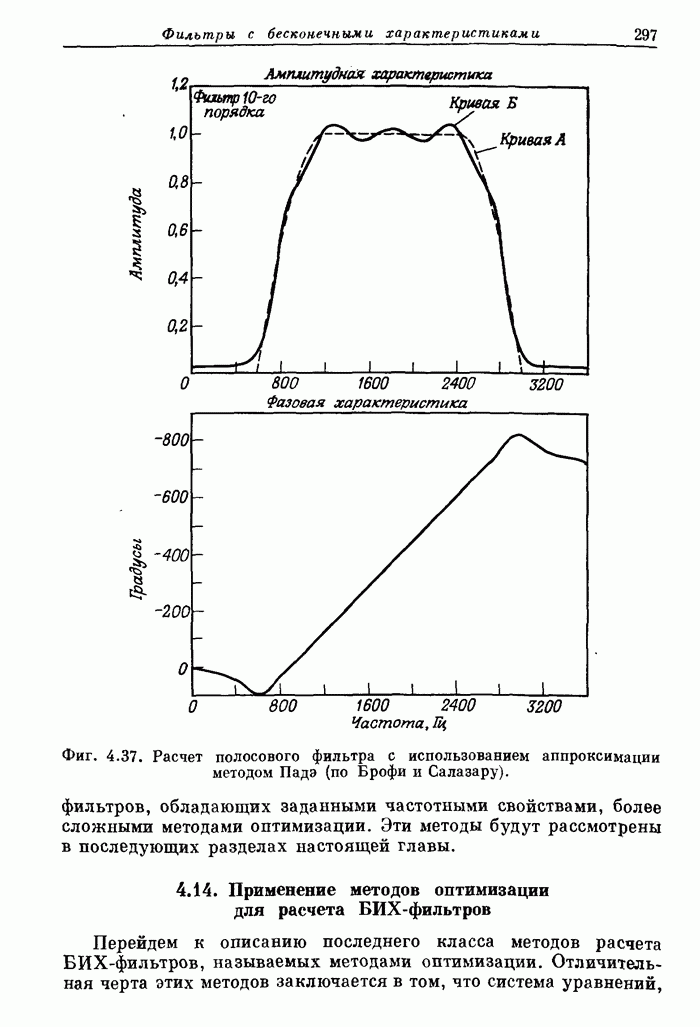
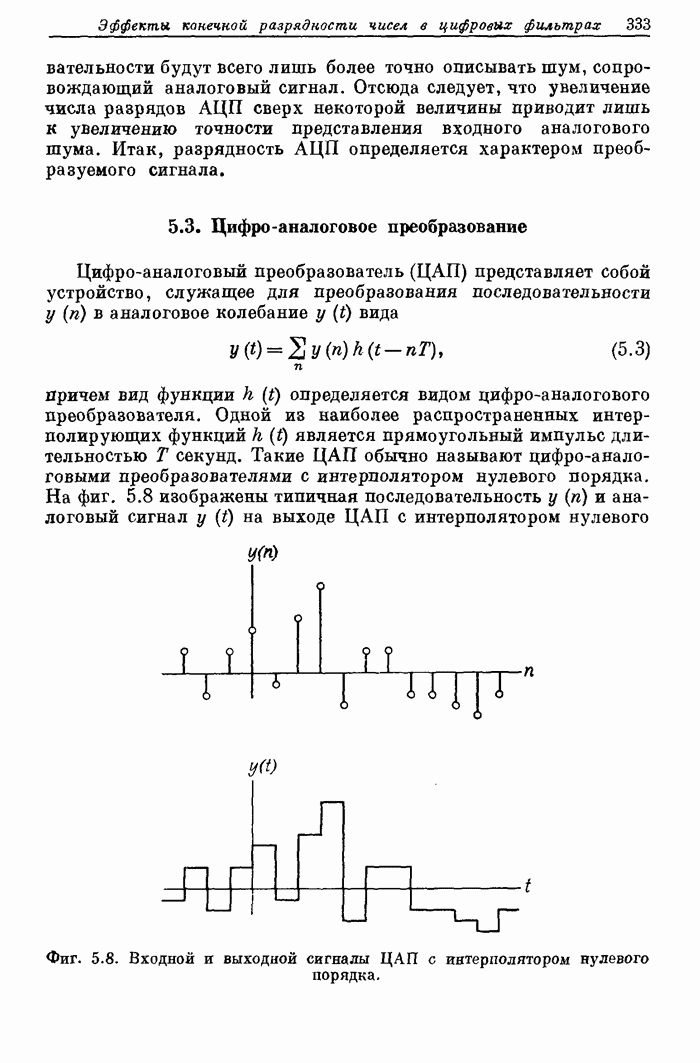
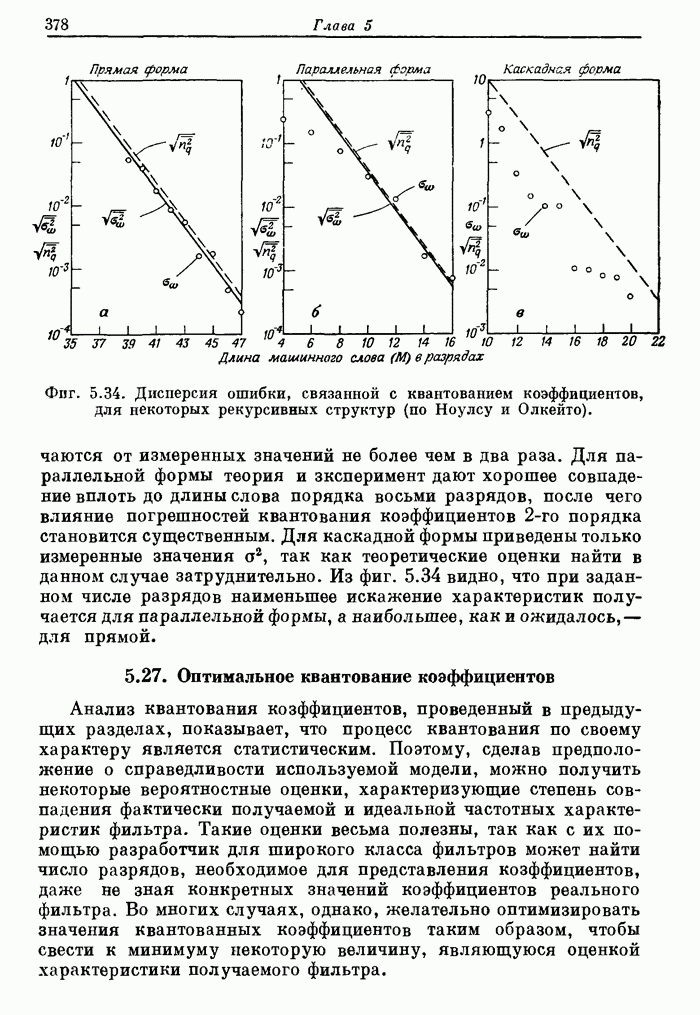
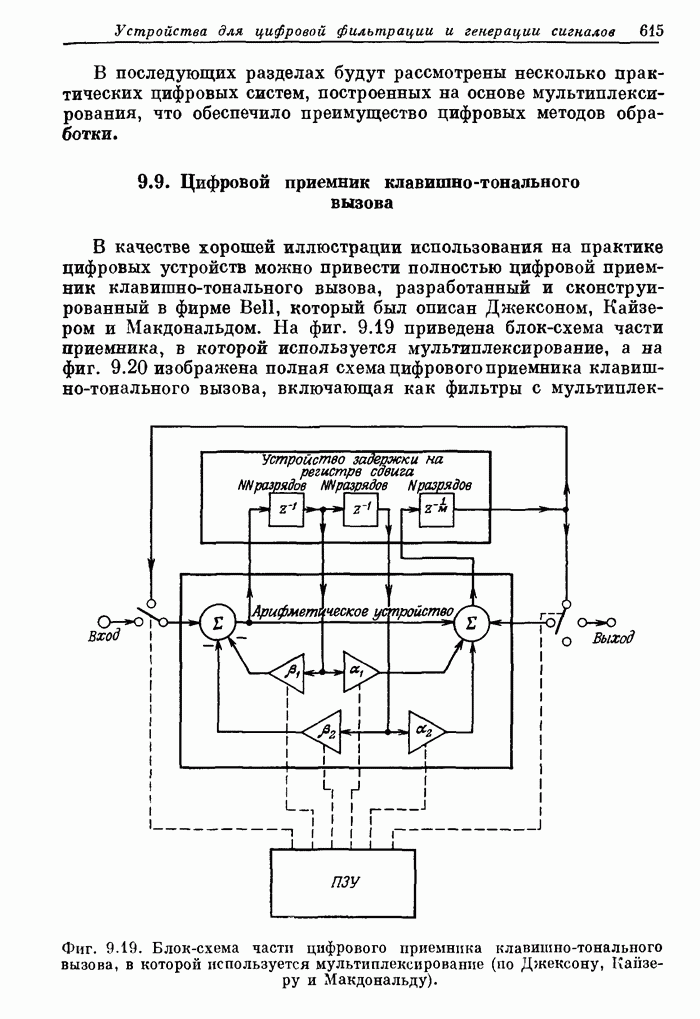
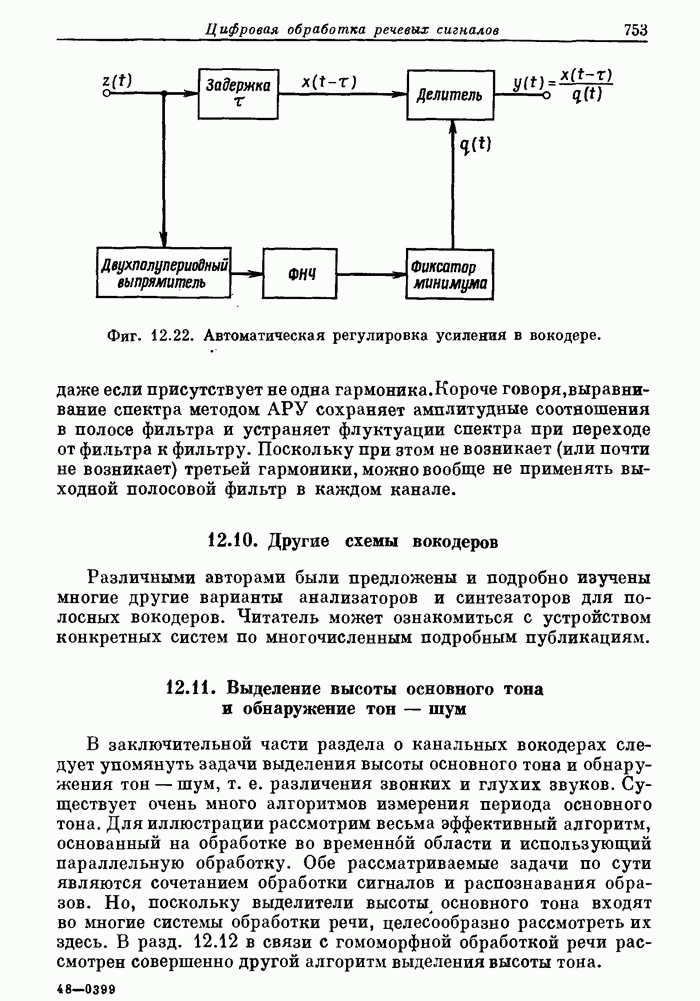
12.20. Система речевого ответа для вычислительной машины
Как уже отмечалось, параметрическое представление речи (с помощью основного тона и формант) применительно к системам речевого ответа для ЦВМ имеет два важных достоинства. Во-первых, так как частота изменения формант сравнима с частотой перемещения элементов голосового тракта, то скорость передачи отсчетов, представляющих параметры, может быть низкой. Следовательно, представление речи формантами является экономичным способом хранения речевой информации в цифровом виде. Вторым преимуществом формантного представления речи является присущая ему гибкость. Поскольку смысловая информация содержится в формантах, а мелодическая (т. е. интонация, темп речи и т. д.) — в периоде основного тона и временном распределении речи, то формантное представление позволяет разделить, «что именно сказано» и «как сказано». Эта гибкость и экономичность позволили построить простую систему речевого ответа для ЦВМ, в которой отдельные звуковые элементы с использованием сглаживания дают связную речь.
Блок-схема системы для синтеза связной речи на основе списка слов, закодированных формантами, приведена на фиг. 12.47. Отдельные слова (или фразы), произнесенные человеком, подвергаются формантному анализу. Через каждые 10 мс определяются частоты трех формант  , амплитуды звонкой и глухой составляющих
, амплитуды звонкой и глухой составляющих  , период основного тона (Р), а также расположение нуля и полюса
, период основного тона (Р), а также расположение нуля и полюса  , служащих для имитации глухих звуков. Эти управляющие параметры сглаживаются с помощью цифрового фильтра, моделируемого на ЦВМ, повторно дискретизуются с частотой, определяемой теоремой о дискретизации сигналов с ограниченным спектром (обычно 33 1/3 Гц), квантуются и заносятся в память, образуя справочную библиотеку.
, служащих для имитации глухих звуков. Эти управляющие параметры сглаживаются с помощью цифрового фильтра, моделируемого на ЦВМ, повторно дискретизуются с частотой, определяемой теоремой о дискретизации сигналов с ограниченным спектром (обычно 33 1/3 Гц), квантуются и заносятся в память, образуя справочную библиотеку.
(см. скан)
Фиг. 12,47 Блок схема системы речевого ответа.
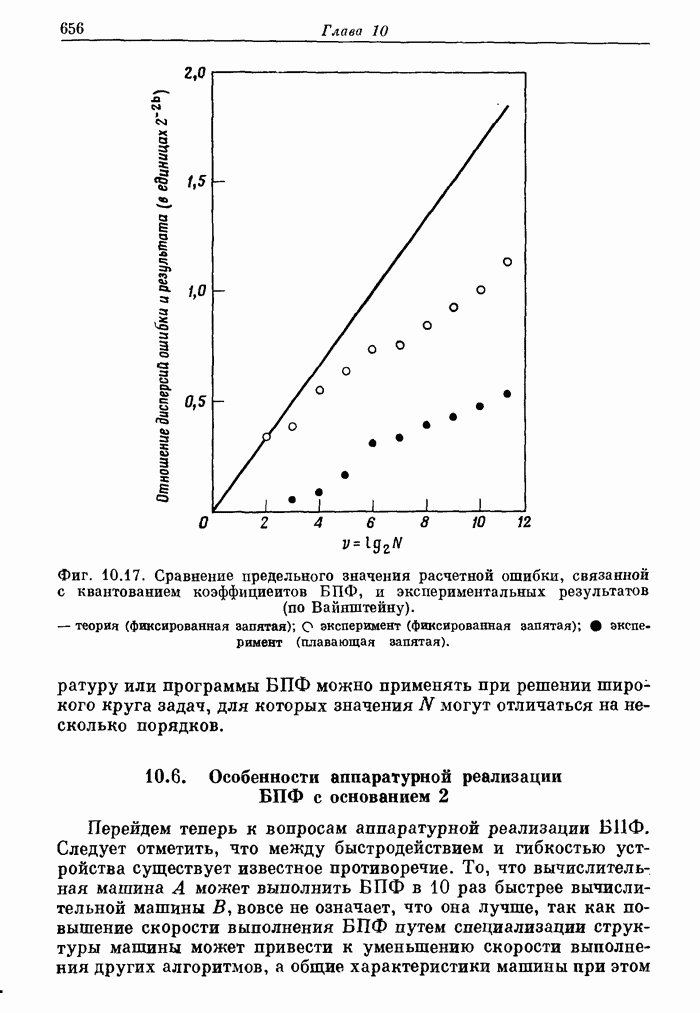
Типичная скорость заполнения памяти для хранения управляющих параметров составляет 700 бит/с, если значения периода основного тона сохраняются. Однако чаще всего значения периода не запоминаются, а вычисляются с помощью специальной программы составления речи. Тогда скорость заполнения памяти равна 533 1/3 бит/с. В табл. 12.1 показано, из чего складывается эта скорость. Данные, приведенные в таблице, были получены путем экспериментального исследования влияния сглаживания и квантования на восприятие синтезированной речи.
Таблица 12.1. Кодирование формантных параметров

Как указано в табл. 12.1, каждые 10 мс определяется, какой произносится звук: звонкий или глухой и результат V/U представляется одноразрядным двоичным числом. Поэтому каждый из заносимых в память наборов параметров может быть отнесен либо только к звонкому, либо к] глухому звуку. Следует отметить, что частота поступления наборов управляющих параметров (33 1/3 Гц) втрое ниже частоты следования отсчетов сигнала V/U.
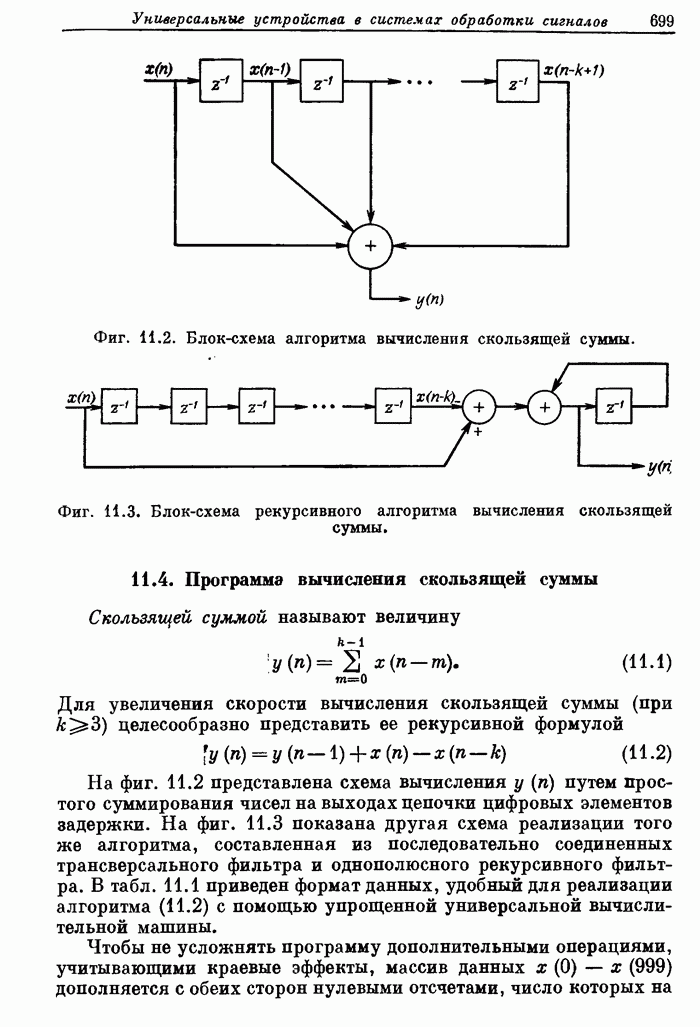
Слова и фразы, представленные формантами, легко приспособить для использования в программе синтеза речи. Слова можно удлинить или укоротить; форманты легко изменить; можно ввести закон изменения основного тона, отличающийся от исходного. Таким образом, характеристики речевого тракта представлены в форме, достаточно гибкой для согласования с временной синхронизацией и высотой основного тона, задаваемыми программой составления речи.
В нижней части фиг. 12.47 показано, каким образом система составляет синтезированное сообщение, сочетая слова и фразы из справочной библиотеки. Во-первых, программа-ответчик для составления каждого конкретного ответа запрашивает последовательность слов. С помощью программы составления речи получаются (с использованием вспомогательной программы) данные о распределении времени в ответной фразе в виде значений продолжительности каждого слова, а затем последовательно извлекаются параметры слов. Слова корректируются так, чтобы их длина соответствовала выбранной длине слов.
(см. скан)
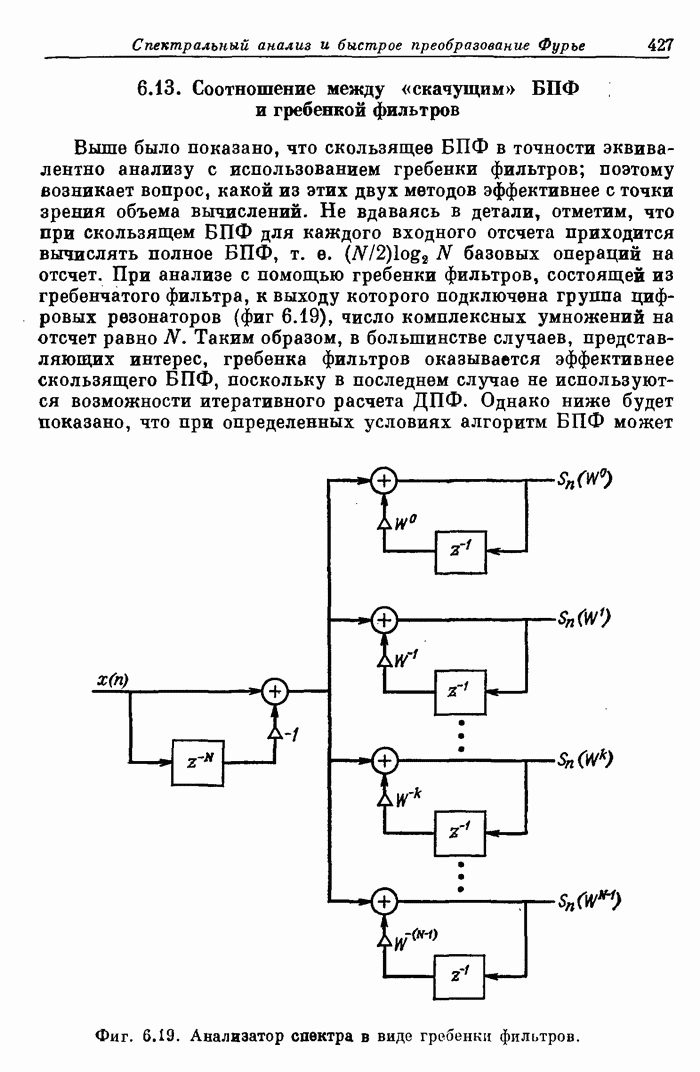
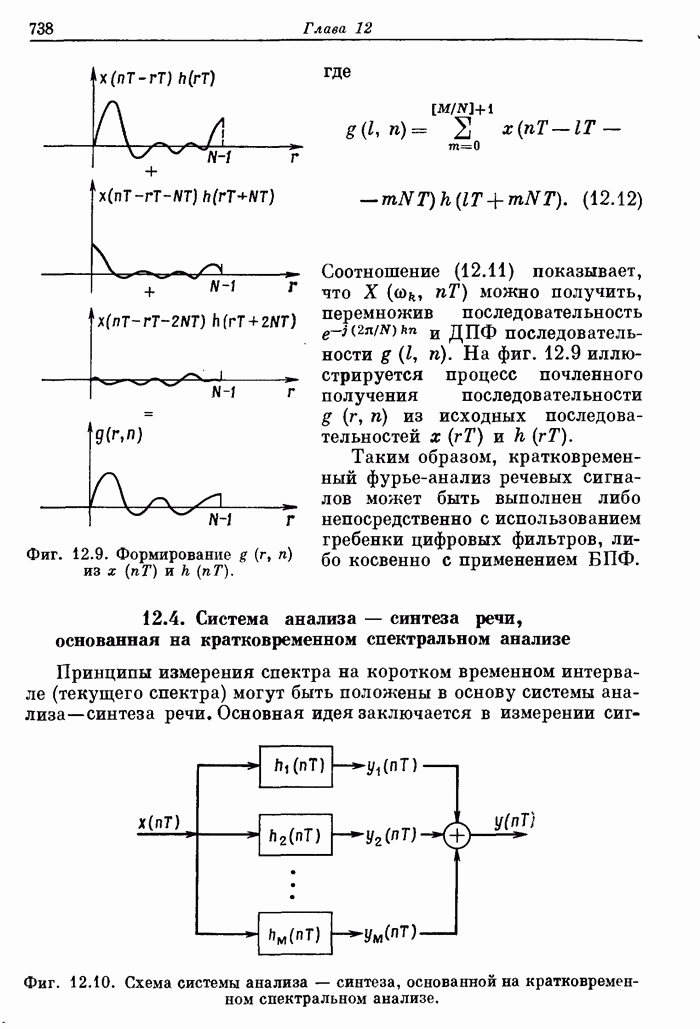
Фиг. 12.48. Спектрограммы телефонного номера, произнесенного человеком и синтезатором речи.
После этого осуществляются сглаживание и интерполяция значений формантных параметров, если конец некоторого слова и начало следующего содержат звонкие звуки. Для этого используется алгоритм интерполяции, имитирующий переход формант от слова к слову в естественной речи. Наконец, для всего ответа получается закон изменения частоты основного тона. Все вычисленные параметры передаются в специализированный цифровой синтезатор речи. Непрерывный синтезированный речевой сигнал получается с помощью цифро-аналогового преобразователя.
Описанная система речевого ответа была использована для голосового воспроизведения телефонных номеров и соединений по устному запросу с помощью вычислительной машины. Из сравнения спектрограмм типичного телефонного номера, произнесенного человеком и машиной (фиг. 12.48), видно, что моменты произнесения звуков и значения формант довольно хорошо согласуются.