2. Вычисление энтропии по статистике английского языка
По одному из методов вычисления энтропии задается ряд последовательных приближений  , как к пределу, которые учитывают все большее число и более тонкие статистические закономерности языка. Приближение
, как к пределу, которые учитывают все большее число и более тонкие статистические закономерности языка. Приближение  может быть названо
может быть названо  -граммной энтропией; она измеряет количество информации, или энтропию, с учетом статистических связей не длиннее, чем на
-граммной энтропией; она измеряет количество информации, или энтропию, с учетом статистических связей не длиннее, чем на  следующих друг за другом букв текста.
следующих друг за другом букв текста.  дается формулой
дается формулой

в которой  — блок из
— блок из  буквы
буквы  -грамма,
-грамма,  — произвольная буква, следующая за
— произвольная буква, следующая за  — вероятность
— вероятность  -граммы
-граммы  — условная вероятность буквы
— условная вероятность буквы  следовать за блоком
следовать за блоком  равная
равная 
Соотношение (1) можно интерпретировать как формулу для вычисления средней неопределенности (условной энтропии) последующей буквы  когда известны предыдущие
когда известны предыдущие  букв. При возрастании
букв. При возрастании  в величине
в величине  учитываются все более и более далекие статистические связи и энтропия Я является предельным значением
учитываются все более и более далекие статистические связи и энтропия Я является предельным значением  при
при 

Л-граммная энтропия  Для малых значений может быть подсчитана из обычных частотных таблиц отдельных букв, двухбуквенных (диграмм) и трехбуквенных сочетаний (триграмм). Если промежутком между буквами и знаками препинания пренебречь, то получим
Для малых значений может быть подсчитана из обычных частотных таблиц отдельных букв, двухбуквенных (диграмм) и трехбуквенных сочетаний (триграмм). Если промежутком между буквами и знаками препинания пренебречь, то получим  -буквенный алфавит и
-буквенный алфавит и  может быть взята (по определению) равной
может быть взята (по определению) равной  или 4,7 бита на букву.
или 4,7 бита на букву.  при использовании частоты появления отдельных букв равна
при использовании частоты появления отдельных букв равна

Диграммное приближение  дает результат
дает результат

Триграммная энтропия равна

Таблицы триграмм, использованные в этих вычислениях, не принимали в расчет трехбуквенных сочетаний, связывающих два слова, к примеру,  и
и  в словосочетании
в словосочетании  Для частичной компенсации этого упущения были составлены исправленные таблицы вероятностей трехбуквенных сочетаний
Для частичной компенсации этого упущения были составлены исправленные таблицы вероятностей трехбуквенных сочетаний  полученных из вероятностей
полученных из вероятностей  взятых из таблиц, с помощью-следующей грубой формулы:
взятых из таблиц, с помощью-следующей грубой формулы:

где  есть вероятность того, что буква
есть вероятность того, что буква  находится на последнем месте в слове,
находится на последнем месте в слове,  — вероятность того, что буква
— вероятность того, что буква  является начальной буквой слова. Таким образом, триграммы внутри слов (в среднем 2,5 на слово) вычислялись в соответствии с таблицей; триграммы, встречающиеся между словами (по одной каждого типа на слово), вычислялись приближенно в предположении независимости последней буквы слова и начальной диграммы следующего слова и, наоборот, последней диграммы слова и начальной буквы следующего слова. В результате этих приближений, а также вследствие того факта, что выборочная ошибка при отождествлении вероятности с выборочной частотой является в этом случае более существенной, полученную величину для
является начальной буквой слова. Таким образом, триграммы внутри слов (в среднем 2,5 на слово) вычислялись в соответствии с таблицей; триграммы, встречающиеся между словами (по одной каждого типа на слово), вычислялись приближенно в предположении независимости последней буквы слова и начальной диграммы следующего слова и, наоборот, последней диграммы слова и начальной буквы следующего слова. В результате этих приближений, а также вследствие того факта, что выборочная ошибка при отождествлении вероятности с выборочной частотой является в этом случае более существенной, полученную величину для  следует считать менее надежной, чем предыдущие.
следует считать менее надежной, чем предыдущие.
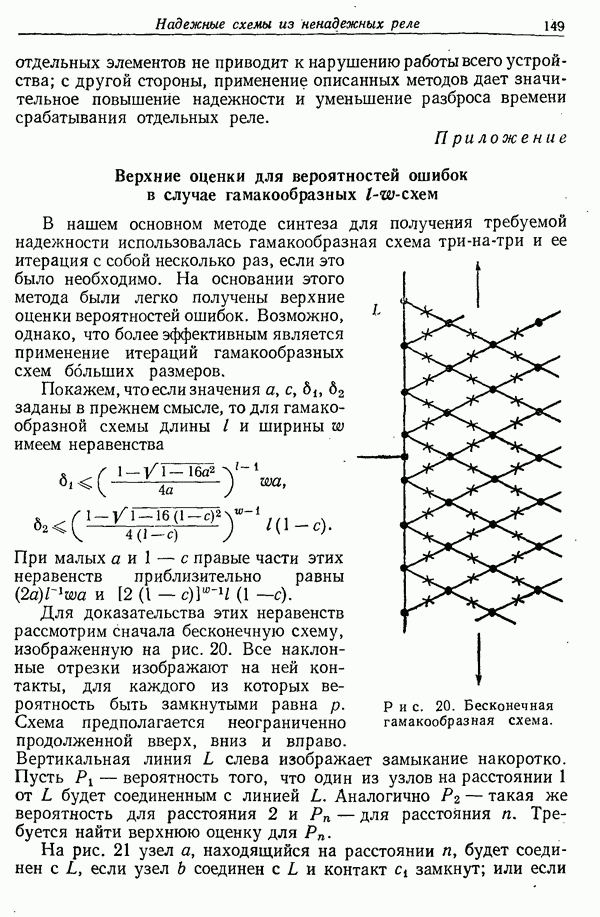
Поскольку таблиц  -граммных частот при
-граммных частот при  не существует,
не существует,  нельзя вычислить тем же путем. Однако были составлены таблицы частоты появления слов, и их можно использовать для получения дальнейших приближений. Рис. 1 изображает в логарифмическом масштабе вероятность слов в порядке убывания частоты их появления. Наиболее часто встречающееся английское слово «the» имеет вероятность 0,071 и изображено над 1. Следующее по частоте слово
нельзя вычислить тем же путем. Однако были составлены таблицы частоты появления слов, и их можно использовать для получения дальнейших приближений. Рис. 1 изображает в логарифмическом масштабе вероятность слов в порядке убывания частоты их появления. Наиболее часто встречающееся английское слово «the» имеет вероятность 0,071 и изображено над 1. Следующее по частоте слово  имеет вероятность 0,034 и изображено над 2 и т. д. При использовании логарифмического масштаба как для
имеет вероятность 0,034 и изображено над 2 и т. д. При использовании логарифмического масштаба как для
равной единице, и что  больших значений
больших значений  то найдем, что наибольшее
то найдем, что наибольшее  равно 8,727. Тогда энтропия равна
равно 8,727. Тогда энтропия равна

или  бита на букву, поскольку средняя длина слова в английском языке равна 4,5 буквы. Можно попытаться отождествить это значение с
бита на букву, поскольку средняя длина слова в английском языке равна 4,5 буквы. Можно попытаться отождествить это значение с  но в действительности ордината кривой
но в действительности ордината кривой  при
при  будет лежать над этим значением. Причина этого заключается в том, что в
будет лежать над этим значением. Причина этого заключается в том, что в  учтены группы из четырех или пяти букв независимо от подразделения на слова. Слово является связанной группой букв с сильными внутренними статистическими связями и, следовательно,
учтены группы из четырех или пяти букв независимо от подразделения на слова. Слово является связанной группой букв с сильными внутренними статистическими связями и, следовательно,  -граммы, находящиеся внутри слов, несут в себе большие статистические ограничения, чем
-граммы, находящиеся внутри слов, несут в себе большие статистические ограничения, чем  -граммы, включающие промежутки между словами. В результате этого полученная нами оценка 2,62 бита на букву более близка, скажем, к
-граммы, включающие промежутки между словами. В результате этого полученная нами оценка 2,62 бита на букву более близка, скажем, к  или
или 
Аналогичные вычисления были проделаны с учетом пробела между словами как дополнительной буквы, приводящей к алфавиту из 27 букв. Ниже собраны результаты для  буквенных вычислений
буквенных вычислений

Оценка 2,3 для  упомянутая выше, была найдена несколькими методами, один из которых состоит в экстраполяции до
упомянутая выше, была найдена несколькими методами, один из которых состоит в экстраполяции до  приведенных результатов для
приведенных результатов для  -буквенного алфавита. Поскольку пробел между словами является почти полностью избыточным, когда рассматриваются последовательности из многих слов, то значения
-буквенного алфавита. Поскольку пробел между словами является почти полностью избыточным, когда рассматриваются последовательности из многих слов, то значения  для
для  -буквенного алфавита равны
-буквенного алфавита равны  или 0,818 от
или 0,818 от  для
для  -буквенного алфавита при больших
-буквенного алфавита при больших 




































































































































































































































































































































































































































































































































































































































































































































































































































 есть вероятность
есть вероятность  по порядку слова, имеем приблизительно
по порядку слова, имеем приблизительно

 дает довольно хорошее приближение вероятностей слов во многих языках.
дает довольно хорошее приближение вероятностей слов во многих языках.

 стремящемся к
стремящемся к  поскольку общая вероятность должна быть равна единице, в то время как
поскольку общая вероятность должна быть равна единице, в то время как  — равна бесконечности. Если предположить (ввиду отсутствия любой более удовлетворительной оценки), что формула
— равна бесконечности. Если предположить (ввиду отсутствия любой более удовлетворительной оценки), что формула  выполняется до тех значений
выполняется до тех значений  пока общая вероятность не станет
пока общая вероятность не станет
