
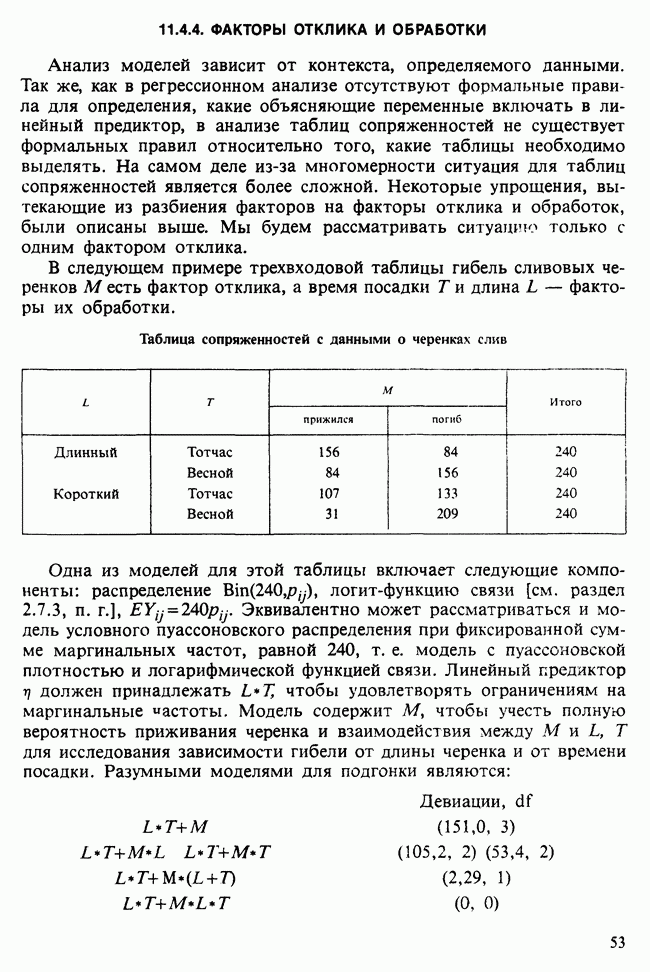
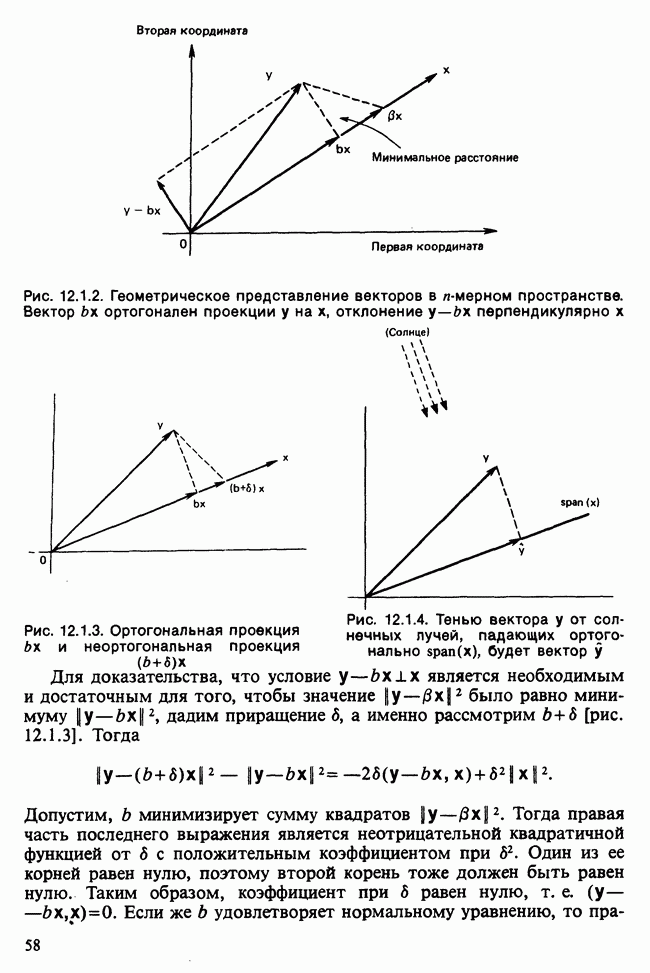
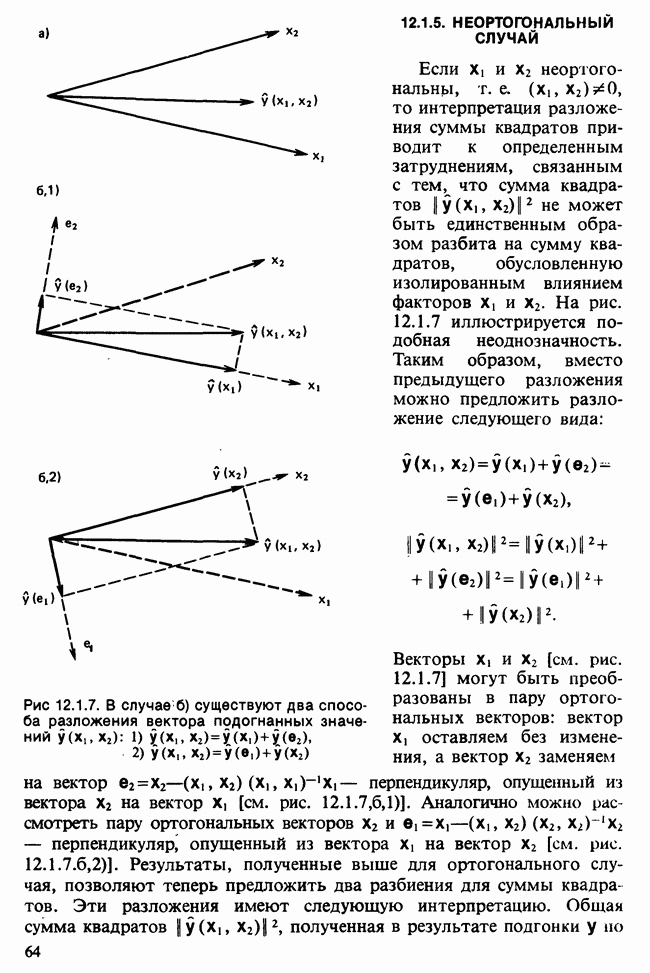
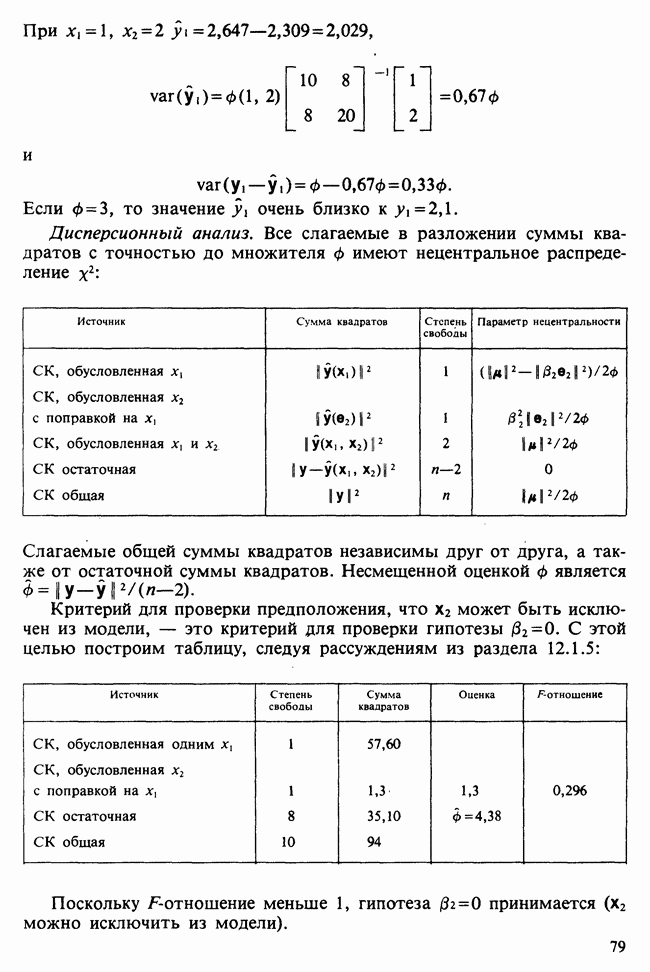
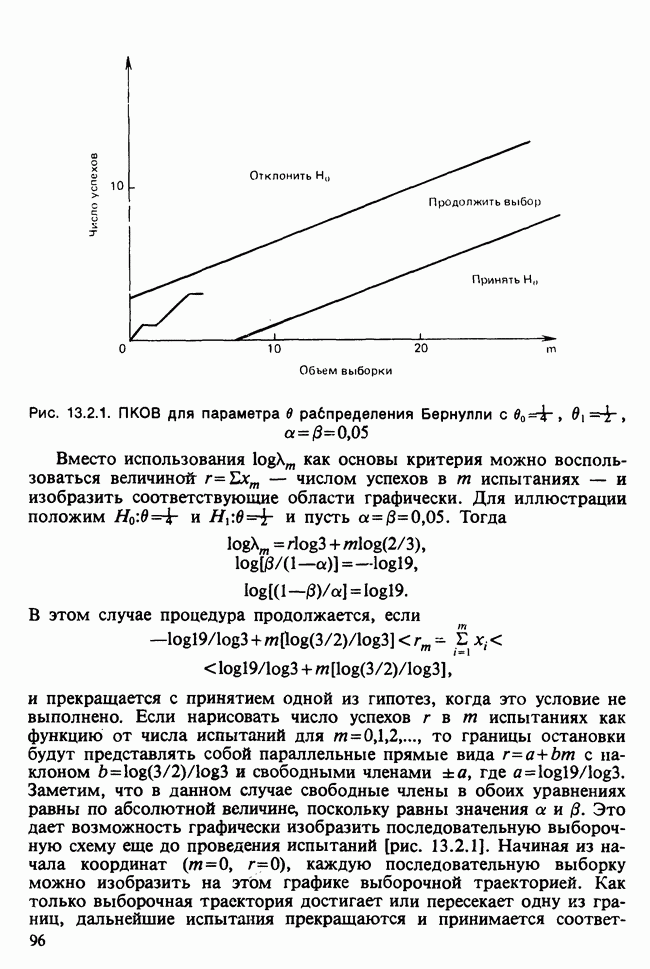
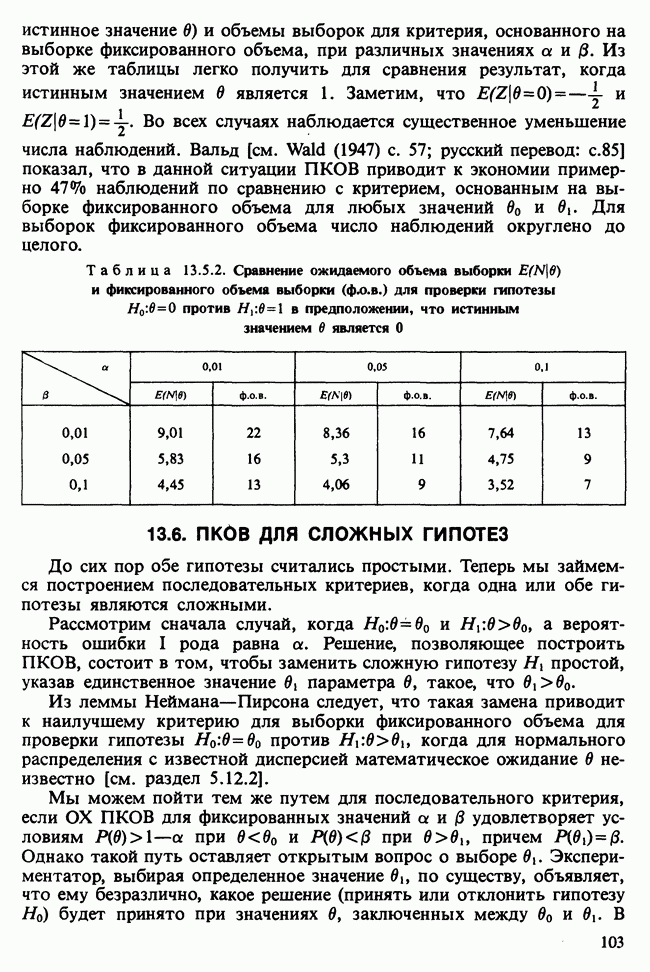
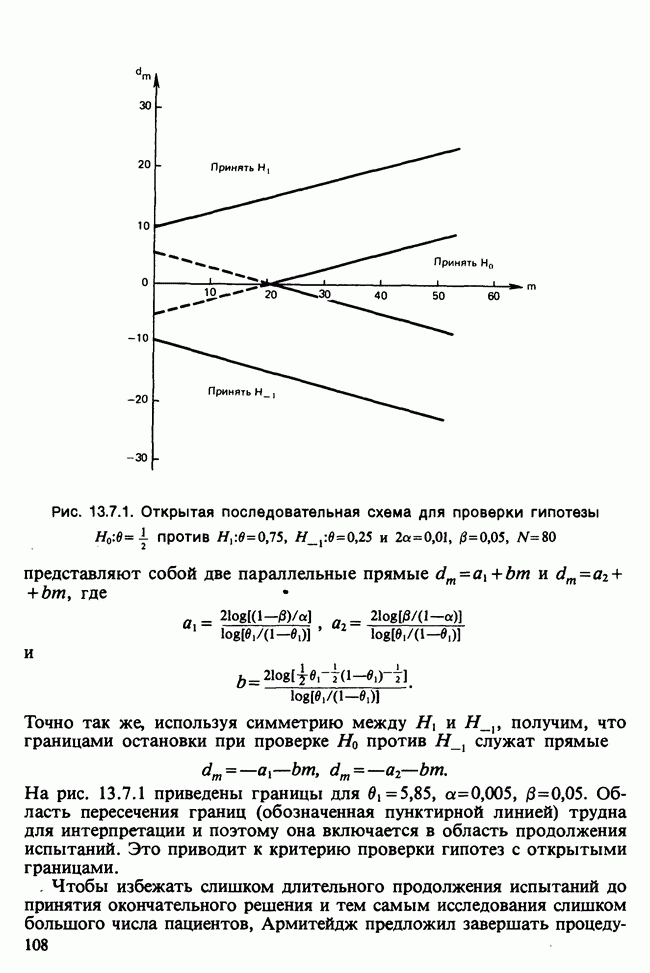
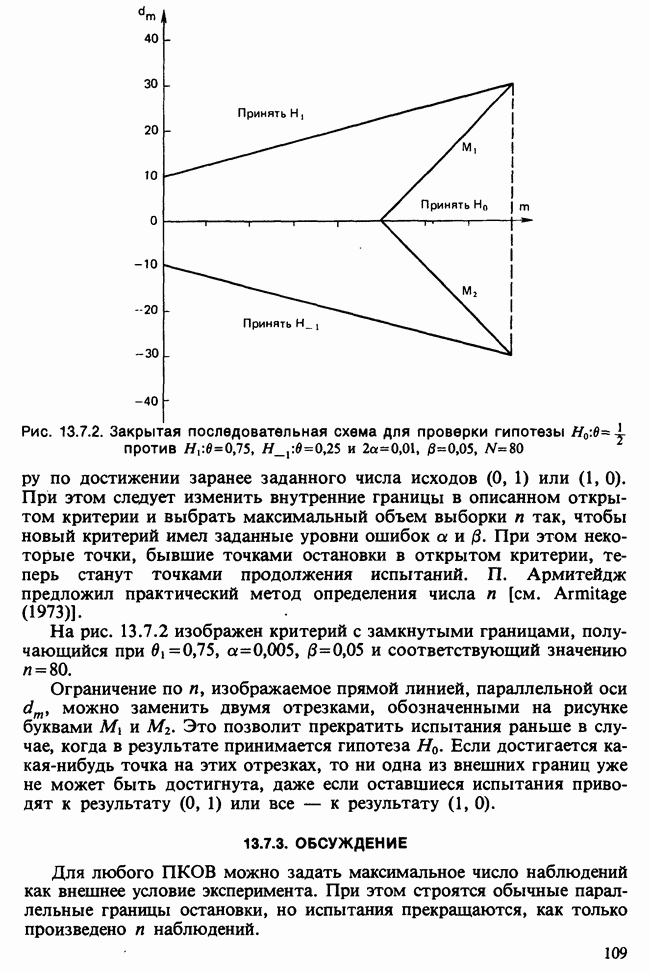
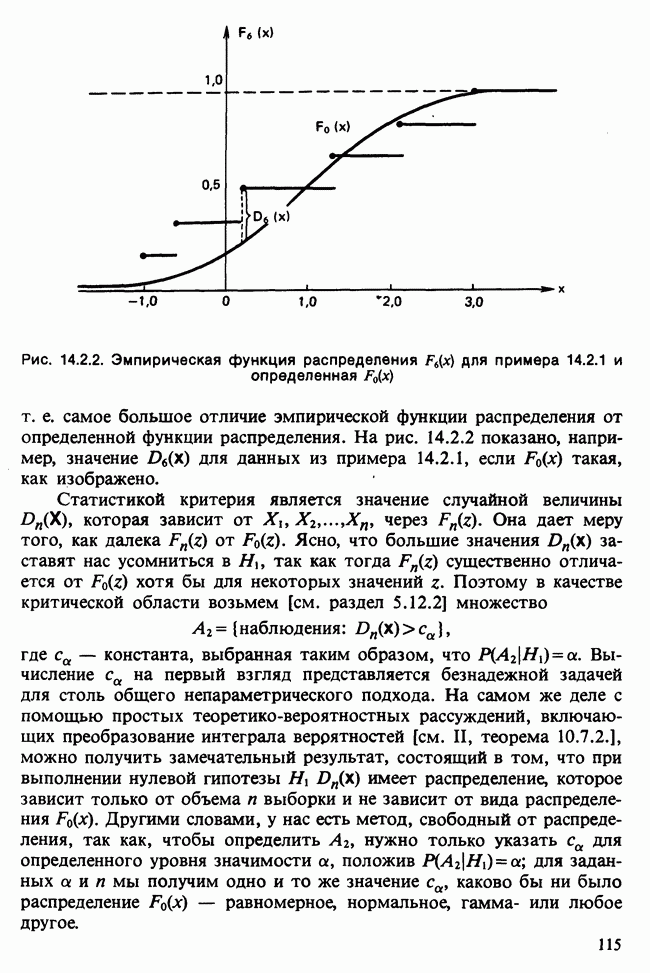
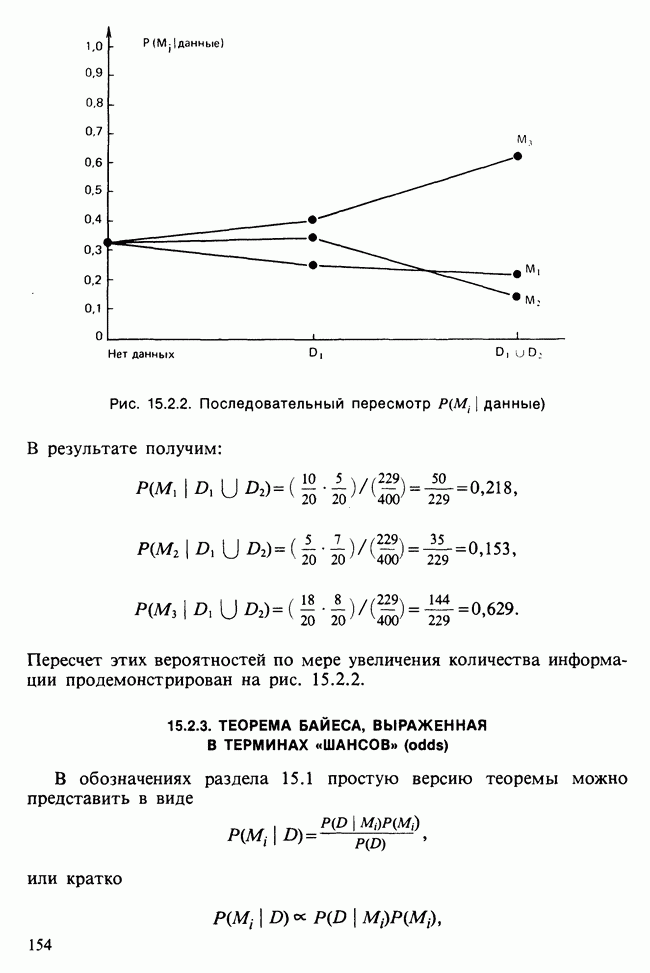
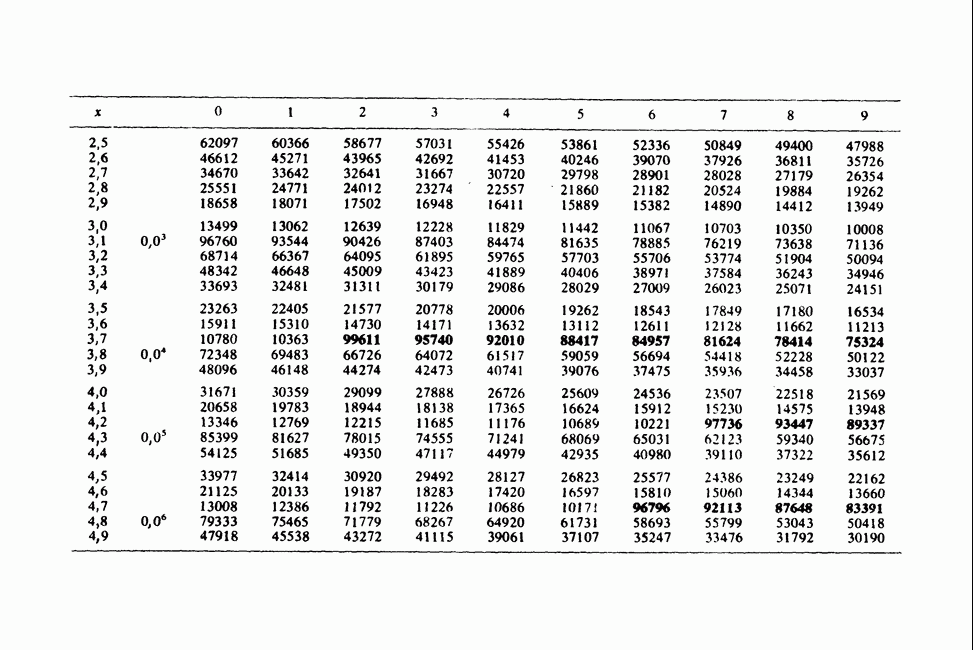
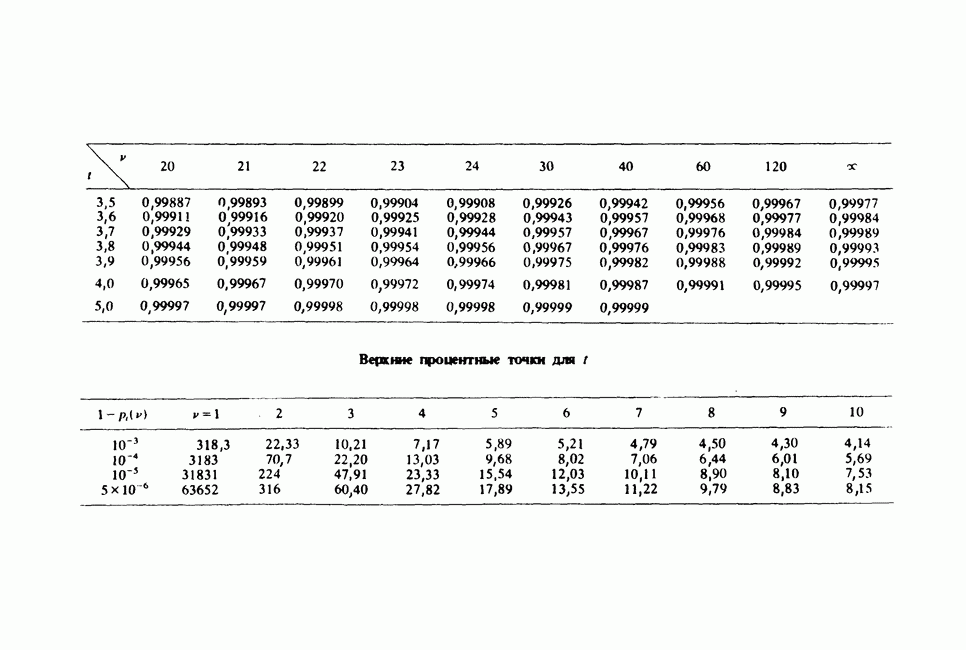
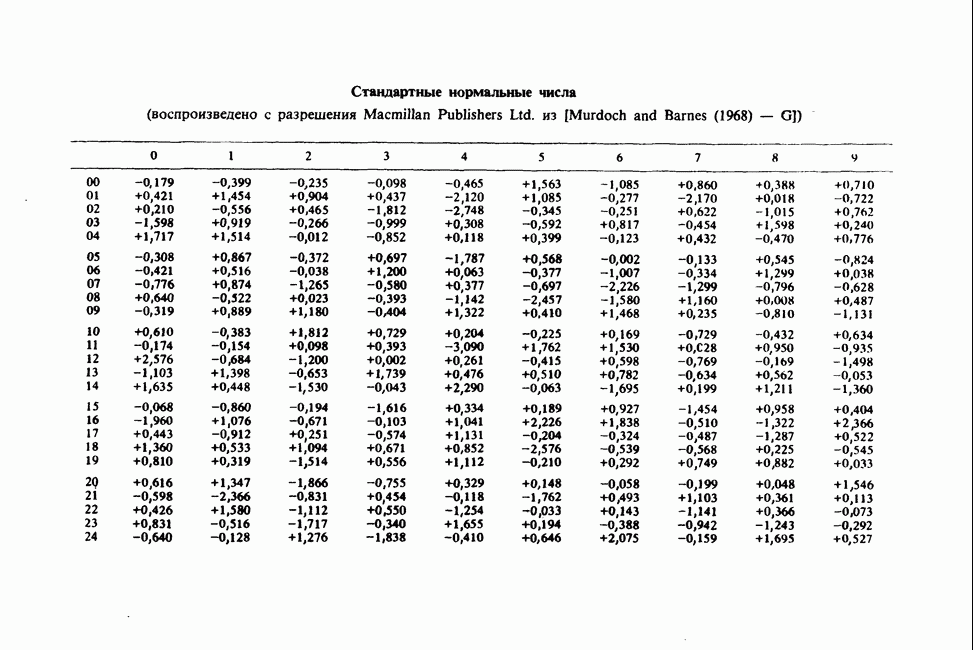
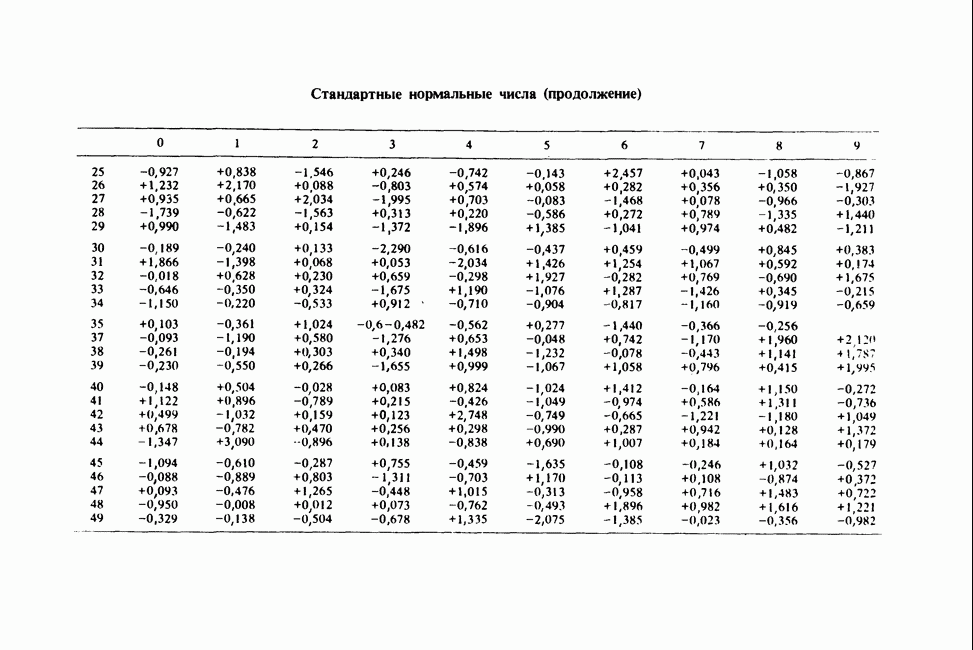
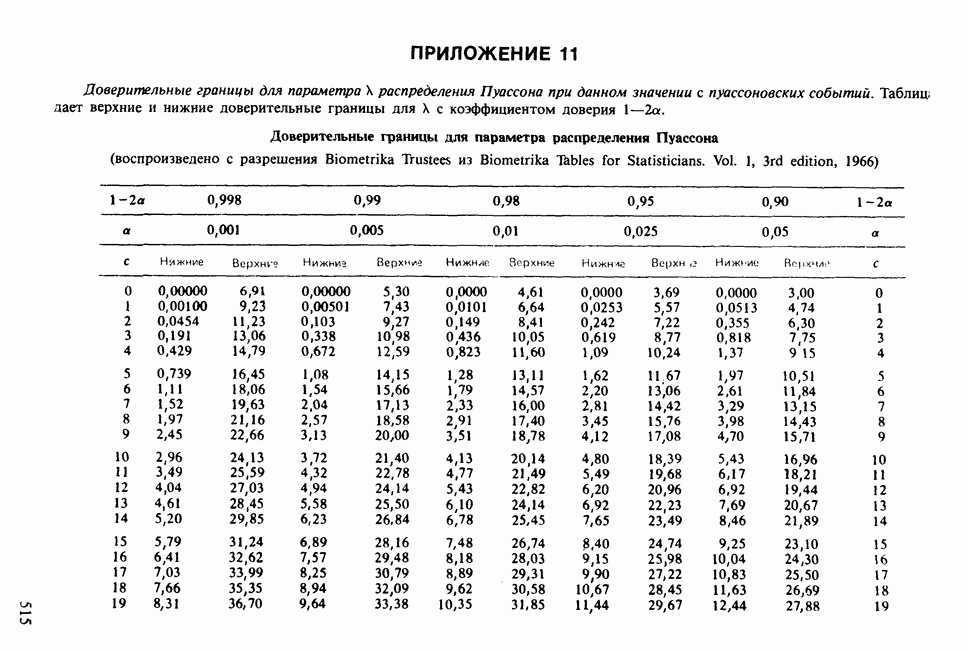
где мы просто произвели последовательную подстановку, например,

Уравнения (18.7.6) показывают, что величины  связаны с
связаны с  линейным преобразованием с единичным якобианом [см. IV, (5.12.2)], хотя это преобразование существенно нелинейно по
линейным преобразованием с единичным якобианом [см. IV, (5.12.2)], хотя это преобразование существенно нелинейно по  . Отсюда
. Отсюда  записывается в виде
записывается в виде

Ее можно вычислить, непосредственно воспользовавшись (18.7.5), для любого набора данных  и любого значения
и любого значения  , задавшись дополнительно некоторым значением
, задавшись дополнительно некоторым значением  Метод ММП заключается в нахождении такого значения
Метод ММП заключается в нахождении такого значения  , при котором (18.7.7) достигает максимума, или, что эквивалентно, достигает минимума сумма квадратов
, при котором (18.7.7) достигает максимума, или, что эквивалентно, достигает минимума сумма квадратов

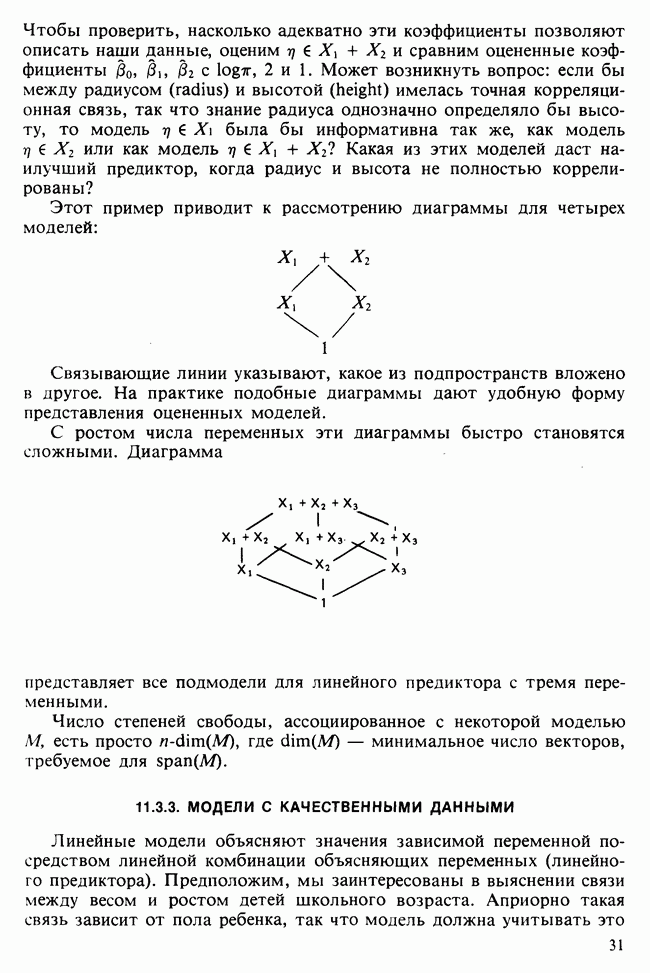
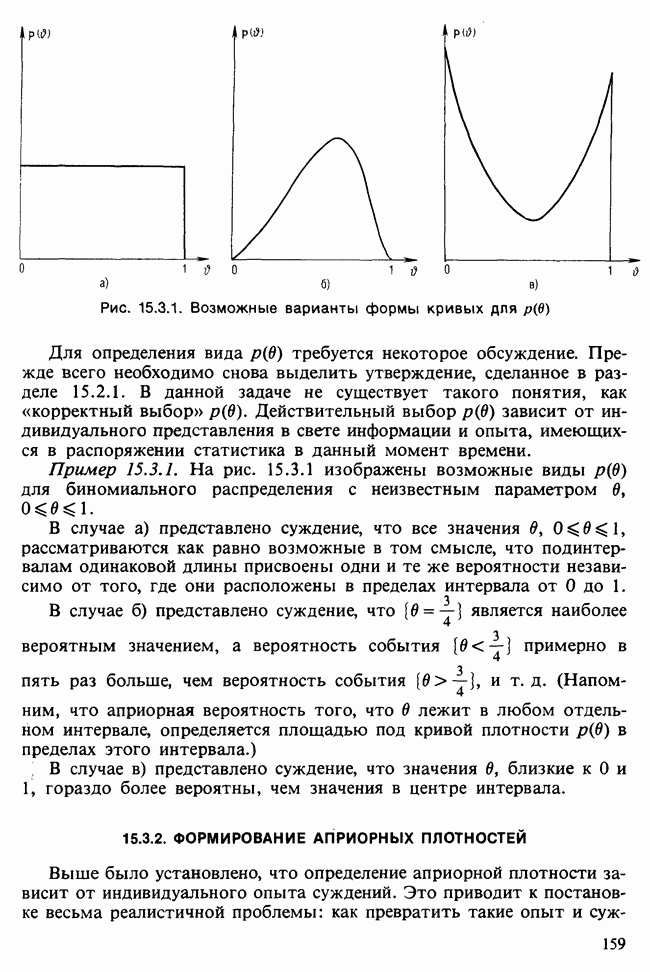
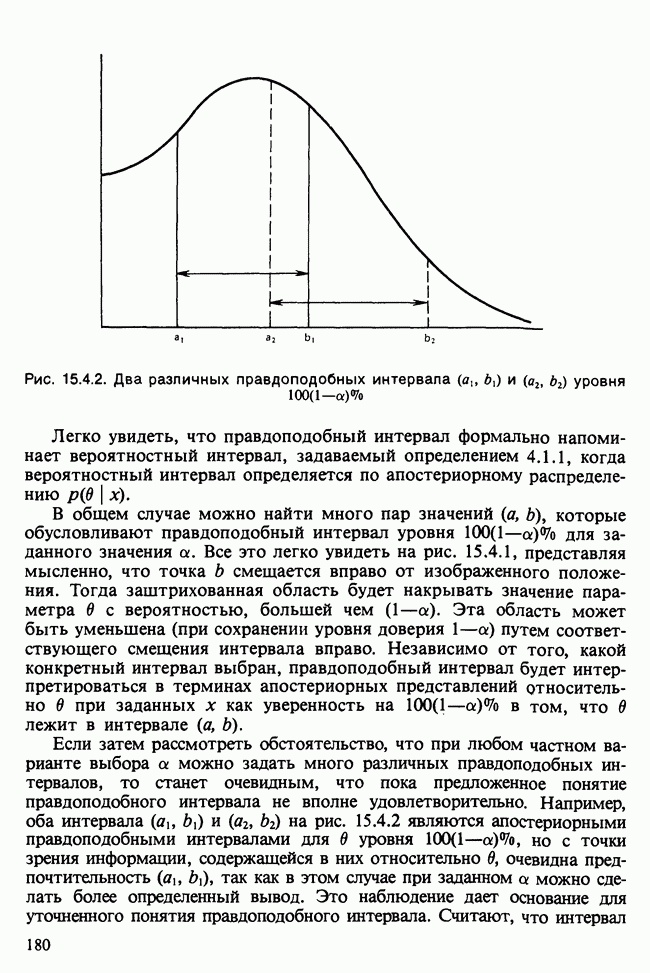
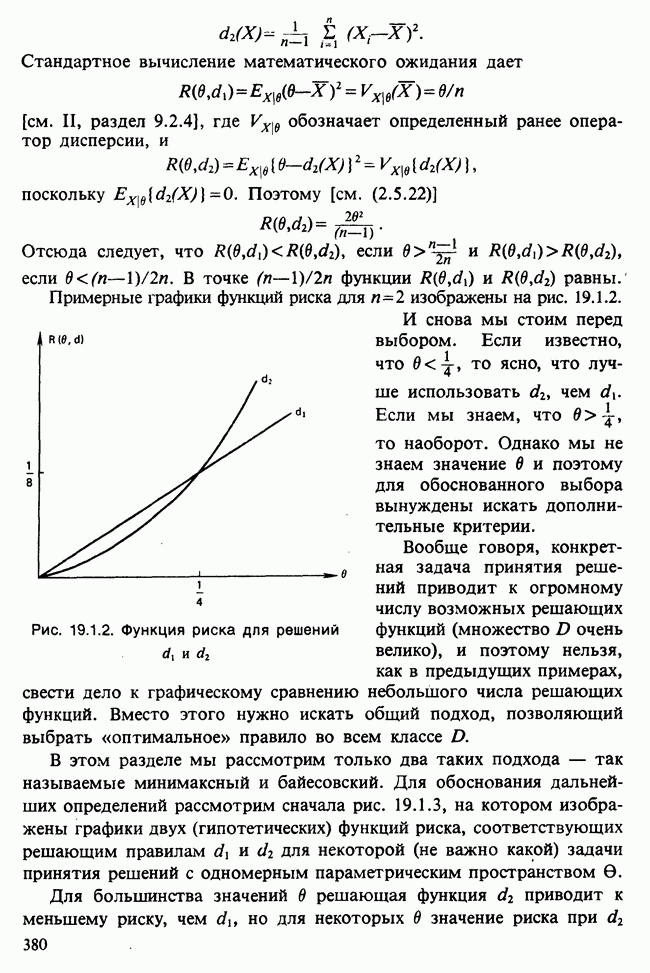
В нашем простом случае минимум можно найти, построив график функции  в интервале
в интервале  . В общем случае модели
. В общем случае модели  можно воспользоваться стандартными процедурами оптимизации [см. III, гл. 11], очень хорошо работающими в этой ситуации.
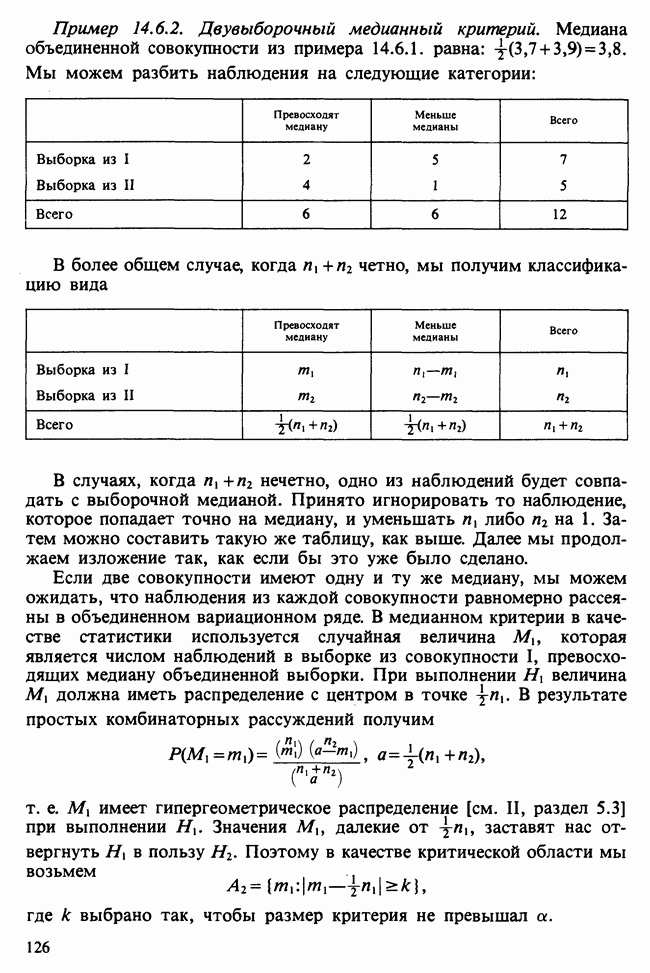
можно воспользоваться стандартными процедурами оптимизации [см. III, гл. 11], очень хорошо работающими в этой ситуации.
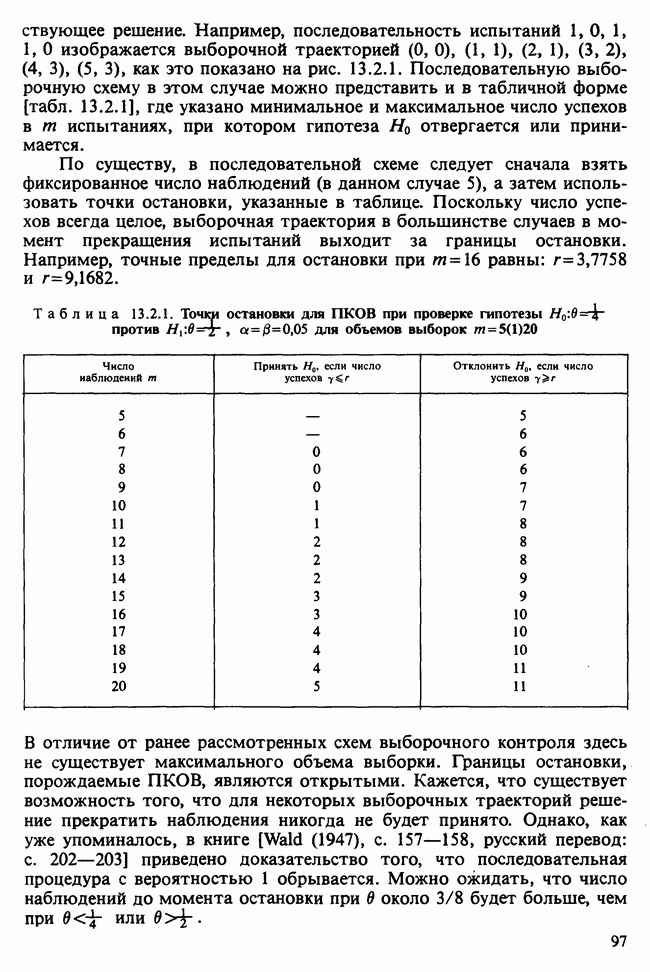
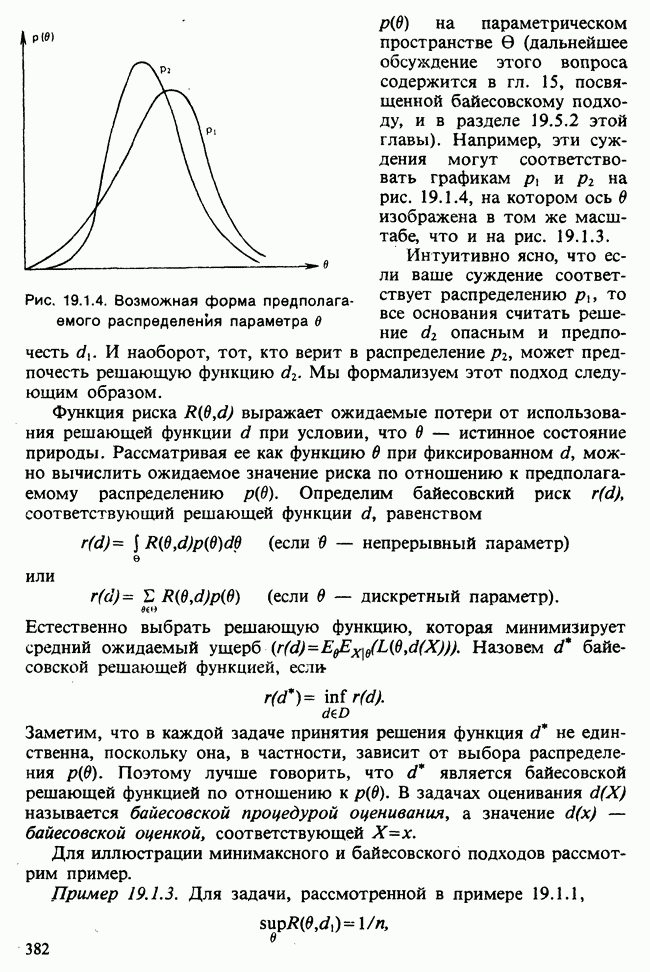
Необходимо рассмотреть теперь проблему определения величины  Проще всего положить
Проще всего положить  — среднему значению, если бы у нас не было вообще никаких выборочных данных. Обозначая через
— среднему значению, если бы у нас не было вообще никаких выборочных данных. Обозначая через  аппроксимацию для
аппроксимацию для  полученную заменой
полученную заменой  на
на  мы видим из (18.7.6), что
мы видим из (18.7.6), что

и эта величина стремится к нулю с ростом  Для значений
Для значений  , не слишком близких к единице, и достаточно больших
, не слишком близких к единице, и достаточно больших  возникающая при таком подходе ошибка будет мала по сравнению с любым истинным значением
возникающая при таком подходе ошибка будет мала по сравнению с любым истинным значением  Полученное таким путем решение мы будем называть решением условной проблемы наименьших квадратов или условным МНК-решением, так как оно сводится к минимизации
Полученное таким путем решение мы будем называть решением условной проблемы наименьших квадратов или условным МНК-решением, так как оно сводится к минимизации
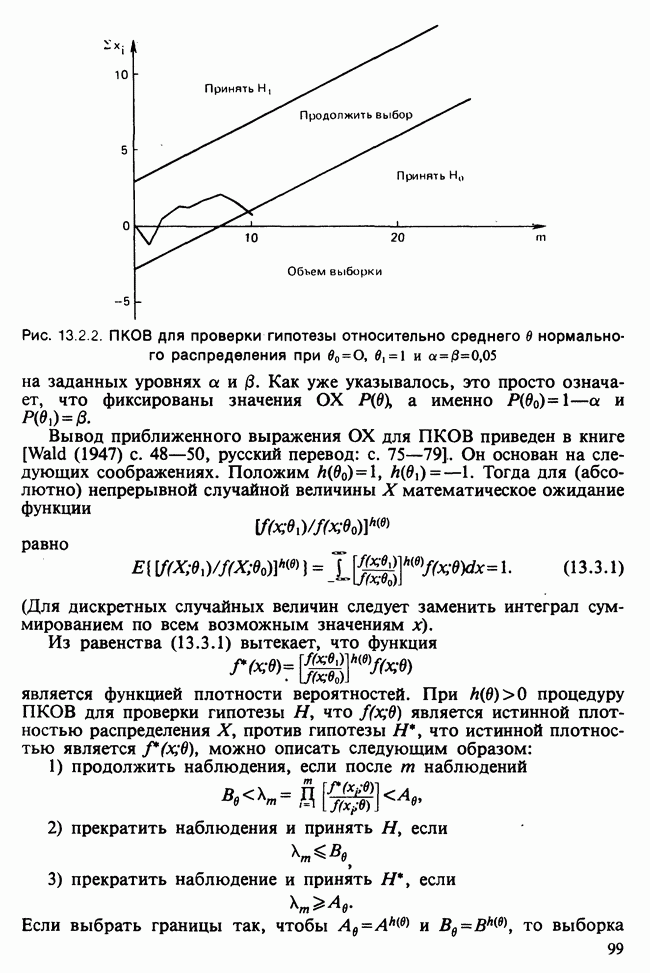
Требуемые дополнительные расчеты, помимо вычисления а  необходимых для нахождения условного минимума суммы квадратов,
необходимых для нахождения условного минимума суммы квадратов,  вычисление К и
вычисление К и  по формулам (18.7.15) и (18.7.16), а затем вычисление
по формулам (18.7.15) и (18.7.16), а затем вычисление  в соответствии с равенством
в соответствии с равенством

если в качестве начального значения взято  Окончательно
Окончательно

Получаемое при этом подходе значение, минимизирующее функцию  мы будем называть точной МНК-оценкой для
мы будем называть точной МНК-оценкой для  . Небольшой дополнительный анализ приводит к точным ММП-оценкам. Воспользуемся тождеством (18.7.17) и разложим на множители
. Небольшой дополнительный анализ приводит к точным ММП-оценкам. Воспользуемся тождеством (18.7.17) и разложим на множители  (18.7.7):
(18.7.7):

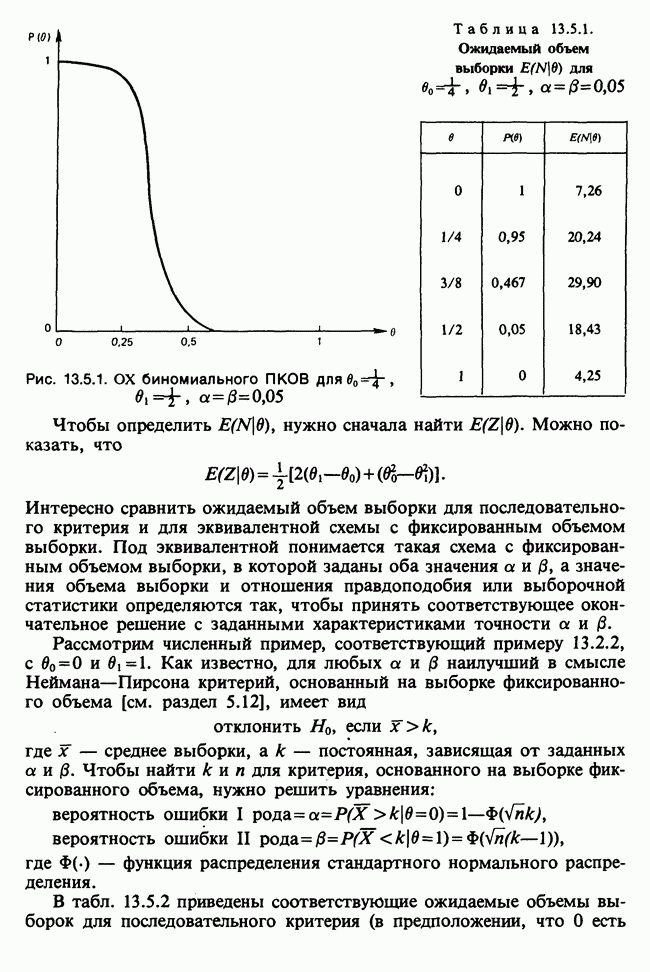
В правой части величина  содержится лишь в первой строке, а множитель
содержится лишь в первой строке, а множитель  введен сюда для того, чтобы интеграл по
введен сюда для того, чтобы интеграл по  в первой строке был равен единице. Поэтому вторая строка, содержащая в качестве компенсации множитель
в первой строке был равен единице. Поэтому вторая строка, содержащая в качестве компенсации множитель  оказывается частной функцией плотности распределения вероятности наблюдений:
оказывается частной функцией плотности распределения вероятности наблюдений:

В сущности первая строка (18.7.20) представляет собой условное распределение неизвестного значения  при известных наблюдениях и является нормальной
при известных наблюдениях и является нормальной  в. со средним
в. со средним  и дисперсией
и дисперсией 
Возвращаясь к (18.7.21), можно найти логарифм функции правдоподобия [см. раздел 6.2.1] и максимизировать его по  получая в результате монотонную функцию от
получая в результате монотонную функцию от

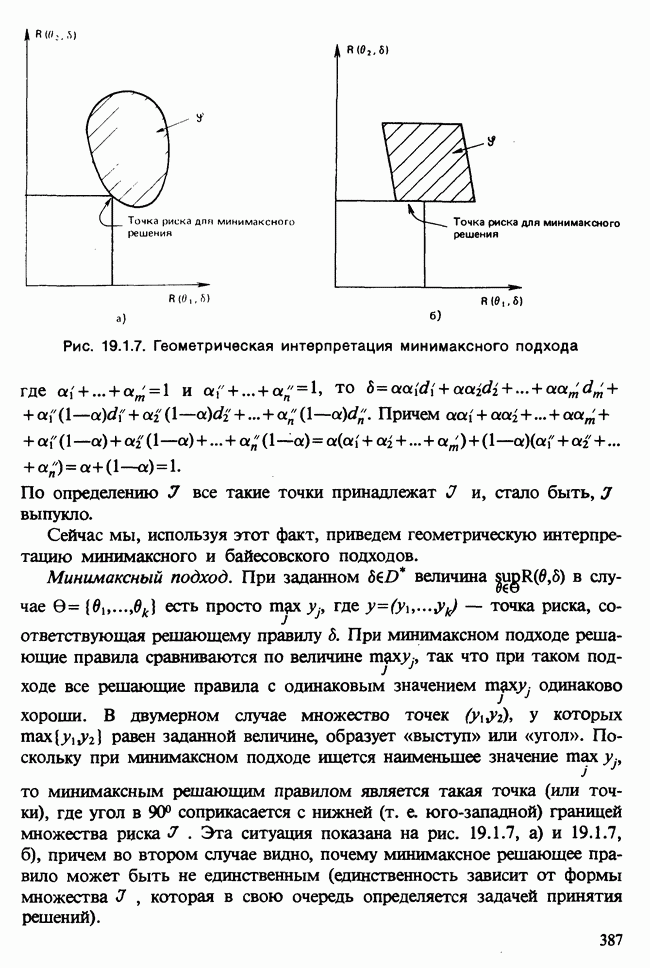
минимум которой и определяет точную ММП-оценку. Заметим, что функция К зависит лишь от  и не зависит от наблюдений, и с ростом
и не зависит от наблюдений, и с ростом  величина
величина  стремится к единице. Поэтому этот множитель существен лишь для малых объемов выборок и в этом случае не представляет труда для вычислений, а при умеренно больших
стремится к единице. Поэтому этот множитель существен лишь для малых объемов выборок и в этом случае не представляет труда для вычислений, а при умеренно больших  без него часто можно обойтись, соглашаясь с незначительным смещением оценки, но сильно сокращая объем вычислений, особенно в случае общей модели
без него часто можно обойтись, соглашаясь с незначительным смещением оценки, но сильно сокращая объем вычислений, особенно в случае общей модели  Этим обстоятельством объясняется использование точных МНК-оценок.
Этим обстоятельством объясняется использование точных МНК-оценок.
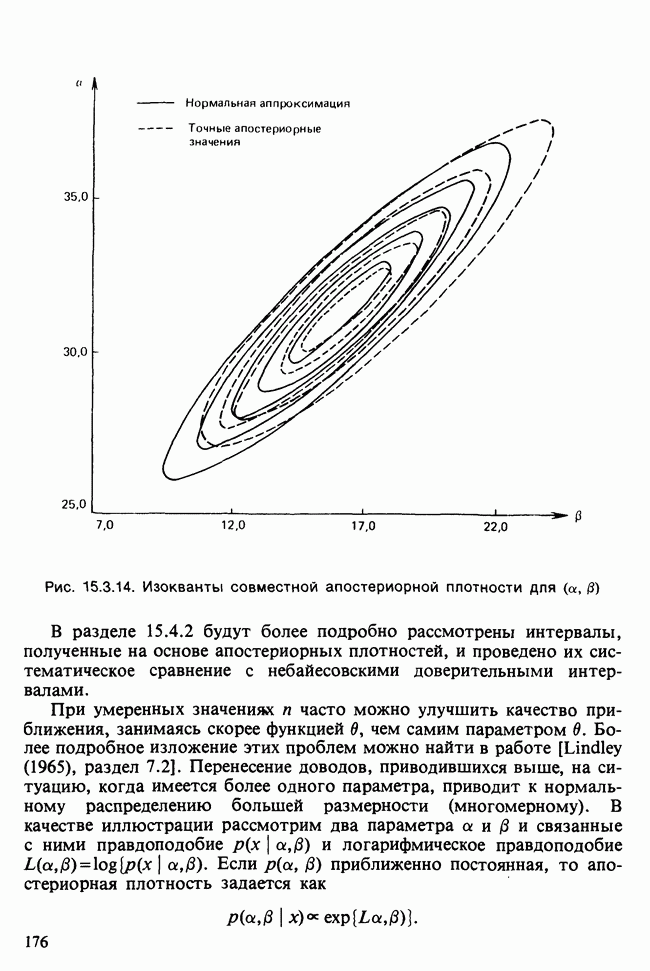
Асимптотически при  описанные оценки становятся неотличимы, и можно показать, что их свойства аналогичны свойствам оценок наибольшего правдоподобия для независимых одинаково распределенных наблюдений. Так, эти оценки — асимптотически несмещенные и асимптотически нормальные, их ковариационную матрицу можно оценить с помощью вычисленного в точке оптимума обратного гессиана от взятого с обратным знаком логарифма функции правдоподобия [см. раздел 6.2.5, п. в)]. Эту информацию обычно получают как дополнительную при применении оптимизационных процедур. Кроме того, можно перенести сюда из стандартной линейной регрессии тесты, основанные на сумме квадратов
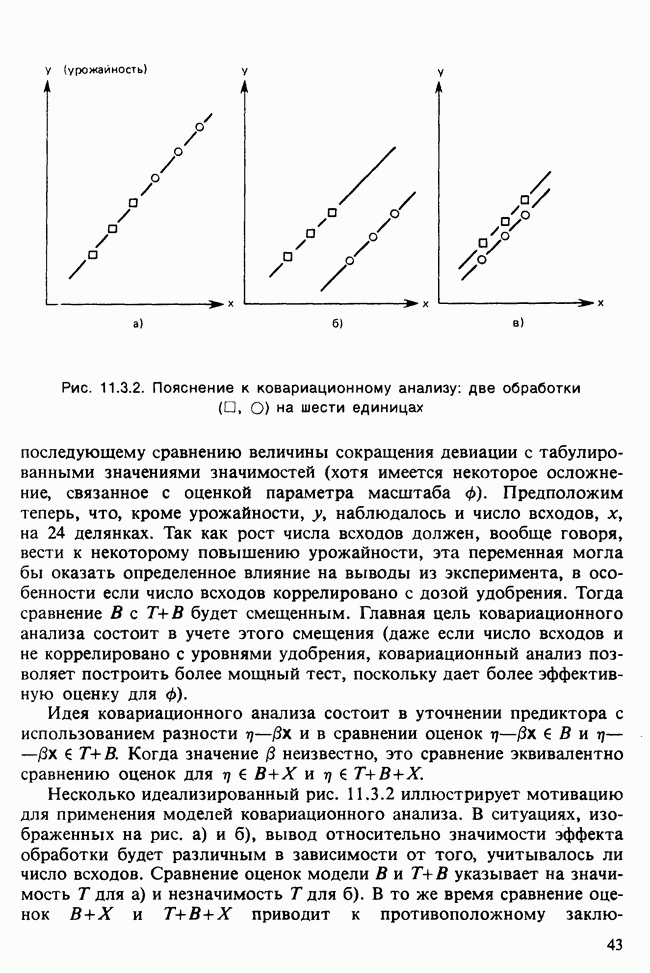
описанные оценки становятся неотличимы, и можно показать, что их свойства аналогичны свойствам оценок наибольшего правдоподобия для независимых одинаково распределенных наблюдений. Так, эти оценки — асимптотически несмещенные и асимптотически нормальные, их ковариационную матрицу можно оценить с помощью вычисленного в точке оптимума обратного гессиана от взятого с обратным знаком логарифма функции правдоподобия [см. раздел 6.2.5, п. в)]. Эту информацию обычно получают как дополнительную при применении оптимизационных процедур. Кроме того, можно перенести сюда из стандартной линейной регрессии тесты, основанные на сумме квадратов  если их использовать осторожно. Тот факт, что остатки а, можно рассматривать как ошибки прогноза на один шаг вперед, полученные при использовании подогнанной модели для последовательного прогноза выборочных данных, убеждает нас в том, что
если их использовать осторожно. Тот факт, что остатки а, можно рассматривать как ошибки прогноза на один шаг вперед, полученные при использовании подогнанной модели для последовательного прогноза выборочных данных, убеждает нас в том, что  осмысленная характеристика качества модели. Эта величина используется в оценке
осмысленная характеристика качества модели. Эта величина используется в оценке

где  — число степеней свободы, связанное с оцениваемыми параметрами, например,
— число степеней свободы, связанное с оцениваемыми параметрами, например,  для модели
для модели  и на единицу больше, если оценивалось также среднее значение
и на единицу больше, если оценивалось также среднее значение 
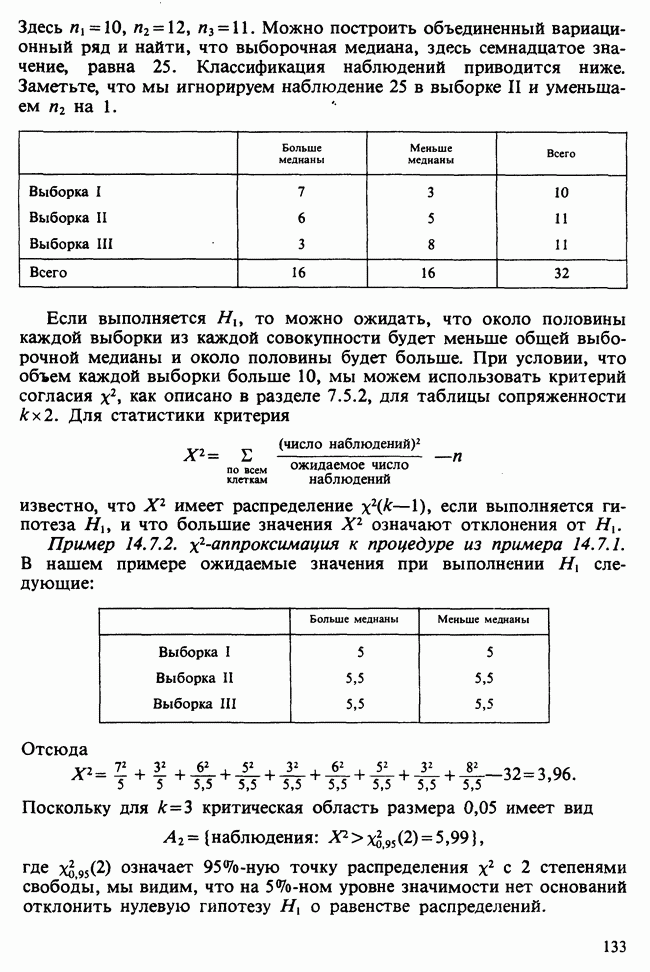
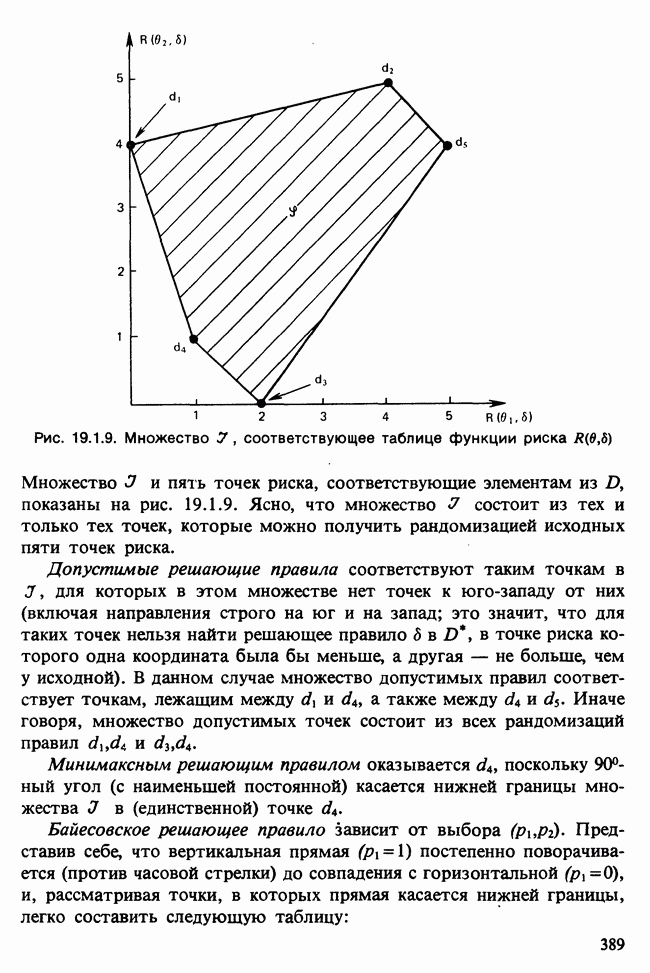
Для примера приведем две модели, подогнанные к первой разности ряда продолжительности дня. Модель  выражается в виде:
выражается в виде:

где для параметров приведены их стандартные ошибки [см. определение 3.1.1]. Сумма квадратов остатков 
Модель  имеет следующий вид:
имеет следующий вид:

где 
Отношение величины, на которую уменьшилась  к дисперсии
к дисперсии  равно
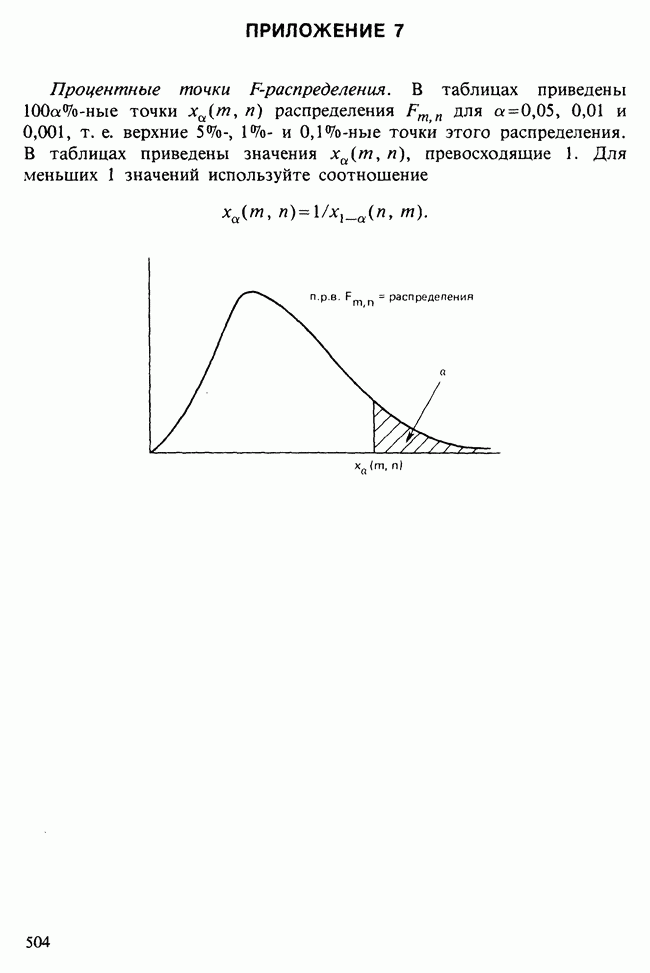
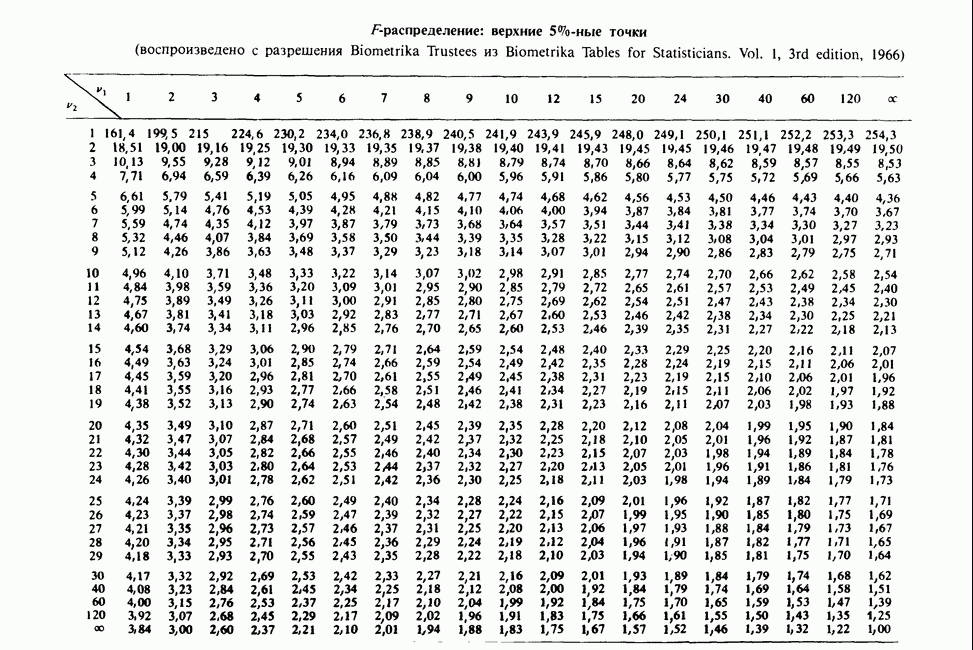
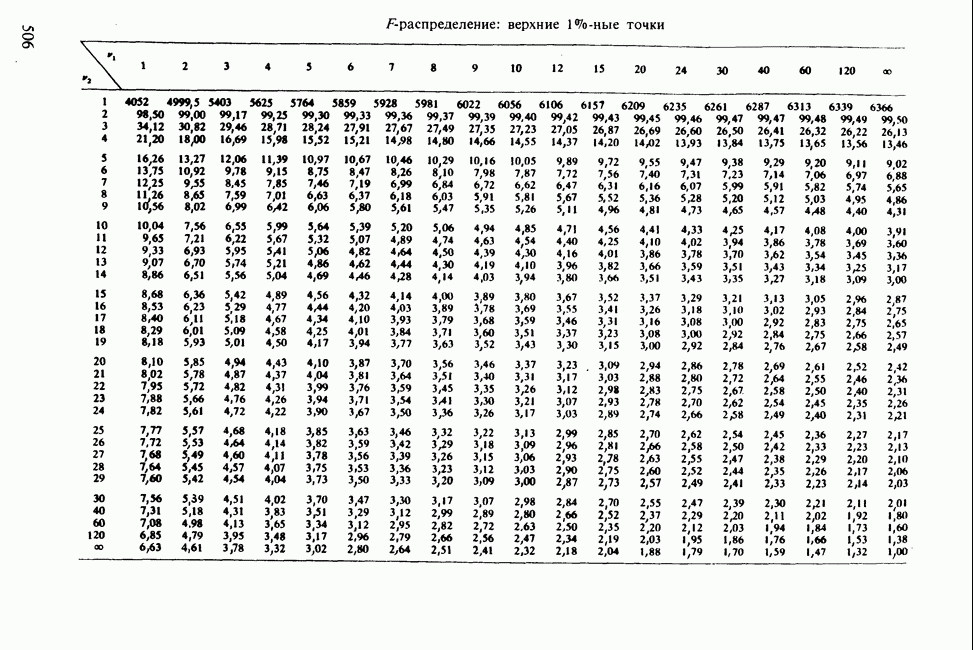
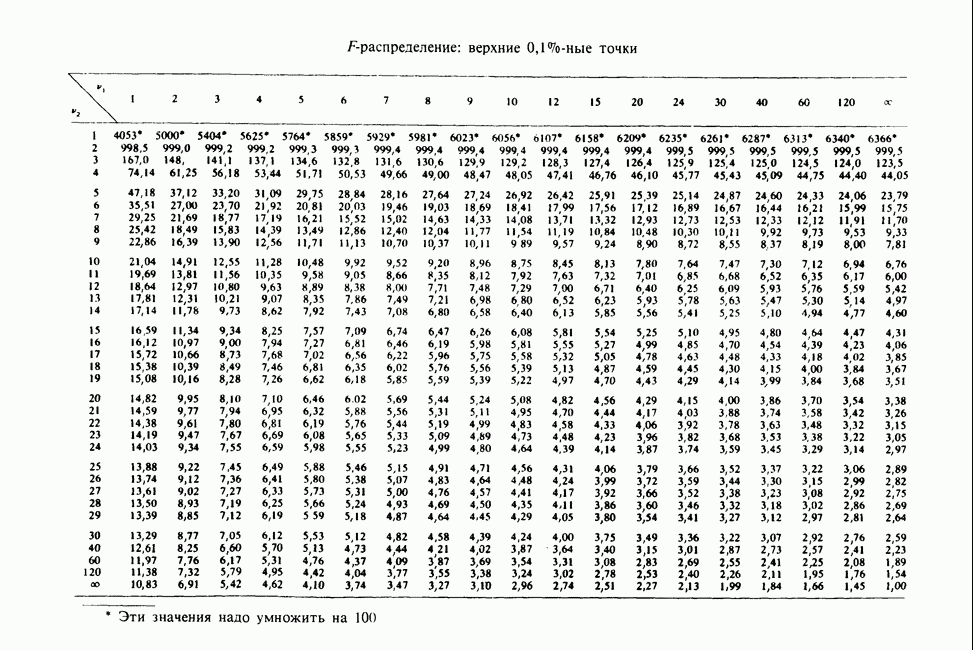
равно  и его не следует считать значимым, так как 4,34 лишь незначительно превосходит верхнюю
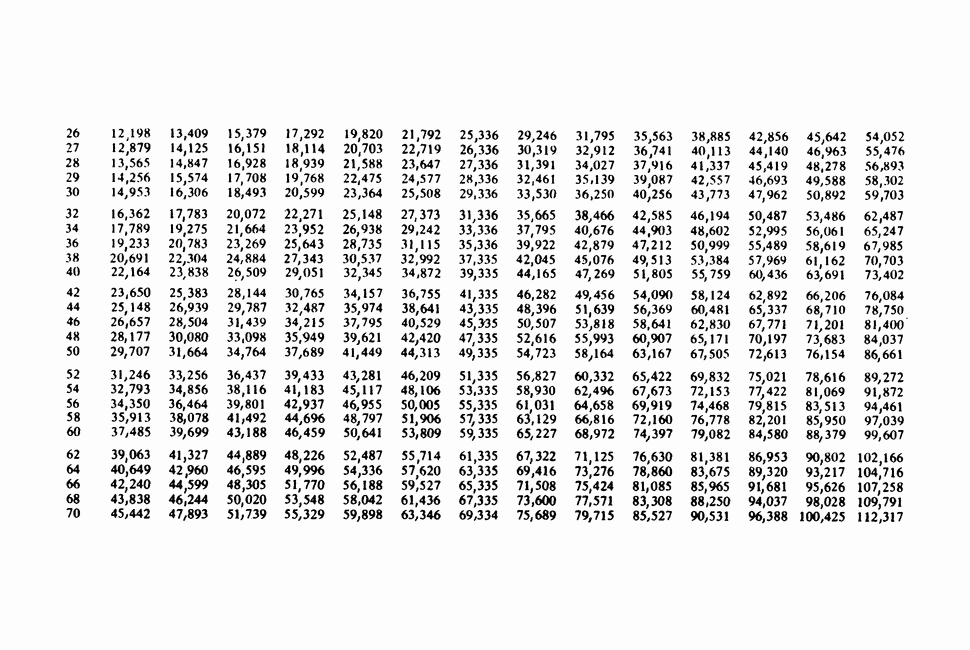
и его не следует считать значимым, так как 4,34 лишь незначительно превосходит верхнюю  -ную точку для распределения хи-квадрат с одной степенью свободы. Аналогично новый параметр
-ную точку для распределения хи-квадрат с одной степенью свободы. Аналогично новый параметр  равен лишь удвоенной величине своей стандартной ошибки, и мы можем сделать вывод, что модель
равен лишь удвоенной величине своей стандартной ошибки, и мы можем сделать вывод, что модель  в лучшем случае является некоторым усовершенствованием модели
в лучшем случае является некоторым усовершенствованием модели  Заметим также, что модель дает значение
Заметим также, что модель дает значение  так что при прогнозе на один шаг вперед обеспечивается
так что при прогнозе на один шаг вперед обеспечивается  -ное снижение дисперсии, но для прогноза более чем на 3 шага вперед модель
-ное снижение дисперсии, но для прогноза более чем на 3 шага вперед модель  вообще не
вообще не
приводит к уменьшению ошибки прогноза. Более того, оценка среднего значения ряда вообще не значима, что создает сомнения по поводу утверждения, что исходный ряд продолжительности дня содержит растущий тренд.




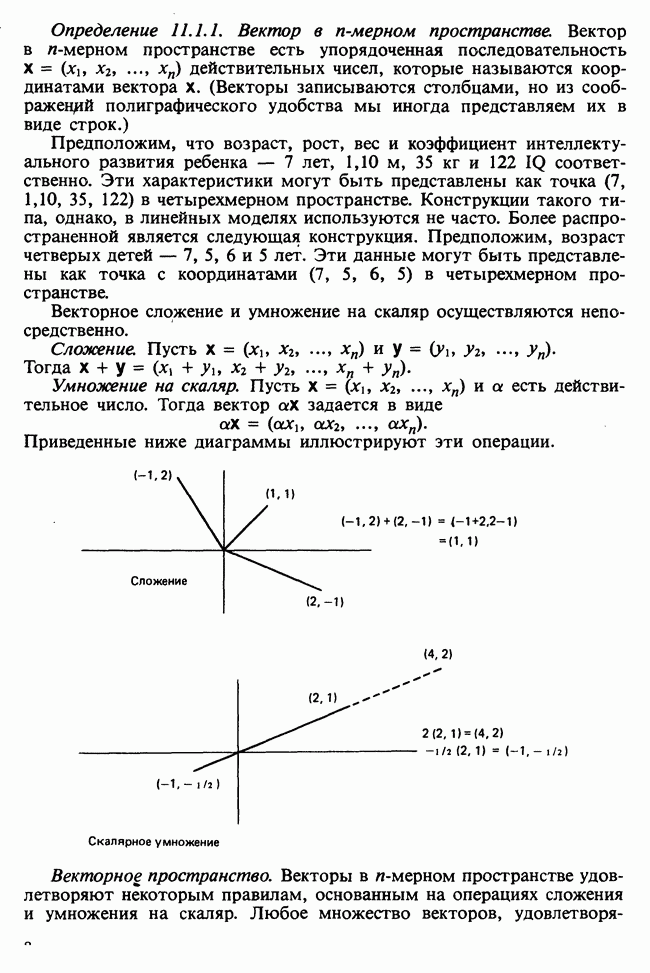




































































































































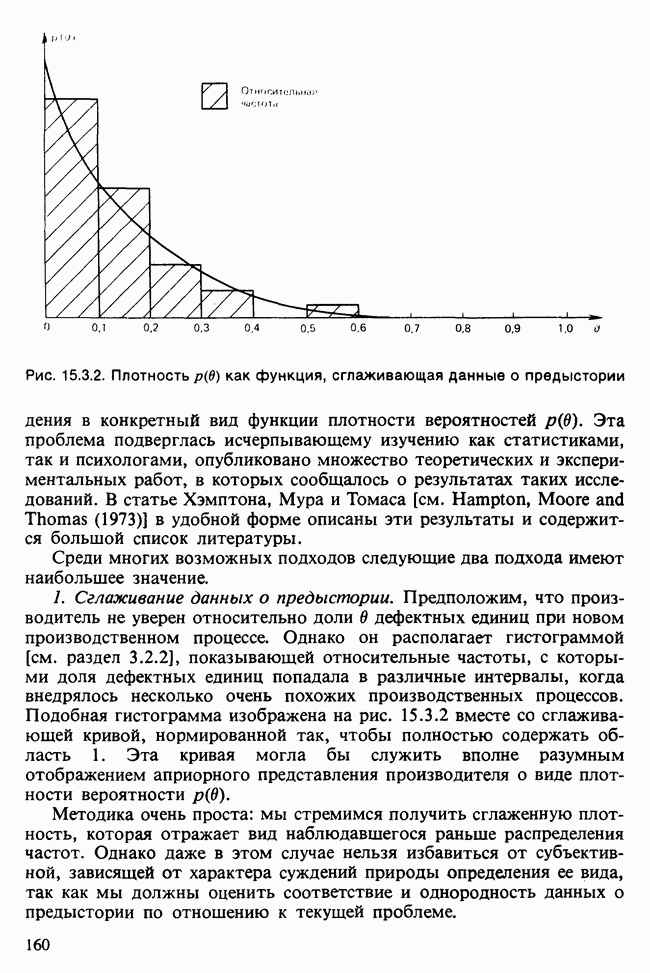

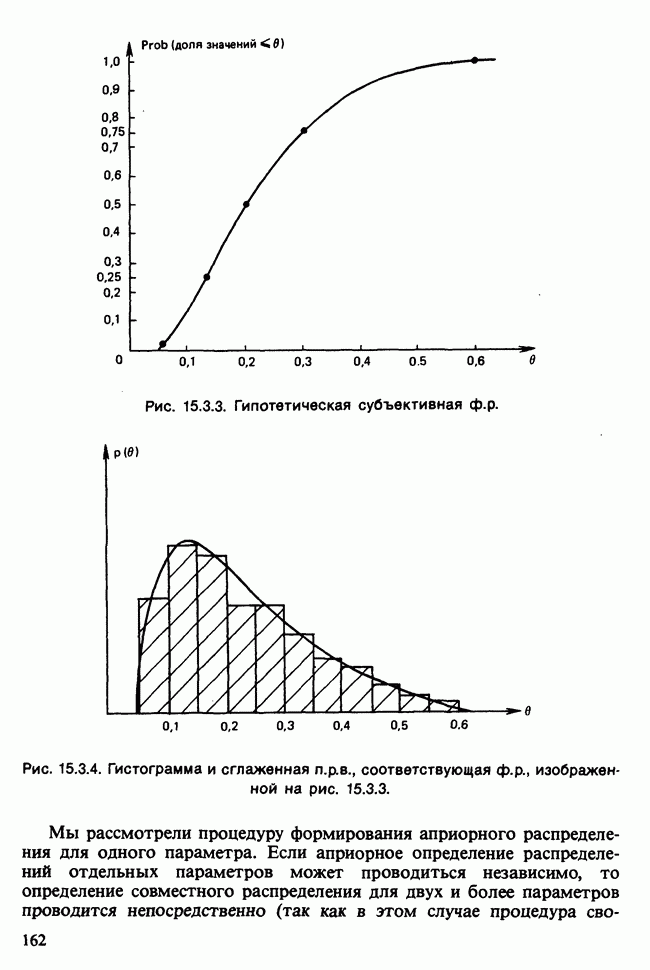


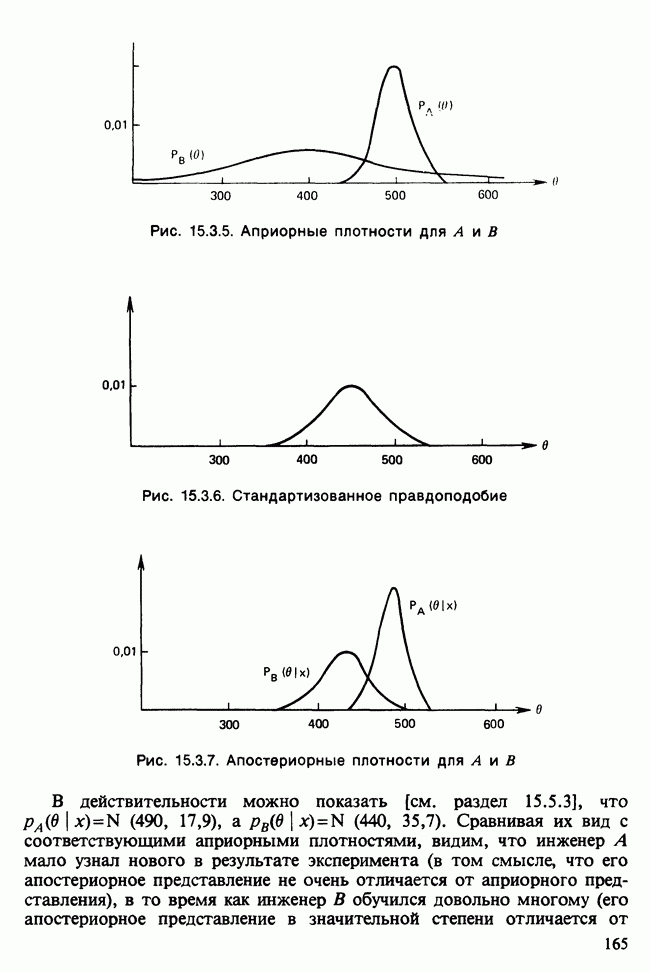
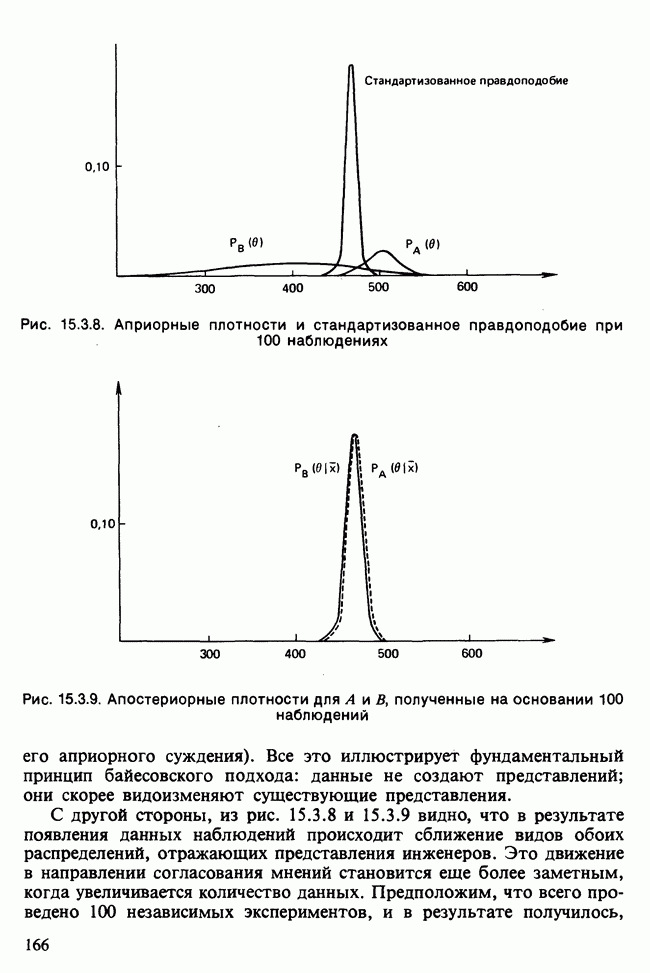


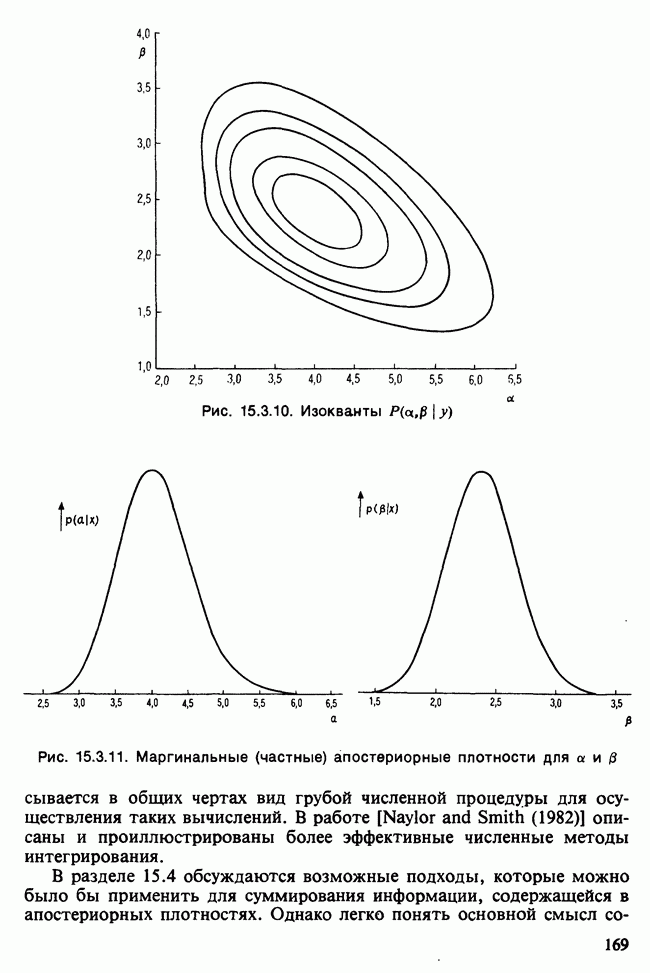
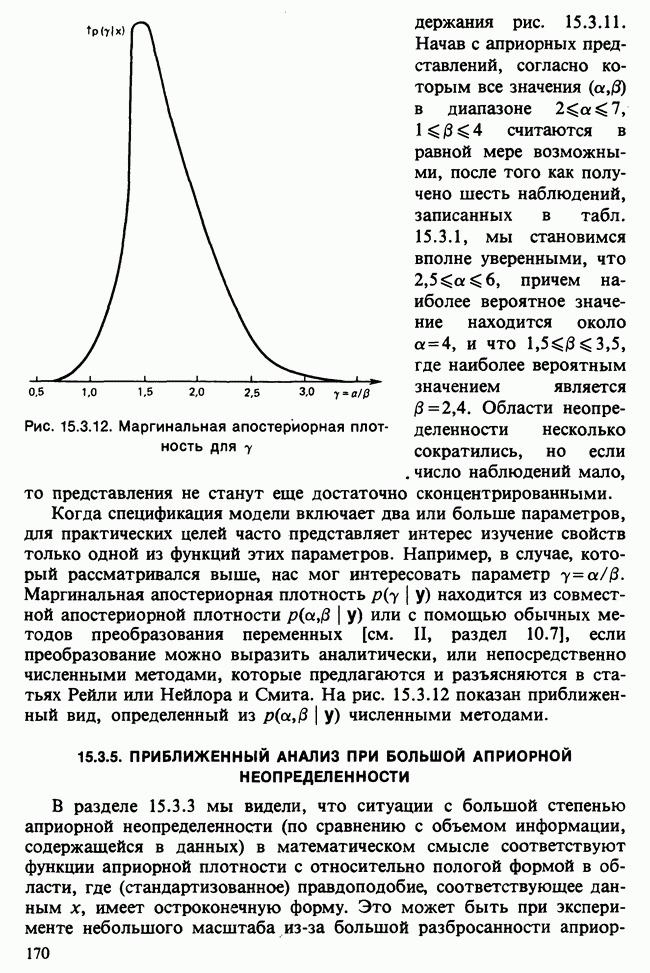
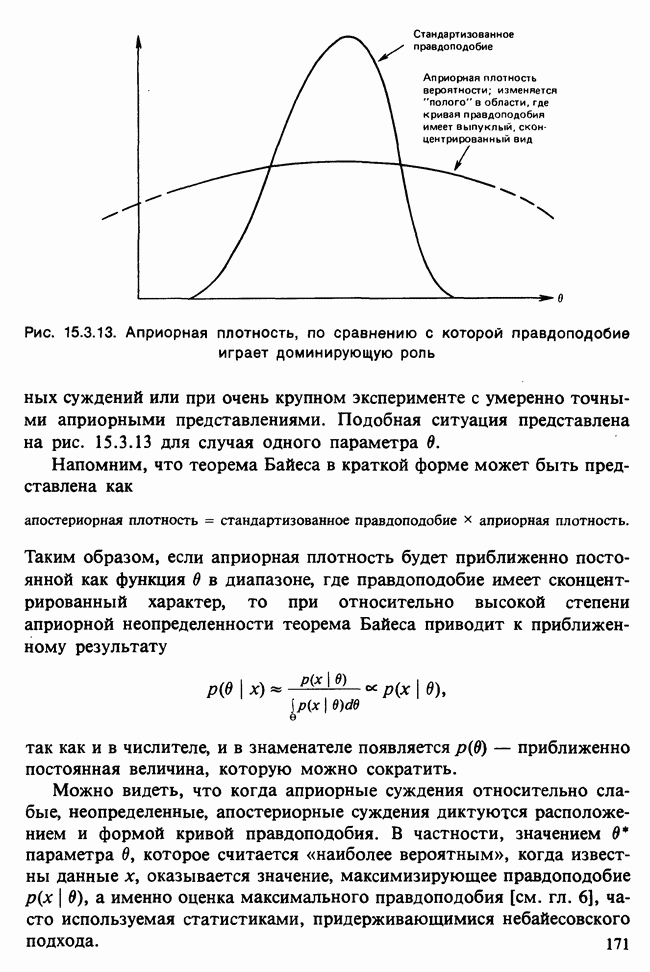








































































































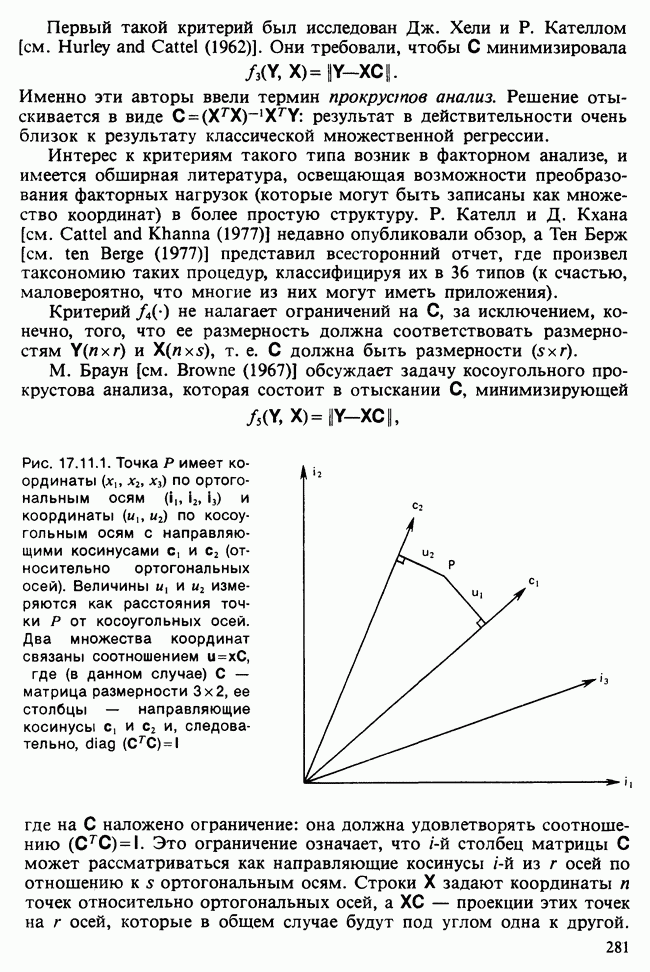







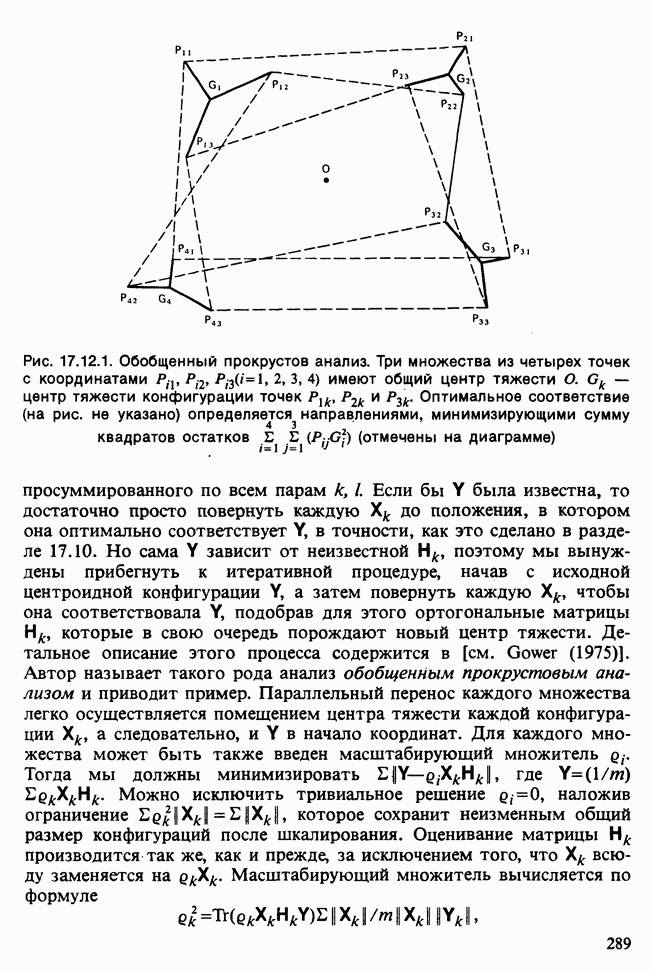











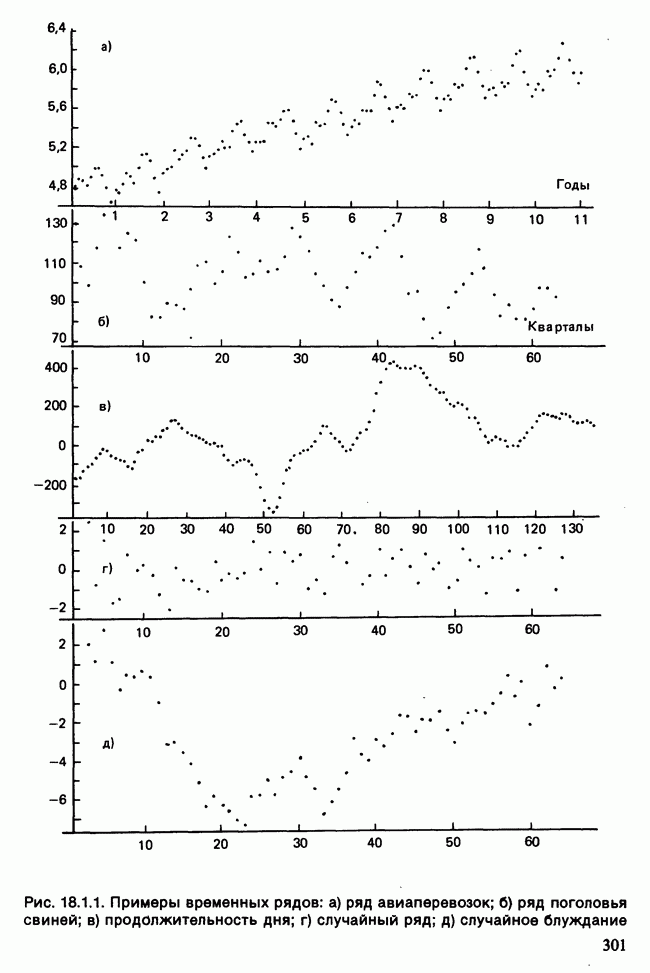

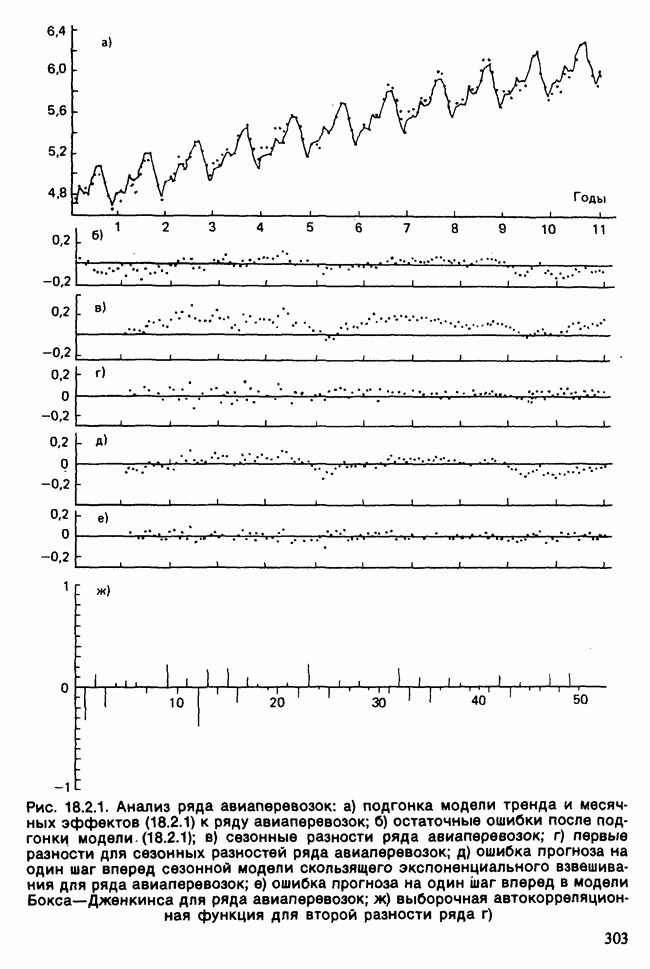

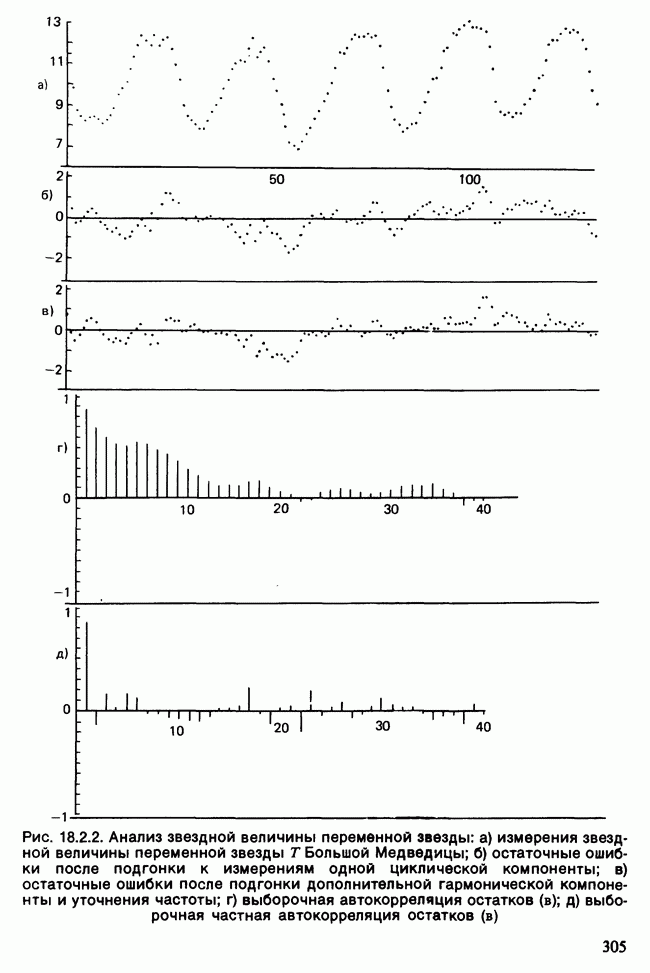



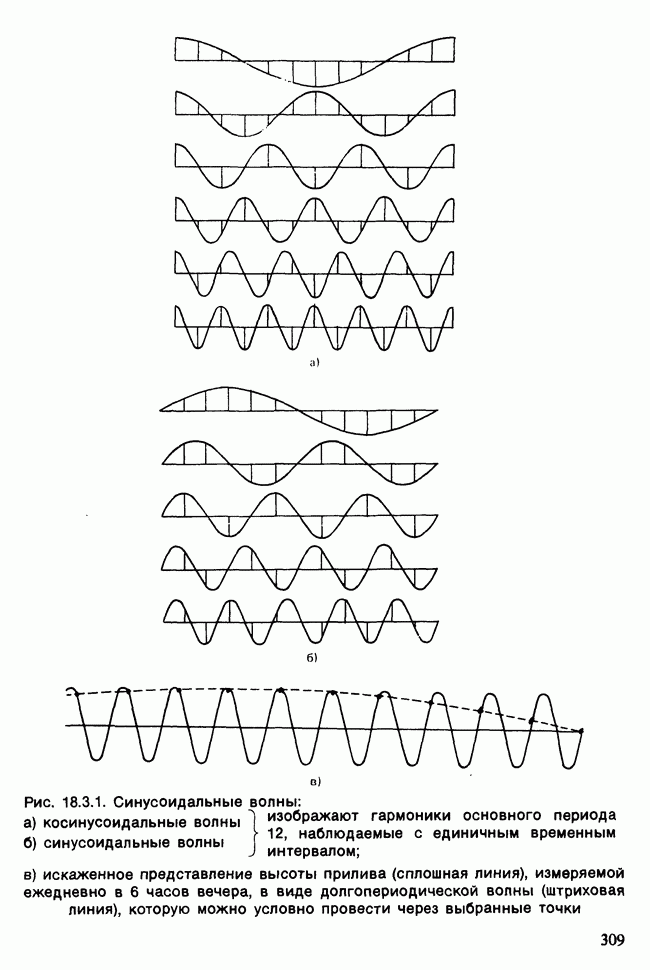



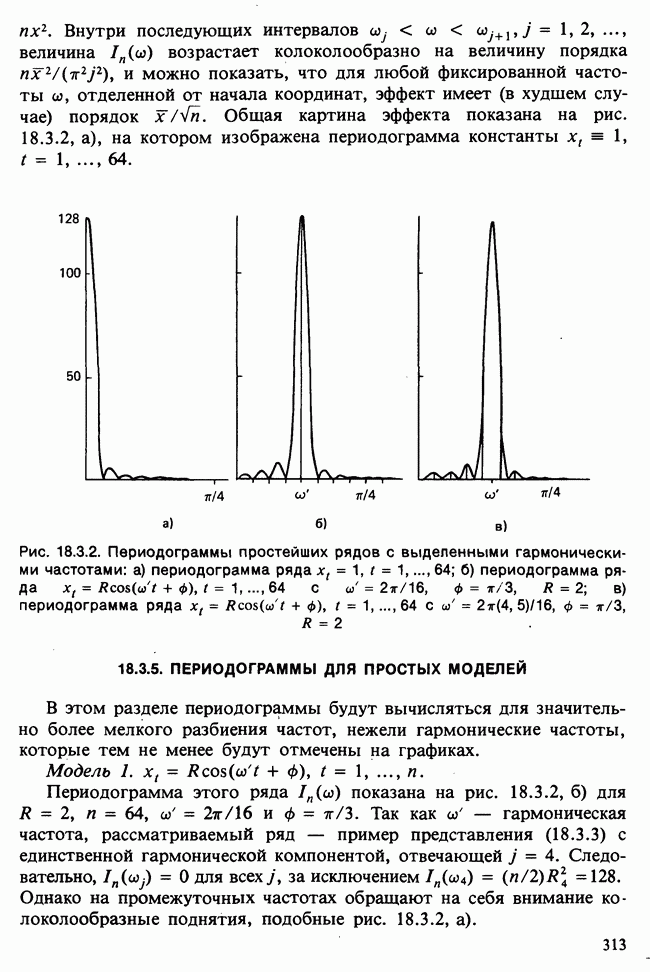

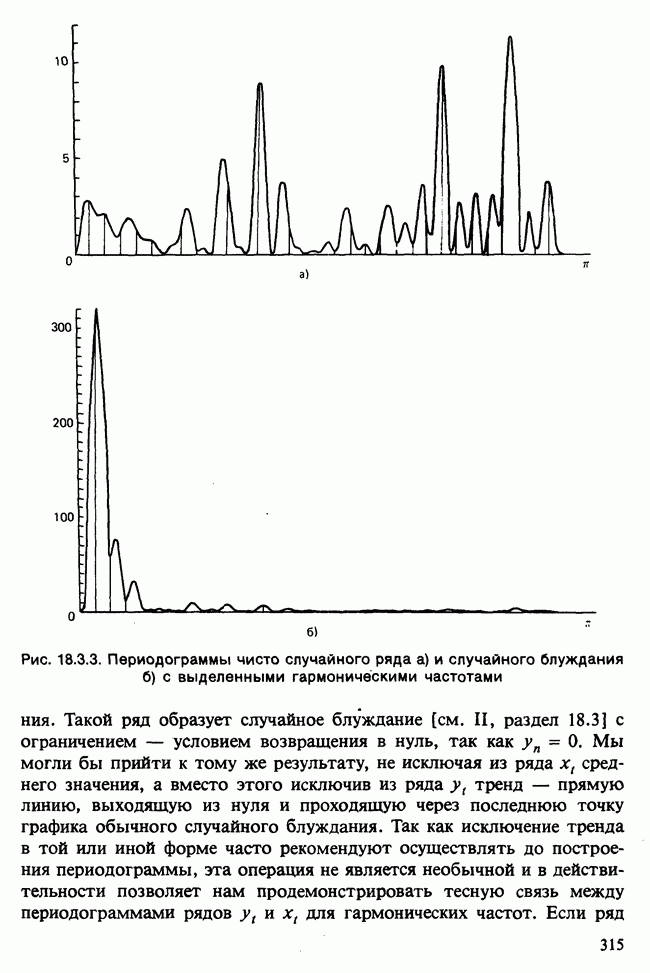

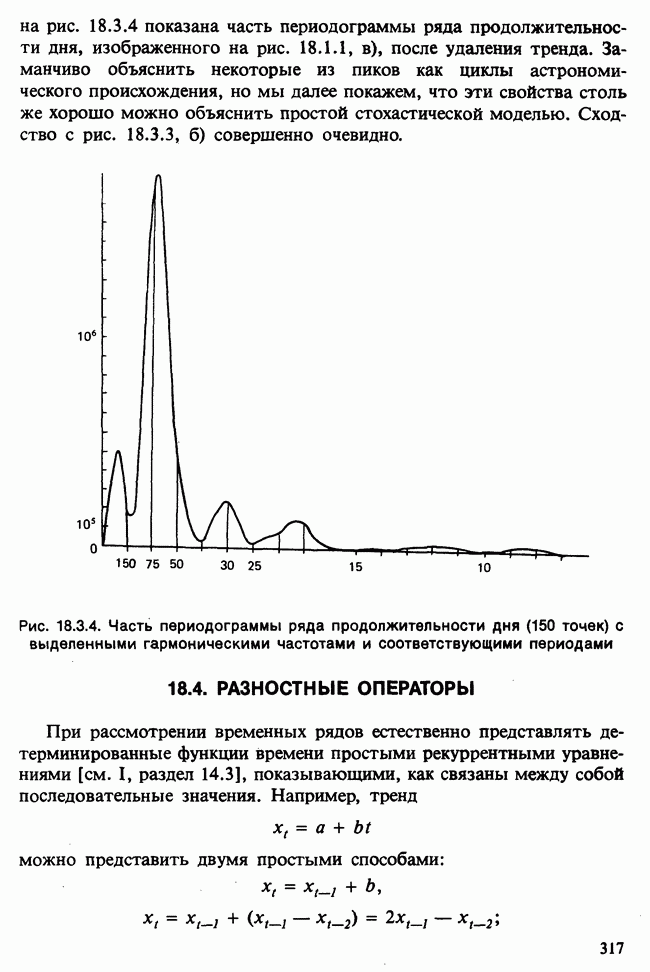













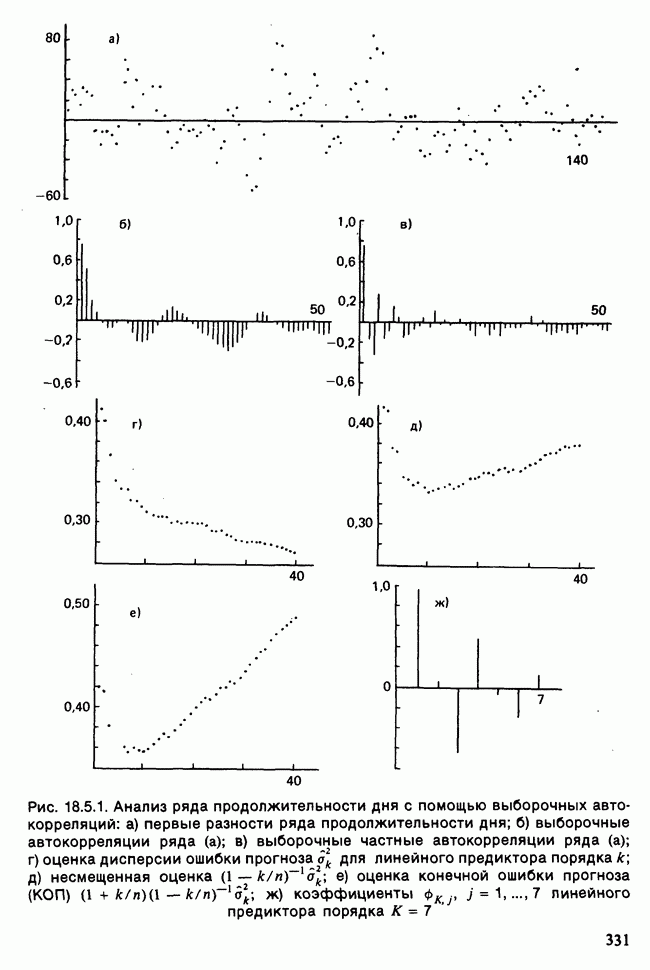
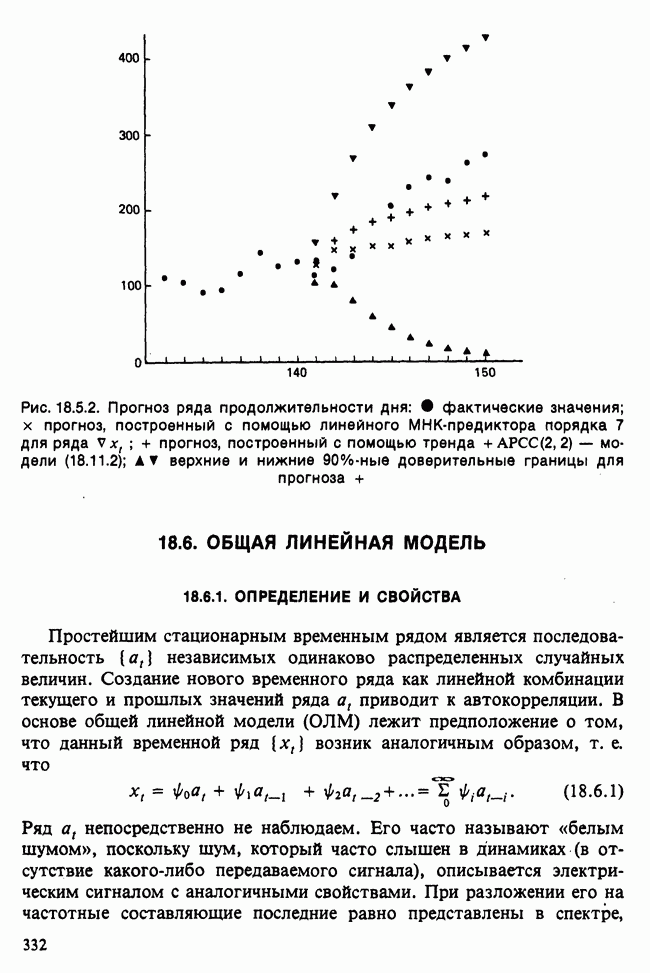





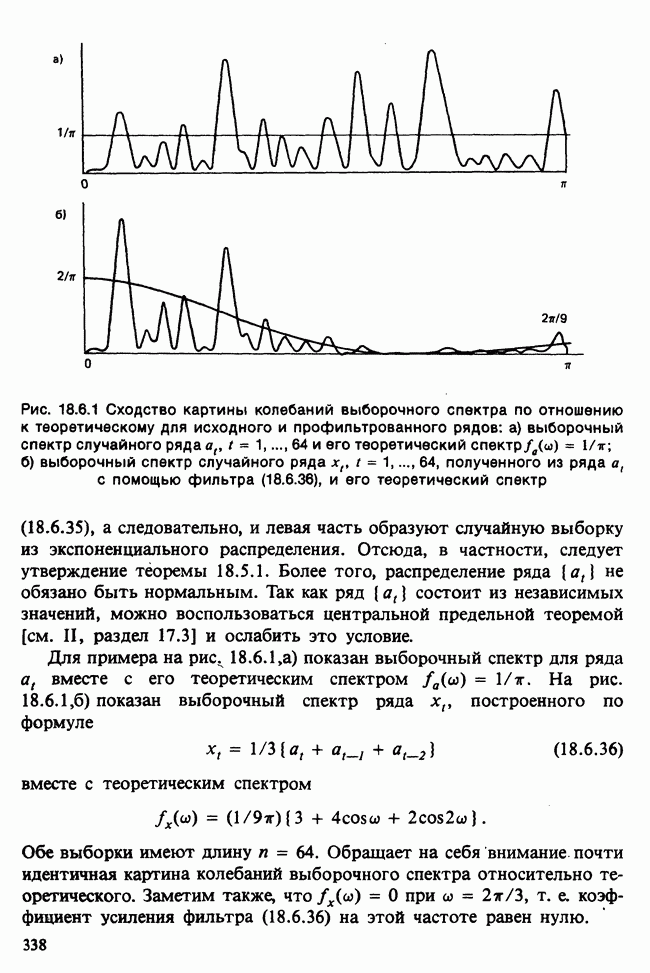























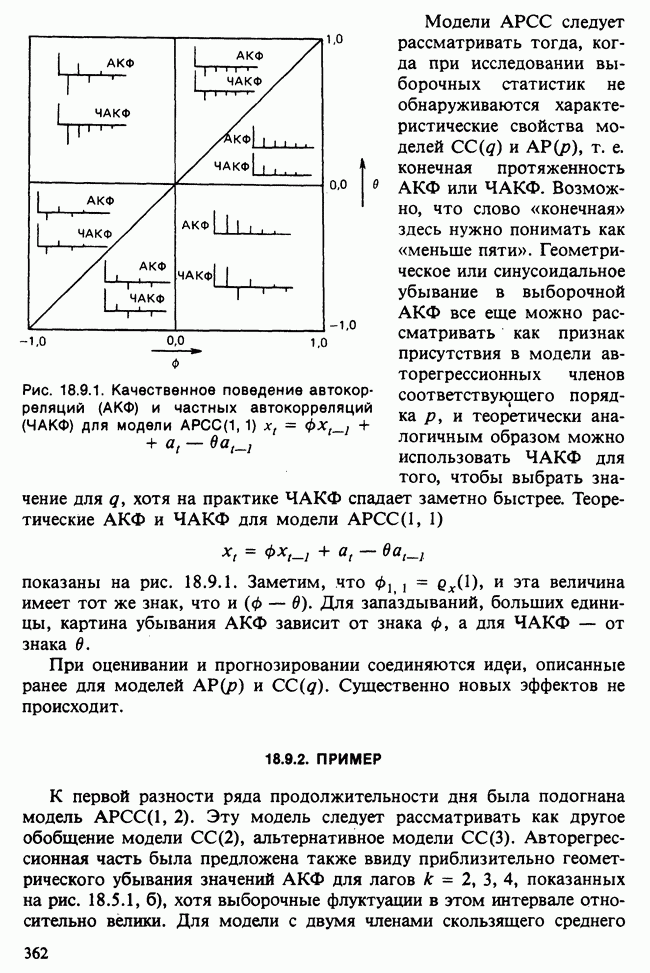


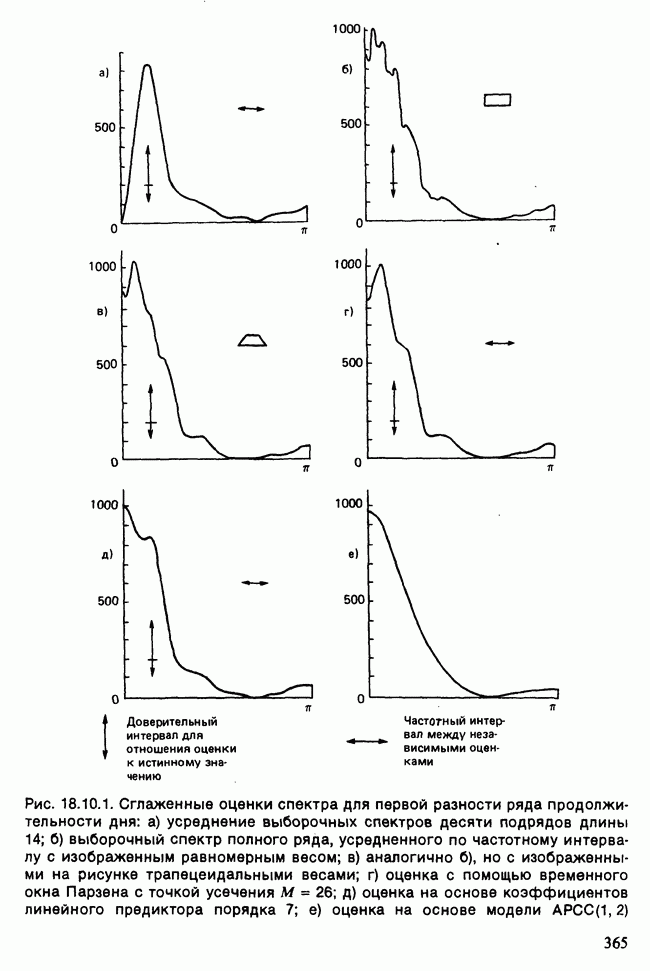



































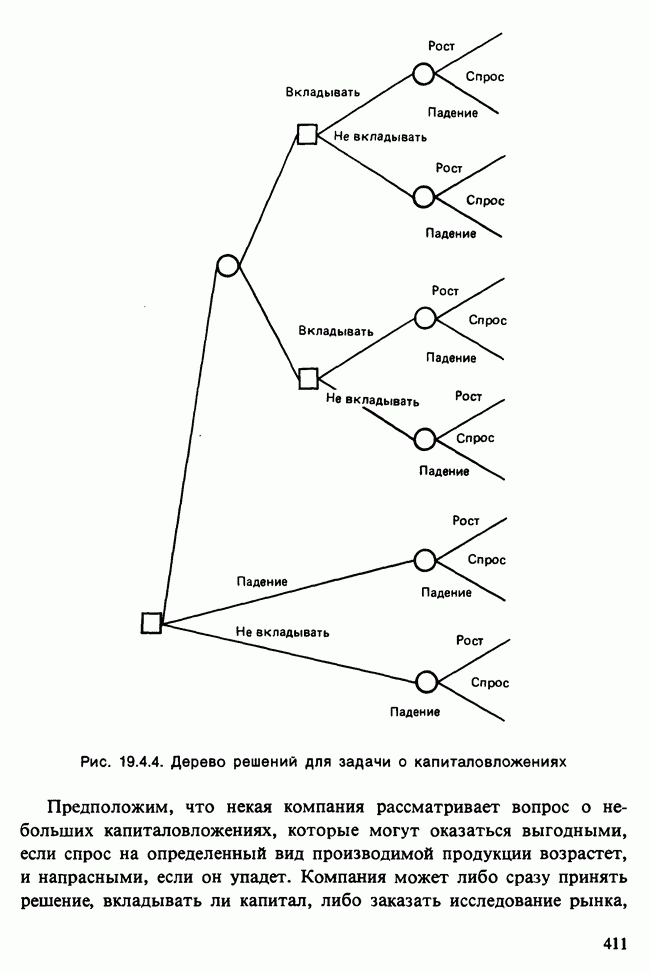

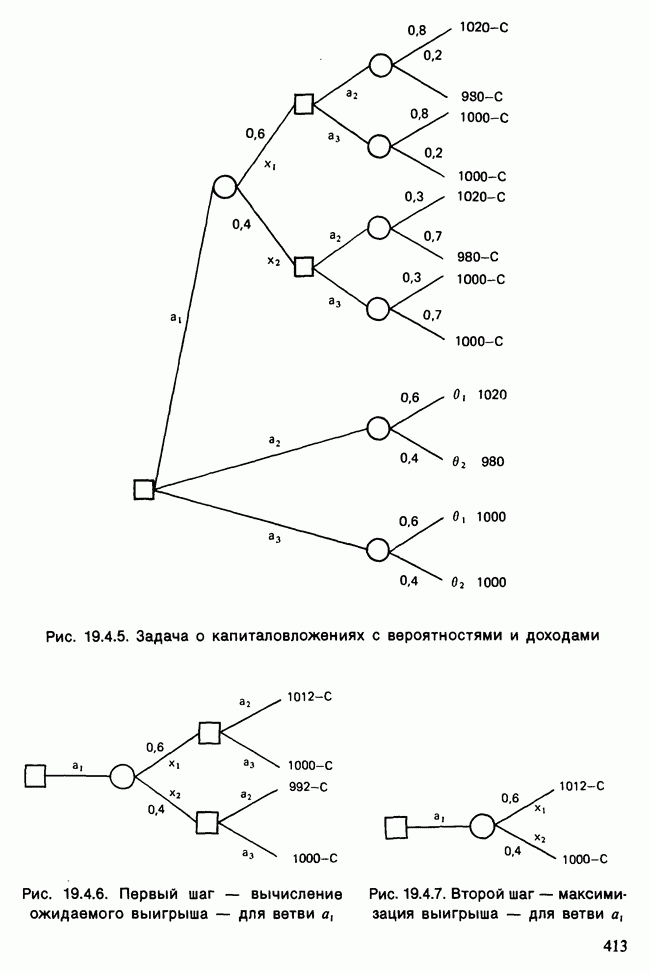












































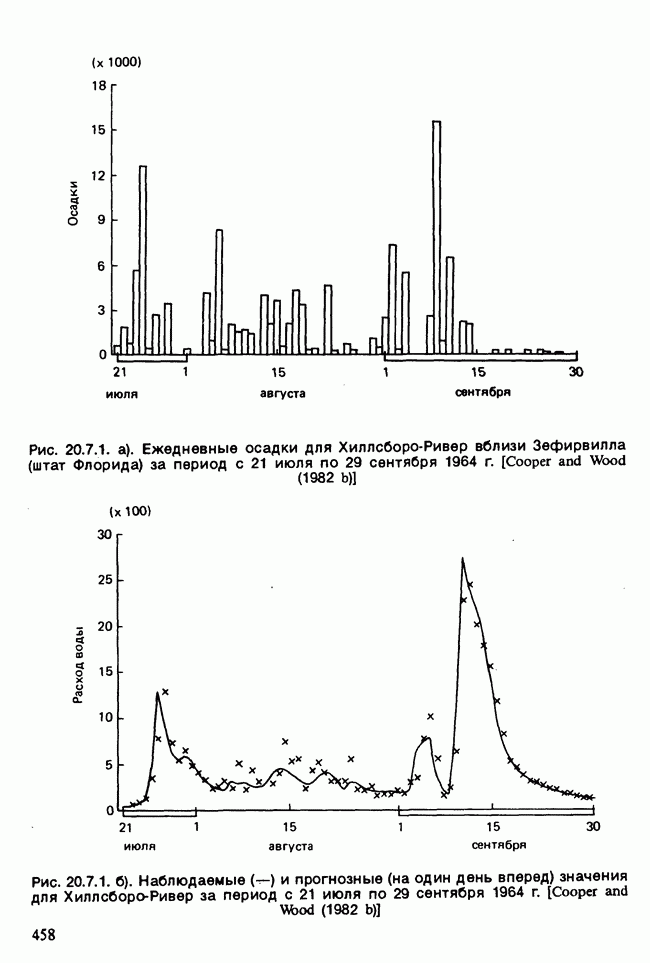
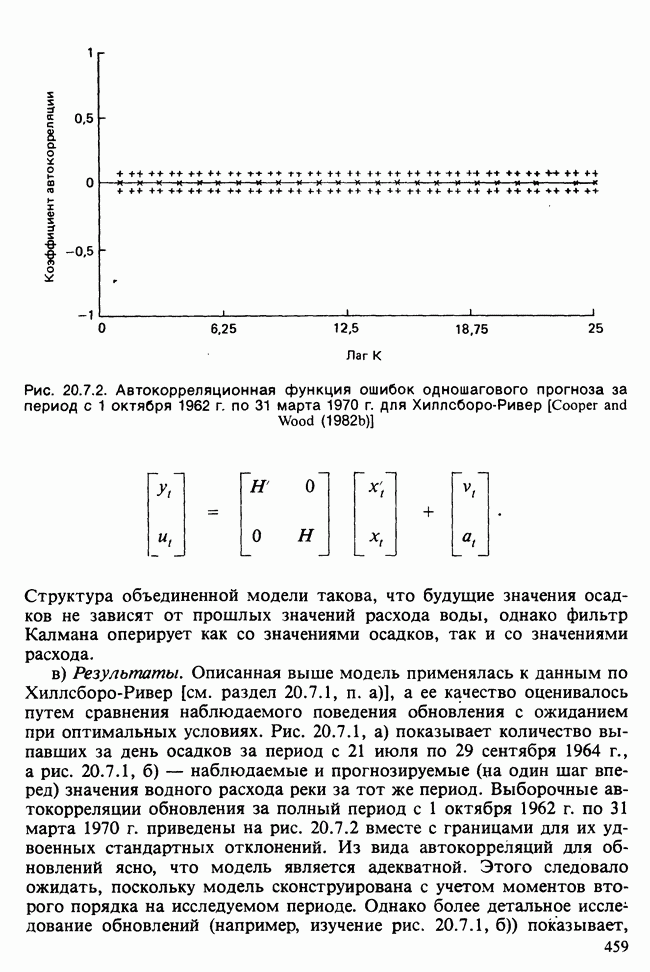





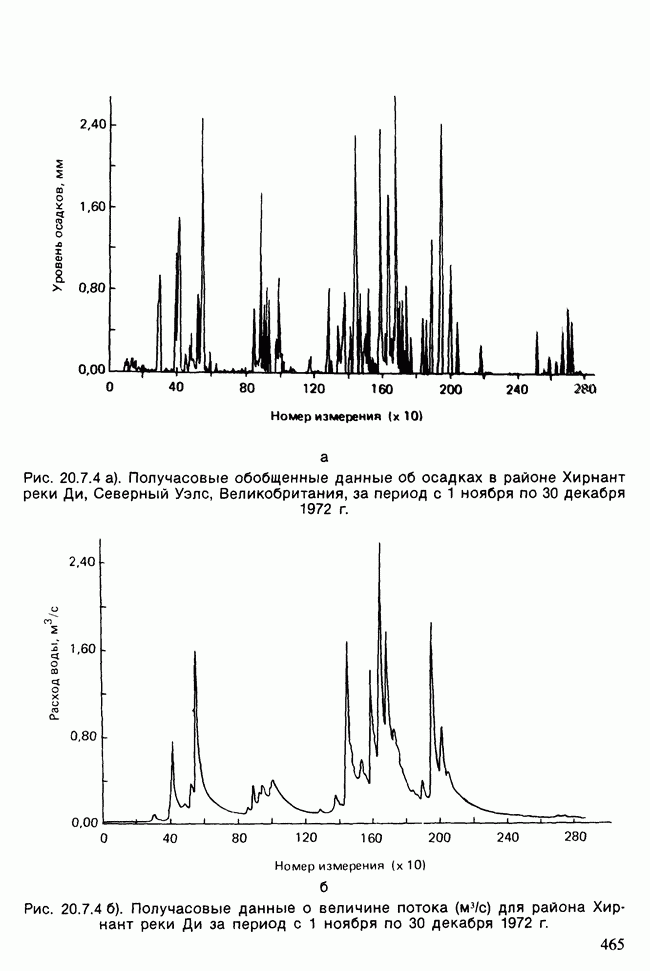
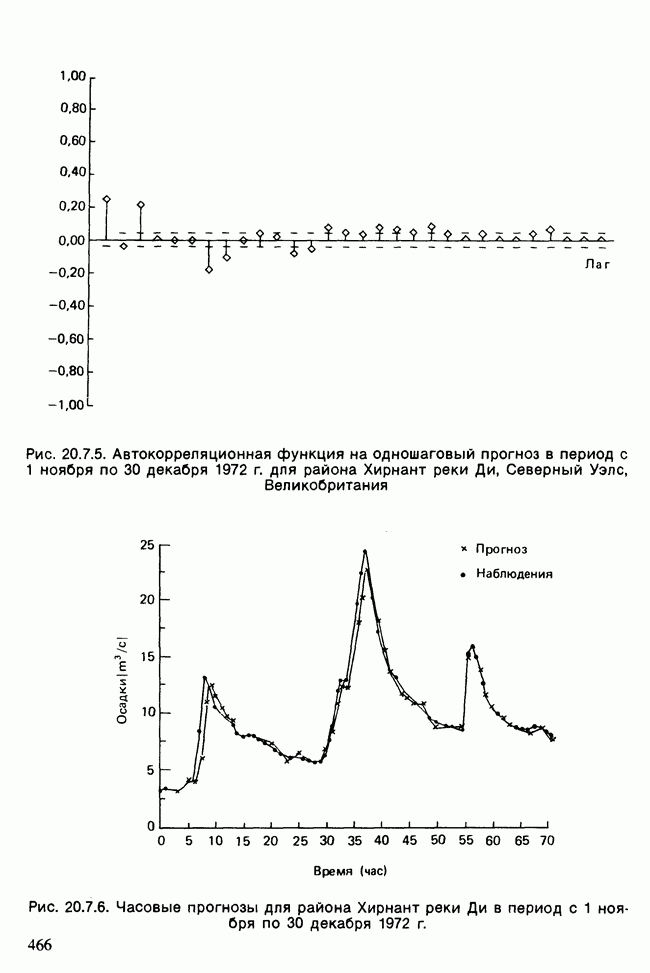











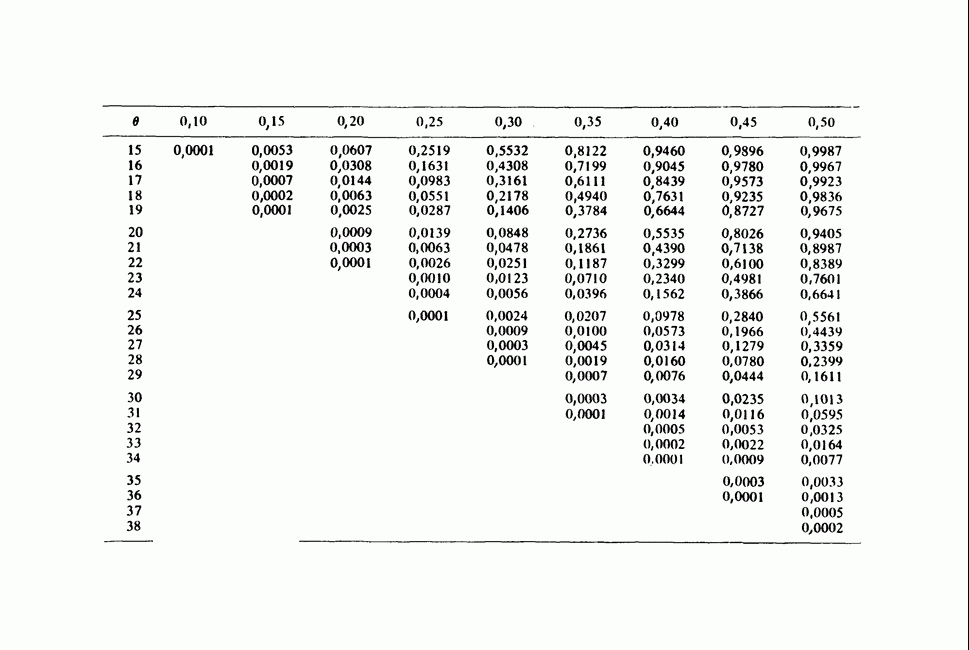

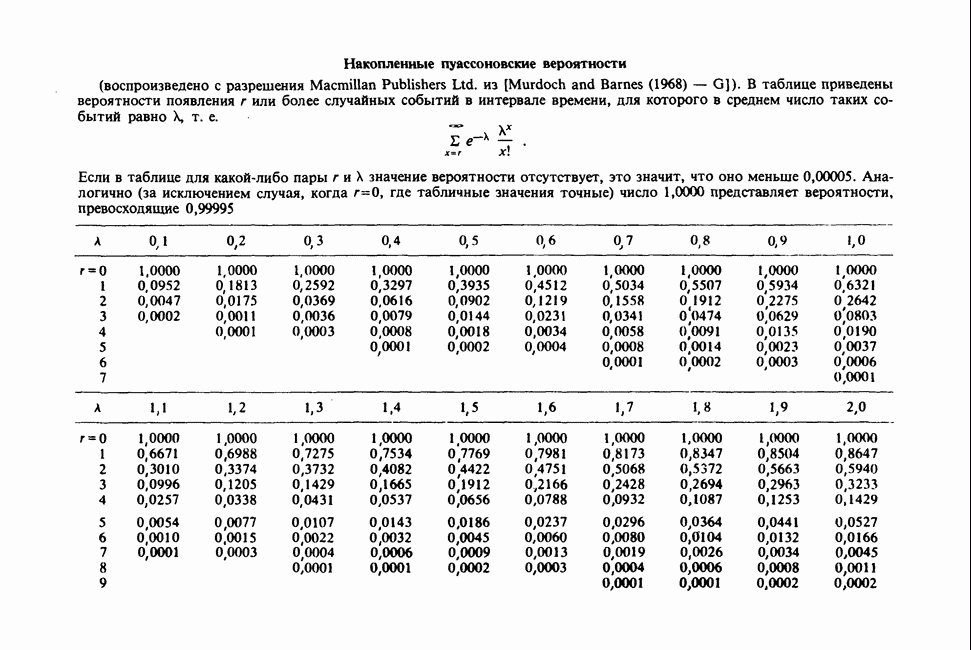
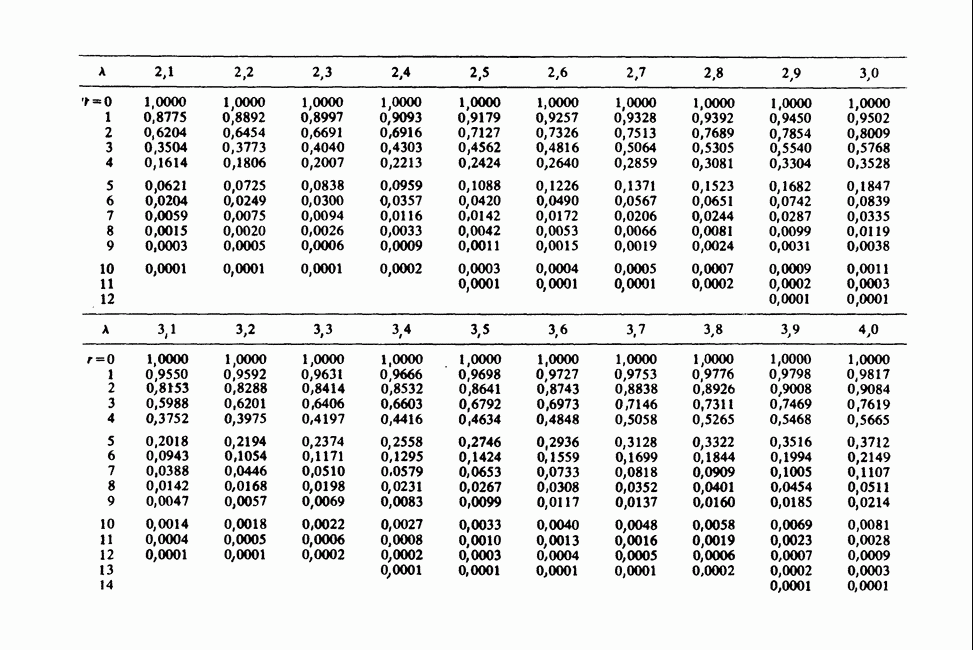
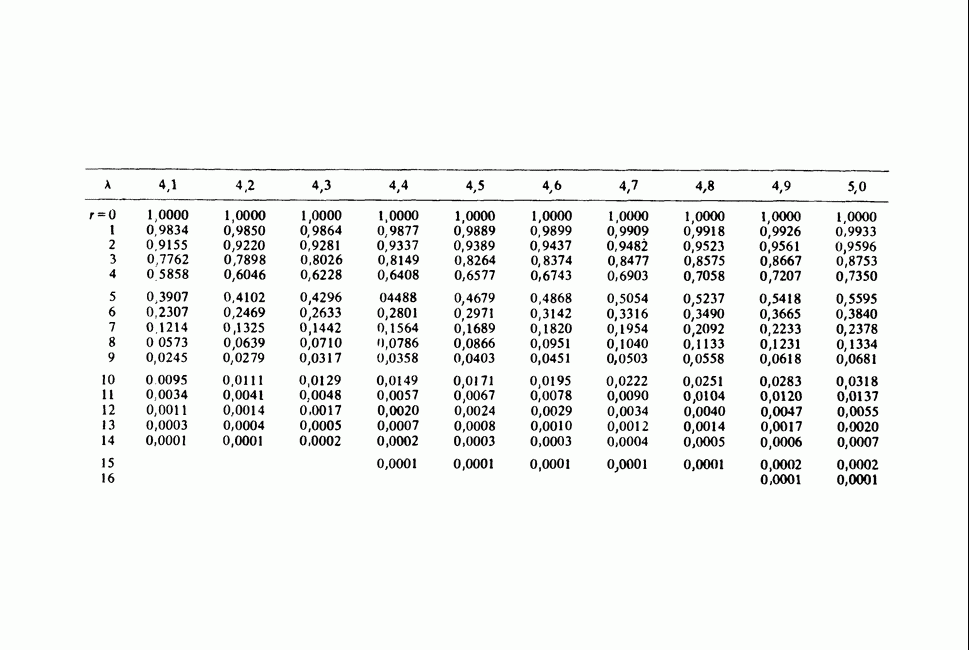

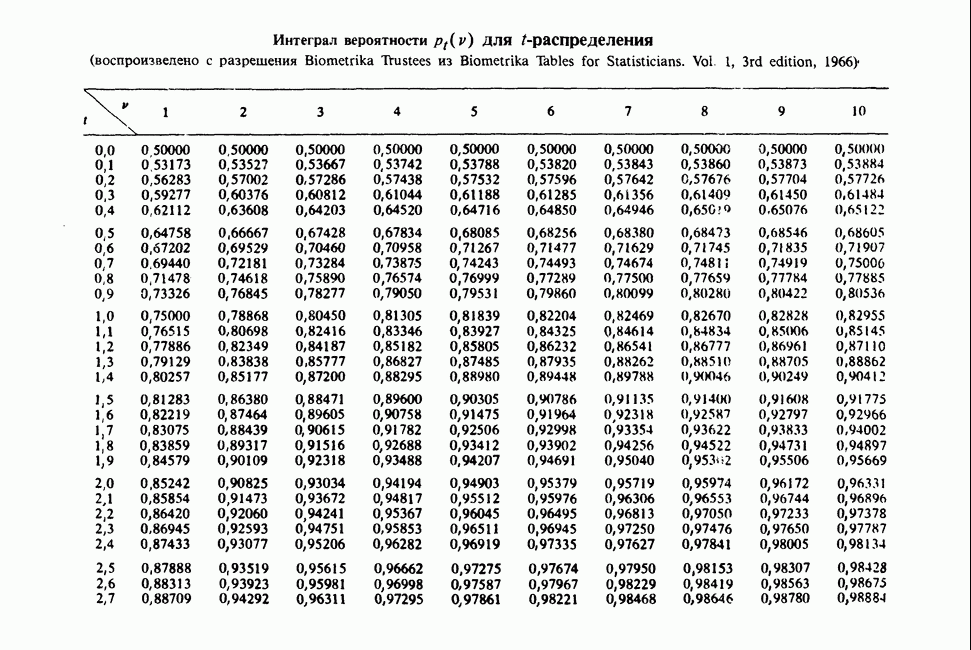

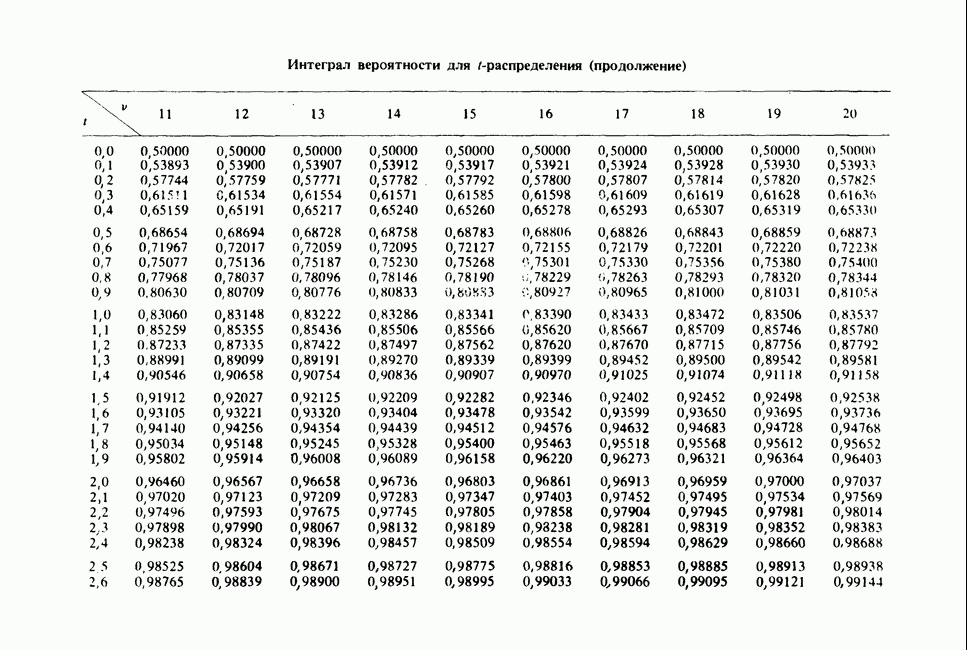

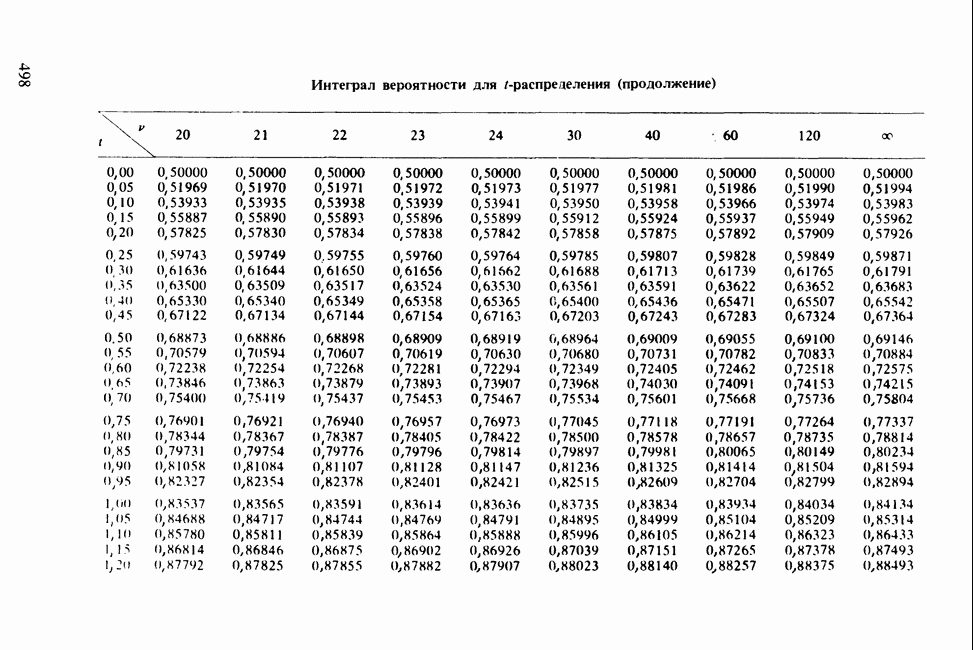
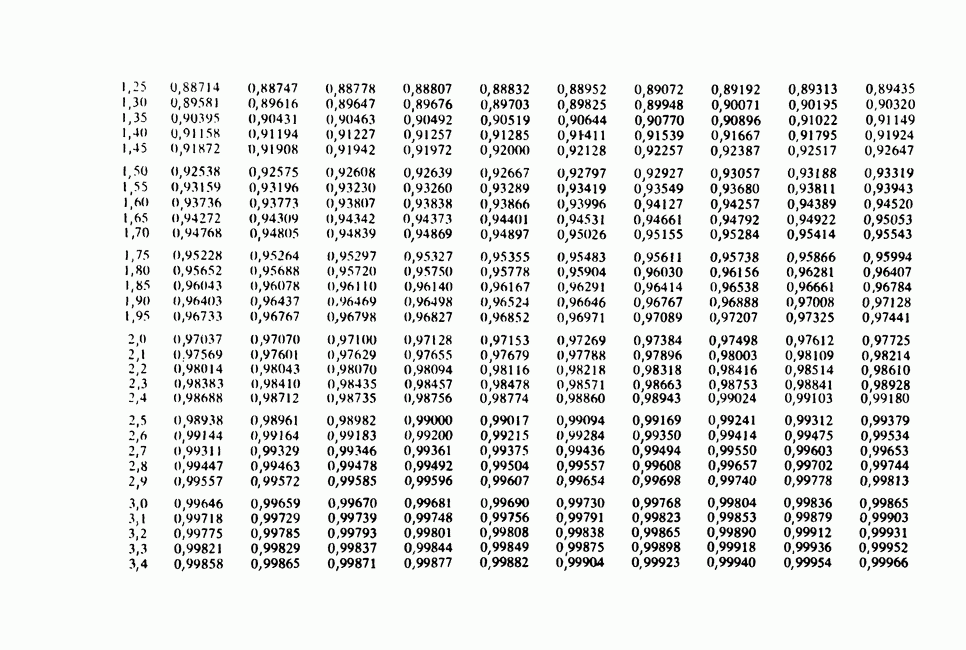



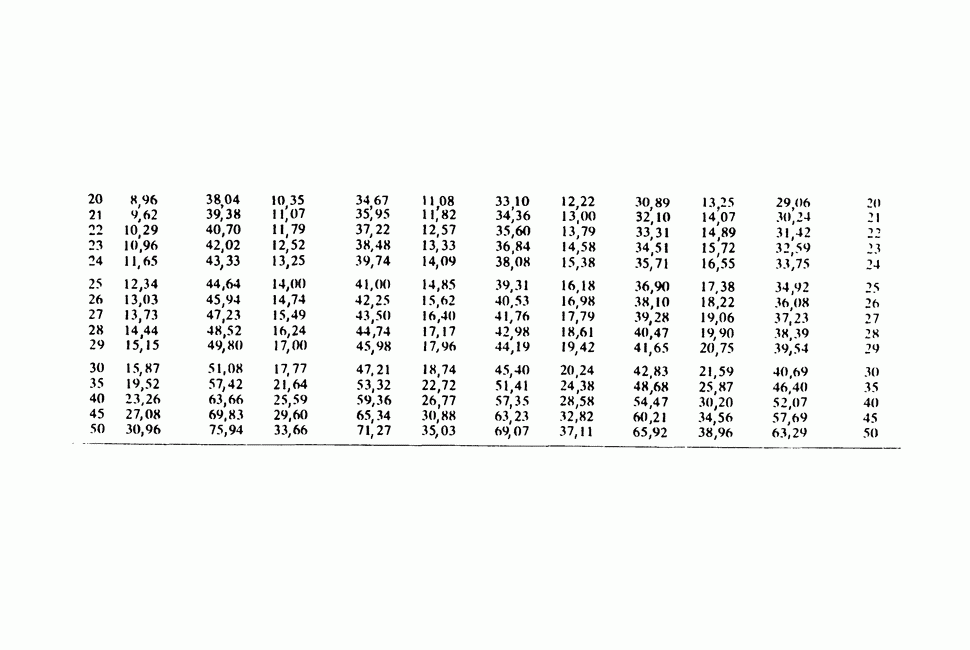
 Отталкиваясь от наблюдений
Отталкиваясь от наблюдений  воспользуемся методом максимума правдоподобия (ММП) [см. гл. 6]. Для этого нам необходимо вычислить для модели функцию плотности распределения вероятности (п. р. в.) [см. II, раздел 10.1.1]. Это легче всего сделать, перейдя от последовательности
воспользуемся методом максимума правдоподобия (ММП) [см. гл. 6]. Для этого нам необходимо вычислить для модели функцию плотности распределения вероятности (п. р. в.) [см. II, раздел 10.1.1]. Это легче всего сделать, перейдя от последовательности  к последовательности
к последовательности  которую мы вновь считаем последовательностью независимых случайных величин, имеющих одинаковое нормальное распределение со средним 0 и дисперсией
которую мы вновь считаем последовательностью независимых случайных величин, имеющих одинаковое нормальное распределение со средним 0 и дисперсией  [см. раздел 1.4.2, п. 2]. Поскольку наш набор данных конечен, необходимо ввести в рассмотрение величину
[см. раздел 1.4.2, п. 2]. Поскольку наш набор данных конечен, необходимо ввести в рассмотрение величину  с тем, чтобы можно было восстановить величины
с тем, чтобы можно было восстановить величины  переписав уравнение модели
переписав уравнение модели




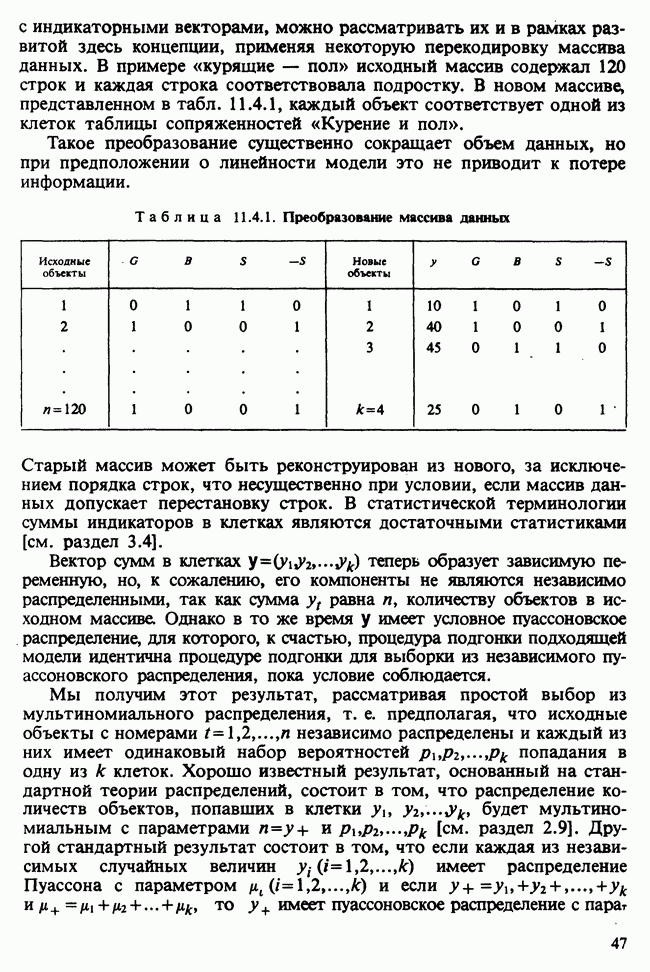
 в сумме квадратов (18.7.8) рассматривают как мешающий параметр и включают вместе с в в число подлежащих минимизации свободных параметров. Это оказывается очень удобным и без труда обобщается на модели
в сумме квадратов (18.7.8) рассматривают как мешающий параметр и включают вместе с в в число подлежащих минимизации свободных параметров. Это оказывается очень удобным и без труда обобщается на модели  ценой удвоения числа параметров. Именно этот метод использовался при построении оценок в последующих примерах. Однако так как величина
ценой удвоения числа параметров. Именно этот метод использовался при построении оценок в последующих примерах. Однако так как величина  входит в выражение для
входит в выражение для  линейно, можно частично облегчить оптимизационную процедуру, точно вычислив и подставив вместо
линейно, можно частично облегчить оптимизационную процедуру, точно вычислив и подставив вместо  значение
значение  минимизирующее функцию
минимизирующее функцию  при данном
при данном  . Для этого целевая функция преобразуется следующим образом:
. Для этого целевая функция преобразуется следующим образом:

 уточним зависимость от
уточним зависимость от  написав на основе (18.7.6) и (18.7.9)
написав на основе (18.7.6) и (18.7.9)

 зависят только от
зависят только от  Тогда
Тогда



 — то значение
— то значение  при котором
при котором  достигает минимума. Минимум по
достигает минимума. Минимум по  в (18.7.12) достигается в точке
в (18.7.12) достигается в точке




