Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
3.3.2. Свойства процедур сглаживанияПерейдем теперь к рассмотрению некоторых свойств указанных методов сглаживания. Одна из основных задач сглаживания состоит в том, чтобы уменьшить случайную ошибку, т. е. сделать дисперсию сглаженной последовательности малой по сравнению с дисперсией исходной последовательности. Теорема 3.3.1. Дисперсия величины
где
Доказательство. Если обозначить правые части уравнений (13) через
а их решения относительно
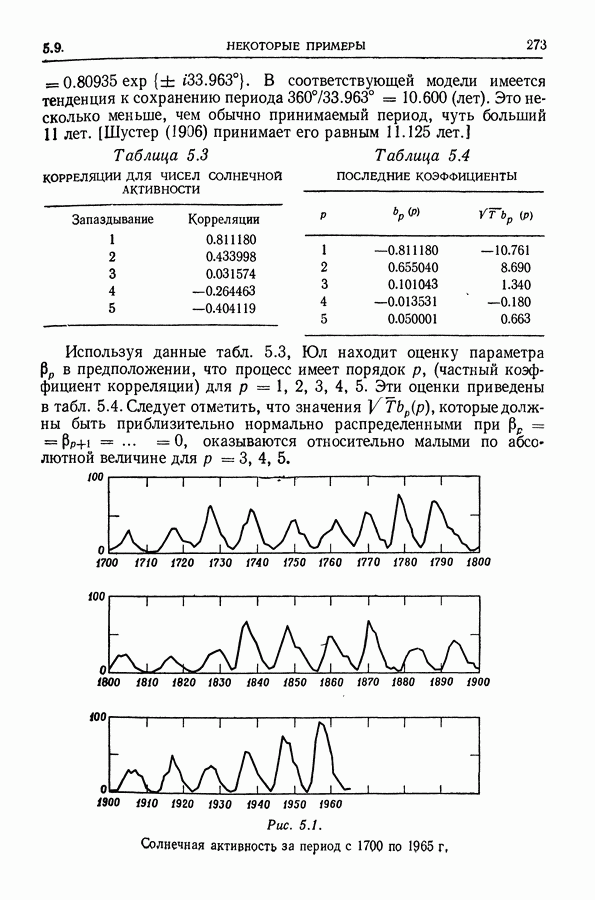
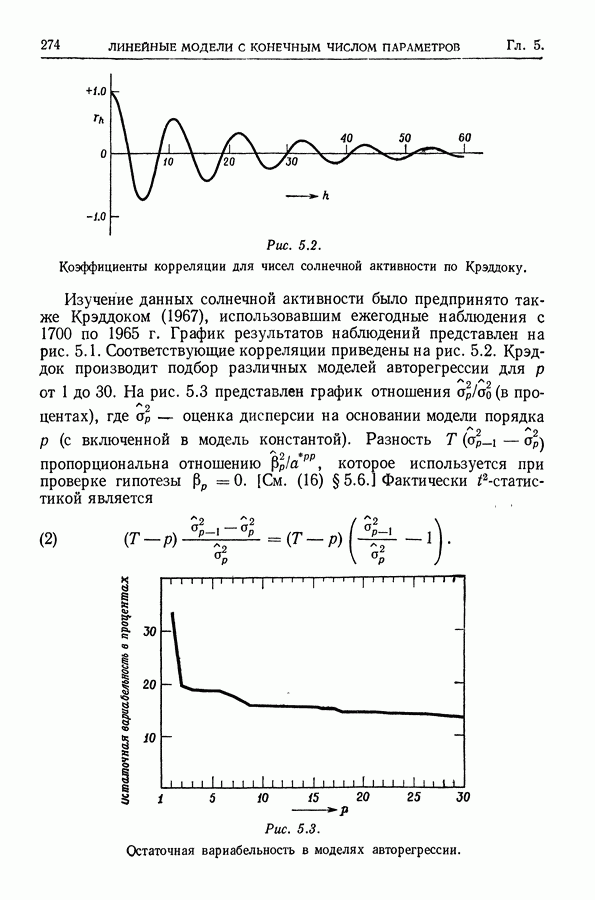
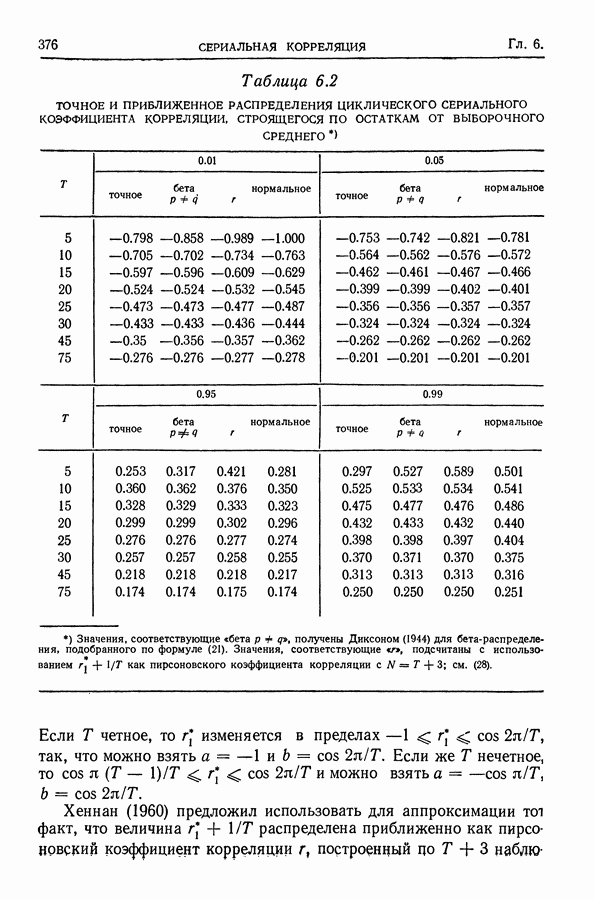
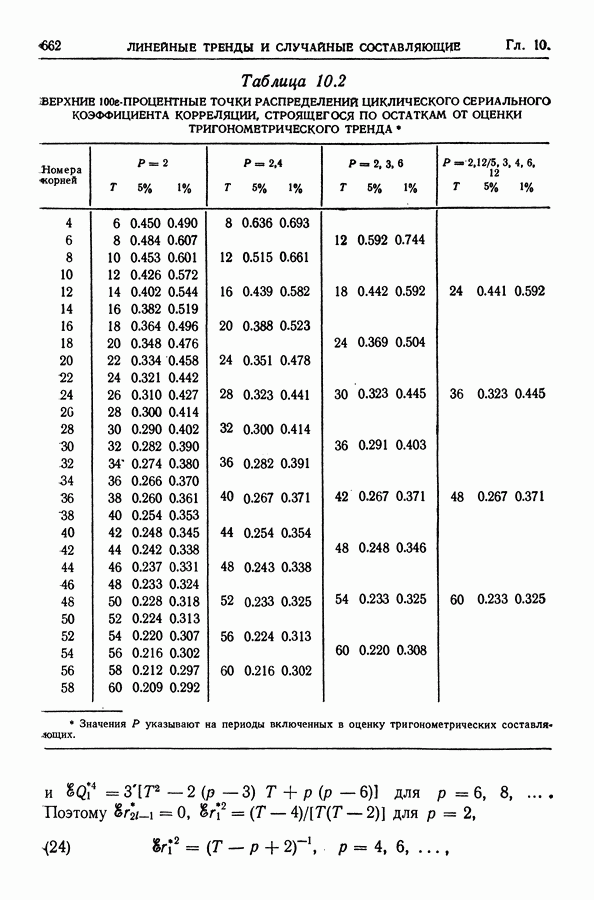
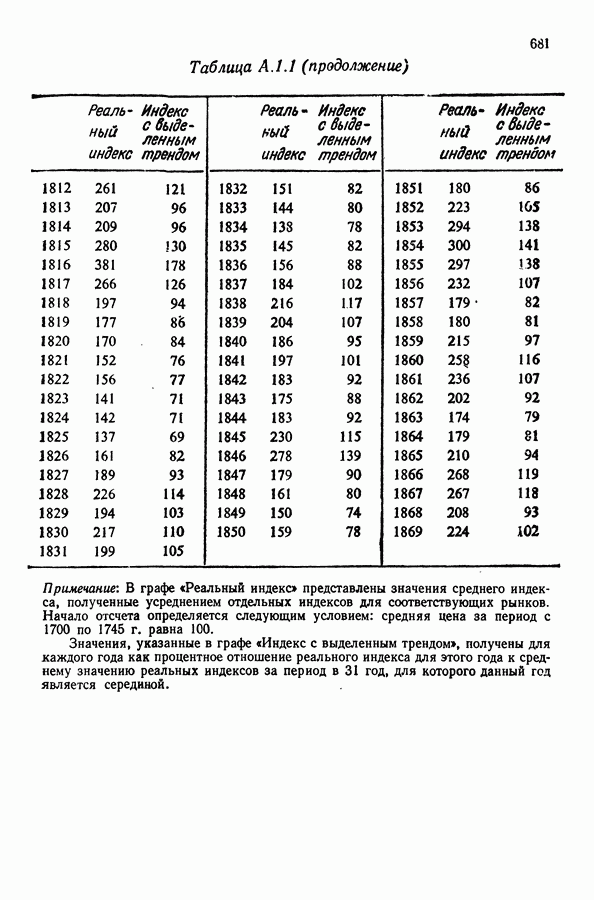
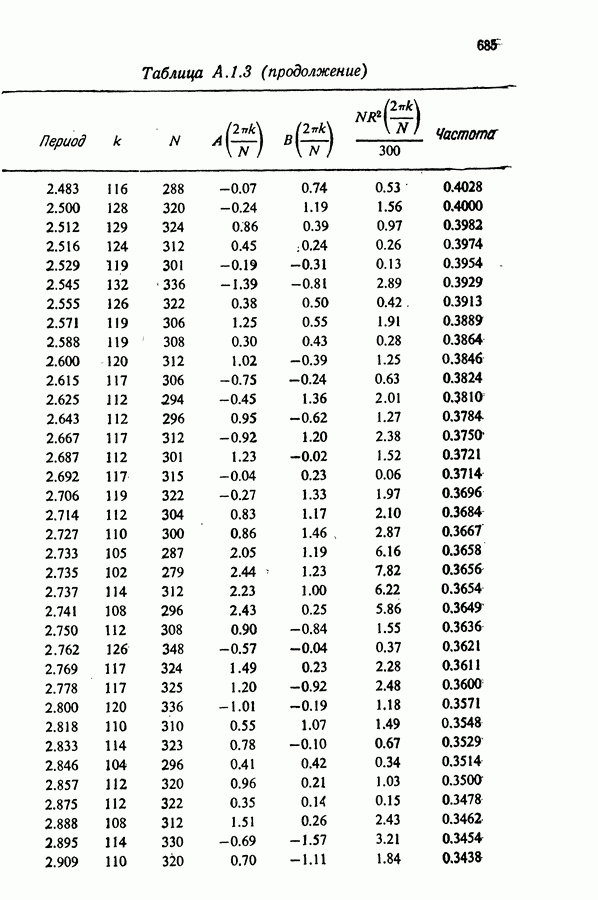
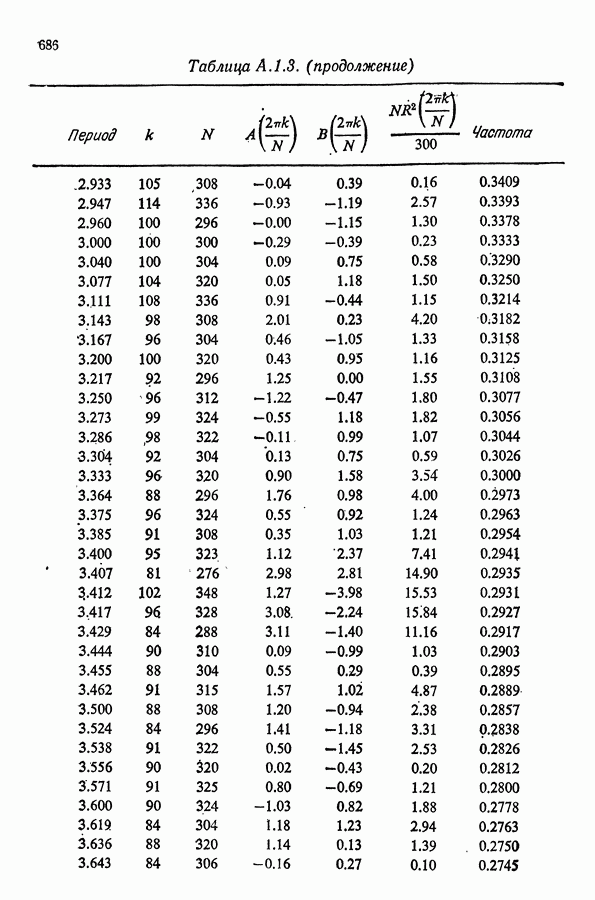
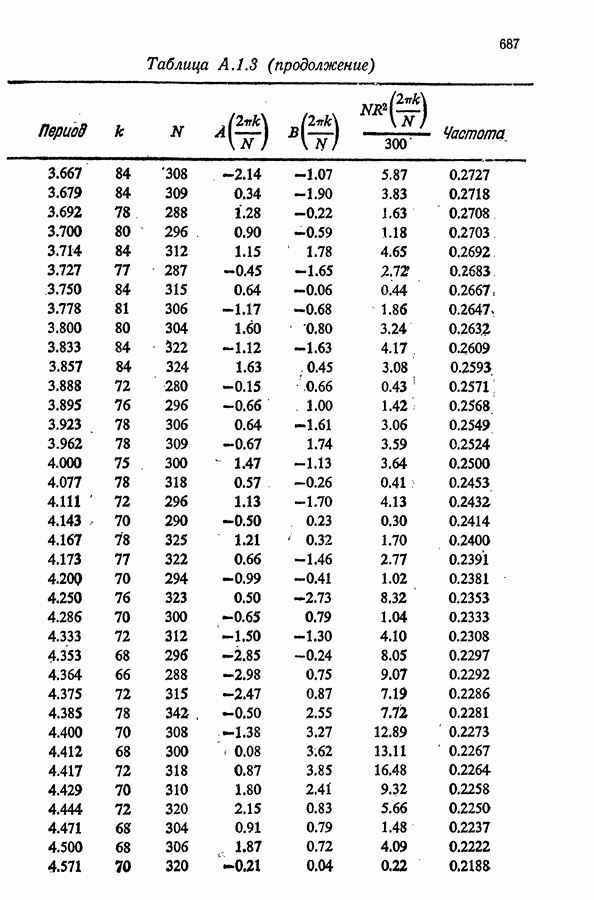
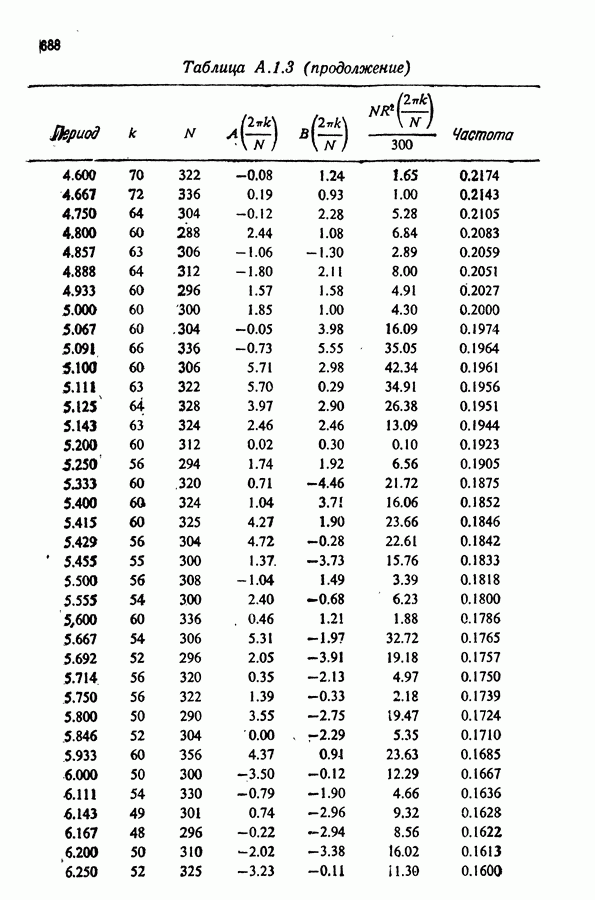
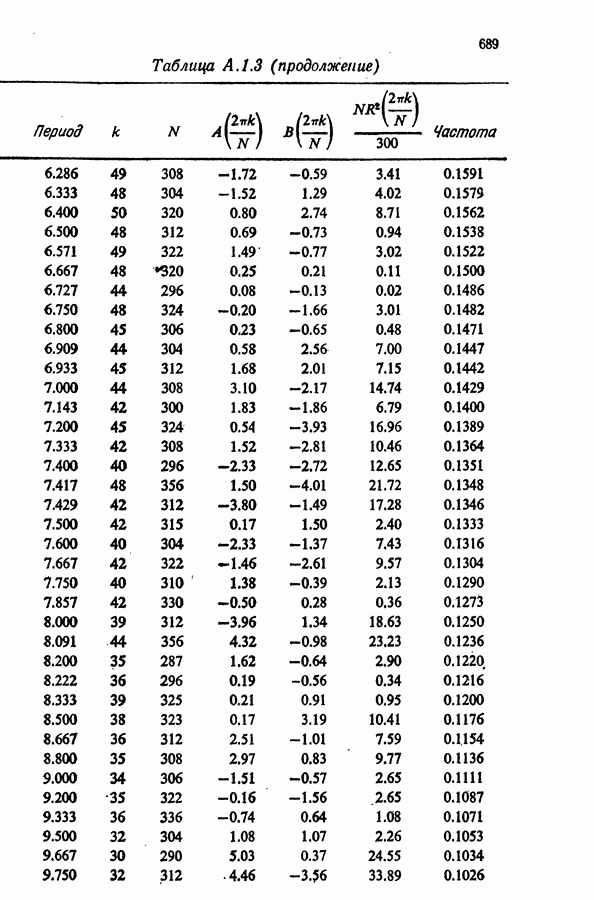
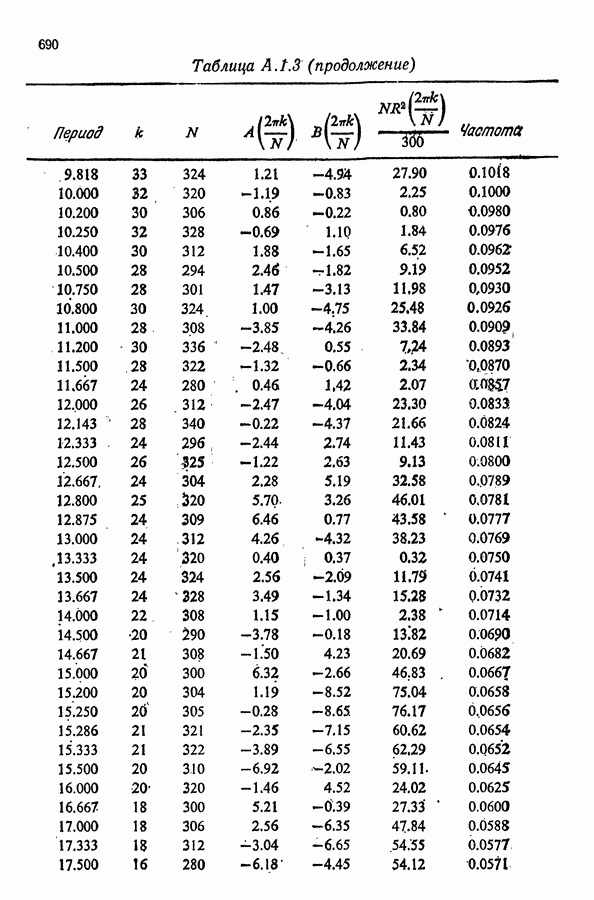
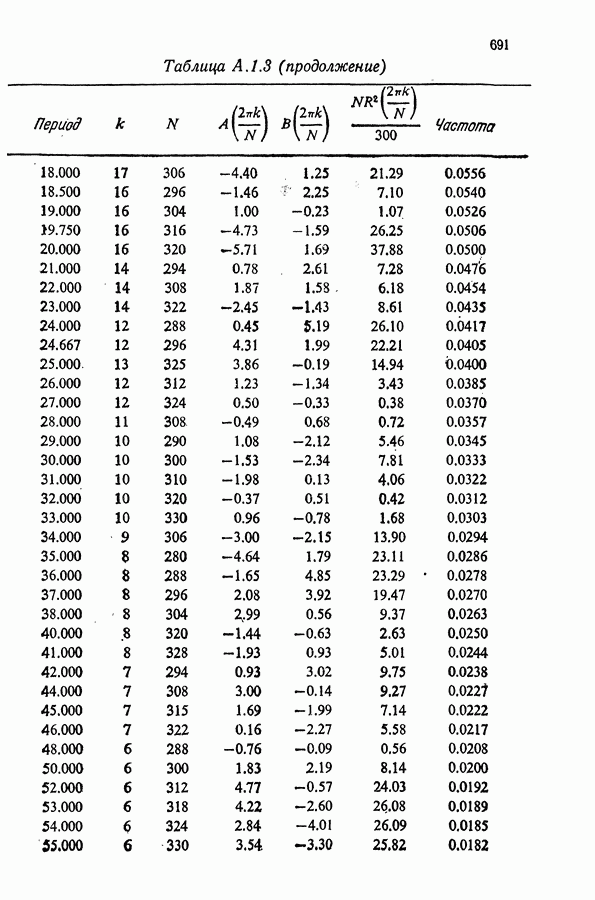
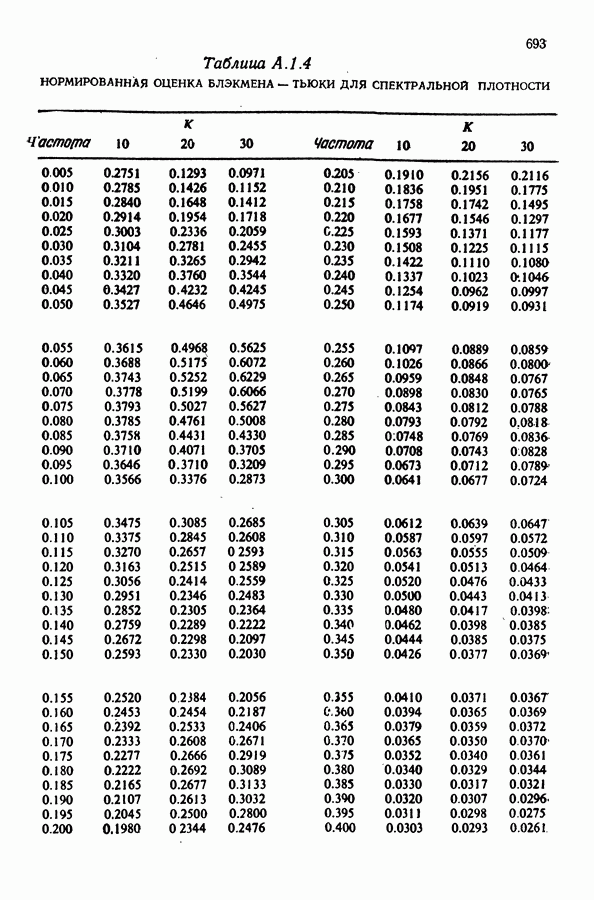
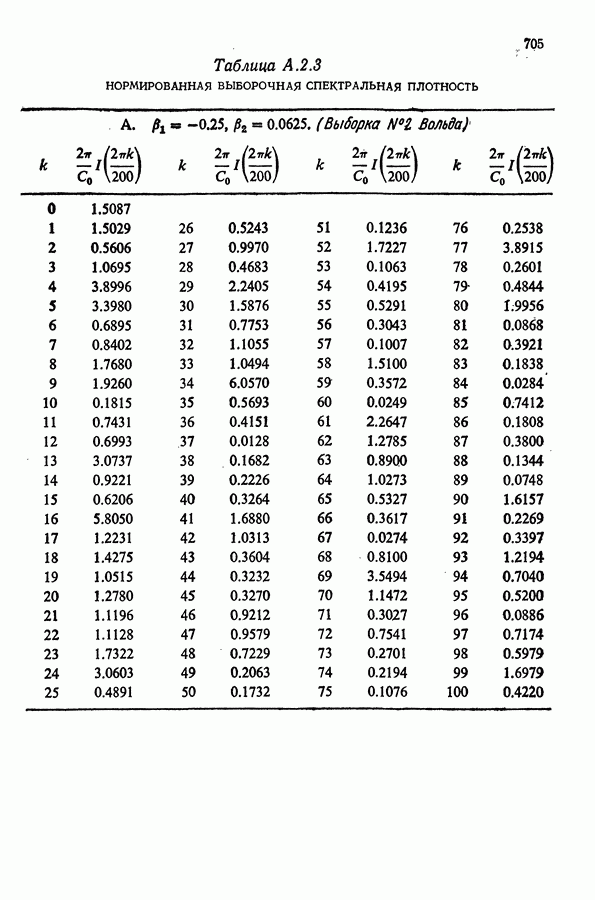
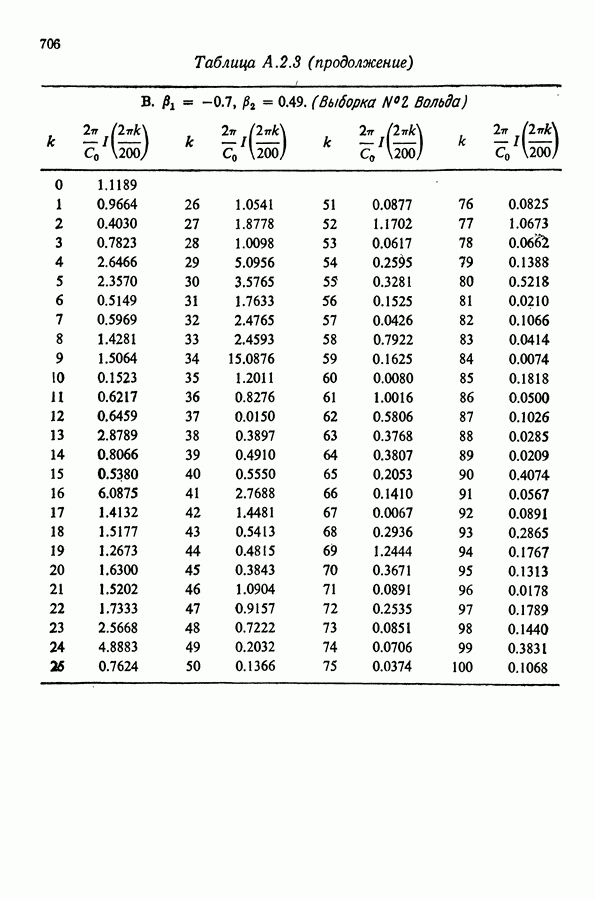
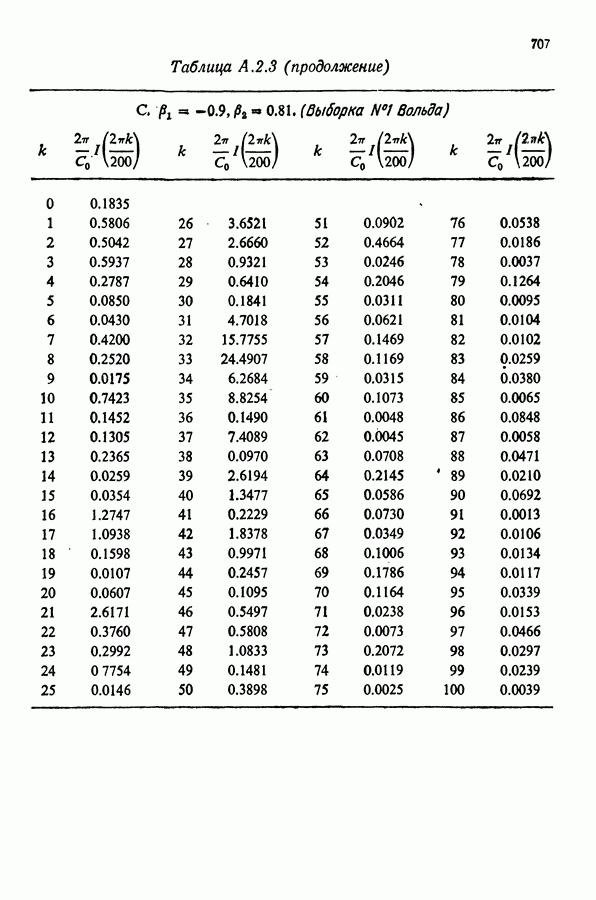
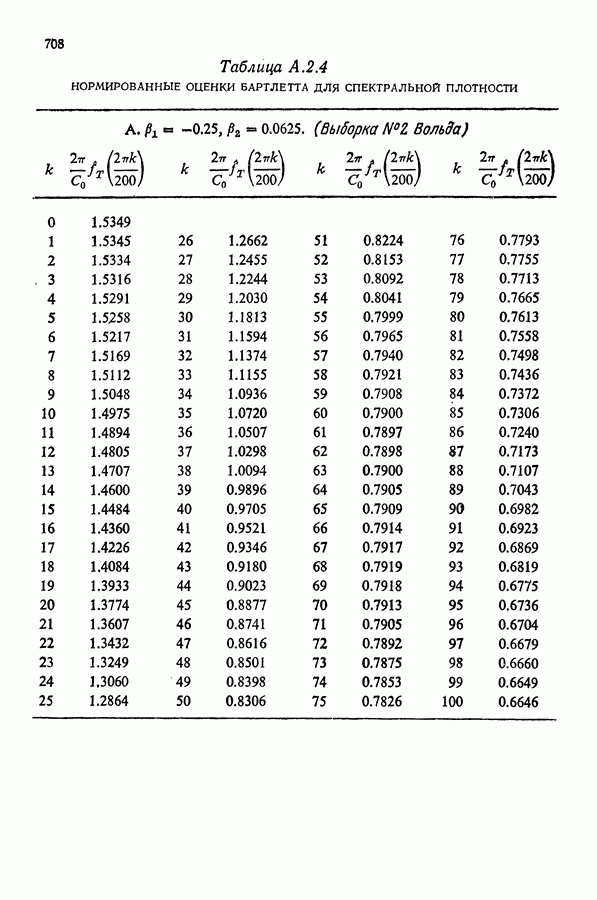
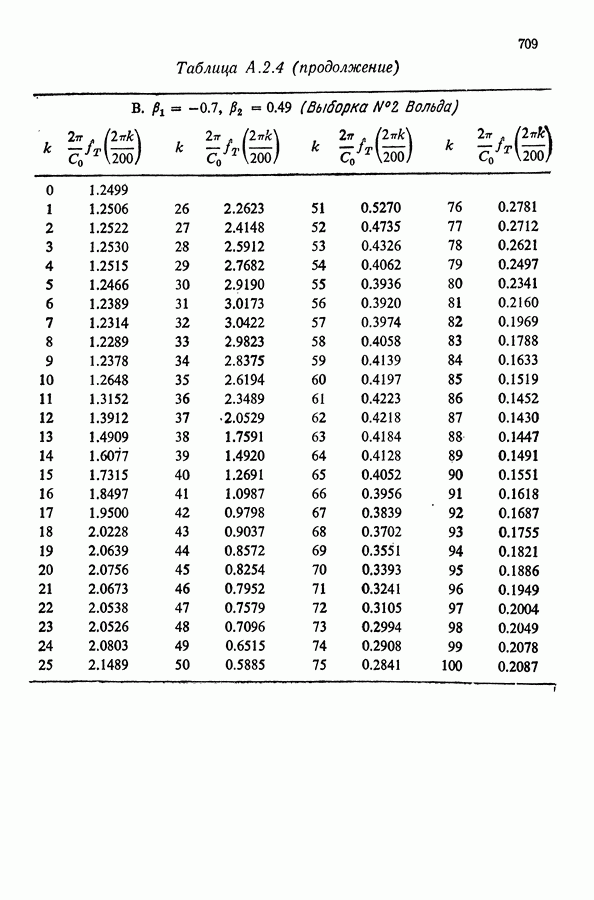
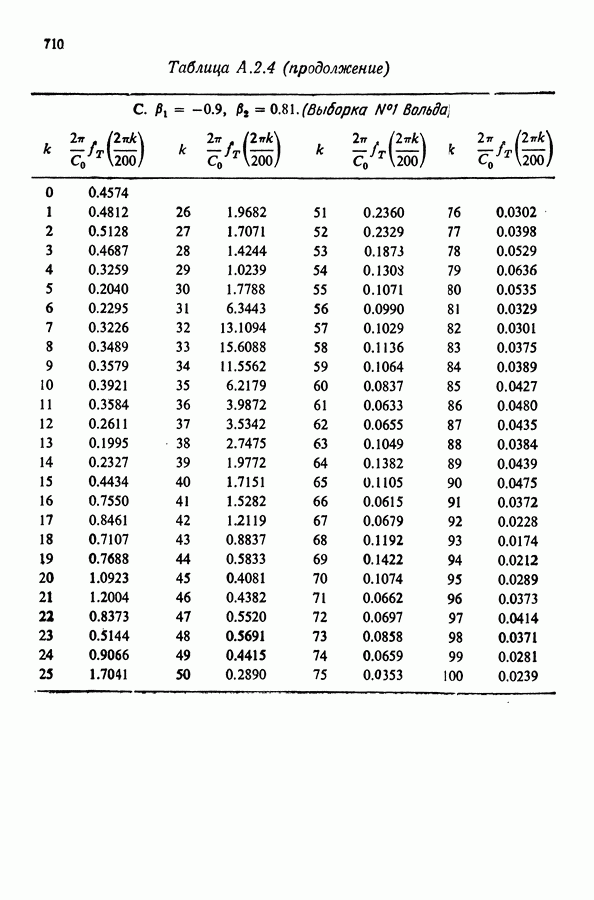
Здесь Таблица 3.4. (см. скан) ДИСПЕРСИИ СГЛАЖЕННЫХ ЗНАЧЕНИЙ Если
а для
В табл. 3.4 приведены дисперсии некоторых сглаженных значений. Для фиксированного для фиксированного значения Отметим также, что разность наблюдаемого и сглаженного значений
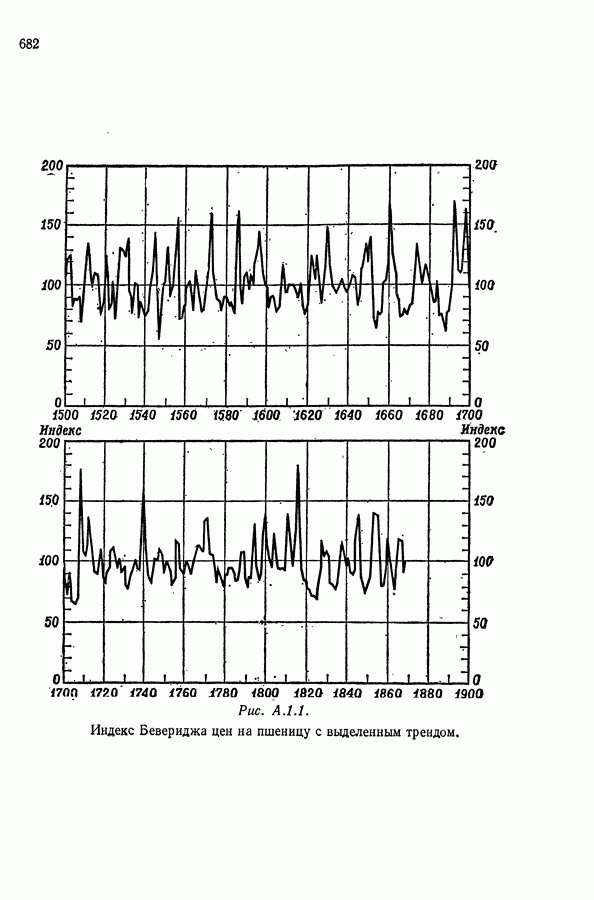
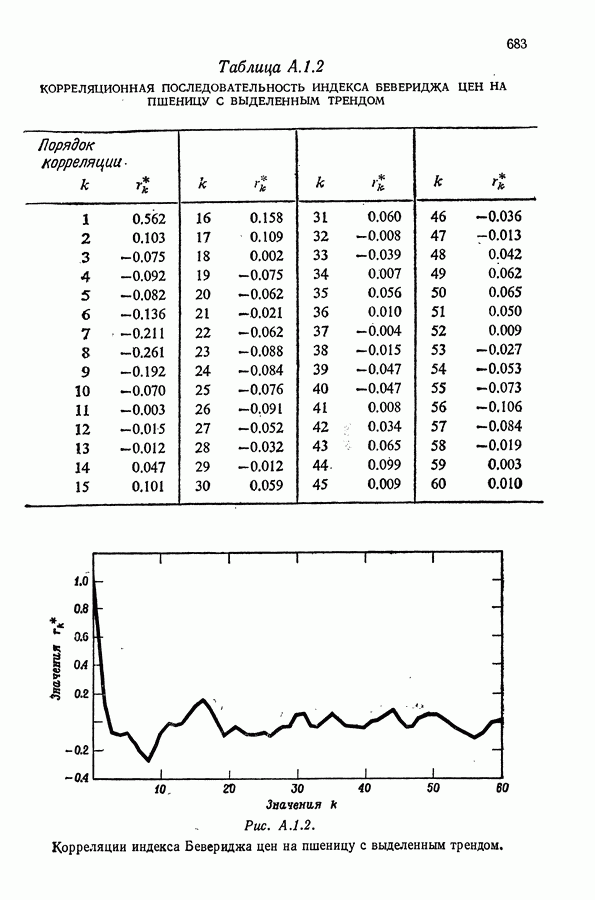
Как было указано выше, последовательные сглаженные величины являются коррелированными. Например, корреляции
Мы изучим еще это явление Если
Если сглаживающая формула основывается на полиноме степени
т. е. разностью между
Тогда использование сглаживающей формулы, основывающейся на полиноме степени ошибке
поскольку выравнивающий полином состоит из элементов соотношения (32) степени до В гл. 4 мы будем изучать случай, когда среднее значение является функцией
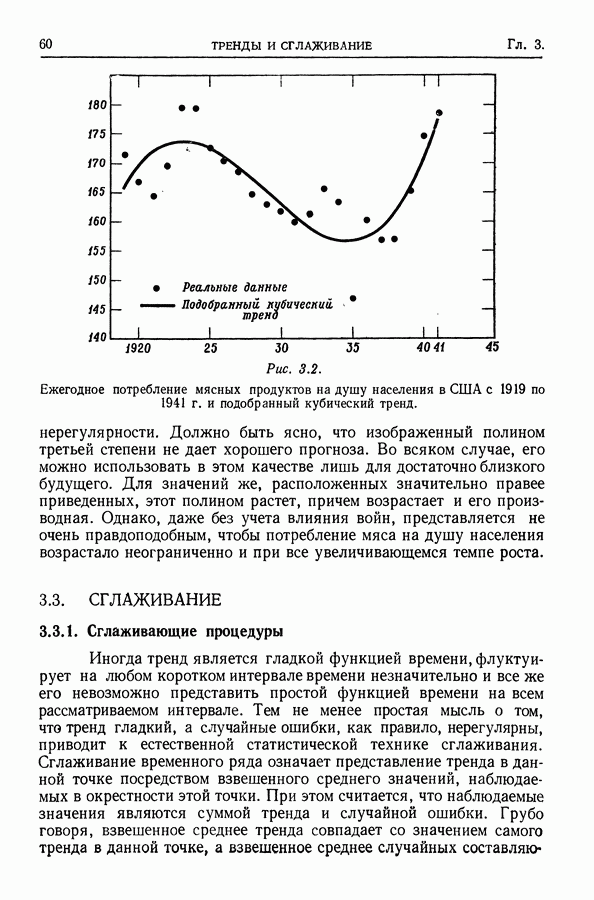
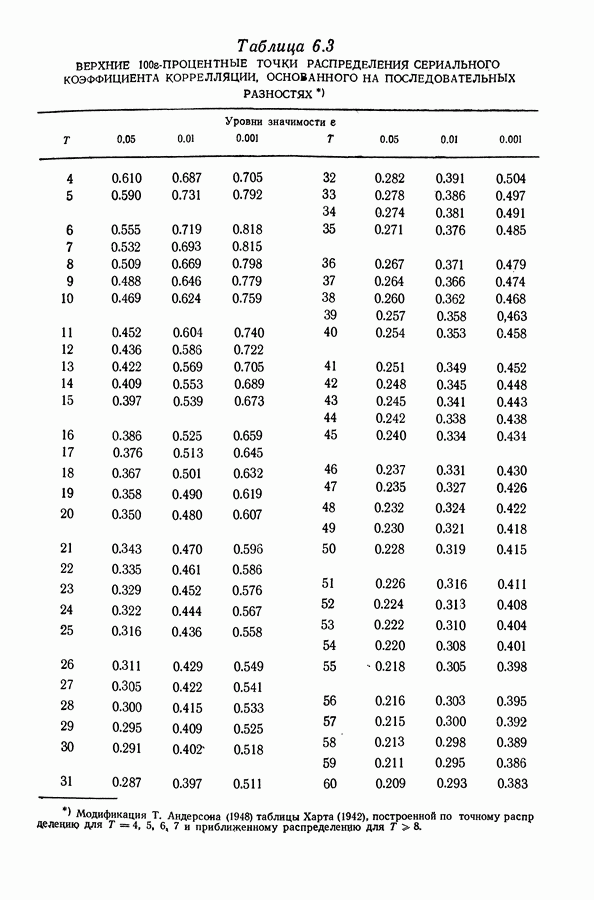
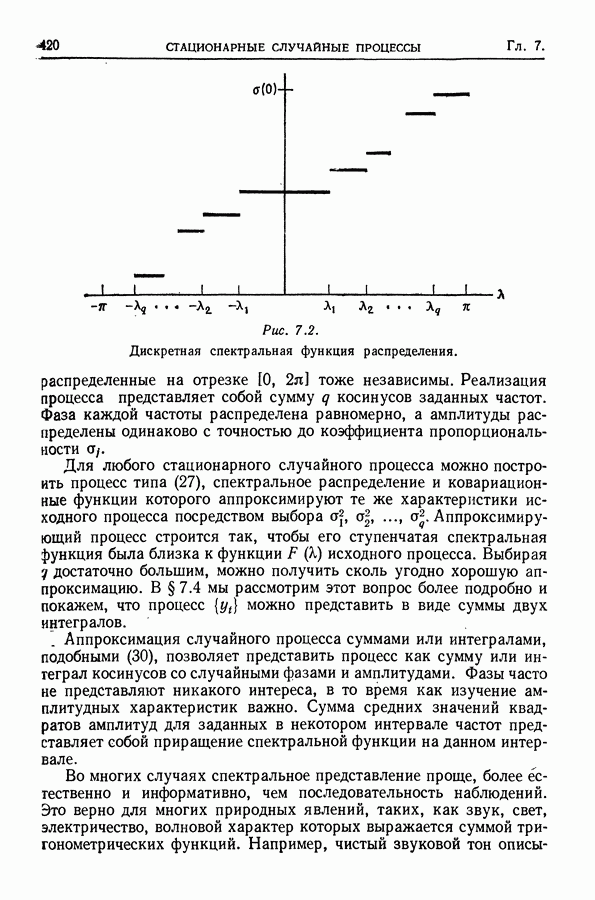
(См. упр. 31.) Таким образом, операция сглаживания здесь просто уменьшает амплитуду функции Основная цель сглаживания состоит в оценивании тренда, или ожидаемого значения себя в отношении Другой подход состоит в том, чтобы выяснить, каково наименьшее Преимуществом сглаживания для оценки тренда является его гибкость в том смысле, что предположения, при которых его можно использовать, не очень обременительны. Однако, поскольку этот метод не основывается на явной вероятностной модели, свойства его не вполне определены и статистические выводы ограничены. Например, тренд здесь не определяется малым числом параметров, для которых можно было бы указать доверительные области. Невозможно проверять гипотезы относительно тренда. Нельзя непосредственно связать функцию, оценивающую тренд, с теорией или с моделью образования наблюдаемого ряда. При сглаживании оценивающая тренд функция годится скорее для целей описания, нежели для целей анализа ряда и его интерпретации. Из-за того, что этот метод не базируется на явной вероятностной модели, он не может быть изложен полностью и строго в терминах математической статистики (по крайней мере кратко). Имеется и серьезная практическая трудность в применении сглаживания. Для того чтобы получить величину Сглаживание само по себе, конечно, не дает средних прогнозирования. Экстраполяция оцененного тренда весьма ненадежна отчасти из-за того, что тренд не оценивается для последних Мы основывали сглаживание на нечетном числе членов с симметричными весами. Если используется четное число членов с симметричными весами, то сглаженное значение интерпретируется как оценка тренда в точке, лежащей посередине между двумя средними точками. Это может оказаться неудобным. Скользящее усреднение с равными весами Сглаживание с использованием скользящего среднего имеет длинную историю, причем к нему пришли первоначально с точки зрения, отличной от статистической. [См. Уиттекер и Робинсон (1926). 1 Иногда бывает необходимо интерполировать между точками, в которых наблюдения производились. В интерполяционных формулах используются последовательные разности. Для того чтобы эти разности вели себя гладким образом, перед интерполированием можно применить формулы сглаживания. С этой точки зрения две сглаживающие процедуры эквивалентны с точностью до некоторого порядка, если разности этого порядка согласуются для каждой пары сглаженных рядов, полученных в результате применения этих двух процедур. (См. § 3.4.) Говорят, что процедура является точной до разностей некоторого порядка, если она не нарушает разностей этого порядка для полиномов. Одной из часто используемых процедур, точных до разностей третьего порядка, является
затем усредняются (с равными весами) 5 последовательных
и поочередному усреднению 7, затем 5 и 5 членов получающихся рядов. Обе эти процедуры сравнительно легко реализуются,
|
 |
Оглавление
|










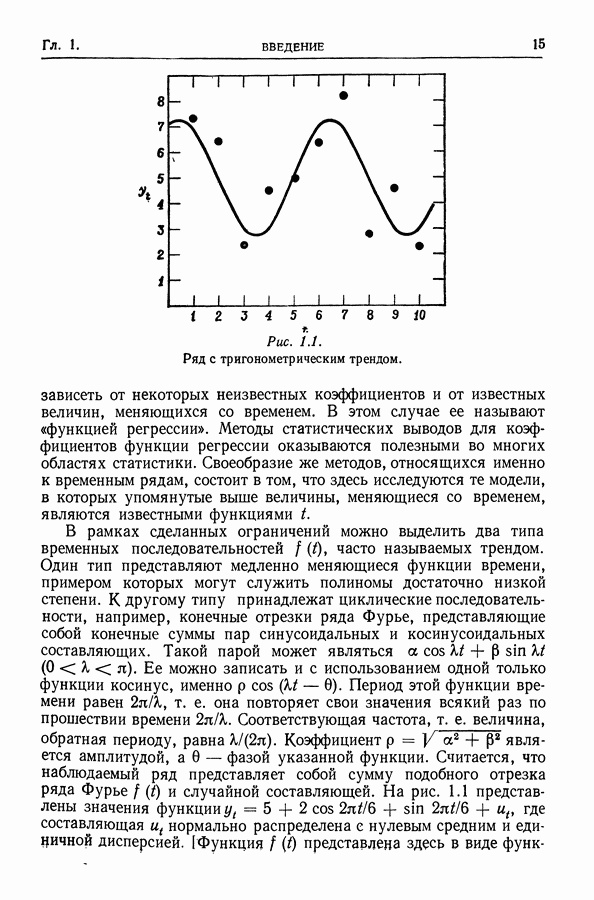








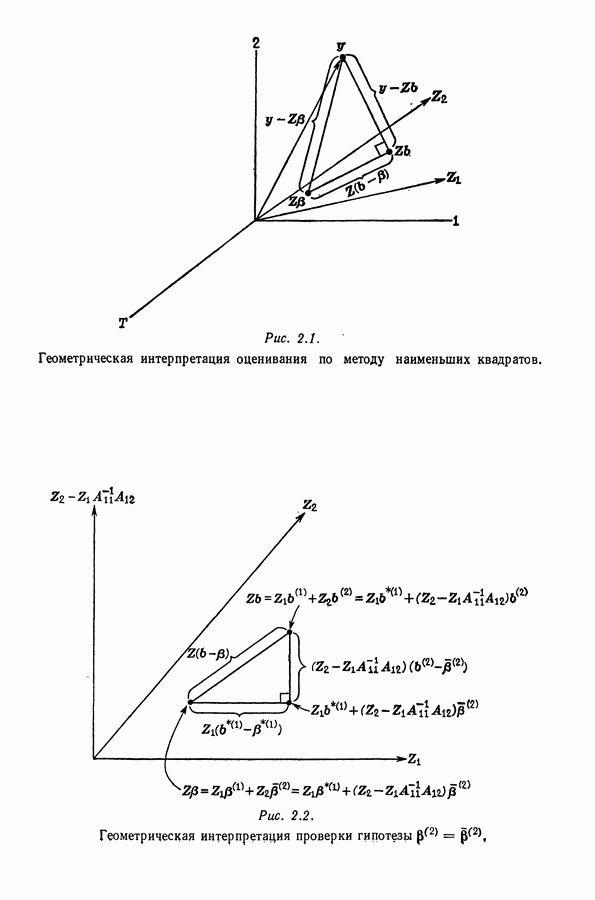



























































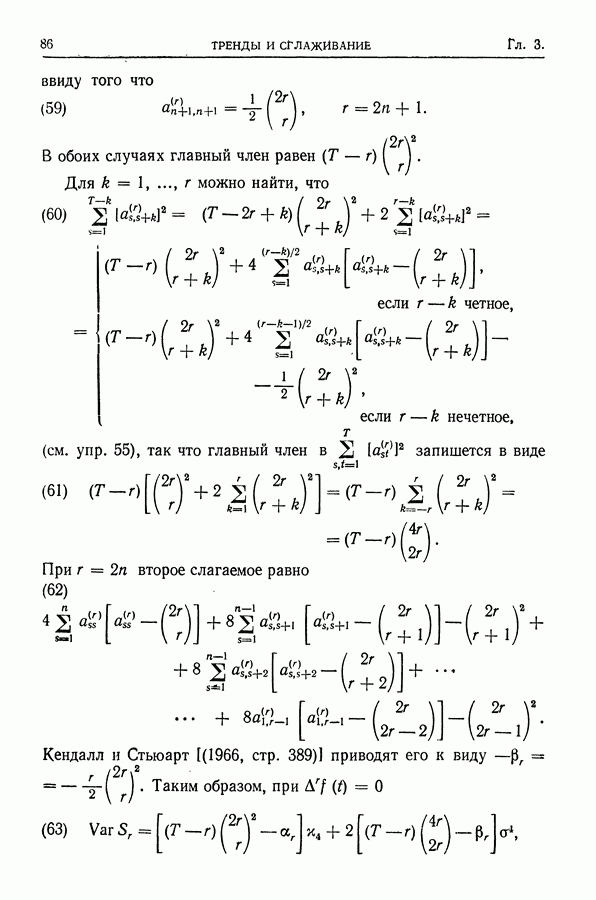














































































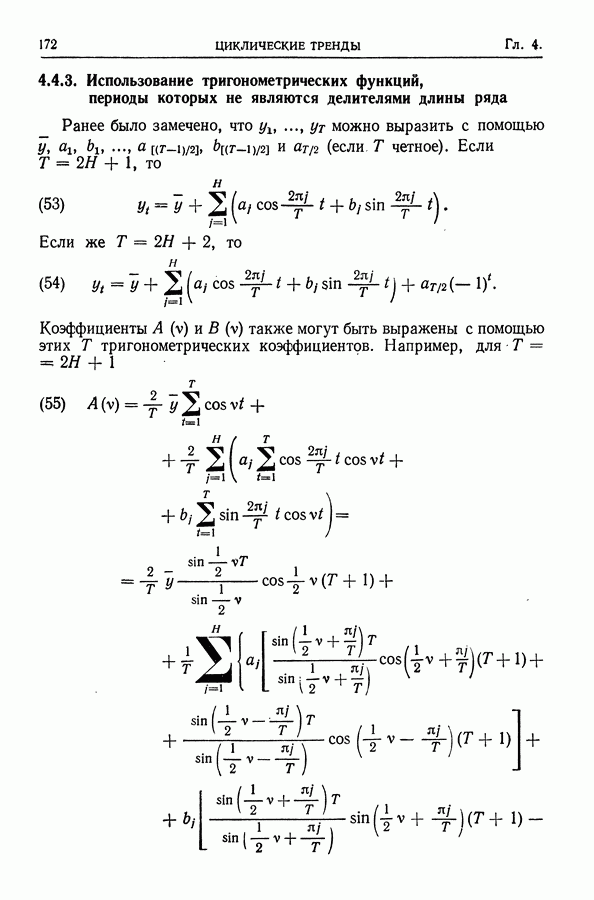
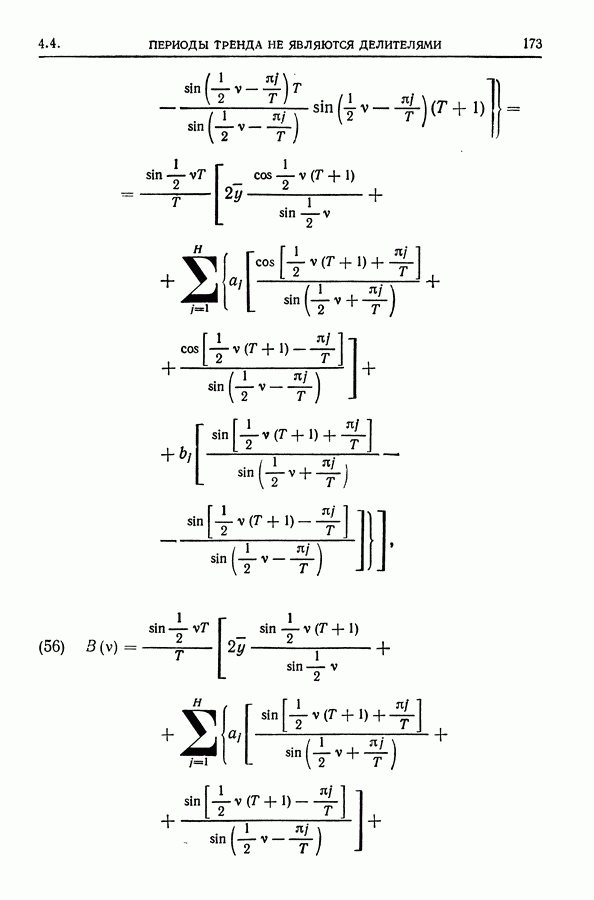
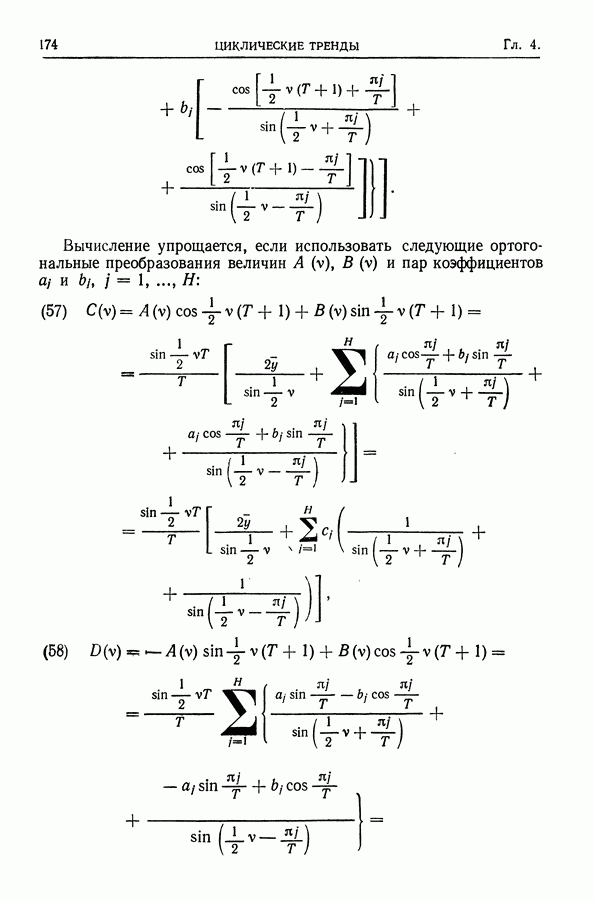

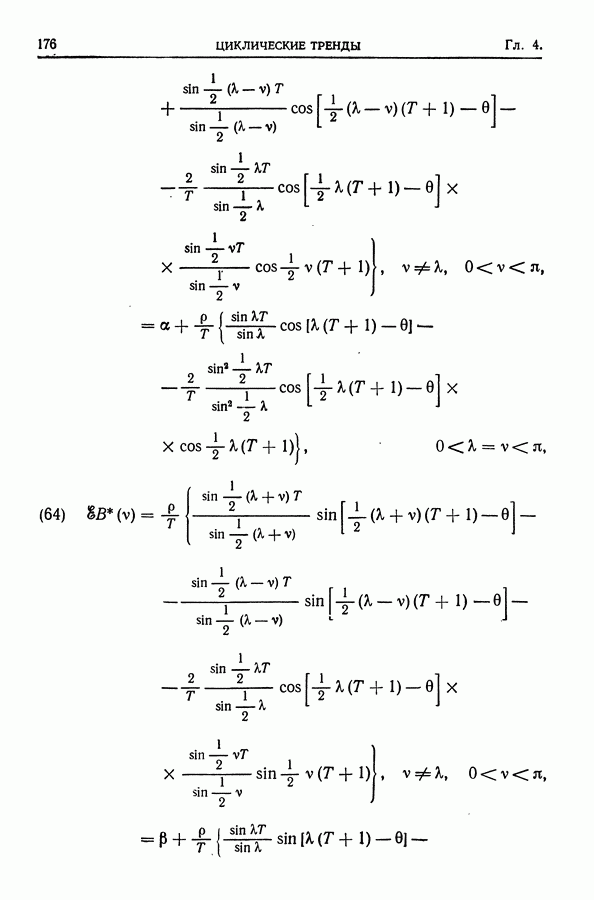
































































































































































































































































































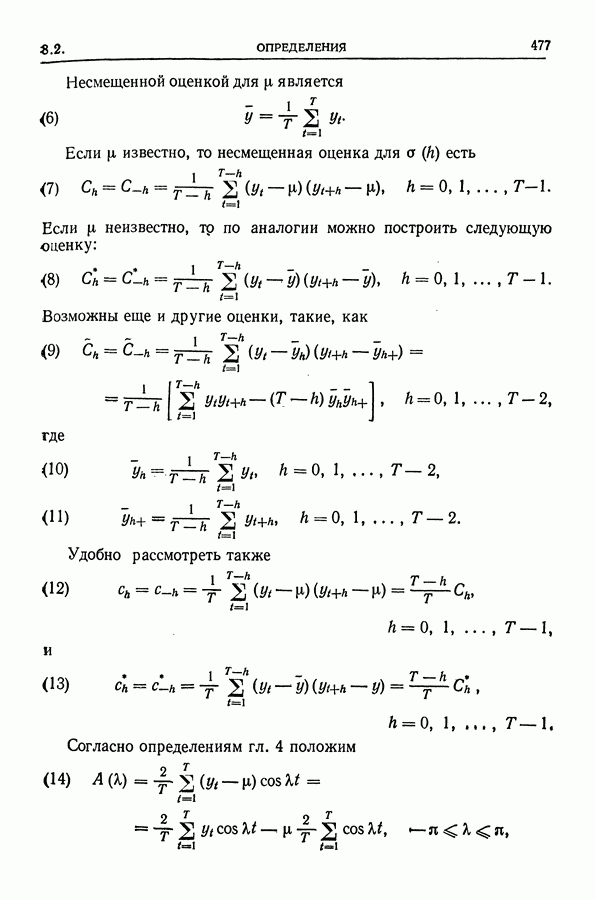
















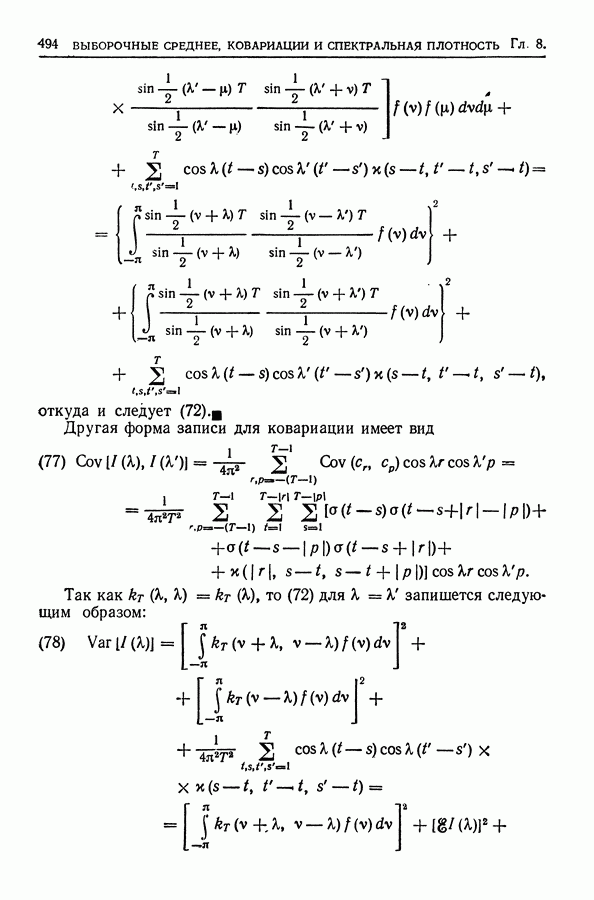
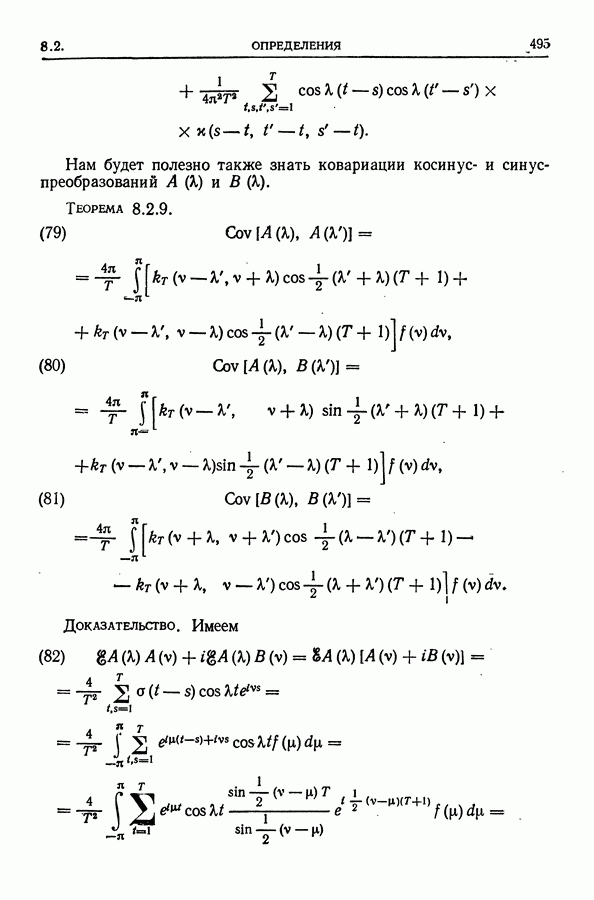

















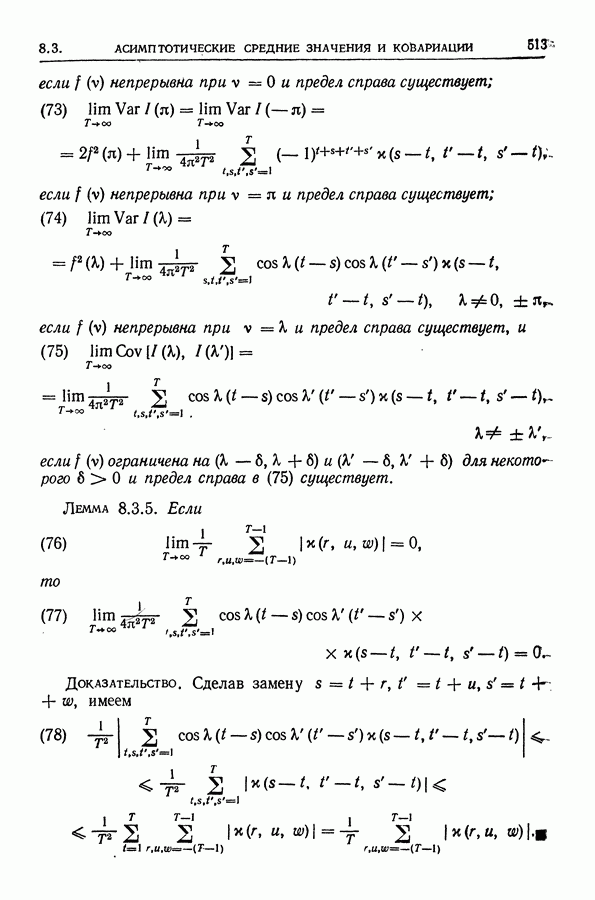






































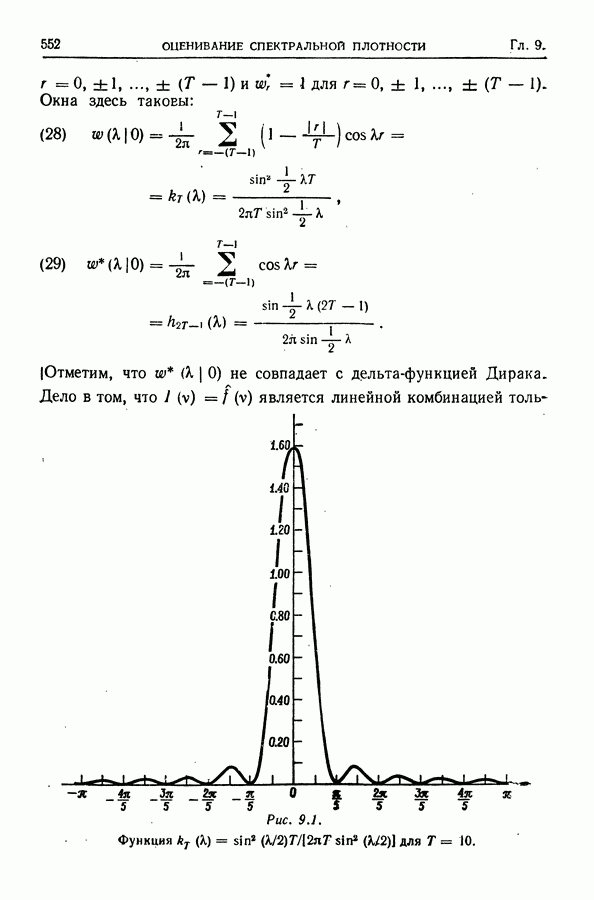
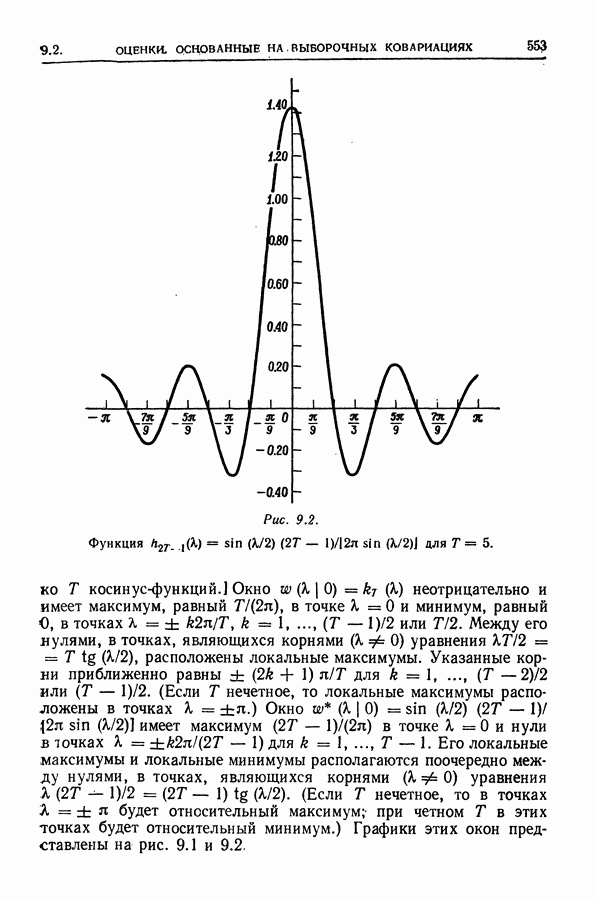





























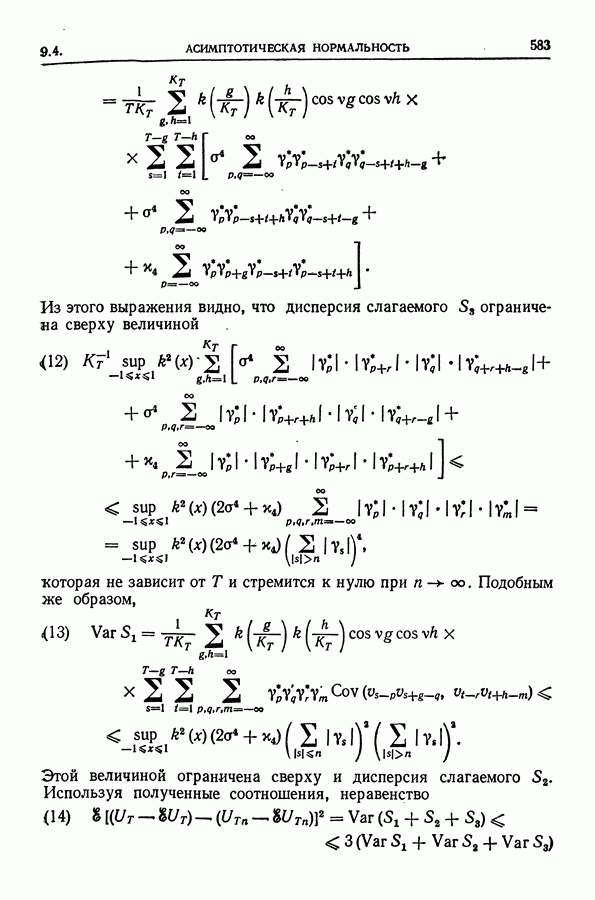








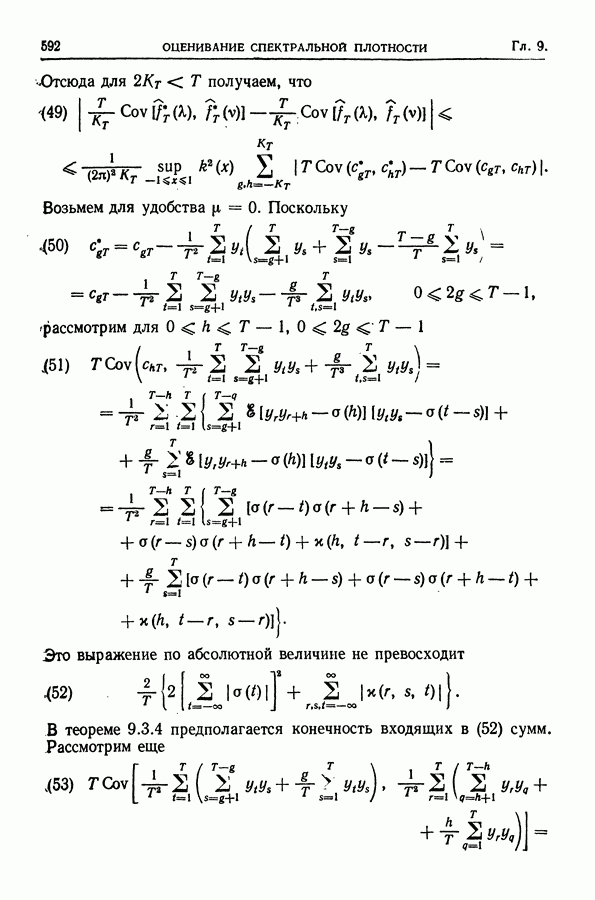




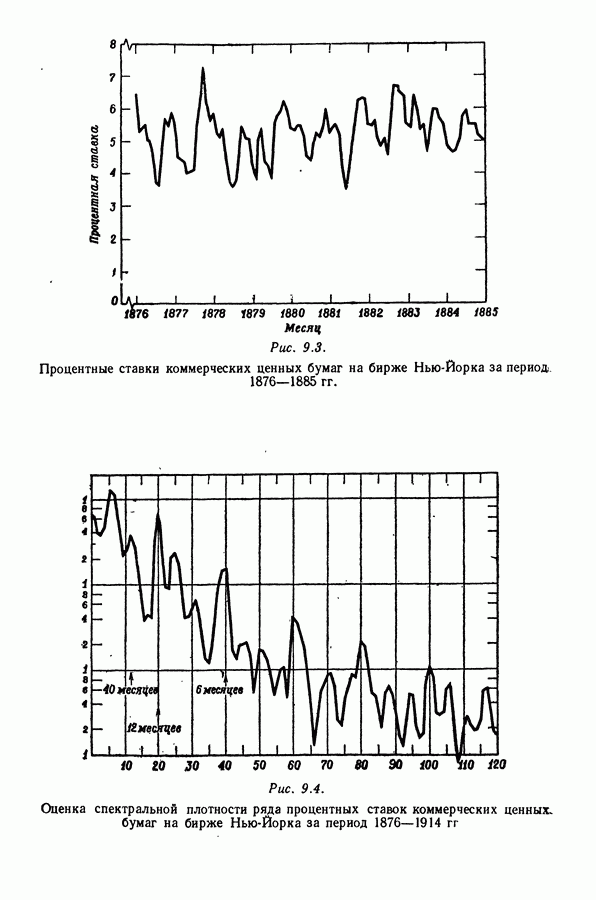









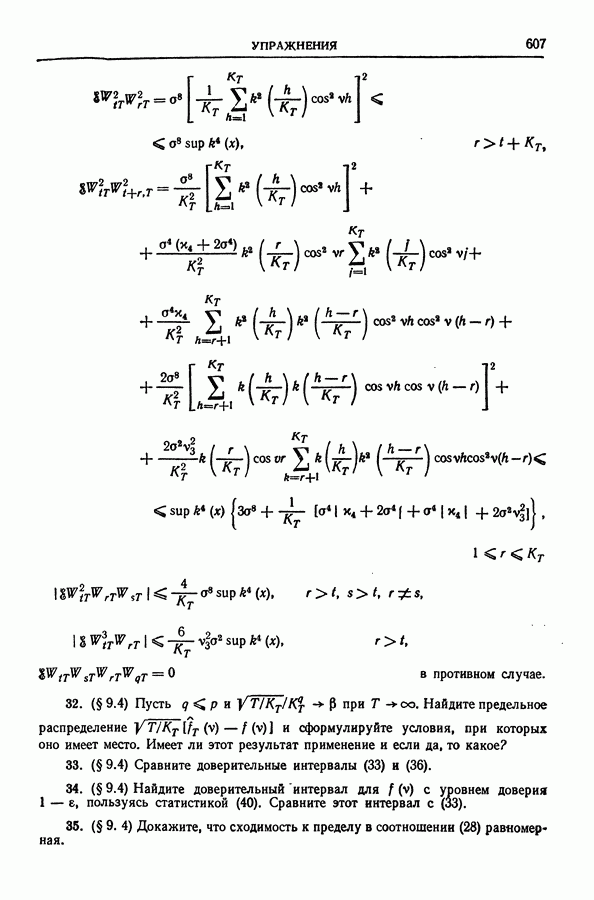



































































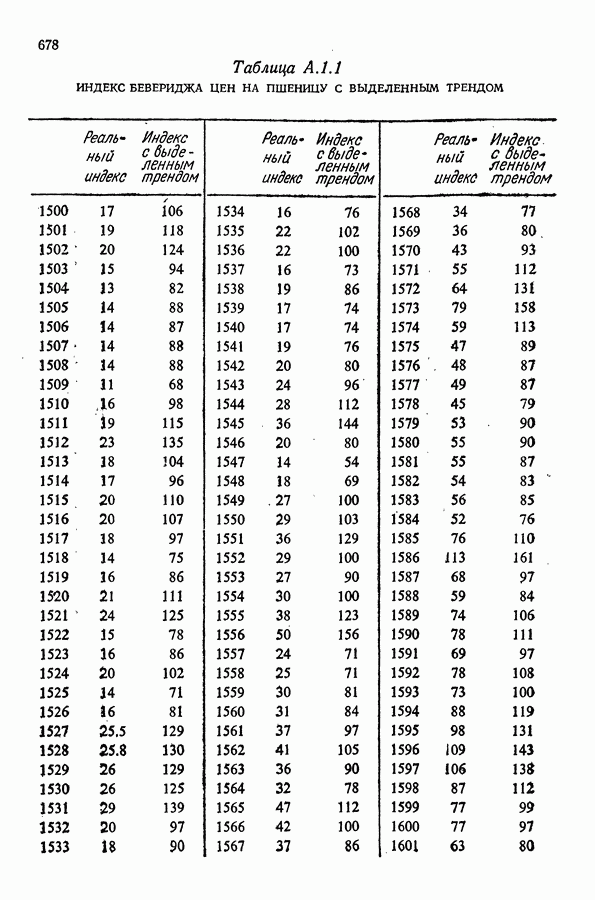
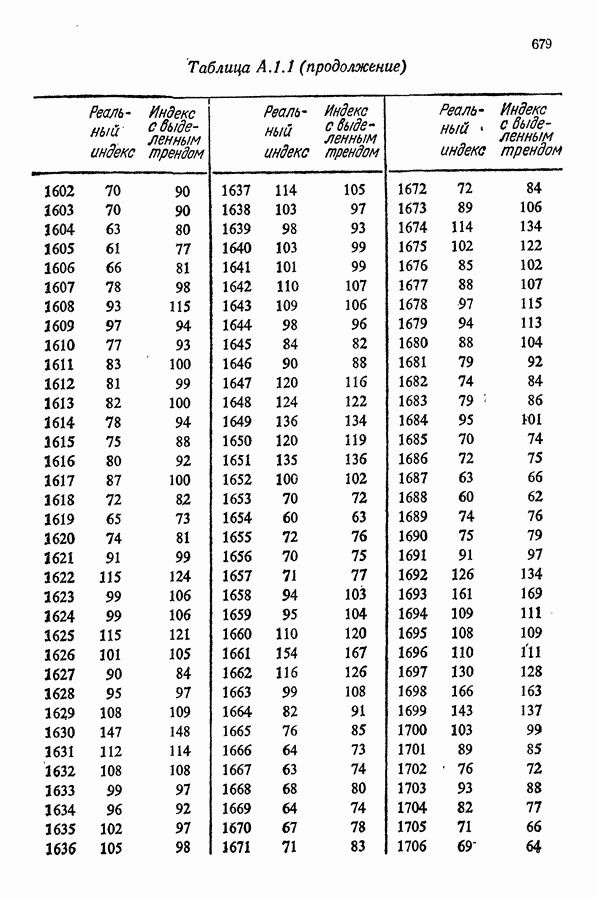
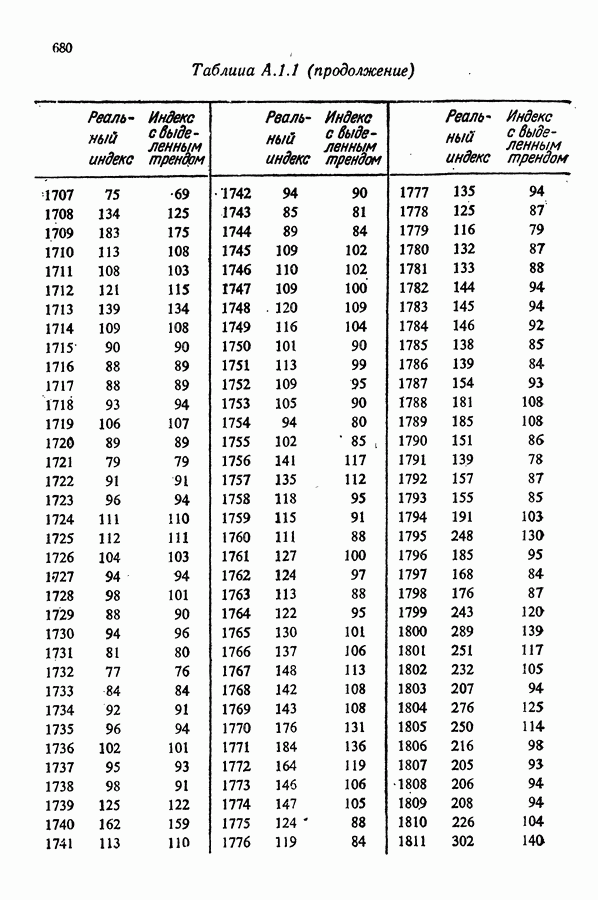
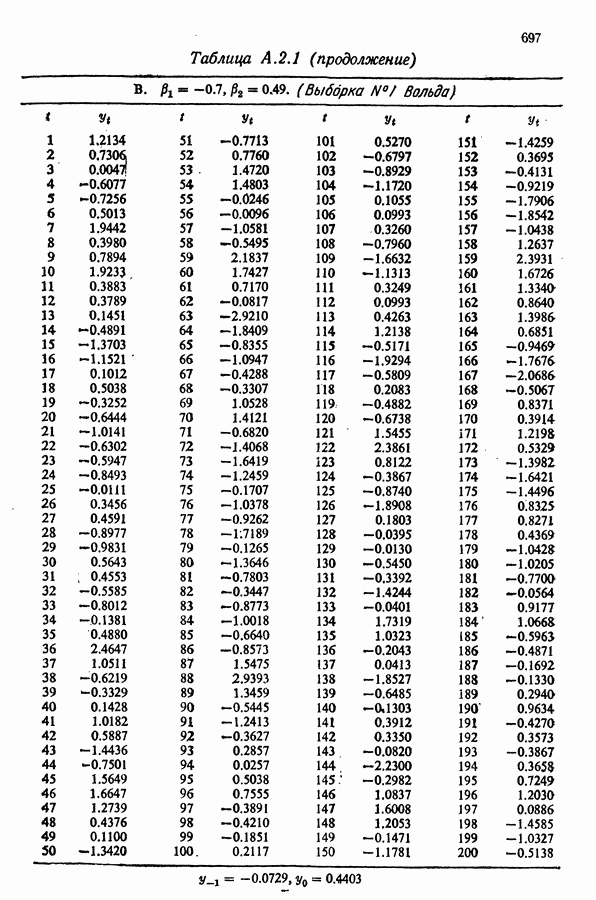
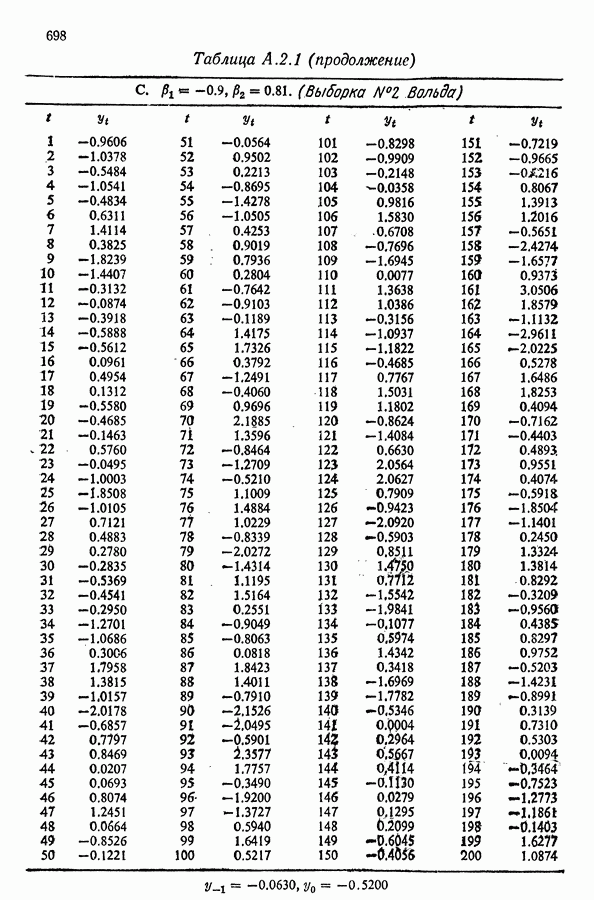
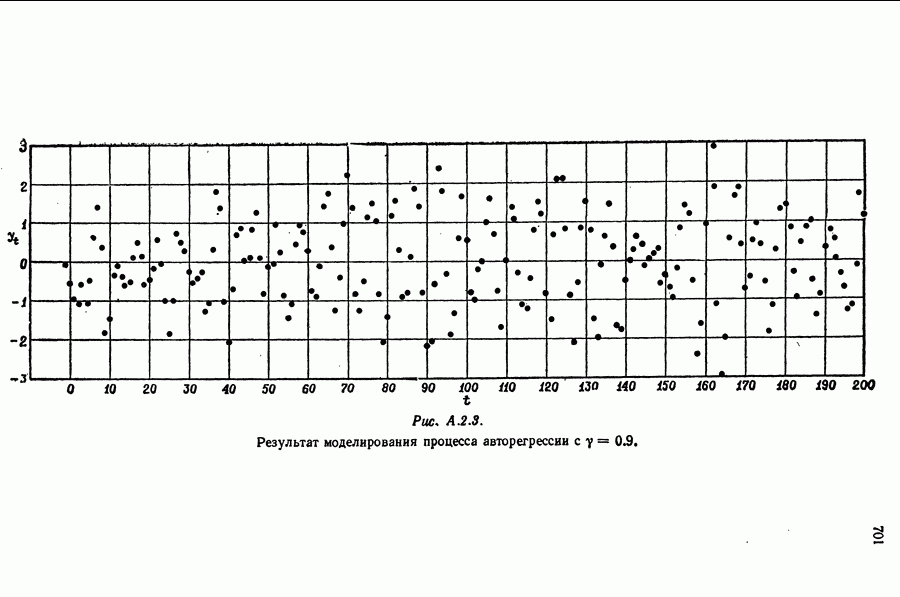
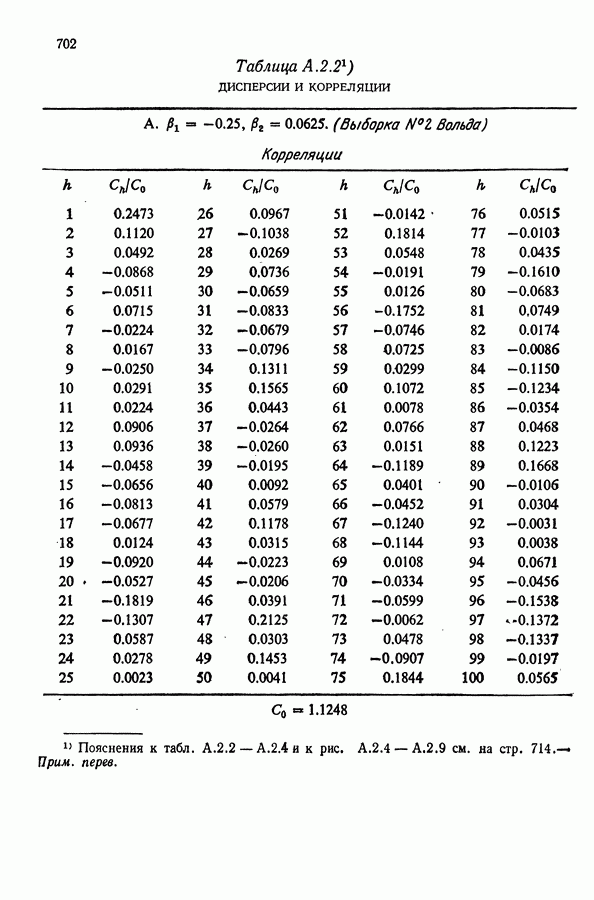
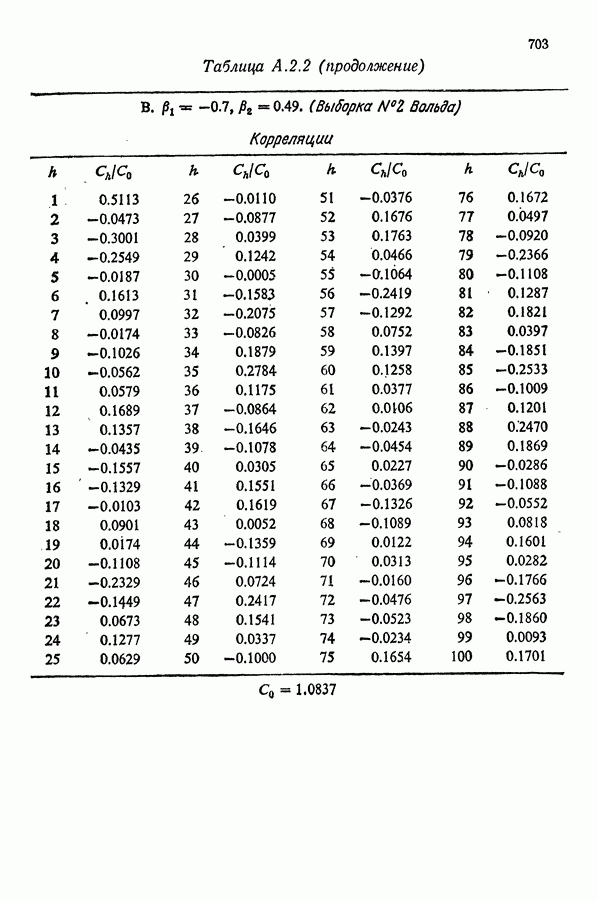
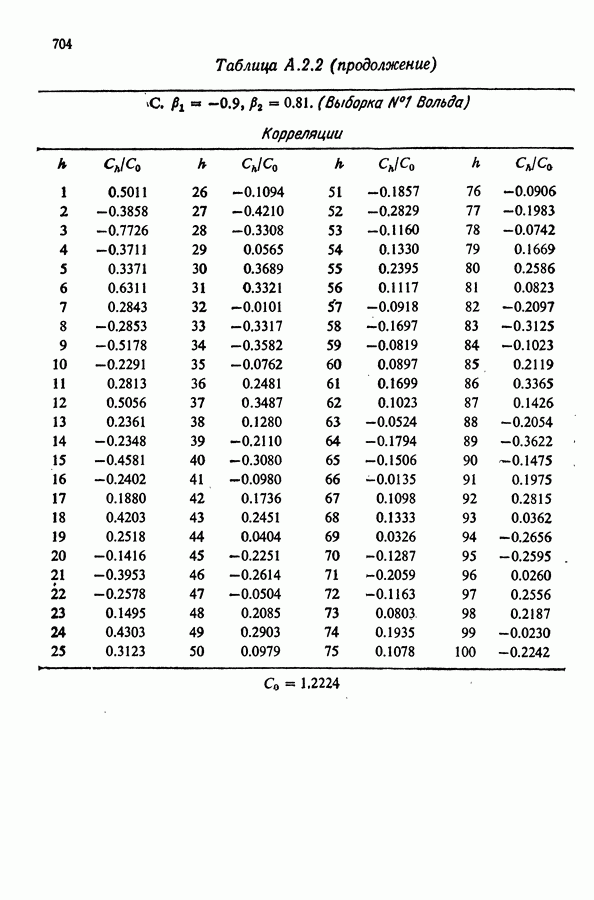
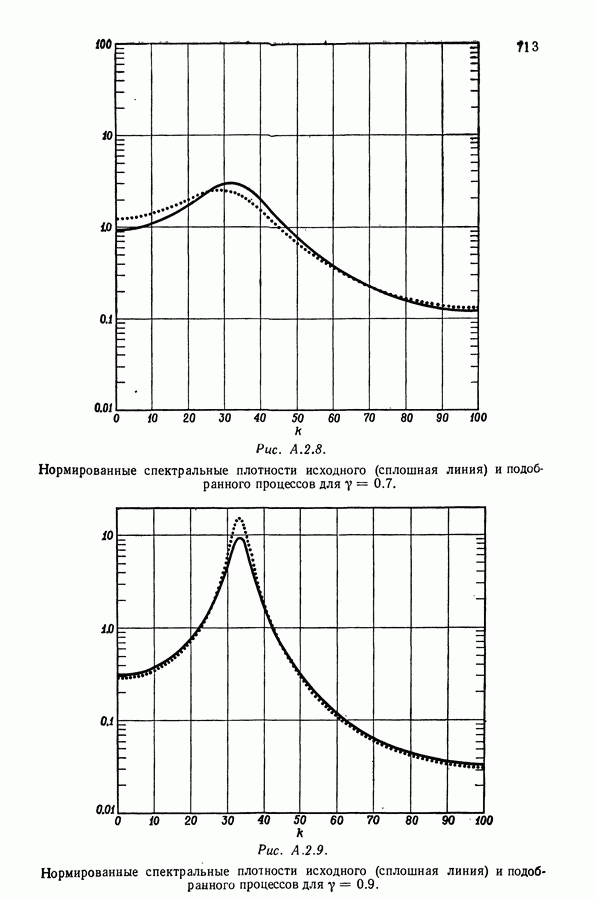

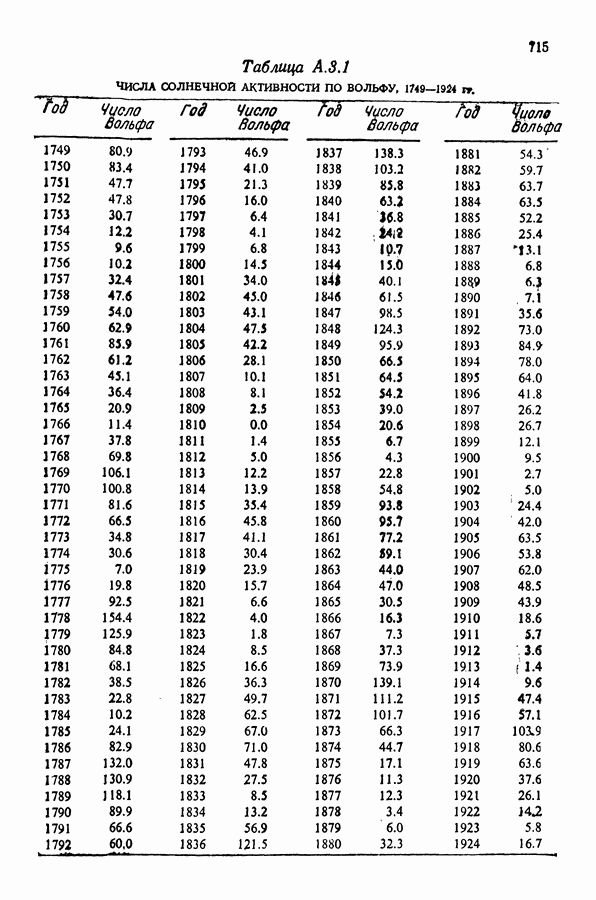























 равна
равна

 верхний левый угловой элемент матрицы
верхний левый угловой элемент матрицы  обратной к матрице В коэффициентов уравнений (13), элементы которой суть
обратной к матрице В коэффициентов уравнений (13), элементы которой суть

 то эти уравнения можно записать в виде
то эти уравнения можно записать в виде 

 в виде
в виде

 Поскольку
Поскольку  не содержат значения
не содержат значения  для
для  то
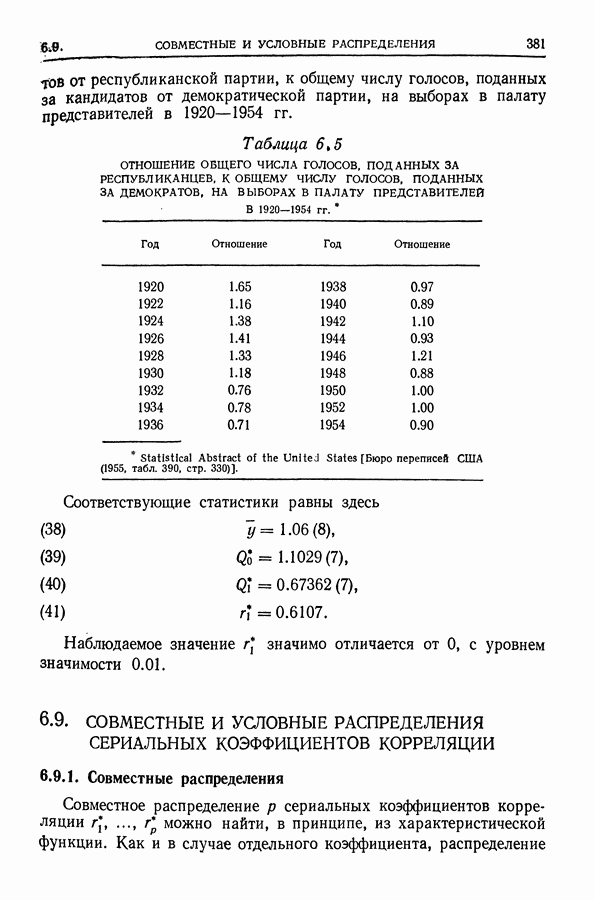
то  является коэффициентом при
является коэффициентом при  Общая теория метода наименьших квадратов утверждает, однако, что дисперсия
Общая теория метода наименьших квадратов утверждает, однако, что дисперсия  равна
равна 

 то дисперсия величины
то дисперсия величины  есть
есть  Для
Для  она равна
она равна



 дисперсия уменьшается с ростом используемого числа точек. При фиксированном числе точек (т. е. при фиксированном
дисперсия уменьшается с ростом используемого числа точек. При фиксированном числе точек (т. е. при фиксированном  дисперсия увеличивается с возрастанием
дисперсия увеличивается с возрастанием  Фактически
Фактически
 которое вдвое меньше разности числа точек и числа неявно подбираемых констант, дисперсия увеличивается с ростом
которое вдвое меньше разности числа точек и числа неявно подбираемых констант, дисперсия увеличивается с ростом 
 не коррелирована с
не коррелирована с  , поскольку оценки коэффициентов регрессии не коррелированы с остатками. (См упр. 7 гл. 2.) Поэтому
, поскольку оценки коэффициентов регрессии не коррелированы с остатками. (См упр. 7 гл. 2.) Поэтому

 с
с  для случая
для случая  равны соответственно
равны соответственно

 после того как разовьем более мощный математический аппарат.
после того как разовьем более мощный математический аппарат.
 и используется сглаживающая формула с коэффициентами
и используется сглаживающая формула с коэффициентами  то систематическая ошибка сглаженной величины имеет вид
то систематическая ошибка сглаженной величины имеет вид

 и тренд является полиномом той же (или меньшей) степени, то систематическая ошибка будет равна 0. В противном случае она отлична от нуля. Предположим, что
и тренд является полиномом той же (или меньшей) степени, то систематическая ошибка будет равна 0. В противном случае она отлична от нуля. Предположим, что  или 1) и коэффициенты те же. Тогда систематическая ошибка выражается соотношением
или 1) и коэффициенты те же. Тогда систематическая ошибка выражается соотношением

 и средним арифметическим соседних значений. Предположим, что
и средним арифметическим соседних значений. Предположим, что  записывается с помощью ортогональных полиномов степени, не превышающей
записывается с помощью ортогональных полиномов степени, не превышающей  (ортогональных на множестве
(ортогональных на множестве  ), в виде
), в виде

 или
или  приводит к систематической
приводит к систематической

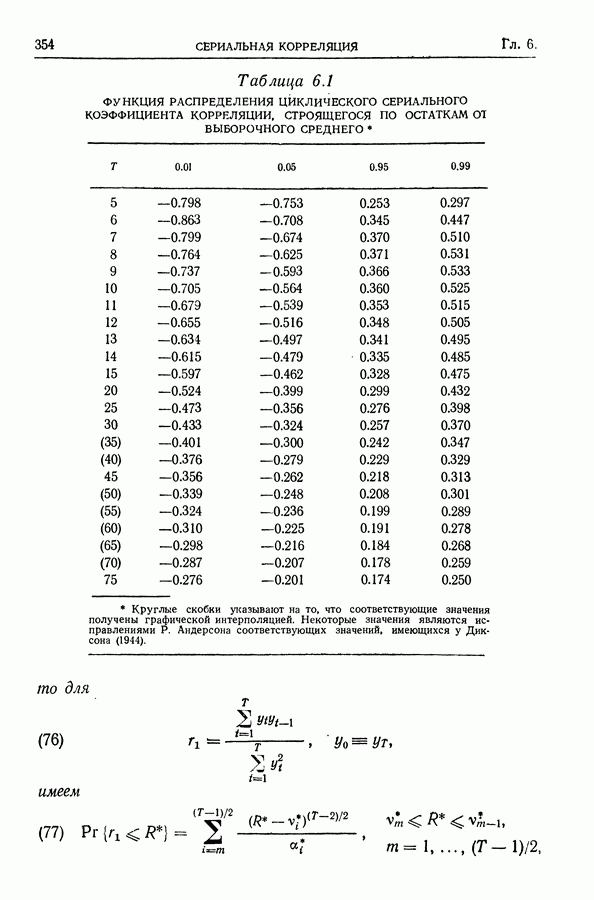
 или
или  включительно и
включительно и  для нечетных
для нечетных  (См. упр. 30.)
(См. упр. 30.)
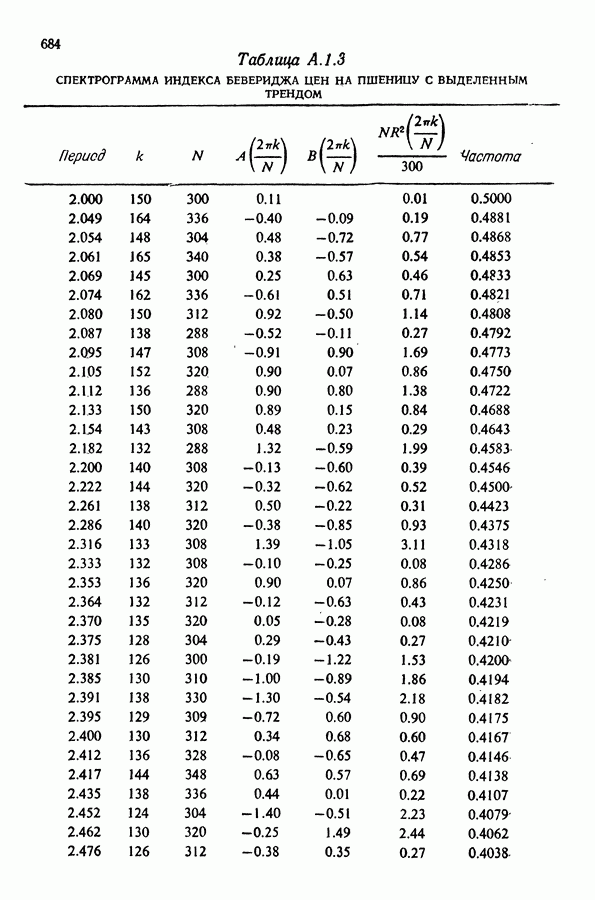
 т. е. косинусом с периодом
т. е. косинусом с периодом  Если при этом коэффициенты
Если при этом коэффициенты  то ожидаемое значение сглаженной переменной запишется в виде
то ожидаемое значение сглаженной переменной запишется в виде

 Если X мало (т. е. период велик), то и это уменьшение мало (упр. 32). При фиксированном X большим значениям
Если X мало (т. е. период велик), то и это уменьшение мало (упр. 32). При фиксированном X большим значениям  (удовлетворяющим неравенству
(удовлетворяющим неравенству  соответствует меньший коэффициент пропорциональности (упр. 33). Если
соответствует меньший коэффициент пропорциональности (упр. 33). Если  (длина скользящего усреднения равна периоду), то сглаженное значение равно нулю.
(длина скользящего усреднения равна периоду), то сглаженное значение равно нулю.
 с наименьшей ошибкой. Ошибка складывается здесь из смещения (30) и случайной составляющей
с наименьшей ошибкой. Ошибка складывается здесь из смещения (30) и случайной составляющей  Первую составляющую можно измерить ее квадратом, а вторую — ее дисперсией
Первую составляющую можно измерить ее квадратом, а вторую — ее дисперсией  При фиксированном
При фиксированном  смещение с увеличением
смещение с увеличением  в большинстве случаев возрастает, а дисперсия убывает. В то же время при фиксированном
в большинстве случаев возрастает, а дисперсия убывает. В то же время при фиксированном  смещение с увеличением
смещение с увеличением  убывает, а дисперсия возрастает. Статистик, которому приходится использовать сглаживающую формулу, должен выбрать значения
убывает, а дисперсия возрастает. Статистик, которому приходится использовать сглаживающую формулу, должен выбрать значения  Он мог бы использовать в качестве меры ошибки среднеквадратичную ошибку, которая является суммой указанной дисперсии и среднего квадрата смещения. Если бы дисперсия
Он мог бы использовать в качестве меры ошибки среднеквадратичную ошибку, которая является суммой указанной дисперсии и среднего квадрата смещения. Если бы дисперсия  случайных ошибок
случайных ошибок  была известна и если бы были известны средние квадраты смещений для каждой комбинации
была известна и если бы были известны средние квадраты смещений для каждой комбинации  то статистик смог бы выбрать комбинацию
то статистик смог бы выбрать комбинацию  минимизирующую эту меру ошибки. Однако здесь трудно дать какую-либо рекомендацию, поскольку дисперсия и среднеквадратичное смещение ведут
минимизирующую эту меру ошибки. Однако здесь трудно дать какую-либо рекомендацию, поскольку дисперсия и среднеквадратичное смещение ведут
 противоположным образом. Если
противоположным образом. Если  мало, то можно удовлетвориться относительно малым
мало, то можно удовлетвориться относительно малым  . Чем более гладкой является
. Чем более гладкой является  тем меньшим может быть выбрано
тем меньшим может быть выбрано  при фиксированном
при фиксированном  тем большим выбрано
тем большим выбрано  при фиксированном
при фиксированном  . В действительности, конечно, эти характеристики не известны, а должны быть оценены по имеющимся данным. Поэтому выбор
. В действительности, конечно, эти характеристики не известны, а должны быть оценены по имеющимся данным. Поэтому выбор  является статистической задачей со многими решениями, которую трудно даже сформулировать, не говоря уже о ее строгом статистическом решении. Поэтому практик должен действовать здесь исходя из своей интуиции и накопленного опыта.
является статистической задачей со многими решениями, которую трудно даже сформулировать, не говоря уже о ее строгом статистическом решении. Поэтому практик должен действовать здесь исходя из своей интуиции и накопленного опыта.
 такое, что средний квадрат смещения близок или равен нулю, когда
такое, что средний квадрат смещения близок или равен нулю, когда  фиксировано или когда
фиксировано или когда  заданная функция переменной
заданная функция переменной  например
например  Мы рассмотрим этот подход в следующем параграфе.
Мы рассмотрим этот подход в следующем параграфе.
 оценивающую тренд в точке необходимо импользовать значения
оценивающую тренд в точке необходимо импользовать значения  Поскольку эта процедура основывается на наблюдениях
Поскольку эта процедура основывается на наблюдениях  то первым сглаженным значением будет
то первым сглаженным значением будет  а последним
а последним  Тем самым, мы не имеем оценок тренда в начале периода наблюдений и в его конце. Для оценки тренда в этих точках необходимо привлекать какие-то другие соображения.
Тем самым, мы не имеем оценок тренда в начале периода наблюдений и в его конце. Для оценки тренда в этих точках необходимо привлекать какие-то другие соображения.
 моментов времени.
моментов времени.
 можно легко осуществить на клавишной вычислительной машине, поскольку сумма
можно легко осуществить на клавишной вычислительной машине, поскольку сумма  измеряется при каждом
измеряется при каждом  путем вычитания одного члена и добавления другого. Эти суммы запоминаются и затем каждая делится на
путем вычитания одного члена и добавления другого. Эти суммы запоминаются и затем каждая делится на  (или умножается на
(или умножается на  Представляет значительный интерес аппроксимация процедуры сглаживания с неравными весами последовательностью процедур сглаживания, использующих равные веса. Конечно, при наличии быстродействующей вычислительной машины нет никакой нужды упрощать коэффициенты.
Представляет значительный интерес аппроксимация процедуры сглаживания с неравными весами последовательностью процедур сглаживания, использующих равные веса. Конечно, при наличии быстродействующей вычислительной машины нет никакой нужды упрощать коэффициенты.
 -то-чечная формула Спенсера. Эта процедура выполняется таким образом. Сначала вычисляются величины
-то-чечная формула Спенсера. Эта процедура выполняется таким образом. Сначала вычисляются величины

 далее — 4 последовательных члена полученного ряда и, наконец, усредняются 4 последовательных члена последнего ряда. Другой процедурой, сохраняющей разности третьего порядка, является
далее — 4 последовательных члена полученного ряда и, наконец, усредняются 4 последовательных члена последнего ряда. Другой процедурой, сохраняющей разности третьего порядка, является  -точечная формула Спенсера, соответствующая вычислению величин
-точечная формула Спенсера, соответствующая вычислению величин
