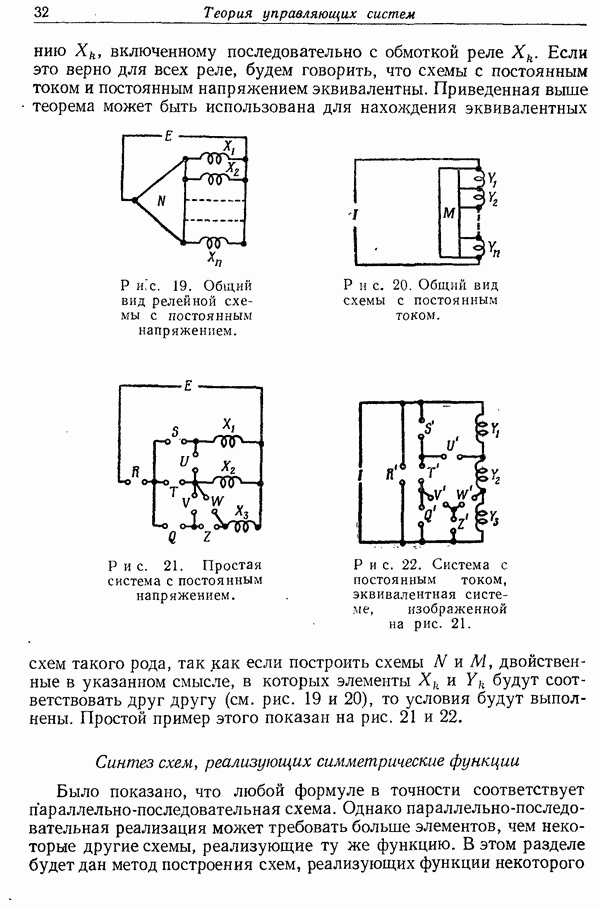
7. Энтропия источника сообщений
Рассмотрим дискретный источник с конечным числом состояний, наподобие источников, рассмотренных выше. Для каждого возможного состояния  имеется некоторое множество вероятностей
имеется некоторое множество вероятностей  создания различных возможных символов
создания различных возможных символов  Следовательно, Для каждого состояния
Следовательно, Для каждого состояния  существует энтропия
существует энтропия  Энтропия источника определяется как среднее значение величин
Энтропия источника определяется как среднее значение величин  которые осреднены в соответствии с вероятностями осуществления соответствующих событий
которые осреднены в соответствии с вероятностями осуществления соответствующих событий

Это энтропия источника на символ текста. Если наш марковский процесс развивается с определенной скоростью, то можно говорить также об энтропии в секунду

где  — средняя частота (появлений в секунду) состояния
— средняя частота (появлений в секунду) состояния  Очевидно,
Очевидно,

где  — среднее число символов, создаваемых за одну секунду. Величины Н или Н измеряют количество информации, создаваемое источником, на символ или в секунду. Если в качестве основания логарифмов выбрано 2, то они представляют из себя количество битов на символ или в секунду.
— среднее число символов, создаваемых за одну секунду. Величины Н или Н измеряют количество информации, создаваемое источником, на символ или в секунду. Если в качестве основания логарифмов выбрано 2, то они представляют из себя количество битов на символ или в секунду.
Если символы в последовательности независимы, то Н просто равняется  , где
, где  — вероятность символа
— вероятность символа  Предположим, что в этом случае рассматривается длинное сообщение, состоящее из
Предположим, что в этом случае рассматривается длинное сообщение, состоящее из  символов. Оно будет с большой вероятностью содержать
символов. Оно будет с большой вероятностью содержать  раз первый символ,
раз первый символ,  раз второй символ и т. д. Отсюда вероятность этого конкретного сообщения будет приближенно равна
раз второй символ и т. д. Отсюда вероятность этого конкретного сообщения будет приближенно равна

или

Таким образом,  приближенно равна логарифму обратной величины вероятности типичной длинной последовательности,
приближенно равна логарифму обратной величины вероятности типичной длинной последовательности,
поделенному на число символов в последовательности. Этот вывод верен и для любого источника. В более точной формулировке мы имеем (см. приложение 3) следующую теорему.
Теорема 3. Для любых заданных  можно найти такое
можно найти такое  что последовательности любой длины
что последовательности любой длины  распадаются на два класса:
распадаются на два класса:
1) множество последовательностей, суммарная вероятность которых меньше чем 
2) сстаток, все члены которого обладают вероятностями, удовлетворяющими неравенству

Другими словами, почти достоверно, что  весьма близко к Н, когда
весьма близко к Н, когда  велико.
велико.
Аналогичный результат получается и для последовательностей, имеющих определенные суммарные вероятности. Рассмотрим снова последовательности длины  Расположим их в ряд в порядке уменьшения вероятностей. Введем величину
Расположим их в ряд в порядке уменьшения вероятностей. Введем величину  — число последовательностей, которые необходимо взять из нашего ряда, начиная с наиболее вероятной последовательности, для того чтобы для взятых последовательностей накопилась суммарная вероятность
— число последовательностей, которые необходимо взять из нашего ряда, начиная с наиболее вероятной последовательности, для того чтобы для взятых последовательностей накопилась суммарная вероятность 
Теорема 4. Когда  не равно нулю или единице,
не равно нулю или единице,

Можно интерпретировать величину  как число бит, требуемых для задания последовательности, когда рассматриваются только наиболее вероятные последовательности с суммарной вероятностью
как число бит, требуемых для задания последовательности, когда рассматриваются только наиболее вероятные последовательности с суммарной вероятностью  Тогда
Тогда  есть число бит на символ, необходимых для задания последовательностей. Теорема гласит, что для больших
есть число бит на символ, необходимых для задания последовательностей. Теорема гласит, что для больших  это число не зависит от
это число не зависит от  и равно Н. Быстрота возрастания логарифма числа сравнительно вероятных последовательностей определяется величиной Н независимо от истолкования смысла слов «сравнительно вероятный». Эти выводы, доказываемые в приложении 3, показывают, что в большинстве случаев длинные, последовательности можно рассматривать так, как если бы их было ровно
и равно Н. Быстрота возрастания логарифма числа сравнительно вероятных последовательностей определяется величиной Н независимо от истолкования смысла слов «сравнительно вероятный». Эти выводы, доказываемые в приложении 3, показывают, что в большинстве случаев длинные, последовательности можно рассматривать так, как если бы их было ровно  и каждая имела вероятность
и каждая имела вероятность 
Следующие две теоремы показывают, что Н и Н могут быть, найдены с помощью предельных операций непосредственно.
следующего символа при условии, что значения  (предшествовавших символов) известно и не изменяется от добавления сведений о любых стоящих ранее символах, то тогда
(предшествовавших символов) известно и не изменяется от добавления сведений о любых стоящих ранее символах, то тогда  является, конечно, условной энтропией следующего символа, когда известны
является, конечно, условной энтропией следующего символа, когда известны  (предыдущих), тогда как
(предыдущих), тогда как  — энтропия на символ последовательности из
— энтропия на символ последовательности из  символов.
символов.
Отношение энтропии источника к максимальному значению, которого могла бы достичь энтропия при тех же символах, назовем относительной энтропией источника. Как будет показано ниже, она является максимальным сжатием, которое можно осуществить кодированием при помощи того же самого алфавита. Единица минус относительная энтропия есть избыточность. Избыточность обычного английского текста, если не рассматривать статистическую структуру, относящуюся более чем к 8 буквам, составляет примерно 50%. Это значит, что когда мы пишем по-английски, то половина знаков текста определяется структурой языка, и лишь половина выбирается свободно. Значение 50% было найдено с помощью нескольких независимых методов, которые все дают приблизительно тот же самый результат. Одним из таких методов было вычисление энтропии приближений к английскому тексту. Другой метод состоял в исключении из образцов английского текста некоторой части букв, после чего делалась попытка их восстановить. Если их удается восстановить, когда 50% текста исключено, избыточность должна быть больше чем 50%. Третий метод связан с некоторыми известными данными работ по криптографии.
Два крайних примера избыточности английской прозы представляют из себя бейсик-инглиш и книга Джемса Джойса. Словарь языка бейсик-инглиш ограничен 850 словами и избыточность его очень велика. Это выражается в увеличении объема текста, которое происходит при переводе на бейсик-инглиш. С другой стороны, Джойс расширяет словарь и это позволяет ему достигнуть сжатия смыслового содержания.
Избыточность языка связана с возможностью построения кроссвордов. Если избыточность равна нулю, то любая последовательность букв представляет собой осмысленный текст, и любое двумерное построение букв представляет из себя кроссворд. Если избыточность слишком велика, то язык налагает столь много ограничений, что уже не могут существовать большие кроссворды.
Более точный анализ показывает, что если предположить случайный характер ограничений, налагаемых языком, то большие
кроссворды становятся возможными, лишь когда избыточность достигает 50%. Если избыточность достигает 33%, то возможны трехмерные кроссворды и т. д.




































































































































































































































































































































































































































































































































































































































































































































































































































 — вероятность того, что источник создает последовательность символов Пусть
— вероятность того, что источник создает последовательность символов Пусть

 содержащие
содержащие  символов. Тогда
символов. Тогда  -монотонно убывающая функция от
-монотонно убывающая функция от  и
и

 — вероятность того, что появится последовательность
— вероятность того, что появится последовательность  и после нее появится символ
и после нее появится символ  — условная вероятность того, что после
— условная вероятность того, что после  появится
появится  Пусть
Пусть

 всем последовательностям
всем последовательностям  из
из  символа и по всем символам
символа и по всем символам  Тогда
Тогда  -монотонно убывающая функция от
-монотонно убывающая функция от 


 символов.
символов.  является лучшим приближением. На самом деле
является лучшим приближением. На самом деле  является энтропией
является энтропией  приближения к источнику рассмотренного выше типа. Если лет никаких статистических связей, распространяющихся более чем насимволов, т. е. если условная вероятность появления
приближения к источнику рассмотренного выше типа. Если лет никаких статистических связей, распространяющихся более чем насимволов, т. е. если условная вероятность появления
