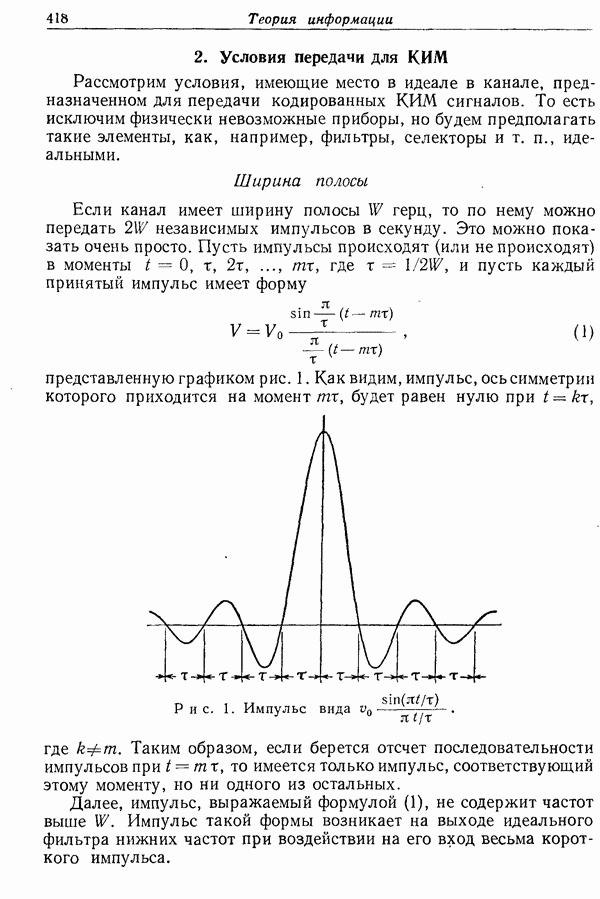
2. Дискретный источник сообщений
Как мы уже видели, при весьма общих условиях логарифм числа возможных сигналов в дискретном канале линейно возрастает со временем. Пропускная способность может быть
охарактеризована заданием скорости этого возрастания, т. е. числа битов в секунду, требуемых для воспроизведения конкретного сигнала.
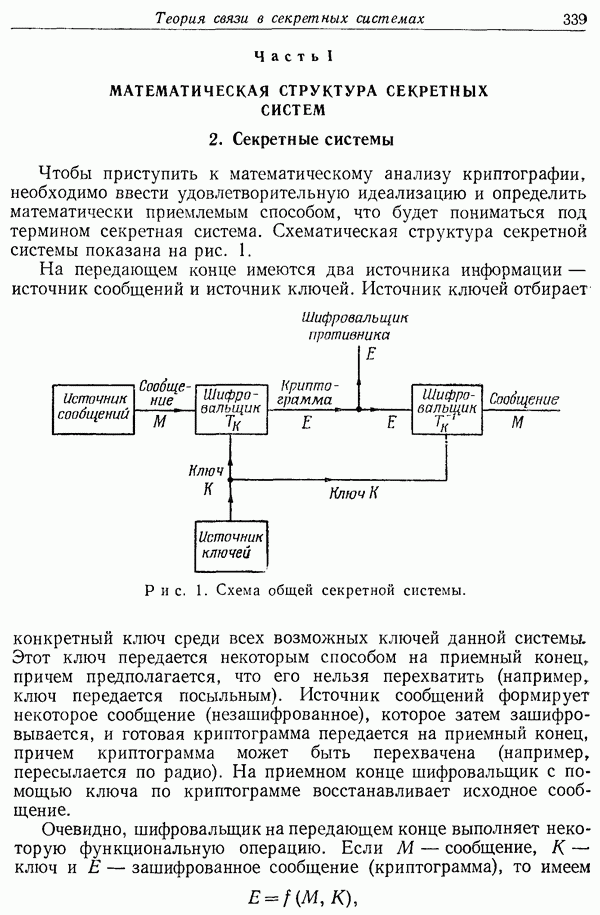
Рассмотрим теперь источник сообщений. Как следует математически описывать источник сообщений и какое количество информации, измеряемое числом битов в секунду, создается данным источником? Главная сторона этого вопроса заключается в использовании статистических сведений об источнике для уменьшения пропускной способности канала путем применения надлежащего
- метода кодирования информации. В телеграфии, например, сообщения, которые должны быть переданы, состоят из последовательностей букв. Эти последовательности, однако, не являются вполне случайными. Вообще говоря, они образуют фразы и имеют статистическую структуру, скажем, английского языка. Буква Е встречается чаще, чем  последовательность
последовательность  чаще, чем
чаще, чем  и т. д.
и т. д.
Наличие такой структуры позволяет получить некоторую экономию времени (или пропускной способности канала) с помощью подходящего кодирования последовательностей сообщений в последовательности сигналов. В ограниченных пределах это уже делается в телеграфии путем использования наиболее короткого символа в канале точки — для наиболее распространенной в английском языке буквы Е, в то время как редко встречающиеся буквы  представляются более длинными последовательностями точек и тире. Этот принцип проводится еще дальше в некоторых коммерческих кодах, где наиболее употребительные слова и фразы представляются четырех- или пятибуквенными кодовыми группами, что дает значительную экономию среднего времени. В стандартизированных и поздравительных телеграммах, используемых в настоящее время, этот принцип развивается еще дальше. Там проводится кодирование одного или двух предложений в относительно короткую последовательность цифр.
представляются более длинными последовательностями точек и тире. Этот принцип проводится еще дальше в некоторых коммерческих кодах, где наиболее употребительные слова и фразы представляются четырех- или пятибуквенными кодовыми группами, что дает значительную экономию среднего времени. В стандартизированных и поздравительных телеграммах, используемых в настоящее время, этот принцип развивается еще дальше. Там проводится кодирование одного или двух предложений в относительно короткую последовательность цифр.
Можно считать, что дискретный источник создает сообщение символ за символом. Он будет выбирать последовательные символы в соответствии с некоторыми вероятностями, зависящими, вообще говоря, как от предыдущих выборов, так и от конкретного рассматриваемого символа. Физическая система или математическая модель системы, которая создает такую последовательность символов, определяемую некоторой заданной совокупностью вероятностей, называется вероятностным процессом. Поэтому можно
считать, что дискретный источник представляется некоторым вероятностным процессом. Обратно, любой вероятностный процесс, который создает дискретную последовательность символов, выбираемых из некоторого конечного множества, может рассматриваться как дискретный источник. Это включает такие случаи, как:
1. Печатные тексты на таких языках, как английский, немецкий, китайский.
2. Непрерывные источники сообщений, которые превращены в дискретные с помощью некоторого процесса квантования. Например, квантованная речь из ИКМ-передатчика или квантованный телевизионный сигнал.
3. Математические случаи, когда просто определяется абстрактно некоторый вероятностный процесс, который порождает последовательность символов. Приведем следующие примеры источников этого последнего типа:
A) пусть имеются пять букв А, В, С, D, Е, каждая из которых выбирается с вероятностью 0,2 независимо от результатов предыдущих выборов. Это привело бы к последовательностям, типичным примером которых является следующая последовательность:

Этот пример был построен при помощи таблицы случайных чисел.
Б) Пусть при использовании тех же самых пяти букв их вероятности будут 0,4; 0,1; 0,2; 0,2; 0,1 соответственно, причем буквы выбираются независимо. Типичным сообщением такого источника является тогда:

 Более сложная структура получается, если последовательные символы выбираются не независимо, а так, что их вероятности зависят от предыдущих букв. В простейшем случае такого типа выбор зависит только от предшествующей буквы, но не от ранее стоящих букв. Тогда статистическая структура может быть описана с помощью множества переходных вероятностей
Более сложная структура получается, если последовательные символы выбираются не независимо, а так, что их вероятности зависят от предыдущих букв. В простейшем случае такого типа выбор зависит только от предшествующей буквы, но не от ранее стоящих букв. Тогда статистическая структура может быть описана с помощью множества переходных вероятностей  т. е. вероятностей того, что за буквой
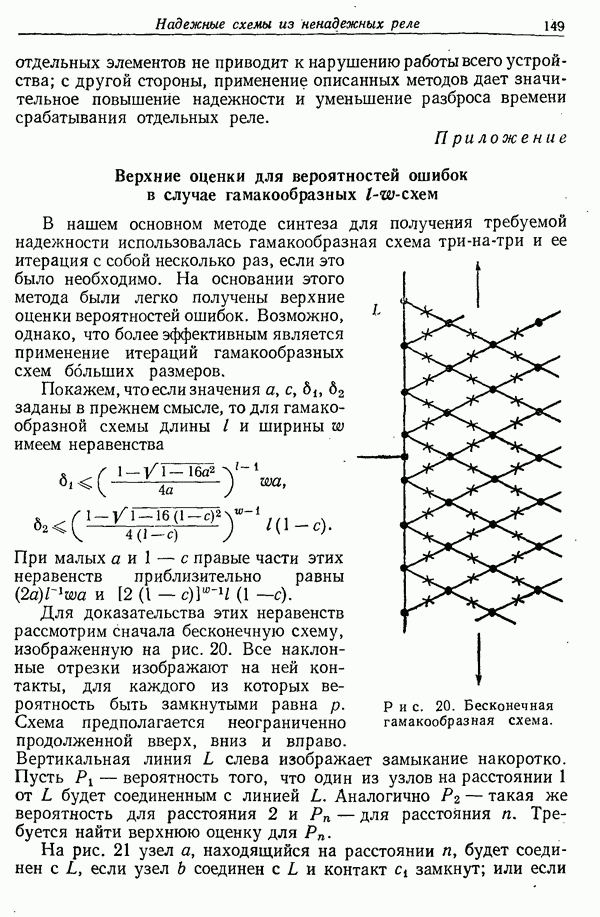
т. е. вероятностей того, что за буквой  следует буква
следует буква  Индексы
Индексы  и
и  пробегают значения, соответствующие всем возможным символам. Другой эквивалентный способ задания этой структуры заключается в том, чтобы задать вероятности «диграмм» (двухбуквенных сочетаний)
пробегают значения, соответствующие всем возможным символам. Другой эквивалентный способ задания этой структуры заключается в том, чтобы задать вероятности «диграмм» (двухбуквенных сочетаний)  т. е. относительные частоты диграмм
т. е. относительные частоты диграмм  Частоты букв
Частоты букв  (вероятности буквы
(вероятности буквы  переходные вероятности
переходные вероятности  и
и
вероятности диграмм  связаны следующими соотношениями:
связаны следующими соотношениями:

В качестве частного примера предположим, что имеются три буквы А, В, С с таблицами вероятностей

Типичное сообщение от такого источника имеет вид

Следующее увеличение сложности заключалось бы во включении частот триграмм (трехбуквенных сочетаний), но не более длинных сочетаний. Выбор буквы зависел бы при этом только от двух предыдущих букв. При этом потребовалось бы задать множество частот триграмм  или, что эквивалентно, множество переходных вероятностей
или, что эквивалентно, множество переходных вероятностей  Следуя далее таким путем, получим последовательно более сложные вероятностные процессы. В общем случае
Следуя далее таким путем, получим последовательно более сложные вероятностные процессы. В общем случае  -грамм (сочетаний из пбукв) для задания статистической структуры требуется множество
-грамм (сочетаний из пбукв) для задания статистической структуры требуется множество  -граммных вероятностей
-граммных вероятностей  или же множество переходных вероятностей
или же множество переходных вероятностей 
Г) Можно также определять вероятностные процессы, которые создают текст, состоящий из последовательности «слов». Предположим, что в языке имеются пять букв А, В, С, D, Е и 16 «слов» с вероятностями появления:

Предположим, что последовательные «слова» выбираются независимо и отделяются друг от друга некоторым промежутком. Типичное сообщение могло бы быть таким:

Если все слова конечной длины, то этот процесс эквивалентен процессу предыдущего типа, но описание может быть проще в терминах структуры слов и их вероятностей. Можно также обобщить и этот случай, вводя переходные вероятности между словами и т. д.
Такие искусственные языки полезны при конструировании простых задач и примеров, имеющих иллюстративные цели. С помощью ряда простых искусственных языков можно также приблизиться к естественному языку. Приближение нулевого порядка получится, если выбирать все буквы с одинаковой вероятностью и независимо. Приближение первого порядка получится, если последовательные буквы выбираются независимо, но каждая буква при этом имеет ту же самую вероятность, что и в естественном языке. Поэтому в приближении первого порядка к английскому языку буква Е выбирается с вероятностью 0,12 (ее частота в нормативном английском языке) и  с вероятностью 0,02, но нет никакой зависимости между смежными буквами и никакой тенденции образовывать предпочтительные диграммы, такие, как
с вероятностью 0,02, но нет никакой зависимости между смежными буквами и никакой тенденции образовывать предпочтительные диграммы, такие, как  и т. д. Для приближения второго порядка вводится структура диграмм. После того как выбрана некоторая буква, следующая буква выбирается в соответствии с частотами, с которыми различные буквы следуют за первой буквой. Для этого требуется таблица частот диграмм
и т. д. Для приближения второго порядка вводится структура диграмм. После того как выбрана некоторая буква, следующая буква выбирается в соответствии с частотами, с которыми различные буквы следуют за первой буквой. Для этого требуется таблица частот диграмм  Для приближения третьего порядка вводится структура триграмм. Каждая буква выбирается с вероятностями, которые зависят от двух предыдущих букв.
Для приближения третьего порядка вводится структура триграмм. Каждая буква выбирается с вероятностями, которые зависят от двух предыдущих букв.