Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
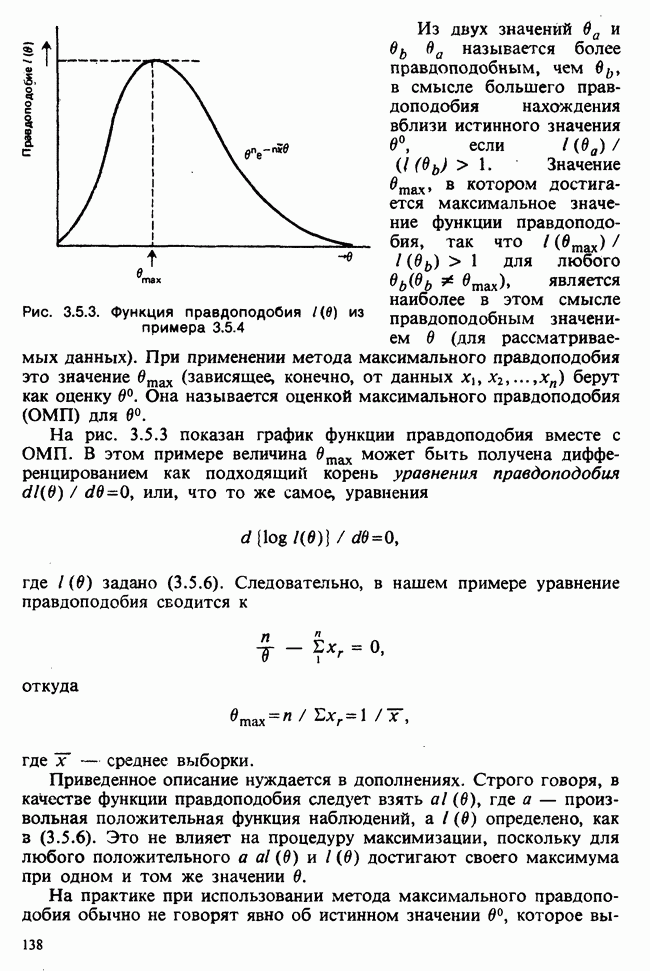
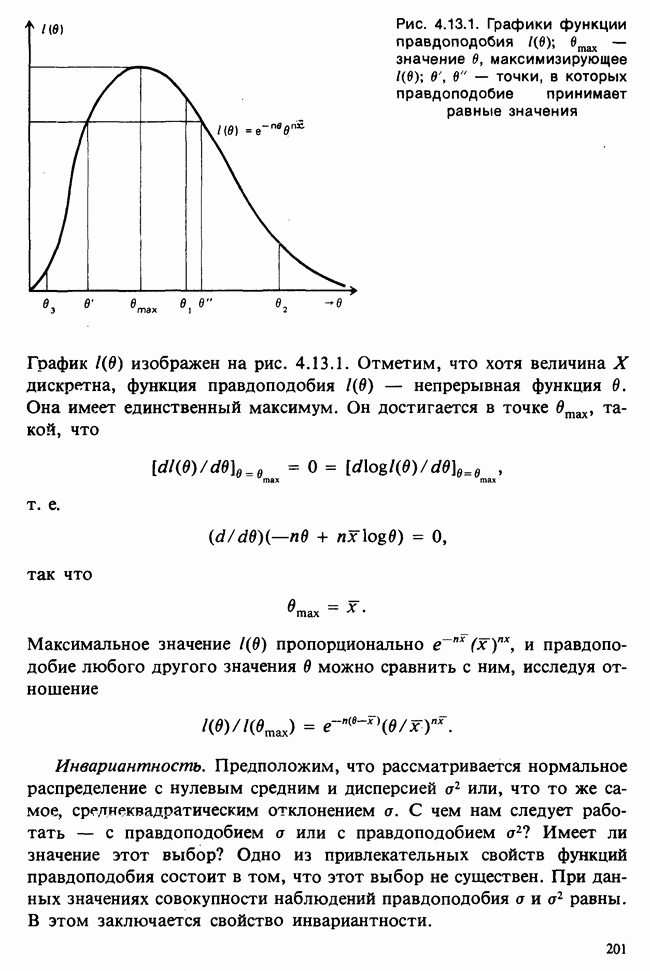
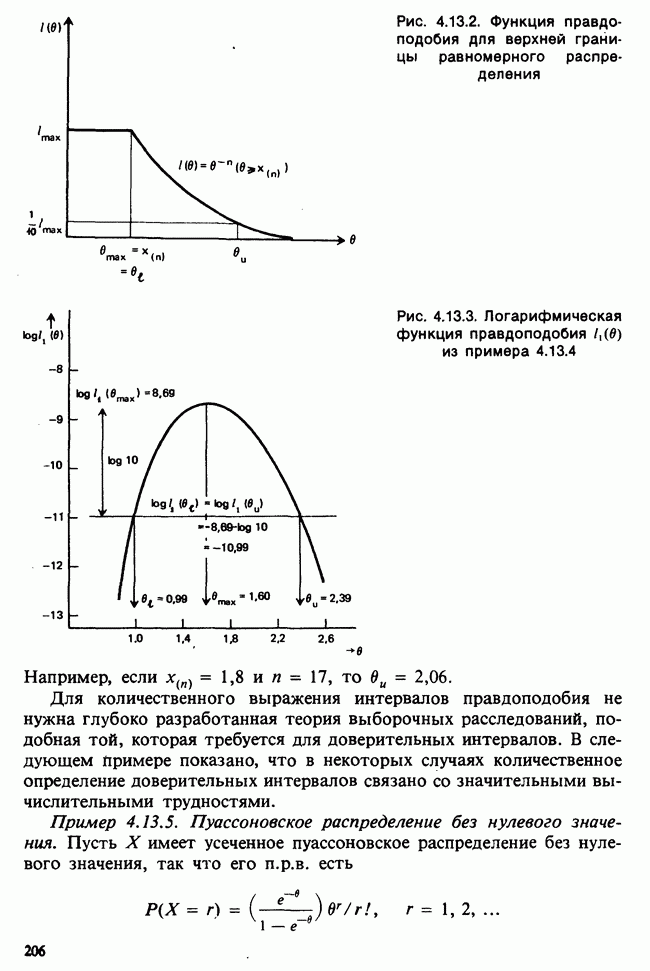
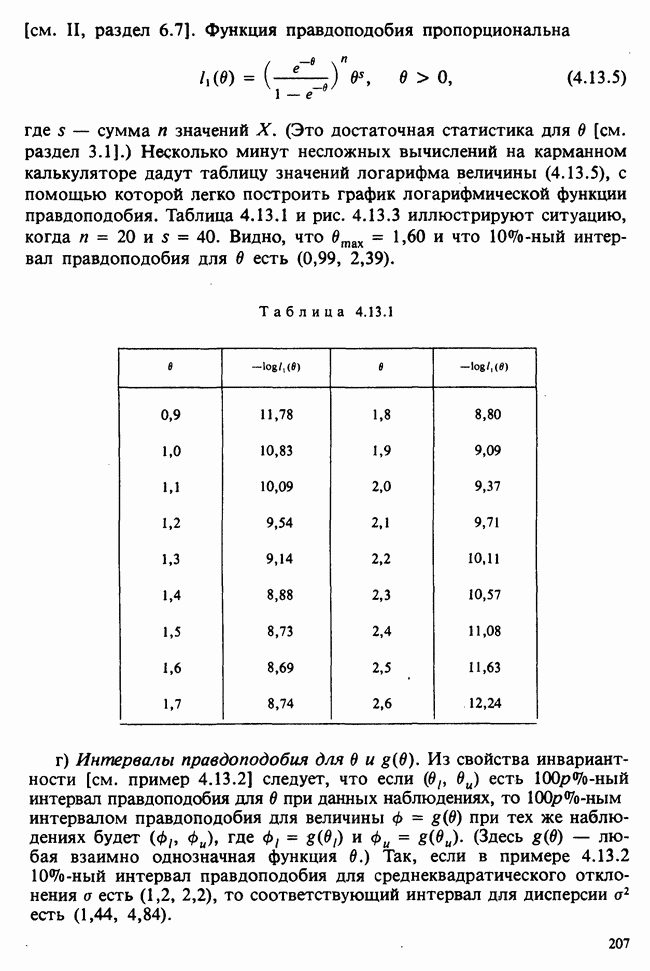
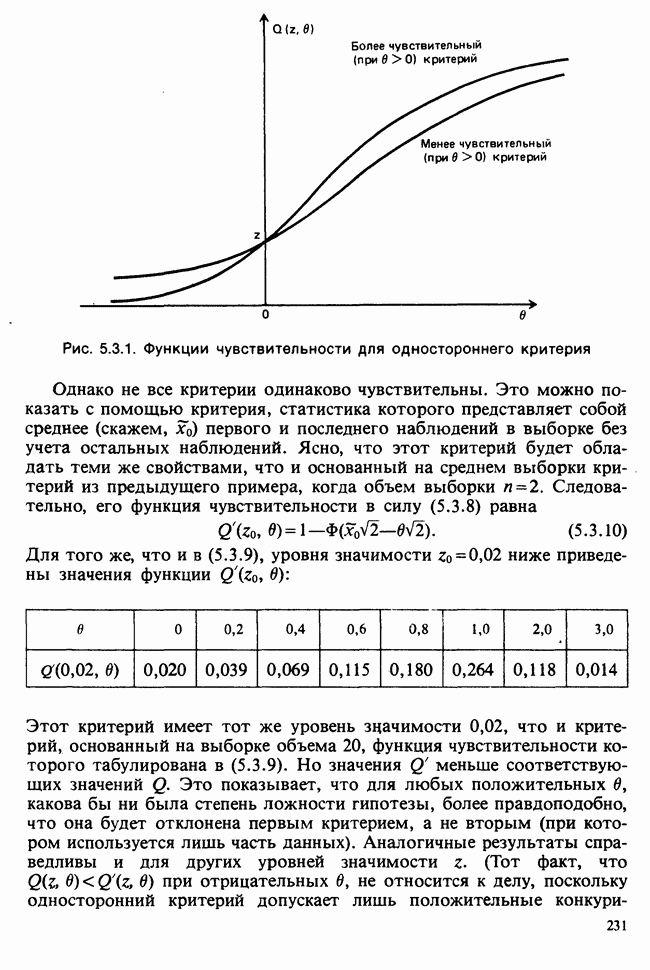
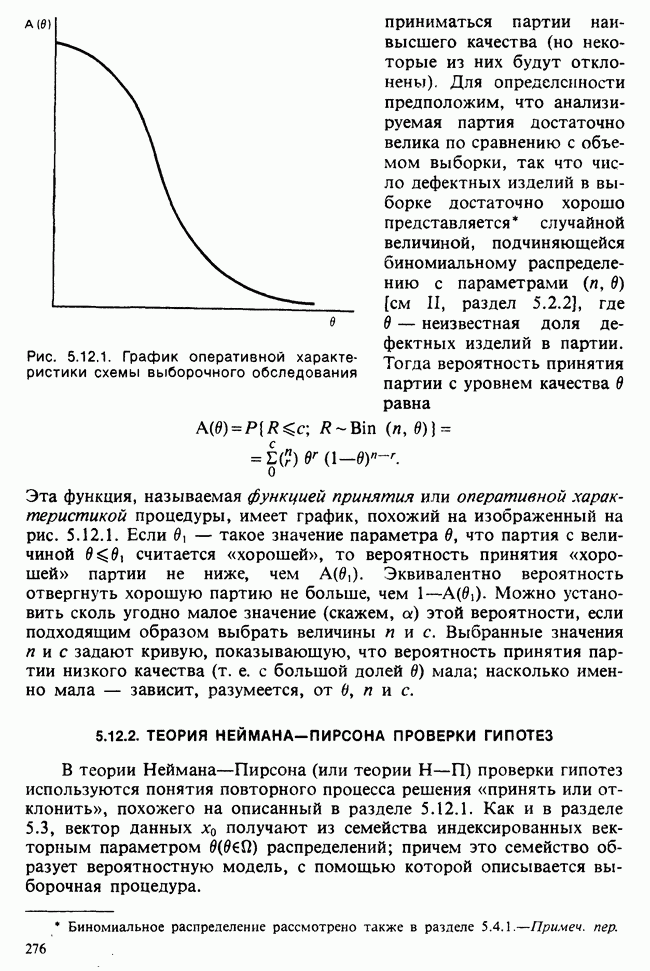
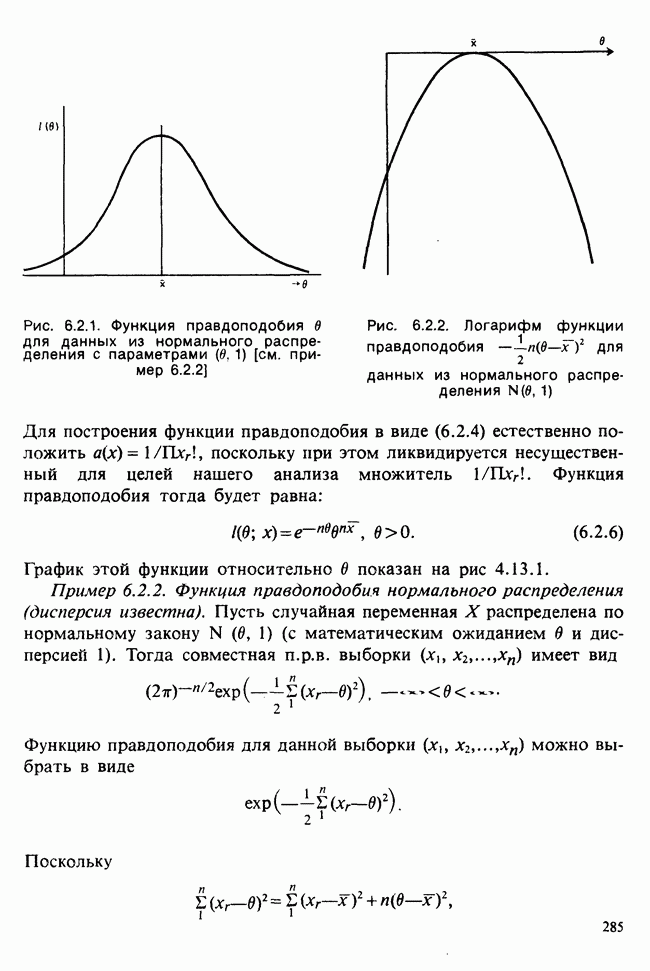
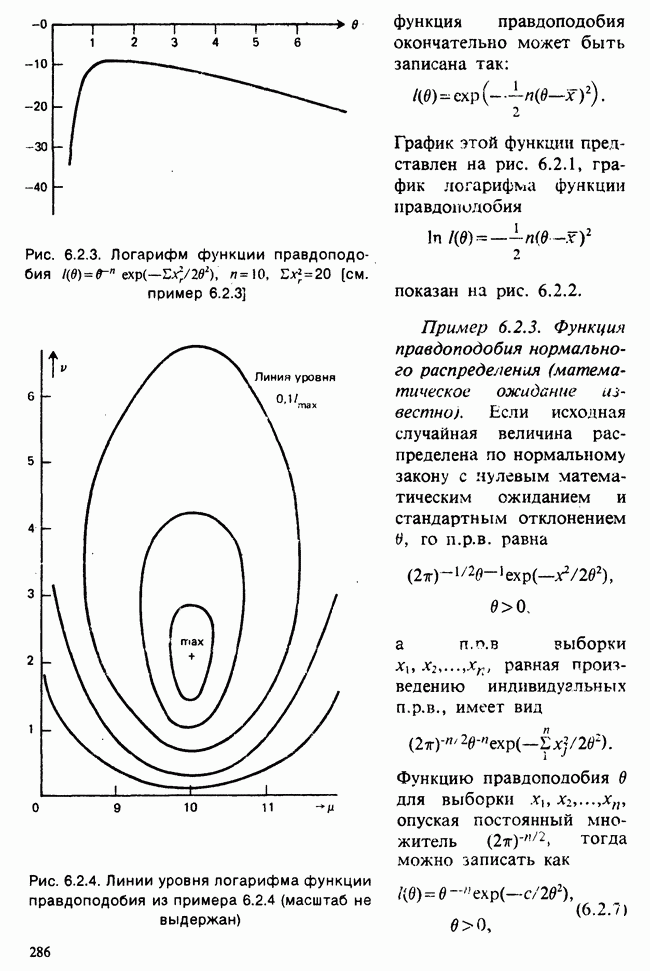
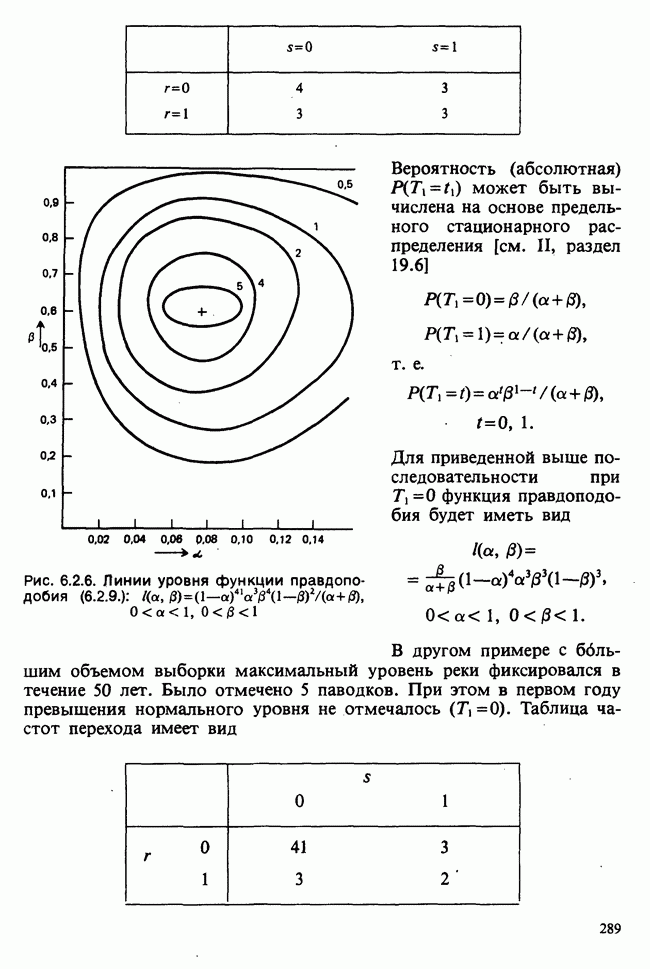
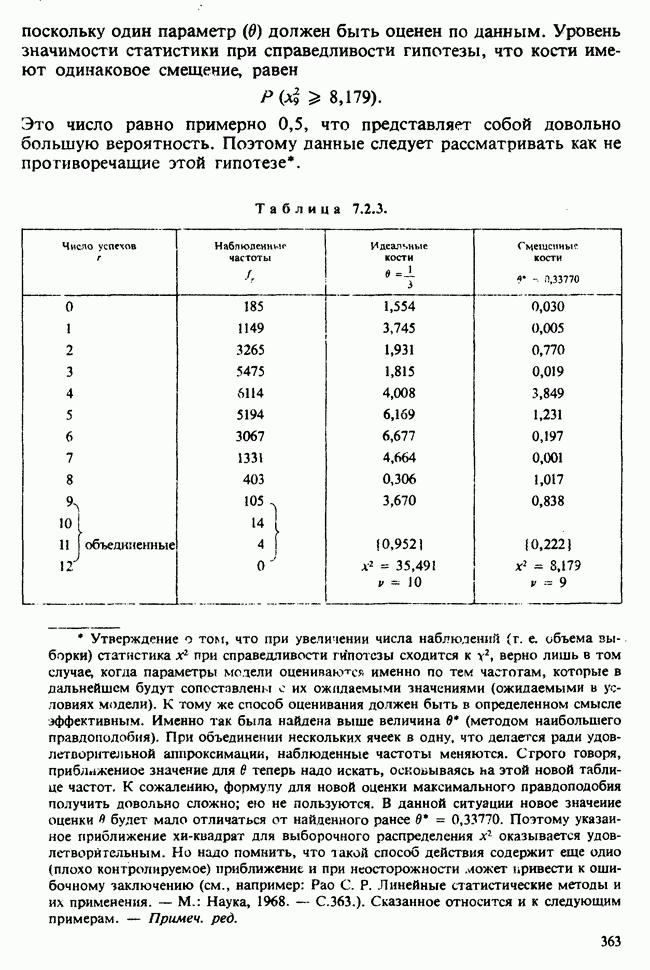
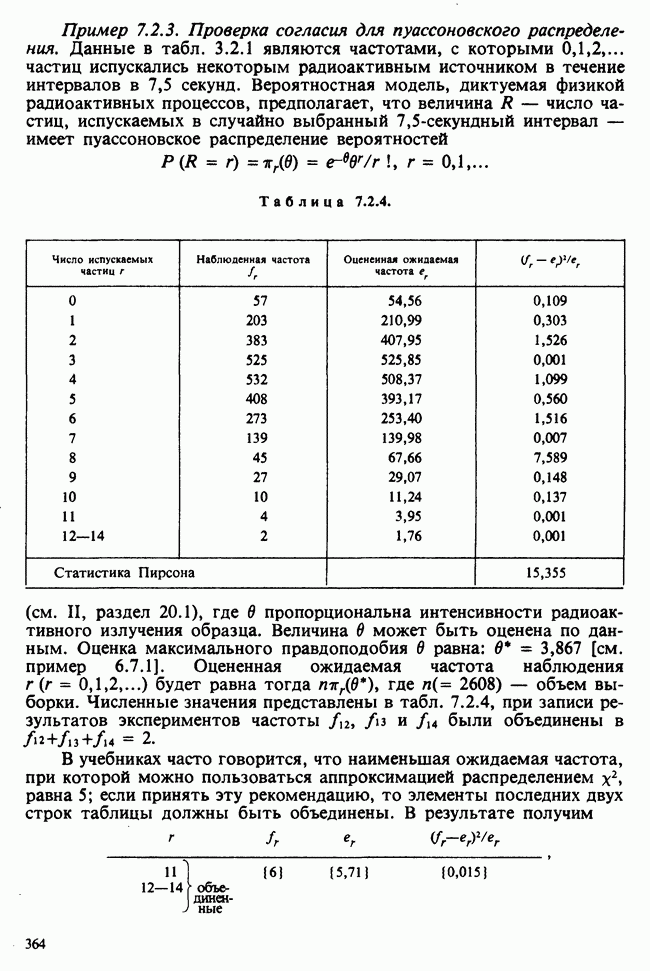
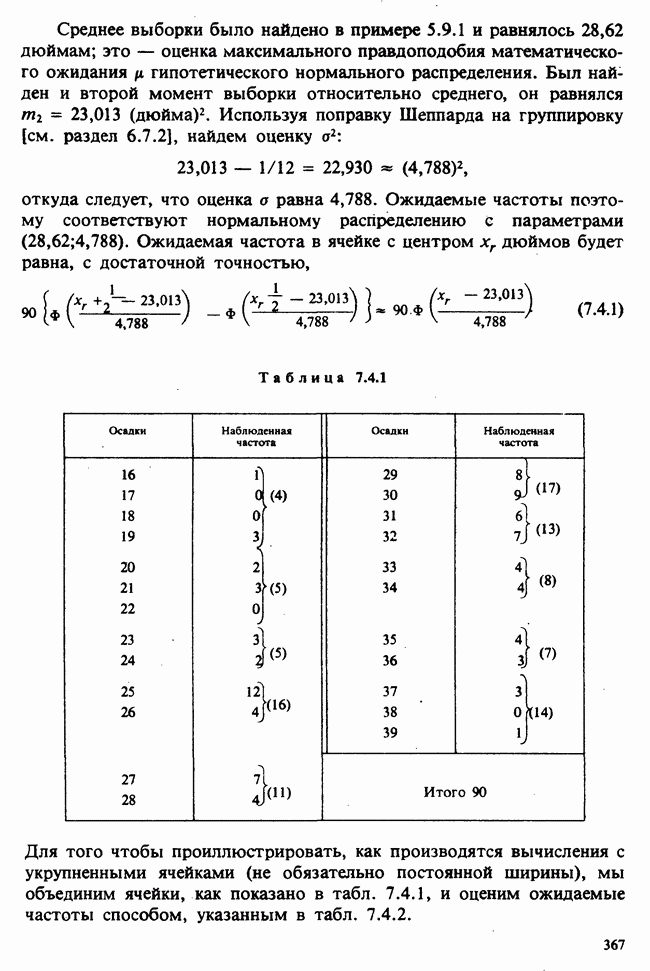
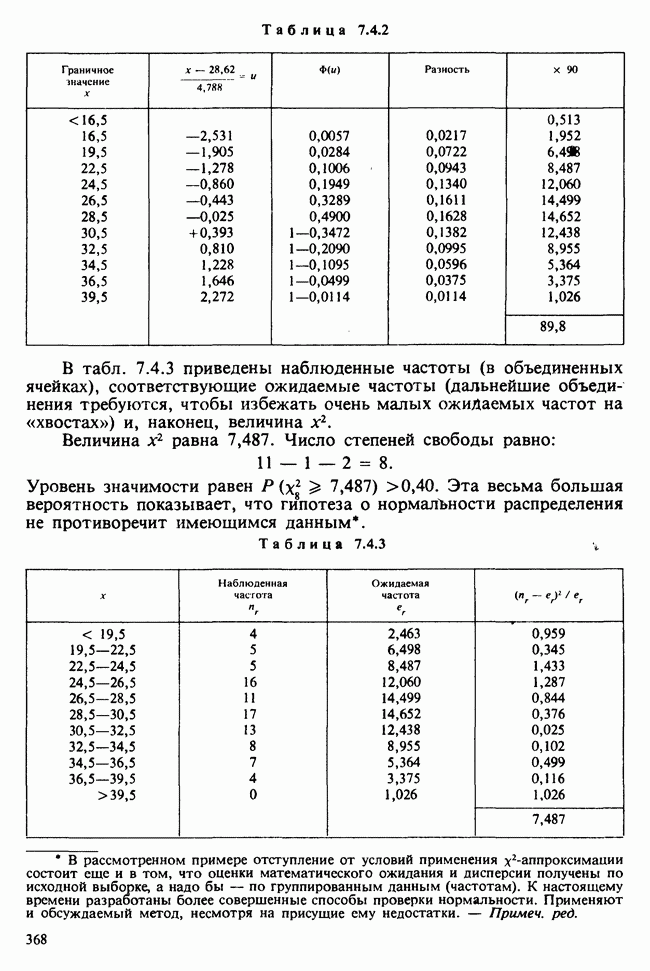
Глава 3. ОЦЕНИВАНИЕ. ВВОДНОЕ ОБОЗРЕНИЕ3.1. ЗАДАЧА ОЦЕНИВАНИЯКогда статистики говорят о проблеме оценивания, они обычно имеют в виду ограниченное толкование этого термина: полученные данные предполагаются наблюдениями из одного или нескольких определенных семейств вероятностных распределений, в которых элементы отличаются друг от друга значениями одного или нескольких параметров. Задача оценивания состоит в том, чтобы извлечь из данных наилучшее статистическое приближение для неизвестных значений параметров, отвечающих наблюдениям, а также объективную меру точности этого приближения. Выбор семейства распределений, соответствующего обсуждаемой задаче, может быть в некоторых случаях обстоятельствами дела указан более или менее однозначно. Однако во многих ситуациях этот выбор далек от единственности. Когда идет речь об оценивании неизвестной доли дефектных изделий в большой партии по случайной выборке из нее определенного объема [см. пример 2.1.1], вполне ясно, что надо подсчитать число дефектных изделий в выборке, а из организации выбора следует, что оно является реализацией гипергеометрического распределения [см. II, раздел 5.3]. При известных условиях это распределение удовлетворительно приближается биномиальным распределением [см. II, раздел 5.2.2]. Если говорят о средней длине изделий в партии, надо работать с семействами распределений длин. Каких именно семейств? В обсуждаемом примере разумно предположить, что флуктуации длин обусловлены многими причинами, поэтому, помня о центральной предельной теореме (см. II, разделы 11.4.2 и 17.3], будем считать это распределение (хотя бы приблизительно) нормальным [см. И, раздел 11.4.3]. В других случаях может не быть ни физических, ни каких-либо причин для того, чтобы предпочесть одно семейство другому; единственной основой для выбора остается сама выборка. Подходящим может оказаться более одного семейства. Этот пример показывает, что теория оценивания для своей завершенности требует метода, который позволил бы решить, может ли подобранное распределение разумно описать имеющуюся выборку. Этот вопрос «согласия» обсуждается в гл. 7. Очевидно, что любая оценка неизвестного параметра должна основываться на выборке. Функция наблюдений (называемая статистикой [см. определение 2.1.1]), которая будет служить оценкой, обычно выбирается с учетом многих требований. Существуют два основных подхода. При первом каждое значение статистики рассматривается как наблюдение над выборочным распределением этой статистики: берут в расчет не только реальное наблюдение, но и все возможные потенциальные наблюдения. При другом подходе свойства оценки обсуждаются исключительно в терминах действительно наблюдаемых величин. Это подход правдоподобия. Более распространен и развит подход с выборочным распределением. На нем основаны несмещенные оценки с минимальной дисперсией, байесовские правила, теория решений и т. д. Этому подходу посвящена ббльшая часть настоящей книги. Методы правдоподобия описаны не столь детально [см. разделы 3.5.4, 4.13.1, 6.2.1]. Рассмотрим пример статистического вывода. Предположим, что у нас есть десять одинаково надежных, но разноречивых измерений По причинам, которые будут ясны позже, могут быть использованы такие статистики:
и (среднее выборки)
(стандартное отклонение выборки). (Здесь оценка параметра в обозначена как Оценивание и оценка. Численное значение оценки х, приведенной выше, можно рассматривать как реализацию индуцированной [см. определение 2.2.1] случайной величины
которая называется оценивателем, соответствующим оценке х. Подобно этому оцениватель, соответствующий выборочному стандартному отклонению
Эта мысль обобщена в следующем определении. Определение 3.1.1. Оценка и оцениватель; стандартная ошибка. Оценка в параметра в по выборке В (3.1.1) и (3.1.2) есть два параметра
X и В каком смысле х хорошая оценка для Это показывает, что оценка х удовлетворяет некоторым требованиям, предъявленным к хорошим оценкам
было справедливым для всех значений Наши рассуждения приводят к идее о том, что свойством хорошей оценки должна быть высокая концентрация вероятности около истинного значения параметра. Мы скажем, что оценка Т имеет равномерно наибольшую концентрацию относительно в, если для любой другой оценки Т
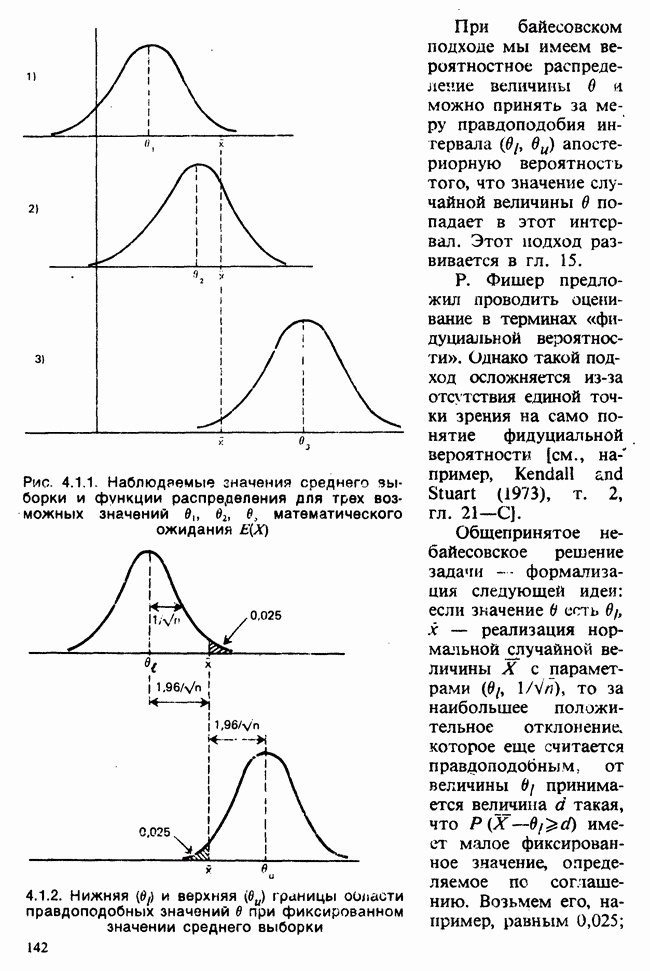
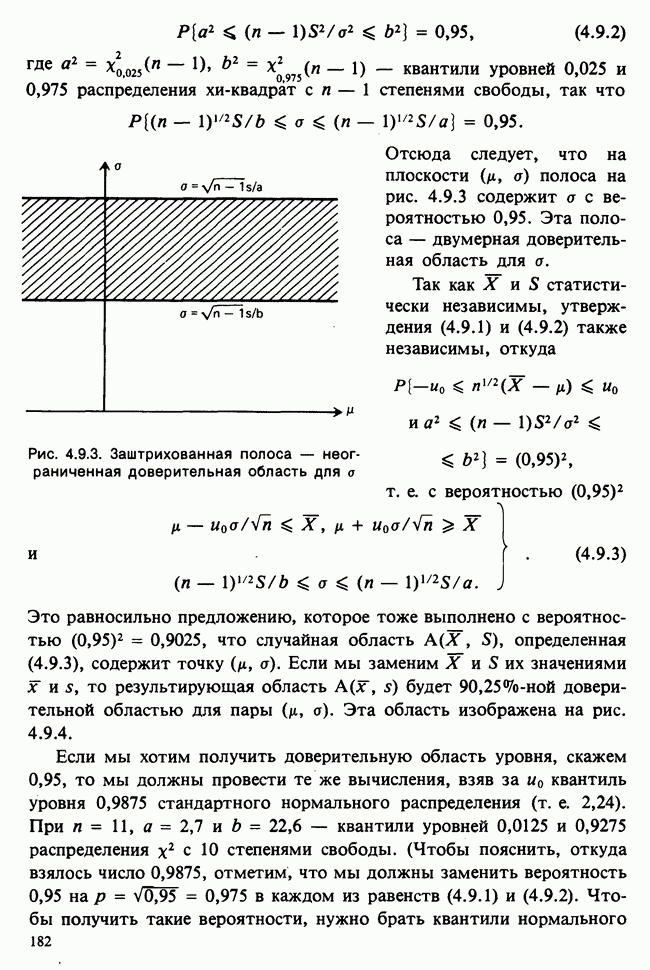
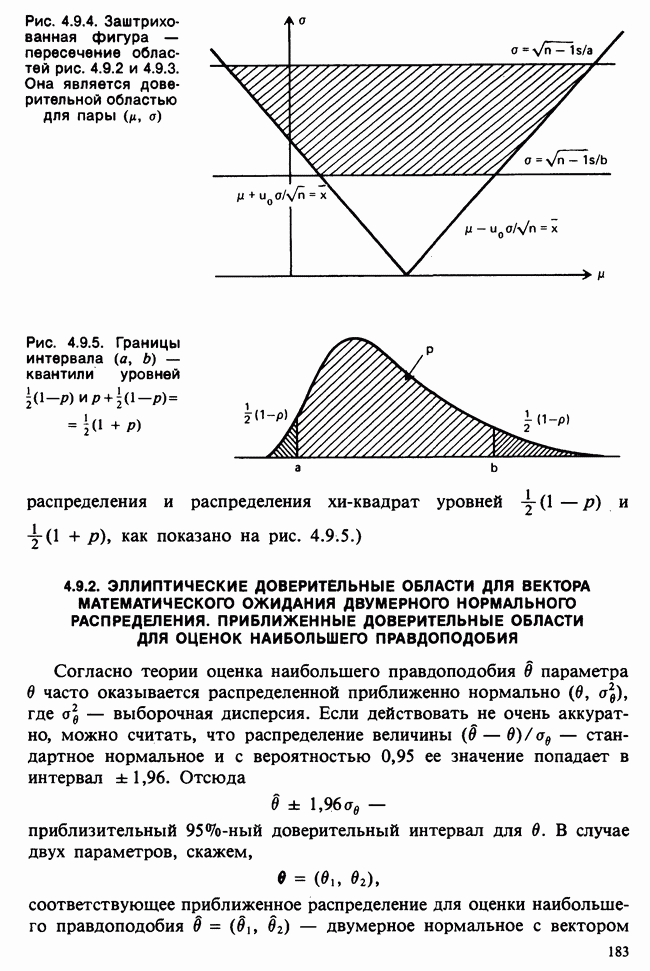
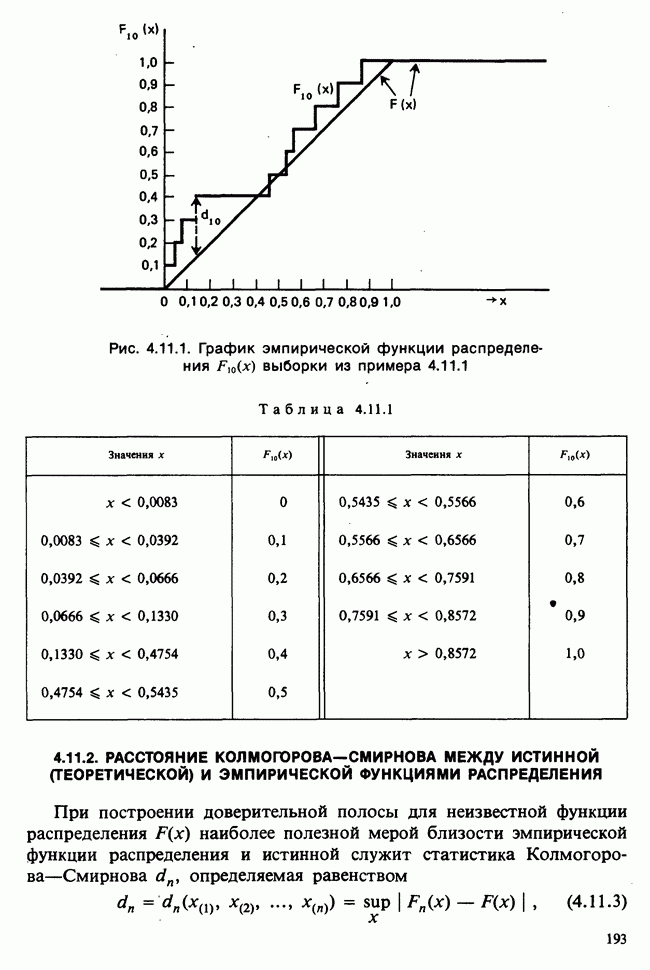
для всех положительных Возвращаясь к нашему примеру, включающему среднее нормальной выборки с параметрами Заменяя неизвестное Это довольно грубое утверждение можно существенно уточнить, например, в терминах доверительных интервалов [см. пример 4.5.2]. Тем не менее оно интуитивно понятно. В статистической практике стандартная ошибка оценки широко применяется как мера точности этой оценки и как основа для более сложных мер. Существуют разные мнения о том, какова должна быть эта мера. Некоторые статистики считают, что удовлетворительное решение (проблемы) дает байесовский подход [см. гл. 15]. В соответствии с этим подходом выборку не считают единственным источником информации и стремятся использовать также ту информацию, что была до проведения опытов (априорную), например уверенность в том, что значение наблюдений это неизвестное значение надо рассматривать как реализацию другого — апостериорного — распределения, т. е. условного распределения С помощью теоремы Байеса [см. гл. 15] можно найти это вероятностное распределение возможных значений Тем, кто не готов встать на точку зрения, согласно которой вероятность может быть приписана интервалам возможных значений величины 1) доверительными интервалами и/или критериями значимости; 2) теорией статистических решений с предписанными значениями риска для возможных ошибок; 3) приписывая постулируемым значениям неизвестного Точечное оценивание и интервальное оценивание. Целью практической процедуры оценивания должен быть не только выбор отдельной статистики, численное значение которой будет обеспечивать требуемое приближение («оценку») искомых параметров, но и построение подходящей меры точности этой оценки. Таким образом, существуют два аспекта одной и той же задачи. Тем не менее часто удобнее обсуждать их порознь; в таком случае выбор статистики называется точечным оцениванием, а определение ее точности — интервальным оцениванием.
|
 |
Оглавление
|











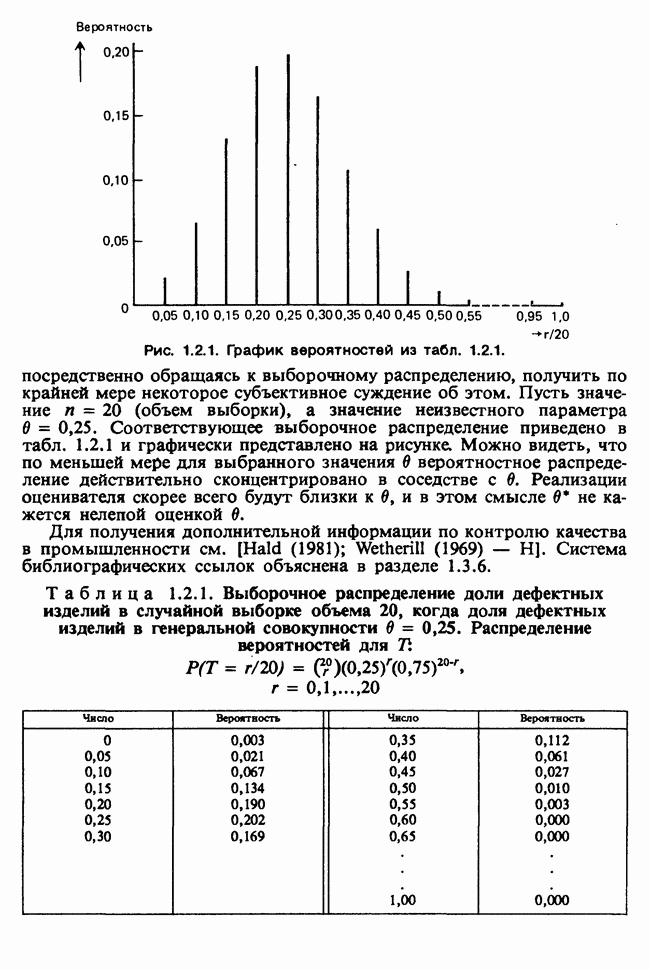

































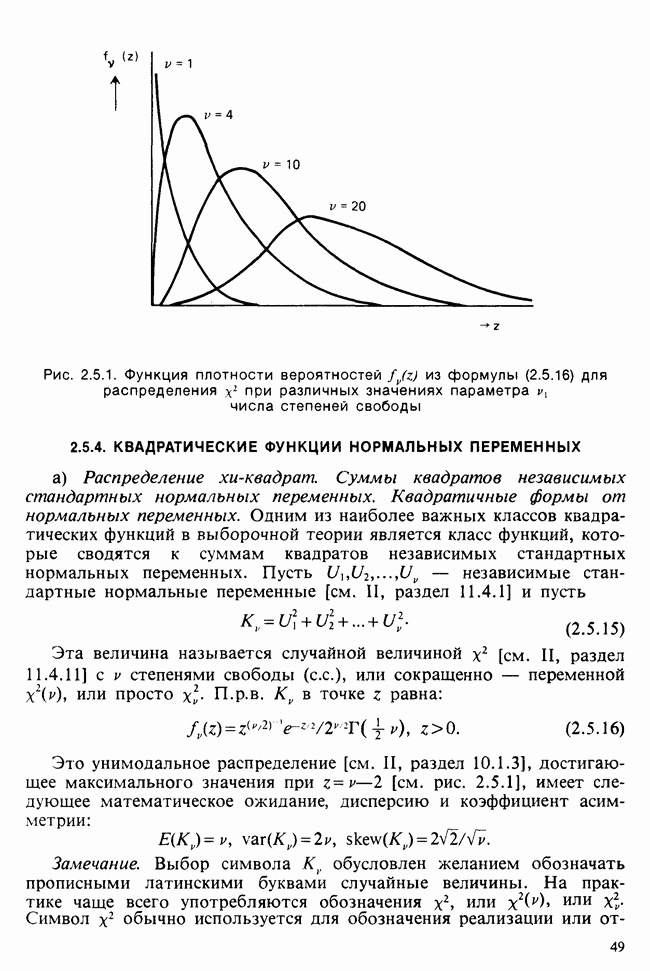











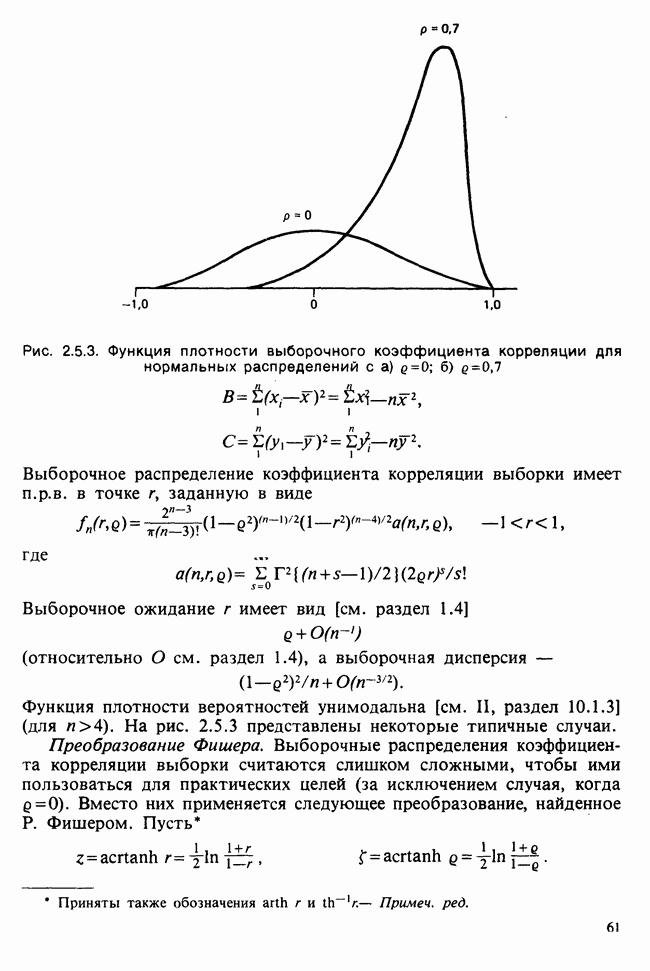












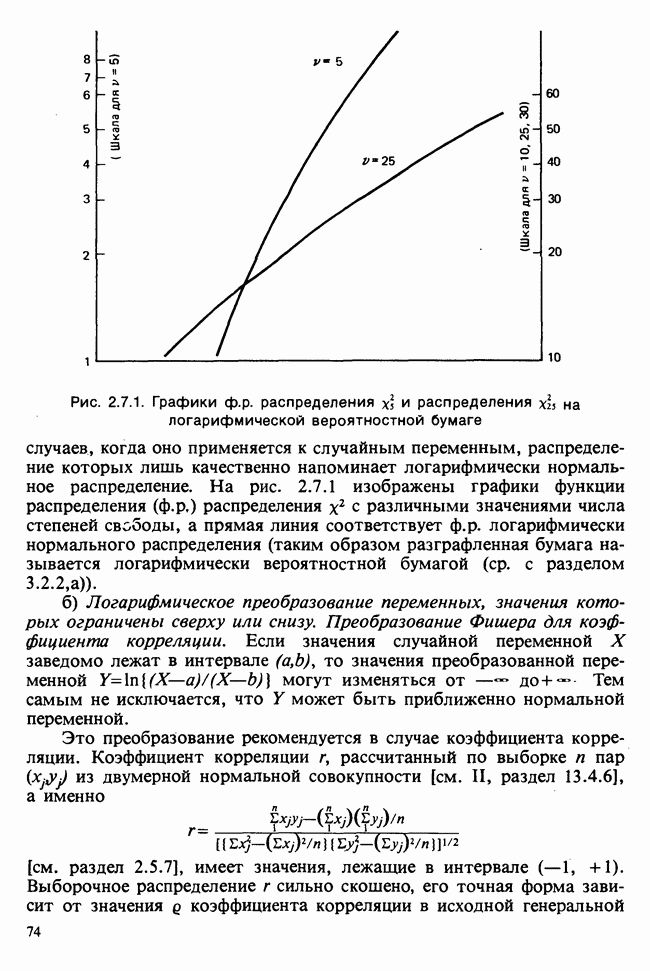















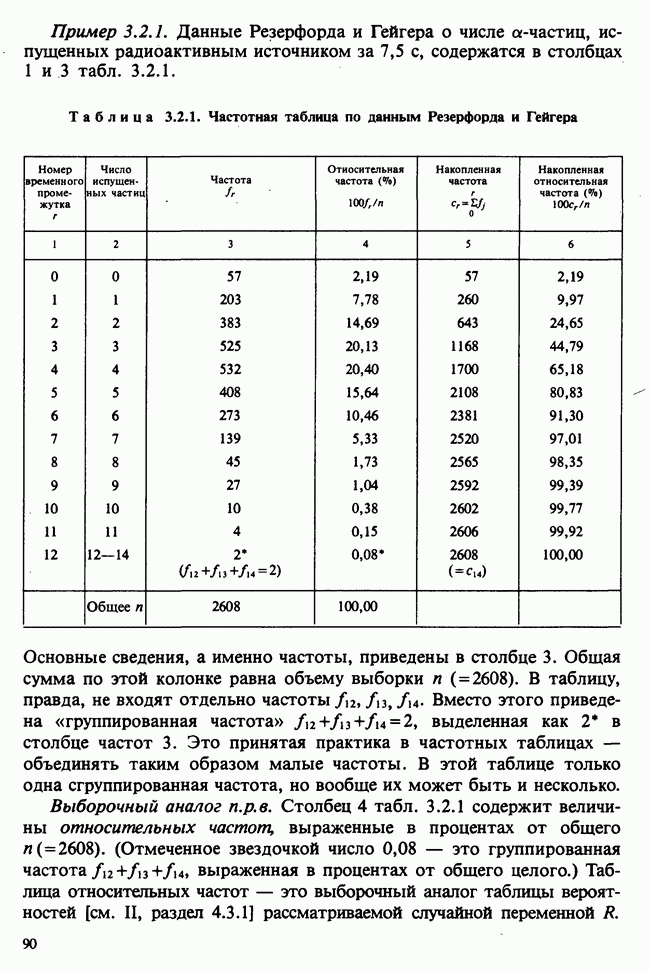


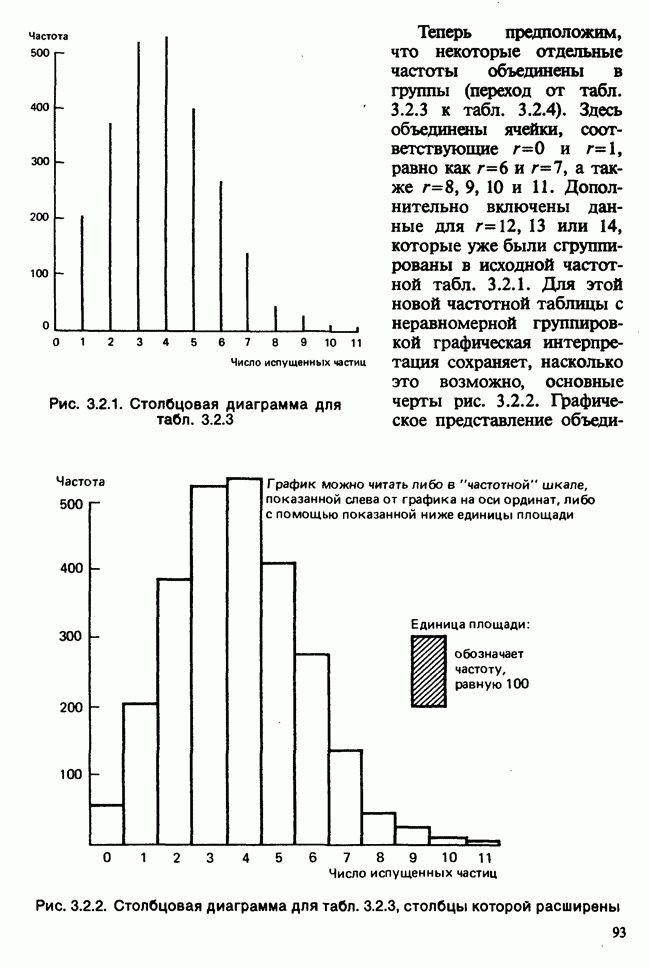
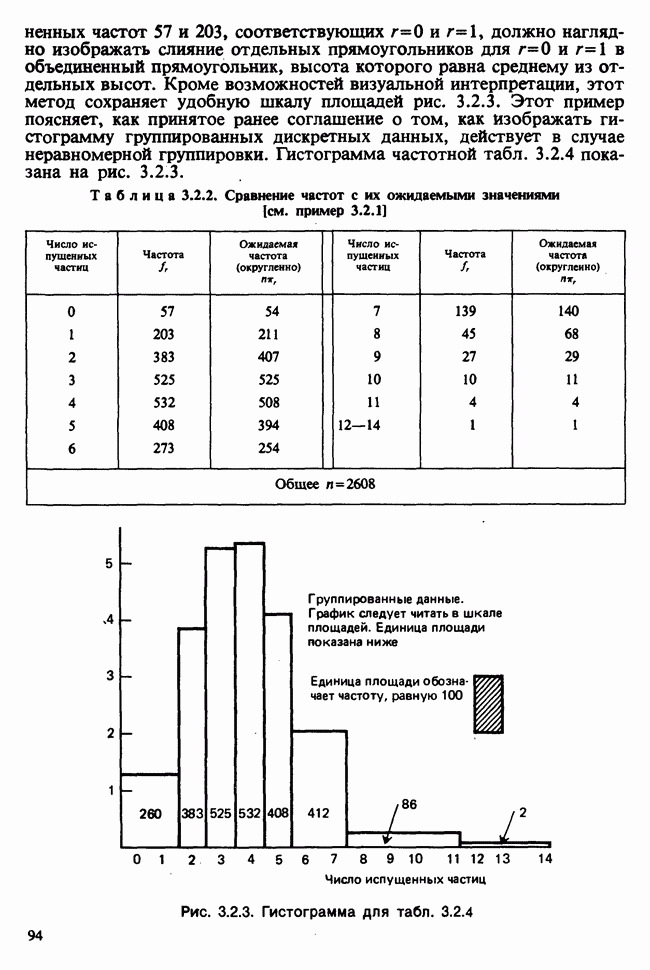

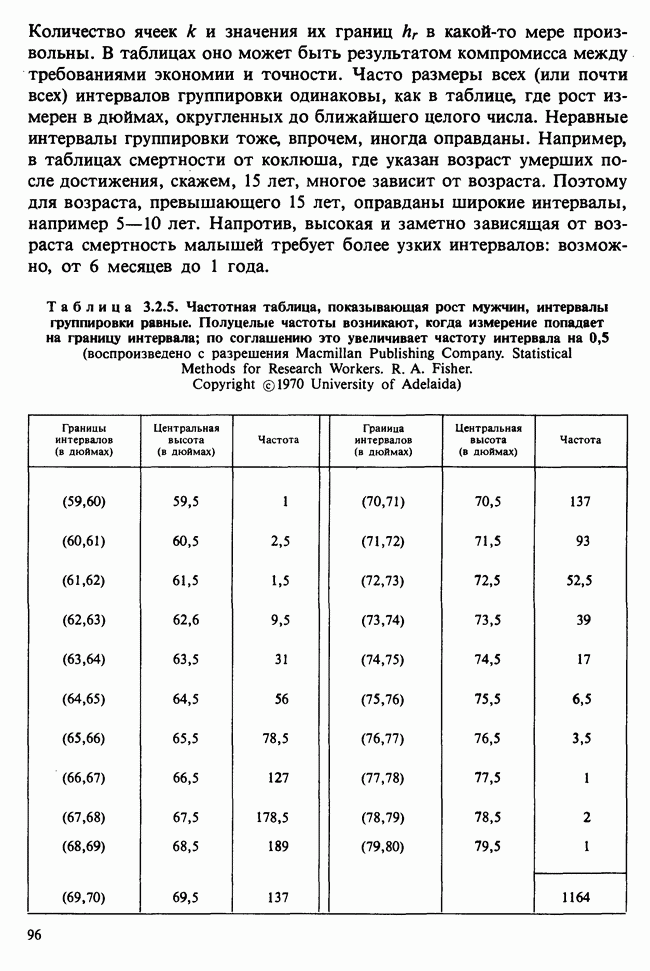
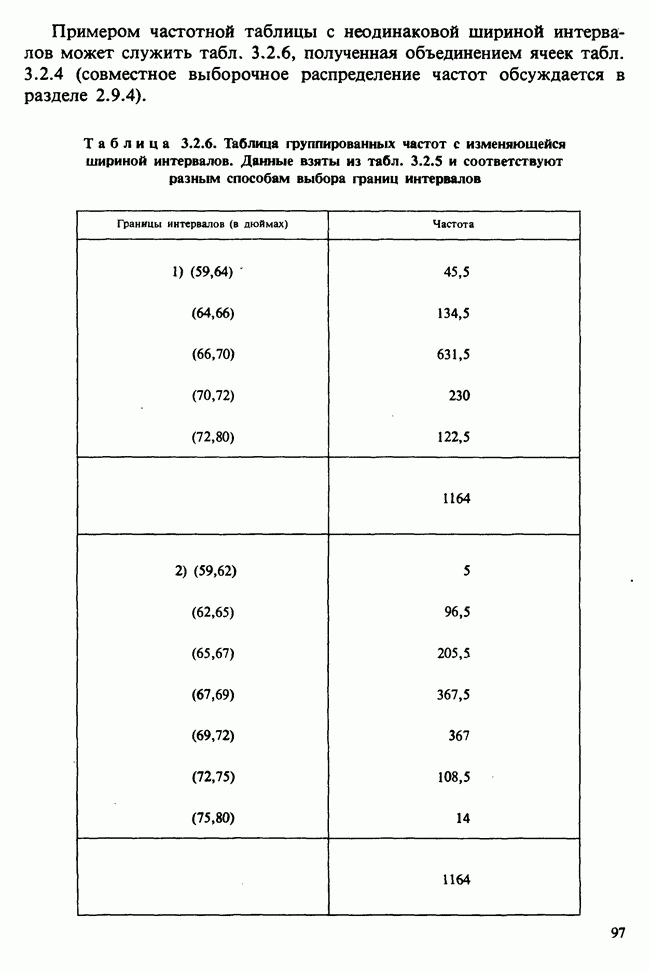
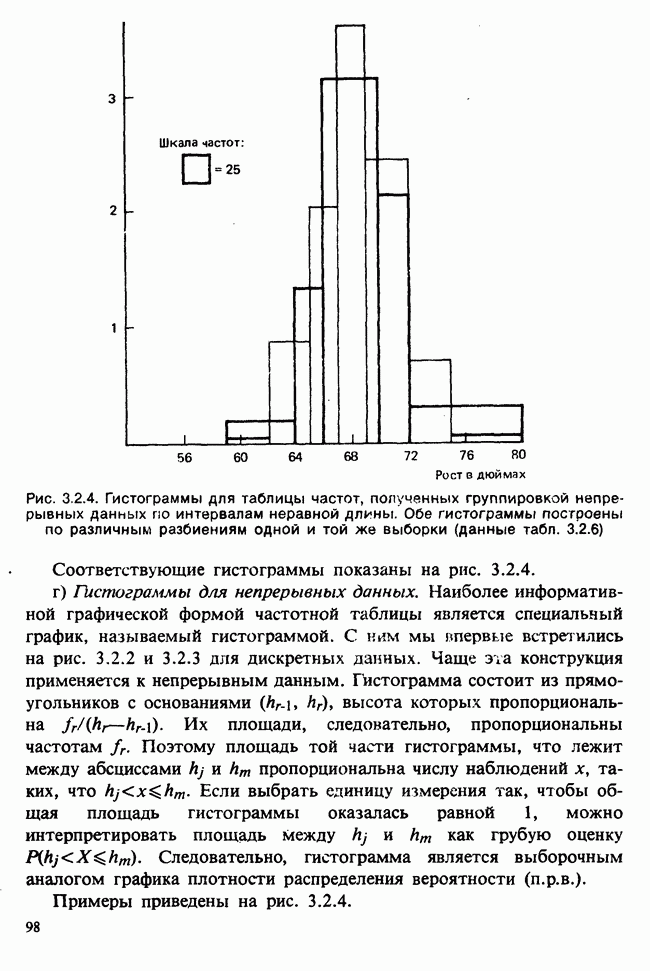































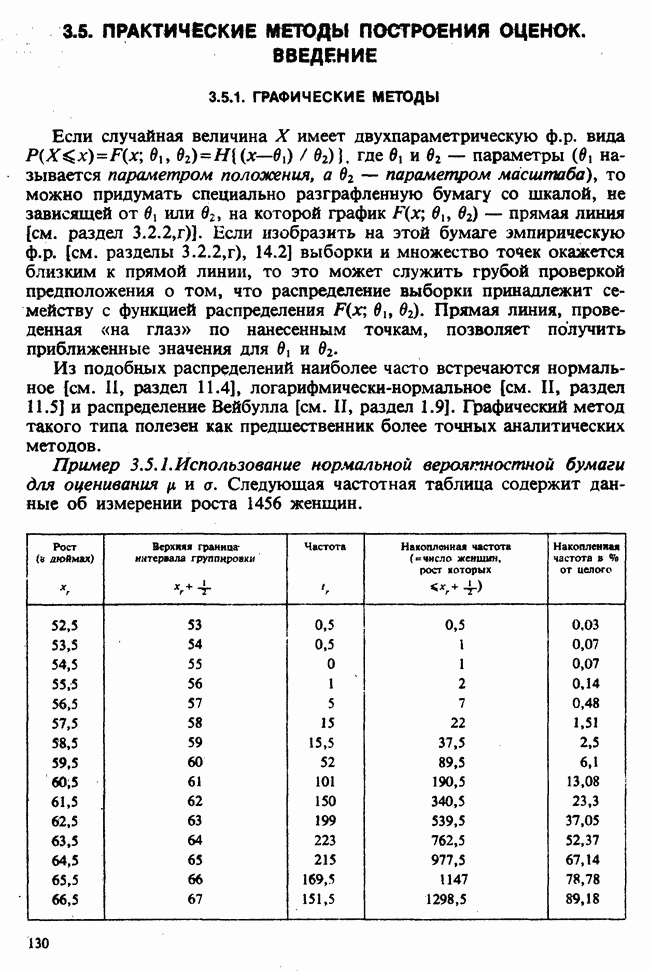
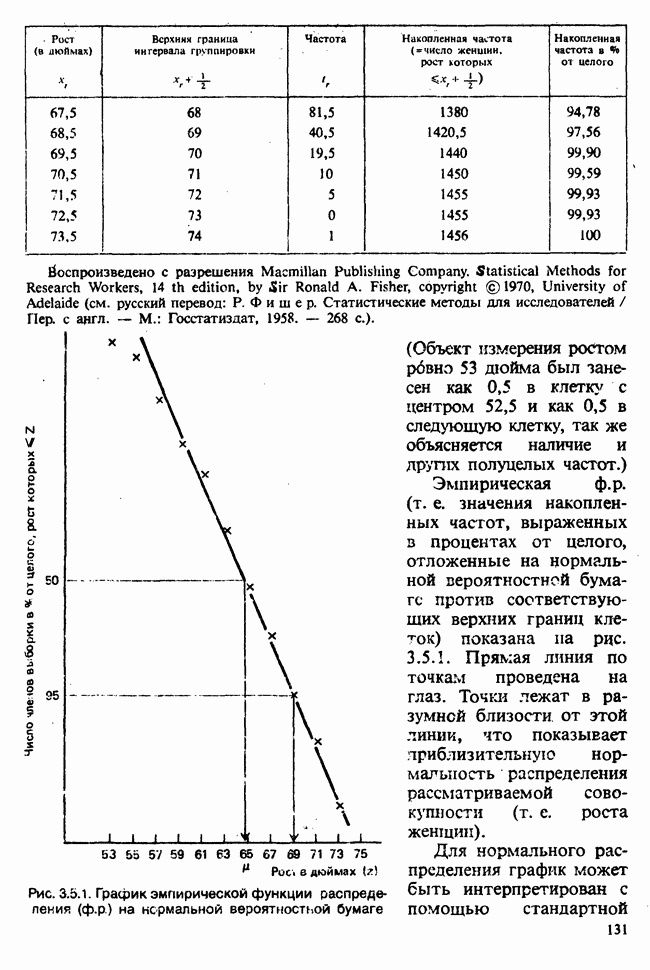





















































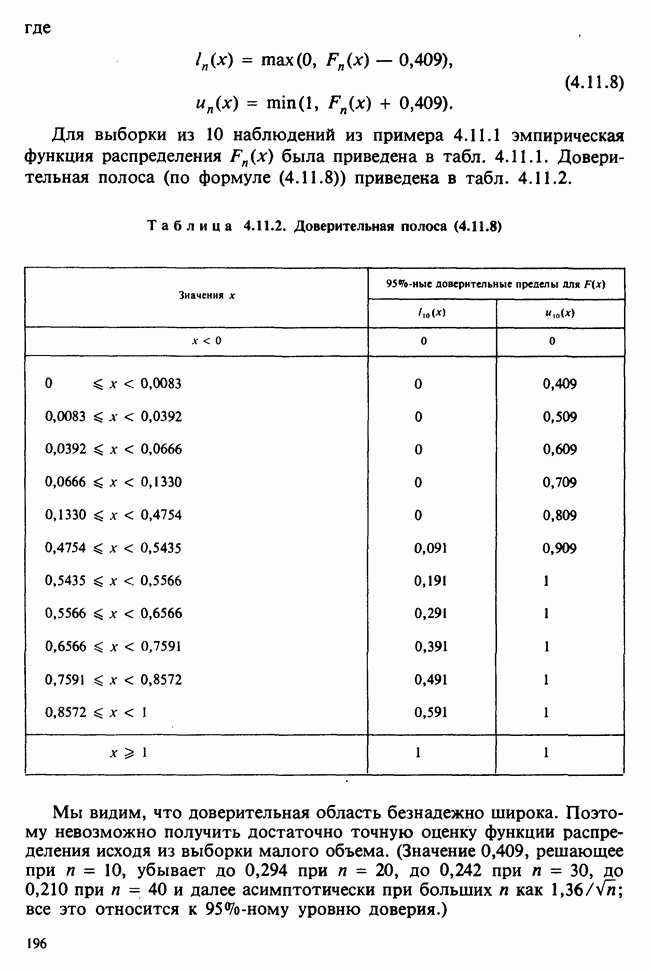









































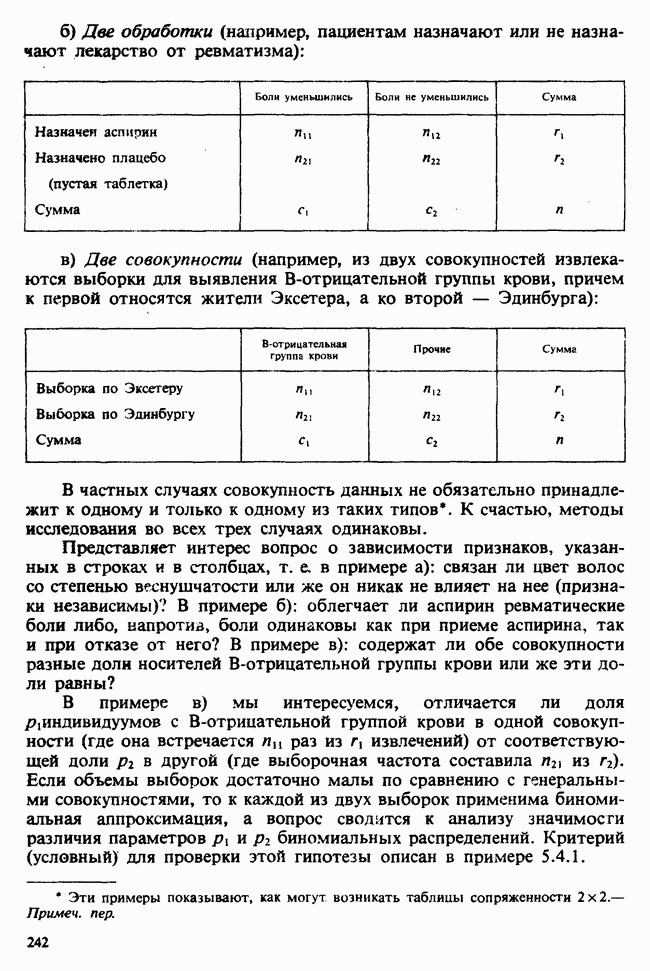
















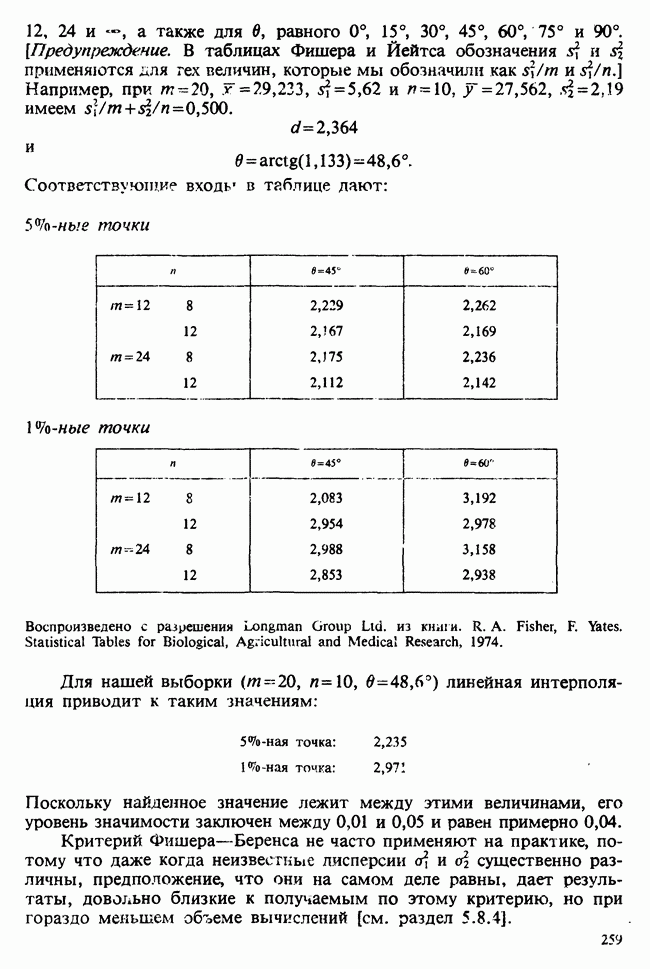












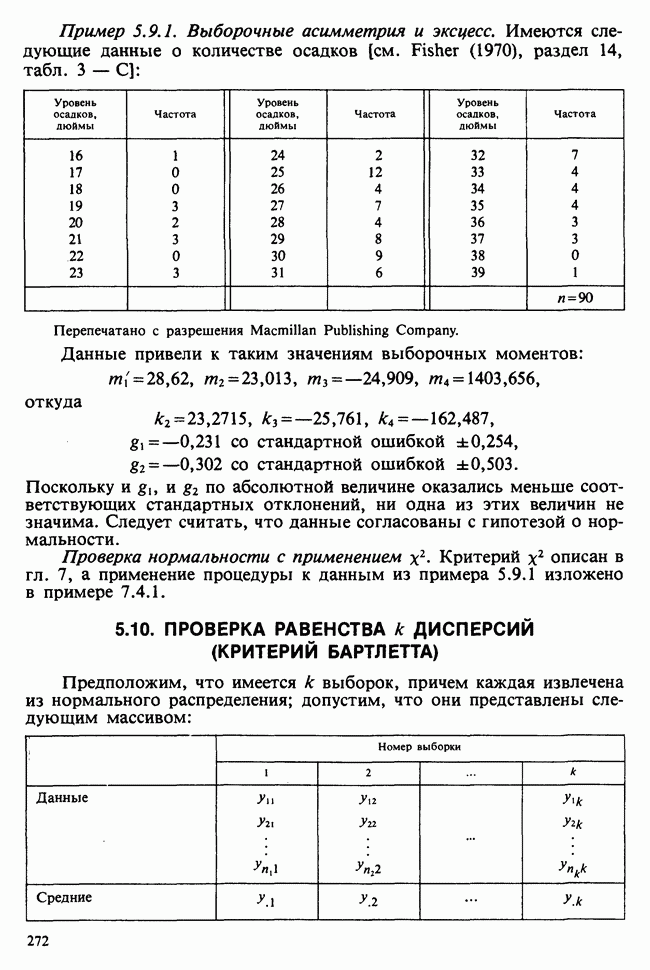


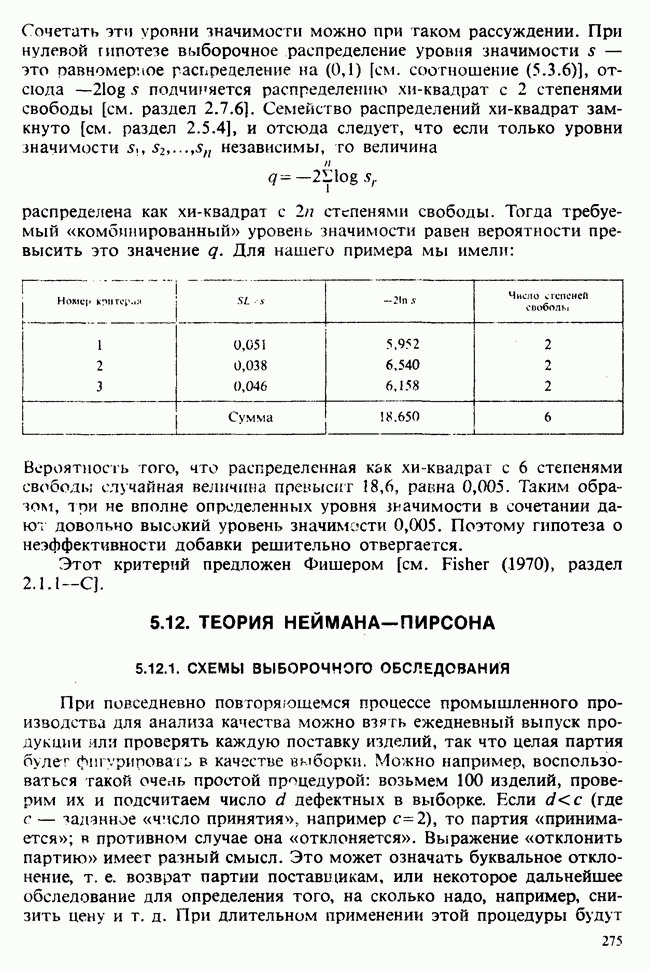














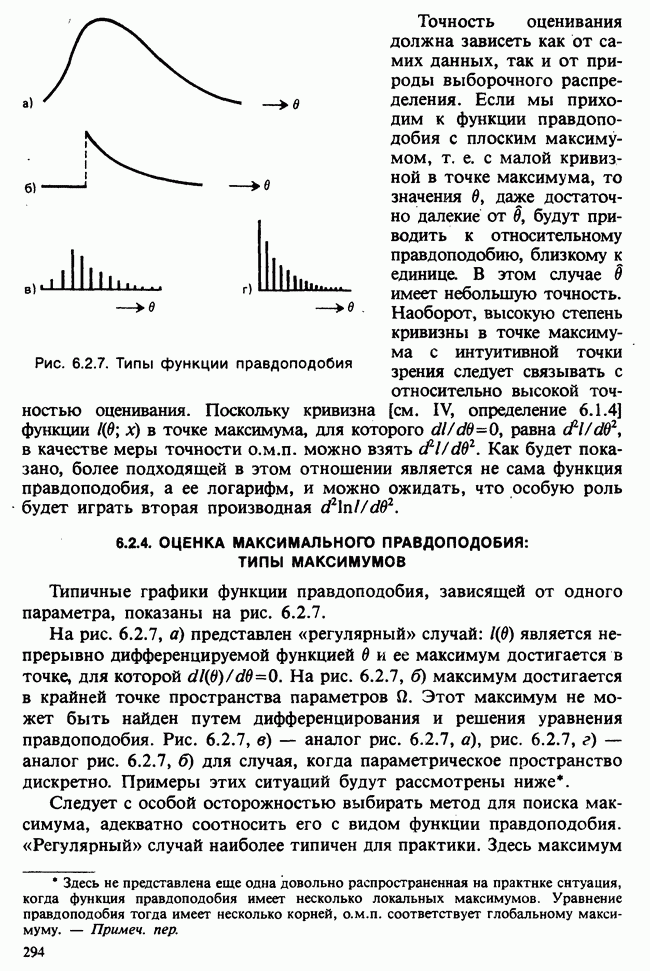
























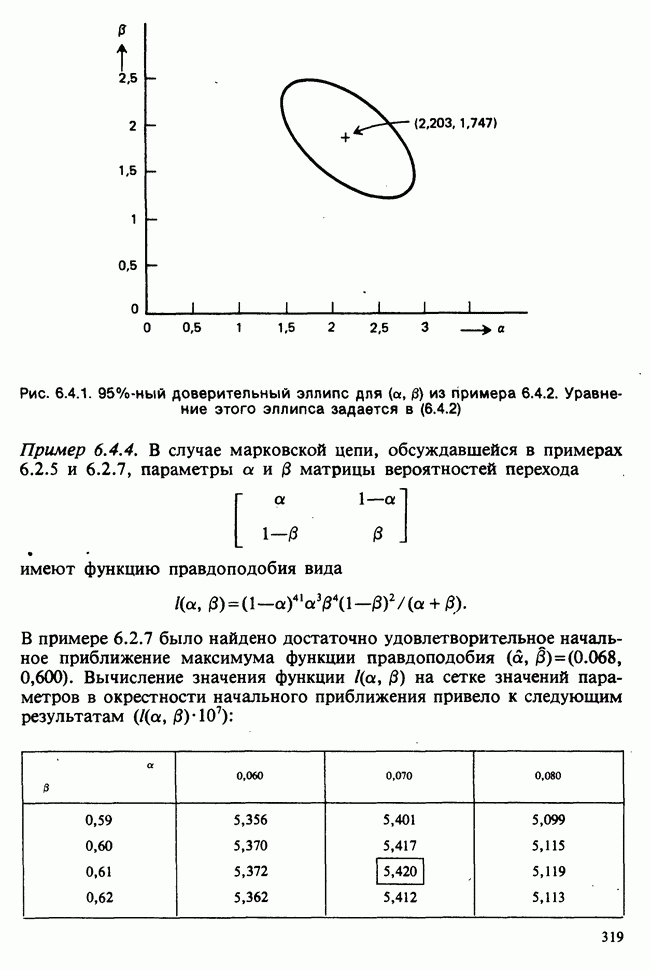



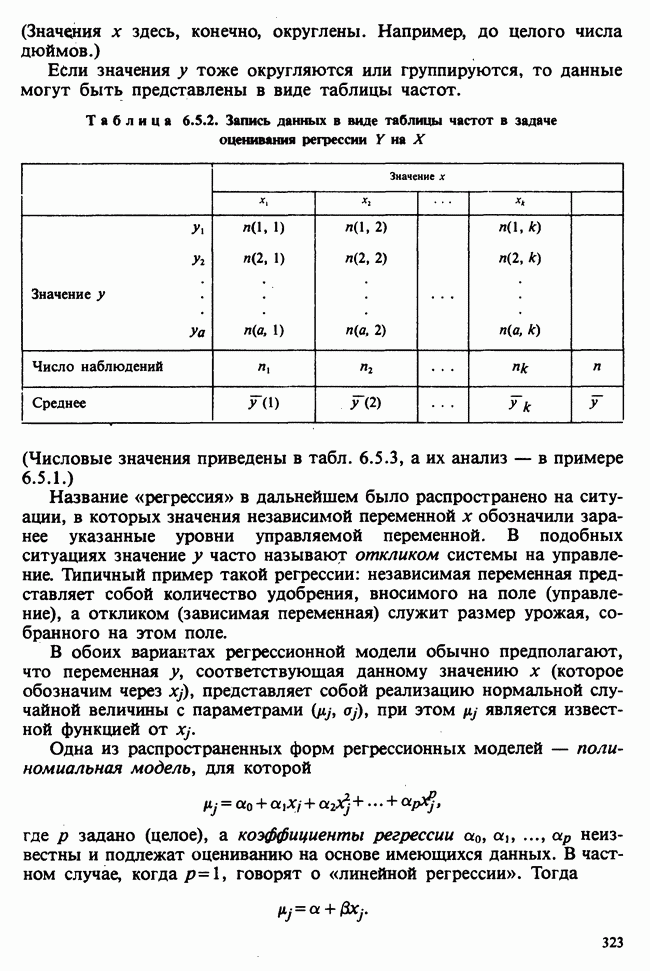





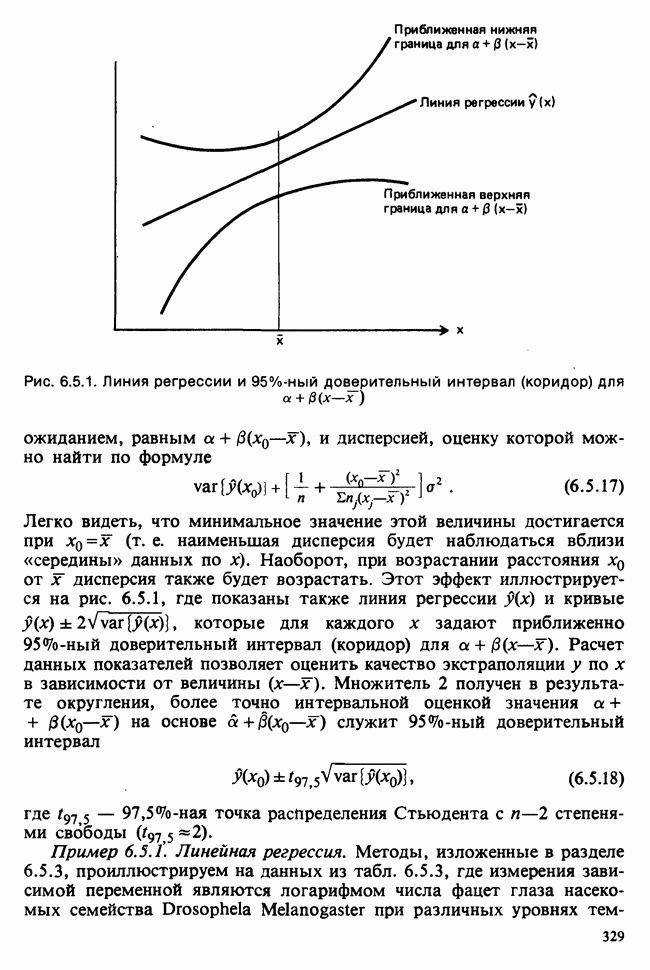
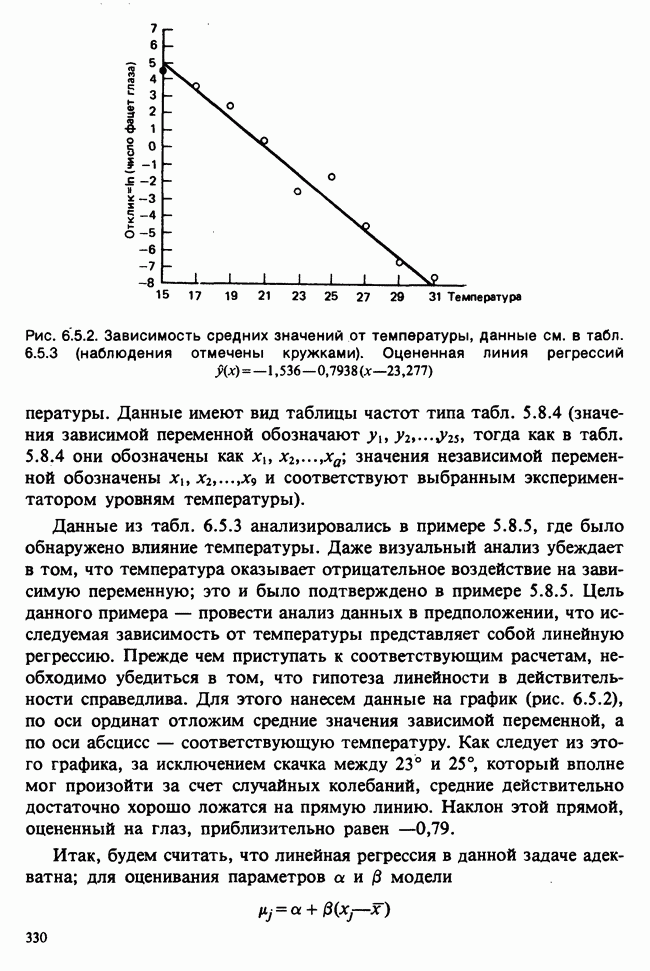
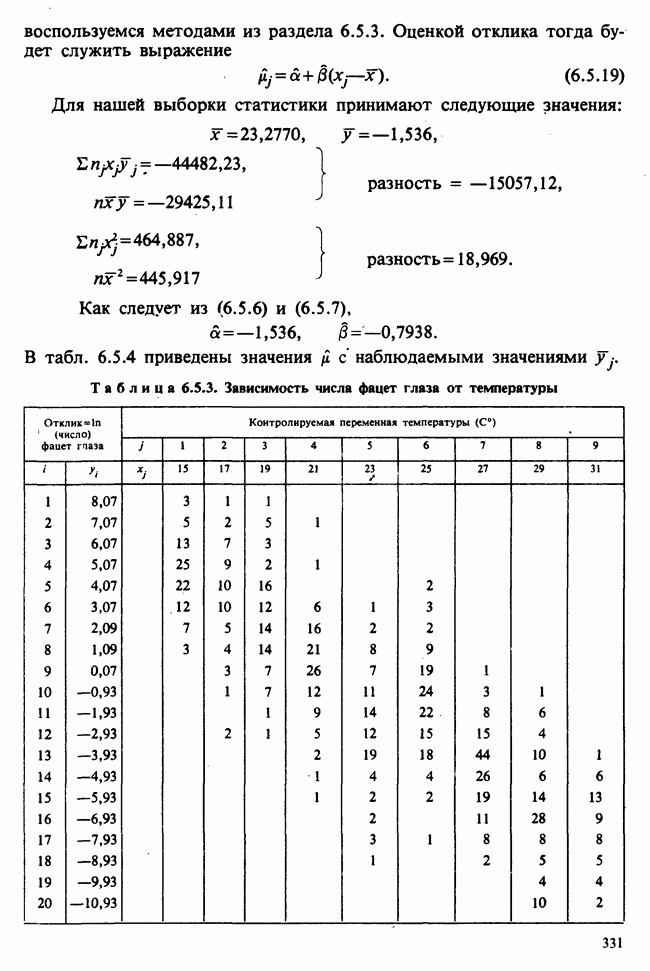
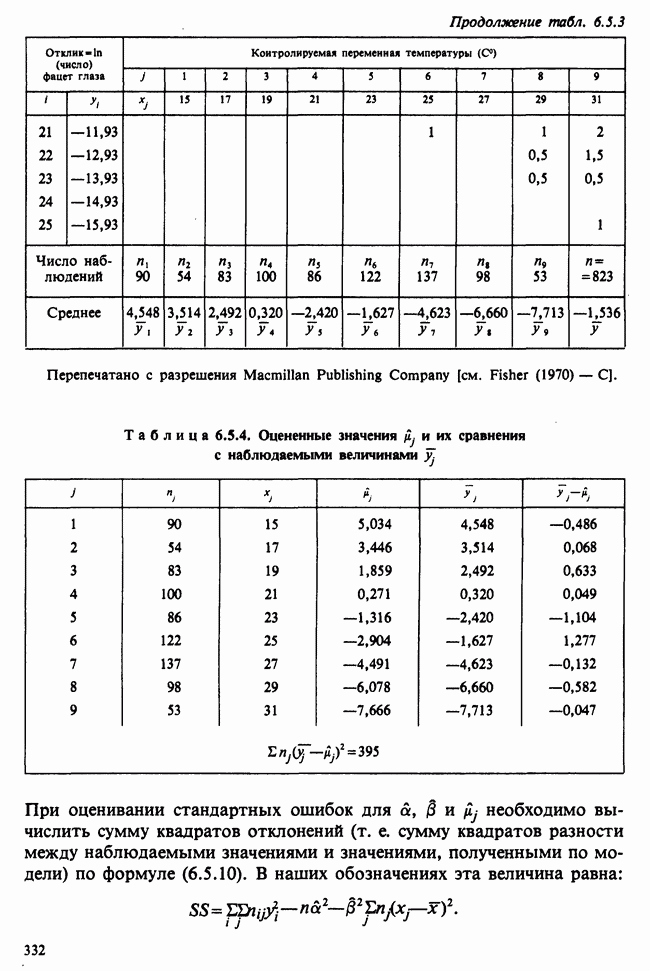



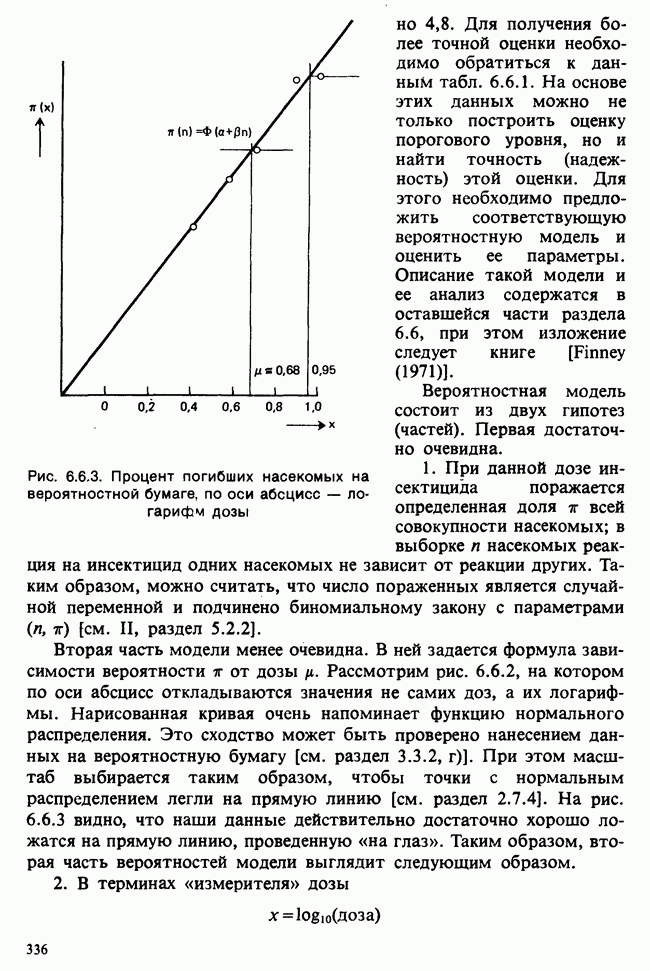


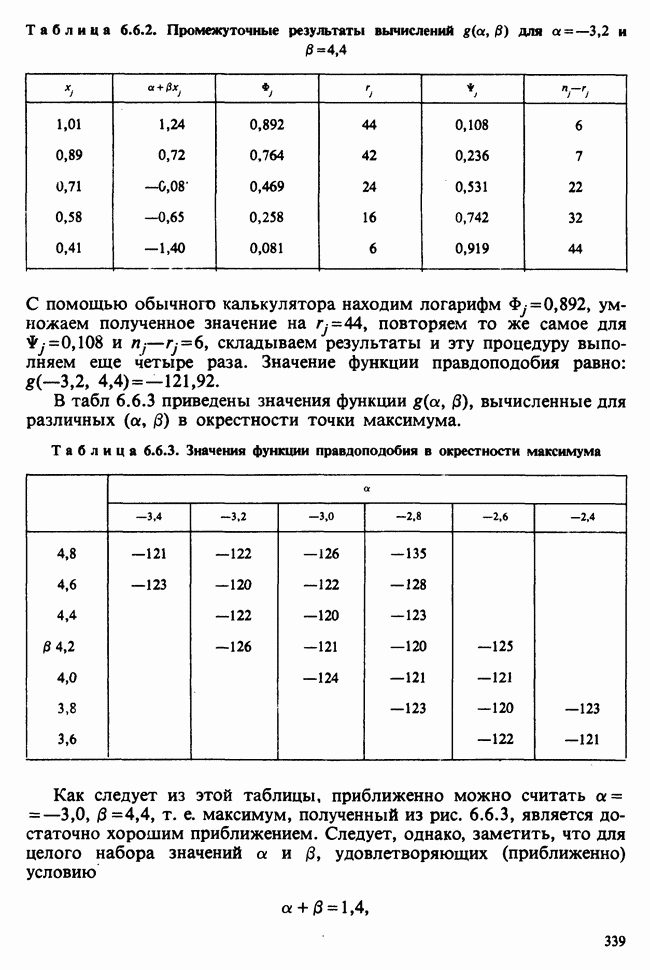


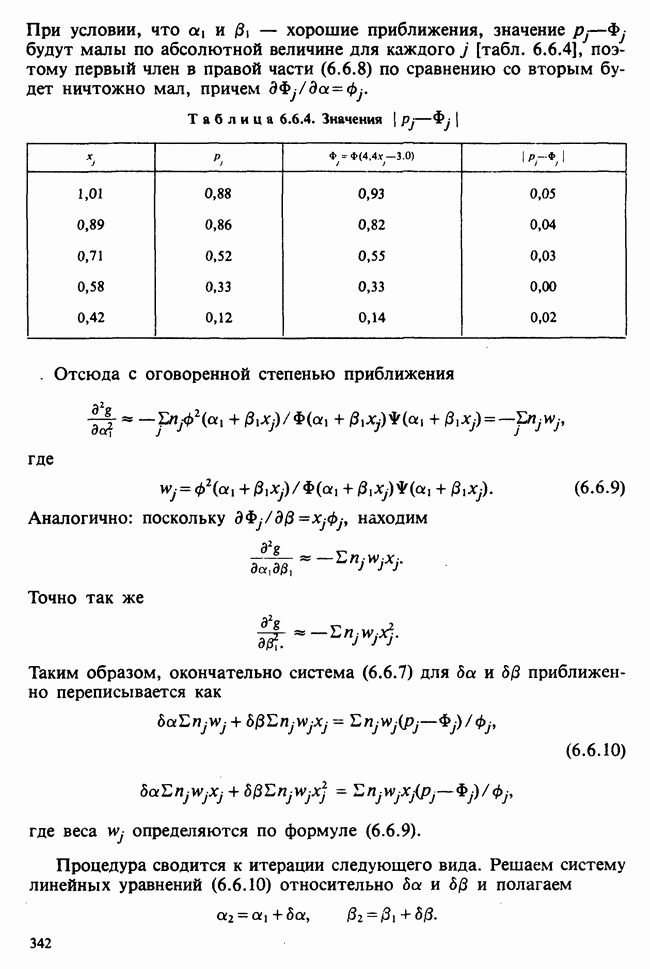

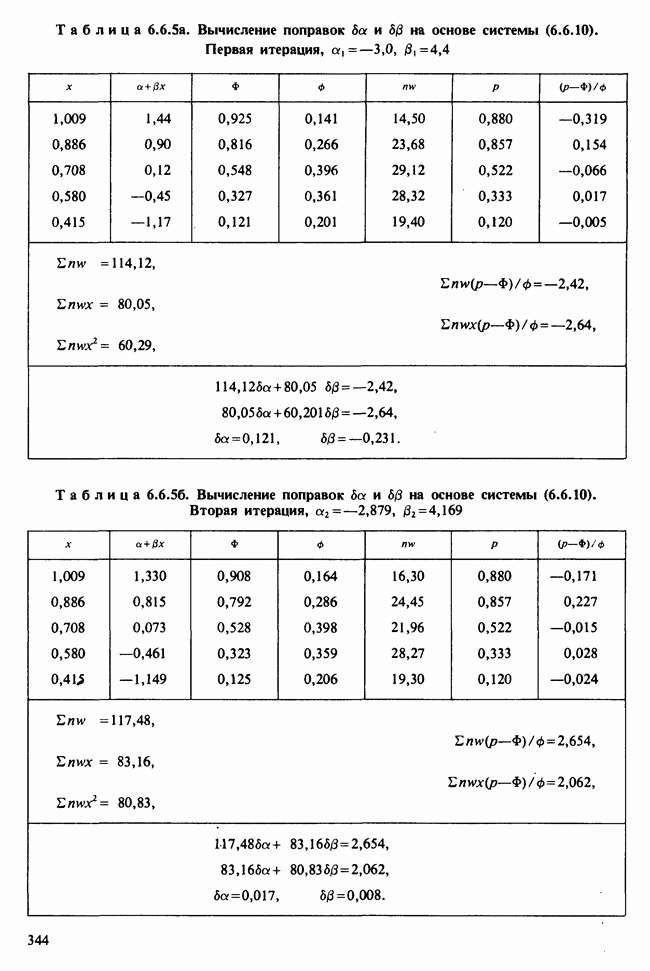

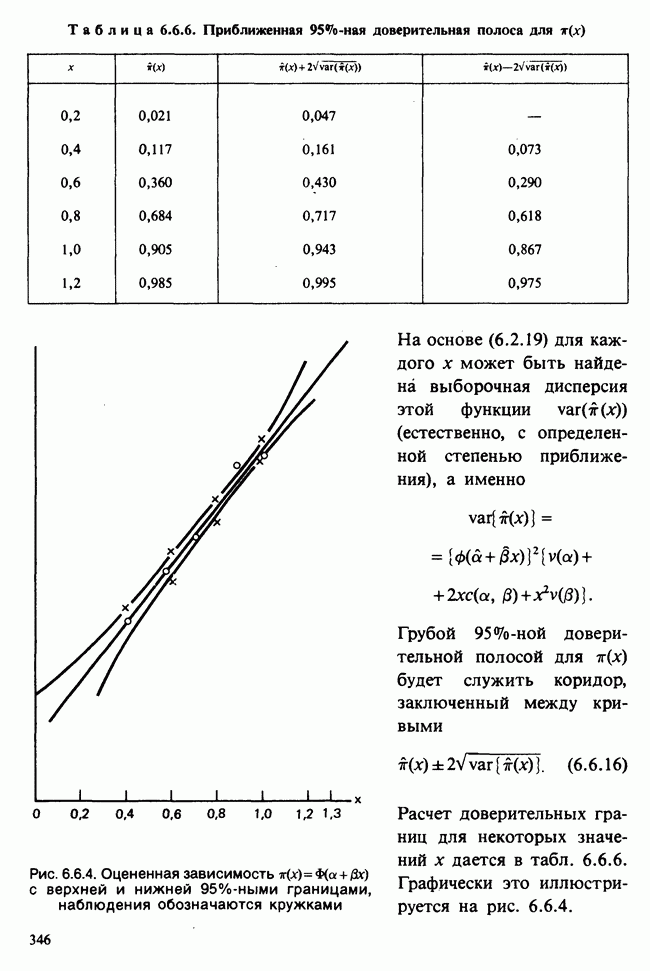









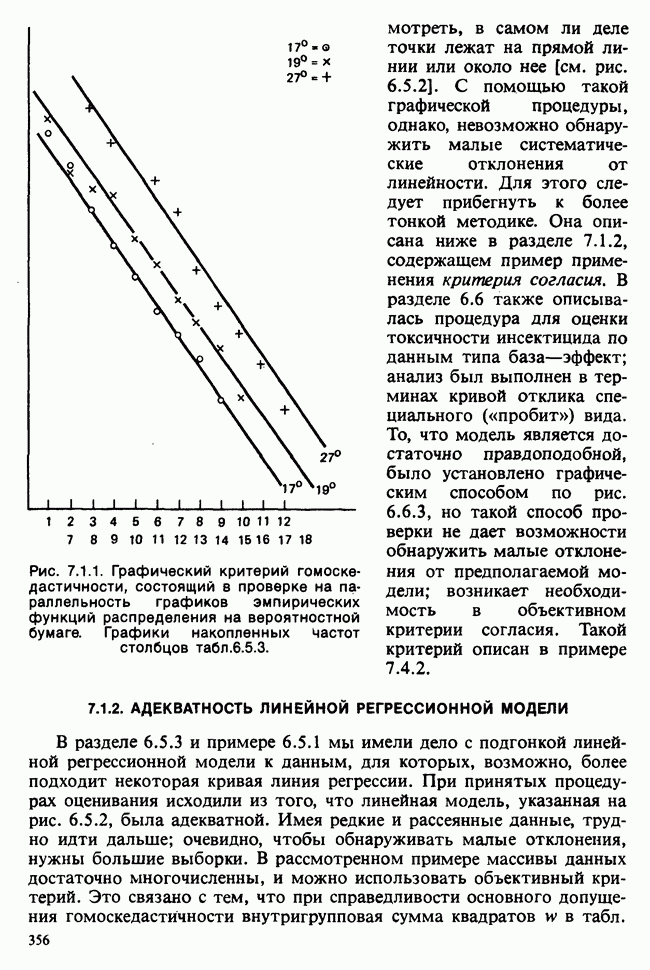
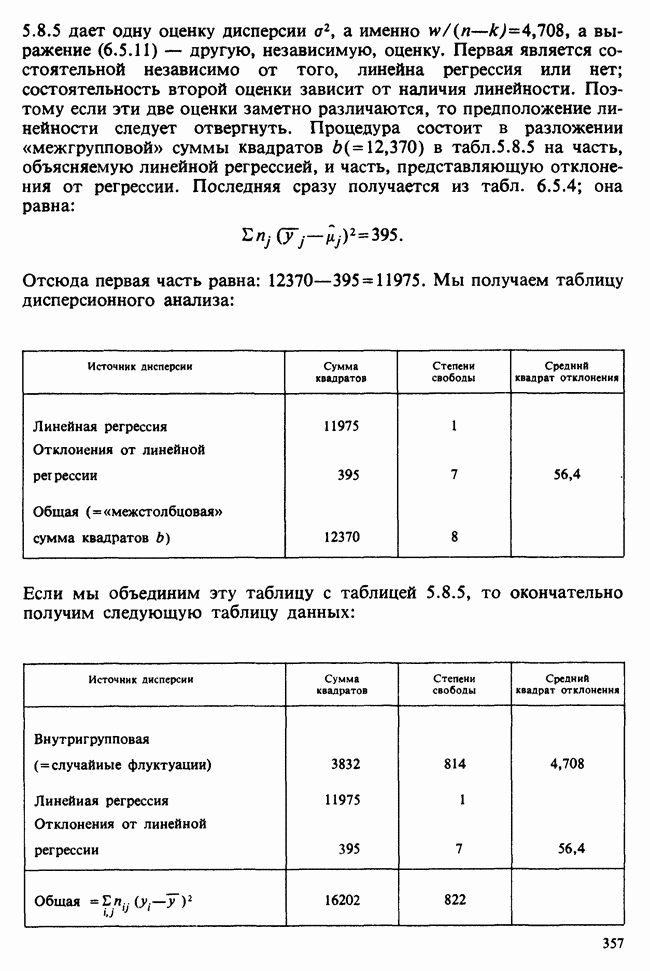

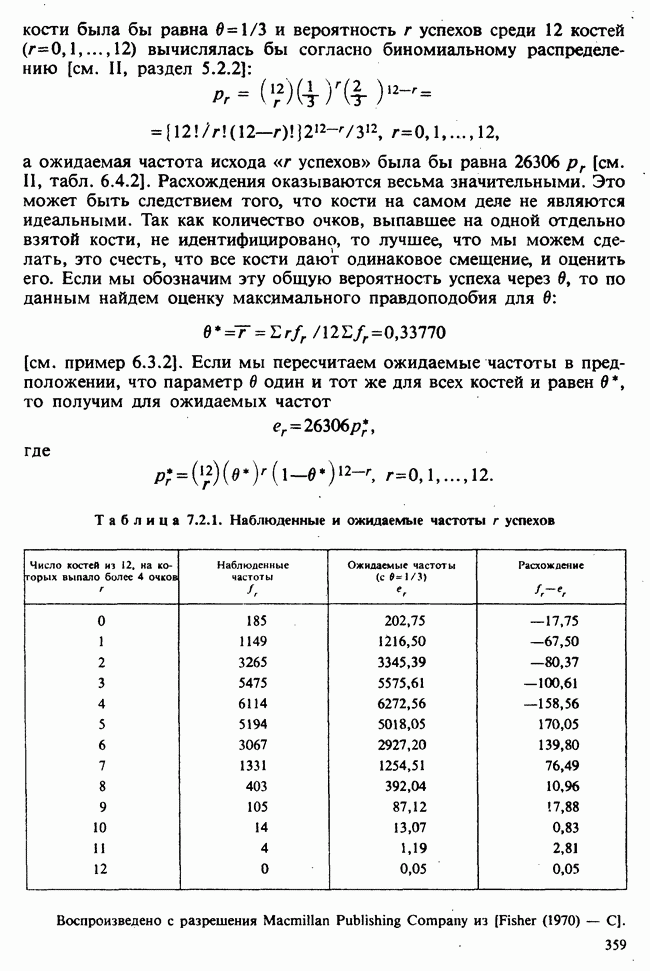
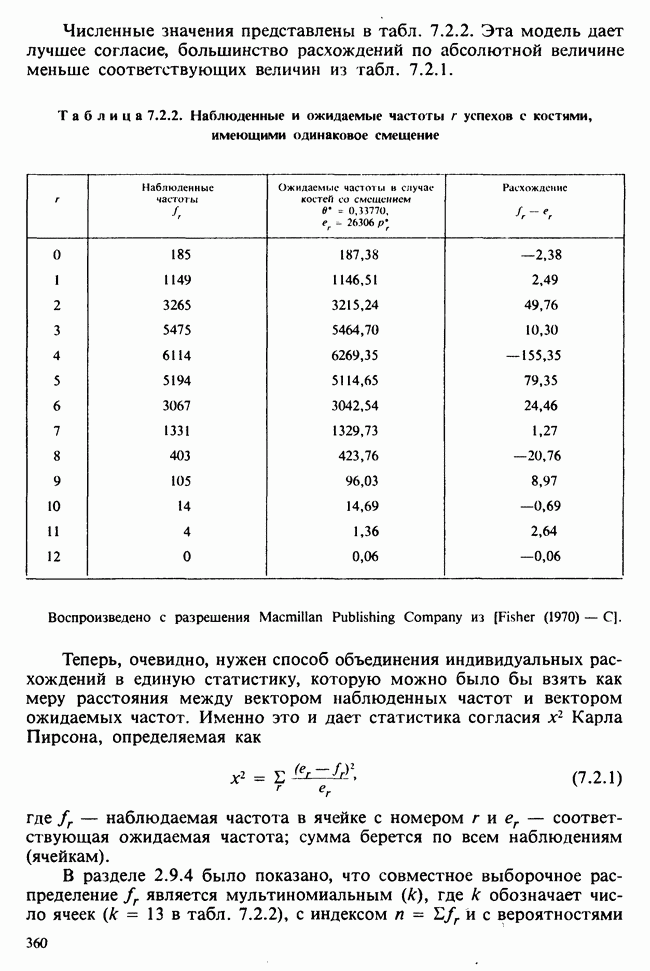









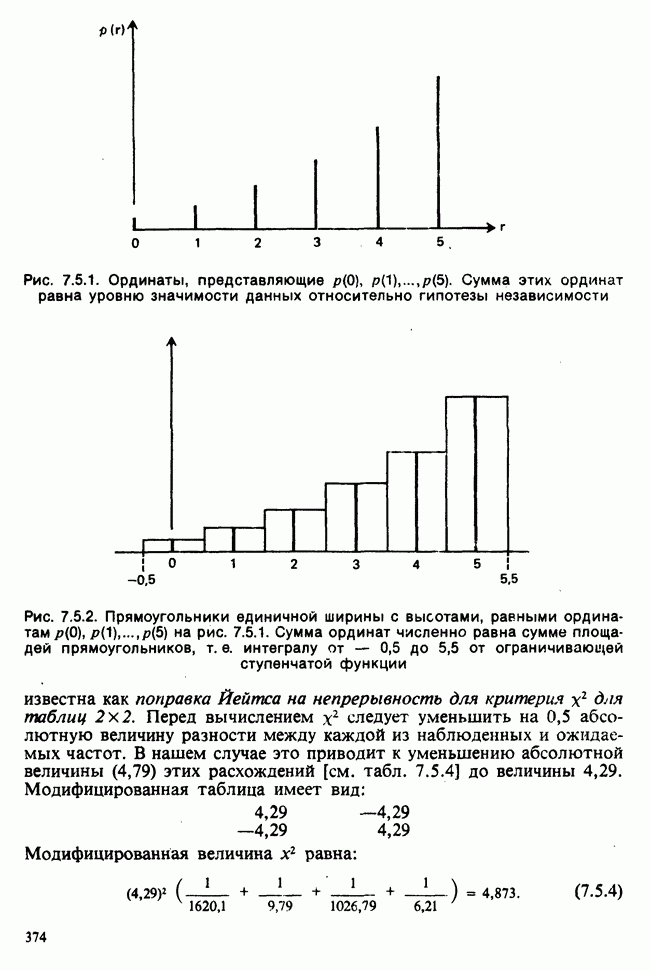


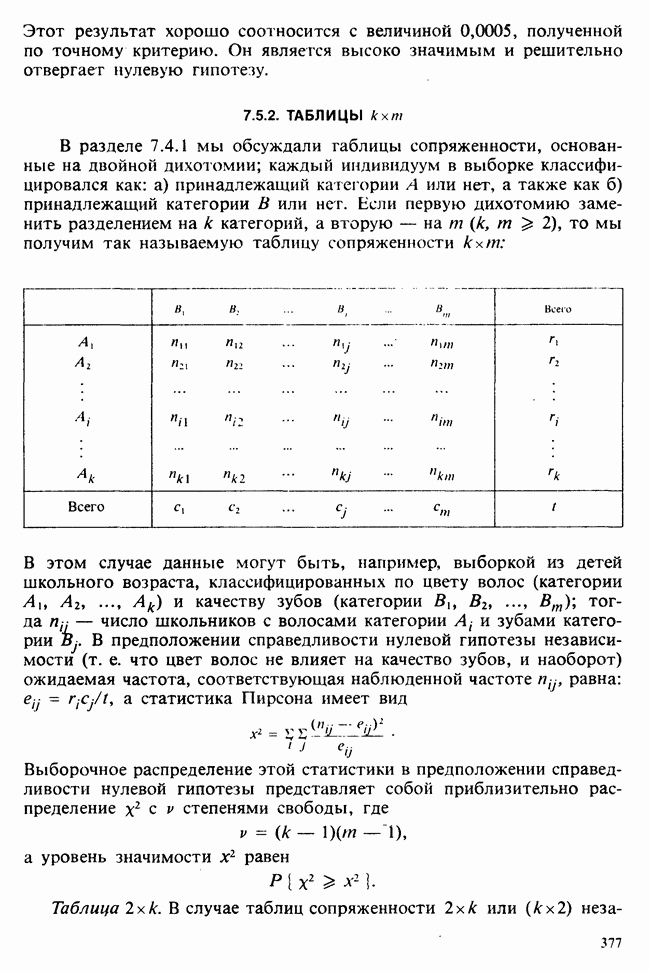













































































































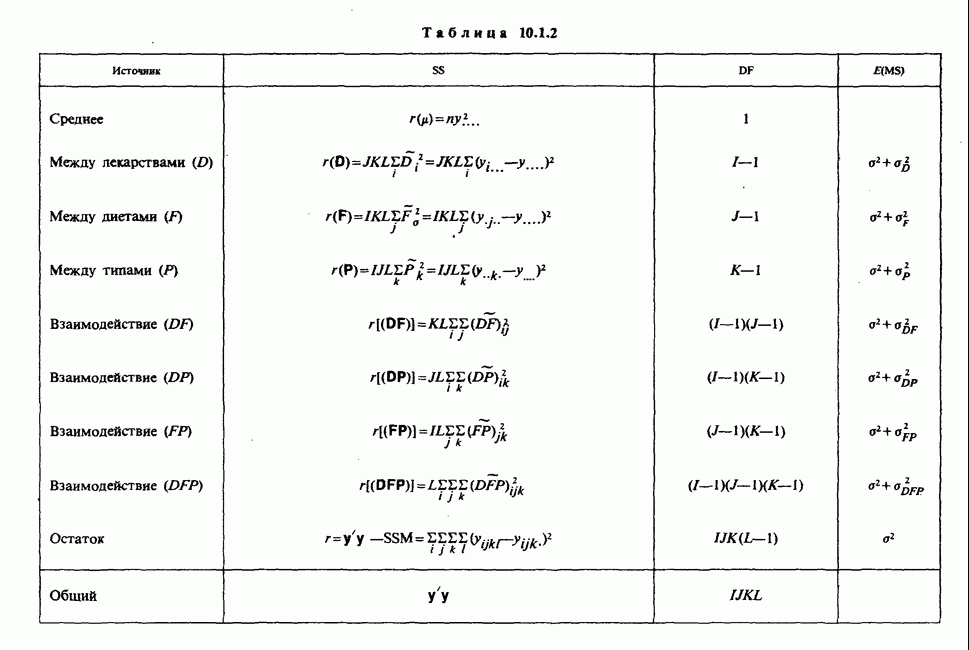








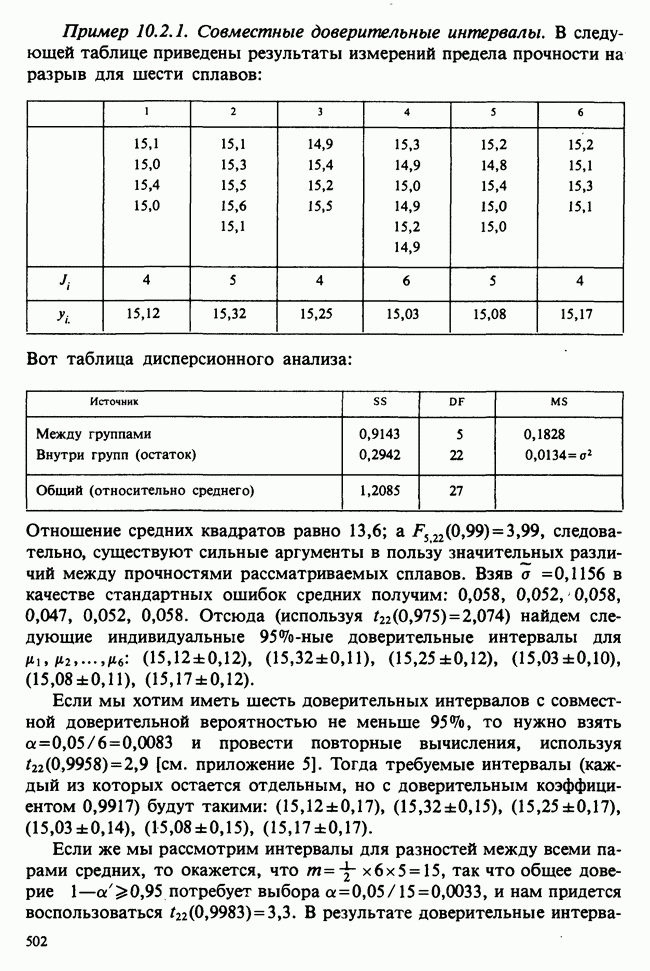





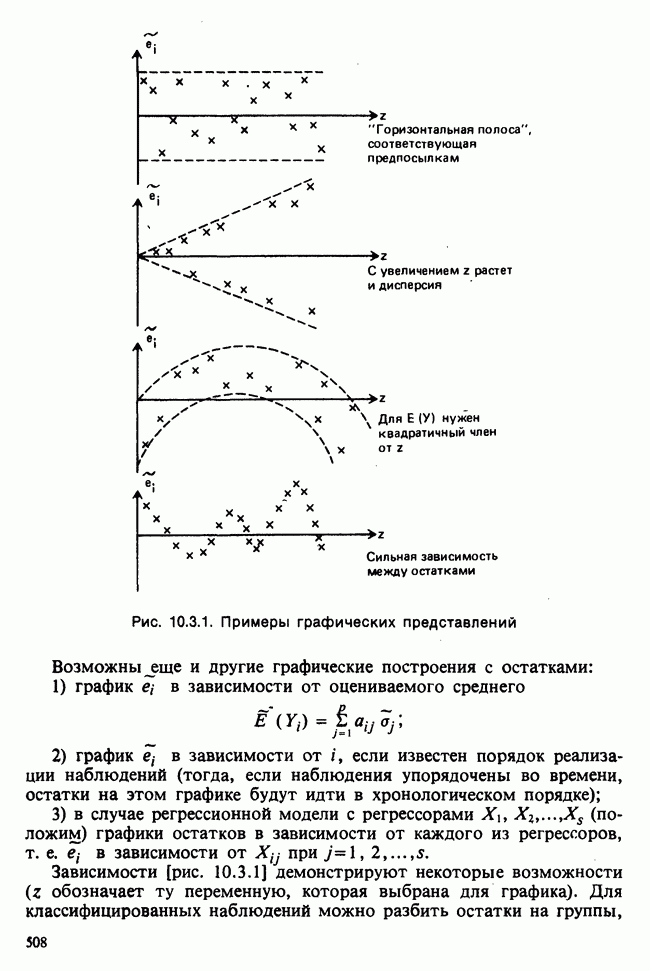

 веса некоторого образца. Какова же величина, скажем его действительного веса? Статистический подход постулирует, что различия между наблюдениями появляются из-за случайных флуктуаций условий эксперимента и наблюдения рассматриваются как реализации [см. II, раздел 4.1] набора случайных переменных
веса некоторого образца. Какова же величина, скажем его действительного веса? Статистический подход постулирует, что различия между наблюдениями появляются из-за случайных флуктуаций условий эксперимента и наблюдения рассматриваются как реализации [см. II, раздел 4.1] набора случайных переменных  Затем предлагается особое семейство вероятностных распределений, к которому принадлежат эти случайные переменные. С учетом наших знаний об экспериментальной процедуре может оказаться разумным остановиться, например, на нормальном семействе, т. е. счесть
Затем предлагается особое семейство вероятностных распределений, к которому принадлежат эти случайные переменные. С учетом наших знаний об экспериментальной процедуре может оказаться разумным остановиться, например, на нормальном семействе, т. е. счесть  независимыми случайными величинами с общим нормальным распределением. Никакой другой информации, кроме этих десяти наблюдений, принимать в расчет не следует. (Альтернативное мнение изложено в гл. 15, посвященной байесовским методам.) Тот конкретный член нормального семейства, который приложим к нашим данным, определяется параметрами
независимыми случайными величинами с общим нормальным распределением. Никакой другой информации, кроме этих десяти наблюдений, принимать в расчет не следует. (Альтернативное мнение изложено в гл. 15, посвященной байесовским методам.) Тот конкретный член нормального семейства, который приложим к нашим данным, определяется параметрами  с неизвестными значениями, которые мы должны оценить. В нашем примере мы отождествляем параметр
с неизвестными значениями, которые мы должны оценить. В нашем примере мы отождествляем параметр  с неизвестной «действительной величиной» веса; параметр а — это мера изменчивости в наблюдениях, порожденной измерительной техникой [см. II, раздел 11.4.3]. Следующим шагом будет нахождение комбинаций наблюдений
с неизвестной «действительной величиной» веса; параметр а — это мера изменчивости в наблюдениях, порожденной измерительной техникой [см. II, раздел 11.4.3]. Следующим шагом будет нахождение комбинаций наблюдений  которую мы будем использовать как статистику [см. раздел 2.1], чье численное значение дает приближенное значение для
которую мы будем использовать как статистику [см. раздел 2.1], чье численное значение дает приближенное значение для  и другой статистики, служащей тем же целям для а. Эти численные значения позволяют получить оценки для
и другой статистики, служащей тем же целям для а. Эти численные значения позволяют получить оценки для  и а.
и а.


 мы будем также применять обозначения вроде в или
мы будем также применять обозначения вроде в или 

 есть
есть

 — это статистика [см. определение 2.1.1], скажем
— это статистика [см. определение 2.1.1], скажем  численное значение которой может быть использовано как приближение к неизвестной величине 0. Выборочное распределение
численное значение которой может быть использовано как приближение к неизвестной величине 0. Выборочное распределение  — это распределение случайной величины
— это распределение случайной величины  где
где  — случайные величины, индуцированные
— случайные величины, индуцированные  [см. определение 2.2.1]. Случайная величина Т — это оцениватель, соответствующий оценке в. Какая-либо подходящая оценка стандартного отклонения Т называется стандартной ошибкой в [см. раздел 4.1.2].
[см. определение 2.2.1]. Случайная величина Т — это оцениватель, соответствующий оценке в. Какая-либо подходящая оценка стандартного отклонения Т называется стандартной ошибкой в [см. раздел 4.1.2].
 , оцениваемых статистиками
, оцениваемых статистиками  и
и  соответственно. Порождаемые ими случайные величины — это
соответственно. Порождаемые ими случайные величины — это  для выборки объема
для выборки объема  и
и

 взаимно независимы [см. раздел 2.5.4, в)]; X распределена нормально с математическим ожиданием
взаимно независимы [см. раздел 2.5.4, в)]; X распределена нормально с математическим ожиданием  и дисперсией
и дисперсией  Распределение
Распределение  легче всего описать, сказав, что величина
легче всего описать, сказав, что величина  распределена по закону хи-квадрат [см. раздел 2.5.4, а)] с 9 степенями свободы.
распределена по закону хи-квадрат [см. раздел 2.5.4, а)] с 9 степенями свободы.
 этот вопрос можно ответить так: маловероятно, что реализация X сильно отличается от
этот вопрос можно ответить так: маловероятно, что реализация X сильно отличается от  для любого фиксированного положительного А и для любого фиксированного X вероятность того, что X лежит в интервале
для любого фиксированного положительного А и для любого фиксированного X вероятность того, что X лежит в интервале  максимальна, если
максимальна, если 
 Мы не хотим этим сказать, что лучшей оценки не может существовать: если, например,
Мы не хотим этим сказать, что лучшей оценки не может существовать: если, например,  такая статистика, что индуцированная переменная
такая статистика, что индуцированная переменная  с большей вероятностью лежит в интервапе
с большей вероятностью лежит в интервапе  , чем X, то мы можем считать, что
, чем X, то мы можем считать, что  лучше, чем X, оценивает
лучше, чем X, оценивает  Если бы неравенство
Если бы неравенство

 и А, то
и А, то  была бы равномерно лучше, чем X, в соответствии с этим критерием.
была бы равномерно лучше, чем X, в соответствии с этим критерием.

 . К сожалению, оценок с таким свойством, как правило, не существует; приходится руководствоваться более скромными соображениями [см. раздел 3.3].
. К сожалению, оценок с таким свойством, как правило, не существует; приходится руководствоваться более скромными соображениями [см. раздел 3.3].
 объема
объема  воспользуемся хорошо известным фактом, что с вероятностью 0,95 реализация х случайной переменной X окажется в интервале
воспользуемся хорошо известным фактом, что с вероятностью 0,95 реализация х случайной переменной X окажется в интервале  [см. приложение 3 и 4].
[см. приложение 3 и 4].
 ее оценкой
ее оценкой  (стандартной ошибкой
(стандартной ошибкой  перефразируем сказанное выше: с высокой вероятностью значение х будет отстоять от
перефразируем сказанное выше: с высокой вероятностью значение х будет отстоять от  не более чем на
не более чем на  потому неизвестное
потому неизвестное  будет лежать на расстоянии, не превышающем
будет лежать на расстоянии, не превышающем  от значения X.
от значения X.
 не меньше
не меньше  и не больше
и не больше  . В других случаях первичная информация может быть более содержательной. Как происходит прирост этой априорной информации? Предлагается мыслить неизвестное
. В других случаях первичная информация может быть более содержательной. Как происходит прирост этой априорной информации? Предлагается мыслить неизвестное  как реализацию некоторой случайной переменной, имеющей какое-то априорное распределение. В свете же имеющихся
как реализацию некоторой случайной переменной, имеющей какое-то априорное распределение. В свете же имеющихся
 при фиксированных значениях наблюдений.
при фиксированных значениях наблюдений.
 . С его помощью, используя значение х, можно строить вероятностные интервалы любого уровня для неизвестного
. С его помощью, используя значение х, можно строить вероятностные интервалы любого уровня для неизвестного  (например, 0,95). Такие выводы — это как раз то, что хотелось бы получить. Есть конечно, определенная степень произвола в выборе априорного распределения. Более серьезная же трудность состоит в том, что для многих статистиков концепция априорного распределения в таких условиях неприемлема. Некоторые из них будут возражать не только против априорного распределения, как не имеющего объективного характера; они скажут, что с неизвестной величиной
(например, 0,95). Такие выводы — это как раз то, что хотелось бы получить. Есть конечно, определенная степень произвола в выборе априорного распределения. Более серьезная же трудность состоит в том, что для многих статистиков концепция априорного распределения в таких условиях неприемлема. Некоторые из них будут возражать не только против априорного распределения, как не имеющего объективного характера; они скажут, что с неизвестной величиной  являющейся константой, нельзя обращаться как со случайной переменной. И все же эти доводы не окончательны. В терминах нашего примера: если а будет, скажем, равной 10 г, а х равным 125 г, то постулированное значение 200 г для
являющейся константой, нельзя обращаться как со случайной переменной. И все же эти доводы не окончательны. В терминах нашего примера: если а будет, скажем, равной 10 г, а х равным 125 г, то постулированное значение 200 г для  надо рассматривать как неправдоподобное в том смысле, что неправдоподобно получить как реализацию значение 125 из нормального распределения
надо рассматривать как неправдоподобное в том смысле, что неправдоподобно получить как реализацию значение 125 из нормального распределения  . Даже Р. Фишер, убежденный противник байесовского подхода, принял подобную точку зрения и развил фидуциальный подход, определенным образом приписывающий вероятность возможным значениям
. Даже Р. Фишер, убежденный противник байесовского подхода, принял подобную точку зрения и развил фидуциальный подход, определенным образом приписывающий вероятность возможным значениям  не привлекая идеи априорного распределения. Несмотря на редкостные аналитические способности Р. Фишера и его глубочайшую статистическую интуицию, теория фидуциального вывода так и не была представлена научному статистическому сообществу в достаточно убедительной форме. Она так и не стала частью принятого канона [см. Kendall and Stuart (1973), т. 2, гл. 21; Barnett (1982) — С].
не привлекая идеи априорного распределения. Несмотря на редкостные аналитические способности Р. Фишера и его глубочайшую статистическую интуицию, теория фидуциального вывода так и не была представлена научному статистическому сообществу в достаточно убедительной форме. Она так и не стала частью принятого канона [см. Kendall and Stuart (1973), т. 2, гл. 21; Barnett (1982) — С].
 остается ограничиться стандартной техникой обращения с вероятностными утверждениями относительно х, которые дают возможность для косвенных вероятностных утверждений о
остается ограничиться стандартной техникой обращения с вероятностными утверждениями относительно х, которые дают возможность для косвенных вероятностных утверждений о  а именно:
а именно:
 степени относительной приемлемости, которая пропорциональна их правдоподобию. Эти концепции обсуждаются более детально в гл. 4. Соответствующая литература указана в разделе 3.6.
степени относительной приемлемости, которая пропорциональна их правдоподобию. Эти концепции обсуждаются более детально в гл. 4. Соответствующая литература указана в разделе 3.6.