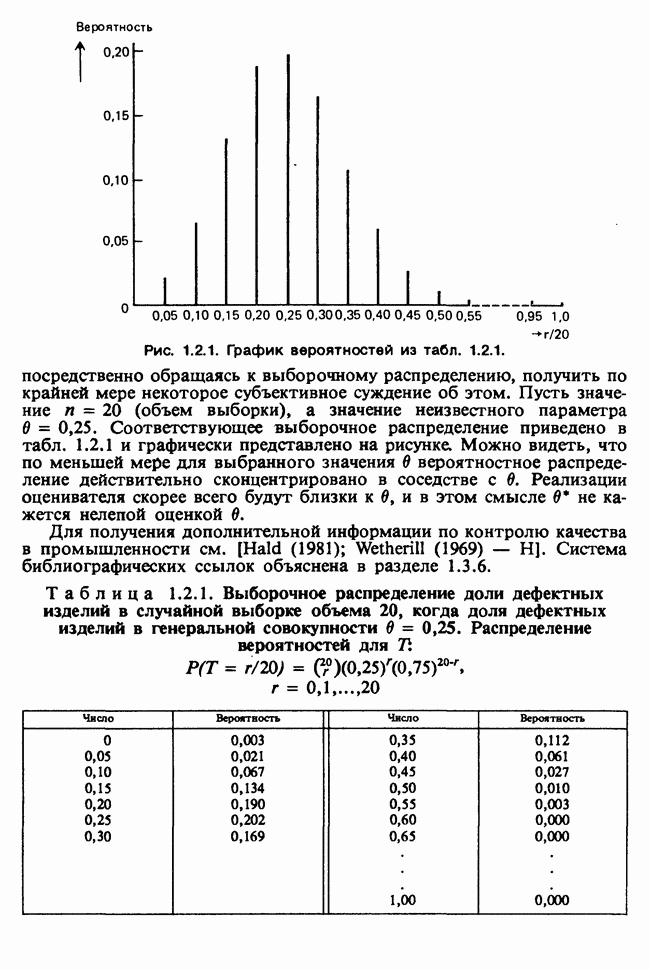
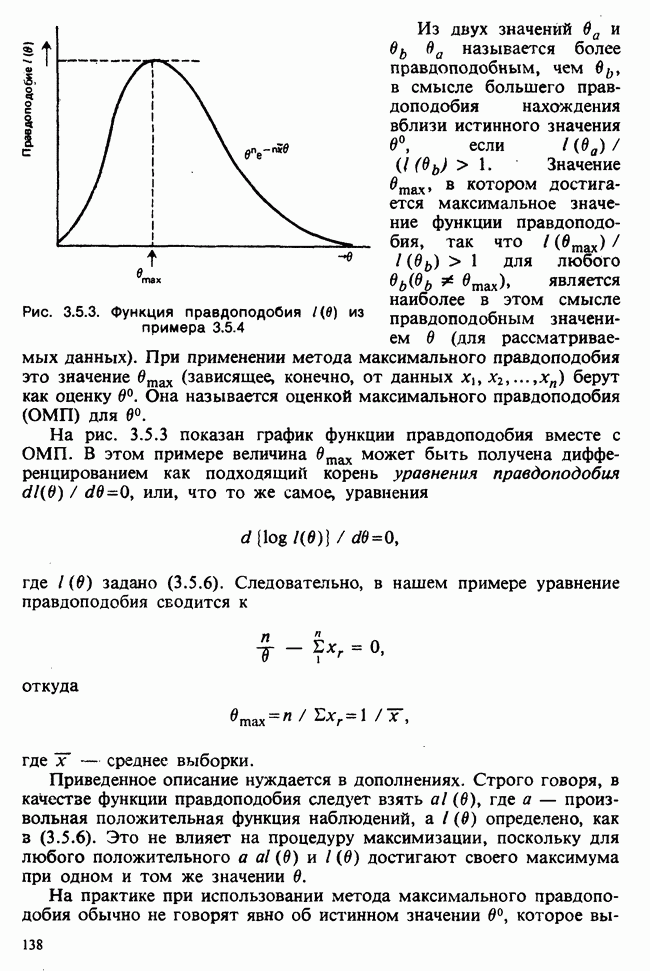
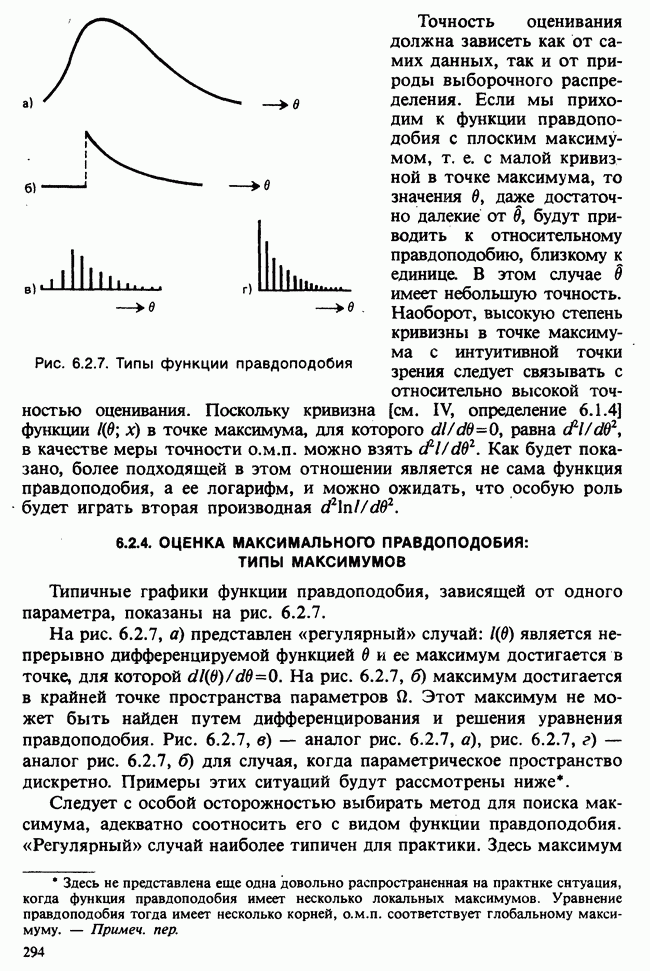
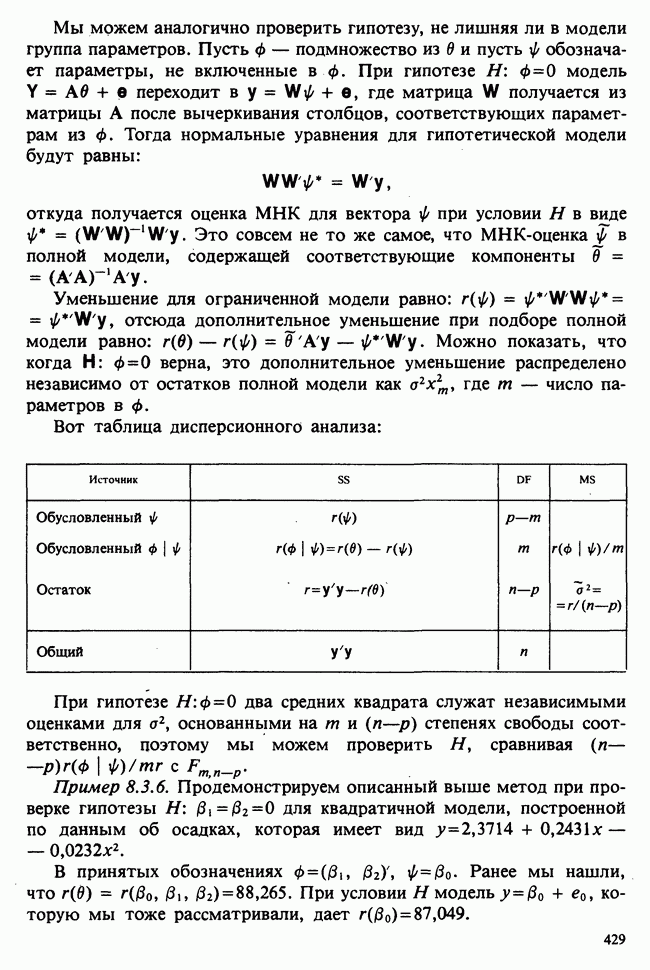
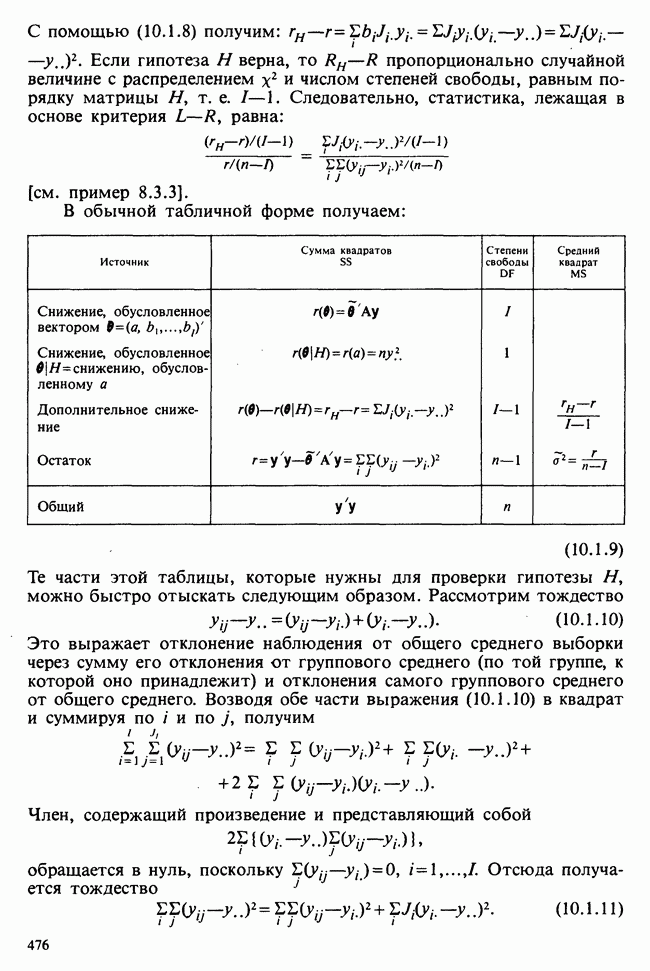
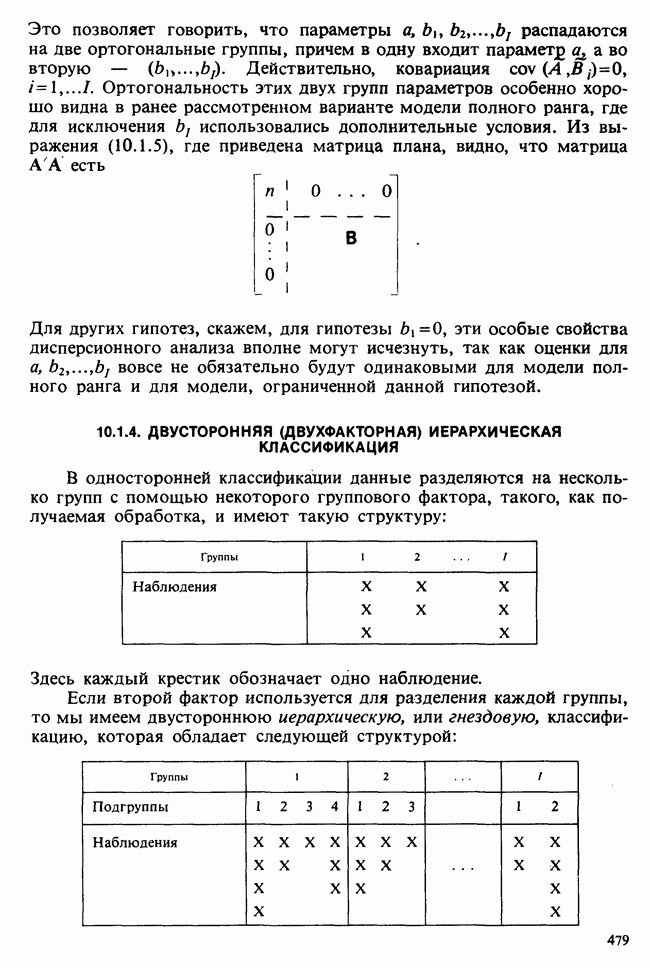
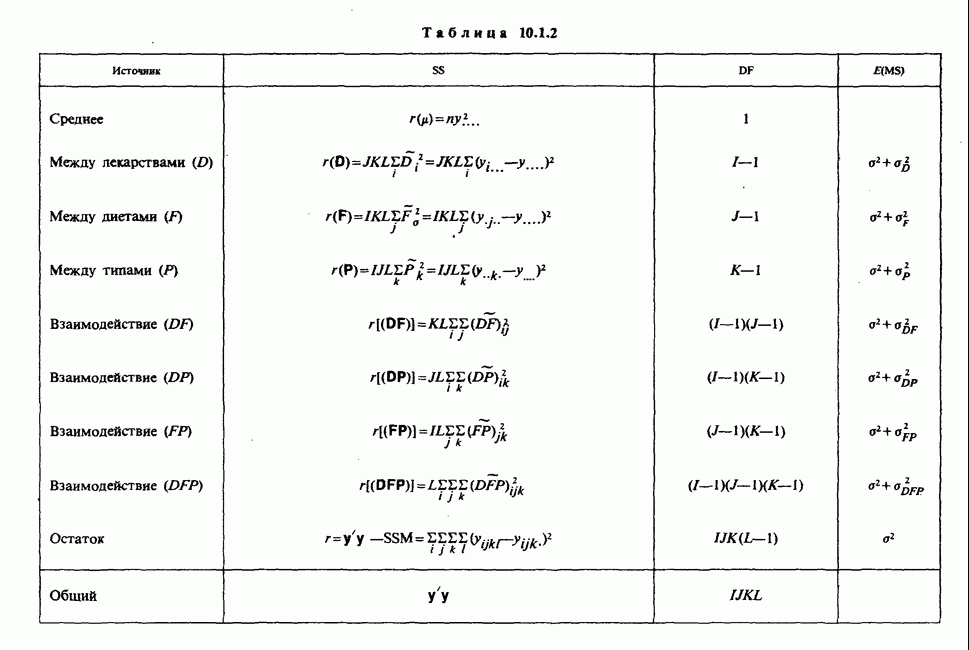
6.5.3. ЛИНЕЙНАЯ РЕГРЕССИЯ С ОДИНАКОВЫМИ ВЕСАМИ
а) Оценки. Наиболее распространенные формы представления данных в задаче оценивания коэффициентов линейной регрессии показаны в табл. 6.5.1 и 6.5.2. Причем мы предполагаем, что

В целях удобства формулу для  в (6.5.1) перепишем в несколько ином виде:
в (6.5.1) перепишем в несколько ином виде:

где

Необходимо оценить три параметра  и а (заметим, что здесь а отлична от а в формуле (6.5.1)). Обозначая а из (6.5.1) через а, мы получаем
и а (заметим, что здесь а отлична от а в формуле (6.5.1)). Обозначая а из (6.5.1) через а, мы получаем

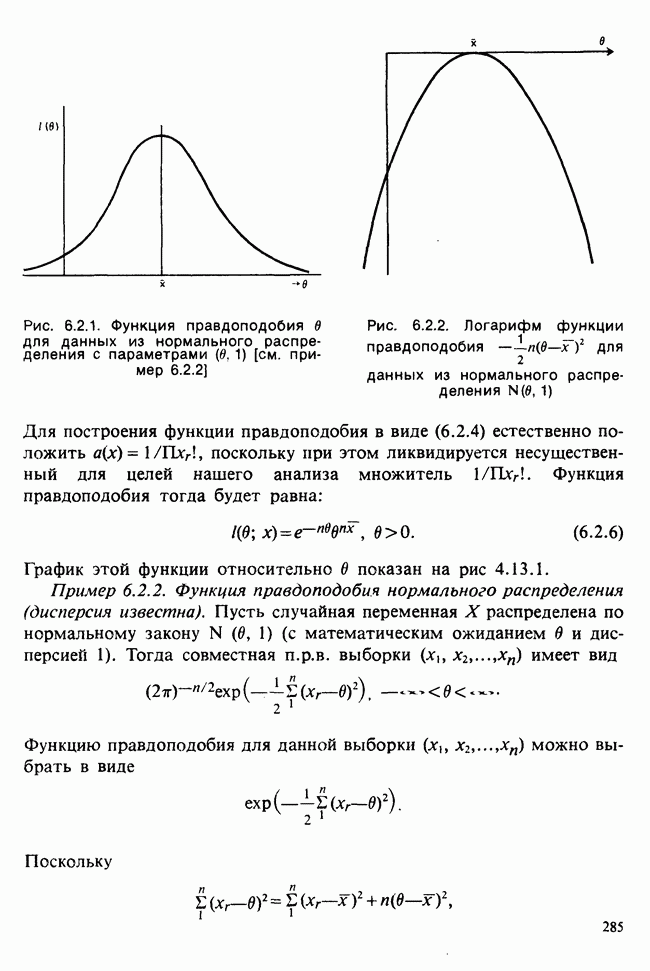
В дальнейшем будем использовать запись (6.5.4). Функция правдоподобия, нетрудно видеть, пропорциональна

где, следуя обозначениям табл. 6.5.1,

где  Логарифм функции правдоподобия равен:
Логарифм функции правдоподобия равен:

 — общий объем выборки. Дифференцируем:
— общий объем выборки. Дифференцируем:

что приводит к

поскольку  по определению х. Аналогично
по определению х. Аналогично

Приравнивая обе производные к нулю, приходим к оценкам максимального правдоподобия:

общее среднее,

где x определяется по формуле (6.5.5).
Если бы  задавались по формуле (6.5.1), а не по формуле (6.5.4), то мы бы имели недиагональную систему уравнений относительно
задавались по формуле (6.5.1), а не по формуле (6.5.4), то мы бы имели недиагональную систему уравнений относительно  решить которую было бы сложнее; по этой причине более простой вид имеют и решения этой системы — (6.5.6) и (6.5.7). Еще одно положительное свойство записи (6.5.4) заключается в том, что оценки
решить которую было бы сложнее; по этой причине более простой вид имеют и решения этой системы — (6.5.6) и (6.5.7). Еще одно положительное свойство записи (6.5.4) заключается в том, что оценки  распределены независимо друг от друга.
распределены независимо друг от друга.
б) Выборочные свойства оценок. Чтобы получить представление о точности этих оценок, нет необходимости пользоваться приближенными формулами из раздела 6.2.5. Поскольку  — линейные функции
— линейные функции  которые по условию нормально распределены, они также имеют нормальное распределение. Выборочные математические ожидания, дисперсия и ковариации будут следующими:
которые по условию нормально распределены, они также имеют нормальное распределение. Выборочные математические ожидания, дисперсия и ковариации будут следующими:

т. е. оценки не смещены:

Таким образом,  независимо распределены [см. II, раздел 13.4.2].
независимо распределены [см. II, раздел 13.4.2].
Теперь найдем оценку для  . Уравнение
. Уравнение  приводит к следующей оценке:
приводит к следующей оценке:

где  обозначает сумму квадратов (Sum of Squared) отклонений:
обозначает сумму квадратов (Sum of Squared) отклонений:

С вычислительной точки зрения формула  лучше, чем
лучше, чем 
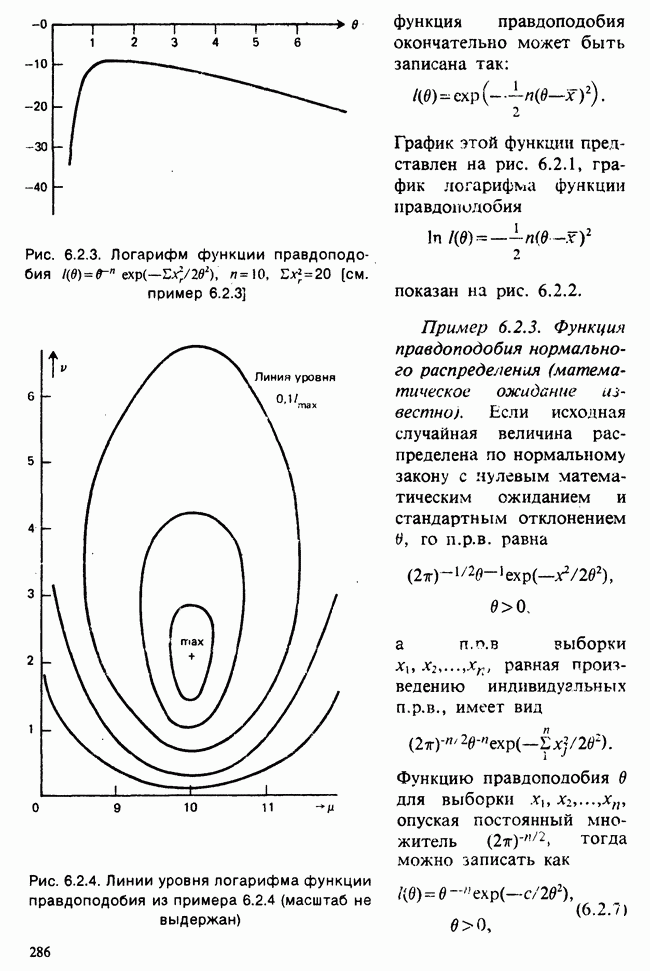
На практике пользуются не оценкой максимального правдоподобия для  а некоторой ее модификацией:
а некоторой ее модификацией:

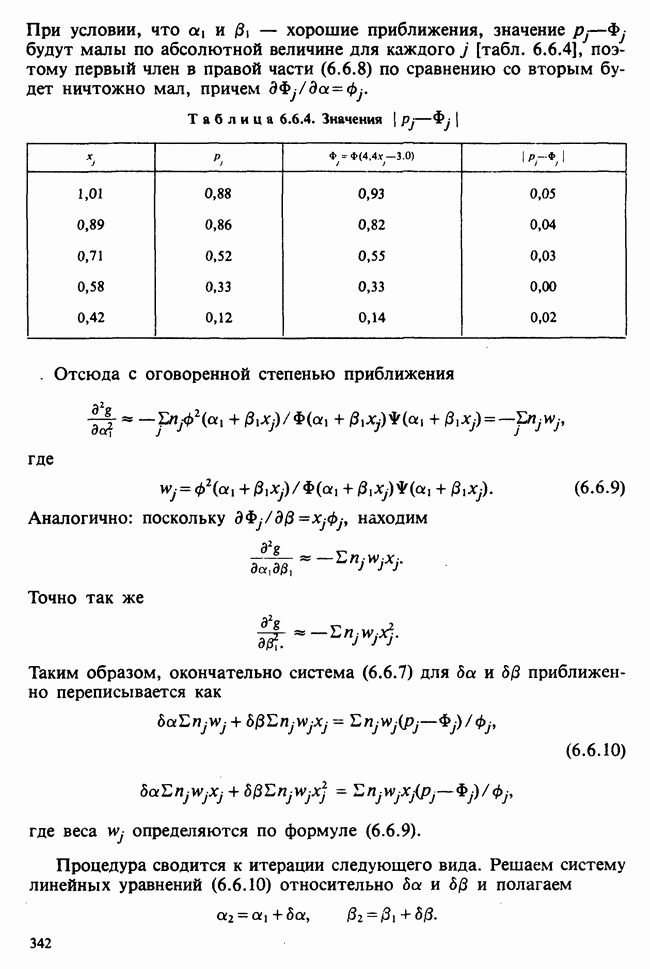
Можно показать, что в отличие от первой оценки она является несмещенной. Однако не свойство несмещенности делает эту оценку предпочтительней. Более важно то, что оценка (6.5.11) согласована с существующими статистическими таблицами. (Несколько замечаний сделаем относительно последней формулы. Читателю может показаться странным, что в (6.5.11) делителем является значение  , а не более привычное
, а не более привычное  Использование
Использование  вместо
вместо  повлекло бы за собой лишь дополнительное видоизменение статистических таблиц, к тому же статистика (6.5.11) является несмещенной оценкой
повлекло бы за собой лишь дополнительное видоизменение статистических таблиц, к тому же статистика (6.5.11) является несмещенной оценкой 
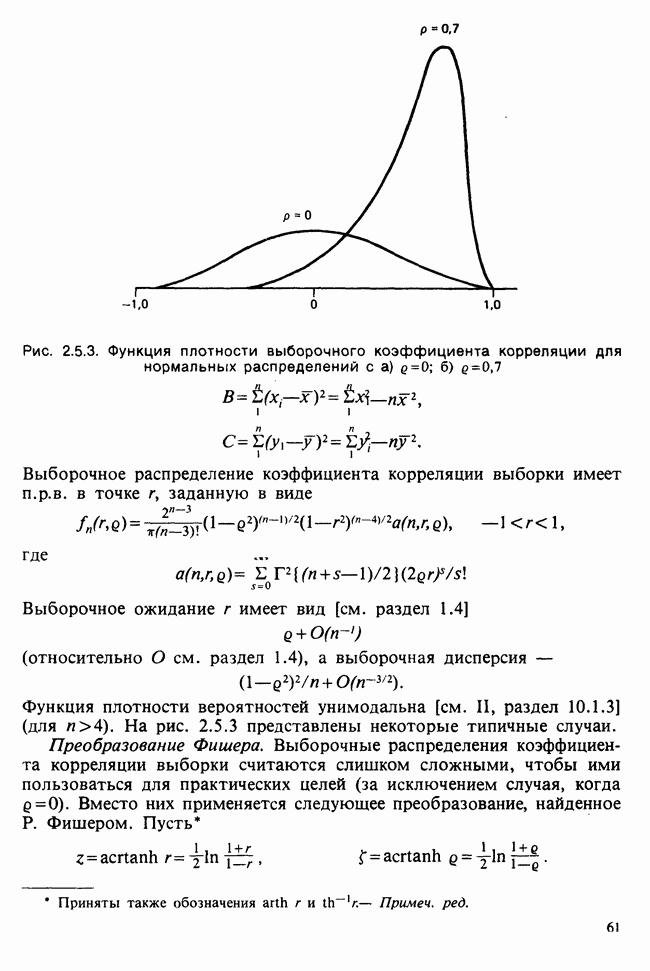
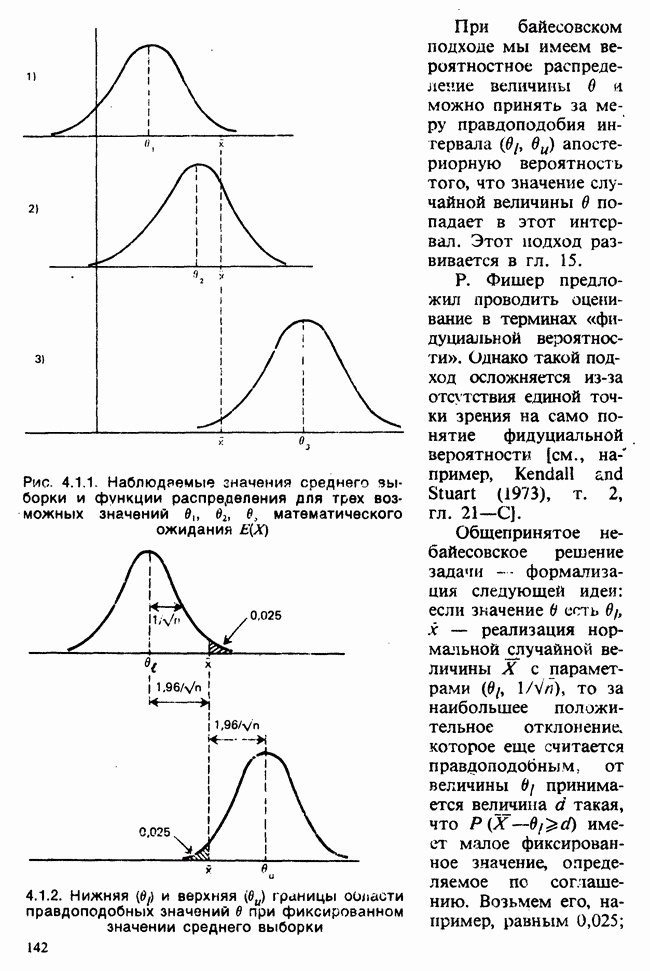
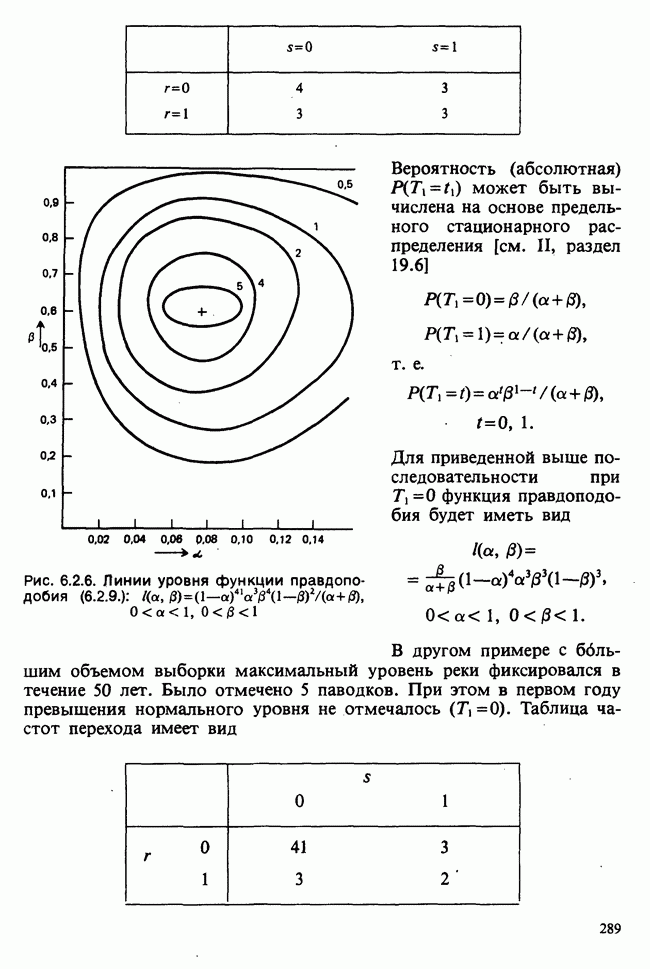
в) Доверительные интервалы для  Как уже было отмечено,
Как уже было отмечено,  являются линейными комбинациями нормально распределенных случайных величин и имеют математические ожидания, равные
являются линейными комбинациями нормально распределенных случайных величин и имеют математические ожидания, равные  соответственно. Их дисперсии можно оценить как
соответственно. Их дисперсии можно оценить как

где  задается формулой (6.5.11), т. е.
задается формулой (6.5.11), т. е.

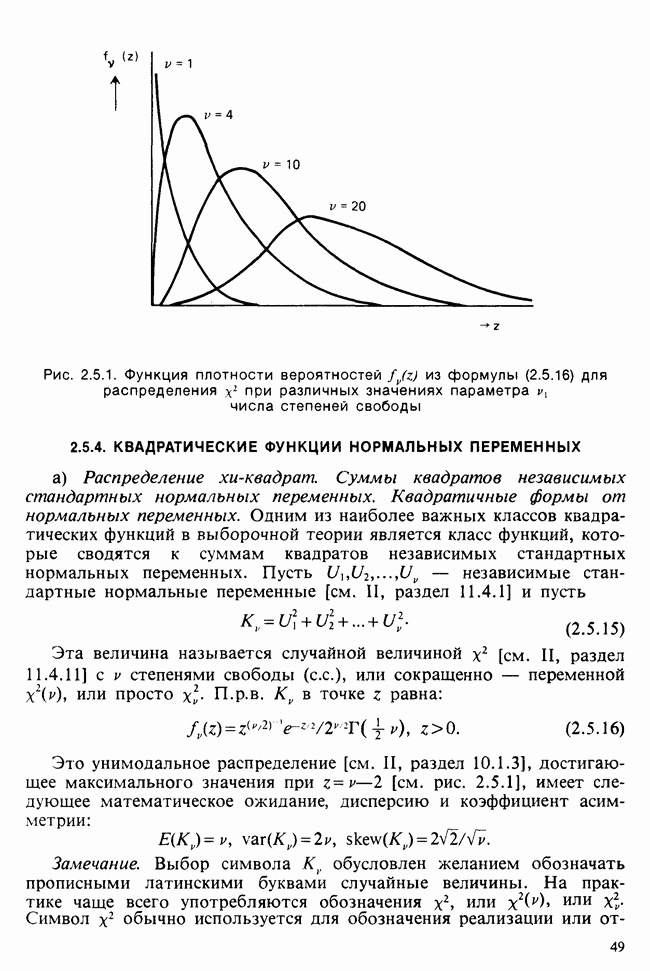
где  определяется в (6.5.10). Можно показать (например, с помощью методов из раздела 2.5.8), что случайная величина
определяется в (6.5.10). Можно показать (например, с помощью методов из раздела 2.5.8), что случайная величина

имеет распределение  степенями свободы [см. раздел 2.5.4, а)] и стохастически независима от
степенями свободы [см. раздел 2.5.4, а)] и стохастически независима от  . Отсюда следует, что
. Отсюда следует, что

имеет распределение Стьюдента с  степенями свободы [см. раздел 2.5.5]. Таким образом, центральным 95%-ным доверительным интервалом для а будет
степенями свободы [см. раздел 2.5.5]. Таким образом, центральным 95%-ным доверительным интервалом для а будет

[ср. с примером 4.5.2], где  является 97,5%-ной точкой распределения Стьюдента с
является 97,5%-ной точкой распределения Стьюдента с  степенями свободы.
степенями свободы.
Аналогично находят 95%-ный доверительный интервал для  :
:

г) Критерий значимости для  Как следует из предыдущих рассуждений (односторонний) уровень значимости для разности
Как следует из предыдущих рассуждений (односторонний) уровень значимости для разности  , где
, где  — гипотетическое значение неизвестного коэффициента регрессии, может быть найден благодаря тому, что случайная величина t имеет распределение Стьюдента с
— гипотетическое значение неизвестного коэффициента регрессии, может быть найден благодаря тому, что случайная величина t имеет распределение Стьюдента с  степенями свободы, где
степенями свободы, где

Аналогичное утверждение справедливо и для  в этом случае
в этом случае

При двухстороннем критерии уровень значимости удваивается.
Критерий, основанный на (6.5.16), — один из наиболее распространенных статистических критериев. Наиболее часто он применяется при условии  в этом случае на основе его проверяется, есть ли значимая (линейная) зависимость у от х.
в этом случае на основе его проверяется, есть ли значимая (линейная) зависимость у от х.
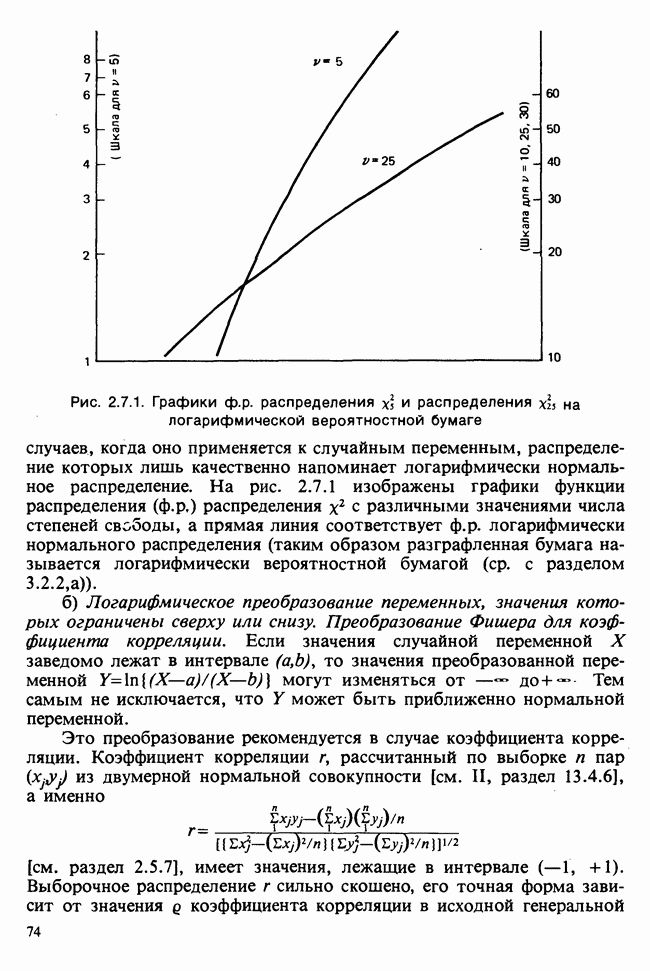
д) Доверительный интервал для  Линейная модель
Линейная модель

эквивалентна

или

где  обозначает оценку ожидаемого отклика при условии, что независимая переменная х примет значение
обозначает оценку ожидаемого отклика при условии, что независимая переменная х примет значение  вычислено по формуле (6.5.5). Поскольку
вычислено по формуле (6.5.5). Поскольку  нормально распределены с параметрами, задаваемыми выражениями (6.5.8) и (6.5.9), случайная величина
нормально распределены с параметрами, задаваемыми выражениями (6.5.8) и (6.5.9), случайная величина  также будет иметь нормальное распределение с математическим
также будет иметь нормальное распределение с математическим

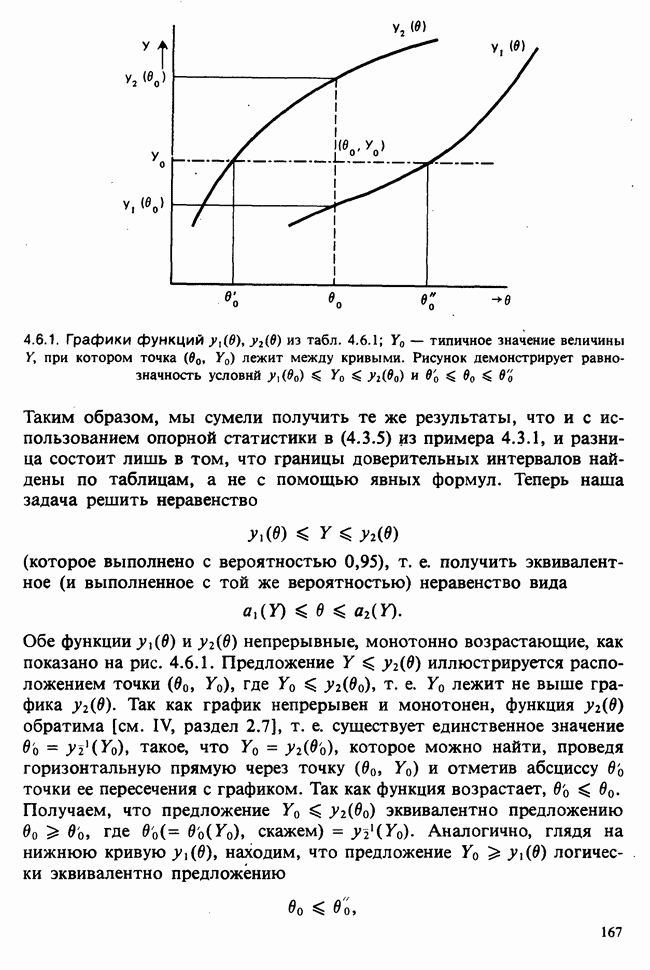
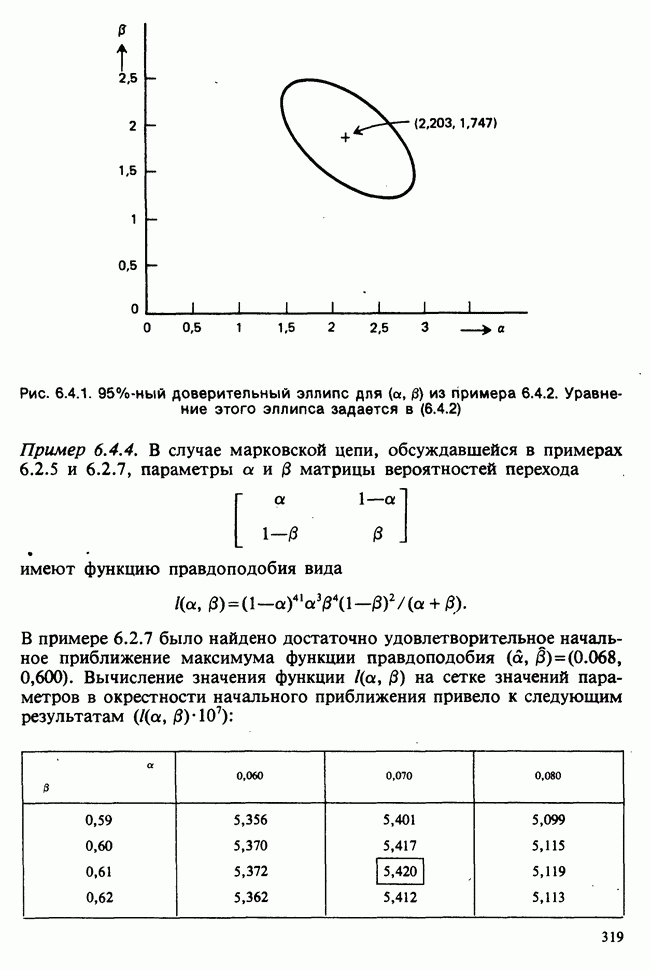
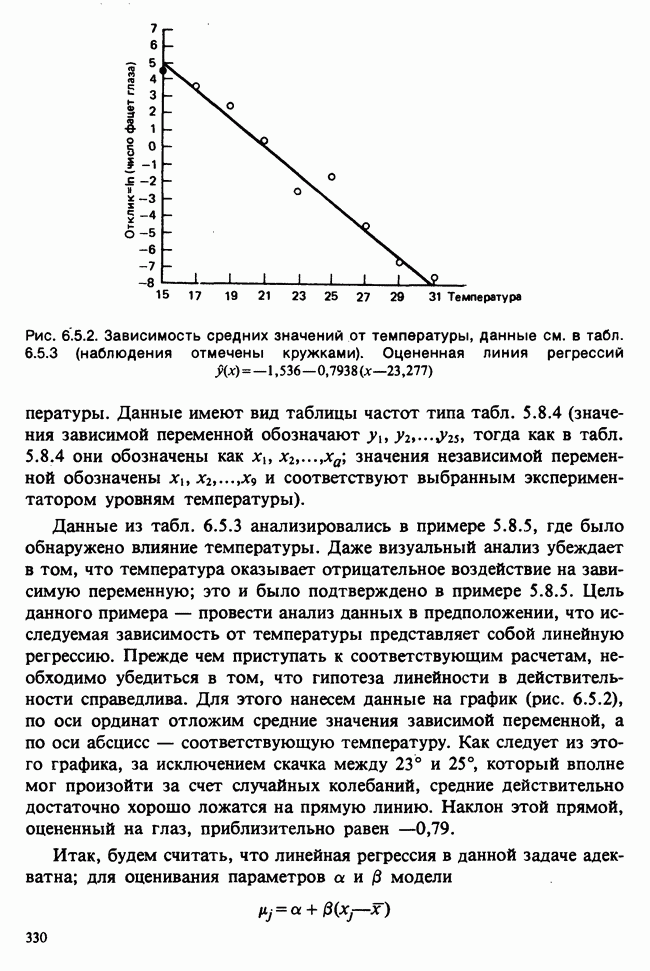
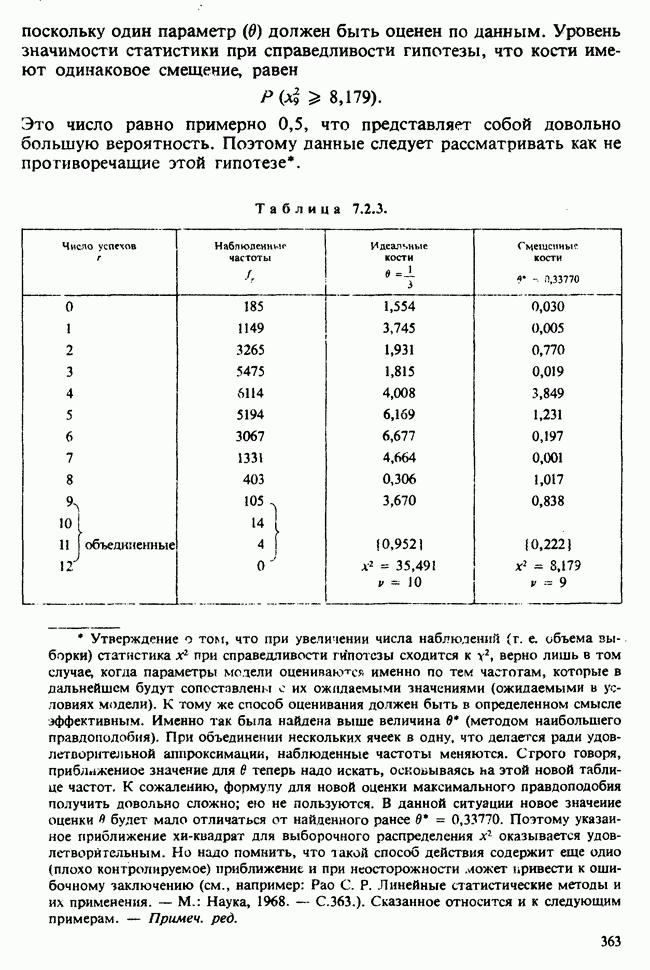
Рис. 6.5.2. Зависимость средних значений от температуры, данные см. в табл. 6.5.3 (наблюдения отмечены кружками). Оцененная линия регрессий  )
)
температуры. Данные имеют вид таблицы частот типа табл. 5.8.4 (значения зависимой переменной обозначают  тогда как в табл. 5.8.4 они обозначены как
тогда как в табл. 5.8.4 они обозначены как  значения независимой переменной обозначены
значения независимой переменной обозначены  и соответствуют выбранным экспериментатором уровням температуры).
и соответствуют выбранным экспериментатором уровням температуры).
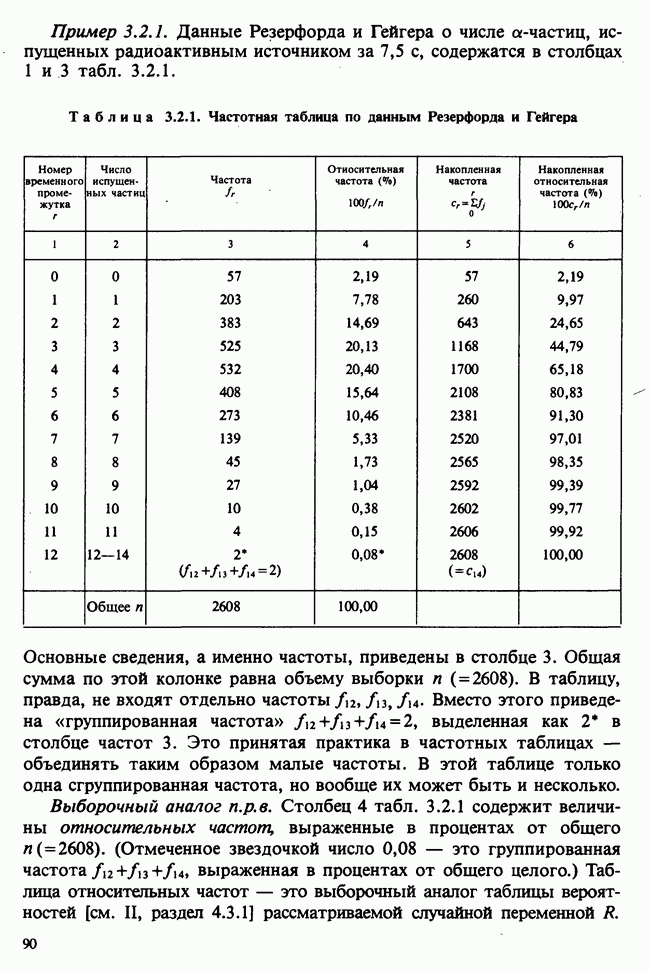
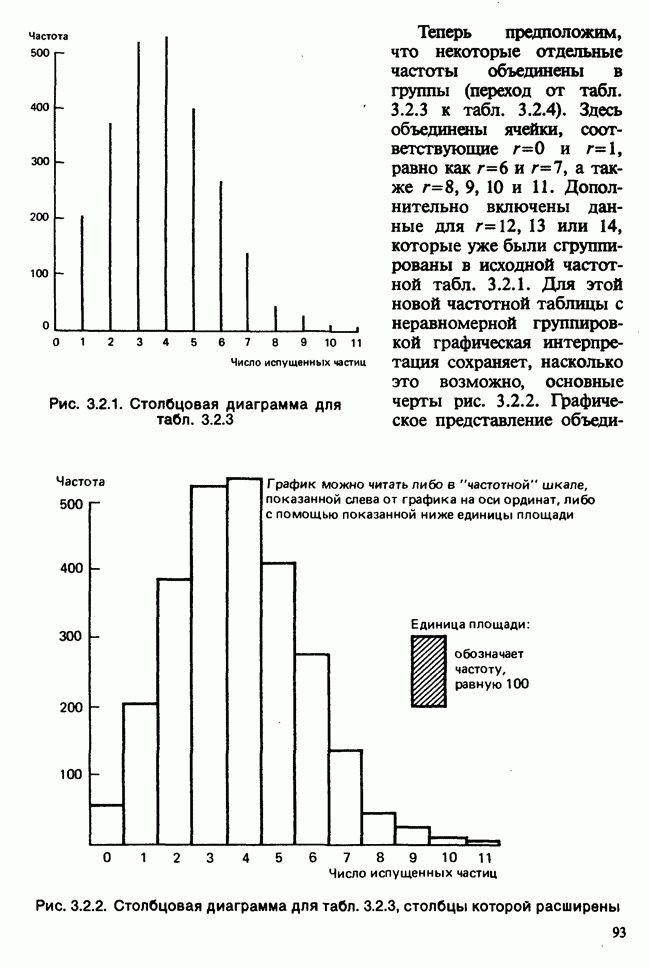
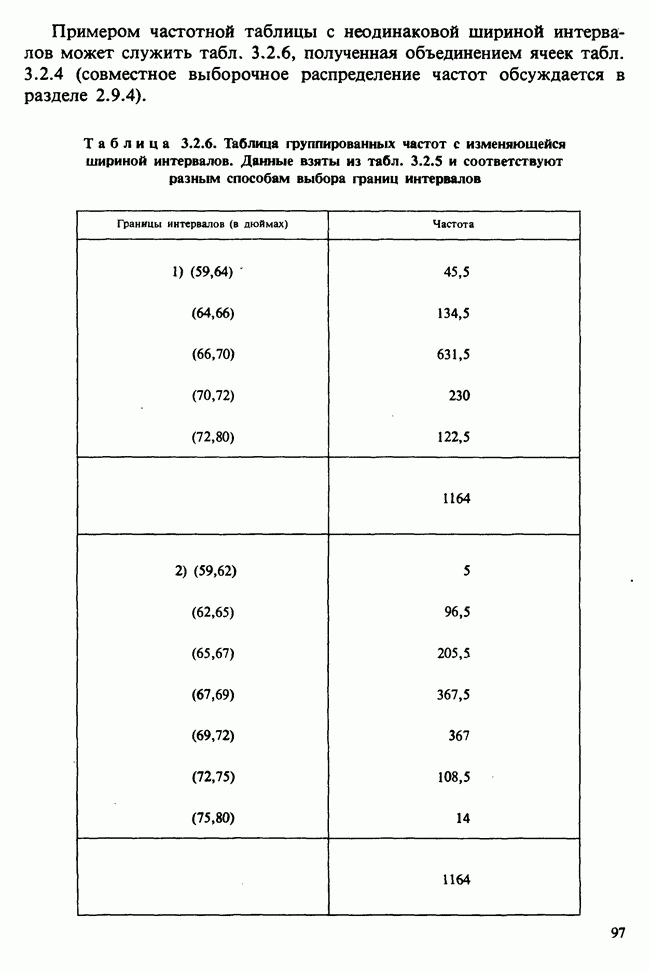
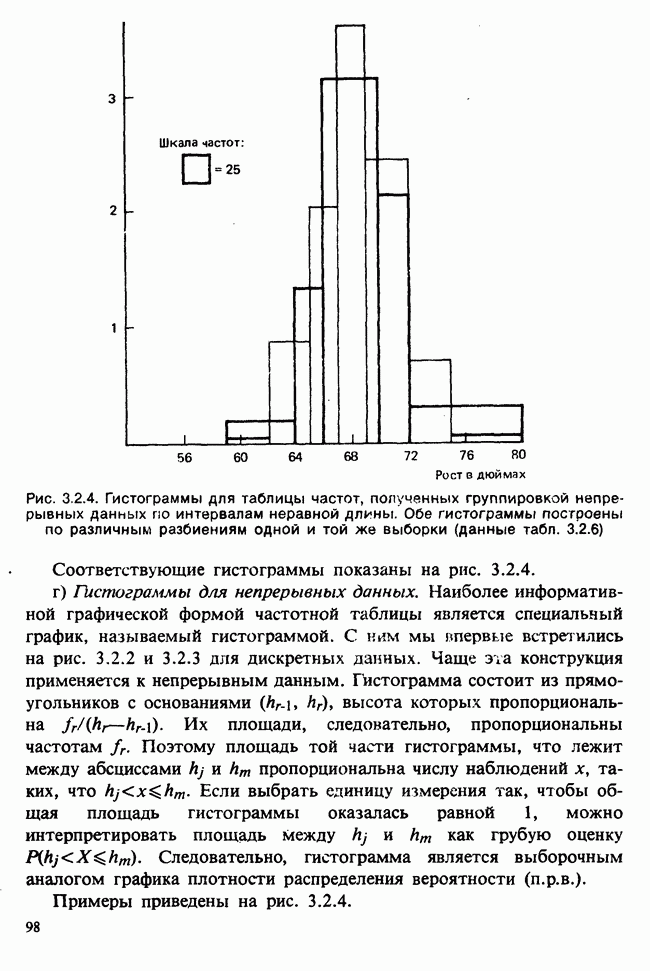
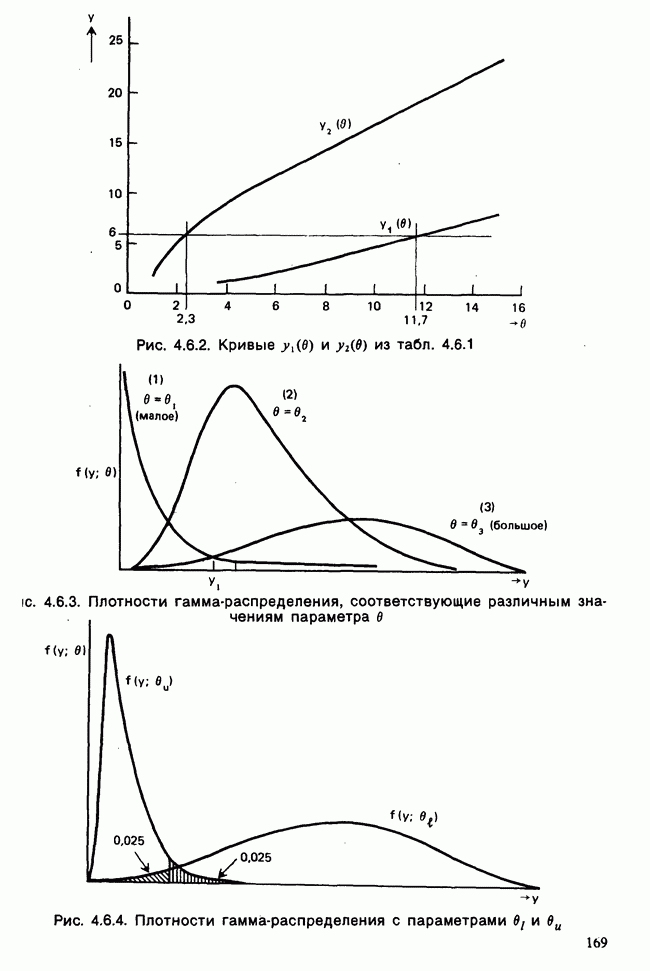
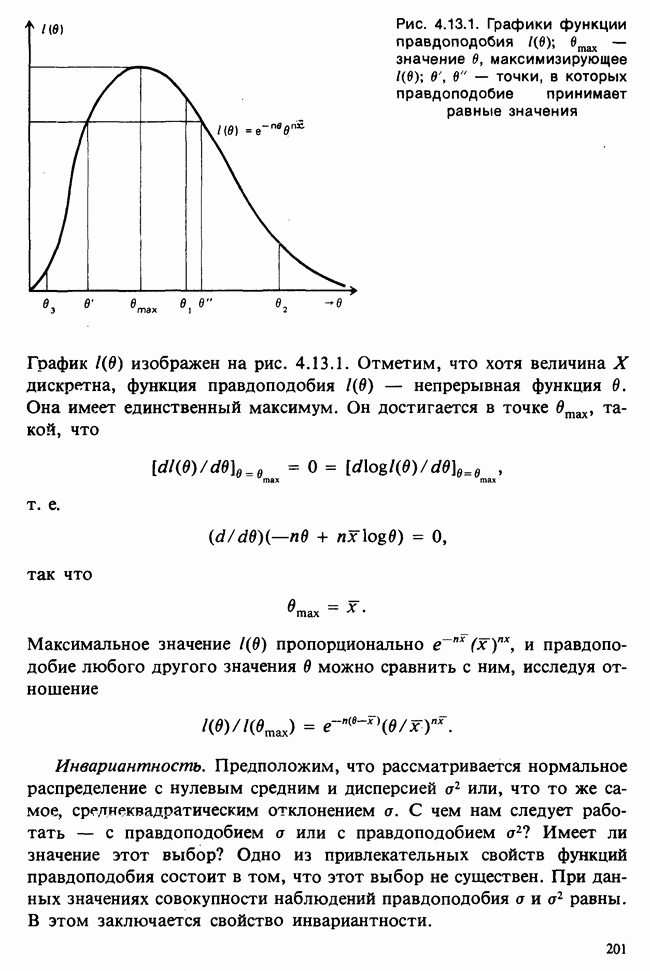
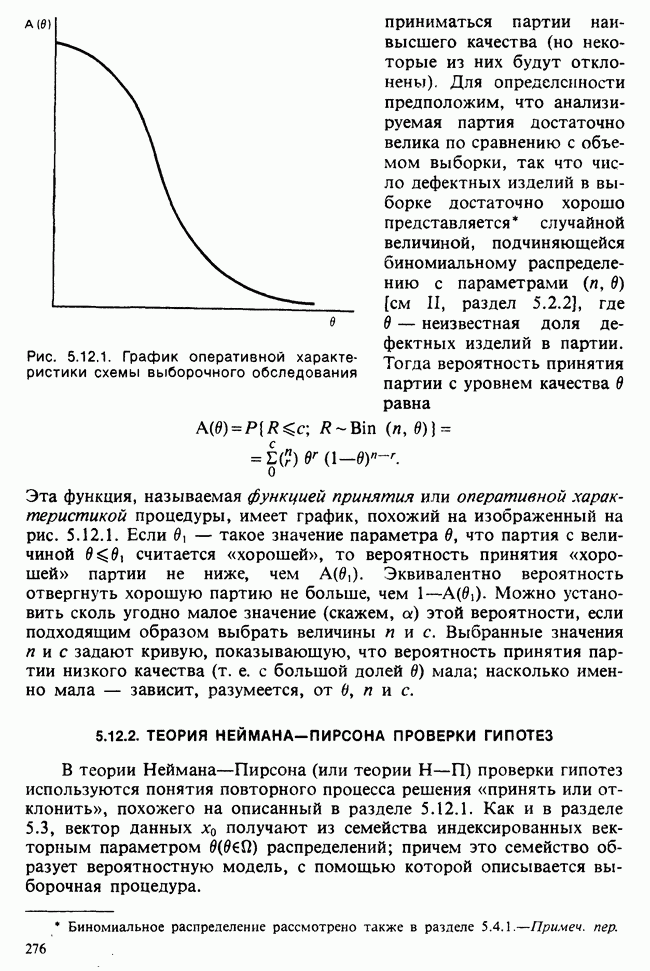
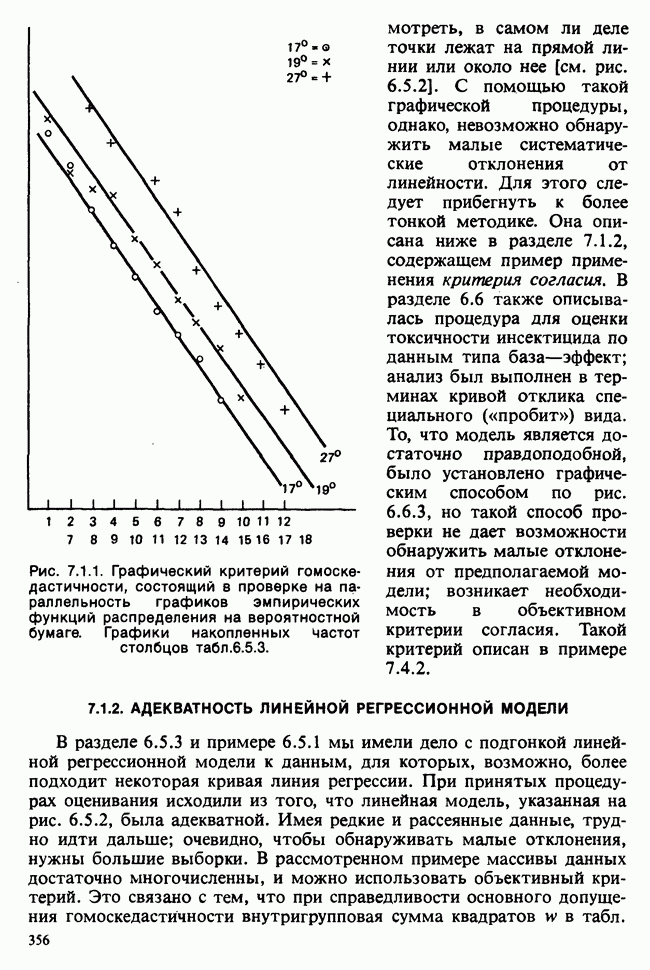
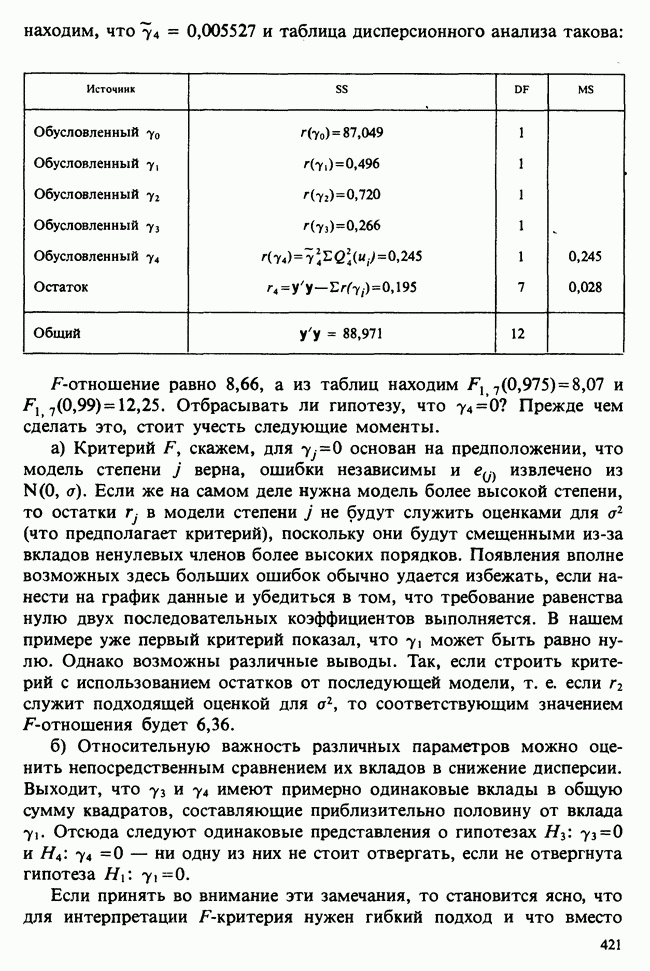
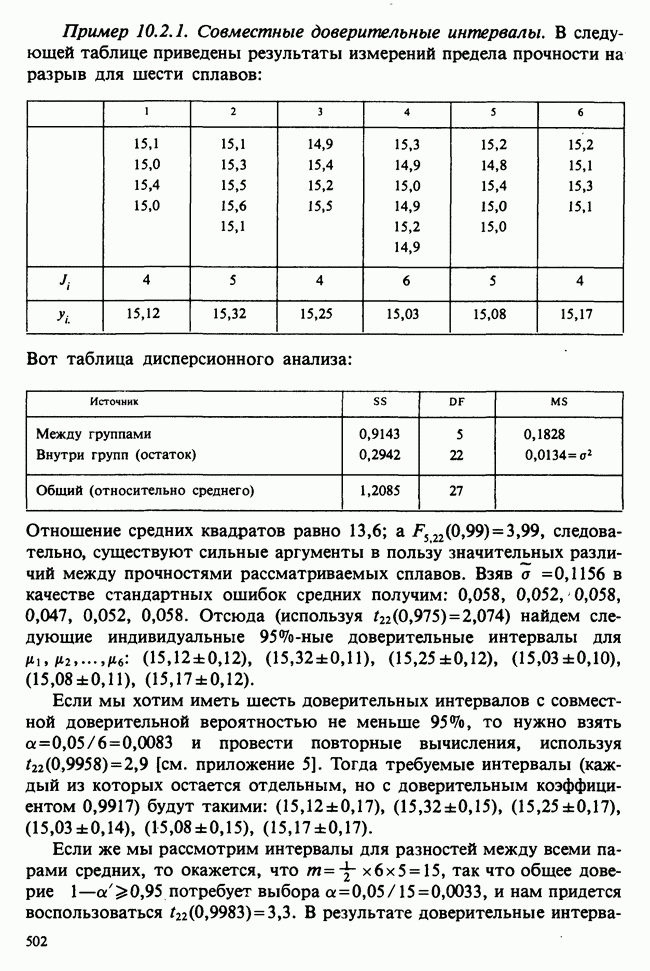
Данные из табл. 6.5.3 анализировались в примере 5.8.5, где было обнаружено влияние температуры. Даже визуальный анализ убеждает в том, что температура оказывает отрицательное воздействие на зависимую переменную; это и было подтверждено в примере 5.8.5. Цель данного примера — провести анализ данных в предположении, что исследуемая зависимость от температуры представляет собой линейную регрессию. Прежде чем приступать к соответствующим расчетам, необходимо убедиться в том, что гипотеза линейности в действительности справедлива. Для этого нанесем данные на график (рис. 6.5.2), по оси ординат отложим средние значения зависимой переменной, а по оси абсцисс — соответствующую температуру. Как следует из этого графика, за исключением скачка между 23° и 25°, который вполне мог произойти за счет случайных колебаний, средние действительно достаточно хорошо ложатся на прямую линию. Наклон этой прямой, оцененный на глаз, приблизительно равен —0,79.
Итак, будем считать, что линейная регрессия в данной задаче адекватна; для оценивания параметров  модели
модели

воспользуемся методами из раздела 6.5.3. Оценкой отклика тогда будет служить выражение

Для нашей выборки статистики принимают следующие значения:

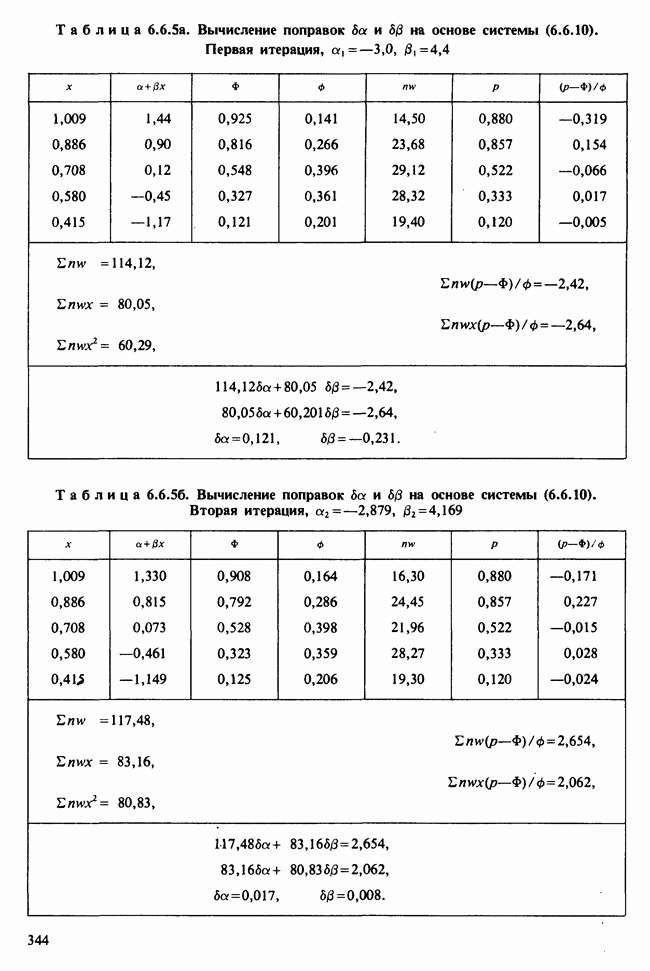
Как следует из (6.5.6) и (6.5.7),

В табл. 6.5.4 приведены значения  с наблюдаемыми значениями у.
с наблюдаемыми значениями у.
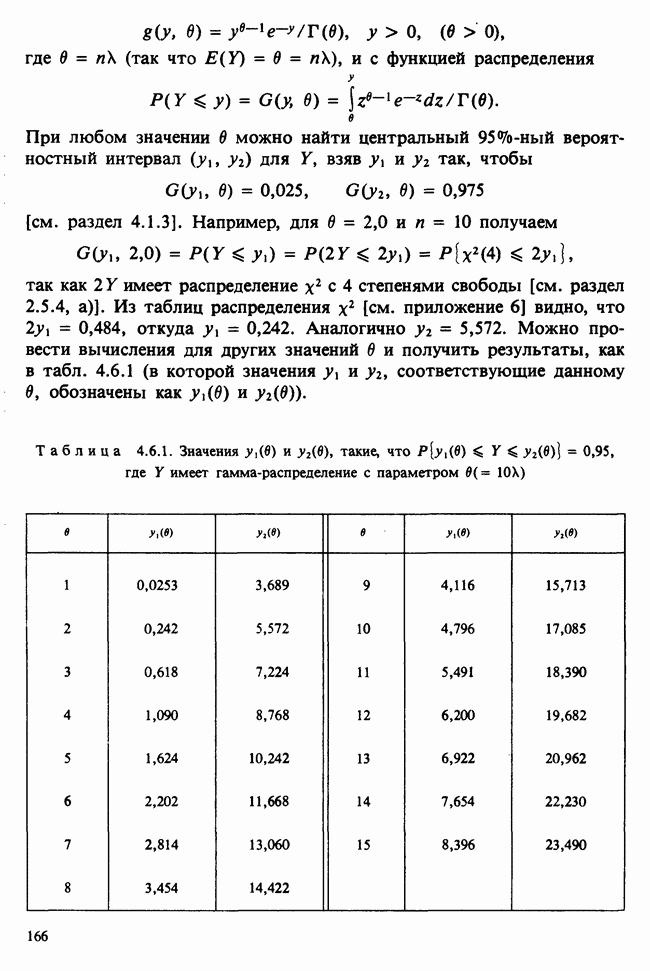
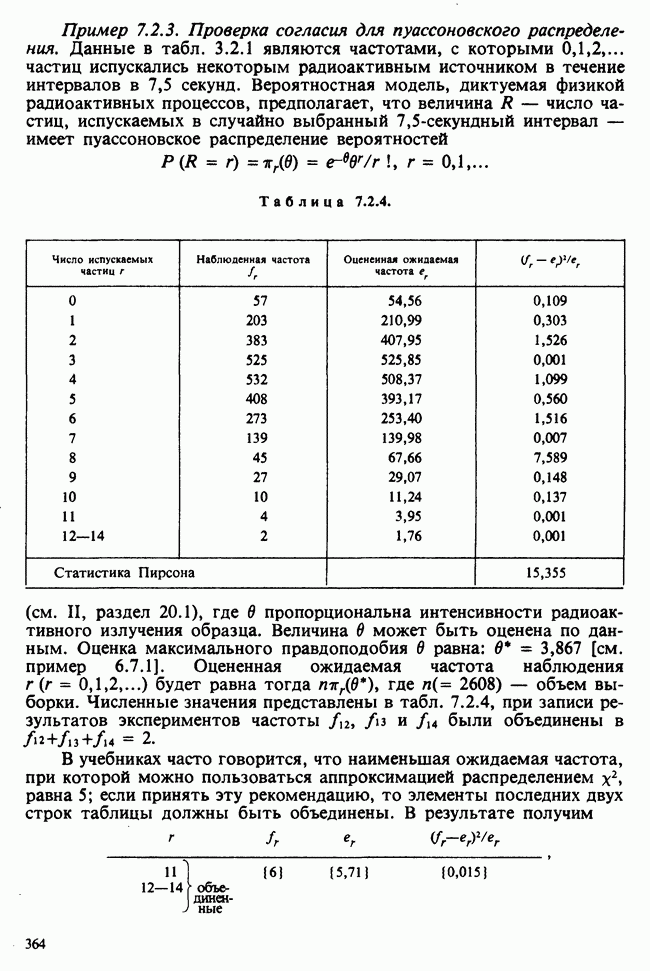
Таблица 6.5.3. (см. скан) Зависимость числа фацет глаза от температуры
Продолжение табл. 6.5.3 (см. скан)
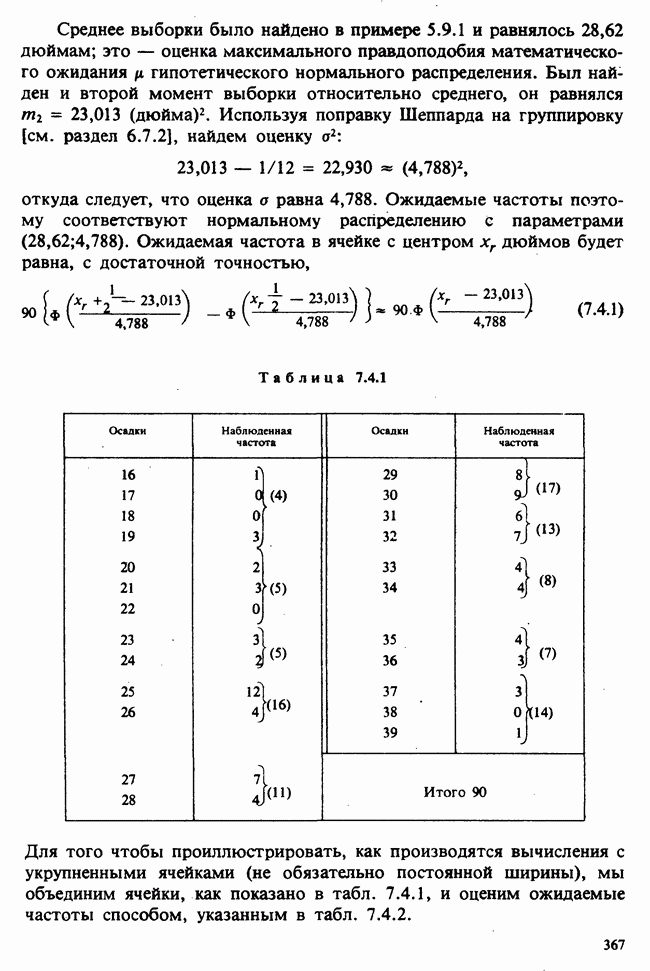
Таблица 6.5.4. (см. скан) Оцененные значения  и их сравнения с наблюдаемыми величинами
и их сравнения с наблюдаемыми величинами 
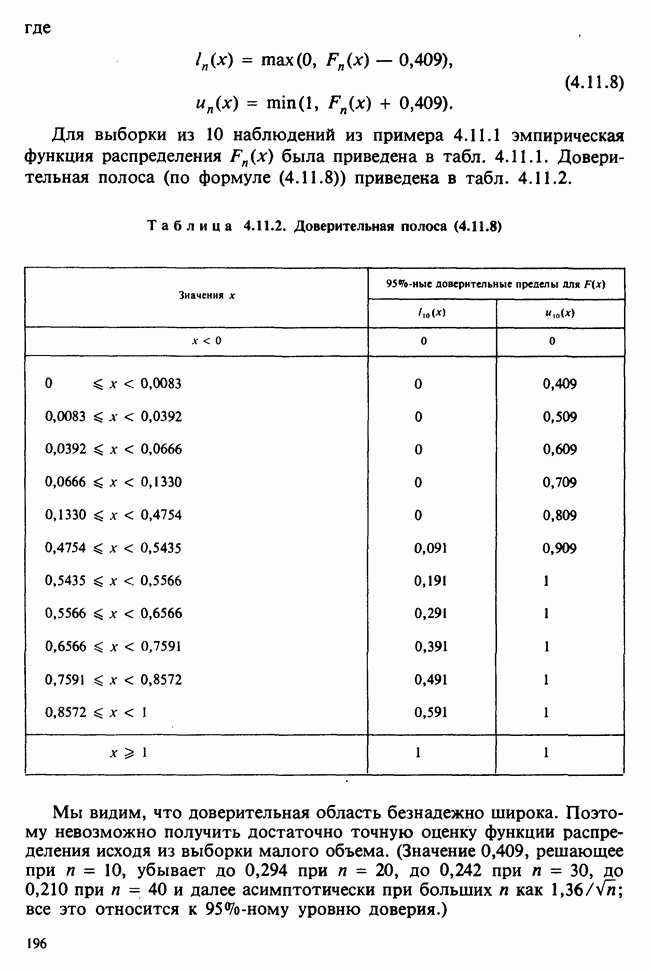
При оценивании стандартных ошибок для  и необходимо вычислить сумму квадратов отклонений (т. е. сумму квадратов разности между наблюдаемыми значениями и значениями, полученными по модели) по формуле (6.5.10). В наших обозначениях эта величина равна:
и необходимо вычислить сумму квадратов отклонений (т. е. сумму квадратов разности между наблюдаемыми значениями и значениями, полученными по модели) по формуле (6.5.10). В наших обозначениях эта величина равна:

Поскольку  первые два члена равны
первые два члена равны  что представляет собой общую сумму квадратов см. (5.8.18), ее численное значение можно найти в табл. 5.8.5, оно равно 16,202. Таким образом,
что представляет собой общую сумму квадратов см. (5.8.18), ее численное значение можно найти в табл. 5.8.5, оно равно 16,202. Таким образом,

Отсюда следует, что оценка дисперсии, определяемая по формуле (6.5.11), равна:

а соответствующие оценки выборочных дисперсий для  вычисляемые по формуле (6.5.12), равны:
вычисляемые по формуле (6.5.12), равны:

95%-ные доверительные интервалы для  определяются в (6.5.13) и (6.5.14). Для параметра а:
определяются в (6.5.13) и (6.5.14). Для параметра а:

для параметра (3:

Для проверки гипотезы  (зависимость от температуры отсутствует), как следует из (6.5.15) и (6.5.16), необходимо найти значение
(зависимость от температуры отсутствует), как следует из (6.5.15) и (6.5.16), необходимо найти значение  -статистики
-статистики

Высокое значение этой статистики не вызывает сомнения в ошибочности гипотезы 
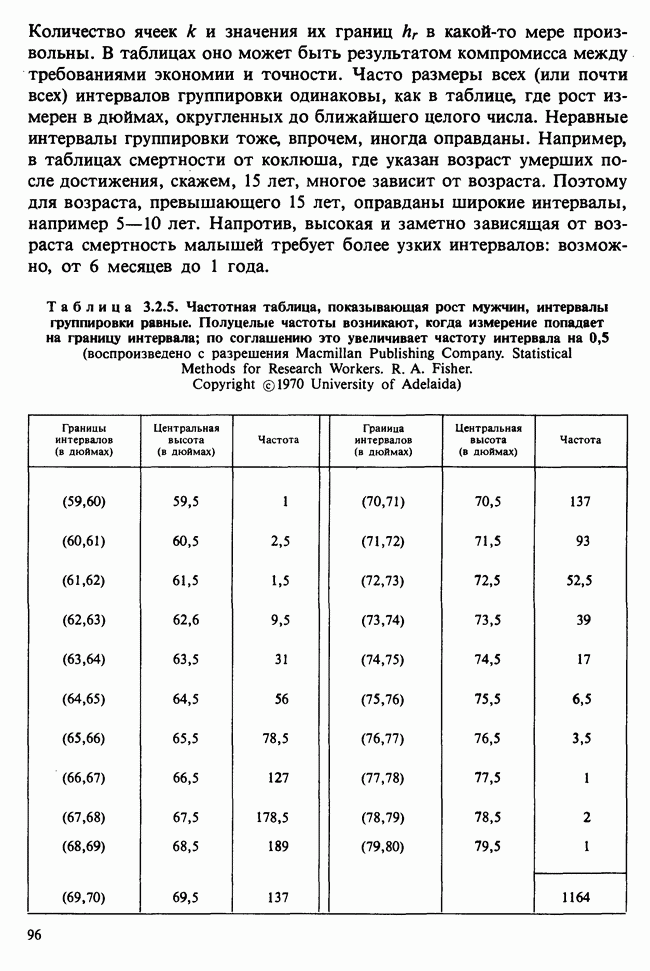
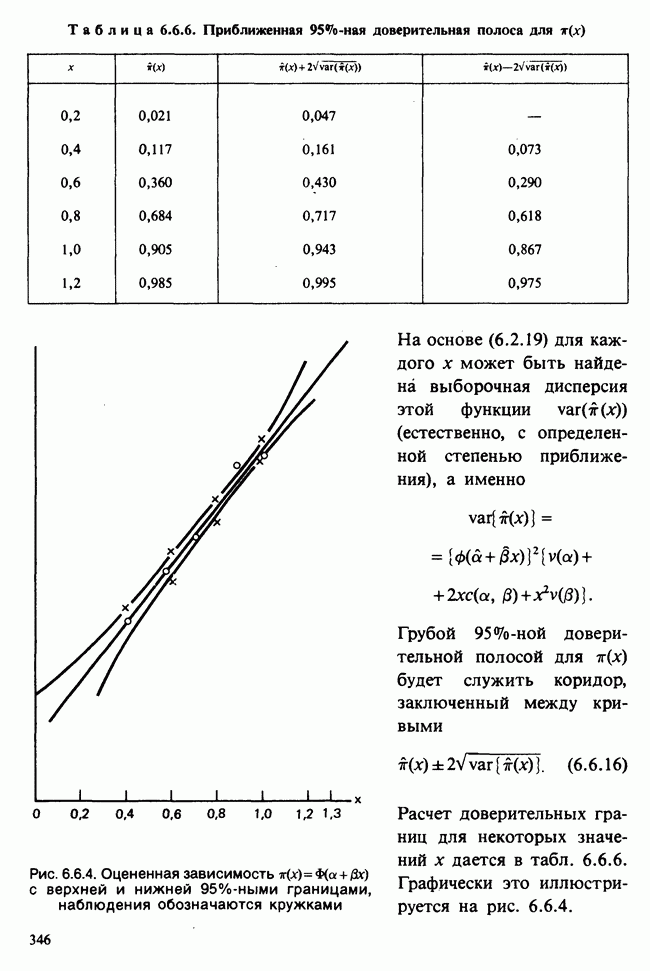
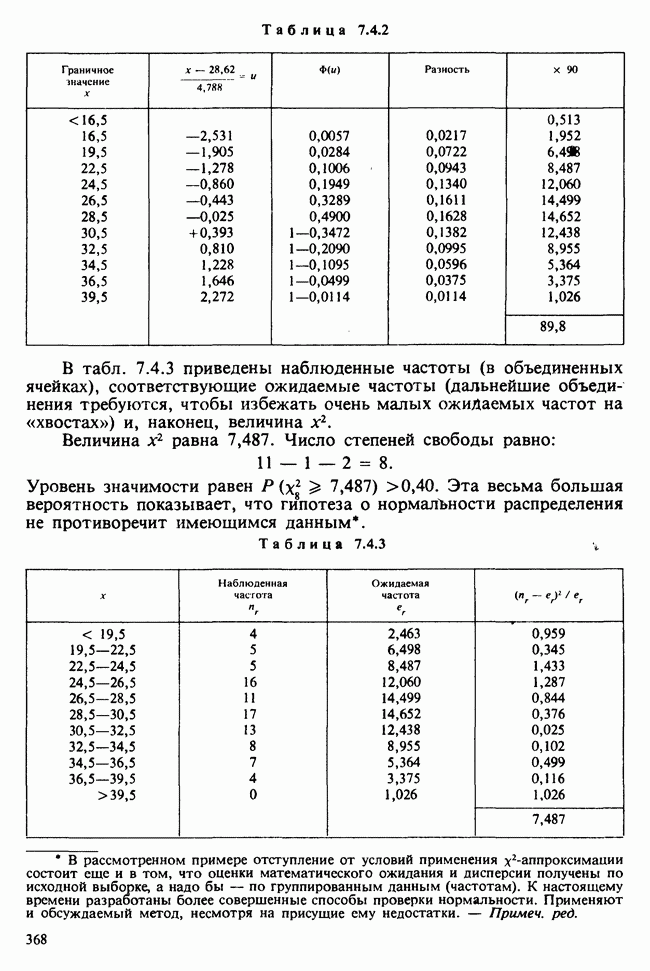
95%-ный доверительный коридор для значений регрессии, задаваемый формулой (6.5.18), требует знания величины  которая вычисляется по формуле (6.5.17); в нашем случае она равна:
которая вычисляется по формуле (6.5.17); в нашем случае она равна:

Подставляя это выражение в (6.5.18) и полагая  находим доверительный коридор для Я. Для некоторых х он показан в табл. 6.5.5.
находим доверительный коридор для Я. Для некоторых х он показан в табл. 6.5.5.






























































































































































































































































































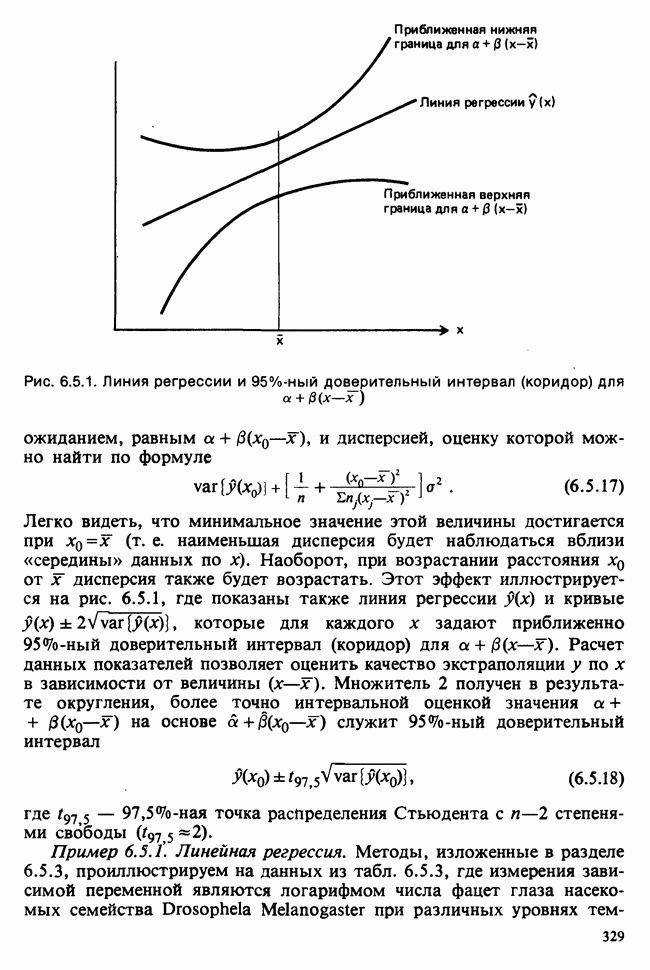





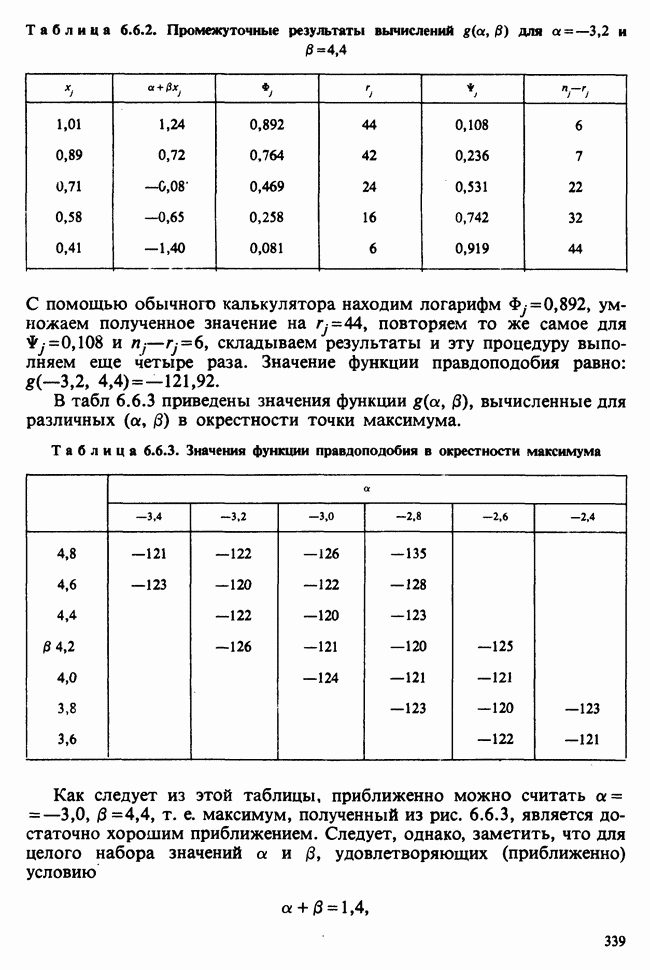














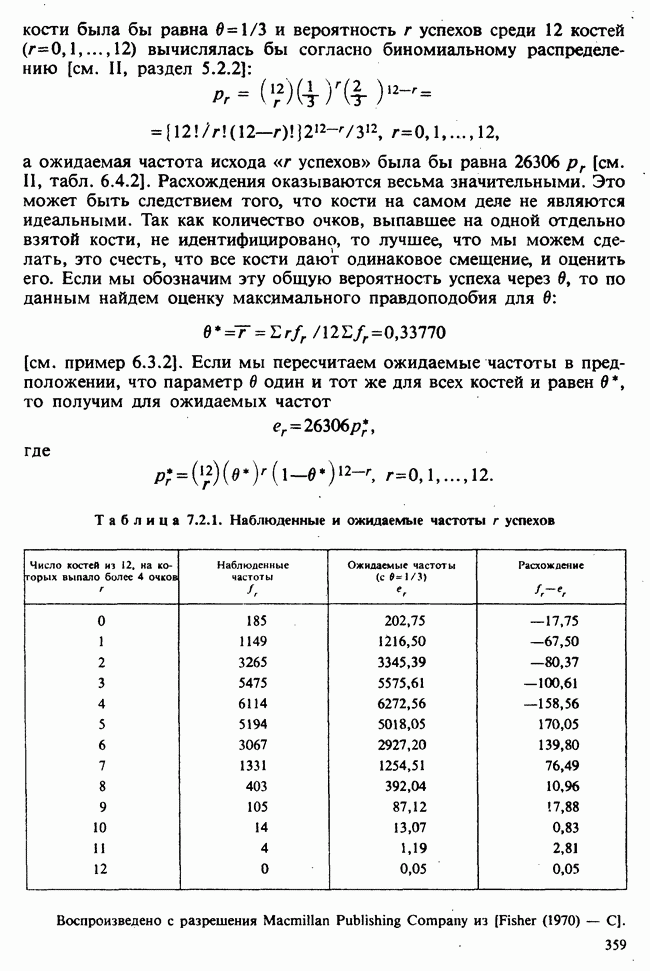
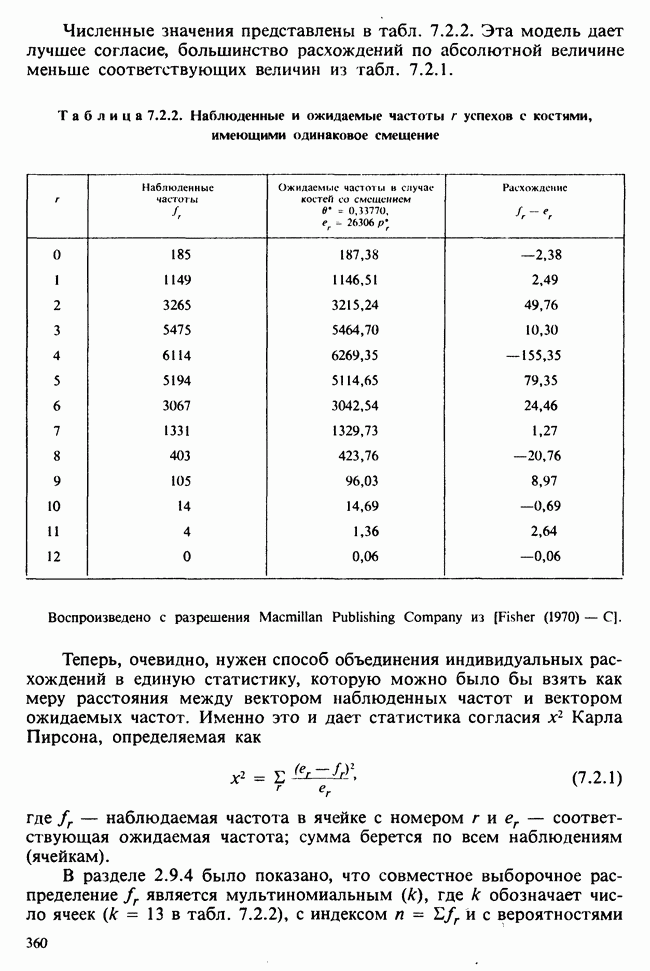









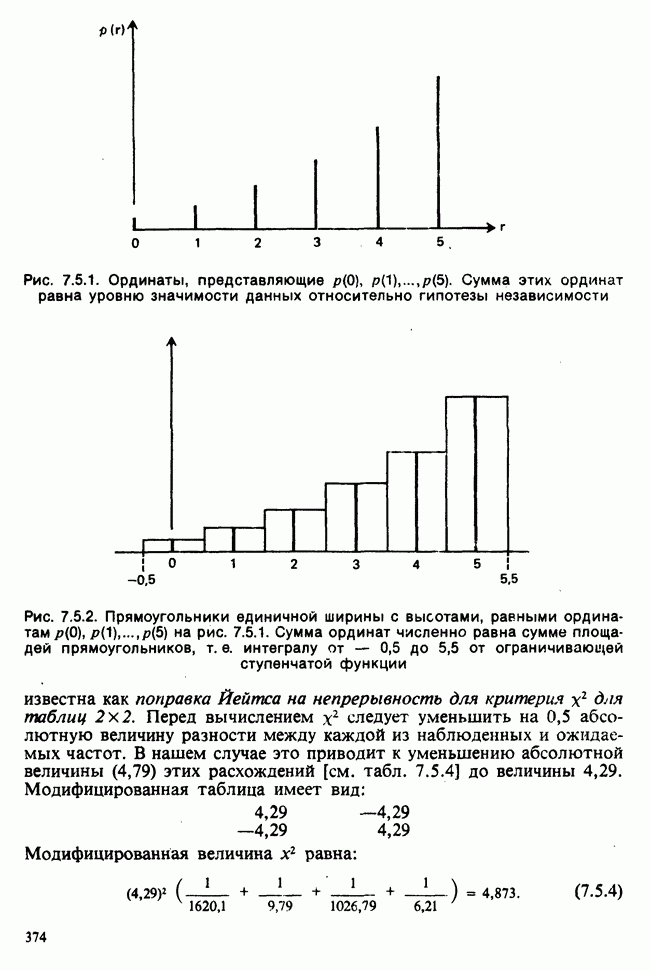


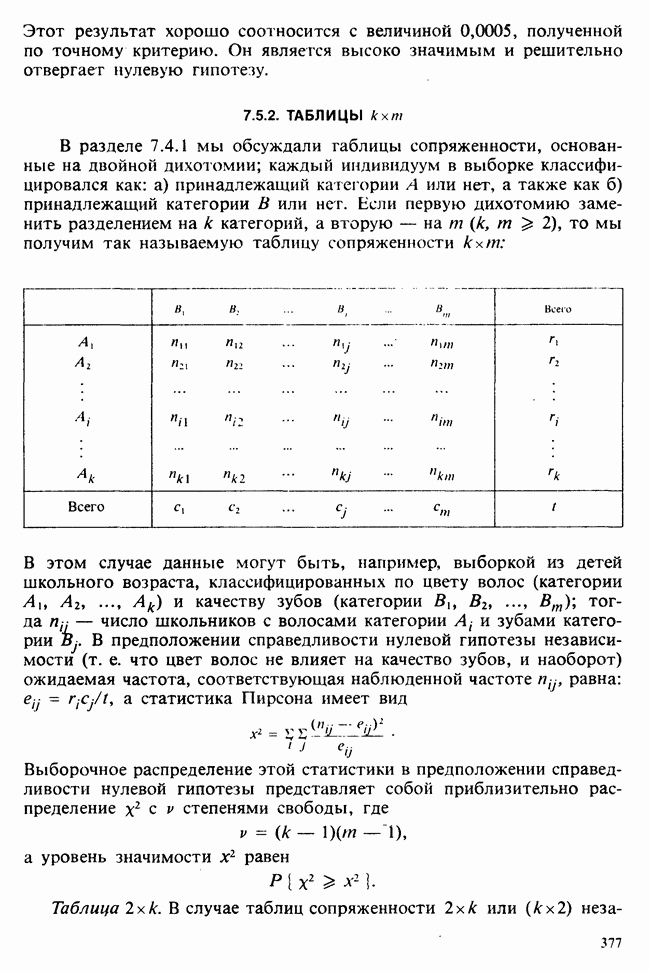


























































































































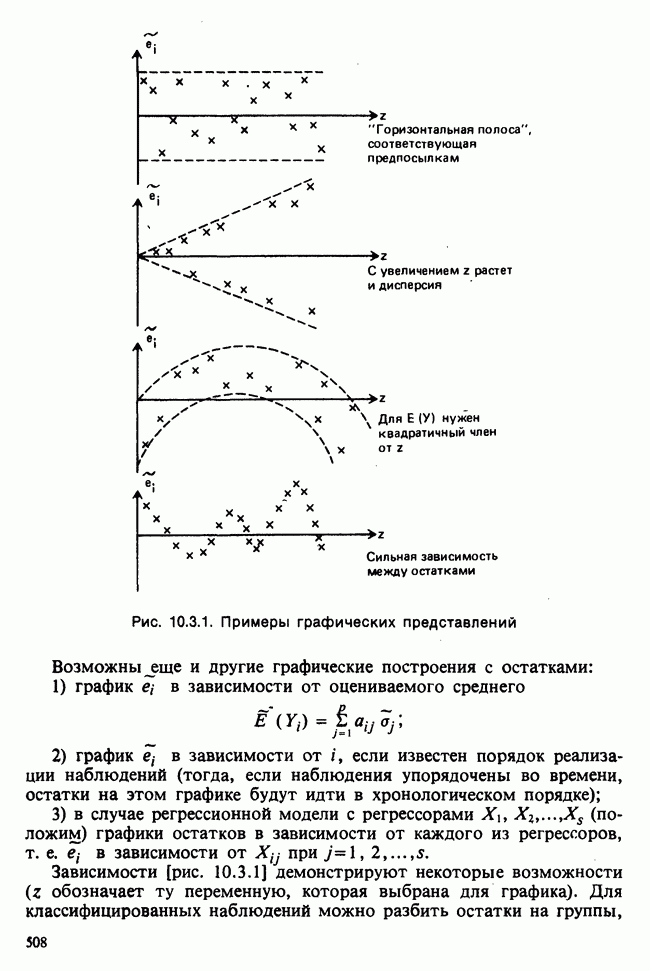



 и дисперсией, оценку которой можно найти по формуле
и дисперсией, оценку которой можно найти по формуле

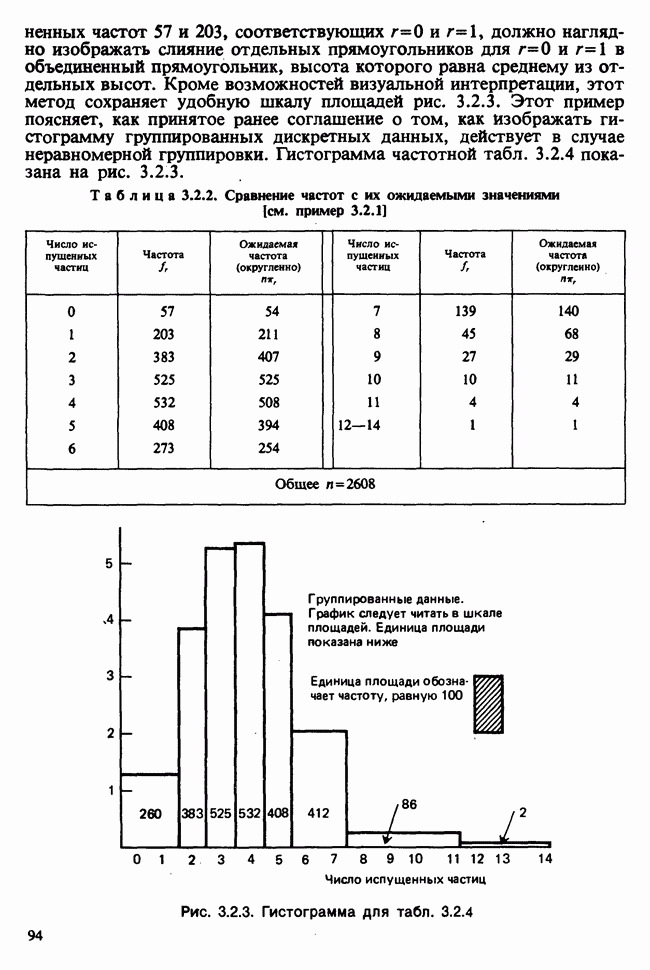
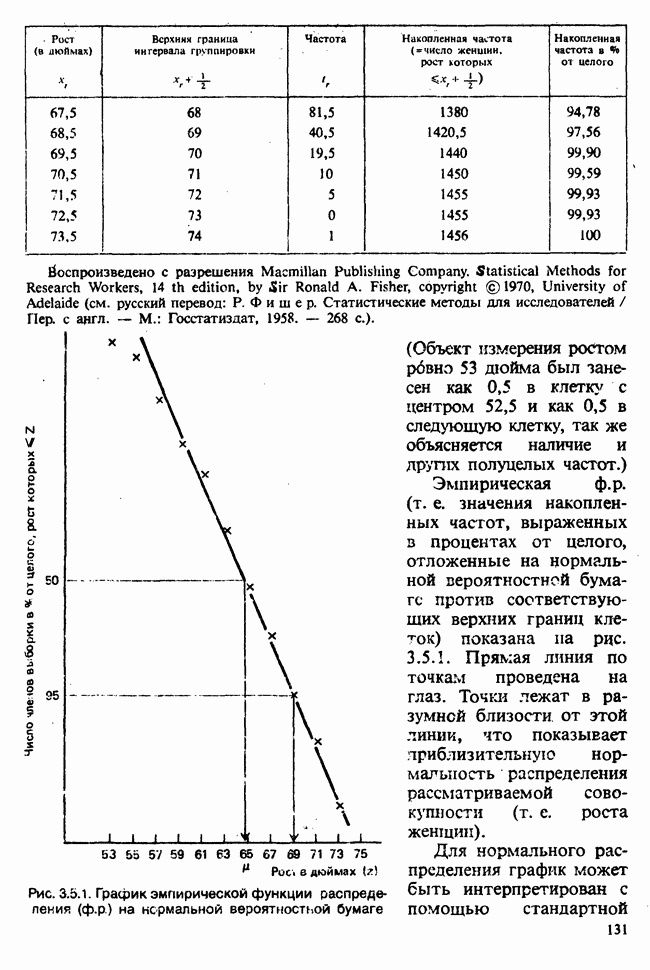
 (т. е. наименьшая дисперсия будет наблюдаться вблизи «середины» данных по х). Наоборот, при возрастании расстояния
(т. е. наименьшая дисперсия будет наблюдаться вблизи «середины» данных по х). Наоборот, при возрастании расстояния  от х дисперсия также будет возрастать. Этот эффект иллюстрируется на рис. 6.5.1, где показаны также линия регрессии
от х дисперсия также будет возрастать. Этот эффект иллюстрируется на рис. 6.5.1, где показаны также линия регрессии  и кривые
и кривые  которые для каждого х задают приближенно 95%-ный доверительный интервал (коридор) для а
которые для каждого х задают приближенно 95%-ный доверительный интервал (коридор) для а  Расчет данных показателей позволяет оценить качество экстраполяции у по х в зависимости от величины
Расчет данных показателей позволяет оценить качество экстраполяции у по х в зависимости от величины  Множитель 2 получен в результате округления, более точно интервальной оценкой значения а
Множитель 2 получен в результате округления, более точно интервальной оценкой значения а  на основе а
на основе а  служит 95%-ный доверительный интервал
служит 95%-ный доверительный интервал

 -ная точка распределения Стьюдента с
-ная точка распределения Стьюдента с  степенями свободы
степенями свободы 
 и нижняя
и нижняя  доверительные границы для коридора значений регрессии
доверительные границы для коридора значений регрессии  где
где 

