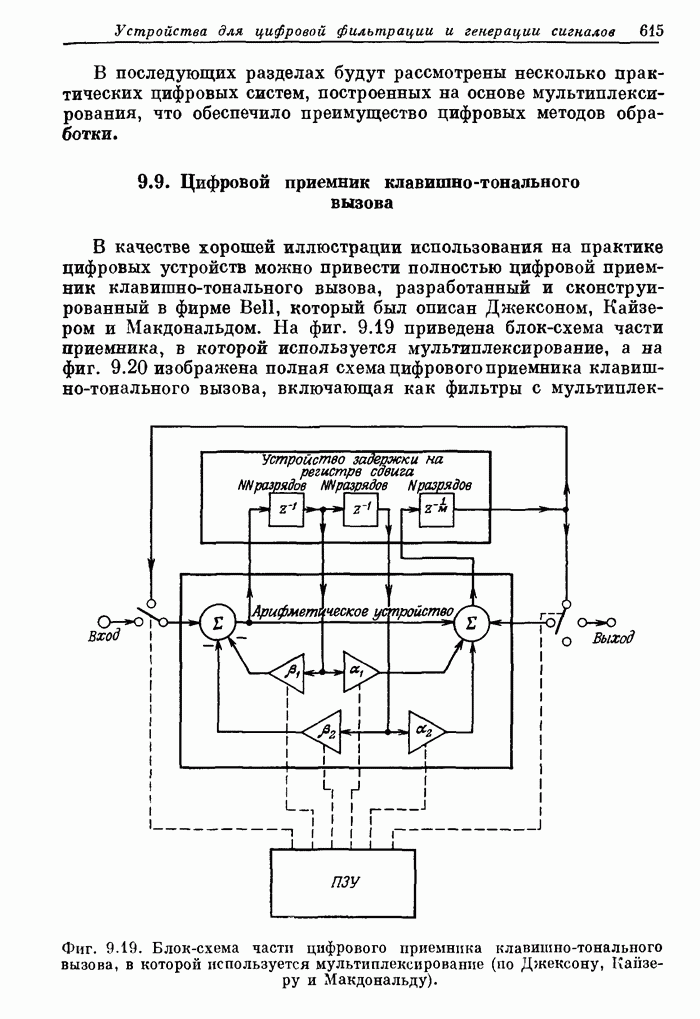
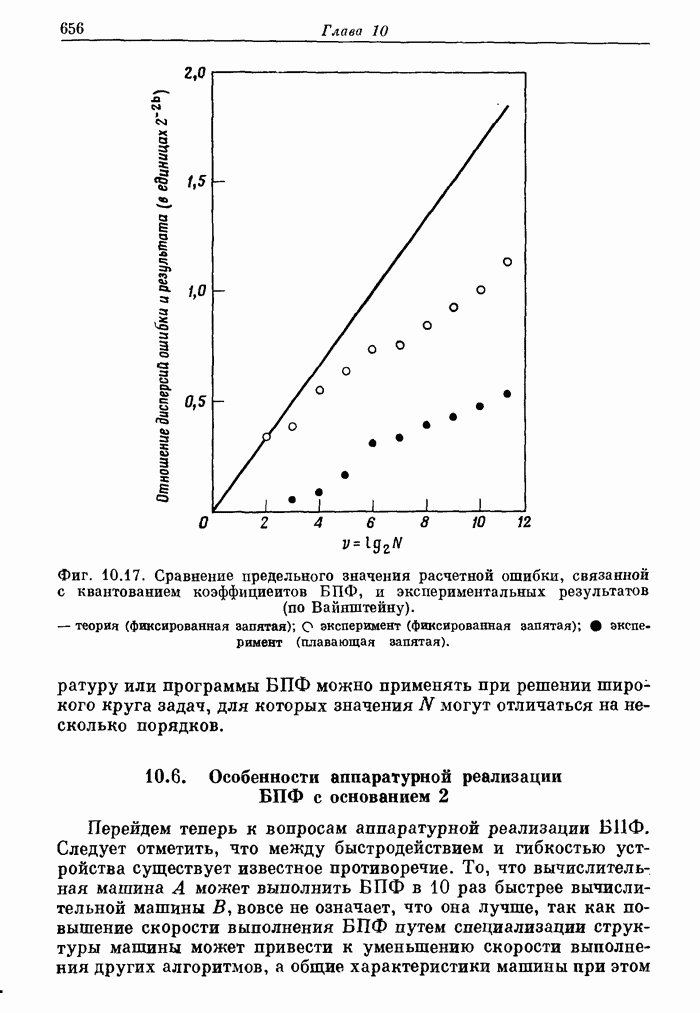
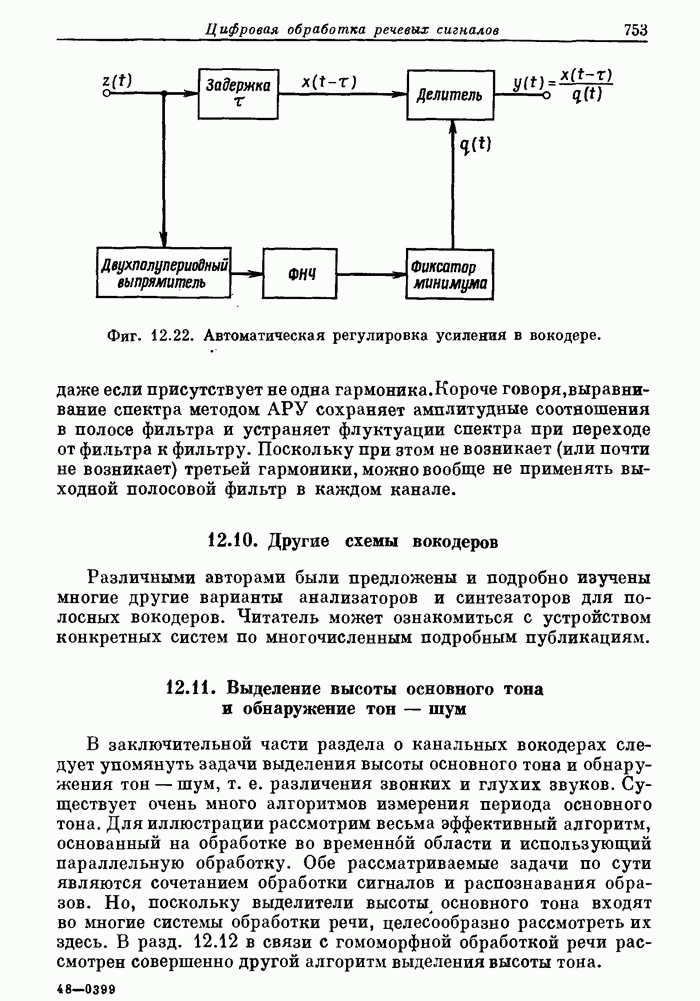
12.2. Модель образования речи
На фиг. 12.1. изображена схема, описывающая механизм образования
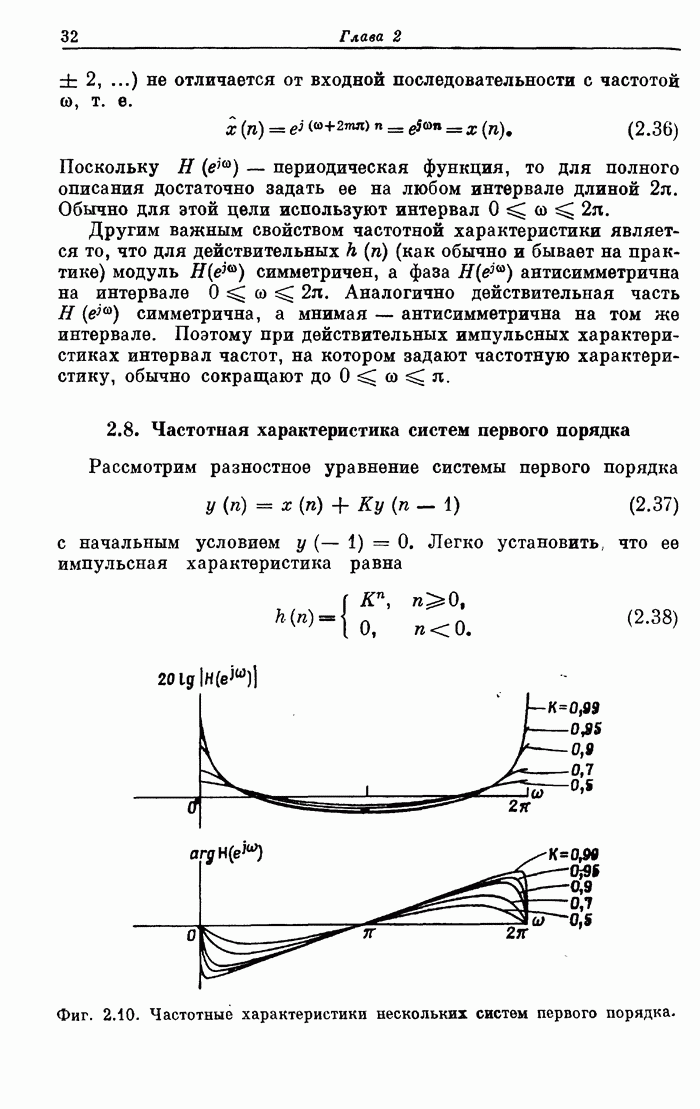
речи в человеческом организме. При разговоре грудная клетка расширяется и сжимается,
прокачивая поток воздуха из легких по трахее через голосовую щель. Если
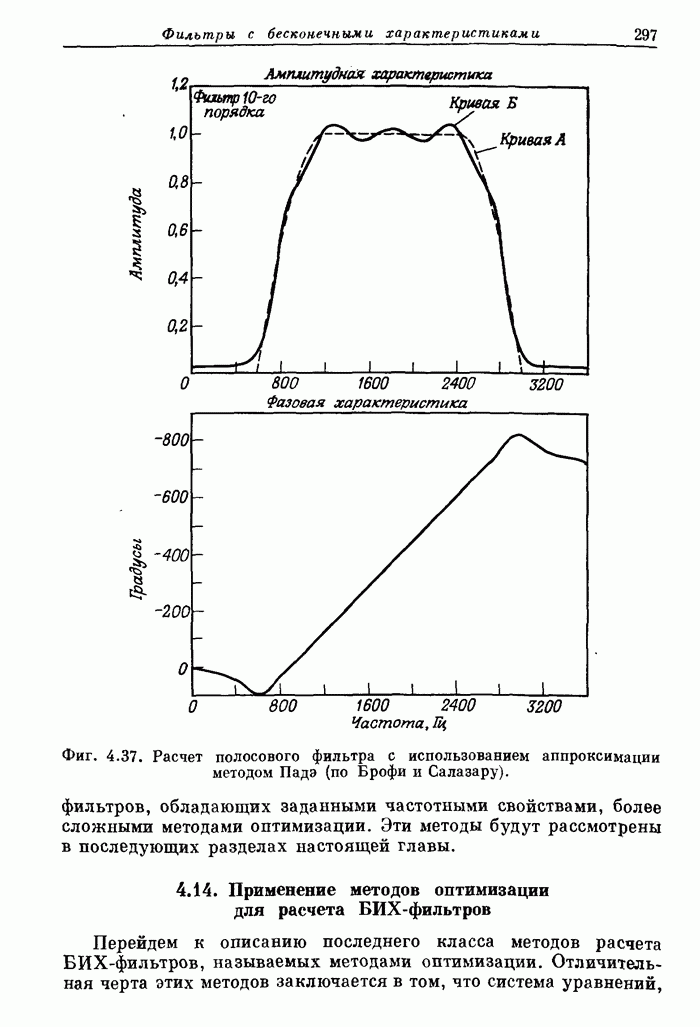
голосовые связки напряжены, как при образовании звонких звуков типа гласных, то
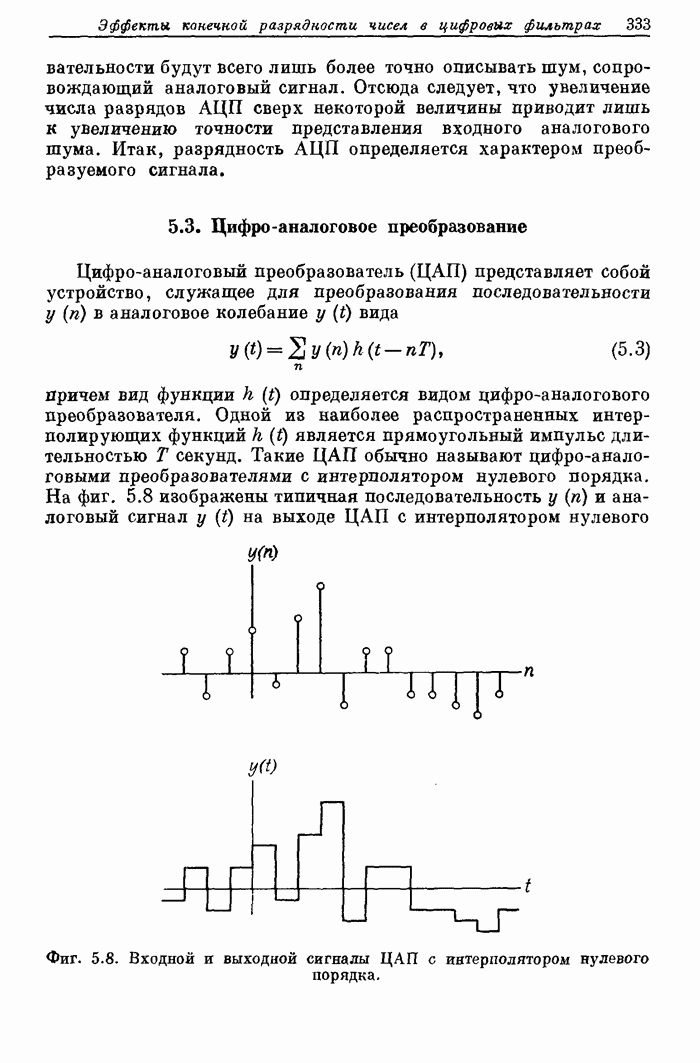
они вибрируют подобно релаксационному генератору и модулируют поток воздуха,
превращая его в короткие импульсы (порции). Если голосовые связки расслаблены,
воздух свободно проходит через голосовую щель, не подвергаясь модуляции.

Фиг. 12.1. Схема механизма образования
речи (по Фланагану).
Воздушный поток проходит через глоточную полость мимо основания
языка и в зависимости от положения мягкого нёба — через ротовую и (или) носовую
полости. Поток воздуха выходит наружу через рот или нос (или обоими путями) и
воспринимается как речь, В случае глухих звуков, таких, как s в слове snow или
p в слове pit,
голосовые связки расслаблены. При этом возможны два режима: либо
образуется турбулентный поток, когда воздух проходит через сужение в голосовом
тракте (как при образовании звука 5), либо возникает короткий взрывной процесс,
вызванный повышенным давлением воздуха за точкой перекрытия голосового тракта
(как в звуке p). При изменении положения артикуляторов (губ, языка, челюсти,
мягкого нёба) во время произнесения непрерывной речи форма отдельных полостей
голосового тракта существенно меняется. На рентгеновском снимке (фиг. 12.2)
голосового тракта мужчины показано положение некоторых артикуляторов и
пунктиром обведены контуры отдельных полостей.

Фиг. 12.2. Рентгеновский снимок голосового тракта
мужчины (по Фланагану).
1 — язык; 2 — рот; 3 — ноздри: 4 — мягкое небо; 6
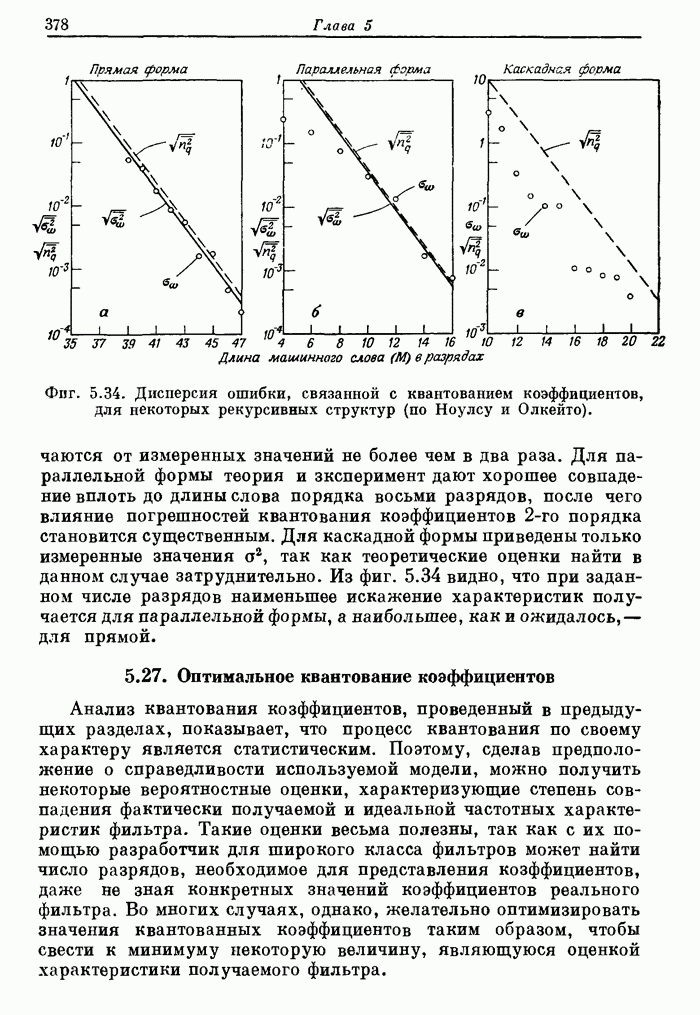
— надгортанный хрящ; 6 — кольцеобразный хрящ; 7 — голосовая щель; 8 —
трахея.
Голосовой тракт человека представляет собой неоднородную
акустическую трубку, простирающуюся от голосовой щели до губ. У взрослого мужчины
она имеет длину около 17 см и частота ее первого (четвертьволнового) резонанса
равна
 (12.1)
(12.1)
Площадь поперечного сечения акустической трубки неодинакова и
зависит от положения артикуляторов, изменяясь от 0 до 20  . Голосовой тракт имеет
некоторые устойчивые виды резонансных колебаний, называемые формантами, которые
существенно зависят от расположения артикуляторов.
. Голосовой тракт имеет
некоторые устойчивые виды резонансных колебаний, называемые формантами, которые
существенно зависят от расположения артикуляторов.

Фиг. 12.3. Схематические профили
голосового тракта и таблица формантных частот для некоторых гласных (по
Фланагану).
Профили голосового тракта для некоторых гласных и типичные для них
значения частот первых трех формант (в Гц) схематически представлены на фиг.
12.3. Спектры этих гласных показаны на фиг. 12.4. Они содержат отчетливые
резонансы. Полезно отметить, что при восприятии звуков на слух основную роль
играют только первые три форманты, хотя высшие форманты и необходимы для
обеспечения качества звучания. На этом факте основана работа нескольких систем
сжатия полосы речевого сигнала, которые будут рассмотрены ниже.

Фиг. 12.4. Спектры некоторых гласных (по
Фланагану).
Как
уже упоминалось, существуют три основных механизма возбуждения голосового
тракта. Для звонких звуков источник находится в голосовой щели и состоит из
широкополосных квазипериодических порций воздуха, формируемых колеблющимися
голосовыми связками. Для глухих звуков типа s
источник находится в точке сужения голосового тракта и является турбулентным
квазислучайным воздушным потоком. И наконец, для глухих звуков типа p (как в слове pop)
источник расположен в точке перекрытия голосового тракта и образуется под
действием скачка давления за точкой перекрытия тракта.
Предположение о независимости вида источника возбуждения и
характеристик голосового тракта является основным почти для всех систем
обработки речи. Именно эта независимость источника и тракта и позволяет ввести
передаточную функцию голосового тракта и рассматривать его возбуждение любым из
трех источников.

Фиг. 12.5. Цифровая модель образования
речи (по Шаферу).
В
большинстве случаев это предположение вполне допустимо. Однако в некоторых
случаях (например, для глухих взрывных звуков, таких, как p в слове pot) оно неверно, и основная модель образования речи становится
непригодной. В большей части данной главы будем считать, что предположение о
независимости источника и тракта справедливо. В этом случае можно построить
простую цифровую модель образования речи (фиг. 12.5). Источниками возбуждения
служат генератор импульсов с внешней синхронизацией с периодом основного тона,
а также генератор случайных чисел. Генератор импульсов через каждые  отсчетов
вырабатывает импульс, соответствующий очередной порции воздуха. Интервал между
импульсами называется периодом основного тона. Он равен величине, обратной
частоте следования порций воздуха или частоте колебания голосовых связок.
Выходная последовательность генератора случайных чисел имитирует и
квазислучайный турбулентный поток, и спад давления при образовании глухих
звуков.
отсчетов
вырабатывает импульс, соответствующий очередной порции воздуха. Интервал между
импульсами называется периодом основного тона. Он равен величине, обратной
частоте следования порций воздуха или частоте колебания голосовых связок.
Выходная последовательность генератора случайных чисел имитирует и
квазислучайный турбулентный поток, и спад давления при образовании глухих
звуков.
Каждый
из источников (или оба) может быть соединен со входом линейного цифрового
фильтра с переменными параметрами, моделирующего голосовой тракт. При этом
коэффициенты фильтра отражают свойства голосового тракта в зависимости от
времени при непрерывной речи. В среднем через каждые 10 мс коэффициенты фильтра
изменяются, отражая тем самым изменение состояния голосового тракта.
Регулировка усиления, введенная между источниками и фильтром,
позволяет управлять громкостью выходного сигнала. Последовательность на выходе
фильтра эквивалентна речевому сигналу, дискретизованному с соответствующей частотой.
Для
управления такой моделью необходимо знать зависимость соответствующих
параметров (частоты основного тона, положения переключателя, громкости и коэффициентов
фильтра) от времени. Основной задачей почти всех систем анализа речи является
оценка параметров модели по реальной речи. Задача большинства систем синтеза
речи состоит в том, чтобы, используя эти параметры, полученные некоторым
способом, образовать искусственный речевой сигнал, неотличимый на слух от
настоящей речи. В системах анализа-синтеза эти две задачи решаются совместно с
общей целью увеличения эффективности (т. е. понижения частоты
дискретизации в системе синтеза до величины, меньшей, чем при обычном
представлении речевых сигналов) и гибкости. (т. е. возможности изменять
речь некоторым желаемым образом путем управления параметрами модели). В
последующих разделах этой главы обсуждаются различные аспекты нескольких
систем, разработанных с учетом этих соображений.