14. Характеристика ненадежности для «случайного» шифра
В предыдущем разделе была вычислена характеристика ненадежности для простой подстановки, примененной к языку с двухбуквенным алфавитом. Но даже для этого почти самого простого шифра и языка полученные формулы уже настолько сложны, что почти бесполезны.. Что же делать в практически интересных случаях, скажем в тех случаях, когда дробная транспозиция применена к английскому тексту с его крайне сложной статистической структурой. Эта сложность сама выдвигает метод подхода. Достаточно сложные проблемы часто могут быть разрешены статистически. Чтобы облегчить дело, введем понятие «случайного» шифра.
Сделаем следующие допущения.
1. Число возможных сообщений длины  равно
равно  таким образом
таким образом  где
где  — число букв алфавита. Предполагается, что число возможных криптограмм длины
— число букв алфавита. Предполагается, что число возможных криптограмм длины  также равно Т.
также равно Т.
2. Все возможные сообщения длины  можно разделить на две группы: группу с высокими и достаточно равномерными априорными вероятностями и группу с пренебрежимо малой полной вероятностью. Высоковероятная группа будет содержать
можно разделить на две группы: группу с высокими и достаточно равномерными априорными вероятностями и группу с пренебрежимо малой полной вероятностью. Высоковероятная группа будет содержать  сообщений, где
сообщений, где  — энтропия источника сообщений на одну букву.
— энтропия источника сообщений на одну букву.
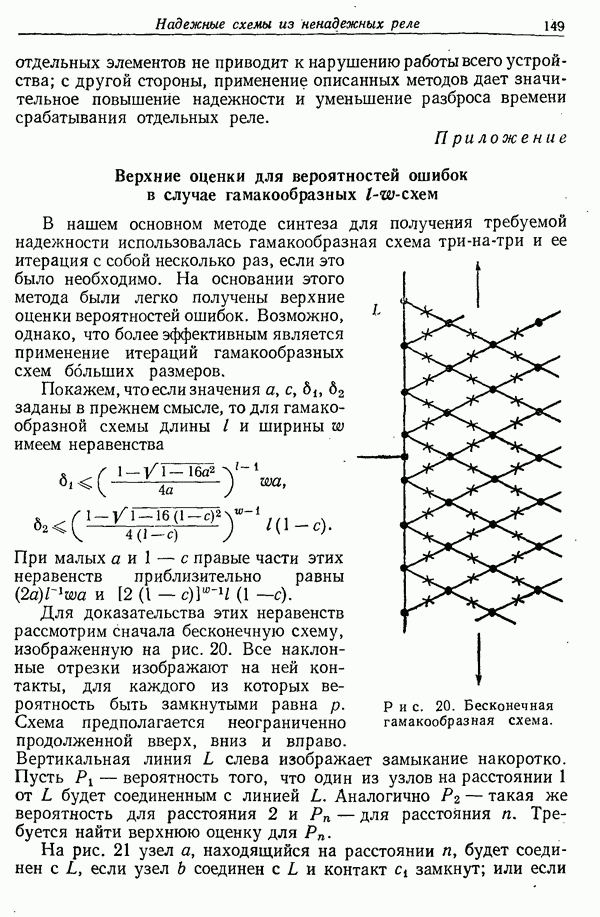
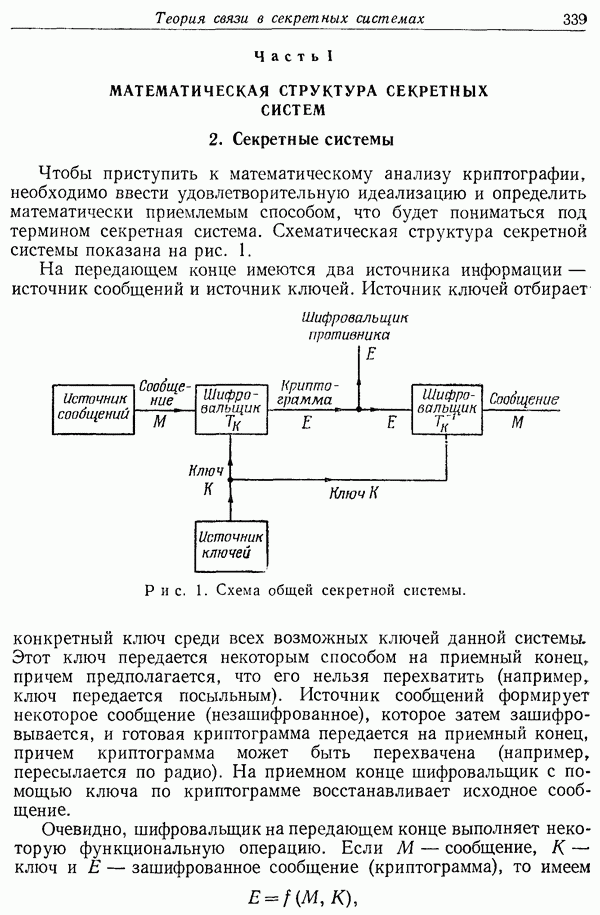
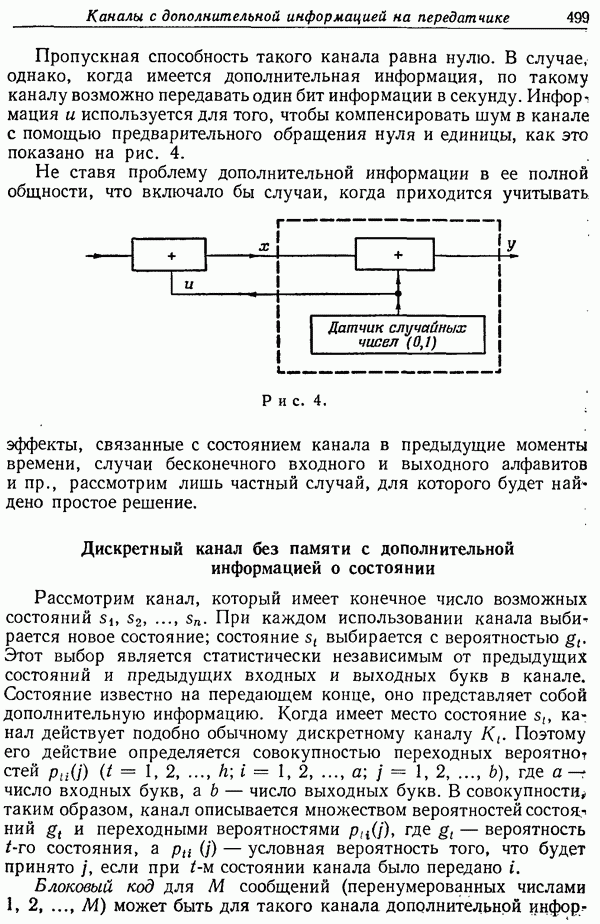
3. Операцию дешифрирования можно представлять графически в виде ряда линий (как на рис. 2 и рис. 4), идущих от каждого Е к различным М. Предположим, что имеется к равновероятных ключей и что от каждого Е будет отходить к линий. Предположим, что для случайного шифра линии от каждого Е отходят к случайному набору возможных сообщений. Тогда случайный шифр будет представлять собой фактически целый ансамбль шифров и его ненадежность будет равна средней ненадежности этого ансамбля.
Ненадежность ключа определяется с помощью равенства

Вероятность того, что от частного Е к высоковероятной группе сообщений отходит ровно  линий, равна
линий, равна

Если перехвачена криптограмма, которой соответствует  таких линий, то ненадежность равна
таких линий, то ненадежность равна  Вероятность такой криптограммы равна
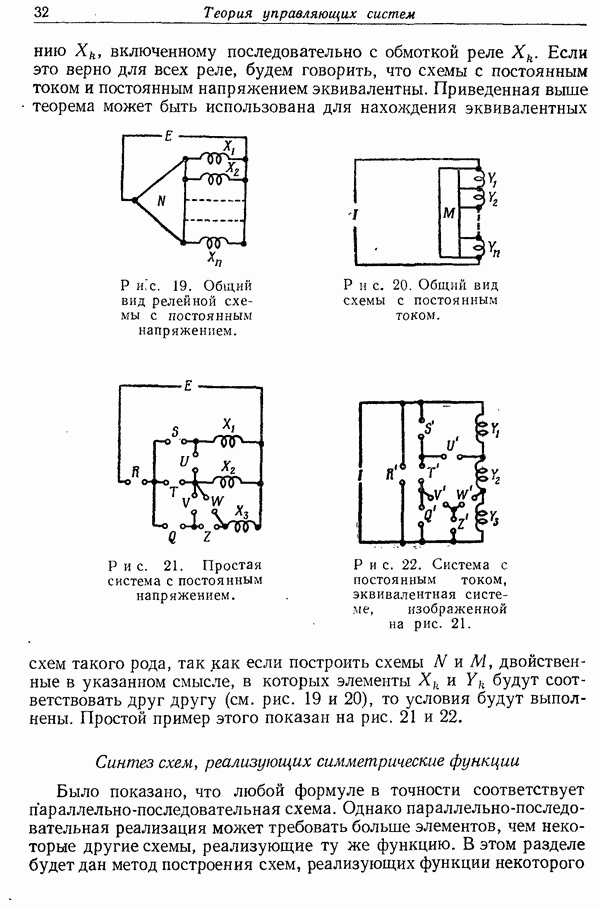
Вероятность такой криптограммы равна  так как она может быть создана из высоковероятных сообщений, каждое из которых имеет вероятность
так как она может быть создана из высоковероятных сообщений, каждое из которых имеет вероятность  с помощью одного из
с помощью одного из  ключей. Отсюда ненадежность равна
ключей. Отсюда ненадежность равна

Требуется найти простое приближенное выражение для  когда
когда  велико. Если для величины
велико. Если для величины  еесреднее значение
еесреднее значение 
много больше 1, то изменение  в области тех
в области тех  для которых биномиальные слагаемые велики, будет малым и мы можем заменить
для которых биномиальные слагаемые велики, будет малым и мы можем заменить  на
на  . Этот множитель можно вынести за знак суммы, которая даст значение т. Таким образом, при этом условии
. Этот множитель можно вынести за знак суммы, которая даст значение т. Таким образом, при этом условии

 — избыточность на букву первоначального языка
— избыточность на букву первоначального языка 
Если  мало по сравнению с к, то биномиальное распределение может быть приближенно пуассоновским:
мало по сравнению с к, то биномиальное распределение может быть приближенно пуассоновским:

где  Отсюда
Отсюда

Заменив  на
на  получим
получим

Это выражение можно использовать, когде X близко к 1. Если же  , то существенным является лишь первый член ряда. Отбрасывая другие, получим
, то существенным является лишь первый член ряда. Отбрасывая другие, получим

Итак, подводя итог вышесказанному, получаем, что  рассматриваемая как функция
рассматриваемая как функция  -числа перехваченных букв — при
-числа перехваченных букв — при  равна
равна  Далее она убывает линейно с наклоном D до окрестности точки
Далее она убывает линейно с наклоном D до окрестности точки  После небольшой переходной области
После небольшой переходной области  начинает убывать экспоненциально со временем «полураспада»
начинает убывать экспоненциально со временем «полураспада»  если D измеряется в битах на букву. Поведение
если D измеряется в битах на букву. Поведение  показано на рис. 7 вместе с аппроксимирующими кривыми.
показано на рис. 7 вместе с аппроксимирующими кривыми.
С помощью аналогичных рассуждений можно подсчитать ненадежность сообщения. Она равна























































































































































































































































































































































































































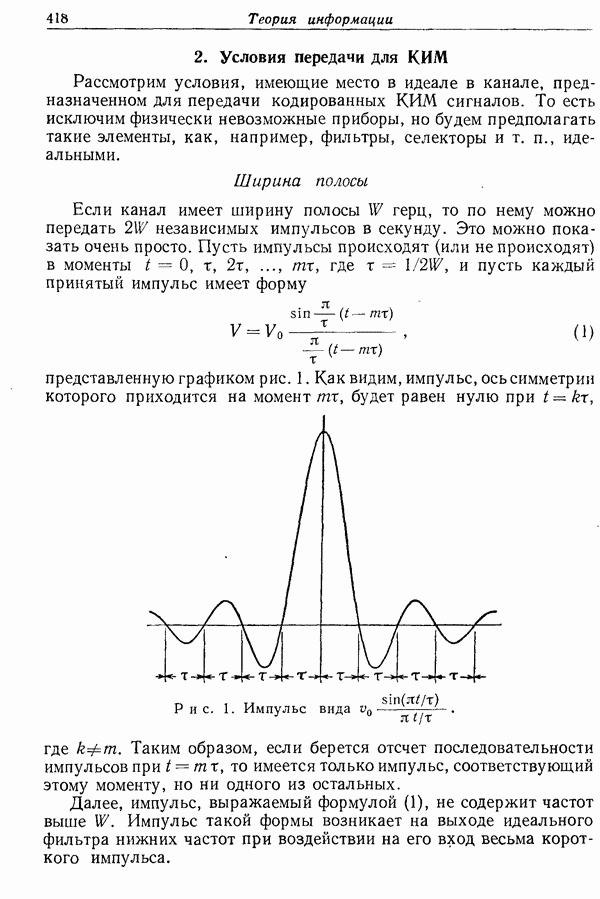














































































































































































































































































































































































































 функция, показанная на рис. 7, причем шкала
функция, показанная на рис. 7, причем шкала  сжата в
сжата в  раз. Таким образом,
раз. Таким образом,  возрастает линейно с наклоном
возрастает линейно с наклоном  до тех пор, пока она не пересечет линию
до тех пор, пока она не пересечет линию  После закругленного перехода она идет ниже кривой
После закругленного перехода она идет ниже кривой 


