7. Вероятность ошибки для ансамбля кодов
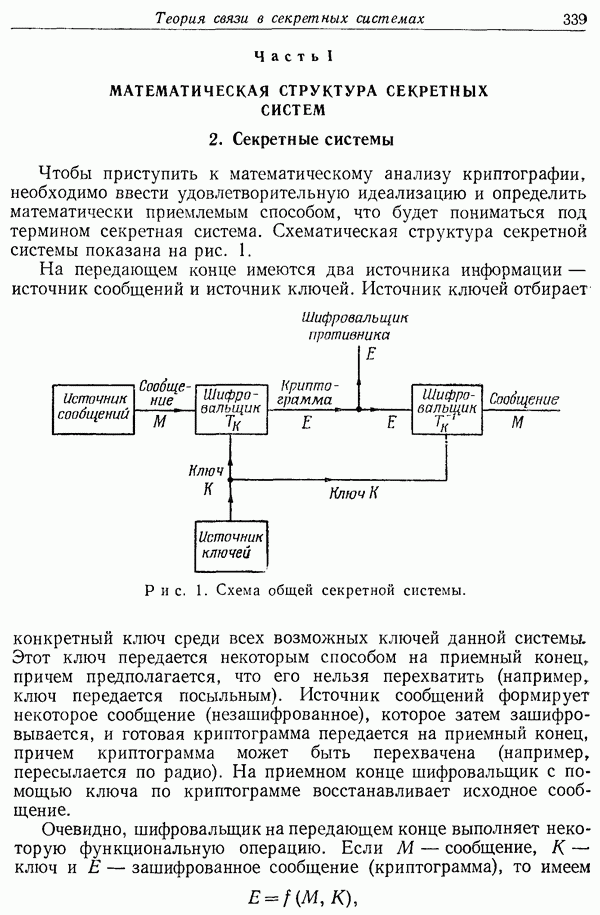
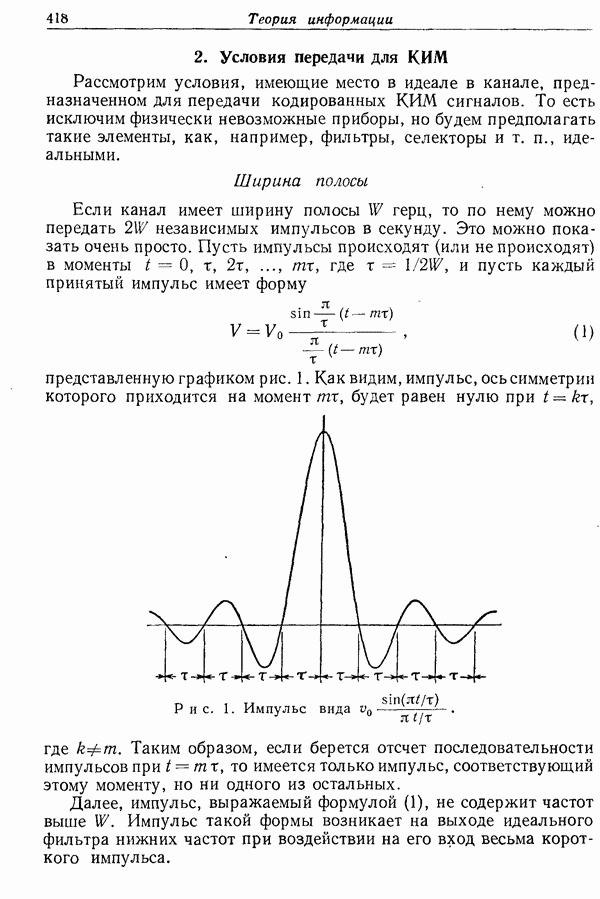
Теорема 1. Пусть на основании распределений вероятностей  для двустороннего дискретного канала без памяти вычисляются функции распределения информации
для двустороннего дискретного канала без памяти вычисляются функции распределения информации  и
и  Пусть
Пусть  — произвольные целые числа, а
— произвольные целые числа, а  — произвольные положительные числа. Тогда случайный ансамбль пар кодов с
— произвольные положительные числа. Тогда случайный ансамбль пар кодов с  сообщениями соответственно имеет (при соответствующих декодирующих функциях) средние вероятности ошибок, ограниченные следующими величинами:
сообщениями соответственно имеет (при соответствующих декодирующих функциях) средние вероятности ошибок, ограниченные следующими величинами:

Кроме того, в ансамбле существует по крайней мере одна пара кодов, для которых индивидуальные вероятности ошибок ограничены удвоенными правыми частями неравенств (13), т. е. удовлетворяют условиям

Теорема для двустороннего канала является обобщением теоремы 1 (из работы, цитированной на стр. 630), в которой устанавливается граница для  в случае одностороннего канала. Доказательство ее является обобщением доказательства для двустороннего канала.
в случае одностороннего канала. Доказательство ее является обобщением доказательства для двустороннего канала.
Статистическая ситуация здесь достаточно сложна. Имеется несколько статистических событий: выбор сообщений  выбор некоторой пары кодов из ансамбля пар кодов, и, наконец, статистика самого канала, в котором получение выходных слов
выбор некоторой пары кодов из ансамбля пар кодов, и, наконец, статистика самого канала, в котором получение выходных слов  имеет вероятность
имеет вероятность  Вероятности ошибок для ансамбля будем вычислять как средние по всем этим статистическим событиям.
Вероятности ошибок для ансамбля будем вычислять как средние по всем этим статистическим событиям.
Вначале определим системы декодирования для различных кодов ансамбля. Для данного  и для каждой пары X,,
и для каждой пары X,,  определим соответствующее множество слов в пространстве
определим соответствующее множество слов в пространстве  обозначаемое
обозначаемое  следующим образом:
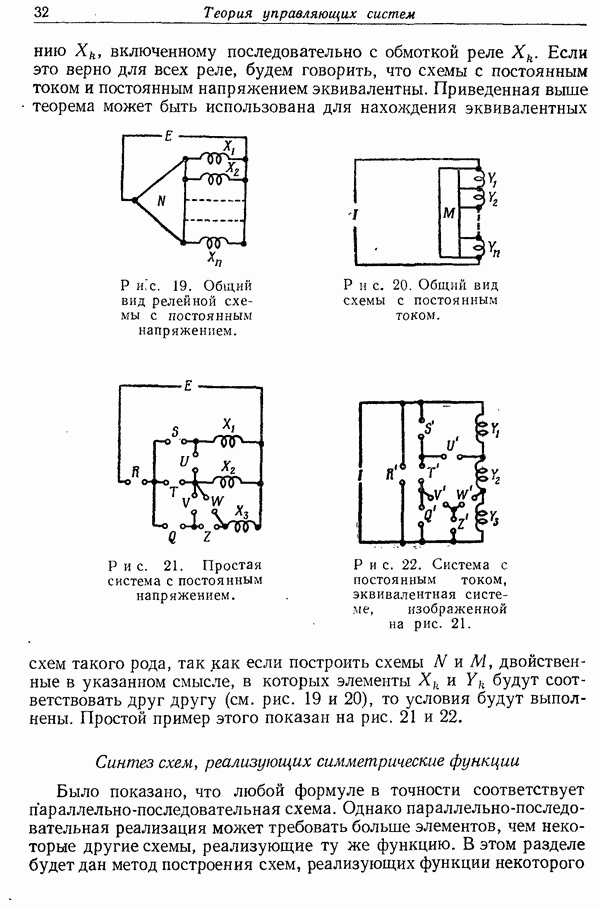
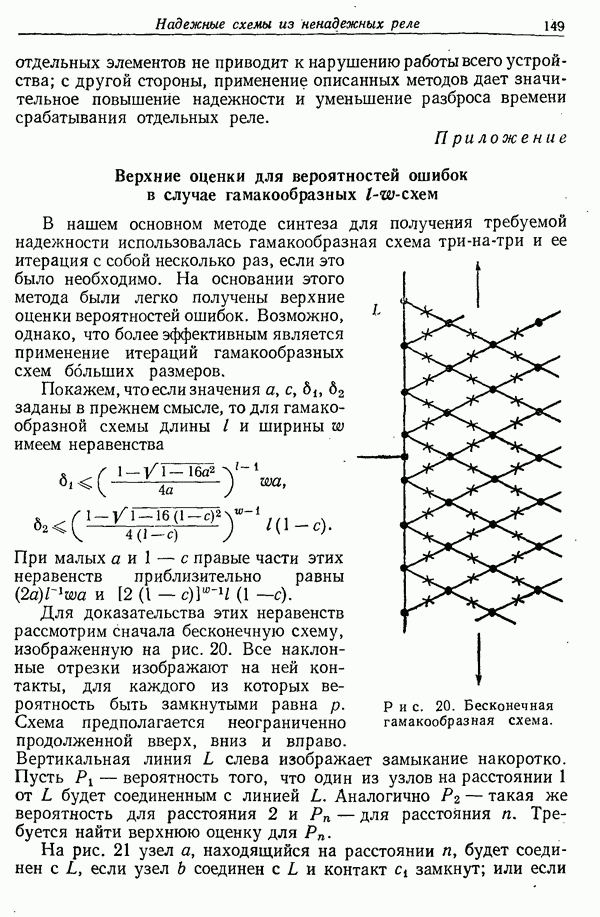
следующим образом:

Таким образом,  представляет собой множество слов из
представляет собой множество слов из  взаимная информация которых с фиксированной парой
взаимная информация которых с фиксированной парой  превышает некоторый уровень
превышает некоторый уровень  Аналогичным путем определим множество
Аналогичным путем определим множество  слов из
слов из  для каждой пары
для каждой пары 

Будем использовать множества 5 и  для того, чтобы определить процесс декодирования и при отыскании верхних границ для вероятностей ошибок. Этот процесс определяется следующим образом. Для любой частной пары кодов из случайного ансамбля предположим, что поступило сообщение
для того, чтобы определить процесс декодирования и при отыскании верхних границ для вероятностей ошибок. Этот процесс определяется следующим образом. Для любой частной пары кодов из случайного ансамбля предположим, что поступило сообщение  и оно отображается в слово
и оно отображается в слово  на входе. Пусть
на входе. Пусть  есть слово, соответствующее блоку из
есть слово, соответствующее блоку из  букв, полученное на конце 1. Рассмотрим подмножество
букв, полученное на конце 1. Рассмотрим подмножество  слов из
слов из  Могут встретиться следующие случаи. 1) Не имеется ни одного сообщения
Могут встретиться следующие случаи. 1) Не имеется ни одного сообщения  отображаемого в подмножество
отображаемого в подмножество  для рассматриваемой пары кодов. В этом случае
для рассматриваемой пары кодов. В этом случае  декодируются, по условию, как сообщение номер один. 2) Имеется в точности одно сообщение, отображаемое в это подмножество. В этом случае оно декодируется в это сообщение. 3) Имеется более чем одно такое сообщение. В этом случае оно декодируется в то из таких сообщений, которое имеет наименьший номер.
декодируются, по условию, как сообщение номер один. 2) Имеется в точности одно сообщение, отображаемое в это подмножество. В этом случае оно декодируется в это сообщение. 3) Имеется более чем одно такое сообщение. В этом случае оно декодируется в то из таких сообщений, которое имеет наименьший номер.
Естественно представлять себе, что вероятность ошибок, которые требуется оценить, вычисляются следующим путем. Для каждой пары кодов подсчитываются вероятности ошибок при всевозможных сообщениях и  осредняя их, получаем вероятности ошибок для данной пары кодов. Затем эти вероятности ошибок осредняются по всему ансамблю пар кодов с использованием приписанных каждой паре кодов весов или вероятностей. Можно, однако, изменить этот порядок осреднения. Можно рассматривать случаи, когда сообщениями являются некоторые фиксированные
осредняя их, получаем вероятности ошибок для данной пары кодов. Затем эти вероятности ошибок осредняются по всему ансамблю пар кодов с использованием приписанных каждой паре кодов весов или вероятностей. Можно, однако, изменить этот порядок осреднения. Можно рассматривать случаи, когда сообщениями являются некоторые фиксированные  которые отображаются в фиксированные
которые отображаются в фиксированные  переходящие затем в слова и
переходящие затем в слова и  При этом со статистической точки зрения остается еще возможность изменения пар кодов, задаваемых теперь отображением оставшихся
При этом со статистической точки зрения остается еще возможность изменения пар кодов, задаваемых теперь отображением оставшихся  сообщений для одного кода и
сообщений для одного кода и  сообщений для другого. При осреднении по этому подмножеству кодов требуется показать, что вероятность того, что любое из этих оставшихся сообщений будет отображено в подмножества
сообщений для другого. При осреднении по этому подмножеству кодов требуется показать, что вероятность того, что любое из этих оставшихся сообщений будет отображено в подмножества  не превосходит соответственно
не превосходит соответственно 
Заметим сначала, что если  принадлежит множеству
принадлежит множеству  то по определению этого множества
то по определению этого множества

Просуммировав полученные неравенства по множеству значений  принадлежащих
принадлежащих  получим
получим

Левое неравенство здесь справедливо, так как сумма вероятностей несовместных событий не может превосходить единицы. Сумму в правой части неравенства можно обозначить через  -Сопоставляя левую и правую часть нашего неравенства, получим
-Сопоставляя левую и правую часть нашего неравенства, получим

Таким образом, полная вероятность любого из множеств  ограничена выражением, содержащим
ограничена выражением, содержащим  но не зависящим от фиксиройанных
но не зависящим от фиксиройанных 
Теперь вспомним, что сообщения отображались во входные слова независимо, с использованием вероятностей  Вероятность в ансамбле пар кодов того, что некоторое фиксированное сообщение будет отображено внутрь
Вероятность в ансамбле пар кодов того, что некоторое фиксированное сообщение будет отображено внутрь  в точности равна
в точности равна  Вероятность попасть в дополнение к этому множеству есть
Вероятность попасть в дополнение к этому множеству есть  Вероятность того, что все остальные сообщения, кроме
Вероятность того, что все остальные сообщения, кроме  будут отображены в это дополнительное множество, равна
будут отображены в это дополнительное множество, равна

Здесь было использовано неравенство  соотношение (19) и, наконец, тот факт, что
соотношение (19) и, наконец, тот факт, что 
Таким образом, установлено, что в подмножестве рассмотренных случаев (тех случаев, когда сообщения  отображаются в
отображаются в  и затем переходят в
и затем переходят в  с вероятностью, не меньшей
с вероятностью, не меньшей  не будет других сообщений, отображаемых внутрь множества
не будет других сообщений, отображаемых внутрь множества  Аналогичные вычисления показывают, что с
Аналогичные вычисления показывают, что с
вероятностью, не меньшей  не будет других сообщений, отображаемых внутрь
не будет других сообщений, отображаемых внутрь  Как уже отмечалось, эти границы не зависят от фиксированных
Как уже отмечалось, эти границы не зависят от фиксированных 
Найдем теперь границу для вероятности того, что поступившее собщение будет отображено внутрь подмножества  Напомним, что из определения
Напомним, что из определения  следует,
следует,

В ансамбле пар кодов некоторое сообщение, скажем  отображается в слова
отображается в слова  с вероятностями, в точности равными
с вероятностями, в точности равными  Следовательно, вероятность того, что поступившее сообщение было отображено внутрь
Следовательно, вероятность того, что поступившее сообщение было отображено внутрь  зависящая от ансамбля пар кодов сообщения и статистики канала, в точности равна
зависящая от ансамбля пар кодов сообщения и статистики канала, в точности равна 
Вероятность того, что поступившее сообщение было отображено вне  равна поэтому
равна поэтому  а вероятность отображения любого другого сообщения внутрь
а вероятность отображения любого другого сообщения внутрь  ограничена, как показано выше, величиной
ограничена, как показано выше, величиной  Вероятность того, что истинно хотя бы одно из этих событий, ограничена поэтому выражением
Вероятность того, что истинно хотя бы одно из этих событий, ограничена поэтому выражением  но тогда это же выражение является границей и для
но тогда это же выражение является границей и для  так как если ни одно из описанных событий не наступило, то декодирование с применением нашего метода даст правильный результат.
так как если ни одно из описанных событий не наступило, то декодирование с применением нашего метода даст правильный результат.
Эти же рассуждения с переменой индексов дают соответствующую границу для  Этим заканчивается доказательство первой части теоремы.
Этим заканчивается доказательство первой части теоремы.
Приступая к доказательству последнего утверждения теоремы, вначале докажем простую комбинаторную лемму, которая будет полезна не только здесь, но и в других вопросах теории кодирования.
Лемма. Предположим, что имеется некоторое множество объектов  с приписанными им вероятностями
с приписанными им вероятностями  и некоторое количество числовых свойств (функций) этих объектов
и некоторое количество числовых свойств (функций) этих объектов  Все они являются неотрицательными,
Все они являются неотрицательными,  и нам известны средние
и нам известны средние  этих свойств объектов
этих свойств объектов

Тогда существует объект  для которого
для которого

Вообще, для любого множества чисел  таких, что
таких, что  существует объект
существует объект  для которого
для которого

Доказательство. Из второй части леммы вытекает первая, если положить  Чтобы доказать вторую часть, обозначим через
Чтобы доказать вторую часть, обозначим через  суммарную вероятность объектов В, для которых
суммарную вероятность объектов В, для которых  Теперь среднее
Теперь среднее  так как
так как  есть вклад в общую сумму тех
есть вклад в общую сумму тех  для которых
для которых  а для всех оставшихся В значения
а для всех оставшихся В значения  Таким образом,
Таким образом,

Общая вероятность  объектов, для которых нарушается какое-либо из наших условий, меньше или равна сумме всех частных
объектов, для которых нарушается какое-либо из наших условий, меньше или равна сумме всех частных  так что
так что

Таким образом, имеется по крайней мере один объект, для которого не нарушается ни одно из наших условий, чем и заканчивается доказательство.
Предположим, например, нам известно, что в комнате находится некоторое число людей, средний возраст которых составляет 40 лет, а средний рост 5 футов. Здесь  , используя более простую формулировку теоремы, можно утверждать, что в комнате имеется некто не старше 80 лет и не выше 10 футов, даже если в комнате находятся пожилые карлики и молодые баскетболисты. Полагая
, используя более простую формулировку теоремы, можно утверждать, что в комнате имеется некто не старше 80 лет и не выше 10 футов, даже если в комнате находятся пожилые карлики и молодые баскетболисты. Полагая  можно утверждать, что присутствует человек не выше 8 футов и не старше
можно утверждать, что присутствует человек не выше 8 футов и не старше  лет.
лет.
Теперь, возвращаясь к доказательству теоремы 1, можно установить последнее предположение. Имеем некоторое множество объектов — пар кодов, и два свойства каждого объекта — вероятность ошибки  для кода в направлении
для кода в направлении  и вероятность ошибки
и вероятность ошибки  для кода в направлении
для кода в направлении  Они являются неотрицательными и их средние ограничены выражениями, содержащимися в первой части теоремы 1. Из комбинаторной леммы следует, что существует по крайней мере одна фиксированная пара кодов, для которой одновременно
Они являются неотрицательными и их средние ограничены выражениями, содержащимися в первой части теоремы 1. Из комбинаторной леммы следует, что существует по крайней мере одна фиксированная пара кодов, для которой одновременно

Этим заканчивается доказательство теоремы 1.




































































































































































































































































































































































































































































































































































































































































































































































































































 произвольно близкими к средней взаимной информации для букв
произвольно близкими к средней взаимной информации для букв  при любых заданных
при любых заданных  и с произвольно малыми вероятностями ошибок. Действительно, пусть
и с произвольно малыми вероятностями ошибок. Действительно, пусть  и в формулировке теоремы
и в формулировке теоремы  Так как
Так как  и притом экспоненциально быстро относительно
и притом экспоненциально быстро относительно  (как функция распределения суммы соответствующим образом нормированных независимых случайных величин граница для
(как функция распределения суммы соответствующим образом нормированных независимых случайных величин граница для  стремится к нулю экспоненциально по
стремится к нулю экспоненциально по  Аналогичные рассуждения можно провести и для границы
Аналогичные рассуждения можно провести и для границы  Выбирая затем возрастающие по
Выбирая затем возрастающие по  последовательности из
последовательности из  при передаче которых аппроксимируются снизу желаемые скорости
при передаче которых аппроксимируются снизу желаемые скорости  получим нужный результат, который можно сформулировать следующим образом.
получим нужный результат, который можно сформулировать следующим образом.
 памяти с вероятностями входных букв
памяти с вероятностями входных букв  и средними взаимными информациями по обоим направлениям
и средними взаимными информациями по обоим направлениям

 существует некоторая пара кодов для всех достаточно больших длин блоков
существует некоторая пара кодов для всех достаточно больших длин блоков  со скоростями передачи по обоим направлениям большими, чем
со скоростями передачи по обоим направлениям большими, чем  соответственно и вероятностями ошибок
соответственно и вероятностями ошибок

 - есть некоторое положительное число, не зависящее от
- есть некоторое положительное число, не зависящее от 
 при различных положительных к.
при различных положительных к.
