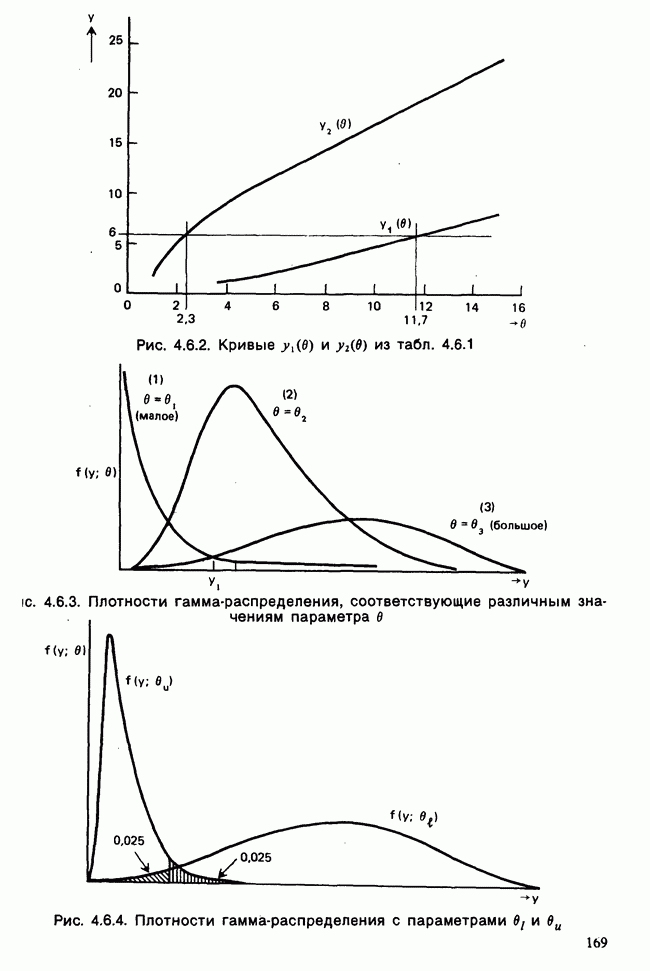
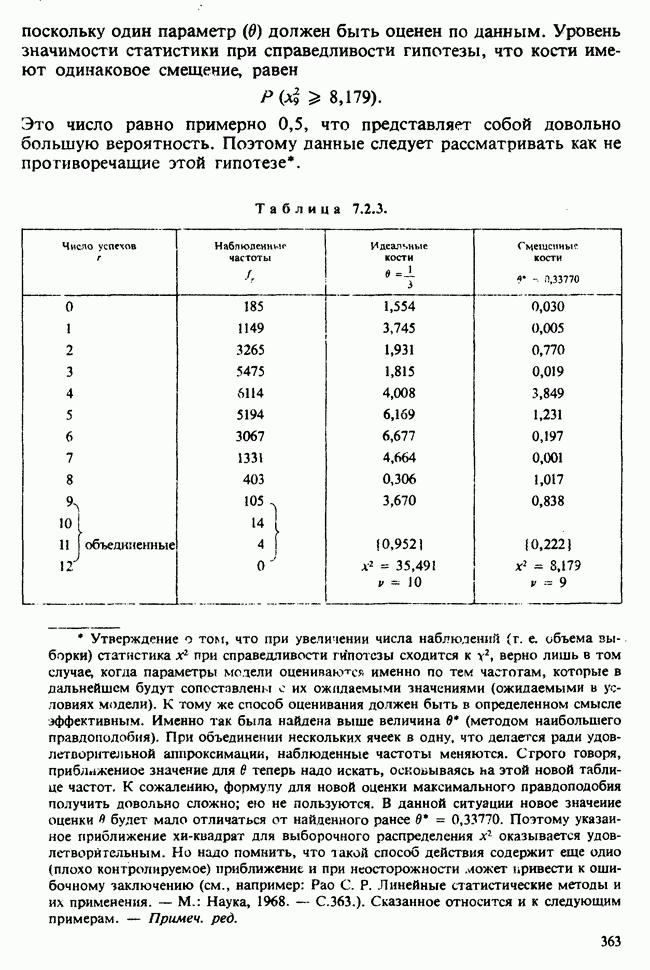
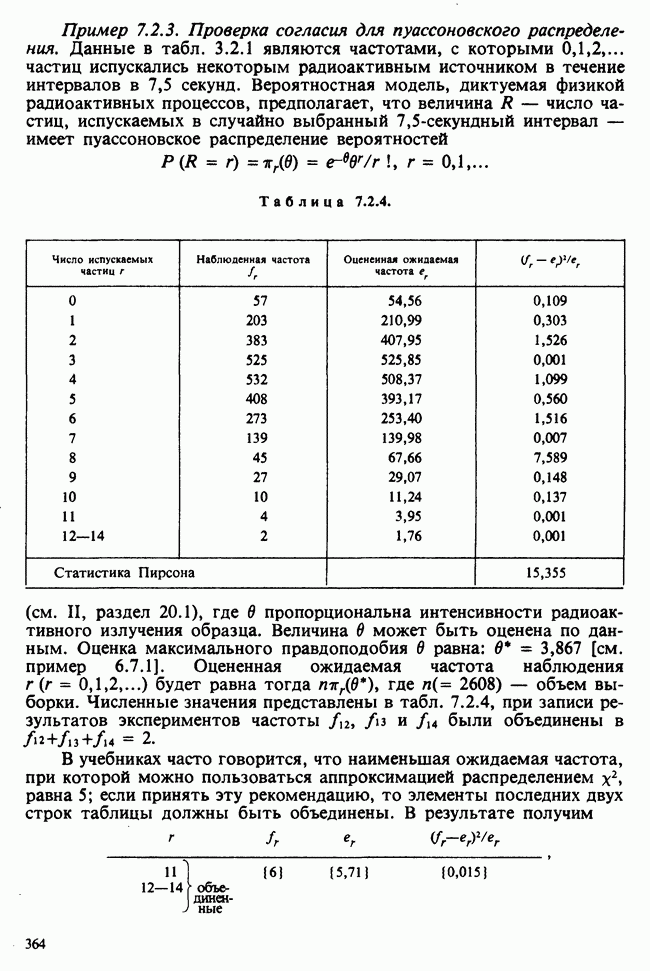
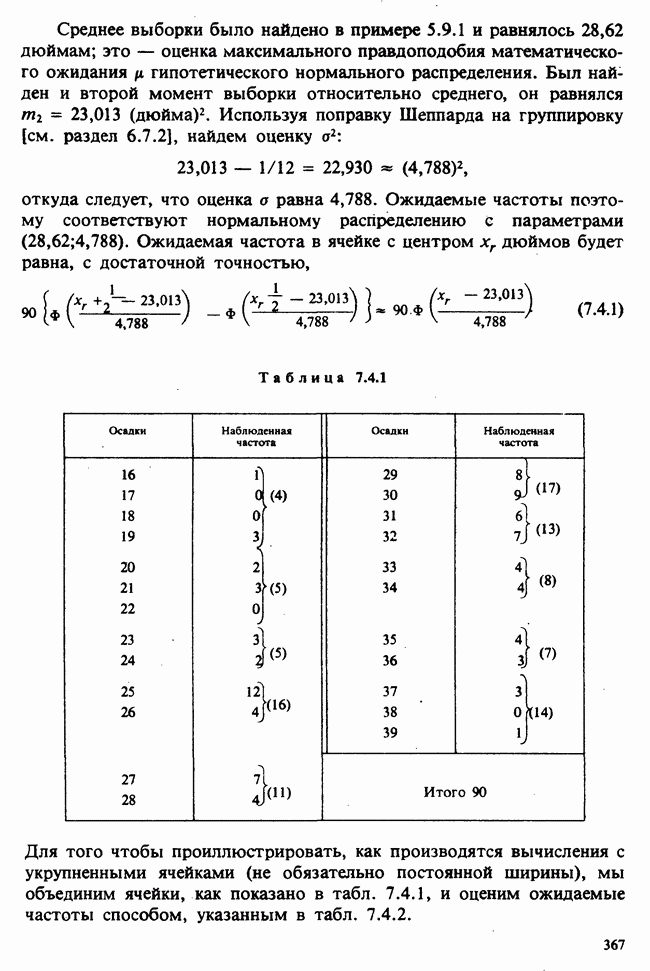
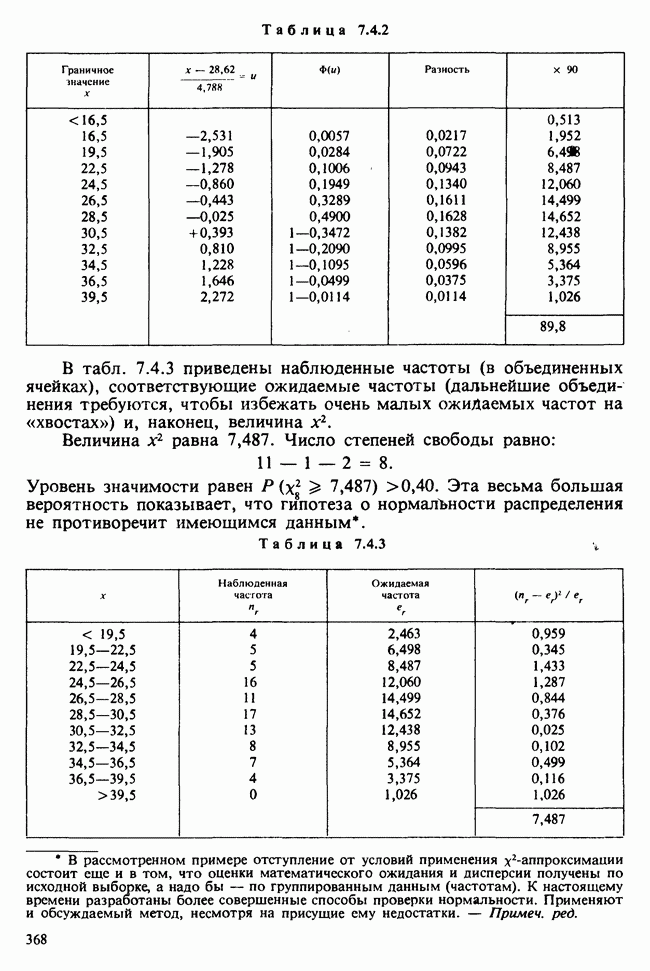
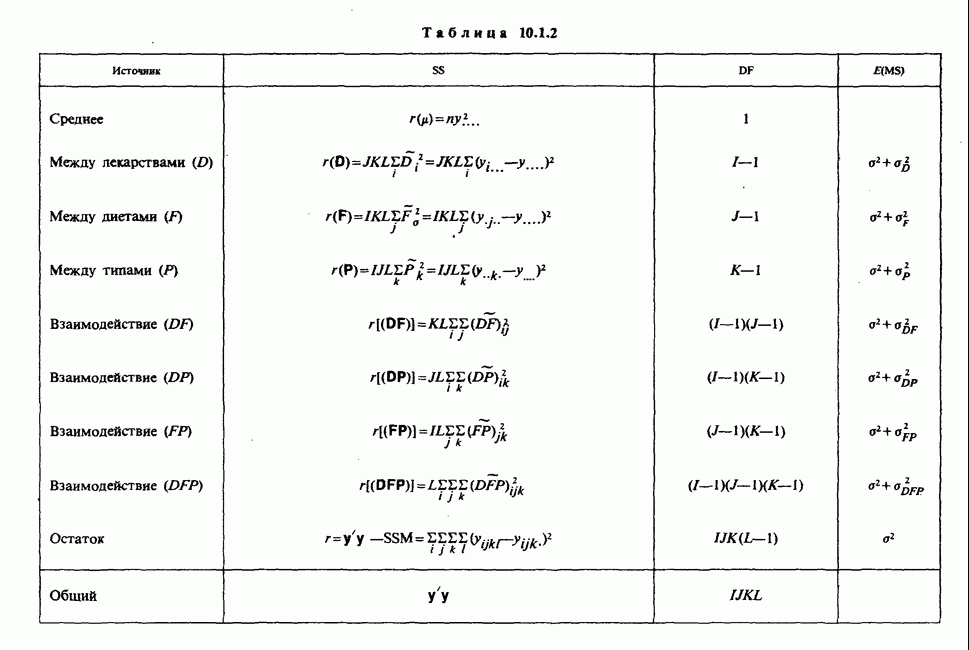
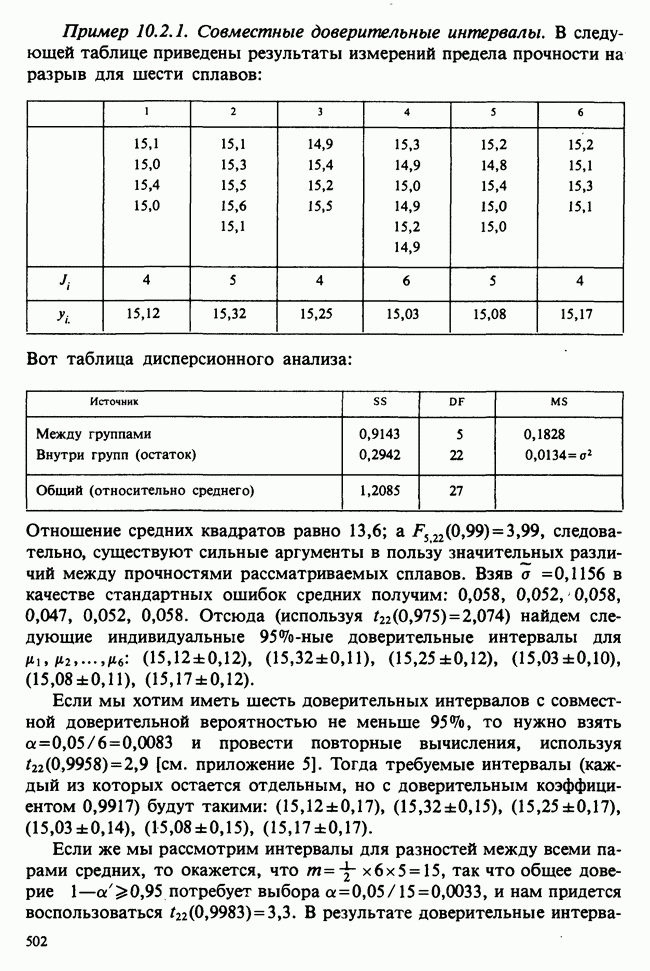
как функцию свободной переменной в, для которой наши данные служат известными и фиксированными коэффициентами. Она называется функцией правдоподобия данных [см. разделы 4.13.1, 6.2.1]. В нашем примере X — непрерывная переменная. Данные  должны рассматриваться как конечные (ограниченные) приближения к бесконечным десятичным дробям, требуемым для точной записи действительных чисел, так что
должны рассматриваться как конечные (ограниченные) приближения к бесконечным десятичным дробям, требуемым для точной записи действительных чисел, так что  означает некоторое число, лежащее в интервале
означает некоторое число, лежащее в интервале  где
где  — размер измерительной сетки, скажем —1 мм, для
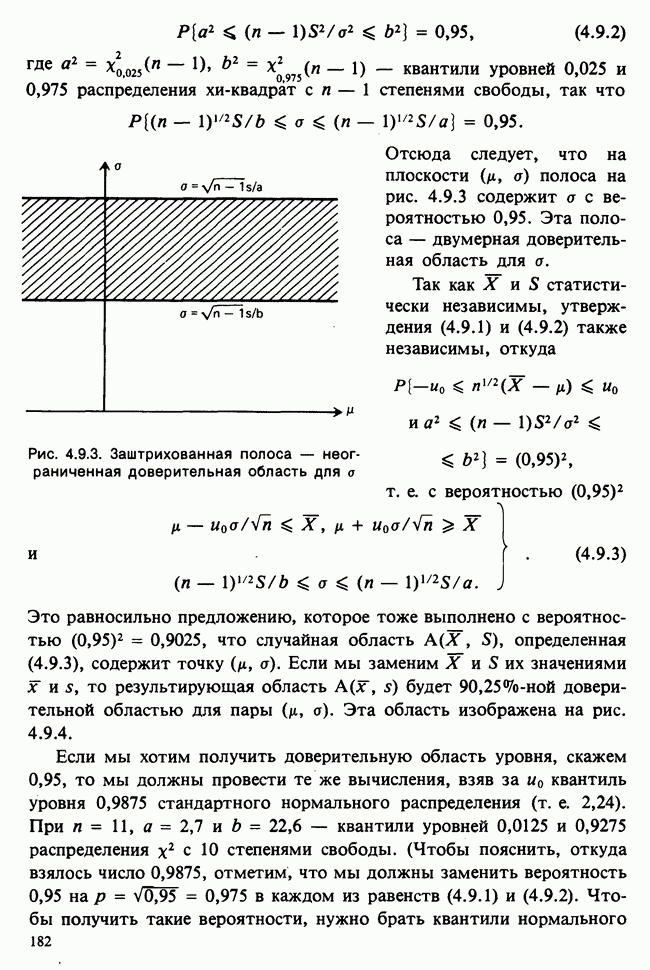
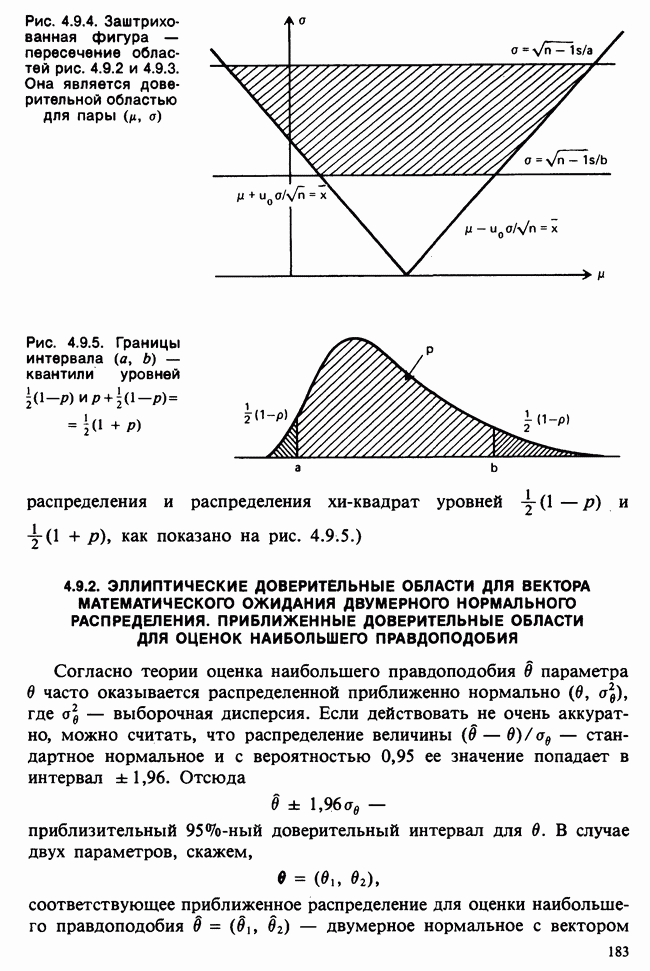
— размер измерительной сетки, скажем —1 мм, для  , измеряемого в миллиметрах. При малых
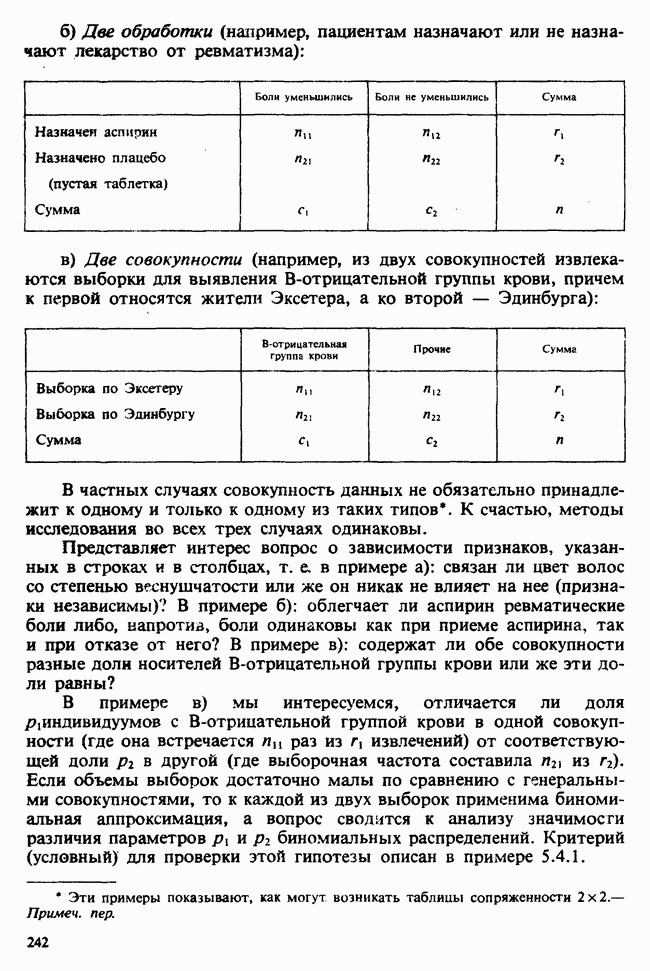
, измеряемого в миллиметрах. При малых  такого порядка вероятность
такого порядка вероятность

может быть заменена с необходимой точностью на

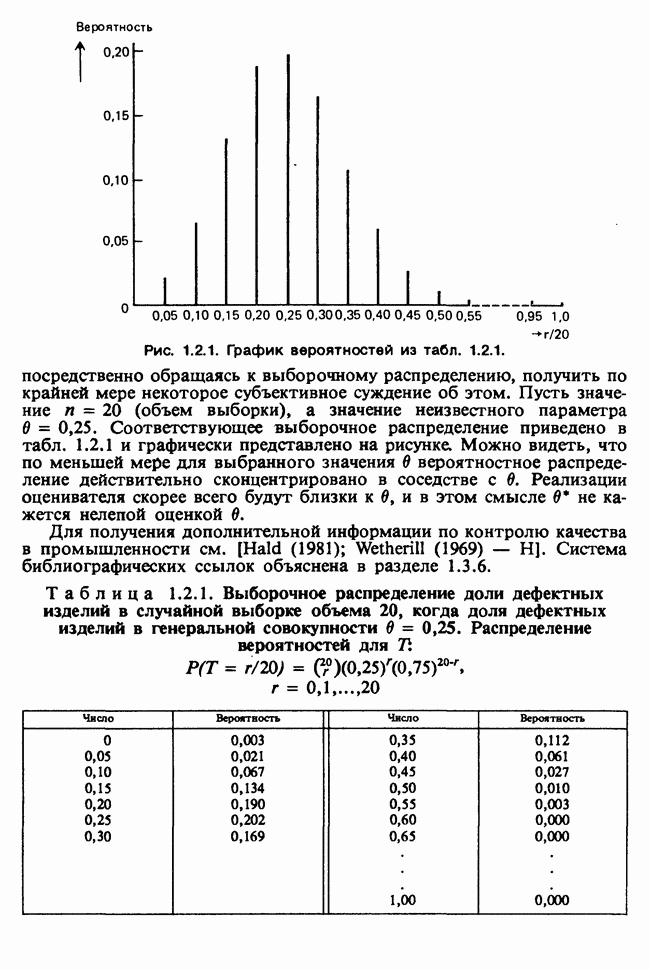
Вероятность получения наблюдаемой выборки для данного значения в будет поэтому равной

Следовательно, для каждого фиксированного значения (скажем,  параметра численное значение правдоподобия пропорционально
параметра численное значение правдоподобия пропорционально  и мы можем, таким образом, принять за значение правдоподобия выражение (которое определяется с точностью до умножения на константу, т. е. функцию данных, не зависящую от
и мы можем, таким образом, принять за значение правдоподобия выражение (которое определяется с точностью до умножения на константу, т. е. функцию данных, не зависящую от  )
)

где  остаются фиксированными, а
остаются фиксированными, а  — неопределенная переменная.
— неопределенная переменная.
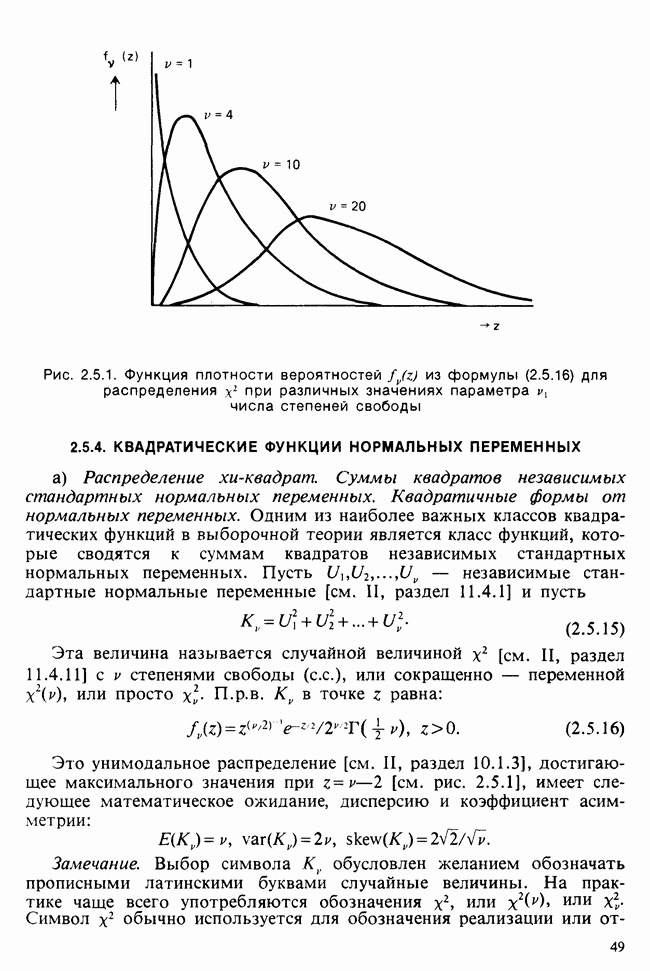
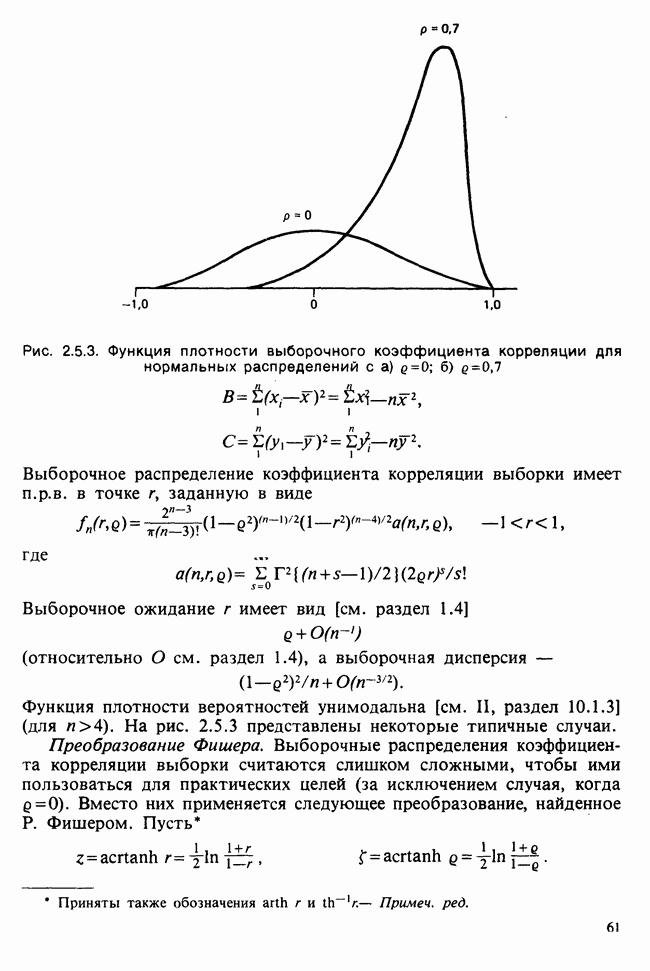
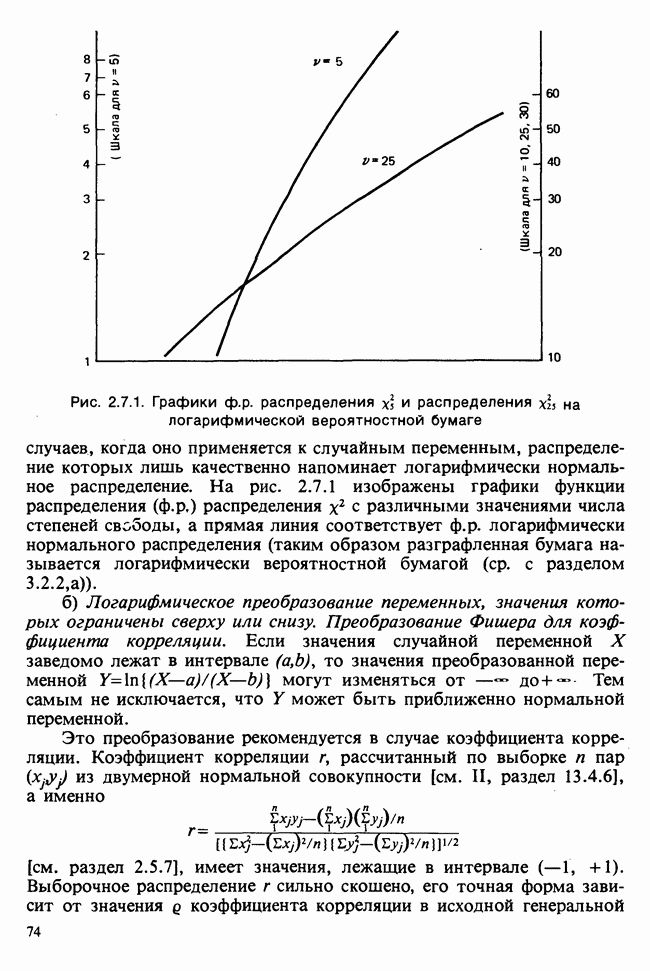
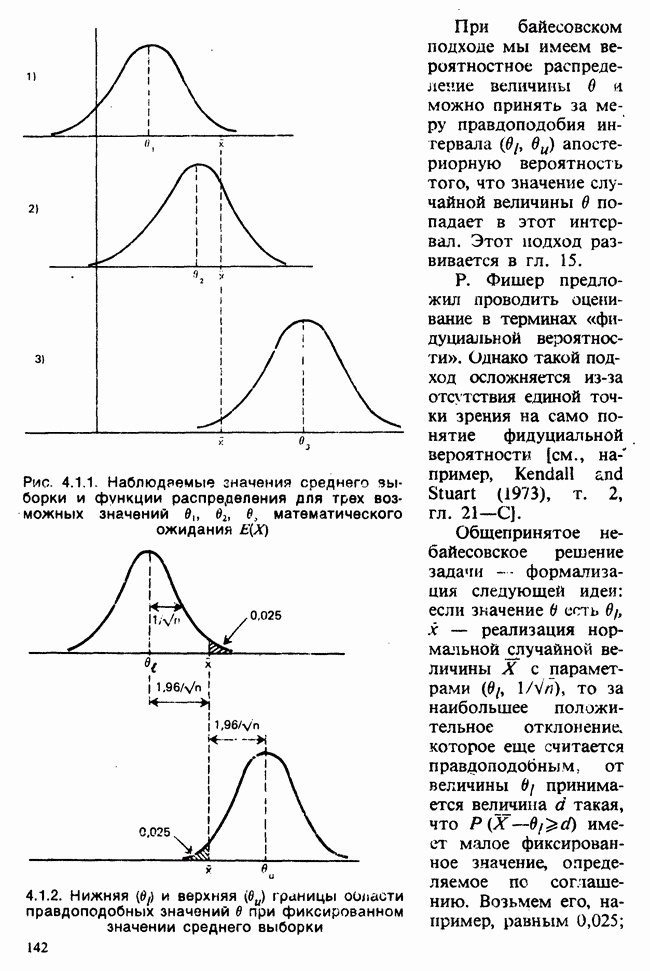
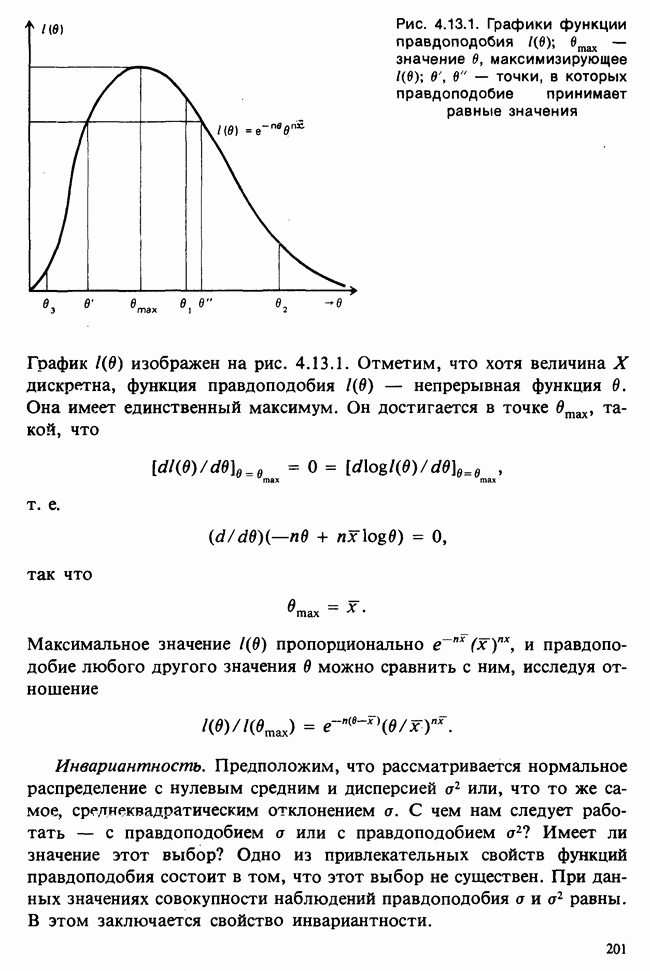
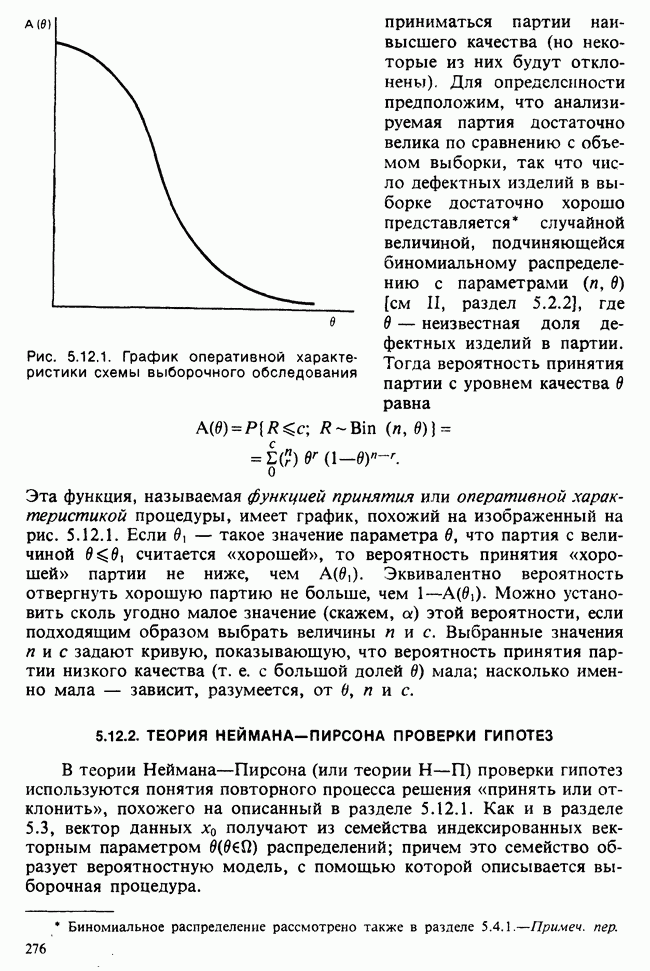
Между вероятностью и правдоподобием есть существенная разница: вероятностные утверждения касаются множества возможных исходов при фиксированном значении  . В утверждениях о правдоподобии, напротив, значения исходов фиксированы и рассматриваются все возможные значения в. При подходящих условиях суммы вероятностей также являются вероятностями, но суммы правдоподобий не являются правдоподобиями и т. д.
. В утверждениях о правдоподобии, напротив, значения исходов фиксированы и рассматриваются все возможные значения в. При подходящих условиях суммы вероятностей также являются вероятностями, но суммы правдоподобий не являются правдоподобиями и т. д.
Несмотря на эти различия, есть и общие свойства. Относительно большие правдоподобия соответствуют вероятным значениям в более, чем относительно малые, так как большие вероятности соответствуют сильно ожидаемым исходам более, чем малые вероятности.

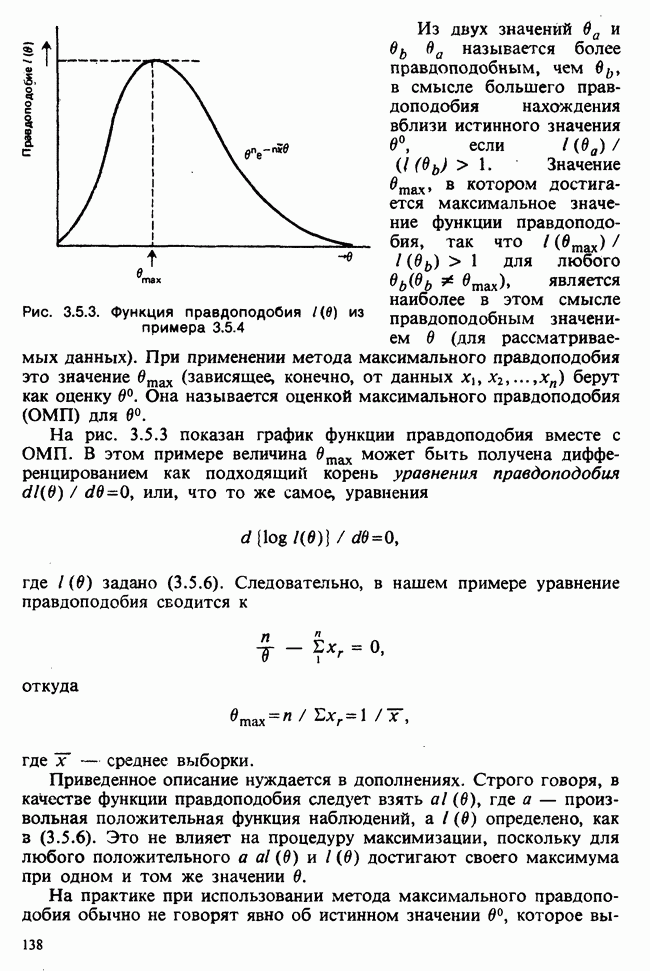
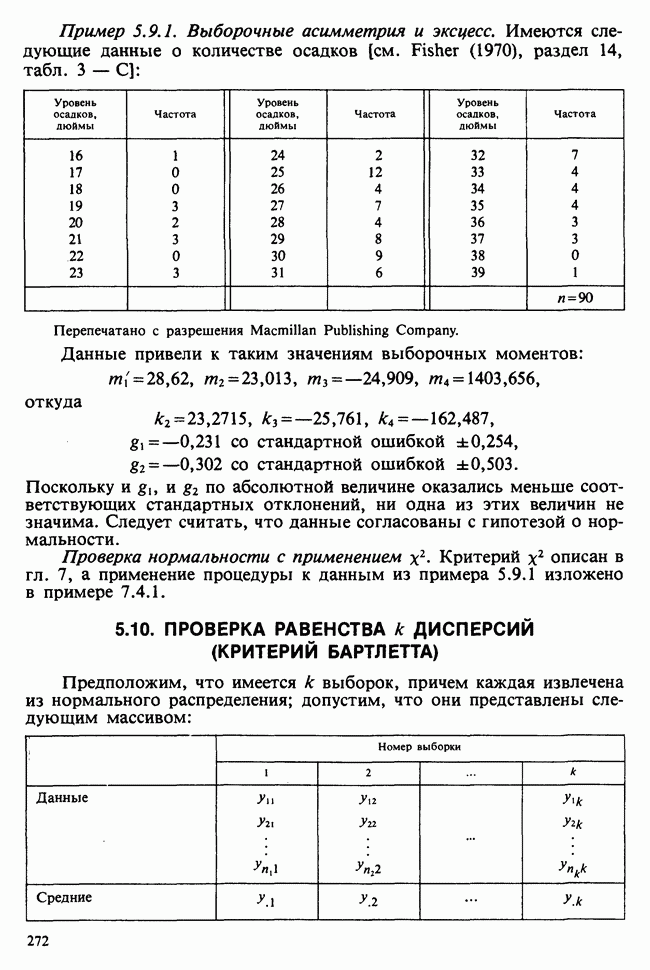
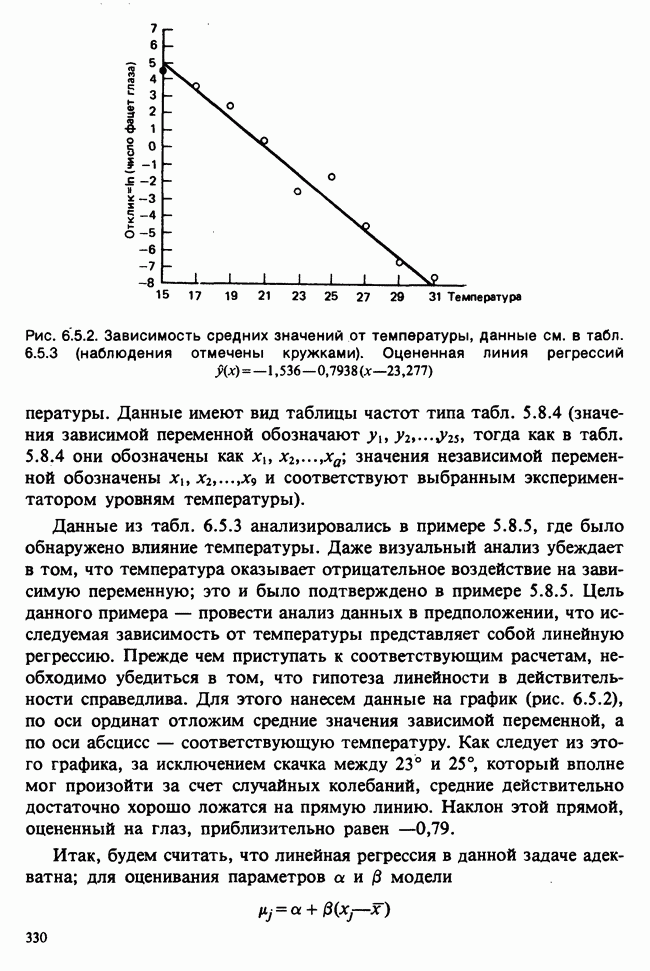
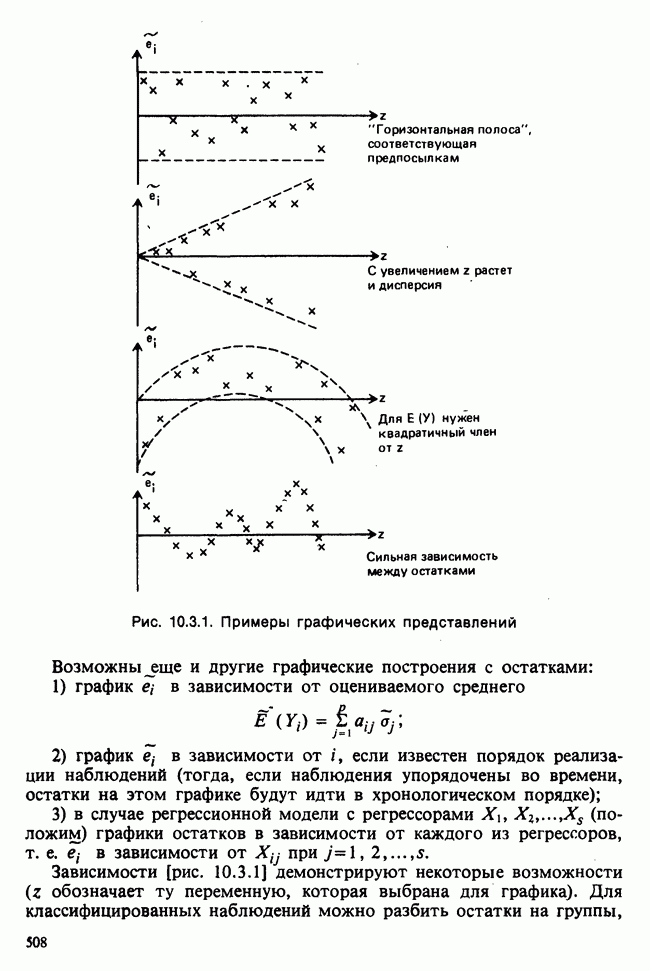
Рис. 3.5.3. Функция правдоподобия  из примера 3.5.4
из примера 3.5.4
Из двух значений  называется более правдоподобным, чем
называется более правдоподобным, чем  в смысле большего правдоподобия нахождения вблизи истинного значения
в смысле большего правдоподобия нахождения вблизи истинного значения  , если
, если  Значение
Значение  в котором достигается максимальное значение функции правдоподобия, так что
в котором достигается максимальное значение функции правдоподобия, так что  для любого
для любого  является наиболее в этом смысле правдоподобным значением
является наиболее в этом смысле правдоподобным значением  (для рассматриваемых данных). При применении метода максимального правдоподобия это значение
(для рассматриваемых данных). При применении метода максимального правдоподобия это значение  (зависящее, конечно, от данных
(зависящее, конечно, от данных  берут как оценку
берут как оценку  . Она называется оценкой максимального правдоподобия
. Она называется оценкой максимального правдоподобия  для
для  .
.
На рис. 3.5.3 показан график функции правдоподобия вместе с  . В этом примере величина
. В этом примере величина  может быть получена дифференцированием как подходящий корень уравнения правдоподобия
может быть получена дифференцированием как подходящий корень уравнения правдоподобия  или, что то же самое, уравнения
или, что то же самое, уравнения

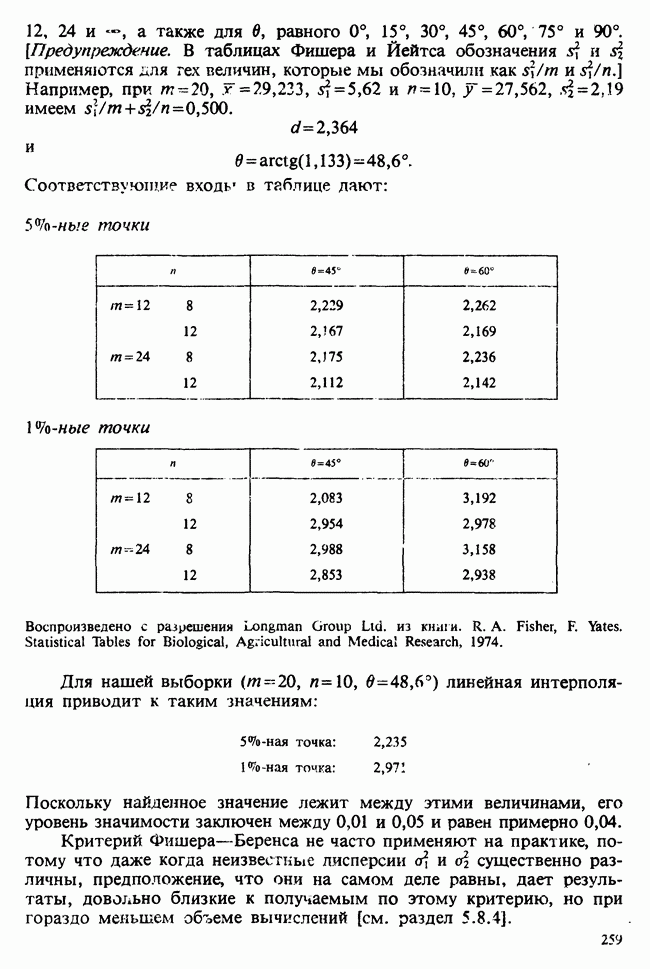
где  задано (3.5.6). Следовательно, в нашем примере уравнение правдоподобия сбодится к
задано (3.5.6). Следовательно, в нашем примере уравнение правдоподобия сбодится к

откуда

где  — среднее выборки.
— среднее выборки.
Приведенное описание нуждается в дополнениях. Строго говоря, в качестве функции правдоподобия следует взять  , где а — произвольная положительная функция наблюдений, а
, где а — произвольная положительная функция наблюдений, а  определено, как в (3.5.6). Это не влияет на процедуру максимизации, поскольку для любого положительного
определено, как в (3.5.6). Это не влияет на процедуру максимизации, поскольку для любого положительного  и
и  достигают своего максимума при одном и том же значении
достигают своего максимума при одном и том же значении  .
.
На практике при использовании метода максимального правдоподобия обычно не говорят явно об истинном значении  , которое
, которое
выделяет определенное  из рассматриваемого семейства плотностей заданного вида
из рассматриваемого семейства плотностей заданного вида  пространство параметров, в примере
пространство параметров, в примере  Вместо этого: 1) говорят (несколько вольно) о задаче оценивания параметра
Вместо этого: 1) говорят (несколько вольно) о задаче оценивания параметра  плотности оаспределения вероятности
плотности оаспределения вероятности  , имея в виду под
, имея в виду под  истинное значение
истинное значение  одновременно говорят о функции правдоподобия
одновременно говорят о функции правдоподобия  имея в виду под в переменную, чья область изменений — пространство параметров
имея в виду под в переменную, чья область изменений — пространство параметров  .
.
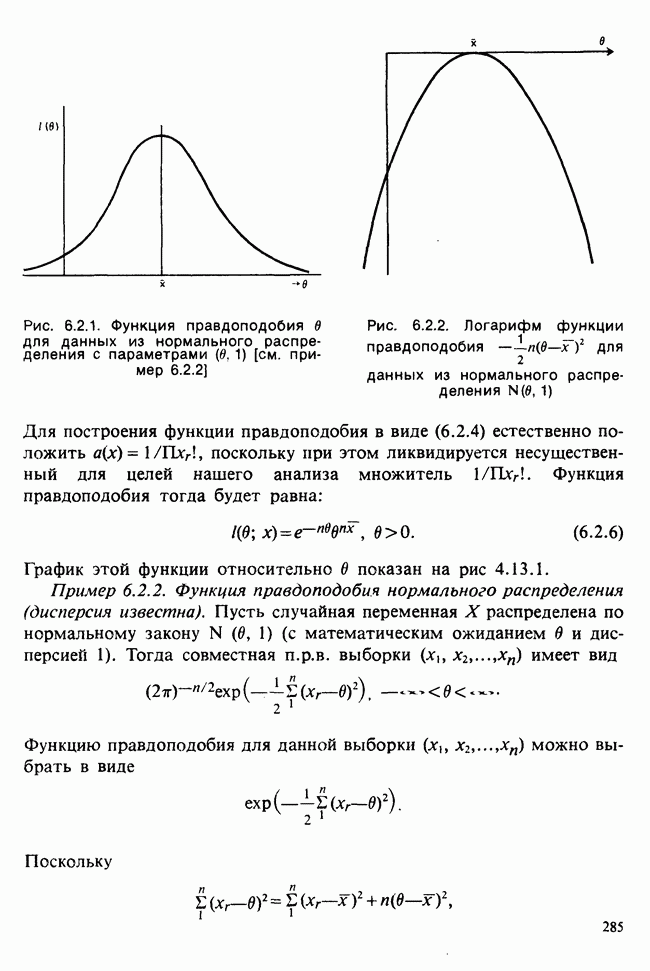
Процедура максимизации часто упрощается, если вместо функции правдоподобия использовать ее логарифм  — логарифмическую функцию правдоподобия, поскольку при этом нужно дифференцировать не произведение, а сумму;
— логарифмическую функцию правдоподобия, поскольку при этом нужно дифференцировать не произведение, а сумму;  достигает своего максимума при том же значении
достигает своего максимума при том же значении  что и
что и  . (Нельзя, однако, думать, что максимум может быть найден дифференцированием в каждом случае. Контрпримеры см. в гл. 6.)
. (Нельзя, однако, думать, что максимум может быть найден дифференцированием в каждом случае. Контрпримеры см. в гл. 6.)
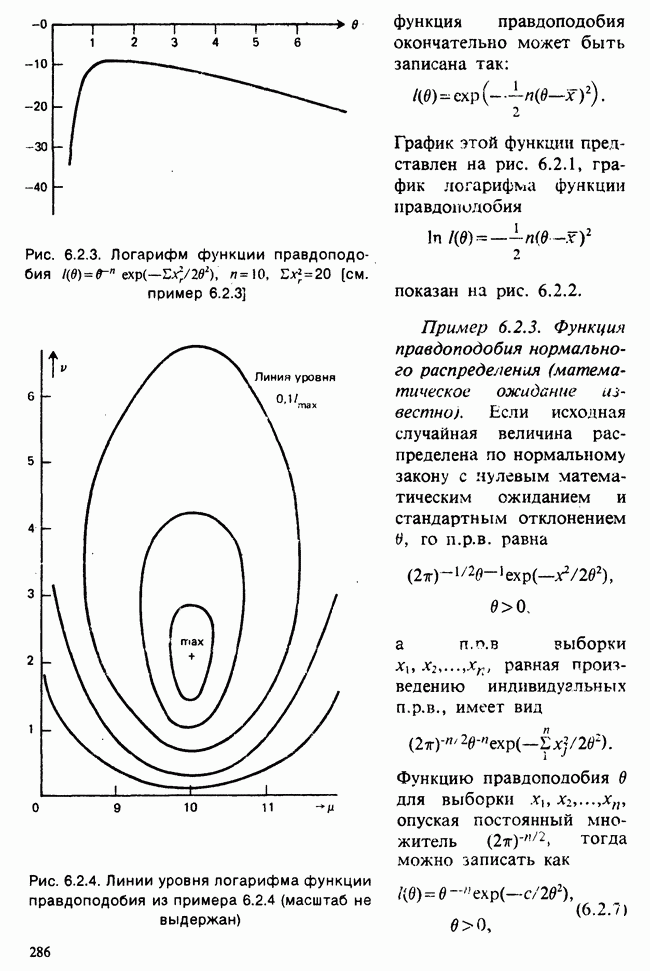
Когда (как в примере 3.5.3) уравнение правдоподобия имеет простое и ясное решение, можно исследовать выборочное распределение оценки непосредственно. Однако чаще решение може быть получено лишь в виде итеративной численной процедуры, и потому прямое изучение выборочного распределения невозможно. В соответствии с общей теорией [см. гл. 6] для подобных случаев возможны простые и эффективные аппроксимации.
Этот метод также применим при нескольких параметрах и когда наблюдения не обязательно независимы и одинаково распределены [см. гл. 6].


















































































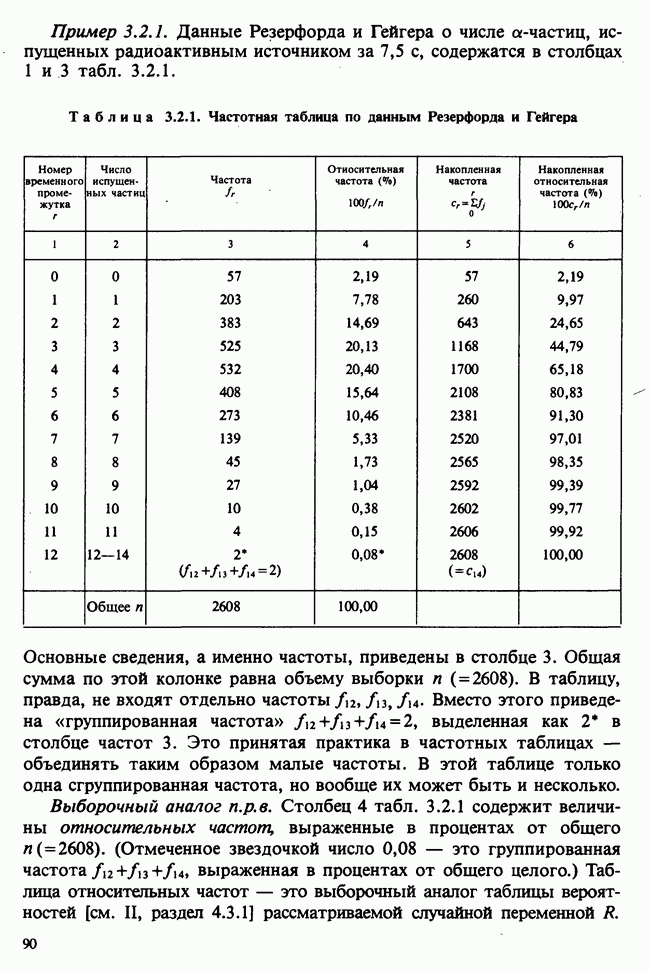


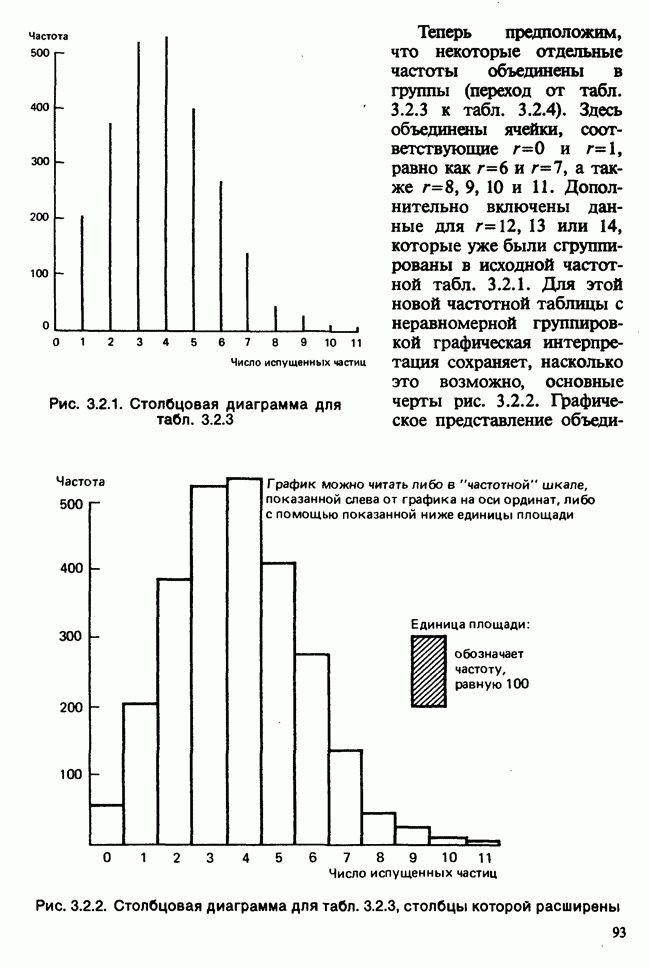
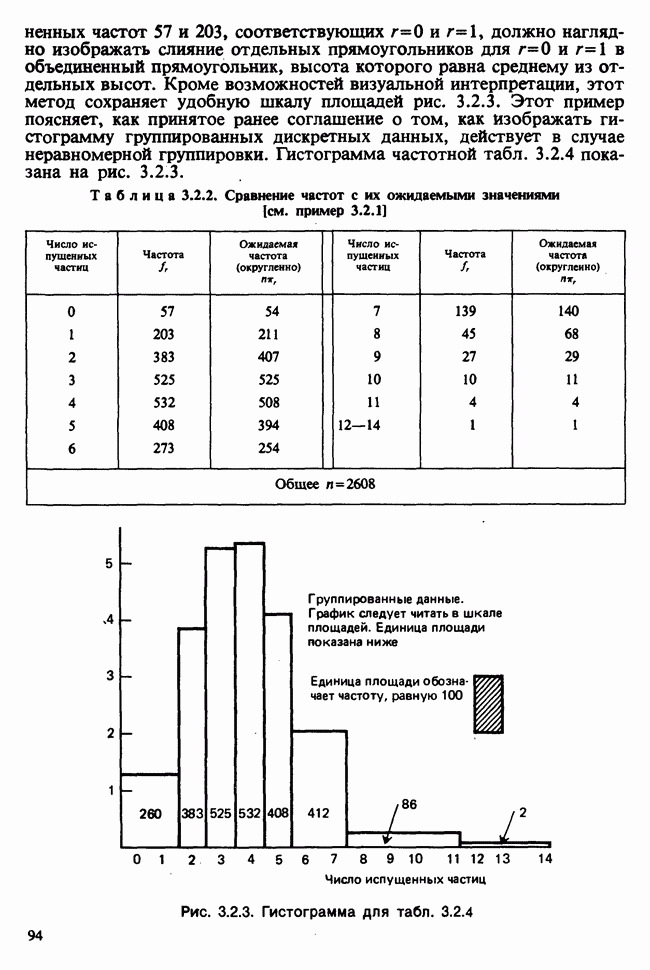

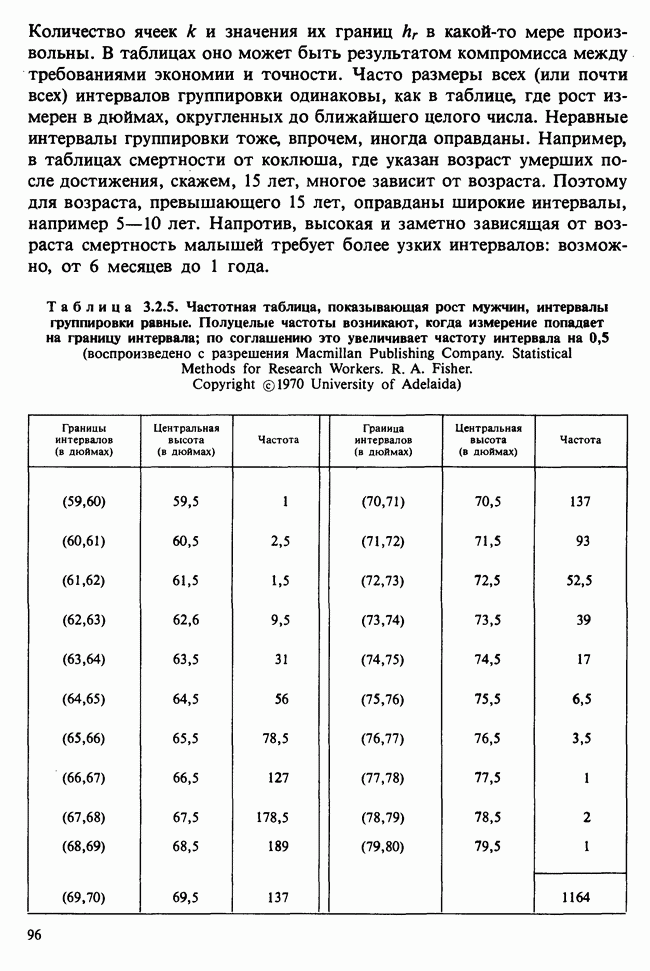































































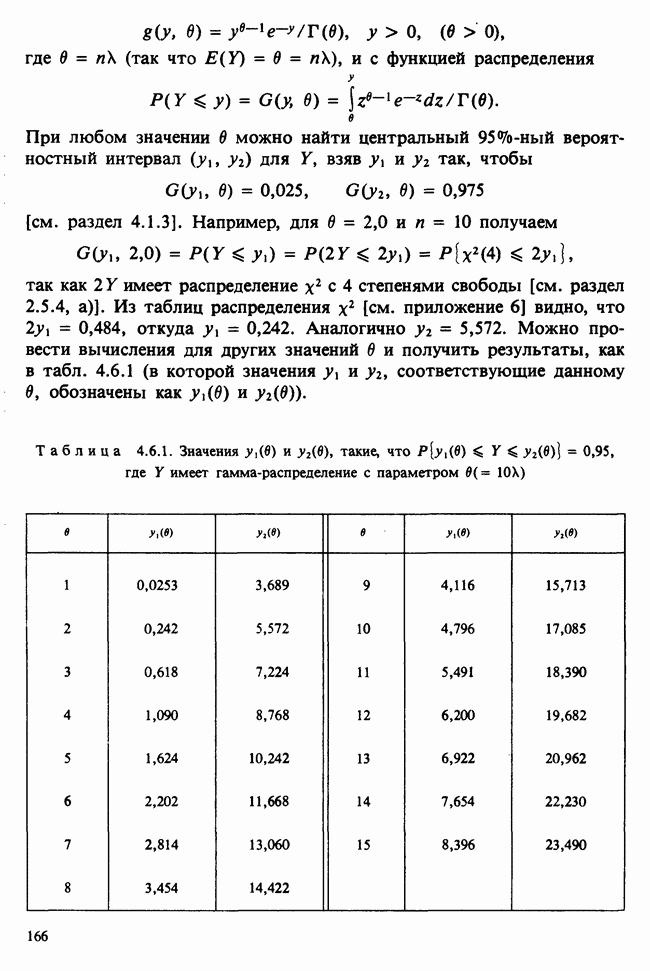
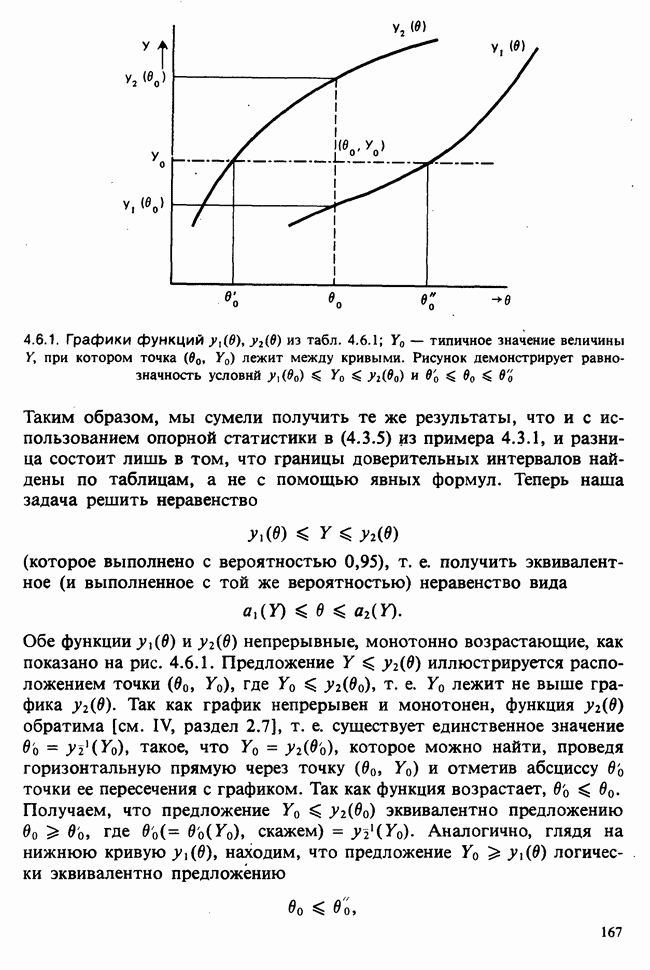






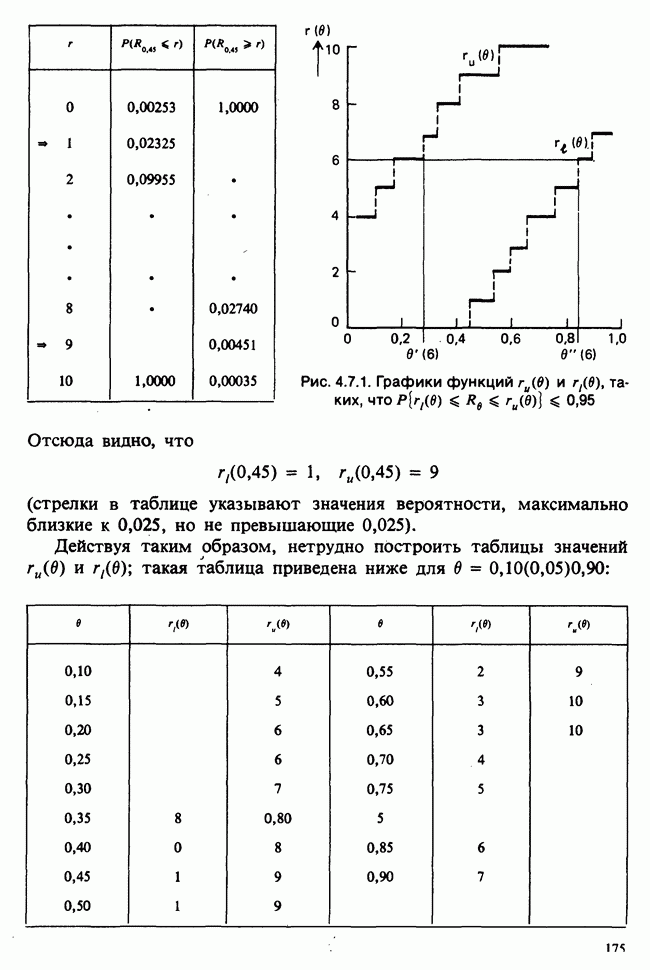























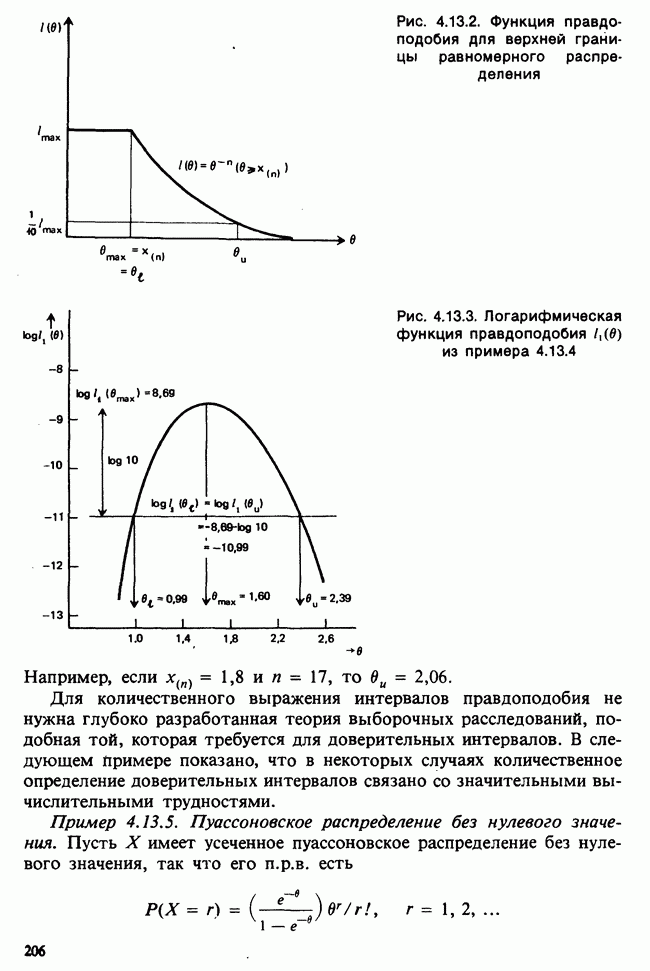
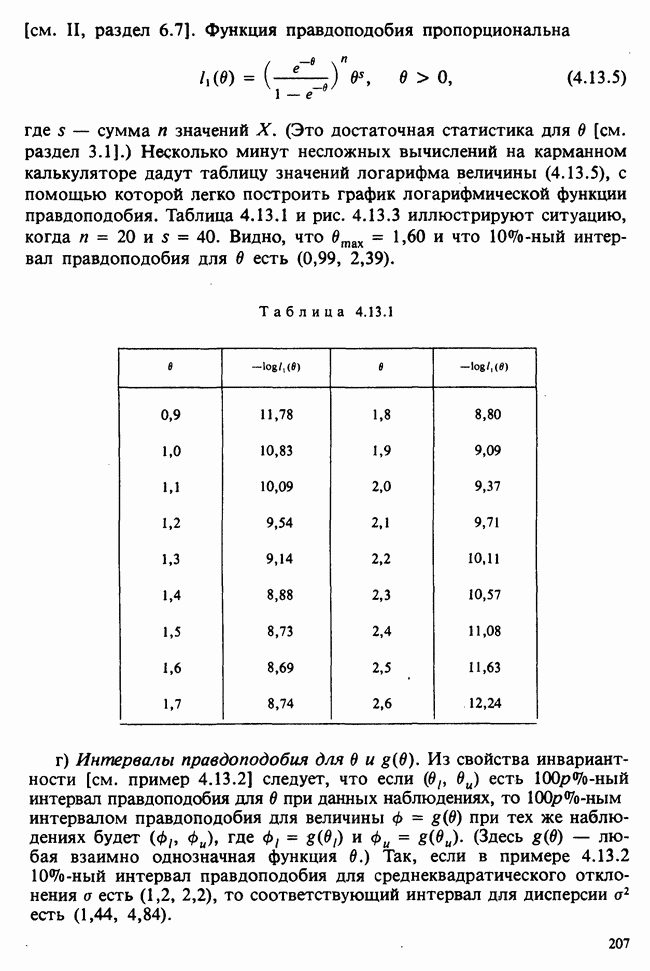























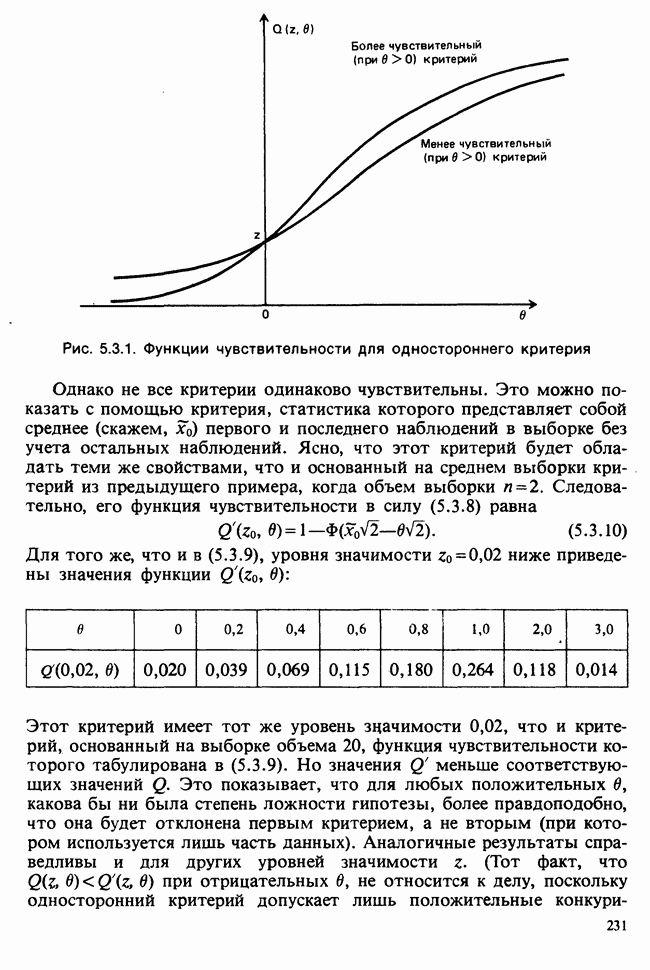








































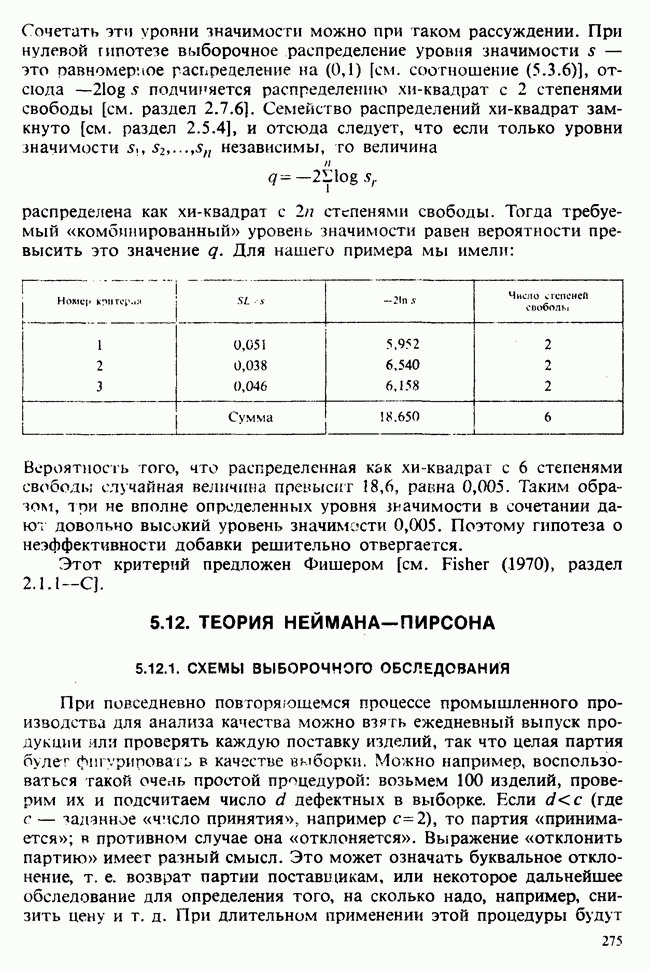














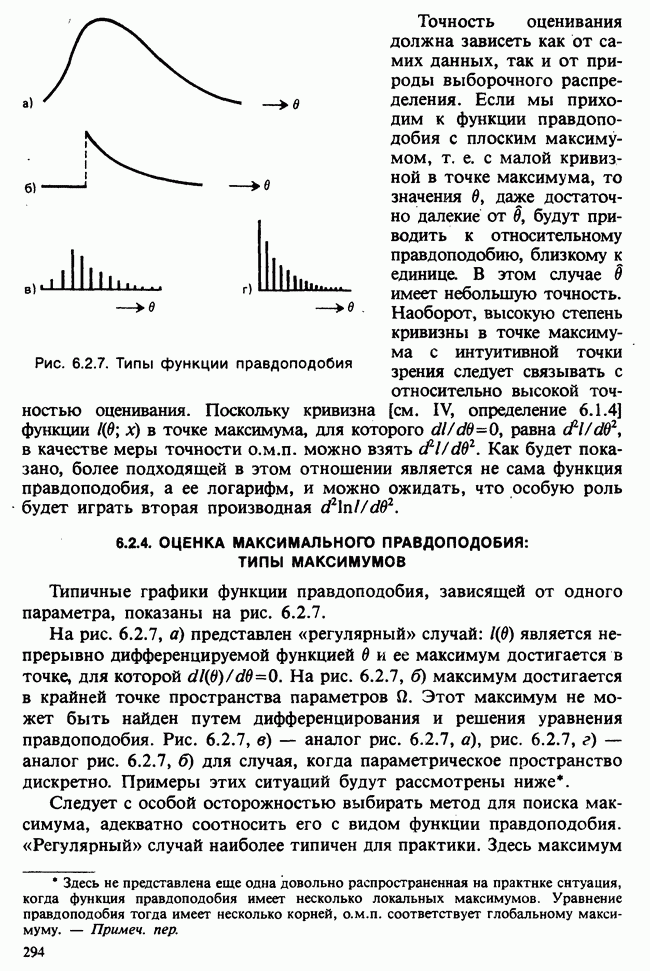
























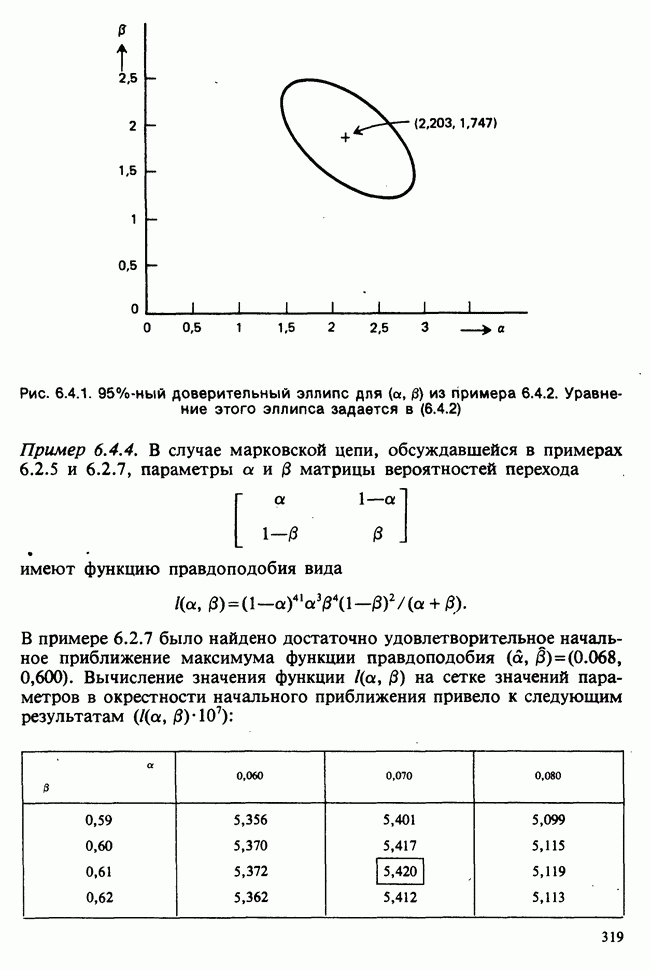



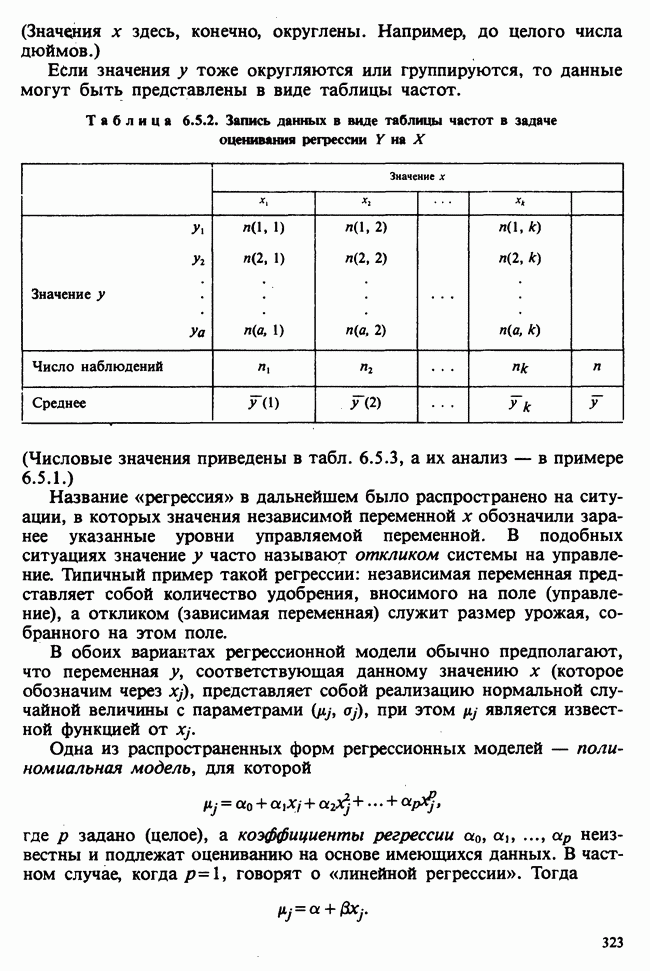





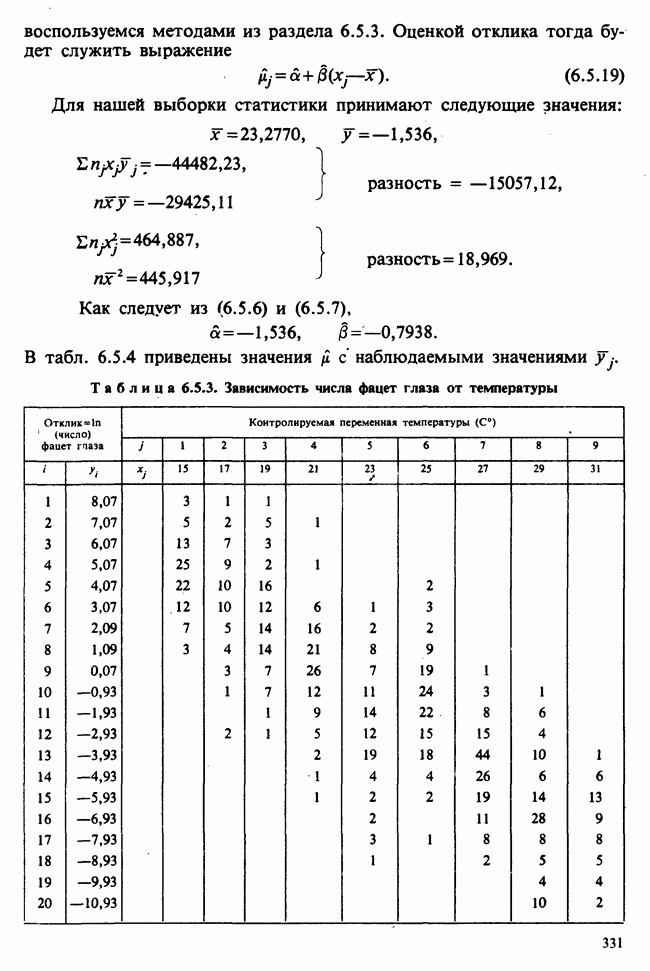
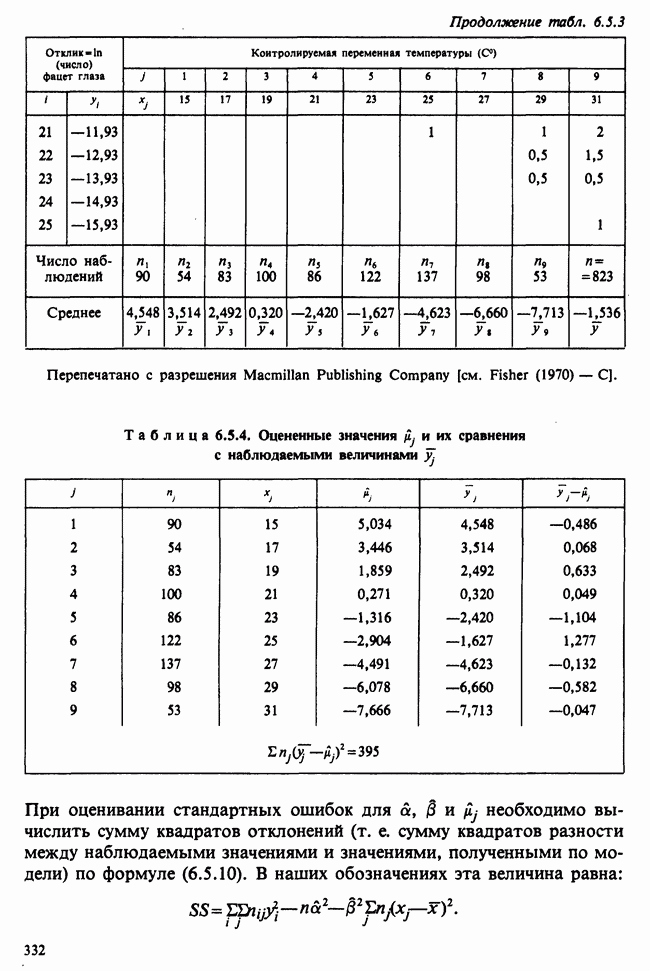



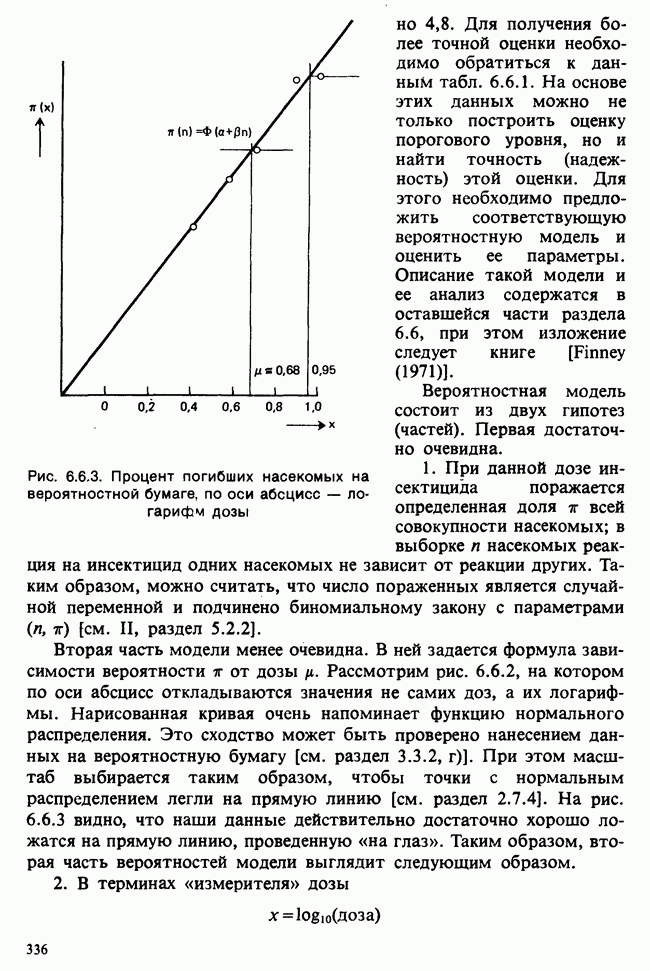


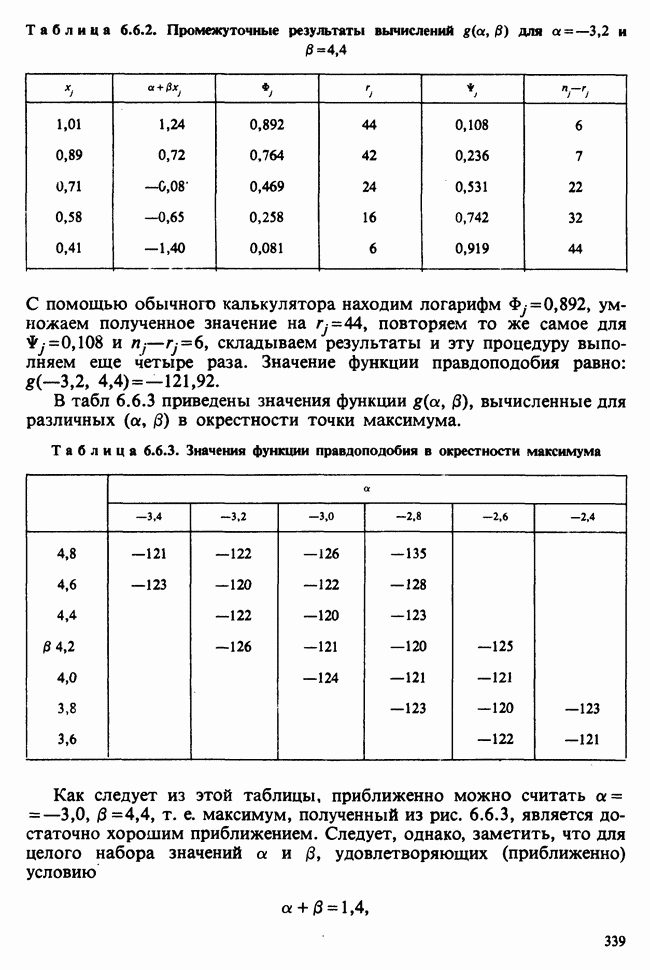


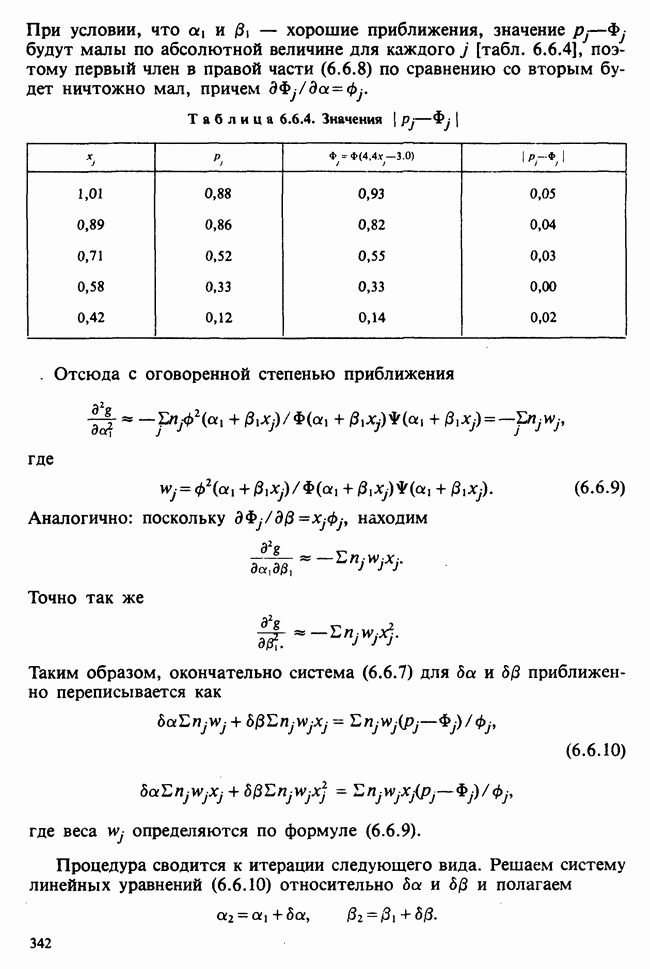

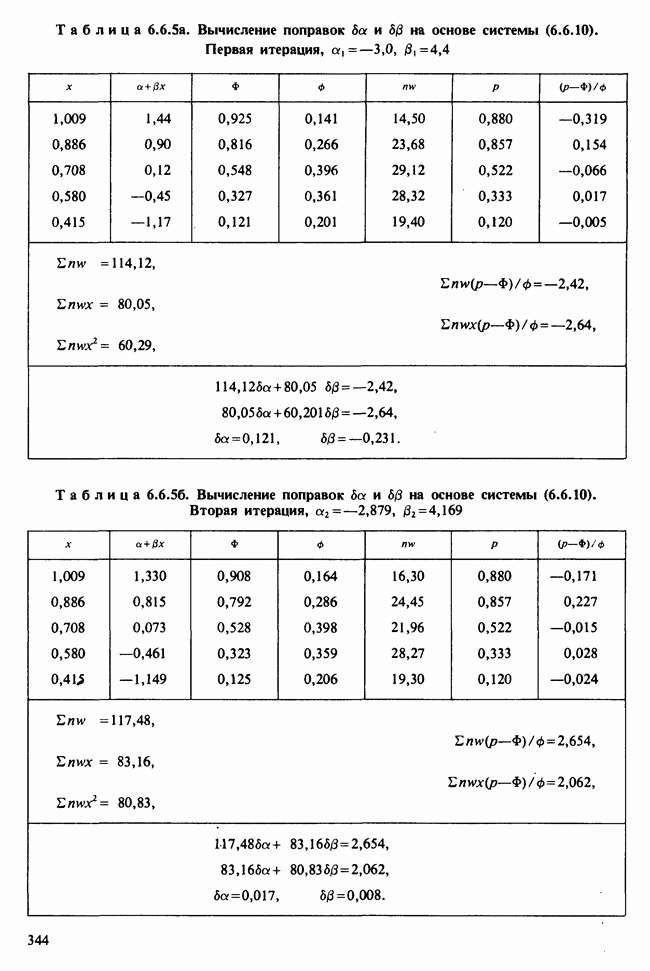

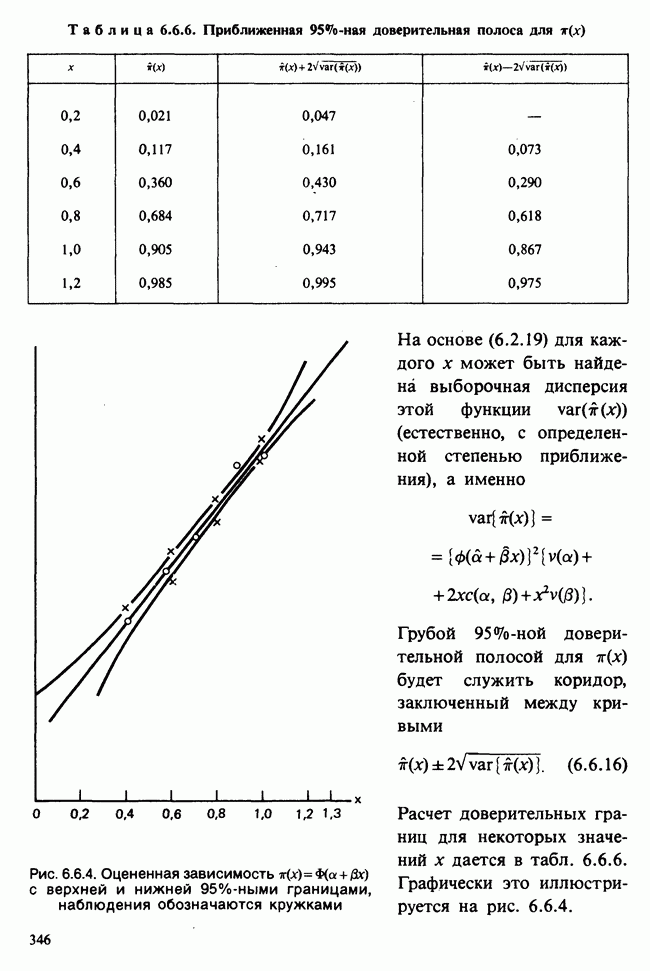



















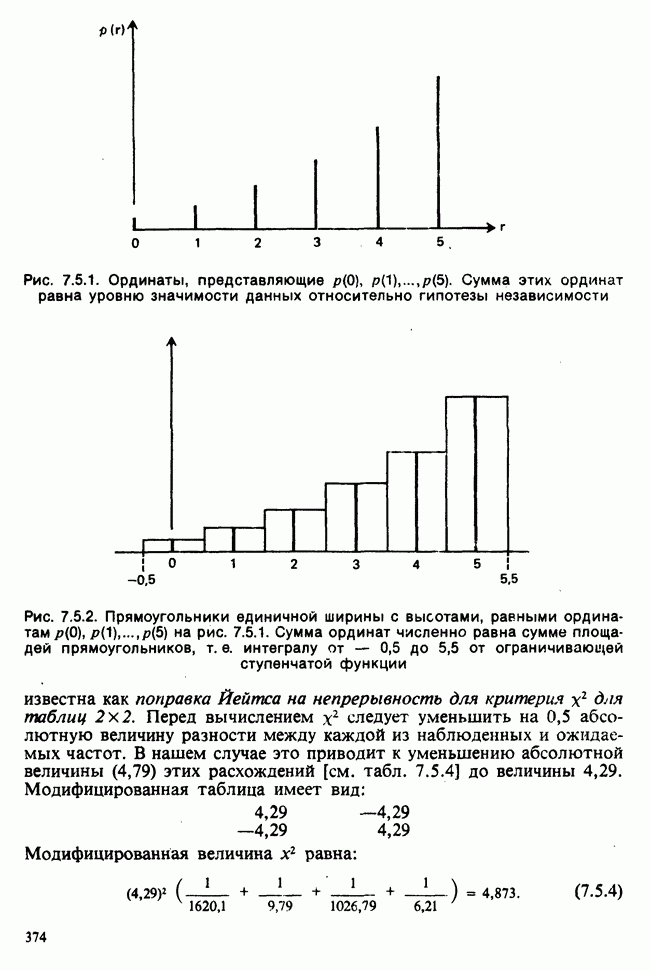


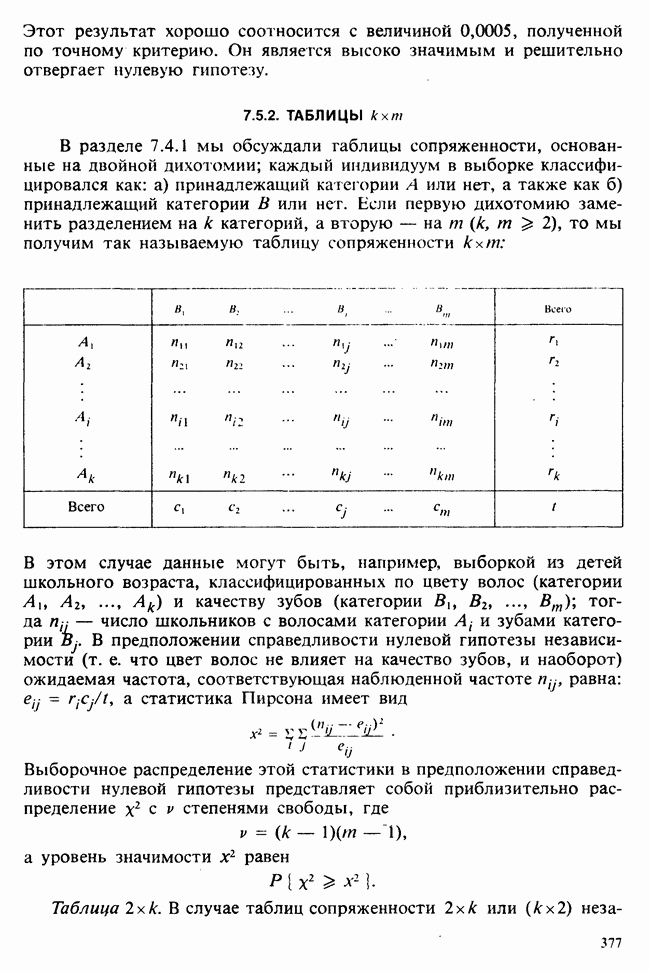



























































































































 принадлежит к однопараметрическому семейству:
принадлежит к однопараметрическому семейству:

 пробегает все положительные значения. То особое значение
пробегает все положительные значения. То особое значение  (скажем,
(скажем,  ), которое свойственно нашему
), которое свойственно нашему  неизвестно. Мы будем называть его истинным значением
неизвестно. Мы будем называть его истинным значением  . Желательно оценить
. Желательно оценить  по данным
по данным  состоящим из независимых наблюдений X. Имея в виду, что
состоящим из независимых наблюдений X. Имея в виду, что  фиксированы, строим функцию
фиксированы, строим функцию

