соответственно и  отображений в случае первого кода,
отображений в случае первого кода,  в случае второго кода. Рассмотрим все пары этих кодов, общее число которых равно
в случае второго кода. Рассмотрим все пары этих кодов, общее число которых равно 
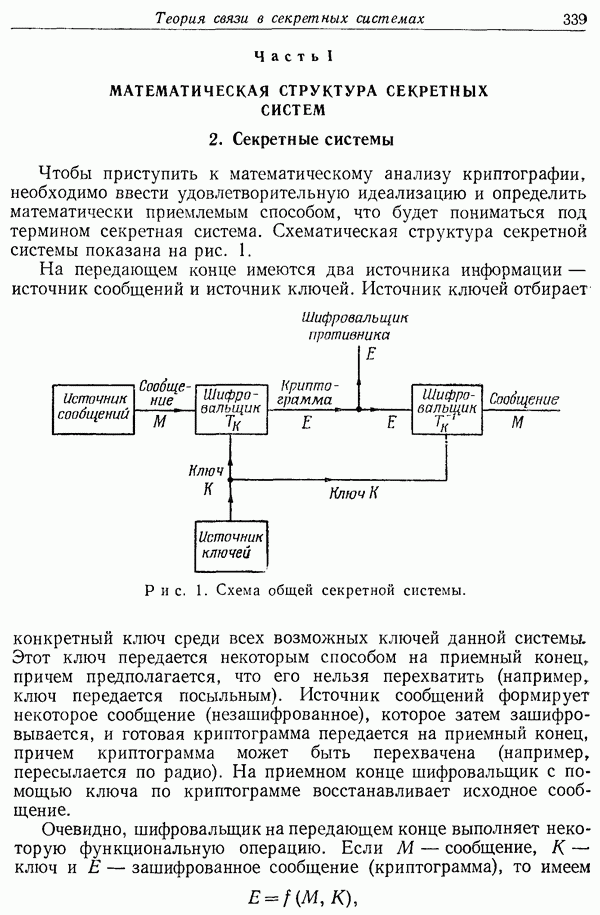
Каждой паре кодов придается некоторый вес, или вероятность, равная вероятности появления этой пары, если оба отображения независимы и целое число отображается в некоторое слово с вероятностью, приписанной этому слову. Таким образом, паре кодов придается вес, равный произведению вероятностей всех тех слов на входах, в которые данные числа отображаются этими кодами. Это множество пар кодов вместе с приписанными им таким образом вероятностями будем называть случайным ансамблем пар кодов, основанным на вероятностях 
Любая заданная пара кодов этого множества может быть использована для передачи информации, если уже выбран метод декодирования. Метод декодирования состоит из применения пары функций  — частный случай функций определенных выше. Здесь
— частный случай функций определенных выше. Здесь  пробегает всевозможные слова длины
пробегает всевозможные слова длины  на входе конца
на входе конца  — всевозможные блоки длины
— всевозможные блоки длины  получаемых на выходе конца 1. Функция
получаемых на выходе конца 1. Функция  принимает значение от 1 до
принимает значение от 1 до  и представляет собой декодируемое сообщение для полученного
и представляет собой декодируемое сообщение для полученного  если было передано
если было передано  (Конечно, в общем случае
(Конечно, в общем случае  используется в процессе декодирования, так как
используется в процессе декодирования, так как  может влиять на
может влиять на  и поэтому содержит информацию, существенную для наилучшего декодирования.)
и поэтому содержит информацию, существенную для наилучшего декодирования.)
Аналогично,  принимает значение от 1 до
принимает значение от 1 до  и представляет собой метод решения задачи о том, какое сообщение
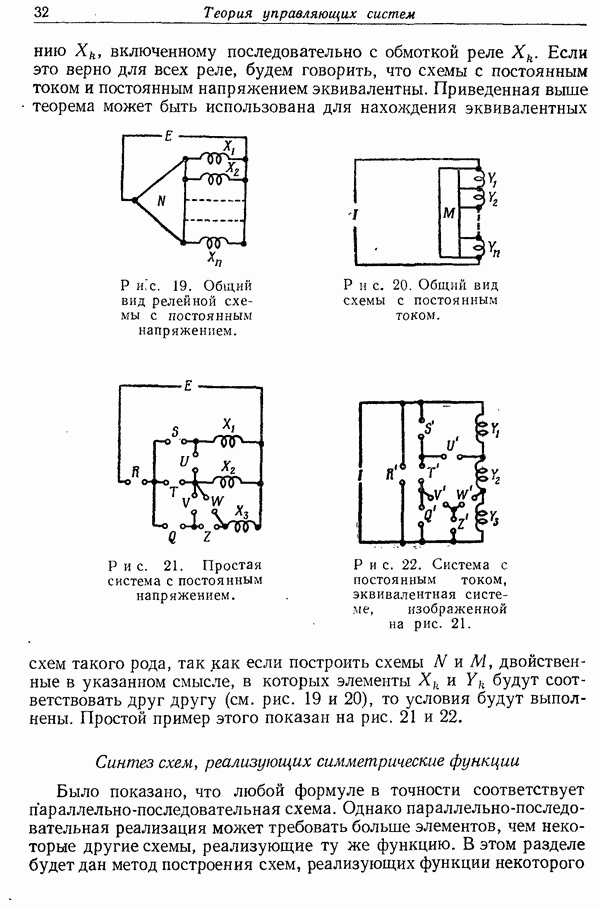
и представляет собой метод решения задачи о том, какое сообщение  было передано на основе информации, имеющейся на конце 2. Заметим здесь, что декодирующие функции
было передано на основе информации, имеющейся на конце 2. Заметим здесь, что декодирующие функции  не обязательно должны быть одинаковыми для всех пар кодов из нашего ансамбля.
не обязательно должны быть одинаковыми для всех пар кодов из нашего ансамбля.
Отметим также, что кодирующие функции для нашего случайного ансамбля являются более специальными, чем в описанном выше общем случае. Последовательность входных букв  для данного сообщения
для данного сообщения  не зависит от полученных букв на конце 1. Для любого частного кода ансамбля существует точное отображение сообщений в последовательности на входе.
не зависит от полученных букв на конце 1. Для любого частного кода ансамбля существует точное отображение сообщений в последовательности на входе.
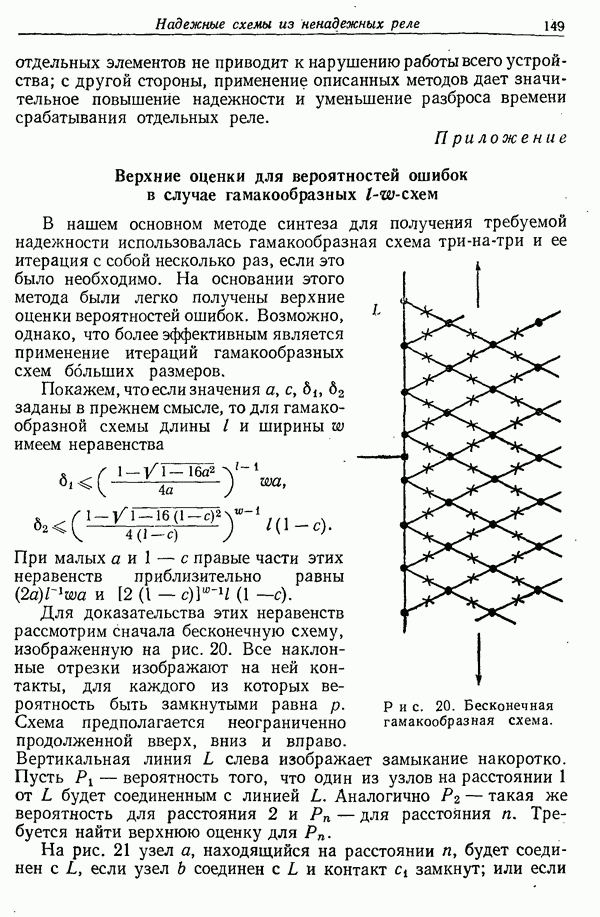
При заданных ансамблях пар кодов, описанных выше, и декодирующих функциях можно вычислить для каждой частной пары кодов две вероятности ошибок:  — вероятность ошибки декодирования для первого кода и
— вероятность ошибки декодирования для первого кода и  — для второго кода. Здесь предполагается, что различные сообщения для первого кода встречаются с вероятностями
— для второго кода. Здесь предполагается, что различные сообщения для первого кода встречаются с вероятностями  аналогичное предположение имеет место и для второго кода.
аналогичное предположение имеет место и для второго кода.
Средними вероятностями ошибок по ансамблю пар кодов назовем средние  при вычислении которых каждая вероятность ошибки для частного кода берется с весом, равным
при вычислении которых каждая вероятность ошибки для частного кода берется с весом, равным
вероятности, приписанной данной паре кодов. Требуется описать некоторый частный метод декодирования, т. е. выбор функций  и затем найти верхние границы для средних вероятностей ошибок по ансамблю кодов.
и затем найти верхние границы для средних вероятностей ошибок по ансамблю кодов.






































































































































































































































































































































































































































































































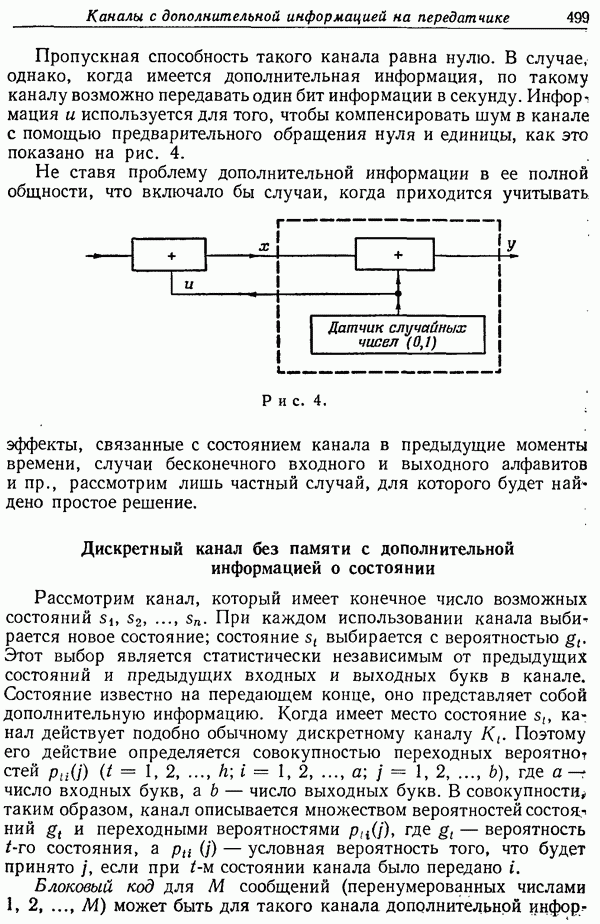































































































































































































































































































































 осредненных по этому ансамблю кодов и затем докажем существование в этом ансамбле отдельных кодов, удовлетворяющих таким границам для их вероятностей ошибок.
осредненных по этому ансамблю кодов и затем докажем существование в этом ансамбле отдельных кодов, удовлетворяющих таким границам для их вероятностей ошибок.
 слов и в направлении 2—1 из
слов и в направлении 2—1 из  слов, строится следующим образом.
слов, строится следующим образом.  целых чисел
целых чисел  (сообщения для первого кода) отображается всевозможными способами в множество слов на входе
(сообщения для первого кода) отображается всевозможными способами в множество слов на входе  длины
длины  Подобным же образом целые числа
Подобным же образом целые числа  (сообщение для второго кода) отображаются всевозможными способами в множество слов на входе
(сообщение для второго кода) отображаются всевозможными способами в множество слов на входе  длины
длины 
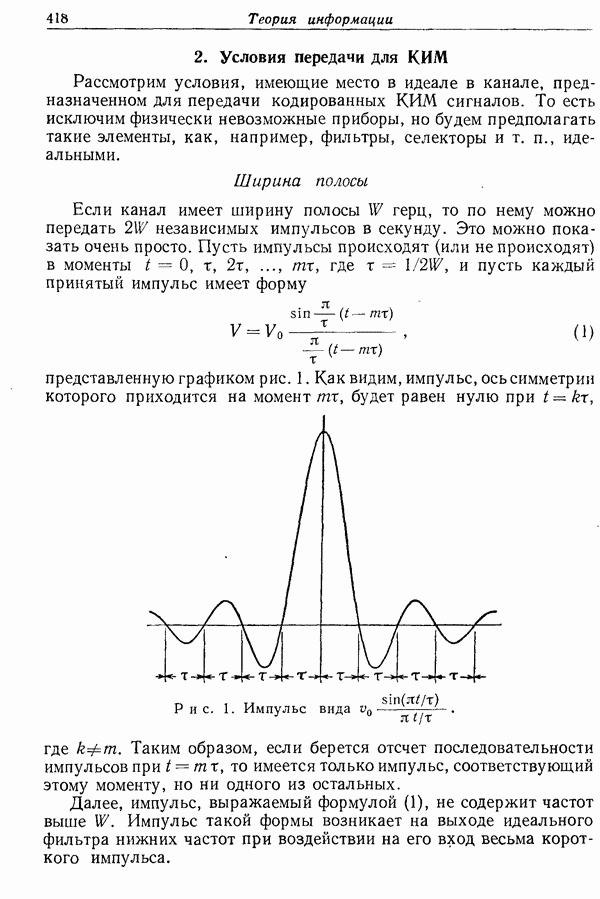
 входных букв, а на конце
входных букв, а на конце  входных букв, тогда различных входных слов длины
входных букв, тогда различных входных слов длины  будет
будет 
