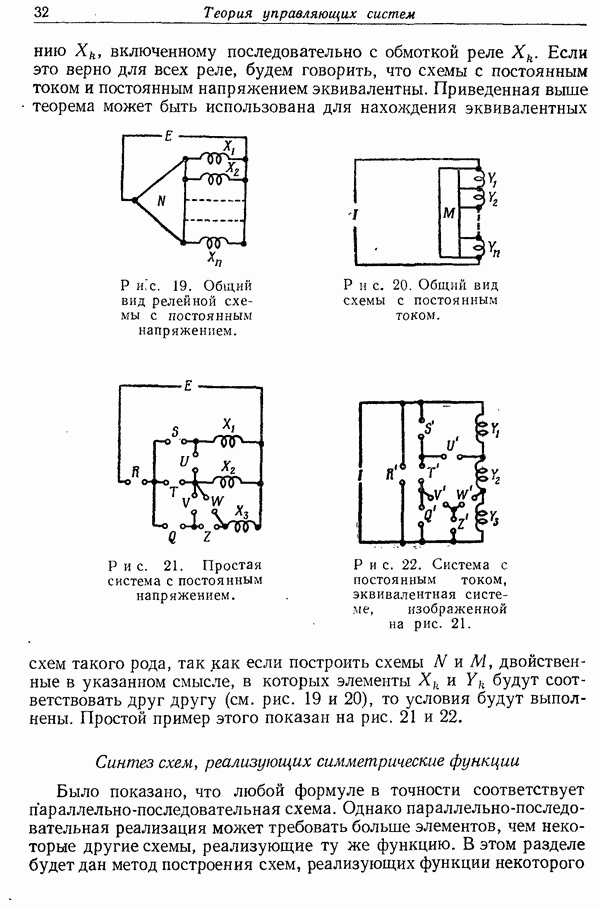
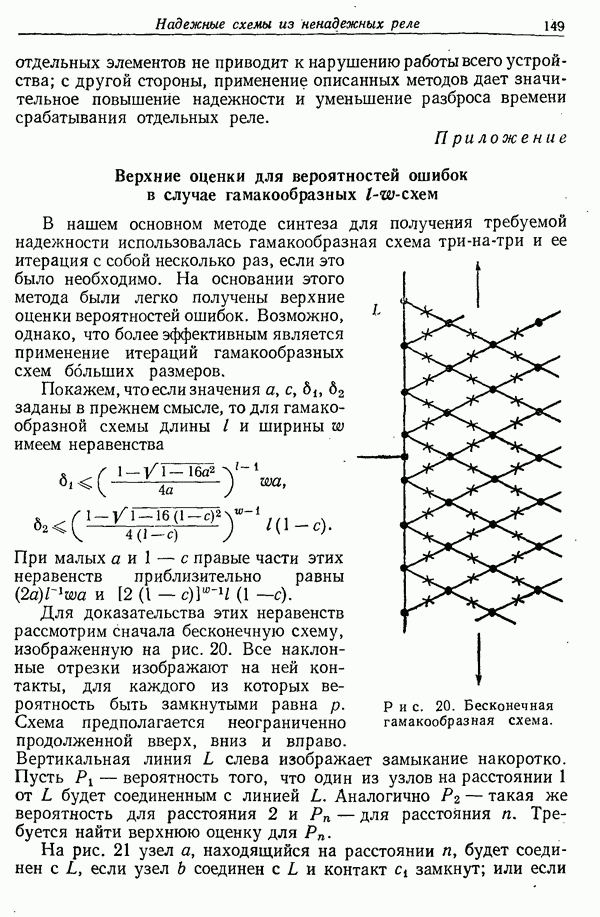
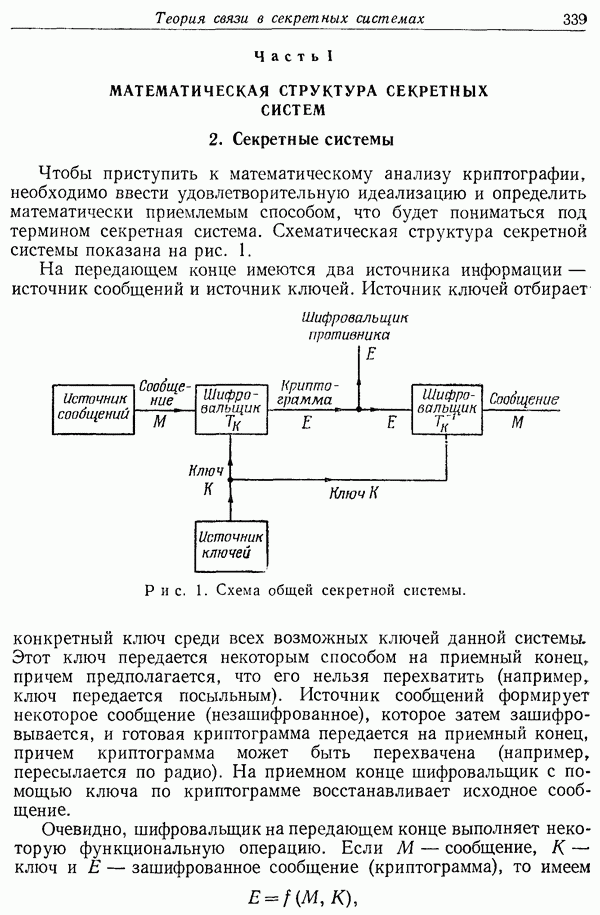
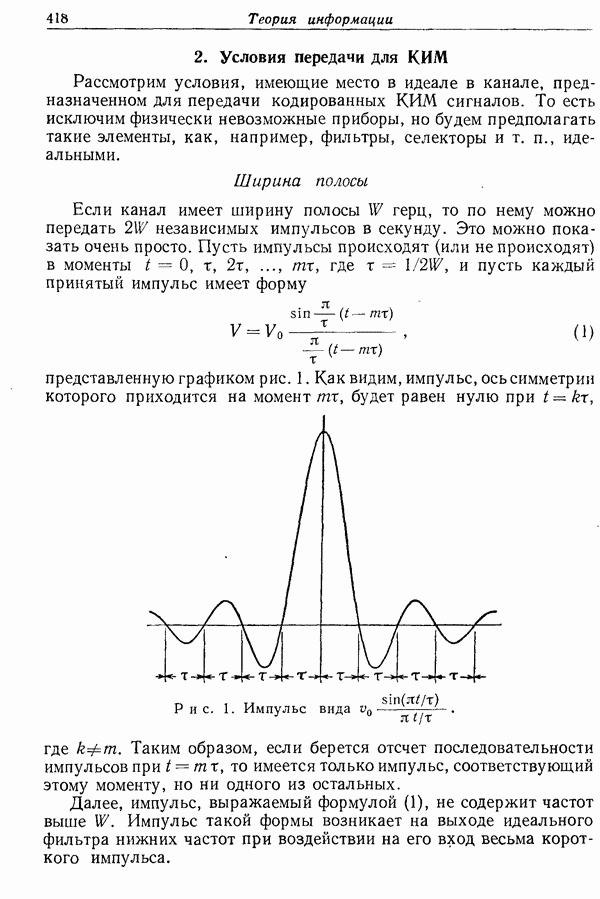
9. Основная теорема для канала без шума
Подтвердим теперь нашу интерпретацию величин Н как скорости создания информации доказательством того факта, что Н определяет пропускную способность канала, необходимую при наиболее эффективном кодировании.
Теорема 9. Пусть источник имеет энтропию Н (бит на символ), а канал имеет пропускную способность С (бит в секунду). Тогда можно закодировать сообщения на выходе источника таким образом, чтобы передавать символы по каналу со средней скоростью  символов в одну секунду, где
символов в одну секунду, где  — сколь угодно мало. Передавать со средней скоростью, большей чем
— сколь угодно мало. Передавать со средней скоростью, большей чем  невозможно.
невозможно.
Обратная часть теоремы, утверждающая, что нельзя превзойти скорость  может быть доказана, если заметить, что энтропия в секунду на входе канала равна энтропии источника, так как передатчик должен быть невырожденным преобразователем, и что эта энтропия не может превосходить пропускной способности канала. Отсюда
может быть доказана, если заметить, что энтропия в секунду на входе канала равна энтропии источника, так как передатчик должен быть невырожденным преобразователем, и что эта энтропия не может превосходить пропускной способности канала. Отсюда  число символов в секунду равно
число символов в секунду равно 
Докажем первую часть теоремы двумя различными способами. Первый способ состоит в рассмотрении множества всех последовательностей из  символов, создаваемых источником. При большом
символов, создаваемых источником. При большом  все эти последовательности можно разделить на две группы, одна из которых содержит меньше чем
все эти последовательности можно разделить на две группы, одна из которых содержит меньше чем  членов, а вторая содержит меньше чем
членов, а вторая содержит меньше чем  членов (где
членов (где  — логарифм числа различных символов) и имеет суммарную вероятность, меньшую чем
— логарифм числа различных символов) и имеет суммарную вероятность, меньшую чем  . С ростом
. С ростом  величины и
величины и  стремятся к нулю. Число сигналов в канале, имеющих длительность Т, больше чем
стремятся к нулю. Число сигналов в канале, имеющих длительность Т, больше чем  , где 0 мало, когда Т велико. Если выбрать
, где 0 мало, когда Т велико. Если выбрать

то найдется достаточное число последовательностей символов в канале для высоковероятностной группы, когда  и Т достаточно велики (сколь бы малым ни было выбрано А), и несколько добавочных последовательностей. Высоковероятностная группа произвольным, взаимнооднозначным образом кодируется в это множество последовательностей символов канала. Остающиеся последовательности источника кодируются в более длинные последовательности канала, начинающиеся и заканчивающиеся одной из добавочных последовательностей, не использованных для высоковероятностной группы, причем эта последовательность действует как начальный и конечный сигналы, указывающие на использование в промежутке иного кода. Между
и Т достаточно велики (сколь бы малым ни было выбрано А), и несколько добавочных последовательностей. Высоковероятностная группа произвольным, взаимнооднозначным образом кодируется в это множество последовательностей символов канала. Остающиеся последовательности источника кодируются в более длинные последовательности канала, начинающиеся и заканчивающиеся одной из добавочных последовательностей, не использованных для высоковероятностной группы, причем эта последовательность действует как начальный и конечный сигналы, указывающие на использование в промежутке иного кода. Между
этими сигналами оставляют временной интервал, достаточный для того, чтобы для этого временного интервала в канале существовало достаточно различных последовательностей для всех маловероятных сообщений. Для этого потребуется, чтобы такой временной интервал равнялся

где  мало. Средняя скорость передачи символов сообщения в 1 секунду будет тогда больше чем
мало. Средняя скорость передачи символов сообщения в 1 секунду будет тогда больше чем

При увеличении  величины
величины  стремятся к нулю и скорость стремится к
стремятся к нулю и скорость стремится к 
Другой способ выполнения такого кодирования и, следовательно, другой способ доказательства теоремы можно описать следующим образом: расположим сообщения длины  в порядке убывания их вероятностей; пусть эти вероятности будут
в порядке убывания их вероятностей; пусть эти вероятности будут  Пусть
Пусть  , — накопленная вероятность до
, — накопленная вероятность до  включительно. Закодируем сначала все сообщения в двоичную систему. Двоичный код для сообщения
включительно. Закодируем сначала все сообщения в двоичную систему. Двоичный код для сообщения  получается путем разложения
получается путем разложения  как двоичного числа. Разложение проводится до
как двоичного числа. Разложение проводится до  позиции, где
позиции, где  целое число, удовлетворяющее соотношению
целое число, удовлетворяющее соотношению

Таким образом, высоковероятные сообщения представляются короткими кодами, а маловероятные — длинными. Из этих неравенств вытекает следующее неравенство:

Код для  будет отличаться от всех последующих кодов одной или более из своих
будет отличаться от всех последующих кодов одной или более из своих  позиций, так как все остающиеся
позиций, так как все остающиеся  по крайней мере на
по крайней мере на  больше и поэтому их двоичные разложения отличаются от кода для
больше и поэтому их двоичные разложения отличаются от кода для  на первых
на первых  позициях. Следовательно, все эти коды различны, и можно восстановить сообщение по его коду. Если последовательности символов канала не являются уже двоичными последовательностями, им можно приписать двоичные числа произвольным образом и преобразовать таким образом двоичный код в сигналы, используемые для канала.
позициях. Следовательно, все эти коды различны, и можно восстановить сообщение по его коду. Если последовательности символов канала не являются уже двоичными последовательностями, им можно приписать двоичные числа произвольным образом и преобразовать таким образом двоичный код в сигналы, используемые для канала.
Среднее число  бит, употребляемых на символ первоначального сообщения, легко оценить. Имеем
бит, употребляемых на символ первоначального сообщения, легко оценить. Имеем

Но

и поэтому

С ростом  величина
величина  стремится к Н — энтропии источника, и
стремится к Н — энтропии источника, и  также стремится к Н.
также стремится к Н.
Отсюда видно, что неэффективность кодирования в случае, когда используется конечное запаздывание на  символов, не должна быть больше, чем
символов, не должна быть больше, чем  плюс разность между истинной энтропией Н и энтропией
плюс разность между истинной энтропией Н и энтропией  сосчитанной для последовательностей длины
сосчитанной для последовательностей длины  Поэтому необходимое увеличение времени по сравнению с идеальным в процентах не превысит
Поэтому необходимое увеличение времени по сравнению с идеальным в процентах не превысит

Этот метод кодирования в сущности совпадает с методом, независимо найденным Р. М. Фано. Его метод состоит в расположении сообщений длины  в порядке убывающих вероятностей. Этот ряд делится на две группы, по возможности с равными вероятностями. Если сообщение относится к первой группе, его первая двоичная цифра будет 0, в противном случае — единица. Эти группы аналогичным образом делятся на подгруппы примерно равной вероятности, и частная подгруппа определяет второй двоичный знак. Этот процесс продолжается до тех пор, пока не получатся подгруппы, содержащие только по одному сообщению. Легко видеть, что, за исключением незначительных отличий (в общем случае в последней цифре), это приводит к тем же результатам, что и при описанном выше арифметическом методе.
в порядке убывающих вероятностей. Этот ряд делится на две группы, по возможности с равными вероятностями. Если сообщение относится к первой группе, его первая двоичная цифра будет 0, в противном случае — единица. Эти группы аналогичным образом делятся на подгруппы примерно равной вероятности, и частная подгруппа определяет второй двоичный знак. Этот процесс продолжается до тех пор, пока не получатся подгруппы, содержащие только по одному сообщению. Легко видеть, что, за исключением незначительных отличий (в общем случае в последней цифре), это приводит к тем же результатам, что и при описанном выше арифметическом методе.