3. Предсказание английского текста
В новом методе оценки энтропии английского языка используется тот факт, что каждый, говорящий на этом языке, обладает огромными трудно учитываемыми сведениями о статистике языка. Знакомство со словами, идиомами, стандартными оборотами и грамматикой позволяет выправить неправильные или пополнить пропущенные буквы при чтении корректур или дополнить неоконченную фразу в разговоре. Экспериментальная демонстрация степени возможности предсказания английского текста может быть следующей: выберем короткий отрывок текста, не известный отгадывающему. Затем предложим ему отгадать первую букву
отрывка. Если догадка оказалась правильной, то об этом сообщается отгадывающему и предлагается определить вторую букву. Если первая буква не отгадана правильно, то она также сообщается, и переходят к следующему отгадыванию. Это продолжается до конца текста. По ходу эксперимента отгадывающий выписывает правильный текст вплоть до последней буквы для использования его при отгадывании очередной буквы. Результат эксперимента такого рода приводится ниже. Пробел между словами считается дополнительной буквой, т. е. имеется  -буквенный алфавит. В строках, помеченных (1), написан исходный текст. В строках, помеченных (2), на месте угаданных букв проставляется черта, а в случае неправильного отгадывания выписывается буква исходного текста.
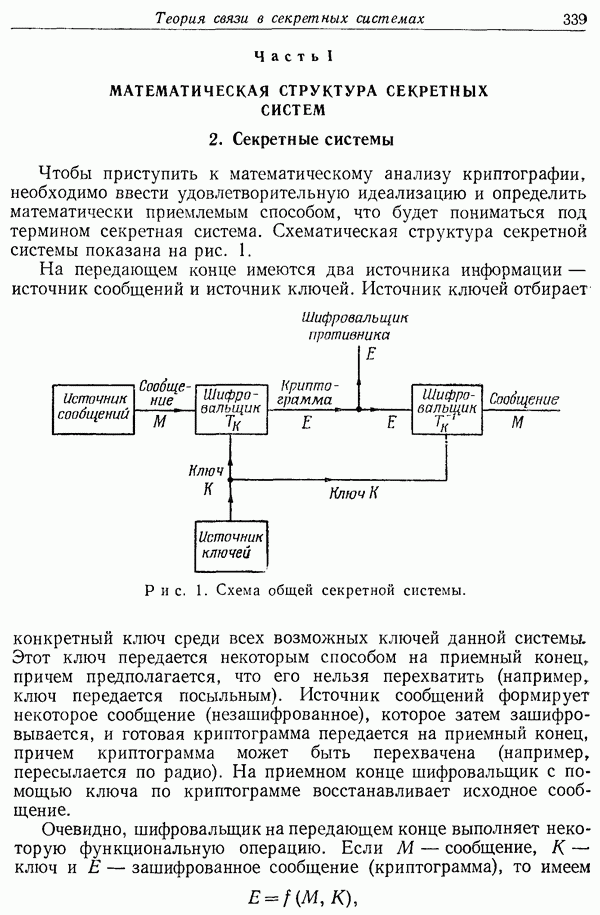
-буквенный алфавит. В строках, помеченных (1), написан исходный текст. В строках, помеченных (2), на месте угаданных букв проставляется черта, а в случае неправильного отгадывания выписывается буква исходного текста.

Из общего числа 129 букв 89 букв, или 69%, были отгаданы правильно. Ошибки, как и следовало ожидать, встречались наиболее часто в начале слов и слогов, где ход мысли может быть наиболее разнообразным. Можно было бы подумать, что вторые строки в (8), которые назовем приведенным текстом, содержат гораздо меньше информации, чем первые. В действительности же обе строки содержат одинаковую информацию в том смысле, что возможно, по крайней мере в принципе, определить первую строку по второй. Для выполнения этого тому, кто отгадывает текст, необходим двойник. Двойник (который если не биологически, то по крайней мере математически идентичен с оригиналом) должен будет отвечать точно так же, как отгадывающий, когда столкнется с аналогичной ситуацией. Предположим теперь, что имеется только приведенный текст (8). Двойнику предлагается отгадать исходный текст. В каждый момент нам известно, правильно выполнено отгадывание или нет, поскольку он отгадывает так же хорошо, как и его предшественник, и присутствие черточки в приведенном тексте соответствует правильному отгадыванию. Буквы, которые он отгадывает неправильно, также доступны, так что на каждом шагу ему может быть предоставлена в точности та информация, которая была получена первым отгадывающим.
От необходимости в двойнике в таком мыслимом эксперименте можно отказаться следующим приемом. Вообще говоря, хорошее предсказание не требует знания более чем  букв предшествующего текста, где
букв предшествующего текста, где  не очень велико. Имеется конечное число
не очень велико. Имеется конечное число
возможных последовательностей из  букв или
букв или  -грамм. Можно предложить кому-либо отгадать следующую букву в каждой возможной
-грамм. Можно предложить кому-либо отгадать следующую букву в каждой возможной  -грамме. Полный список этих предсказаний может быть затем использован как для получения приведенного текста, так и для осуществления обратного восстанавливающего процесса.
-грамме. Полный список этих предсказаний может быть затем использован как для получения приведенного текста, так и для осуществления обратного восстанавливающего процесса.
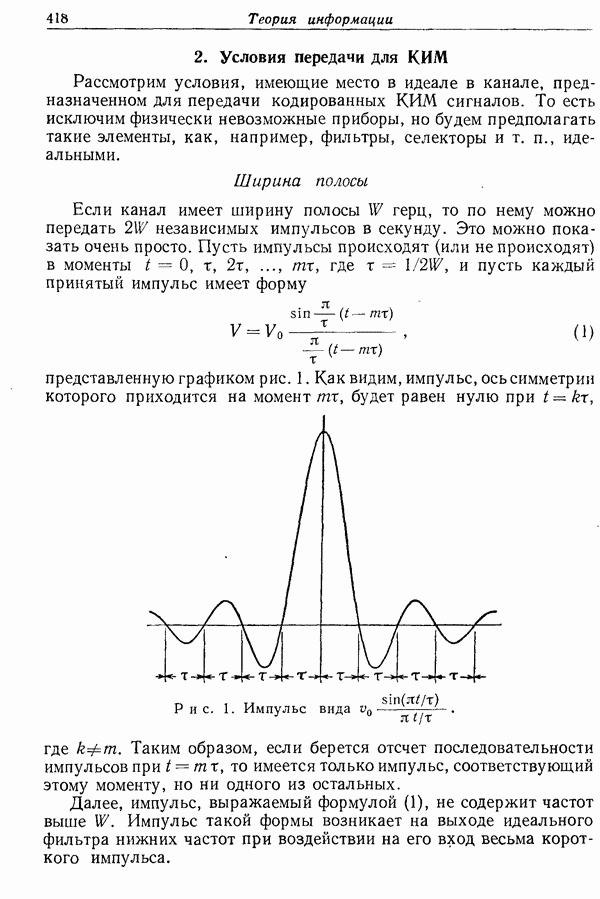
Для применения такого приема приведенный текст следует рассматривать как закодированную форму исходного, т. е. как результат пропускания текста чёрез обратимый преобразователь.

Рис. 2. Система связи, использующая приведенный текст.
В самом деле, система связи может быть построена таким образом, чтобы только приведенный текст передавался от одного пункта к другому. Для этого достаточно, как показано на рис. 2, системы с двумя одинаковыми предсказывающими устройствами.
Описанный эксперимент может быть обобщен для получения дальнейшей информации о возможности предсказания английского текста. Как и раньше, отгадывающему известен текст до текущего момента и ему предлагается отгадать следующую букву. В случае ошибки ему сообщается об этом и предлагается отгадывать снова. Так продолжается до тех пор, пока не будет найдена правильная буква. Типичный результат такого эксперимента показан ниже. В строках, обозначенных (1), выписан исходный текст, а цифры в строках, обозначенных (2), указывают, сколько отгадываний потребовалось на данную букву.

Из 102 букв 79 букв было отгадано с первого раза, 8 букв со второго, 3 буквы с третьего раза, четыре и пять угадываний понадобилось для трех букв и только восемь букв требовалось отгадывать более пяти раз. Результаты такого характера можно считать типичными при предсказывании хорошо умеющим отгадывать и при
работе с нормативным литературным английским текстом. Статьи из газеты, научные работы или поэзия требуют меньшего числа попыток.
Приведенный текст в этом случае также содержит ту же информацию, что и исходный. Опять, используя двойника, предлагаем ему на каждой стадии отгадывать текст столько раз, сколько единиц соответствует цифре в приведенном тексте, и таким путем обнаружить исходный текст. Для  того чтобы исключить субъективный элемент, можно просить отгадывающего указать для каждой
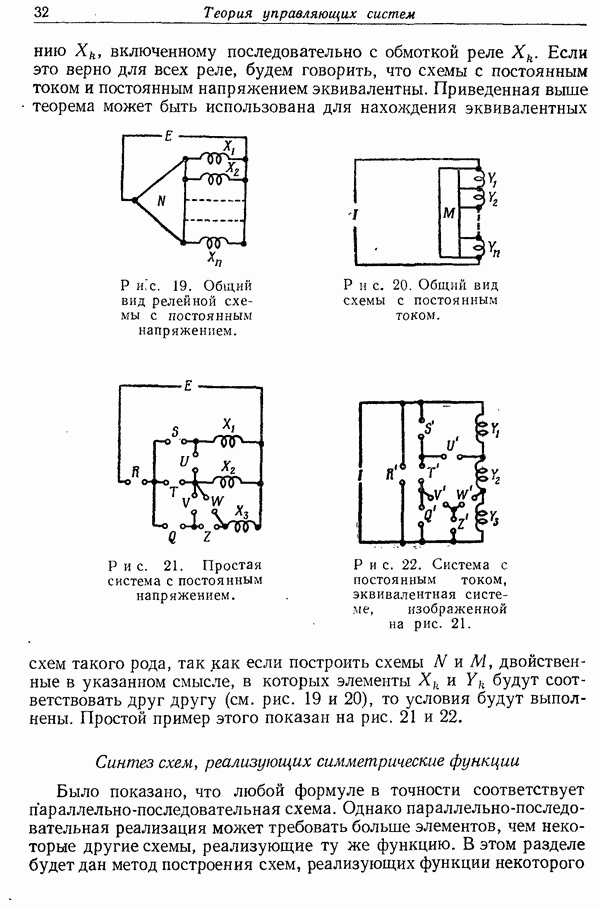
того чтобы исключить субъективный элемент, можно просить отгадывающего указать для каждой  -граммы текста наиболее вероятную букву, вторую по вероятности букву и т. д. Эта совокупность данных может служить как для предсказания, так и для отгадывания.
-граммы текста наиболее вероятную букву, вторую по вероятности букву и т. д. Эта совокупность данных может служить как для предсказания, так и для отгадывания.
Как и раньше, приведенный текст можно рассматривать как закодированный вариант исходного. Именно английский язык с алфавитом в 27 символов,  пробел, переведен на новый язык с алфавитом
пробел, переведен на новый язык с алфавитом  Перевод выполнен таким образом, что символ 1 имеет теперь наибольшую частоту. Символы 2, 3, 4 имеют последовательно все меньшие и меньшие частоты, и заключительные символы
Перевод выполнен таким образом, что символ 1 имеет теперь наибольшую частоту. Символы 2, 3, 4 имеют последовательно все меньшие и меньшие частоты, и заключительные символы  встречаются вообще очень редко. Таким образом, перевод в значительной степени упростил рассматриваемую статистическую структуру. Избыточность, которая проявлялась вначале в сложных зависимостях между группами букв, теперь свелась к значительной разнице между вероятностями новых, символов. Это, как будет видно позднее, явится основой для оценки энтропии с помощью таких экспериментов.
встречаются вообще очень редко. Таким образом, перевод в значительной степени упростил рассматриваемую статистическую структуру. Избыточность, которая проявлялась вначале в сложных зависимостях между группами букв, теперь свелась к значительной разнице между вероятностями новых, символов. Это, как будет видно позднее, явится основой для оценки энтропии с помощью таких экспериментов.
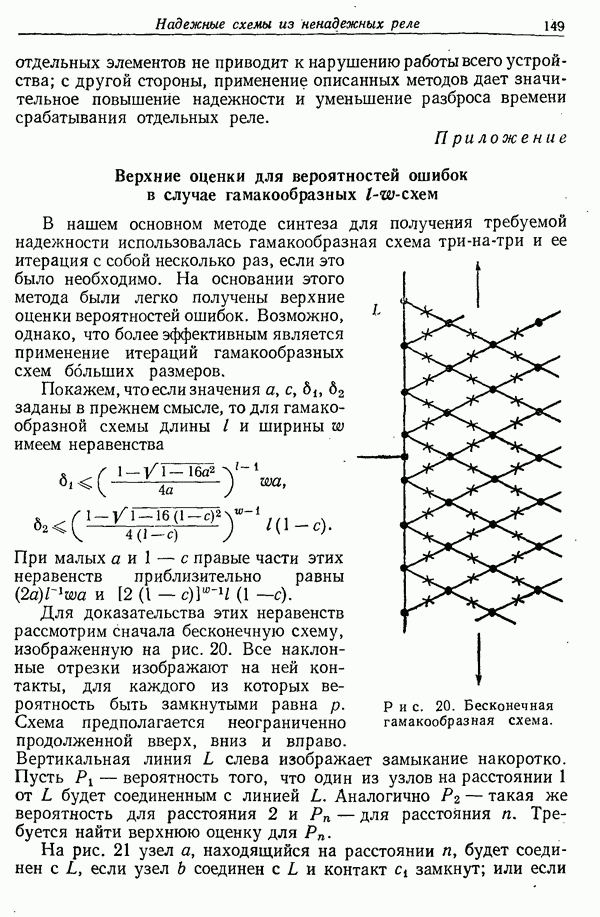
Для определения того, как возможность предсказания зависит от числа  предшествующих букв, известных отгадывающему, был выполнен более сложный эксперимент. Сотня выборок по 15 букв английского текста была выбрана случайным образом из книги. Отгадывающему было предложено отгадывать текст по одной букве в каждой выборке, как в предыдущем эксперименте. Таким образом, была получена сотня выборок, где отгадывающий знал
предшествующих букв, известных отгадывающему, был выполнен более сложный эксперимент. Сотня выборок по 15 букв английского текста была выбрана случайным образом из книги. Отгадывающему было предложено отгадывать текст по одной букве в каждой выборке, как в предыдущем эксперименте. Таким образом, была получена сотня выборок, где отгадывающий знал  предшествующих букв. Отгадывающему могут быть предоставлены все средства, которые он пожелает, например, различные статистические таблицы, однобуквенные, двухбуквенные и трехбуквенные таблицы, таблицы частот начальных букв в словах, сводка частот наиболее употребительных слов и любой словарь. Выборки для эксперимента были взяты из книги «Виргинец Джефферсон» Дюма Малона. Полученные результаты вместе с аналогичным экспериментом, когда отгадывающему были известны 100 букв, собраны в табл. 1. (см. стр. 678—679). Столбец соответствует числу известных предшествующих букв; номер строки указывает число отгадываний. На пересечении
предшествующих букв. Отгадывающему могут быть предоставлены все средства, которые он пожелает, например, различные статистические таблицы, однобуквенные, двухбуквенные и трехбуквенные таблицы, таблицы частот начальных букв в словах, сводка частот наиболее употребительных слов и любой словарь. Выборки для эксперимента были взяты из книги «Виргинец Джефферсон» Дюма Малона. Полученные результаты вместе с аналогичным экспериментом, когда отгадывающему были известны 100 букв, собраны в табл. 1. (см. стр. 678—679). Столбец соответствует числу известных предшествующих букв; номер строки указывает число отгадываний. На пересечении  столбца и 5-й строки стоит число раз, при которых опознавание правильной буквы произошло при
столбца и 5-й строки стоит число раз, при которых опознавание правильной буквы произошло при  отгадывании, когда известны предыдущие
отгадывании, когда известны предыдущие  букв.
букв.
Например, цифра 19 на пересечении  столбца и 2-й строки означает, что при известных пяти предшествующих буквах правильная буква была получена в девятнадцати случаях из ста при втором угадывании. Первые два столбца этой таблицы были получены не экспериментально, как описано выше, а были вычислены непосредственно с помощью известных частот отдельных букв и диграмм. Таким образом, если ни одна из предшествующих букв не задана, то наиболее вероятным символом является промежуток между словами (вероятность 0,182) в случае, если первое угадывание оказалось ошибочным, следующим должно быть Е (вероятность 0,107) и т. д. Эти вероятности суть частоты, с которыми правильные угадывания произойдут при первом, втором и т. д. эксперименте при наилучшем предсказании. Подобным же образом простое вычисление при помощи таблицы диграмм дает результаты для
столбца и 2-й строки означает, что при известных пяти предшествующих буквах правильная буква была получена в девятнадцати случаях из ста при втором угадывании. Первые два столбца этой таблицы были получены не экспериментально, как описано выше, а были вычислены непосредственно с помощью известных частот отдельных букв и диграмм. Таким образом, если ни одна из предшествующих букв не задана, то наиболее вероятным символом является промежуток между словами (вероятность 0,182) в случае, если первое угадывание оказалось ошибочным, следующим должно быть Е (вероятность 0,107) и т. д. Эти вероятности суть частоты, с которыми правильные угадывания произойдут при первом, втором и т. д. эксперименте при наилучшем предсказании. Подобным же образом простое вычисление при помощи таблицы диграмм дает результаты для  столбца. Поскольку частотные таблицы определены по весьма длинным выборкам из английского текста, то эти два столбца подчинены меньшим статистическим ошибкам, чем остальные.
столбца. Поскольку частотные таблицы определены по весьма длинным выборкам из английского текста, то эти два столбца подчинены меньшим статистическим ошибкам, чем остальные.
Далее будет показано, что предсказание действительно улучшается, если не учитывать статистических флуктуаций, зависящих от знания прошлого; так, это подтверждается большим количеством правильных угадываний и меньшим числом угадываний, требующих много проб.
Был проделан также один эксперимент с «обратным» предсказанием, когда приходилось угадывать букву, предшествующую уже известным. Хотя задача субъективно гораздо более трудная, но результаты были ненамного хуже. Так, для выборки в 101 букву из той же самой книги были получены следующие результаты:

Следует учесть, что  -граммная энтропия
-граммная энтропия  для обратного языка равна
для обратного языка равна  -граммной энтропии для прямого языка, что можно видеть из второго выражения в уравнении (1). Оба члена имеют одно и то же значение в прямом и обратном случаях.
-граммной энтропии для прямого языка, что можно видеть из второго выражения в уравнении (1). Оба члена имеют одно и то же значение в прямом и обратном случаях.