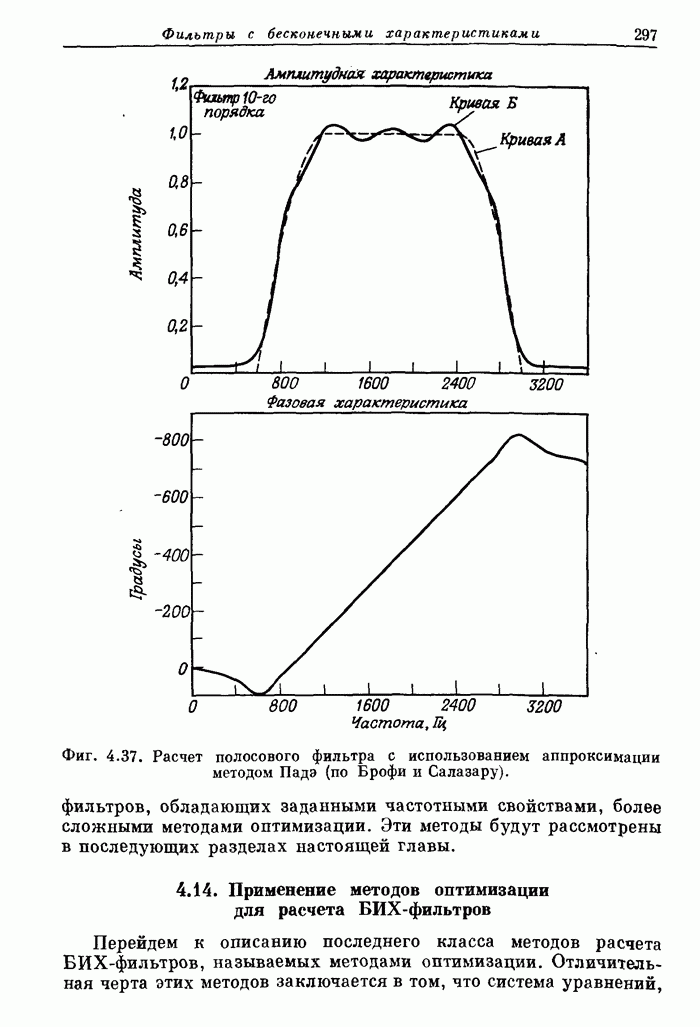
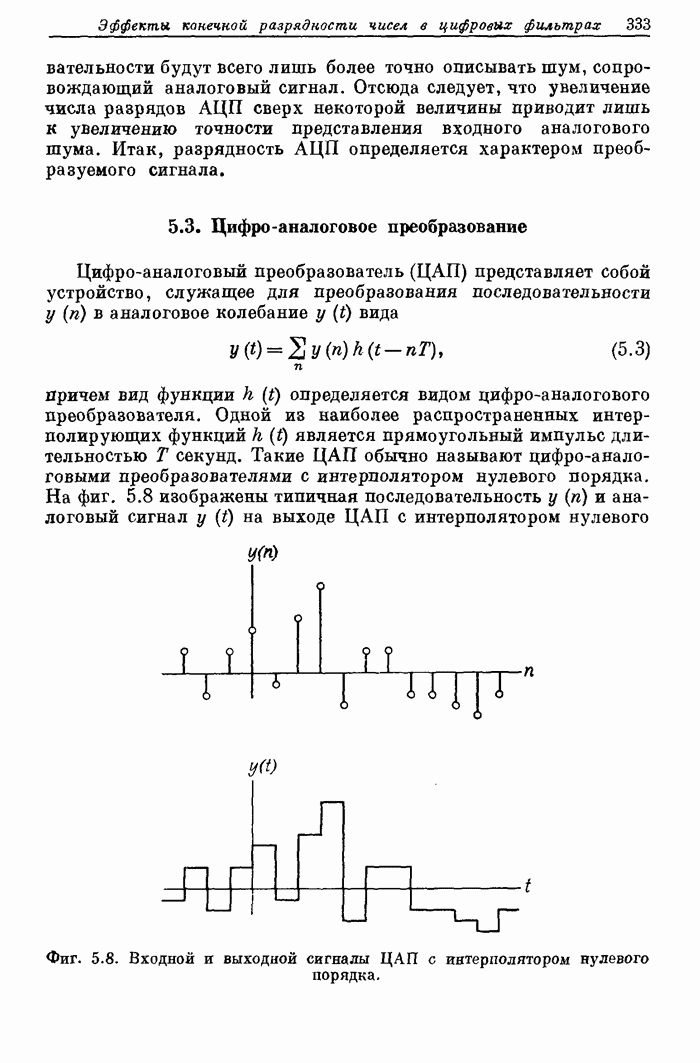
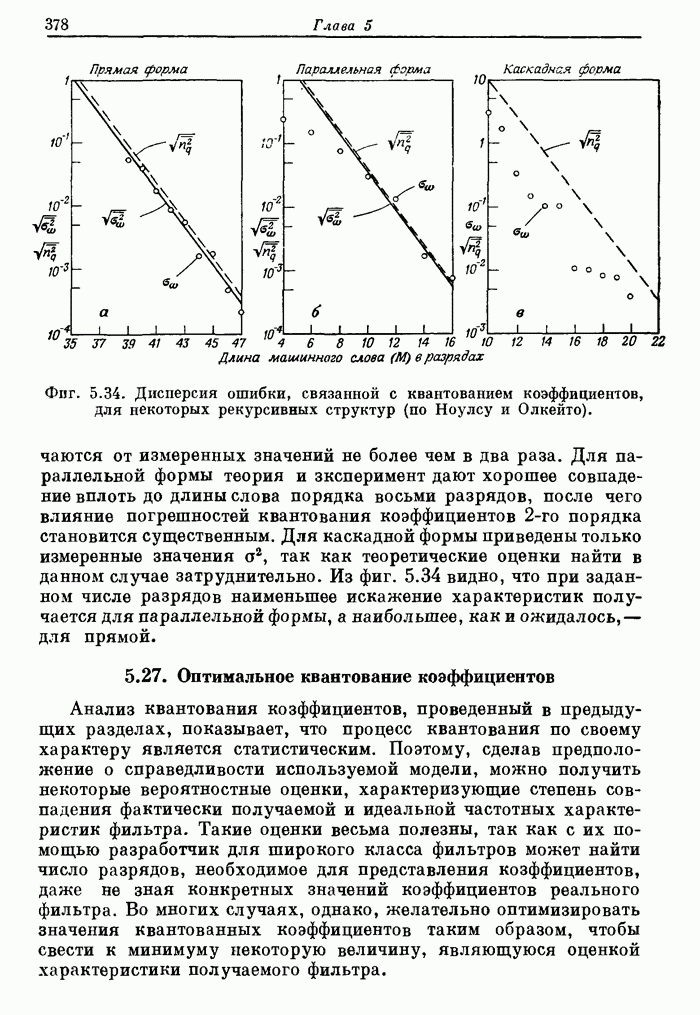
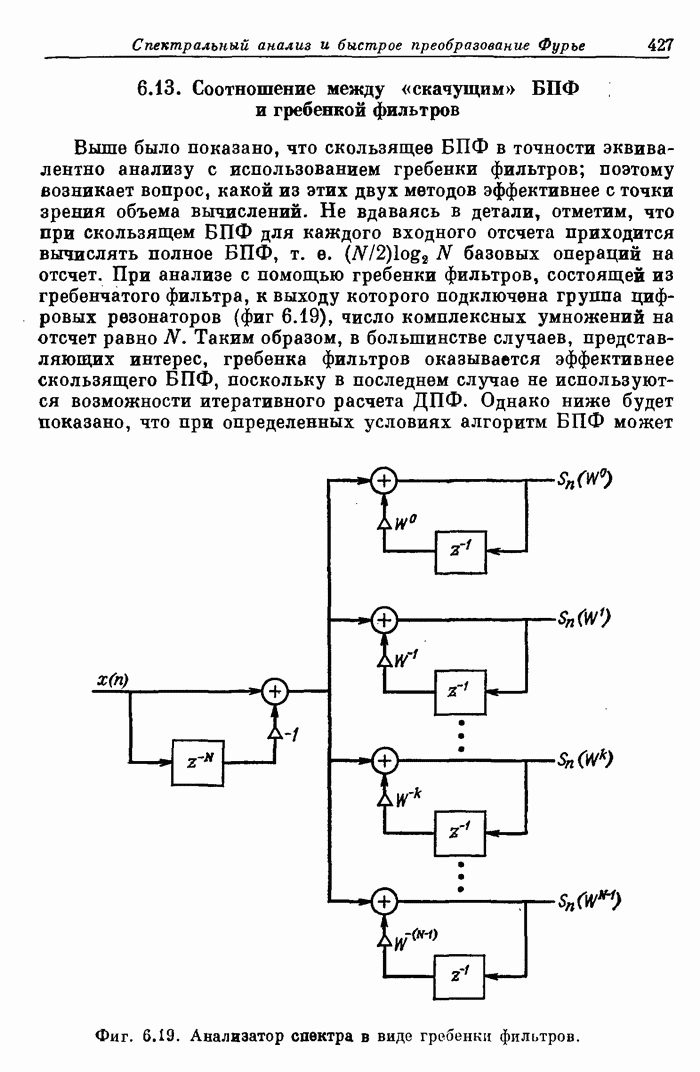
11.17. Процессор Линкольновской лаборатории LSP (Lincoln Signal Processor 2) для обработки сигналов
Разработка
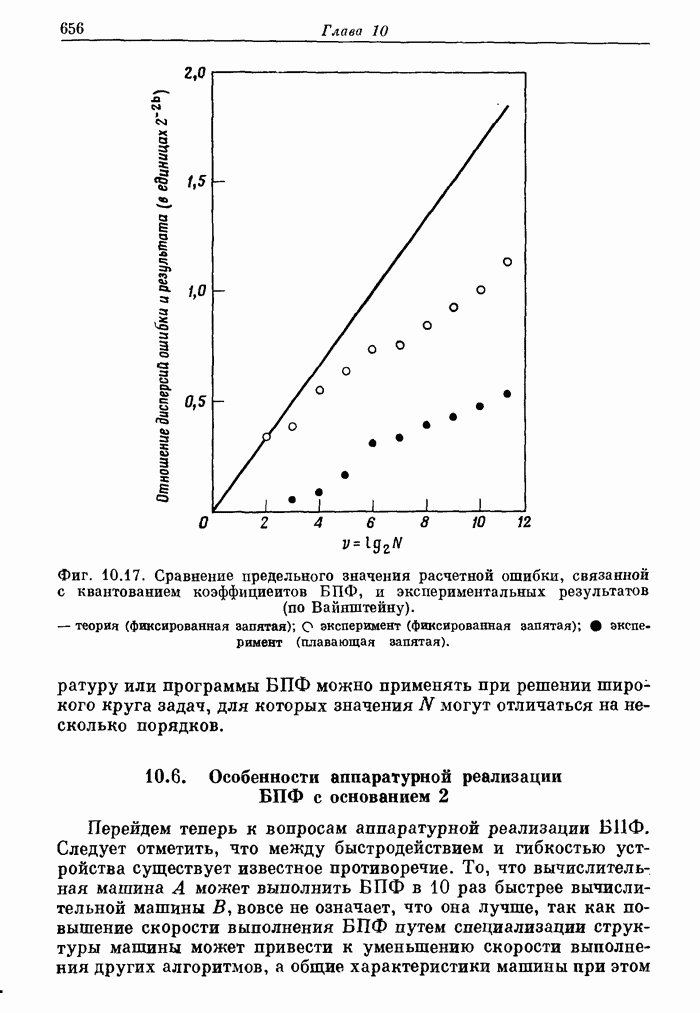
FDP в значительной мере была экспериментом, позволившим накопить опыт
применения параллелизма при обработке сигналов. В целом эту разработку можно
считать успешной и полезной, так как она доказала, что подобное сочетание
гибкости и быстродействия в среднем более выгодно, чем высокое быстродействие
без гибкости или гибкость без быстро действия. Кроме того, приобретенный опыт
позволяет разрабатывать и более эффективные системы обработки сигналов. Чтобы
показать это, рассмотрим сначала структуру FDP.
Во-первых, следует отметить, что в FDP,
как и в большинстве универсальных ЦВМ, много времени расходуется на обращение
к памяти, индексацию и переходы. Во-вторых, для эффективного использования
четырех параллельных АУ приходится с большими затратами времени составлять
весьма сложные программы. (Накопление библиотеки стандартных программ
впоследствии ускорит процесс программирования.) В-третьих, FDP построен на базе ЭСЛ-микросхем
с невысокой степенью интеграции, быстродействие которых примерно вдвое ниже,
чем у современных улучшенных ЭСЛ-микросхем. Предварительный анализ показал, что
можно построить процессор большей мощности, более дешевый и компактный и проще
программируемый, чем FDP.
В-четвертых, при проектировании FDP
много внимания уделялось упрощению системы ввода—вывода, которая, однако, оказалась
неудобной для работы в реальном времени. В-пятых, объем памяти FDP ограничен архитектурой процессора. В-шестых, структура FDP малопригодна для обработки чисел с плавающей запятой, а также для
выполнения программ численного анализа, требующих высокой точности.
При
разработке процессора LSP2
была сделана попытка за счет использования более современных элементов устранить
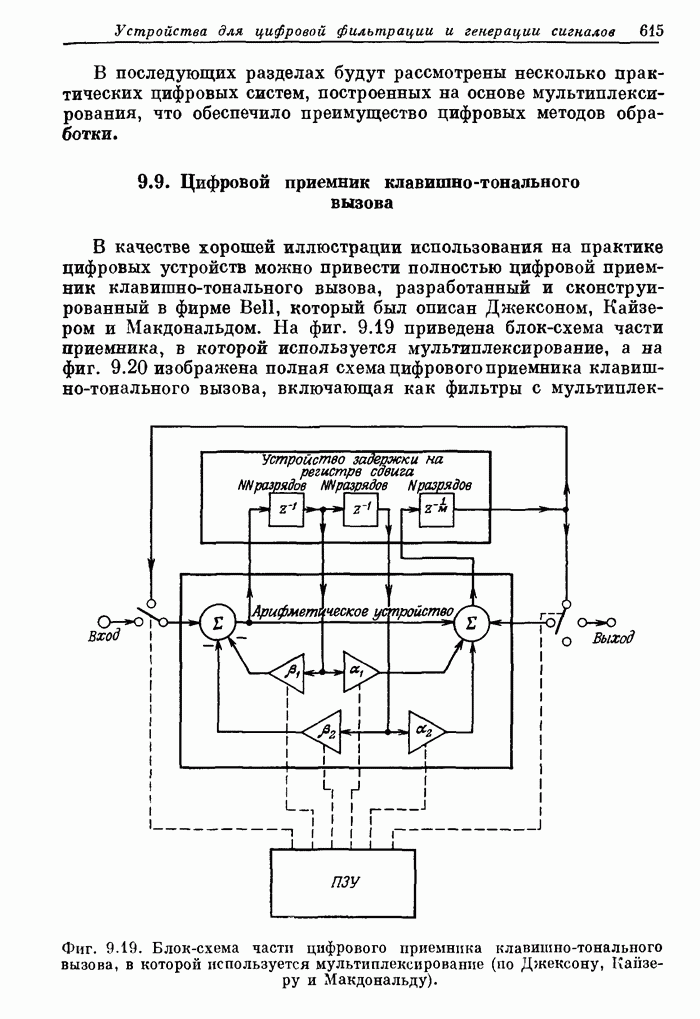
некоторые из перечисленных недостатков. Общая структурная схема процессора
изображена на фиг. 11.14. Основой схемы является распределительная система,
содержащая три шины. К ней подключены быстродействующее ЗУ небольшой емкости  , различные функциональные
блоки и ЗУ большого объема
, различные функциональные
блоки и ЗУ большого объема  , связанное с внешними устройствами и
ЗУ программы
, связанное с внешними устройствами и
ЗУ программы  .
.
Перечислим
некоторые соображения, определившие структуру LSP2:
1. Быстродействующее
ЗУ вводится для того, чтобы освободить
многие операции с индексами и обращения к памяти от вычислений, необходимых
для этих операций. Для пояснения введем сначала формат команды обращения к ЗУ :
Она
содержит адреса  и
и
 трех
полей памяти , а также код КОП,
определяющий нужный функциональный блок. По этой команде из двух полей ЗУ , обозначенных через
трех
полей памяти , а также код КОП,
определяющий нужный функциональный блок. По этой команде из двух полей ЗУ , обозначенных через  , извлекаются два
числа и по шинам передаются
на входы выбранного функционального блока. Результат (умножения, сложения и
т. д.) поступает на шину и записывается в ЗУ по адресу . Все это происходит за один
командный цикл, длительность которого (в зависимости от исполняемой операции)составляет
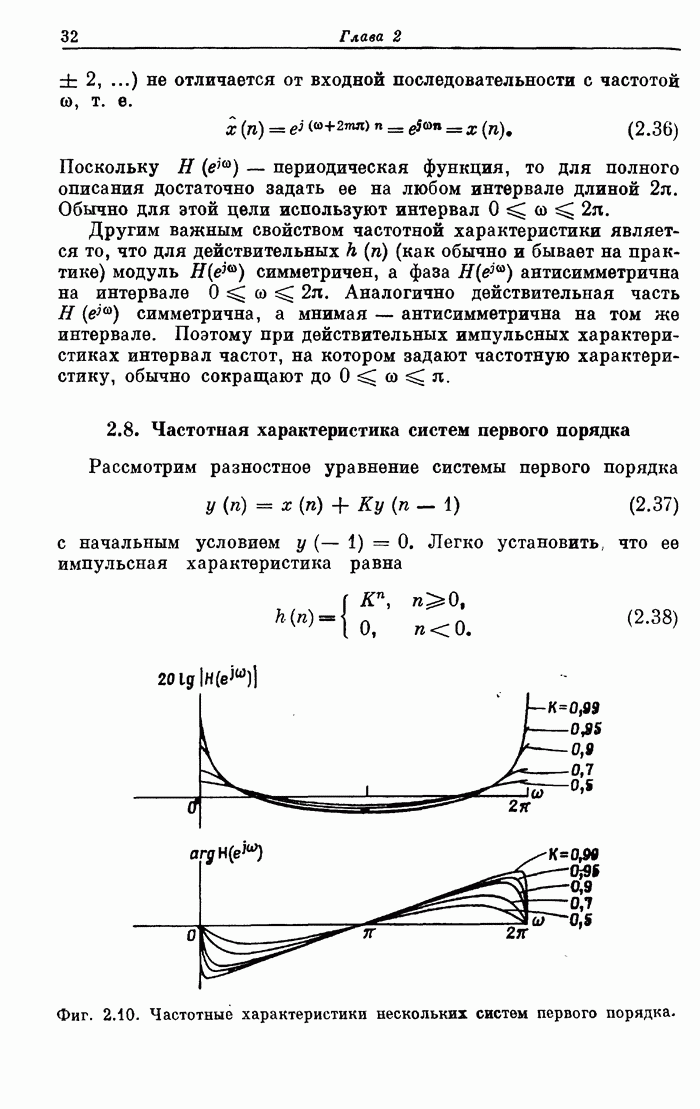
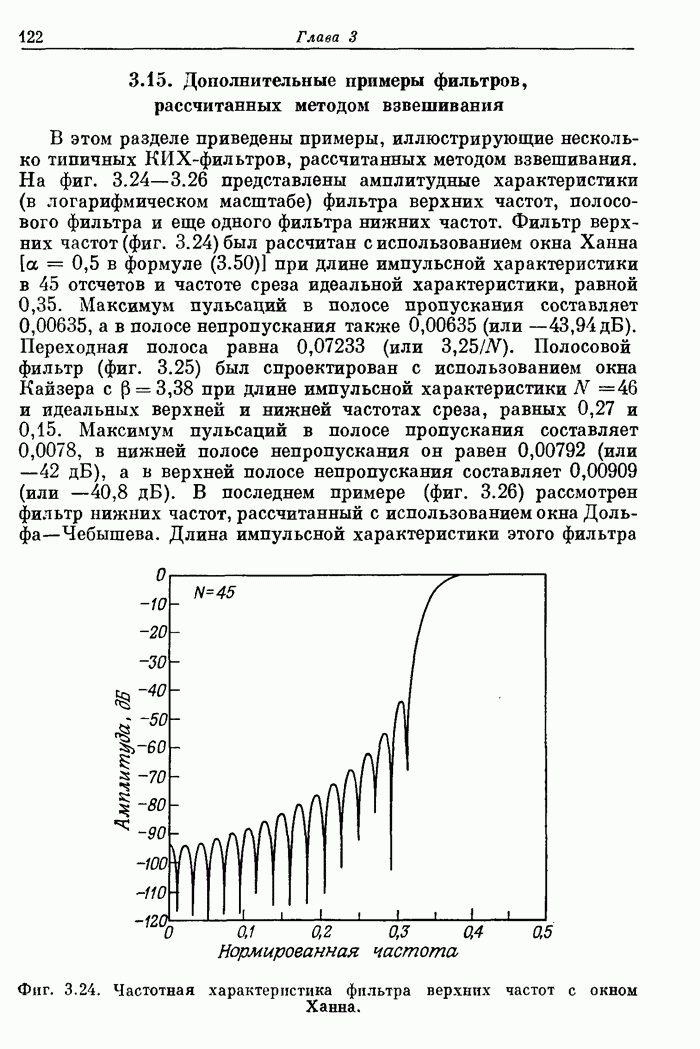
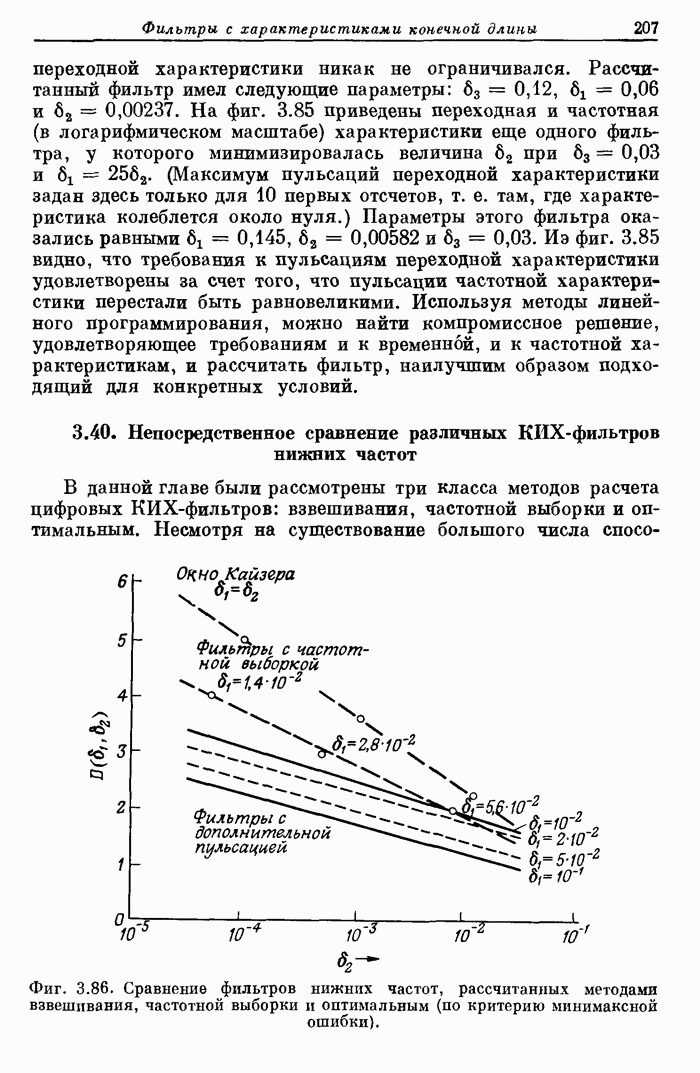
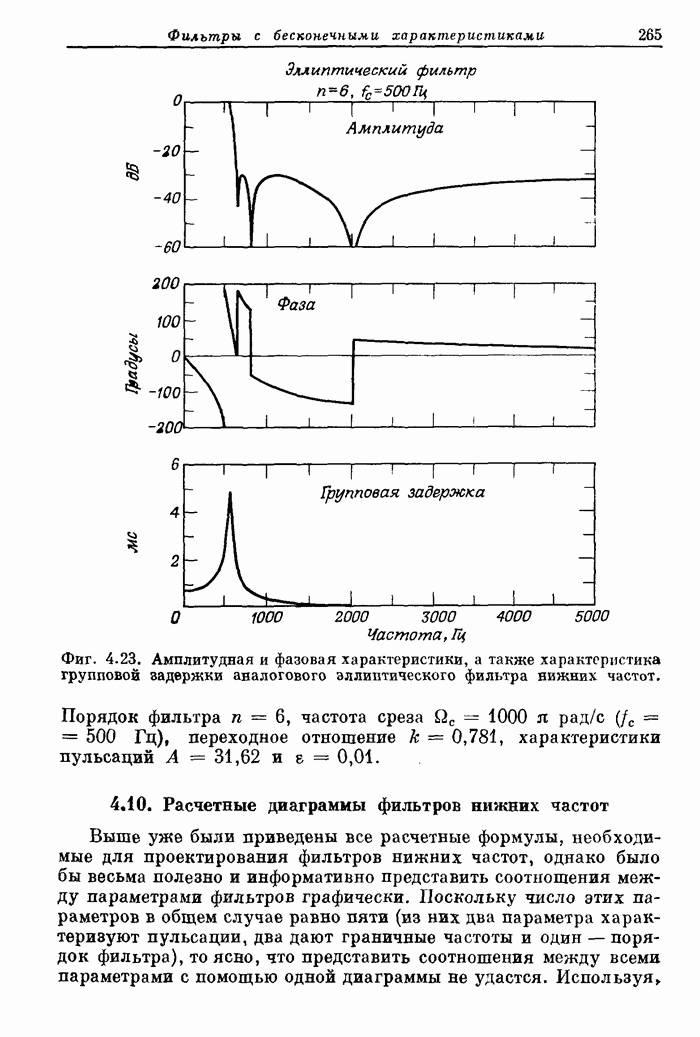
от 60 до 150 нс. На фиг. 11.15 схематично показано, как осуществляется
управление при выполнении команд.
, извлекаются два
числа и по шинам передаются
на входы выбранного функционального блока. Результат (умножения, сложения и
т. д.) поступает на шину и записывается в ЗУ по адресу . Все это происходит за один
командный цикл, длительность которого (в зависимости от исполняемой операции)составляет
от 60 до 150 нс. На фиг. 11.15 схематично показано, как осуществляется
управление при выполнении команд.

Фиг.
11.14. Блок-схема процессора  .
.

Фиг.
11.15. Временная последовательность выполнения операции в процессоре .
Для
примера рассмотрены три последовательных сложения. После вызова команды,
занимающего 60 нс, за 30 нс числа извлекаются из памяти и подаются на шины . Для обеспечения
такого быстродействия намять содержит два независимых ЗУ для
адресов  ,
обращение к которым происходит одновременно. Вслед за этим производится
собственно сложение, занимающее 20 нс. Результат операции возвращается в не сразу: сначала
он заносится во вспомогательный регистр, а записывается в во время выполнения следующей
команды. Такой прием позволяет сэкономить время, уходящее на запись в . Трудностей с
условными переходами не возникает, поскольку результат сложения имеется во
вспомогательном регистре, из которого поступают данные, требующиеся при вызове
условного перехода.
,
обращение к которым происходит одновременно. Вслед за этим производится
собственно сложение, занимающее 20 нс. Результат операции возвращается в не сразу: сначала
он заносится во вспомогательный регистр, а записывается в во время выполнения следующей
команды. Такой прием позволяет сэкономить время, уходящее на запись в . Трудностей с
условными переходами не возникает, поскольку результат сложения имеется во
вспомогательном регистре, из которого поступают данные, требующиеся при вызове
условного перехода.
Преимущества
использования быстродействующей оперативной памяти обусловлены тем, что с ее
помощью можно обрабатывать значительные числовые массивы без обращения к
основному ЗУ и даже без индексации. Хорошим подтверждением этому служит
выполнение БПФ небольшого объема. Допустим, что содержит 64 слова и нужно выполнить
32-точечное БПФ. После занесения всех 32 чисел в программа БПФ может быть выполнена
полностью без обращений к и без переходов. Можно показать, что
в этом случае БПФ вычисляется в почти в шесть раз быстрее, чем в  . С учетом того,
что гораздо
проще (но работает почти вдвое быстрее), такое улучшение архитектуры системы
следует считать значительным шагом вперед.
. С учетом того,
что гораздо
проще (но работает почти вдвое быстрее), такое улучшение архитектуры системы
следует считать значительным шагом вперед.
2.
Введение функциональных блоков связано с успехами в области создания быстродействующих
микросхем. Это позволило ввести в процессор больше элементов, используемых
только для арифметических операций, и не загружать их реализацией множества
других функций. На первый взгляд такой подход кажется менее экономичным, но
экономия на схемах управления, упрощение структуры и увеличение модульности
процессора оправдывают его. Например, при наличии функционального блока с двумя
умножителями для выполнения базовой операции БПФ требуется шесть команд. Если
же имеется блок умножения комплексных чисел, то для получения того же
результата достаточно трех команд. Аналогично нетрудно ввести и другие
специализированные функциональные блоки. Так, некоторые образцы , предназначенные
для ускорения решения некоторых частных задач, могут иметь специализированные
блоки деления или извлечения квадратного корня. В большинстве ЦВМ добавление
специализированных функциональных блоков связано с расходами на переходные
(согласующие) устройства. В такие блоки являются просто
сменными узлами.
3.
В основным
ЗУ является .
В зависимости от размеров машины адрес может состоять из 12 или 16 разрядов. С
помощью специального переключения предусмотрено увеличение разрядности адресов
с 12 до 16. Адресация ЗУ может быть прямой в соответствии с
кодом команды либо косвенной с учетом регистров . Это означает, что играет сразу две
роли: служит памятью для обрабатываемых чисел и запоминает индексы, т. е. для
этих действий не требуется параллельно работающих блоков. Но это также
означает, что вычисления и операции с индексами нельзя проводить одновременно,
как в ,
поэтому для могут
потребоваться дополнительные команды. Однако в силу принципиально
последовательной логики работы программирование для него должно
быть более простым.
4.
Связь машины с внешними устройствами осуществляется через память ЗУ имеет две
входные и две выходные линии передачи данных, а также шесть управляющих
(командных) линий, соединяющих его с другими устройствами. Поскольку многие операции
выполняются с помощью без
привлечения ,
а вводом и выводом управляют два отдельных устройства, LSP2
может весьма эффективно работать в реальном времени. Имеется в виду, что обе
части программы (как вычислительная, так и осуществляющая ввод—вывод)
выполняются без потерь времени. В частности, в имеются возможности приоритетного
прерывания и прямого доступа к ЗУ , что позволяет объединять несколько
процессоров для параллельной, причем весьма эффективной работы.
В
настоящее время система находится в стадии разработки и,
чтобы оценить ее характеристики, необходимо накопить опыт работы с ней. Этот
краткий обзор приведен здесь потому, что разработка является естественным
следствием опыта, накопленного при работе с , а также продолжающегося развития
техники быстродействующих микросхем.