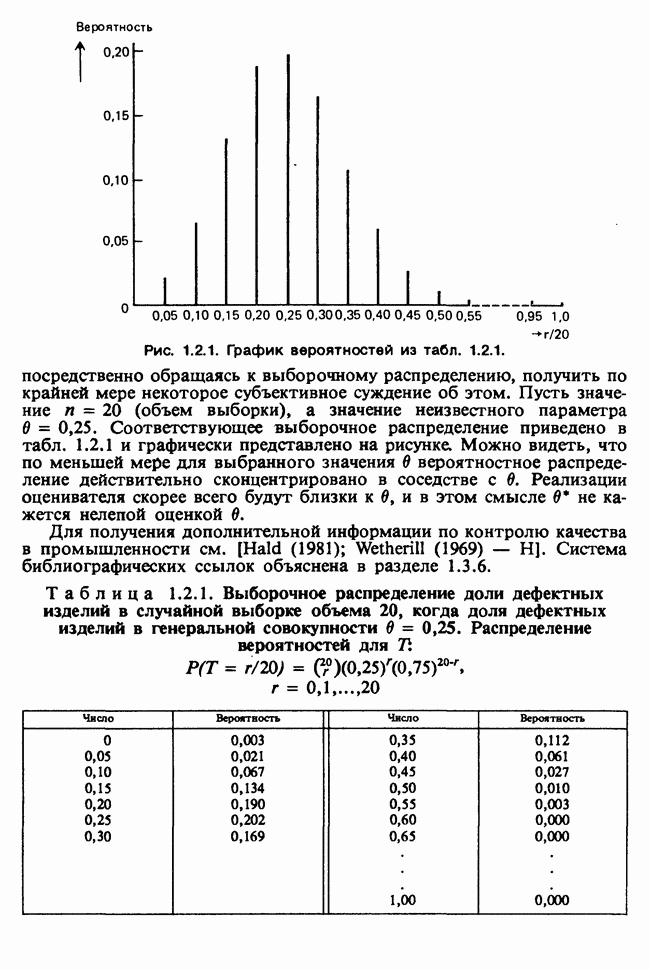
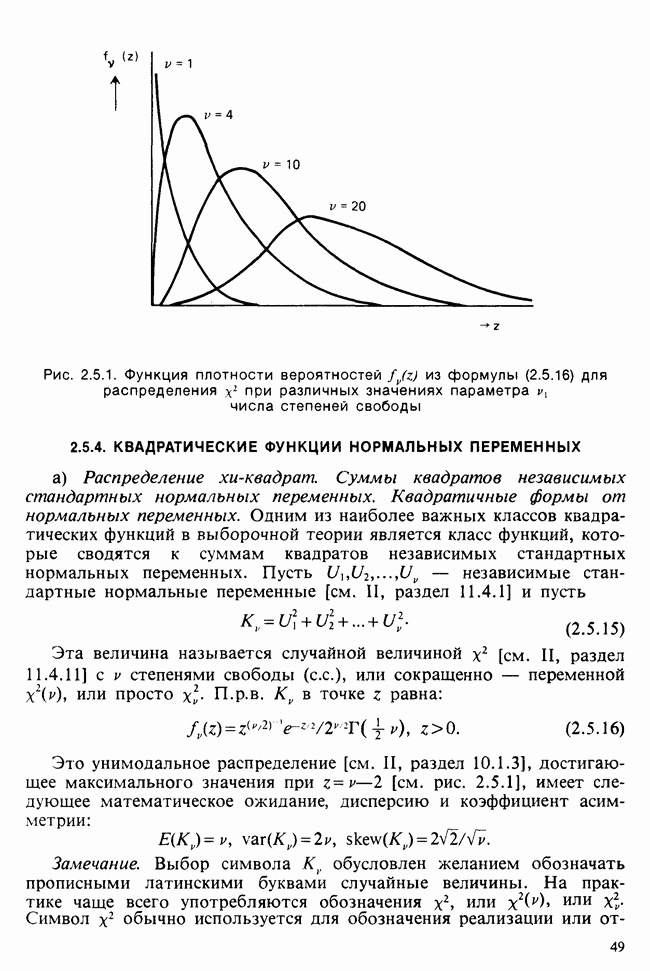
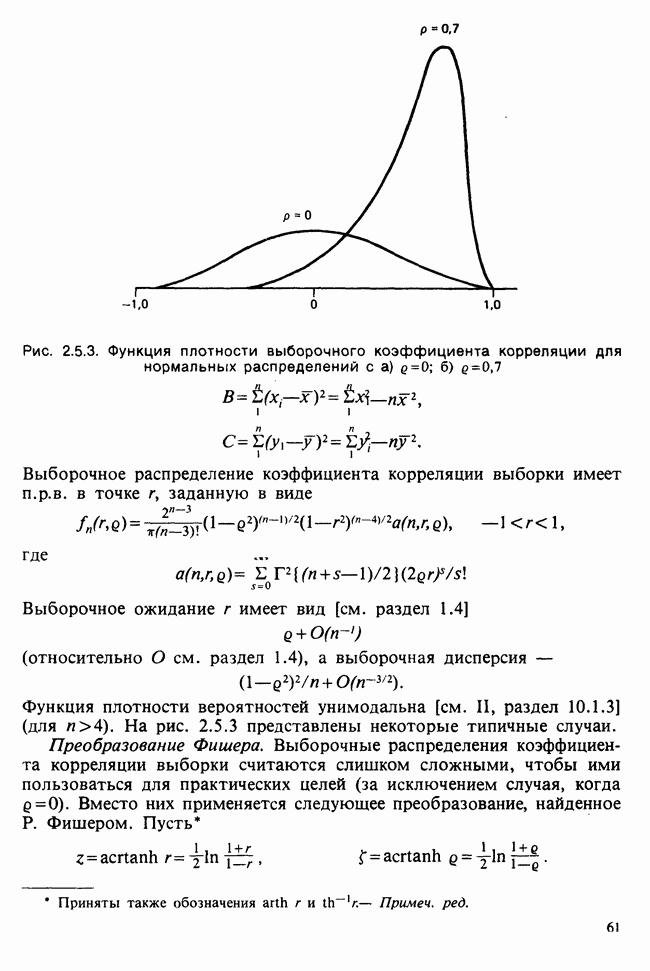
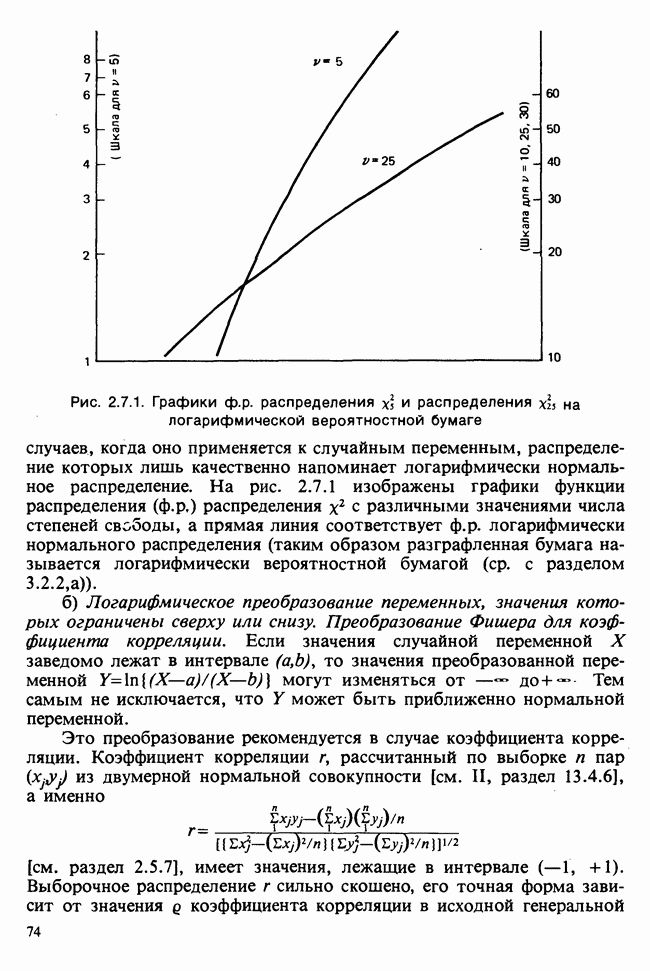
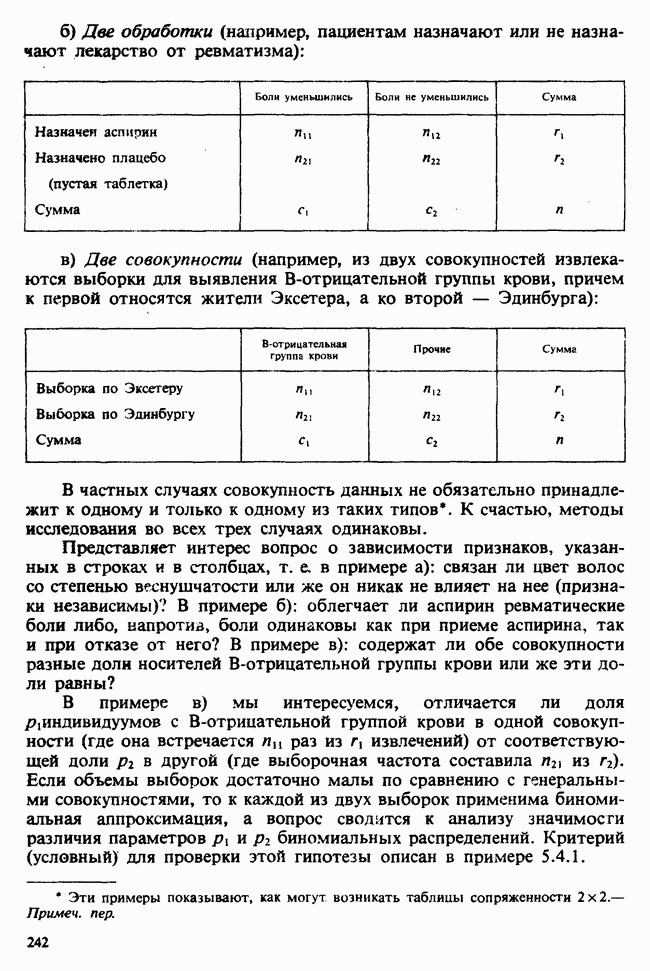
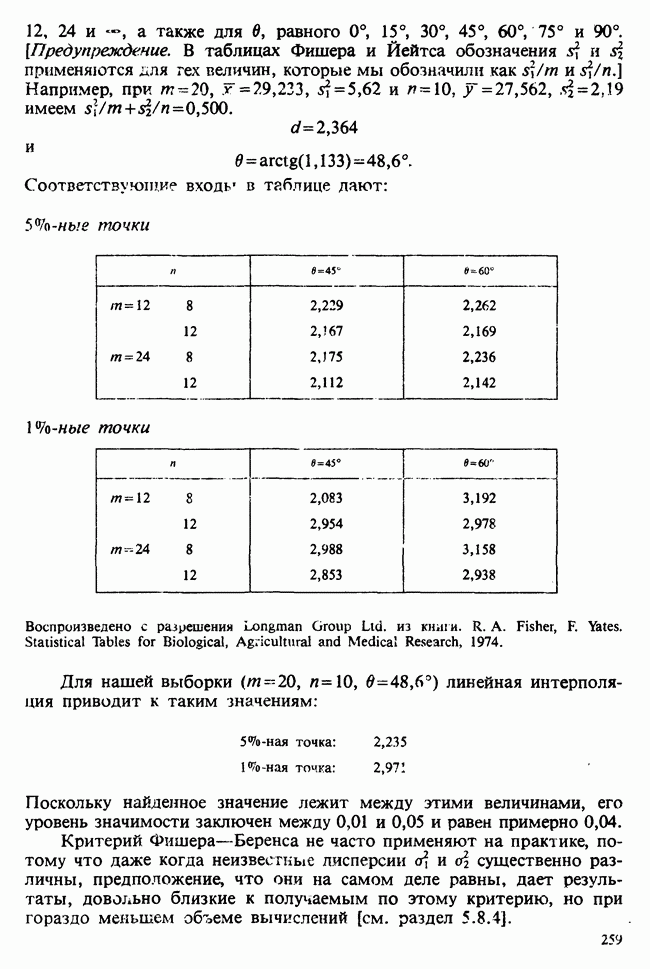
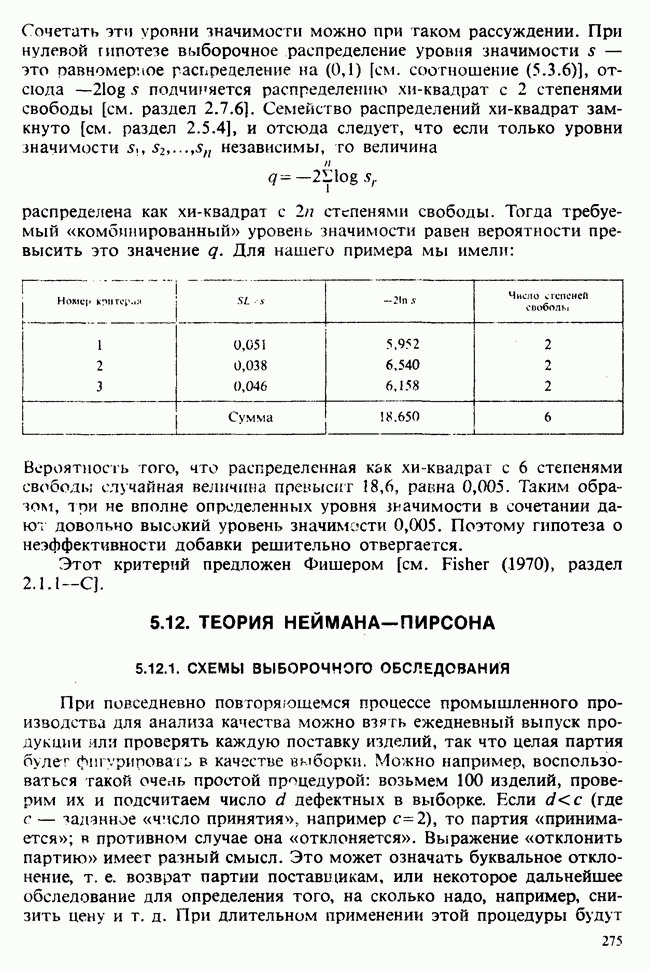
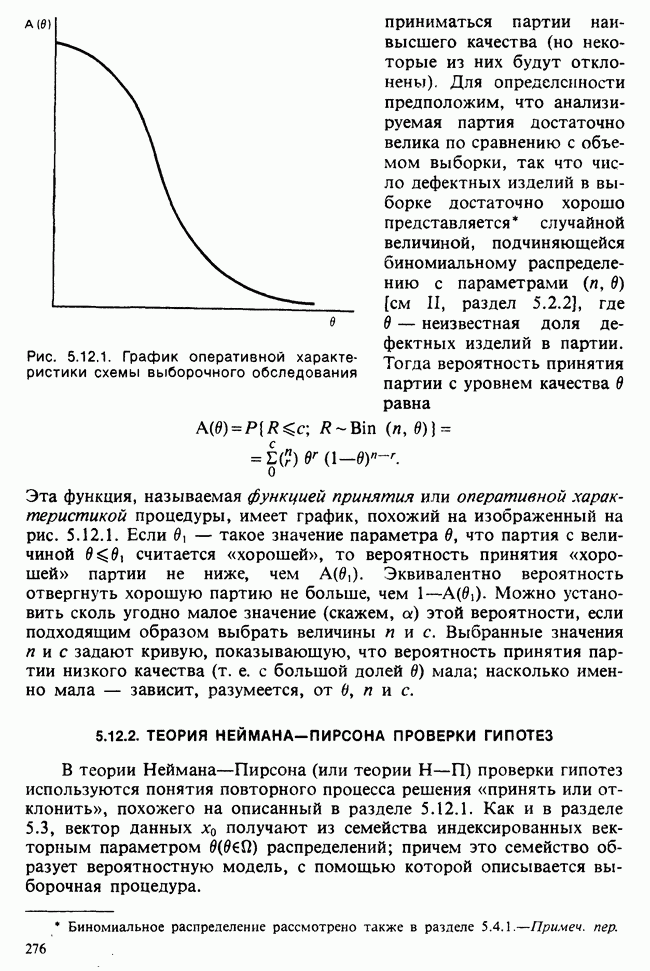
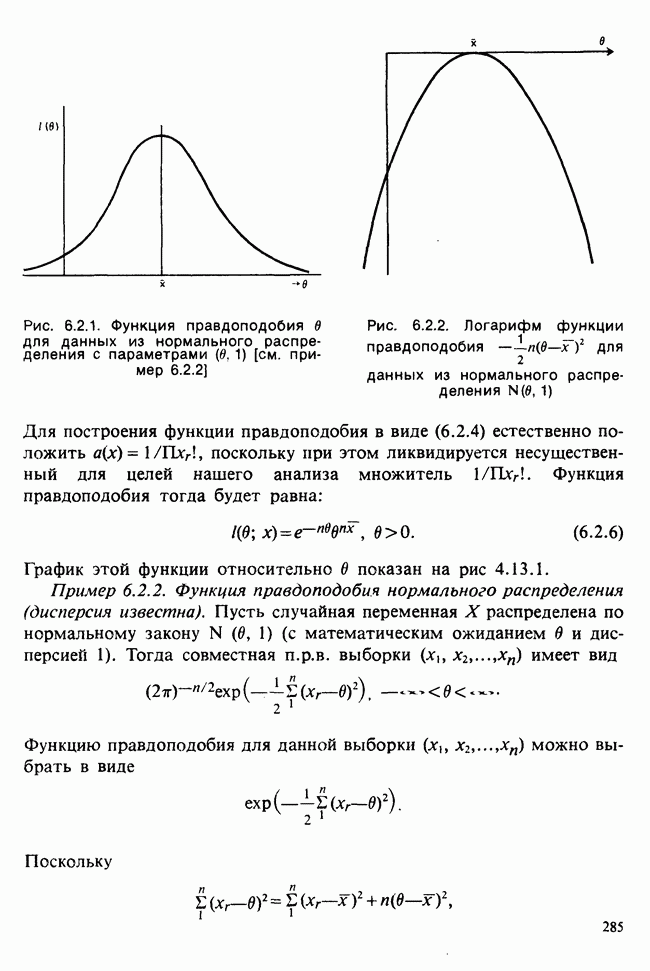
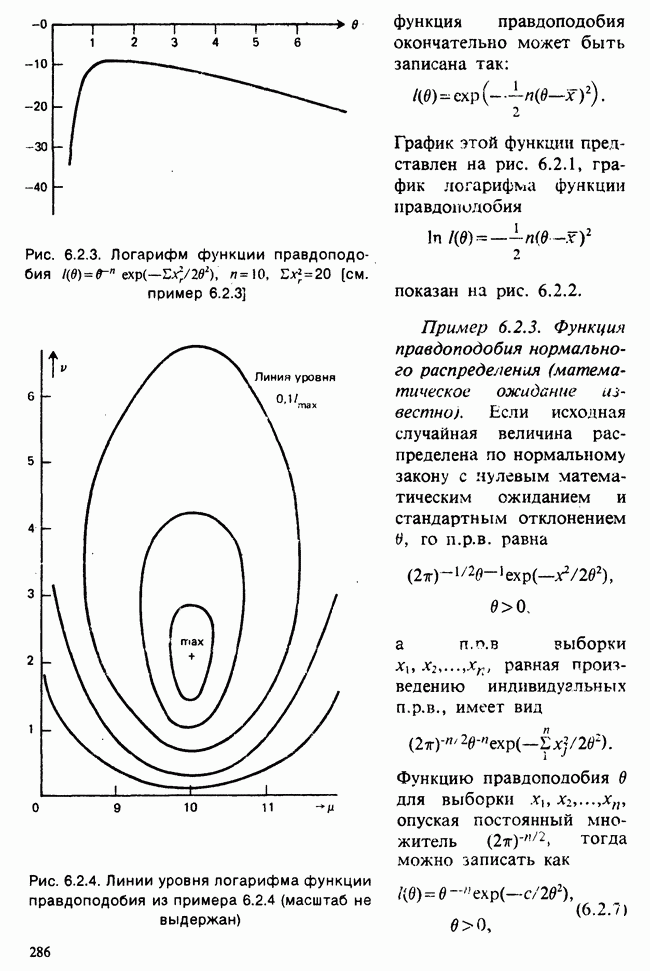
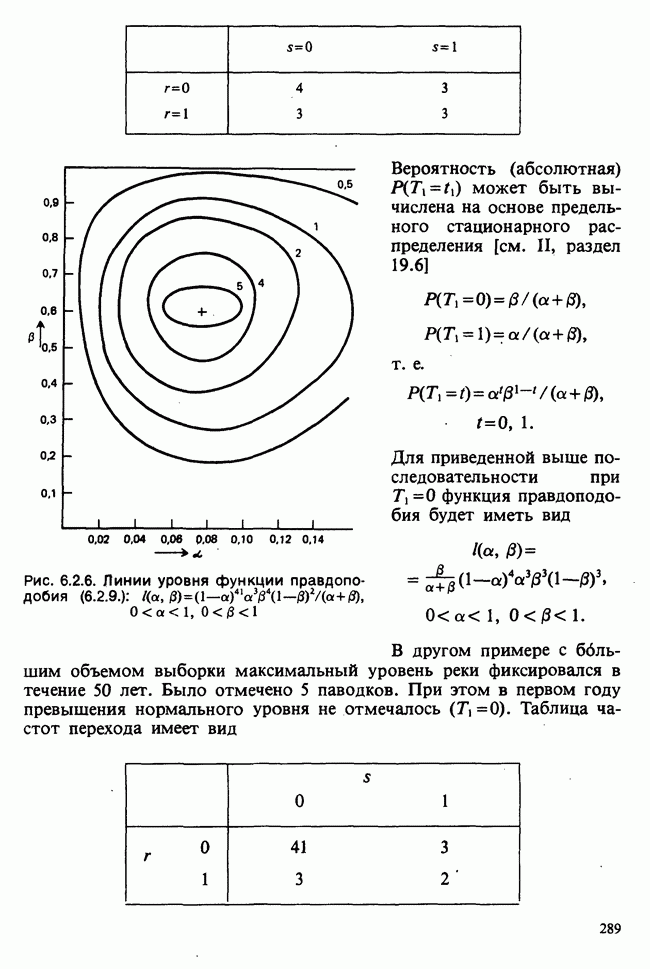
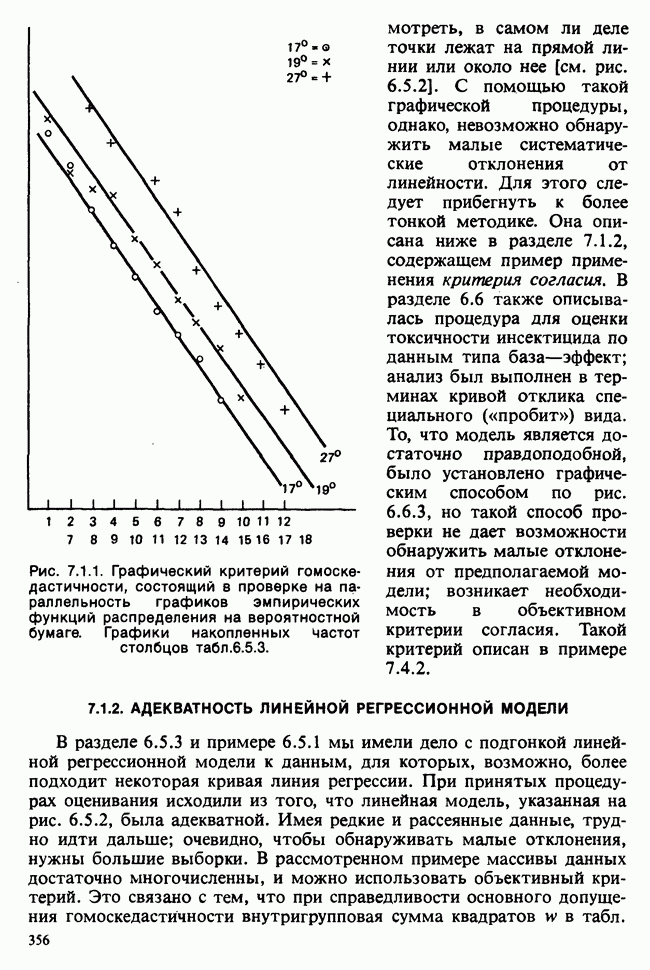
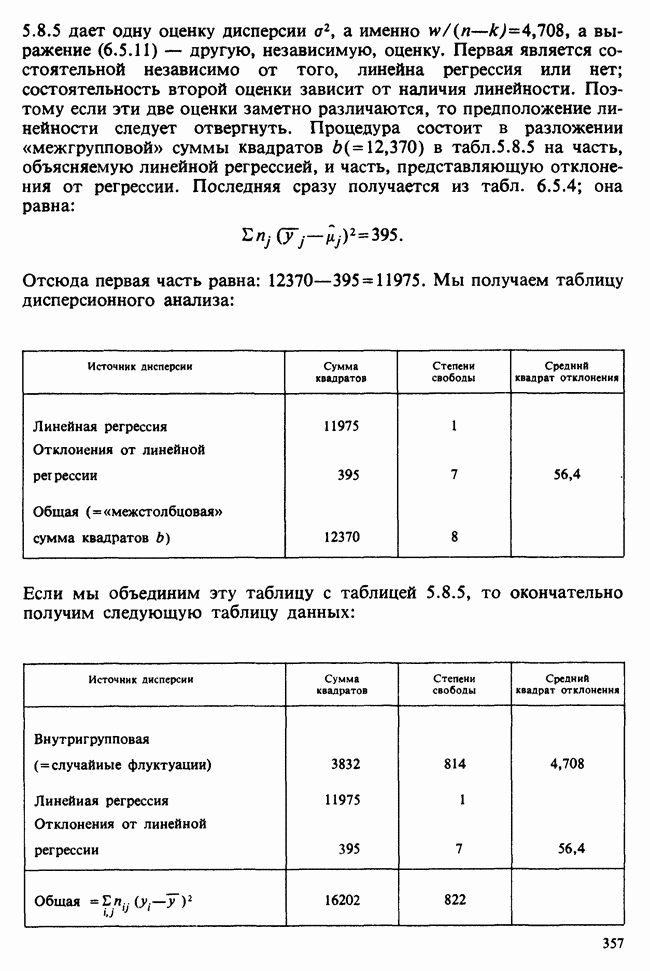
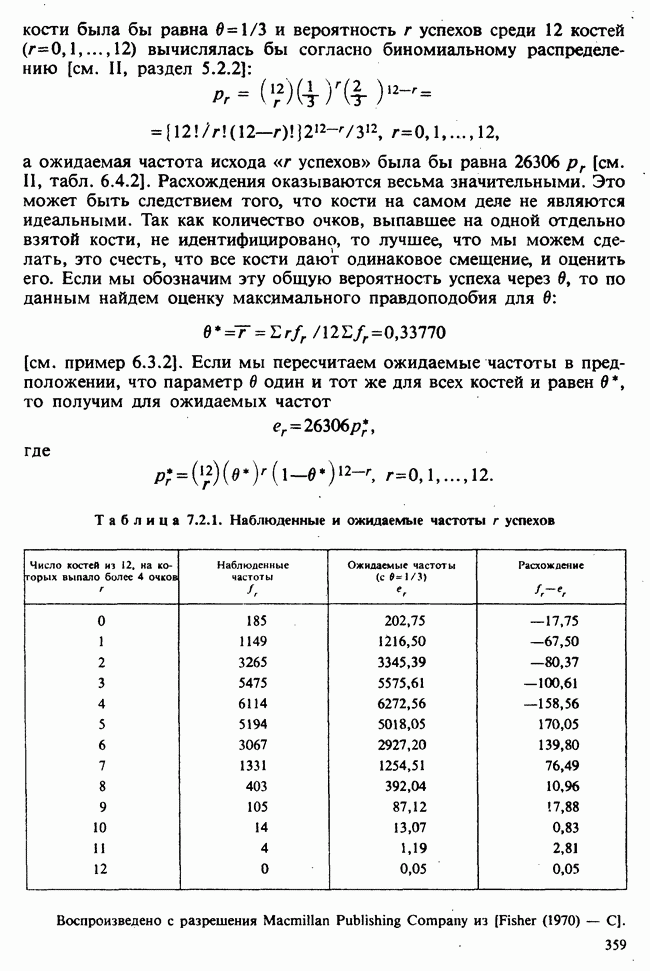
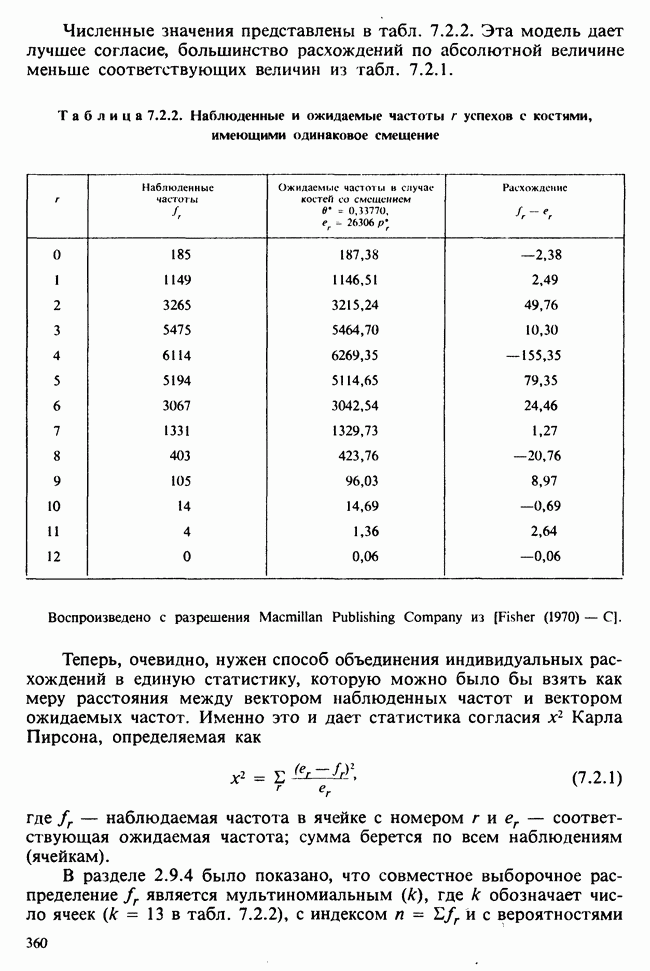
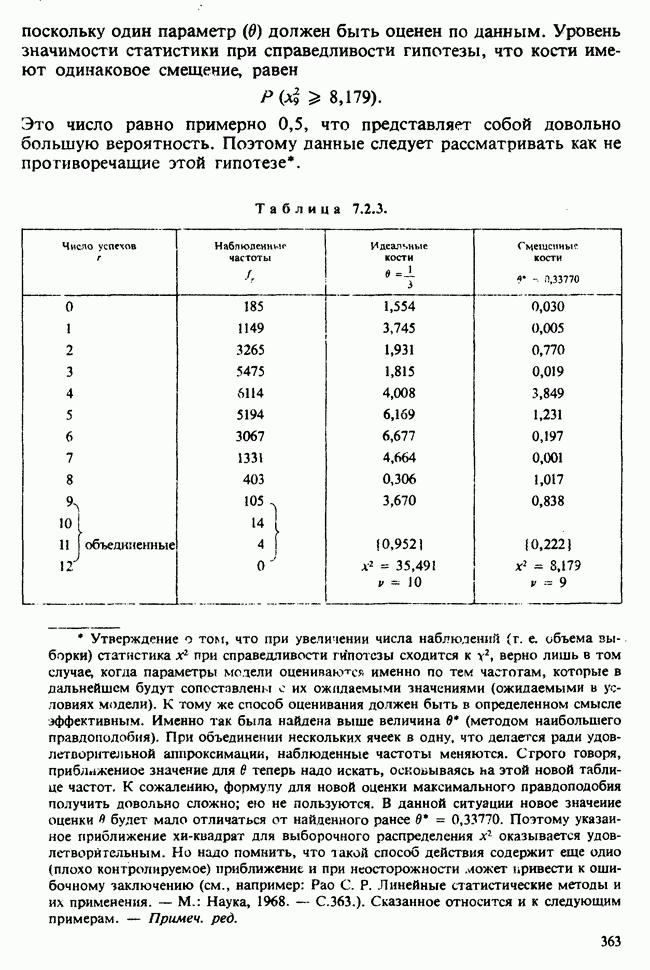
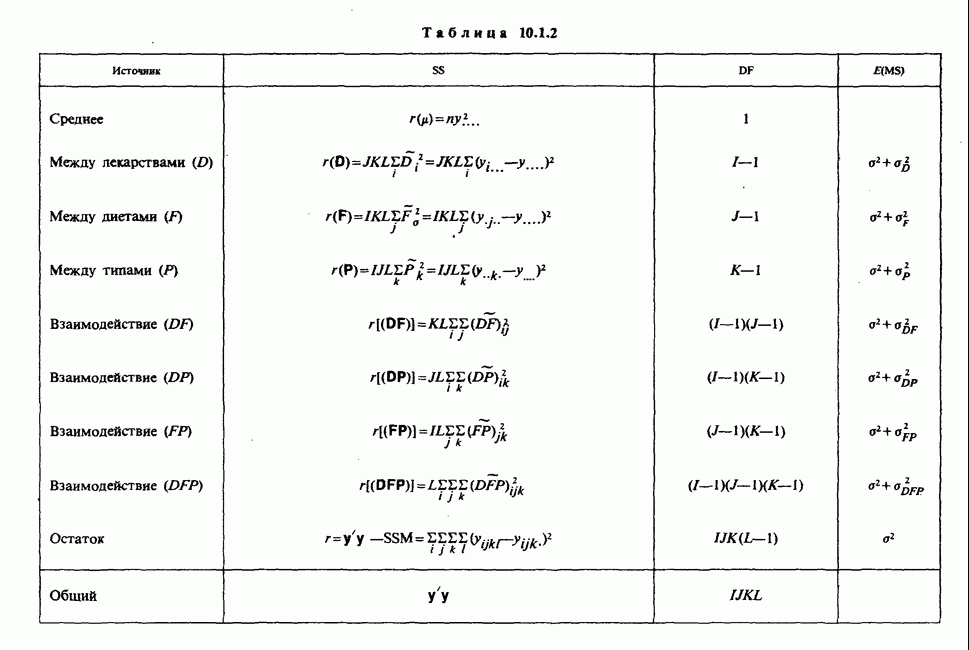
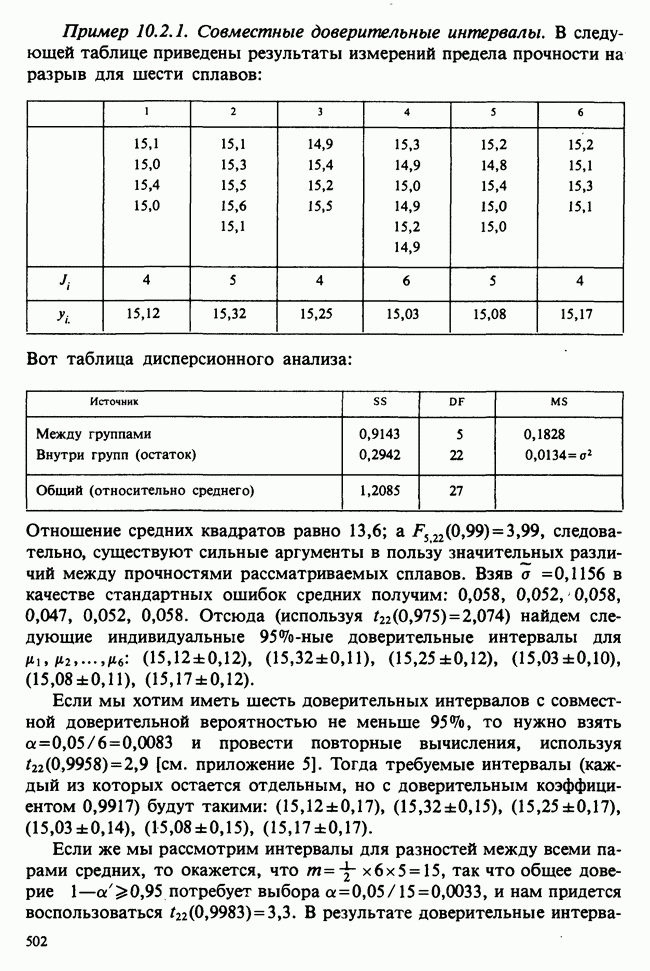
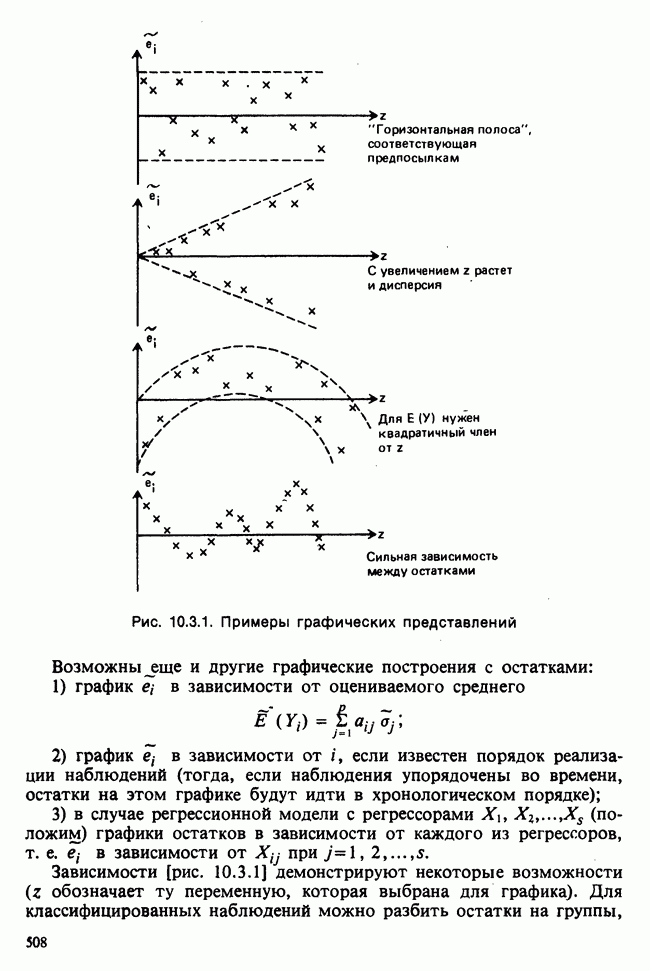
8.2.2. МАТРИЧНОЕ ПРЕДСТАВЛЕНИЕ ЛИНЕЙНЫХ МОДЕЛЕЙ
В примерах 8.2.1 и 8.2.2 мы имели дело с линейными моделями, поскольку в обоих случаях каждое наблюдение выражается как линейная функция от параметров плюс ошибка. В терминах раздела 8.1 функция  представляет собой линейную функцию вектора параметров
представляет собой линейную функцию вектора параметров  можно записать в виде
можно записать в виде
Пример 8.2.3. Продолжение примера 8.2.1. Для модели измерений из примера 8.2.1 матрица А — просто вектор из единиц размера  матрица
матрица 
Пример 8.2.4. Продолжение примера 8.2.2. Для этого примера вектор параметров  и мы имеем:
и мы имеем:

Здесь 

а поскольку  получаем
получаем

(продолжение в примере 8.2.8)
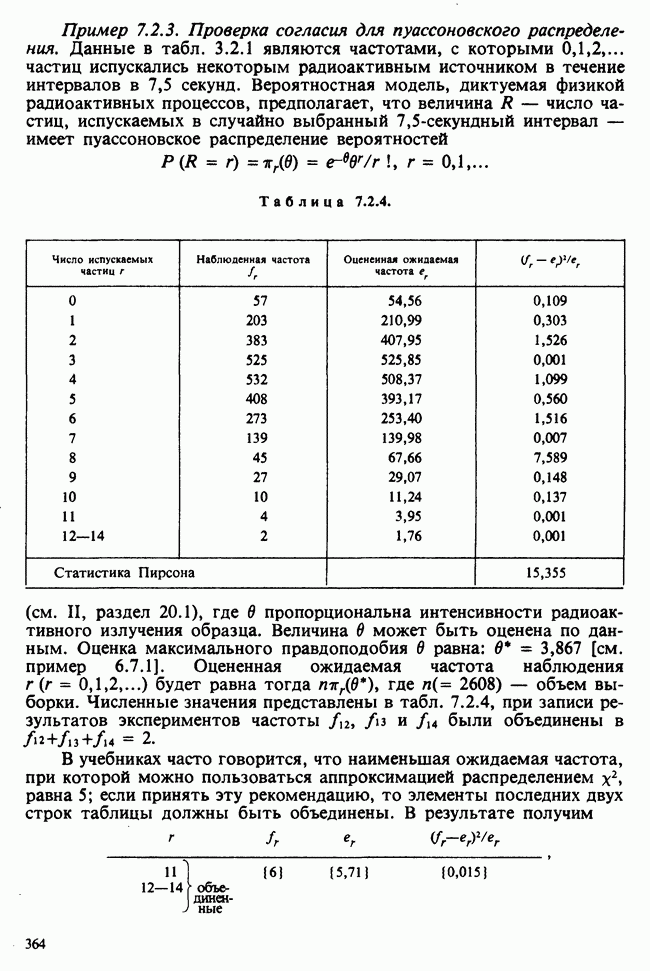
Пример 8.2.5. Регрессия. Часто зависимость между переменной У и несколькими «независимыми» переменными  приближают «линейной моделью» вида
приближают «линейной моделью» вида

[ср. с разделом 3.5.5], где  — заданные функции от
— заданные функции от  — неизвестные параметры (заменившие
— неизвестные параметры (заменившие  в общих формулировках, приведенных выше). Наблюдения
в общих формулировках, приведенных выше). Наблюдения  получаются при различных комбинациях известных
получаются при различных комбинациях известных
значений переменных  Обычный случай — множественная линейная регрессия [ср. с примером 6.5.1], когда
Обычный случай — множественная линейная регрессия [ср. с примером 6.5.1], когда  так что модель принимает вид
так что модель принимает вид

(В примере 6.5.1 обсуждается случай, когда есть только одна переменная-регрессор  ) Используемая здесь терминология может ввести в заблуждение. Действительно, наша модель линейна, поскольку она представляет собой линейную функцию от параметров
) Используемая здесь терминология может ввести в заблуждение. Действительно, наша модель линейна, поскольку она представляет собой линейную функцию от параметров  . Кроме того, регрессия называется линейной, поскольку линейны зависимости
. Кроме того, регрессия называется линейной, поскольку линейны зависимости  от каждой независимой переменной
от каждой независимой переменной  Вместе с тем следующая модель линейна по параметрам
Вместе с тем следующая модель линейна по параметрам  , следовательно, линейна:
, следовательно, линейна:

но она выражает нелинейную зависимость  от единственного регрессора х, а значит, это уже нелинейная регрессия. Такая регрессия называется полиномиальной. Нелинейную зависимость
от единственного регрессора х, а значит, это уже нелинейная регрессия. Такая регрессия называется полиномиальной. Нелинейную зависимость  от нескольких регрессоров можно явно представить в виде линейной модели
от нескольких регрессоров можно явно представить в виде линейной модели

где для большей ясности переобозначены параметры.
Чтобы записать эту модель в матричной форме, предположим, что фактические значения переменных  для
для  наблюдения
наблюдения  равны
равны  . В случае, например, множественной линейной регрессии имеем
. В случае, например, множественной линейной регрессии имеем

т. е.

где

И в этом случае, как правило, требуется численное обращение матрицы 
Наконец, рассмотрим еще один пример нелинейной модели:

Хотя здесь и представлена линейная зависимость  от
от  модель нелинейна по параметрам, и мы не можем выразить ее в матричной форме
модель нелинейна по параметрам, и мы не можем выразить ее в матричной форме  а значит, все формулы, полученные ранее, не применимы.
а значит, все формулы, полученные ранее, не применимы.
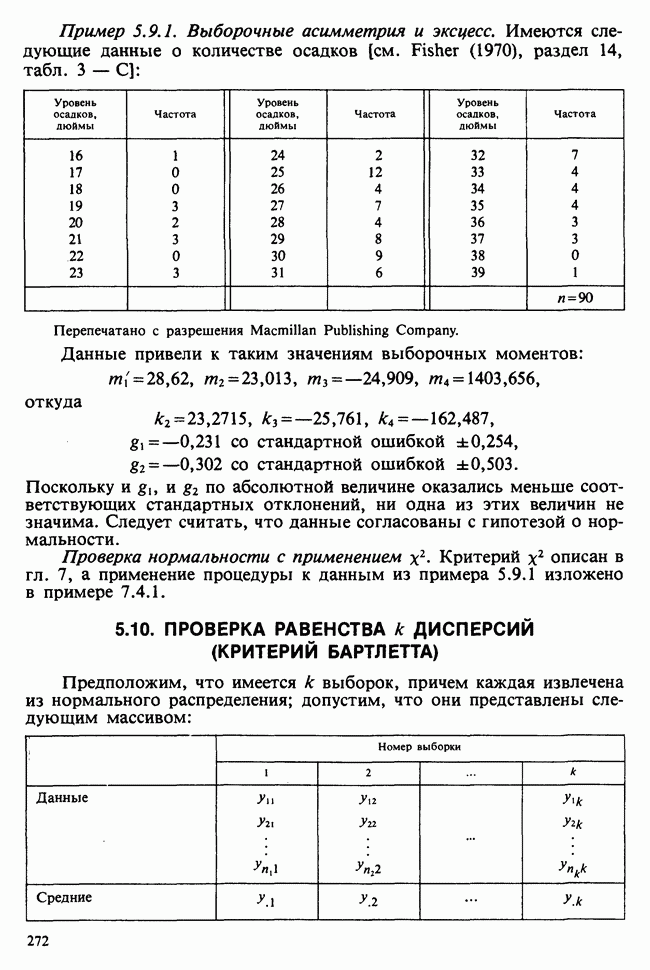
Пример 8.2.6. Односторонняя классификация (однофакторная классификация, классификация с одним входом). Допустим, что данные разделены на  групп с
групп с  наблюдениями в
наблюдениями в  группе,
группе,  . Тогда результаты можно обозначить так:
. Тогда результаты можно обозначить так:  при
при  Данные можно свести в таблицу:
Данные можно свести в таблицу:
(см. скан)
Полагая, что наблюдения в  группе — это случайная выборка из распределения с математическим ожиданием получим модель
группе — это случайная выборка из распределения с математическим ожиданием получим модель

где  — фактические значения случайной величины с математическим ожиданием нуль. Эту модель можно представить в виде
— фактические значения случайной величины с математическим ожиданием нуль. Эту модель можно представить в виде  или так:
или так:

Эта идея естественно обобщается на модели с несколькими сопутствующими переменными. В таком случае матрица плана будет состоять из нескольких столбцов с элементами О или 1, указывающими структуру данных, а затем из нескольких столбцов, содержащих значения сопутствующих переменных.






























































































































































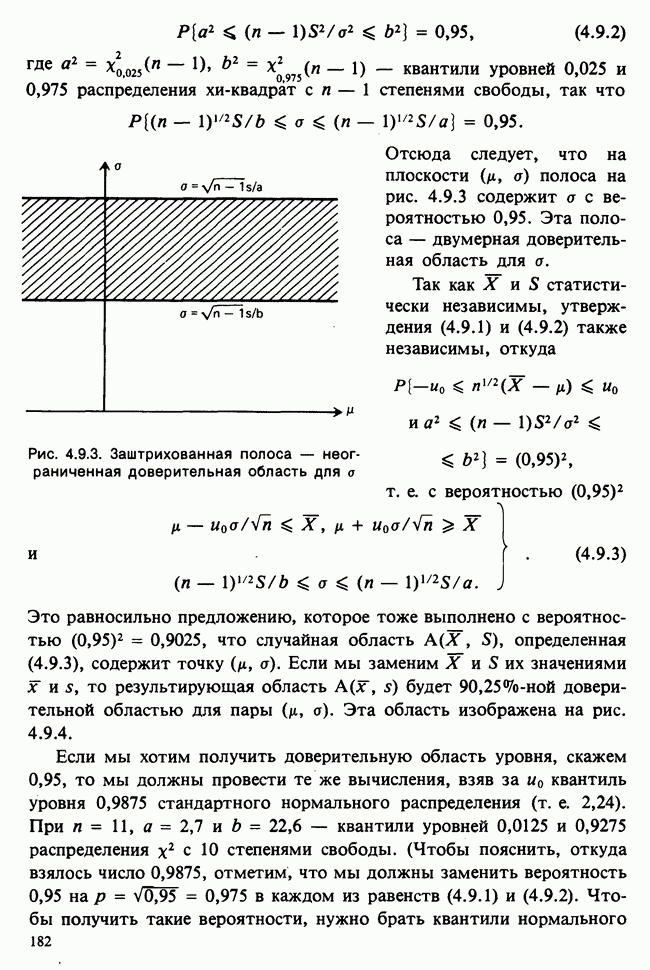
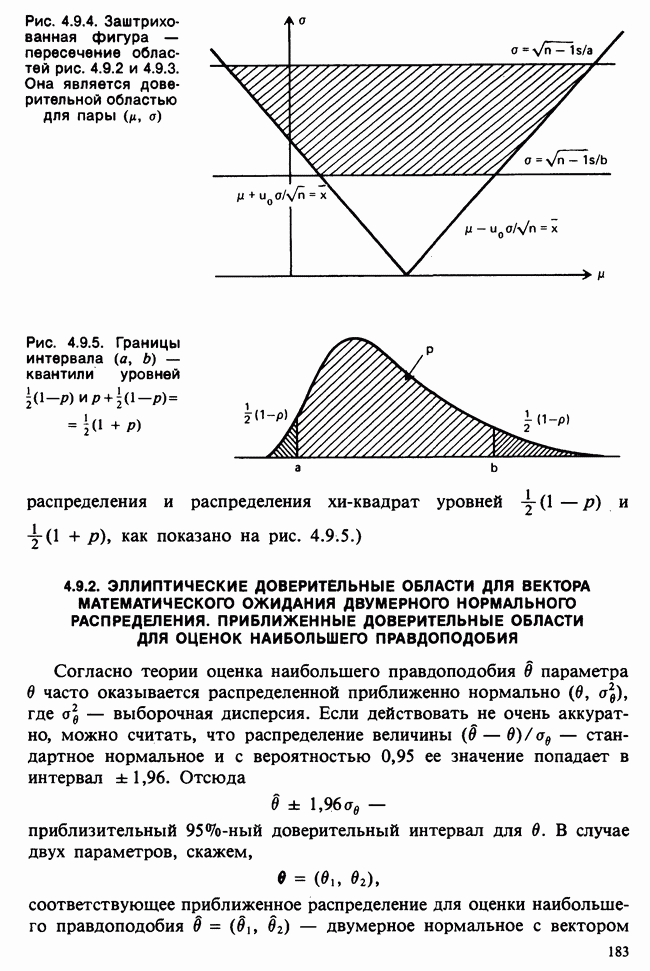









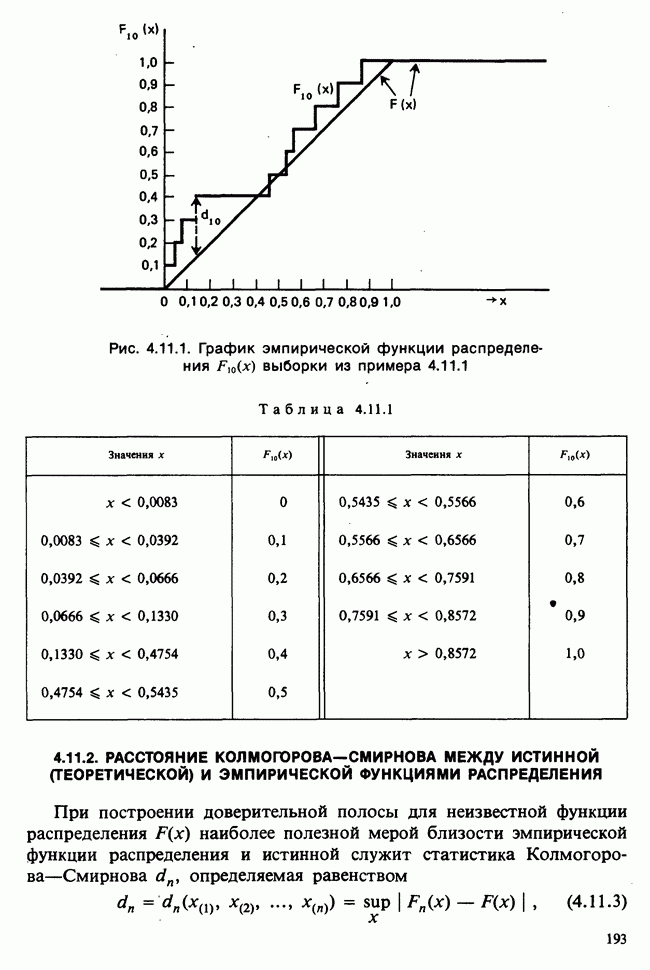


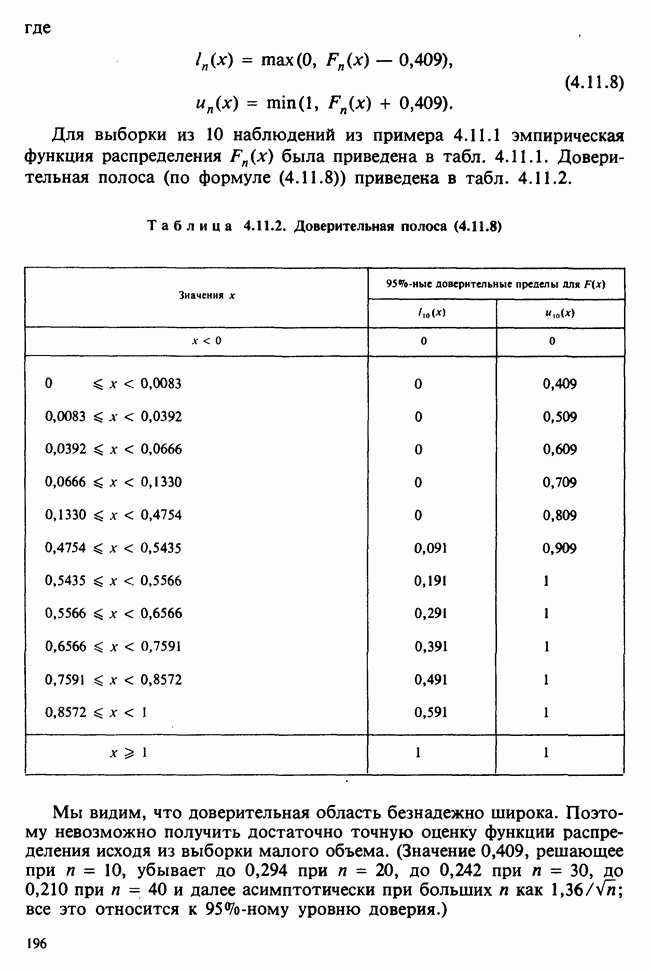





















































































































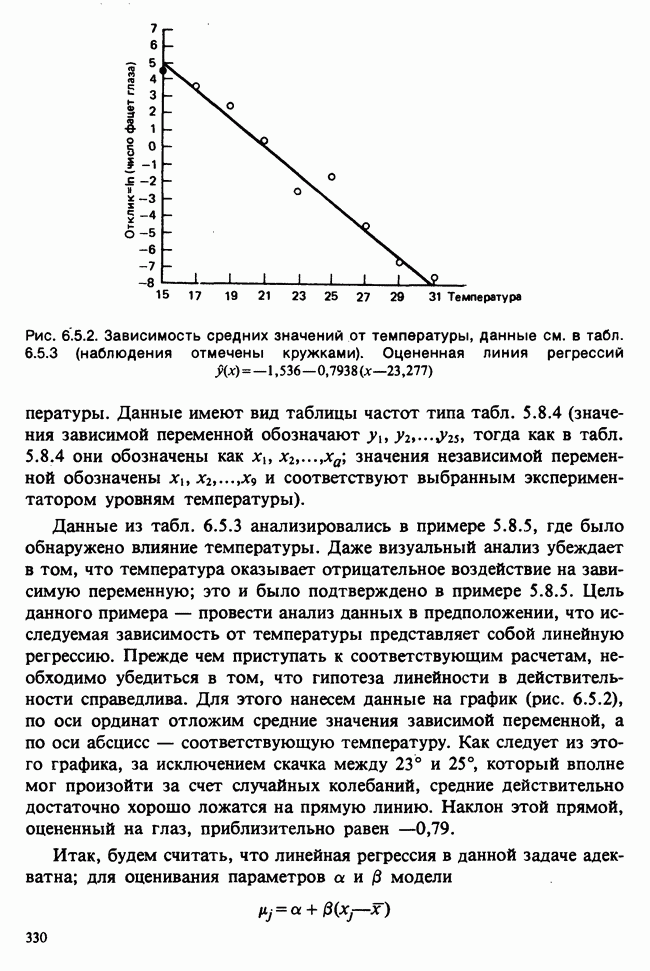
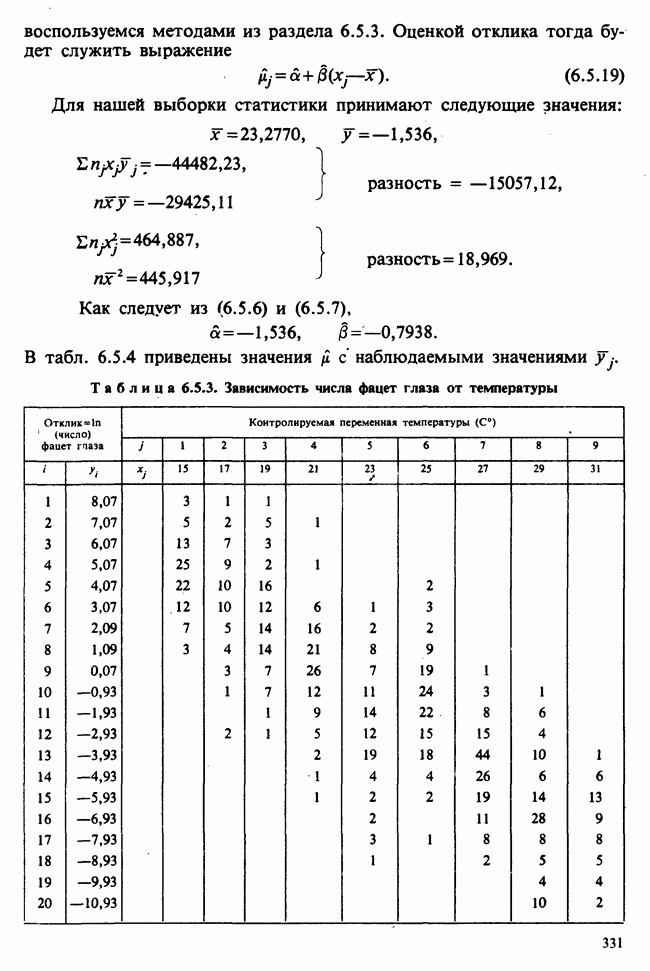
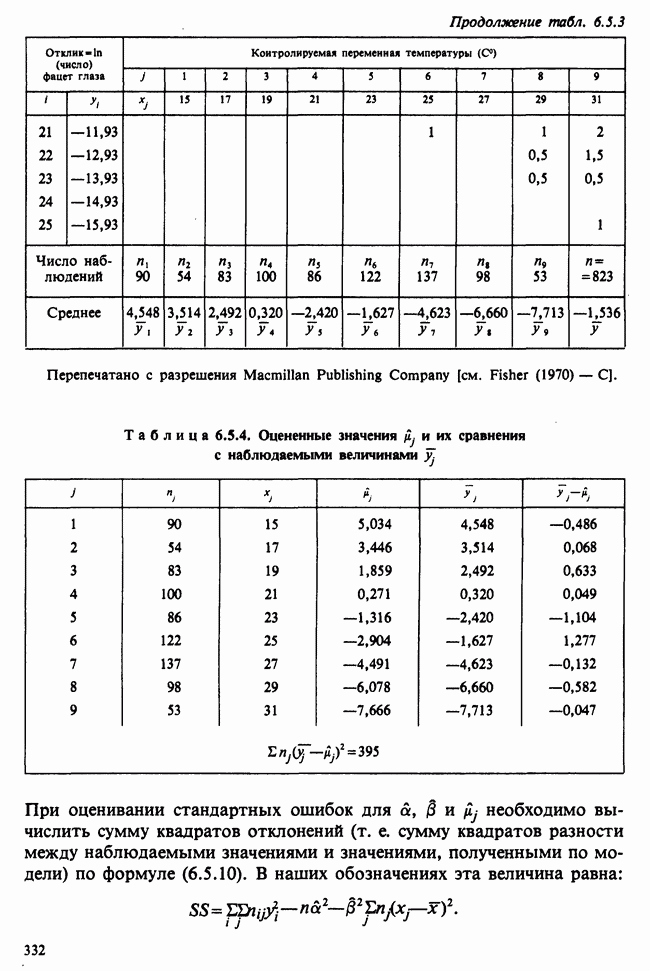



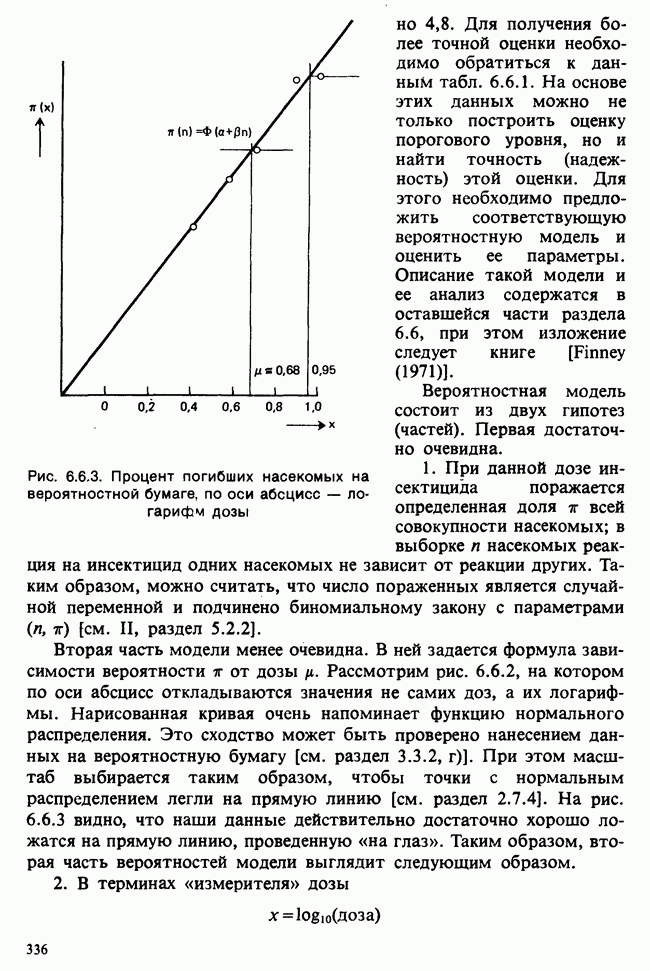


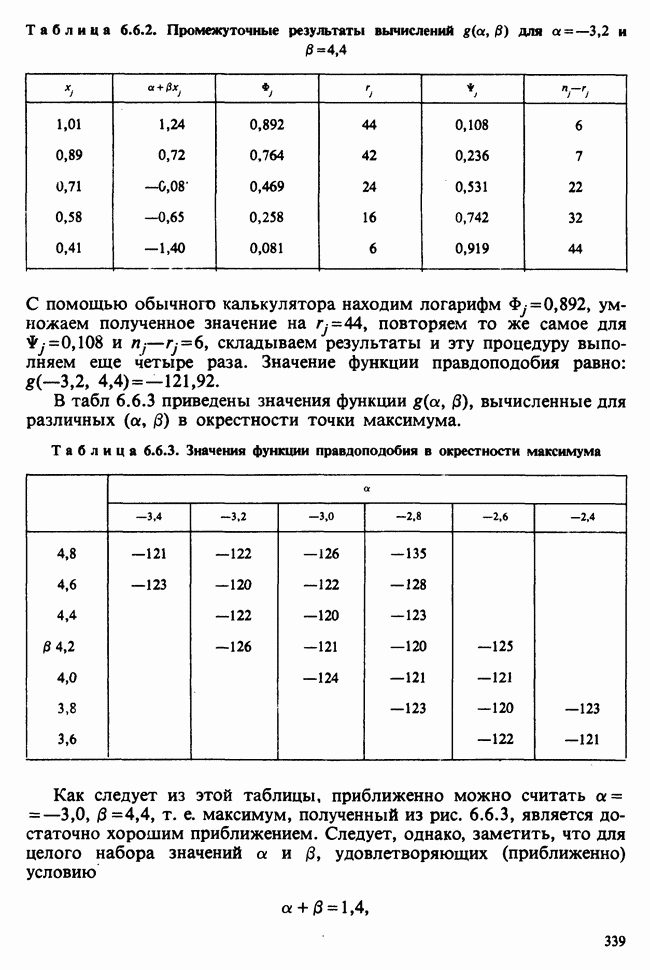


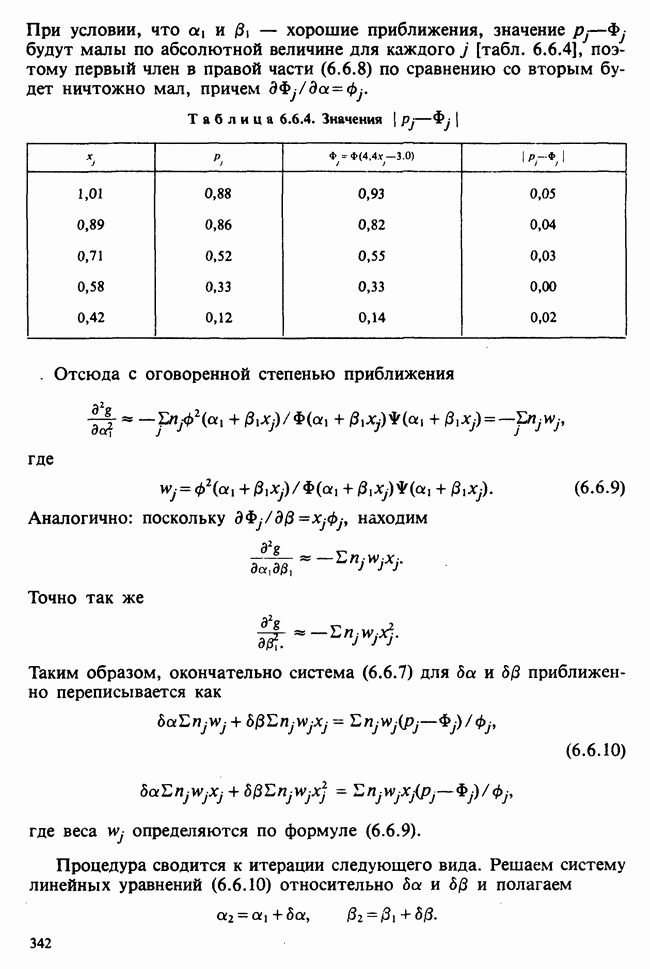

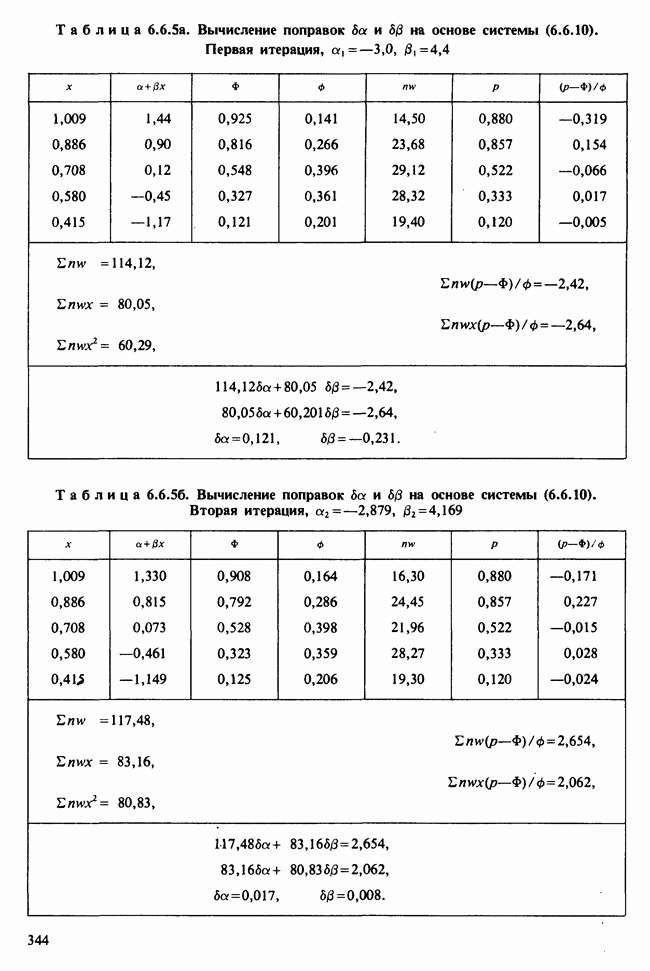

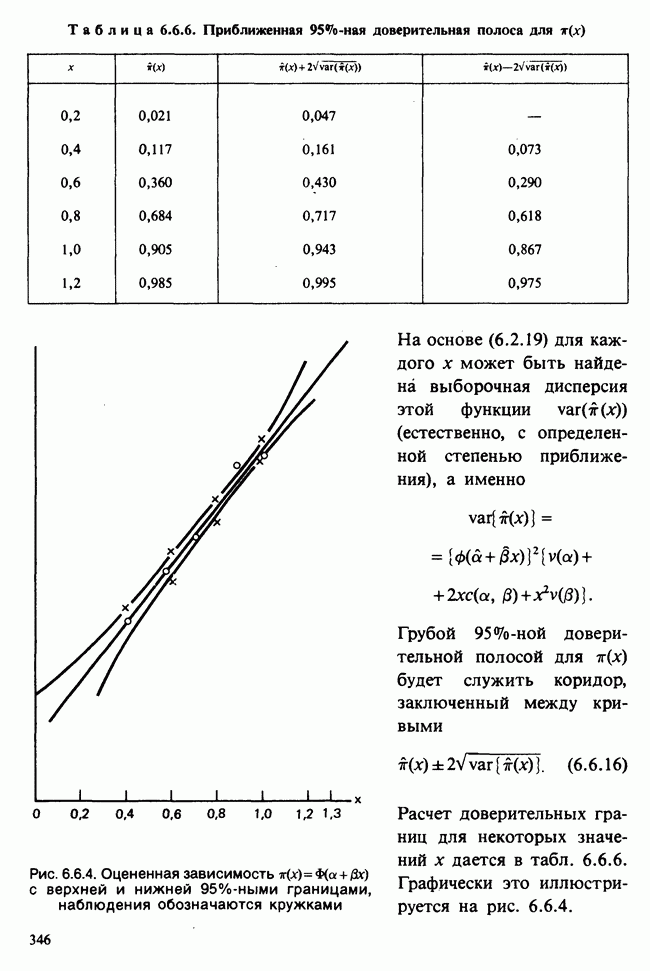














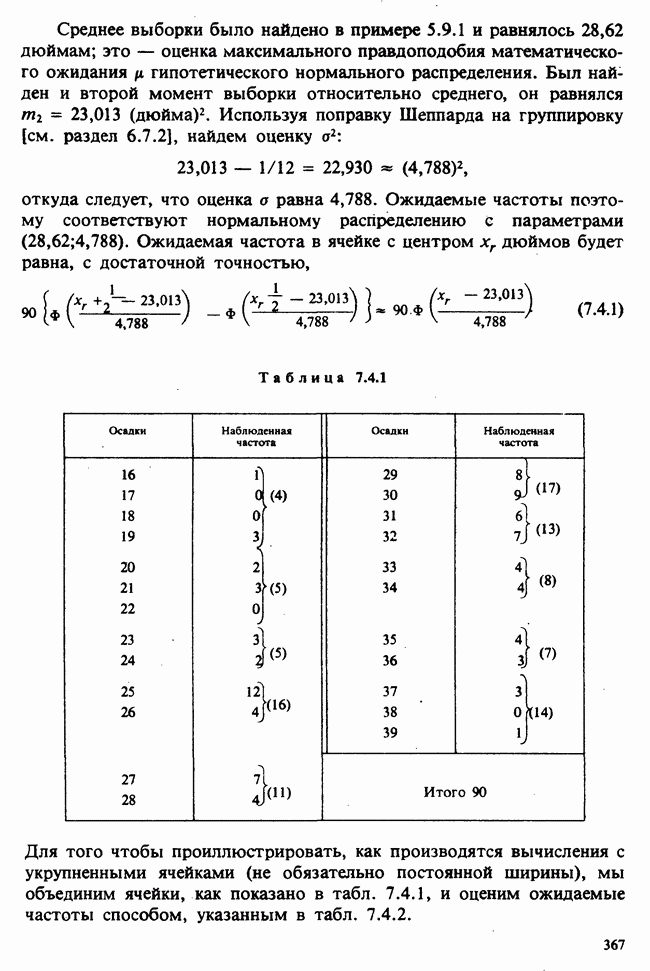
















































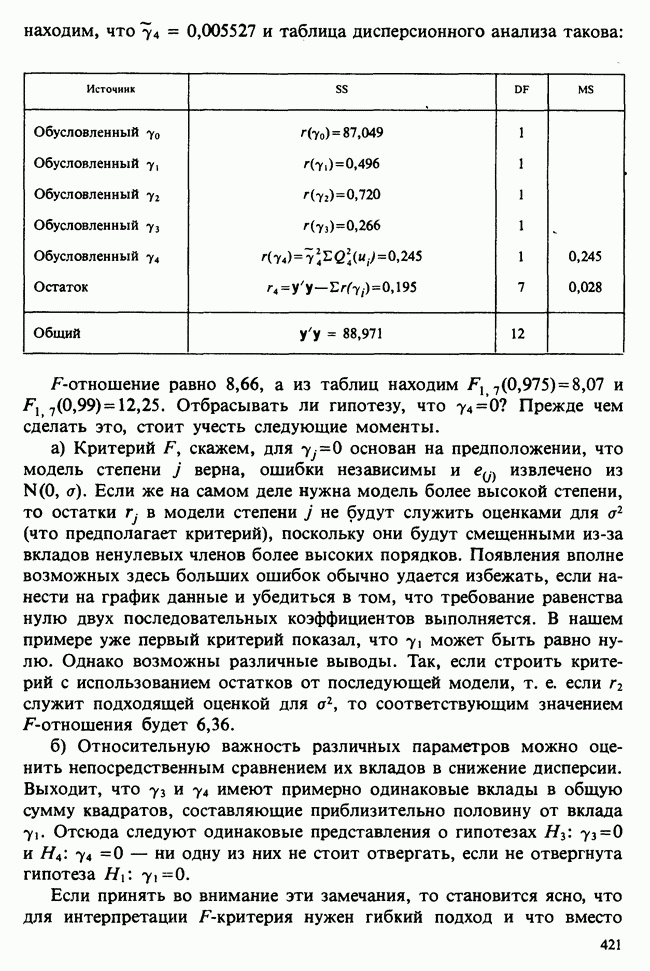







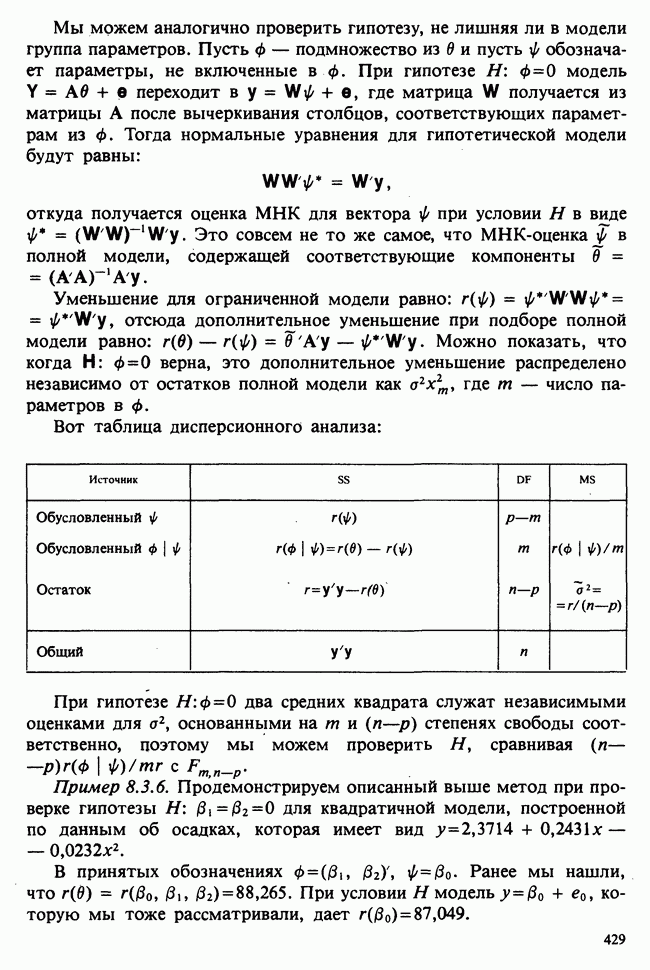














































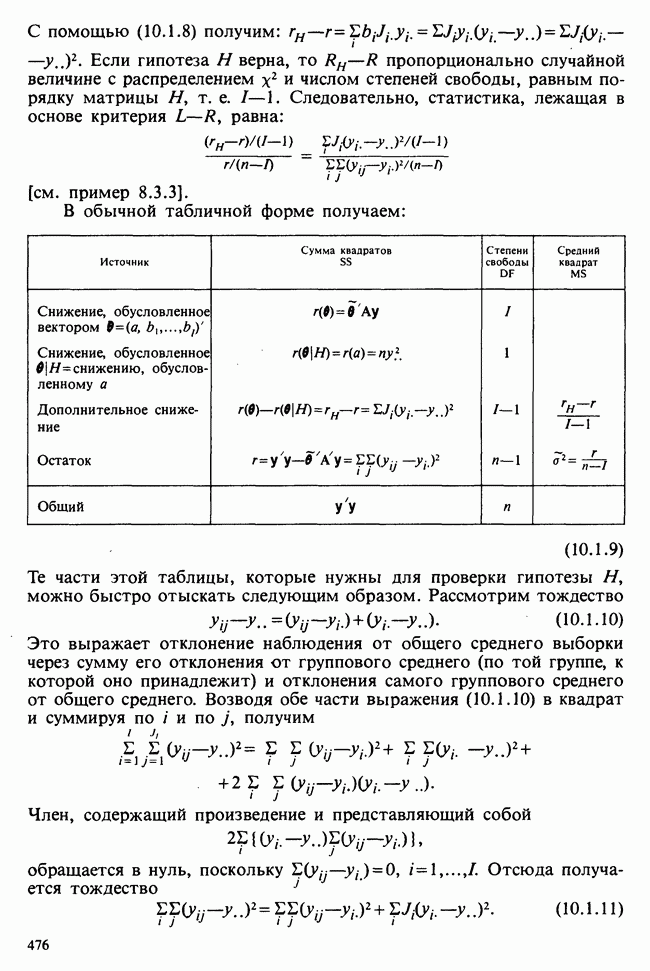


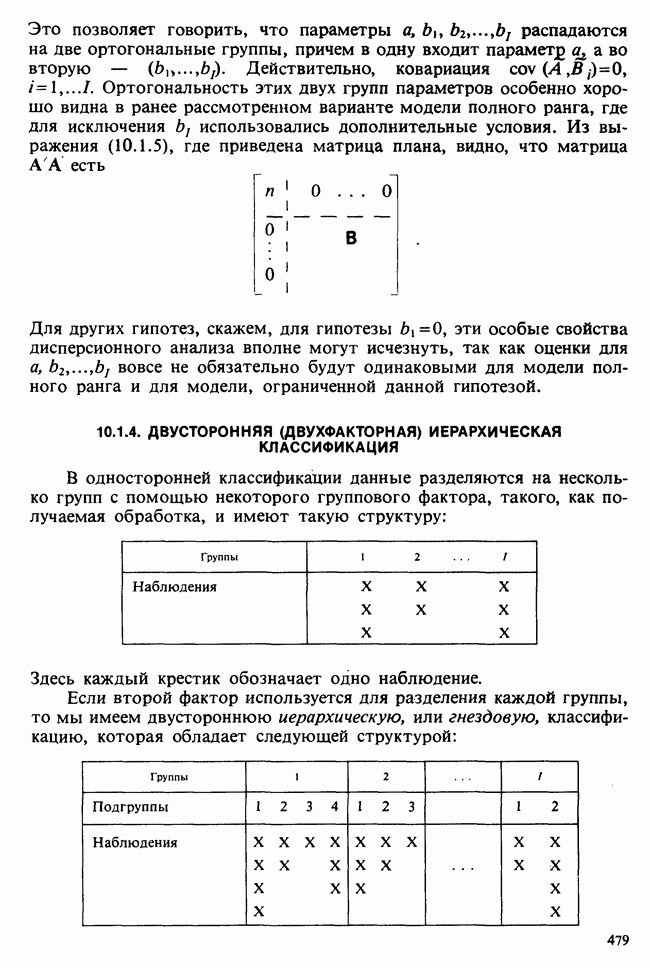





























 — известные константы. Запишем:
— известные константы. Запишем:  и обозначим
и обозначим  -матрицу, составленную из констант
-матрицу, составленную из констант  через А (она известна как матрица плана). Тогда мы можем записать модель в сжатой форме:
через А (она известна как матрица плана). Тогда мы можем записать модель в сжатой форме:  . А для экспериментальных значений
. А для экспериментальных значений  где
где  — наблюдаемые значения
— наблюдаемые значения  , а
, а  — вектор ошибок. Отсюда сумма квадратов, подлежащая минимизации, примет вид
— вектор ошибок. Отсюда сумма квадратов, подлежащая минимизации, примет вид

 в данном случае линейны и их можно записать так:
в данном случае линейны и их можно записать так:



 столбцов матрицы А линейно независимы (это и есть случай полного ранга). Тогда ранг
столбцов матрицы А линейно независимы (это и есть случай полного ранга). Тогда ранг  матрицы А будет равен
матрицы А будет равен  . Отсюда следует, что симметричная матрица
. Отсюда следует, что симметричная матрица  тоже имеет ранг
тоже имеет ранг  а поскольку ее размер
а поскольку ее размер  , то она не вырождена и имеет обратную
, то она не вырождена и имеет обратную  . Вот единственное решение нормальных уравнений:
. Вот единственное решение нормальных уравнений:

 и служащее МНК-оценкой для
и служащее МНК-оценкой для  . Случай, когда
. Случай, когда  обсуждается в гл. 10.
обсуждается в гл. 10.

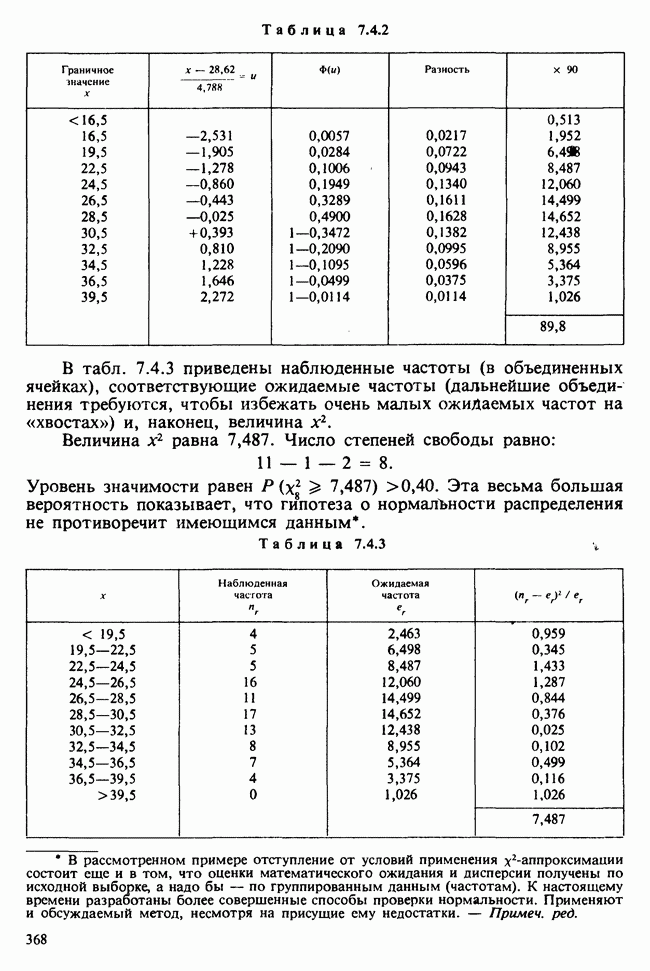
 ). Совсем иная ситуация, например, если все
). Совсем иная ситуация, например, если все  наблюдений сделать при одних и тех же значениях
наблюдений сделать при одних и тех же значениях  Для отыскания МНК-оценок
Для отыскания МНК-оценок  нам нужна матрица
нам нужна матрица  которая получается обычным численным обращением матрицы
которая получается обычным численным обращением матрицы  на компьютере. А для однофакторной линейной регрессии, которая в наших обозначениях имеет вид
на компьютере. А для однофакторной линейной регрессии, которая в наших обозначениях имеет вид

 Обозначив фактические значения х через
Обозначив фактические значения х через  получим
получим

 . Воспользовавшись соотношением
. Воспользовавшись соотношением  найдем МНК-оценки:
найдем МНК-оценки:


 — значение x, полученное в
— значение x, полученное в  наблюдении. Записав
наблюдении. Записав  получим
получим

 — диагональная матрица с диагональными элементами
— диагональная матрица с диагональными элементами  Запишем
Запишем



 среднему по
среднему по  группе наблюдений (здесь и далее мы будем обозначать суммирование по данному индексу подстрочным знаком плюс
группе наблюдений (здесь и далее мы будем обозначать суммирование по данному индексу подстрочным знаком плюс  , а усреднение — точкой
, а усреднение — точкой 

 выбраны так, что для
выбраны так, что для  мы имеем
мы имеем  если данное наблюдение принадлежит
если данное наблюдение принадлежит  группе и
группе и  в противном случае. Соответствующие значения
в противном случае. Соответствующие значения  приводятся в
приводятся в  столбце матрицы плана А. В таком случае регрессор становится качественной переменной, обеспечивающей только указание структуры данных, тогда как переменные из примера 8.2.5 были количественными.
столбце матрицы плана А. В таком случае регрессор становится качественной переменной, обеспечивающей только указание структуры данных, тогда как переменные из примера 8.2.5 были количественными.
 групп мы можем иметь дополнительные сведения о количественной переменной
групп мы можем иметь дополнительные сведения о количественной переменной  известной как сопутствующая переменная. В этом случае получается такая модель:
известной как сопутствующая переменная. В этом случае получается такая модель:


 , причем матрица плана А, приведенная в предыдущем примере [см. (8.2.3)], пополняется столбцом с элементами
, причем матрица плана А, приведенная в предыдущем примере [см. (8.2.3)], пополняется столбцом с элементами 
