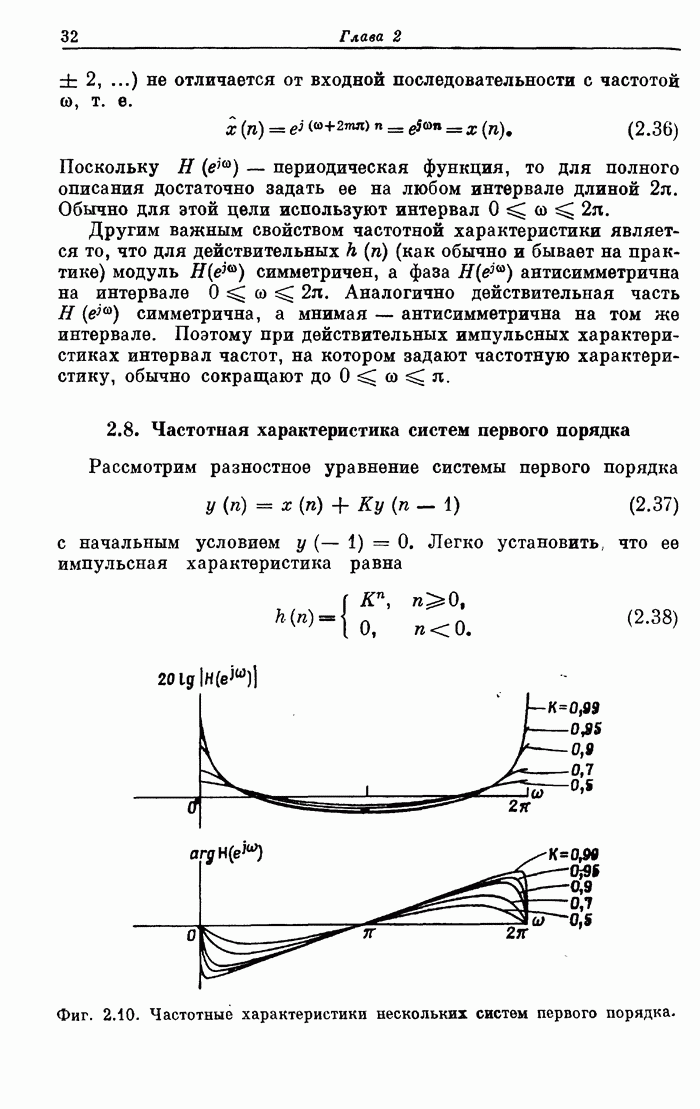
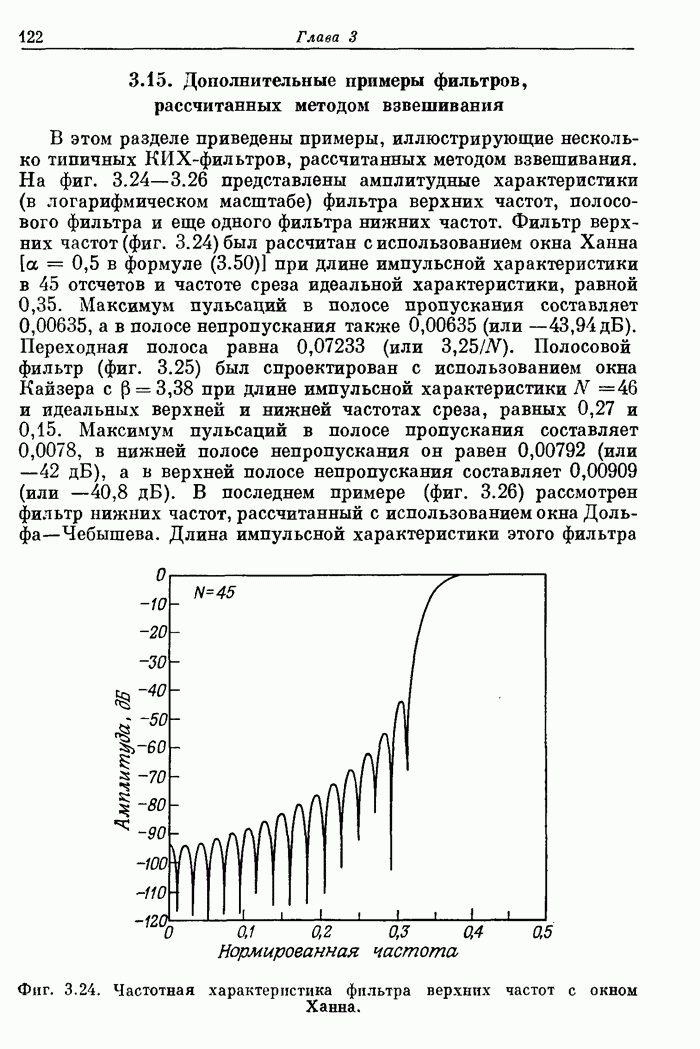
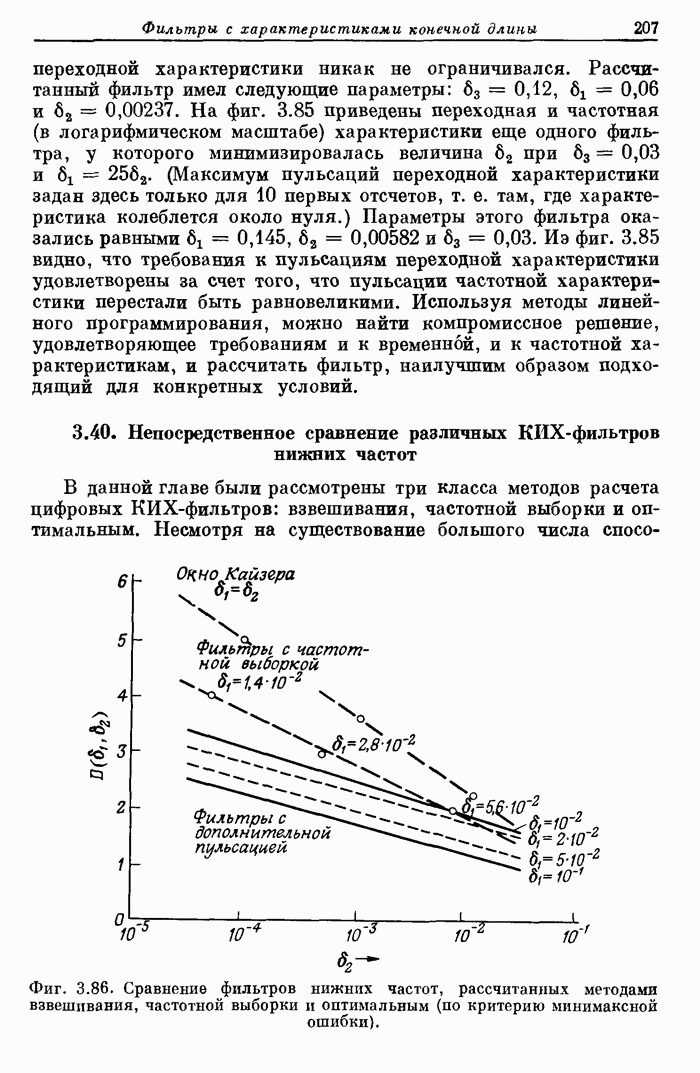
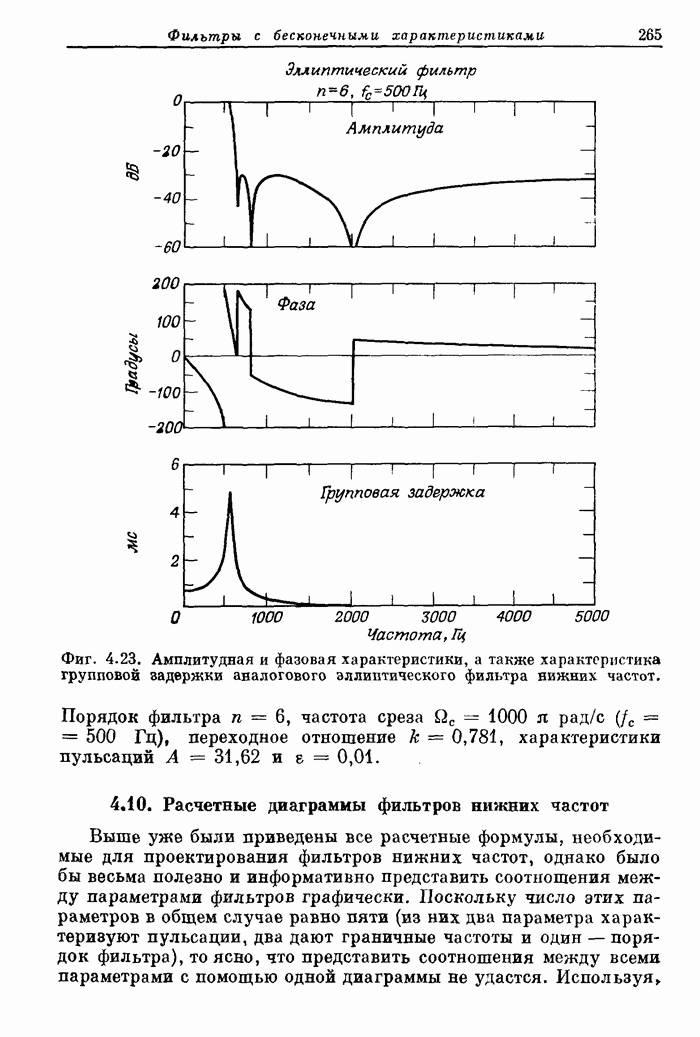
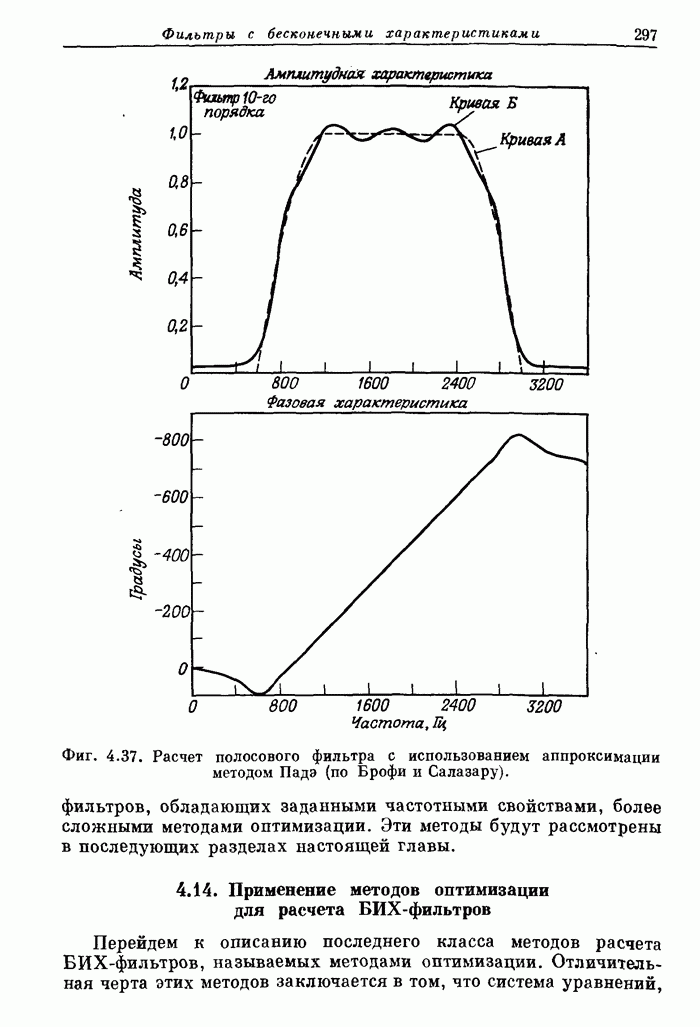
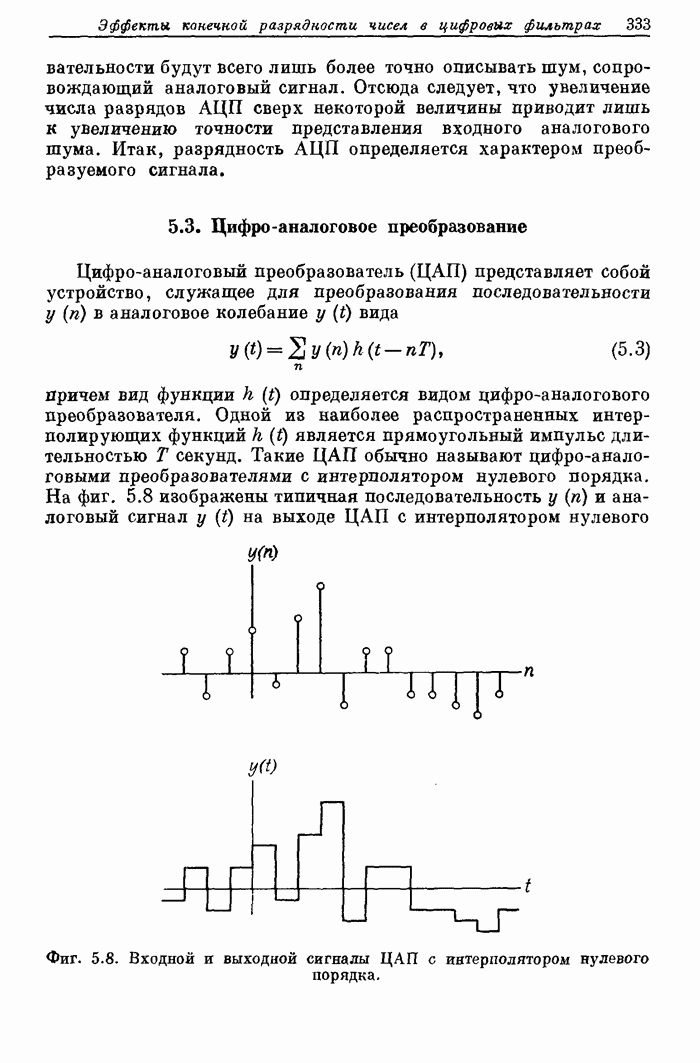
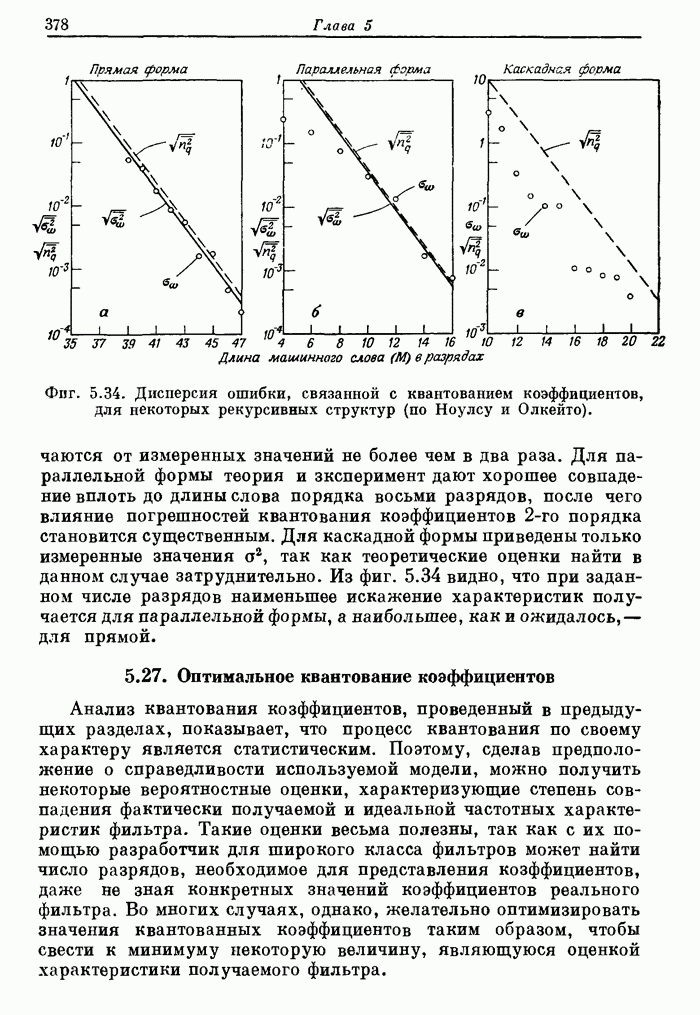
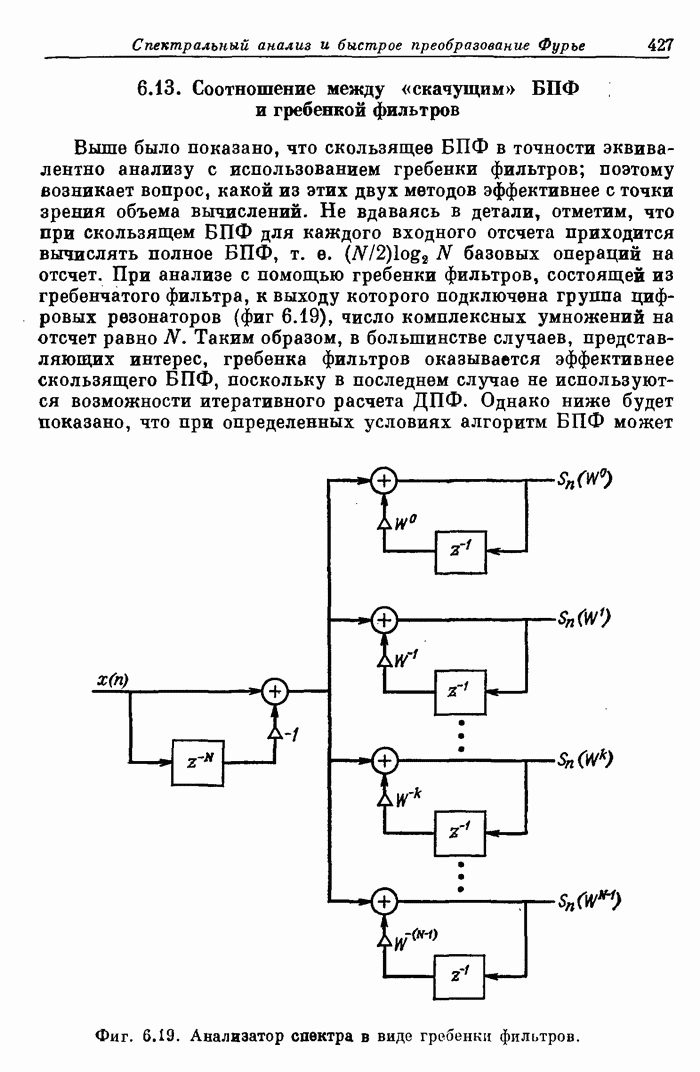
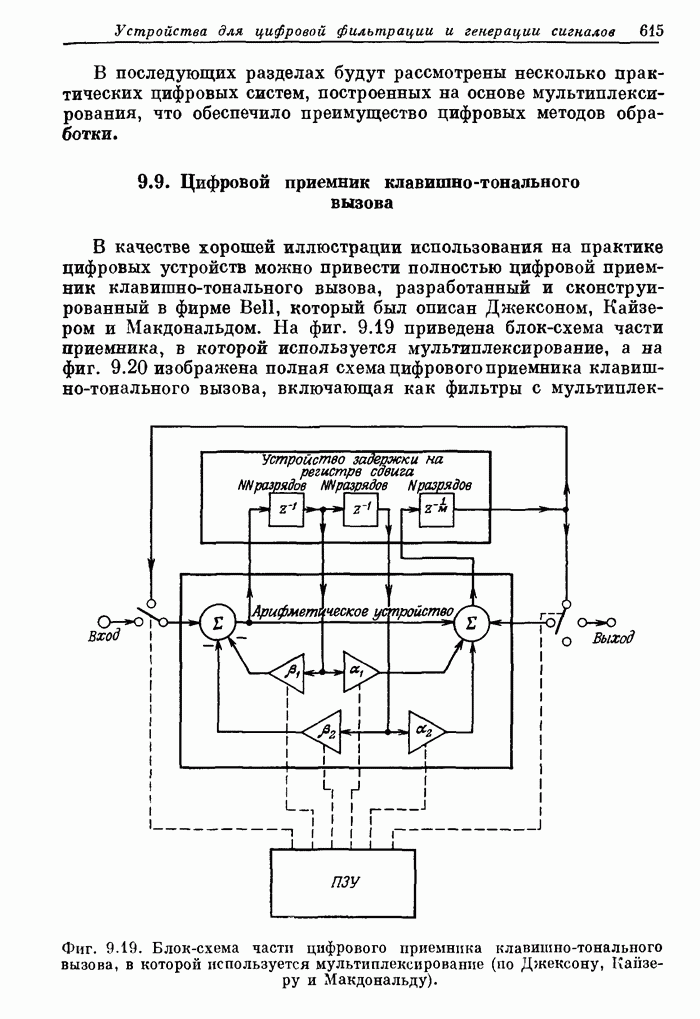
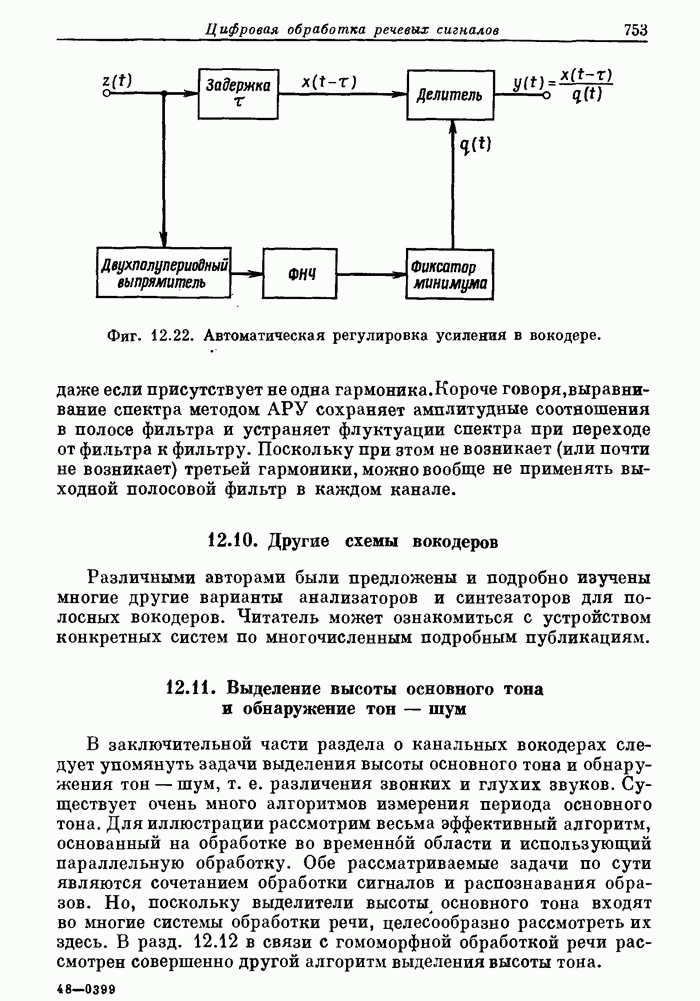
10.15. Структуры БПФ с повышенным уровнем параллелизма
Выше
было принято, что эффективность схемы БПФ равна 100%, если все ее
арифметические устройства выполняют базовые операции без перерывов. В
рассмотренных поточных структурах эффективность можно довести до 100% с помощью
входного буферного накопителя, согласованного с конкретными обрабатываемыми
сигналами. В отличие от этих схем универсальные ЦВМ, работа которых основана на
последовательном выполнении операций, будут обычно иметь существенно меньшую
эффективность. В данном разделе будут описаны схемы БПФ, также обеспечивающие
100%-ную эффективность, но при более высоком уровне параллелизма, чем в
рассмотренных ранее схемах.
1.
Естественным обобщением поточных схем БПФ с основаниями 2 и 4 являются схемы с
основанием  .
Для данного (например,
.
Для данного (например,
 ) всегда
можно построить поточную схему, как показано на фиг. 10.36. Схема имеет линий передачи
данных, в которые по обе стороны от АУ включено по
) всегда
можно построить поточную схему, как показано на фиг. 10.36. Схема имеет линий передачи
данных, в которые по обе стороны от АУ включено по  схем задержки (см. фиг.
10.36, б]. Арифметическое устройство предназначено для выполнения -точечного ДПФ с
последующим умножением на поворачивающих множителей. Сравним
теперь три поточных схемы БПФ с основаниями 2, 4 и 8. Если тактовая частота во
всех случаях одинакова, то схема с более высоким основанием сможет обработать
больше данных, так как в поточной схеме БПФ с основанием данные обрабатываются
сразу по линиям.
В табл. 10.3 для некоторых частных случаев сопоставлены уровни параллелизма в
схемах с основаниями 2, 4 и 8. Здесь указано фактическое количество умножителей
и сумматоров действительных чисел. Комплексное умножение, например,
эквивалентно четырем умножениям и двум сложениям действительных чисел. Напомним
также, что при основании 4 схема в принципе может обеспечить вдвое большее
быстродействие, чем при основании 2, а при основании 8 — вдвое большее, чем при
основании 4 (если только тактовая частота во всех случаях одинакова). (Это
означает, что АУ схемы с основанием 8 должно обеспечить выполнение восьмиточечного
ДПФ и семи умножений на поворачивающие множители за то же время, за которое АУ
схемы с основанием 4 выполняют четырехточечное ДПФ и три поворота, а АУ схемы
с основанием 2 — двухточечное ДПФ и один поворот.)
схем задержки (см. фиг.
10.36, б]. Арифметическое устройство предназначено для выполнения -точечного ДПФ с
последующим умножением на поворачивающих множителей. Сравним
теперь три поточных схемы БПФ с основаниями 2, 4 и 8. Если тактовая частота во
всех случаях одинакова, то схема с более высоким основанием сможет обработать
больше данных, так как в поточной схеме БПФ с основанием данные обрабатываются
сразу по линиям.
В табл. 10.3 для некоторых частных случаев сопоставлены уровни параллелизма в
схемах с основаниями 2, 4 и 8. Здесь указано фактическое количество умножителей
и сумматоров действительных чисел. Комплексное умножение, например,
эквивалентно четырем умножениям и двум сложениям действительных чисел. Напомним
также, что при основании 4 схема в принципе может обеспечить вдвое большее
быстродействие, чем при основании 2, а при основании 8 — вдвое большее, чем при
основании 4 (если только тактовая частота во всех случаях одинакова). (Это
означает, что АУ схемы с основанием 8 должно обеспечить выполнение восьмиточечного
ДПФ и семи умножений на поворачивающие множители за то же время, за которое АУ
схемы с основанием 4 выполняют четырехточечное ДПФ и три поворота, а АУ схемы
с основанием 2 — двухточечное ДПФ и один поворот.)
Таблица 10.3
|
|
Основание
2
|
Основание
4
|
Основание
8
|
|
N
|
число
умножений
|
число
сложений
|
число
умножений
|
число
сложений
|
число
умножений
|
число
сложений
|
|
64
4096
|
16
40
|
32
68
|
24
60
|
60
126
|
44
116
|
118
144
|

Фиг. 10.36.
Поточная блок-схема выполнения 1-го и  -гo
этапов БПФ с основанием .
-гo
этапов БПФ с основанием .
2. Для
расширения возможностей системы было бы желательно увеличить уровень
параллелизма, введя в нее не  , и даже не
, и даже не  , a
, a  параллельно
работающих АУ. Эффективный алгоритм для такой схемы, представляющий
16-точечное БПФ с постоянной структурой, иллюстрируется на фиг. 10.3.
Преимуществом данной схемы является малое число переключений, необходимое при
пересылке чисел из АУ в регистры памяти и обратно. Каждое АУ принимает данные из
двух (комплексных) регистров и засылает результаты в два других регистра. Эти
взаимосвязи на всех этапах БПФ остаются постоянными. Результаты обработки будут
получены в двоично-инверсном порядке, но за счет введения двух дополнительных
соединений на каждое АУ перестановку можно устранить.
параллельно
работающих АУ. Эффективный алгоритм для такой схемы, представляющий
16-точечное БПФ с постоянной структурой, иллюстрируется на фиг. 10.3.
Преимуществом данной схемы является малое число переключений, необходимое при
пересылке чисел из АУ в регистры памяти и обратно. Каждое АУ принимает данные из
двух (комплексных) регистров и засылает результаты в два других регистра. Эти
взаимосвязи на всех этапах БПФ остаются постоянными. Результаты обработки будут
получены в двоично-инверсном порядке, но за счет введения двух дополнительных
соединений на каждое АУ перестановку можно устранить.
Вероятно,
наиболее быстрый и экономичный метод введения коэффициентов заключается в том,
чтобы хранить их в определенной последовательности в каждом из АУ. Так, для
алгоритма фиг. 10.3 в АУ7 используются коэффициенты  . В любом АУ для хранения
коэффициентов требуется не более регистров, поэтому для всех АУ потребуется
. В любом АУ для хранения
коэффициентов требуется не более регистров, поэтому для всех АУ потребуется  или меньше
регистров. Хотя эта величина существенно превышает необходимое число
коэффициентов, равное , важно исключить операцию
распределения коэффициентов из центрального ЗУ по арифметическим устройствам.
или меньше
регистров. Хотя эта величина существенно превышает необходимое число
коэффициентов, равное , важно исключить операцию
распределения коэффициентов из центрального ЗУ по арифметическим устройствам.
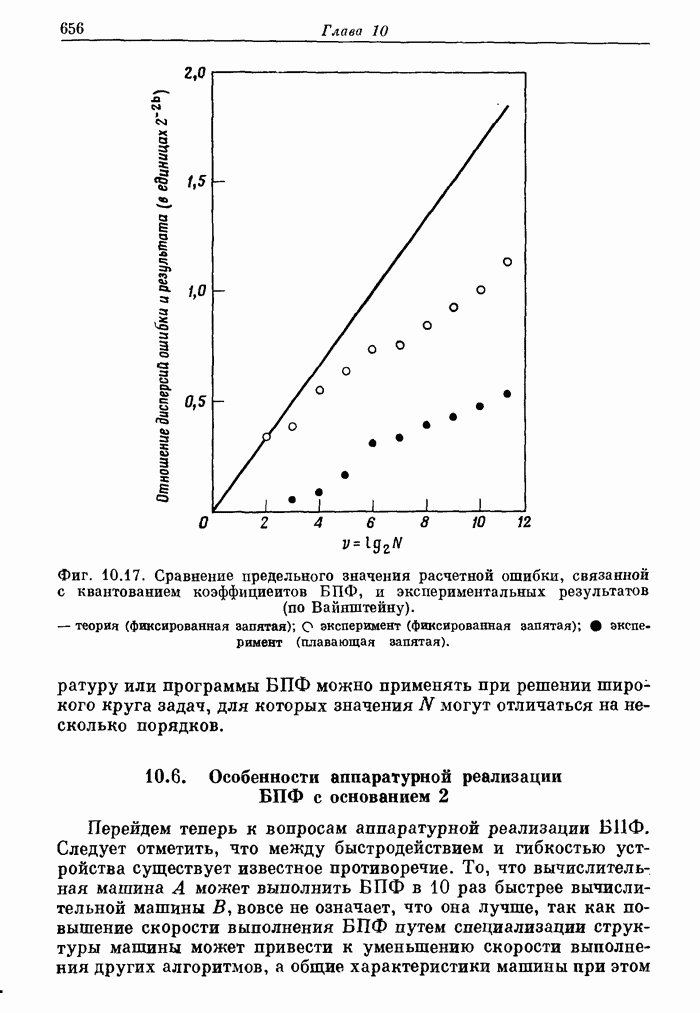
Чтобы
оценить быстродействие рассматриваемой системы, представим, что базовая
операция выполняется за  секунд. Тогда для выполнения всего
БПФ потребуется
секунд. Тогда для выполнения всего
БПФ потребуется  секунд.
секунд.
3.
Имея полный набор из АУ, можно увеличить быстродействие
еще в раз,
если использовать поточную схему для реализации алгоритма фиг. 10.3. Тогда
каждый из незачерненных кружков будет соответствовать целому АУ, а каждая точка
— регистру. Такая структура является предельной, так как матрица АУ и поточная
организация обработки обеспечивают получение результатов БПФ с тактовой
частотой.
В
такой схеме в каждом из АУ хранится только один коэффициент, причем
часто он  или
или
 , так что
умножитель в таком АУ просто не нужен. С помощью формулы (10.2) можно рассчитать,
сколько умножителей фактически требуется для получения
, так что
умножитель в таком АУ просто не нужен. С помощью формулы (10.2) можно рассчитать,
сколько умножителей фактически требуется для получения  -точечного БПФ. В табл. 10.4
приведено это количество умножителей
-точечного БПФ. В табл. 10.4
приведено это количество умножителей  при разных для матричной схемы
выполнения БПФ по основанию 2 с поточной обработкой и предельным уровнем
параллелизма.
при разных для матричной схемы
выполнения БПФ по основанию 2 с поточной обработкой и предельным уровнем
параллелизма.
4.
Если необходимо выполнять БПФ при больших (например,
при  ), то
использование схем, описанных в пп. 2 и 3, потребует огромного количества
оборудования, а именно 2048 арифметических устройств в первом случае и 21 502
— во втором. С другой стороны, в поточной схеме с основанием 2 используются 12
АУ. По количеству используемой аппаратуры схема поточного БПФ с основанием 8 () эквивалентна 48
АУ схемы с основанием 2.
), то
использование схем, описанных в пп. 2 и 3, потребует огромного количества
оборудования, а именно 2048 арифметических устройств в первом случае и 21 502
— во втором. С другой стороны, в поточной схеме с основанием 2 используются 12
АУ. По количеству используемой аппаратуры схема поточного БПФ с основанием 8 () эквивалентна 48
АУ схемы с основанием 2.
Таблица 10.4
|
|
2
|
4
|
8
|
16
|
32
|
64
|
|
|
0
|
0
|
2
|
10
|
34
|
98
|
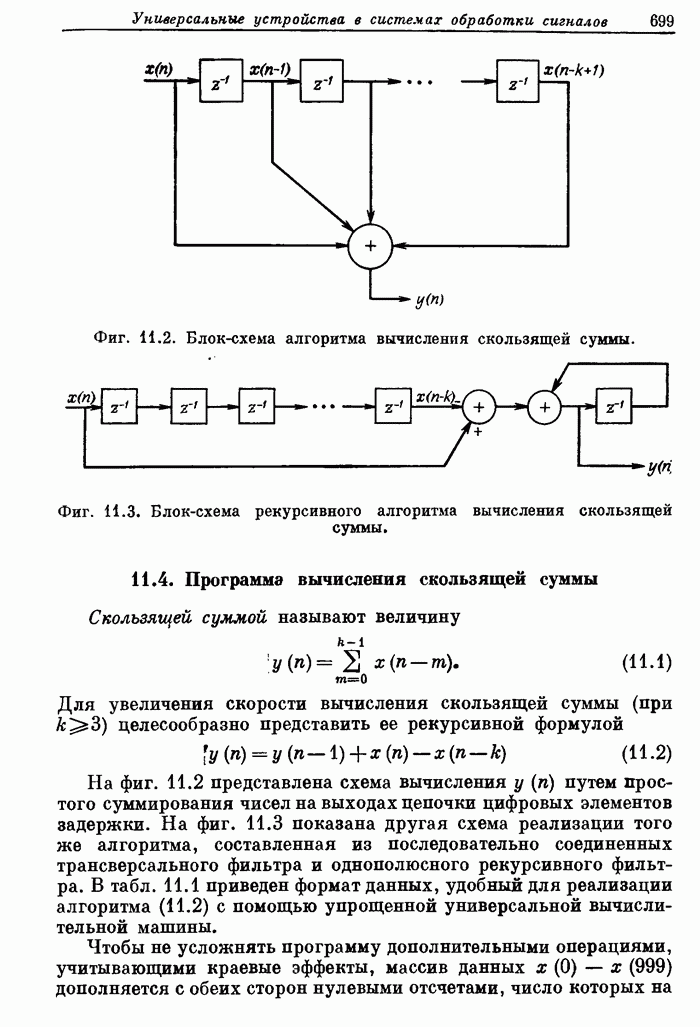
Существует
еще одна структура, занимающая промежуточное положение между системой с
основанием 2 и предельной системой. В ней используется специально
организованный блок памяти, с помощью которого входной массив представляется в
виде двумерной матрицы и обрабатывается сначала по строкам, а затем по
столбцам. При ,
например, матрица имеет размер  , так что в системе параллельно
работают 32 АУ и уровень параллелизма почти втрое больше, чем в поточной системе
с основанием 2.
, так что в системе параллельно
работают 32 АУ и уровень параллелизма почти втрое больше, чем в поточной системе
с основанием 2.
Требуемое
двумерное ЗУ можно построить на серийно выпускаемых микросхемах памяти. Принцип
его построения иллюстрируется на фиг. 10.37 для матрицы из  элементов. Если входные
отсчеты имеют номера 0—15, как показано на фиг. 10.37, а, то весь массив
можно разместить в четырех микросхемах ЗУ (каждая из которых содержит по
четыре слова) согласно фиг. 10.37, б. При необходимости прочитать (или
записать)
элементов. Если входные
отсчеты имеют номера 0—15, как показано на фиг. 10.37, а, то весь массив
можно разместить в четырех микросхемах ЗУ (каждая из которых содержит по
четыре слова) согласно фиг. 10.37, б. При необходимости прочитать (или
записать)  -ю
строку или -й
столбец все четыре требуемые для этого адреса можно найти в приведенной на фиг.
10.37, б специальной таблице; цифры в скобках указывают номера
считываемых отсчетов, пронумерованных согласно фиг. 10.37, а. Заметим,
что при считывании строк для последовательных микросхем ЗУ адреса увеличиваются
на единицу, а при считывании столбцов они одинаковы. Отметим также, что
последовательным строкам соответствуют одни и те же наборы адресов,
отличающиеся только круговой перестановкой.
-ю
строку или -й
столбец все четыре требуемые для этого адреса можно найти в приведенной на фиг.
10.37, б специальной таблице; цифры в скобках указывают номера
считываемых отсчетов, пронумерованных согласно фиг. 10.37, а. Заметим,
что при считывании строк для последовательных микросхем ЗУ адреса увеличиваются
на единицу, а при считывании столбцов они одинаковы. Отметим также, что
последовательным строкам соответствуют одни и те же наборы адресов,
отличающиеся только круговой перестановкой.
Строка
(или столбец) считывается параллельно и через пакетный переключатель поступает
в блок обработки, состоящий из четырех АУ. Пакетный переключатель коммутируется
по схеме кругового переключателя и служит для того, чтобы режим работы АУ не
зависел от номера обрабатываемой строки или столбца. Например, при считывании
нулевой строки [см. фиг. 10.37, б] отсчет 0 поступает в АУ0,
отсчет 1 — в АУ1, отсчет 2 — в АУ2, отсчет 3 — в АУЗ. При считывании первой
строки отсчет 4 (считываемый из микросхемы I)
поступает в АУ0, отсчет 5 (микросхема II) —
в АУ1, отчет 6 (микросхема III) —
в АУ2, отсчет 7 (микросхема IV) —
в АУЗ. На фиг. 10.38 приведена таблица необходимых соединений. Число, стоящее
в -м
столбце, указывает, какая микросхема подключается к -му АУ. Переход от одной
строки ЗУ к другой (или от одного столбца к другому) осуществляется с помощью
пакетного переключателя. Отметим, что соединения в пакетном переключателе
одинаковы для строки и столбца ЗУ с одинаковыми номерами.
Конкретные
схемы построения процессора могут быть самыми различными, начиная со схем
реализации любого из алгоритмов БПФ и кончая матричными поточными схемами.

Фиг.
10.37. Размещение отсчетов в микросхемах памяти для матрицы размером ( ).
).