Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
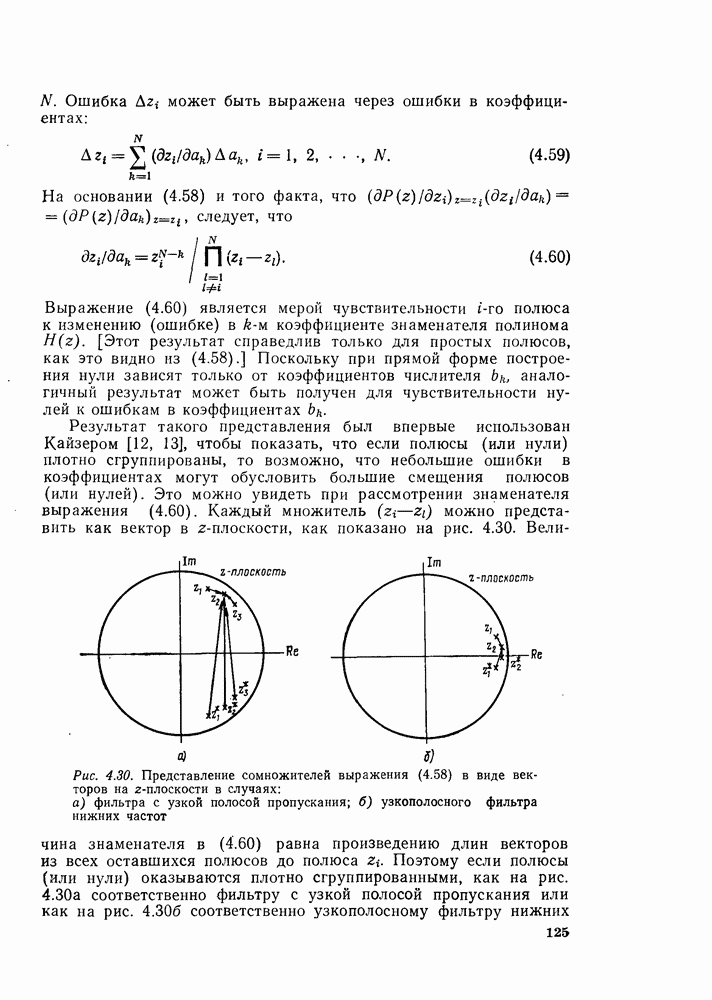
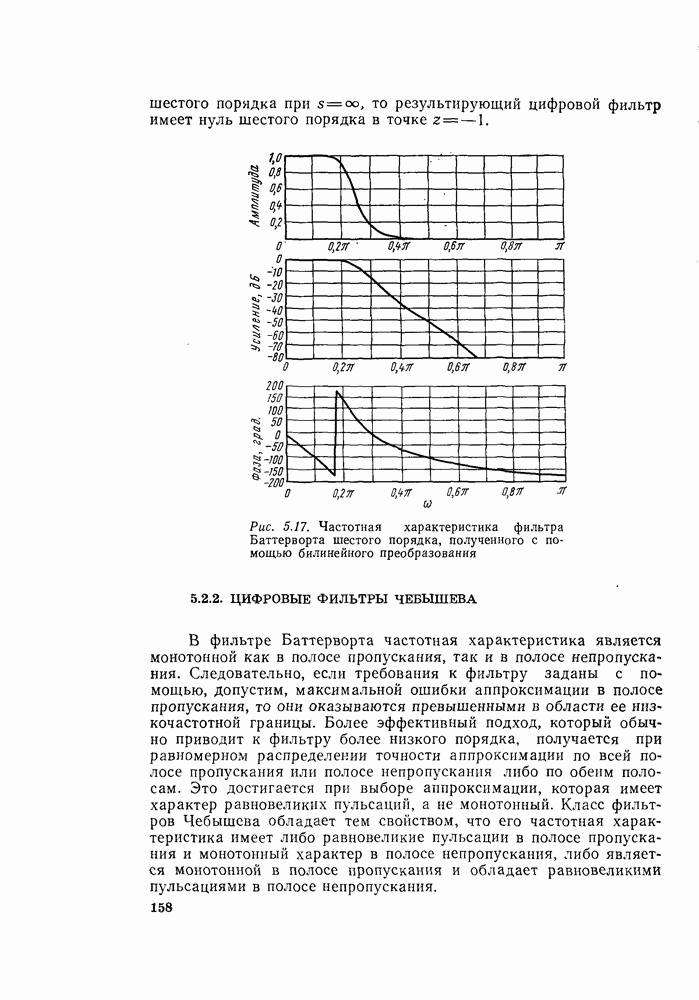
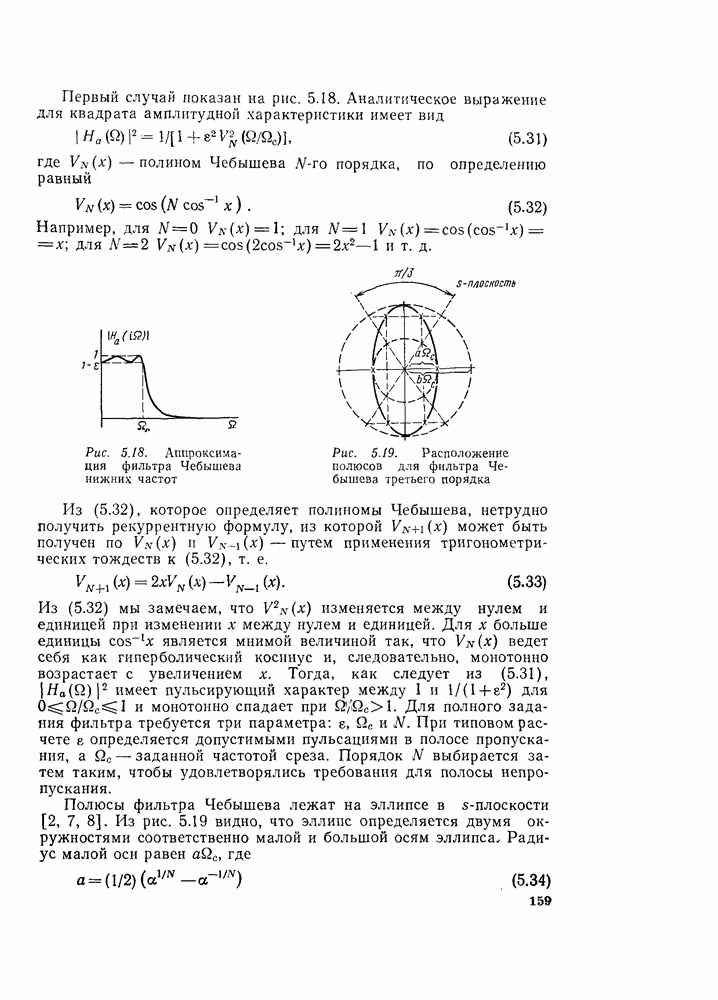
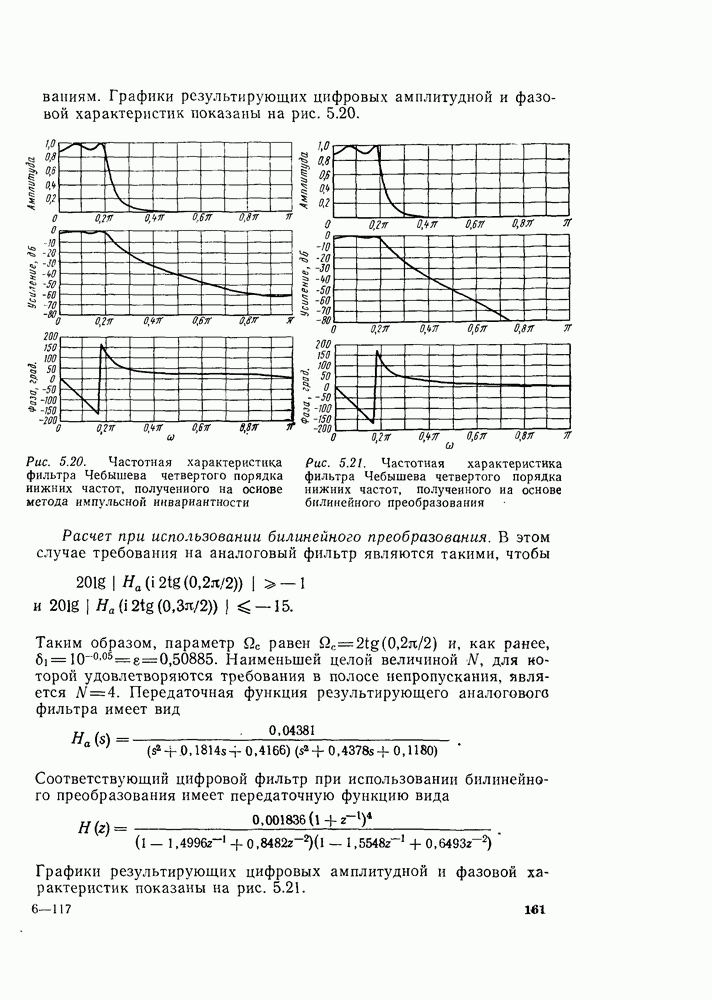
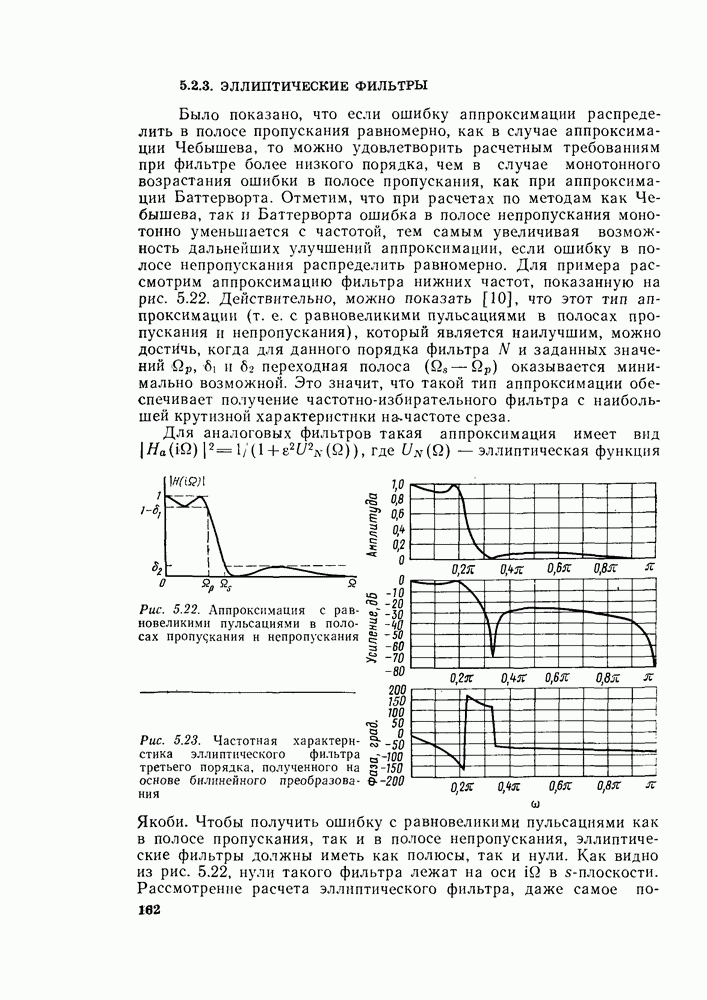
6.2.1. ВЫЧИСЛЕНИЯ С ЗАМЕЩЕНИЕМГраф вычислений, изображенный на рис. 6.7, ойисывает алгоритм вычисления дискретного преобразования Фурье. В графе на рис. 6.7 важны ветви, соединяющие узлы, и передачи каждой ветви. Как бы не были переставлены узлы в этом графе, он всегда будет представлять одно и то же вычисление при условии, что соединения между узлами и передачи этих соединений остаются прежними. Частный вид графа, изображенного на рис. 6.7, появился в результате вывода алгоритма путем разделения исходной последовательности на четные и нечетные точки, а затем получения все более мелких подпоследовательностей аналогичным образом. Интересным промежуточным результатом этого вывода является то, что граф рис. 6.7 вдобавок к описанию эффективной процедуры вычисления дискретного преобразования Фурье предлагает полезный способ запоминания исходных данных и результатов вычислений в промежуточных массивах. Чтобы убедиться в этом, полезно отметить, что согласно рис. 6.7 на каждой ступени вычислений происходит преобразование множества из
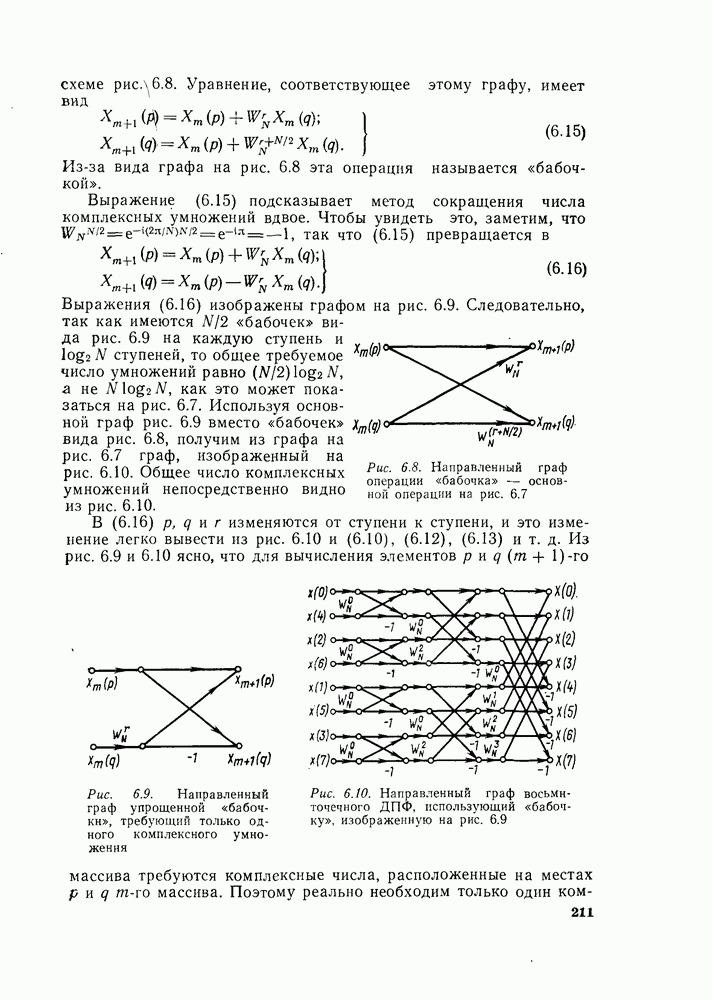
Используя эту запись и это упорядочение, можно видеть, что основным вычислением в графе на рис. 6.7 является вычисление по схеме рис. 6.8. Уравнение, соответствующее этому графу, имеет вид
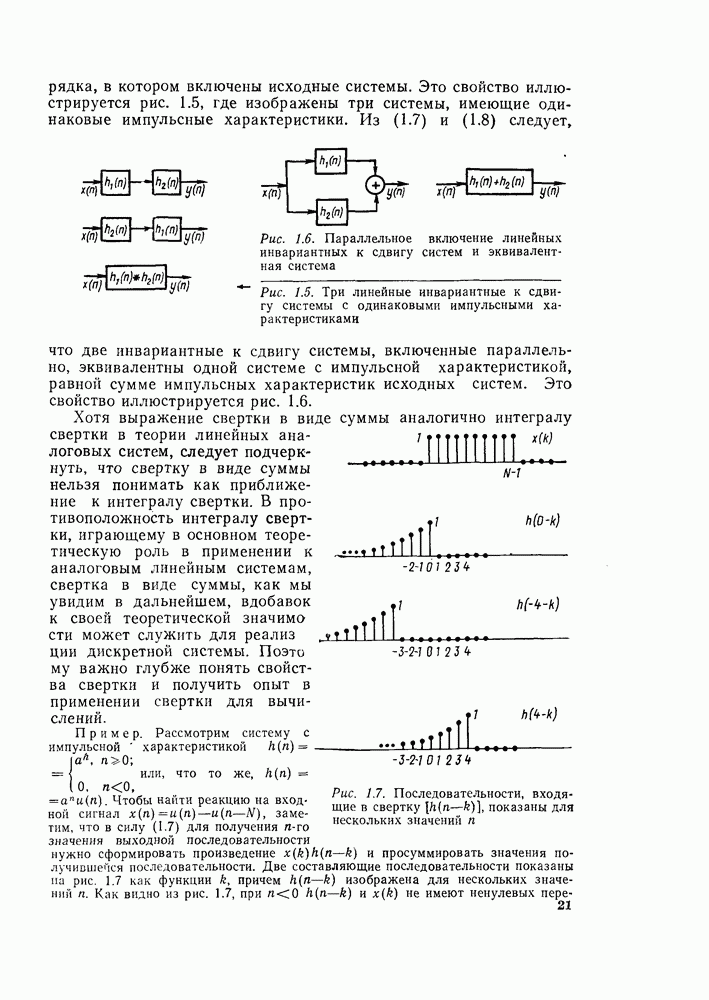
Из-за вида графа на рис. 6.8 эта операция называется «бабочкой». Выражение (6.15) подсказывает метод сокращения числа комплексных умножений вдвое. Чтобы увидеть это, заметим, что
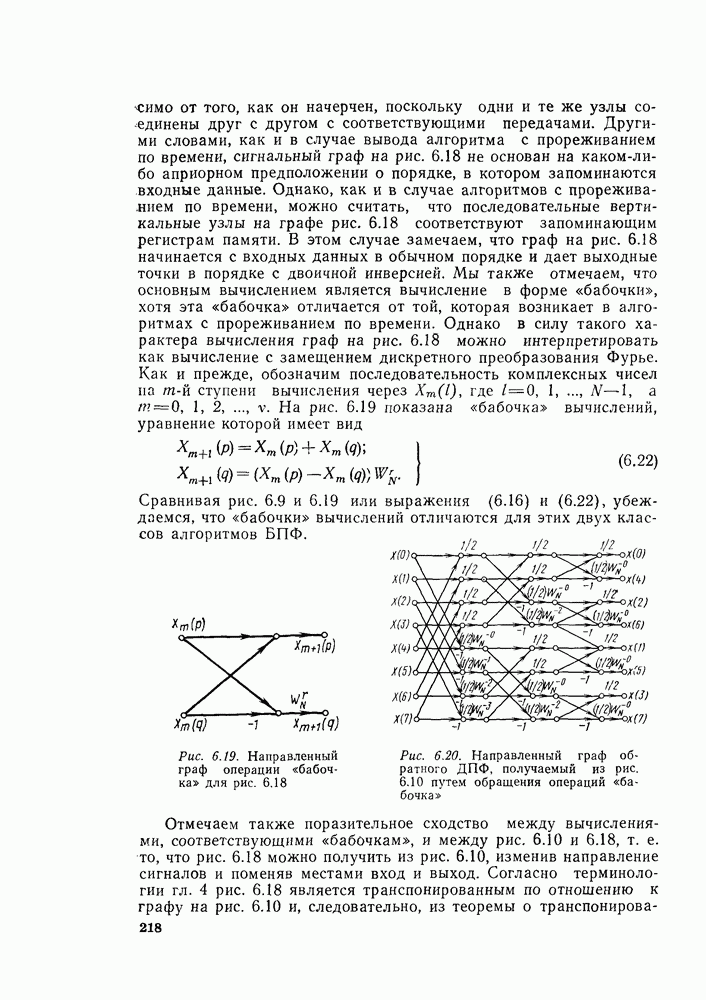
Выражения (6.16) изображены графом на рис. 6.9. Следовательно, так как имеются В (6.16)
Рис. 6.8. Направленный граф операции «бабочка» — основной операции на рис. 6.7
Рис. 6.9. Направленный граф упрощенной «бабочки», требующий только одного комплексного умножения
Рис. 6.10. Направленный граф восьмиточечного ДПФ, использующий «бабочку», изображенную на рис. 6.9 Из рис. 6.9 и 6.10 ясно, что для вычисления элементов комплексный массив из Чтобы вычисления выполнялись так, как сказано выше, входные данные должны быть записаны в необычном порядке, который называется двоичной инверсией. Чтобы понять смысл этой терминологии, заметим, что для рассматриваемого восьмиточечного графа требуются три двоичные цифры для нумерации данных. Если мы запишем индексы в (6.14) в двоичной форме, получим
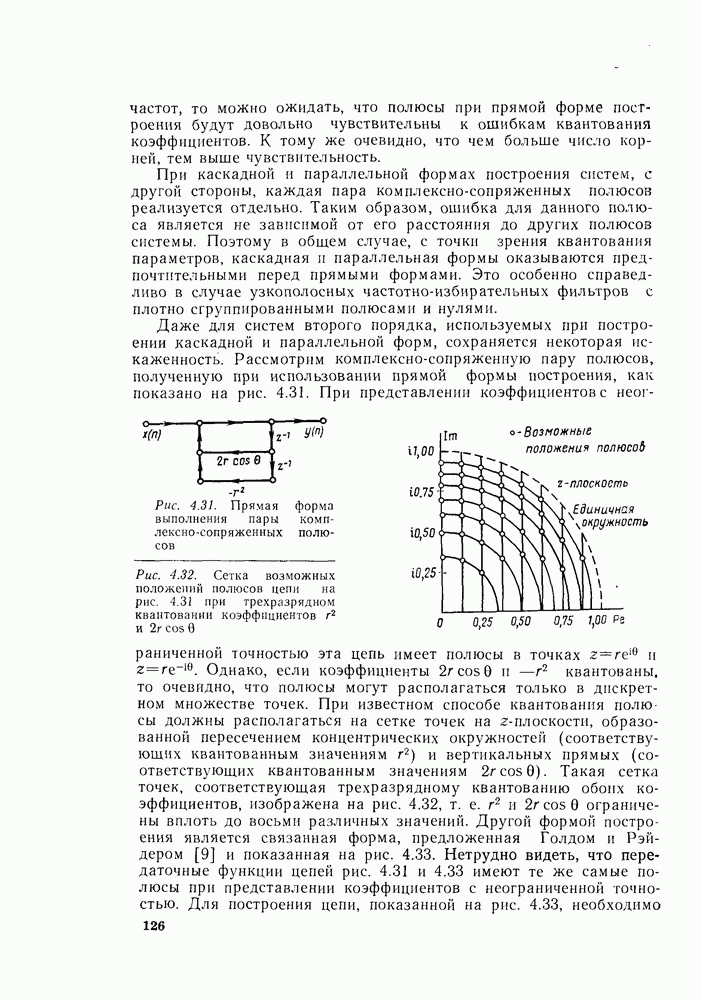
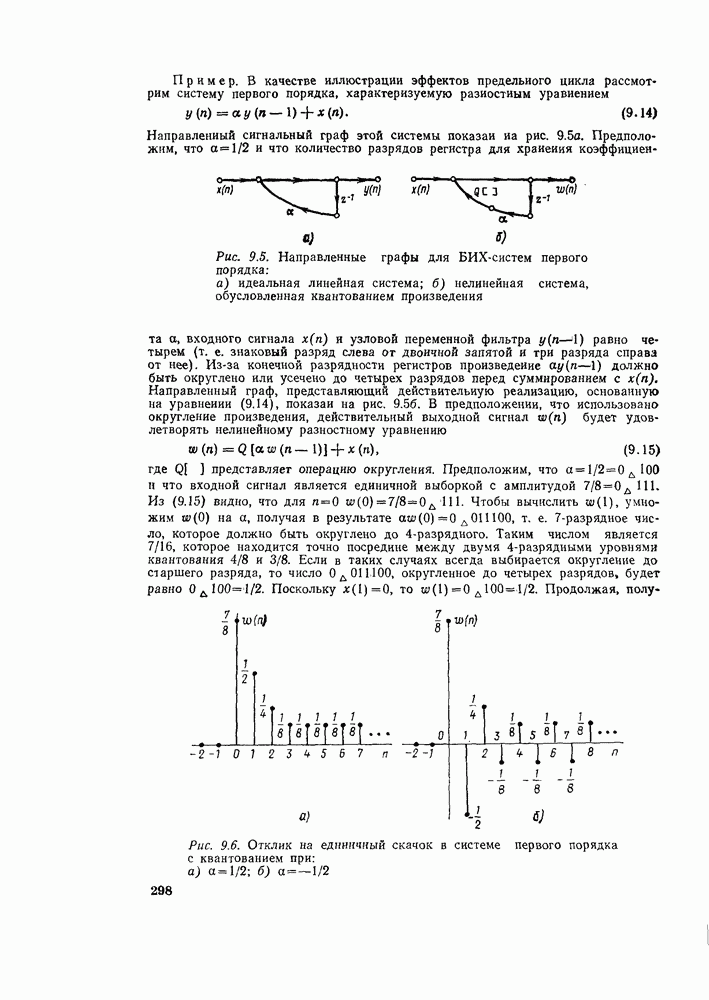
Если Понять, почему для алгоритма с замещением необходима двоичная инверсия, можно, если вспомнить процесс, который привел к алгоритму, изображенному на рис. 6.7. Последовательность
Рис. 6.11. Дерево, изображающее двоичную инверсию сделать, рассматривая второй разряд в индексе. Рассматривая сначала подпоследовательность с четными номерами, убеждаемся, что если второй разряд равен 0, то значение соответствует четному числу этой подпоследовательности, а если второй разряд равен 1, то — нечетному. Тот же процесс проводится и для подпоследовательности, сформированной из нечетных членов исходной подпоследовательности. Этот процесс повторяется до тех пор, пока не получится N подпоследовательностей длины 1. Эта сортировка на четные и нечетные подпоследовательности изображена на рис. 6.11. Таким образом, необходимость упорядочения последовательности
|
 |
Оглавление
|






















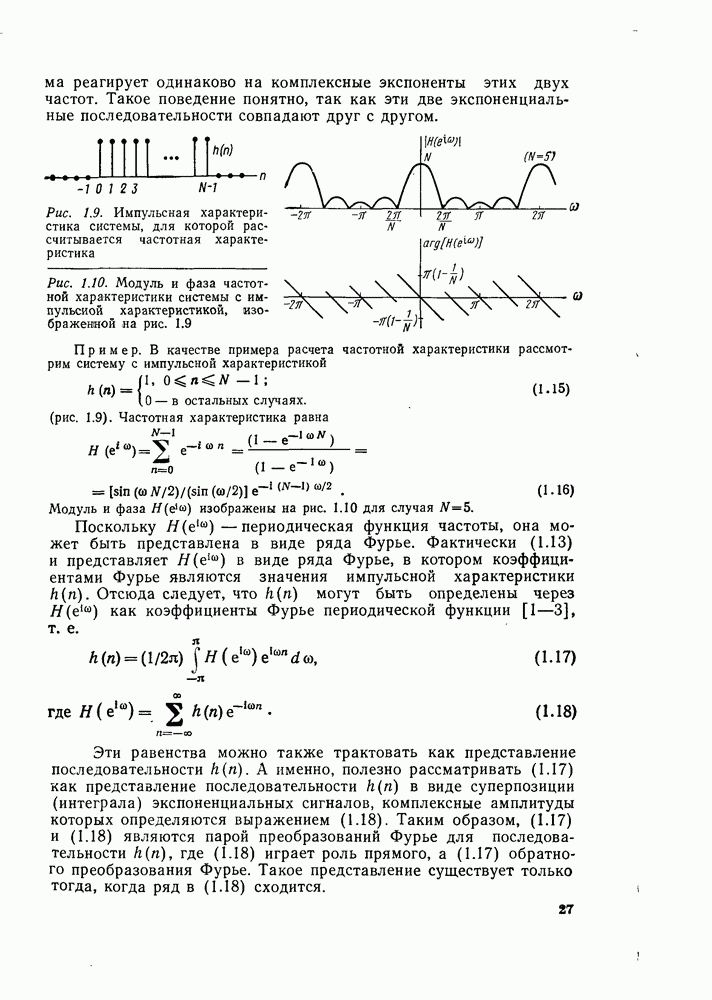









































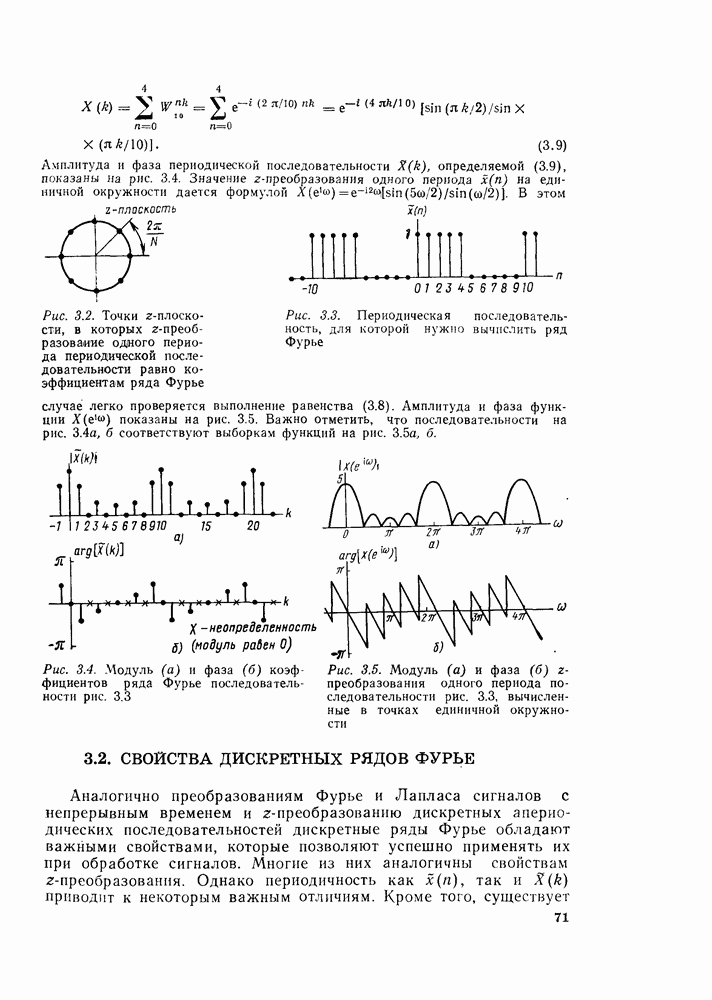






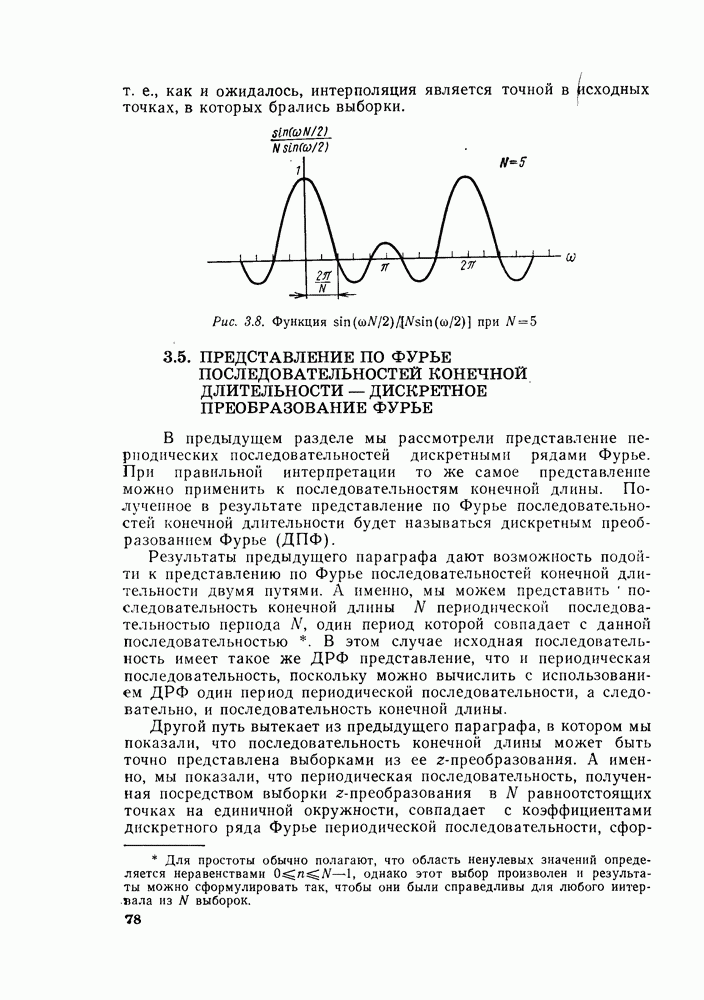


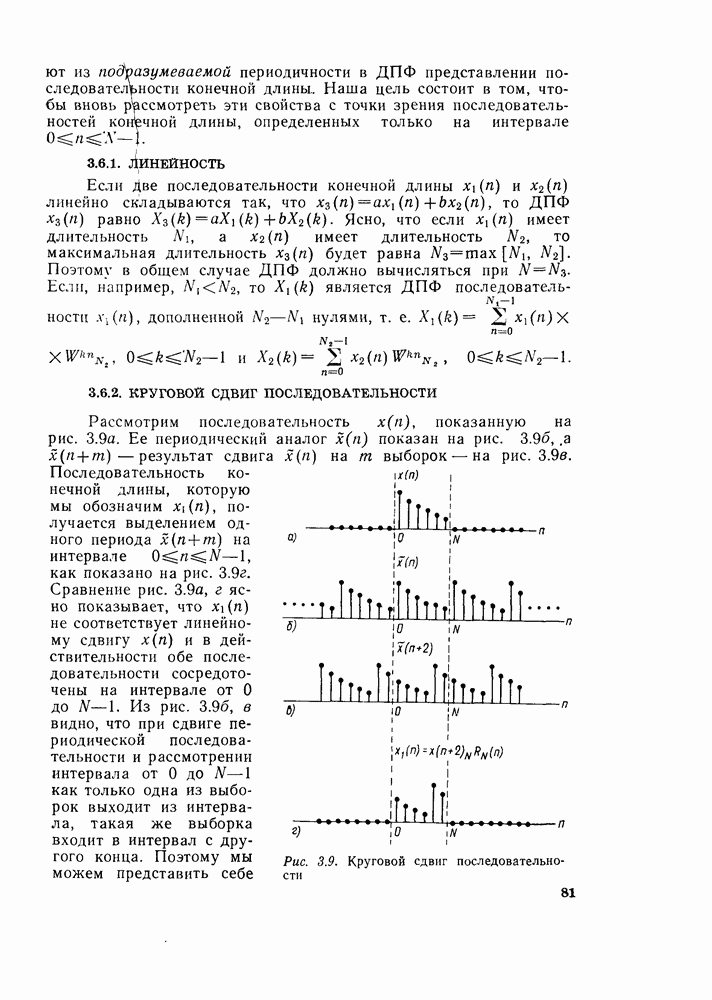




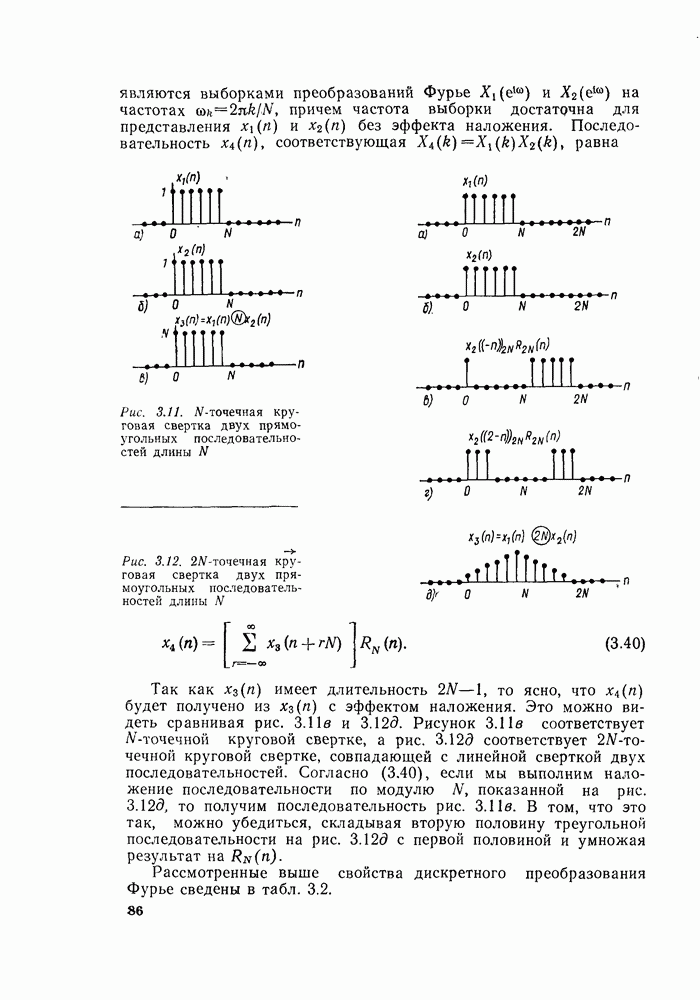




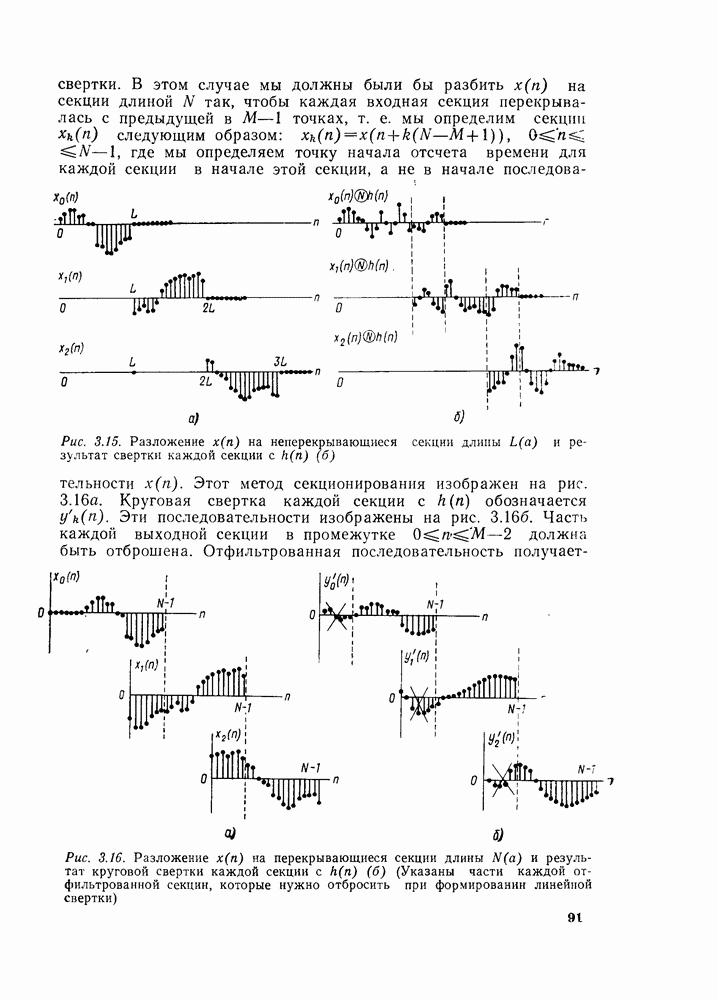









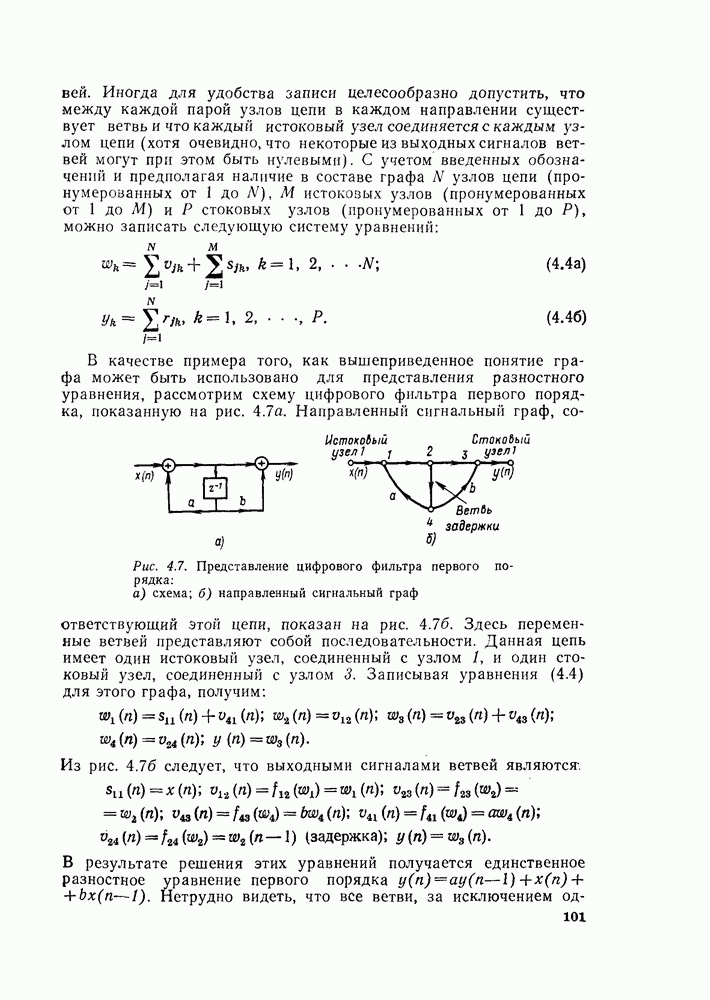










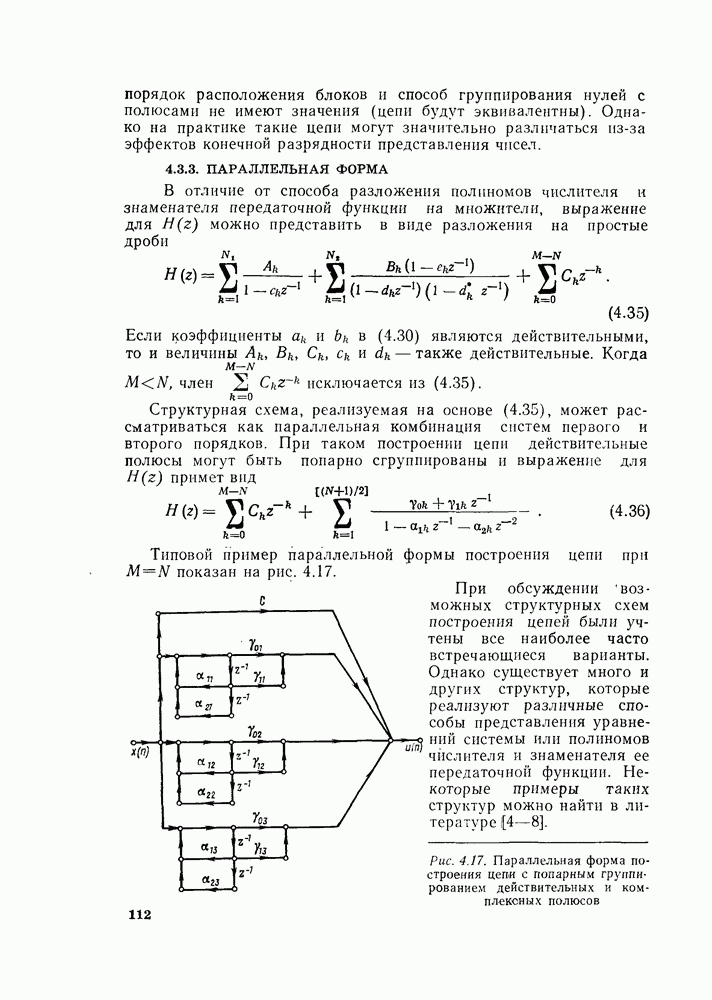







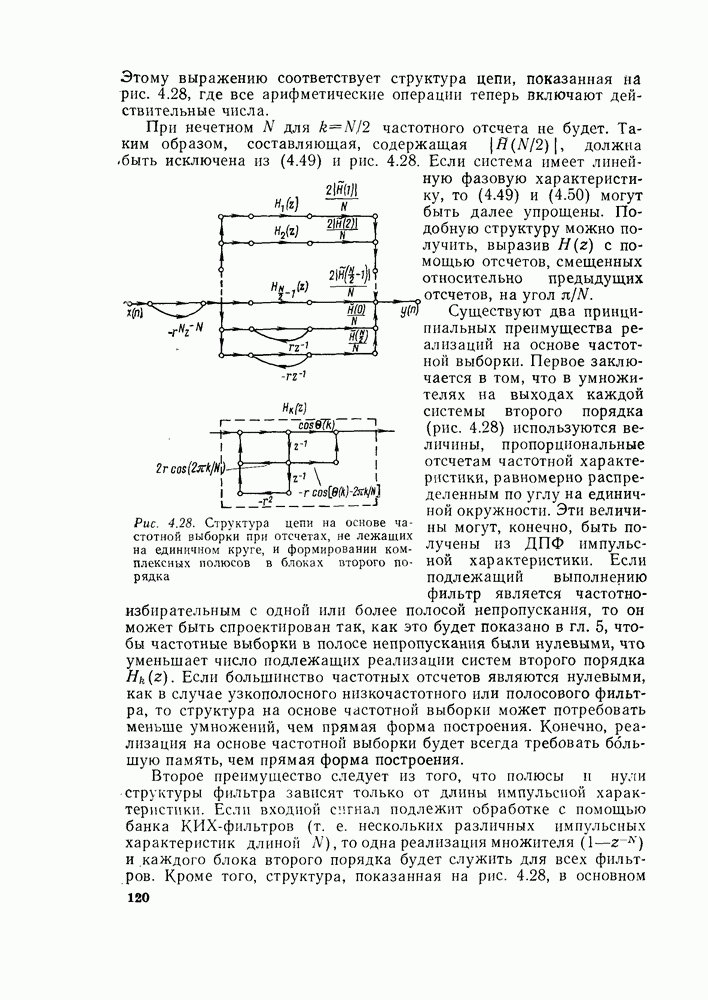






































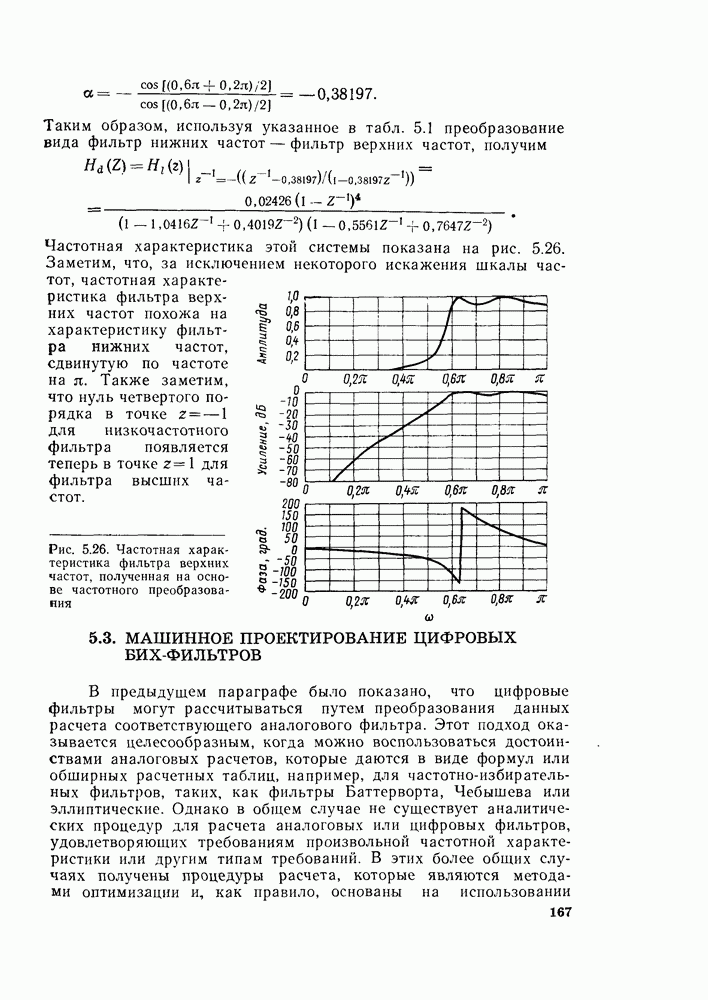



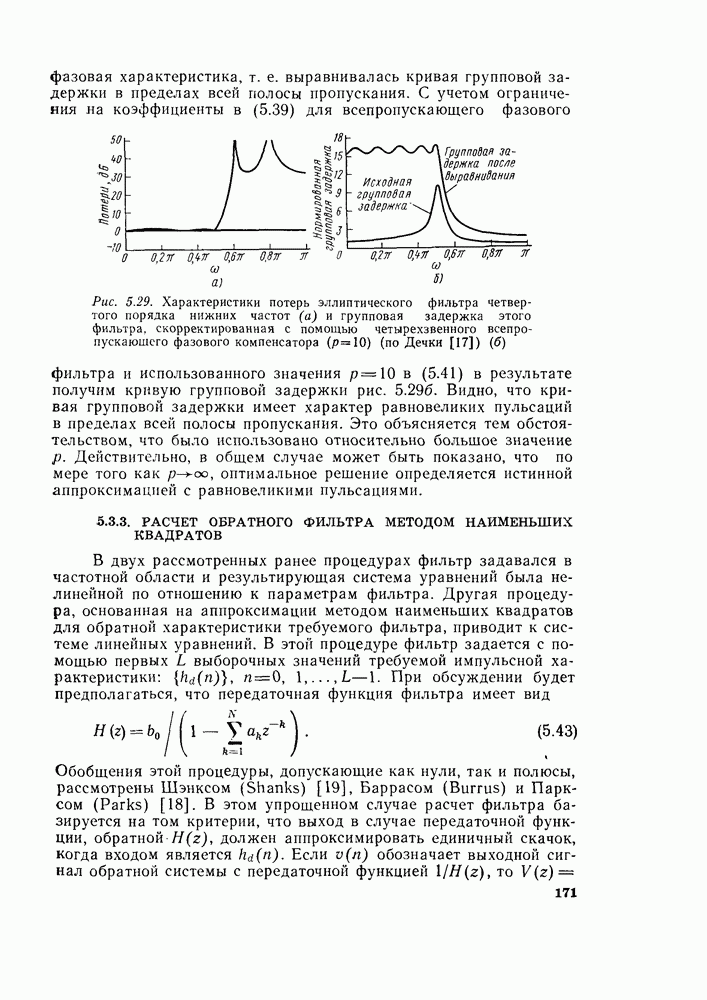



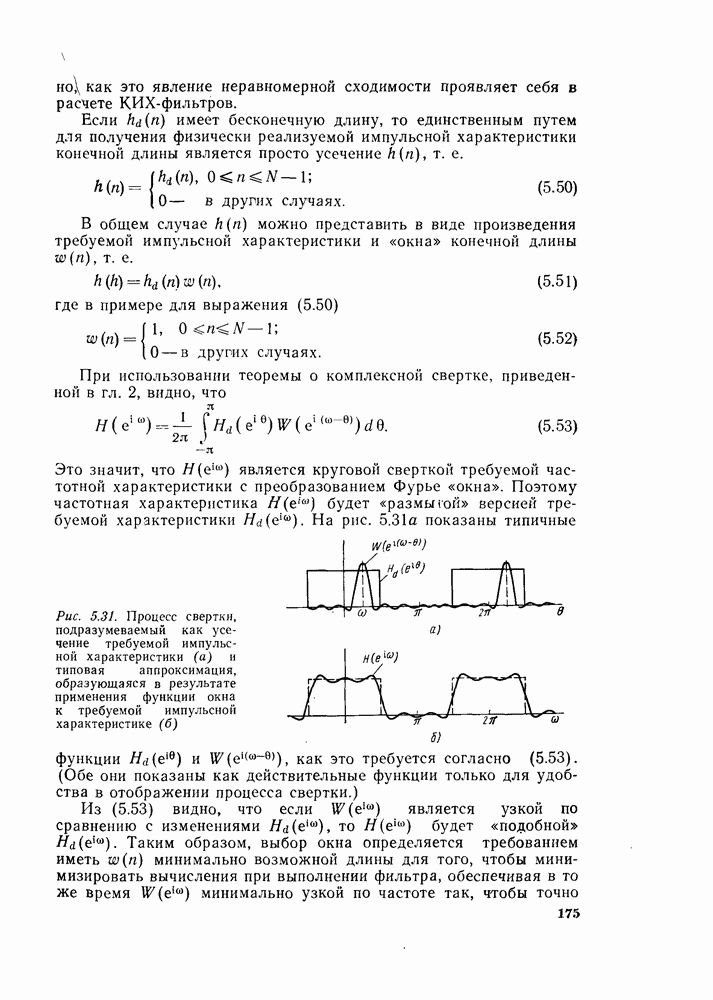
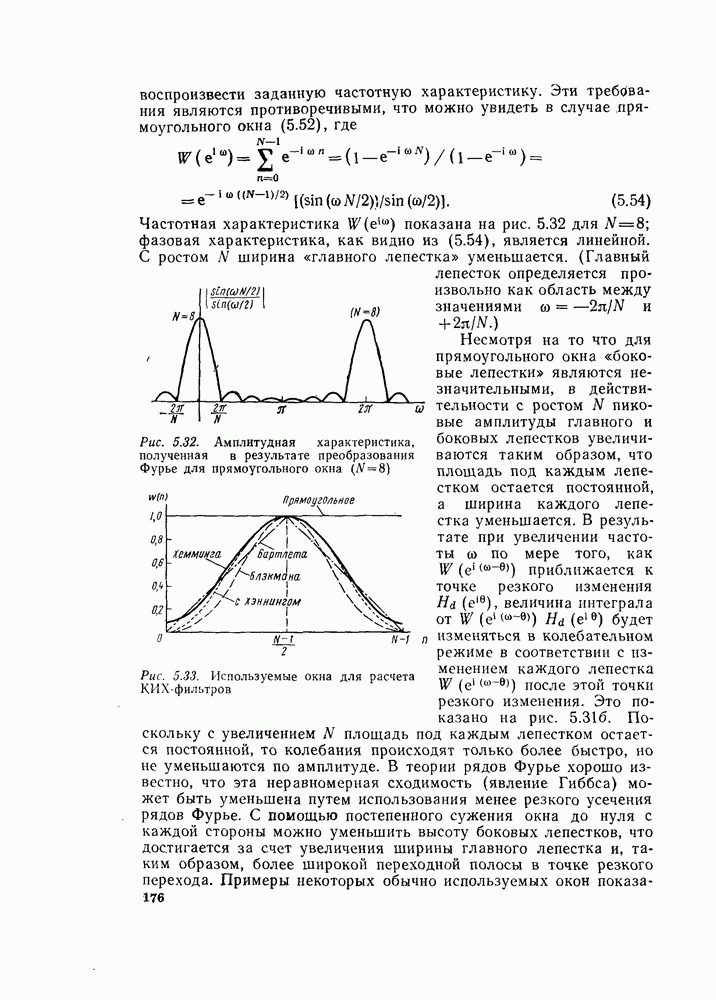

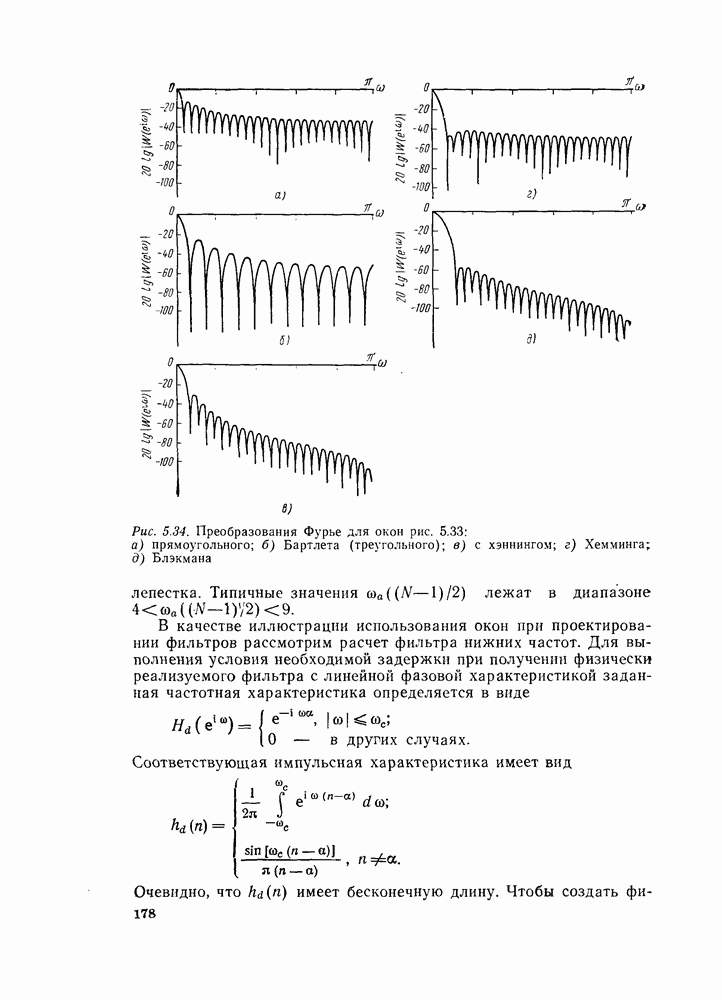
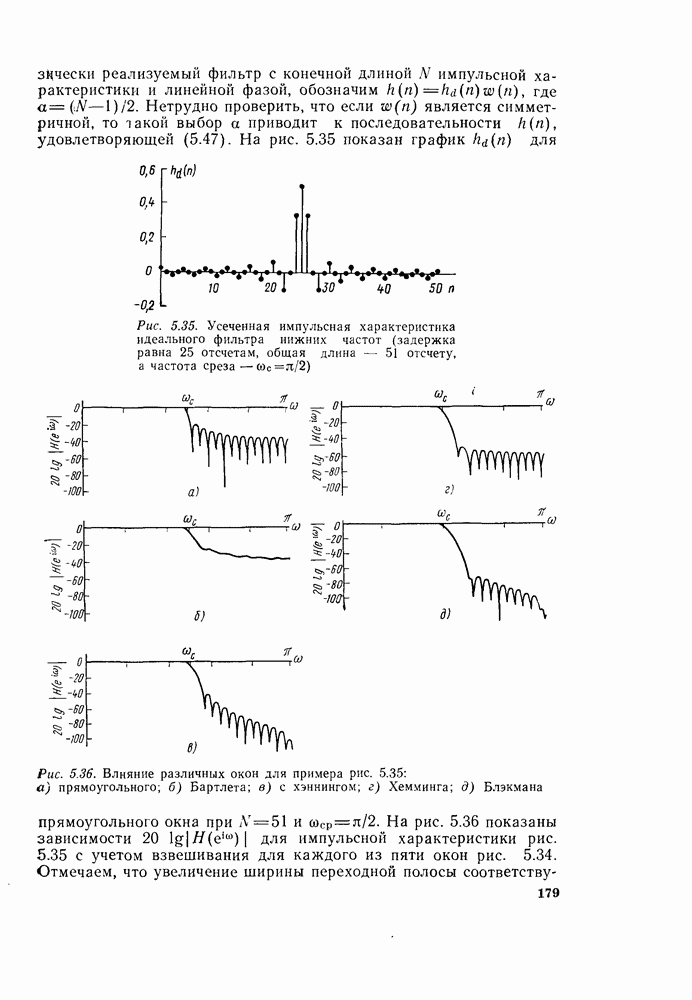
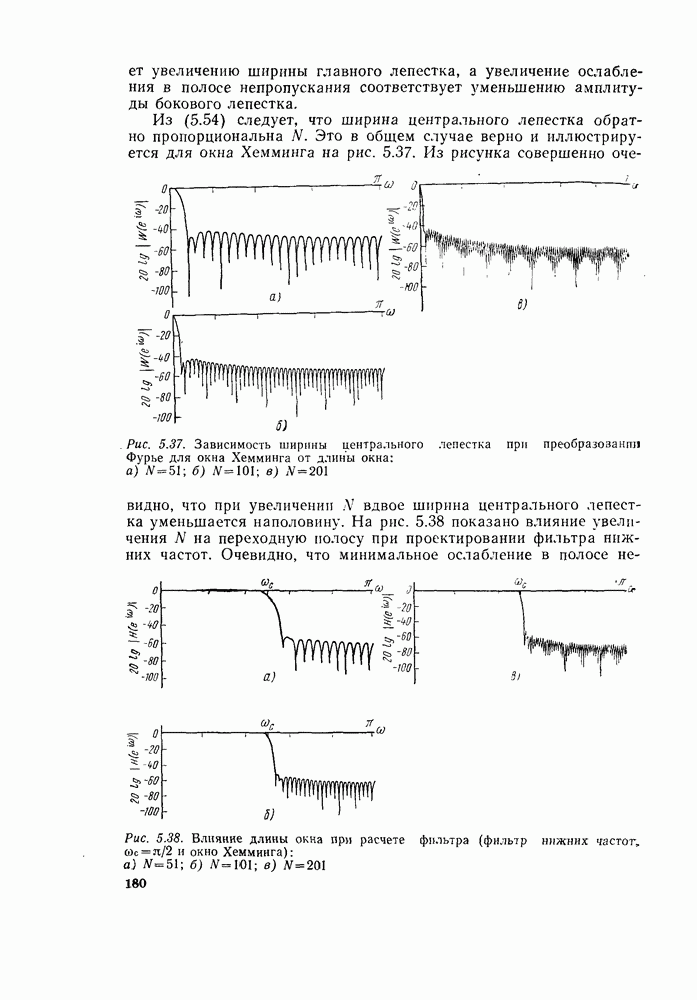



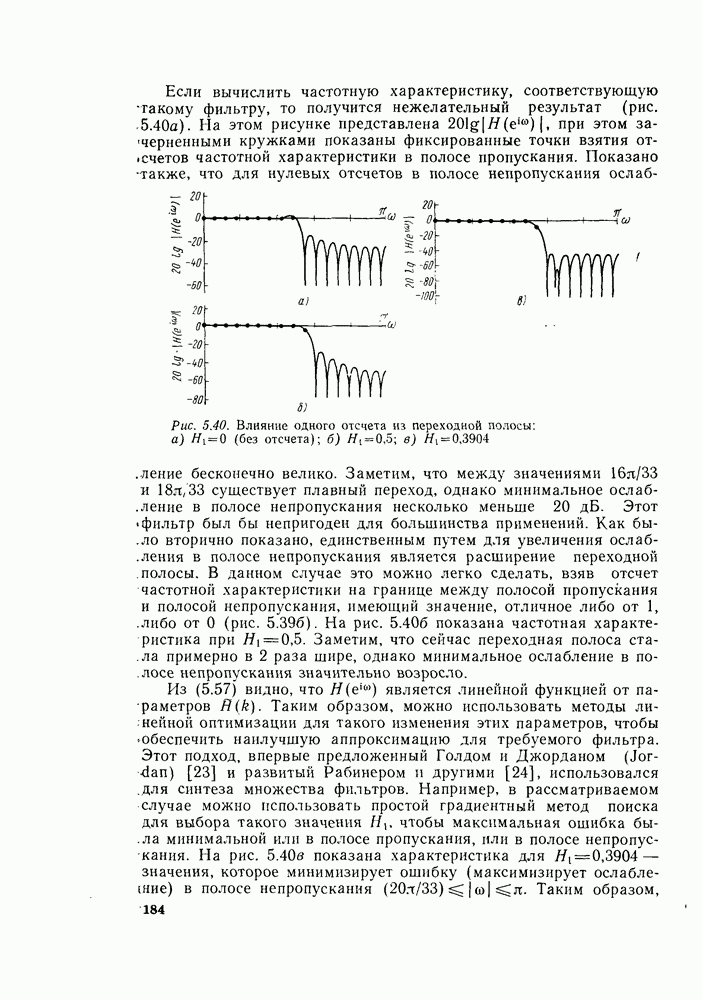
















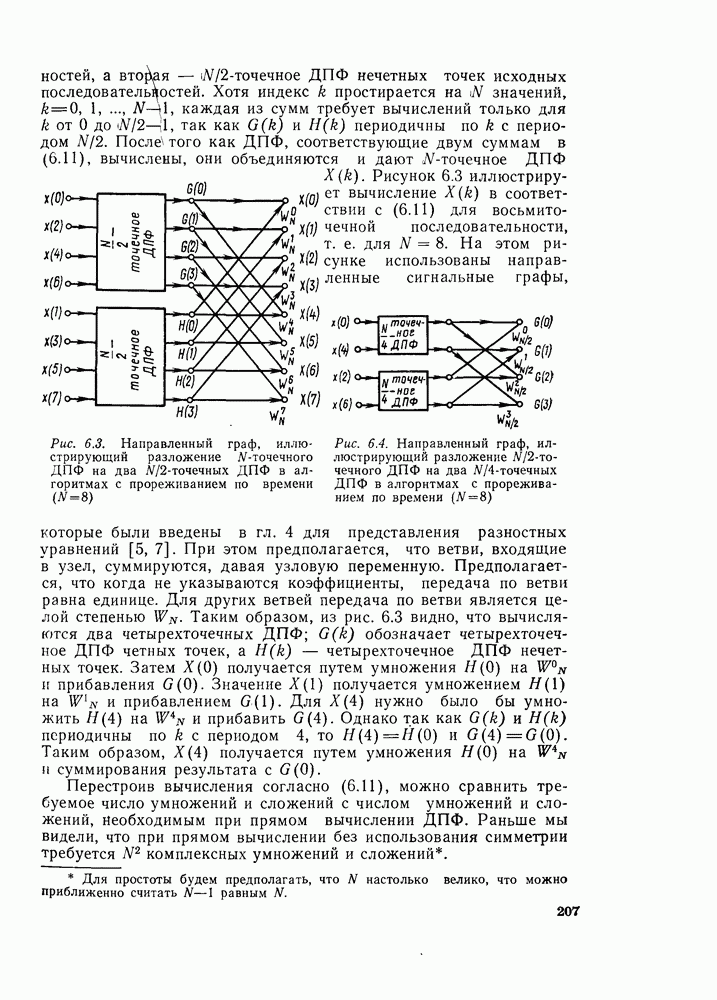







































































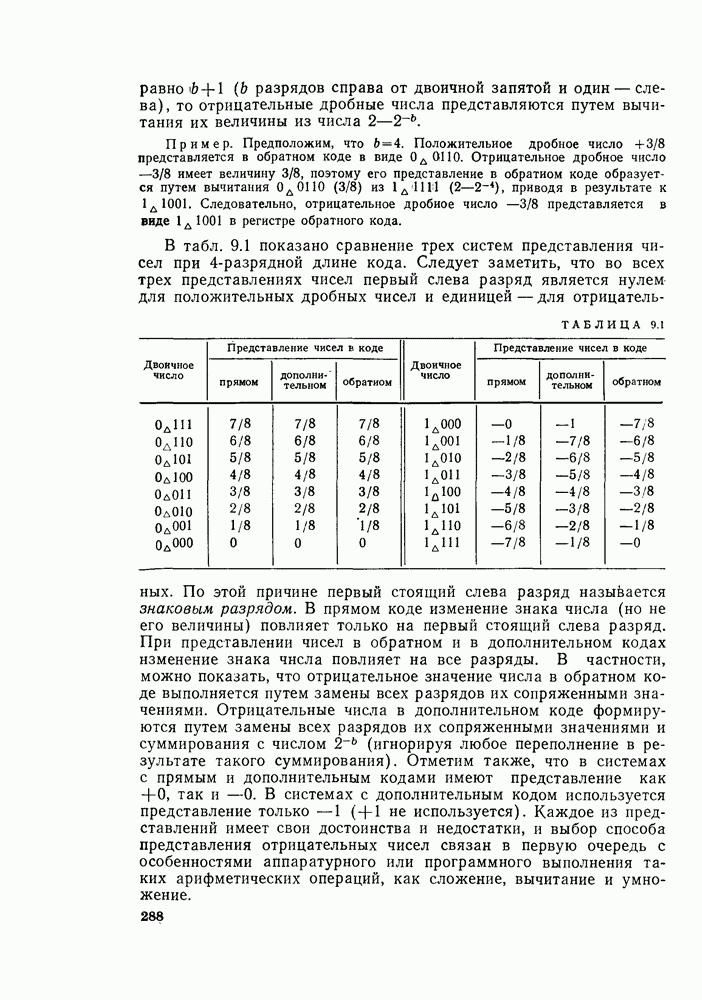


















































































































 комплексных чисел в другое множество из
комплексных чисел в другое множество из  комплексных чисел. Этот процесс повторяется
комплексных чисел. Этот процесс повторяется  раз, давая в результате дискретное преобразование Фурье. При конкретных вычислениях согласно рис. 6.7 можно использовать два массива (комплексных) запоминающих регистров: один — для вычисленных данных, а другой — для данных, используемых для вычислений. Например, при вычислении первого массива согласно рис. 6.7 одно множество запоминающих регистров содержало бы входные данные, а второе множество запоминающих регистров — результаты первой стадии вычислений. Несмотря на то что граф на рис. 6.7 не связан с порядком, в котором запоминаются входные данные, упорядочим множество комплексных чисел так, как они появляются на рис. 6.7 (сверху вниз). Обозначим последовательность комплексных чисел, получающихся на
раз, давая в результате дискретное преобразование Фурье. При конкретных вычислениях согласно рис. 6.7 можно использовать два массива (комплексных) запоминающих регистров: один — для вычисленных данных, а другой — для данных, используемых для вычислений. Например, при вычислении первого массива согласно рис. 6.7 одно множество запоминающих регистров содержало бы входные данные, а второе множество запоминающих регистров — результаты первой стадии вычислений. Несмотря на то что граф на рис. 6.7 не связан с порядком, в котором запоминаются входные данные, упорядочим множество комплексных чисел так, как они появляются на рис. 6.7 (сверху вниз). Обозначим последовательность комплексных чисел, получающихся на  ступени вычисления, через
ступени вычисления, через  где
где  Кроме того, для удобства обозначим множество входных выборок через
Кроме того, для удобства обозначим множество входных выборок через  Можно считать
Можно считать  входным массивом,
входным массивом,  (О выходным массивом на m + 1-й ступени вычислений. Таким образом, для случая
(О выходным массивом на m + 1-й ступени вычислений. Таким образом, для случая  , как показано на рис. 6.7,
, как показано на рис. 6.7,


 так что (6.15) превращается в
так что (6.15) превращается в

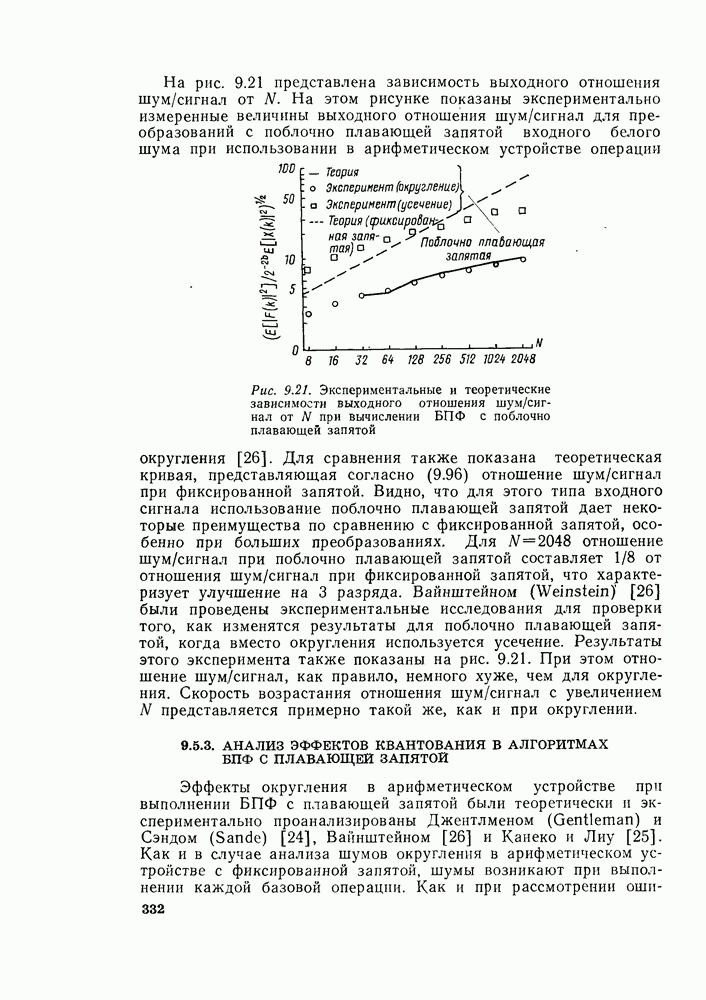
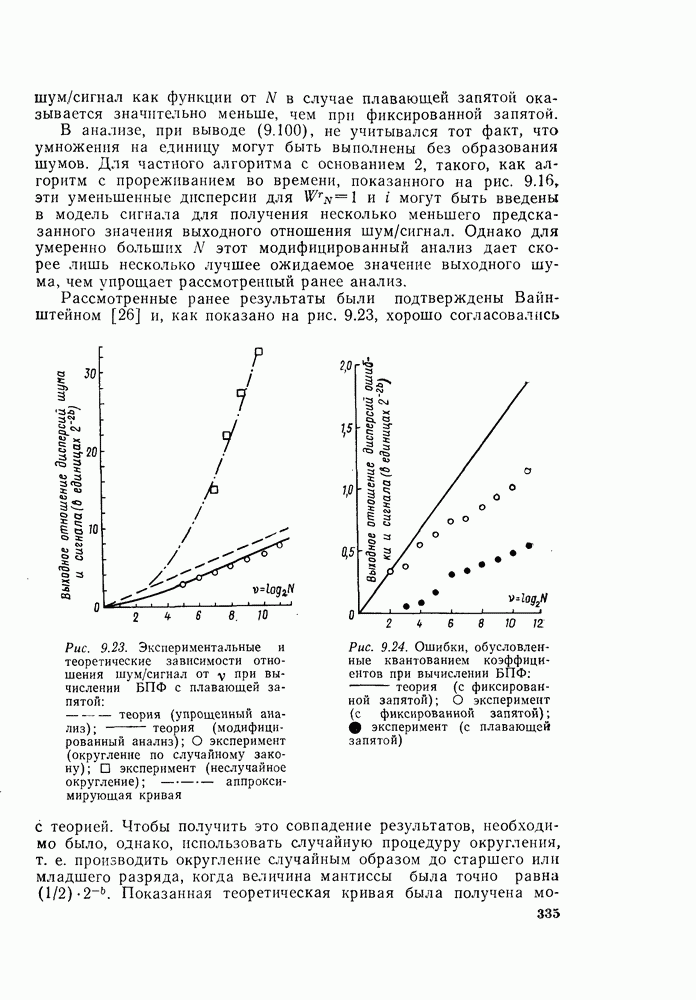
 «бабочек» вида рис. 6.9 на каждую ступень и
«бабочек» вида рис. 6.9 на каждую ступень и  ступеней, то общее требуемое число умножений равно
ступеней, то общее требуемое число умножений равно  а не
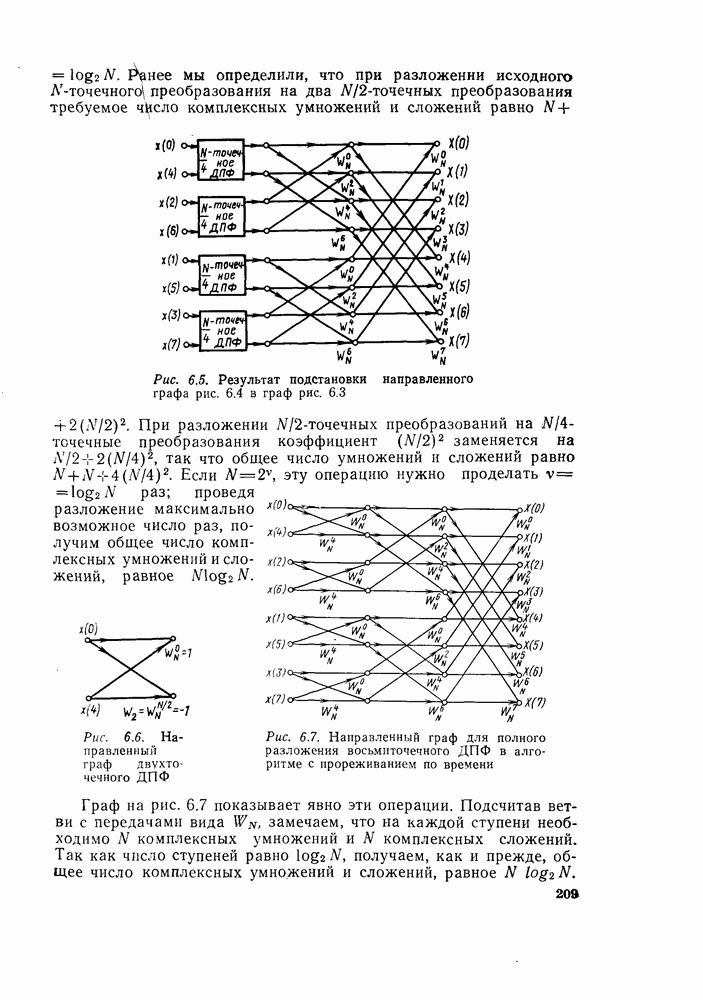
а не  как это может показаться на рис. 6.7. Используя основной граф рис. 6.9 вместо «бабочек» вида рис. 6.8, получим из графа на рис. 6.7 граф, изображенный на рис. 6.10. Общее число комплексных умножений непосредственно видно из рис. 6.10.
как это может показаться на рис. 6.7. Используя основной граф рис. 6.9 вместо «бабочек» вида рис. 6.8, получим из графа на рис. 6.7 граф, изображенный на рис. 6.10. Общее число комплексных умножений непосредственно видно из рис. 6.10.
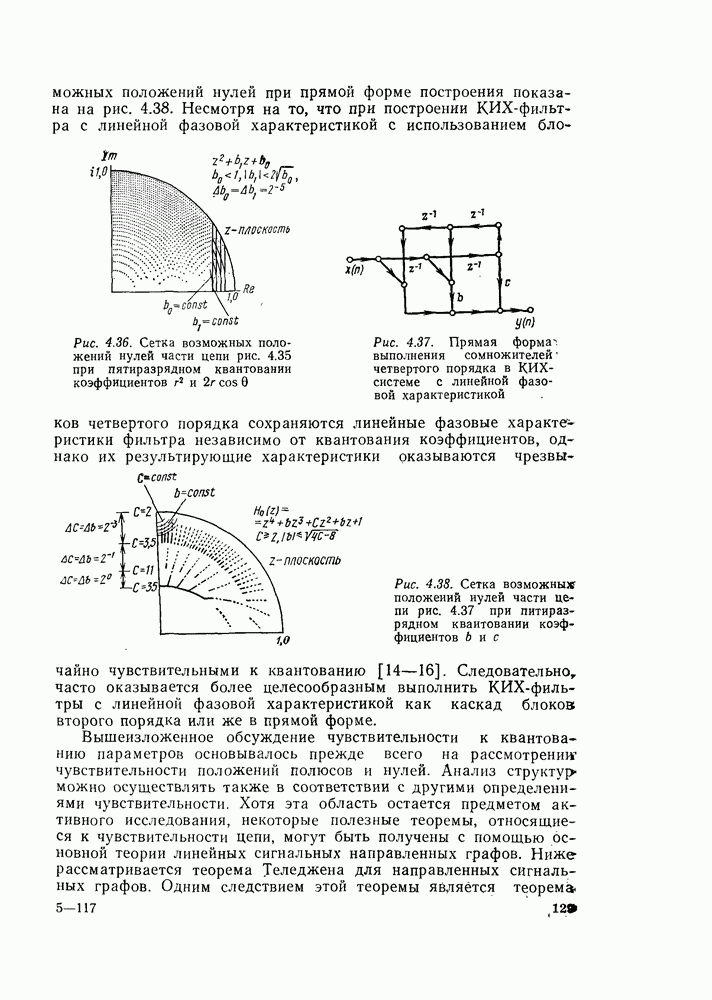
 изменяются от ступени к ступени, и это изменение легко вывести из рис. 6.10 и (6.10), (6.12), (6.13) и т. д.
изменяются от ступени к ступени, и это изменение легко вывести из рис. 6.10 и (6.10), (6.12), (6.13) и т. д.



 массива требуются комплексные числа, расположенные на местах
массива требуются комплексные числа, расположенные на местах  массива. Поэтому реально необходим только один
массива. Поэтому реально необходим только один
 запоминающих регистров для того, чтобы выполнять вычисления, если запоминать
запоминающих регистров для того, чтобы выполнять вычисления, если запоминать  в тех же самых запоминающих регистрах, что и
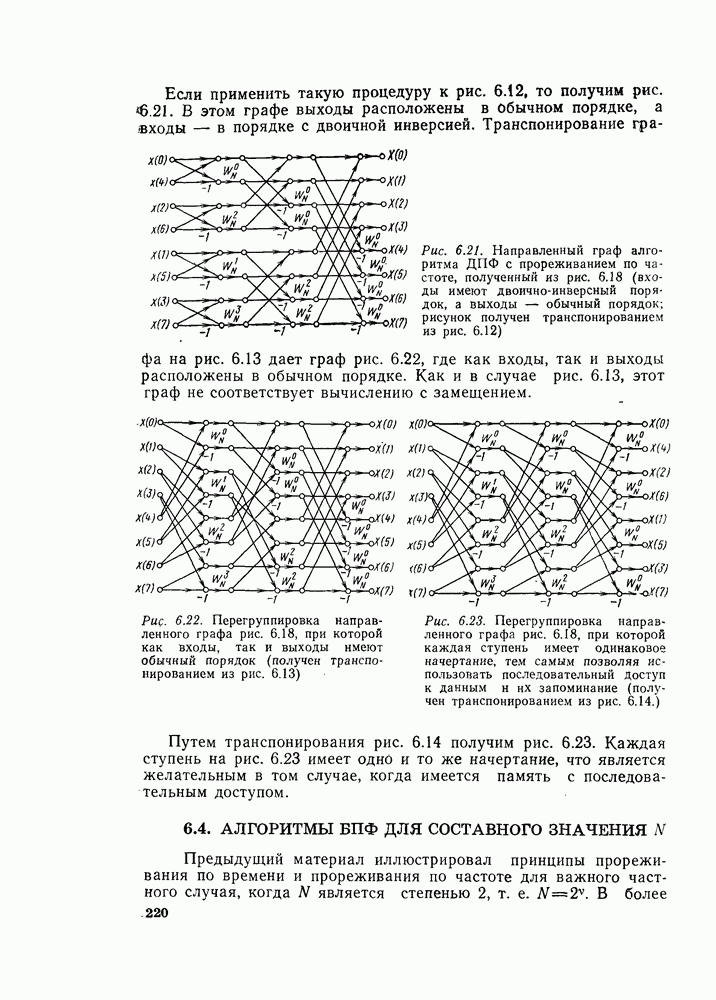
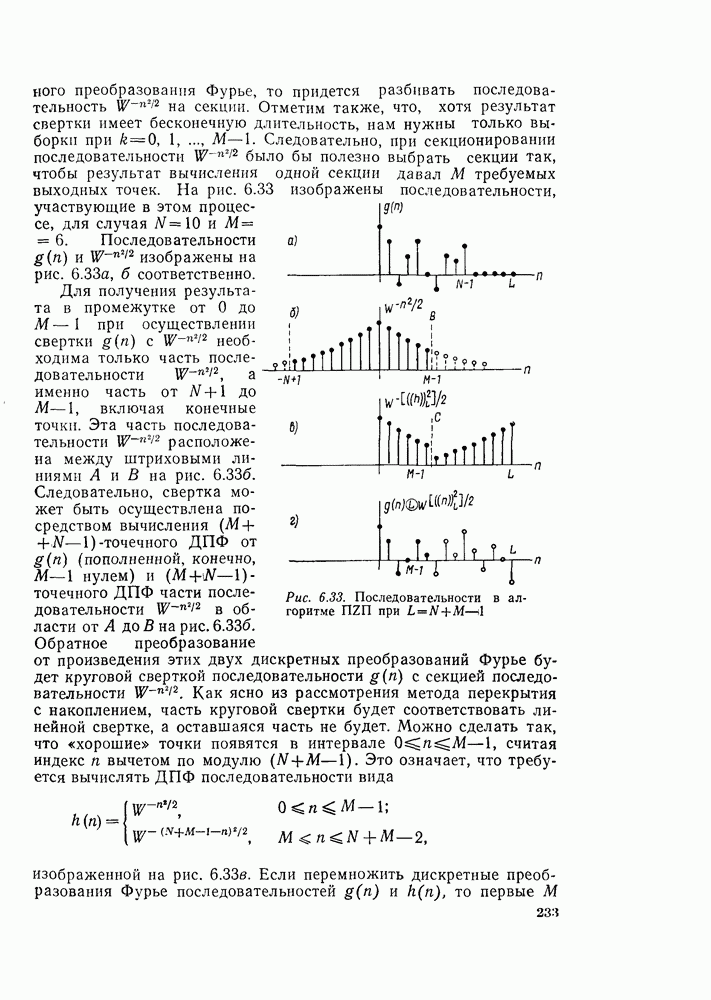
в тех же самых запоминающих регистрах, что и  соответственно. Этот тип вычисления обычно называется вычислением «с замещением». Преимуществом его является то, что результаты вычисления нового массива могут быть записаны в те же самые запоминающие ячейки, что и исходный массив. Графы на рис. 6.7 и 6.9 представляют вычисление с замещением, при этом мы связали узлы графа, находящиеся на одной горизонтальной линии, с одной и той же ячейкой памяти. Вычисления между двумя массивами состоят из операций «бабочка», в которой входные и выходные узлы на одной горизонтали примыкают друг к другу.
соответственно. Этот тип вычисления обычно называется вычислением «с замещением». Преимуществом его является то, что результаты вычисления нового массива могут быть записаны в те же самые запоминающие ячейки, что и исходный массив. Графы на рис. 6.7 и 6.9 представляют вычисление с замещением, при этом мы связали узлы графа, находящиеся на одной горизонтальной линии, с одной и той же ячейкой памяти. Вычисления между двумя массивами состоят из операций «бабочка», в которой входные и выходные узлы на одной горизонтали примыкают друг к другу.


 — двоичное представление номеров последовательности
— двоичное представление номеров последовательности  то элемент последовательности
то элемент последовательности  запоминается в массиве на месте
запоминается в массиве на месте  Это означает, что при определении положения
Это означает, что при определении положения  во входном массиве нужно заменить порядок двоичных разрядов индекса
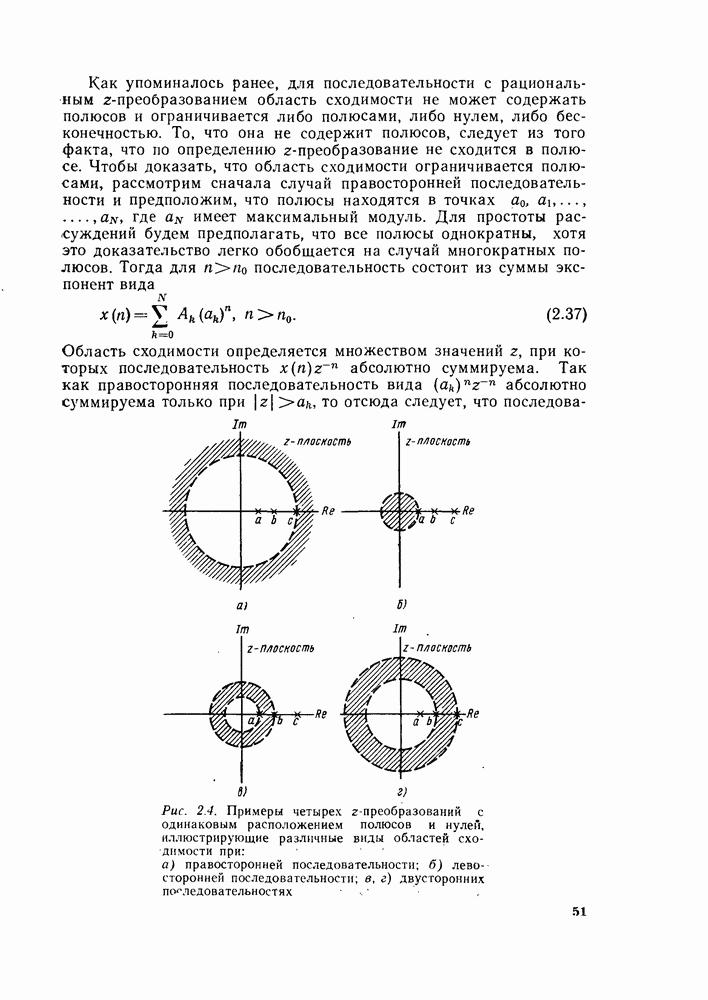
во входном массиве нужно заменить порядок двоичных разрядов индекса  на обратный.
на обратный.
 была сначала разделена на четные и нечетные выборки, причем четные выборки появились в верхней половине рис. 6.3, а нечетные — в нижней. Формально такое разделение данных можно провести путем рассмотрения младшего разряда
была сначала разделена на четные и нечетные выборки, причем четные выборки появились в верхней половине рис. 6.3, а нечетные — в нижней. Формально такое разделение данных можно провести путем рассмотрения младшего разряда  в индексе
в индексе  Если этот младший разряд равен 0, то значение последовательности соответствует выборке с четным номером и, следовательно, появится в верхней половине, а если младший разряд равен 1, значение последовательности соответствует выборке с нечетным номером и, следовательно, появится в нижней половине массива
Если этот младший разряд равен 0, то значение последовательности соответствует выборке с четным номером и, следовательно, появится в верхней половине, а если младший разряд равен 1, значение последовательности соответствует выборке с нечетным номером и, следовательно, появится в нижней половине массива  Затем четные и нечетные подпоследовательности, в свою очередь, сортируются на четные и нечетные части, и это можно
Затем четные и нечетные подпоследовательности, в свою очередь, сортируются на четные и нечетные части, и это можно

 в соответствии с инверсией разрядов является результатом способа разложения ДПФ исходной последовательности на ДПФ последовательностей меньшей длины.
в соответствии с инверсией разрядов является результатом способа разложения ДПФ исходной последовательности на ДПФ последовательностей меньшей длины.