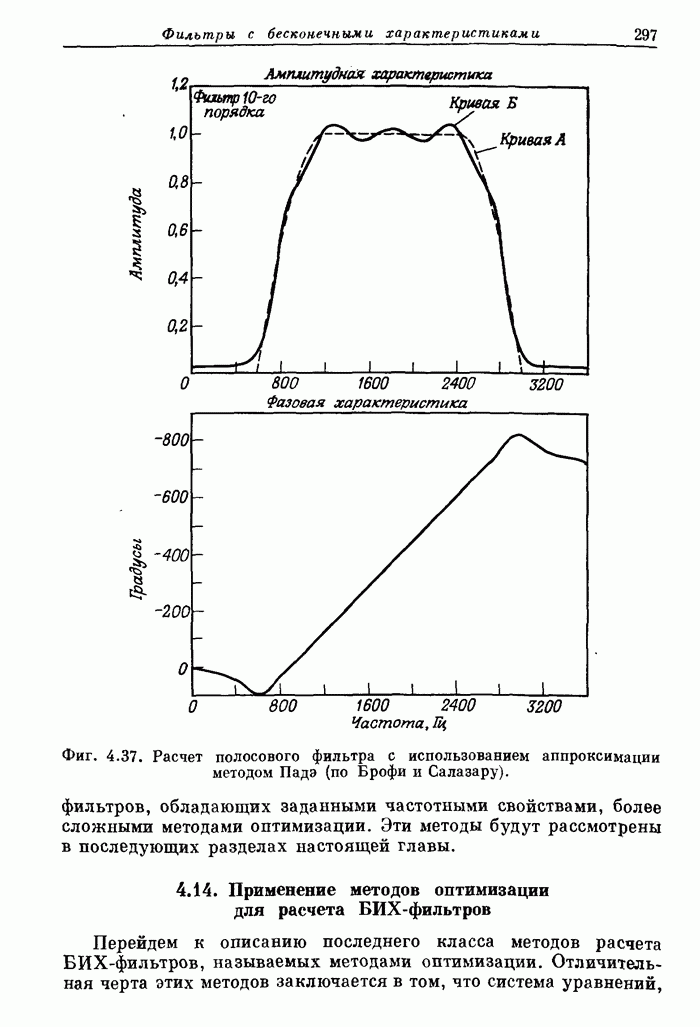
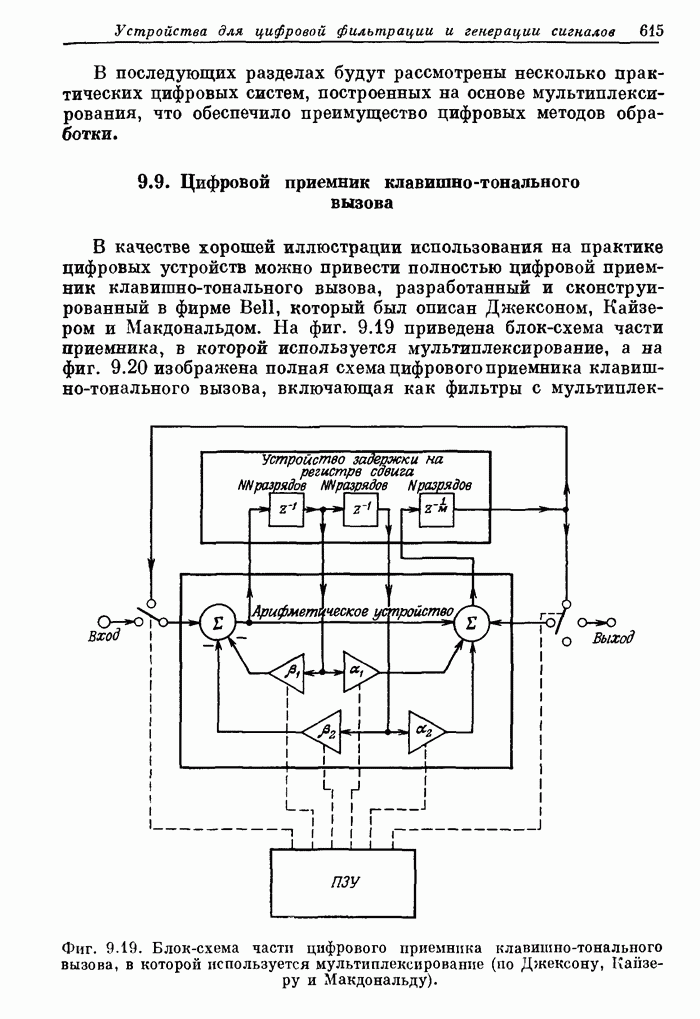
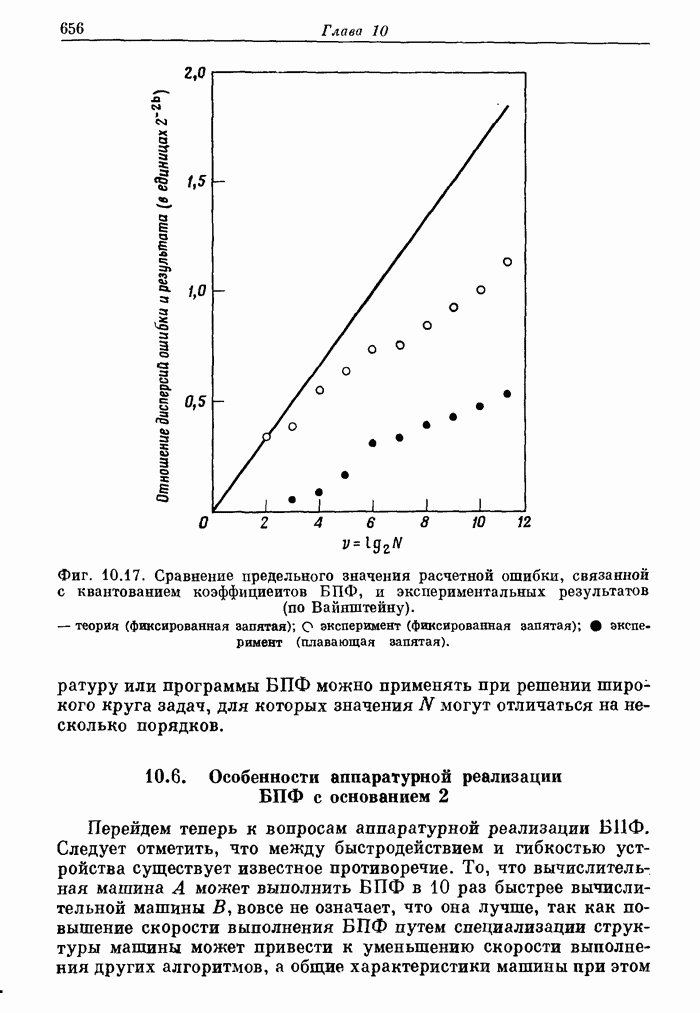
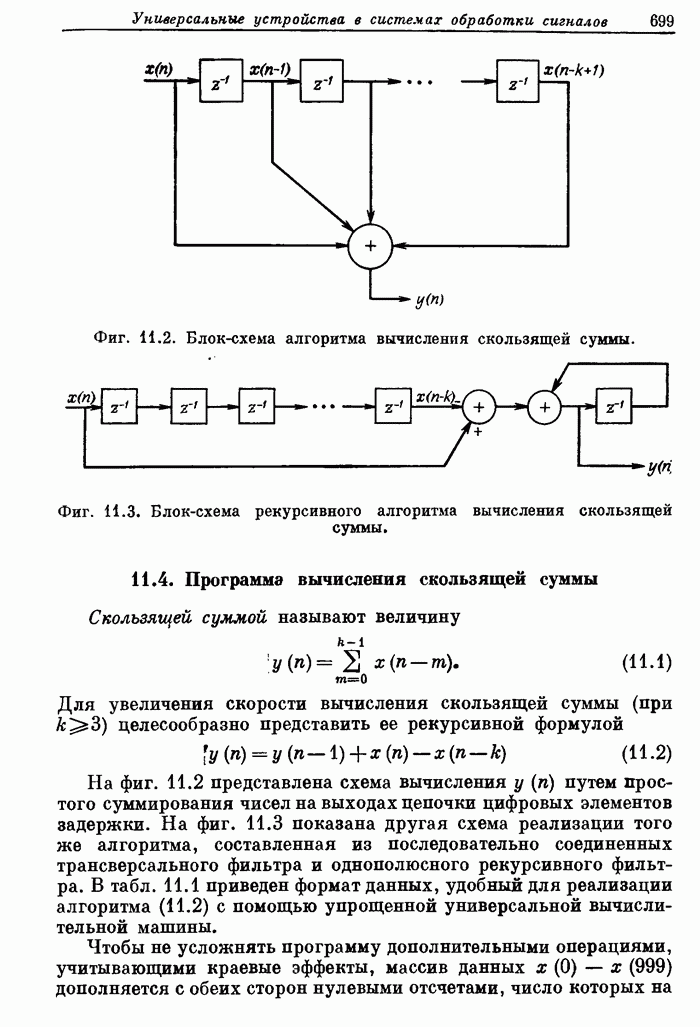
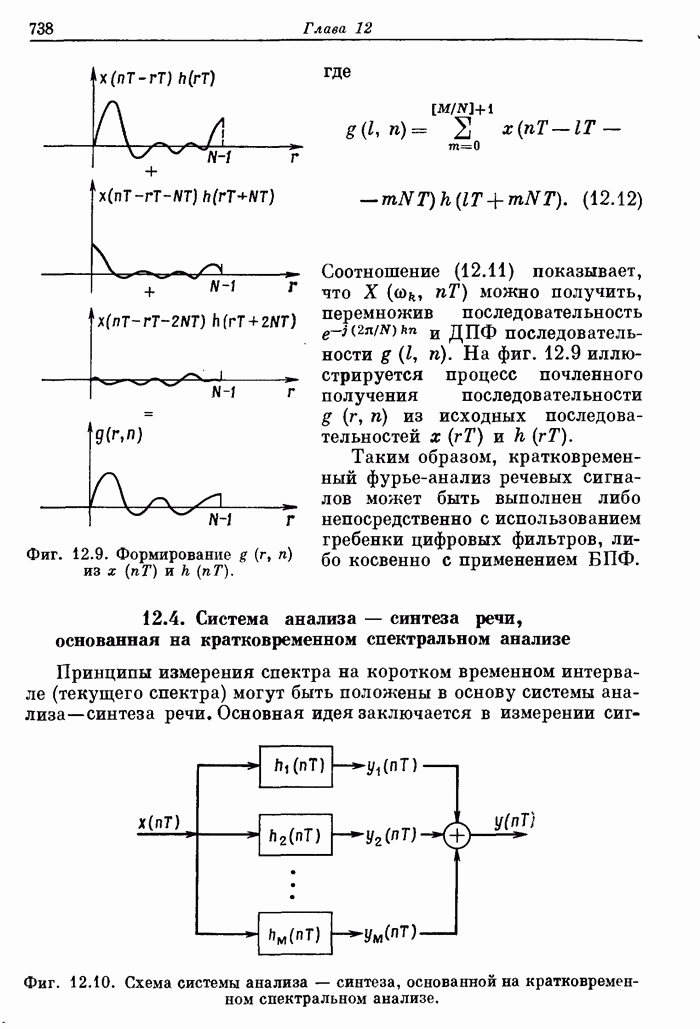
10.12. Поточные схемы БПФ с основанием 2
Рассмотрим
сначала, как, имея  параллельно работающих
арифметических устройств, наиболее эффективно реализовать алгоритмы БПФ, аналогичные
приведенному на фиг. 10.1. Количественной мерой эффективности может
служить доля времени, в течение которого АУ заняты выполнением базовых операций.
параллельно работающих
арифметических устройств, наиболее эффективно реализовать алгоритмы БПФ, аналогичные
приведенному на фиг. 10.1. Количественной мерой эффективности может
служить доля времени, в течение которого АУ заняты выполнением базовых операций.

Фиг. 10.24. Поточная схема выполнения первого этапа
БПФ.
Предположим
пока, что отсчеты сигнала  и т.д. поступают на вход
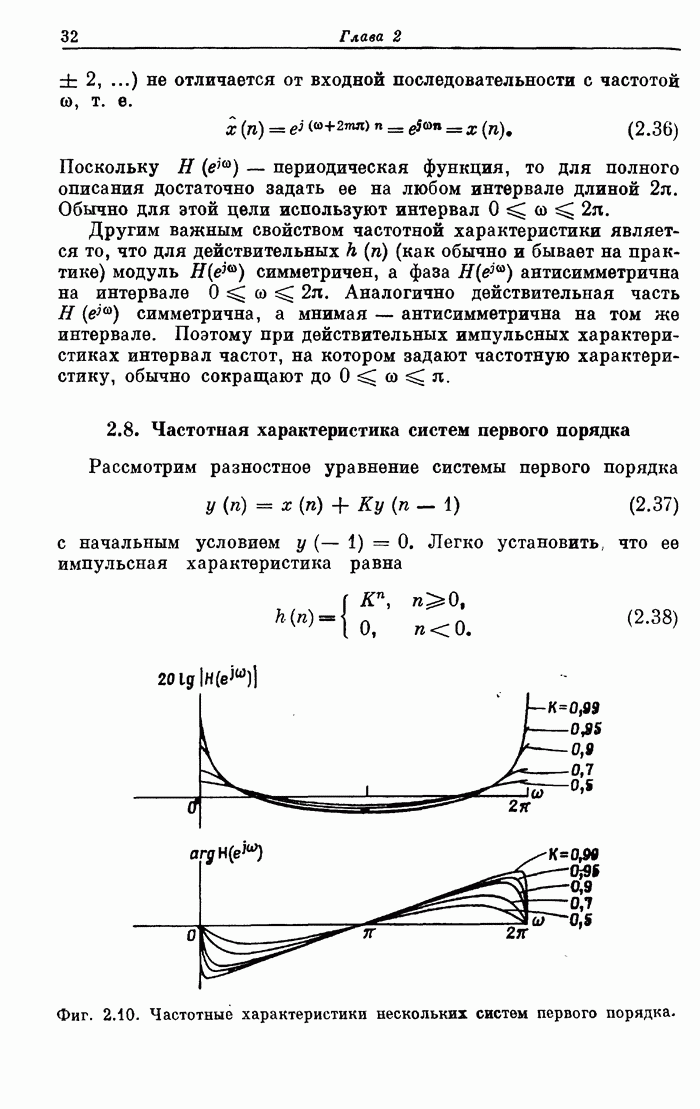
последовательно. Для этого случая на фиг. 10.24 приведена очень простая
блок-схема выполнения первого этапа алгоритма БПФ, соответствующего, например,
схеме на фиг. 10.1. Первые восемь отсчетов
и т.д. поступают на вход
последовательно. Для этого случая на фиг. 10.24 приведена очень простая
блок-схема выполнения первого этапа алгоритма БПФ, соответствующего, например,
схеме на фиг. 10.1. Первые восемь отсчетов  вводятся в восьми каскадную схему
задержки
вводятся в восьми каскадную схему
задержки  .
Следующие восемь отсчетов подаются на второй вход системы. Если длительность
базовой операции в точности равна интервалу дискретизации, то весь
первый этап БПФ будет выполнен за восемь таких интервалов, следующих после
момента переключения. Результаты первого этапа [обозначим их через
.
Следующие восемь отсчетов подаются на второй вход системы. Если длительность
базовой операции в точности равна интервалу дискретизации, то весь
первый этап БПФ будет выполнен за восемь таких интервалов, следующих после
момента переключения. Результаты первого этапа [обозначим их через  ] будут появляться
на выходе блока базовой операции парами. Поскольку коэффициенты
] будут появляться
на выходе блока базовой операции парами. Поскольку коэффициенты  изменяются от
отсчета к отсчету, ЗУ коэффициентов должно выдавать их с частотой поступления
отсчетов сигнала. Из фиг. 10.1 видно, что на втором этапе структурная форма
первого этапа повторяется дважды. Следовательно, на втором этапе необходимо
использовать устройство, обрабатывающее отсчеты
изменяются от
отсчета к отсчету, ЗУ коэффициентов должно выдавать их с частотой поступления
отсчетов сигнала. Из фиг. 10.1 видно, что на втором этапе структурная форма
первого этапа повторяется дважды. Следовательно, на втором этапе необходимо
использовать устройство, обрабатывающее отсчеты  и
и  , аналогично тому, как обрабатывались
отсчеты
, аналогично тому, как обрабатывались
отсчеты  .
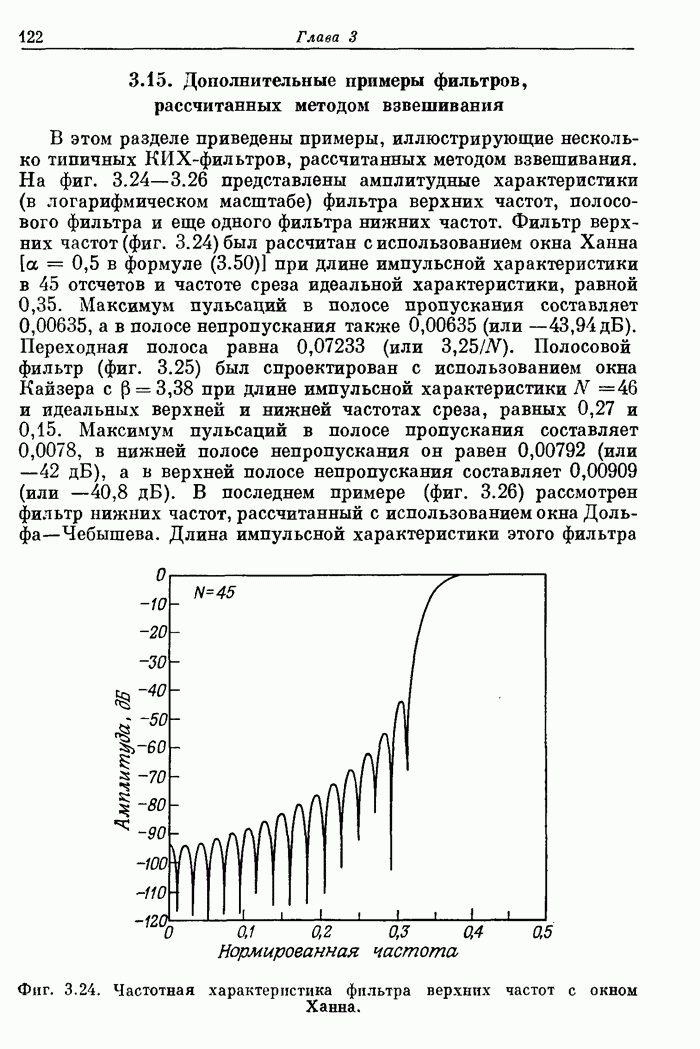
Соответствующая блок-схема изображена на фиг. 10.25. С помощью задержек и
переключений частично обработанные отсчеты выстраиваются так, как это
требуется в алгоритме фиг. 10.1. Временное разнесение между отсчетами, обрабатываемыми
совместно, составляет восемь интервалов дискретизации на первом этапе и четыре
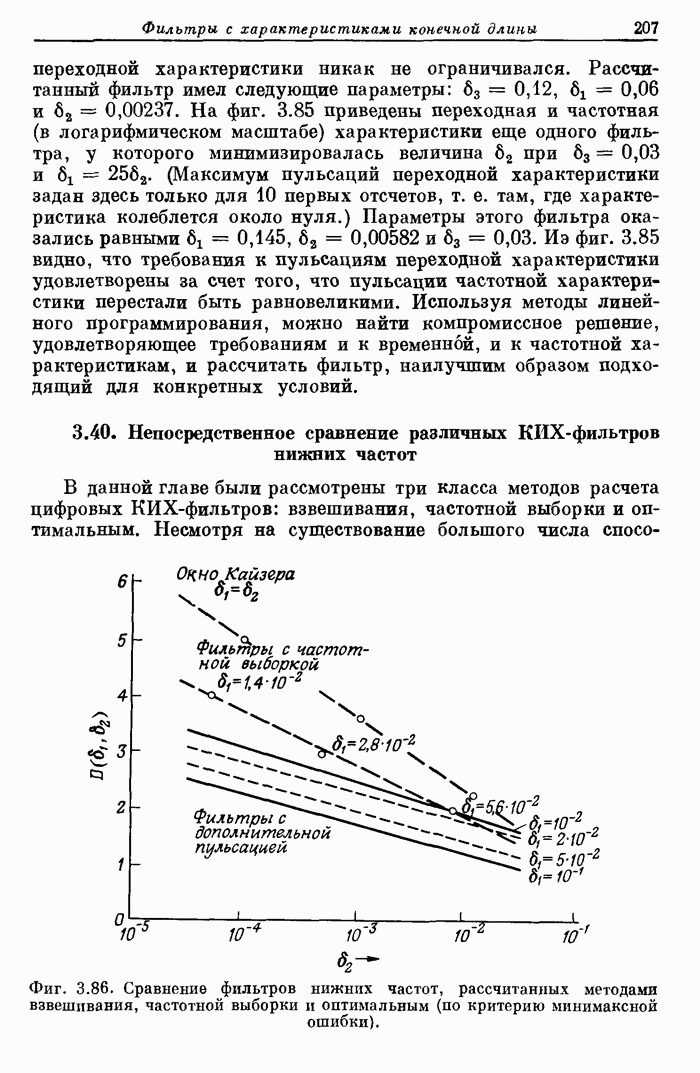
— на втором. Полная поточная схема 16-точечного БПФ изображена на фиг. 10.26.
Анализируя эту схему, можно заметить определенную симметрию и, экстраполируя,
получить поточные схемы БПФ для больших
.
Соответствующая блок-схема изображена на фиг. 10.25. С помощью задержек и
переключений частично обработанные отсчеты выстраиваются так, как это
требуется в алгоритме фиг. 10.1. Временное разнесение между отсчетами, обрабатываемыми
совместно, составляет восемь интервалов дискретизации на первом этапе и четыре
— на втором. Полная поточная схема 16-точечного БПФ изображена на фиг. 10.26.
Анализируя эту схему, можно заметить определенную симметрию и, экстраполируя,
получить поточные схемы БПФ для больших  .
Сделаем несколько замечаний относительно схемы фиг. 10.26.
.
Сделаем несколько замечаний относительно схемы фиг. 10.26.
1. От
этапа к этапу задержка отсчетов уменьшается вдвое.
2. Арифметические
устройства на всех приведенных схемах заняты только половину времени.
3. Частота
переключений от этапа к этапу увеличивается вдвое.
4. Период
синхронизации системы равен, очевидно, интервалу дискретизации.
5. Отсчеты
на выходе появляются во времени в двоично-инверсном порядке.
Для
доказательства последнего положения отметим, что номера на фиг. 10.26
совпадают с (необозначенными) номерами регистров в схеме на фиг. 10.1. Так как
в схеме фиг. 10.1 выходная последовательность расположена в двоично-инверсном
порядке, то и в схеме фиг. 10.26 будет такой же порядок. Короче говоря, данная
схема представляет собой один из возможных вариантов аппаратурной реализации
алгоритма фиг. 10.1. Поэтому преобразование, выполняемое в этой схеме,
обладает всеми свойствами указанного алгоритма и, кроме того, имеет специфические
временные характеристики, не указанные на фиг. 10.1. Последнее замечание можно
подтвердить тем, что в поточной схеме БПФ имеются два выхода, на которых
одновременно появляются две гармоники спектра. Важно отметить, что числа,
приведенные в последних двух строках фиг. 10.26, фактически представляют собой
двоично-инверсные номера выходных гармоник.
Доказательство
положения 2 является довольно сложным, так как время работы арифметических
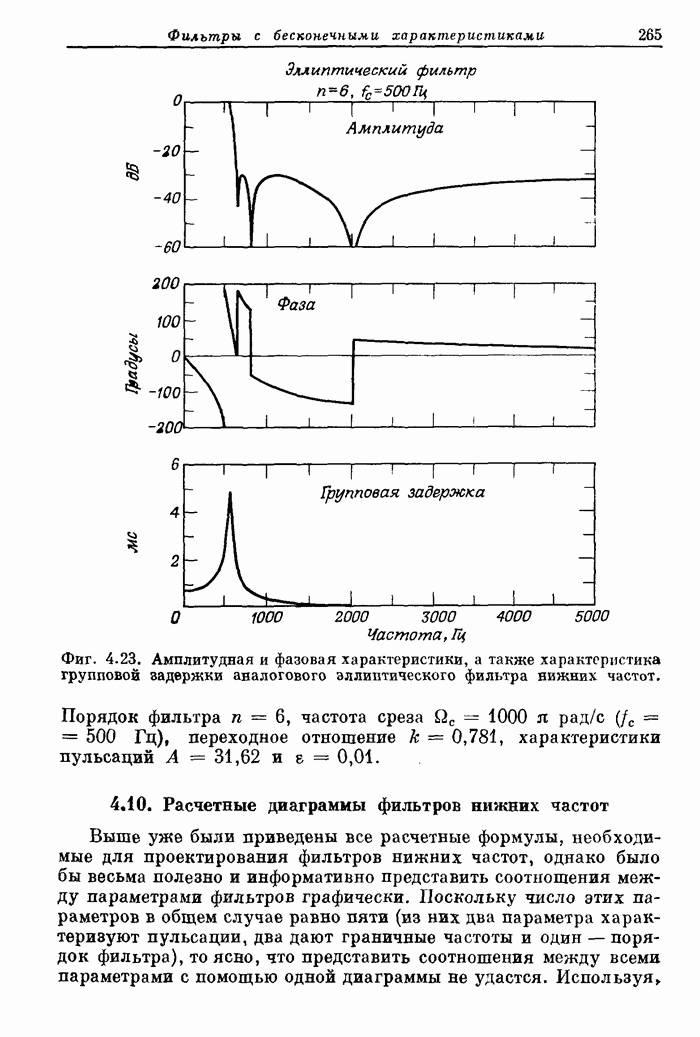
устройств зависит от метода ввода данных в процессор. Потребуем, например,
чтобы данные обрабатывались в виде смежных массивов в реальном времени (фиг.
10.27). Согласно схемам, представленным на фиг. 10.24 — 10.26, обработка не
может быть начата до тех пор, пока в процессор не поступит половина всех
обрабатываемых отсчетов. После этого первый этап завершается за последующие  циклов.
циклов.

Фиг.
10.25. Поточная схема выполнения двух первых этапов 16-точечного БПФ по
основанию 2 с прореживанием по частоте.

Фиг.
10.26. Полная поточная схема выполнения 16-точечного БПФ по основанию 2 с
прореживанием по частоте.

Фиг.
10.27. Временные диаграммы работы арифметических устройств при обработке
последовательных массивов.

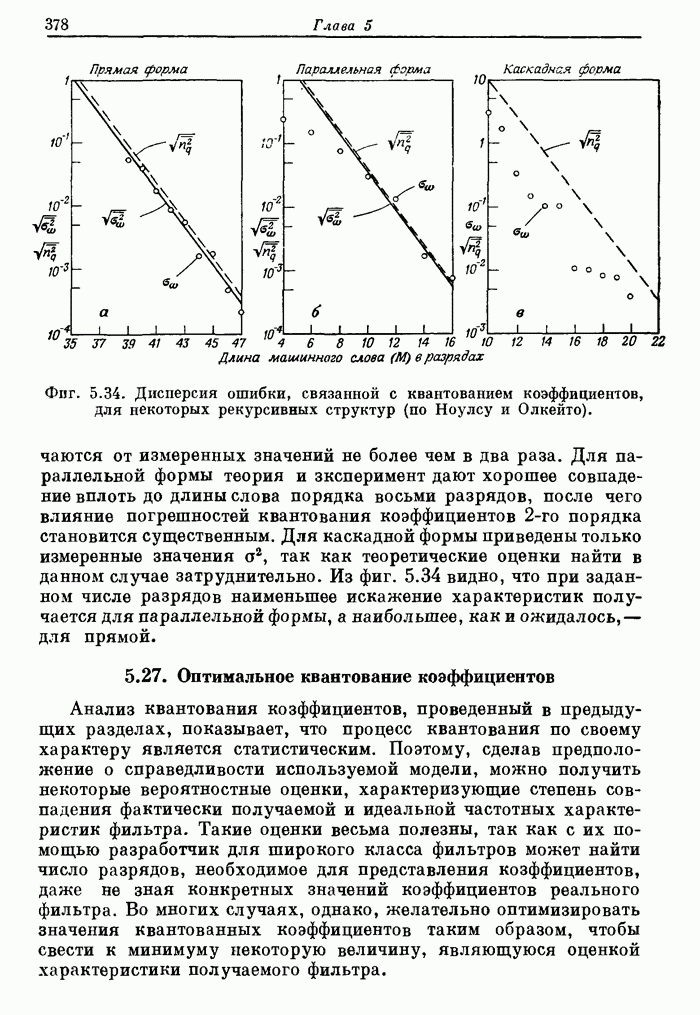
Фиг.
10.28. Включение входного буферного накопителя, позволяющего обрабатывать
последовательные массивы в реальном времени со 100% -ной эффективностью.
Затем
выполнение базовых операций первого этапа прекращается до тех пор, пока первые отсчетов
следующего массива не заполнят схему задержки . В остальных АУ происходит то же
самое, но с некоторым запаздыванием. Следовательно, эффективность поточного
процессора равна 50%, так как каждое из АУ простаивает точно половину времени.
На фиг. 10.28 показано, каким образом с помощью входной буферной памяти
эффективность процессора может быть доведена до 100%. После полного накопления
первого массива отсчеты с выходов  и
и  начинают одновременно поступать в
процессор. Из-за наличия двух параллельных линий ввода тактовая частота
процессора может быть в два раза меньше частоты дискретизации входного сигнала.
Таким образом, первый этап БПФ завершается как раз к тому моменту, когда
следующий массив уже поступил в буфер и полностью готов к обработке. Остальные
этапы БПФ выполняются аналогично, но с запаздыванием, характерным для поточных
схем. Преимуществом этого эффективного метода является возможность понижения
тактовой частоты процессора в два раза или же возможность обработки данных,
следующих с удвоенной частотой, если используется система фиг. 10.26. Все это
достигается введением входного буферного накопителя и соответствующей
коммутации.
начинают одновременно поступать в
процессор. Из-за наличия двух параллельных линий ввода тактовая частота
процессора может быть в два раза меньше частоты дискретизации входного сигнала.
Таким образом, первый этап БПФ завершается как раз к тому моменту, когда
следующий массив уже поступил в буфер и полностью готов к обработке. Остальные
этапы БПФ выполняются аналогично, но с запаздыванием, характерным для поточных
схем. Преимуществом этого эффективного метода является возможность понижения
тактовой частоты процессора в два раза или же возможность обработки данных,
следующих с удвоенной частотой, если используется система фиг. 10.26. Все это
достигается введением входного буферного накопителя и соответствующей
коммутации.

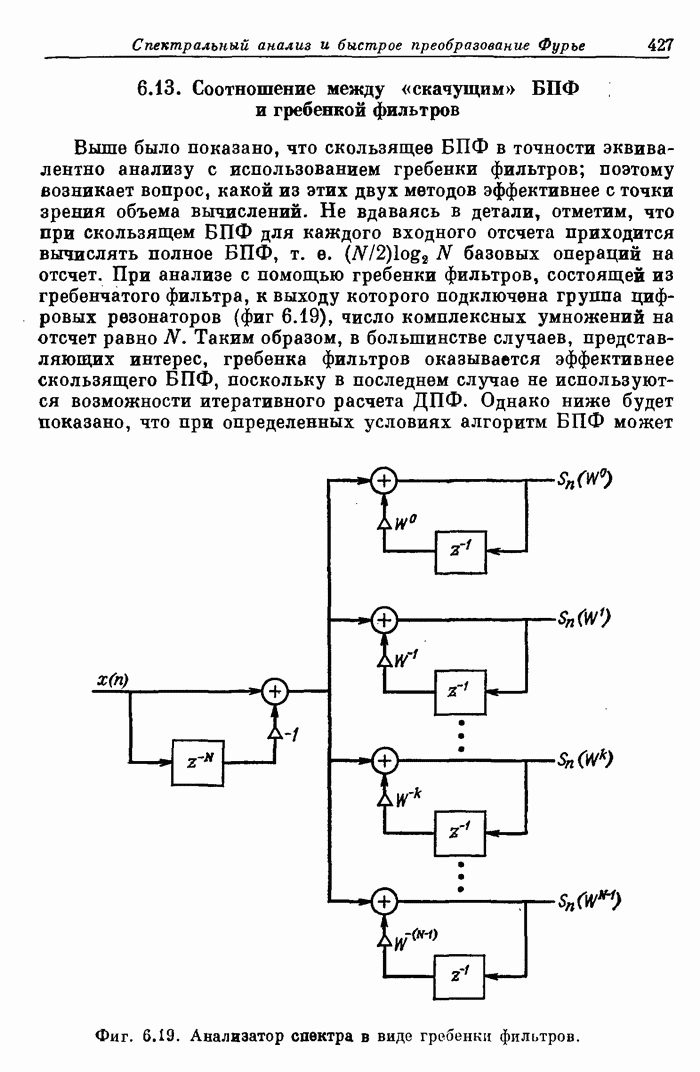
Фиг.
10.29. Входная часть обработки в реальном времени перекрывающихся массивов.
В интересном
частном случае обработки в реальном времени, когда обрабатываемые массивы
наполовину перекрываются (фиг. 10.29), входная линия просто подключается и к
устройству задержки , и к первому АУ. Как и в
предыдущем случае (фиг. 10.28), эффективность системы будет равна 100%, так как
все АУ будут работать без перерывов. Данный частный случай хорошо согласуется с
алгоритмом вычисления свертки методом БПФ и поэтому является весьма полезным.
В
заключение несколько уточним замечания, сделанные ранее относительно схемы фиг.
10.26. Замечание 1 в целом справедливо, но изменения, связанные с накоплением
входных отсчетов, повлияют на способ создания задержки на первом этапе.
Например, в схеме фиг. 10.28 эта задержка создается с помощью входного буферного
накопителя. Замечание 2 может не выполняться, так как существуют схемы с полной
загрузкой АУ (см. фиг. 10.28, 10.29). Замечание 3 справедливо для всех этапов,
за исключением, возможно, первого, причем тактовая частота процессора может
быть понижена (см. схему на фиг. 10.28) по сравнению с частотой дискретизации.
Во всех рассмотренных выше схемах выходные гармоники следуют в
двоично-инверсном порядке и рассчитываются согласно алгоритму фиг. 10.1.
Существуют и другие варианты алгоритма БПФ с основанием 2, для которых также
можно построить поточные схемы БПФ, но к настоящему времени они представляются
не столь изящными и более громоздкими.
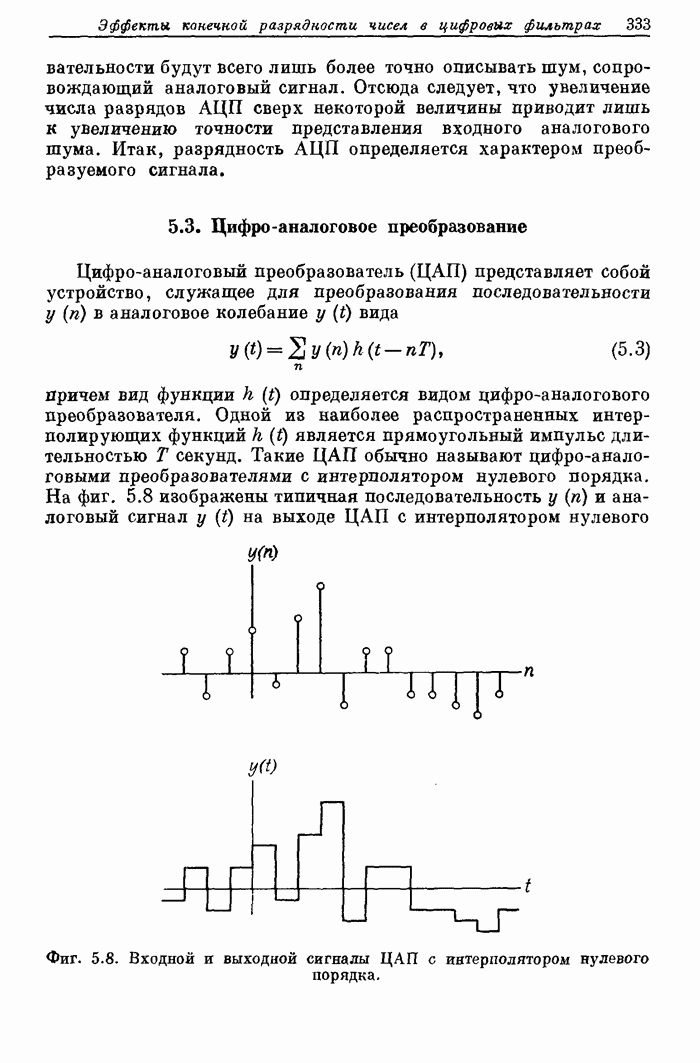
Отметим
также, что при анализе схемы фиг. 10.26 специального времени для выполнения
арифметических операций отведено не было. Учет этого времени никак не повлияет
на общую структуру схемы, но приведет к замедлению работы процессора на число
тактов, необходимых для выполнения базовой операции. Если это число больше 1,
то и сами АУ должны строиться по поточной схеме.