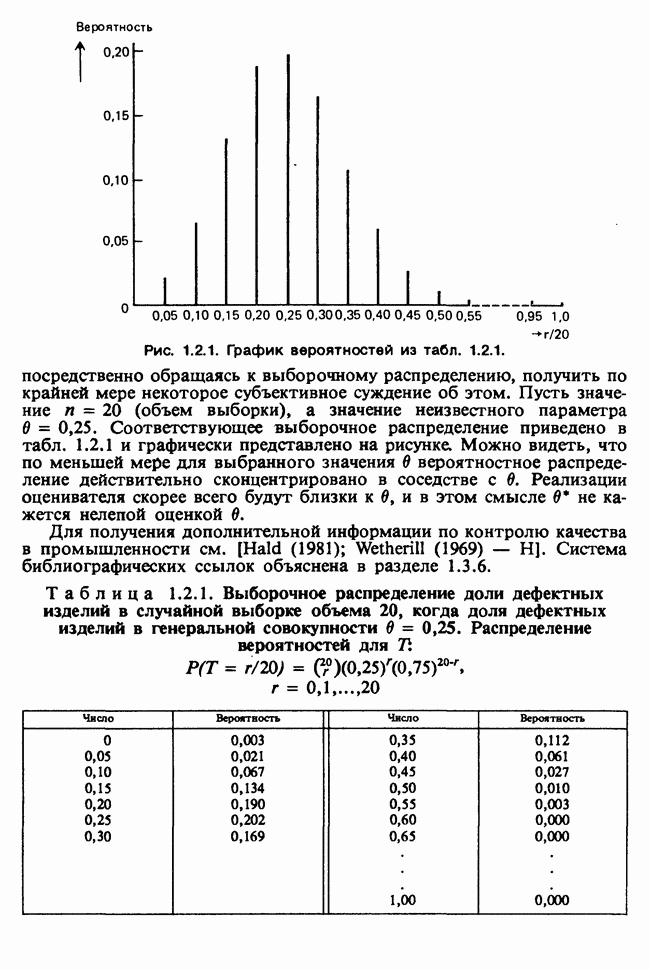
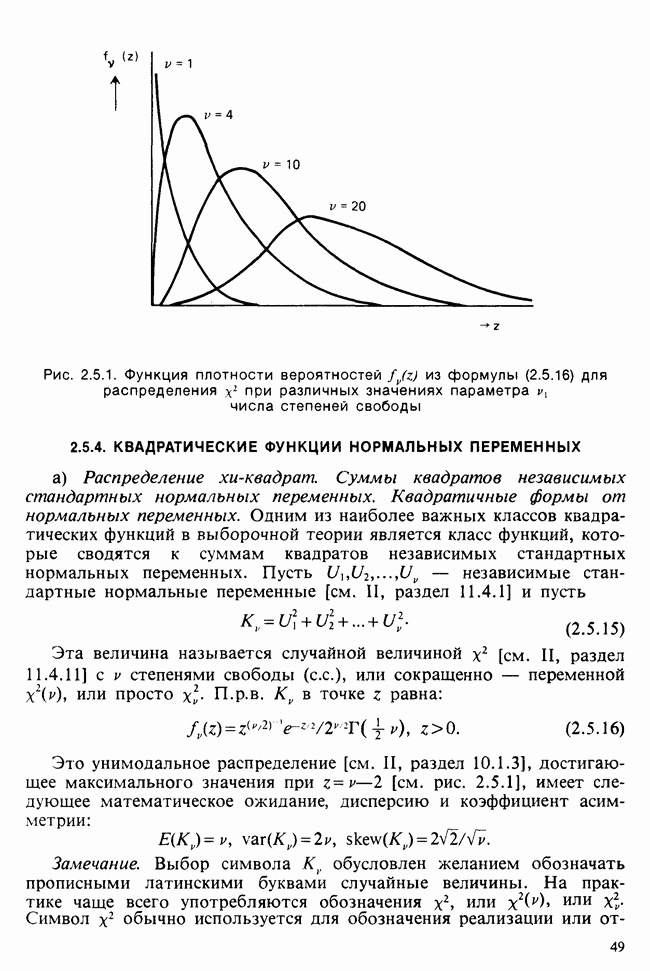
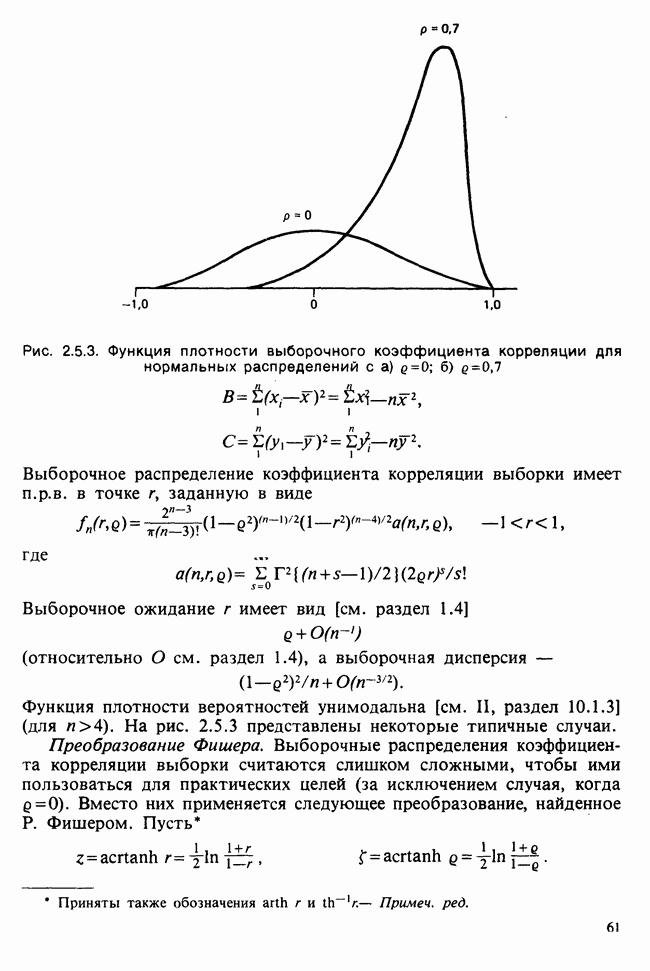
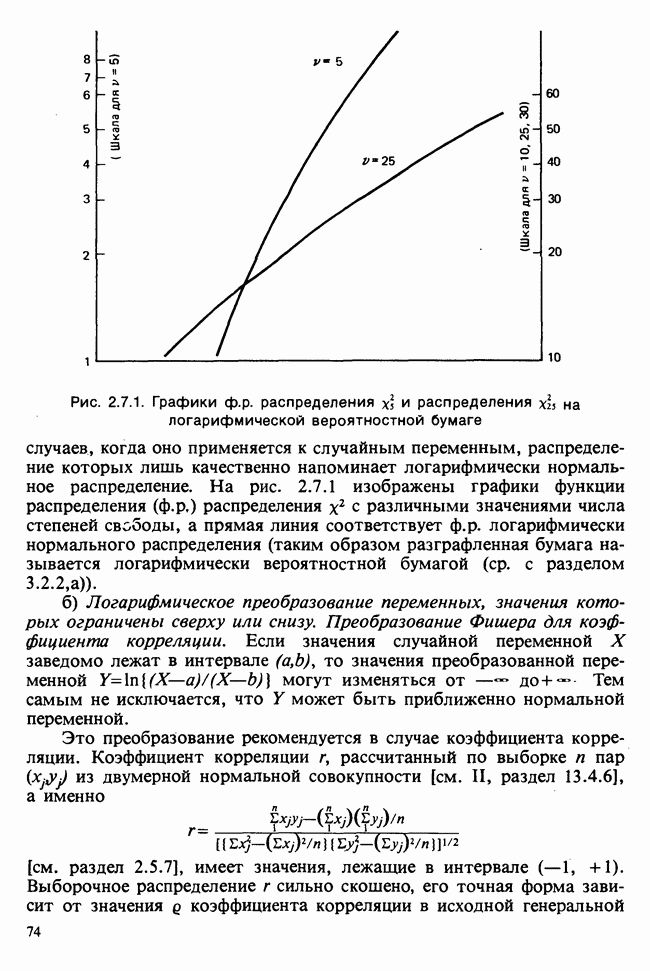
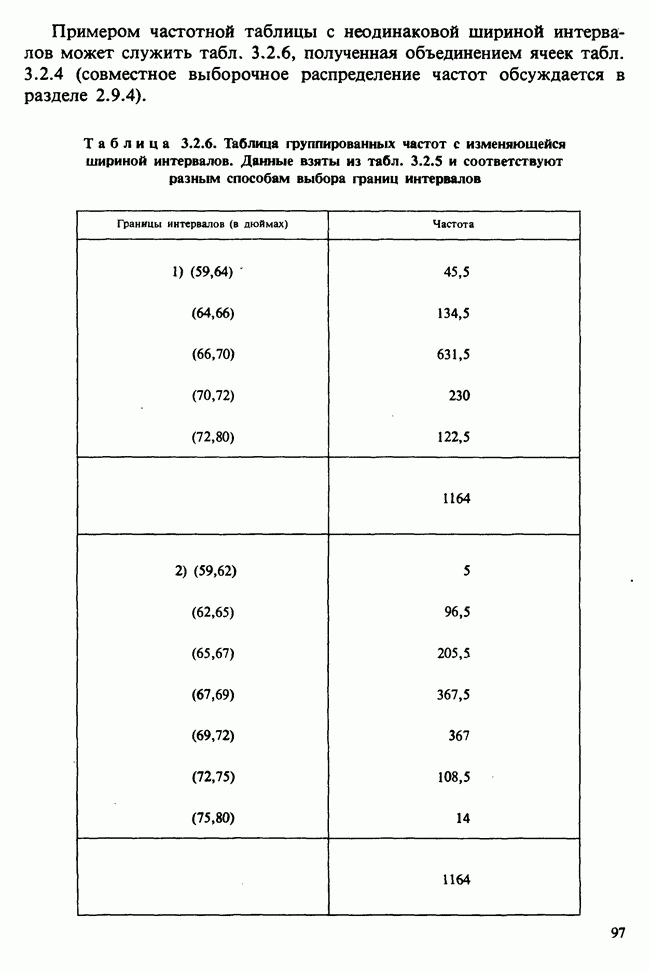
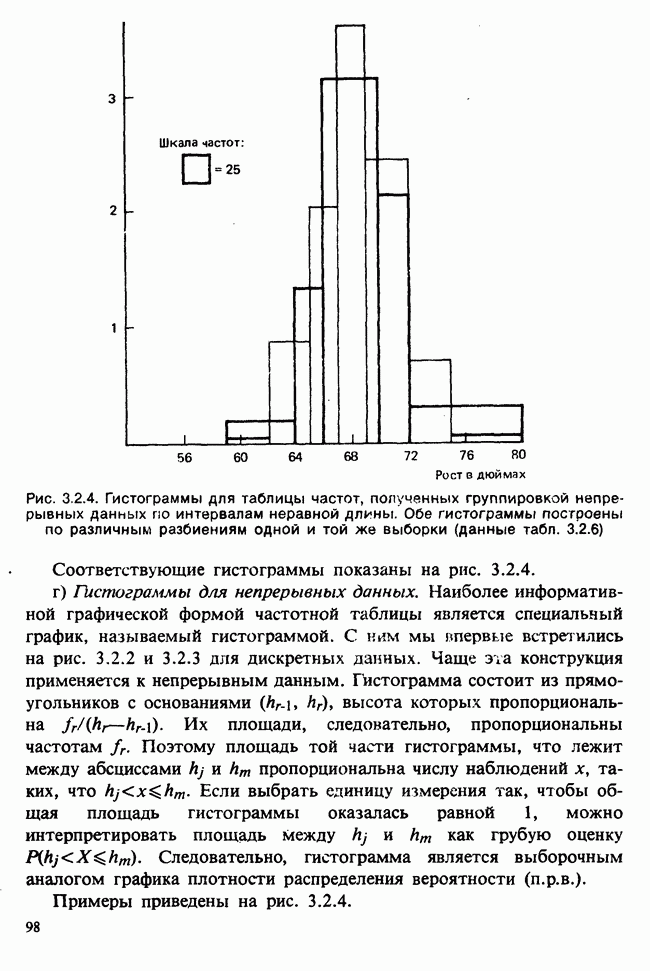
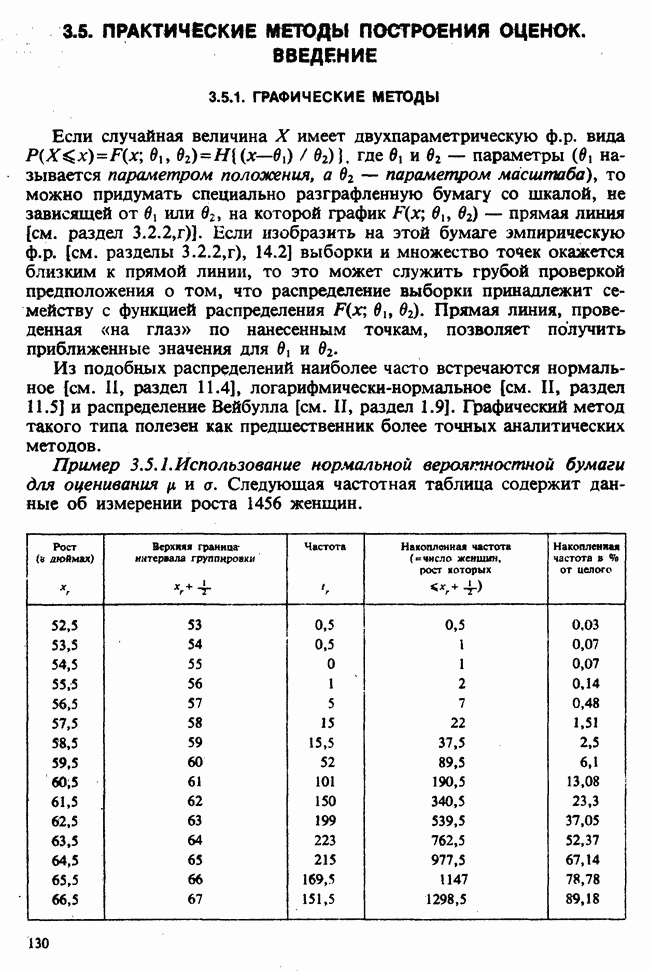
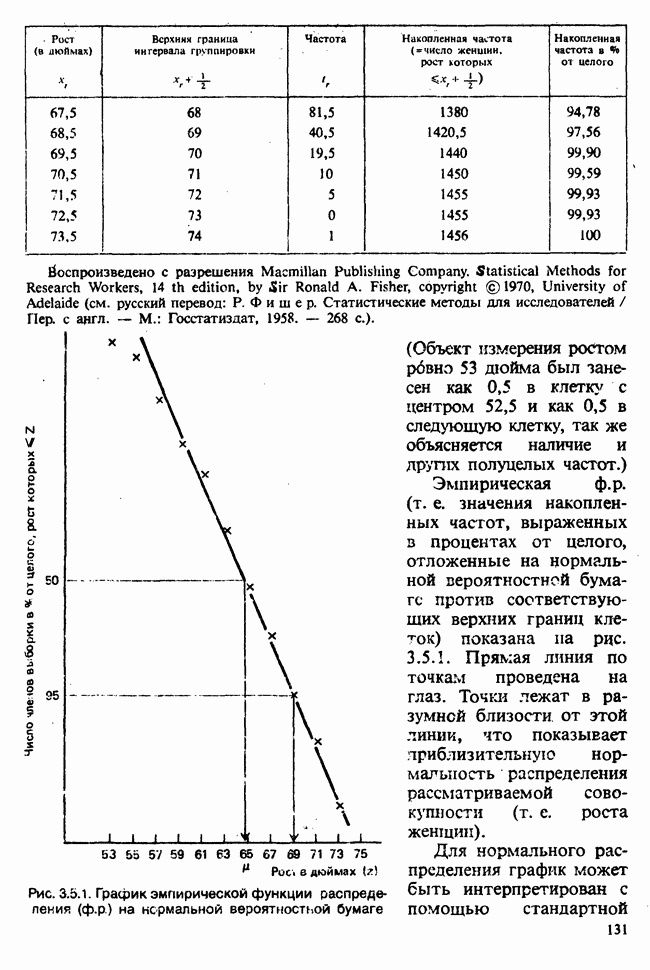
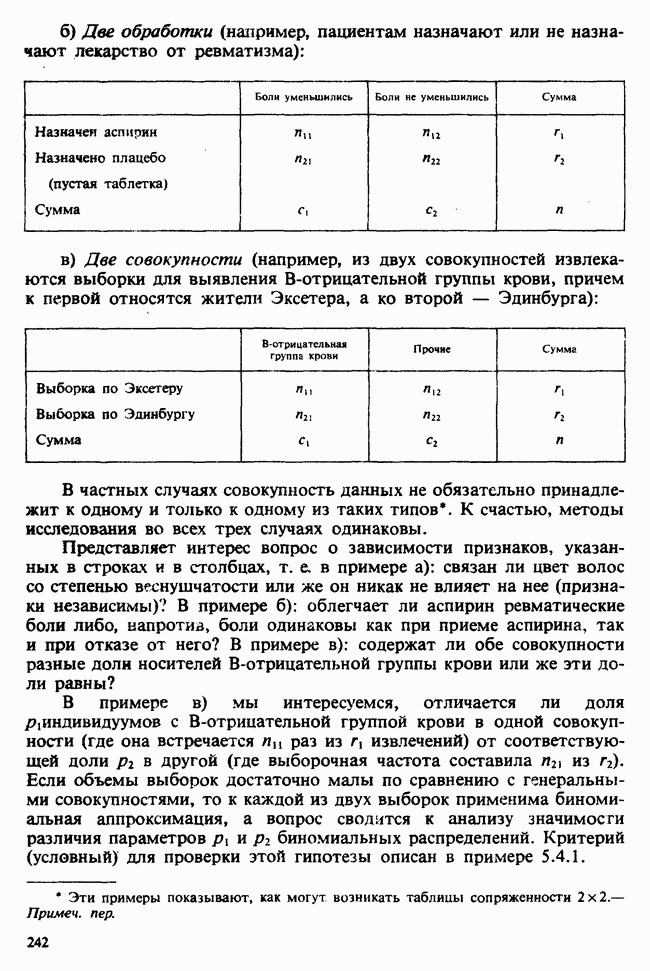
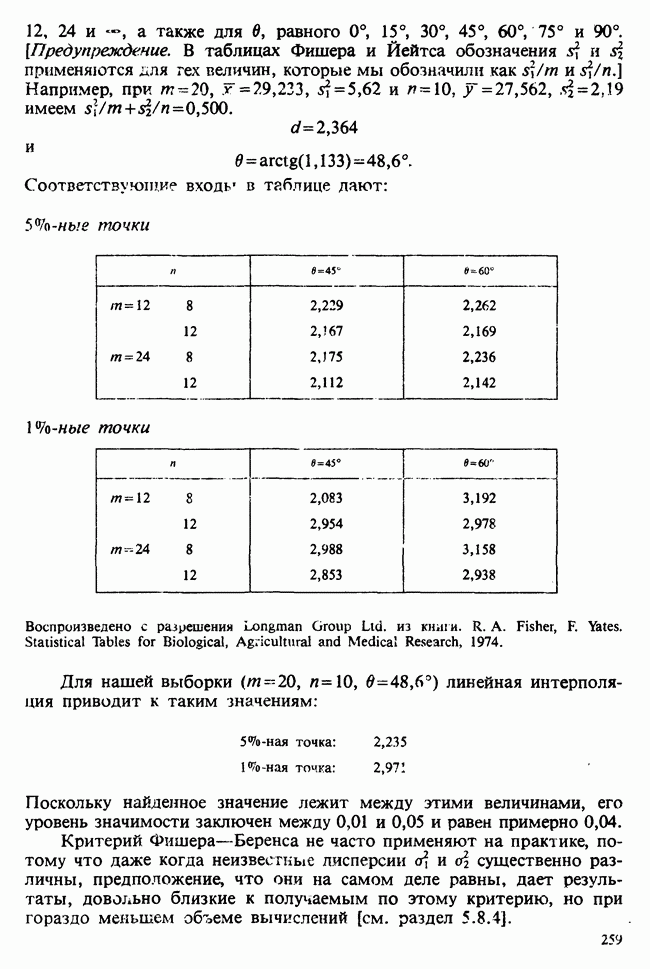
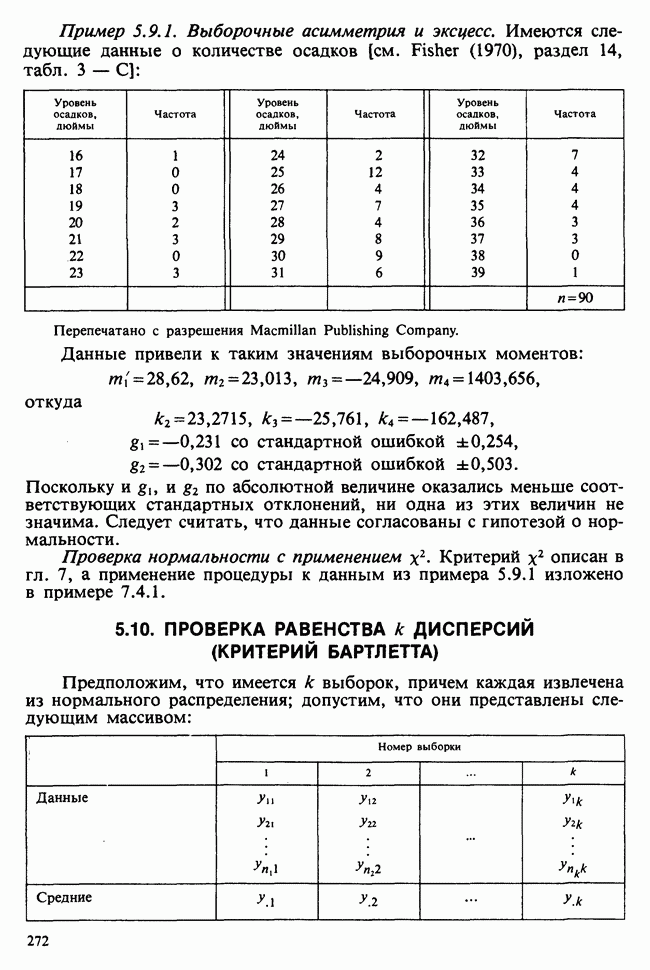
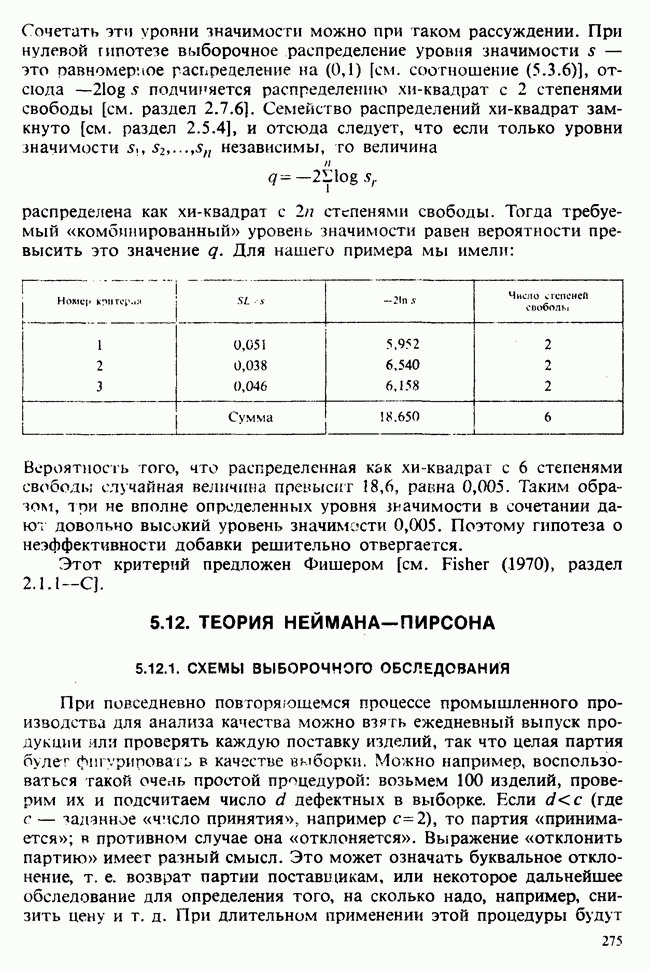
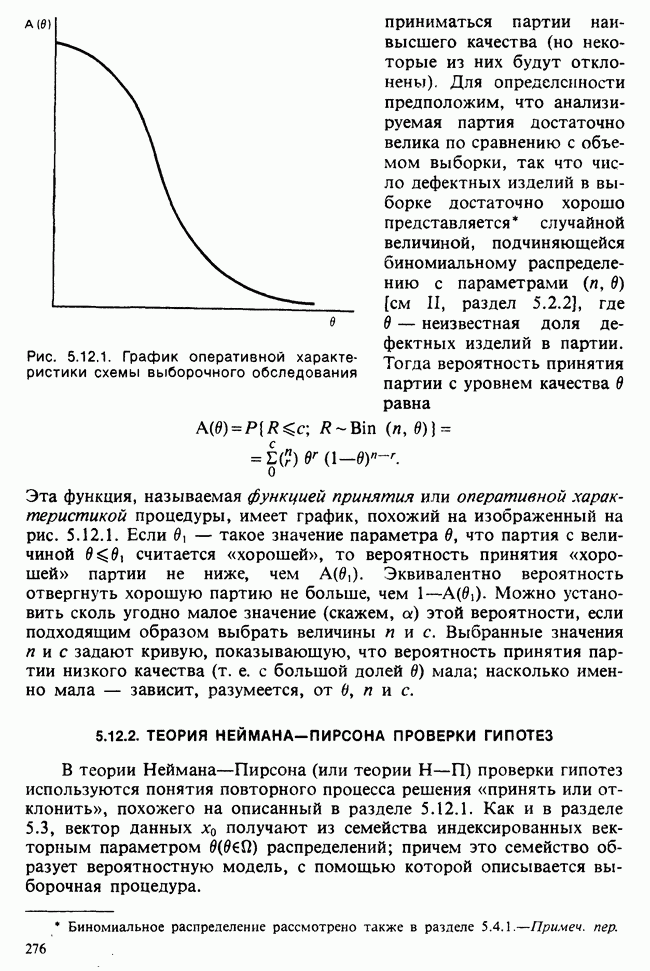
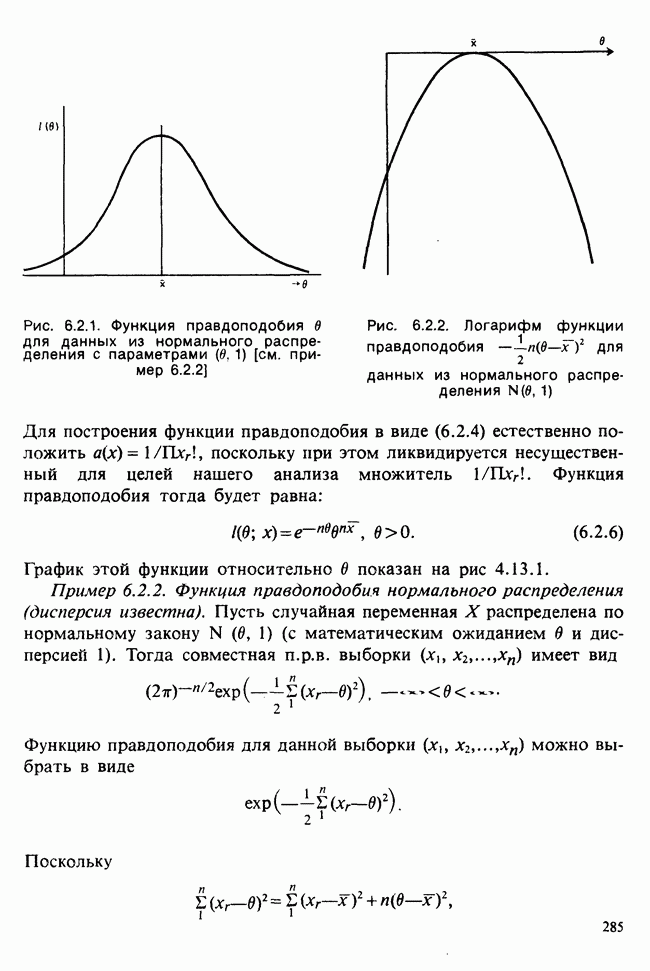
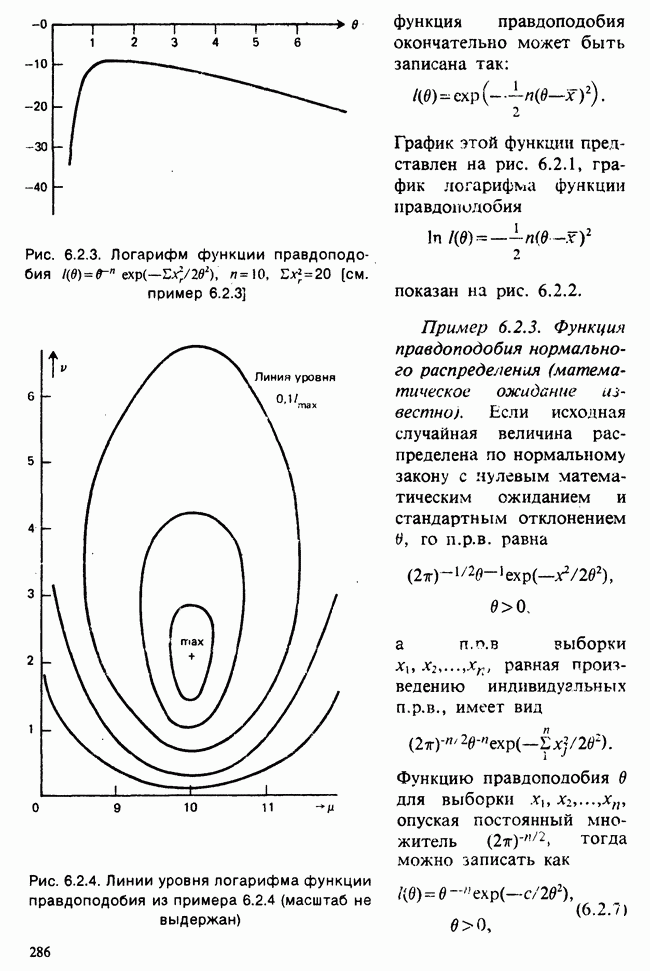
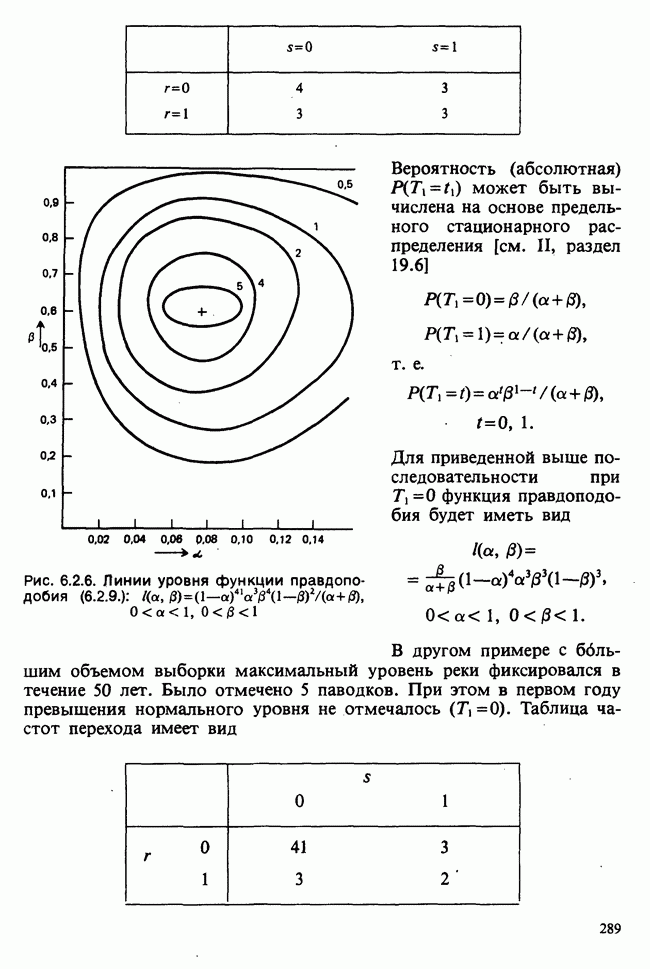
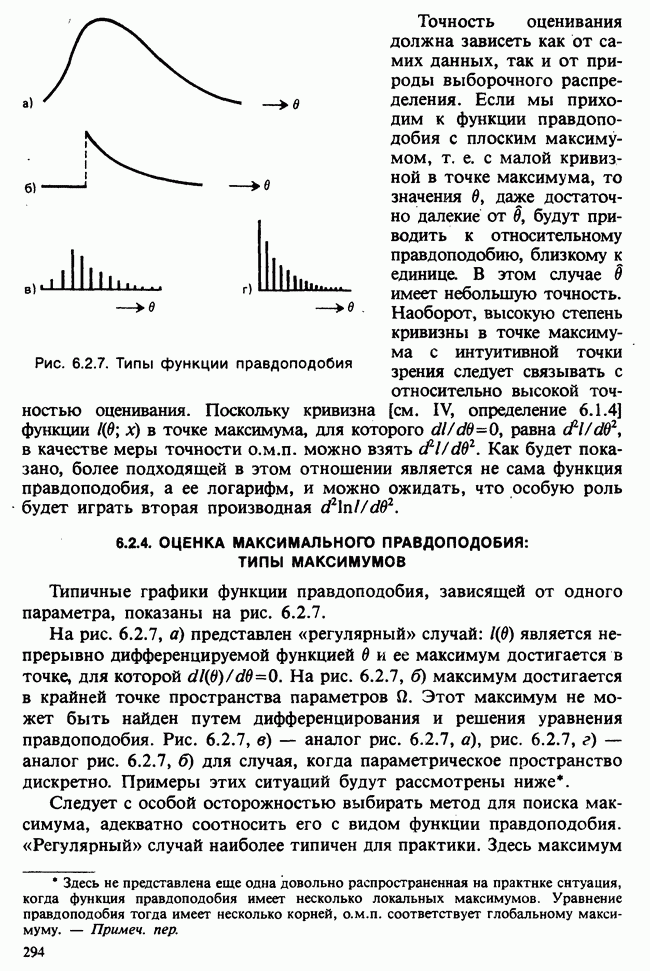
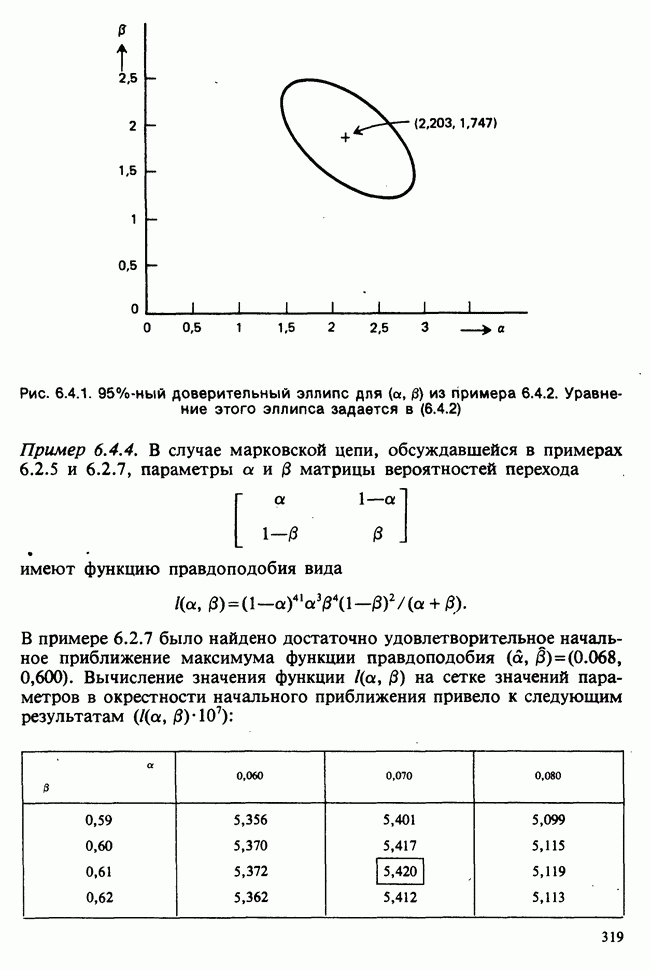
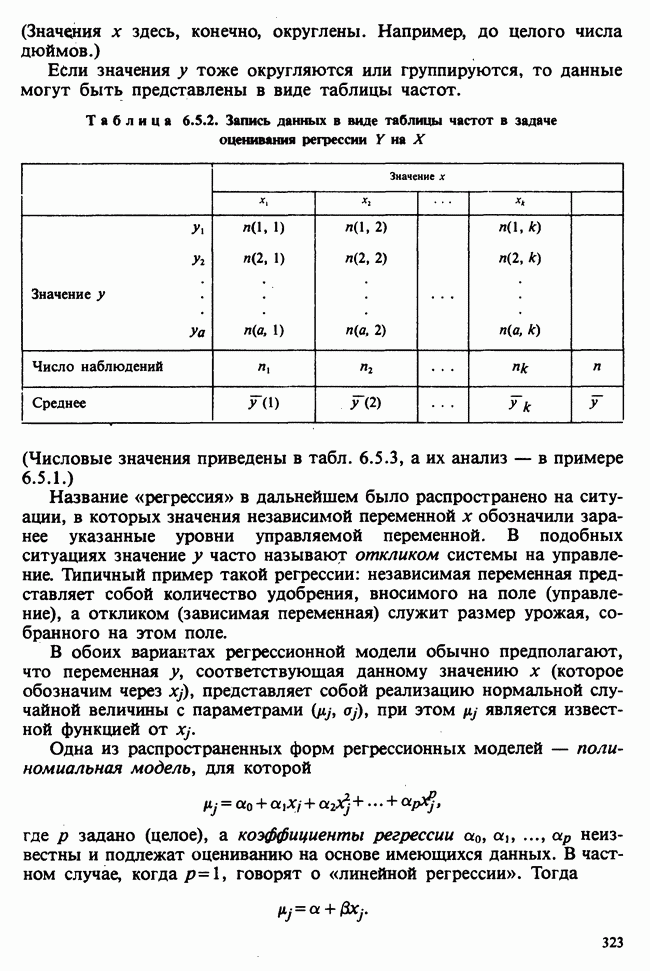
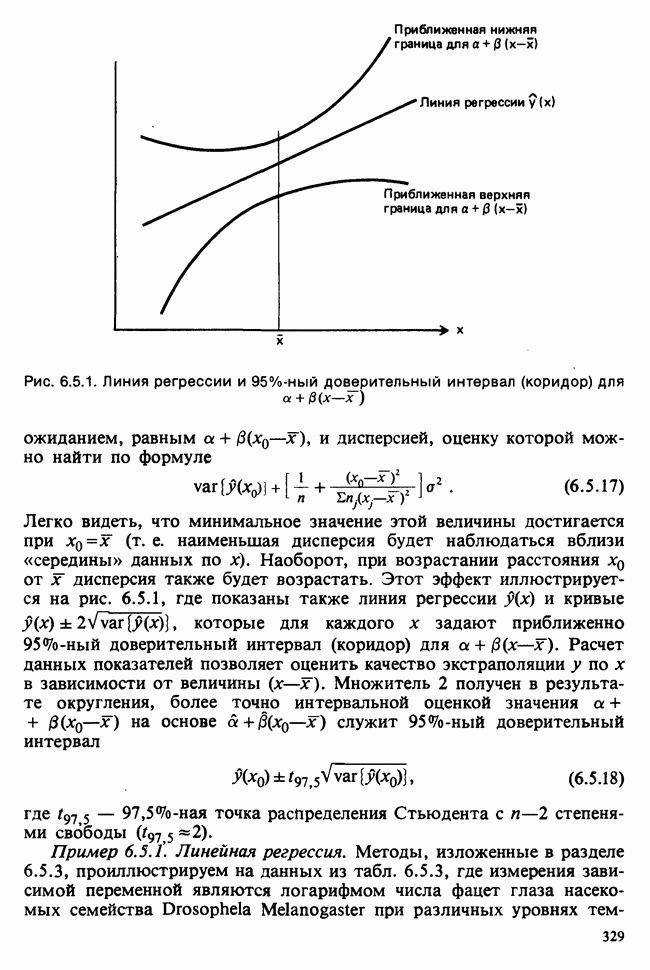
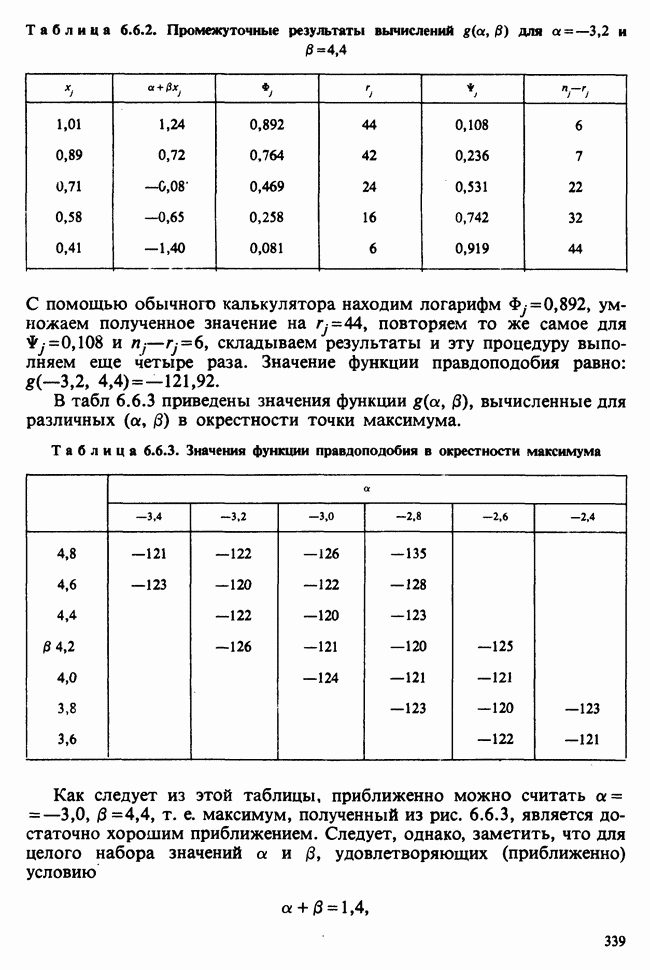
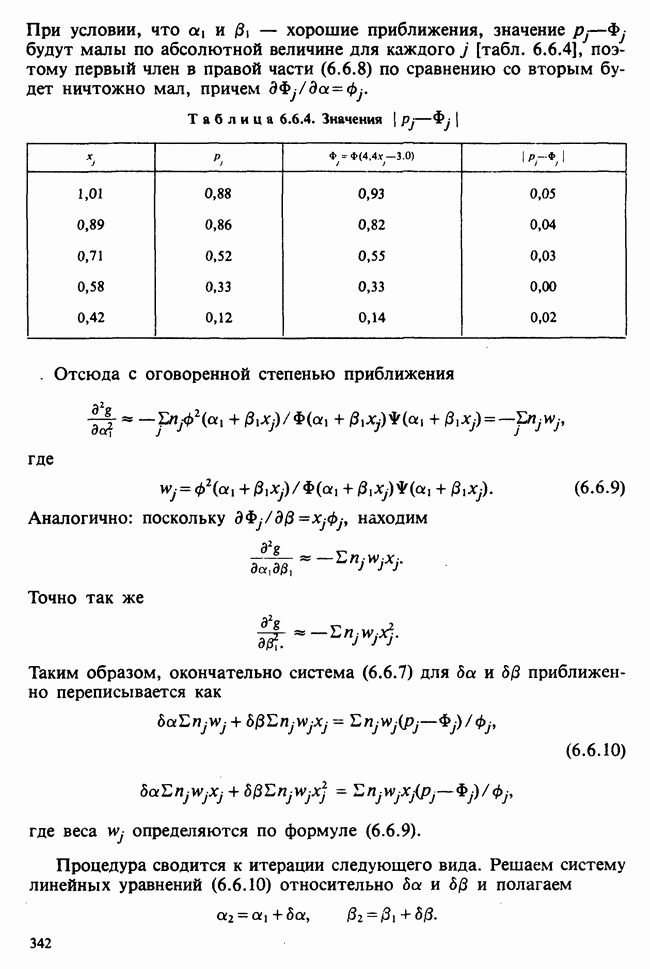
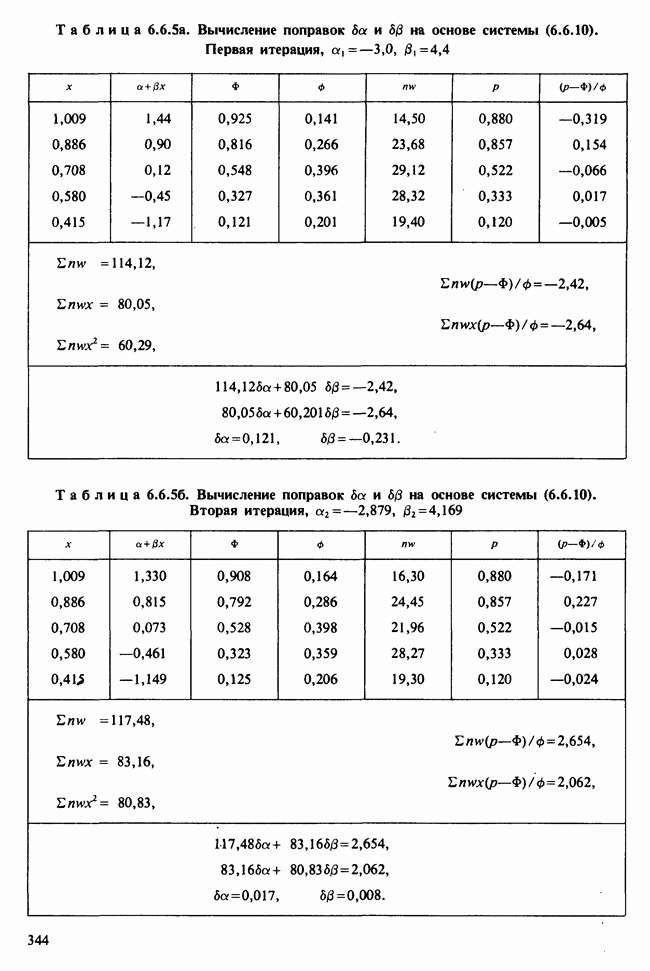
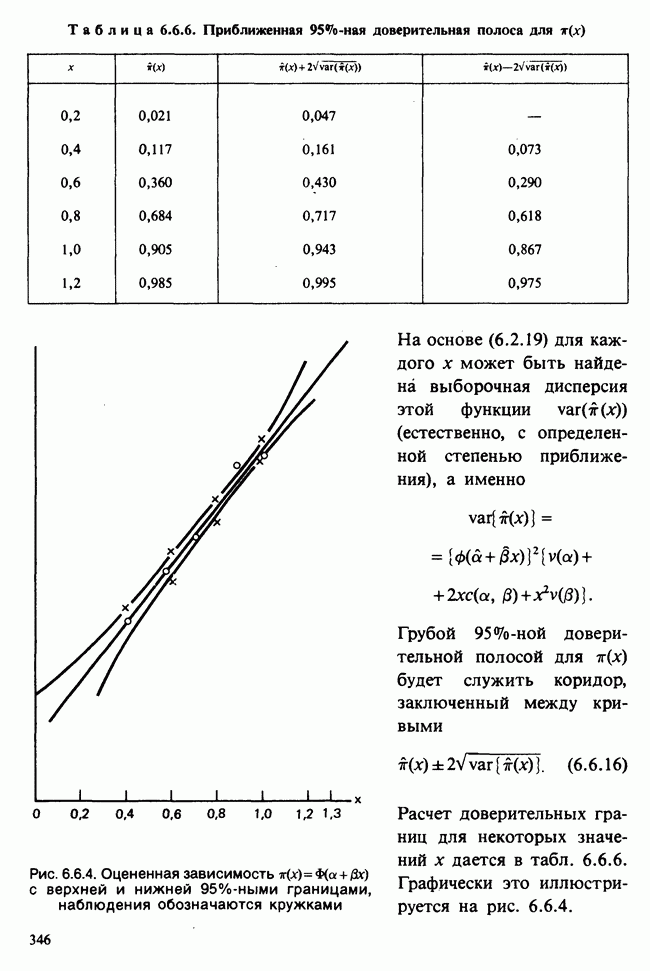
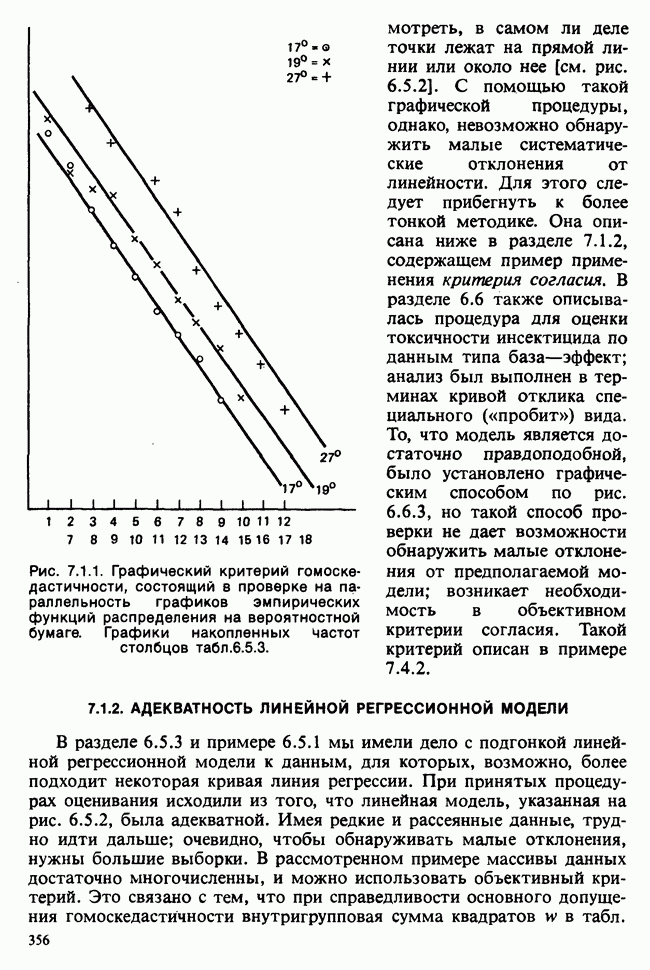
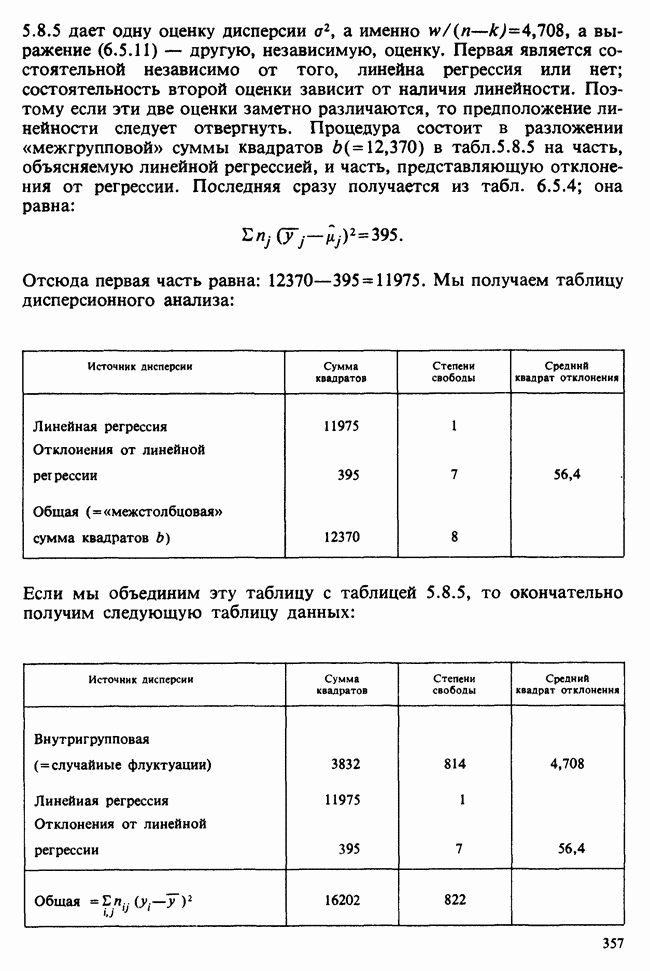
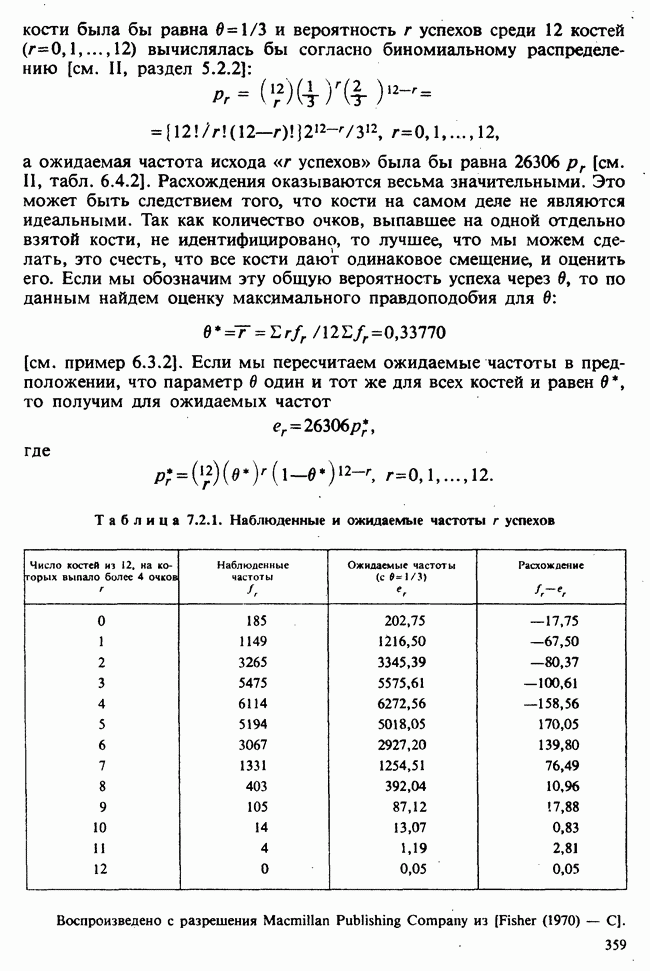
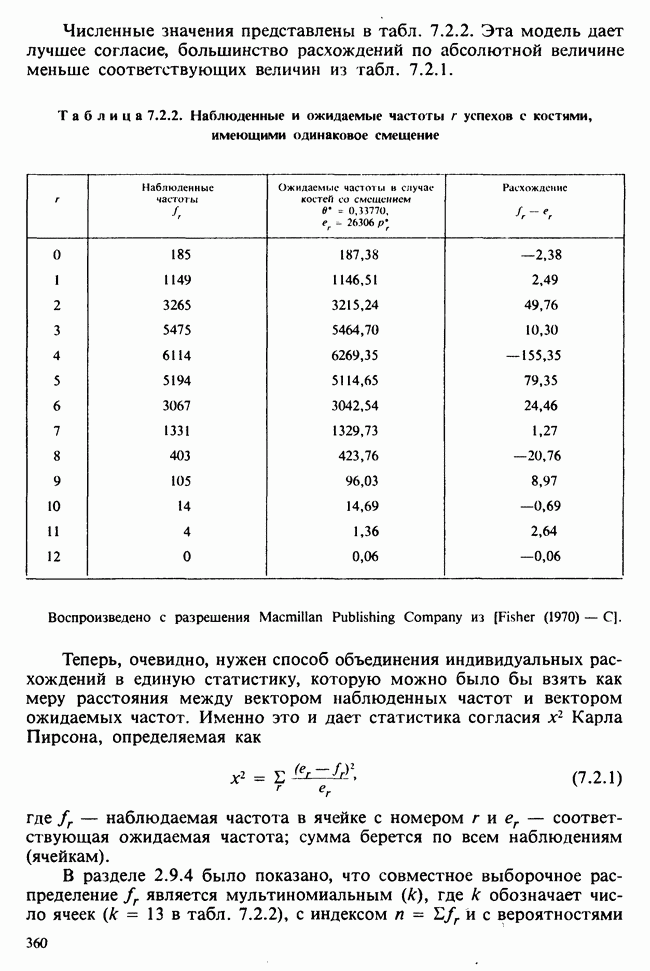
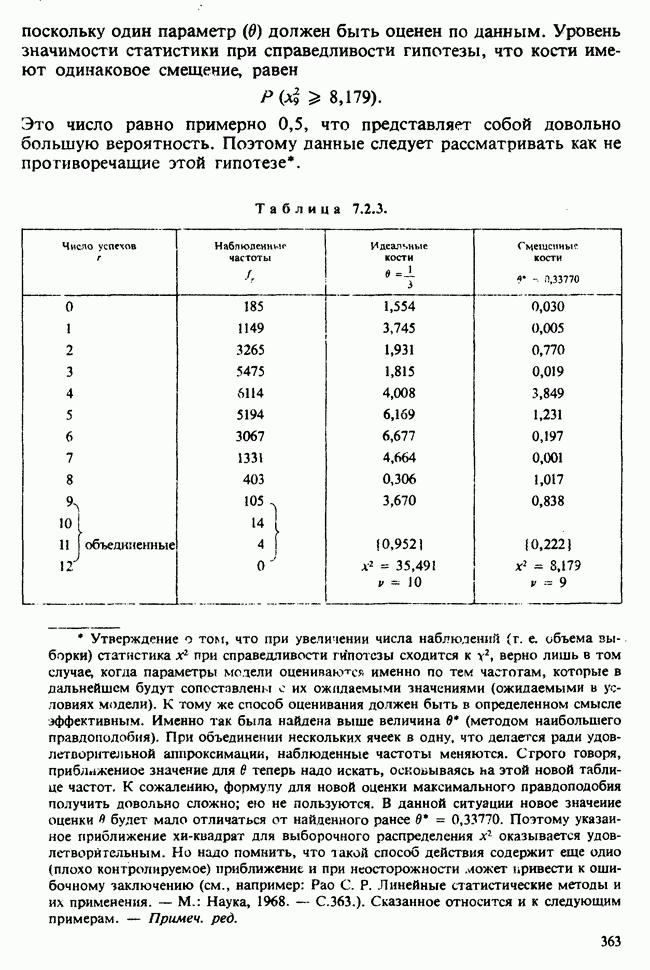
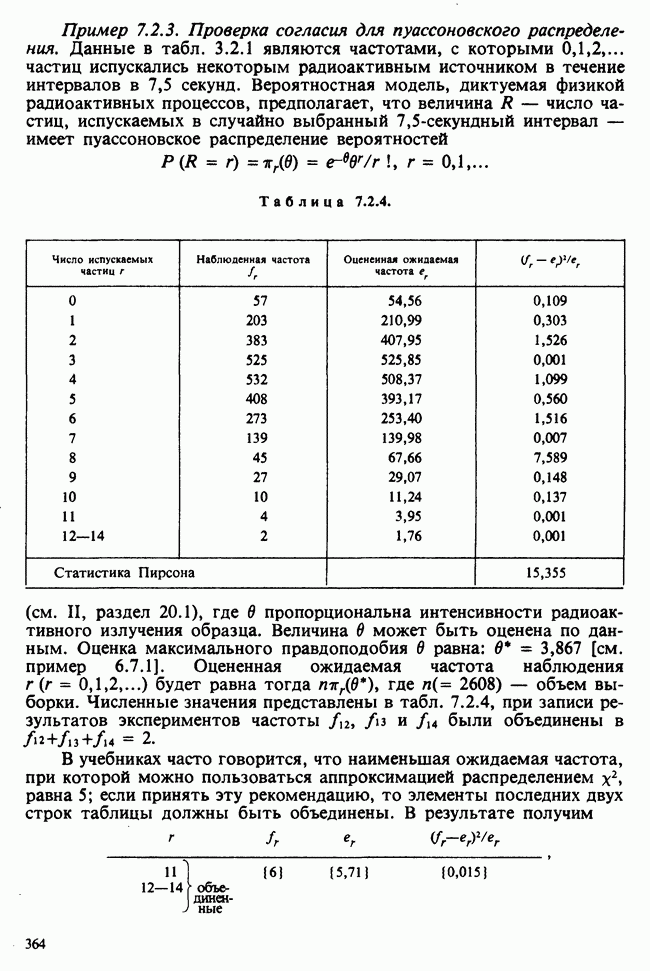
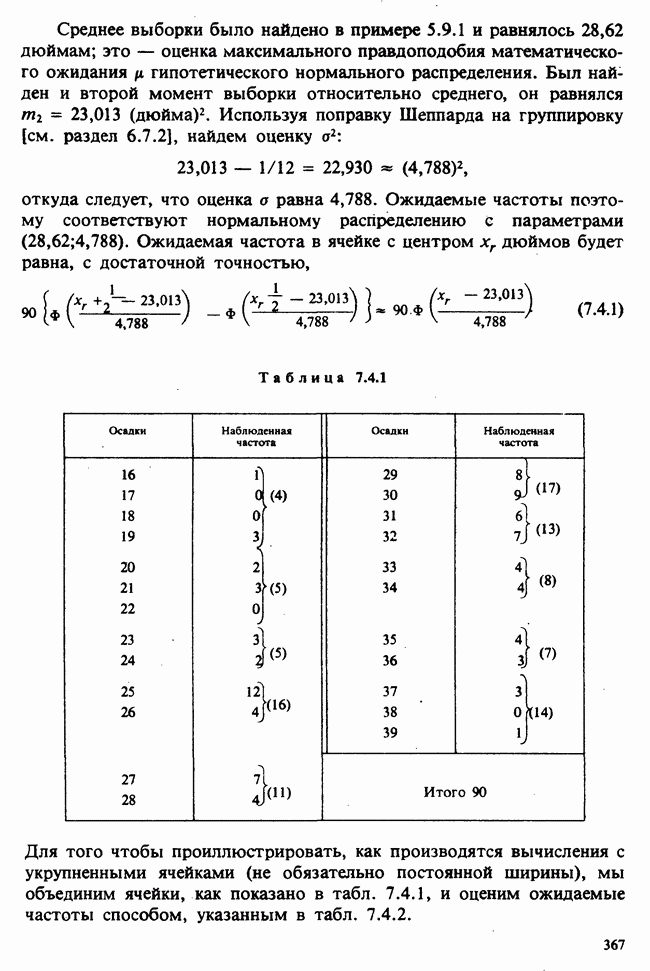
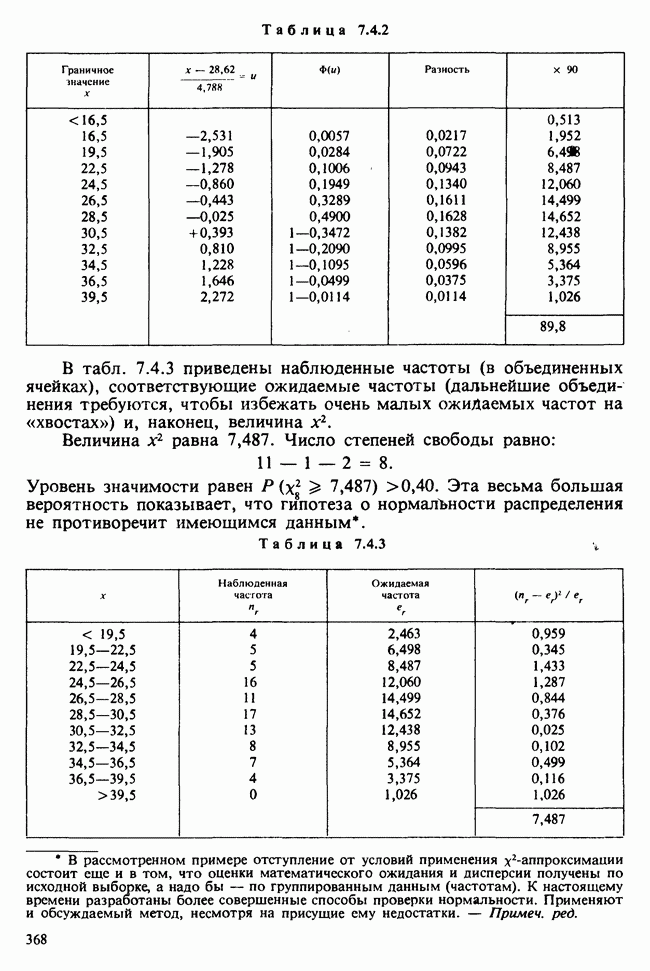
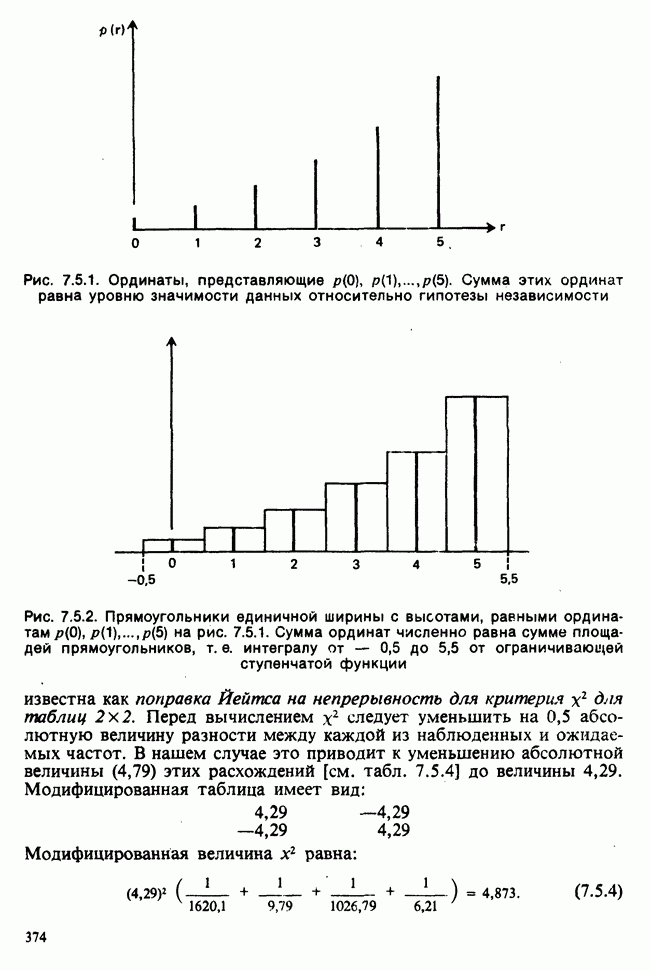
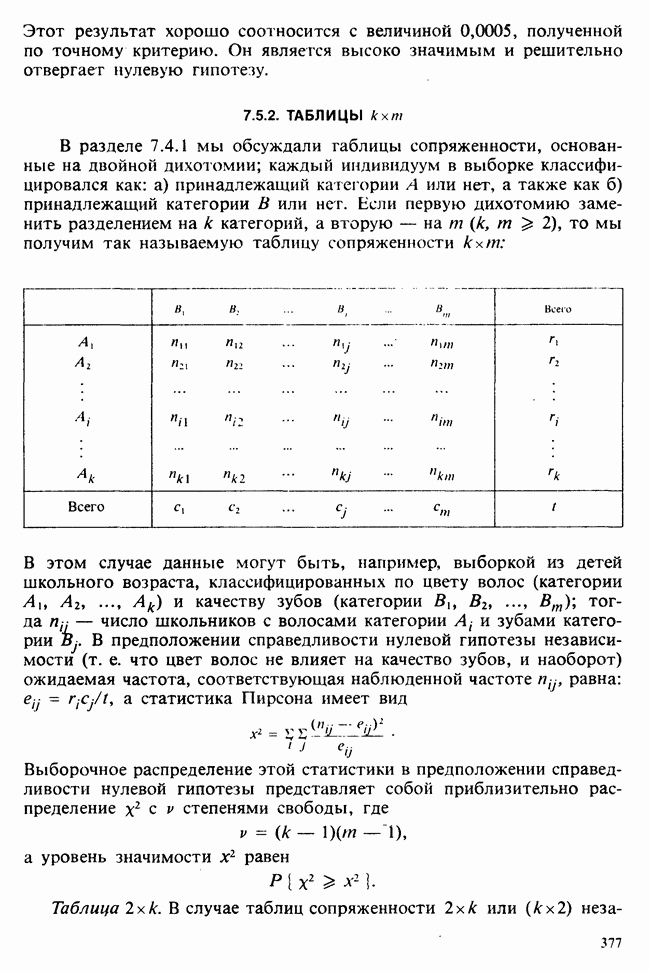
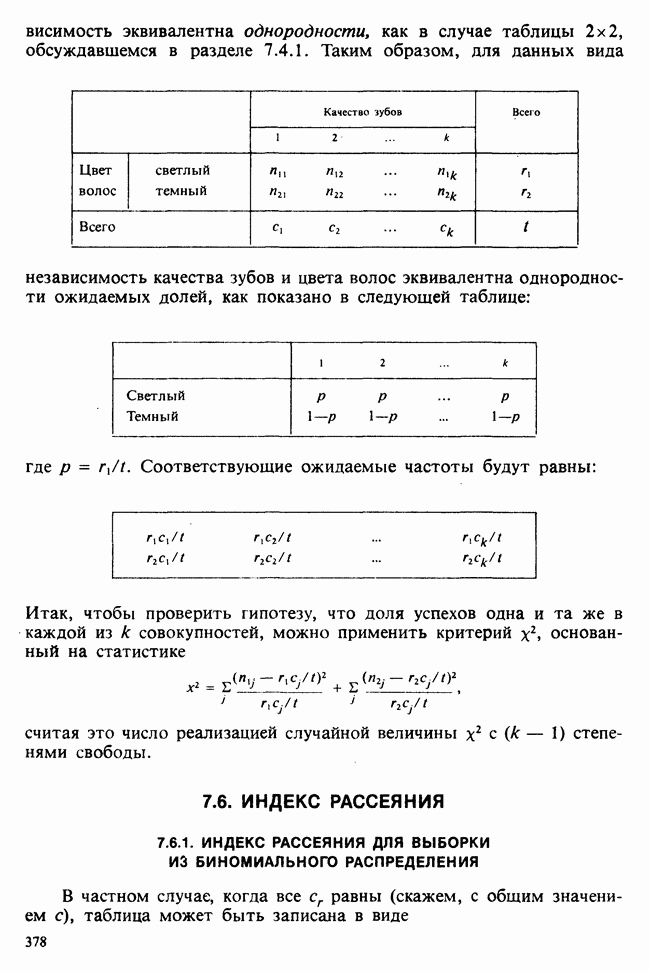
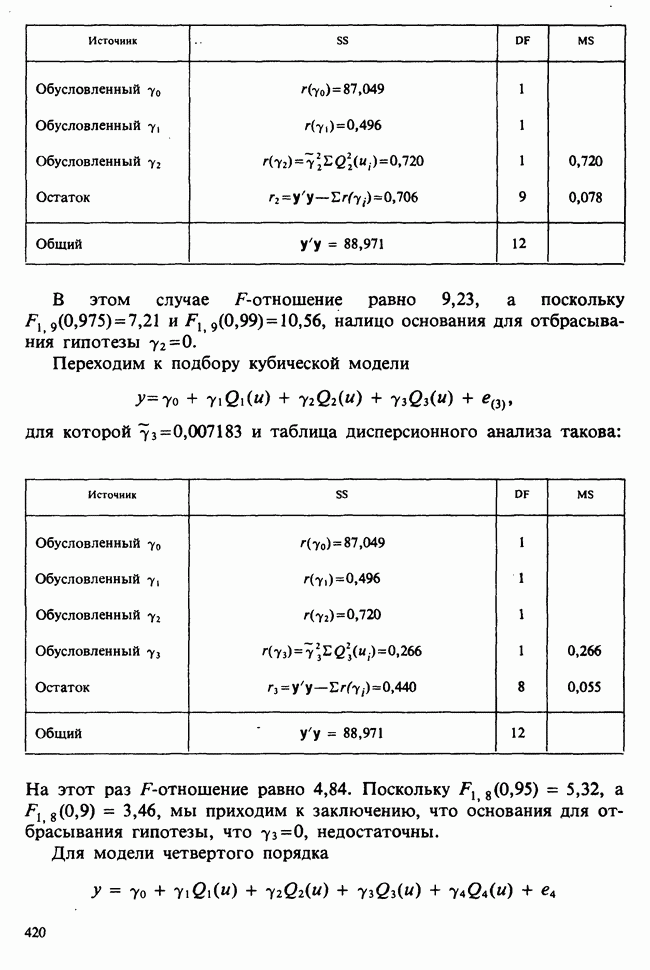
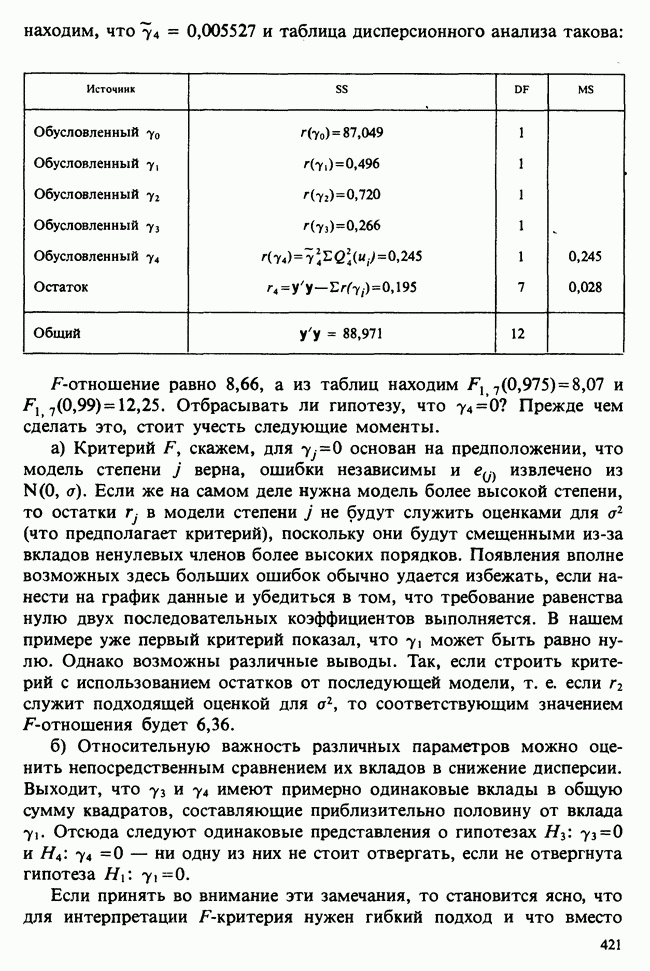
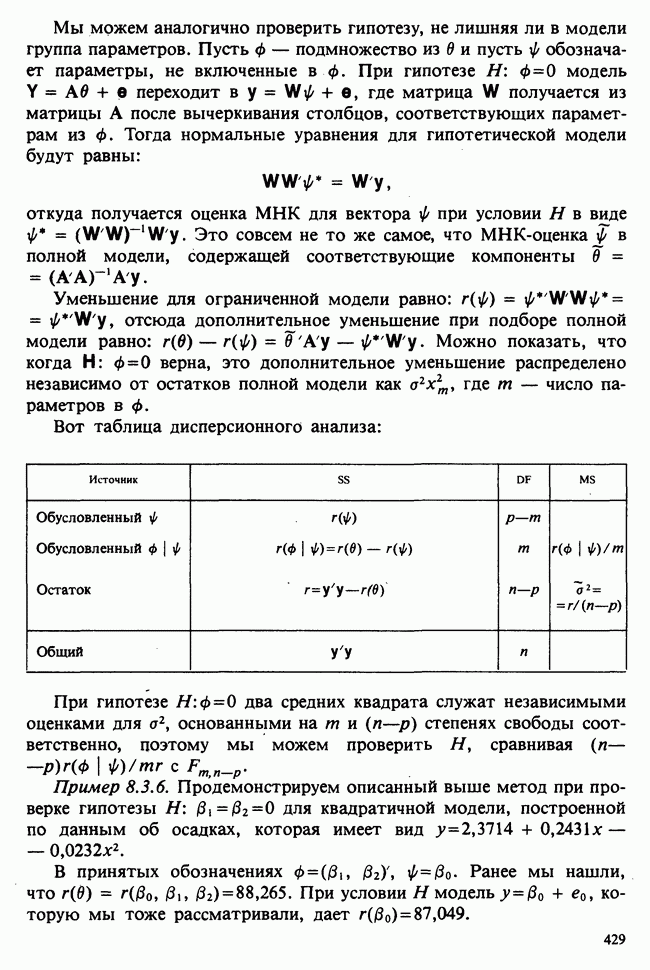
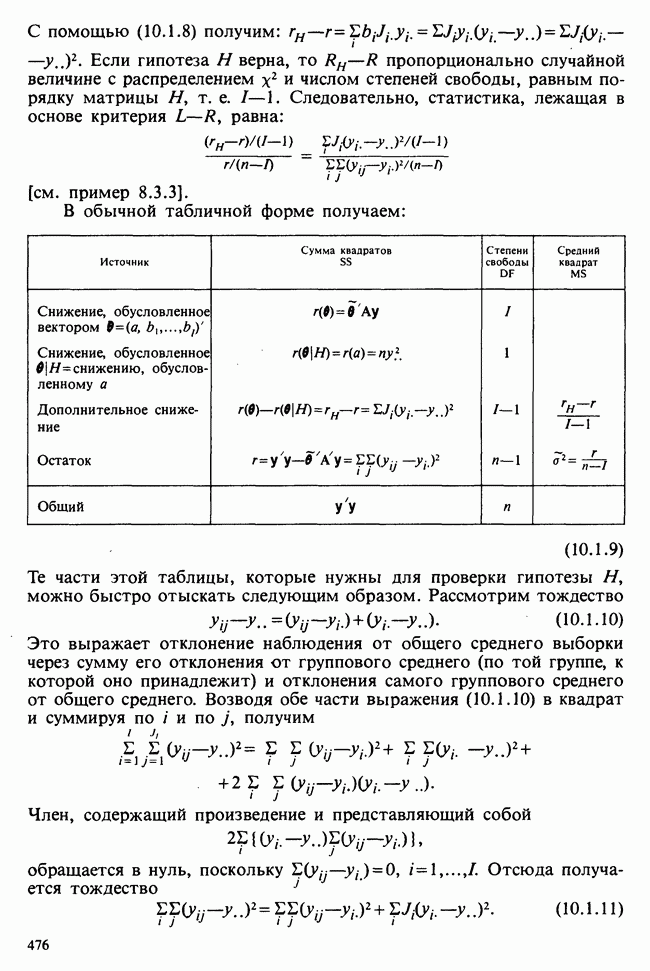
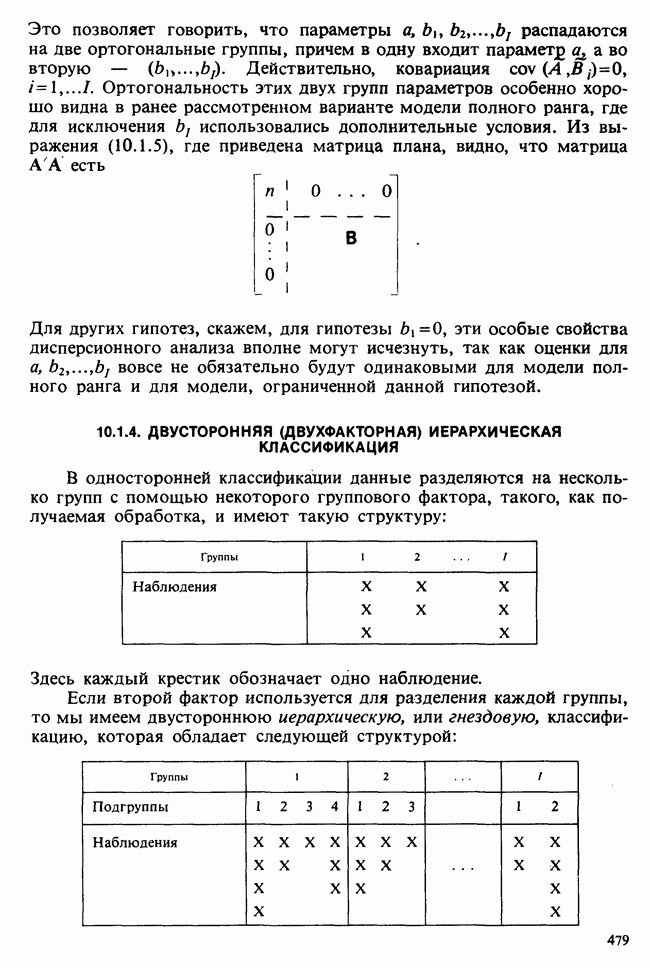
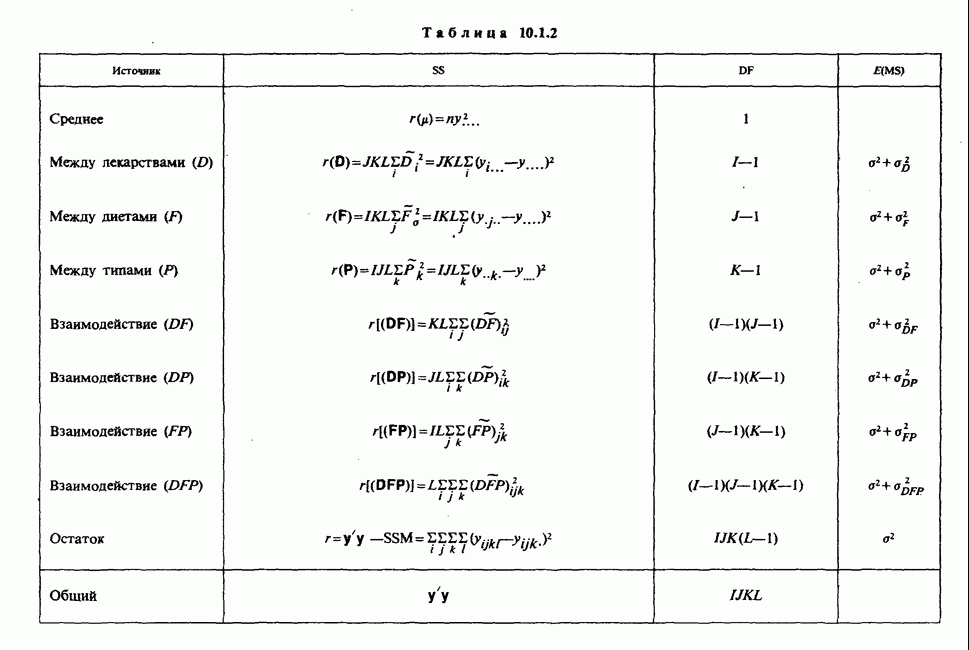
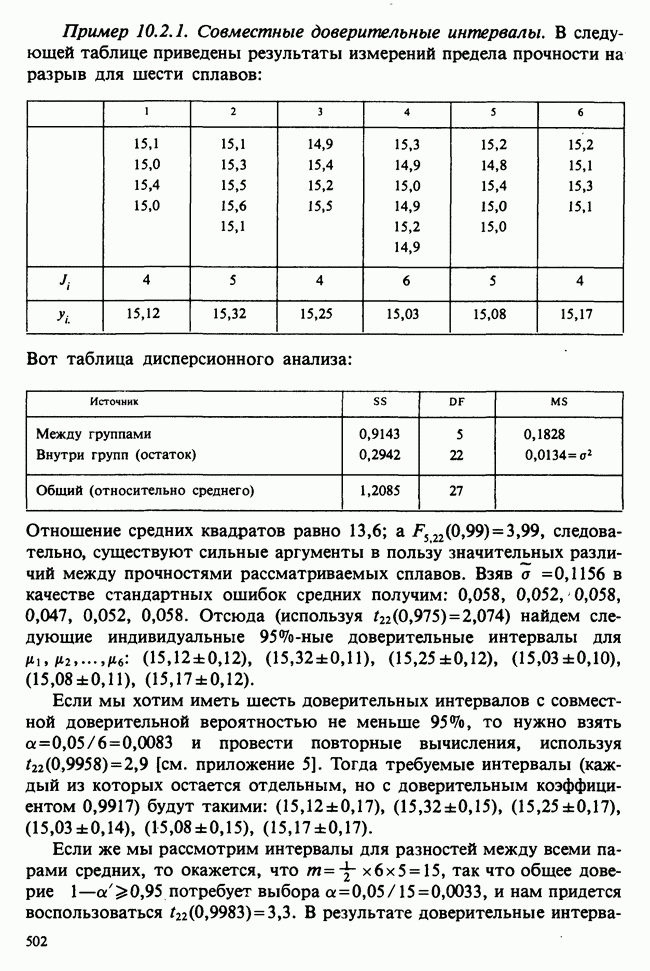
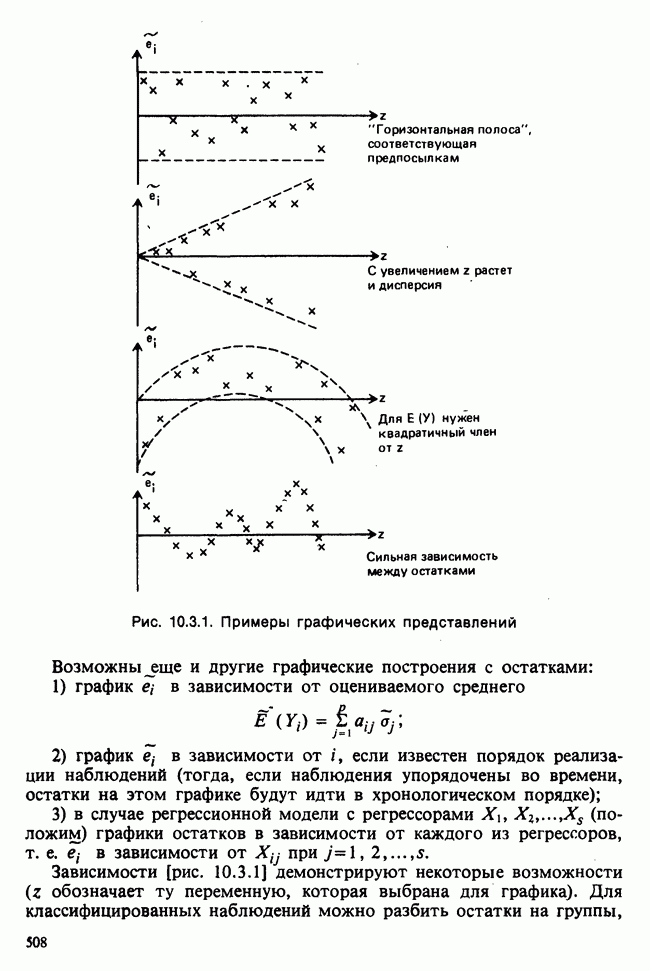
1.4. СОГЛАШЕНИЯ И ОБОЗНАЧЕНИЯ
Мы завершаем эту главу замечаниями, касающимися обозначений и других соглашений, которые используются в Справочнике. Некоторые из них стандартны, другие же требуют пояснения.
1.4.1. МАТЕМАТИЧЕСКИЕ СОГЛАШЕНИЯ
Логарифм: если не оговорено другое,  всегда означает
всегда означает  натуральный логарифм, логарифм по основанию е.
натуральный логарифм, логарифм по основанию е.
Символ принадлежности к множеству:  означает, что х — элемент множества (набора класса) [см. I, раздел 1.1].
означает, что х — элемент множества (набора класса) [см. I, раздел 1.1].
Символ О: мы часто имеем дело со статистиками [см. определение
2.1.1], скажем  определенными по выборке объема
определенными по выборке объема  некоторые свойства которой могут быть выражены в виде
некоторые свойства которой могут быть выражены в виде  где
где  — некоторая функция, а
— некоторая функция, а  — ошибка, которая изчезает с ростом
— ошибка, которая изчезает с ростом  Выражение
Выражение  например, означает, что
например, означает, что  имеет тот же порядок, что и
имеет тот же порядок, что и  для больших значений
для больших значений  ведет себя, приблизительно как
ведет себя, приблизительно как  для некоторой константы а. Аналогичный смысл имеет выражение
для некоторой константы а. Аналогичный смысл имеет выражение  [см. IV, определение 2.3.3].
[см. IV, определение 2.3.3].
1.4.2. СТАТИСТИЧЕСКИЕ И ВЕРОЯТНОСТНЫЕ ОБОЗНАЧЕНИЯ И СОКРАЩЕНИЯ
1. Сокращения
ф. р. — (кумулятивная) функция распределения [см. И, разделы 4.3.2, 10.3].
 — распределение
— распределение  как в
как в  означает, что X и
означает, что X и  имеют общее распределение.
имеют общее распределение.
с. с. — степени свободы [см. раздел 2.5.4].
н. о. р. — независимые и одинаково распределенные, как в н. о. р. величины  .
.
п. р. в. — функция плотности распределения вероятности, называемая также функцией частот. В этой книге мы используем выражение п. р. в. как для дискретных, так и для непрерывных распределений. Те, кто возражает против термина «плотность» для дискретного распределения, может интерпретировать п. р. в. как точечную  функцию распределения [см. II, разделы 4.3.1, 10.1].
функцию распределения [см. II, разделы 4.3.1, 10.1].
с. в. — случайная величина, с. п. — случайная переменная [см. II, гл. 4].
~ (тильда) — распределено как. Итак,  означает, что распределение X есть нормальное с параметрами и ст. Некоторые читатели могут быть настроены против этого обозначения, потому что тильда используется в других разделах математики, например, для обозначения отношения эквивалентности [см. I, раздел 1.3.3], а также асимптотической эквивалентности [см. IV, определение 2.3.2]. Для других же удобство такого обозначения перевешивает возражения.
означает, что распределение X есть нормальное с параметрами и ст. Некоторые читатели могут быть настроены против этого обозначения, потому что тильда используется в других разделах математики, например, для обозначения отношения эквивалентности [см. I, раздел 1.3.3], а также асимптотической эквивалентности [см. IV, определение 2.3.2]. Для других же удобство такого обозначения перевешивает возражения.
2. Обозначения стандартных распределений
Bernoulli  — распределение Бернулли с параметром (вероятностью) успеха
— распределение Бернулли с параметром (вероятностью) успеха  , т. е. распределение с.в. R с п.р.в.
, т. е. распределение с.в. R с п.р.в.

[см. II, раздел 5.2.1].
 — распределение
— распределение  для которой
для которой

[см. II, раздел 5.2.2].
 — распределение
— распределение 

Здесь а называют параметром масштаба, а  — параметром формы [см. II, раздел 11.3.1].
— параметром формы [см. II, раздел 11.3.1].
MVN — многомерное нормальное распределение [см. II, раздел 13.4].
 — нормальное распределение с ожидаемым значением
— нормальное распределение с ожидаемым значением  и стандартным отклонением а. (Дисперсия есть
и стандартным отклонением а. (Дисперсия есть  ). Некоторые авторы используют поэтому обозначения
). Некоторые авторы используют поэтому обозначения  или
или  [См. II, 11.4.]
[См. II, 11.4.]
 — распределение
— распределение  для которой
для которой

[см. II, раздел 5.4].
 — распределение
— распределение  задаваемой для каждого х как
задаваемой для каждого х как

[см. II, раздел 10.7.1].
3. Соглашение об использовании прописных букв для обозначения случайных величин
Мы будем придерживаться следующей системы обозначений: прописные латинские буквы обозначают случайные переменные, а соответствующие строчные латинские буквы — их реализации (наблюденные значения). Итак, мы говорим о совокупности  наблюдений над с.в. X. В то же время иногда допустимы отклонения от этого правила, например использование
наблюдений над с.в. X. В то же время иногда допустимы отклонения от этого правила, например использование  как имени соответствующего распределения.
как имени соответствующего распределения.
Строгая приверженность к соглашениям — признак педантичности, и профессиональные статистики не всегда беспокоятся по этому поводу. Однако учащимся и тем, кто еще не стал специалистом, мы рекомендуем их придерживаться.
4. Обозначения для моментов и связанных с ними величин
Мы используем символ  для обозначения математического ожидания (ожидаемого значения) или
для обозначения математического ожидания (ожидаемого значения) или  [см. II, гл. 8]. Применяются также варианты
[см. II, гл. 8]. Применяются также варианты  . Наше сокращение для дисперсии X есть
. Наше сокращение для дисперсии X есть  ; широко используются также символы
; широко используются также символы  Для стандартного отклонения X мы используем
Для стандартного отклонения X мы используем  , для ковариации X и
, для ковариации X и  , для коэффициента корреляции между X и
, для коэффициента корреляции между X и  а для асимметрии
а для асимметрии  [см. II., гл. 9].
[см. II., гл. 9].
5. Нестандартные обозначения: индуцированные случайные величины, статистические копии
Совокупность взаимно независимых наблюдений  случайной величины X (т.е. выборку) можно рассматривать и как совокупность, составленную из наблюдения х, над некоторой случайной величиной
случайной величины X (т.е. выборку) можно рассматривать и как совокупность, составленную из наблюдения х, над некоторой случайной величиной  наблюдения
наблюдения  над некоторой случайной величиной
над некоторой случайной величиной  и т.д., где
и т.д., где  считаются статистическими копиями X. Это значит, что они независимы и распределены одинаково, так же как распределена случайная величина X:
считаются статистическими копиями X. Это значит, что они независимы и распределены одинаково, так же как распределена случайная величина X:

Утверждение  есть реализация
есть реализация  наблюденное значение)
наблюденное значение)  может быть обращено. Итак, «X есть случайная величина, индуцированная
может быть обращено. Итак, «X есть случайная величина, индуцированная  означает, что выборочное распределение [см. гл. 2] х есть distr. Так, статистика
означает, что выборочное распределение [см. гл. 2] х есть distr. Так, статистика  (среднее значение выборки), которая принимает некоторое определенное численное значение для данной выборки, имеет выборочное распределение, которое может быть получено с помощью стандартных процедур из общего распределения
(среднее значение выборки), которая принимает некоторое определенное численное значение для данной выборки, имеет выборочное распределение, которое может быть получено с помощью стандартных процедур из общего распределения  , а случайная величина, вероятностное распределение которой совпадает с этим выборочным распределением, является случайной величиной, индуцированной
, а случайная величина, вероятностное распределение которой совпадает с этим выборочным распределением, является случайной величиной, индуцированной  Естественно обозначить ее символом
Естественно обозначить ее символом  , где
, где  — статистические копии X.
— статистические копии X.
Говорить о выборочном распределении некоторой статистики, имея в виду вероятностное распределение соответствующей индуцированной случайной величины, столь же педантично по отношению к сказанному выше, сколь и использование различий в обозначениях между случайной величиной X и ее реализацией  в обоих случаях целью является ясность изложения.
в обоих случаях целью является ясность изложения.
6. Два смысла обозначения  вероятность А при условии К
вероятность А при условии К
Один смысл  есть «условная вероятность предложения (события) А при условии, что предложение В истинно» [см. II, раздел 6.5]. Тогда
есть «условная вероятность предложения (события) А при условии, что предложение В истинно» [см. II, раздел 6.5]. Тогда  обе вероятности
обе вероятности  имеют смысл.
имеют смысл.
Однако мы часто используем  в смысле «вероятность предложения А, вычисленная в предположениях Н», обычно сокращая это до «вероятность А при Н», где Н является гипотезой. Например, пусть А — предложение
в смысле «вероятность предложения А, вычисленная в предположениях Н», обычно сокращая это до «вероятность А при Н», где Н является гипотезой. Например, пусть А — предложение  нормально распределенная случайная величина
нормально распределенная случайная величина  где значение
где значение  неизвестно и Н есть гипотеза, что
неизвестно и Н есть гипотеза, что 
Еще одна неоднозначность возникает при использовании выражений  или
или  где
где  случайная величина, распределение которой зависит от неизвестного параметра
случайная величина, распределение которой зависит от неизвестного параметра  означает вероятность получить значение
означает вероятность получить значение  в качестве наблюдения. Эта выроятность зависит от параметра в. То же относится и к выражениям
в качестве наблюдения. Эта выроятность зависит от параметра в. То же относится и к выражениям  и т.д. На практике обычно ясно из контекста, какой смысл подразумевается.
и т.д. На практике обычно ясно из контекста, какой смысл подразумевается.
7. Номенклатура для табличных значений: процентные точки
В статистической практике часто необходимы таблицы функций различных вероятностных распределений. Для некоторых наиболее употребительных распределений доступны таблицы, которые можно назвать прямыми. Например, в приложении 3 приведена обычная таблица функции  стандартного нормального интеграла (стандартной функции нормального распределения), а в приложении 5 — аналогичная таблица для функции распределения Стьюдента. Однако с целью экономии места таблицы даны в обратной форме. Так, для стандартного нормального распределения таблицы обратной формы содержат значения и в зависимости от Ф (вместо
стандартного нормального интеграла (стандартной функции нормального распределения), а в приложении 5 — аналогичная таблица для функции распределения Стьюдента. Однако с целью экономии места таблицы даны в обратной форме. Так, для стандартного нормального распределения таблицы обратной формы содержат значения и в зависимости от Ф (вместо  в зависимости от
в зависимости от  ), т.е. дается значение
), т.е. дается значение  такое, что
такое, что  как, например, в приложении 4.
как, например, в приложении 4.
Для случайной величины  значение такое, что
значение такое, что

называют верхней  -процентной точкой распределения
-процентной точкой распределения  величину
величину  такую что
такую что

называют нижней процентной точкой; при этом

Выражение «процентные точки» без уточнения «верхние» или «нижние» обычно означает «верхние процентные точки».
Процентные точки используются, например, в наиболее доступных таблицах распределения Стьюдента (но не в приведенных в Справочнике), а также в таблицах  и
и  -распределений [см. приложения 6,7].
-распределений [см. приложения 6,7].
Нижние процентные точки иногда называют квантилями (фрактилями). Специальный случай — нижний и верхний квартили, которые являются соответственно 25%-ным и 75%-ным квантилями; медиана же есть 50%-ная точка.
1.5. ЛИТЕРАТУРА ДЛЯ ДАЛЬНЕЙШЕГО ЧТЕНИЯ
(см. скан)