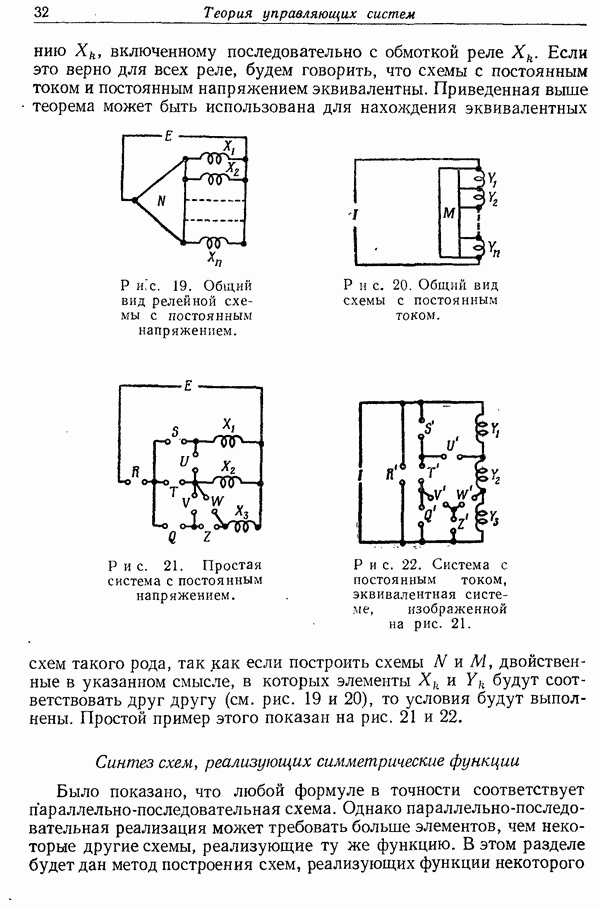
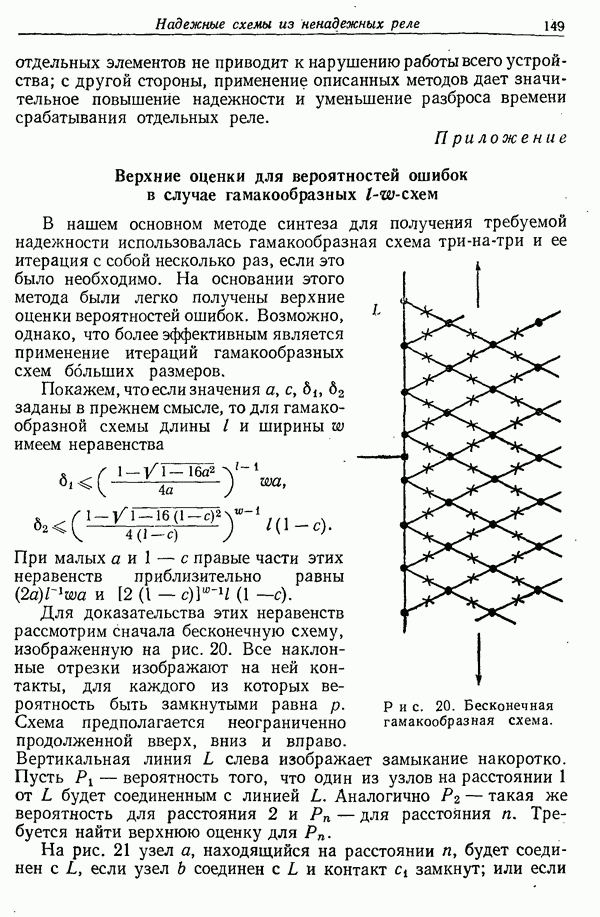
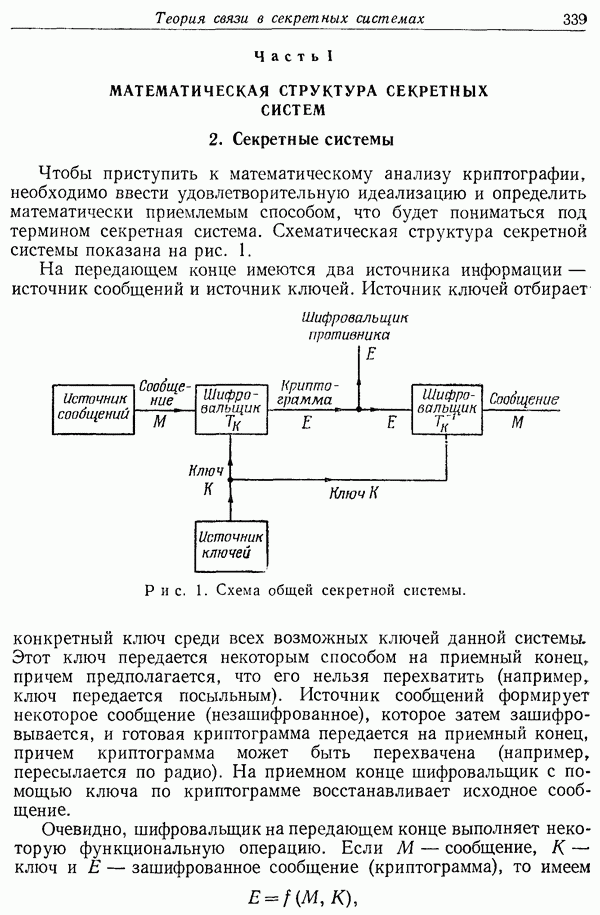
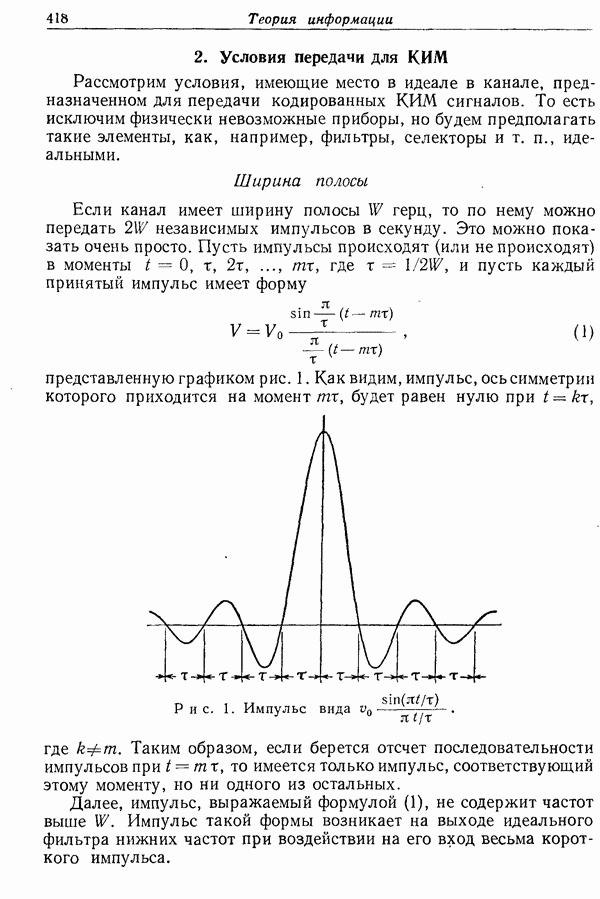
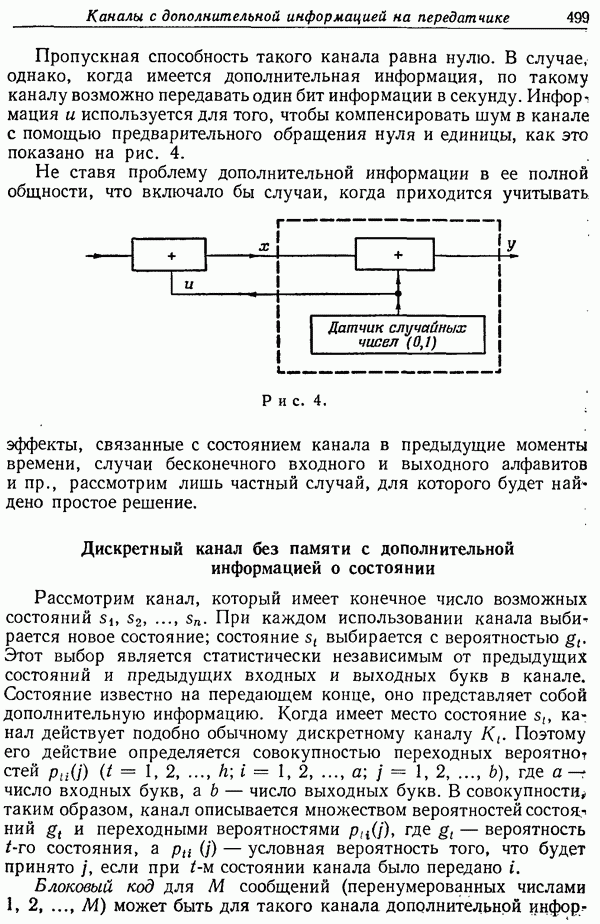
6. Результаты эксперимента для английского языка
На основании данных табл. 1 были вычислены верхние и нижние границы в неравенстве (17). Данные были сначала несколько сглажены для уничтожения выборочных отклонений. Малым числам в этой таблице можно доверять меньше всего, и они были усреднены по группам. Таким образом, в  столбце числа 47, 18 и 14 не были изменены, а для оставшихся строк от (4-й до 20-й) сумма, равная 21, была разделена по ним равномерно. Верхние границы, даваемые неравенством (17), были затем вычислены для каждого столбца и получены результаты, приведенные ниже.
столбце числа 47, 18 и 14 не были изменены, а для оставшихся строк от (4-й до 20-й) сумма, равная 21, была разделена по ним равномерно. Верхние границы, даваемые неравенством (17), были затем вычислены для каждого столбца и получены результаты, приведенные ниже.

Очевидно, что в этих числах имеется еще значительная статистическая ошибка, связанная с идентификацией наблюденных выборочных частот с вероятностями предсказания. Надо также вспомнить, что нижняя граница была выведена только для устройства идеального предсказания, в то время как использованные нами частоты получены из предсказания, сделанного человеком.

Рис. 4. Верхняя и нижняя границы, полученные экспериментальным путем для энтропии английского языка с  -буквенным алфавитом.
-буквенным алфавитом.
Некоторые грубые вычисления показывают, однако, что расхождение между действительным значением  и нижней оценкой, полученной идеальным устройством предсказания (объясняющаяся тем, что условные вероятности не имели прямоугольного распределения), вполне компенсирует неумение человека предсказывать идеально.
и нижней оценкой, полученной идеальным устройством предсказания (объясняющаяся тем, что условные вероятности не имели прямоугольного распределения), вполне компенсирует неумение человека предсказывать идеально.
Таким образом, можно в достаточной степени уверенно сказать, что обе группы независимы от статистических ошибок.
Полученные значения нанесены под рубрикой  на рис. 4.
на рис. 4.
Автор благодарен миссис Мэри Шэннон и  Оливеру за помощь в экспериментальной работе и за большое число советов и критических замечаний по поводу теоретической части статьи.
Оливеру за помощь в экспериментальной работе и за большое число советов и критических замечаний по поводу теоретической части статьи.