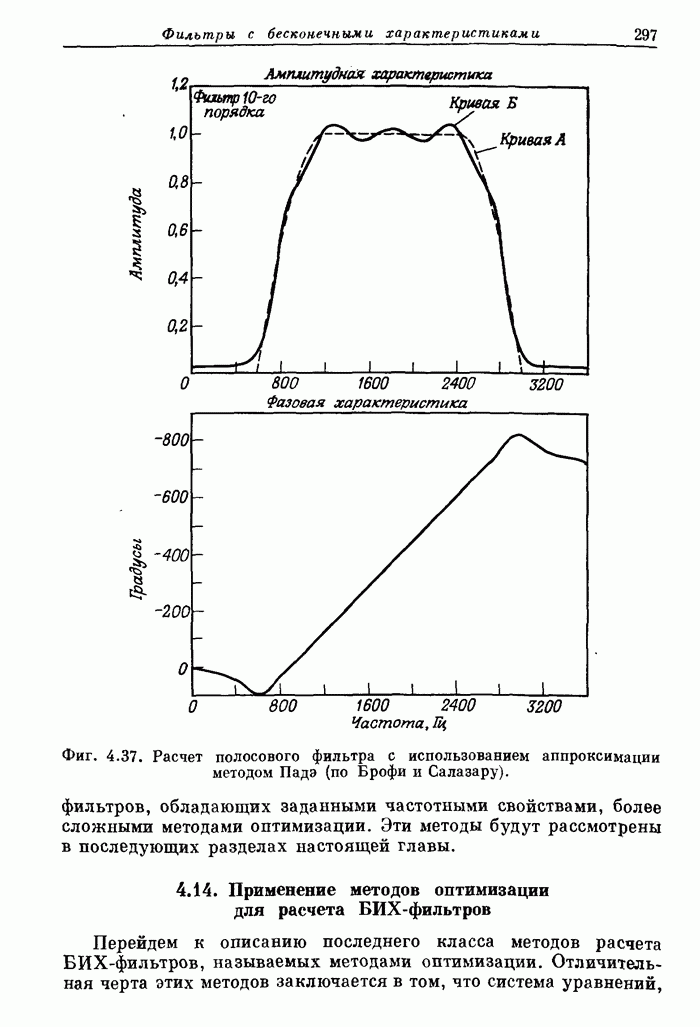
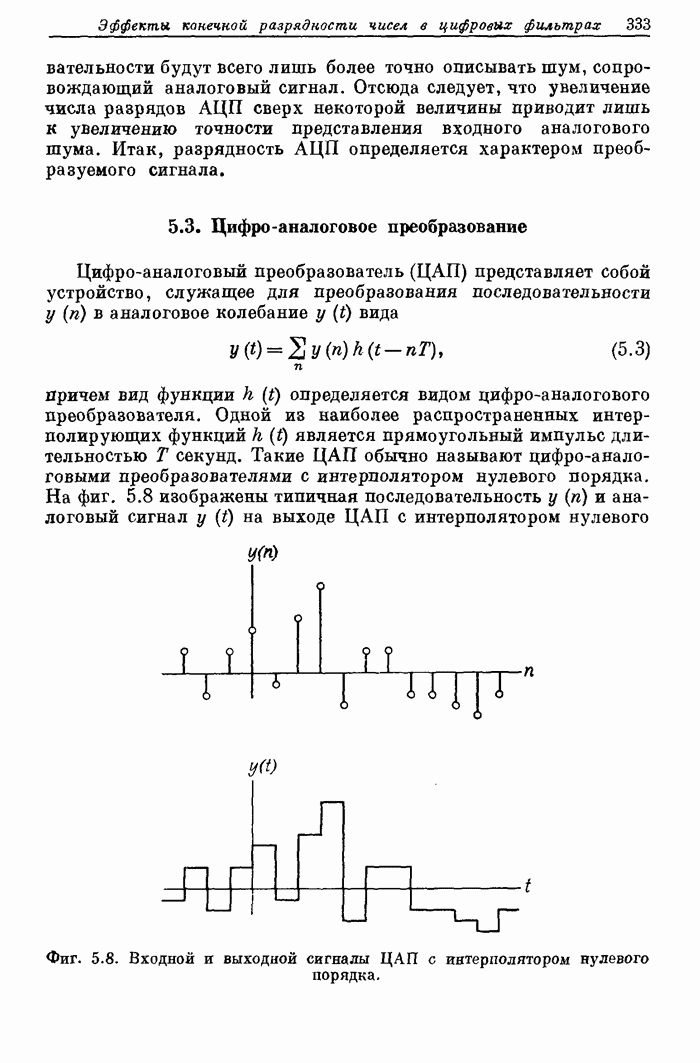
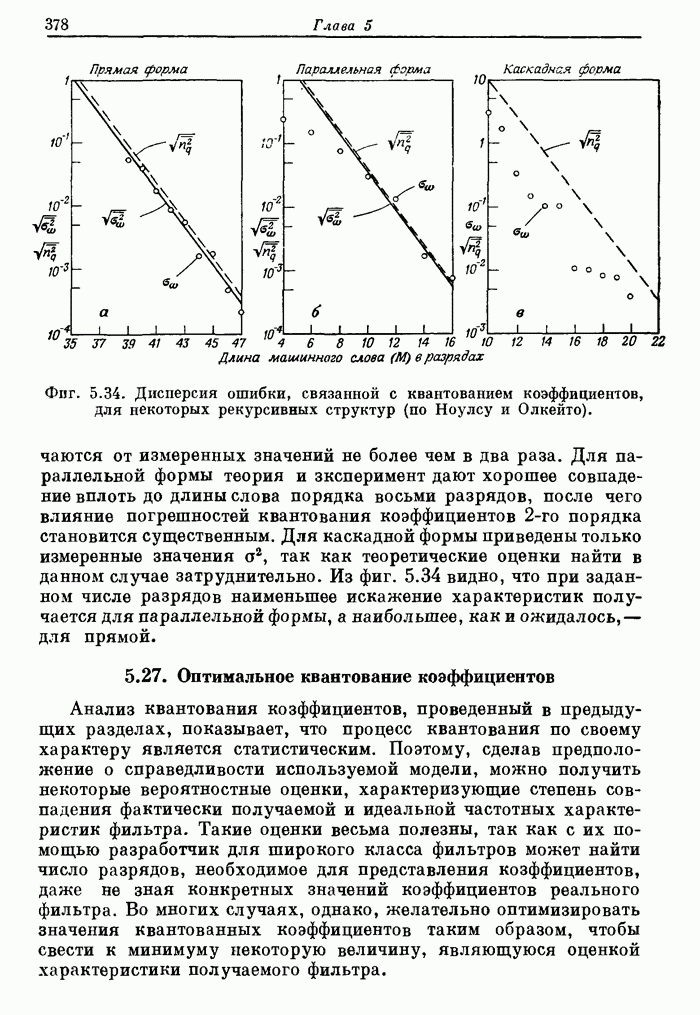
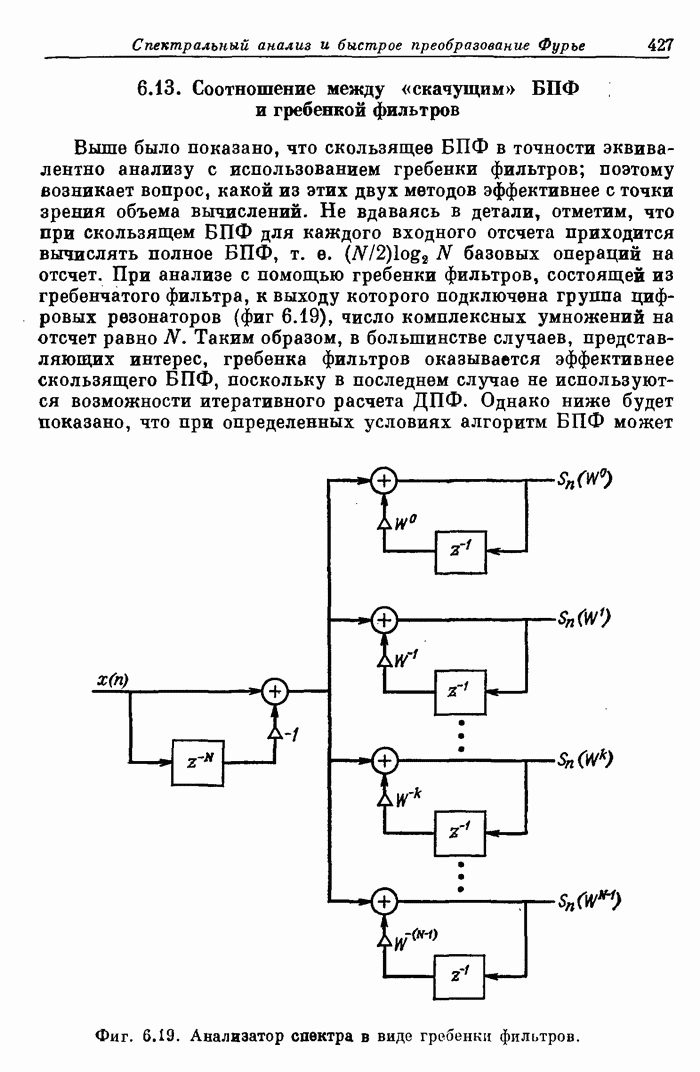
11.13. Обзор методов увеличения быстродействия, использованных в FDP
Перечислим
методы, использованные в FDP для ускорения
обработки:
1.
Параллельная работа ЗУ данных  и
и  позволяет вдвое сократить число
циклов обращения к памяти. Так, во внутреннем цикле БПФ в арифметическое
устройство, выполняющее базовую операцию БПФ, необходимо ввести два комплексных
числа и затем вывести в ЗУ два комплексных результата. В FDP
для этого используются четыре цикла обращения к памяти, тогда как без
распараллеливания ЗУ потребовалось бы восемь циклов.
позволяет вдвое сократить число
циклов обращения к памяти. Так, во внутреннем цикле БПФ в арифметическое
устройство, выполняющее базовую операцию БПФ, необходимо ввести два комплексных
числа и затем вывести в ЗУ два комплексных результата. В FDP
для этого используются четыре цикла обращения к памяти, тогда как без
распараллеливания ЗУ потребовалось бы восемь циклов.
2.
Поточное выполнение команд позволяет вызывать их через каждые 150 нс. Все
команды (кроме умножения) полностью выполняются за 400 нс, т.е. поточная
обработка приводит к  -кратному увеличению быстродействия.
При проектировании FDP было принято, что поточная обработка
используется для всех команд. Это облегчает определение времени выполнения
любых программ. С помощью дополнительных аппаратурных связей можно было бы
проводить обработку поточным способом только для определенных последовательностей
команд и видов данных. Недостаток такого подхода заключается в усложнении
расчета времени выполнения программы, что затрудняет программирование задач
обработки в реальном времени.
-кратному увеличению быстродействия.
При проектировании FDP было принято, что поточная обработка
используется для всех команд. Это облегчает определение времени выполнения
любых программ. С помощью дополнительных аппаратурных связей можно было бы
проводить обработку поточным способом только для определенных последовательностей
команд и видов данных. Недостаток такого подхода заключается в усложнении
расчета времени выполнения программы, что затрудняет программирование задач
обработки в реальном времени.

Фиг. 11.12. Допустимые сочетания команд.
3.
Применение многоцелевых команд сокращает необходимое число тактов, так как
некоторые команды, например команды обращения к памяти и условного перехода,
можно вызывать и выполнять одновременно. Понятно, что выполнение команды
условного перехода определяется результатами предыдущих команд, но не зависит
от команды, выполняемой одновременно с ней. На фиг. 11.12 приведены допустимые
сочетания операций, задаваемых левой и правой половинами 36-разрядного слова
кода команды.
4.
Четырехкратное распараллеливание арифметики также уменьшает число тактов, хотя
в этом случае в отличие от других перечисленных методов ускорения процессора
дать количественную оценку увеличения быстродействия довольно трудно. Такую
оценку можно получить непосредственным расчетом, составив программы для
типичного алгоритма и рассчитав время их выполнения в предположении, что
используются одно, два или четыре АУ.
В качестве простейшего примера рассмотрим задачу суммирования  чисел.
Допустим сначала, что имеются всего одно ЗУ и одно АУ, причем регистр
чисел.
Допустим сначала, что имеются всего одно ЗУ и одно АУ, причем регистр  очищен. Программа
в этом случае имеет вид
очищен. Программа
в этом случае имеет вид
Символ
 означает
условный переход (и добавление к индексу единицы), если в индексном регистре
означает
условный переход (и добавление к индексу единицы), если в индексном регистре  содержится
отрицательное число; в противном случае переход не выполняется. Главная особенность
этой несложной программы состоит в том, что третья строка выполняется раньше
команды условного перехода, записанной во второй строке. Таким образом,
внутренний цикл содержит две команды и выполняется за 300 нс.
содержится
отрицательное число; в противном случае переход не выполняется. Главная особенность
этой несложной программы состоит в том, что третья строка выполняется раньше
команды условного перехода, записанной во второй строке. Таким образом,
внутренний цикл содержит две команды и выполняется за 300 нс.
Предположим теперь, что имеются два ЗУ ( и ) и два АУ (АУ1 и АУ2), причем регистры  и
и  очищены. Пусть,
кроме того, суммируемый массив разделен на две половины, содержащие но
очищены. Пусть,
кроме того, суммируемый массив разделен на две половины, содержащие но  чисел и хранящиеся
в ЗУ и .
Программа имеет вид
чисел и хранящиеся
в ЗУ и .
Программа имеет вид
Внутренний цикл снова состоит из двух команд, но, поскольку АУ1 и
АУ2 работают параллельно, число его повторений уменьшается вдвое; после
окончания цикла рассчитывается сумма  . Таким образом, удвоение числа
арифметических и запоминающих устройств почти вдвое увеличивает
быстродействие. При наличии четырех АУ программа имеет вид
. Таким образом, удвоение числа
арифметических и запоминающих устройств почти вдвое увеличивает
быстродействие. При наличии четырех АУ программа имеет вид
Примечательно,
что внутренний цикл по-прежнему состоит из двух команд, т. е. программа
выполняется вдвое быстрее предыдущей и в четыре раза быстрее программы для
одного АУ. Эти простые примеры подтверждают, что способ задания команд, принятый
в FDP, позволяет эффективно использовать возможности параллельной
арифметики FDP.
Во
всех приведенных программах опущены команды адресации памяти и установки нужных
значений индексов. Однако в данном элементарном случае никаких дополнительных
команд не требуется.