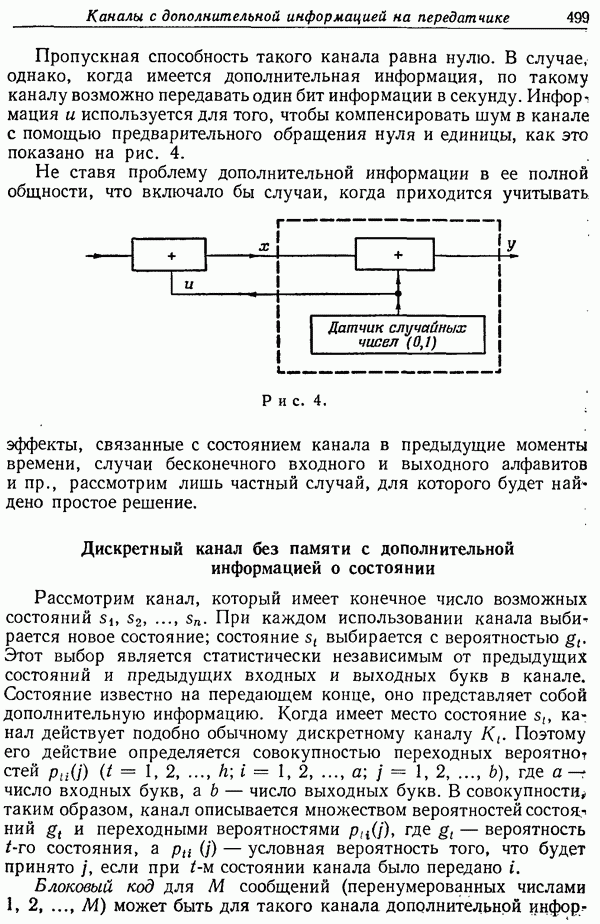
НЕКОТОРЫЕ РЕЗУЛЬТАТЫ ТЕОРИИ КОДИРОВАНИЯ ДЛЯ КАНАЛОВ С ШУМАМИ
Краткое содержание
В работе развиваются и уточняются некоторые положения теории кодирования для каналов связи с шумами. Прежде всего с помощью уточнения рассуждений, основанных на методе «случайного» кодирования, дается оценка сверху вероятности ошибки при оптимальном кодировании в случае конечного дискретного канала без памяти. Затем выводится уравнение, позволяющее определить пропускную способность канала с конечным числом состояний в том случае, когда состояния могут быть вычислены и на передающем и на приемном концах. Анализируется также более сложный случай, когда состояние вычислимо на передающем конце, но не обязательно вычислимо на приемном конце.
Оценка вероятности ошибки для дискретного конечного канала без памяти
Дискретный конечный канал без памяти, у которого входной и выходной алфавиты состоят из конечного числа символов (букв), задается совокупностью переходных вероятностей

таких, что  и все
и все  Здесь
Здесь  означает вероятность того, что на выходе будет принята буква
означает вероятность того, что на выходе будет принята буква  если на входе передавалась буква
если на входе передавалась буква  Кодовое слово длины
Кодовое слово длины  определяется как последовательность
определяется как последовательность  букв на входе (т. е. как
букв на входе (т. е. как  целых чисел, каждое из которых выбрано из совокупности чисел
целых чисел, каждое из которых выбрано из совокупности чисел  . Блоковый код из блоков длины
. Блоковый код из блоков длины  с М возможными словами — это отображение совокупности целых чисел от 1 до М (номеров последовательных сигналов) в множество кодовых слов длины
с М возможными словами — это отображение совокупности целых чисел от 1 до М (номеров последовательных сигналов) в множество кодовых слов длины  Система декодирования для такого кода — это отображение всех
Система декодирования для такого кода — это отображение всех
выходных слов длины  в совокупность целых числ
в совокупность целых числ  , т. е. это некоторая процедура, позволяющая решить, каков был первоначальный номер переданного сообщения.
, т. е. это некоторая процедура, позволяющая решить, каков был первоначальный номер переданного сообщения.
Будем предполагать, что все целые числа от 1 до М используются с одной и той же вероятностью  Для некоторого кода и системы декодирования определим вероятность ошибки
Для некоторого кода и системы декодирования определим вероятность ошибки  как вероятность того, что переданное число будет принято как слово, которому соответствует другое число, т. е. как вероятность декодирования переданного сообщения как другое сообщение. Таким образом,
как вероятность того, что переданное число будет принято как слово, которому соответствует другое число, т. е. как вероятность декодирования переданного сообщения как другое сообщение. Таким образом,

где и пробегает все целые числа от 1 до М, и пробегает все прини маемые слова длины  — совокупность таких слов, декодируемых не как
— совокупность таких слов, декодируемых не как  . Символ
. Символ  означает вероятность получить на выходе
означает вероятность получить на выходе  если было передано сообщение и. Так, если и соответствует слову
если было передано сообщение и. Так, если и соответствует слову  на входе,
на входе,  слово
слово  на выходе, то
на выходе, то

В то время как при кодировании мы предположили, что все сообщения имеют равные вероятности  при изучении каналов полезно бывает приписать разным словам на входе разные вероятности. В самом деле предположим, что в данном канале мы произвольно задали вероятности различных слов и длины
при изучении каналов полезно бывает приписать разным словам на входе разные вероятности. В самом деле предположим, что в данном канале мы произвольно задали вероятности различных слов и длины  на входе и что
на входе и что  — вероятность, приписанная слову и. Тогда для вероятностей всех пар, состоящих из слова длины
— вероятность, приписанная слову и. Тогда для вероятностей всех пар, состоящих из слова длины  на входе и слова длины
на входе и слова длины  на выходе, будем иметь
на выходе, будем иметь

где и и  — слова длины
— слова длины  на входе и выходе,
на входе и выходе,  — вероятность того, что на выходе будет принято слово
— вероятность того, что на выходе будет принято слово  если было передано слово и (т. е.
если было передано слово и (т. е.  — это произведение переходных вероятностей для соответствующих букв, входящих в состав слов
— это произведение переходных вероятностей для соответствующих букв, входящих в состав слов  Если вероятности
Если вероятности  заданы, то любая числовая функция от и и
заданы, то любая числовая функция от и и  становится случайной величиной. В частности, случайной величиной становится
становится случайной величиной. В частности, случайной величиной становится  — удельная (отнесенная к одной букве) взаимная информация и и и:
— удельная (отнесенная к одной букве) взаимная информация и и и:

Обозначим через  функцию распределения этой случайной величины, т. е. положим
функцию распределения этой случайной величины, т. е. положим

Функция  конечно, зависит от сделанного нами выбора вероятностей
конечно, зависит от сделанного нами выбора вероятностей  Сейчас мы докажем теорему, позволяющую при помощи функции
Сейчас мы докажем теорему, позволяющую при помощи функции  оценить вероятность ошибки для некоторого возможного кода.
оценить вероятность ошибки для некоторого возможного кода.
Теорема 1. Пусть некоторые вероятности  для слов и длины
для слов и длины  на входе приводят к функции распределения
на входе приводят к функции распределения  информации на букву. Тогда для любого заданного целого числа М и любого
информации на букву. Тогда для любого заданного целого числа М и любого  существуют такой блоковый код с М возможными словами и такая система декодирования, что если возможные сообщения передаются с равными вероятностями, то вероятность ошибки ограничена сверху так:
существуют такой блоковый код с М возможными словами и такая система декодирования, что если возможные сообщения передаются с равными вероятностями, то вероятность ошибки ограничена сверху так:

где 
Доказательство. Для данных М и 0 рассмотрим пары (и,  слов на входе и выходе и определим множество Т, состоящее их тех пар, для которых
слов на входе и выходе и определим множество Т, состоящее их тех пар, для которых  Если и выбраны с вероятностями
Если и выбраны с вероятностями  то вероятность того, что пара
то вероятность того, что пара  принадлежит множеству Т, равна
принадлежит множеству Т, равна 
Рассмотрим теперь ансамбль кодов, образованных следующим образом. Числам  сопоставляются независимо друг от друга различные возможные слова на входе
сопоставляются независимо друг от друга различные возможные слова на входе  с вероятностями, соответственно равными
с вероятностями, соответственно равными  Эта операция приводит к ансамблю кодов, каждый из которых использует М (или меньше) слов на входе. Если имеются В различных слов
Эта операция приводит к ансамблю кодов, каждый из которых использует М (или меньше) слов на входе. Если имеются В различных слов  то это множество содержит в точности
то это множество содержит в точности  различных кодов, отвечающих
различных кодов, отвечающих  различным способам сопоставления М числам В слов на входе. Коды имеют различные вероятности. Так, например, код, в котором всем числам сопоставлено одно и то же слово на входе и
различным способам сопоставления М числам В слов на входе. Коды имеют различные вероятности. Так, например, код, в котором всем числам сопоставлено одно и то же слово на входе и  (крайне вырожденный случай) имеет вероятность
(крайне вырожденный случай) имеет вероятность  Код, в котором
Код, в котором  числам соответствует слово
числам соответствует слово  имеет вероятность
имеет вероятность  Мы будем иметь дело со средней вероятностью ошибки для этого множества кодов. Под последней мы будем понимать среднюю вероятность ошибки, когда коды взвешены согласно только что определенным вероятностям. Предположим, что при употреблении любого из этих кодов каждое число передается с вероятностью
Мы будем иметь дело со средней вероятностью ошибки для этого множества кодов. Под последней мы будем понимать среднюю вероятность ошибки, когда коды взвешены согласно только что определенным вероятностям. Предположим, что при употреблении любого из этих кодов каждое число передается с вероятностью  Отметим, что для некоторых выборов несколько чисел могут соответствовать одному и тому же слову на входе. Тогда это слово будет употребляться, с большей вероятностью, чем другие.
Отметим, что для некоторых выборов несколько чисел могут соответствовать одному и тому же слову на входе. Тогда это слово будет употребляться, с большей вероятностью, чем другие.
Для произвольного кода из нашего ансамбля определим процедуру декодирования следующим образом. Любое принятое  декодируется как число, имеющее наибольшую условную вероятность быть принятым как
декодируется как число, имеющее наибольшую условную вероятность быть принятым как  Если эта условная вероятность одинакова для нескольких чисел, мы (по условию) декодируем
Если эта условная вероятность одинакова для нескольких чисел, мы (по условию) декодируем  как меньшее из них. В силу того что все числа имеют одну и ту же безусловную вероятность передачи
как меньшее из них. В силу того что все числа имеют одну и ту же безусловную вероятность передачи  при декодировании выбирается одно из тех чисел, для которых вероятность того, что они преобразуются в результате передачи в данное и на выходе, наибольшая.
при декодировании выбирается одно из тех чисел, для которых вероятность того, что они преобразуются в результате передачи в данное и на выходе, наибольшая.
Вычислим теперь среднюю по нашему ансамблю кодов вероятность ошибки или «неопределенности»  При этом будем пессимистически включать в число ошибок все случаи, когда имеется несколько равновероятных возможностей для получения
При этом будем пессимистически включать в число ошибок все случаи, когда имеется несколько равновероятных возможностей для получения 
В произвольном фиксированном коде из нашего ансамбля кодов некоторое слово на входе и или пара (и,  вообще говоря, будут встречаться с вероятностями, отличными от
вообще говоря, будут встречаться с вероятностями, отличными от  Однако в среднем по этому ансамблю каждое слово и имеет вероятность
Однако в среднем по этому ансамблю каждое слово и имеет вероятность  и каждая пара (и,
и каждая пара (и,  — вероятность
— вероятность  так как числам сопоставлялись слова и с вероятностями, в точности равными
так как числам сопоставлялись слова и с вероятностями, в точности равными  . И действительно, какому-либо фиксированному сообщению, скажем числу 1, сопоставлялось слово и с вероятностью
. И действительно, какому-либо фиксированному сообщению, скажем числу 1, сопоставлялось слово и с вероятностью  Пусть теперь в некотором частном случае числу 1 сопоставлялось и, а было принято
Пусть теперь в некотором частном случае числу 1 сопоставлялось и, а было принято  При этом будет иметь место ошибка или неопределенность, если в рассматриваемом коде существует одно или более чисел, отображаемых внутрь множества
При этом будет иметь место ошибка или неопределенность, если в рассматриваемом коде существует одно или более чисел, отображаемых внутрь множества  , состоящего из всех таких слов на входе, что для них вероятность приема на выходе слова
, состоящего из всех таких слов на входе, что для них вероятность приема на выходе слова  больше или равна соответствующей вероятности для и. В силу того что слова на входе сопоставлялись числам независимо друг от друга, легко подсчитать долю кодов, для которых имеет место только что описанное положение. В самом деле, пусть
больше или равна соответствующей вероятности для и. В силу того что слова на входе сопоставлялись числам независимо друг от друга, легко подсчитать долю кодов, для которых имеет место только что описанное положение. В самом деле, пусть

Таким образом,  — это вероятность, приписанная совокупности всех слов, для которых условная вероятность приема на выходе слова
— это вероятность, приписанная совокупности всех слов, для которых условная вероятность приема на выходе слова  больше или равна соответствующей вероятности для и. Доля кодов, в которых число 2 не отображается ни в одно из слов множества
больше или равна соответствующей вероятности для и. Доля кодов, в которых число 2 не отображается ни в одно из слов множества  (в силу независимости сопоставления слов на входе числам), равна
(в силу независимости сопоставления слов на входе числам), равна  Доля кодов, для которых в
Доля кодов, для которых в  нет элементов, соответствующих другим числам, равна
нет элементов, соответствующих другим числам, равна  Подобное рассуждение приложимо и к любому другому числу так же, как к числу 1. Таким образом, в среднем по ансамблю вероятность ошибки или неопределенности, возникающей, когда при передаче сообщения, соответствующего слову
Подобное рассуждение приложимо и к любому другому числу так же, как к числу 1. Таким образом, в среднем по ансамблю вероятность ошибки или неопределенности, возникающей, когда при передаче сообщения, соответствующего слову
на входе и, оно принимается как  в точности равна выражению
в точности равна выражению

Отсюда для средней вероятности ошибки или неопределенности получается выражение

Постараемся теперь оценить эту вероятность при помощи функции распределения  величины информации. Разобьем сначала сумму на две части: сумму по определенному выше множеству Т пар
величины информации. Разобьем сначала сумму на две части: сумму по определенному выше множеству Т пар  для которых
для которых  и сумму по дополнительному к Т множеству Т:
и сумму по дополнительному к Т множеству Т:

Так как выражение  представляет собой вероятность, то мы только увеличим первую сумму, если заменим это выражение на 1. После этого первый член становится равным
представляет собой вероятность, то мы только увеличим первую сумму, если заменим это выражение на 1. После этого первый член становится равным  что по определению совпадает с
что по определению совпадает с  Чтобы оценить вторую сумму, воспользуемся прежде всего тем, что в силу хорошо известного неравенства
Чтобы оценить вторую сумму, воспользуемся прежде всего тем, что в силу хорошо известного неравенства  эта сумма только увеличится от замены в ней
эта сумма только увеличится от замены в ней

на  и станет еще больше после замены последнего выражения на
и станет еще больше после замены последнего выражения на  Итак,
Итак,

Покажем теперь, что для и и и, принадлежащих Г, имеет место неравенство  В самом деле, для и и
В самом деле, для и и  из Т
из Т

т. е.

Если

Суммирование обеих сторон последнего неравенства по и  дает
дает

(Первое из этих неравенств вытекает из того, что сумма вероятностей несовместимых событий не может превосходить единицы.) Мы получили тем самым, что

Используя это неравенство в нашей оценке величины  найдем, что
найдем, что

при этом опять учтено то обстоятельство, что сумма вероятностей несовместимых событий не превосходит единицы. Так как средняя по ансамблю кодов вероятность  удовлетворяет неравенству
удовлетворяет неравенству  то должен существовать некоторый частный код, удовлетворяющий этому же неравенству. Это завершает доказательство.
то должен существовать некоторый частный код, удовлетворяющий этому же неравенству. Это завершает доказательство.
Теорема 1 является одним из тех результатов, которые указывают на тесную связь между вероятностью ошибки для кодов в каналах с шумом и функцией распределения  величины взаимной информации. Теорема 1 показывает, что если, выбрав вероятность
величины взаимной информации. Теорема 1 показывает, что если, выбрав вероятность  для слов на входе, мы получили некоторую функцию распределения
для слов на входе, мы получили некоторую функцию распределения  то можно создать код, вероятность ошибки для которого оценивается при помощи
то можно создать код, вероятность ошибки для которого оценивается при помощи  Сейчас установим некоторую обратную зависимость: свяжем с
Сейчас установим некоторую обратную зависимость: свяжем с  произвольный заданный код. При этом покажем, что вероятность ошибки для кода (при оптимальном декодировании) тесно связана с соответствующей функцией
произвольный заданный код. При этом покажем, что вероятность ошибки для кода (при оптимальном декодировании) тесно связана с соответствующей функцией 
Теорема 2. Пусть некоторый фиксированный код имеет  равновероятных сообщений и пусть функция распределения удельной взаимной информации I между сообщениями и принятыми словами равна
равновероятных сообщений и пусть функция распределения удельной взаимной информации I между сообщениями и принятыми словами равна  Тогда оптимальная система приема для этого кода приводит к вероятности ошибки
Тогда оптимальная система приема для этого кода приводит к вероятности ошибки  удовлетворяющей неравенствам
удовлетворяющей неравенствам

Отметим, что  имеет здесь несколько иной смысл, чем в теореме 1. Здесь она связана с взаимной информацией между сообщениями и принятыми словами, а в теореме 1 — с взаимной информацией между словами на входе и принятыми словами. Если, как это обычно
имеет здесь несколько иной смысл, чем в теореме 1. Здесь она связана с взаимной информацией между сообщениями и принятыми словами, а в теореме 1 — с взаимной информацией между словами на входе и принятыми словами. Если, как это обычно
бывает, все сообщения сопоставляются при кодировании различным словам на входе, то в обоих случаях приходим к одной и той же величине.
Доказательство. Установим сначала оценку снизу.  Из определения функции
Из определения функции  следует, что вероятность выполнения неравенства
следует, что вероятность выполнения неравенства

равна  Здесь и — сообщение,
Здесь и — сообщение,  принятое слово. Но наше неравенство равносильно неравенству
принятое слово. Но наше неравенство равносильно неравенству

или (так как  неравенству
неравенству

Рассмотрим теперь пары  для которых неравенство
для которых неравенство

имеет место, и представим себе соответствующие линии, соединяющие точки и и  окрашенными в черный цвет, а все другие линии, соединяющие и с
окрашенными в черный цвет, а все другие линии, соединяющие и с  в красный. Разделим теперь точки
в красный. Разделим теперь точки  на два класса. Класс
на два класса. Класс  состоит из тех
состоит из тех  которые декодируются в такие и, что и и
которые декодируются в такие и, что и и  соединены красной линией (а также из тех
соединены красной линией (а также из тех  которые декодируются в и, вообще не соединенные с
которые декодируются в и, вообще не соединенные с  Класс
Класс  составляют те
составляют те  , которые декодируются в и, соединенные с
, которые декодируются в и, соединенные с  черной линией. Мы установили, что с вероятностью
черной линией. Мы установили, что с вероятностью  пара
пара  будет соединена черной линией. Те
будет соединена черной линией. Те  которые включены в эти пары, будут попадать в два класса,
которые включены в эти пары, будут попадать в два класса,  с вероятностями, скажем,
с вероятностями, скажем,  Если при этом
Если при этом  окажется в
окажется в  то произойдет ошибка, так как на самом деле и было соединено с
то произойдет ошибка, так как на самом деле и было соединено с  черной линией, а декодирование приводит к и, соединенному с
черной линией, а декодирование приводит к и, соединенному с  красной линией (или вовсе не соединенному). Следовательно, рассматриваемые случаи приводят к ошибке, возникающей с вероятностью
красной линией (или вовсе не соединенному). Следовательно, рассматриваемые случаи приводят к ошибке, возникающей с вероятностью  Если же наше покажется принадлежащим классу
Если же наше покажется принадлежащим классу  то
то  Это означает, что по крайней мере с такой же вероятностью эти и могут быть получены не из рассматриваемых здесь,
Это означает, что по крайней мере с такой же вероятностью эти и могут быть получены не из рассматриваемых здесь,
а из других и. Если сложить для этих  вероятности всех пар
вероятности всех пар  исключая те пары, которые соответствуют друг другу по системе декодирования, то получим по меньшей мере вероятность
исключая те пары, которые соответствуют друг другу по системе декодирования, то получим по меньшей мере вероятность  и все эти случаи будут соответствовать неправильному декодированию. Таким образом, получаем следующее неравенство для вероятности ошибки
и все эти случаи будут соответствовать неправильному декодированию. Таким образом, получаем следующее неравенство для вероятности ошибки

Установим теперь оценку сверху. Рассмотрим систему декодирования, определенную следующим образом. Если для любого принятого  существует некоторое и, такое, что
существует некоторое и, такое, что  то это
то это  декодируется в указанное и. Очевидно, что для данного у не может существовать более чем одно такое и, ибо в противном случае сумма соответствующих событий имела бы вероятность, превосходящую единицу. Если же для данного и не имеется ни одного такого и, то декодирование выберем произвольно. Например, можно условиться, что все такие
декодируется в указанное и. Очевидно, что для данного у не может существовать более чем одно такое и, ибо в противном случае сумма соответствующих событий имела бы вероятность, превосходящую единицу. Если же для данного и не имеется ни одного такого и, то декодирование выберем произвольно. Например, можно условиться, что все такие  декодируются в первое из имеющихся на входе сообщений. Вероятность ошибки при таком декодировании меньше или равна вероятности всех пар
декодируются в первое из имеющихся на входе сообщений. Вероятность ошибки при таком декодировании меньше или равна вероятности всех пар  для которых
для которых  Иначе говоря,
Иначе говоря,  где
где  — совокупность пар
— совокупность пар  для которых
для которых  Условие
Условие  эквивалентно условию
эквивалентно условию  или условию
или условию

Последнее равносильно условию

Сумма  по определению является значением функции распределения величины
по определению является значением функции распределения величины  в точке
в точке  т. е.
т. е.