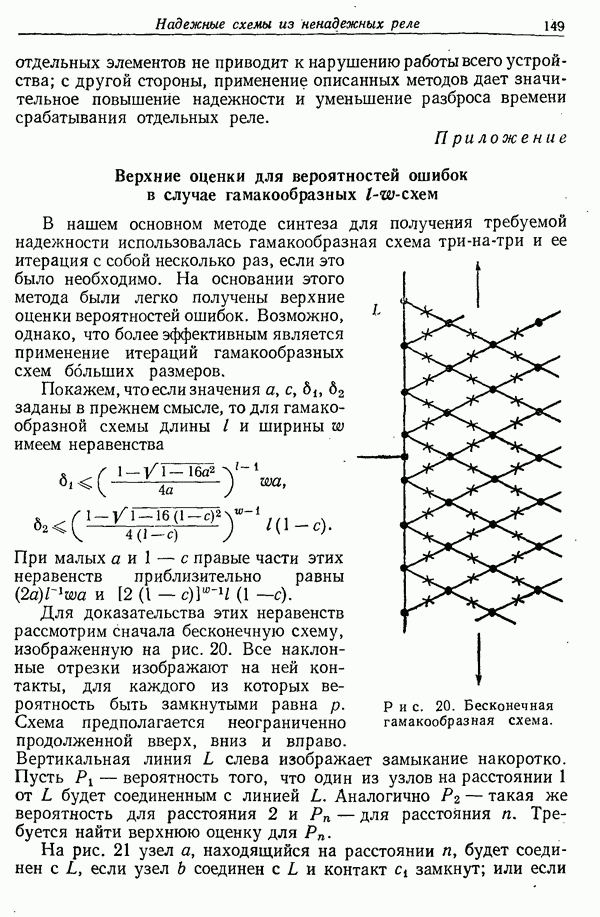
Лемма 1. Предположим, что имеется эргодический источник с вероятностями букв  мерой искажения отдельных букв
мерой искажения отдельных букв  с заданным множеством переходных вероятностей
с заданным множеством переходных вероятностей  так что
так что

Пусть  — вероятностная мера последовательности
— вероятностная мера последовательности  из пространства воспроизводимых последовательностей, получающаяся, если последовательные буквы источника имеют вероятности перехода
из пространства воспроизводимых последовательностей, получающаяся, если последовательные буквы источника имеют вероятности перехода  независимо от предыдущих и последующих букв в буквы алфавита
независимо от предыдущих и последующих букв в буквы алфавита  Тогда при данном
Тогда при данном  для всех достаточно больших длин блоков
для всех достаточно больших длин блоков  существует множество а сообщений длины
существует множество а сообщений длины  с общей вероятностью
с общей вероятностью  и для каждого
и для каждого  принадлежащего а, множество
принадлежащего а, множество  блоков длины
блоков длины  скажем
скажем  такое, что
такое, что

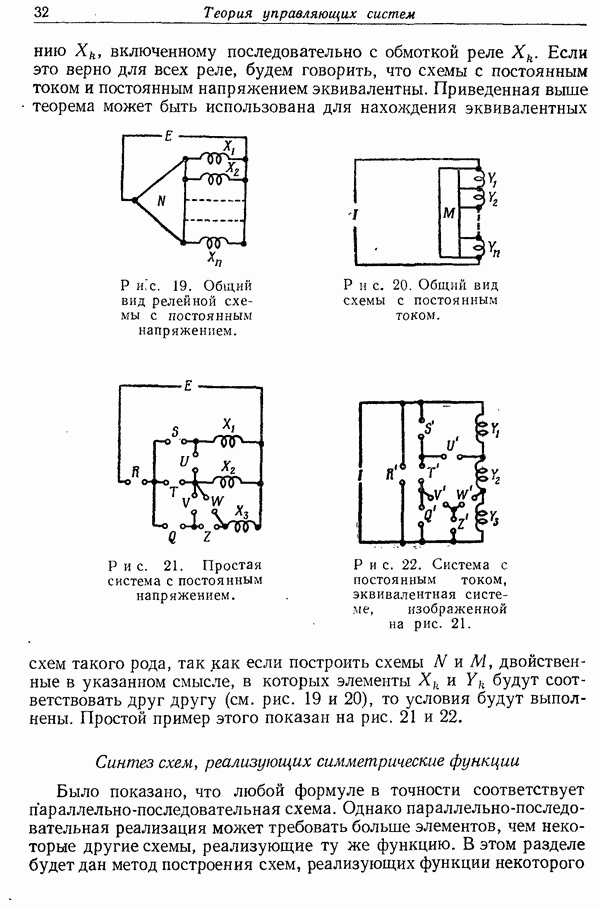
Другими словами, говоря не совсем строго, длинные сообщения будут с высокой вероятностью попадать в некоторое подмножество а. Каждому элементу  этого подмножества сопоставлено множество
этого подмножества сопоставлено множество  последовательностей
последовательностей  Искажения между
Искажения между  и элементами множества
и элементами множества  могут быть (самое худшее) лишь немногим больше, чем
могут быть (самое худшее) лишь немногим больше, чем  и логарифм полной вероятности по мере
и логарифм полной вероятности по мере  множества
множества  ограничен величиной
ограничен величиной 
Для доказательства леммы рассмотрим блоки сообщения длины  и блоки длины
и блоки длины  в алфавите
в алфавите  и рассмотрим две случайные величины: искажение
и рассмотрим две случайные величины: искажение  между
между  -блоком и
-блоком и  -блоком и (неусредненную) взаимную информацию, имеющие вид
-блоком и (неусредненную) взаимную информацию, имеющие вид

Здесь  — буква
— буква  -блока и
-блока и  — буква
— буква  -блока. Как
-блока. Как  так и
так и  — случайные величины, принимающие различные значения, соответствующие различным выборам
— случайные величины, принимающие различные значения, соответствующие различным выборам  и
и  и
и  — суммы
— суммы  случайных величин, являющихся функциями значений совместного процесса
случайных величин, являющихся функциями значений совместного процесса  идентичны друг другу с точностью до сдвига на
идентичны друг другу с точностью до сдвига на  позиций.
позиций.
Так как совместный процесс эргодичен, то можно применить
эргодическую теорему и утверждать, что, когда  велико,
велико,  и
и  с вероятностью, почти равной 1, близки к своим средним значениям. В частности, для любых данных
с вероятностью, почти равной 1, близки к своим средним значениям. В частности, для любых данных  если
если  достаточно велико, то с вероятностью, большей или равной
достаточно велико, то с вероятностью, большей или равной  будем иметь неравенство
будем иметь неравенство

Точно так же с вероятностью, не меньшей  будем иметь неравенство
будем иметь неравенство

Пусть у — множество пар  для которых верны оба неравенства. Тогда
для которых верны оба неравенства. Тогда  так как каждое из условий может исключать самое большее множество вероятности
так как каждое из условий может исключать самое большее множество вероятности  Теперь для любого
Теперь для любого  определим
определим  как множество
как множество  такое, что
такое, что  принадлежит у; пусть а есть множество, образованное из
принадлежит у; пусть а есть множество, образованное из  для которых справедливо неравенство
для которых справедливо неравенство  . Вероятность множества а должна удовлетворять условию
. Вероятность множества а должна удовлетворять условию  так как в противном случае полная вероятность множества, дополнительного к у, будет не меньше
так как в противном случае полная вероятность множества, дополнительного к у, будет не меньше  первое
первое  было бы вероятностью того, что
было бы вероятностью того, что  не принадлежит а, второе
не принадлежит а, второе  — условной вероятностью того, что для таких
— условной вероятностью того, что для таких  последовательность букв
последовательность букв  не принадлежит
не принадлежит  а произведение их дает нижнюю границу вероятности множества, дополнительного к
а произведение их дает нижнюю границу вероятности множества, дополнительного к  . Это приводит к противоречию. Если
. Это приводит к противоречию. Если  то
то

Суммируя эти неравенства по всем  получаем
получаем

Если  то, как показано выше,
то, как показано выше,  и неравенство может быть приведено к следующему виду:
и неравенство может быть приведено к следующему виду:

Установлено, таким образом, что для любого  при достаточно большой длине блока
при достаточно большой длине блока  существует множество
существует множество  элементов
элементов  и множества
и множества  элементов
элементов  определяемые для каждого
определяемые для каждого  следующими тремя свойствами:
следующими тремя свойствами:

Отсюда, очевидно, вытекает, что для любого  и достаточно большого
и достаточно большого  будут справедливы неравенства
будут справедливы неравенства

так как можно выбрать  и
и  достаточно малыми, чтобы удовлетворить этим упрощенным условиям, в которых используется одно и то же
достаточно малыми, чтобы удовлетворить этим упрощенным условиям, в которых используется одно и то же  . Этим завершается доказательство леммы.
. Этим завершается доказательство леммы.
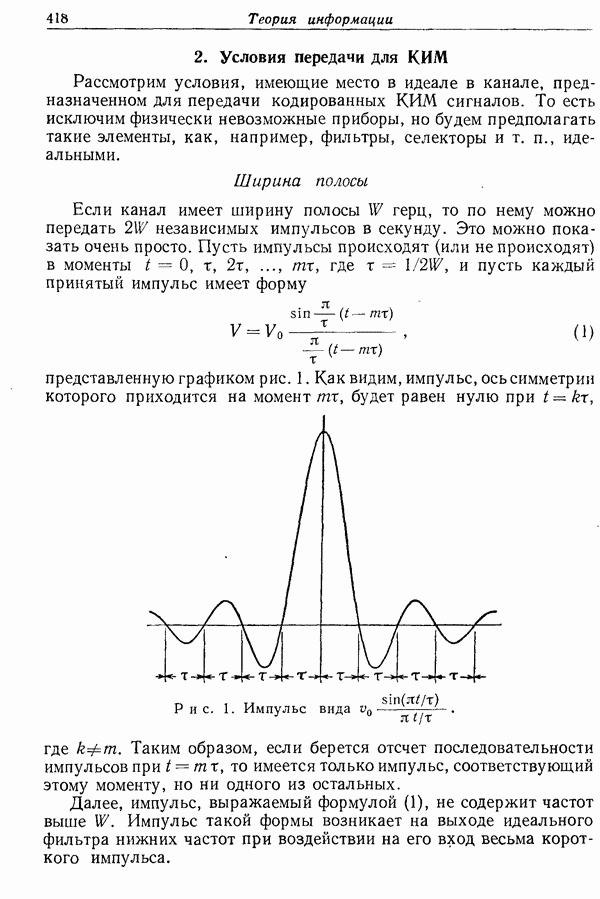
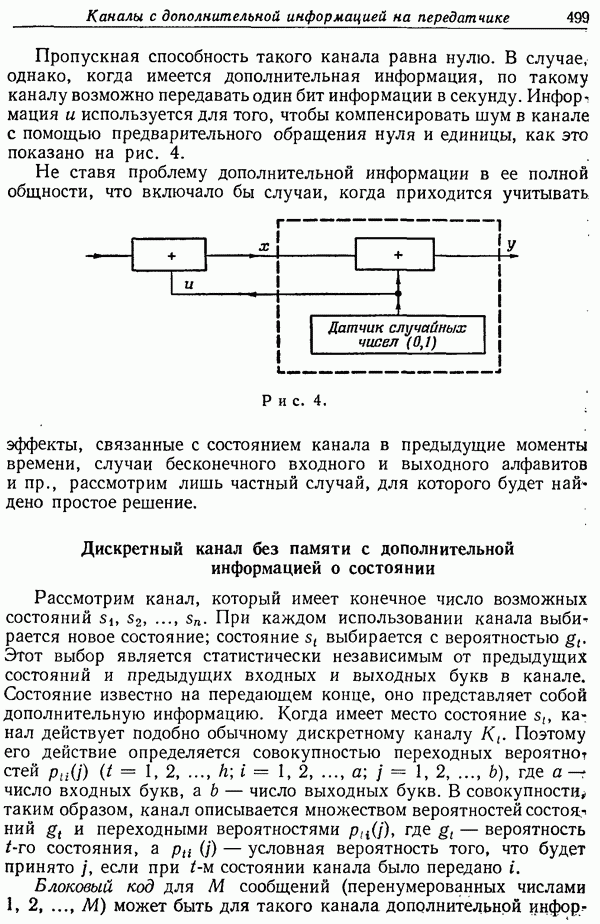
Прежде чем перейти к общей проблеме кодирования, рассмотрим систему передачи, схематически изображенную на рис. 4.

Рис. 4.
Имеется эргодический источник и задана мера искажения отдельных букв, которой соответствует функция  Требуется кодировать сообщения в последовательности и таким образом, чтобы исходные сообщения могли восстанавливаться воспроизводящим устройством со средним искажением, не превосходящим
Требуется кодировать сообщения в последовательности и таким образом, чтобы исходные сообщения могли восстанавливаться воспроизводящим устройством со средним искажением, не превосходящим  (где
(где  — некоторый фиксированный допустимый уровень искажения). Рассмотрим два устройства для блокового кодирования и для воспроизведения. На вход кодирующего устройства поступает вырабатываемая источником последовательность блоков длины
— некоторый фиксированный допустимый уровень искажения). Рассмотрим два устройства для блокового кодирования и для воспроизведения. На вход кодирующего устройства поступает вырабатываемая источником последовательность блоков длины  а на выходе появляются блоки из алфавита и, соответствующие каждому возможному
а на выходе появляются блоки из алфавита и, соответствующие каждому возможному  -блоку.
-блоку.
Цель, которая поставлена здесь, состоит в том, чтобы кодировать сообщения так, чтобы при условии воспроизведения с искажением, не превосходящим  сделать энтропию последовательностей и возможно более низкой. Энтропия, о которой здесь идет речь, есть энтропия на букву исходного сообщения или, иначе говоря, ее можно рассматривать как энтропию последовательности и в секунду, если считать, что источник создает одну букву в секунду.
сделать энтропию последовательностей и возможно более низкой. Энтропия, о которой здесь идет речь, есть энтропия на букву исходного сообщения или, иначе говоря, ее можно рассматривать как энтропию последовательности и в секунду, если считать, что источник создает одну букву в секунду.
Покажем, что для любого  и любого
и любого  могут быть найдены такие кодирующие и воспроизводящие устройства, что
могут быть найдены такие кодирующие и воспроизводящие устройства, что
 но при
но при  длина кодового блока, вообще говоря, возрастает. Этот вывод, конечно, тесно связан с нашей интерпретацией
длина кодового блока, вообще говоря, возрастает. Этот вывод, конечно, тесно связан с нашей интерпретацией  как эквивалентной скорости источника при искажении
как эквивалентной скорости источника при искажении  и легко вытекает из следующей теоремы.
и легко вытекает из следующей теоремы.
Теорема 2. Пусть заданы эргодический источник, мера искажения  и скорость
и скорость  зависящая от искажения и
зависящая от искажения и  (и вычисленная на основе заданных частот отдельных букв); заданы
(и вычисленная на основе заданных частот отдельных букв); заданы  Тогда для любого достаточно большого
Тогда для любого достаточно большого  существует множество А, содержащее М слов длины
существует множество А, содержащее М слов длины  из алфавита
из алфавита  со следующими свойствами:
со следующими свойствами:

2) среднее искажение между  -словом длины
-словом длины  и ближайшим наименее искаженным к нему словом из множества Л меньше или равно
и ближайшим наименее искаженным к нему словом из множества Л меньше или равно 
Из этой теоремы следуют (если не учитывать в свойстве  которое будет в дальнейшем устранено) изложенные выше выводы. А именно если в качестве кодирующего устройства использовать устройство, которое отображает любое
которое будет в дальнейшем устранено) изложенные выше выводы. А именно если в качестве кодирующего устройства использовать устройство, которое отображает любое  -слово на ближайший к нему элемент из множества А, а воспроизводящееустройство осуществляет просто тождественное преобразование, энтропия кодированной последовательности, приходящаяся на букву источника, не может превзойти
-слово на ближайший к нему элемент из множества А, а воспроизводящееустройство осуществляет просто тождественное преобразование, энтропия кодированной последовательности, приходящаяся на букву источника, не может превзойти  так как она имеет максимальное значение, равное
так как она имеет максимальное значение, равное  , когда все М элементов из множества А равновероятны, а в силу условий теоремы
, когда все М элементов из множества А равновероятны, а в силу условий теоремы

Докажем эту теорему, используя метод случайного кодирования. Рассмотрим ансамбль способов выбора элементов множества А. Оценивая среднее искажение для этого ансамбля, найдем, что в нем существует по крайней мере один код с требуемыми свойствами.
Ансамбль кодов определен следующим образом. Для данного  существует множество переходных вероятностей
существует множество переходных вероятностей  определяющих минимум
определяющих минимум  равный
равный  Множество вероятностей букв вместе с этими переходными вероятностями задает меру
Множество вероятностей букв вместе с этими переходными вероятностями задает меру  в пространстве воспроизведенных слов. Мера
в пространстве воспроизведенных слов. Мера  для отдельной буквы алфавита, скажем буквы
для отдельной буквы алфавита, скажем буквы  , есть
, есть  Мера
Мера  для слова, состоящего из букв
для слова, состоящего из букв  равна
равна 
В ансамбле кодов с кодовыми словами длины  соотнесем всевозможными способами слова длины
соотнесем всевозможными способами слова длины  целым числам от 1 до М. Каждому целому числу соотнесено некоторое слово, скажем
целым числам от 1 до М. Каждому целому числу соотнесено некоторое слово, скажем
с вероятностью  причем вероятности для различных целых чисел статистически независимы. Это в точности такой же прием, как и при построении ансамбля случайных кодов для канала без памяти, за исключением того, что здесь целые числа отображаются на пространство
причем вероятности для различных целых чисел статистически независимы. Это в точности такой же прием, как и при построении ансамбля случайных кодов для канала без памяти, за исключением того, что здесь целые числа отображаются на пространство  с помощью меры
с помощью меры  Таким образом, получаем множество кодов (если в алфавите
Таким образом, получаем множество кодов (если в алфавите  имеются
имеются  букв, то в ансамбле будет
букв, то в ансамбле будет  различных кодов), каждый из которых будет иметь соответствующую вероятность. Код, в котором целому числу
различных кодов), каждый из которых будет иметь соответствующую вероятность. Код, в котором целому числу  соотнесено
соотнесено  имеет вероятность
имеет вероятность 
Теперь используем лемму 1, чтобы оценить среднее искажение для этого ансамбля кодов (используя для вычисления среднего искажения вероятности различных кодов). Заметим, во-первых, что если  есть мера
есть мера  множества
множества  слов
слов  в ансамбле кодов, то вероятность того, что это множество
в ансамбле кодов, то вероятность того, что это множество  не содержит кодовых слов, будет равна
не содержит кодовых слов, будет равна  Последнее выражение есть произведение вероятностей того, что множество
Последнее выражение есть произведение вероятностей того, что множество  не содержит кодового слова 1, кодового слова 2 и т. д. Поэтому вероятность того, что множество
не содержит кодового слова 1, кодового слова 2 и т. д. Поэтому вероятность того, что множество  содержит по крайней мере одно кодовое слово, равна
содержит по крайней мере одно кодовое слово, равна  Теперь, обращаясь к лемме 1, видим, что для среднего искажения имеет место оценка
Теперь, обращаясь к лемме 1, видим, что для среднего искажения имеет место оценка

Здесь  — наибольшее искажение, возможное между буквами алфавитов
— наибольшее искажение, возможное между буквами алфавитов  и
и  Первый член
Первый член  определяется
определяется  -словами, которые не содержатся в множестве а. Их общая вероятность меньше или равна
-словами, которые не содержатся в множестве а. Их общая вероятность меньше или равна  и при наличии их в сообщении среднее искажение меньше или равно
и при наличии их в сообщении среднее искажение меньше или равно  Второй член ограничивает сверху вклад, который обусловлен случаями, когда множество
Второй член ограничивает сверху вклад, который обусловлен случаями, когда множество  соответствующее сообщению
соответствующее сообщению  не содержит ни одного кодового слова. Вероятность таких кодов в ансамбле не превосходит
не содержит ни одного кодового слова. Вероятность таких кодов в ансамбле не превосходит  а искажение не превосходит
а искажение не превосходит  Наконец, если сообщение содержится во множестве а и в
Наконец, если сообщение содержится во множестве а и в  существует по крайней мере одно кодовое слово, то в соответствии с леммой 1 искажение ограничено величиной е. Далее
существует по крайней мере одно кодовое слово, то в соответствии с леммой 1 искажение ограничено величиной е. Далее  и для х такого, что
и для х такого, что  справедливо соотношение
справедливо соотношение

то (используя знакопеременность и монотонное убывание членов разложения логарифма) получаем

Если взять М (число точек) равным по величине  если это не целое число, равным наименьшему целому, превосходящему эту величину), то выражение, приведенное выше, будет равно
если это не целое число, равным наименьшему целому, превосходящему эту величину), то выражение, приведенное выше, будет равно  Следовательно, при таком выборе М получаем оценку для среднего искажения
Следовательно, при таком выборе М получаем оценку для среднего искажения 

при условии, что в соответствии с леммой  будет выбрано достаточно малым для того, чтобы удовлетворить неравенству
будет выбрано достаточно малым для того, чтобы удовлетворить неравенству  — достаточно большим, чтобы удовлетворить неравенству
— достаточно большим, чтобы удовлетворить неравенству  Кроме того, ей
Кроме того, ей  должны быть выбраны так. чтобы
должны быть выбраны так. чтобы  наименьшее из целых чисел, большее или равное
наименьшее из целых чисел, большее или равное  было бы меньше или равно
было бы меньше или равно  Поскольку лемма 1 справедлива для всех достаточно больших
Поскольку лемма 1 справедлива для всех достаточно больших  и любого положительного 8, все эти требования могут быть удовлетворены одновременно.
и любого положительного 8, все эти требования могут быть удовлетворены одновременно.
Таким образом, утверждения теоремы доказаны для среднего искажения ансамбля кодов. Отсюда следует, что существует по крайней мере один специфический код в этом ансамбле со средним искажением, ограниченным  . Этим завершается доказательство теоремы.
. Этим завершается доказательство теоремы.
Следствие. Теорема 2 остается справедливой, если в утверждении  заменить на 0. Она также остается справедливой, если в утверждении 1) сохранить
заменить на 0. Она также остается справедливой, если в утверждении 1) сохранить  а в утверждении 2) заменить его на
а в утверждении 2) заменить его на
0, при условии что в этом случае  т. е. наименьшего
т. е. наименьшего  для которого определена функция
для которого определена функция 
Этим следствием устанавливается, что можно достичь или даже превзойти одну координату точки кривой  и аппроксимировать сколь угодно точно вторую координату, за исключением, быть может, точки с абсциссой
и аппроксимировать сколь угодно точно вторую координату, за исключением, быть может, точки с абсциссой  Чтобы доказать это первое утверждение следствия, заметим прежде всего, что оно справедливо для
Чтобы доказать это первое утверждение следствия, заметим прежде всего, что оно справедливо для  такого, что
такого, что  Действительно, можно достигнуть точки
Действительно, можно достигнуть точки  при
при  и длине кодового слова 1, образованного из такой буквы алфавита
и длине кодового слова 1, образованного из такой буквы алфавита  которая задает среднее искажение для этого кода, не превосходящее
которая задает среднее искажение для этого кода, не превосходящее  При
При  применим теорему 2 для аппроксимации
применим теорему 2 для аппроксимации  Поскольку функция
Поскольку функция  строго убывающая, то эта аппроксимация приведет к кодам
строго убывающая, то эта аппроксимация приведет к кодам  если только
если только  в теореме 2 сделать достаточно малым.
в теореме 2 сделать достаточно малым.
Подобным же образом получается второе упрощение, указанное в следствии. Выбираем  несколько меньшее, чем желаемое
несколько меньшее, чем желаемое 
т. e. такое, что  и используем теорему 2 для аппроксимации этой точки кривой.
и используем теорему 2 для аппроксимации этой точки кривой.
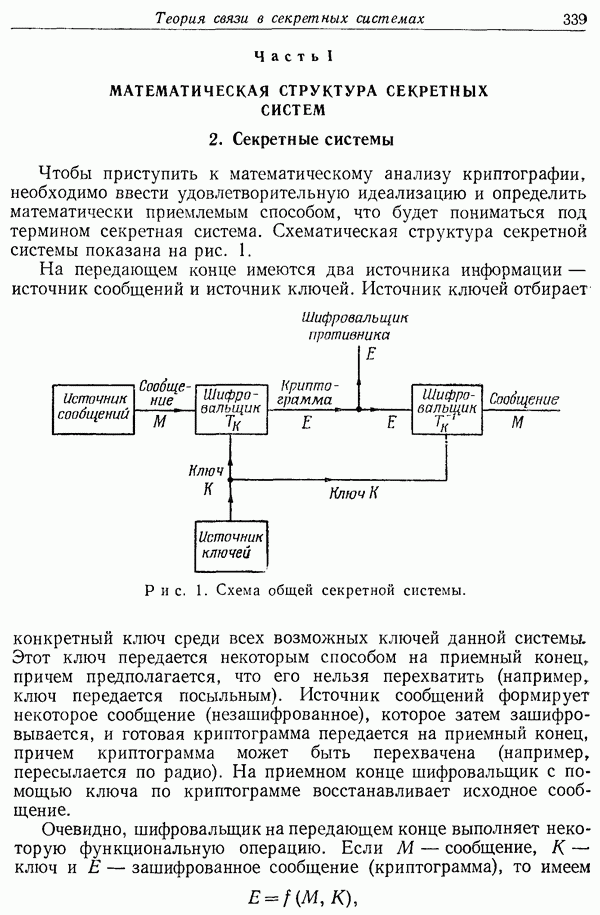
Предположим теперь, что имеется канал без памяти с пропускной способностью С. В соответствии с теоремой кодирования для таких каналов возможно создать коды и системы декодирования, позволяющие передавать со скоростью на одну букву, приближающейся к С, и вероятностью ошибки, меньшей или равной  для любого
для любого  Комбинируя такой код для канала с кодом указанного выше типа для источника с заданным уровнем искажения
Комбинируя такой код для канала с кодом указанного выше типа для источника с заданным уровнем искажения  получим следующий результат.
получим следующий результат.
Теорема 3. Даны источник, характеризуемый функцией  и канал без памяти с пропускной способностью
и канал без памяти с пропускной способностью  даны
даны  Тогда существует для достаточно больших
Тогда существует для достаточно больших  и
и  блоковый код, который соотносит слова длины
блоковый код, который соотносит слова длины  источника словам длины
источника словам длины  на входе канала, и декодирующее устройство, которое отображает слова на выходе канала на воспроизводимые слова длины
на входе канала, и декодирующее устройство, которое отображает слова на выходе канала на воспроизводимые слова длины  При этом удовлетворяются условия
При этом удовлетворяются условия

Таким образом, можно достигнуть желаемого уровня искажения  (большего, чем
(большего, чем  и в то же время приблизиться к использованию канала для передачи со скоростью, соответствующей
и в то же время приблизиться к использованию канала для передачи со скоростью, соответствующей  Это можно сделать, подобно тому как это сделано в следствии к теореме 2, аппроксимируя кривую
Это можно сделать, подобно тому как это сделано в следствии к теореме 2, аппроксимируя кривую  в точке левее
в точке левее  скажем, в
скажем, в  Такой код будет иметь
Такой код будет иметь  слов, где
слов, где  может быть сделано как угодно малым при помощи выбора достаточно большого
может быть сделано как угодно малым при помощи выбора достаточно большого  Код для канала образуется из М слов длины
Код для канала образуется из М слов длины  где
где  — наибольшее целое число, удовлетворяющее условию
— наибольшее целое число, удовлетворяющее условию  Выбирая
Выбирая  достаточно большим, можно сделать вероятность ошибки как угодно близкой к нулю, так как это соответствует скорости передачи, меньшей пропускной способности канала. Комбинация этих двух кодов приводит к общему коду со средним искажением, не превышающим
достаточно большим, можно сделать вероятность ошибки как угодно близкой к нулю, так как это соответствует скорости передачи, меньшей пропускной способности канала. Комбинация этих двух кодов приводит к общему коду со средним искажением, не превышающим 





































































































































































































































































































































































































































































































































































































































































































































































































































 букв сигнала к
букв сигнала к  буквам сообщения. Рассмотрим эргодический источник сообщений с мерой искажения отдельной буквы
буквам сообщения. Рассмотрим эргодический источник сообщений с мерой искажения отдельной буквы  Выбор такого более общего источника вместо источника с независимыми буквами, рассмотренного в теореме 1, окажется полезным при последующем обобщении теоремы. И для эргодического источника будут иметься, конечно, вероятности отдельных букв Тогда можно определить
Выбор такого более общего источника вместо источника с независимыми буквами, рассмотренного в теореме 1, окажется полезным при последующем обобщении теоремы. И для эргодического источника будут иметься, конечно, вероятности отдельных букв Тогда можно определить  через эти вероятности точно так же, как в случае источника независимых букв.
через эти вероятности точно так же, как в случае источника независимых букв.