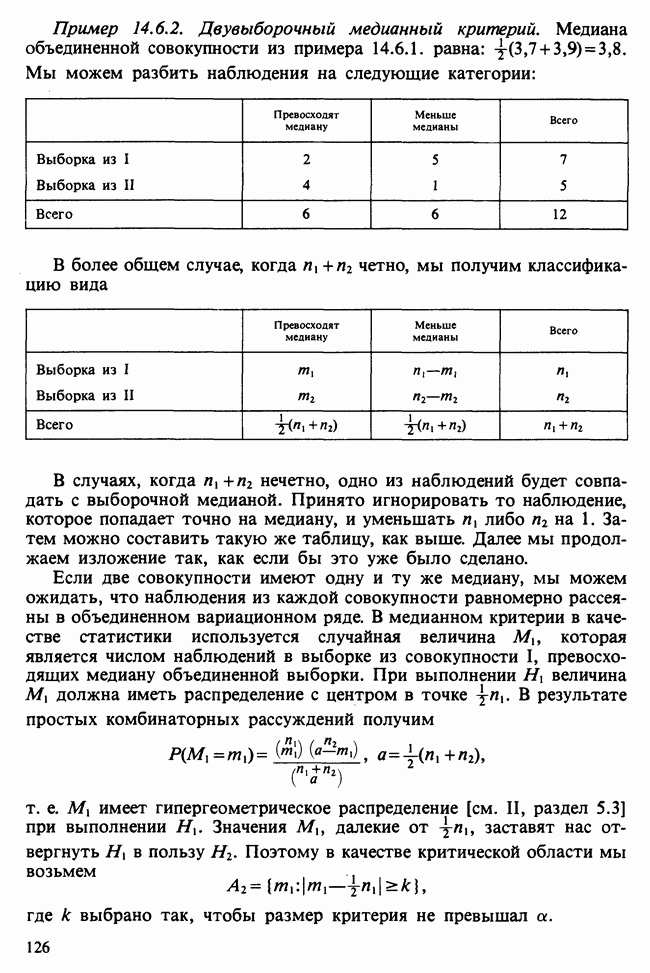
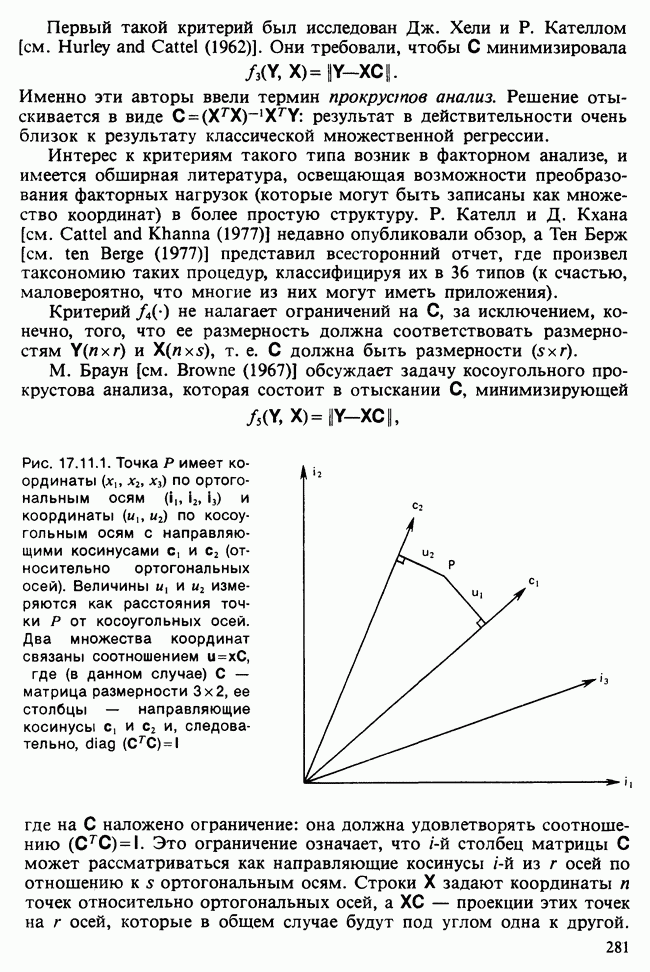
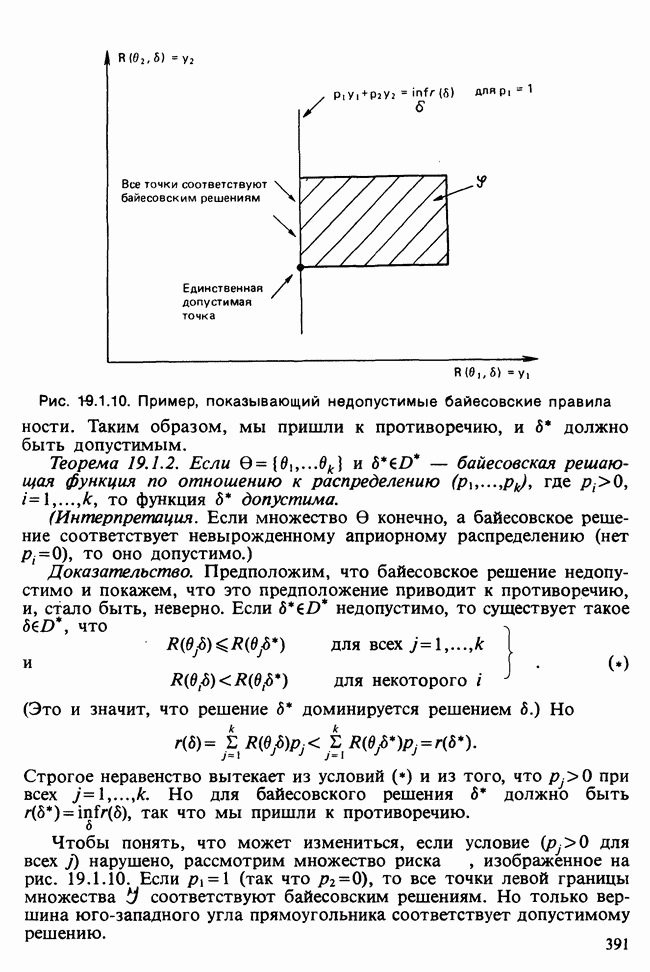
минимальное значение  . В [Morrison (1972), с. 241] показано, что это правило эквивалентно правилу, основанному на
. В [Morrison (1972), с. 241] показано, что это правило эквивалентно правилу, основанному на  .
.
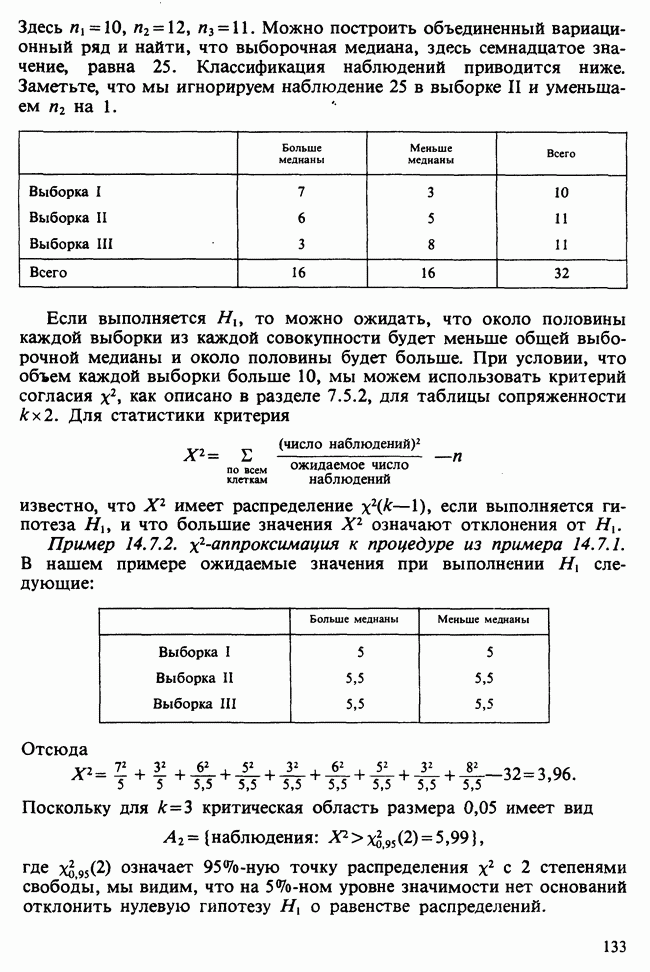
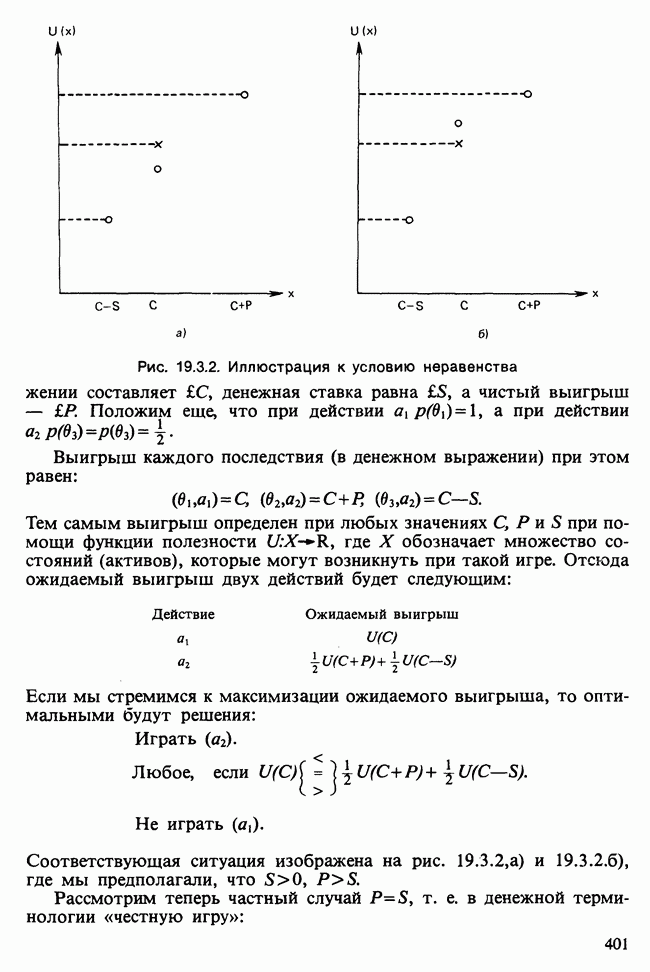
Рао [см. Rao (1973)] предложил правило, основанное на полной средней потере от ошибочной классификации в некоторую, например  совокупность:
совокупность:

где  — вероятность ошибочной классификации наблюдения из совокупности
— вероятность ошибочной классификации наблюдения из совокупности  в совокупность
в совокупность  а потери
а потери  определены раньше
определены раньше  Выбирается совокупность, для которой значение потери минимально. Предполагается, что распределения совокупностей известны. Эйтчинсон и Дансмор [см. Aitchinson and Dunsmore (1975), гл. 11] рассматривают байесовский подход, когда параметры неизвестны, но известна форма функций плотности. Неизвестным параметрам приписываются некоторые априорные распределения, и по заданным для каждой совокупности выборкам вычисляются апостериорные распределения.
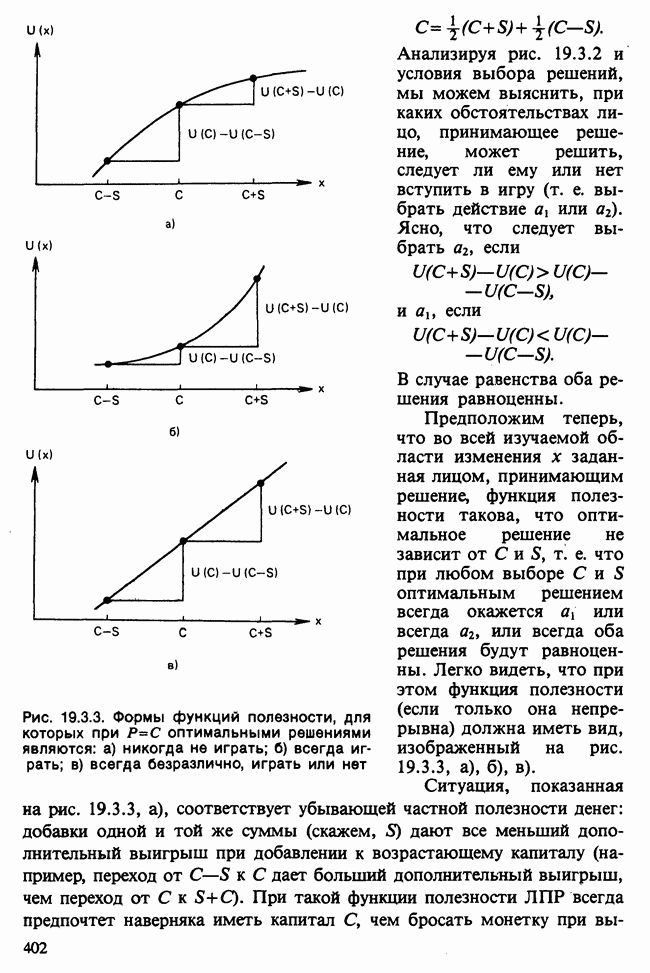
Выбирается совокупность, для которой значение потери минимально. Предполагается, что распределения совокупностей известны. Эйтчинсон и Дансмор [см. Aitchinson and Dunsmore (1975), гл. 11] рассматривают байесовский подход, когда параметры неизвестны, но известна форма функций плотности. Неизвестным параметрам приписываются некоторые априорные распределения, и по заданным для каждой совокупности выборкам вычисляются апостериорные распределения.
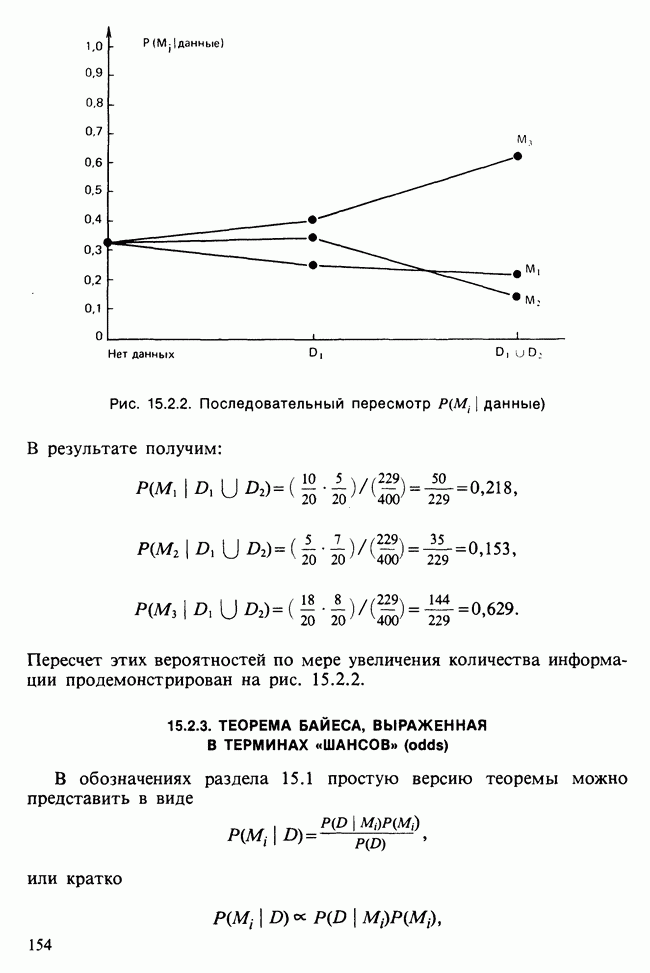
Новое наблюдение х классифицируется с помощью вычисления предиктивной вероятности [см. гл. 15]:

и выбирается совокупность с наибольшим значением такой вероятности. Значение  есть маргинальное предиктивное распределение для х в предположении, что х принадлежит совокупности
есть маргинальное предиктивное распределение для х в предположении, что х принадлежит совокупности  — вероятность появления наблюдения из совокупности
— вероятность появления наблюдения из совокупности 
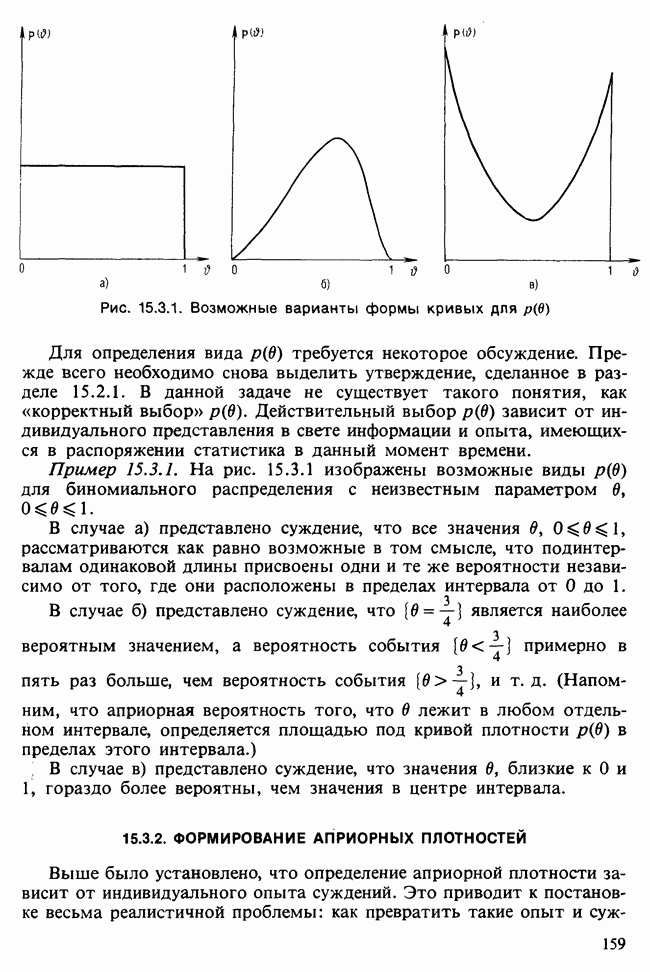
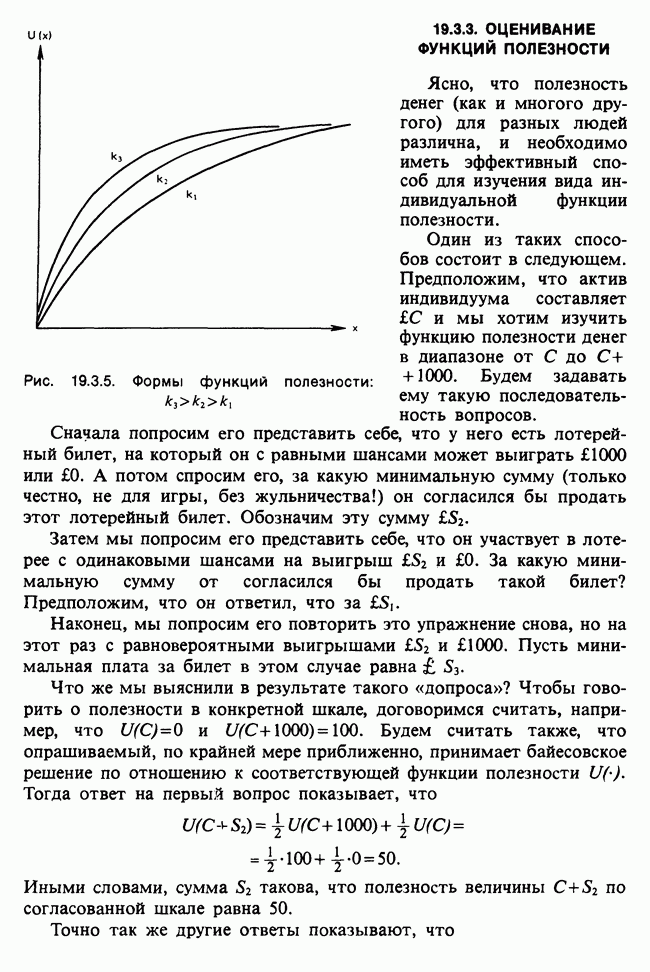
Для иллюстрации этого подхода рассмотрим случайную одномерную величину X с плотностью  , где единственному параметру
, где единственному параметру  приписывается априорное распределение
приписывается априорное распределение  Тогда для заданной случайной выборки
Тогда для заданной случайной выборки  рассматриваемой как Data, апостериорное распределение
рассматриваемой как Data, апостериорное распределение  будет следующим:
будет следующим:

Предиктивная вероятность нового наблюдения есть

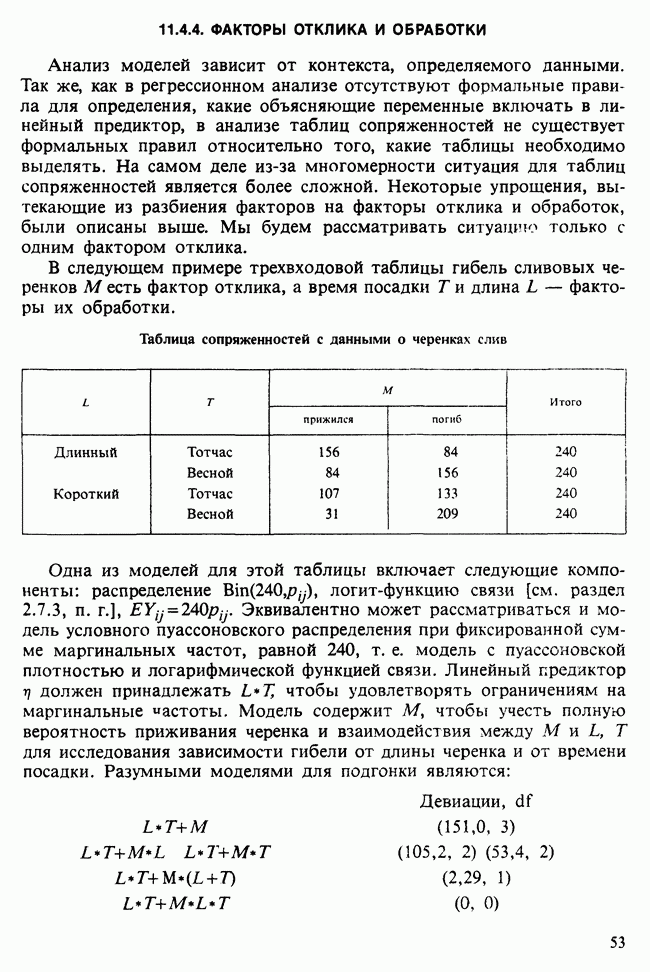
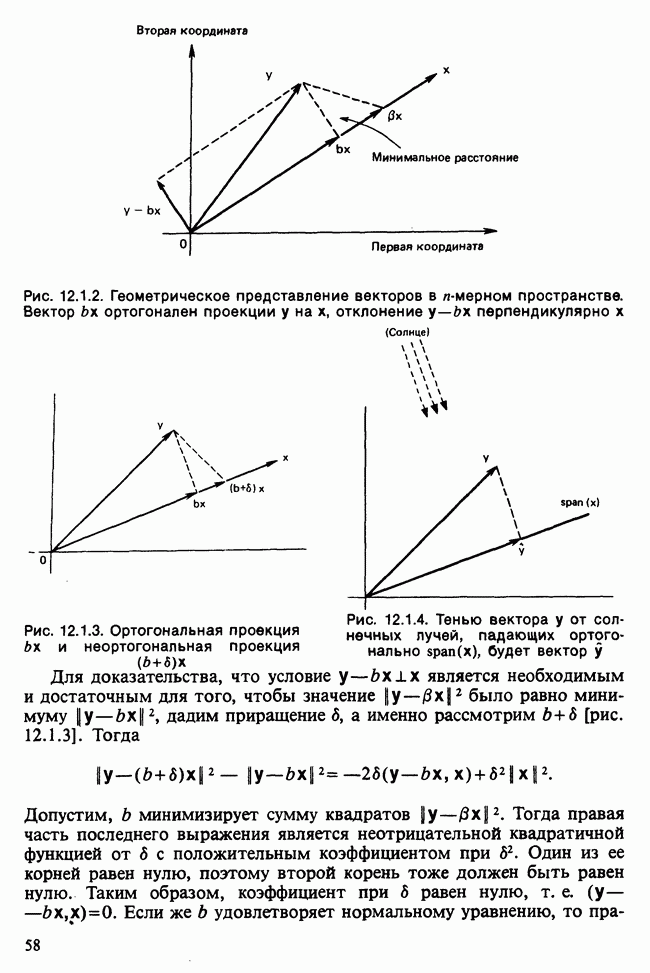
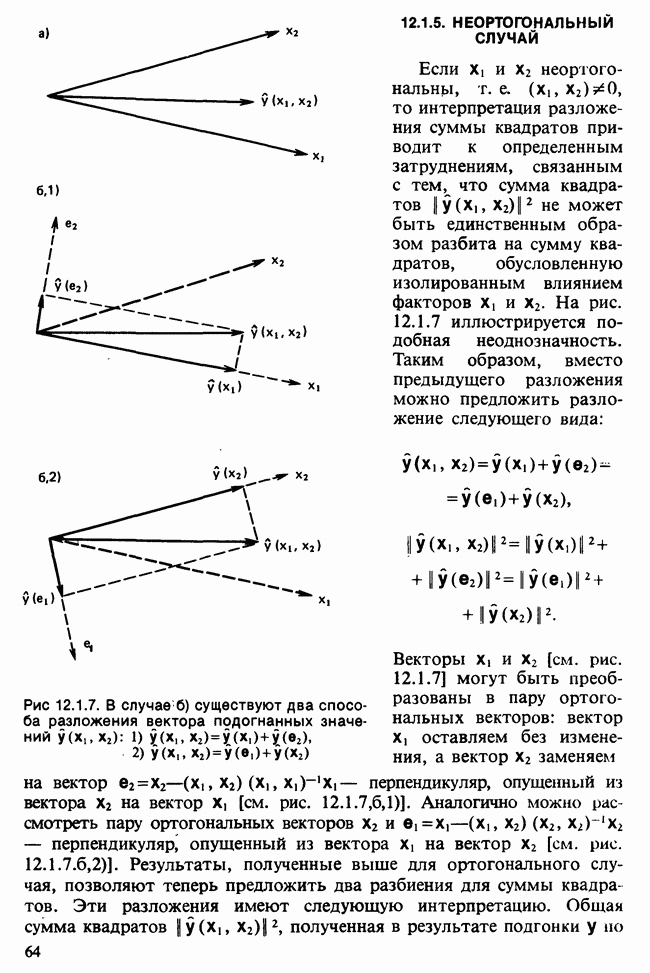
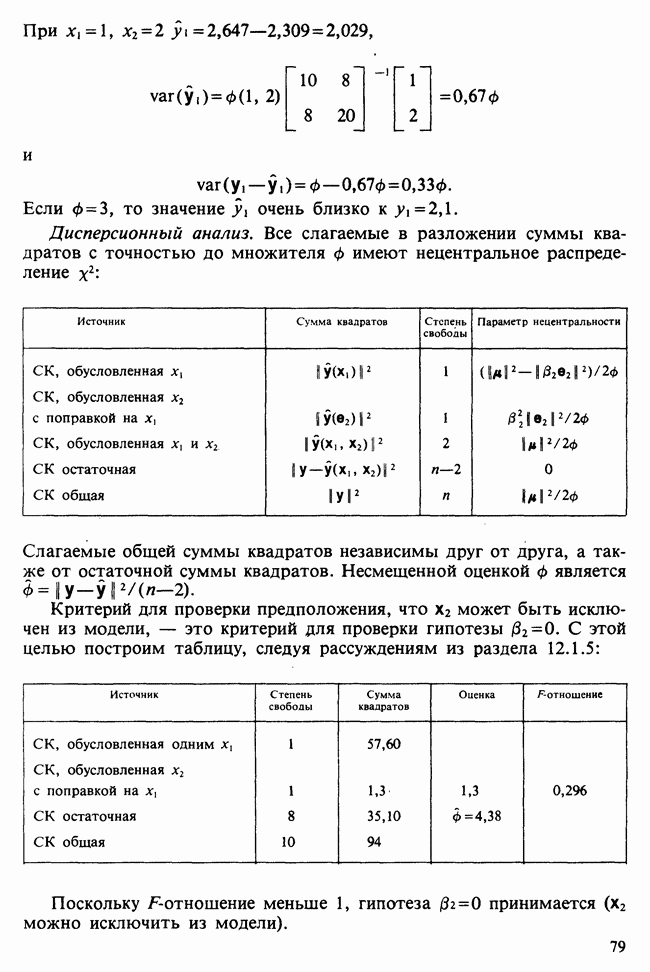
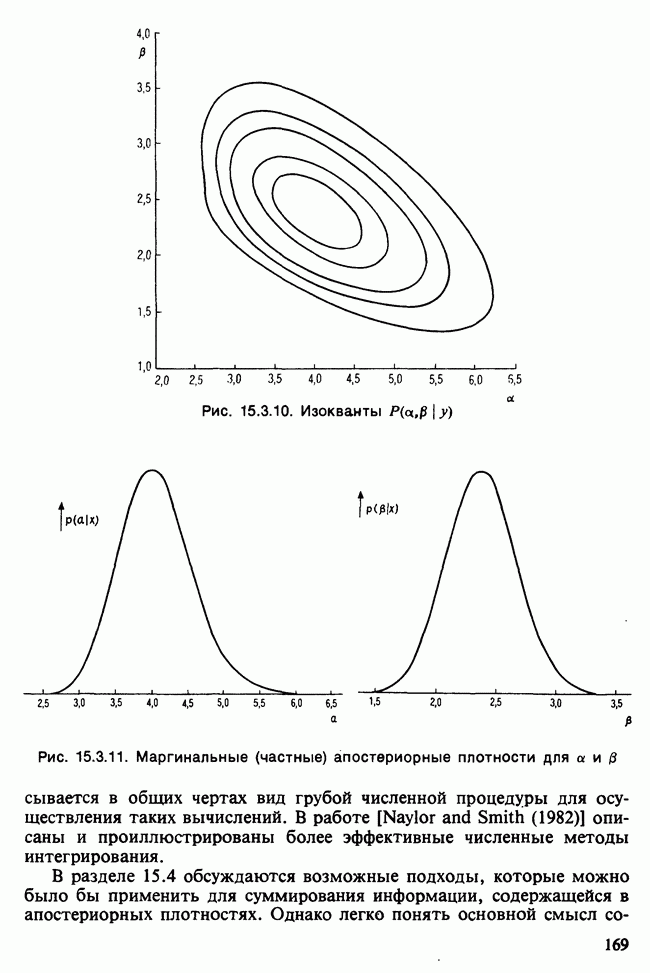
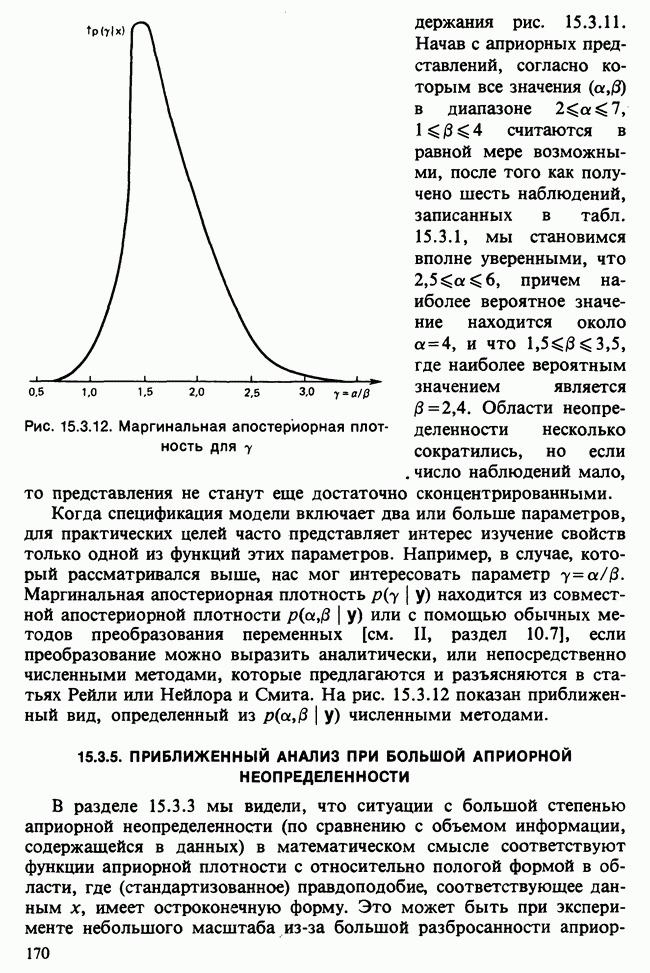
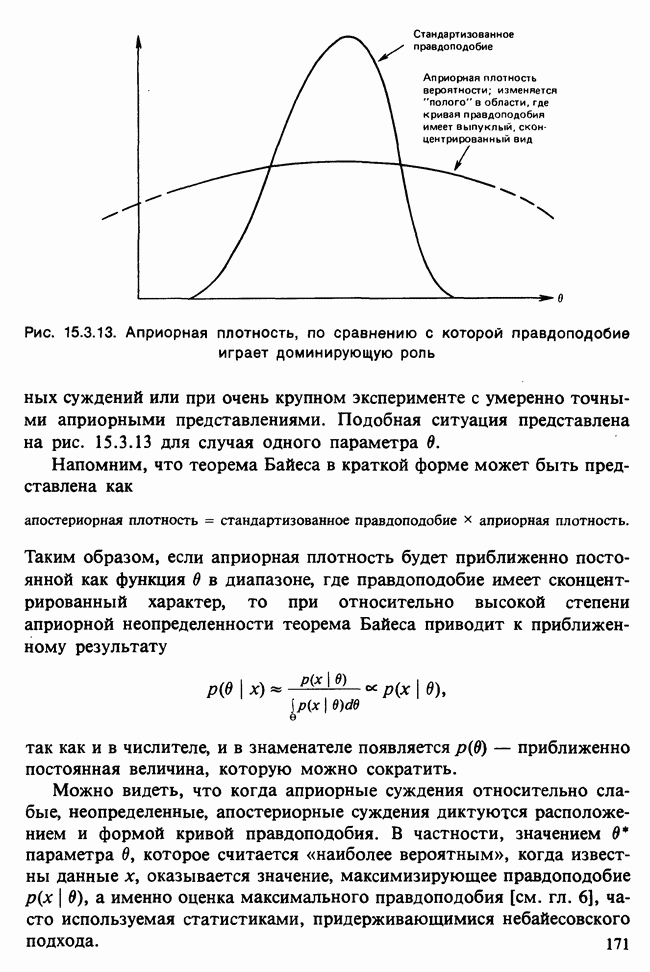
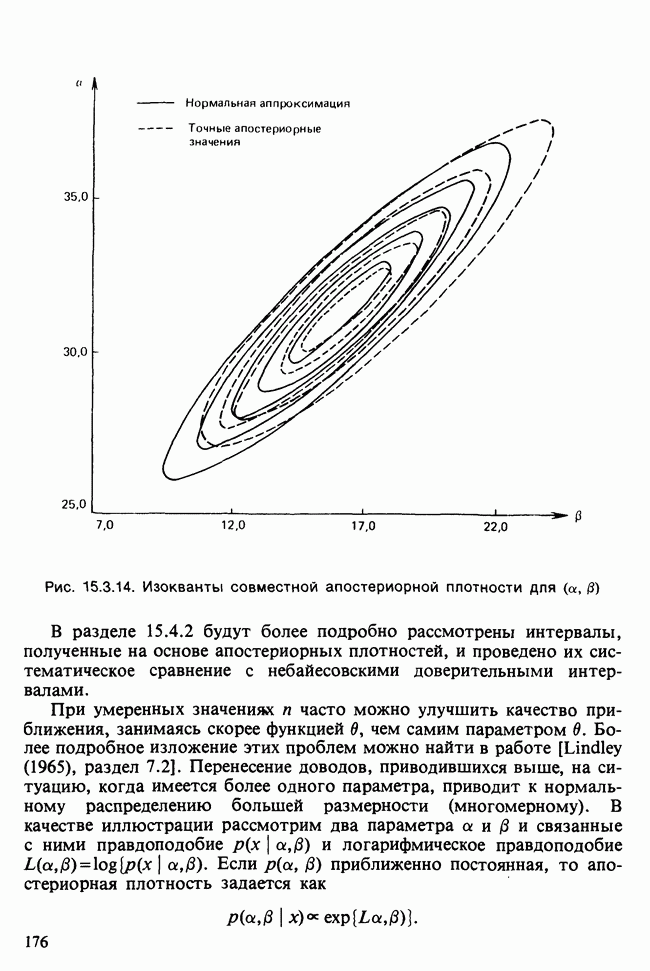
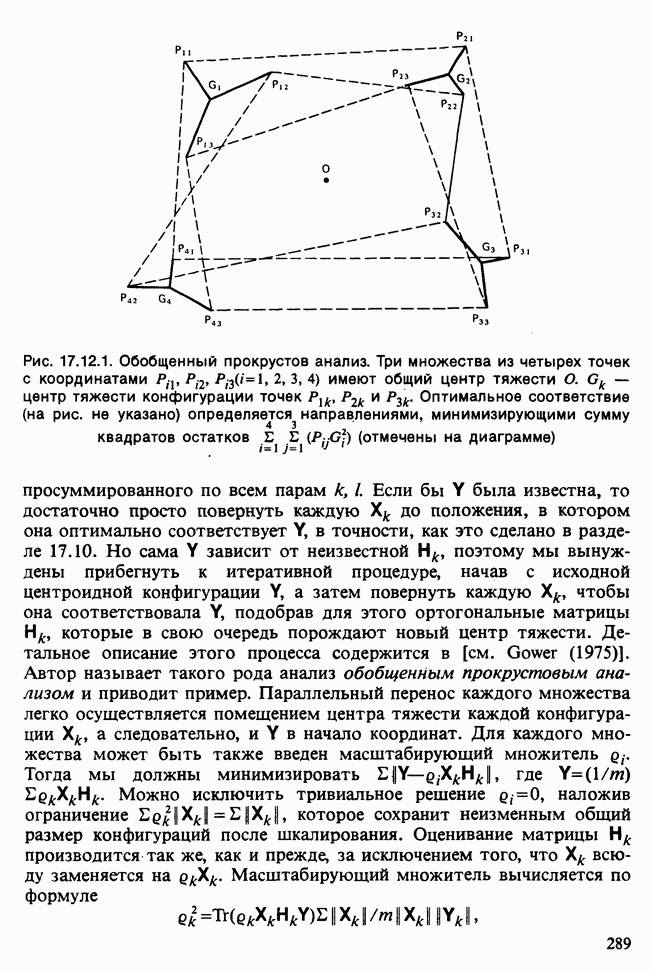
В разделе 16.3.5 обсуждалось применение метода главных компонент к данным о лесе. Было показано, что большая часть дисперсии объясняется с помощью двух первых главных компонент. Графическое отображение значений главных компонент в этом случае позволяет выделить кластеры, рассматриваемые как разные совокупности. Для каждого нового наблюдения можно вычислить значения двух первых главных компонент, и с их помощью наблюдение может быть классифицировано в один из существующих кластеров.
Чтобы избежать пересечения кластеров, иногда вычисляют средние значения главных компонент для кластеров и новое наблюдение классифицируют по близости к этим средним. Другой метод, основанный на сокращении размерности данных с помощью канонических корреляций, представлен в работе [Maxwell (1977), гл. 9].




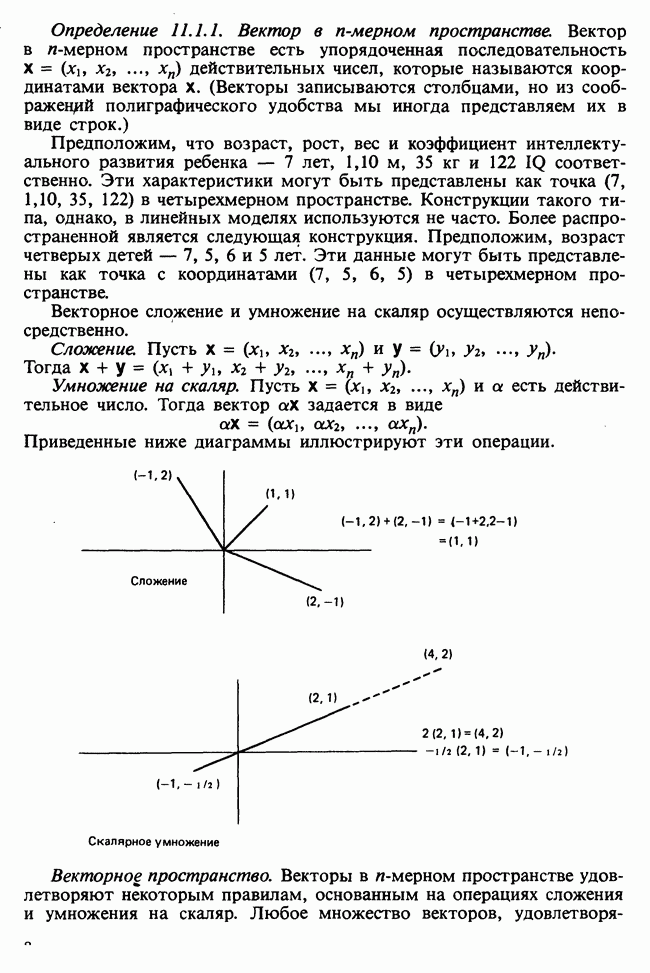






















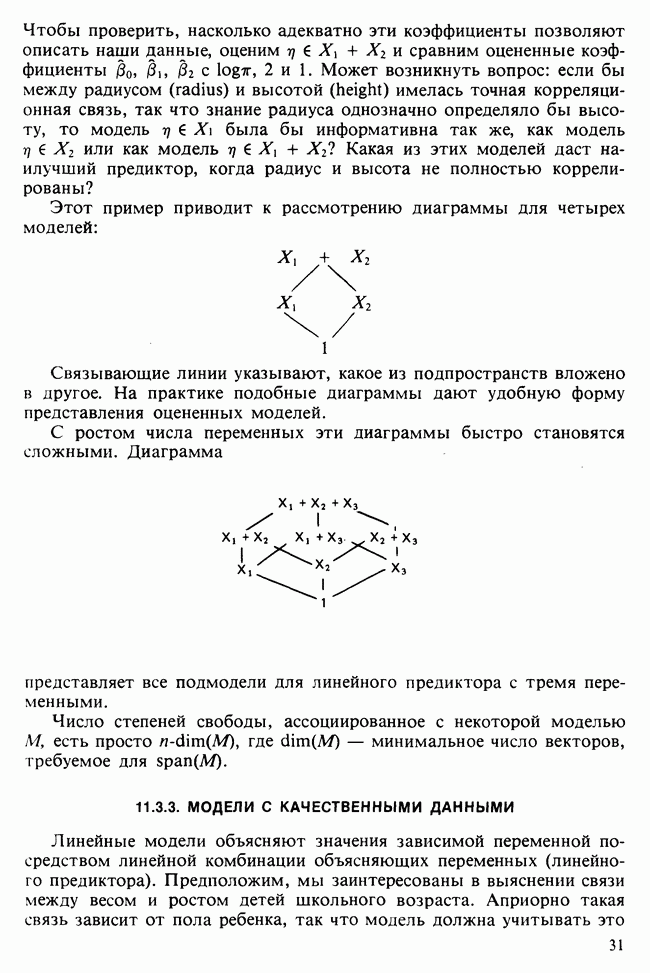











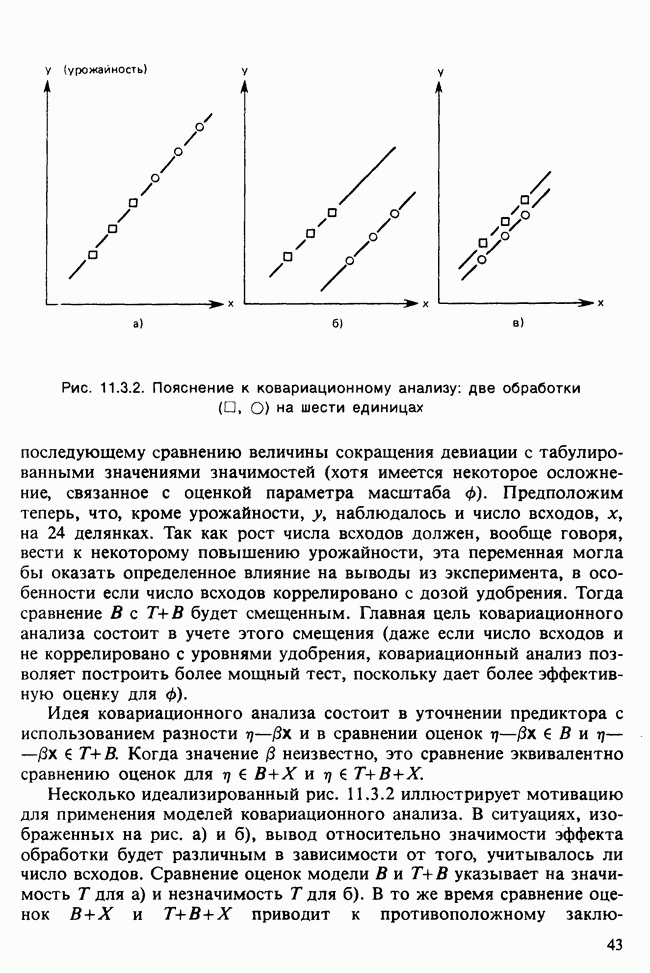



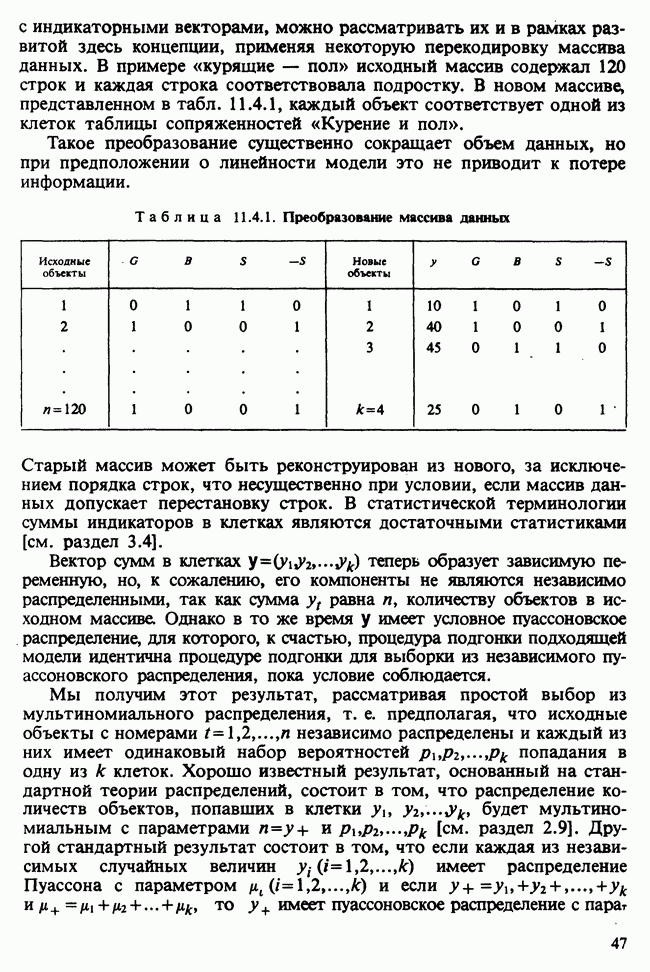












































































































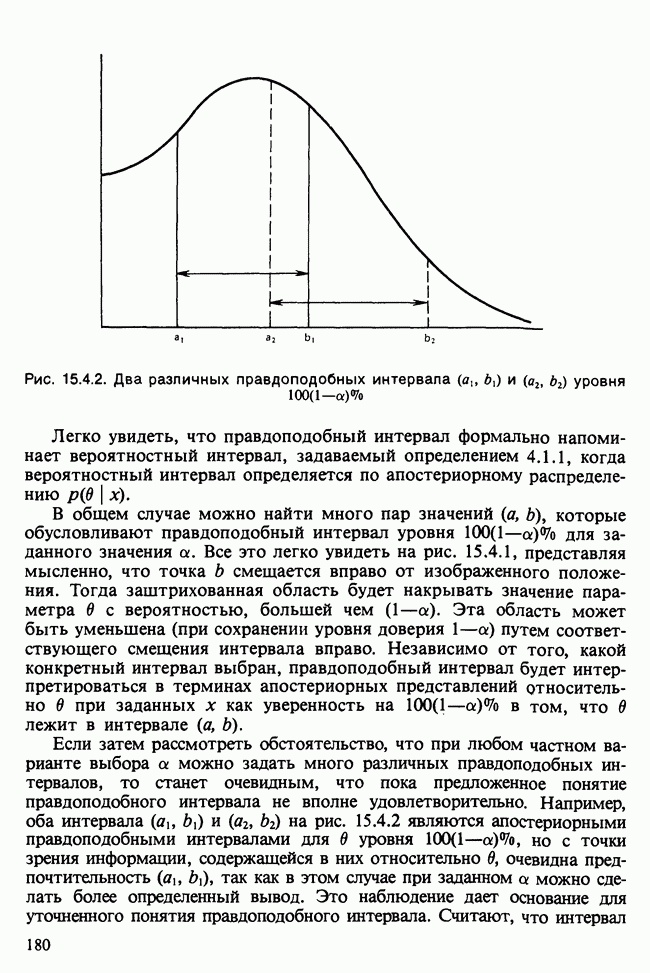






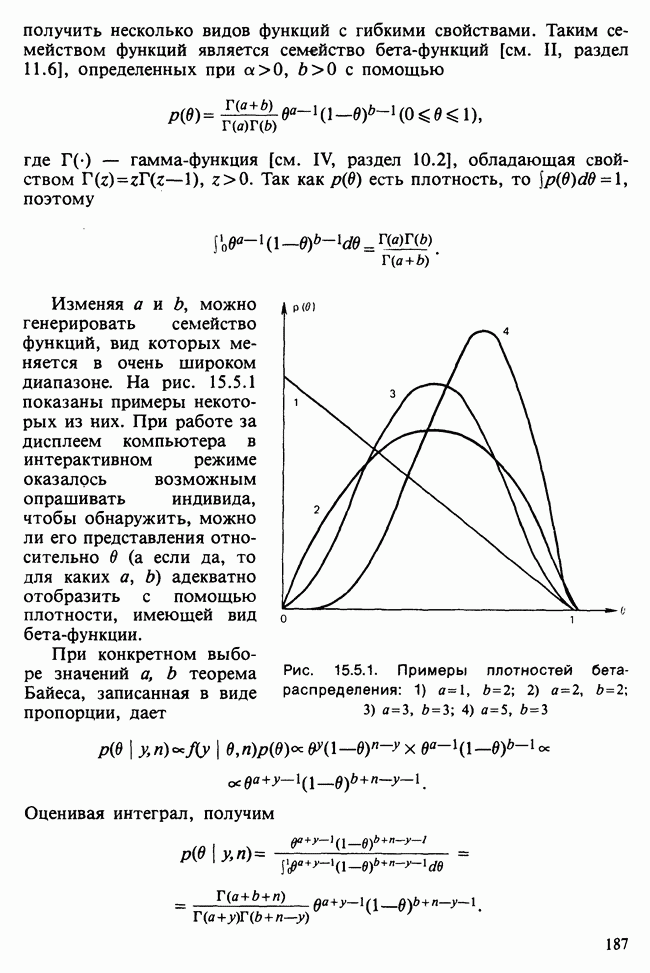





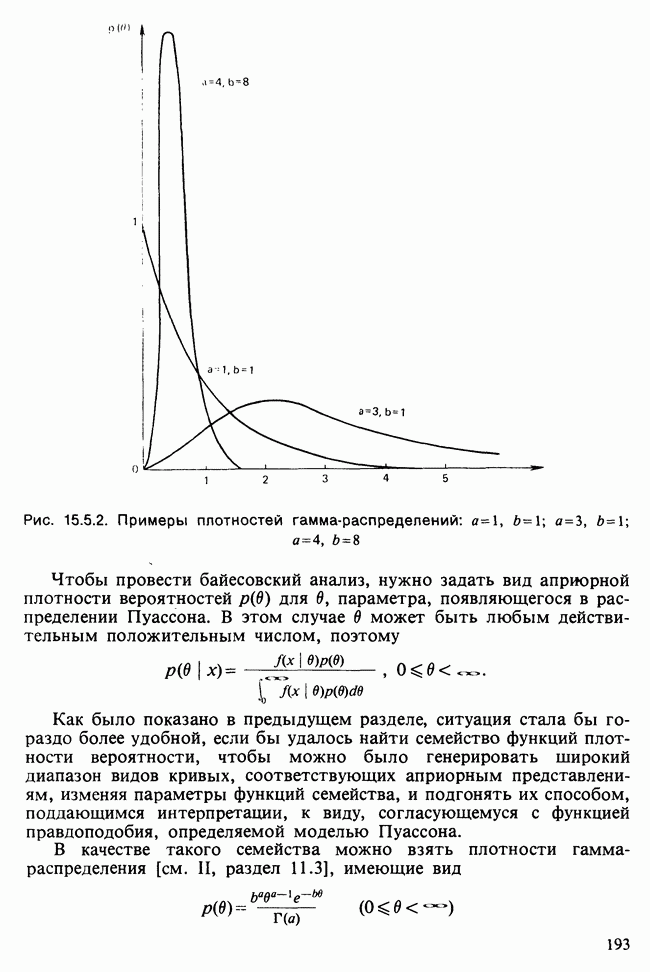






























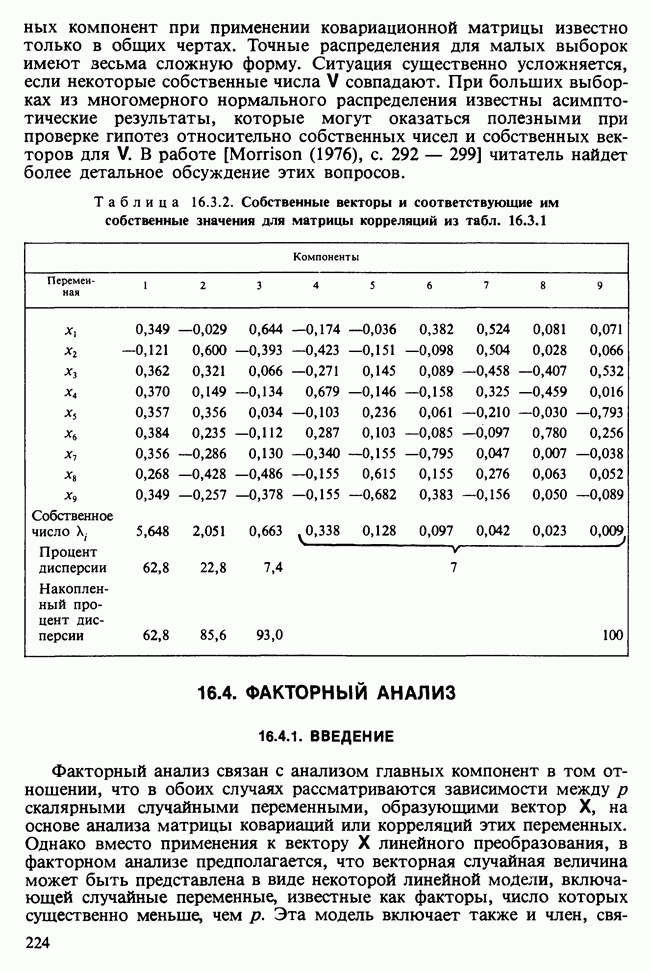










































































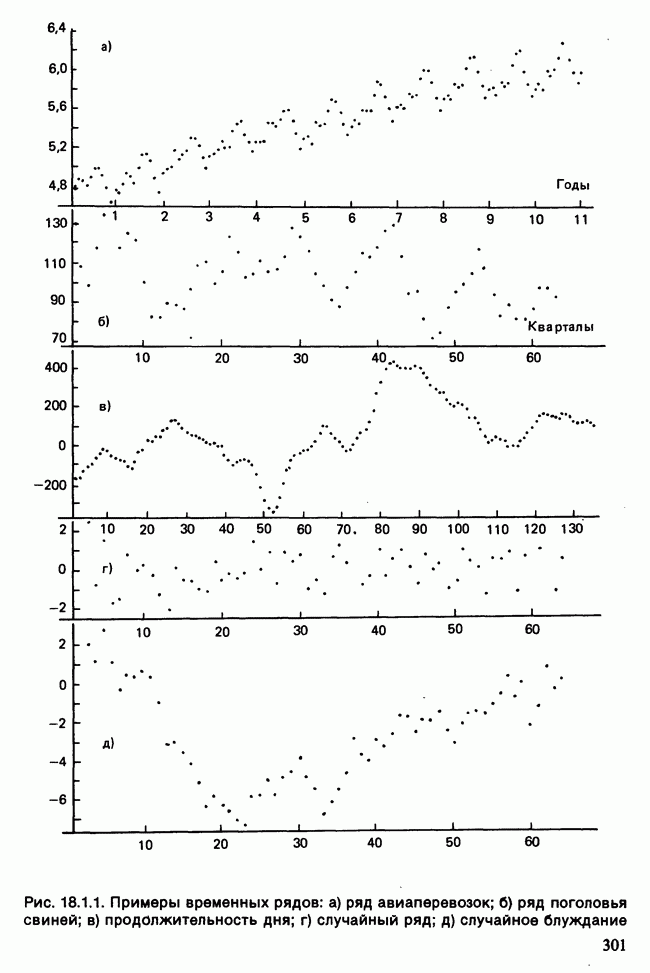

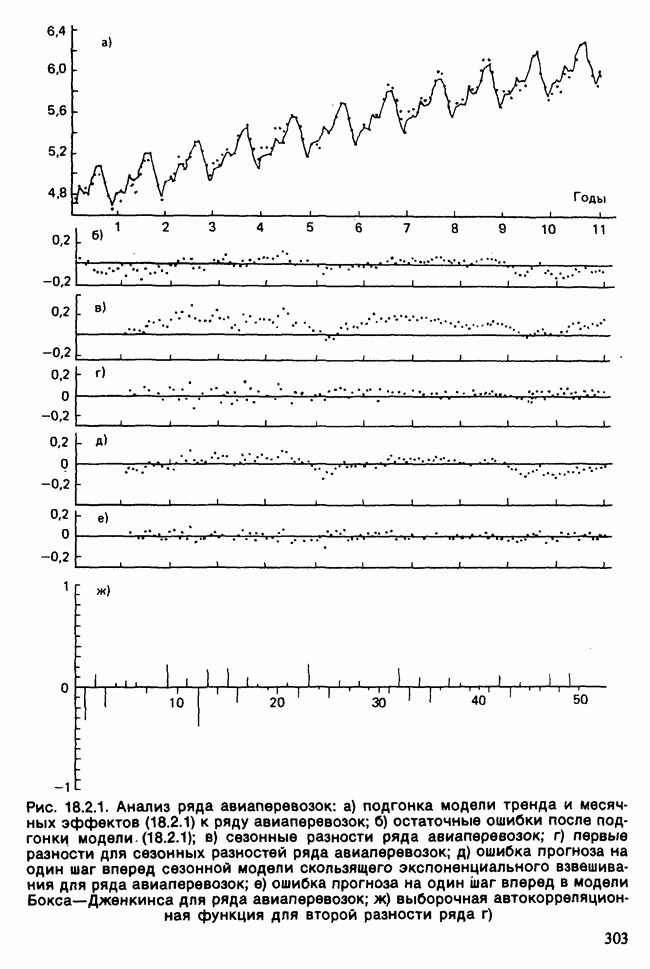









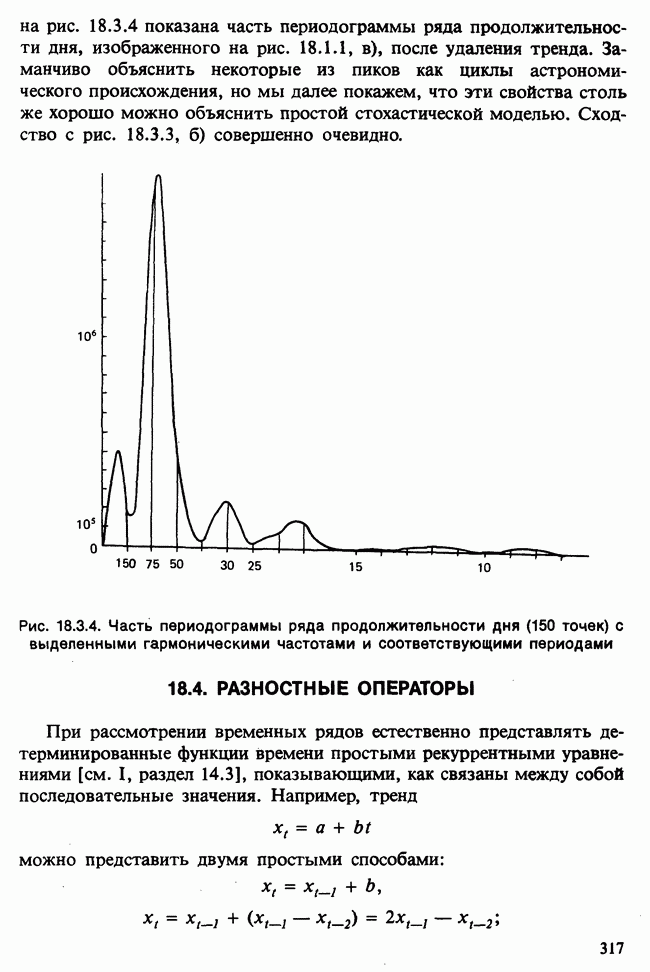













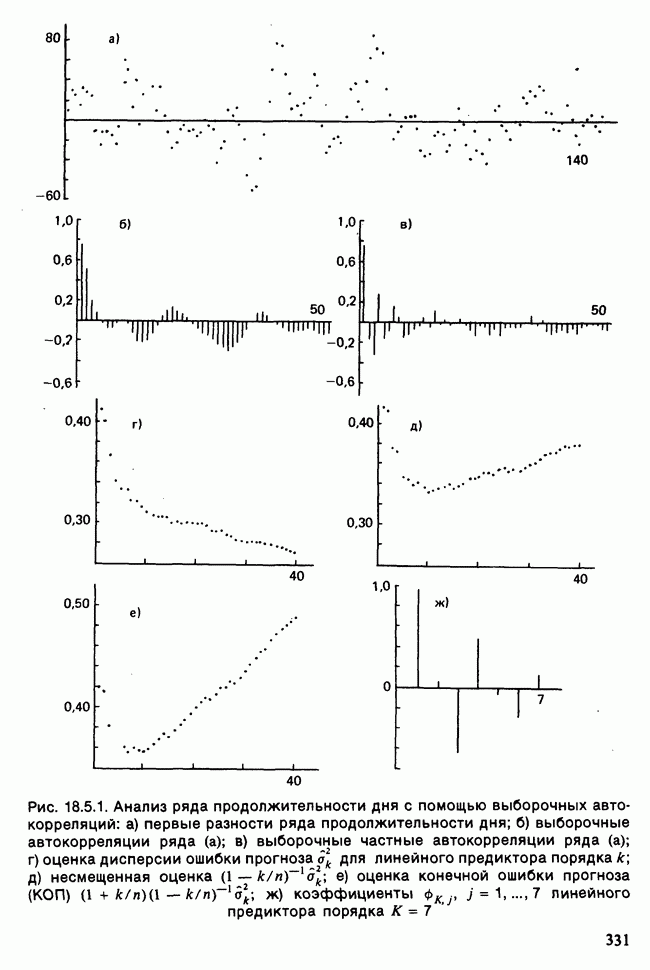
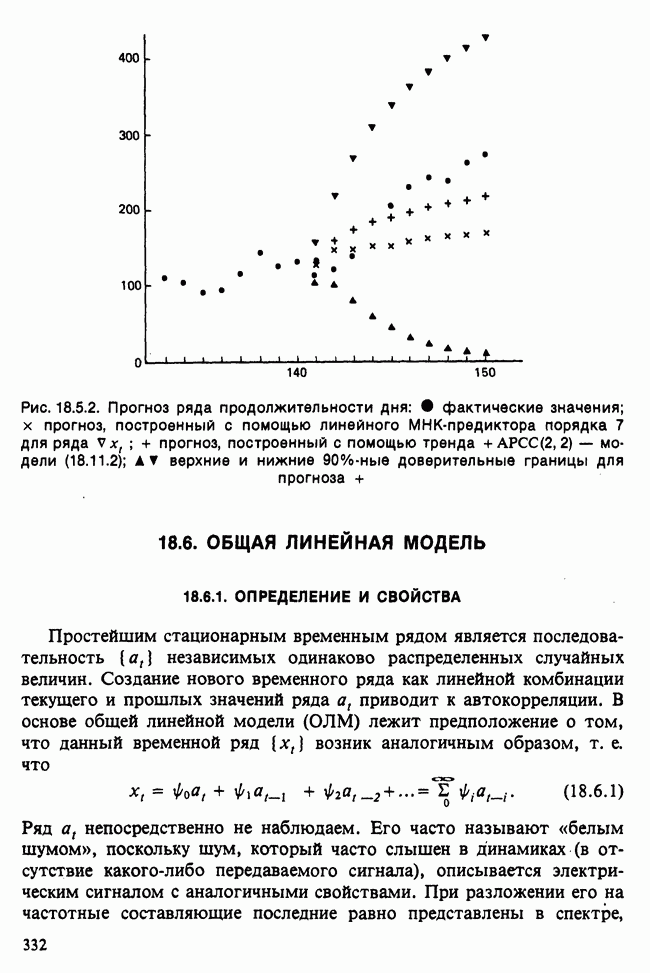





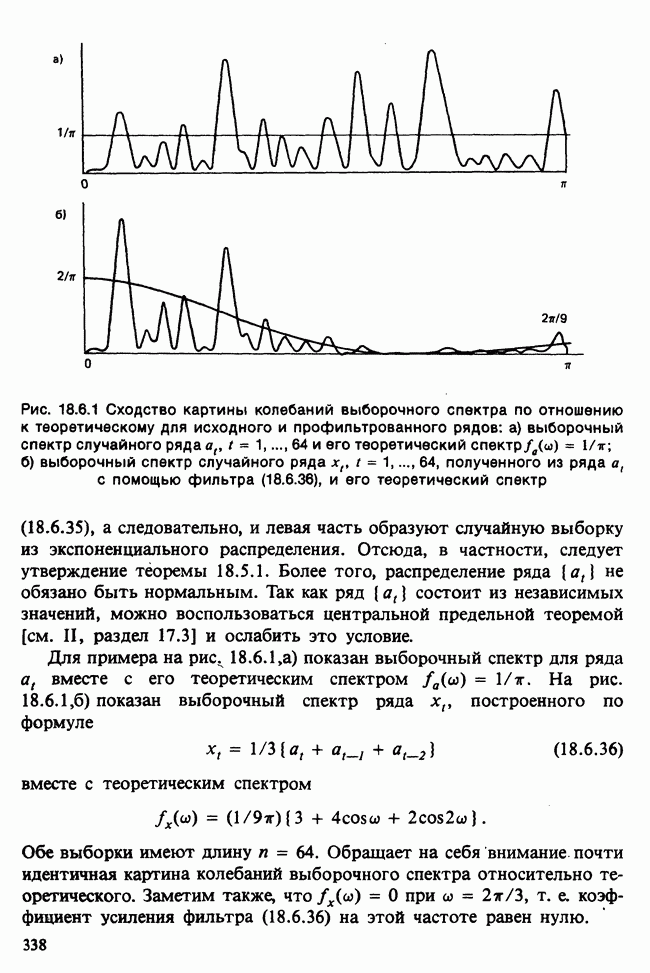























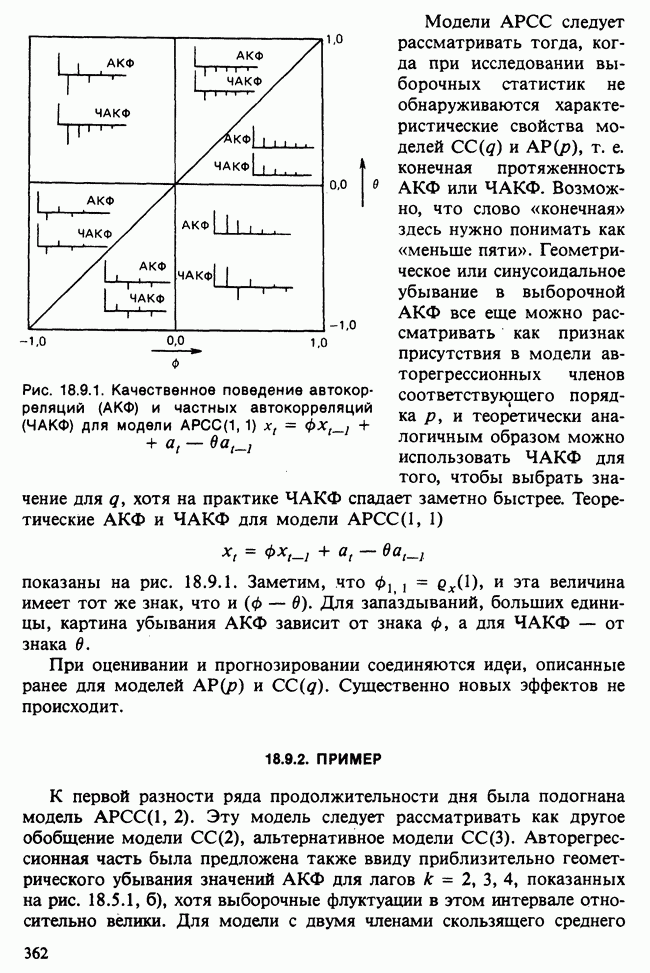


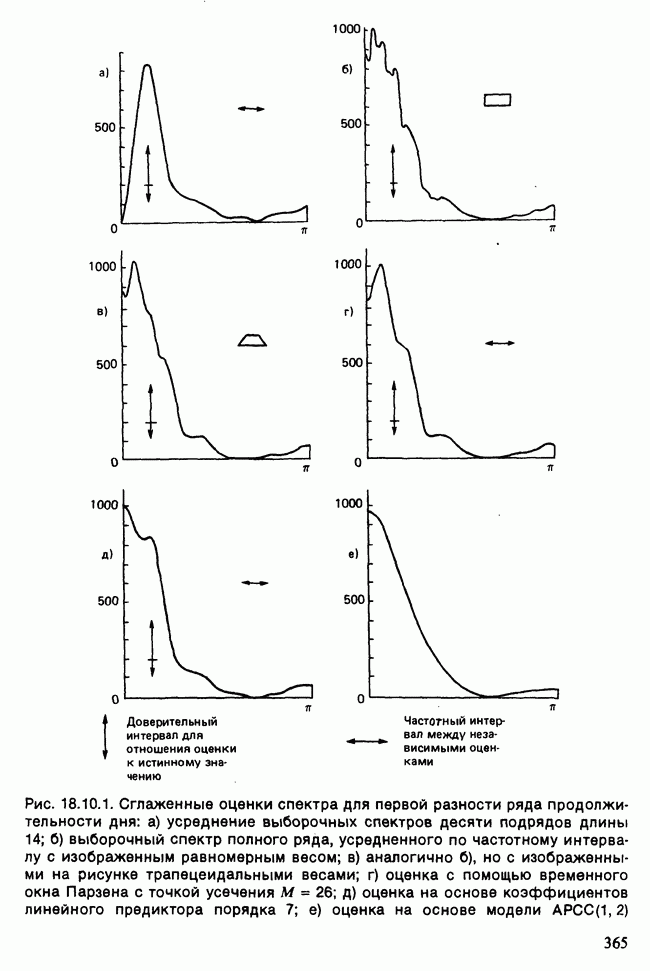



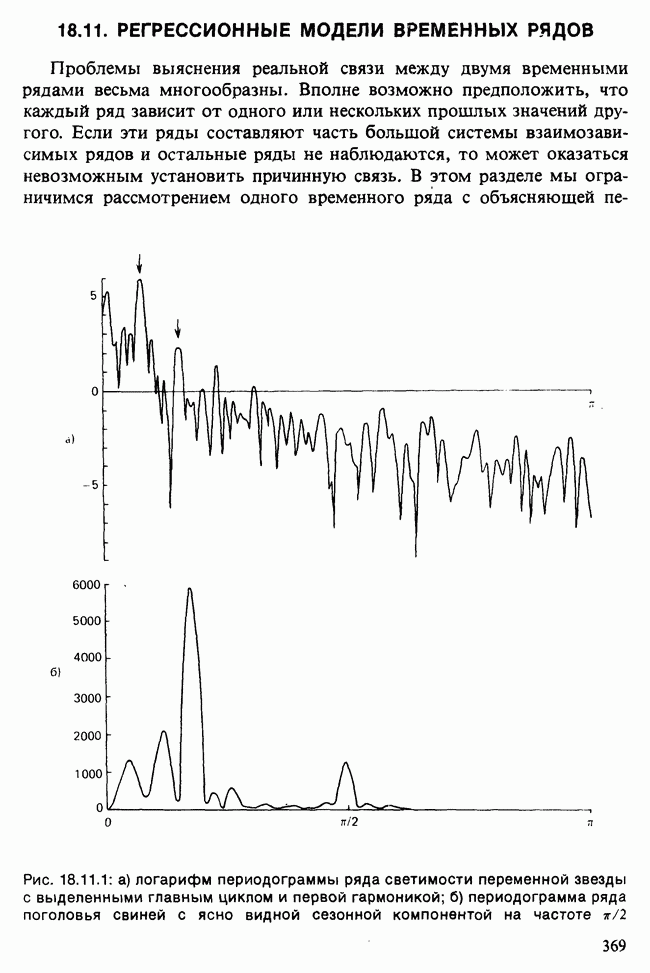









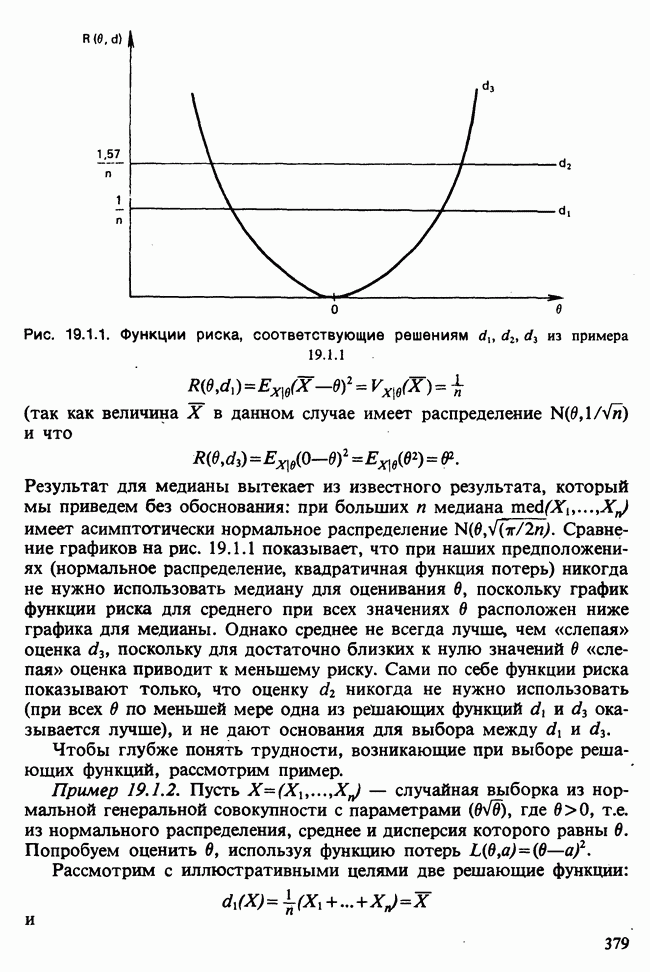





















































































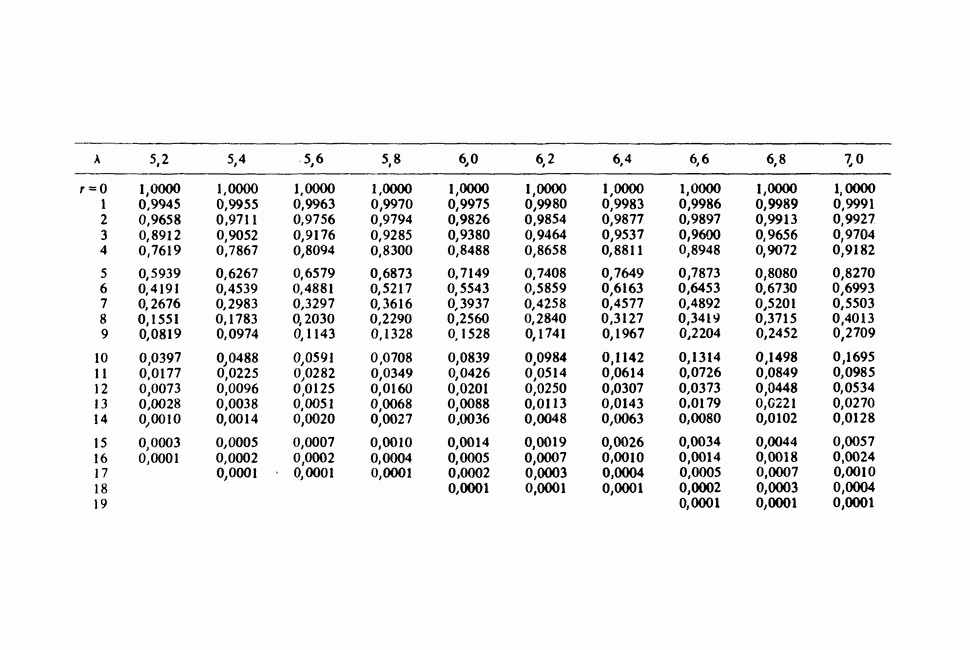
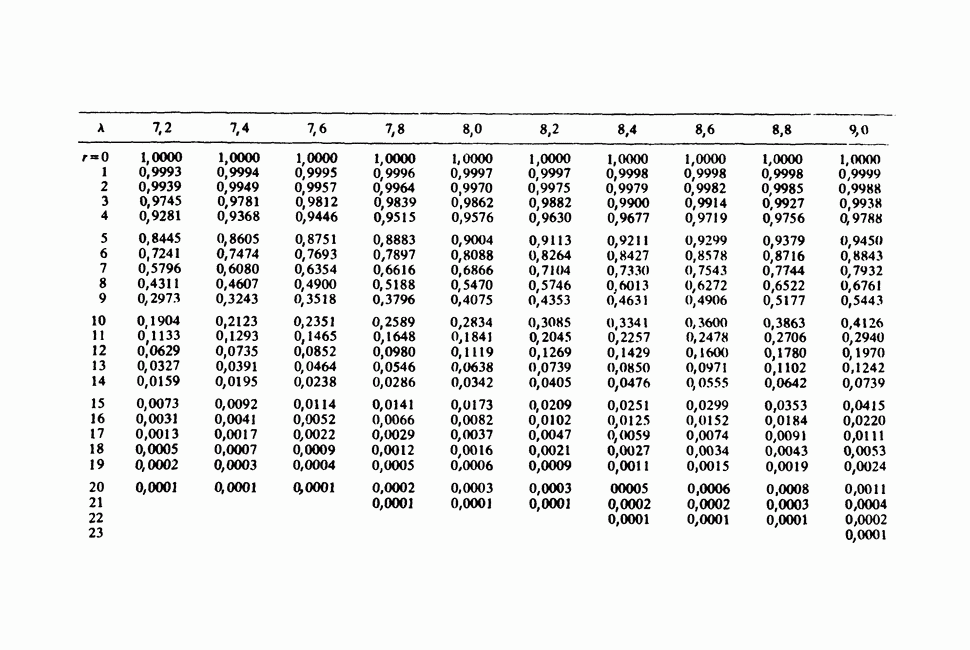
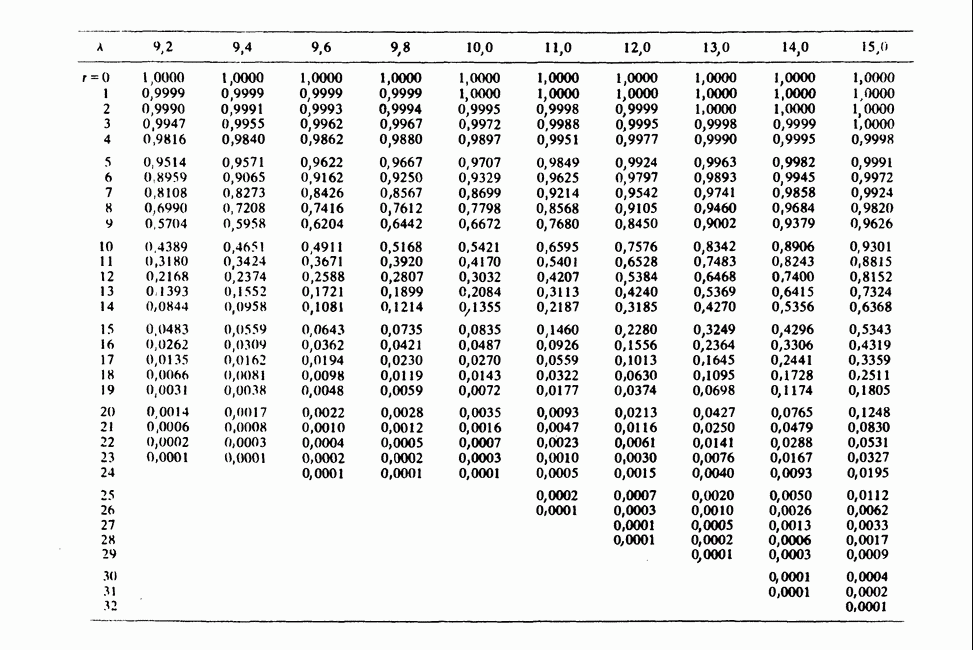

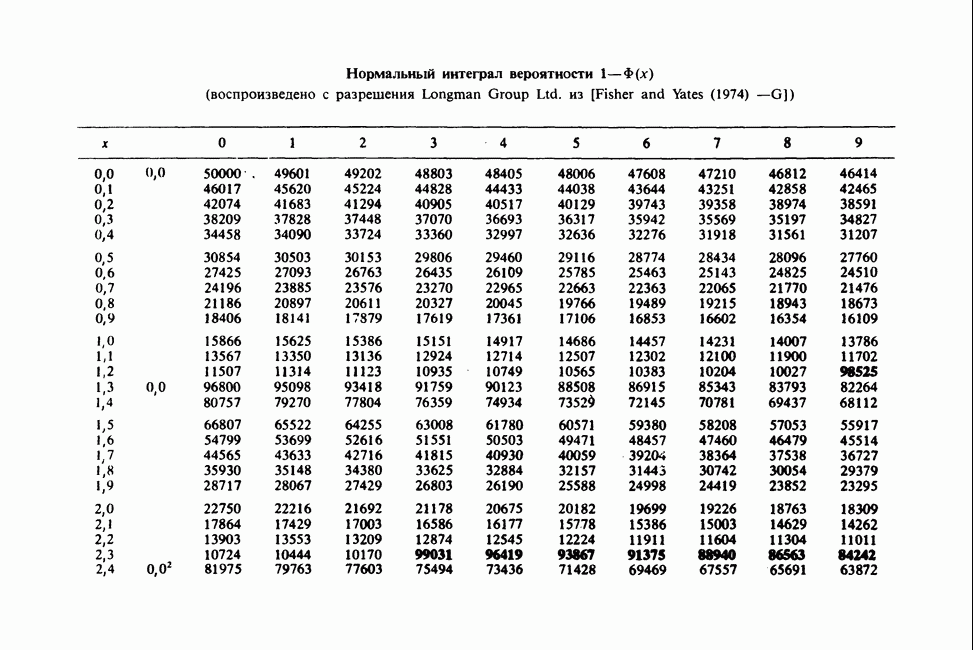





 и
и  индивидуальные наблюдения будут тогда классифицированы в одну из них [см., например, Morrison (1972), с. 239—245].
индивидуальные наблюдения будут тогда классифицированы в одну из них [см., например, Morrison (1972), с. 239—245].
 совокупностей и что
совокупностей и что  — значение дискриминантной функции для классификации между совокупностями
— значение дискриминантной функции для классификации между совокупностями  и у. Тогда, если для всех пар совокупностей предполагается
и у. Тогда, если для всех пар совокупностей предполагается  правило классификации может быть таким: классифицировать в совокупность
правило классификации может быть таким: классифицировать в совокупность  если 0 для всех
если 0 для всех 

