Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
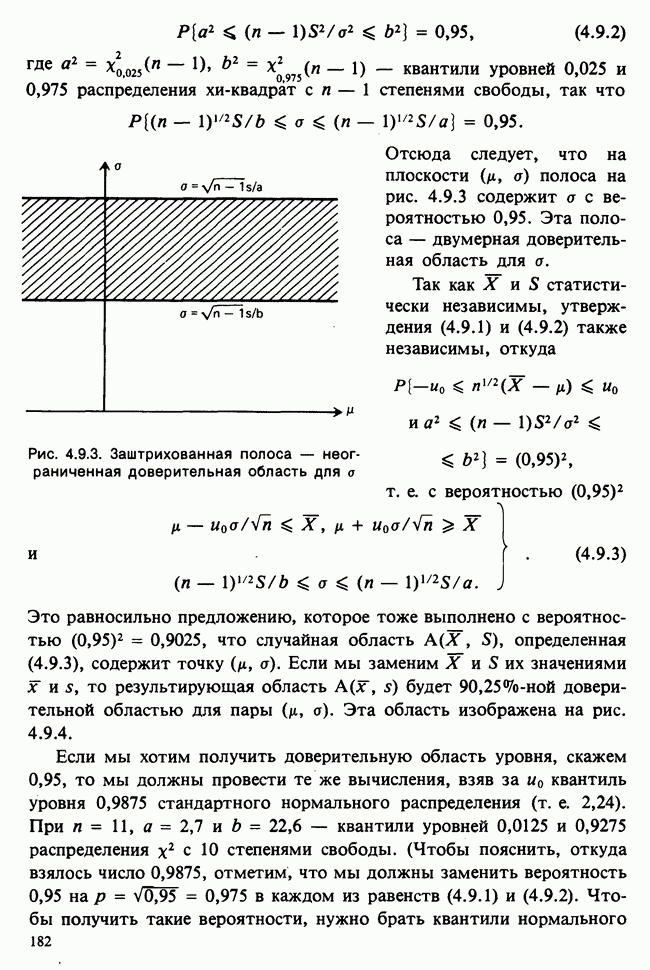
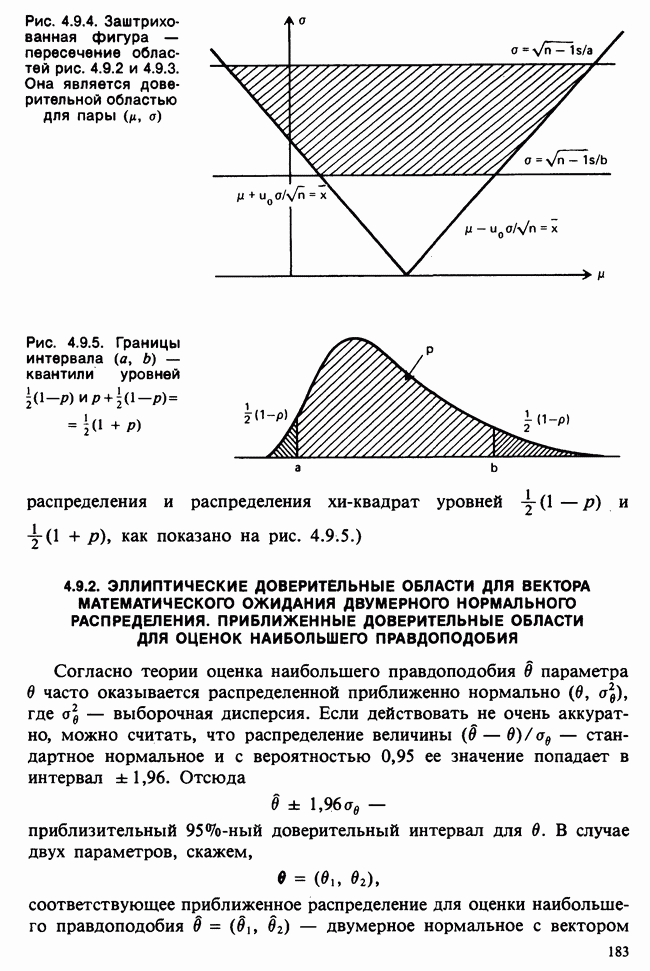
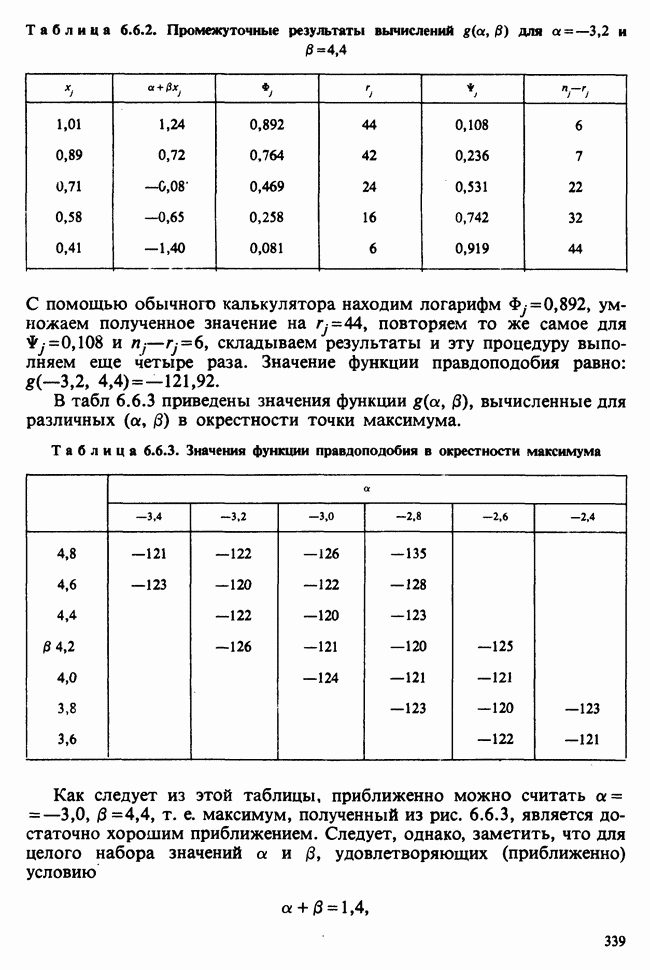
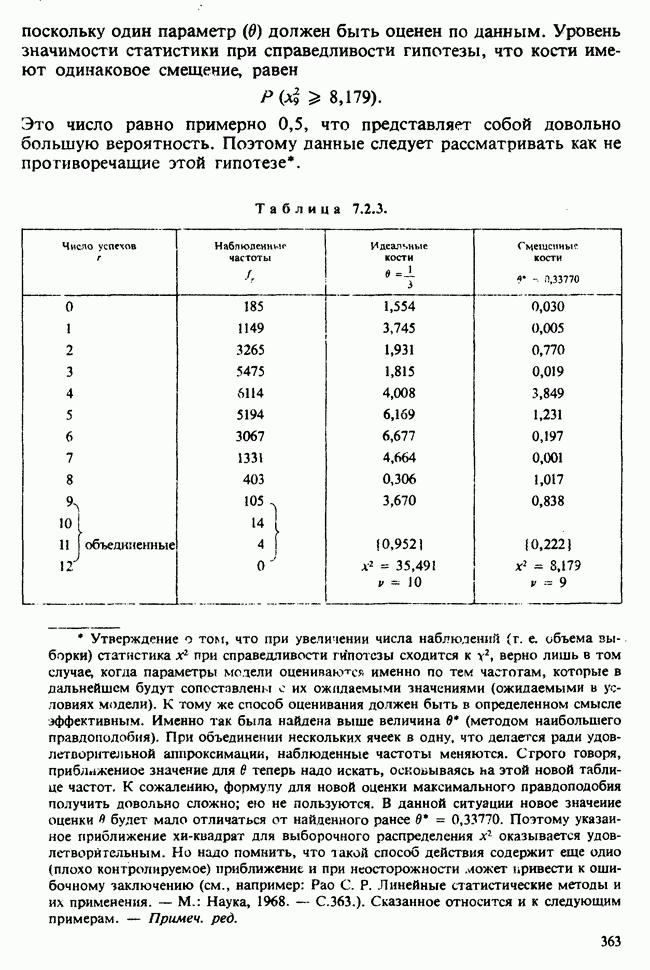
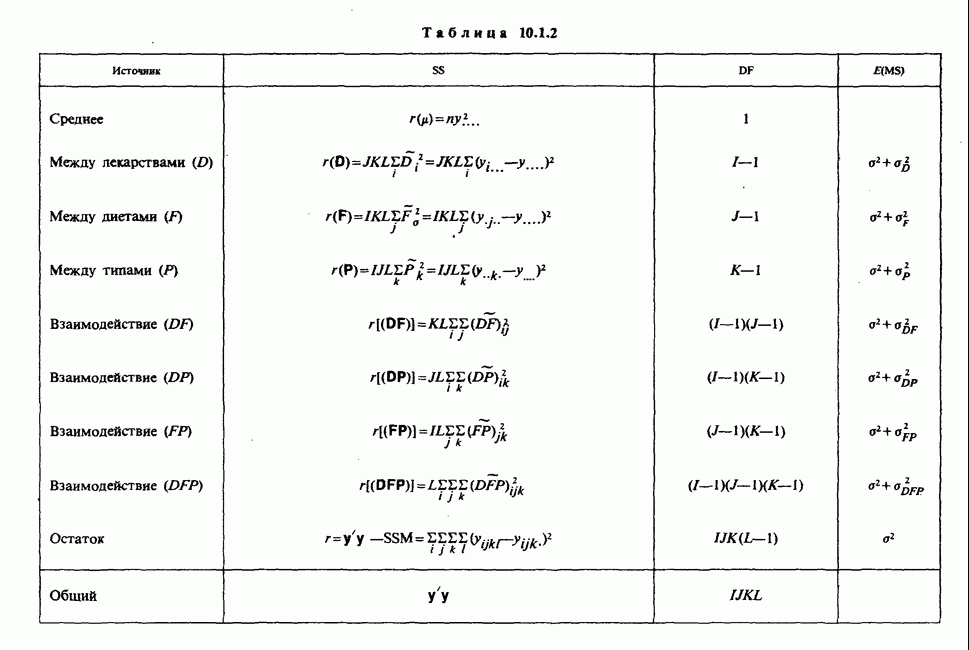
10.1.5. ДВУСТОРОННЯЯ (ДВУХФАКТОРНАЯ) ПЕРЕКРЕСТНАЯ КЛАССИФИКАЦИЯВ описанной выше иерархической классификации каждая группа была связана с различными множествами подгрупп. Так, в примере с загрязнением окружающей среды различные (по необходимости) множества городов выбирались в каждой стране. Когда же в каждую группу входят одни и те же подгруппы, получается иная структура (план). Например, для одного группового фактора (страна) мы могли бы интересоваться годовой Долей умерших за период в несколько лет от множества болезней, общих для всех рассматриваемых стран. Такие данные образуют перекрестную классификацию:
Каждый крестик обозначает долю умерших в отдельном году. Может оказаться, что у нас нет одинакового числа данных во всех ячейках, т. е. для любых комбинаций стран и болезней. Мы будем говорить о факторе-строке и о факторе-столбце. В рассматриваемом примере это соответственно «болезни» и «страны». Если болезни не окажутся общими для всех стран (как могло бы случиться при включении тропических болезней и стран умеренного климата), то в представленном выше расположении появились бы пустые ячейки, а перекрестная классификация оказалась бы неполной. Тогда практически получился бы возврат к иерархической классификации, в которой отдельные подгруппы оказались бы общими для нескольких групп. Мы обозначаем
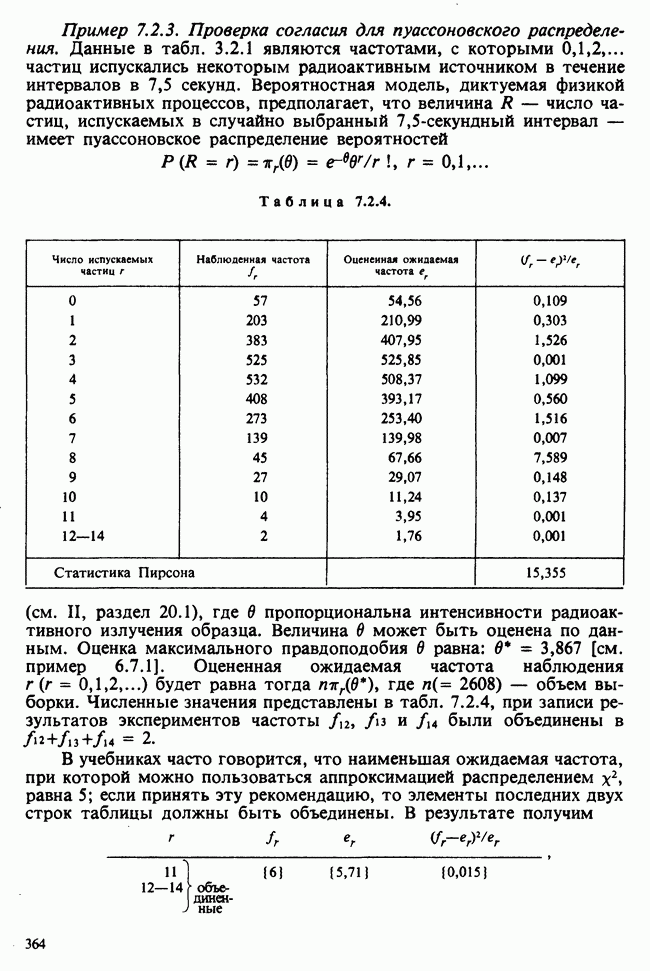
в которой для каждой ячейки оценивается один параметр, представляющий собой теоретическое среднее этой ячейки. Как и в случае иерархической классификации, мы будем пользоваться вырожденной моделью, соответствующей структуре данных и содержащей ясные параметры для интересующих эффектов:
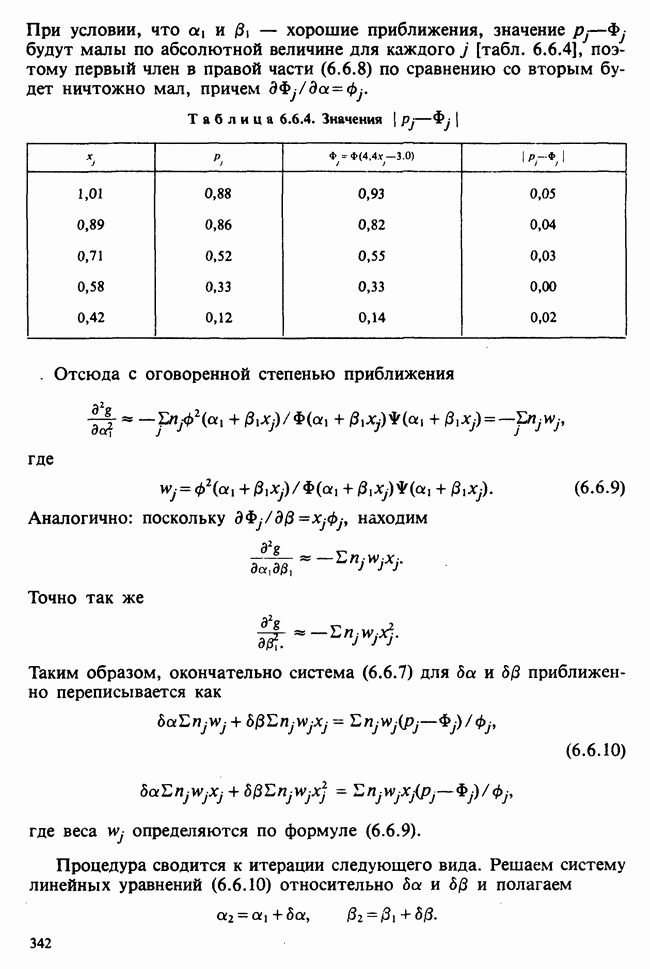
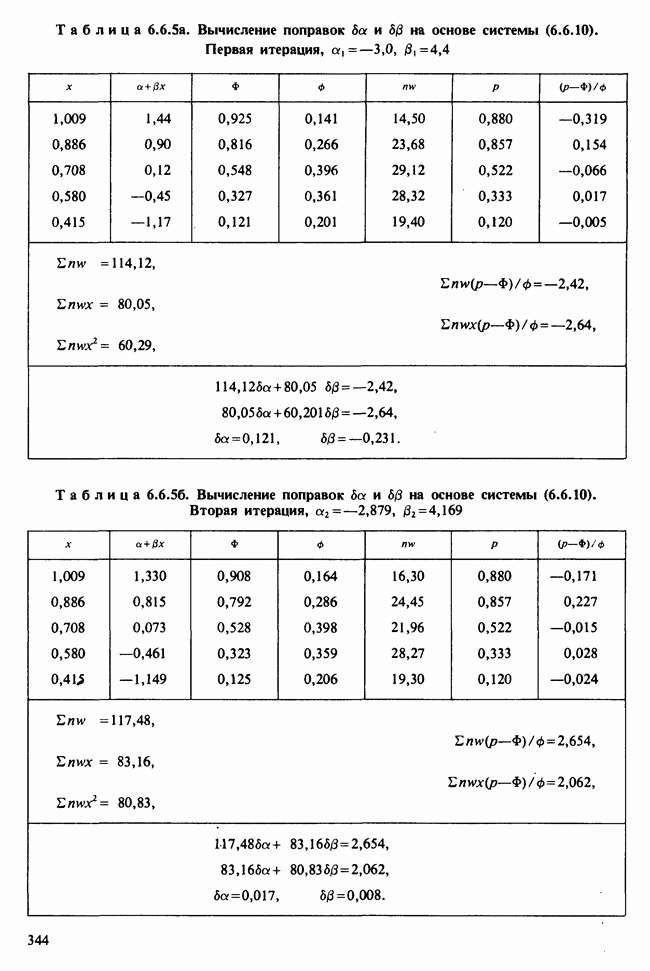
где параметры
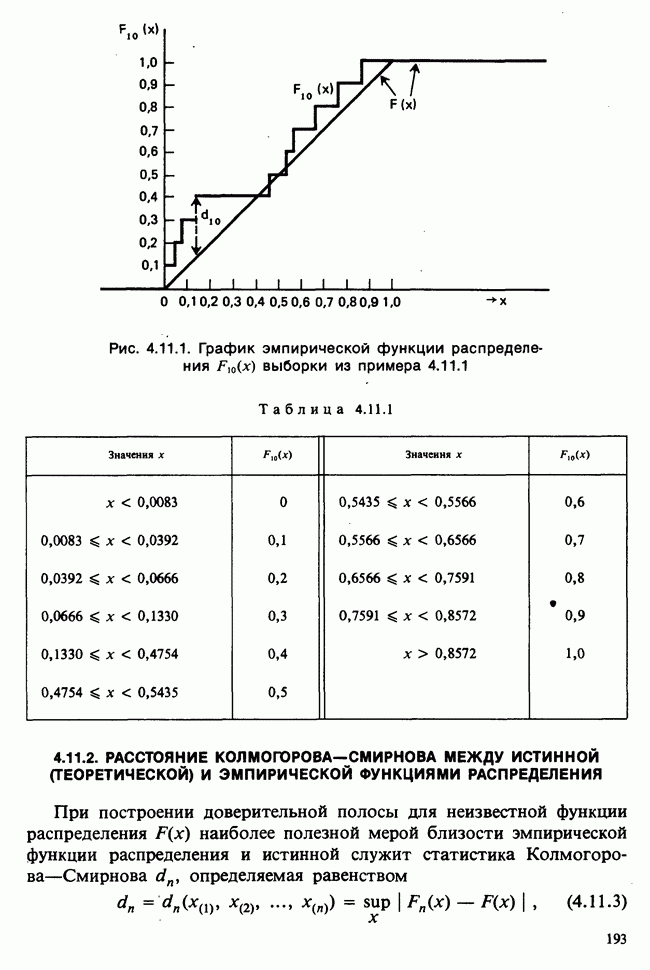
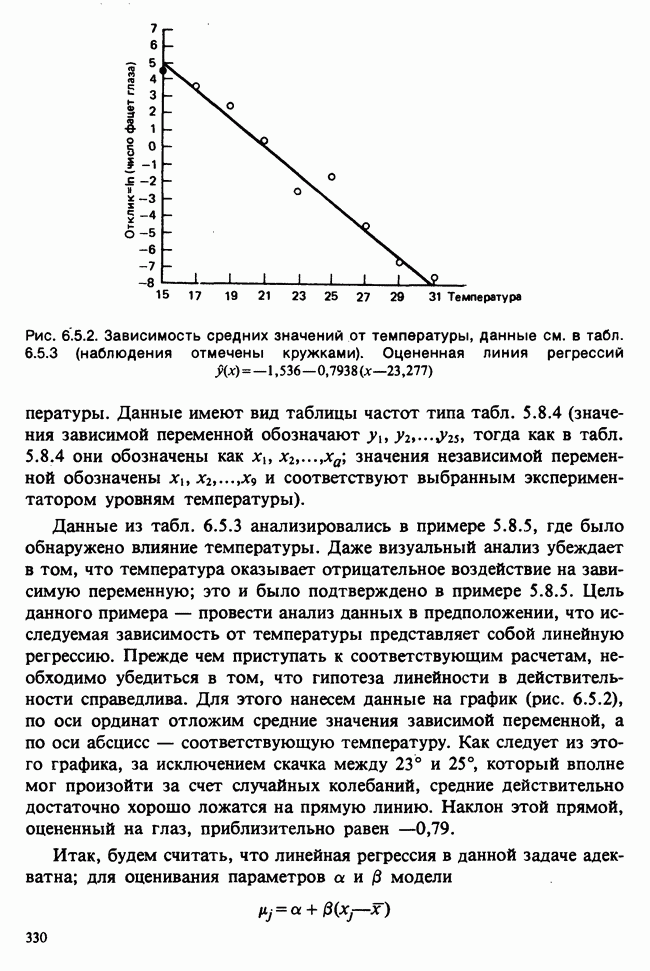
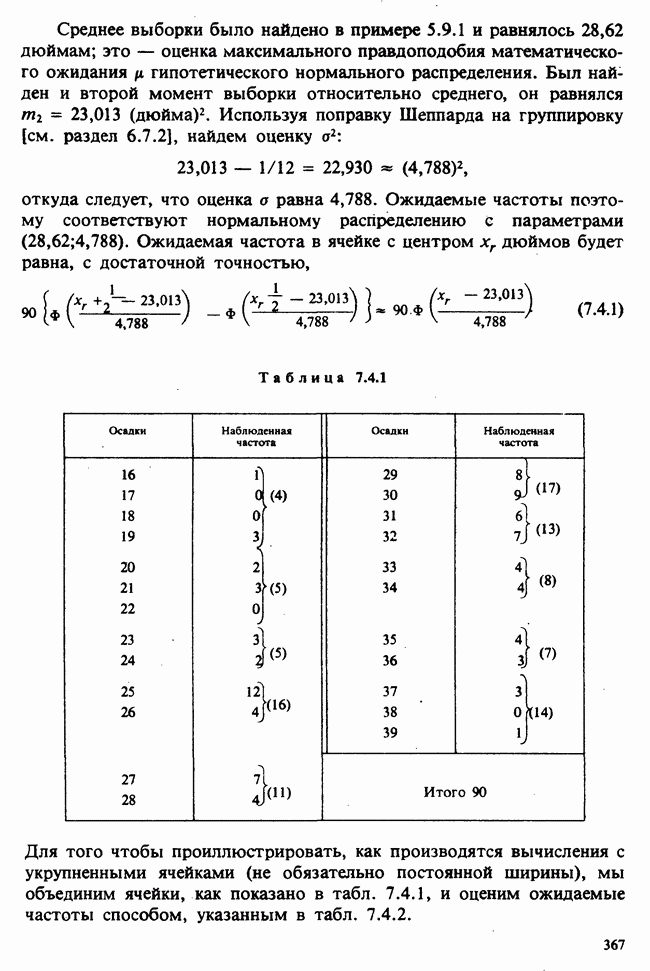
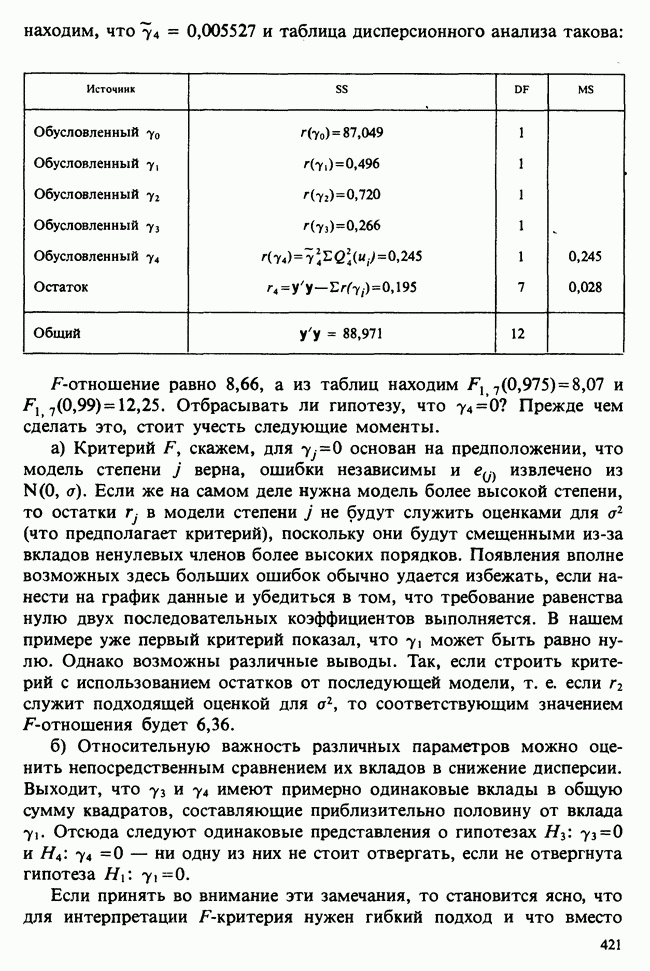
Рис. 10.1.1. Эффект обработок, когда нет взаимодействий
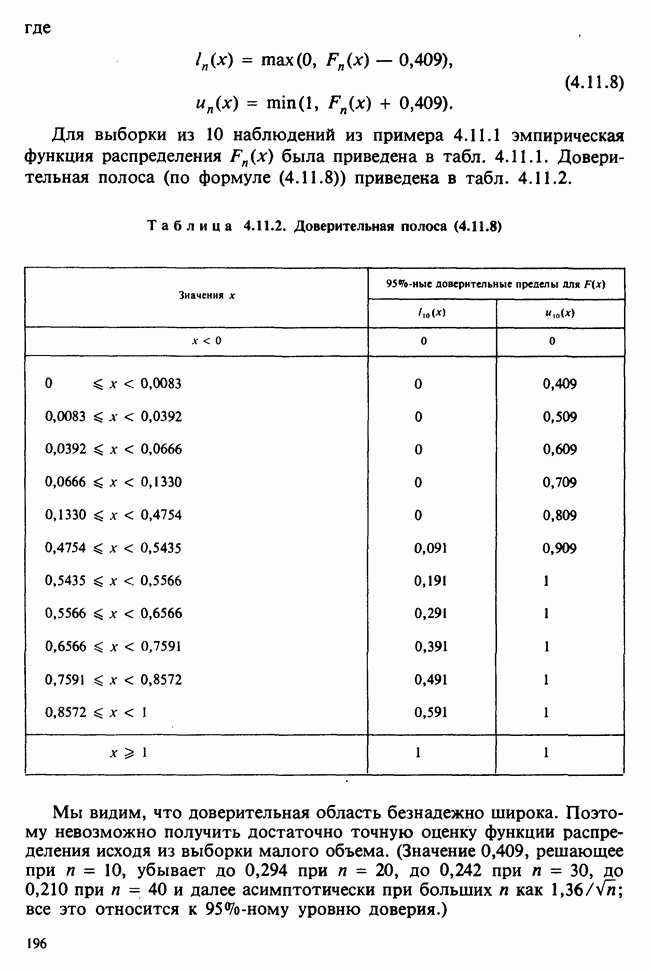
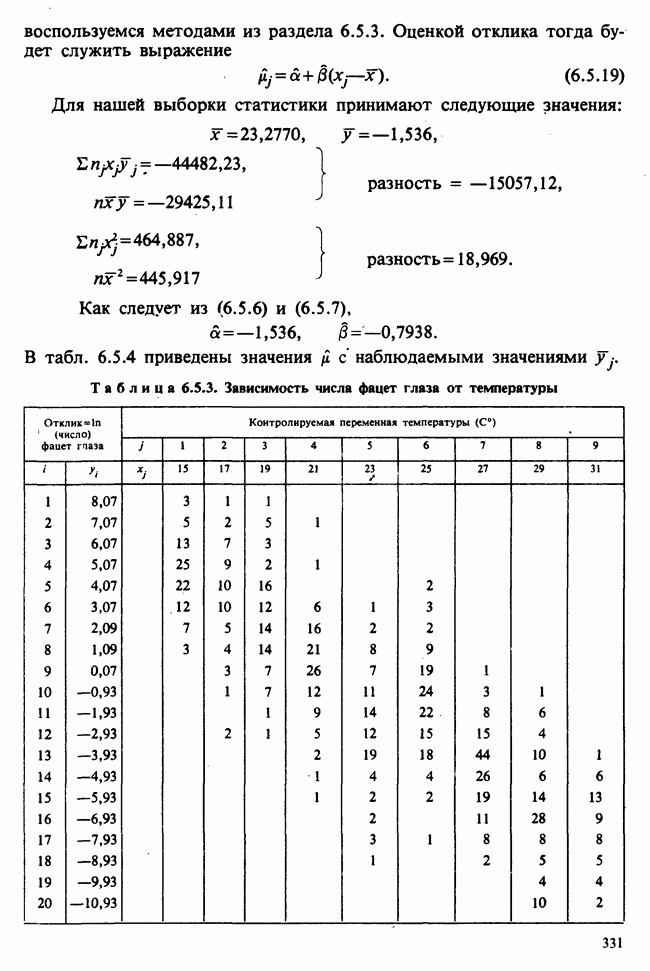
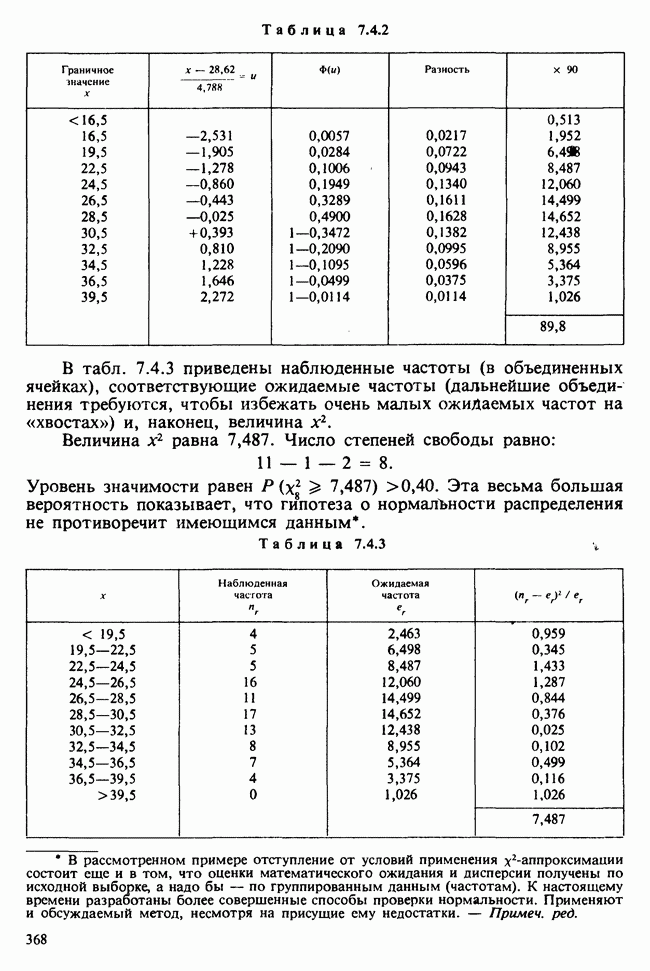
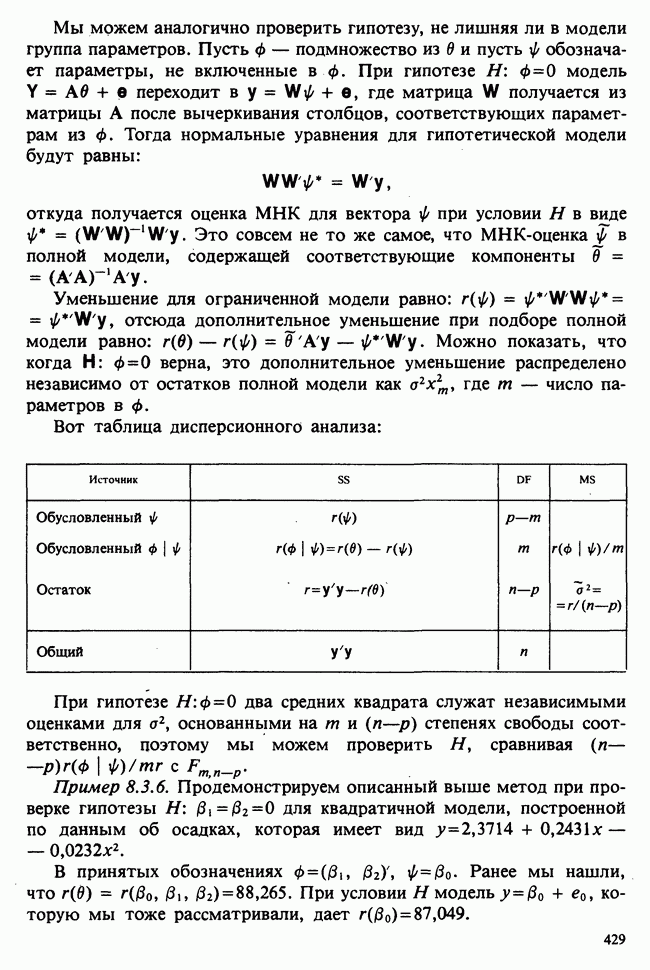
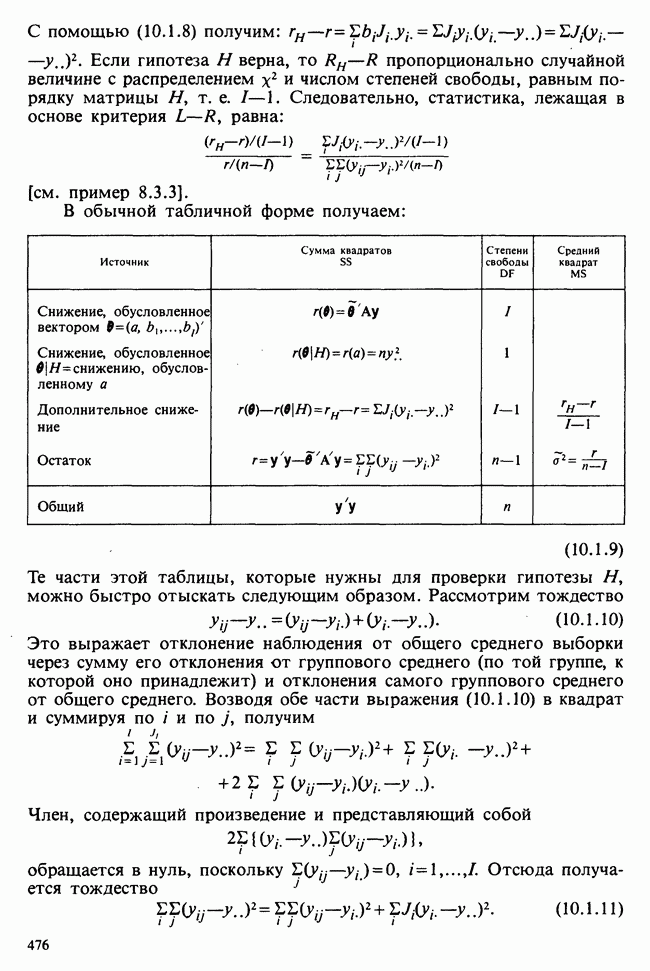
Рис. 10.1.2. Эффект обработок, когда есть взаимодействие включаются в модель в обшей ситуации, когда эффекты строк и столбцов действуют не аддитивно. Если же мы исключим параметры взаимодействий, то останется такая модель:
Для рассмотренного выше примера это адекватно только в том случае, когда разность ожидаемых долей умерших для любых двух болезней одинакова во всех странах, а разность долей умерших в любых двух странах одинакова для всех болезней. (И конечно, никакая из этих моделей не годилась бы, если бы изучаемые доли менялись во времени.) Для иллюстрации характерных особенностей взаимодействий рассмотрим пример с двумя лекарствами, каждое из которых может сочетаться с двумя режимами питания (диетами)
Когда взаимодействия отсутствуют, ситуация такая, как, на рис. 10.1.1. В этом случае ожидаемые разности между диетами одинаковы для обоих лекарств, а ожидаемые разности между лекарствами одни и те же для двух диет. Причем диета 1 всегда лучше, чем диета 2, а лекарство 2 всегда лучше, чем лекарство 1. Но если только есть взаимодействие, то это уже другой случай, что видно из рис. 10.1.2. В первом из представленных на этом рисунке варианте нет большой разницы как между диетами, так и между лекарствами, но для лекарства 1 лучше диета 2, тогда как для лекарства 2, наоборот, лучше диета 1. Это означает, что лекарства и диеты взаимодействуют. Во втором варианте нет большой разницы между лекарствами, но диета 1 всегда лучше, чем диета 2, и это, в частности, верно для лекарства 1, что снова указывает на взаимодействие лекарства и диет. Короче говоря, взаимодействие означает, что различие между лекарствами зависит от диеты, и наоборот. Отклик
где А — матрица, а Пропорциональные частоты. О пропорциональных частотах говорят, когда
где
Это, в частности, справедливо, когда во всех ячейках одинаковое число наблюдений, т. е. когда Когда же условие пропорциональности частот выполняется, мы выбираем следующие
Из условий на параметры взаимодействия следует, что
При подобных дополнительных ограничениях все параметры получают простую и удобную интерпретацию. Так МНК-оценки параметров получают в результате минимизации (по
с учетом приведенных выше дополнительных условий. Это дает:
Эти результаты отнюдь не удивительны с точки зрения тех интерпретаций параметров, которые приведены выше. Отсюда сумма квадратов остатков равна:
Общее число наблюдений равно:
Параметры образуют четыре ортогональные группы:
Сумма квадратов, обусловленная построением данной модели, в таком случае имеет вид
и каждое из слагаемых вносит свой вклад в Можно найти явные выражения для всех этих различных сумм квадратов, на которые раскладывается общая сумма квадратов модели, и без обращения к деталям метода наименьших квадратов. Достаточно воспользоваться следующим разбиением:
Возводя обе части этого тождества в квадрат и суммируя по
поскольку все члены, содержащие парные произведения, равны нулю. Как и в примерах, рассмотренных выше, уменьшение, обусловленное величиной Таблица 10.1.1. (см. скан) Гипотезы проверяются сравнением каждого среднего квадрата с
имеет распределение
имеет распределение
имеет распределение Интерпретация этих проверок идет по следующим направлениям. Мы уже говорили, что отсутствие взаимодействия означает, что эффекты строк и столбцов проявляются аддитивно. Допустим, что строки соответствуют различным сортам пшеницы, а столбцы — различным удобрениям. Тогда если гипотеза При использовании выражения В частном случае, когда частоты ячеек равны (см. скан) Если же в каждой ячейке содержится только по одному наблюдению
Она содержит
а остаточная сумма квадратов та же, что и (см. скан) Следовательно, мы можем проверить эффекты строк и столбцов обычным путем, сравнивая средние квадраты и обращаясь к F-критерию. Подчеркнем, что этот подход состоятелен лишь в том случае, когда верна аддитивная модель. Если же есть взаимодействия, их средний квадрат в качестве оценки Вернемся теперь к общей модели с неравными частотами ячеек, когда не удовлетворяется условие пропорциональности частот и параметры не образуют ортогональных групп. В этой ситуации для проверки, скажем, гипотезы
Более подробное обсуждение этих проблем содержится в работах [Kendall and Stuart (1966)] и [Scheff (1959)].
|
 |
Оглавление
|











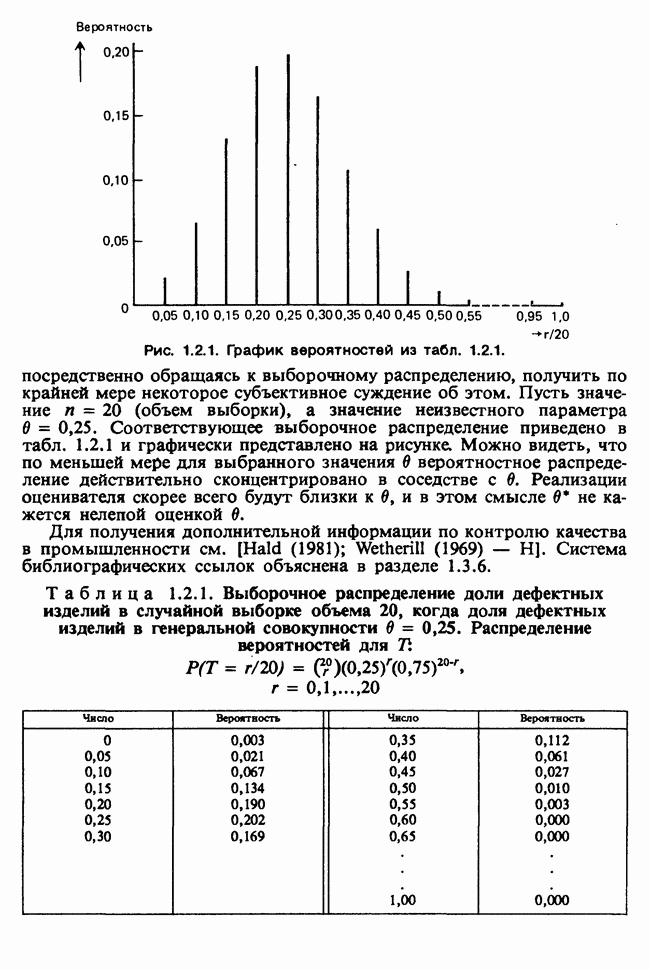

































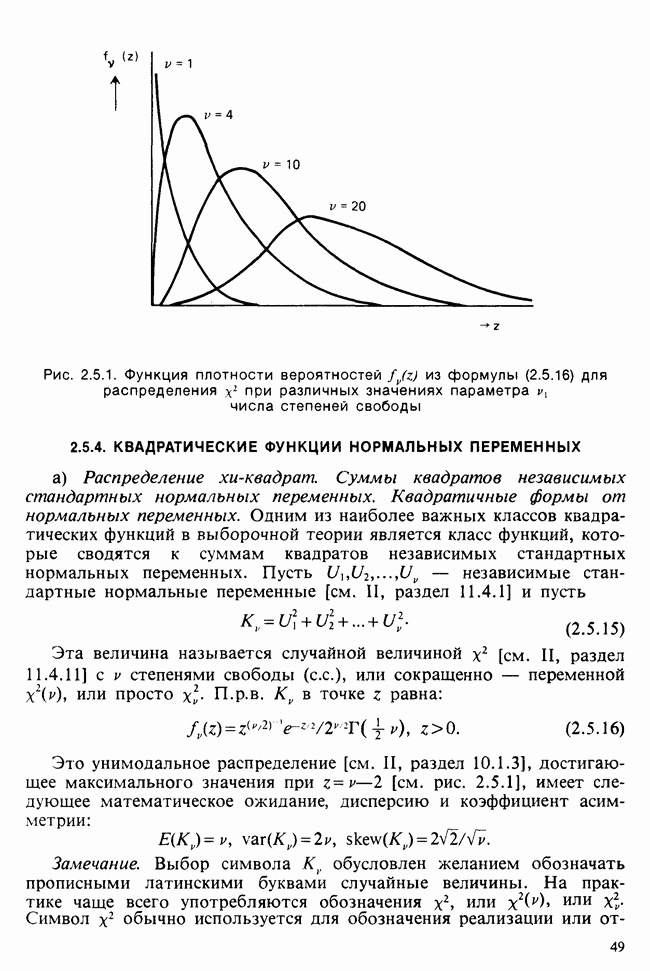











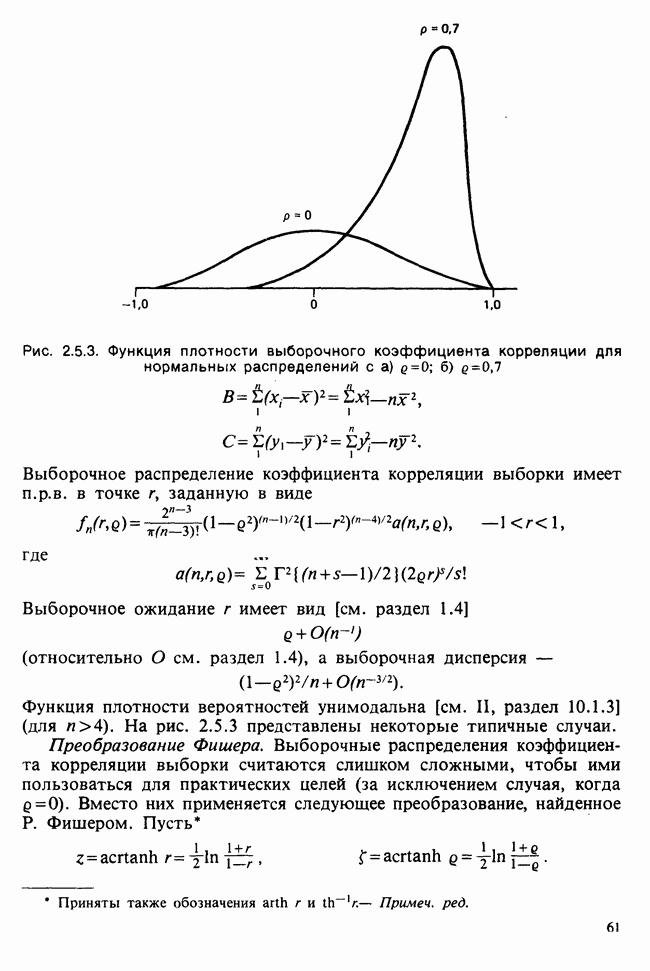












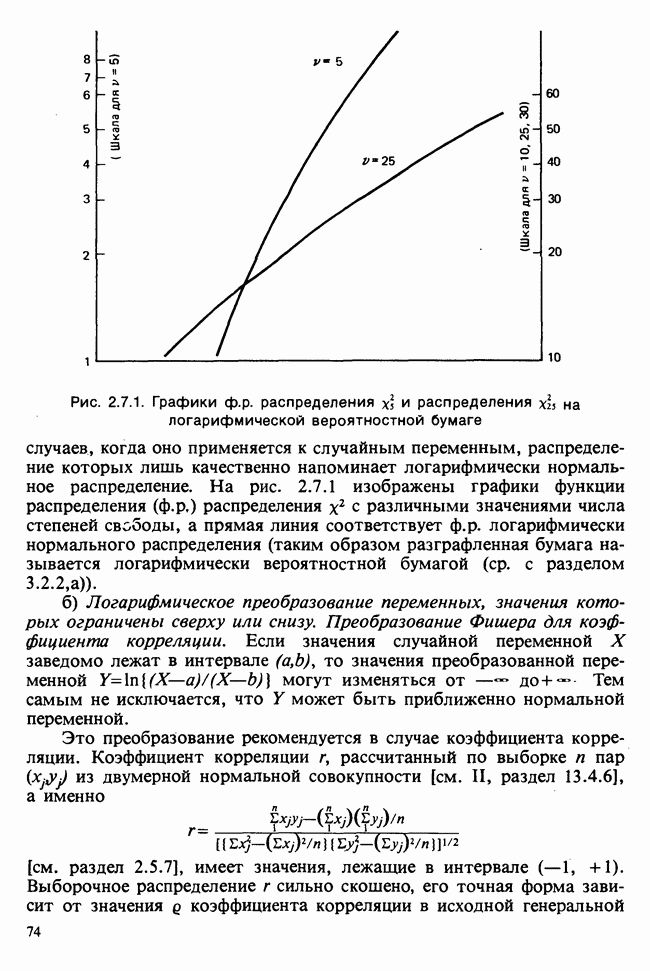















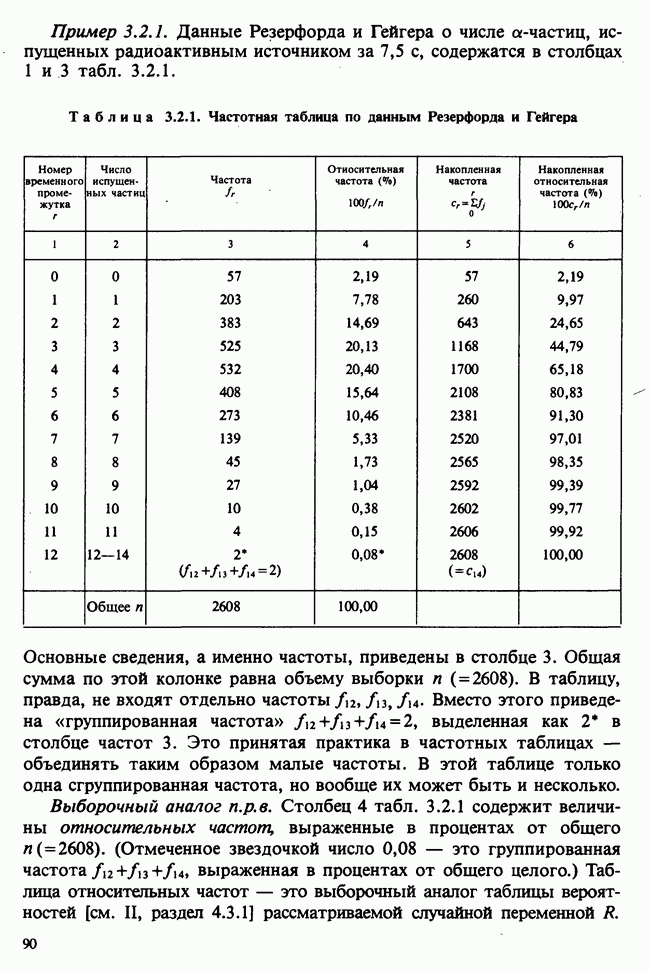


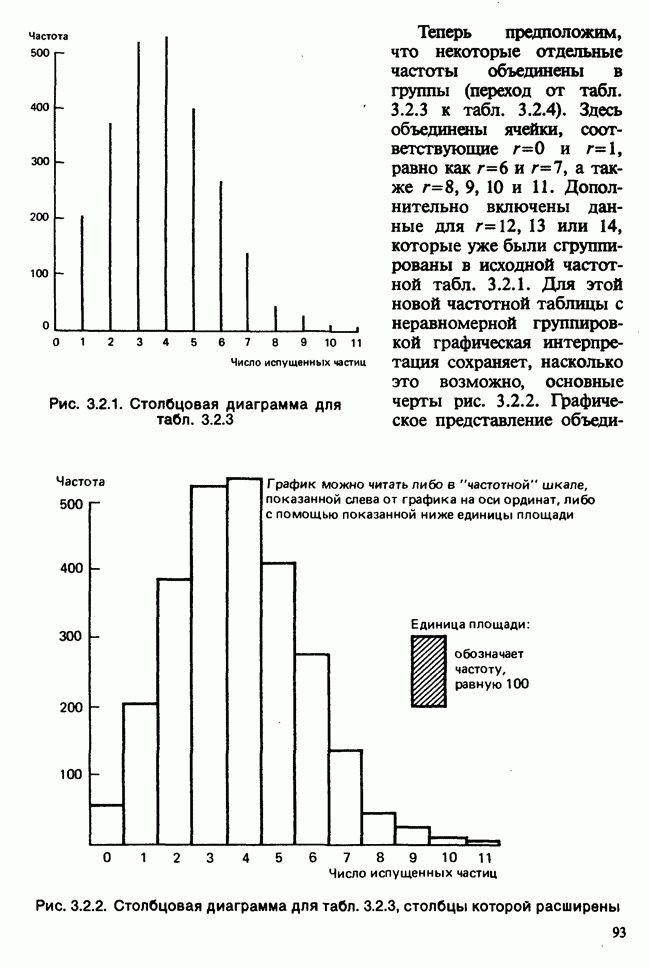
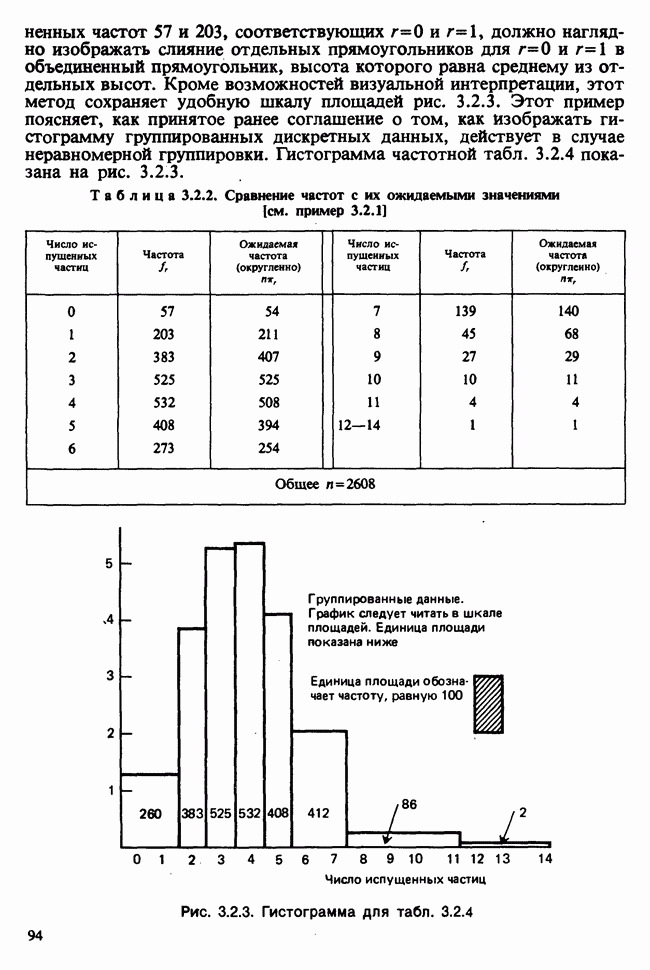

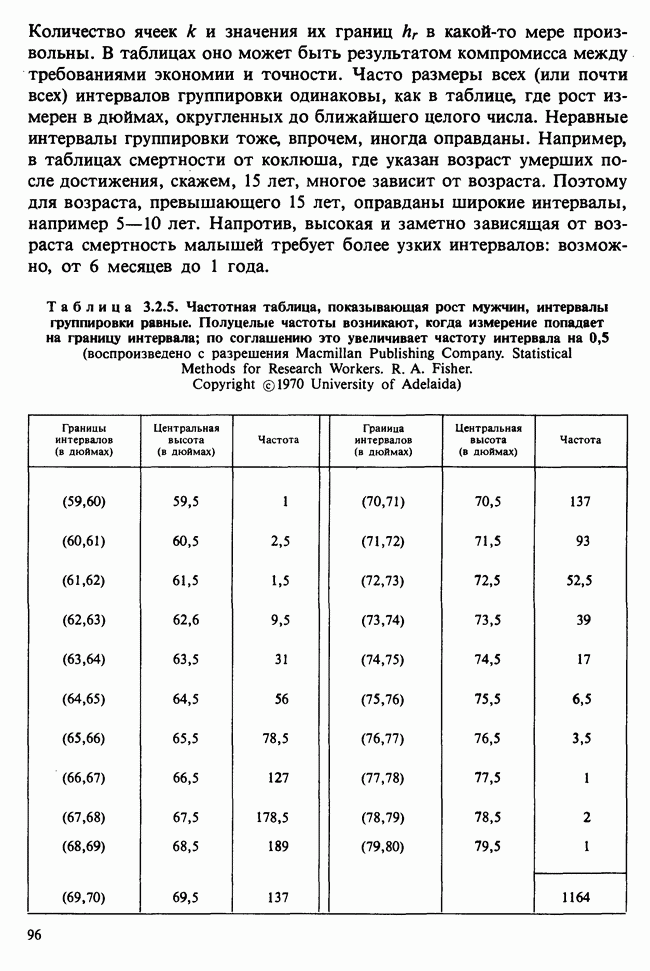





























































































































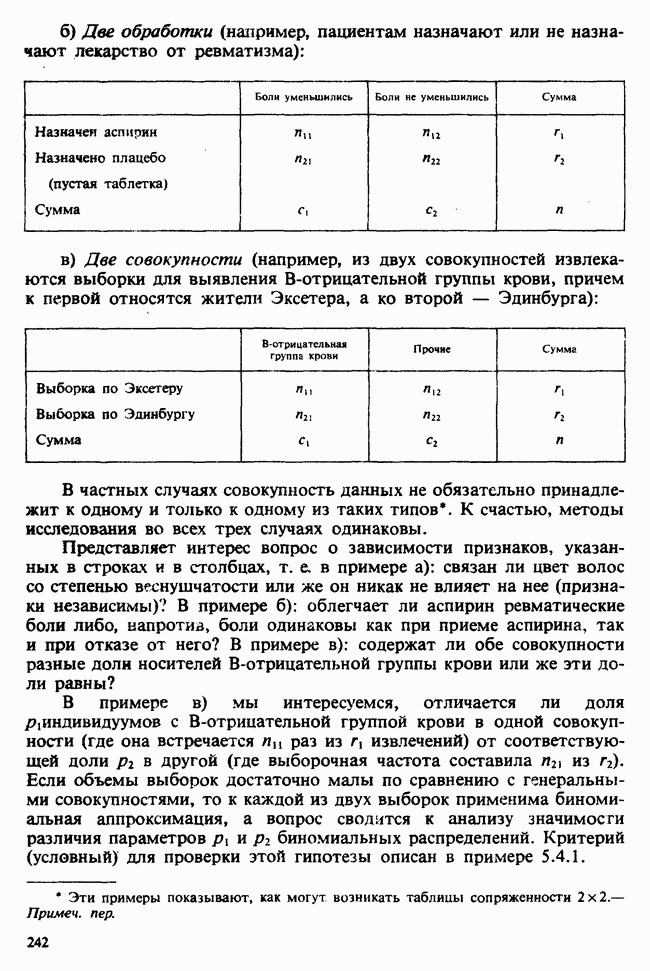
















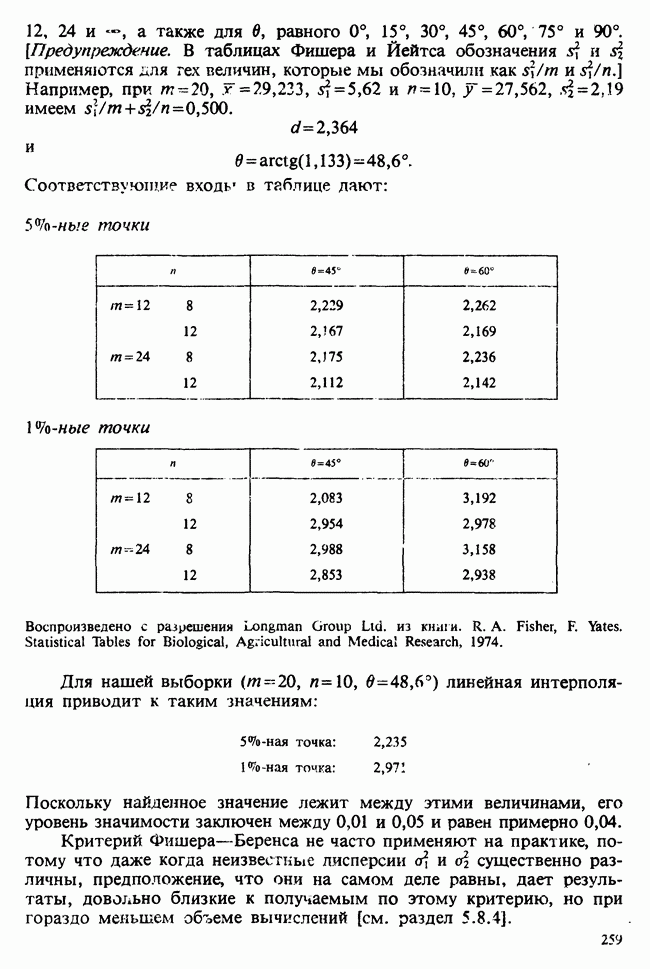












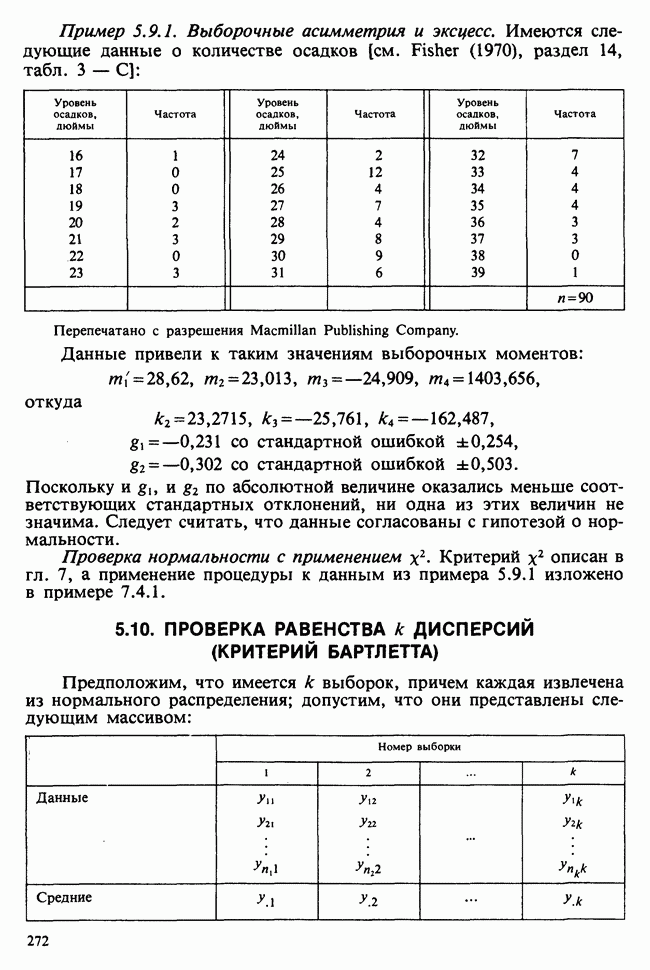


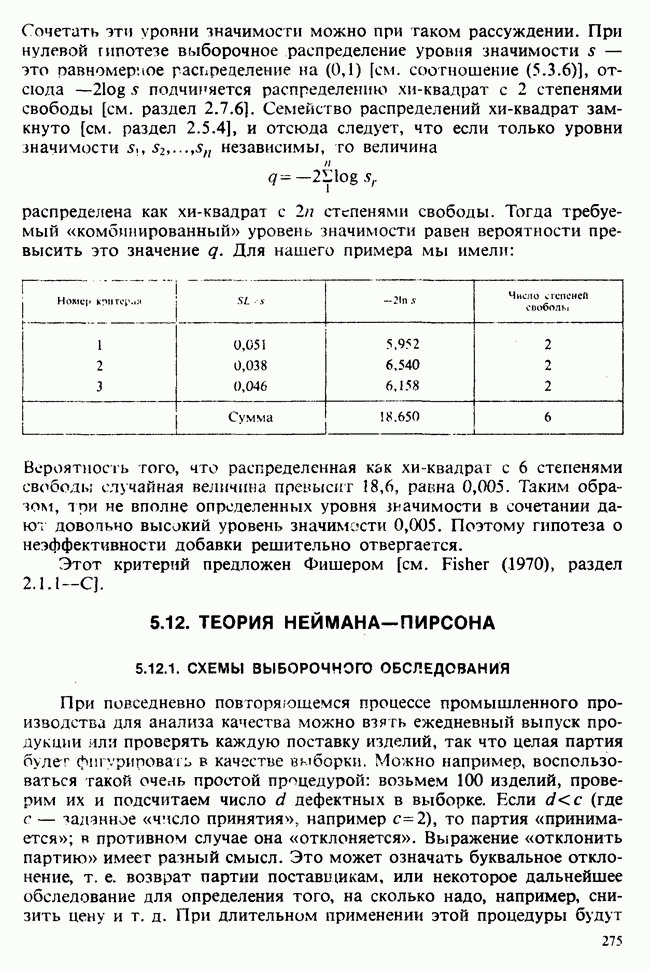
































































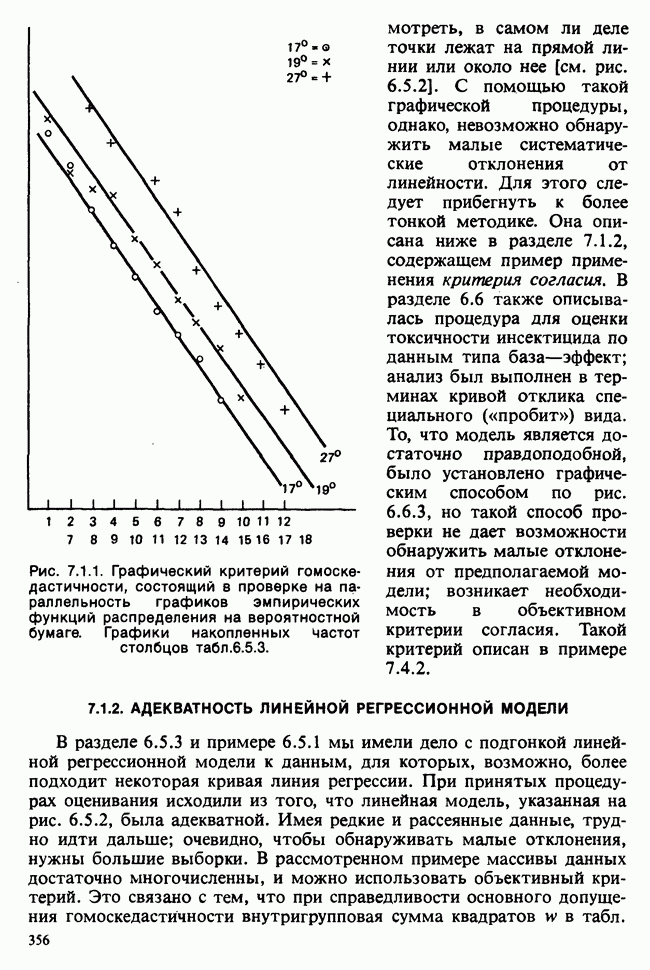
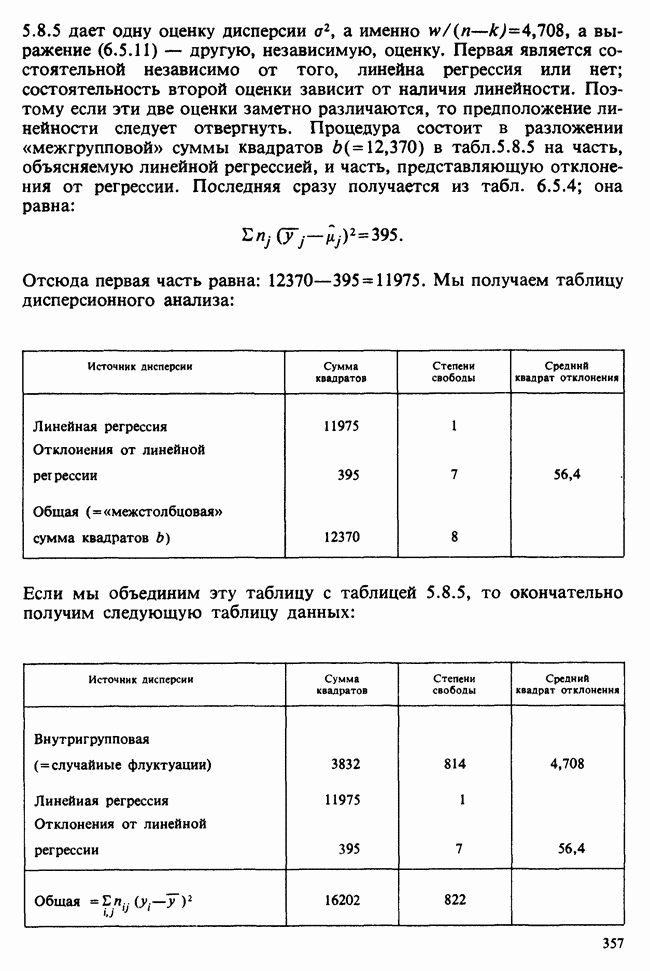

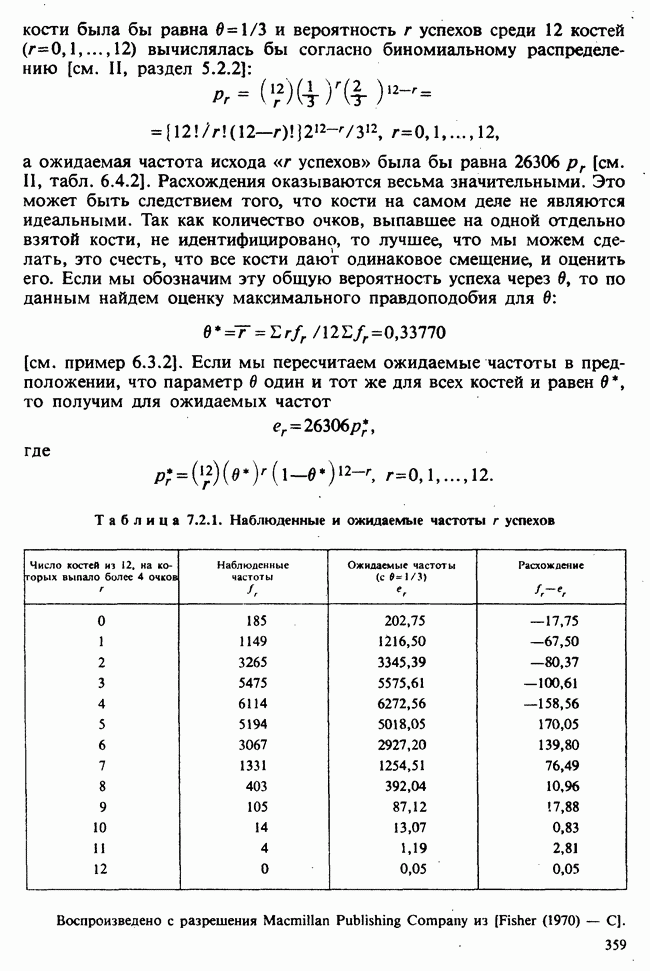
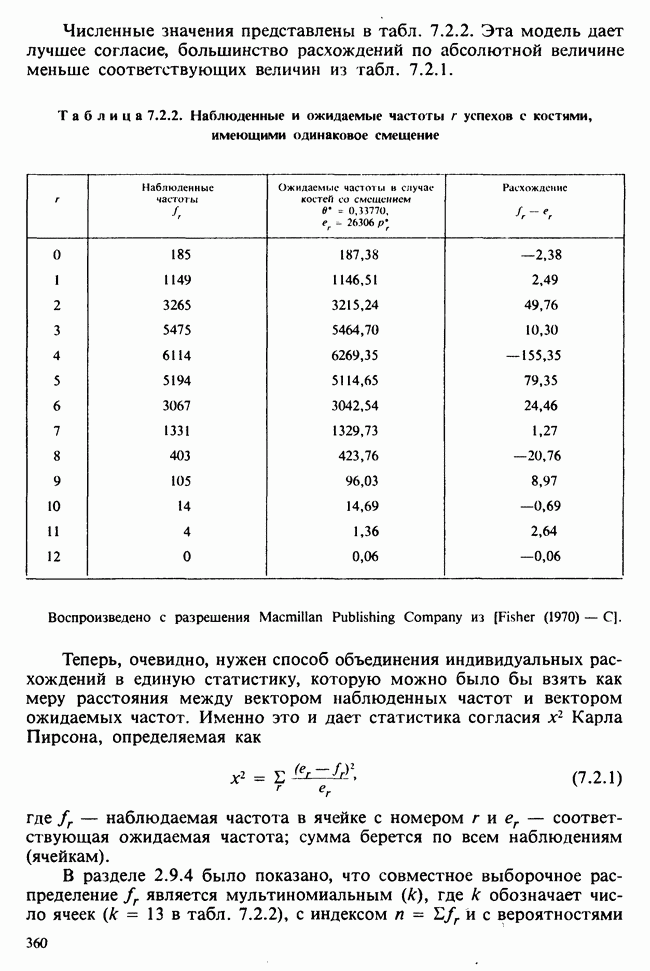









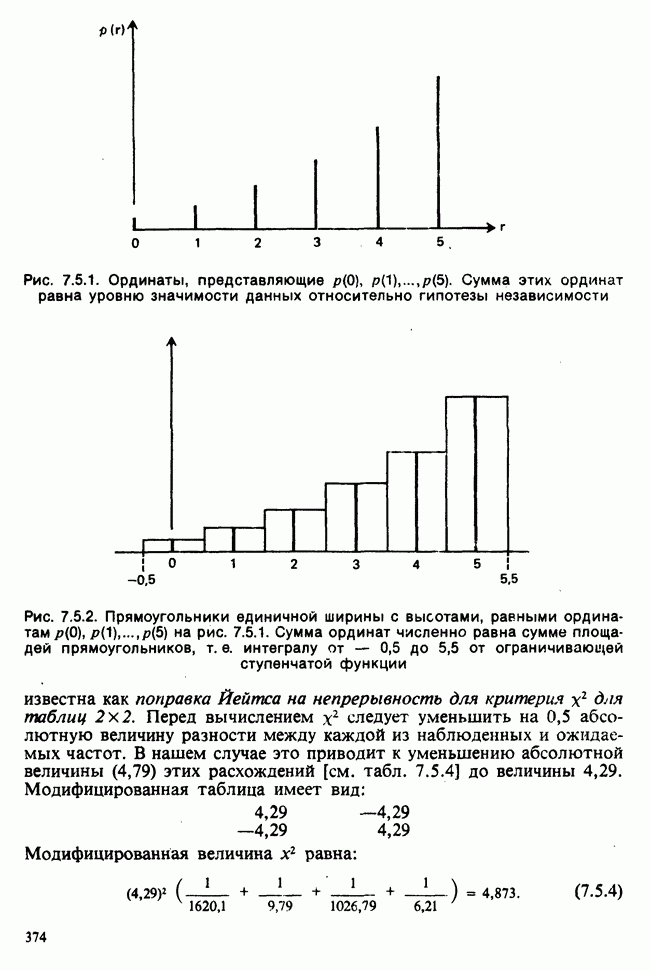


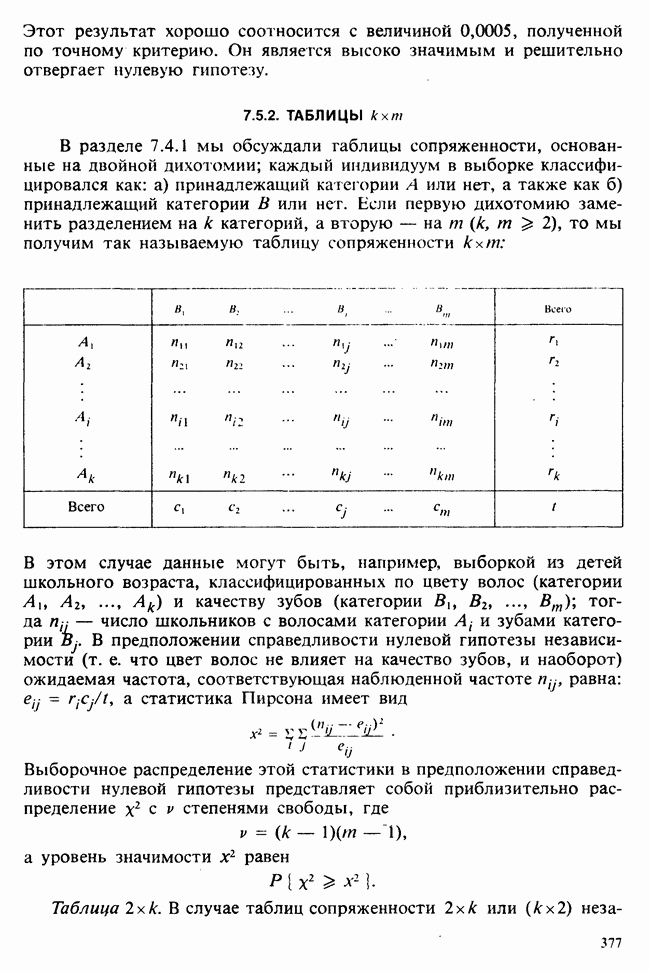




























































































































 наблюдение в
наблюдение в  ячейке (строка
ячейке (строка  и столбец
и столбец  через
через  , где
, где  Следовательно, существует
Следовательно, существует  ячеек и ячейка
ячеек и ячейка  содержит К у наблюдений. Вот модель полного ранга:
содержит К у наблюдений. Вот модель полного ранга:


 представляют эффекты строк,
представляют эффекты строк,  — эффекты столбцов,
— эффекты столбцов,  — взаимодействия [см. раздел 8.9.1] между строками и столбцами. Эти эффекты взаимодействия
— взаимодействия [см. раздел 8.9.1] между строками и столбцами. Эти эффекты взаимодействия


 Она является менее обшей, чем модель полного ранга, поскольку охватывает только
Она является менее обшей, чем модель полного ранга, поскольку охватывает только  параметров, а это значит, что
параметров, а это значит, что



 не изменится, если в модель вместо
не изменится, если в модель вместо  подставить величину
подставить величину  вместо
вместо  — величину
— величину  вместо
вместо  — величину
— величину  а вместо
а вместо  что указывает на присутствие в модели
что указывает на присутствие в модели  избыточных параметров (и наоборот, мы можем просто вычесть это число параметров модели полного ранга, т. е.
избыточных параметров (и наоборот, мы можем просто вычесть это число параметров модели полного ранга, т. е.  из соответствующей величины
из соответствующей величины  для получения вырожденной модели). Следовательно,
для получения вырожденной модели). Следовательно,  линейно независимых дополнительных условий достаточны для получения единственного набора параметров методом наименьших квадратов. Вообще говоря, МНК-оценки не удается просто выразить через наблюдения. А их численные значения находят в результате решения обычных уравнений:
линейно независимых дополнительных условий достаточны для получения единственного набора параметров методом наименьших квадратов. Вообще говоря, МНК-оценки не удается просто выразить через наблюдения. А их численные значения находят в результате решения обычных уравнений:

 — дополнительные условия. Правда, для пропорциональных частот можно найти явные выражения.
— дополнительные условия. Правда, для пропорциональных частот можно найти явные выражения.

 — общее число наблюдений в ячейках
— общее число наблюдений в ячейках  строки, а
строки, а  — общее число наблюдений в ячейках
— общее число наблюдений в ячейках  столбца. Другими словами, числа в ячейках в любой данной строке (столбце) пропорциональны общему числу наблюдений в данном столбце (строке). Точно так же мы имеем
столбца. Другими словами, числа в ячейках в любой данной строке (столбце) пропорциональны общему числу наблюдений в данном столбце (строке). Точно так же мы имеем

 что известно как сбалансированный случай [см. раздел 9.7].
что известно как сбалансированный случай [см. раздел 9.7].
 независимых дополнительных условий:
независимых дополнительных условий:


 и когда
и когда  . А в сбалансированном случае
. А в сбалансированном случае  эти условия упрощаются:
эти условия упрощаются:

 — это математическое ожидание среднего по всем наблюдениям,
— это математическое ожидание среднего по всем наблюдениям,  — математическое ожидание среднего наблюдений в
— математическое ожидание среднего наблюдений в  строке (так что
строке (так что  эффект
эффект  строки),
строки),  — математическое ожидание среднего наблюдений в
— математическое ожидание среднего наблюдений в  столбце (так что
столбце (так что  — эффект
— эффект  столбца). Среднее наблюдений в ячейке
столбца). Среднее наблюдений в ячейке  имеет ожидание
имеет ожидание  Когда взаимодействия нет, мы видим, что оно отличается от
Когда взаимодействия нет, мы видим, что оно отличается от  просто суммой эффектов строки и столбца. Такую ситуацию для краткости называют аддитивной.
просто суммой эффектов строки и столбца. Такую ситуацию для краткости называют аддитивной.
 ) суммы квадратов
) суммы квадратов



 , а число независимых параметров есть
, а число независимых параметров есть  . Следовательно, величина
. Следовательно, величина  пропорциональна переменной
пропорциональна переменной  степенями свободы,
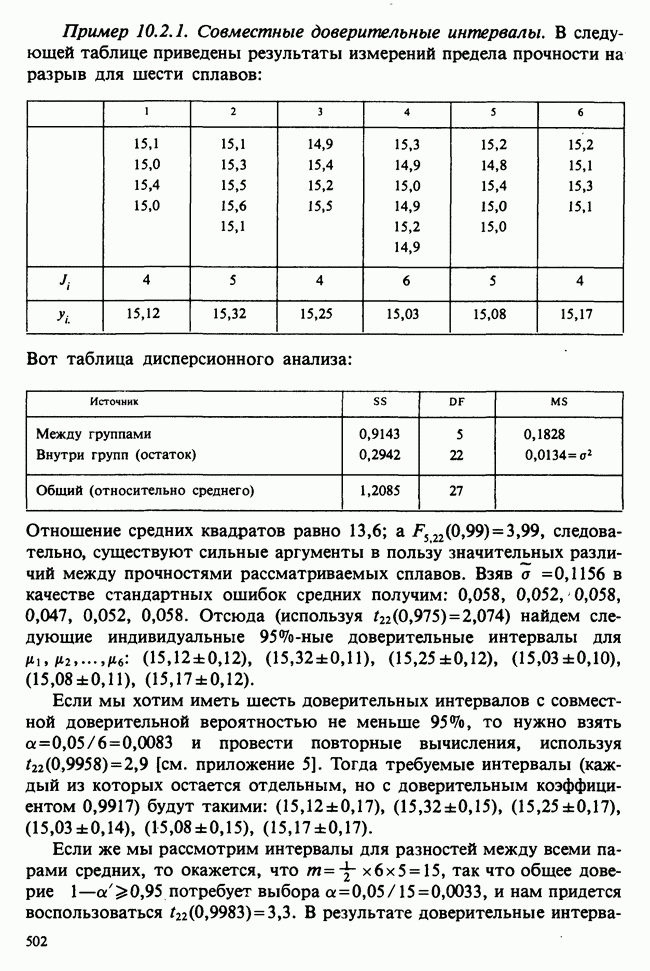
степенями свободы,  . Прежде всего представляют интерес три гипотезы:
. Прежде всего представляют интерес три гипотезы:



 (общую сумму квадратов
(общую сумму квадратов  ), обусловленную подбором параметров данной группы, безотносительно к тому, включены ли другие параметры в модель. Значит, мы можем проверить три сформулированные выше гипотезы, сравнивая соответствующие члены средних квадратов с оценкой
), обусловленную подбором параметров данной группы, безотносительно к тому, включены ли другие параметры в модель. Значит, мы можем проверить три сформулированные выше гипотезы, сравнивая соответствующие члены средних квадратов с оценкой  Для каждого из этих членов число включенных независимых параметров дает соответствующее число степеней свободы (с учетом дополнительных условий). Выходит, что
Для каждого из этих членов число включенных независимых параметров дает соответствующее число степеней свободы (с учетом дополнительных условий). Выходит, что  имеет 1 степень свободы,
имеет 1 степень свободы,  степеней свободы,
степеней свободы,  степеней свободы и
степеней свободы и  степеней свободы.
степеней свободы.

 , получим
, получим

 а именно
а именно  можно присоединить к общей сумме квадратов относительного среднего, полученной методом наименьших квадратов, поскольку справа мы имеем
можно присоединить к общей сумме квадратов относительного среднего, полученной методом наименьших квадратов, поскольку справа мы имеем  соответственно. Три последние суммы квадратов известные как СК между строками, СК между столбцами и СК взаимодействия. Таблица дисперсионного анализа представлена табл. 10.1.1.
соответственно. Три последние суммы квадратов известные как СК между строками, СК между столбцами и СК взаимодействия. Таблица дисперсионного анализа представлена табл. 10.1.1.
 причем столбец ожидаемых средних квадратов показывает, что в каждом из этих случаев используется верхний хвост F-распределения. Когда верна гипотеза
причем столбец ожидаемых средних квадратов показывает, что в каждом из этих случаев используется верхний хвост F-распределения. Когда верна гипотеза  (что нет эффектов строки), величина
(что нет эффектов строки), величина

 . Когда верна гипотеза
. Когда верна гипотеза  (что нет эффектов столбца), величина
(что нет эффектов столбца), величина

 . Когда верна гипотеза
. Когда верна гипотеза  (что нет эффектов взаимодействия), величина
(что нет эффектов взаимодействия), величина


 не отвергается, а гипотеза
не отвергается, а гипотеза  отвергается, мы заключаем, что существуют действительные различия между сортами и что различие между двумя заданными сортами должно быть одинаковым для всех удобрений. Иными словами, если сорт А лучше, чем сорт В, то это соотношение останется неизменным для всех удобрений. Если же, наоборот, взаимодействие существует, а гипотеза
отвергается, мы заключаем, что существуют действительные различия между сортами и что различие между двумя заданными сортами должно быть одинаковым для всех удобрений. Иными словами, если сорт А лучше, чем сорт В, то это соотношение останется неизменным для всех удобрений. Если же, наоборот, взаимодействие существует, а гипотеза  отбрасывается, то различие между сортами оказывается зависящим от рассматриваемого удобрения, а отбрасывание
отбрасывается, то различие между сортами оказывается зависящим от рассматриваемого удобрения, а отбрасывание  происходит потому, что существуют различия в эффектах сортов, усредненных по всем удобрениям. Вообще (т. е. после усреднениям по всем рассматриваемым удобрениям) сорт А может быть лучше, чем сорт
происходит потому, что существуют различия в эффектах сортов, усредненных по всем удобрениям. Вообще (т. е. после усреднениям по всем рассматриваемым удобрениям) сорт А может быть лучше, чем сорт  хотя при некоторых удобрениях сорт В мог бы и превосходить сорт А. Понятно, что интерпретация таблицы дисперсионного анализа гораздо проще, когда нет взаимодействия. Если гипотеза
хотя при некоторых удобрениях сорт В мог бы и превосходить сорт А. Понятно, что интерпретация таблицы дисперсионного анализа гораздо проще, когда нет взаимодействия. Если гипотеза  была отвергнута в отличие от гипотез
была отвергнута в отличие от гипотез  и
и  мы могли бы заключить, что существуют различия между средними ячеек, но не проявляются различия в сортах, усредненных по всем удобрениям, и наоборот, в удобрениях, усредненных по всем сортам.
мы могли бы заключить, что существуют различия между средними ячеек, но не проявляются различия в сортах, усредненных по всем удобрениям, и наоборот, в удобрениях, усредненных по всем сортам.
 получается общий критерий для всех трех гипотез (т. е. для общего среднего в ячейке,
получается общий критерий для всех трех гипотез (т. е. для общего среднего в ячейке,  Когда верны все три гипотезы, величина
Когда верны все три гипотезы, величина  представляет собой наблюдение из распределения
представляет собой наблюдение из распределения  с числом степеней свободы, равным
с числом степеней свободы, равным  Тогда функция этого критерия примет вид
Тогда функция этого критерия примет вид  что, как известно, имеет распределение
что, как известно, имеет распределение 
 таблица дисперсионного анализа упрощается и принимает вид:
таблица дисперсионного анализа упрощается и принимает вид:
 то нельзя построить рассмотренные выше критерии, поскольку остаток теперь
то нельзя построить рассмотренные выше критерии, поскольку остаток теперь  , что равно нулю. Происходит это потому, что число наблюдений оказывается равным
, что равно нулю. Происходит это потому, что число наблюдений оказывается равным  а это точно равно числу независимых параметров. Значит, данные можно подогнать точно, без остаточной вариации. Правда, если нет взаимодействий (все
а это точно равно числу независимых параметров. Значит, данные можно подогнать точно, без остаточной вариации. Правда, если нет взаимодействий (все  ), то модель принимает вид
), то модель принимает вид

 параметров, из них
параметров, из них  независимых, если учесть два дополнительных условия
независимых, если учесть два дополнительных условия  Применение к этой модели метода наименьших квадратов позволяет получить оценки
Применение к этой модели метода наименьших квадратов позволяет получить оценки

 для взаимодействия в более общей модели. Таблица дисперсионного анализа тогда принимает вид:
для взаимодействия в более общей модели. Таблица дисперсионного анализа тогда принимает вид:
 не годится и необходимо обеспечить, чтобы
не годится и необходимо обеспечить, чтобы  если мы хотим проверить эффекты строк и столбцов.
если мы хотим проверить эффекты строк и столбцов.
 нам нужно знать дополнительное снижение в
нам нужно знать дополнительное снижение в  когда параметры строки подбираются в дополнение к остальным параметрам. Аналогично и для всех остальных гипотез, Из-за отсутствия ортогональности эти суммы квадратов не будут входить в сумму квадратов модели аддитивно. Метод наименьших квадратов не удается применить в полном объеме, так как процедура, основанная на (10.1.14), не приведет к нужным суммам квадратов, поскольку при отсутствии пропорциональности частот не пропадает член, содержащий парные произведения. В такой ситуации нет смысла сохранять те дополнительные условия, которые были в случае пропорциональных частот, и обычно (новое) численное решение системы нормальных уравнений получают при наипростейших ограничениях:
когда параметры строки подбираются в дополнение к остальным параметрам. Аналогично и для всех остальных гипотез, Из-за отсутствия ортогональности эти суммы квадратов не будут входить в сумму квадратов модели аддитивно. Метод наименьших квадратов не удается применить в полном объеме, так как процедура, основанная на (10.1.14), не приведет к нужным суммам квадратов, поскольку при отсутствии пропорциональности частот не пропадает член, содержащий парные произведения. В такой ситуации нет смысла сохранять те дополнительные условия, которые были в случае пропорциональных частот, и обычно (новое) численное решение системы нормальных уравнений получают при наипростейших ограничениях:
