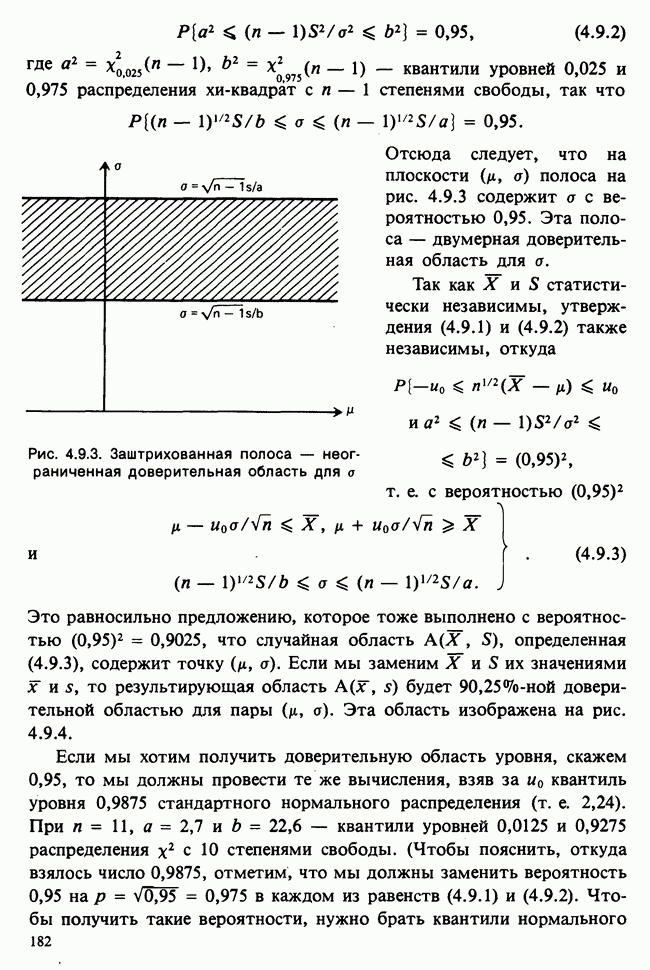
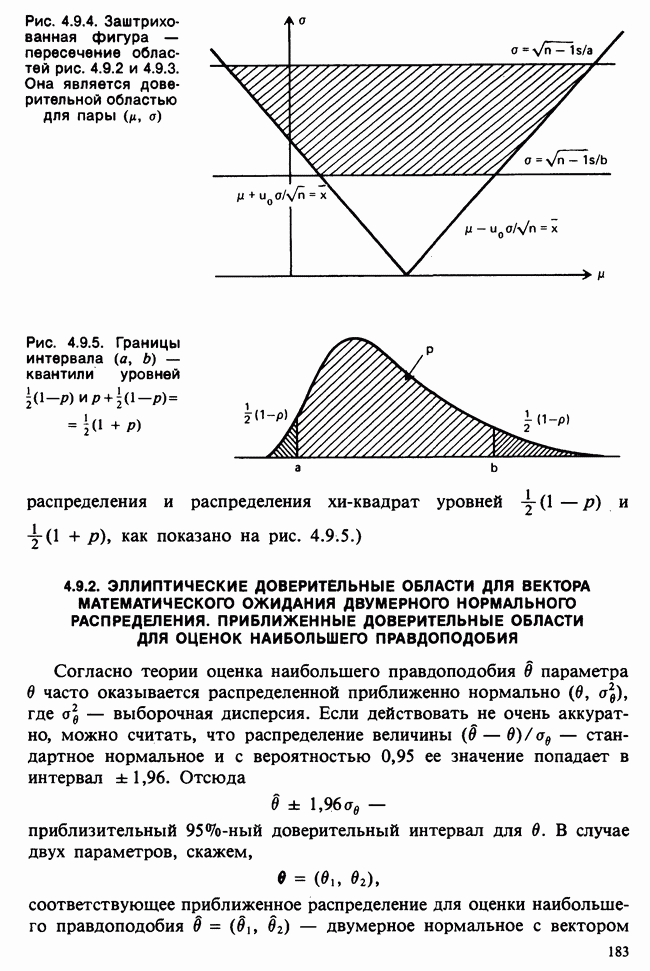
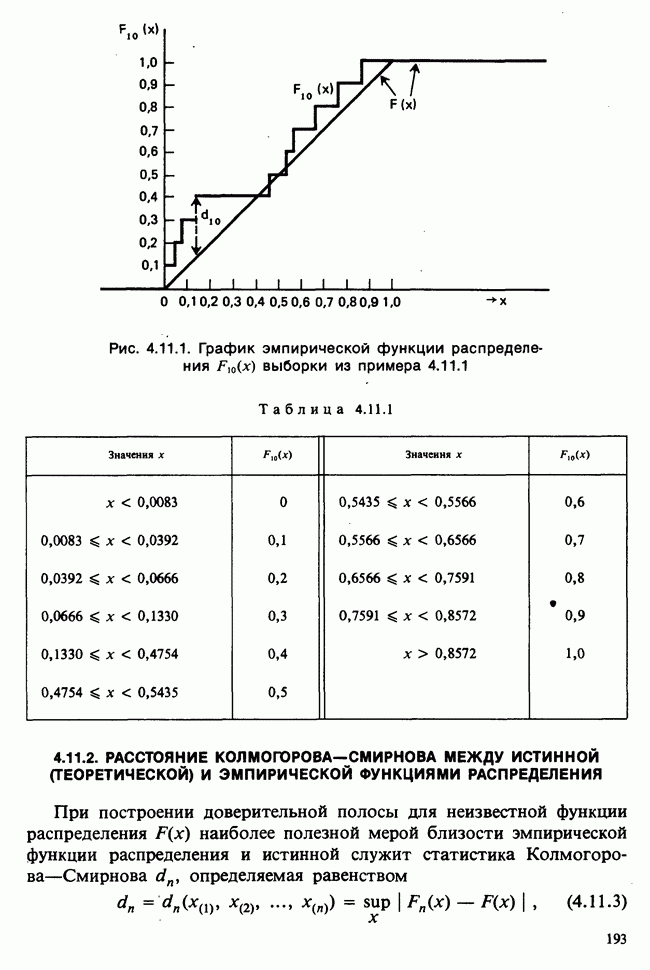
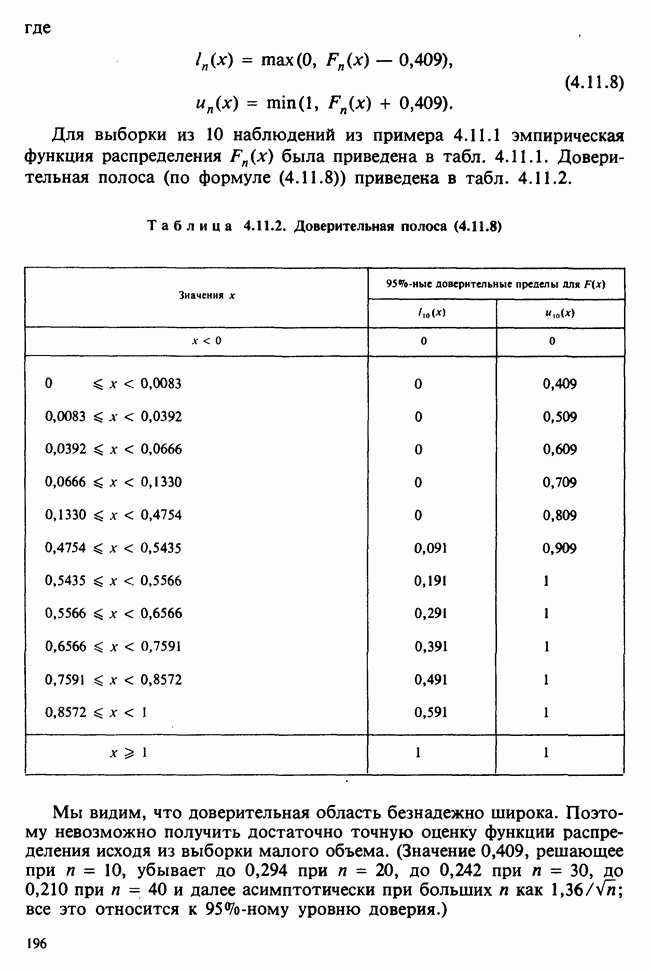
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
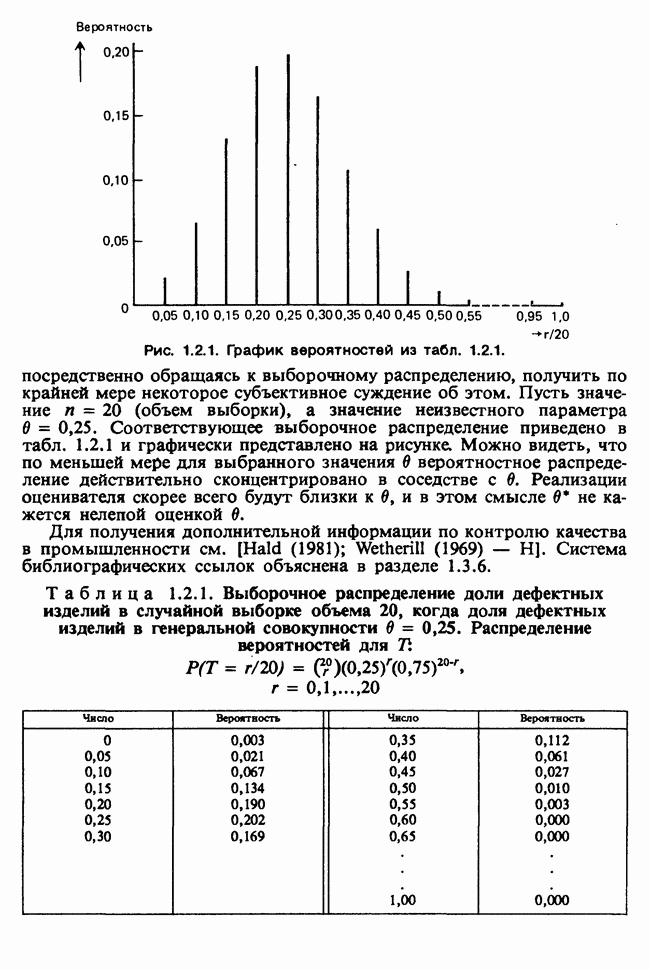
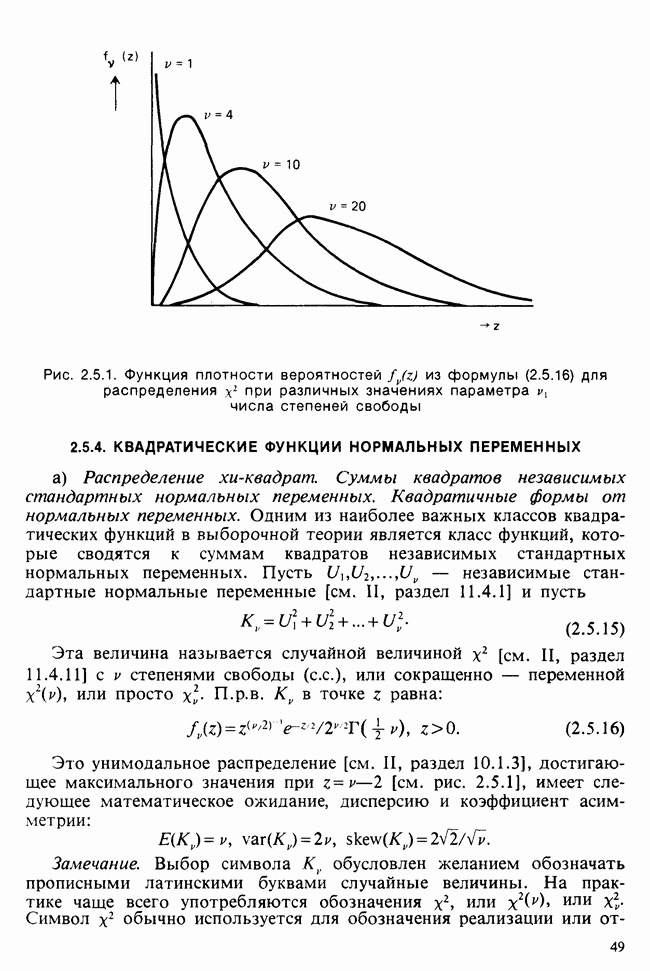
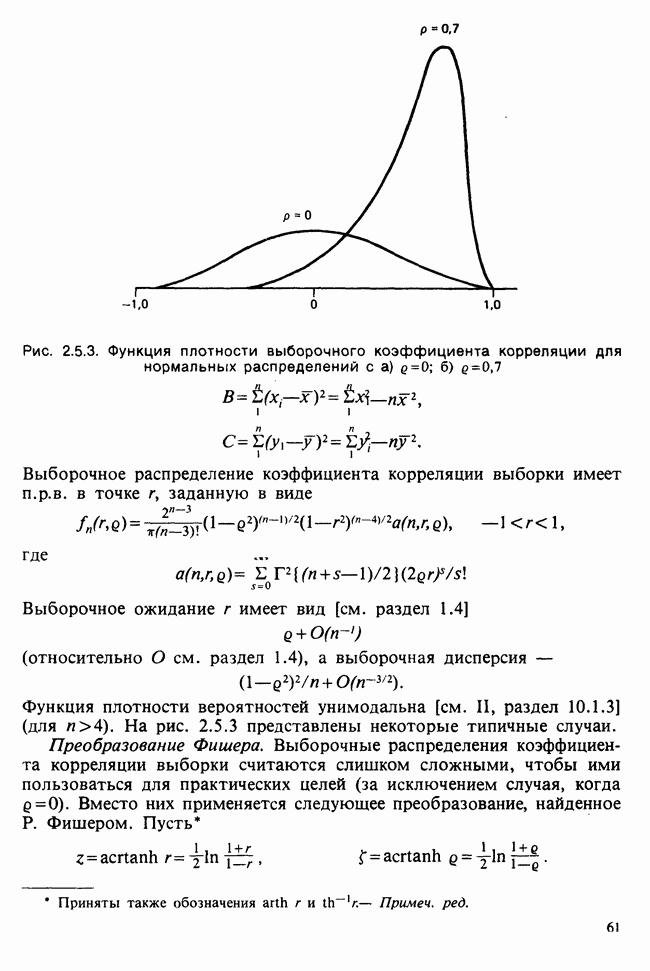
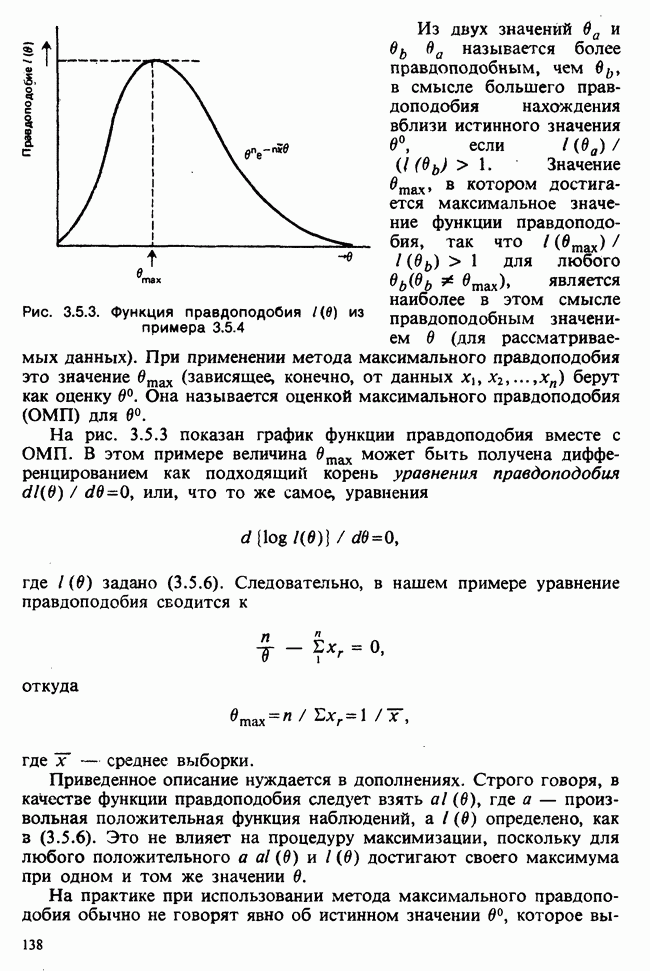
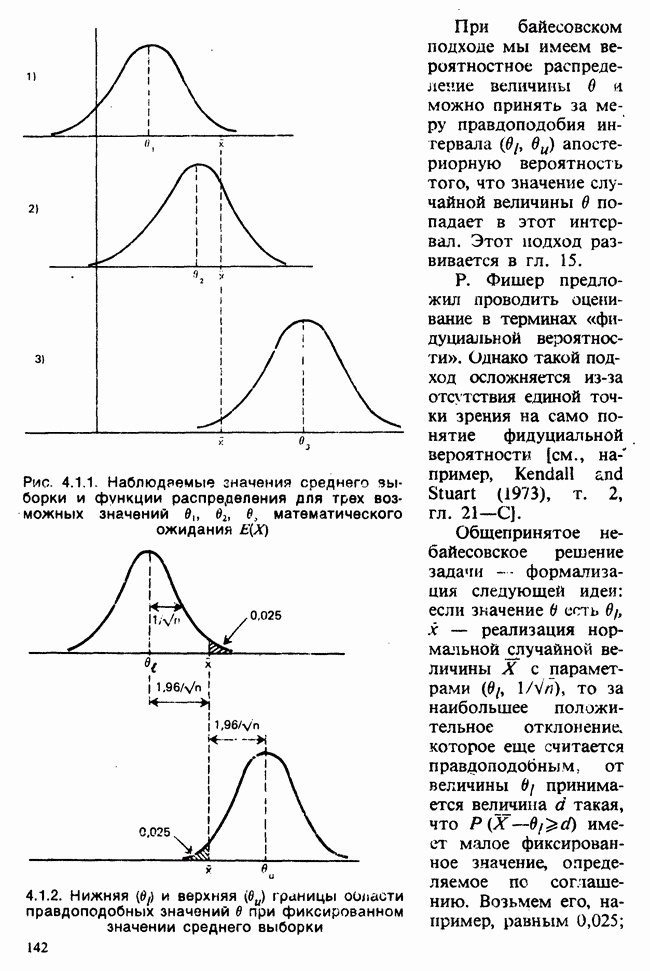
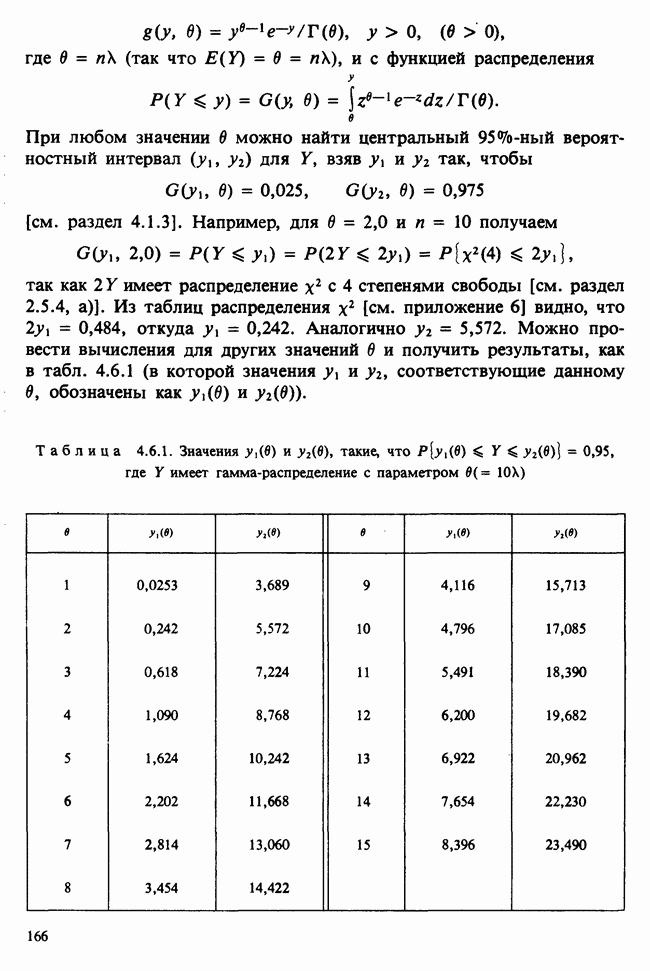
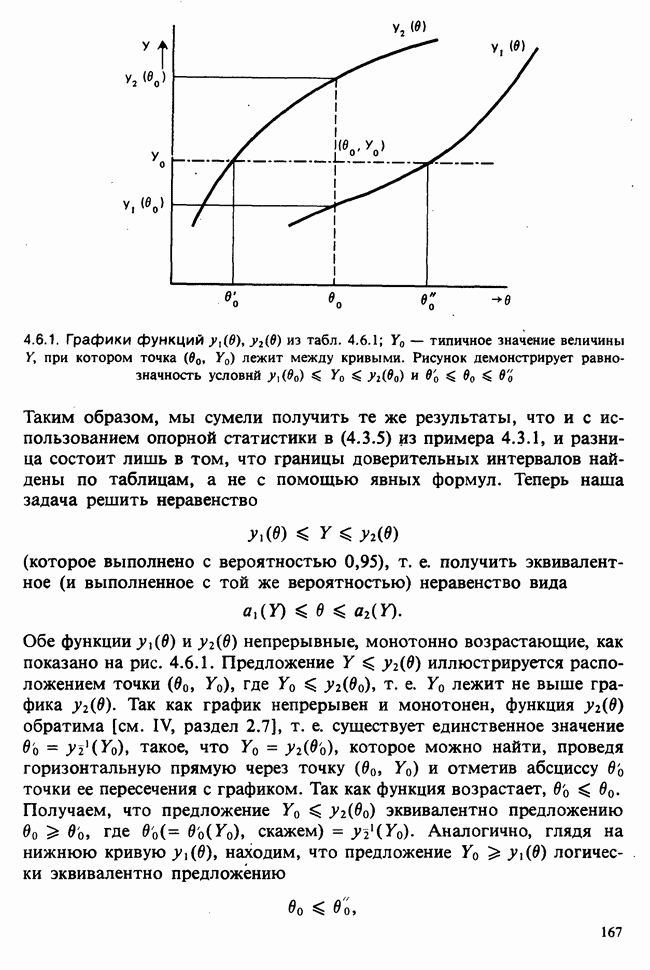
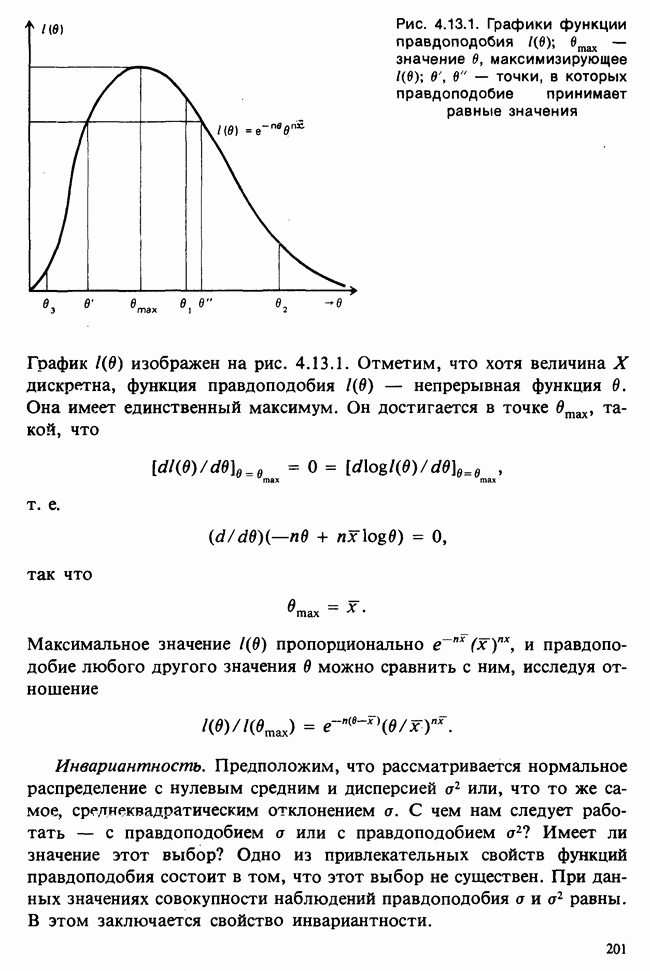
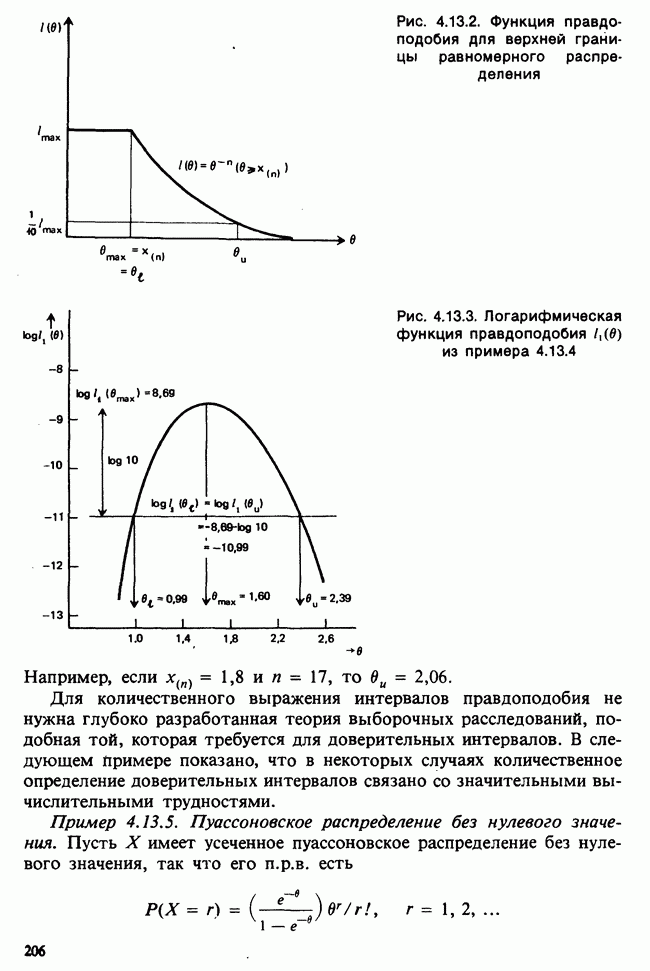
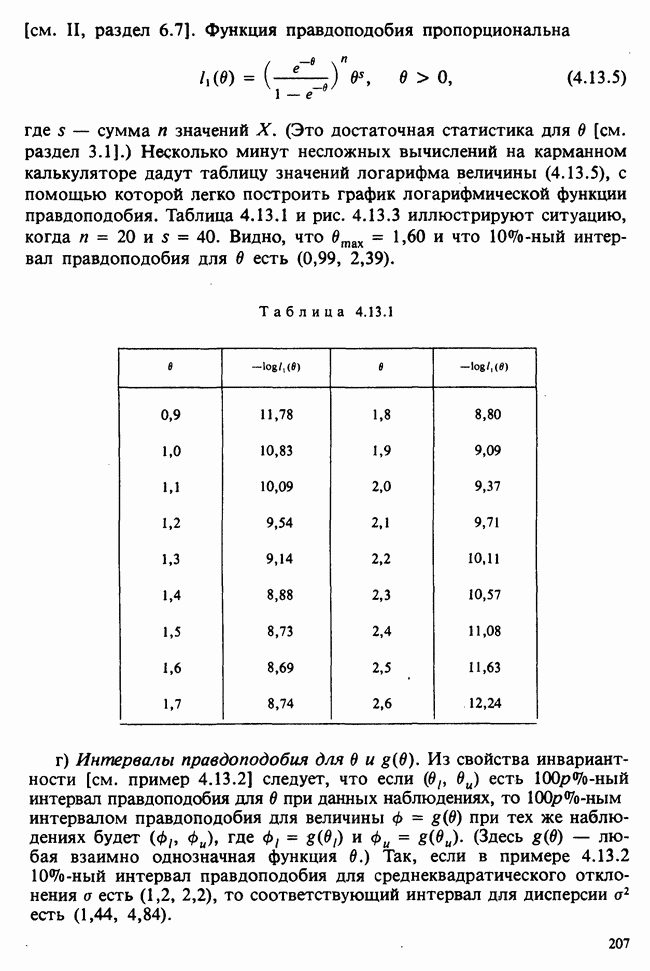
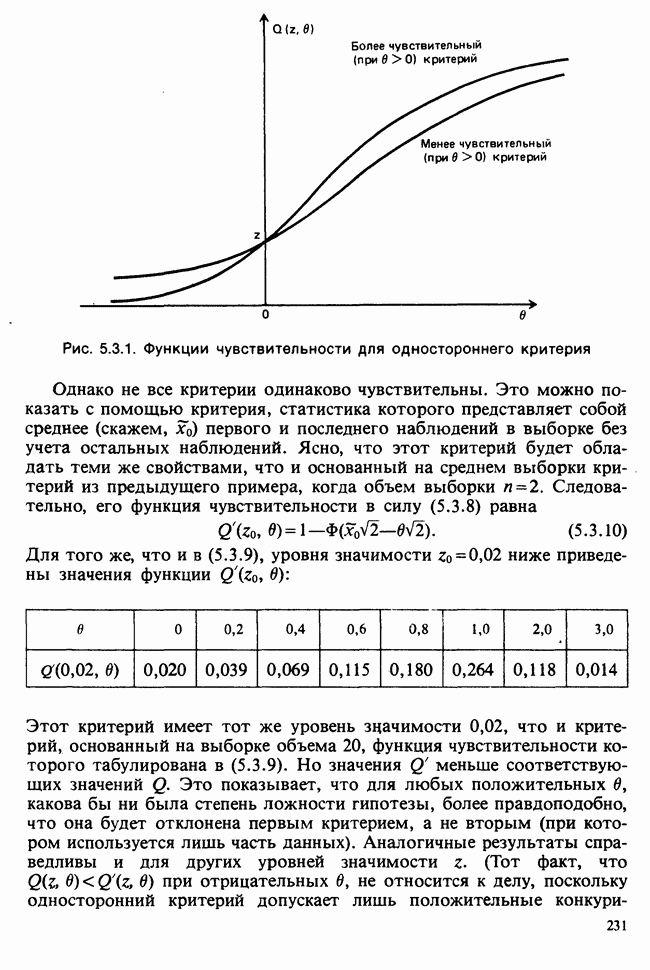
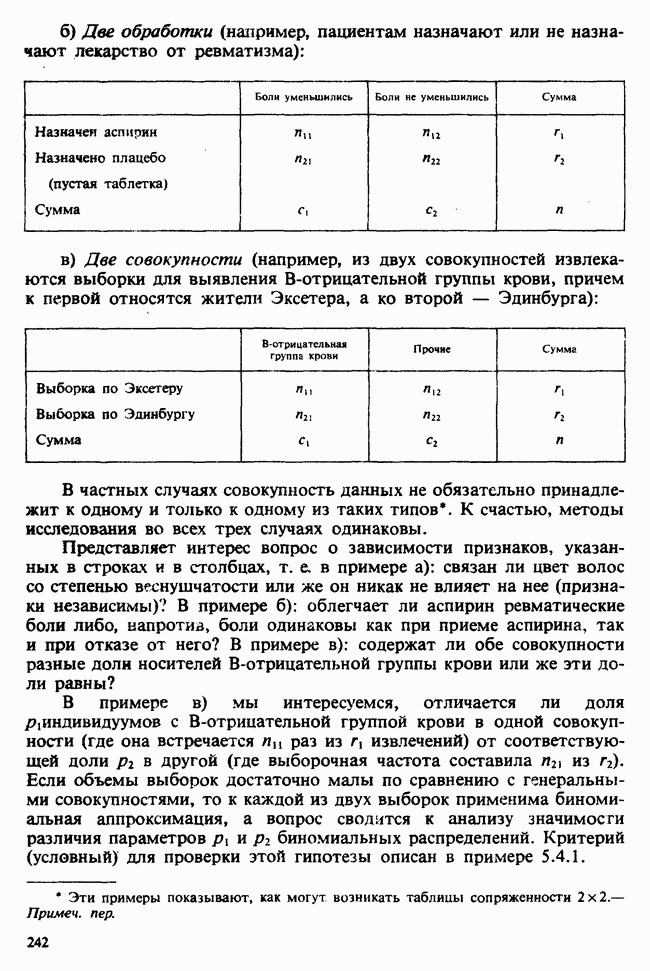
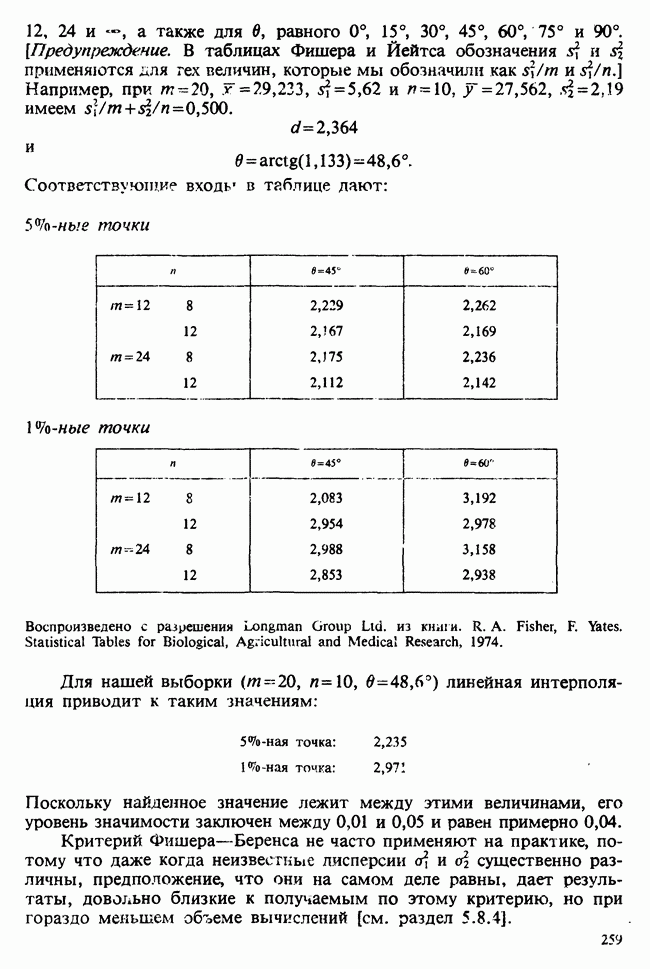
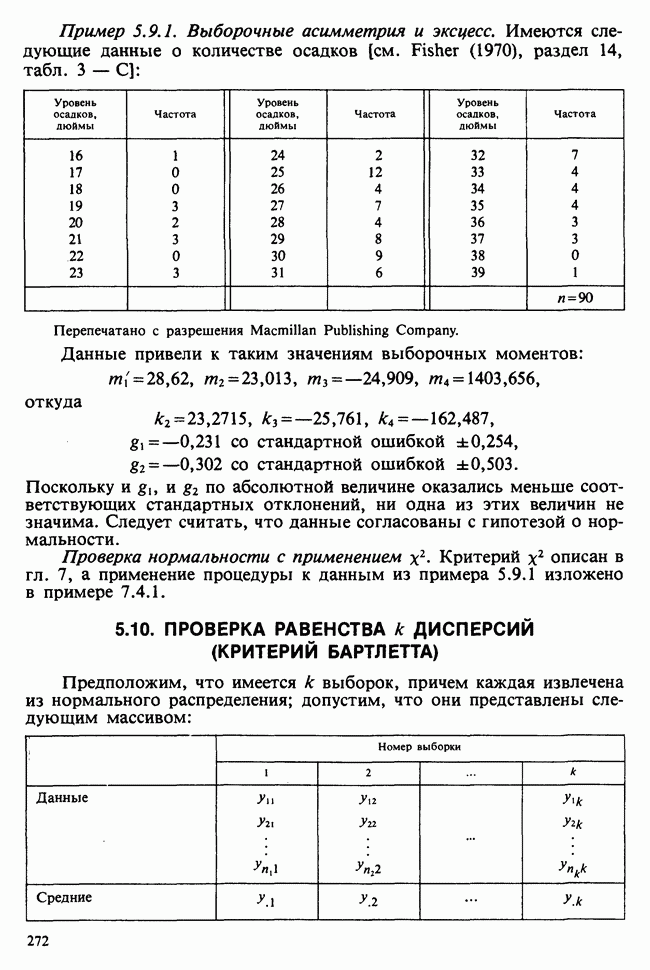
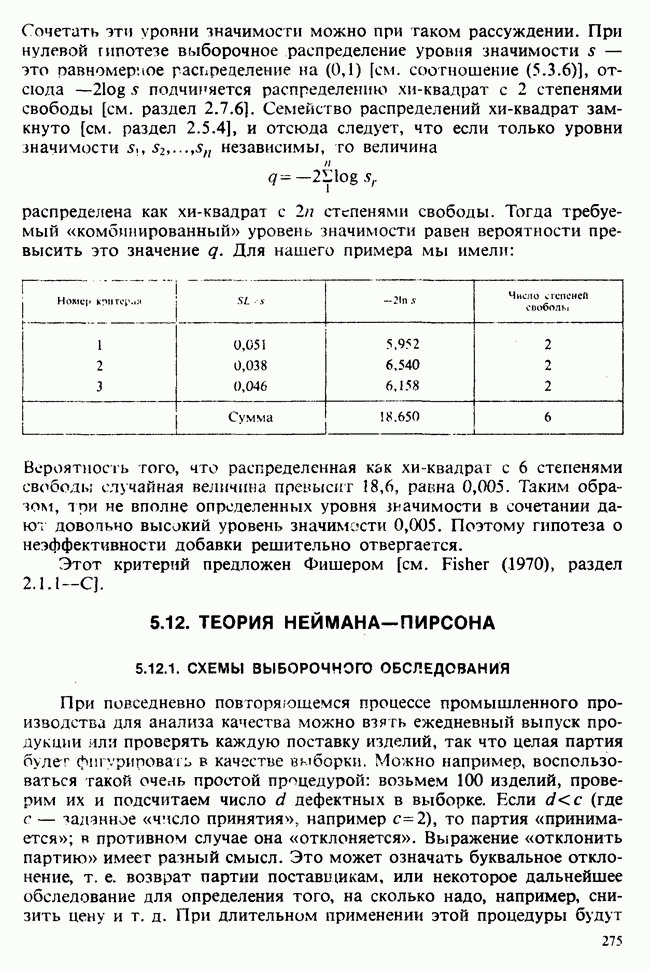
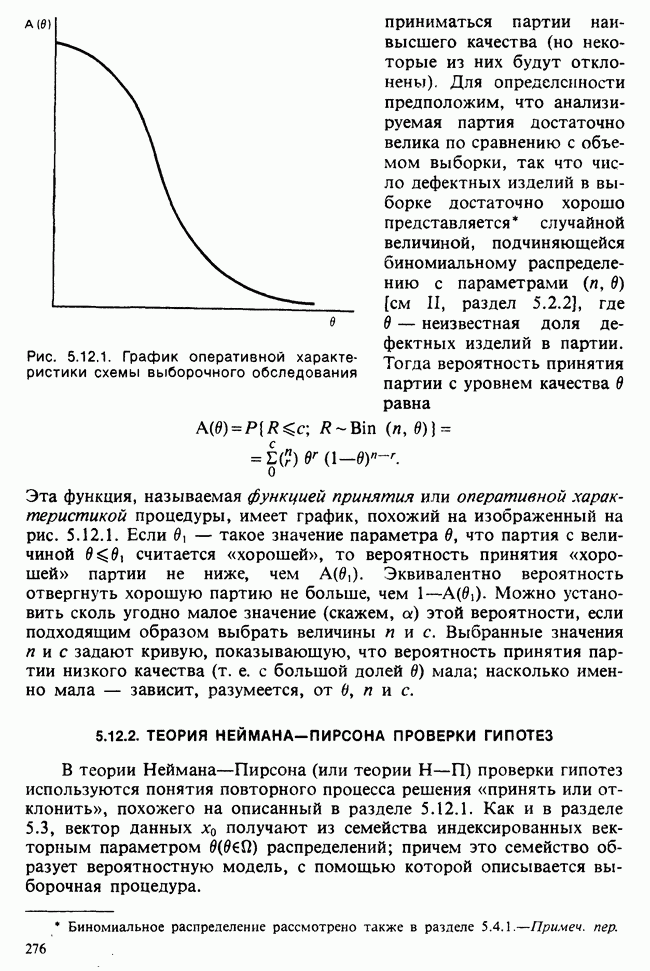
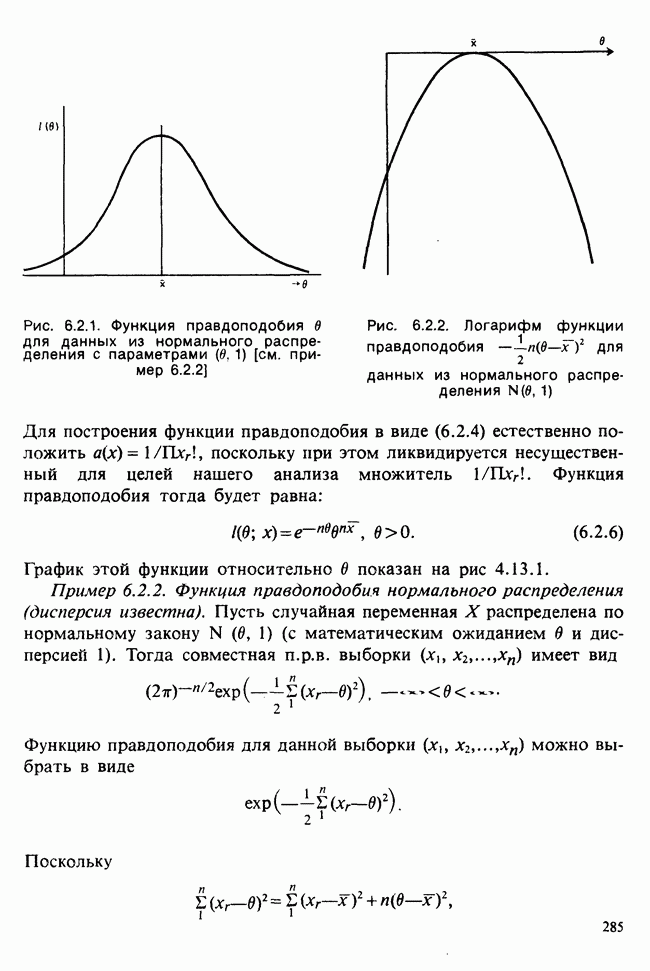
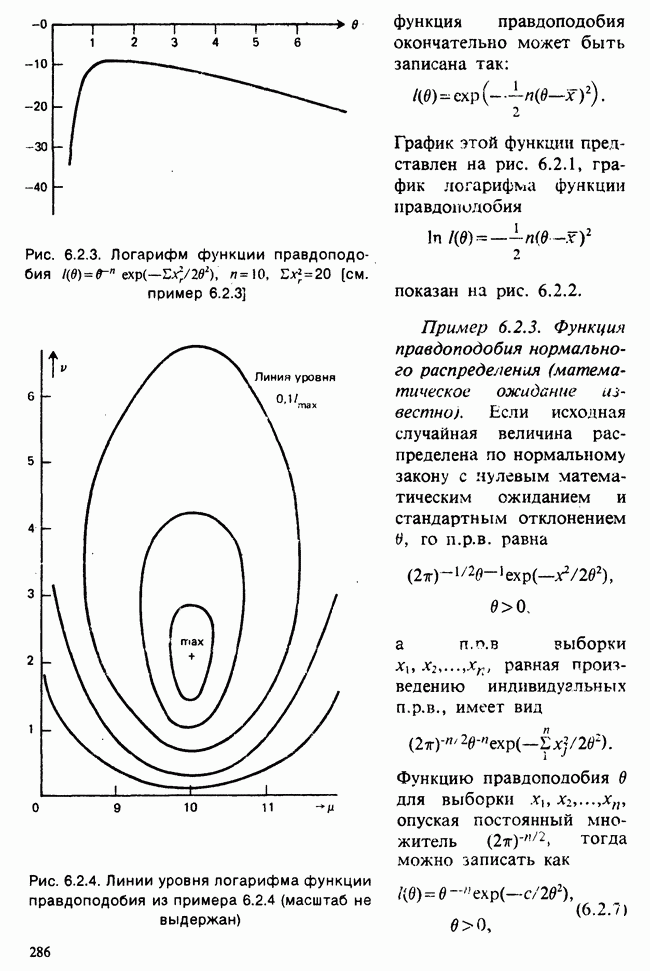
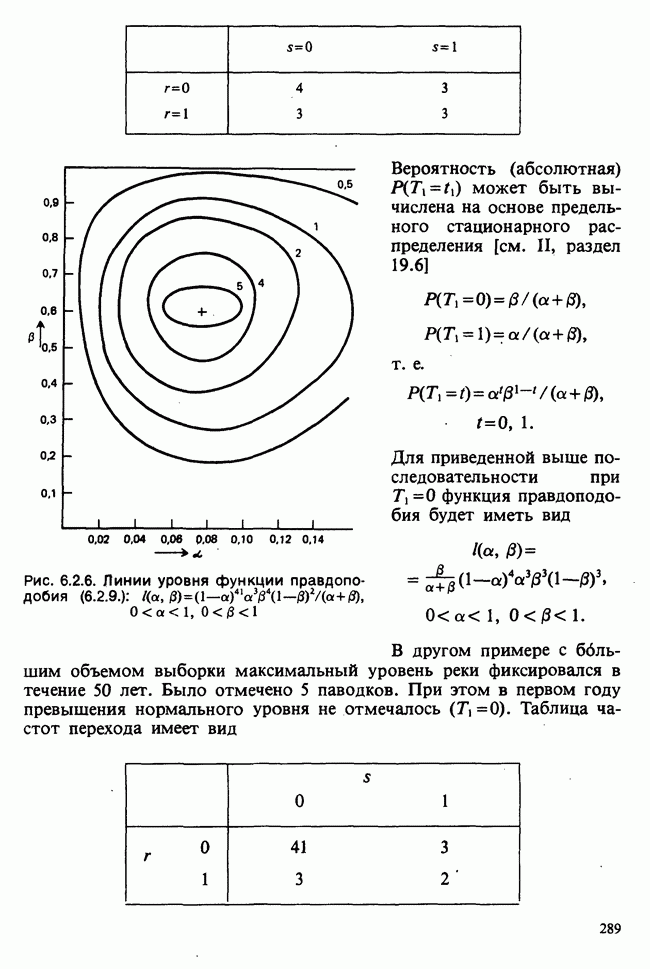
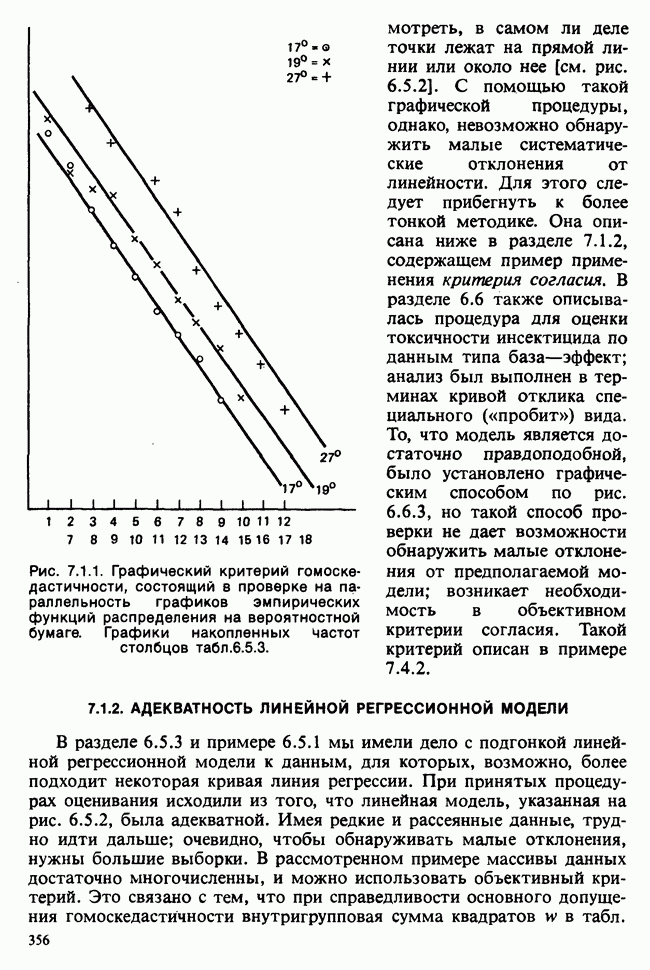
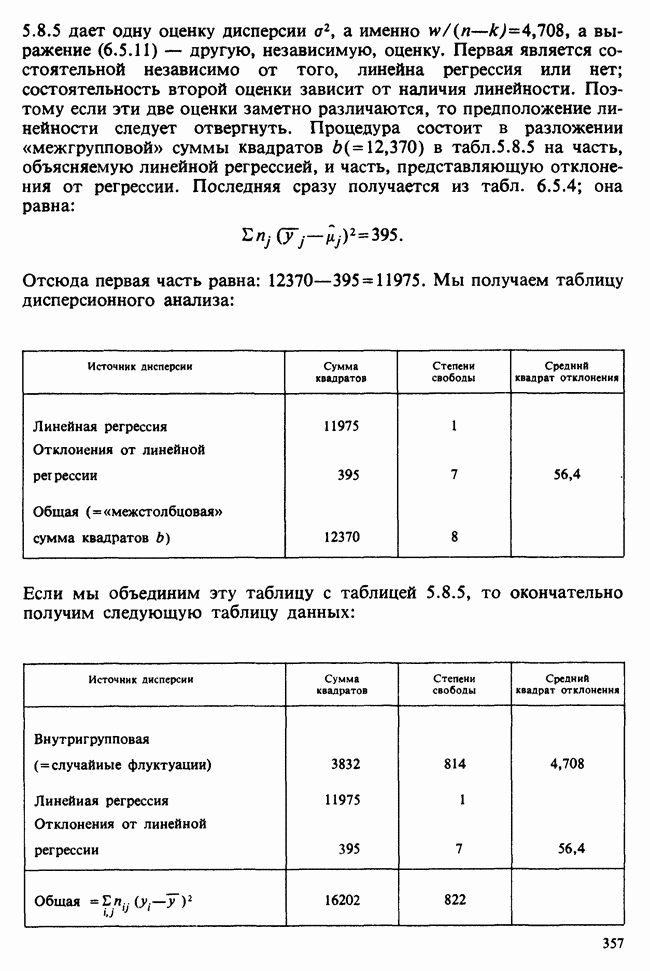
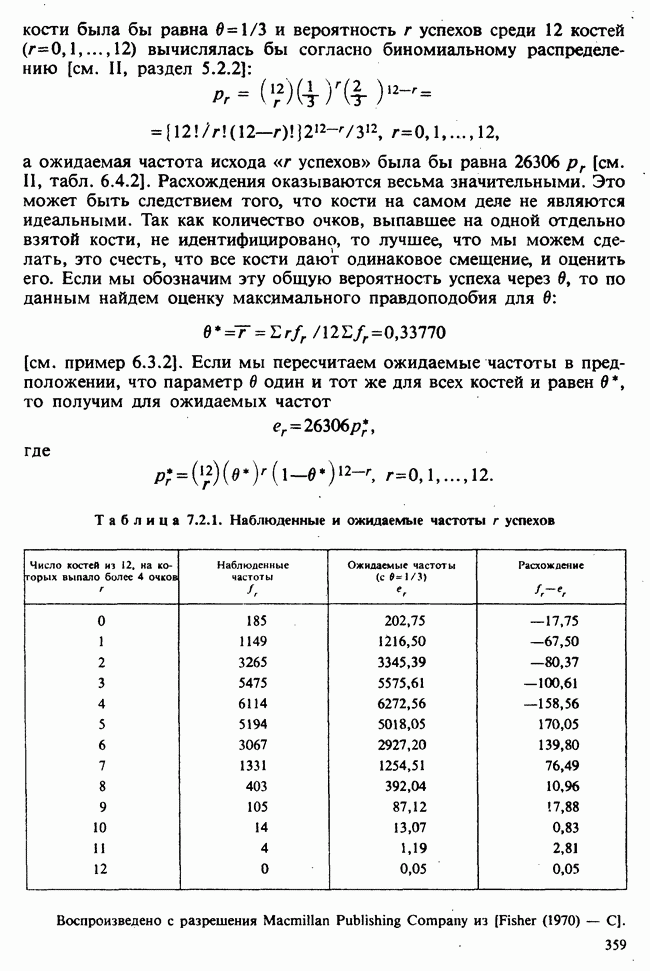
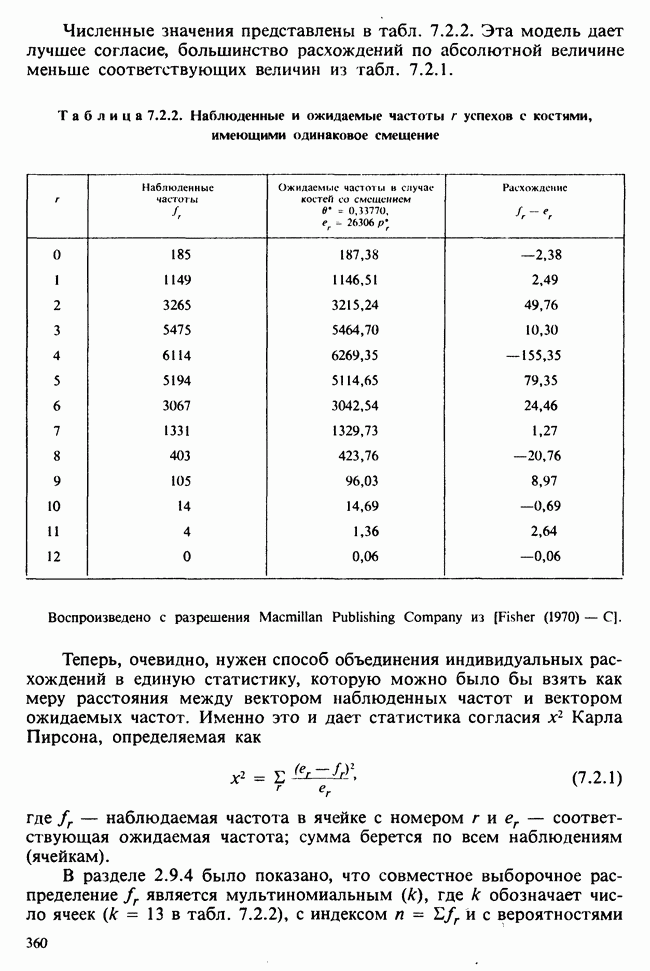
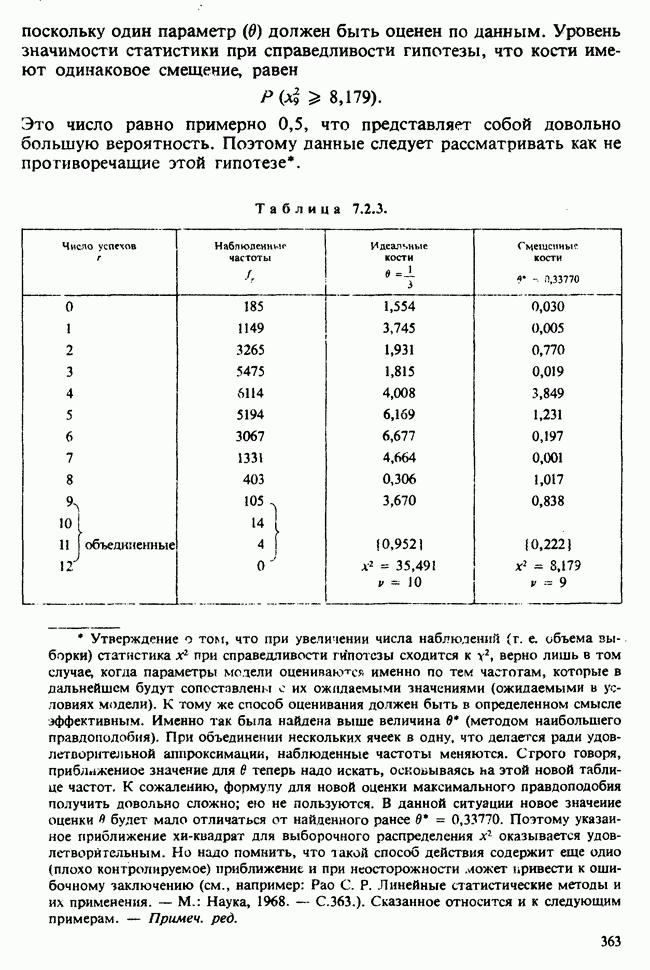
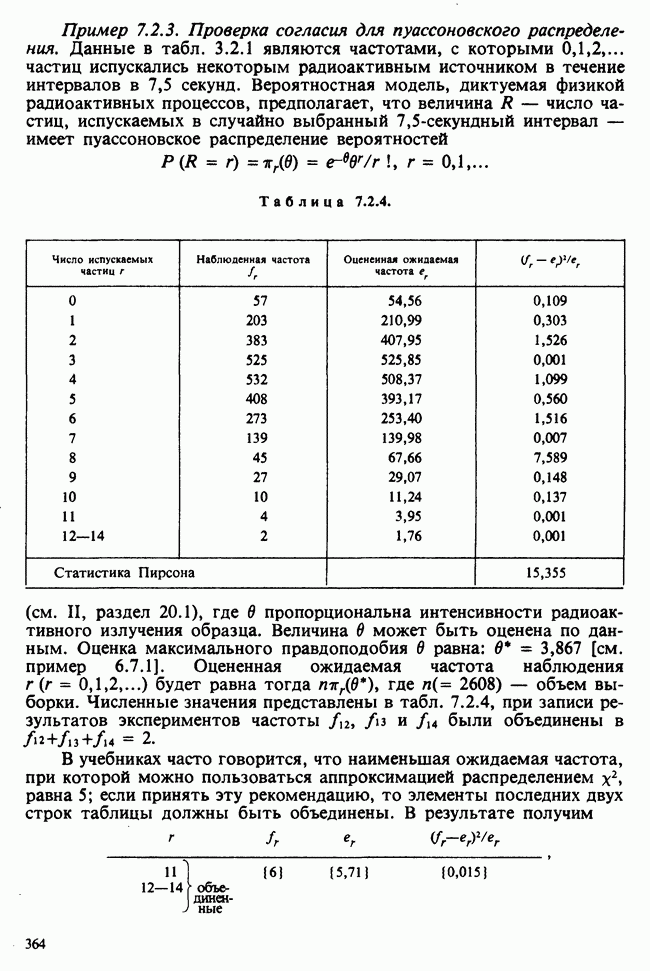
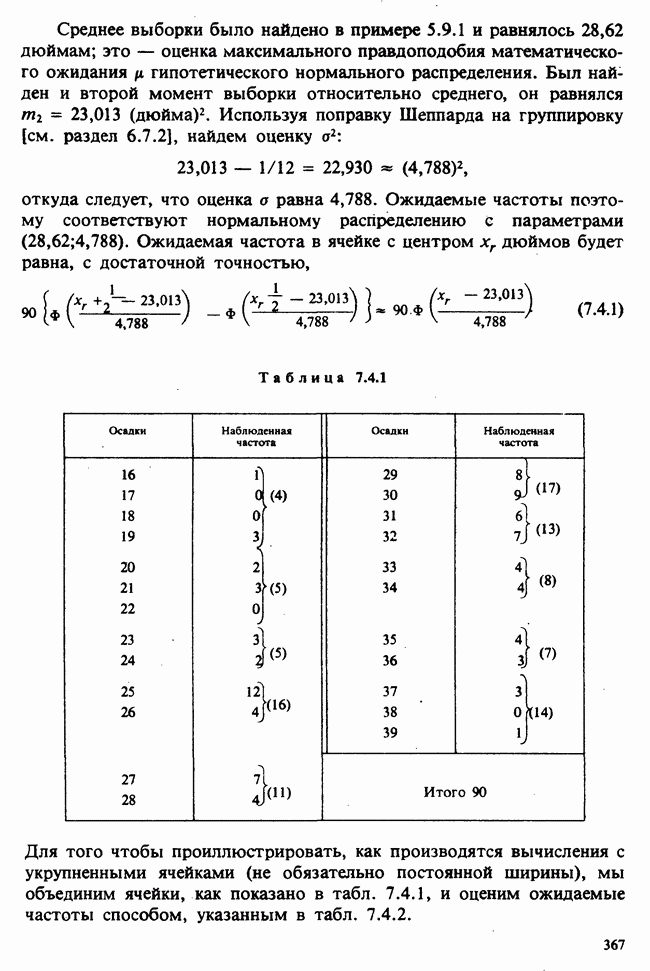
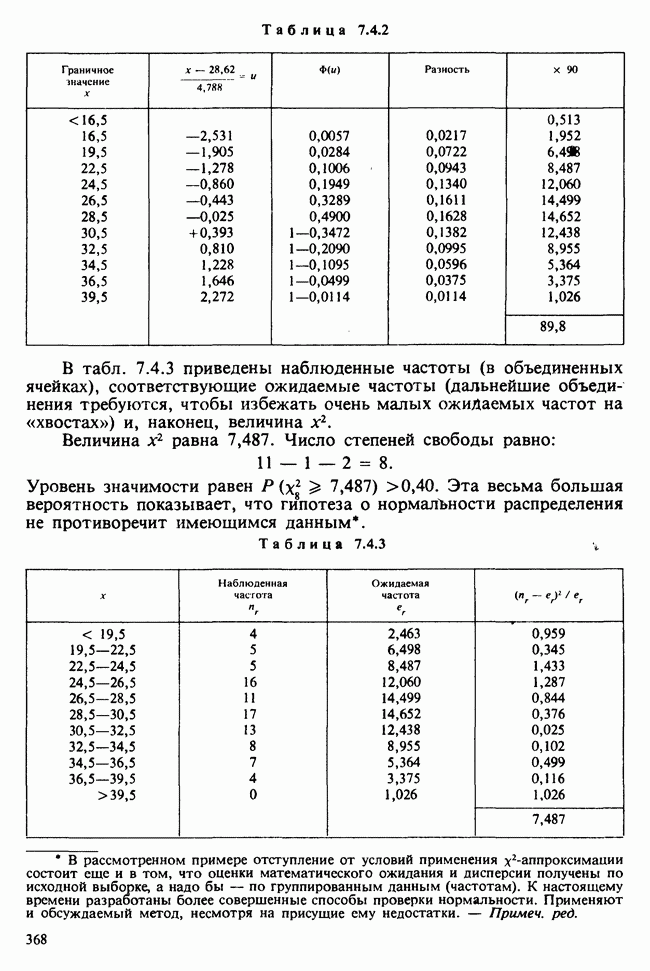
1.3. ТЕМА ЭТОЙ КНИГИХотя термин «статистика» значительно шире, чем «прикладная теория вероятностей», концепции и методы статистики тесно связаны с концепциями и методами теории вероятностей. Возможно, идеальным было бы развитие теории вероятностей и статистики как единой интегрированной дисциплины. В серии «Handbook of Applicable Mathematics», однако, было решено посвятить один том (т. II) теории вероятностей и один том (т. VI) статистике. Это не означает, конечно, что том II целиком должен быть изучен перед попыткой обратиться к настоящему тому! Напротив, методы, изложенные здесь, чаще всего понятны читателю и реже требуются лишь отдельные сведения по основам теории вероятностей. Во всех случаях, когда такие сведения необходимы, даются ссылки на соответствующие разделы тома II. Аналогично обстоит дело с ссылками на другие тома серии «Handbook of Applicable Mathematics». Очевидно, что и теория вероятностей, и статистика имеют свой круг проблем. Однако среди них есть общие для обеих этих дисциплин. Например, в нашем случае вопрос относительно независимости квадратичных форм нормально распределенных случайных величин, который мог бы прекрасно вписаться в том, посвященный теории вероятностей, в действительности был признан как имеющий большой интерес для статистики и рассмотрел в настоящем Справочнике. То же относится к центральным распределениям (см. раздел 2.8). Тематика, охваченная Справочником, кратко представлена в разделах 1.3.1-1.3.5, в то время как в разделе 1.3.6 перечислены некоторые проблемы, не рассмотренные здесь. Прежде чем приступить к краткому описанию содержания, необходимо сказать несколько слов о порядке изложения материала. Одна из основных целей серии «Handbook of Applicable Mathematics» состоит в том, чтобы предоставить читателю удобный подбор математических процедур и результатов. Казалось бы, расположение материала в алфавитном порядке» как в энциклопедии, наилучшим образом соответствовало бы указанной цели. Однако такой порядок привел бы к большому числу довольно коротких и сильно взаимосвязанных разделов. Принимая в расчет частично упорядоченную структуру математики, издатели считают, что группирование материала в однородные по содержанию главы больше отвечает поставленной цели: это обеспечивает большую непрерывность и осмысленность изложения, как в традиционных учебных курсах, а благодаря развитой системе перекрестных ссылок сохраняет и преимущество энциклопедии. Однако поскольку эта книга не является учебным пособием, расположение материала в ней достаточно произвольно, ссылки даются как на более поздние главы, так и на более ранние. В частности, гл. 2 содержит материал, относящийся к выборочным распределениям, которые связаны с тематикой, рассмотренной позднее. Каждая из других глав представляет какую-либо одну важную тему. В одном или двух случаях было признано удобным разделить материал, относящийся к одной, главной, теме, на две главы. Теперь рассмотрим кратко содержание Справочника. 1.3.1. ВЫБОРОЧНЫЕ РАСПРЕДЕЛЕНИЯ. МЕТОДЫ, СВОБОДНЫЕ ОТ РАСПРЕДЕЛЕНИЯСтатистик должен получить свои выводы, используя наличную выборку. Каждое наблюдение является реализацией случайной величины. Известно множество значений, которые может принимать случайная величина; некоторые из них имеют ббльшую вероятность появления, чем другие. Значение, которое наблюдалось, представляет собой реализацию. Вероятности возможных реализаций характеризуются распределением вероятностей случайной величины. В исключительных случаях вероятность реализации может быть указана в виде числа, определяемого из распределения вероятностей. Но обычно функции распределения вероятностей бывают заданы с точностью до одного-двух параметров, значения которых не известны. Это приводит к проблеме поиска таких комбинаций выборочных значений, которые бы давали наилучшее приближение для неизвестных параметров. Каждая такая комбинация есть статистика, и, как и любое наблюдаемое значение, статистика представляет собой реализацию некоторой случайной величины. Если Итак, выборочное распределение статистики позволяет судить, может ли предложенная статистика служить оценкой интересующего нас параметра. (Здесь, как и всюду в книге, мы использовали соглашение об обозначениях, согласно которому случайные переменные обозначаются прописными латинскими буквами (например , X), а реализации этой случайной переменной — строчными латинскими буквами (например, х или Выборочное распределение, таким образом, весьма важно. Поэтому в книге выделена глава, где сосредоточена информация о выборочных распределениях статистик, имеющих большое значение для практики. Однако статистические процедуры, которые сильно зависят от выборочных распределений, могут быть подвергнуты критике, поскольку выборочные распределения статистик зависят от предположений относительно распределений, лежащих в основе самой вероятностной модели. Если эти предположения не выполнены, то конструкция в целом нарушается. На практике наиболее широко используемые процедуры являются устойчивыми (робастными), т. е. сравнительно нечувствительны к тем отклонениям от вероятностной модели, которые не выходят за пределы разумно допустимых. Ясно, что наиболее устойчивыми среди всех процедур будут такие (если они существуют), которые эффективны без каких-либо предположений о распределении. Такие процедуры в самом деле существуют и называются свободными от распределения (или непараметрическими). Эти методы рассмотрены в гл. 14. 1.3.2. ОЦЕНКИ, ТЕСТЫ, РЕШЕНИЯОбманчиво короткий заголовок этого раздела соответствует тому, что в действительности составляет ббльшую часть данной книги. Проблема оценивания была схематично описана в разделе 1.3.1. Гл. 3 расширяет это описание и подводит к систематическому подходу, позволяющему находить хорошие оценки. В ней рассмотрены и графические методы представления информации, содержащейся в выборке, а также некоторые формальные критерии, например, оценка параметра должна иметь ту же физическую размерность, что и оцениваемый параметр, оценка должна быть связана с интересующим нас параметром, а не с другими параметрами, оценка должна иметь возможно меньшую вариабельность (измеренную ее стандартным отклонением). Оказывается, что в некоторых случаях можно сконцентрировать всю информацию относительно некоторого параметра, содержащуюся в выборке, в одной («достаточной») статистике. Эта концепция также обсуждается в гл. 3, в конце которой есть и короткий раздел, посвященный практическим приемам конструирования оценок, имеющих желательные свойства. Ясно, что разумная процедура оценивания не должна ограничиваться лишь выбором приближенного численного значения для неизвестного параметра; она должна что-то говорить и о надежности этого приближения. Хотя эти два аспекта единой проблемы оценивания тесно связаны, иногда удобно обсуждать их отдельно. Соответственно мы говорим о точечном оценивании и об интервальном оценивании. Гл. 4 в основном посвящена интервальному оцениванию. В ней рассматриваются: а) «доверительные интервалы», связанные с поведением статистик в повторных выборках, теория которых сильно зависит от выборочных распределений; б) правдоподобные интервалы, один из аспектов функции правдоподобия, которая позволяет среди всех возможных значений параметра выделить правдоподобные с учетом имеющихся данных (выборки); в) байесовские интервалы, сконструированные на основе подхода, при котором выборка рассматривается как средство для изменения и уточнения априорной информации, имеющейся в наличии до получения выборки (этот подход подробно обсуждается в гл. 15). Поскольку в целом статистика как научная дисциплина основана на идее случайной изменчивости, каждая оценка подвержена ошибке; если получены две различные оценки параметра — одна при одном наборе условий, а другая при другом, — непосредственно не ясно, соответствует ли имеющееся между ними различие различию между параметрами. Например, параметром может быть вероятность определенного заболевания при приеме препарата А (одно условие) или препарата В (другое условие). Вопрос об их различии решается с помощью статистического критерия (теста) или критерия значимости; эта процедура описана в гл. 5. Один из подходов к статистическим критериям (проверке гипотез) связан с именем Р. А. Фишера [см. Box (1978) - D], который рассматривает проверку гипотезы как пробный шаг в проведении научного исследования, позволяющий получить ученому объективный критерий, с помощью которого можно судить об истинности гипотезы. Другой подход связан в основном с именами Дж. Неймана и Э. Пирсона, которые рассматривают процедуру проверки гипотезы как правило, с помощью которого должен быть сделан выбор между одним способом действия и другим либо принято решение об истинности одной гипотезы в противовес другой. В обычной статистической практике реальные процедуры при этих двух подходах не очень различаются. Сравнительно недавно теория принятия решений стала самостоятельной дисциплиной, задачей которой является анализ потерь и выигрышей при принятии неправильных и правильных решений. Достижения этой дисциплины важны и полезны в теории оценивания, проверке статистических гипотез и в других областях. Эти вопросы обсуждаются в гл. 19. Одна из частных проблем теории проверки статистических гипотез — оценка пригодности вероятностной модели, предложенной для объяснения данных. С достаточным основанием можно предположить, что некоторая последовательность нерегулярно возникающих событий (например, отсчетов счетчика Гейгера) представляет собой пуассоновский процесс (см. II, раздел 20.1). После того как интересующий нас параметр оценен по имеющимся данным, возникает вопрос, насколько предложенная модель соответствует выборке. Являются ли выборочные значения действительно близкими к тем, которые можно ожидать, используя подогнанную модель? Наиболее широко применяемая для решения подобного вопроса процедура позволяет вычислить некоторую статистику, введенную Карлом Пирсоном, и воспользоваться критерием, основанным на ее выборочном распределении. Это пирсоновский критерий согласия хи-квадрат Существуют различные методы конструирования «точечных» оценок и определения их надежности. Наиболее полезен из них метод максимального правдоподобия, который обсуждается в гл. 6. Там же приведены и примеры его применения. Другой известный метод, который может рассматриваться либо как специальный случай метода максимального правдоподобия, либо как независимая процедура подгонки, — метод наименьших квадратов. Этот метод и более или менее систематизированный набор правил для проверки статистических гипотез (все это называется дисперсионным анализом или сокращенно ANOVA) описаны в гл. 8. Те методы оценивания и проверки гипотез, о которых говорилось выше, предназначены для данных, представленных «фиксированной» выборкой. Это значит, что сначала была завершена процедура выбора, а затем ее результаты были подвергнуты обработке. В некоторых ситуациях порции данных поступают последовательно. Для подобных выборочных процедур разработаны специальные методы проверки гипотез. В этих методах доказательства в пользу интересующей нас гипотезы или против нее накапливаются одновременно с ростом выборки до тех пор, пока они не станут убедительными. Тогда выборочная процедура прерывается. Такие процедуры проверки гипотез называются последовательными. Они рассматриваются в гл. 13. Сельское хозяйство, пожалуй, в наиболее сильной степени подвержено влиянию природной изменчивости. По этой причине в ранний период своего развития сельскохозяйственная наука встретилась с большими трудностями при сравнении различных сортов семян и удобрений. Важнейшая роль сельского хозяйства, немалая стоимость и большая продолжительность полевых исследований требуют эффективного планирования действий. Это обусловило развитие планирования сравнительных экспериментов, науки (или искусства), не ограниченной теперь только сельским хозяйством. В гл. 9 дано введение в эту обширную дисциплину, а гл. 10 посвящена методам анализа данных, получаемых в результате таких экспериментов. Эти методы основаны на линейной модели, в которой предполагается, что отклик системы (например, урожай пшеницы) в зависимости от имеющихся стимулов (например, количества удобрения) представляет собой линейную функцию. Концепция линейности может быть, впрочем, успешно расширена до более сложных моделей, нелинейных, как в большинстве случаев применения дисперсионного анализа. Например, токсичность некоторых лекарственных препаратов является нулевой, если их доза не превышает пороговой величины; затем токсичность возрастает с увеличением дозы, сначала медленно, затем быстрее, потом снова медленнее. Прирост токсичности сходит на нет при приближении к стопроцентной смертельной дозе (см. пример 1.1.2). Иногда говорят, что кривая отклика, измеряющая при установленной дозе процент погибших в эксперименте животных, имеет Такое обобщение линейной модели обсуждается в гл. 11 и 12. 1.3.3. БАЙЕСОВСКИЙ ВЫВОДМы уже упоминали байесовскую статистику, названную так в честь английского математика 18-го столетия Р. Томаса Байеса [см. Pearson and Kendall (1970) - D]. Если говорить просто, при байесовском подходе параметр, который должен быть оценен, рассматривают как случайную величину. В этом случае его свойства следует описывать в терминах распределения вероятностей. При выборочном контроле в промышленности, обсуждавшемся в примере 1.2.1, доля дефектных изделий в партии оценивалась с помощью значения некоторой статистики, основанной только на выборке из этой партии. Предположим теперь, что данная партия сама представляет собой одну из множества партий, относительно которых опытным путем установлено, что доля дефектных изделий в них При «новейшем байесовском подходе» к статистическому выводу учитывают то обстоятельство, что всегда имеется некоторая априорная информация о неизвестном параметре, возможно, менее точная, чем в случае, описанном выше, но все же достаточная для получения априорного распределения, из которого конструируется апостериорное. Эти проблемы обсуждаются в гл. 15. 1.3.4. МНОГОМЕРНЫЙ АНАЛИЗТолько в простейших ситуациях статистик имеет дело с единственной случайной величиной. Обычно каждый объект из выборки может быть подвергнут нескольким различным измерениям, например, можно измерить рост, обхват талии, вес человека. В этом случае статистика интересует, ведут ли себя компоненты вектора наблюдений независимо друг от друга; если нет, то как можно описать их совместное поведение; являются ли некоторые из компонентов более информативными для разделения на классы и т. д. Классический подход к решению подобных задач обсуждается в гл. 17. В гл. 18 приведен обзор современного состояния этих проблем. 1.3.5. ВРЕМЕННЫЕ РЯДЫПоследняя тема, которой мы коснемся в этом описании разделов статистики, охваченных книгой, связана с анализом последовательности наблюдений (каждое из них подвержено случайному разбросу), порождаемых источником, который сам изменяется, развивается или флуктуирует. Такими наблюдениями могут быть, например, ежедневные измерения уровня воды в Темзе на Марлоу, еженедельное количество дождевых осадков в Сан-Франциско, ежечасные замеры концентрации определенного химиката в камере повышенного давления для какого-нибудь химического процесса, ежемесячная статистика дорожно-транспортных происшествий и т. д. Вариации в данных представляют собой смесь в неизвестных пропорциях закономерных колебаний (таких, как, например, чистый синусоидальный сезонный эффект) с флуктуациями, подчиненными некоторому (неизвестному и, возможно, изменяющемуся во времени) рапределению вероятностей. Поведение системы в момент времени Теория временных рядов рассматривается в гл. 18. Важный метод, известный как фильтр Калмана, описан в гл. 20. 1.3.6. БИБЛИОГРАФИЧЕСКИЕ ССЫЛКИРодственные темы в книге связаны системой перекрестных ссылок. Используются также ссылки на другие тома серии «Handbook of Applicable Mathematics». Отсылки за пределы Справочника организованы по-разному: внутри глав и для тома в целом. Список книг (литература для дальнейшего чтения) для конкретной главы приведен в конце ее. Это позволяет получить дополнительную информацию. В тексте ссылки на эти работы выглядят так: [см. Barnett (1982), гл. 1]. В т. 2 Справочника приведен общий для обоих его томов список литературы. Он разбит на разделы: А — библиография; В — словари, энциклопедии, справочники; С — общие работы, охватывающие широкий круг вопросов; D — исторические и библиографические материалы; Е — руководства по статистическим таблицам; F — таблицы случайных чисел, подчиненных конкретным распределениям; G — таблицы статистических функций; Н — специальные темы, не рассмотренные или кратко изложенные в Справочнике. Ссылки на эти источники в тексте обозначены так: [см. Kendall and Buckland (1971) - B]. 1.3.7. ПРИЛОЖЕНИЕ: СТАТИСТИЧЕСКИЕ ТАБЛИЦЫСерьезное статистическое исследование предполагает интенсивное использование таблиц [см. список литературы, раздел G]. Однако во многих случаях читатель обнаружит, что будет достаточным небольшое собрание таблиц в приложении. Это таблицы биномиального, пуассоновского, нормального распределений, распределения Стьюдента и распределения хи-квадрат, 5000 случайных цифр, 500 чисел, распределенных по стандартному нормальному закону, и диаграммы для определения доверительных интервалов параметров биномиального и пуассоновского законов. 1.3.8. ТЕМЫ, НЕ РАССМОТРЕННЫЕ В СПРАВОЧНИКЕИдеальная книга по статистике должна содержать сбалансированное описание теории и практики с охватом всех аспектов предмета. Она должна быть понятна читателям и иметь умеренный объем. Издатели считают, что этот идеал не был достигнут: в частности, некоторым темам отведено слишком много места, другим слишком мало, а иные не рассмотрены вовсе. Главный акцент в Справочнике сделан на интерпретацию данных. Практическим деталям сбора данных уделено меньше внимания: краткое введение в планирование сравнительных экспериментов содержится в гл. 9. Для получения более подробной информации о планировании, скажем, выборочных обследований, читатель должен обратиться к списку литературы [см. Arkin (1963); Barnett (1974); Cochran (1963); Deming (1950); Hanson, Hurwitz and Madow (1953); Stuart (1976); Yates (1960) — Н]. Другие темы постигла та же судьба либо потому, что они были сочтены слишком специальными, либо из-за близости их к границам рассматриваемой области, либо потому, что они являются предметом будущих публикаций в серии «Handbook of Applicable Mathematics». Сюда относятся основания и общие принципы нечеткого вывода, приложения математического программирования и методов оптимизации в статистике, анализ специальных типов данных, таких, как направленные данные или экстремальные значения, использование и возможности пакетов статистических программ, статистическое моделирование и метод Монте-Карло, выборочный контроль в промышленности и контроль качества. Работы, посвященные этим проблемам, можно найти в разделе Н списка литературы.
|
 |
Оглавление
|





















































































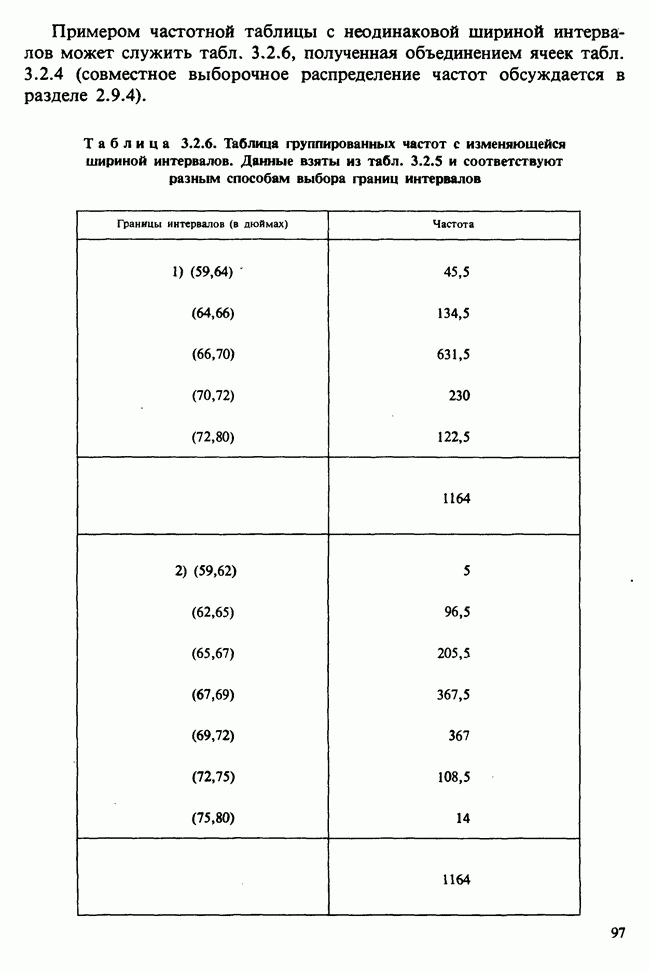
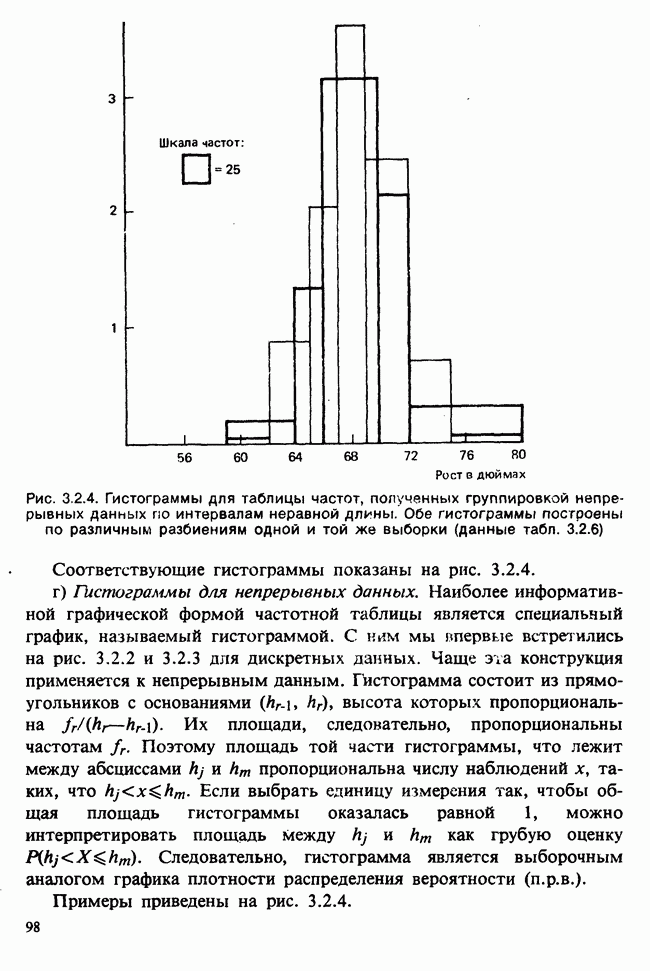































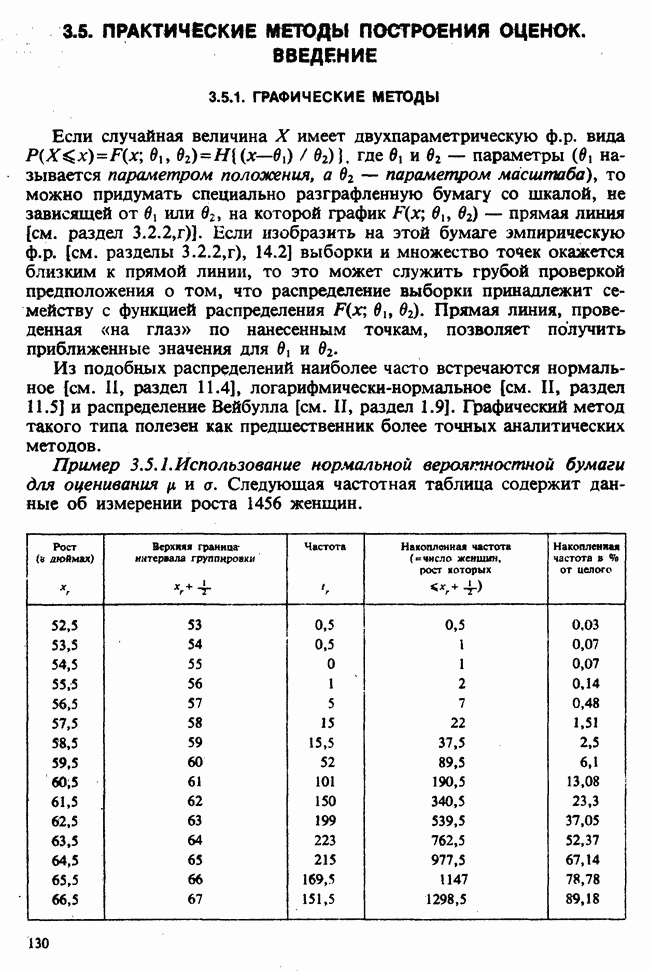
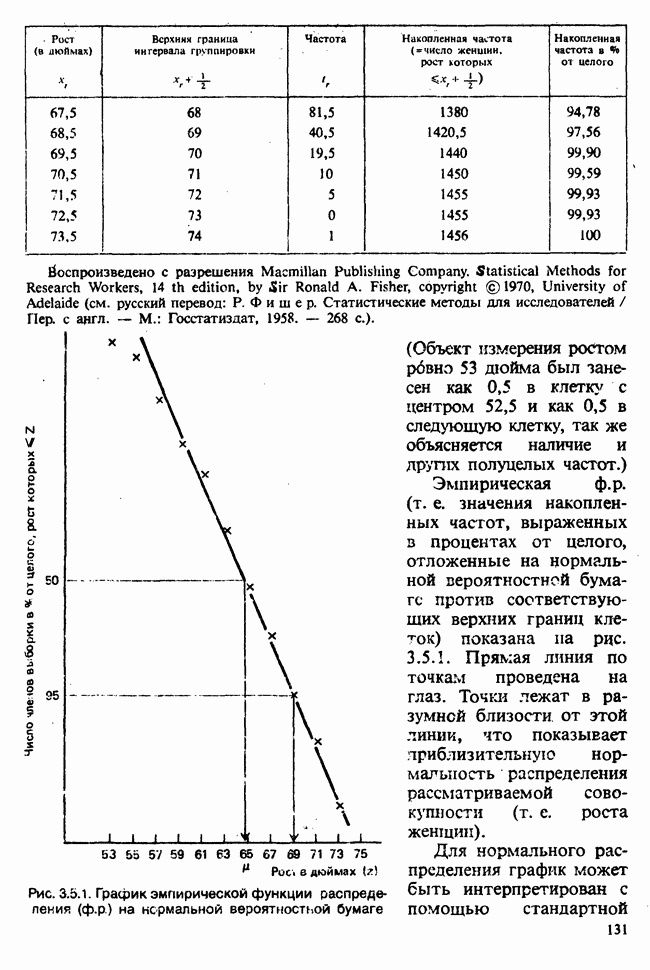










































































































































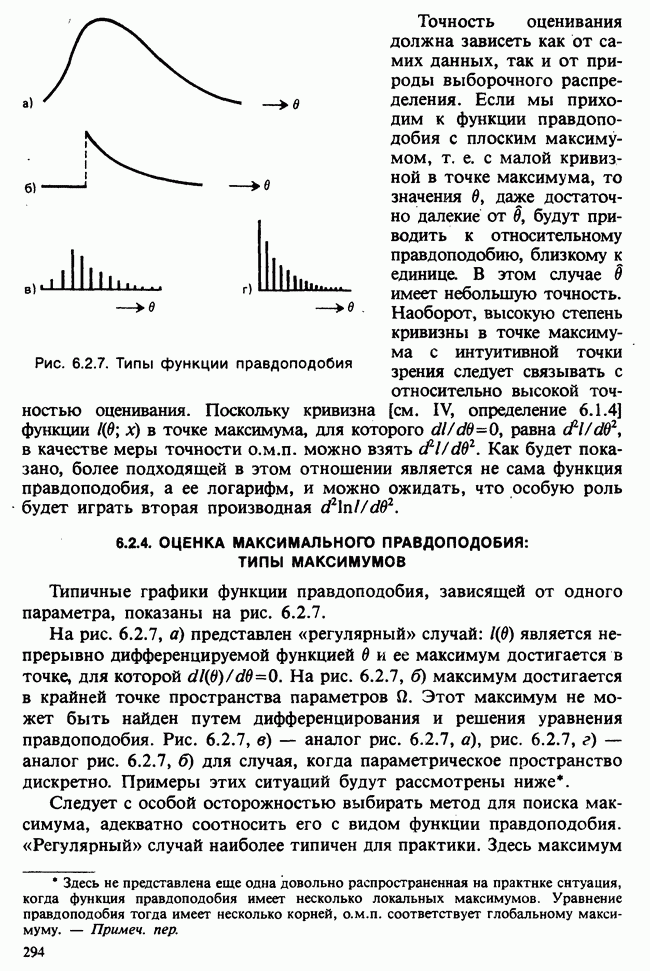
























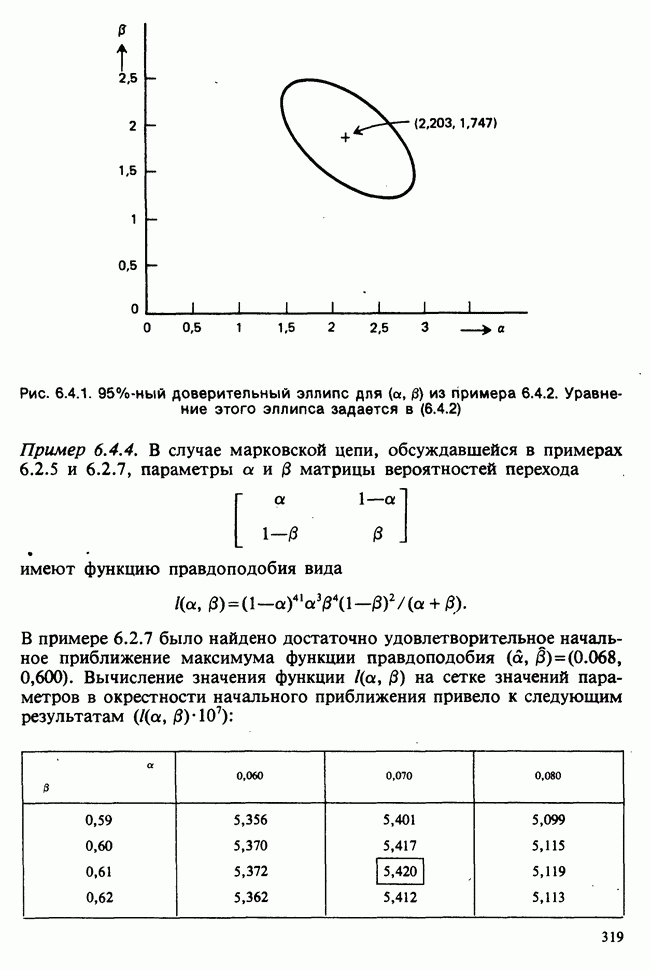



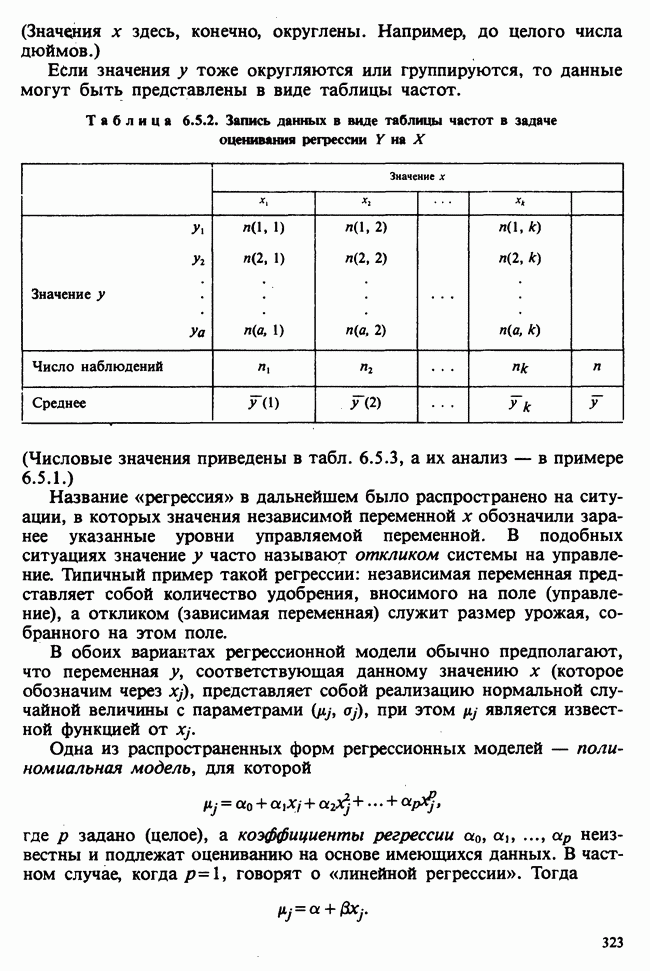





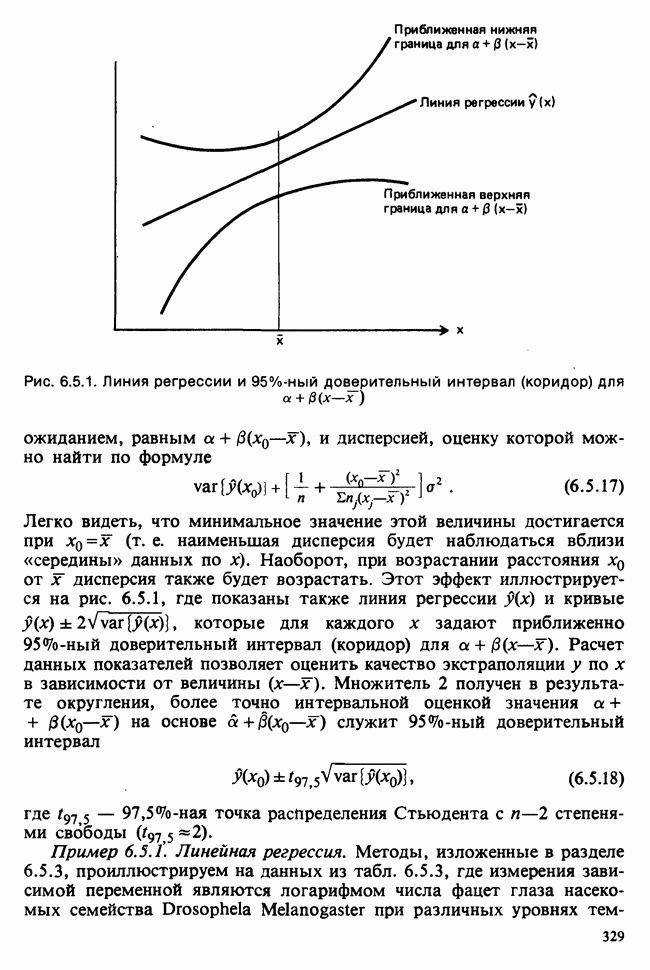







































































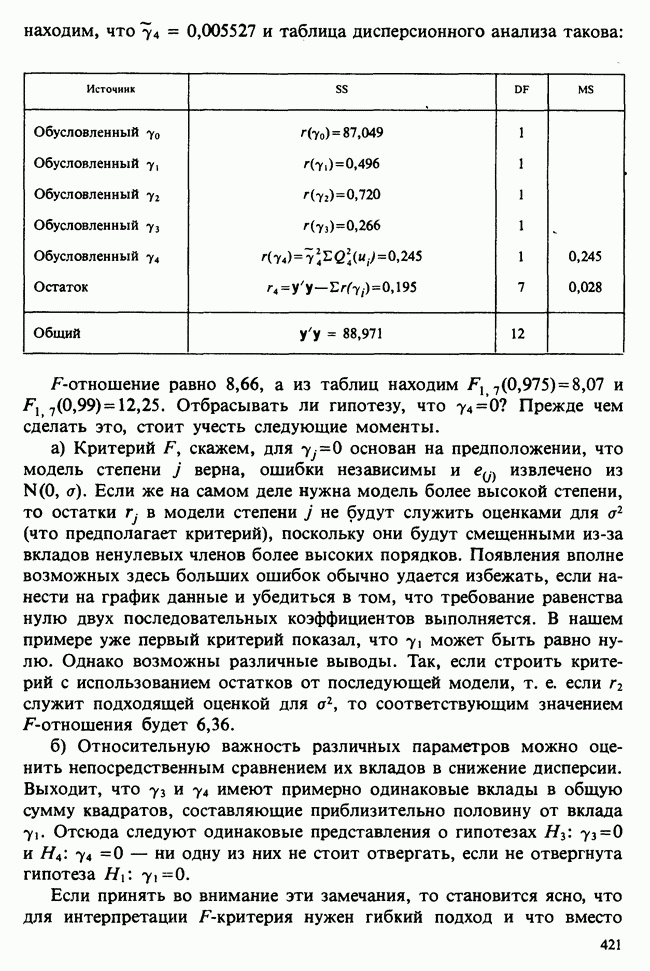







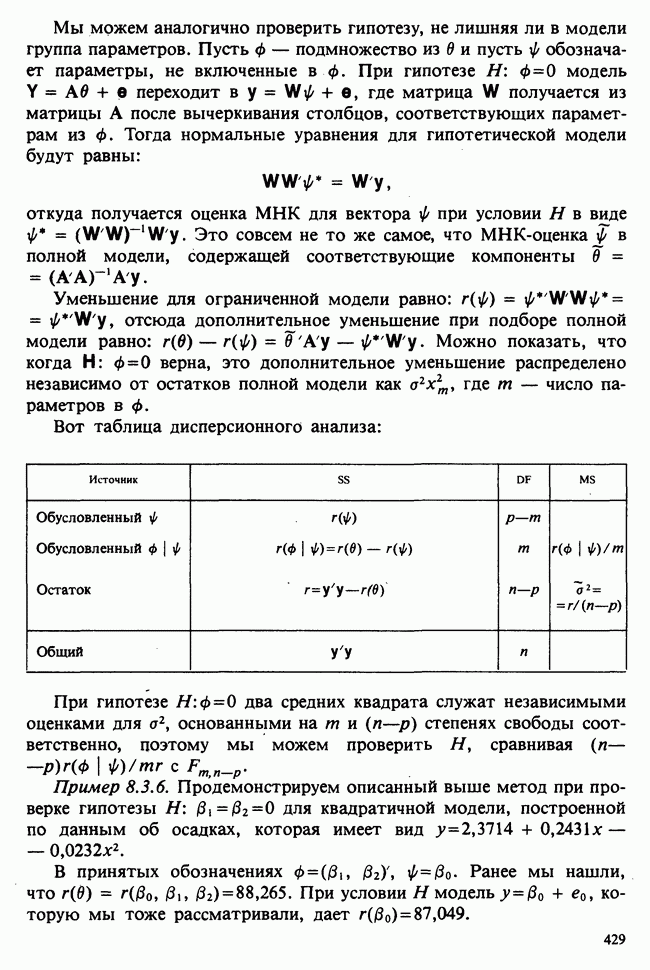














































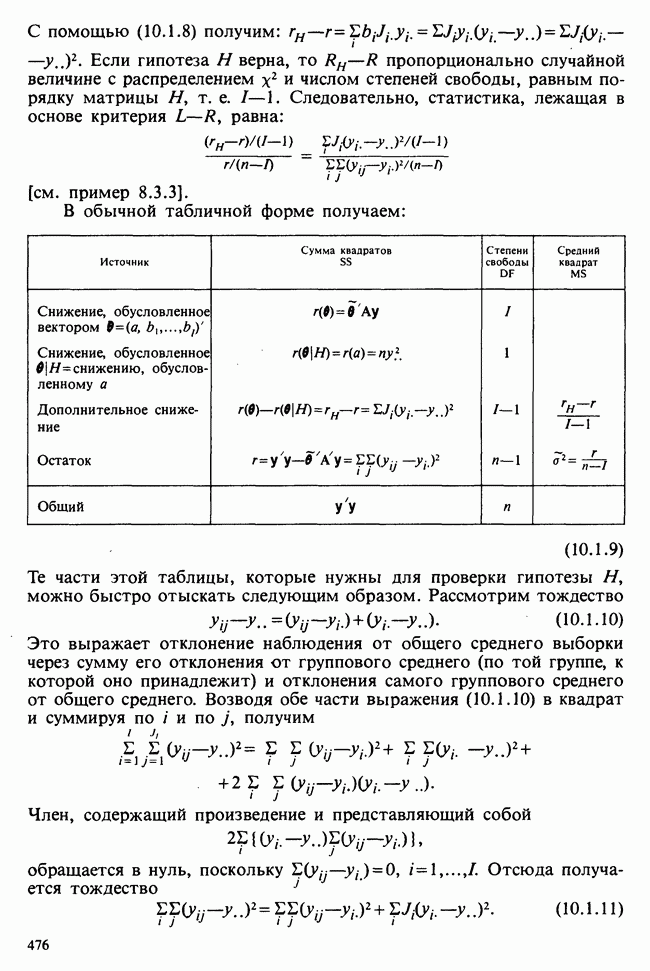


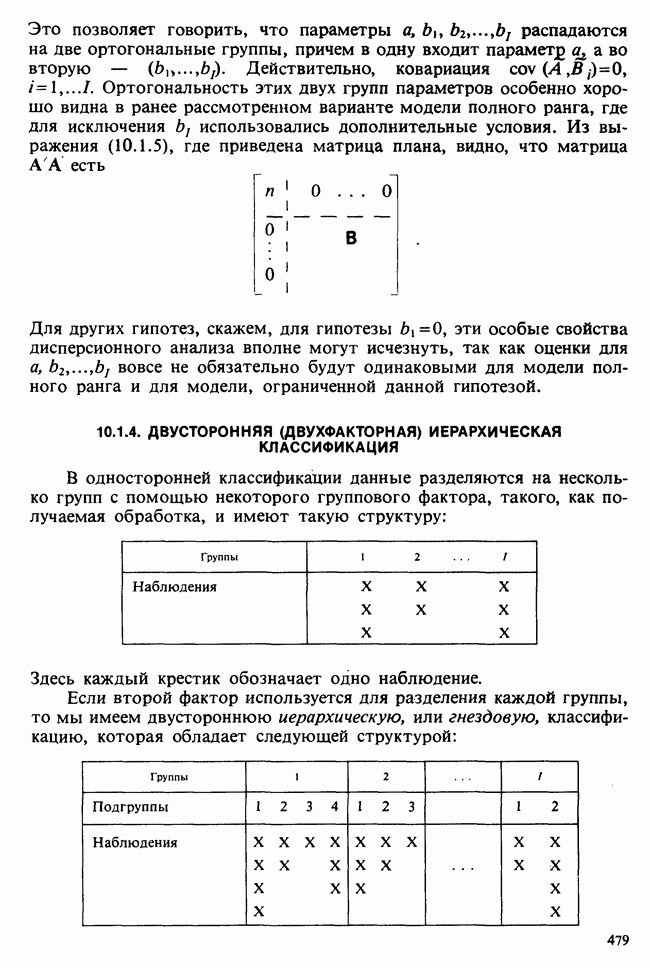



























 — независимые наблюдения из распределения
— независимые наблюдения из распределения  с математическим ожиданием
с математическим ожиданием  и стандартным отклонением а (это параметры семейства нормальных распределений), то мы можем рассматривать
и стандартным отклонением а (это параметры семейства нормальных распределений), то мы можем рассматривать  как реализацию случайной величины
как реализацию случайной величины  — как реализацию случайной величины
— как реализацию случайной величины  — как реализацию
— как реализацию  , где
, где  — независимые случайные величины, распределенные согласно
— независимые случайные величины, распределенные согласно  . Мы можем назвать
. Мы можем назвать  случайной величиной, индуцированной
случайной величиной, индуцированной  — индуцированной
— индуцированной  — индуцированной
— индуцированной  Статистика
Статистика  так называемое выборочное среднее, есть реализация случайной величины
так называемое выборочное среднее, есть реализация случайной величины  которая может рассматриваться как индуцированная х. Из свойств нормального распределения [см. II, раздел 11.4.5] следует, что распределение вероятностей для индуцированной случайной величины X есть
которая может рассматриваться как индуцированная х. Из свойств нормального распределения [см. II, раздел 11.4.5] следует, что распределение вероятностей для индуцированной случайной величины X есть  Это — выборочное распределение статистики х, которое с точностью до
Это — выборочное распределение статистики х, которое с точностью до  и а позволяет судить о вероятностях различных значений реализаций X (конечно, одно из них есть значение статистики х, полученное по нашей выборке). В частности, соответствующая плотность вероятностей достигает максимального значения при
и а позволяет судить о вероятностях различных значений реализаций X (конечно, одно из них есть значение статистики х, полученное по нашей выборке). В частности, соответствующая плотность вероятностей достигает максимального значения при  и поэтому х представляет собой разумную оценку для
и поэтому х представляет собой разумную оценку для  . С помощью выборочного распределения можно также получить и вероятность того, что наше значение х расположено от
. С помощью выборочного распределения можно также получить и вероятность того, что наше значение х расположено от  на расстоянии, ббльшем, чем заданное (в масштабе
на расстоянии, ббльшем, чем заданное (в масштабе  ).
).
 )
)
 , описанный в гл. 7.
, описанный в гл. 7.
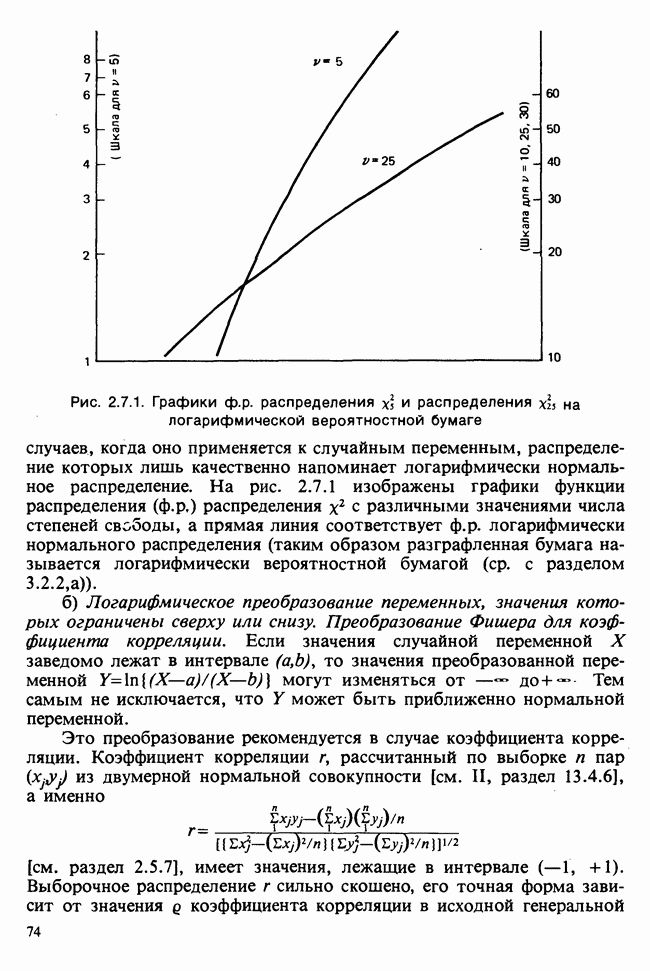
 -образную форму. Можно найти преобразование, которое переводит ее в прямую линию. Так несколько неожиданно мы приходим к линейной модели, для которой может быть применен метод наименьших квадратов (усложненный, однако, различием в разбросе откликов).
-образную форму. Можно найти преобразование, которое переводит ее в прямую линию. Так несколько неожиданно мы приходим к линейной модели, для которой может быть применен метод наименьших квадратов (усложненный, однако, различием в разбросе откликов).
 независимо изменяется от одной партии к другой известным образом: например, в
независимо изменяется от одной партии к другой известным образом: например, в  партий доля дефектных изделий
партий доля дефектных изделий  . Значение в для исследуемой выборки можно рассматривать как реализацию некоторой случайной величины с известным (априорным) распределением вероятностей. Используя теорему Байеса [см. II, раздел 16.10], можно скомбинировать выборочную величину с априорным распределением, чтобы улучшить вероятностные характеристики оценки (ее апостериорное распределение). Это уменьшает неопределенность вывода о значении в для данной партии.
. Значение в для исследуемой выборки можно рассматривать как реализацию некоторой случайной величины с известным (априорным) распределением вероятностей. Используя теорему Байеса [см. II, раздел 16.10], можно скомбинировать выборочную величину с априорным распределением, чтобы улучшить вероятностные характеристики оценки (ее апостериорное распределение). Это уменьшает неопределенность вывода о значении в для данной партии.
 может зависеть от ее поведения в более ранние моменты
может зависеть от ее поведения в более ранние моменты  Целью изучения такой системы обычно служит предсказание (прогноз) ее поведения.
Целью изучения такой системы обычно служит предсказание (прогноз) ее поведения.