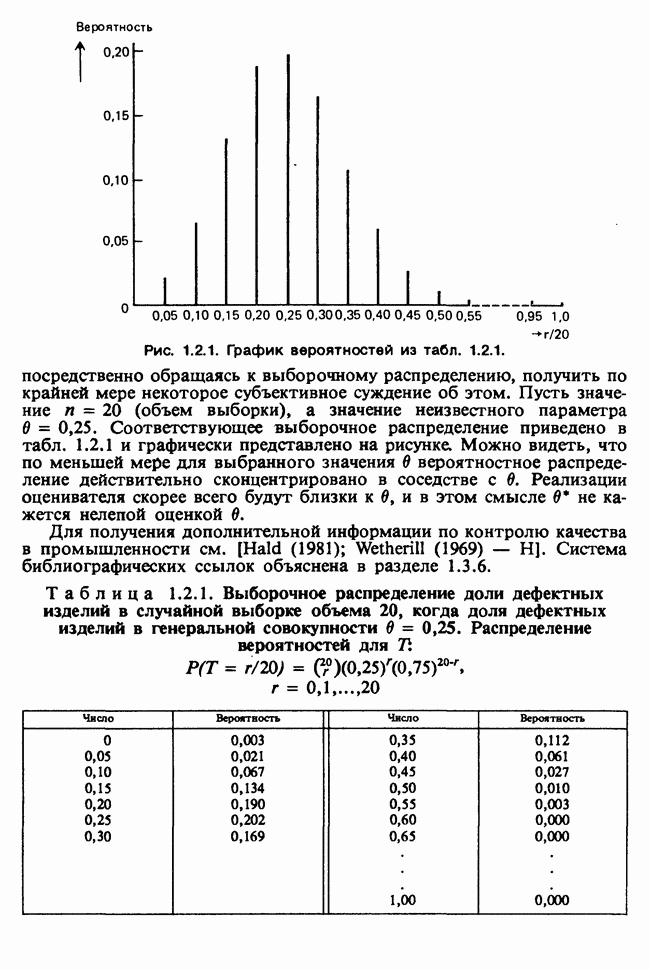
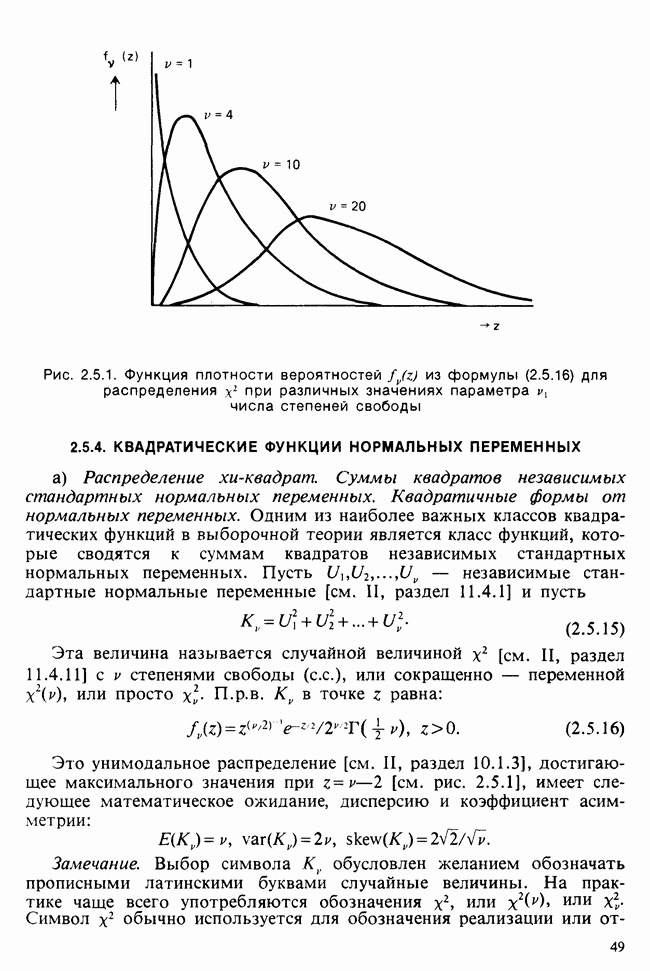
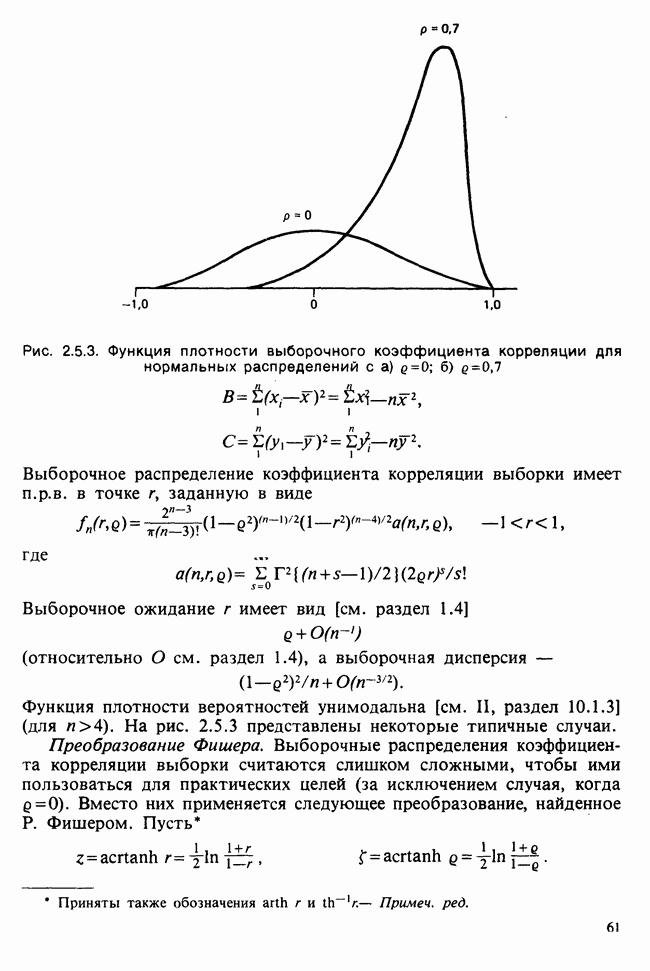
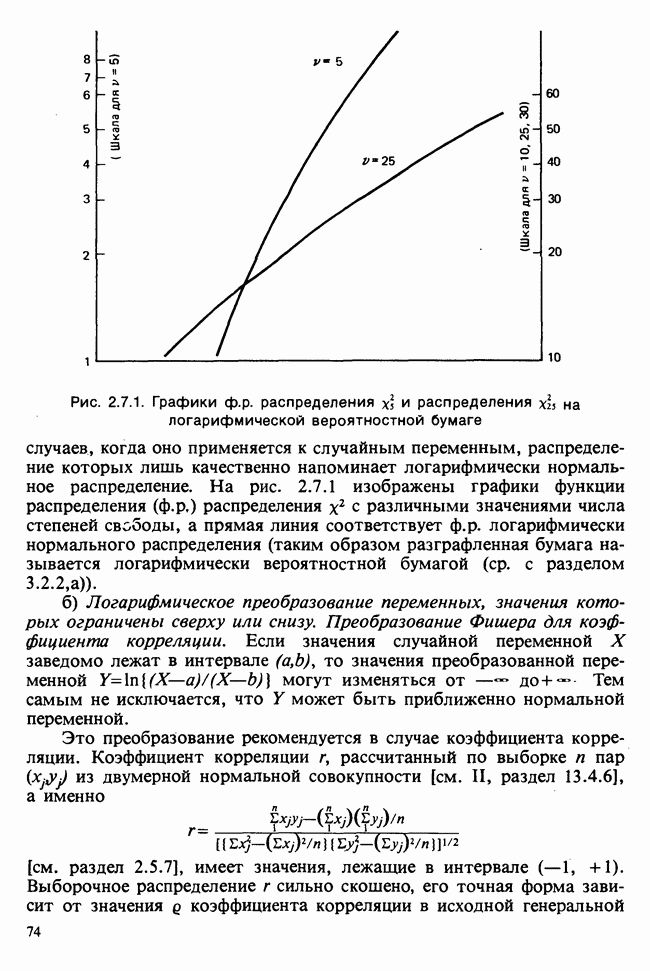
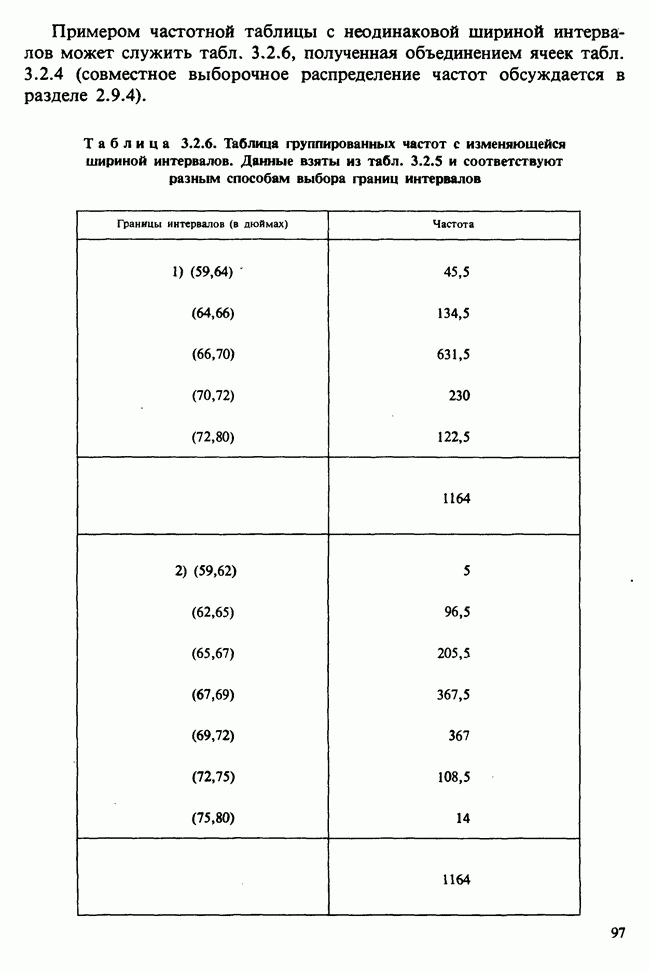
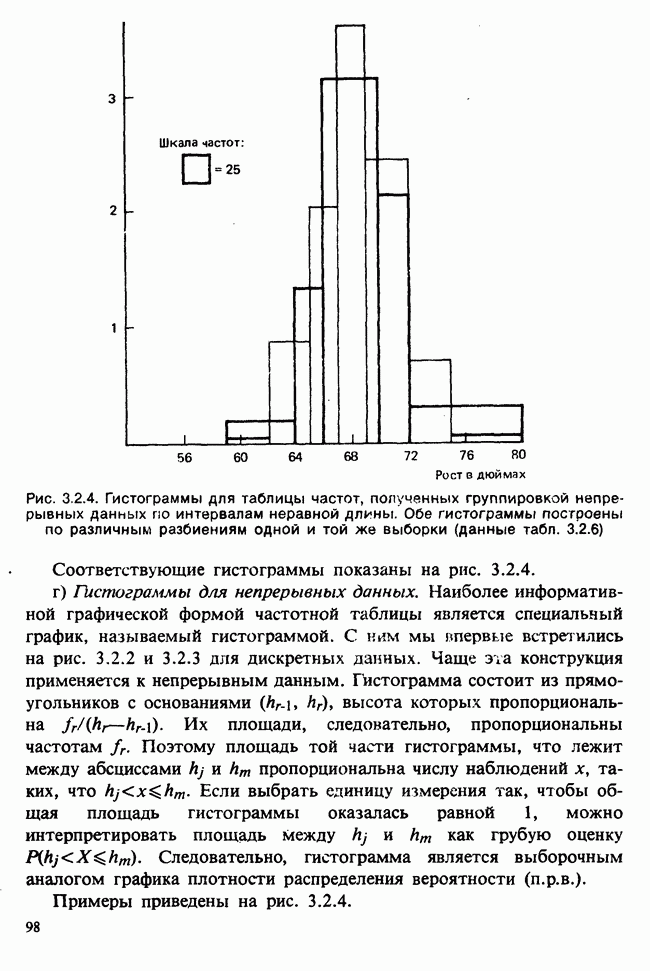
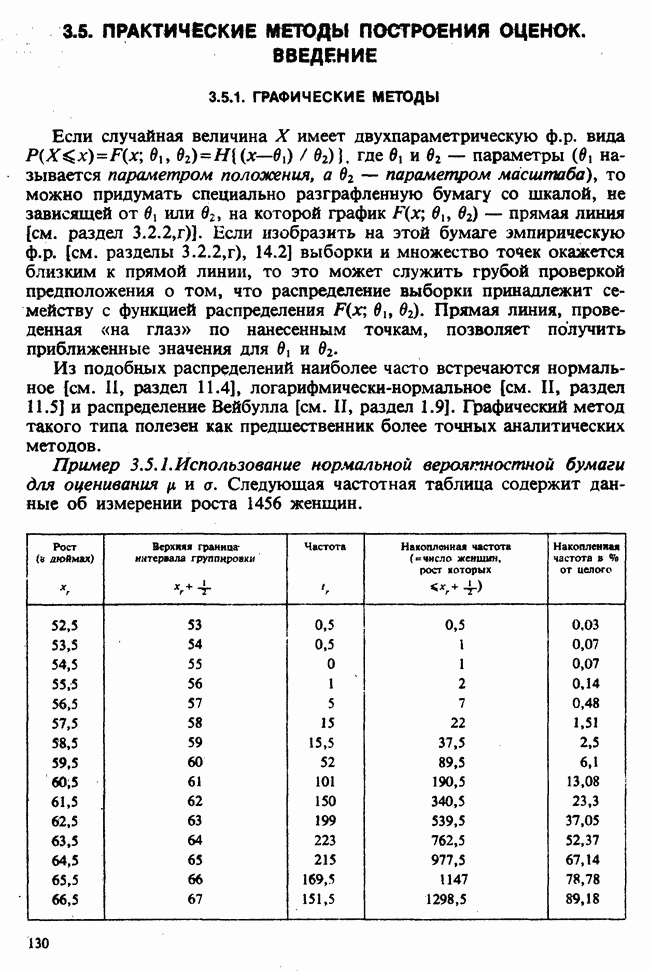
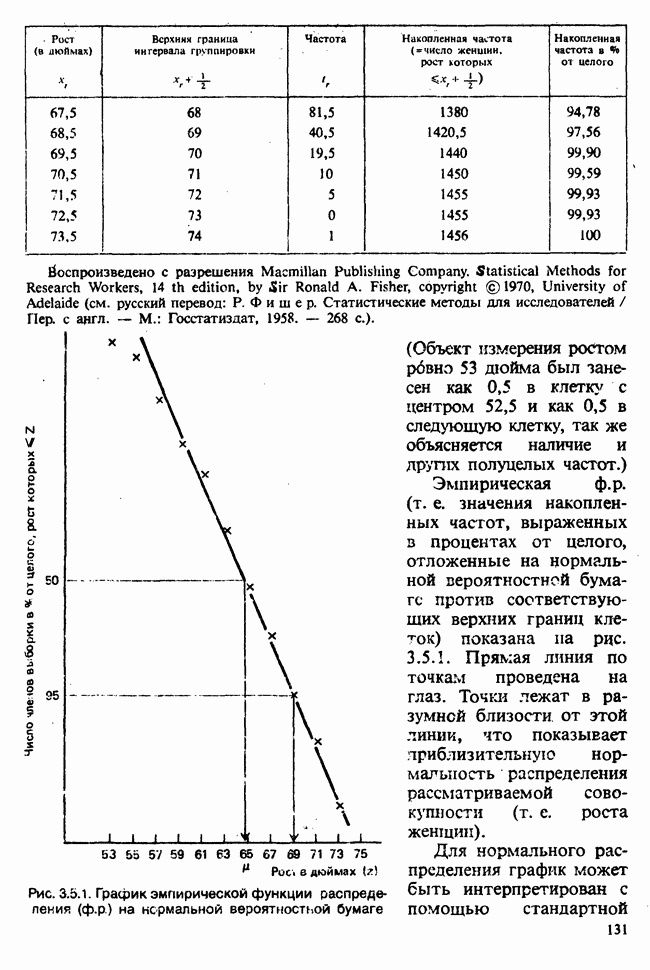
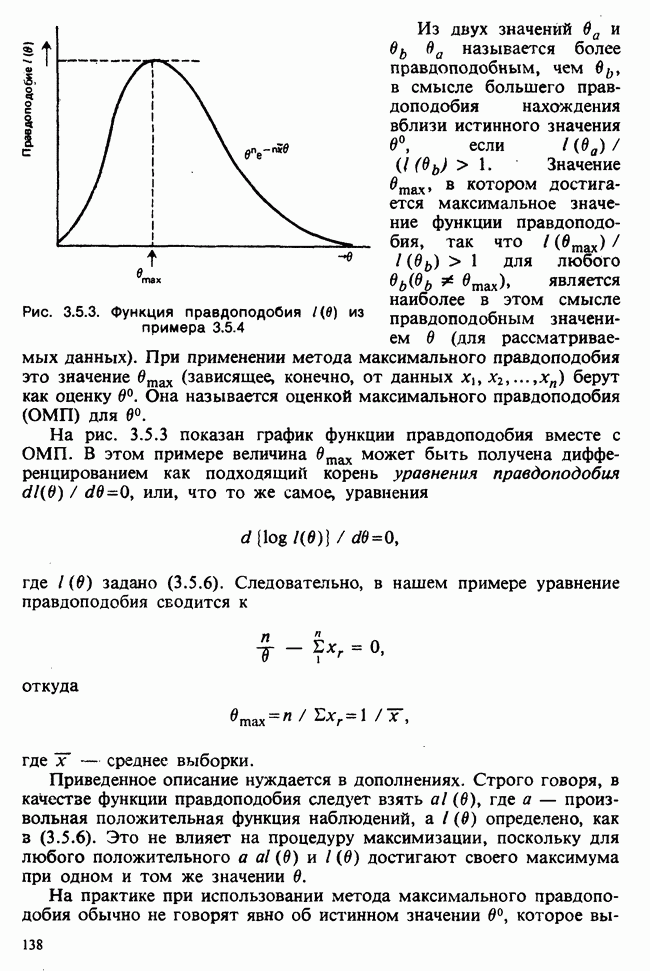
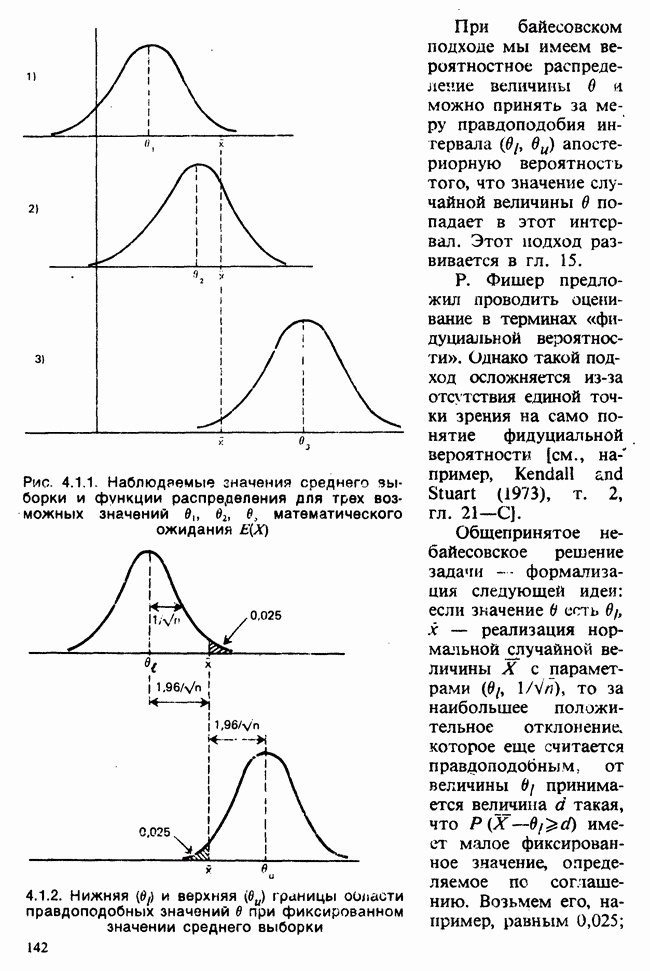
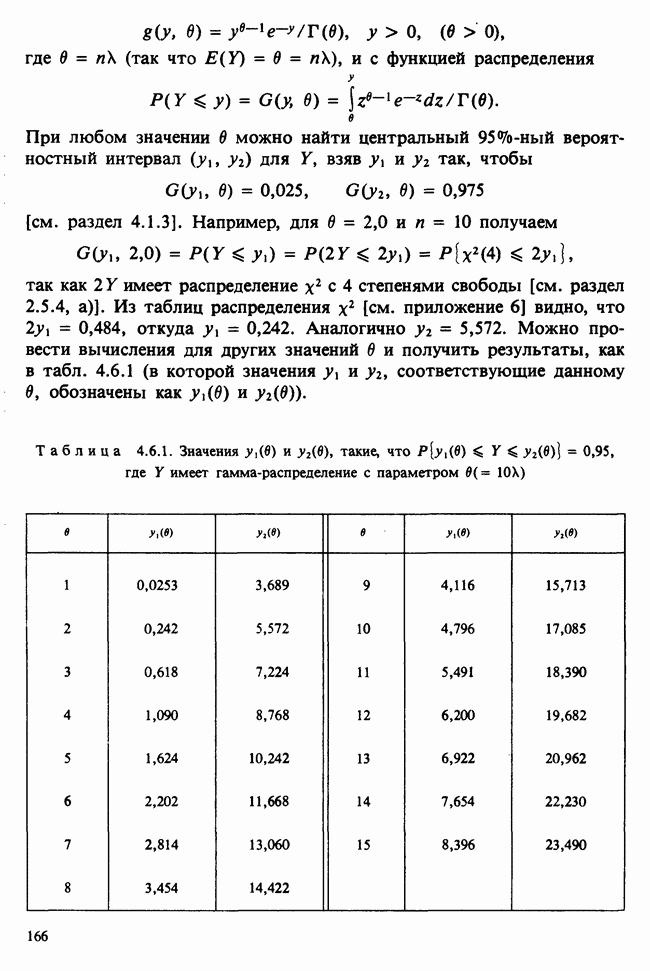
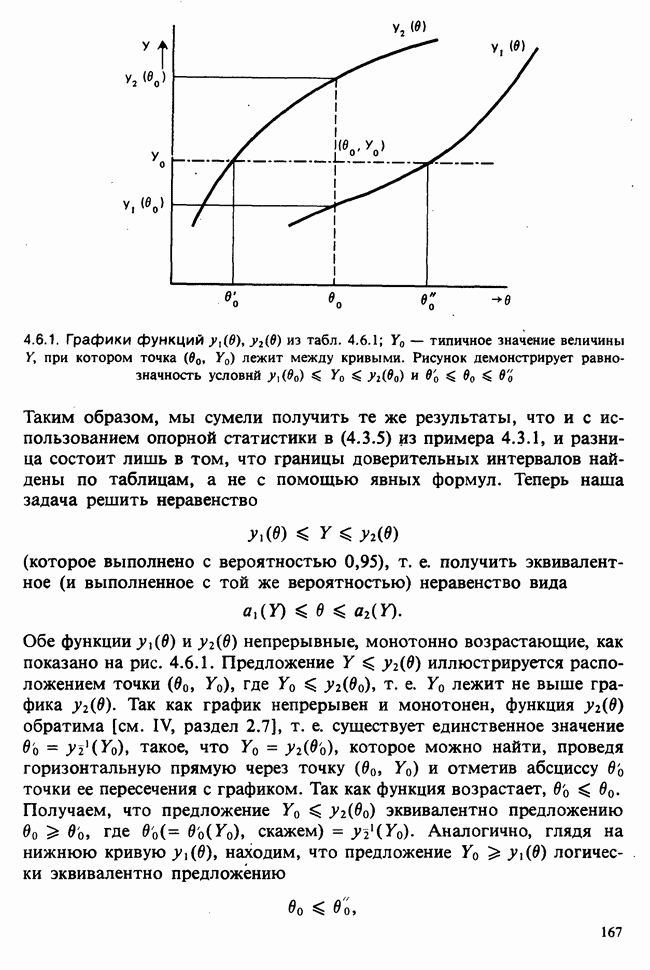
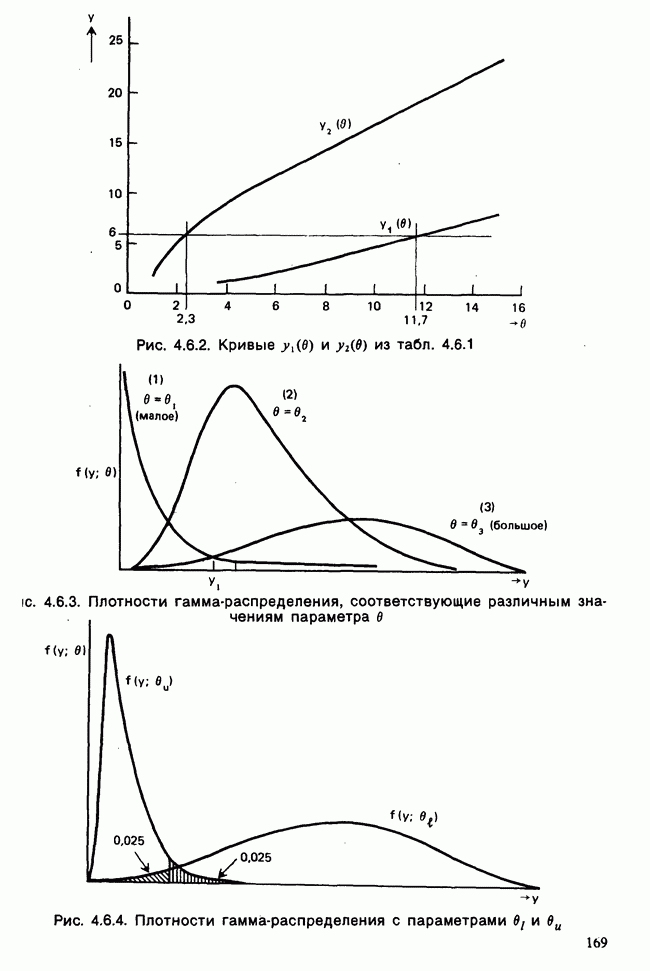
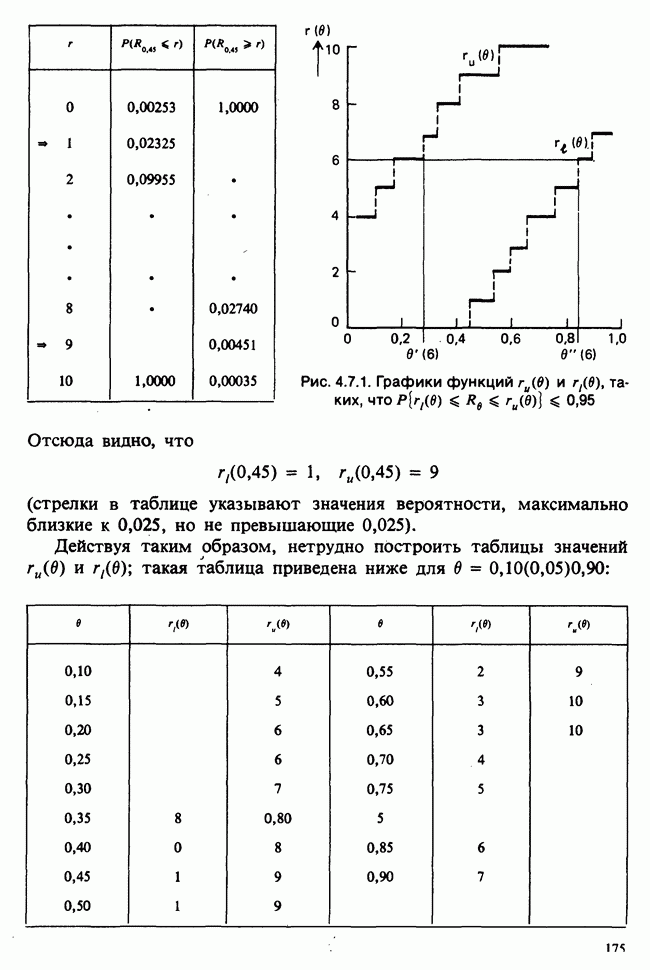
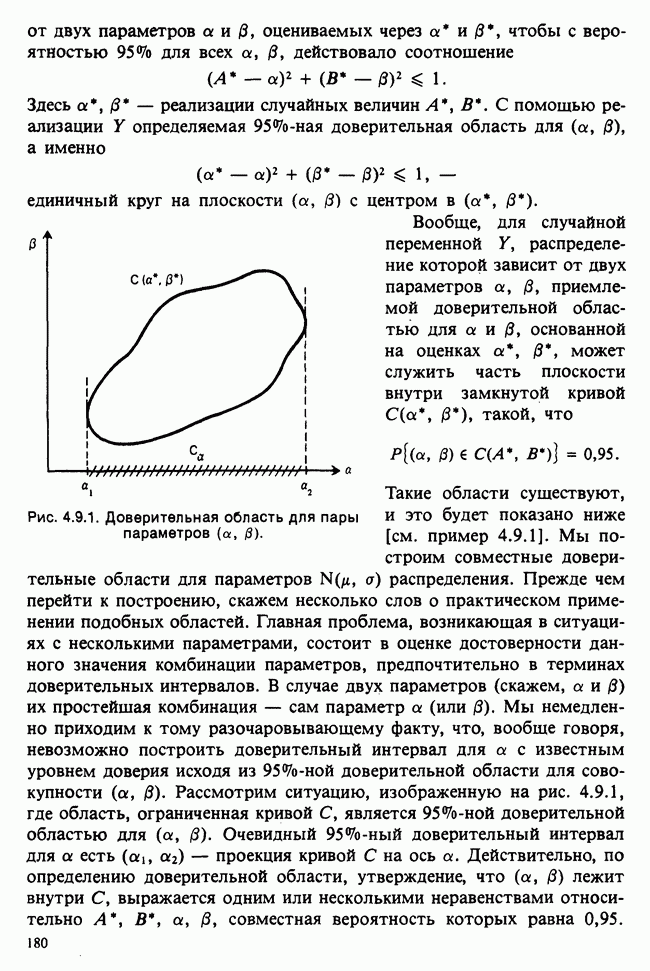
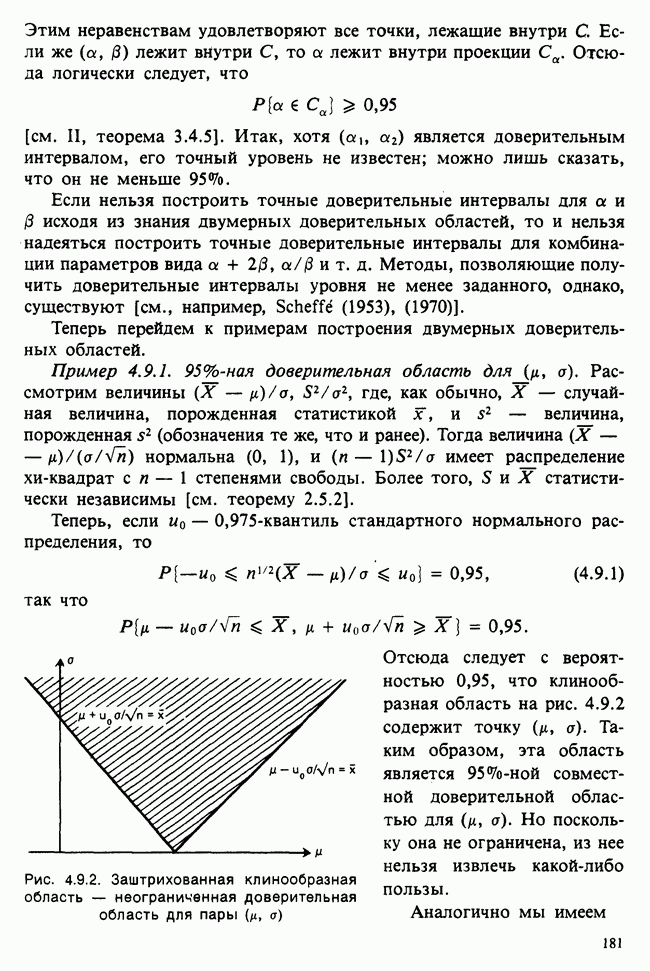
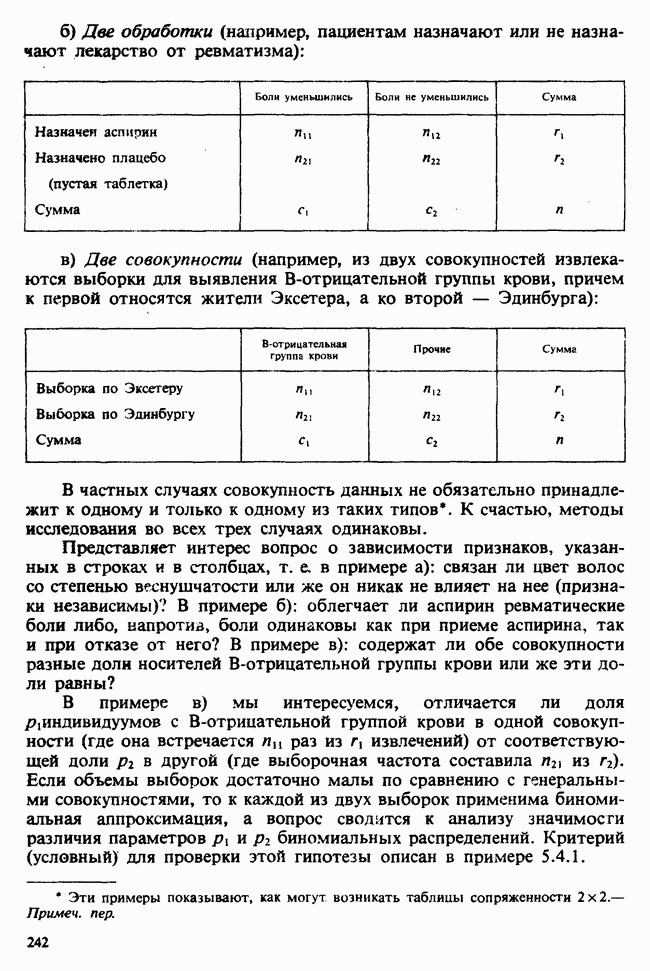
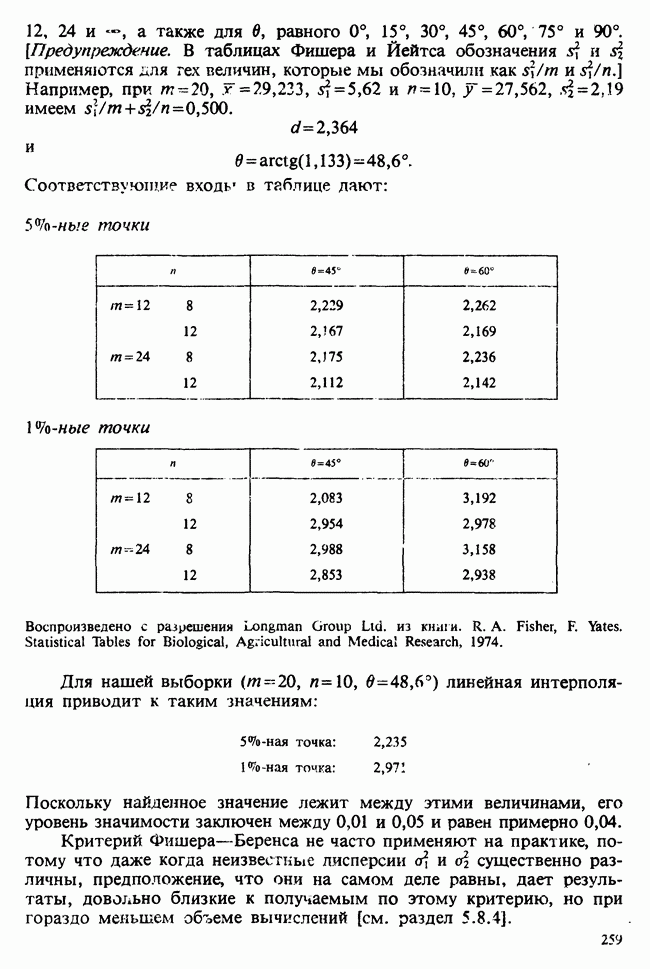
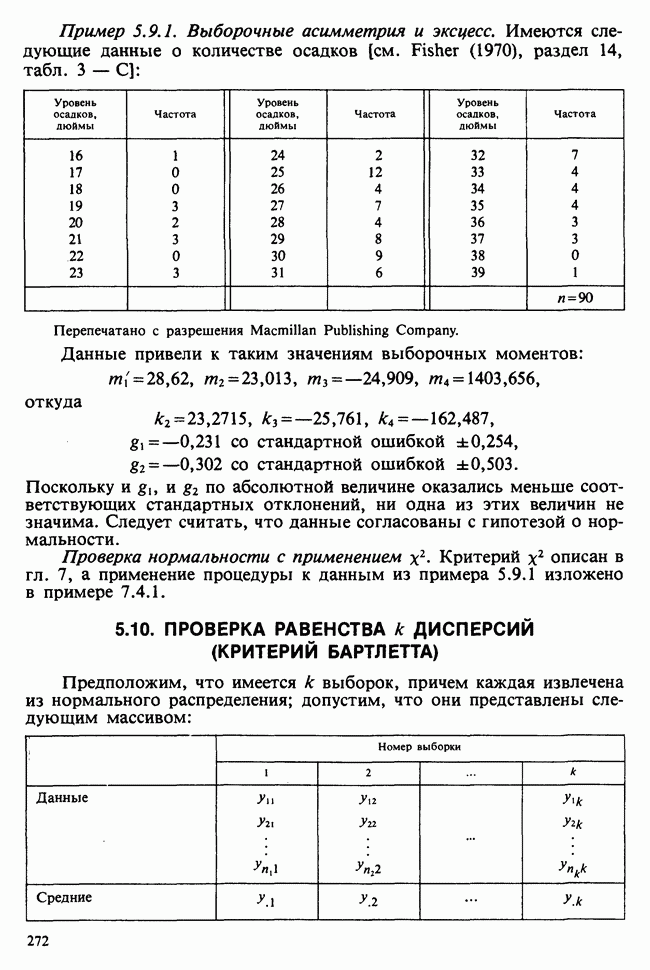
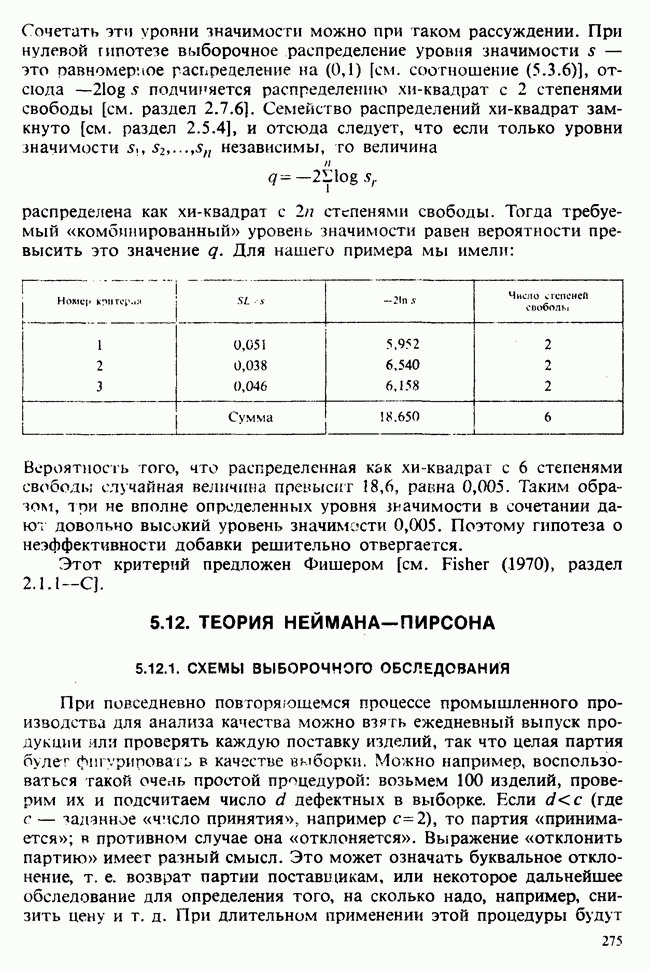
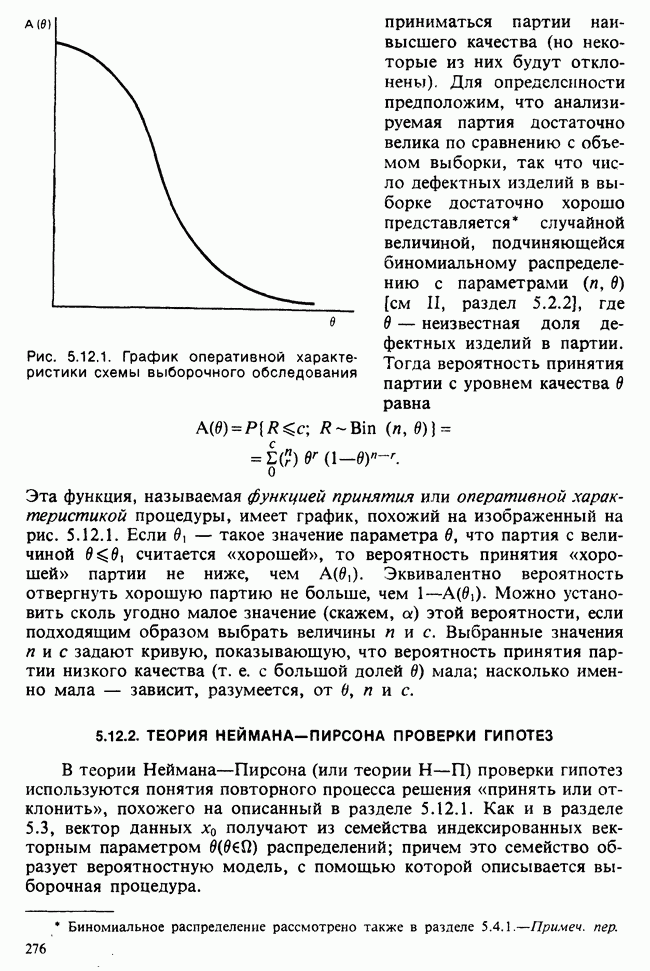
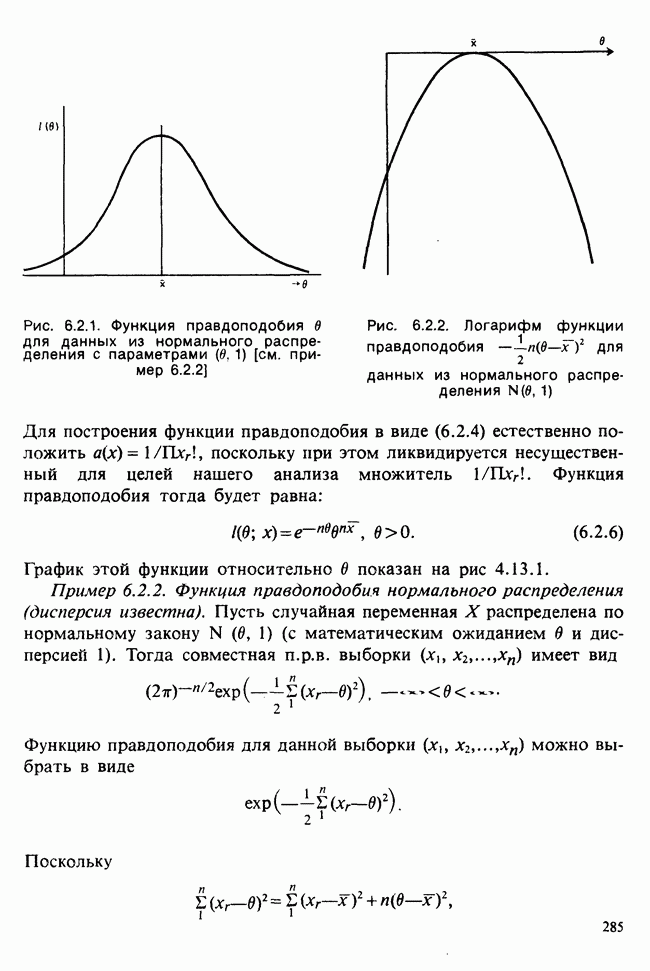
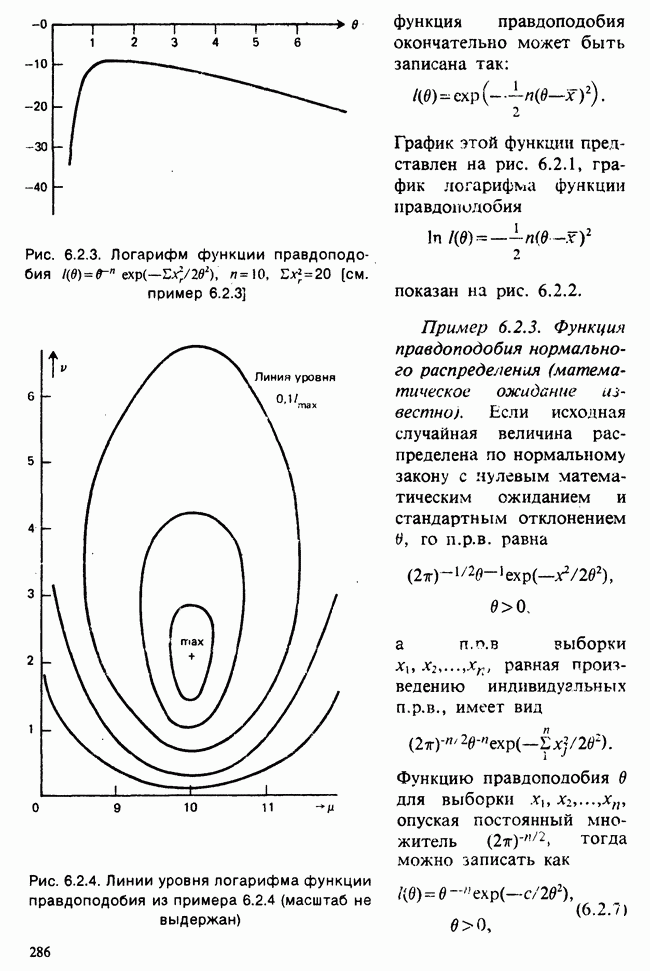
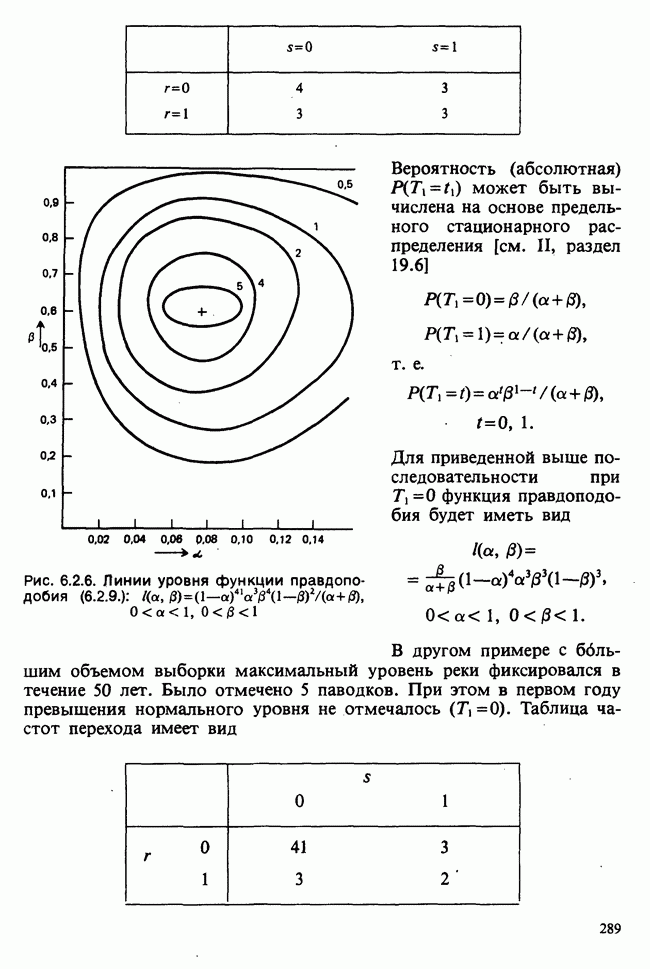
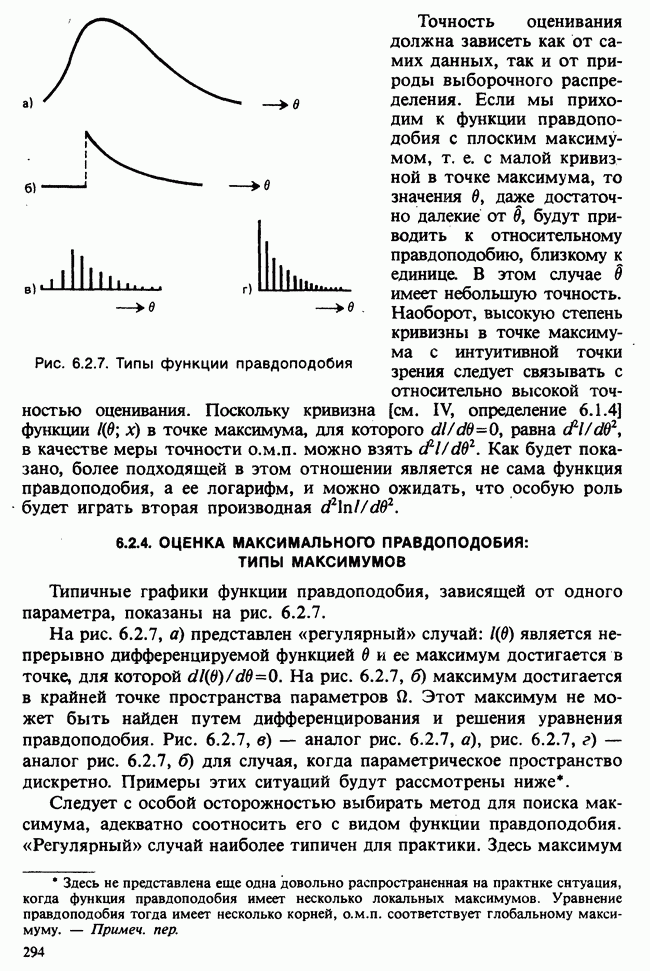
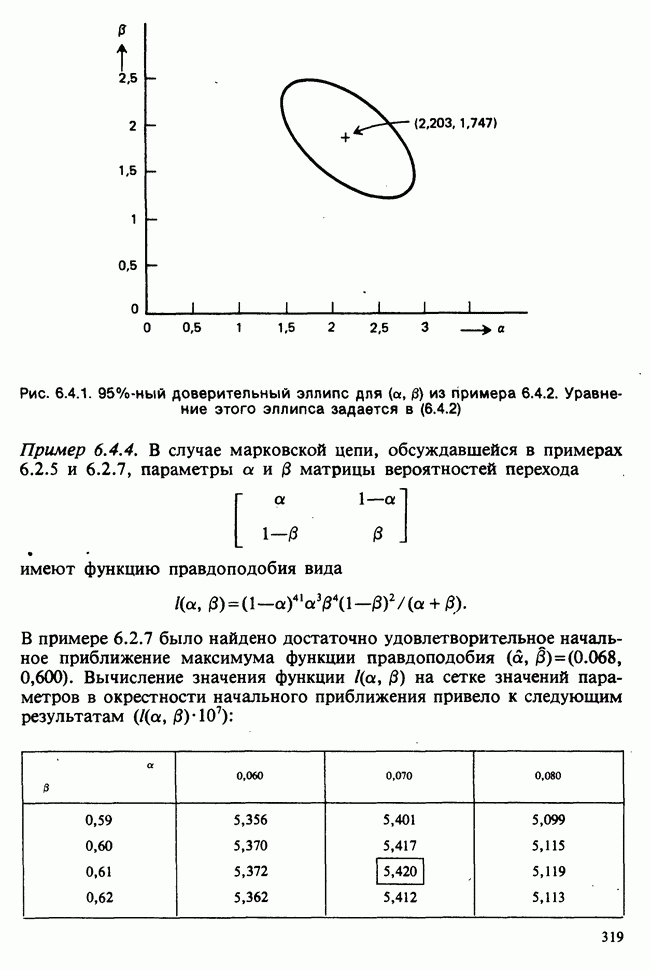
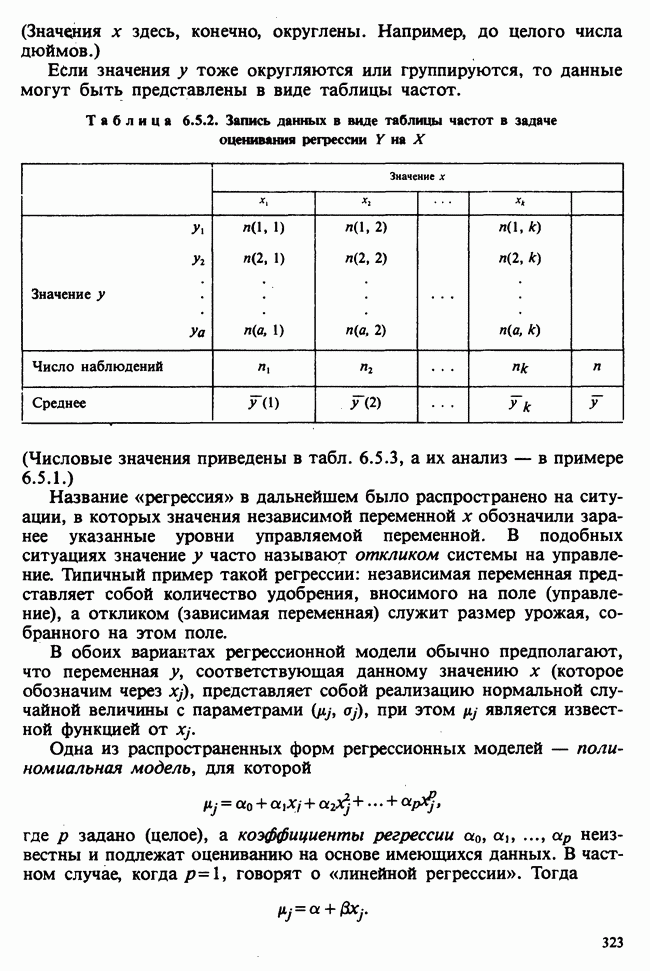
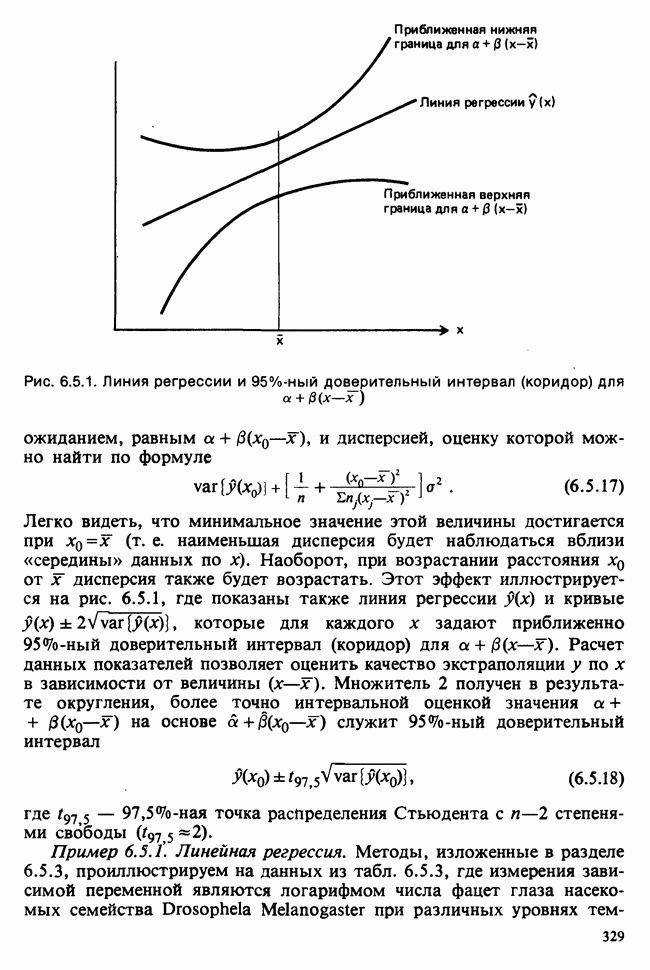
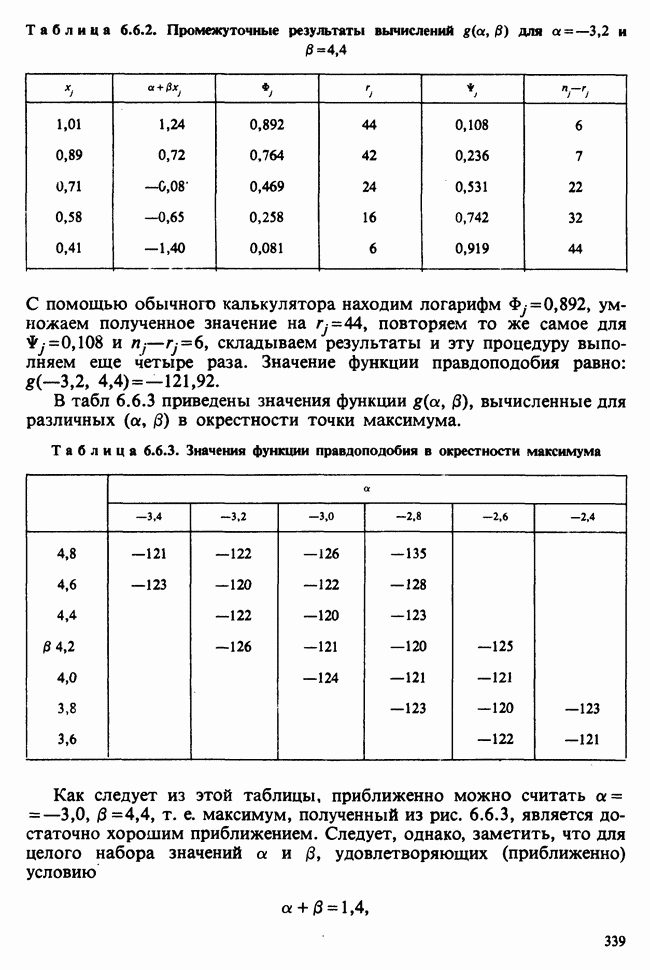
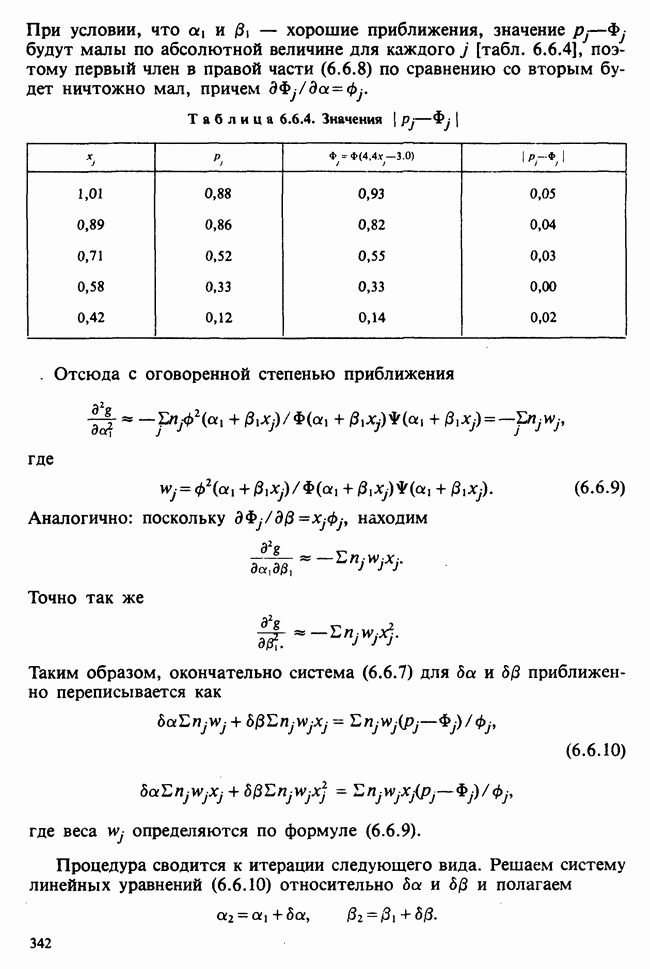
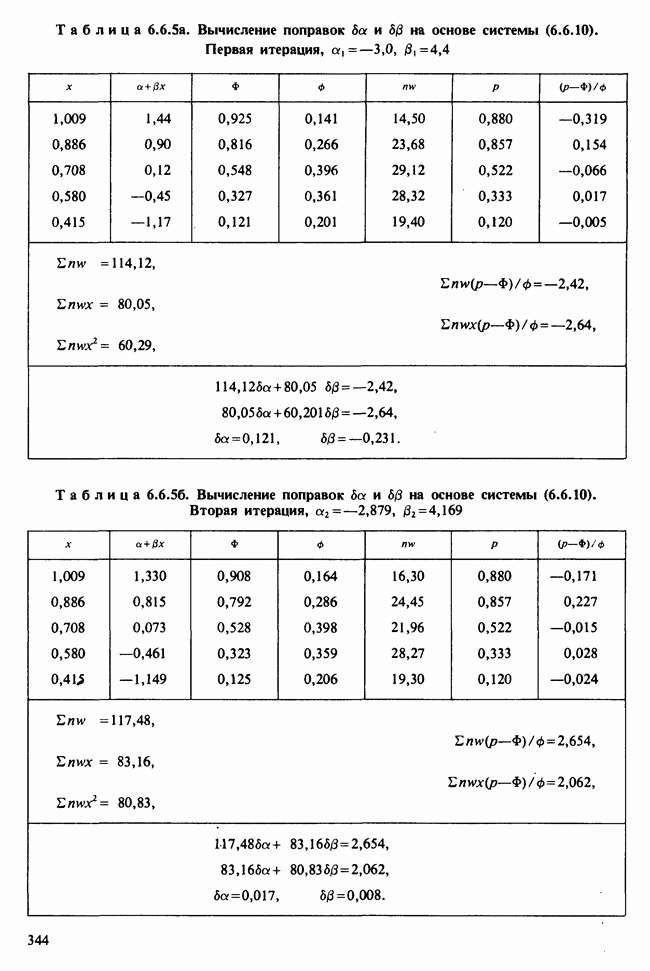
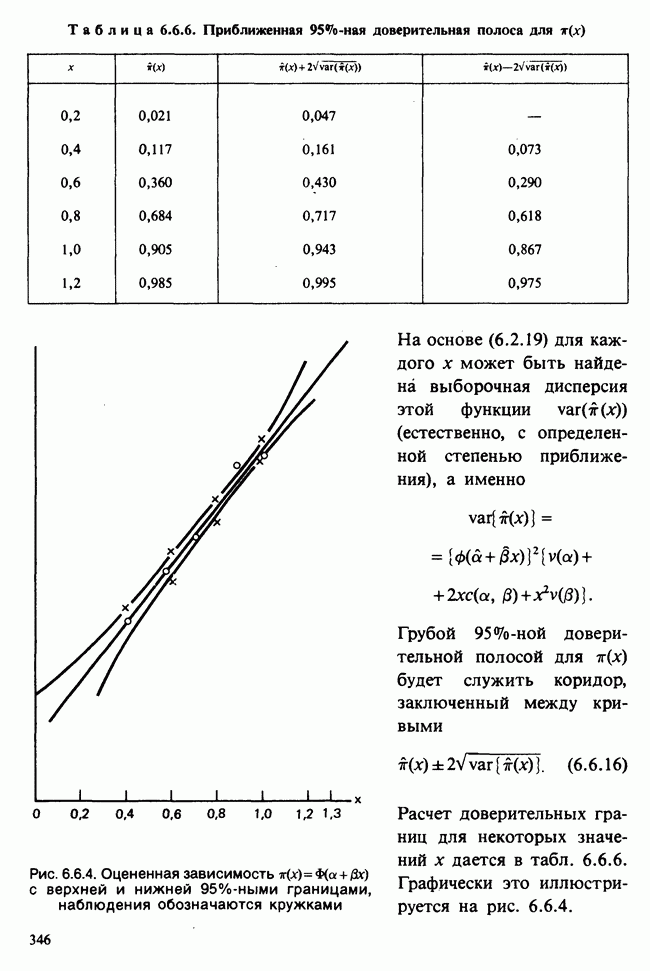
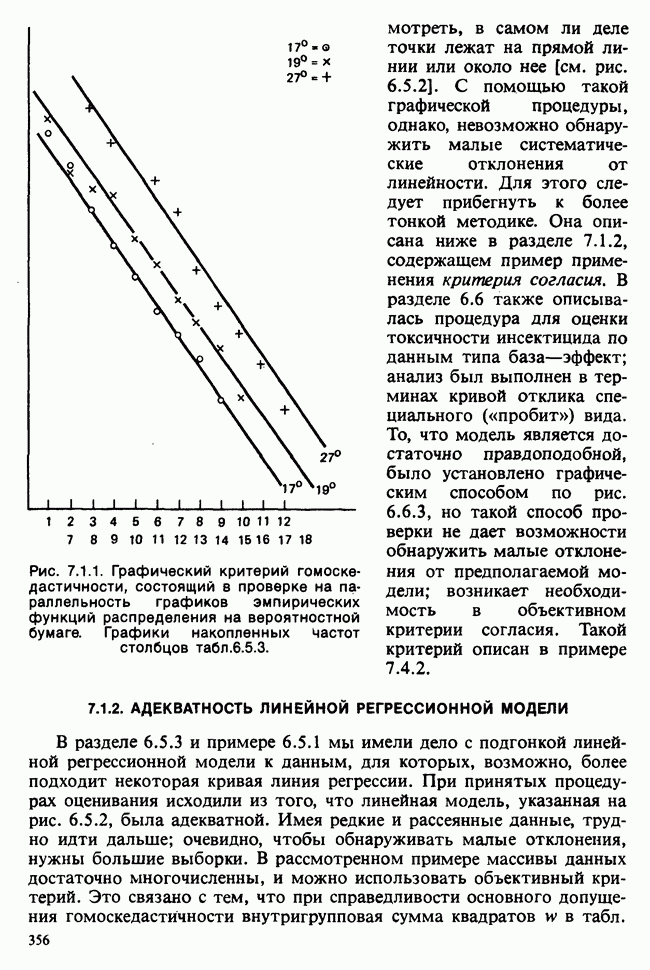
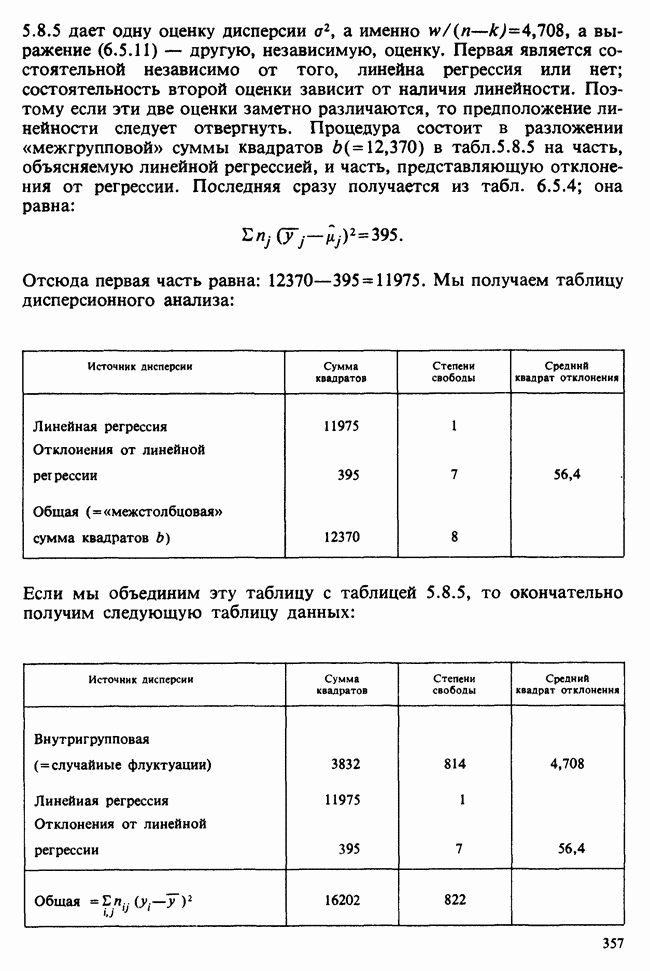
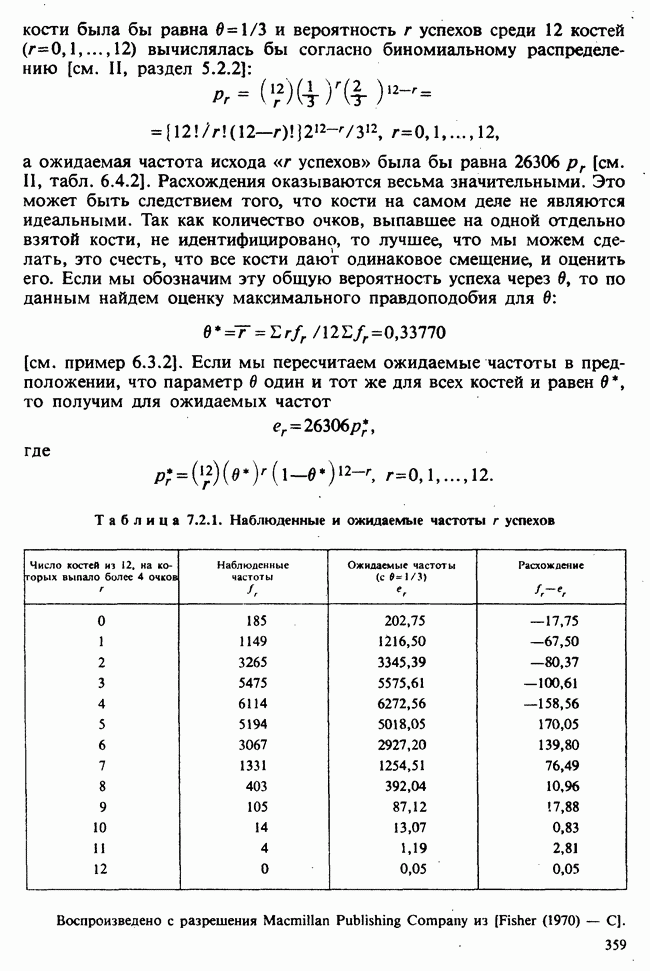
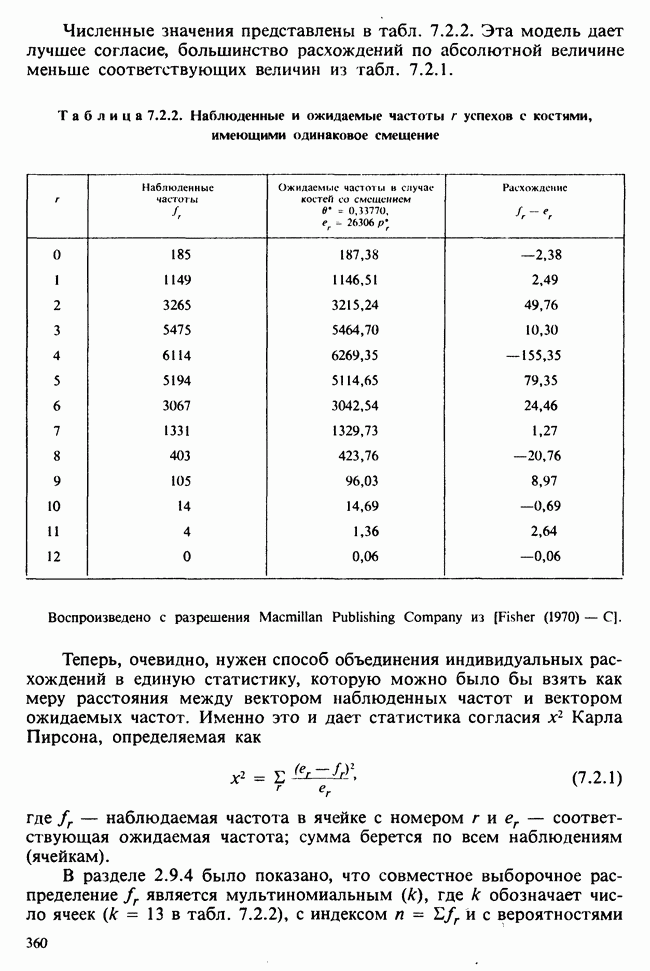
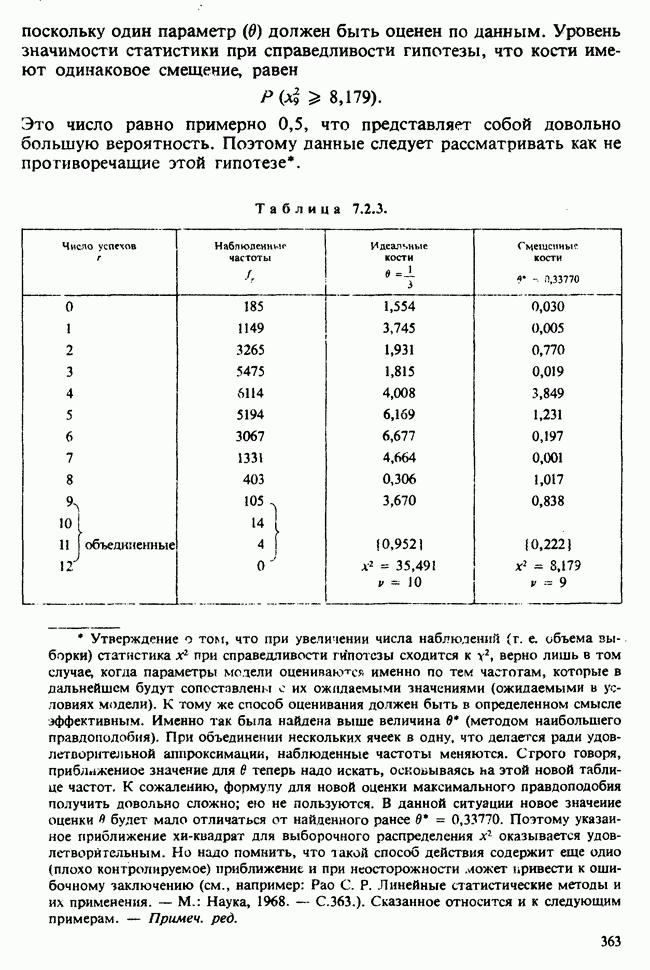
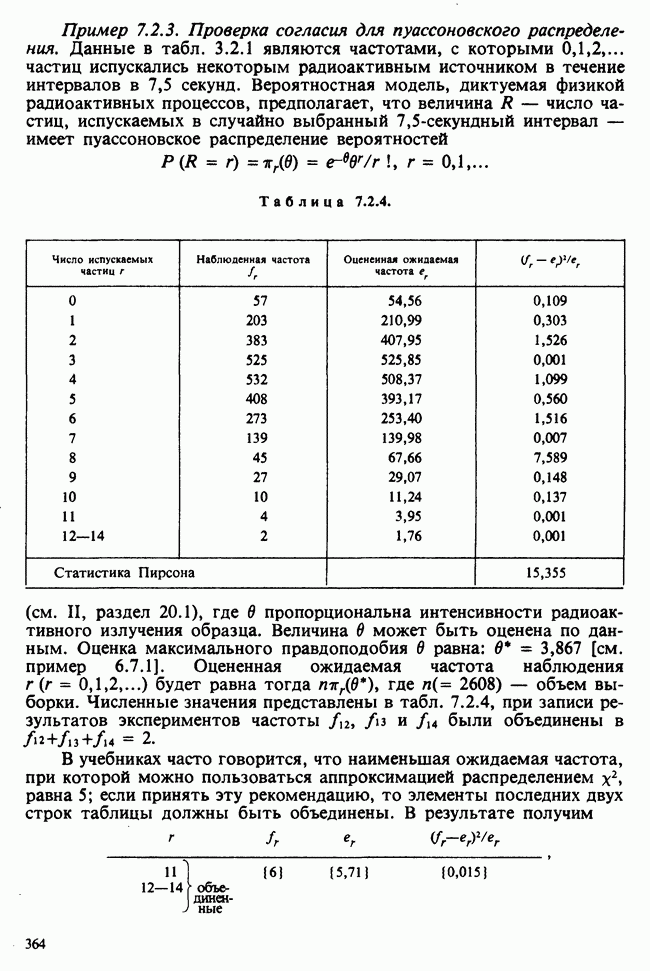
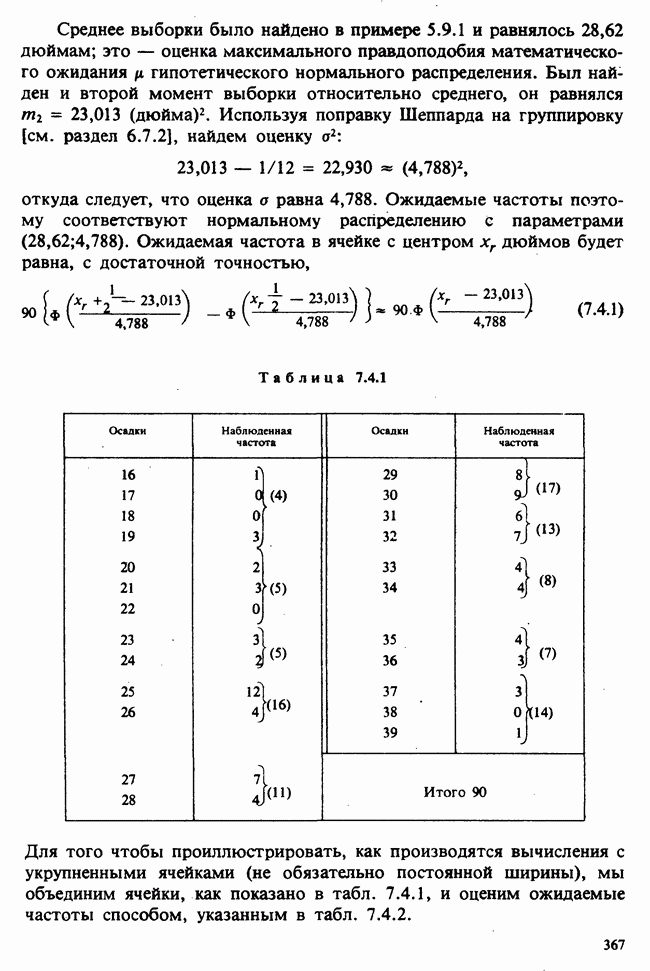
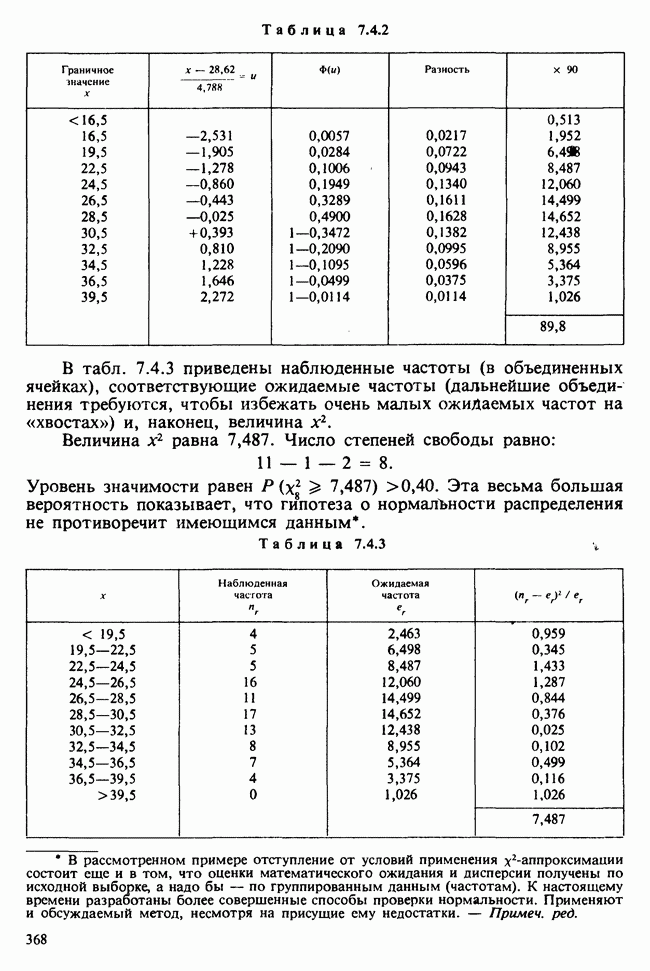
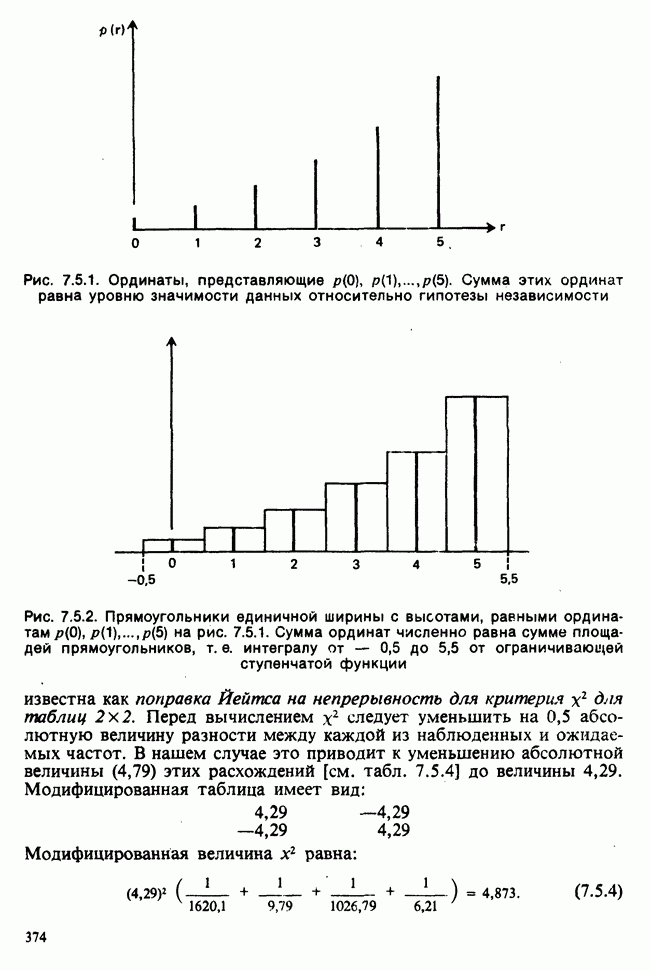
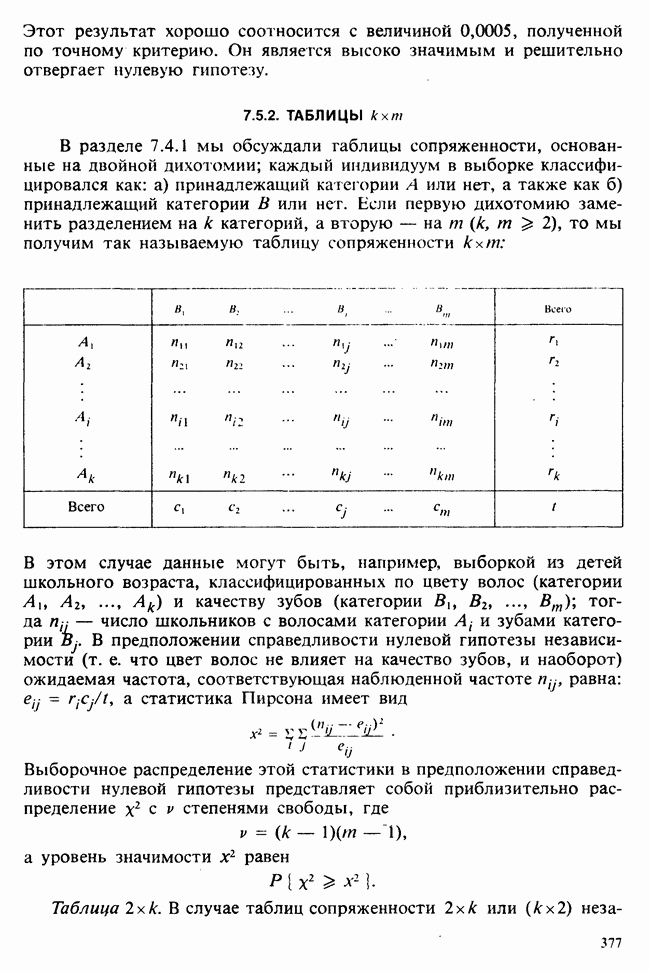
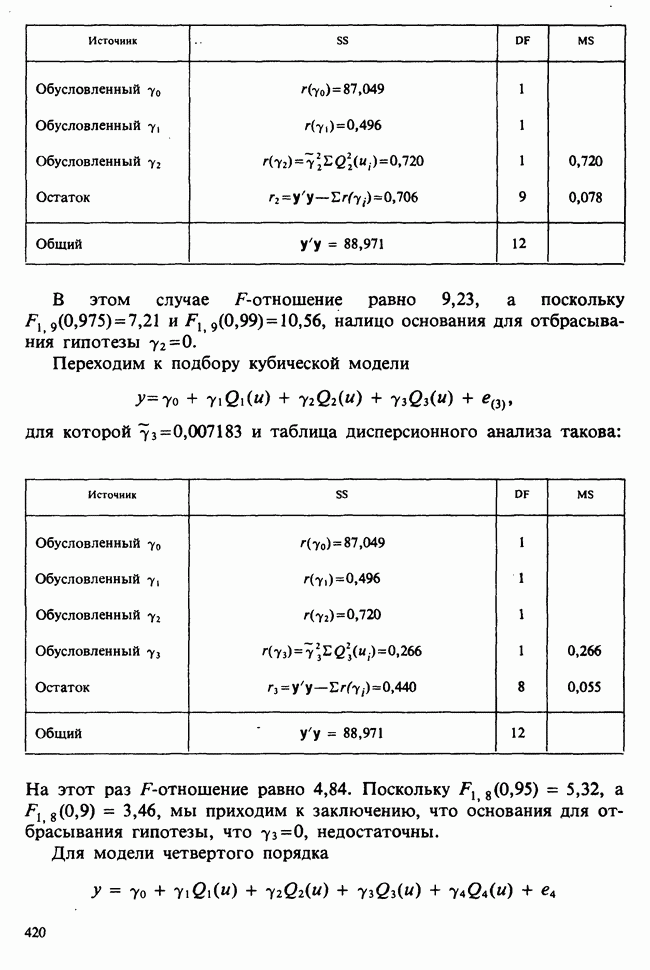
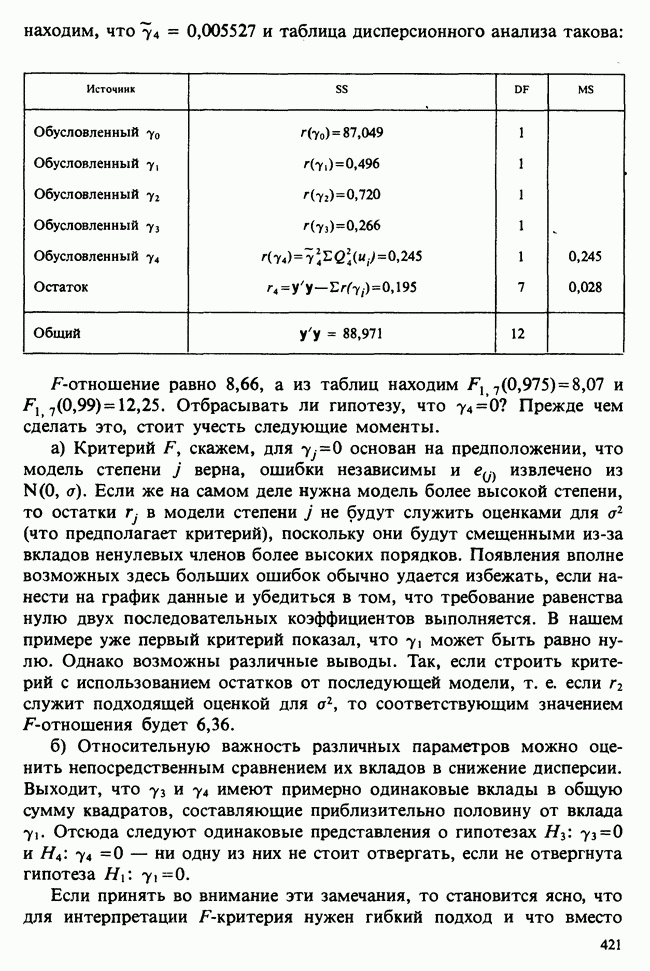
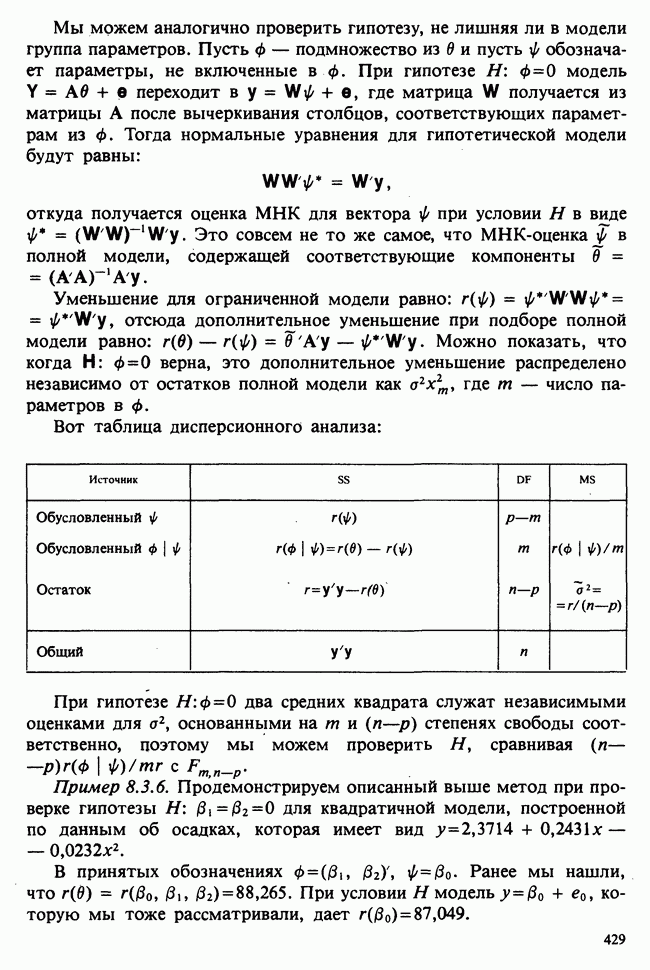
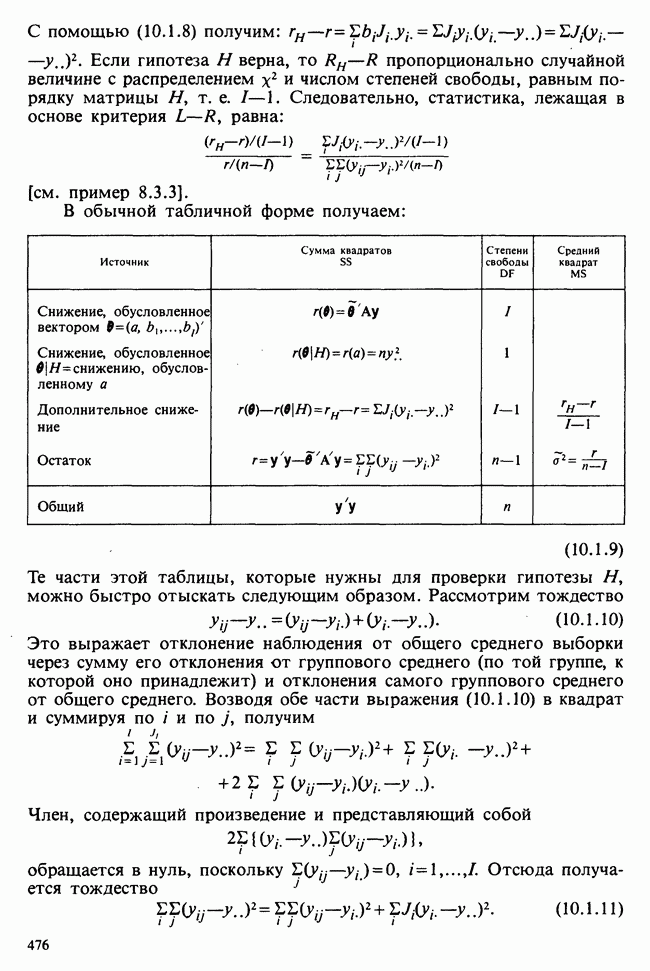
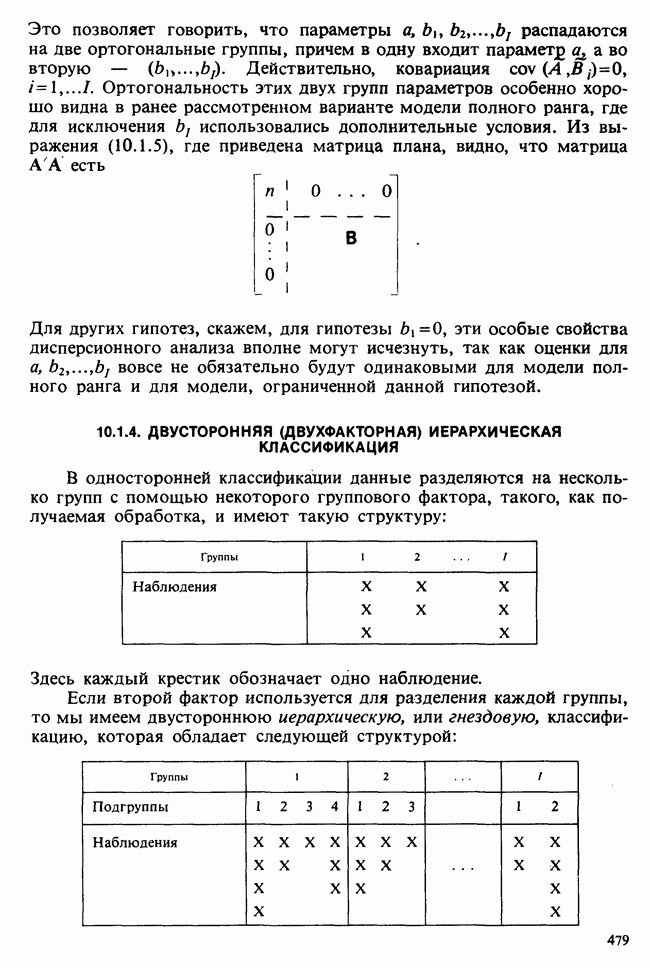
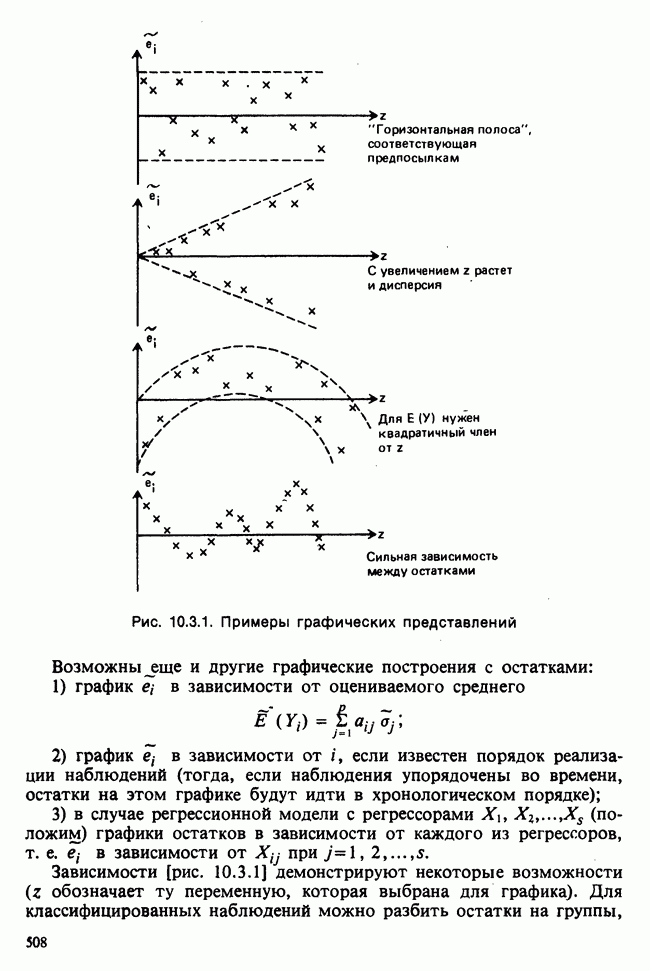
10.3. ПРЕДПОЛОЖЕНИЯ ОТНОСИТЕЛЬНО ОШИБОК
10.3.1. ОСНОВНЫЕ ПРЕДПОЛОЖЕНИЯ
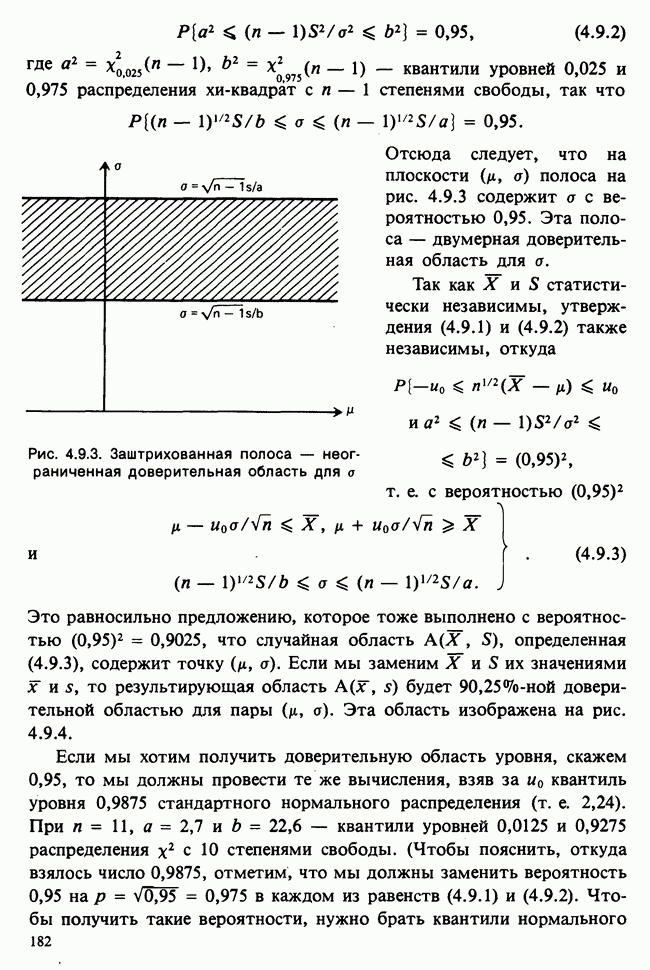
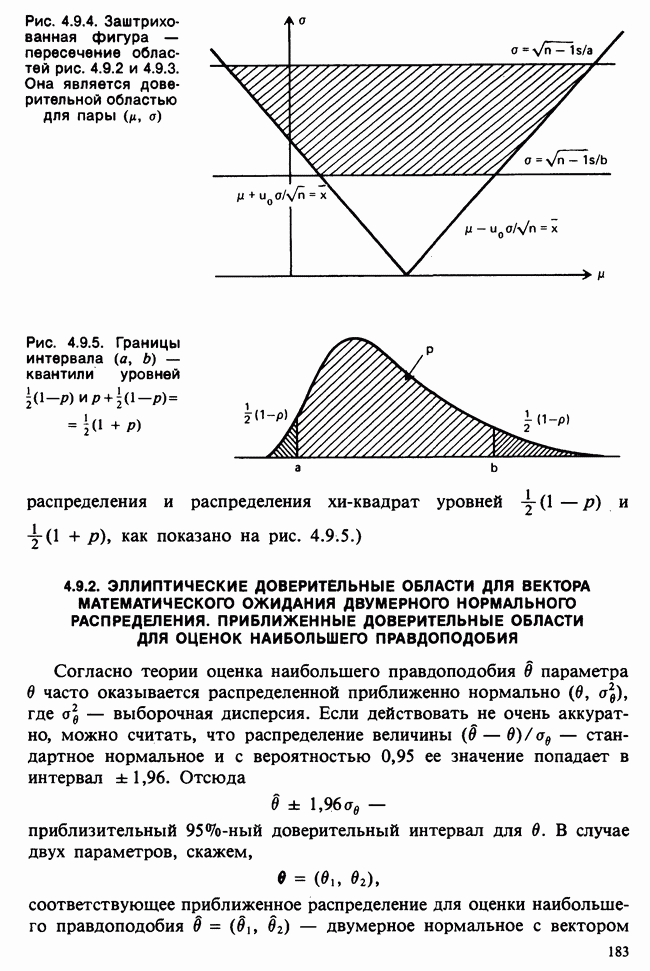
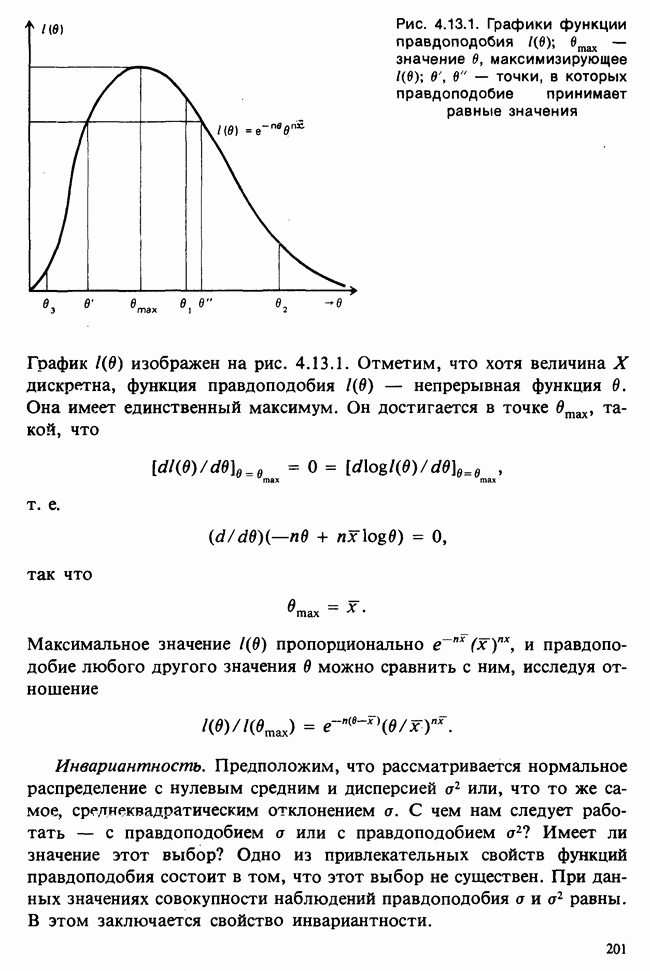
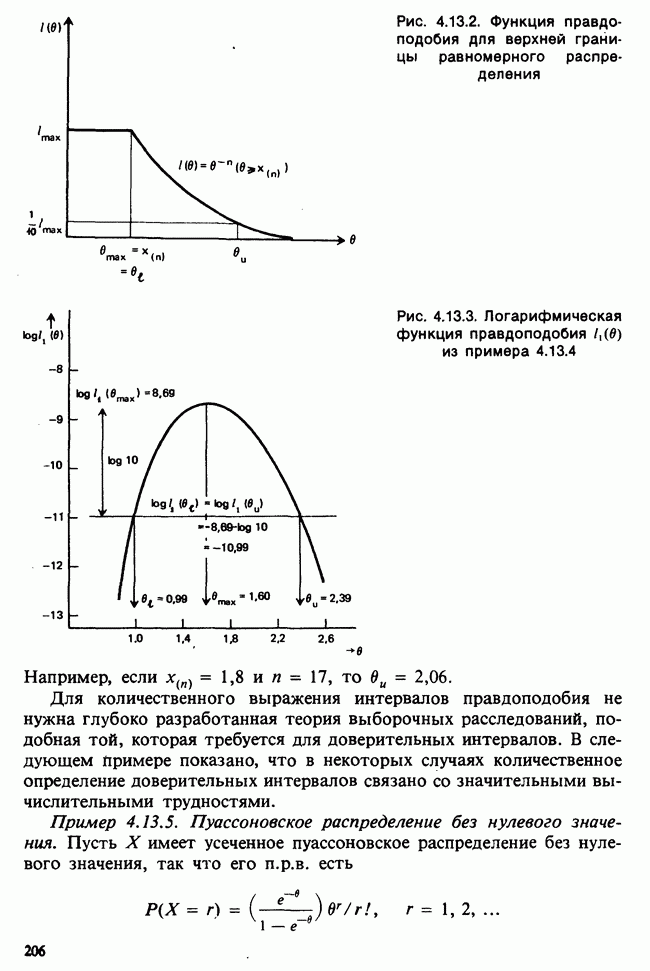
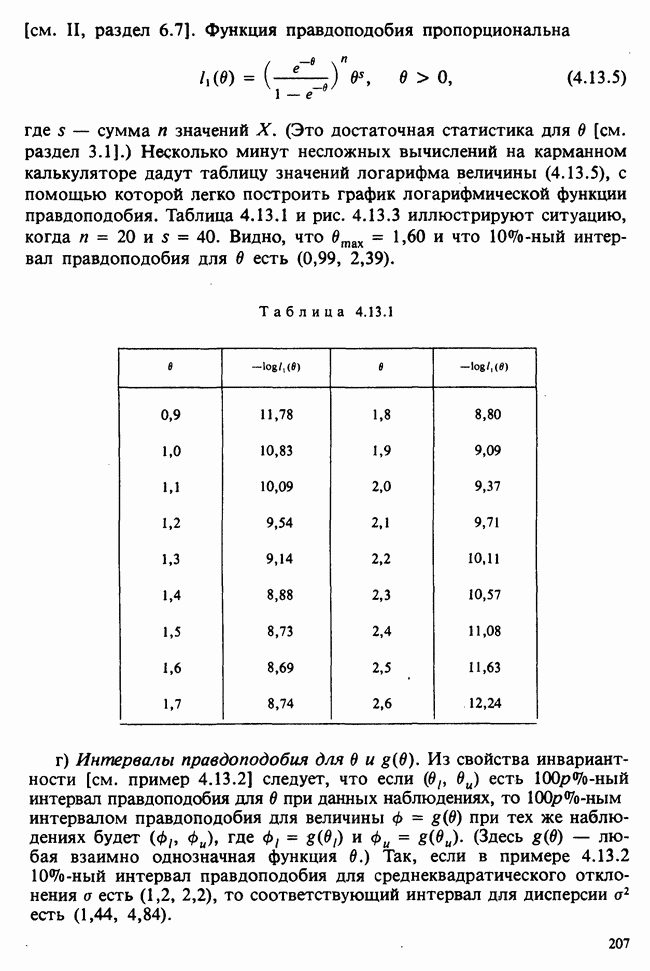
Продолжим краткое рассмотрение предположений, лежащих в основе представленного выше анализа. Детальное обсуждение этих вопросов приведено в работах [Kendall and Stuart (1966)] и [Scheffd (1959)]. Напомним предположения, принимаемые относительно ошибок  в линейной модели
в линейной модели 
1) ошибки имеют нулевые математические ожидания,
2) ошибки независимы,
3) ошибки имеют одинаковые дисперсии (гомоскедастичность),
4) ошибки распределены по нормальному закону.
Напомним также, что последнее предположение требуется для проверок гипотез и построения доверительных интервалов, но не требуется для получения результатов, приведенных в разделе 8.2, где рассматриваются средние и свойства второго порядка оценивателей МНК.
Первое из предположений не создает проблем. Даже если ошибки и имеют ожидание  мы можем ввести его как дополнительный параметр в модель или, если он присутствует в модели, модифицировать. В первом случае это означает переход от
мы можем ввести его как дополнительный параметр в модель или, если он присутствует в модели, модифицировать. В первом случае это означает переход от  и исправление матрицы А введением нового первого столбца, состоящего из единиц. Во втором случае, полагая, что
и исправление матрицы А введением нового первого столбца, состоящего из единиц. Во втором случае, полагая, что  есть тот самый компонент
есть тот самый компонент  для всех
для всех  мы должны заменить
мы должны заменить  на
на  и рассматривать его далее как параметр, входящий в модель.
и рассматривать его далее как параметр, входящий в модель.
Второе предположение более важное. Обычно считают само собой разумеющимся, что физическая установка или метод получения выборки делают это предположение разумным. Дисперсионный анализ, представленный ранее как чисто алгебраические тождества, свободен от предположений 1—4. Однако если мы хотим воспользоваться им для проверки гипотез, то нам потребуются предположения 3 и 4. Предположение о постоянстве ошибок тоже важно. Без него, когда ошибки гетероскедастичны, наши методы могут привести к глубоким заблуждениям в результате нарушения уровня значимости даже для сбалансированного плана (т. е. имеющего одинаковое число наблюдений в
каждой группе или ячейке). Если, как в разделе 8.2.6, заранее известно, что дисперсии отличаются постоянным множителем, то мы можем прибегнуть к описанному методу преобразований, дающему новую модель, к которой применимы наши методы. На практике такую исчерпывающую информацию часто просто неоткуда взять, но можно использовать различные преобразования, стабилизирующие дисперсию [см. раздел 2.7.3] для преодоления некоторых видов гетероскедастичности, обычно встречающихся в классифицированных данных. Если, например, дисперсия в группе пропорциональна групповому среднему, мы преобразуем наблюдения по закону  , а если групповому среднему пропорциональна стандартная ошибка, то по закону
, а если групповому среднему пропорциональна стандартная ошибка, то по закону  [см. Kendall and Stuart (1966); Scheffe (1959)].
[см. Kendall and Stuart (1966); Scheffe (1959)].
Последнее предположение о нормальном законе распределения ошибок на практике выполняется лишь приближенно, но, к счастью, метод дисперсионного анализа устойчив к нарушениям нормальности, т. е. должны произойти значительные нарушения нормальности прежде, чем стандартные критерии дисперсионного анализа начнут существенно реагировать.