3. Последовательные приближения к английскому языку
Чтобы дать наглядную картину того, как эти последовательные приближения аппроксимируют естественный язык, ниже приводятся типичные последовательности букв для таких приближений к английскому языку. Во всех случаях использовался  -буквенный «алфавит» (26 букв и пробел между буквами).
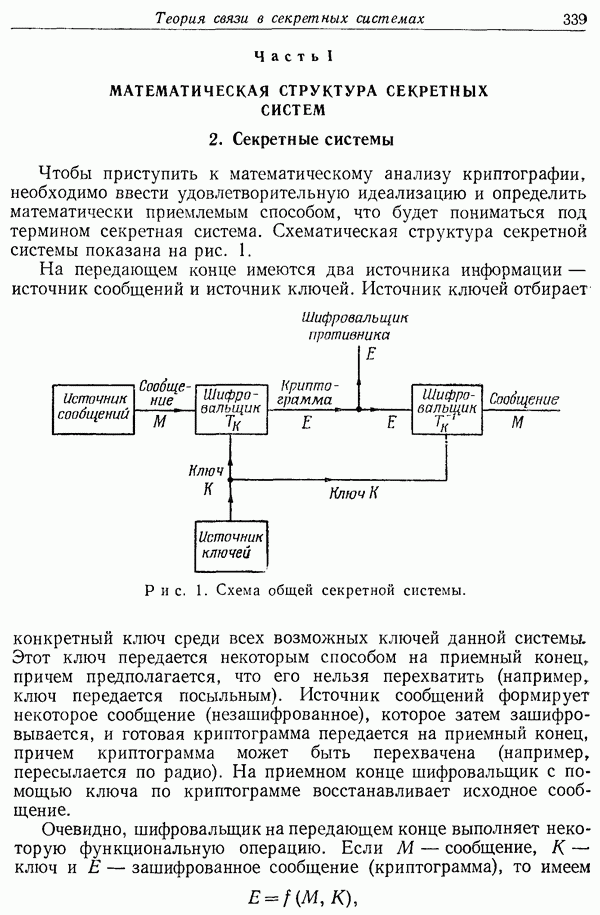
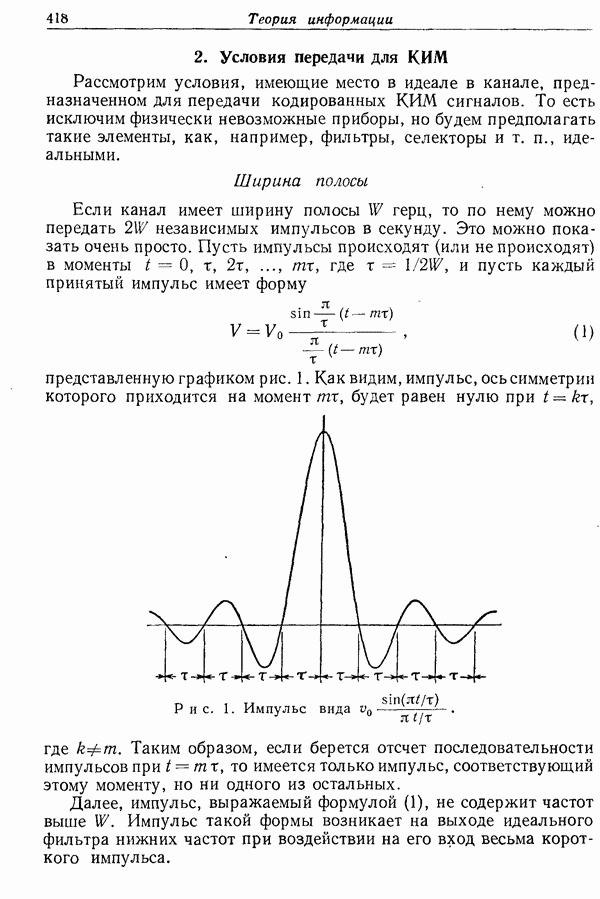
-буквенный «алфавит» (26 букв и пробел между буквами).
1. Приближение нулевого порядка (символы независимы и равновероятны):

2. Приближение первого порядка (символы независимы, но с частотами, свойственными английскому тексту):

3. Приближение второго порядка (структура диграмм такая же, как в английском языке):

4. Приближение третьего порядка (структура триграмм такая же, как в английском языке).

5. Приближение первого порядка на уровне слов. Вместо того чтобы продолжать процесс приближения с помощью структур тетраграмм ..... n-грамм, легче и лучше сразу перейти к словарным единицам. Здесь слова выбираются независимо, но с соответствующими им частотами:

6. Приближение второго порядка на уровне слов. Переходные вероятности от слова к слову являются правильными, но никакая дальнейшая структура не учитывается:

С каждым из шагов, проделанных выше, сходство с обычным английским текстом возрастает довольно заметно. Отметим, что эти примеры имеют достаточно хорошую структуру в пределах расстояний, которые приблизительно в два раза превышают расстояния, учтенные при конструировании. Например, в случае 3 статистический процесс обеспечивает формирование приемлемого текста для двухбуквенных последовательностей, но и четырехбуквенные последовательности из этой выборки обычно могут быть вставлены в осмысленные предложения. В примере 6 последовательности из четырех или более слов могут быть довольно легко вставлены в предложения без необычных или натянутых конструкций. Последовательность из десяти слов «attack on an English writer that the character of this» не является совершенно неприемлемой. Таким образом, оказывается, что достаточно сложный вероятностный процесс дает удовлетворительное представление дискретного источника.
Первые два примера были построены с помощью таблиц случайных чисел, а также (для примера 2) таблицы частот различных букв.
Точно так же можно было бы построить и примеры 3, 4 и 5 , так как частоты диграмм, триграмм и отдельных слов известны, но мы использовали более простой эквивалентный метод. Например, чтобы построить пример 3, можно открыть книгу случайным образом и выбрать также случайно букву на странице. Эта буква записывается. Затем книга открывается на другой странице и читается до тех пор, пока не встречается записанная буква. Следующая за ней буква записывается. Затем на другой странице ищется эта последняя буква и записывается следующая за ней и так далее. Аналогичный процесс был использован для составления примеров 4, 5 и 6. Было бы интересно сделать дальнейшие приближения, но на следующей стадии необходимая для этого работа становится огромной.