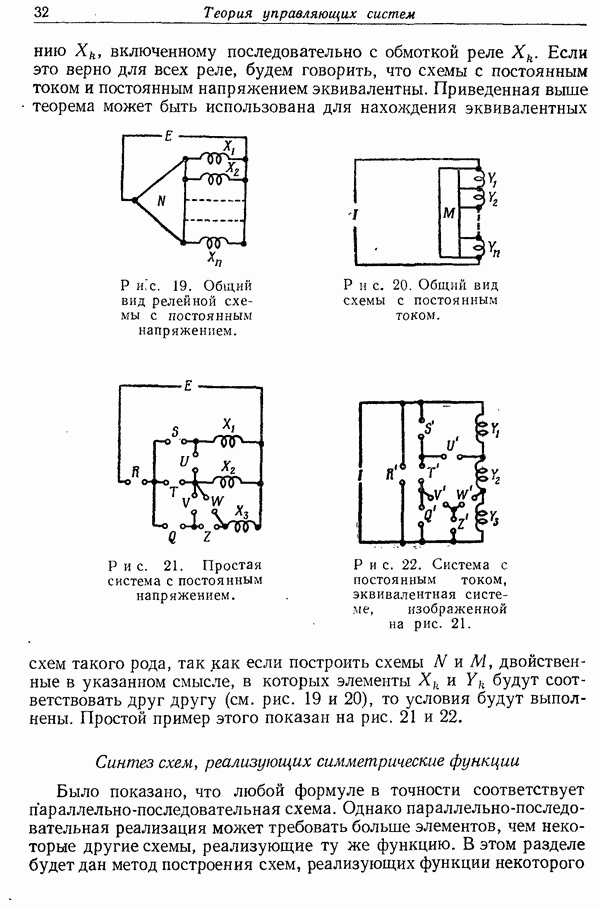
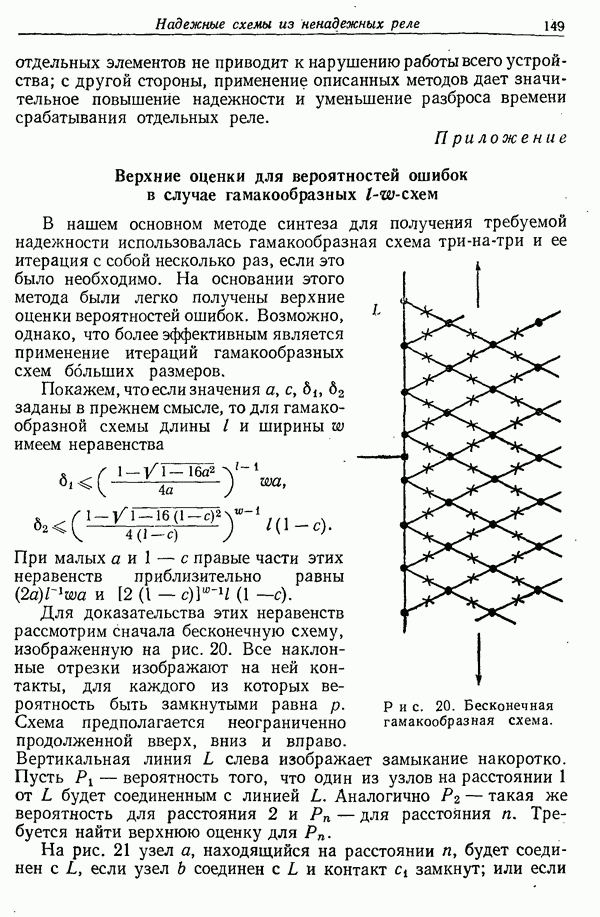
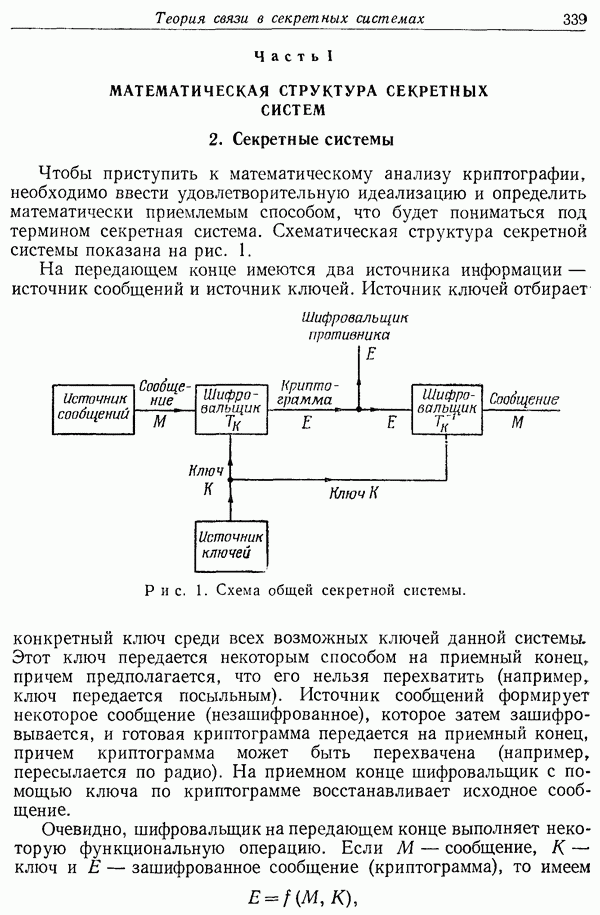
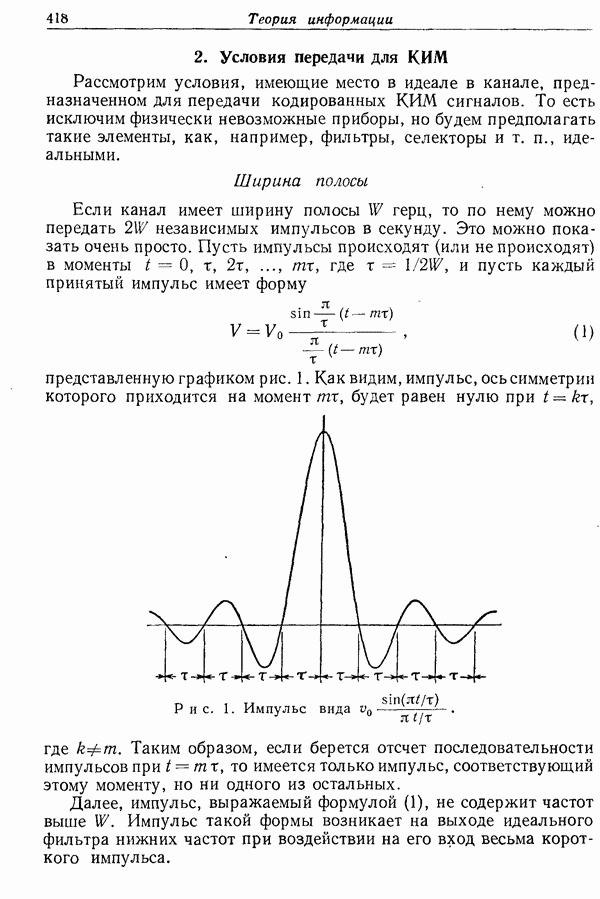
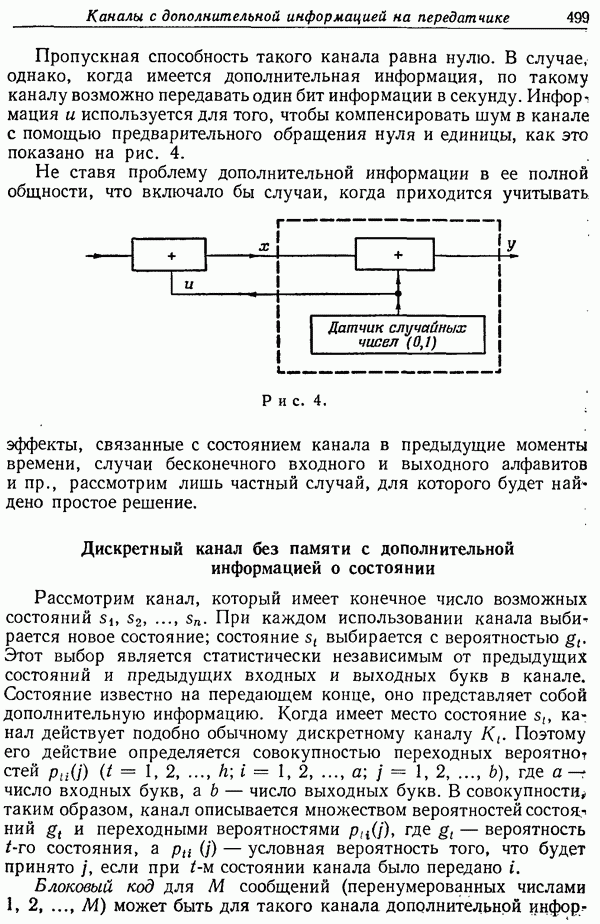
ПРЕДСКАЗАНИЕ И ЭНТРОПИЯ ПЕЧАТНОГО АНГЛИЙСКОГО ТЕКСТА
1. Введение
В опубликованной ранее работе были введены понятия энтропии и избыточности языка. Энтропия есть статистический параметр, который измеряет в известном смысле среднее количество информации, приходящейся на одну букву языкового текста. Если данный язык перевести на язык двоичных знаков (0 или 1) наиболее эффективным образом, то энтропия Н равна среднему числу двоичных знаков (бит), приходящихся на одну букву исходного языка. Избыточность в свою очередь измеряет количество ограничений в языковом тексте, определяемое его статистической структурой; например, в английском языке наибольшая частота появления буквы Е, частое явление буквы Н вслед за Т и  вслед за
вслед за  По ранее произведенной оценке при учете статистических связей не более чем между восемью последовательными буквами оказалось, что энтропия равна примерно 2,3 бита на одну букву и избыточность составляет около 50 %.
По ранее произведенной оценке при учете статистических связей не более чем между восемью последовательными буквами оказалось, что энтропия равна примерно 2,3 бита на одну букву и избыточность составляет около 50 %.
С тех пор был найден новый метод для оценки этих количеств, более тонкий и учитывающий длительные статистические связи, влияние отдельных фраз друг на друга и т. д. Этот метод основан на изучении возможности предсказания английского текста: насколько точно может быть предсказана очередная буква, когда известны предыдущие  букв текста. Далее будут приведены результаты некоторых экспериментов по предсказанию и теоретический анализ идеального предсказания. Комбинируя экспериментальные и теоретические результаты, можно дать оценки сверху и снизу для энтропии и избыточности. Из проводимого анализа вытекает, что в нормативном английском литературном тексте длительные статистические связи (до 100 букв) уменьшают энтропию приблизительно на один бит на букву с соответствующей избыточностью в 75%. Избыточность может быть еще выше, если учитывать связи
букв текста. Далее будут приведены результаты некоторых экспериментов по предсказанию и теоретический анализ идеального предсказания. Комбинируя экспериментальные и теоретические результаты, можно дать оценки сверху и снизу для энтропии и избыточности. Из проводимого анализа вытекает, что в нормативном английском литературном тексте длительные статистические связи (до 100 букв) уменьшают энтропию приблизительно на один бит на букву с соответствующей избыточностью в 75%. Избыточность может быть еще выше, если учитывать связи
между разными параграфами, главами и т. д. Однако при увеличении длин рассматриваемых текстов рассматриваемые параметры становятся более неустойчивыми и неопределенными и делаются существенно зависимыми от типа изучаемого текста.