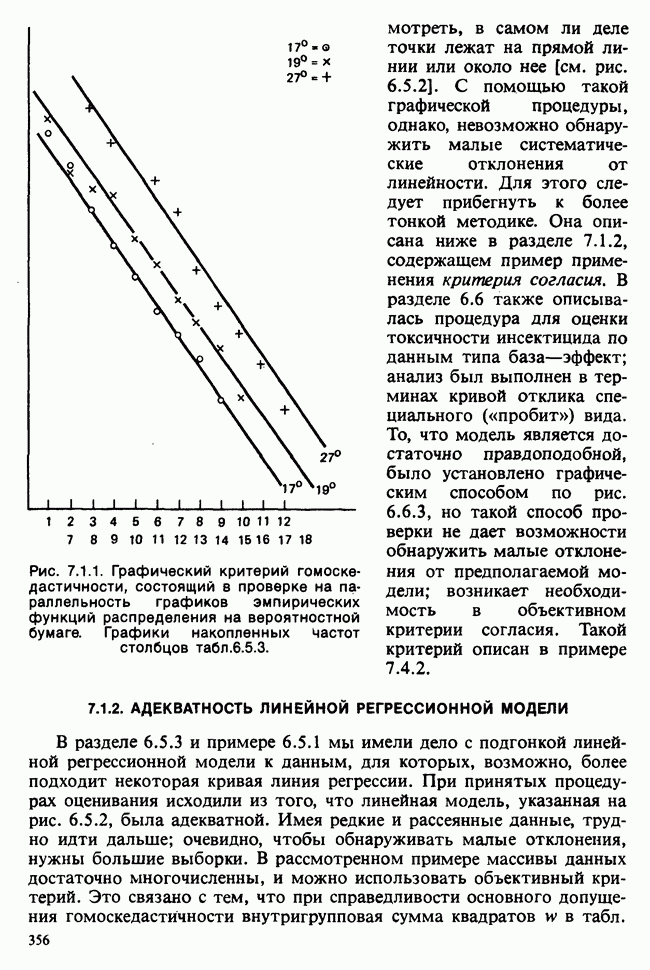
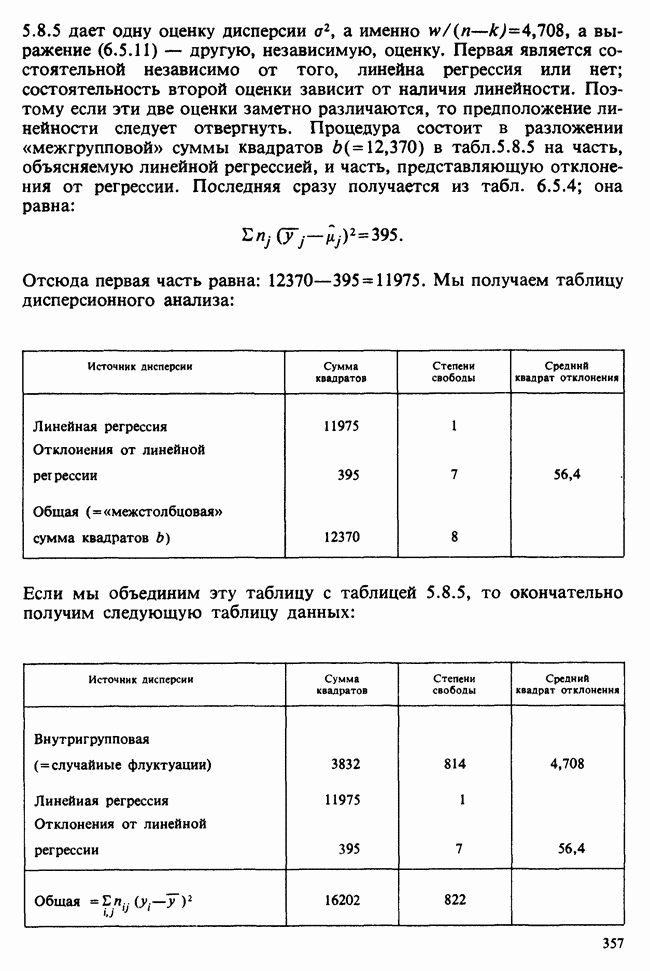
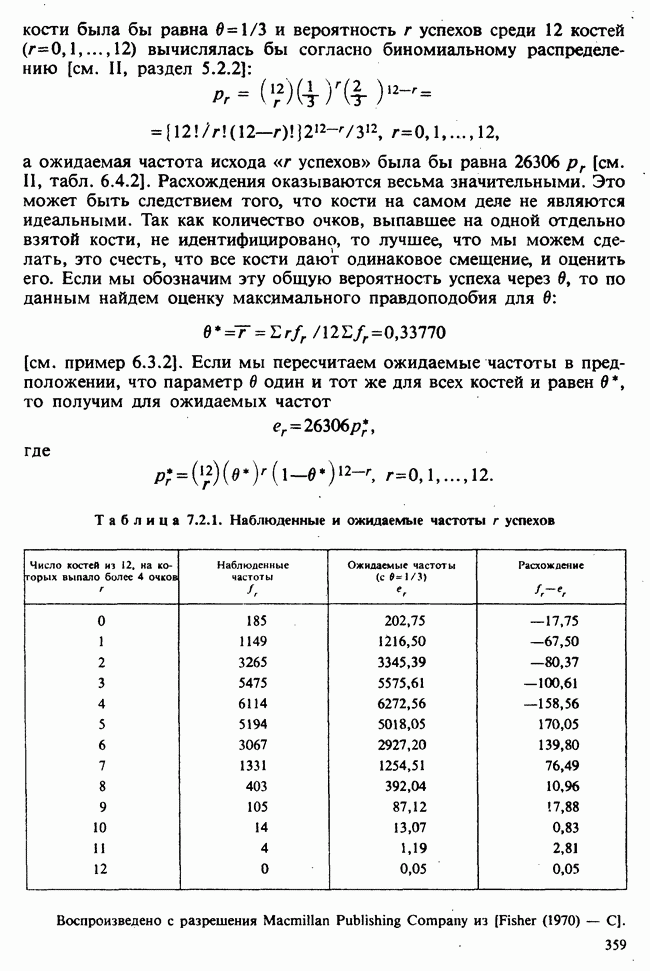
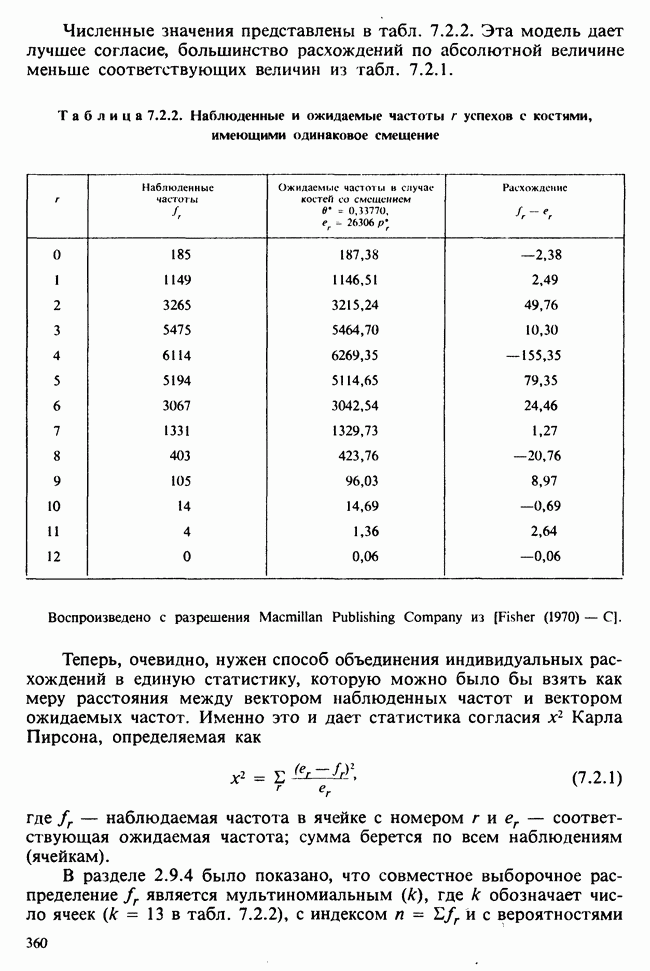
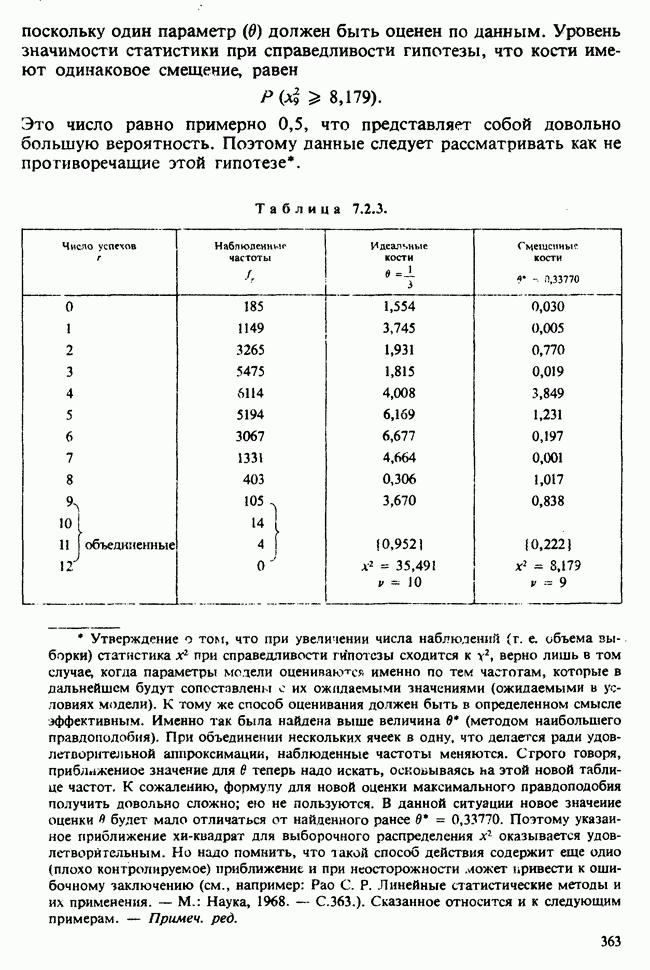
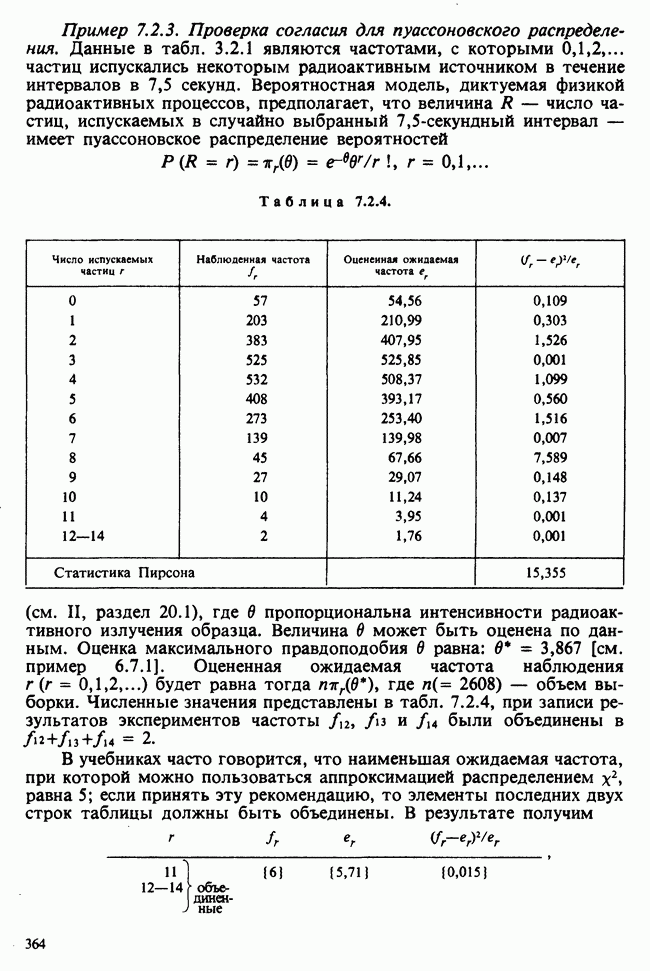
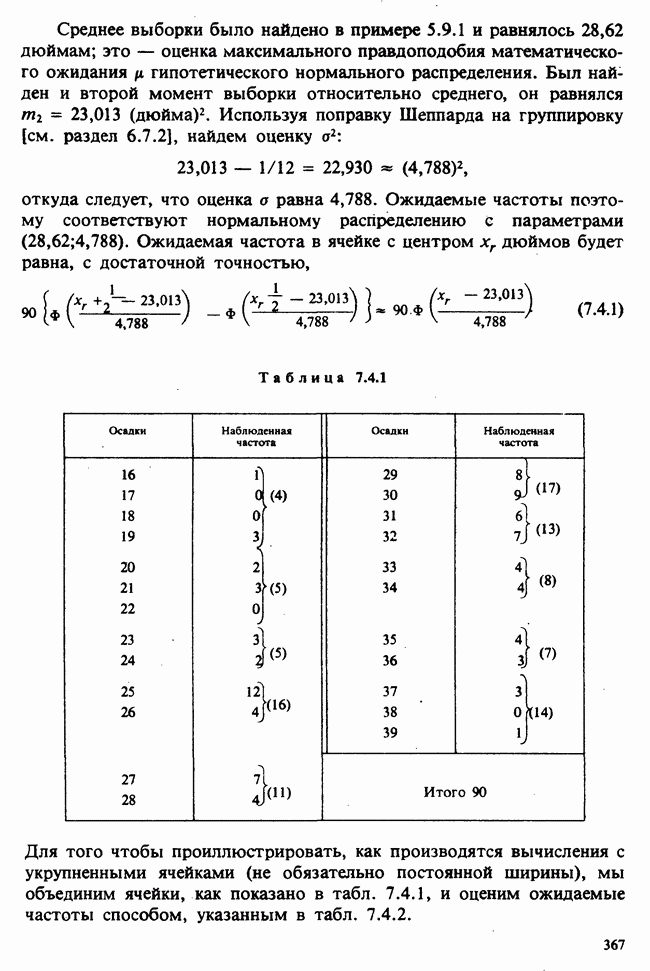
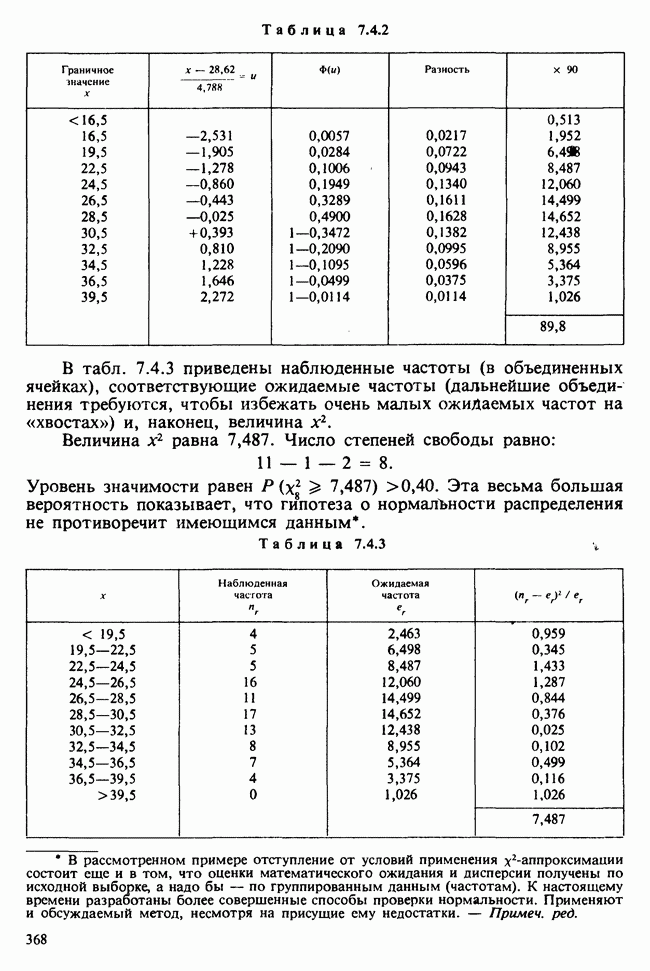
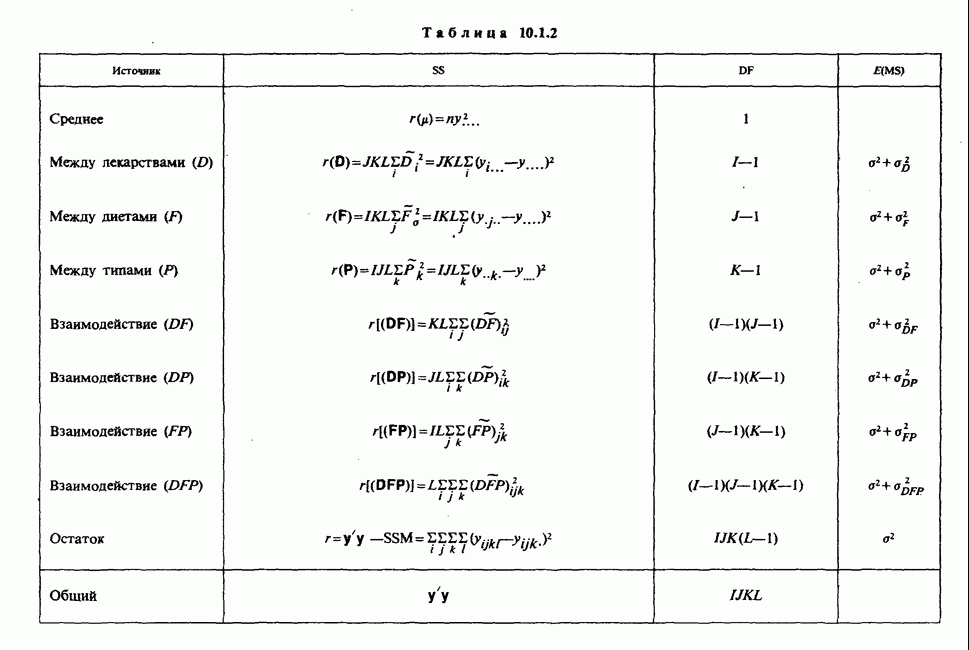
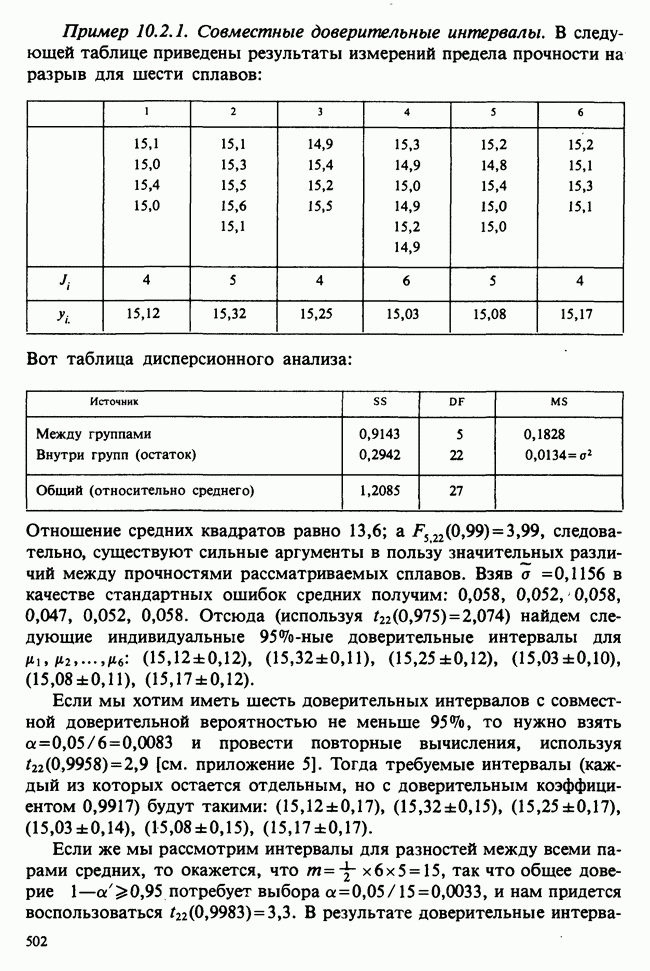
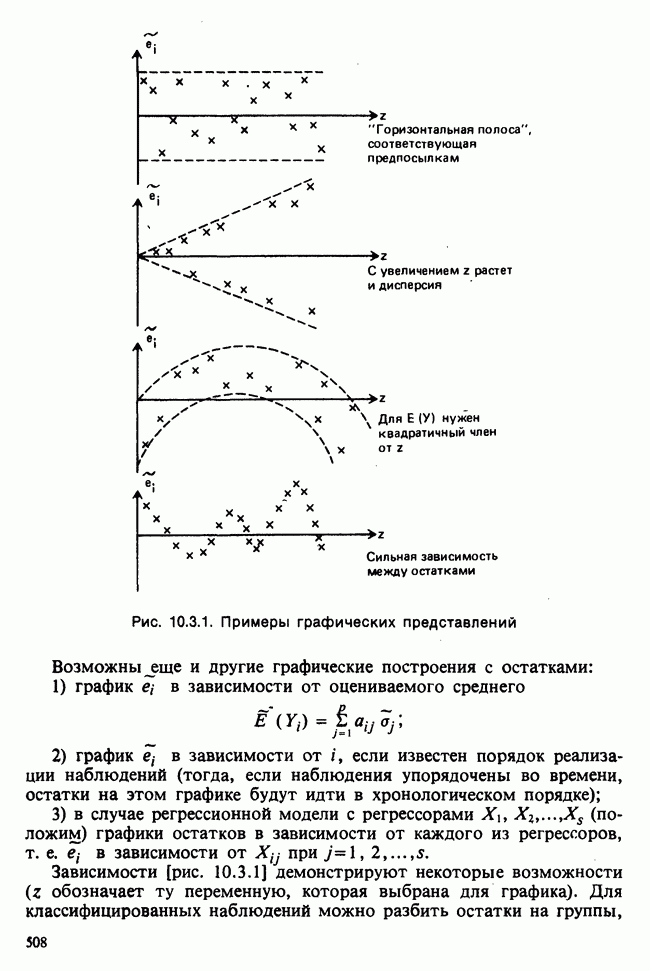
5.2.1. ДВУХСТОРОННИЙ БИНОМИАЛЬНЫЙ КРИТЕРИЙ. СОСТАВНЫЕ ЧАСТИ, ПРОЦЕДУРА И ИНТЕРПРЕТАЦИЯ
В следующем примере описан простой критерий, иллюстрирующий общий подход и основные понятия. В частности, вводятся ключевые понятия области значимости и уровня значимости. Рассмотрим исследование, в котором проводится сравнение частоты рождения мальчиков в индейских семьях английского города, в котором значительную долю населения составляют выходцы из Вест-Индии. Средняя частота по Великобритании составляет 52%. Исходные данные представляют собой упорядоченный по датам список всех новорожденных в индейских семьях за исследуемый год.
а) Вероятностная модель. Выбор подходящей вероятностной модели — это первый шаг при построении критерия. Мы примем простейшую возможную модель, а именно такую, когда рождения считаются взаимно независимыми испытаниями Бернулли [см. II, раздел 5.2.1], каждое из которых с одной и той же вероятностью, скажем  приводит к рождению мальчика. Для настоящего критерия эта модель в дальнейшем сомнению не подвергается. (Открытыми остаются такие вопросы, как возможность более частого появления новорожденных мальчиков у одной из возрастных групп матерей по сравнению с прочими, которые и сами могли бы составить содержание отдельного исследования; однако поскольку такая модель непосредственно не связана с критерием, то она и не обсуждается.)
приводит к рождению мальчика. Для настоящего критерия эта модель в дальнейшем сомнению не подвергается. (Открытыми остаются такие вопросы, как возможность более частого появления новорожденных мальчиков у одной из возрастных групп матерей по сравнению с прочими, которые и сами могли бы составить содержание отдельного исследования; однако поскольку такая модель непосредственно не связана с критерием, то она и не обсуждается.)
Для формального описания модели пусть  обозначает пол
обозначает пол  ребенка, появившегося в последовательности данных, причем для мальчика
ребенка, появившегося в последовательности данных, причем для мальчика  а для девочки
а для девочки  так что
так что  обозначает общую численность мальчиков в выборке. Тогда при
обозначает общую численность мальчиков в выборке. Тогда при  значение
значение  представляет собой реализацию случайной величины
представляет собой реализацию случайной величины  имеющей распределение Бернулли [см. II, раздел 5.2.1]:
имеющей распределение Бернулли [см. II, раздел 5.2.1]:

а совместное распределение данных описывается формулой 

б) Сокращение данных. Статистика критерия. Работать одновременно с  составными частями информации неудобно. Стоит свести их в одну статистику, в связи с чем мы заменим исходную вероятностную модель, приведенную в
составными частями информации неудобно. Стоит свести их в одну статистику, в связи с чем мы заменим исходную вероятностную модель, приведенную в  , сокращенной версией, а именно выборочным распределением этой статистики. Наиболее эффективное сокращение данных осуществляется с помощью достаточной для интересующего нас параметра
, сокращенной версией, а именно выборочным распределением этой статистики. Наиболее эффективное сокращение данных осуществляется с помощью достаточной для интересующего нас параметра  статистики, поскольку при таком сокращении информация не теряется. В нашей ситуации подходящей достаточной статистикой служит
статистики, поскольку при таком сокращении информация не теряется. В нашей ситуации подходящей достаточной статистикой служит  т. е. зарегистрированная
т. е. зарегистрированная
численность мальчиков. Ее выборочное распределение, т. е. распределение соответствующей случайной величины В, реализацией которой и оказывается  имеет вид [см. II, раздел 5.2.2]
имеет вид [см. II, раздел 5.2.2]

в) Нулевая гипотеза, нулевое распределение. Нужно ответить на вопрос: отличается ли величина  от среднего по Великобритании значения 0,52? Предпочтительнее иная формулировка этого вопроса, при которой он звучит так: согласованы ли данные с предположением, что
от среднего по Великобритании значения 0,52? Предпочтительнее иная формулировка этого вопроса, при которой он звучит так: согласованы ли данные с предположением, что  Чтобы ответить на него, примем рабочую гипотезу, что величина
Чтобы ответить на него, примем рабочую гипотезу, что величина  равна именно 0,52. Это предположение и называется нулевой гипотезой и обозначается так:
равна именно 0,52. Это предположение и называется нулевой гипотезой и обозначается так:

Совместное распределение величин  обусловленное этим предположением, получается, если подставить такое значение
обусловленное этим предположением, получается, если подставить такое значение  в соотношение (5.2.1), что приводит к нулевому распределению
в соотношение (5.2.1), что приводит к нулевому распределению  или распределению
или распределению  при нулевой гипотезе Н, т. е.
при нулевой гипотезе Н, т. е.

Нулевое распределение статистики критерия получится, если взять (5.2.1) при отвечающем нулевой гипотезе значении  т. е.
т. е.

в нашем случае при 
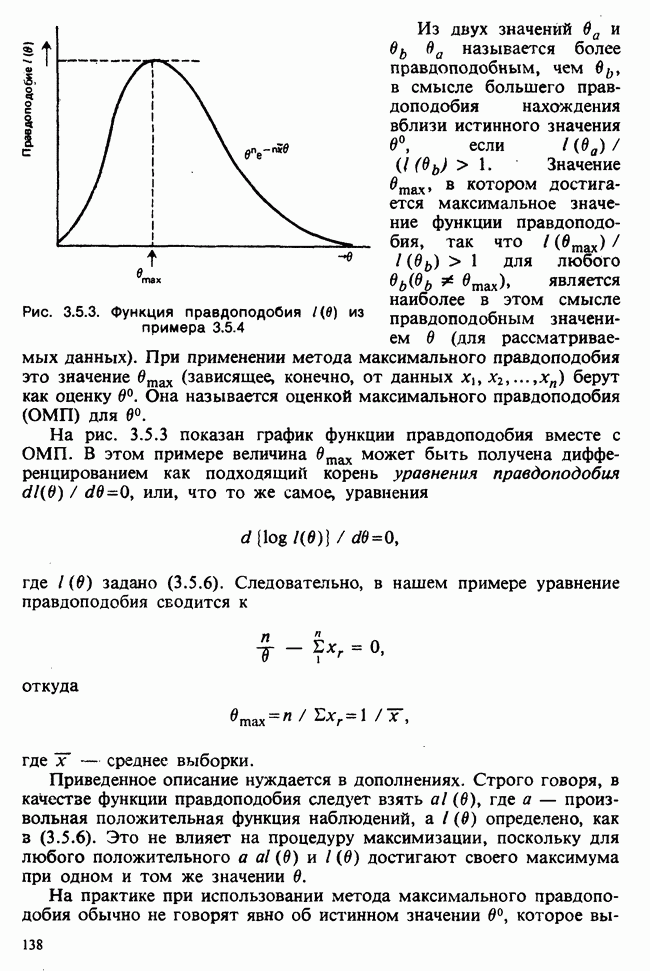
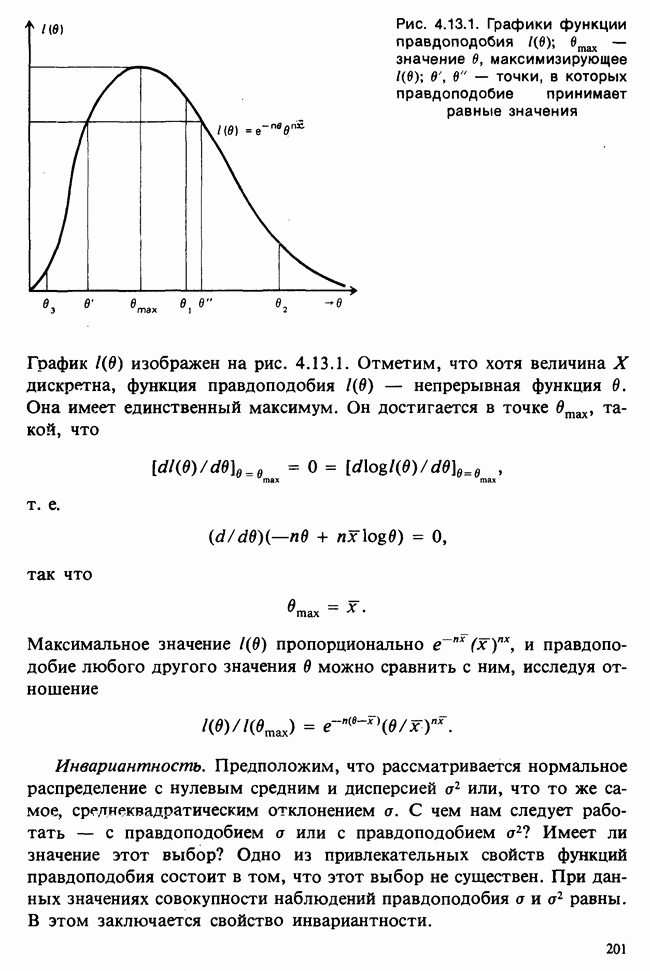
В основе критерия лежит такая идея: если нулевая гипотеза и данные согласованы с довольно высокой степенью правдоподобия (в определяемом ниже смысле), то мы считаем, что она подтверждается данными; в противном же случае мы считаем, что гипотеза не согласована с данными, т. е. данные значимо отклоняются от гипотезы. То, что понимается под выражением «достаточно (или недостаточно) высокая степень правдоподобия», обсуждается ниже в п. д) и е).
В настоящем примере нулевая гипотеза оказывается простой: при ней значение параметра становится точно известным. (В пример входит только один параметр. При построении более «хитрых» критериев могли бы встретиться несколько параметров [см. раздел 8.3.3]. Тогда нулевая гипотеза называется простой, если она определяет значение всех параметров.)
Приведем пример критерия, для которого нулевая гипотеза сложная. Среди  новорожденных у матерей в возрасте 20—25 лет — 6, мальчиков, а среди новорожденных у матерей в возрасте 30—35 лет
новорожденных у матерей в возрасте 20—25 лет — 6, мальчиков, а среди новорожденных у матерей в возрасте 30—35 лет  мальчиков. Нужно проверить значимость различия частот
мальчиков. Нужно проверить значимость различия частот  . В этом случае нулевая гипотеза предполагает, что вероятность рождения мальчика одинакова для обеих групп. Однако это общее для обеих групп значение вероятности не определяется нулевой гипотезой, так что она не будет «простой». Этот и ему подобные критерии обсуждаются в разделе 5.4.1.
. В этом случае нулевая гипотеза предполагает, что вероятность рождения мальчика одинакова для обеих групп. Однако это общее для обеих групп значение вероятности не определяется нулевой гипотезой, так что она не будет «простой». Этот и ему подобные критерии обсуждаются в разделе 5.4.1.
г) Альтернативная гипотеза. Цель критерия в том, чтобы усмотреть, можно ли считать данные согласованными с нулевой гипотезой или же они настолько сильно расходятся с ней, что даже опровергают ее. При этом важно знать, какое расхождение считать умеренным. В настоящем примере против Н можно выдвинуть так называемую альтернативную гипотезу вида

Таким образом, гипотеза Н отвергается для тех данных, в которых доля мальчиков существенно выше или существенно ниже, чем 0,52. В этом случае критерий называют двусторонним. (Пример одностороннего критерия приведен в разделе 5.2.3.)
д) Согласованность выборки с гипотезой Н. Исходный вопрос о согласованности  наблюдений с нулевой гипотезой (5.2.2) теперь можно заменить эквивалентным — о согласованности наблюденного значения
наблюдений с нулевой гипотезой (5.2.2) теперь можно заменить эквивалентным — о согласованности наблюденного значения  с нулевым распределением (5.2.3). Это распределение унимодально, и для него близкая к центру область имеет высокую вероятность, тогда как его. хвосты — это области малой вероятности. Если значение В попало в имеющую высокую вероятность область, когда гипотеза Н на самом деле верна, то можно заключить, что выборка явно не опровергает гипотезу Н: она согласуется с Н. Однако если наблюдается крайнее, практически невероятное при Н значение
с нулевым распределением (5.2.3). Это распределение унимодально, и для него близкая к центру область имеет высокую вероятность, тогда как его. хвосты — это области малой вероятности. Если значение В попало в имеющую высокую вероятность область, когда гипотеза Н на самом деле верна, то можно заключить, что выборка явно не опровергает гипотезу Н: она согласуется с Н. Однако если наблюдается крайнее, практически невероятное при Н значение  то это следует считать явным расхождением с Н.
то это следует считать явным расхождением с Н.
Представленное здесь рассуждение — это обычное доказательство от противного в аристотелевой логике. В соответствии с ней, если из А следует В, то из не-В следует не-А для произвольных высказываний А и В. Статистический вариант этого принципа таков: если В — вероятностное следствие А, то не-А будет вероятностным следствием не-В. Возьмем в качестве суждения А высказывание «Н верна», а в качестве суждения В — «наблюденное значение  вероятно, будет близким к моде нулевого распределения». Тогда статистический «закон исключенного третьего», или «принцип рассуждения от противного», утверждает, что гипотеза, вероятно, не верна, если наблюденное значение
вероятно, будет близким к моде нулевого распределения». Тогда статистический «закон исключенного третьего», или «принцип рассуждения от противного», утверждает, что гипотеза, вероятно, не верна, если наблюденное значение  удалено от моды нулевого распределения. Неясно только, какое крайнее значение
удалено от моды нулевого распределения. Неясно только, какое крайнее значение  достаточно для отклонения гипотезы Н. Из вида исходного примера можно понять, что гипотеза Н отклоняется или для очень больших (близких к
достаточно для отклонения гипотезы Н. Из вида исходного примера можно понять, что гипотеза Н отклоняется или для очень больших (близких к  ) значений
) значений  или для очень малых (близких к нулю): критерий должен быть «двусторонним». Непонятно, однако, какие именно значения считать очень большими или очень малыми.
или для очень малых (близких к нулю): критерий должен быть «двусторонним». Непонятно, однако, какие именно значения считать очень большими или очень малыми.
е) Области значимости, уровень значимости (вероятность значимости). Критическая область. Есть немало привлекательных подходов к определению значимости данного значения  для отклонения Н. В качестве первой попытки можно было бы считать
для отклонения Н. В качестве первой попытки можно было бы считать  значимым в этом смысле, если вероятность
значимым в этом смысле, если вероятность  [обозначения см. в разделе 1.4.2] мала. Здесь, однако, возникает сложная ситуация: при достаточно большом объеме выборки вероятность
[обозначения см. в разделе 1.4.2] мала. Здесь, однако, возникает сложная ситуация: при достаточно большом объеме выборки вероятность  обязательно
обязательно
будет мала, каково бы ни было значение  Следовательно, надо заменить вероятность одной точки
Следовательно, надо заменить вероятность одной точки  эквивалентной мерой, которая стандартизована таким образом, что позволяет избежать осложнений. Добиться этого можно различными способами. Обычный путь состоит в том, что решение основывают на вероятности, которую Н приписывает специальному множеству возможных значений статистики критерия В, причем это множество выбирают так, что когда Н верна, то и его вероятность мала. Искомое множество состоит из всех значений, которые в известном смысле (см. ниже) еще более крайние, чем фактическое
эквивалентной мерой, которая стандартизована таким образом, что позволяет избежать осложнений. Добиться этого можно различными способами. Обычный путь состоит в том, что решение основывают на вероятности, которую Н приписывает специальному множеству возможных значений статистики критерия В, причем это множество выбирают так, что когда Н верна, то и его вероятность мала. Искомое множество состоит из всех значений, которые в известном смысле (см. ниже) еще более крайние, чем фактическое  . Это множество называется областью значимости
. Это множество называется областью значимости  , а используемая для измерения значимости
, а используемая для измерения значимости  при отклонении гипотезы Н величина — это уровень значимости SL (Significance level), или
при отклонении гипотезы Н величина — это уровень значимости SL (Significance level), или  определенный как вероятность принадлежности множеству области значимости, вычисленная в предположении, что справедлива нулевая гипотеза, т. е.
определенный как вероятность принадлежности множеству области значимости, вычисленная в предположении, что справедлива нулевая гипотеза, т. е.

Так определенный уровень значимости называют еще вероятностью значимости выборок, чтобы отличить от близкого понятия, используемого при подходе Неймана—Пирсона. Этот подход к проверке гипотез связан с теорией принятия решений. Он излагается в разделе 5.12.
Общая концепция, которую мы будем развивать, состоит в том, что выборка согласуется с нулевой гипотезой Н, когда вероятность значимости в определенном смысле велика, и не согласуется, когда эта вероятность мала [см. раздел 5.2.2].
Критическая область. Следует отметить, что специалисты по прикладной статистике часто не определяют область значимости и уровень значимости, отвечающий их данным. Вместо этою они находят условное множество значимости, которое при фактических наблюдениях имеет довольно низкий уровень значимости а (например,  и тем самым обеспечивает высокую условную надежность отклонения
и тем самым обеспечивает высокую условную надежность отклонения  нулевой гипотезы [см. раздел 5.2.1, з]. Это условное множество значимости называется критической областью размера
нулевой гипотезы [см. раздел 5.2.1, з]. Это условное множество значимости называется критической областью размера  Вместо определения фактического уровня значимости своей выборки приверженцы такого подхода проверяют, не попадает ли статистика их критерия в критическую область. Если попадает, то говорят, что выборка на уровне а значима, а нулевая гипотеза отклоняется на уровне а; в противном случае говорят, что выборка на уровне а не значима.
Вместо определения фактического уровня значимости своей выборки приверженцы такого подхода проверяют, не попадает ли статистика их критерия в критическую область. Если попадает, то говорят, что выборка на уровне а значима, а нулевая гипотеза отклоняется на уровне а; в противном случае говорят, что выборка на уровне а не значима.
Этот подход будет подробнее изложен в разделе 5.12.
Какие значения будут не менее крайними, чем  Определение области значимости осмысленно только тогда, когда разъяснена фраза «не менее крайние, чем». Для того чтобы осознать нетривиальность этого, предположим, что
Определение области значимости осмысленно только тогда, когда разъяснена фраза «не менее крайние, чем». Для того чтобы осознать нетривиальность этого, предположим, что  меньше, чем ожидаемое при Н значение. Например, при
меньше, чем ожидаемое при Н значение. Например, при  ожидаемое значение равно 10,4, а наблюденное значение
ожидаемое значение равно 10,4, а наблюденное значение  меньше его. Возможные значения, столь же или более крайние, чем 5, но меньшие (в том смысле, что они находятся на «нижнем хвосте») — это 5, 4, 3, 2, 1,0. Каково же соответствующее
меньше его. Возможные значения, столь же или более крайние, чем 5, но меньшие (в том смысле, что они находятся на «нижнем хвосте») — это 5, 4, 3, 2, 1,0. Каково же соответствующее
множество на «верхнем хвосте»? Иначе говоря, как можно определить, что наблюдение  которое больше, чем ожидаемое значение 10,4, столь же далеко (как большое наблюдение), сколь и
которое больше, чем ожидаемое значение 10,4, столь же далеко (как большое наблюдение), сколь и  (но рассматриваемое как малое наблюдение)? Применяются такие методы.
(но рассматриваемое как малое наблюдение)? Применяются такие методы.
Упорядочение по расстоянию. При таком подходе «большое» значение  и «малое»
и «малое»  в равной степени значимы, если они одинаково отстоят от
в равной степени значимы, если они одинаково отстоят от  величины, отстоящие от
величины, отстоящие от  дальше, чем любое из них, конечно, более значимы. Здесь
дальше, чем любое из них, конечно, более значимы. Здесь  обозначает математическое ожидяние В при гипотезе Н, т. е. среднее ожидаемое значение распрелеления (5.2.3). Пробпема сравнения обоих хвостов получает решение при следующем определении области значимости, порожденной наблюдением
обозначает математическое ожидяние В при гипотезе Н, т. е. среднее ожидаемое значение распрелеления (5.2.3). Пробпема сравнения обоих хвостов получает решение при следующем определении области значимости, порожденной наблюдением 

так что уровень значимости наблюдения  равен
равен

Участвующие в этом вычислении точки распределения В показаны на рис. 5.2.1.
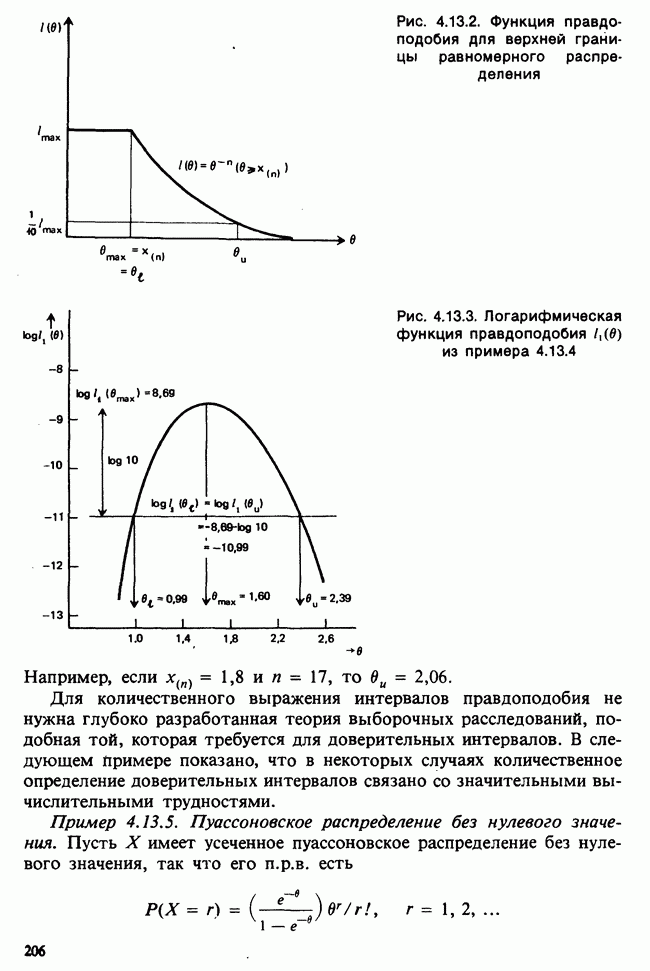
Таким образом, если среди 20 новорожденных оказалось 5 мальчиков,  при нулевой гипотезе случайная величина В подчиняется биномиальному распределению
при нулевой гипотезе случайная величина В подчиняется биномиальному распределению  с пэпаметрами (20, 0,52), то
с пэпаметрами (20, 0,52), то  , а уровень значимости данных составляет
, а уровень значимости данных составляет

(см. рис. 5.2.1).
Из таблиц биномиального распределения [см. Приложение  ] находим
] находим  .
.
Упорядочение по вероятности. Предположим вначале, что наблюдение  случайной величины В «мало» в том гмысле, что
случайной величины В «мало» в том гмысле, что  (в представленном на рис. 5.2.1 примере
(в представленном на рис. 5.2.1 примере  «мало»). При связанном с упорядочением по вероятности подходе значение
«мало»). При связанном с упорядочением по вероятности подходе значение  сопоставляют с имеющим такую же вероятность, но «большим» значением
сопоставляют с имеющим такую же вероятность, но «большим» значением  если понимать «большое» в том смысле, что
если понимать «большое» в том смысле, что  а равенство вероятностей рассматривают как условие
а равенство вероятностей рассматривают как условие

Может, однако, случиться, что при таком возможном значении  точное равенство вероятностей не достигается. В нашем примере при
точное равенство вероятностей не достигается. В нашем примере при  когда при гипотезе Н распределение В оказывается биномиальным с параметрами (20, 0,52), возникает такая ситуация:
когда при гипотезе Н распределение В оказывается биномиальным с параметрами (20, 0,52), возникает такая ситуация:


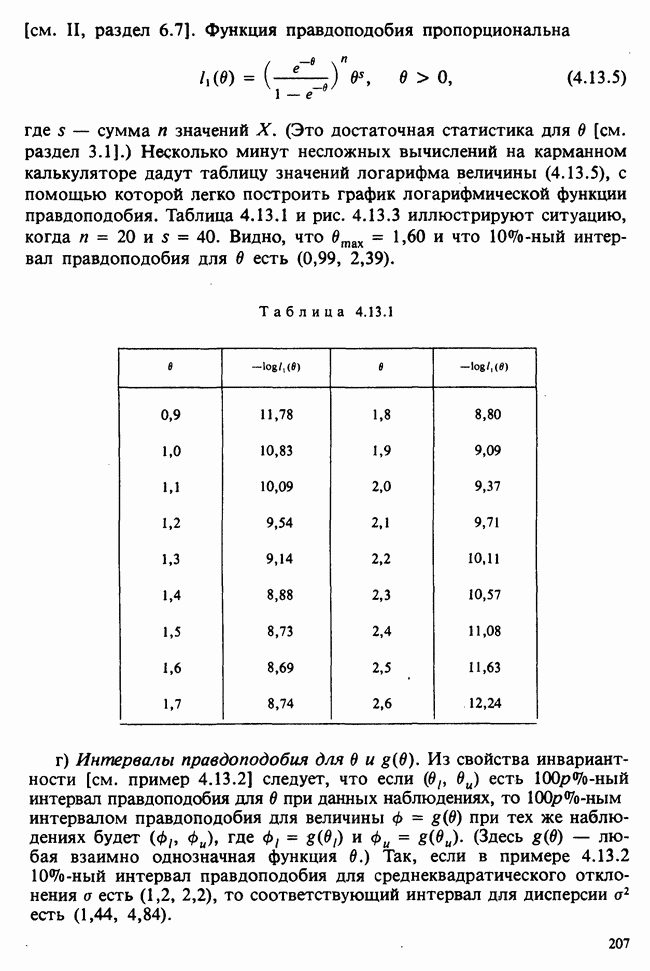
Рис. 5.2.1. При гипотезе Н случайная величина В подчиняется биномиальному распределению с параметрами (20, 0,52), так что  Значение 5 находится ниже
Значение 5 находится ниже  на расстоянии 10,4-5=5,4. «Равноотстоящая» точка выше
на расстоянии 10,4-5=5,4. «Равноотстоящая» точка выше  это
это  Ближайшей к ней возможной реализацией, столь же крайней (или критической), как 5, служит 16. Множество точек, не менее крайних (или критических), чем наблюденное значение, — это
Ближайшей к ней возможной реализацией, столь же крайней (или критической), как 5, служит 16. Множество точек, не менее крайних (или критических), чем наблюденное значение, — это 
Поэтому 15 — слишком малое, а 16 - слишком большое из возможных значений  равновероятных с
равновероятных с  (см. рис. 5.2.2). В таком случае требование равенства вероятностей при Н значений
(см. рис. 5.2.2). В таком случае требование равенства вероятностей при Н значений  заменяется условием, что
заменяется условием, что  — наименьшее целое число, для которого
— наименьшее целое число, для которого

В рассматриваемом примере это приводит к значению 
Порожденная наблюдением  область значимости — это
область значимости — это

а уровень значимости наблюдения  равен
равен

В нашем примере, когда из 20 новорожденных только 5 мальчиков, уровень значимости составляет

(Описанная процедура применима, когда наблюдение  «мало». Если же оно «велико», то используется очевидная модификация.)
«мало». Если же оно «велико», то используется очевидная модификация.)
В этом примере величина  одна и та же как при подходе, основанном на расстояниях, так и при подходе с применением «наименьших вероятностей». На самом деле оба подхода всегда приводят к одинаковым результатам, если нулевое распределение симметрично, и к почти одинаковым, когда нулевое распределение «почти» симметрично; различие возникает, только когда нулевое распределение имеет заметную асимметрию. В такой ситуации предпочтительнее упорядочение по вероятности.
одна и та же как при подходе, основанном на расстояниях, так и при подходе с применением «наименьших вероятностей». На самом деле оба подхода всегда приводят к одинаковым результатам, если нулевое распределение симметрично, и к почти одинаковым, когда нулевое распределение «почти» симметрично; различие возникает, только когда нулевое распределение имеет заметную асимметрию. В такой ситуации предпочтительнее упорядочение по вероятности.

Рис. 5.2.2. Часть биномиального распределения вероятностей с параметрами (20, 0,52), для которой 
Упорядочение с помощью отношения правдоподобия. Для статистики критерия  представляющей собой реализацию биномиально распределенной случайной величины В с параметрами
представляющей собой реализацию биномиально распределенной случайной величины В с параметрами  функция правдоподобия для
функция правдоподобия для  [см. раздел 4.13.1] пропорциональна
[см. раздел 4.13.1] пропорциональна

В нашем случае  так что
так что

а гипотеза Н состоит в том, что  и
и

Когда  пробегает всю область
пробегает всю область  а величина
а величина  фиксирована, максимум
фиксирована, максимум  достигается, если
достигается, если  принимает «наиболее правдоподобное» значение
принимает «наиболее правдоподобное» значение  Этот максимум равен:
Этот максимум равен:

Отношение

называется статистикой отношения правдоподобия. Ее значение для нашего примера равно

При произвольном значении  случайной величины В статистика отношения правдоподобия принимает значение, скажем,
случайной величины В статистика отношения правдоподобия принимает значение, скажем,  равное
равное

так что, когда  имеем
имеем

При основанном на отношении правдоподобия упорядочении значение  будет «более крайним» по сравнению с
будет «более крайним» по сравнению с  если
если

откуда область значимости — это

а уровень значимости равен

(Это придает точную форму той мысли, что ожидаемое значение X должно быть большим, т. е. близким к единице, когда гипотеза Н верна, и малым, если Н неверна.)
Для удобства вычислений  обычно заменяют на
обычно заменяют на

и в этом случае областью значимости служит множество

В нашем примере возможные значения  и соответствующие значения
и соответствующие значения  связаны соотношением
связаны соотношением


Наблюденное значение  Меньшцм значениям 4, 3, 2, 1,0, отвечают значения
Меньшцм значениям 4, 3, 2, 1,0, отвечают значения  не превосходящие 6,1; то же относится и к значениям 16, 17, 18, 19, 20. Таким образом, область значимости
не превосходящие 6,1; то же относится и к значениям 16, 17, 18, 19, 20. Таким образом, область значимости

Уровень значимости составляет

Область значимости совпала с полученной при упорядочении по вероятности, а потому и критерий имеет тот же уровень значимости, т. е. 0,023. Это типичное явление для простых критериев такого вида. На самом деле метод отношения правдоподобия рассчитан на более сложные ситуации, в особенности на содержащие более одного параметра [см. раздел 5.5].
ж) Интерпретация уровня значимости. Степень доверия. В нашем числовом примере (5 из 20 новорожденных — мальчики) мы нашли, что  Как следует расценить это с точки зрения подтверждения или отклонения согласия данных с нулевой гипотезой
Как следует расценить это с точки зрения подтверждения или отклонения согласия данных с нулевой гипотезой
(5.2.2), в силу которой доля мальчиков среди всех выбранных новорожденных равна среднему по Великобритании значению 0,52? Если мы скажем, что это во многом — вопрос соглашения, наш ответ, возможно, вызовет разочарование. Однако на интуитивном уровне можно применить следующие рассуждения [см. раздел 5.3]. Если нулевая гипотеза Н верна, то неправдоподобно, что полученное значение статистики критерия заметно отличается от ожидаемого значения. Но, конечно, даже когда гипотеза Н верна, может оказаться, что в каком-то частном случае статистика критерия заметно отличается от своего математического ожидания; при этом уровень значимости будет мал. Однако и вероятность такого события тоже невелика. На самом деле при любом  вероятность получить уровень значимости, не превосходящий а, в точности равна а. Более строго [см. раздел 5.3], когда Н верна, то
вероятность получить уровень значимости, не превосходящий а, в точности равна а. Более строго [см. раздел 5.3], когда Н верна, то

Поэтому только в одном случае из тысячи значение  окажется не более 0,001, когда верна гипотеза Н. Эта вероятность крайне мала. Разумно поэтому считать уровень значимости 0,001 достаточным доводом против принятия Н. В силу подобных причин на практике принята интерпретация уровней значимости в соответствии с приведенной ниже табл. 5.2.1. Из нее видно, что полученный в нашем числовом примере (5 мальчиков из 20 новорожденных) уровень значимости 2,3% достаточно низок, так что можно, не сомневаясь, отклонить нулевую гипотезу.
окажется не более 0,001, когда верна гипотеза Н. Эта вероятность крайне мала. Разумно поэтому считать уровень значимости 0,001 достаточным доводом против принятия Н. В силу подобных причин на практике принята интерпретация уровней значимости в соответствии с приведенной ниже табл. 5.2.1. Из нее видно, что полученный в нашем числовом примере (5 мальчиков из 20 новорожденных) уровень значимости 2,3% достаточно низок, так что можно, не сомневаясь, отклонить нулевую гипотезу.
Если бы численность мальчиков составила для выборки 7, то основанный на подходе «равных расстояний» уровень значимости  оказался бы
оказался бы

Столь большое значение  следует интерпретировать как согласие данных с нулевой гипотезой.
следует интерпретировать как согласие данных с нулевой гипотезой.
з) Степень недоверия. Отметим, что чем меньшее значение  тем сильнее это свидетельствует, в частности, против Н. Возможно, удобнее было бы принять прямое, а не косвенное измерение силы доводов против Н. Однако удобно это или нет, но уровень значимости слишком глубоко «укоренился», чтобы его можно было отбросить. Более того, с его помощью мы можем измерить то, что называется степенью недоверия к основной гипотезе Н. Она представляет собой дополнительную к уровню значимости величину:
тем сильнее это свидетельствует, в частности, против Н. Возможно, удобнее было бы принять прямое, а не косвенное измерение силы доводов против Н. Однако удобно это или нет, но уровень значимости слишком глубоко «укоренился», чтобы его можно было отбросить. Более того, с его помощью мы можем измерить то, что называется степенью недоверия к основной гипотезе Н. Она представляет собой дополнительную к уровню значимости величину:

Близкий к нулю уровень значимости интерпретируется как близость степени недоверия к 1, т. е. как очень сильный довод против Н. Близкий же к единице уровень значимости показывает, что степень недоверия близка к нулю, т. е. доводы против Н слабы, что фактически указывает на согласие выборки с нулевой гипотезой.