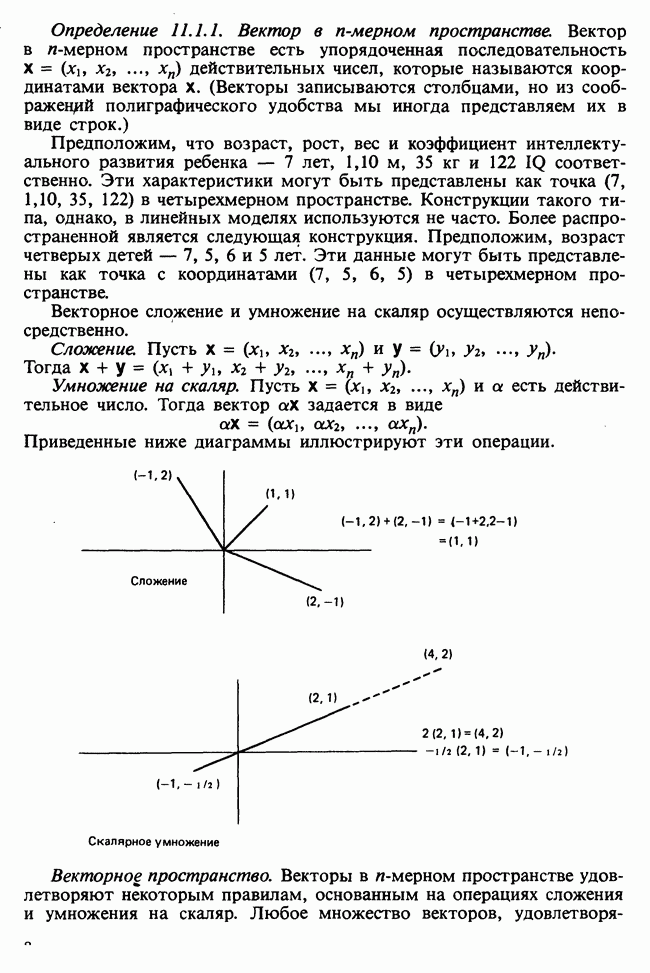
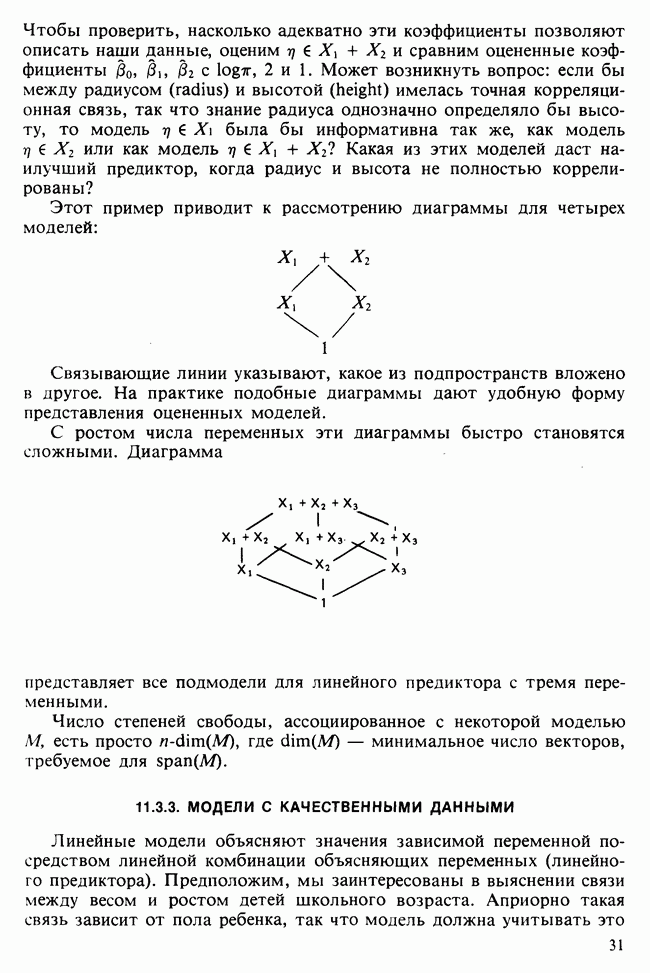
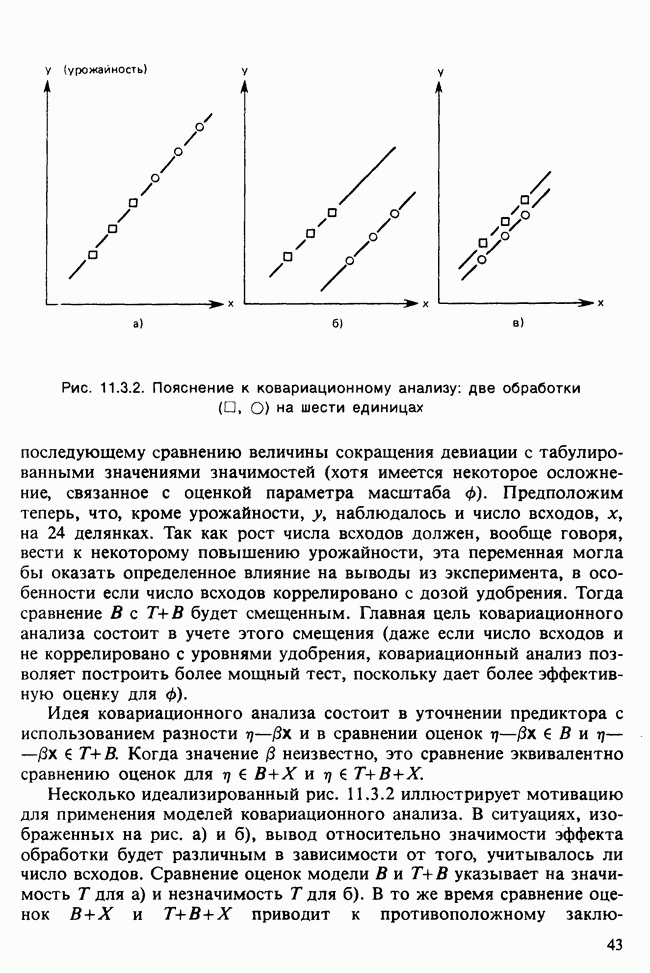
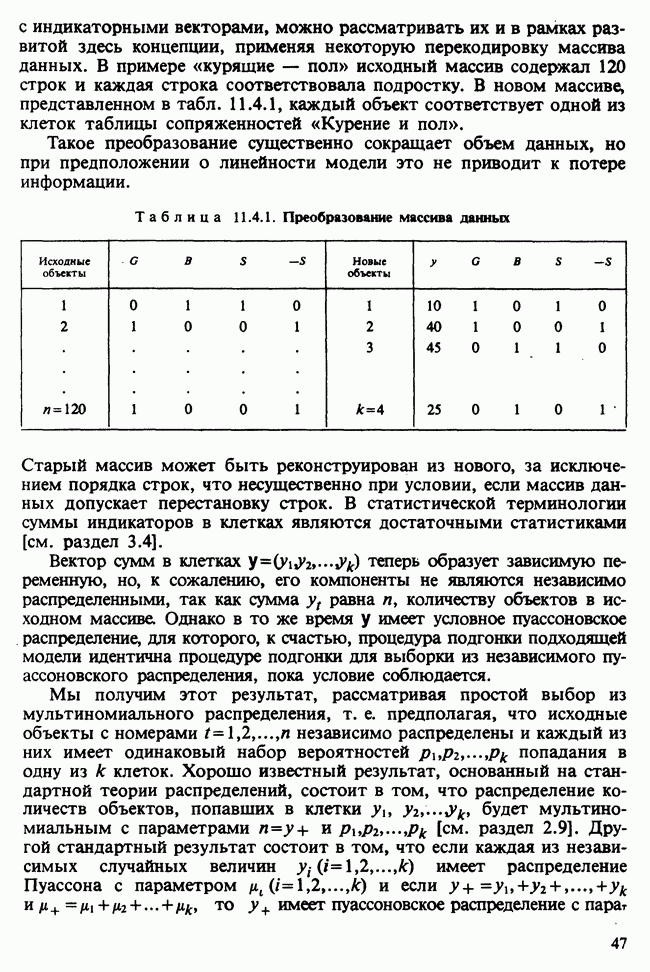
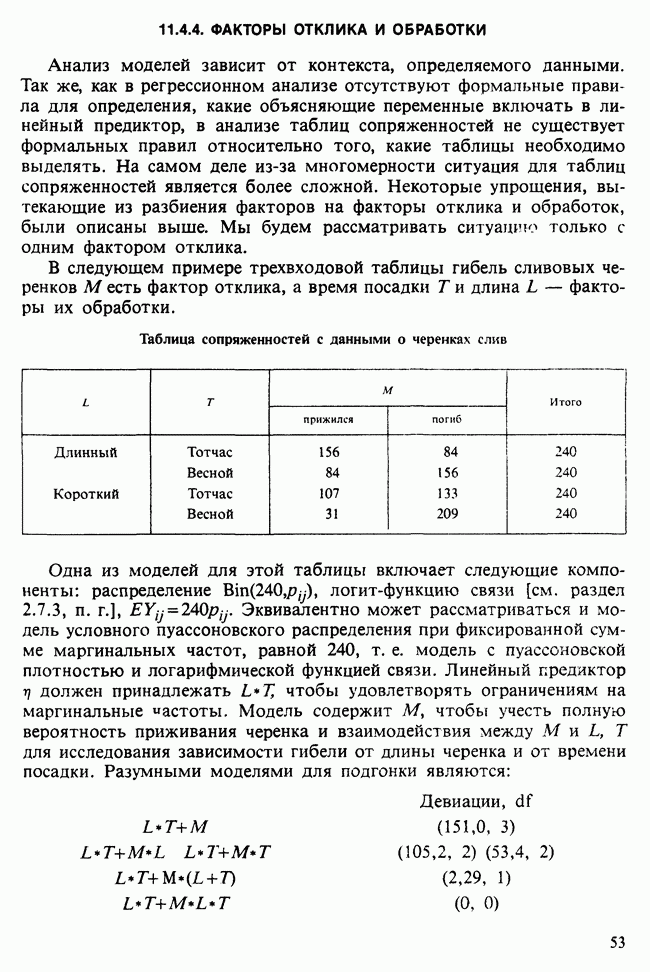
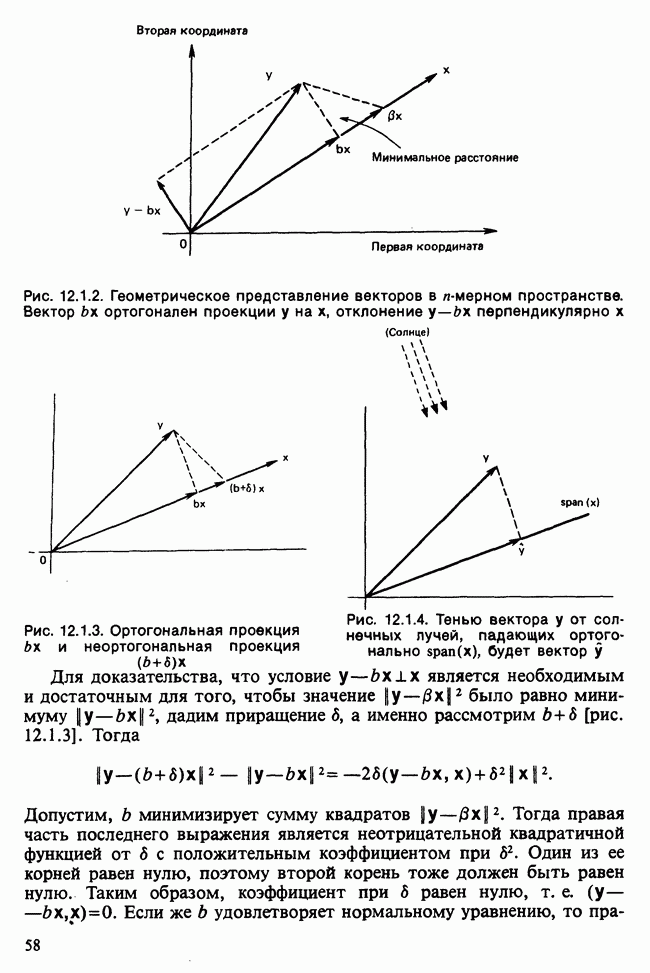
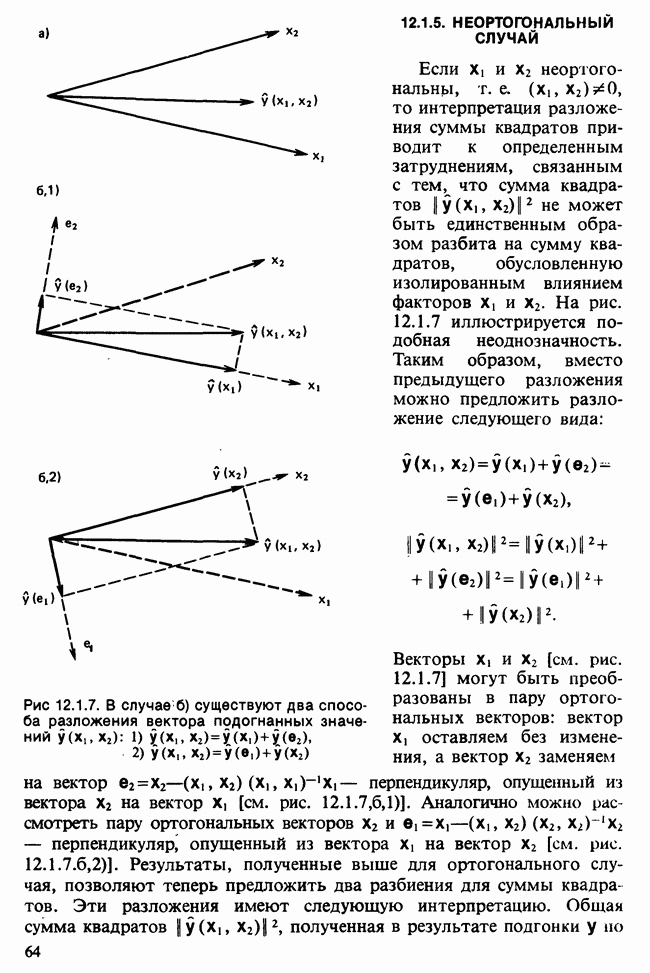
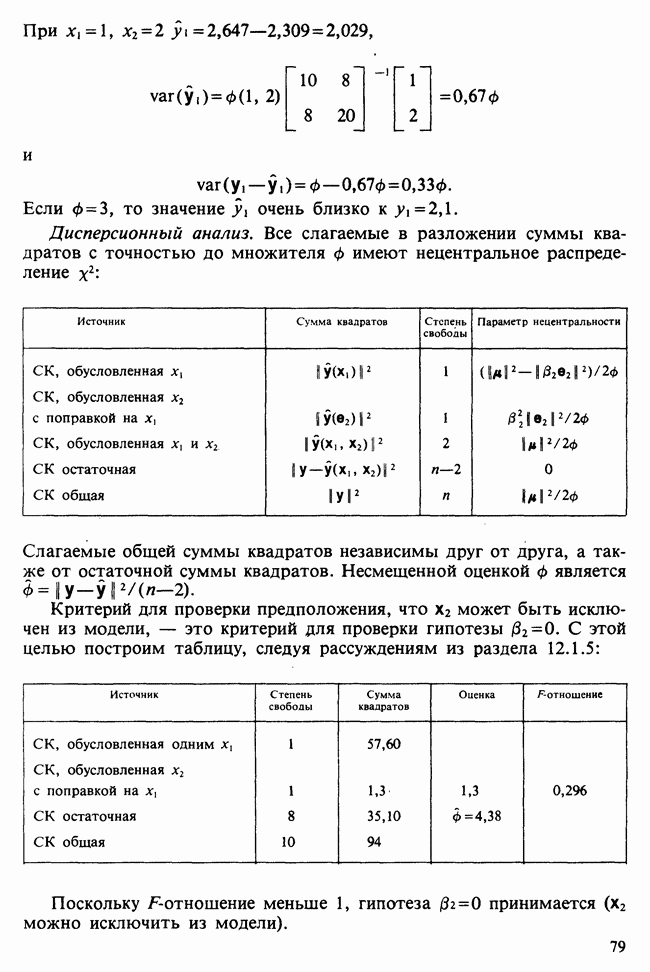
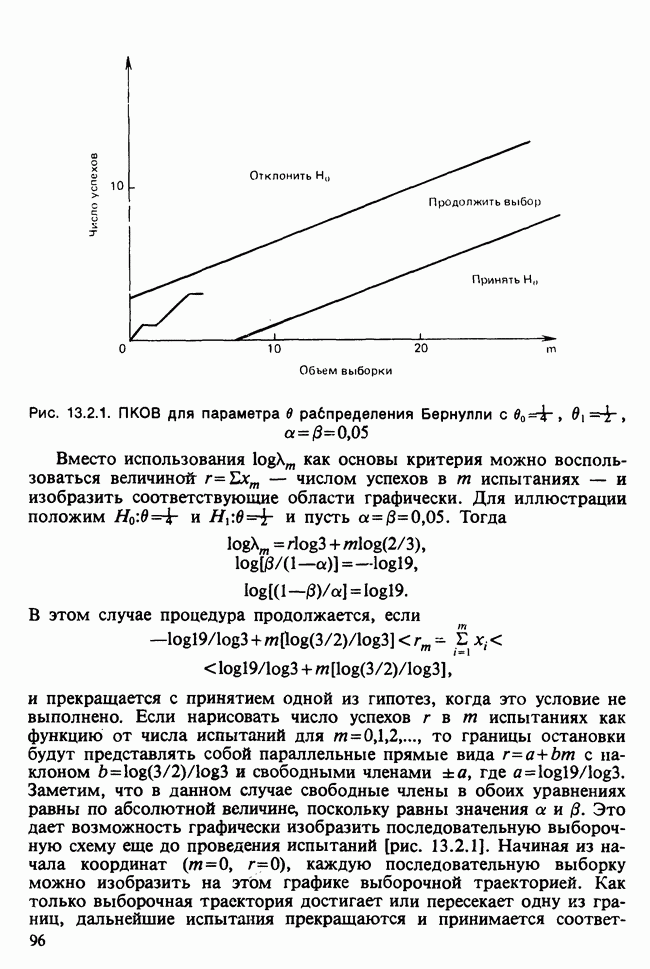
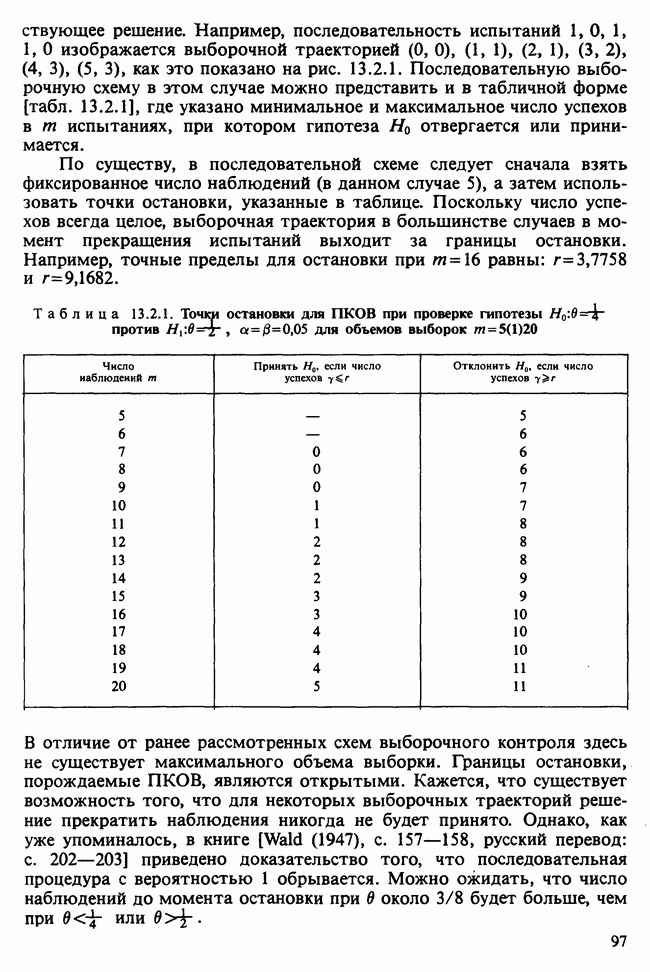
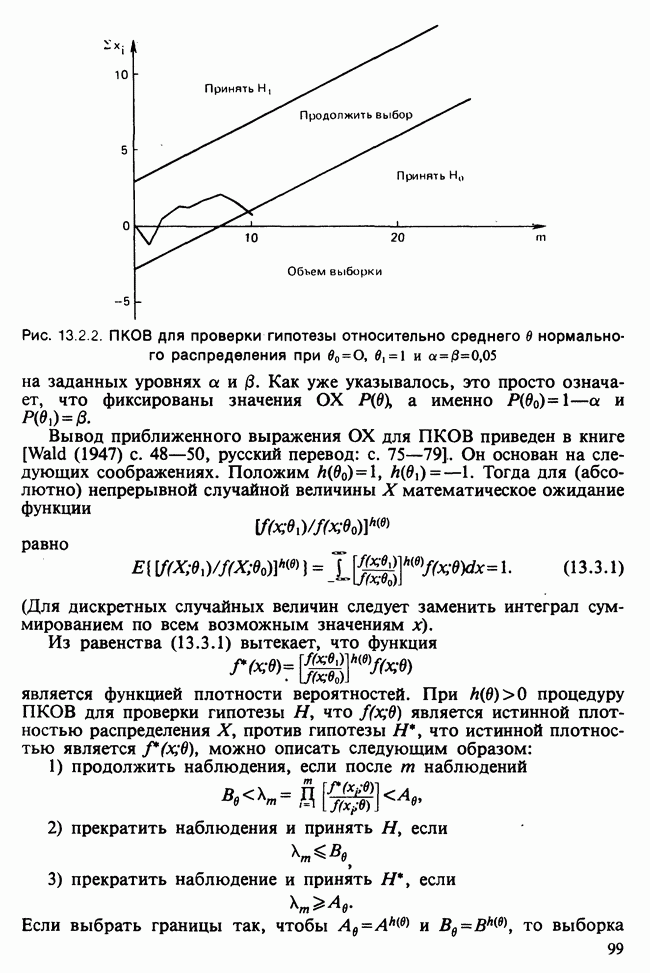
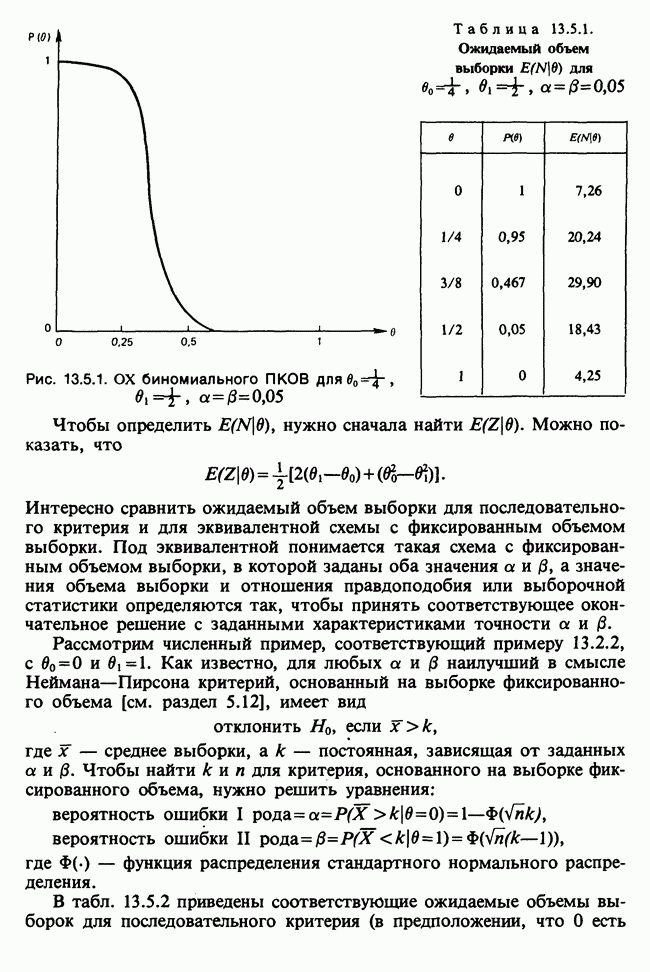
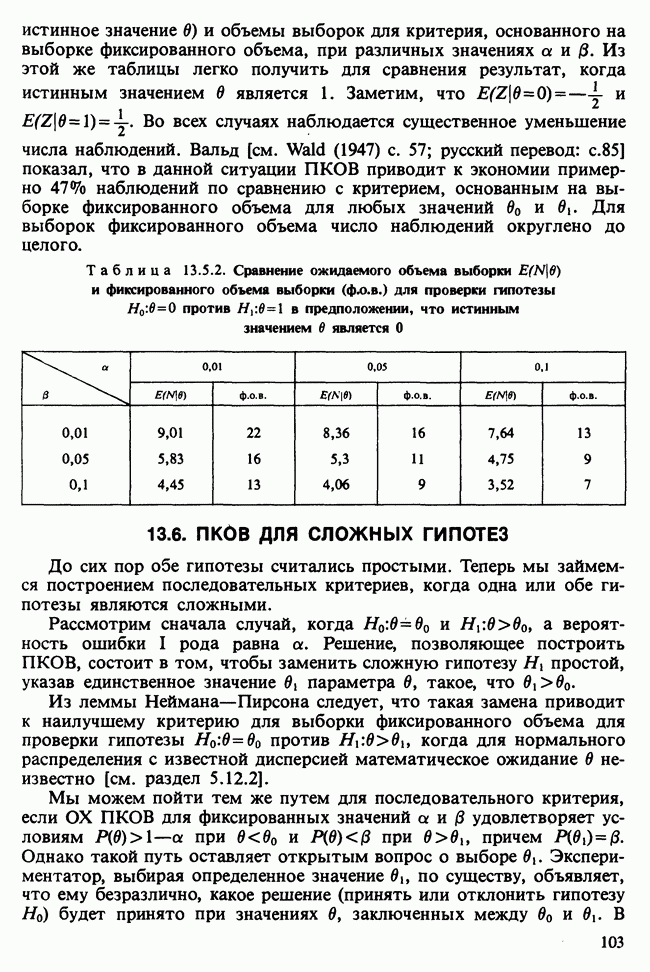
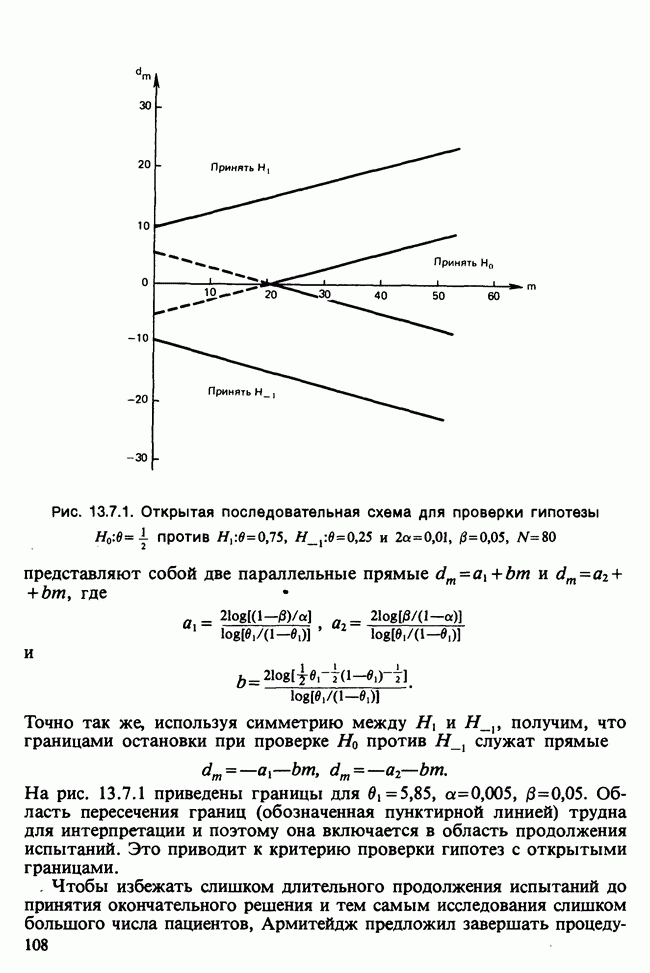
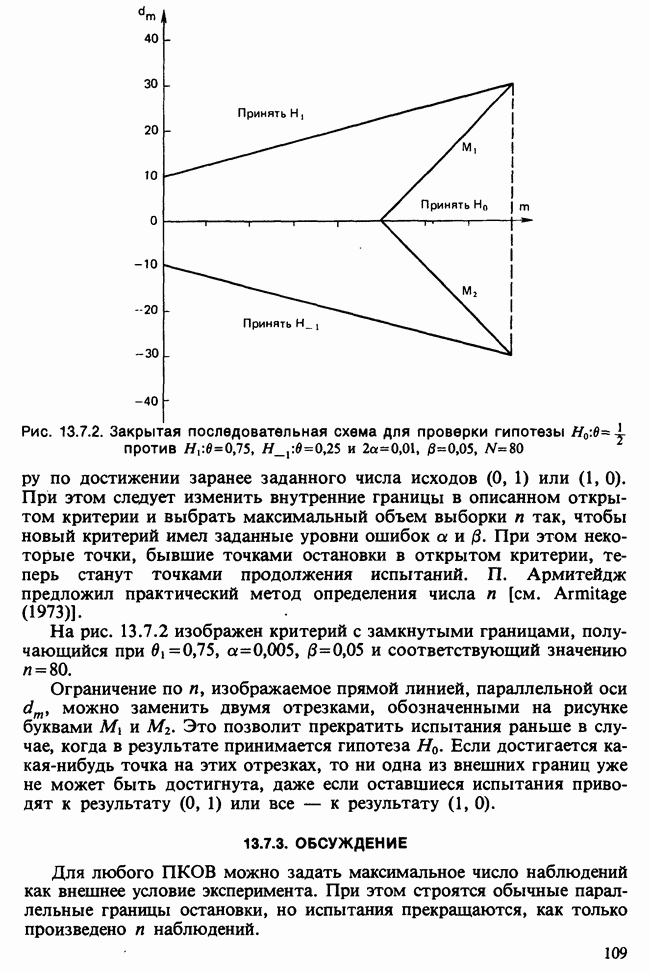
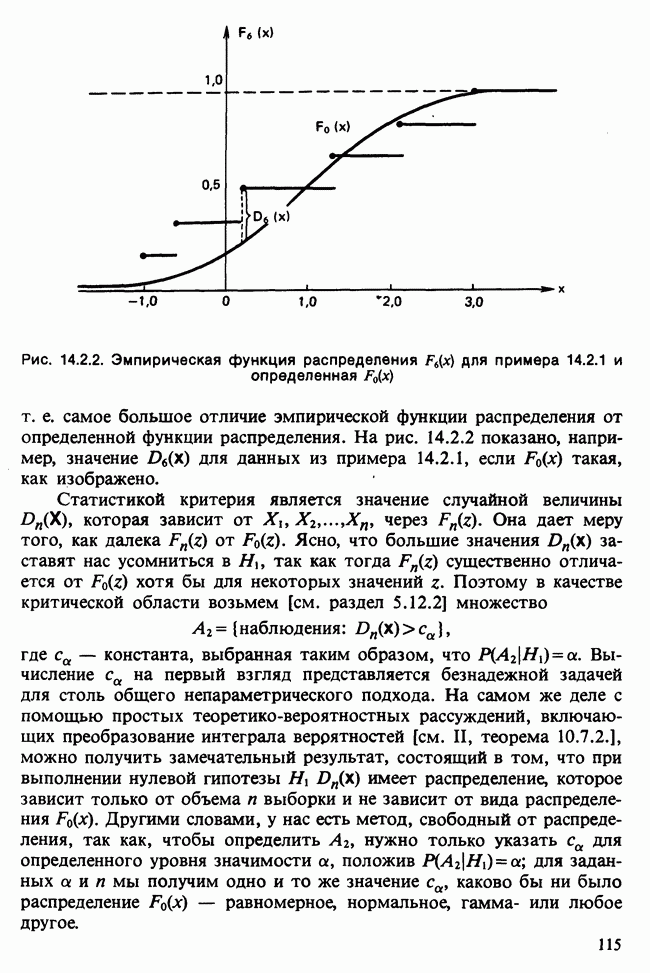
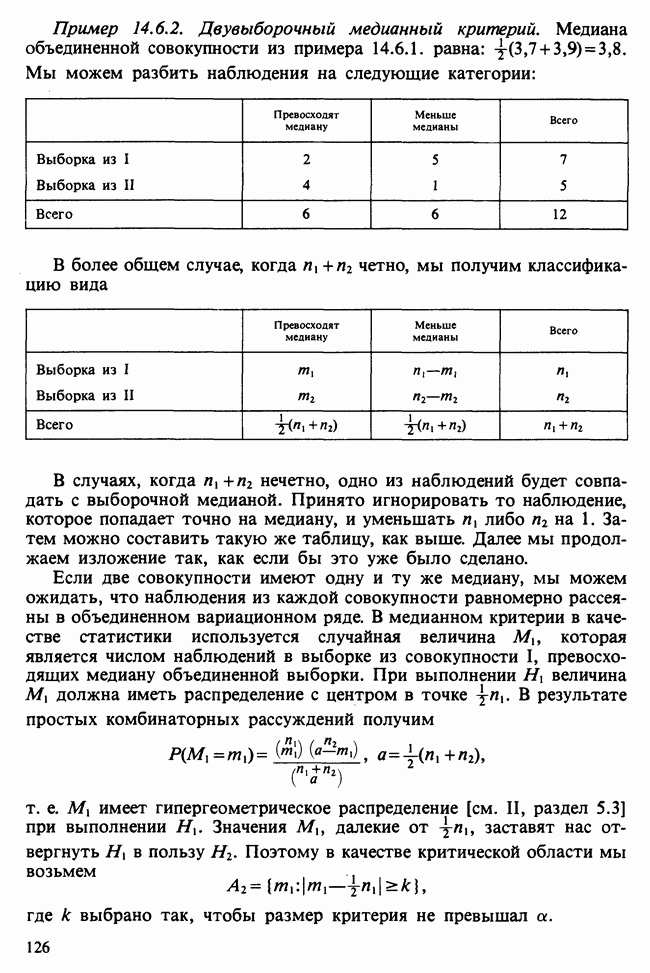
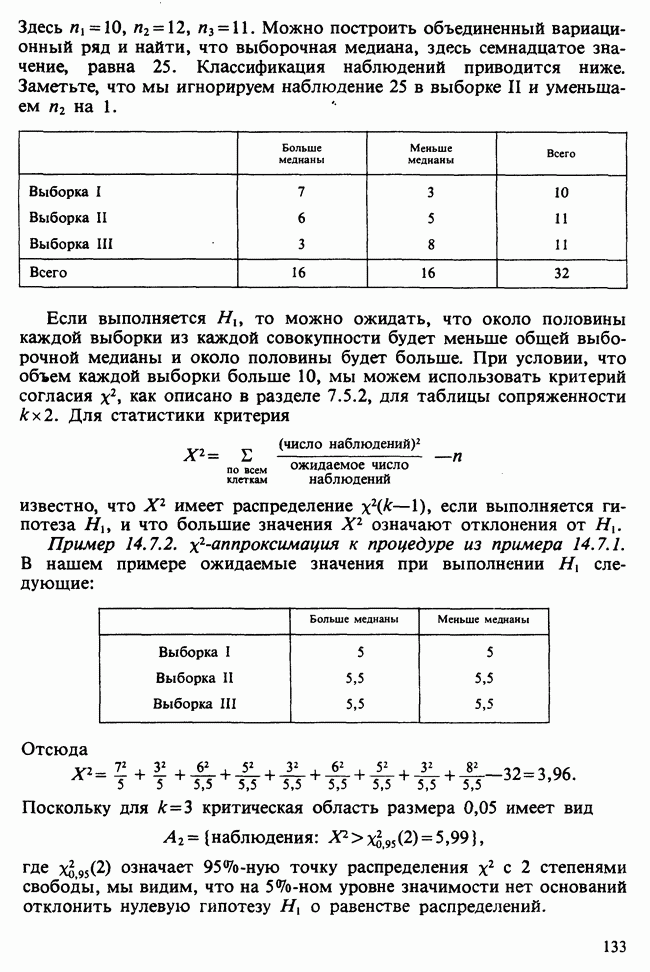
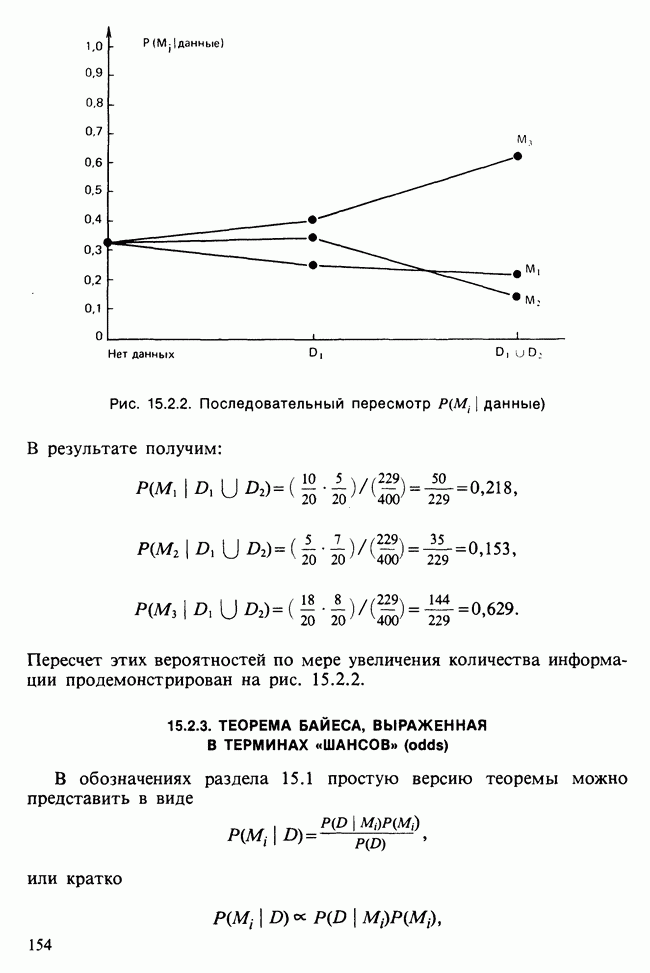
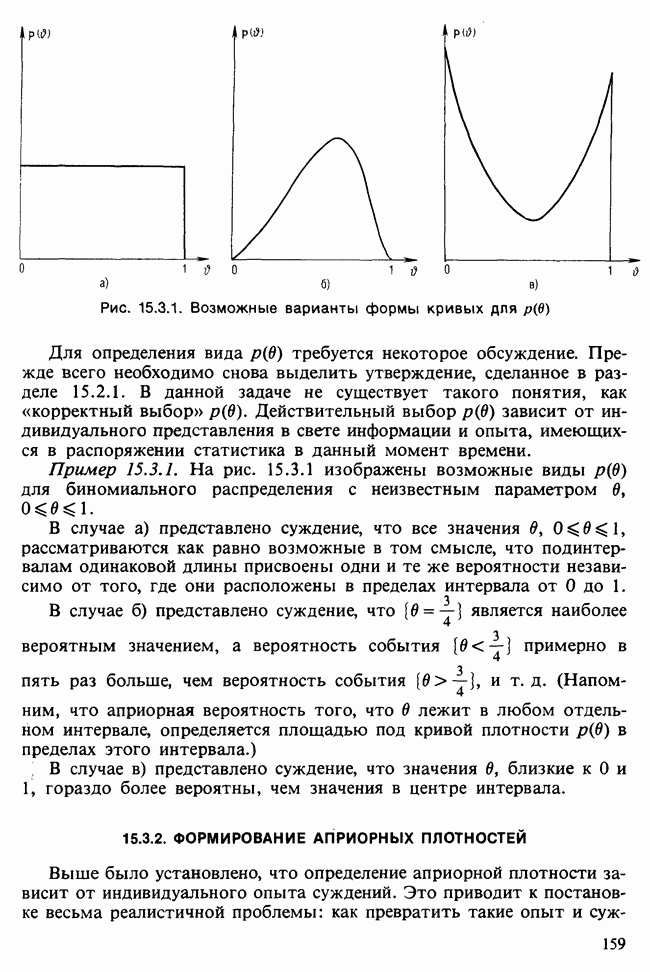
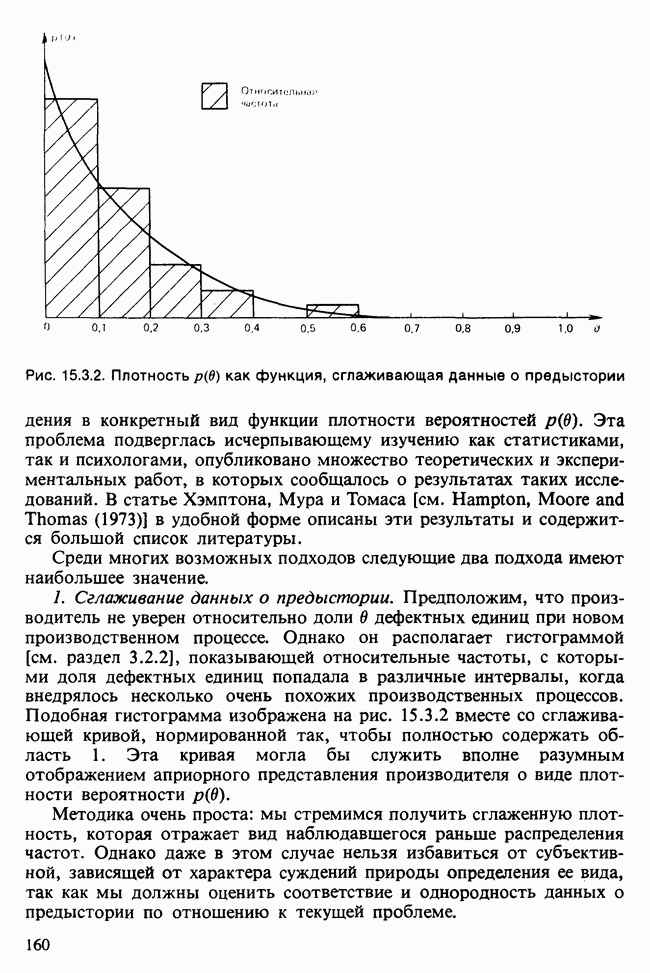
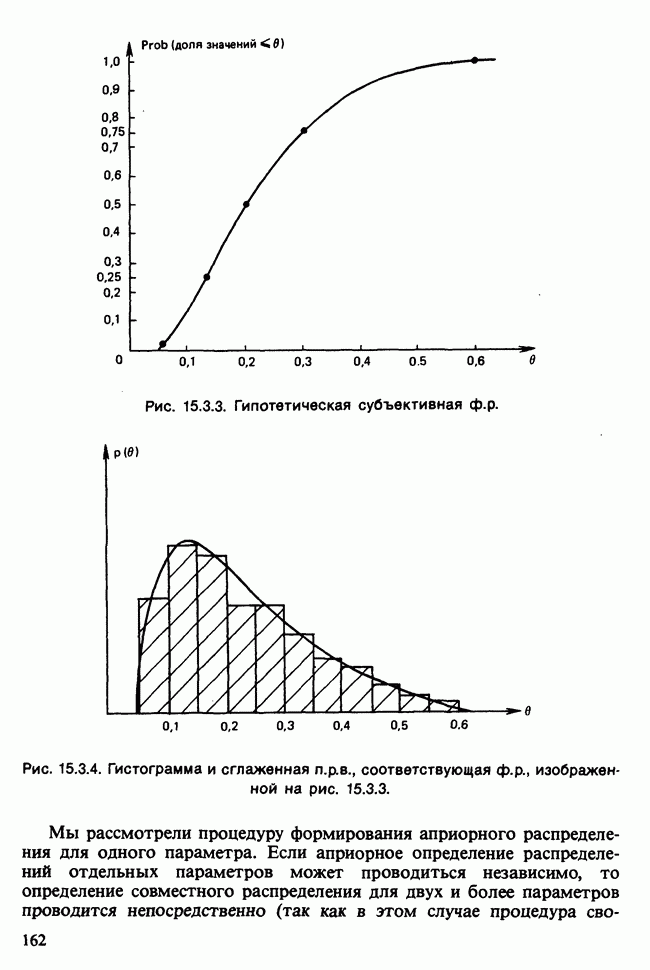
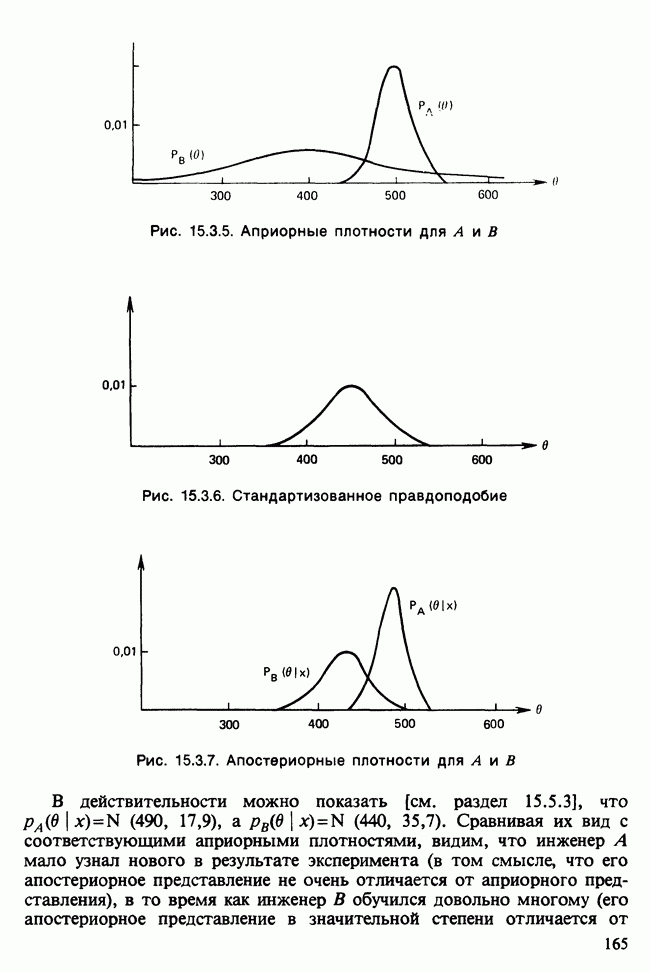
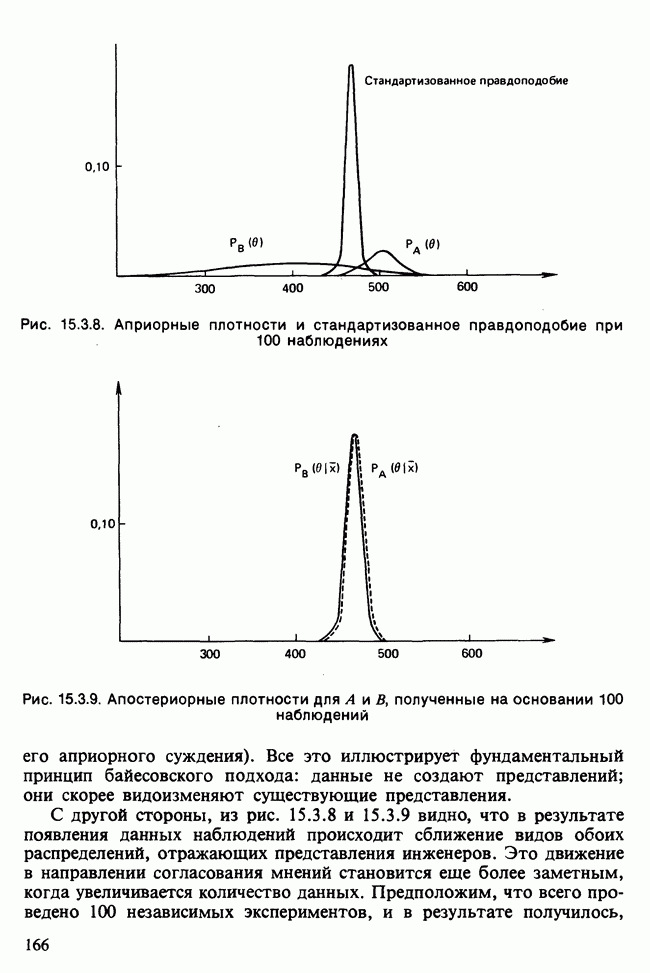
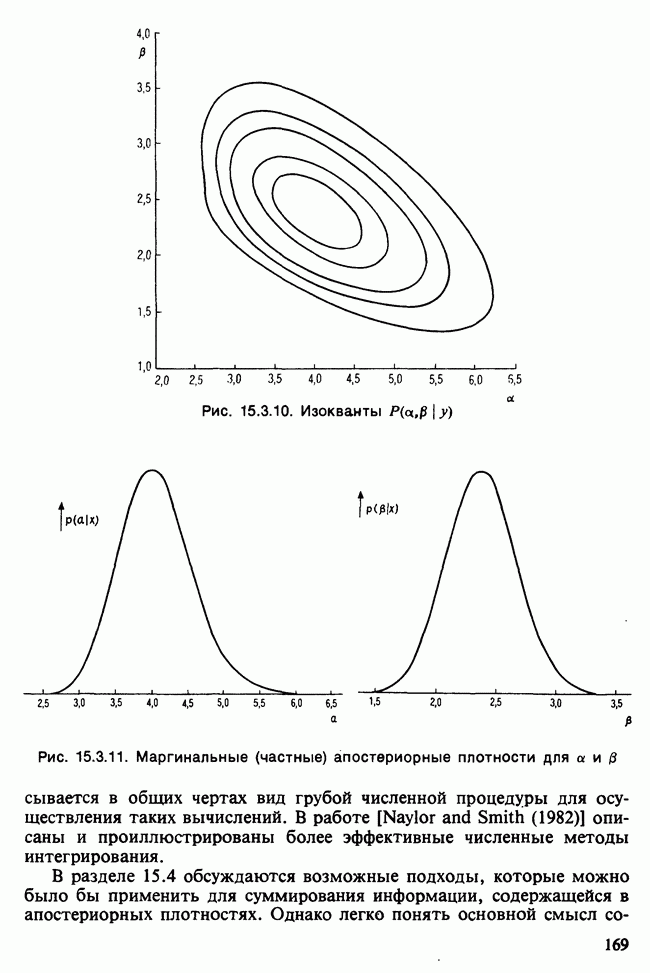
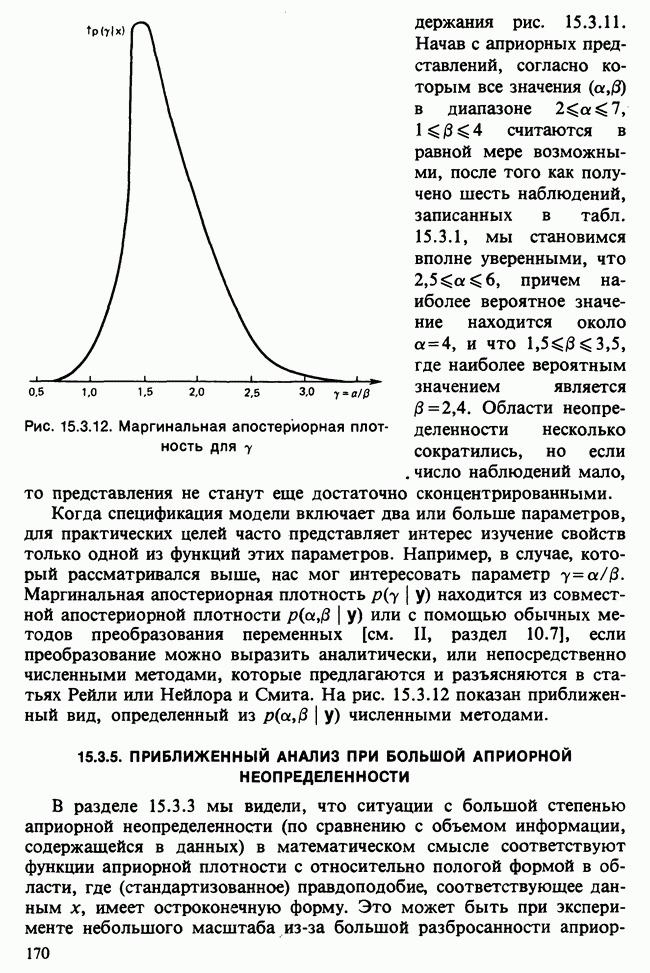
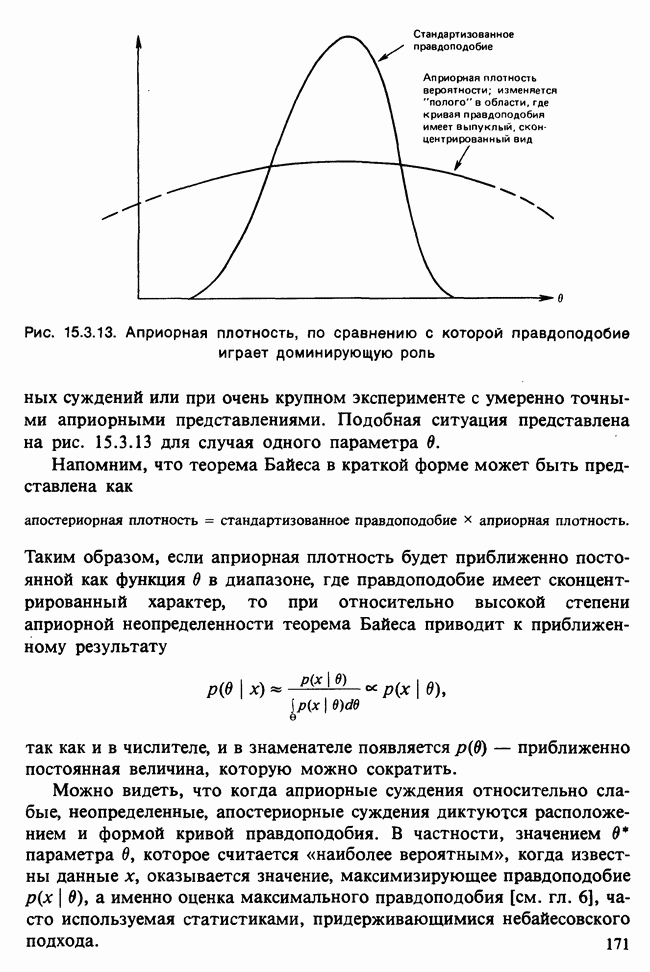
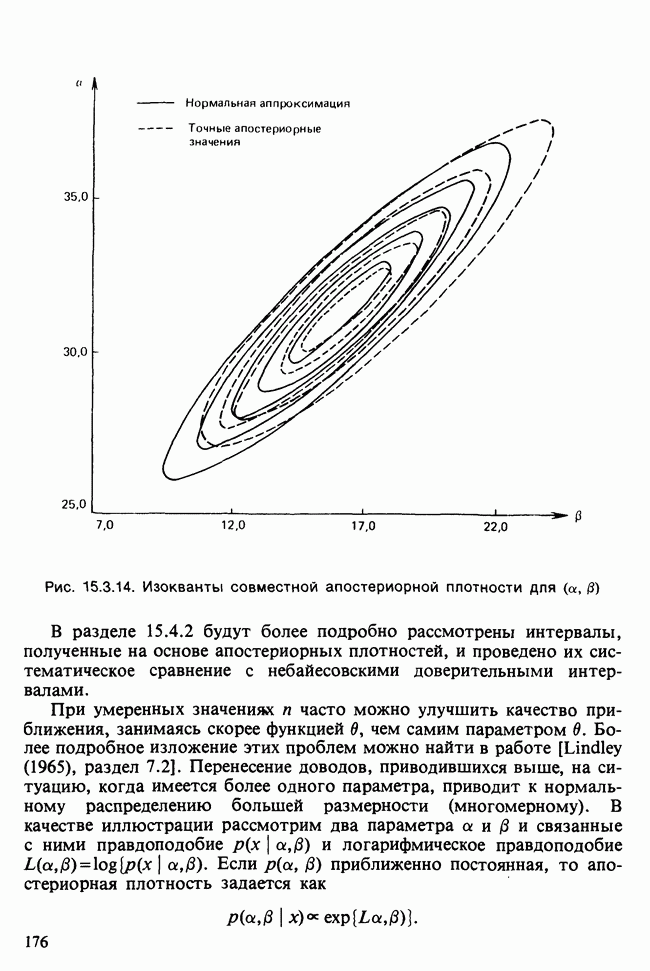
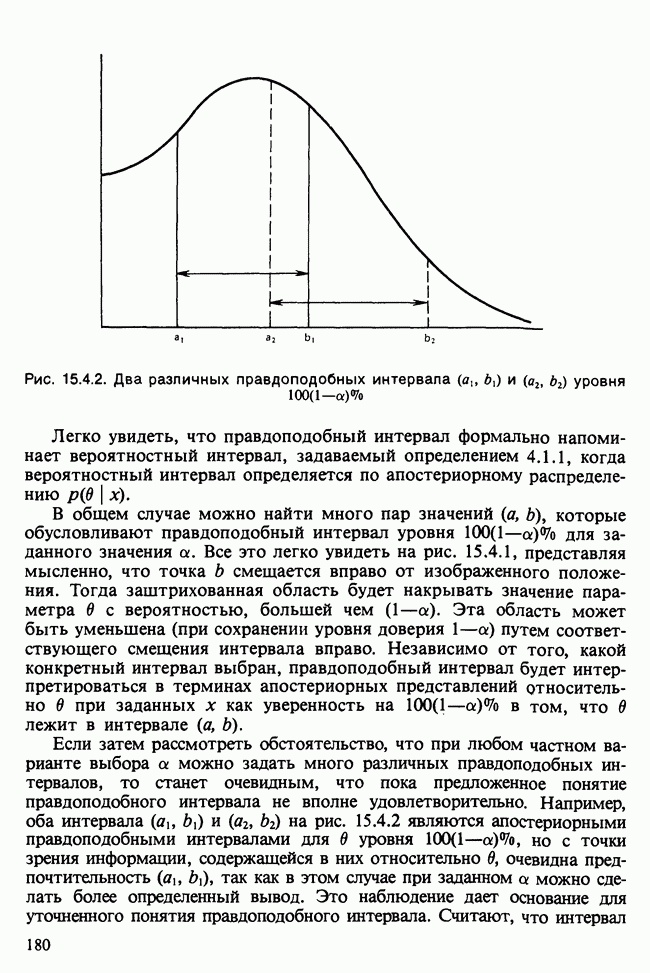
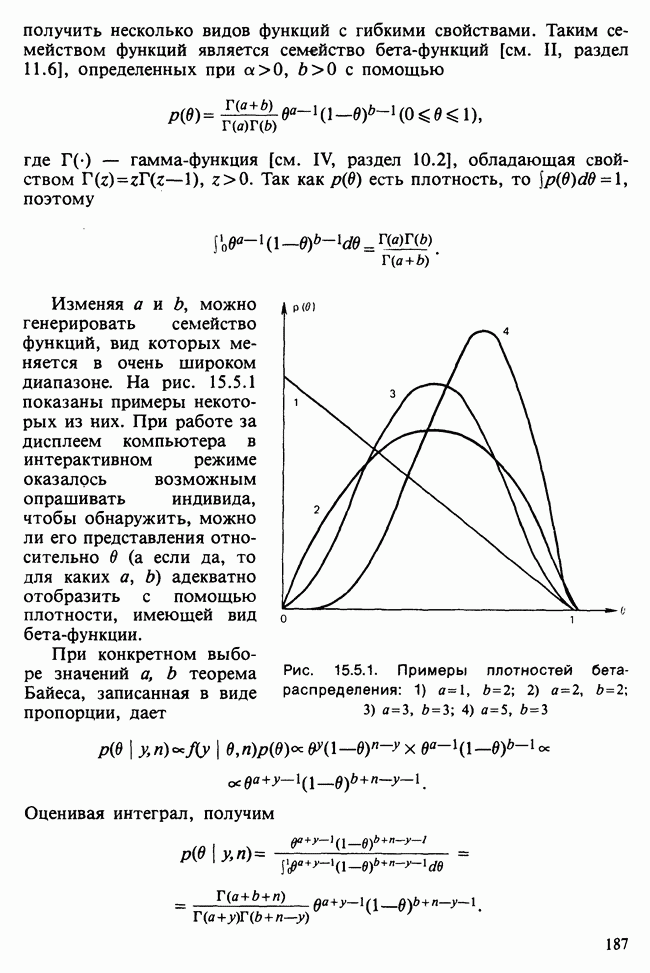
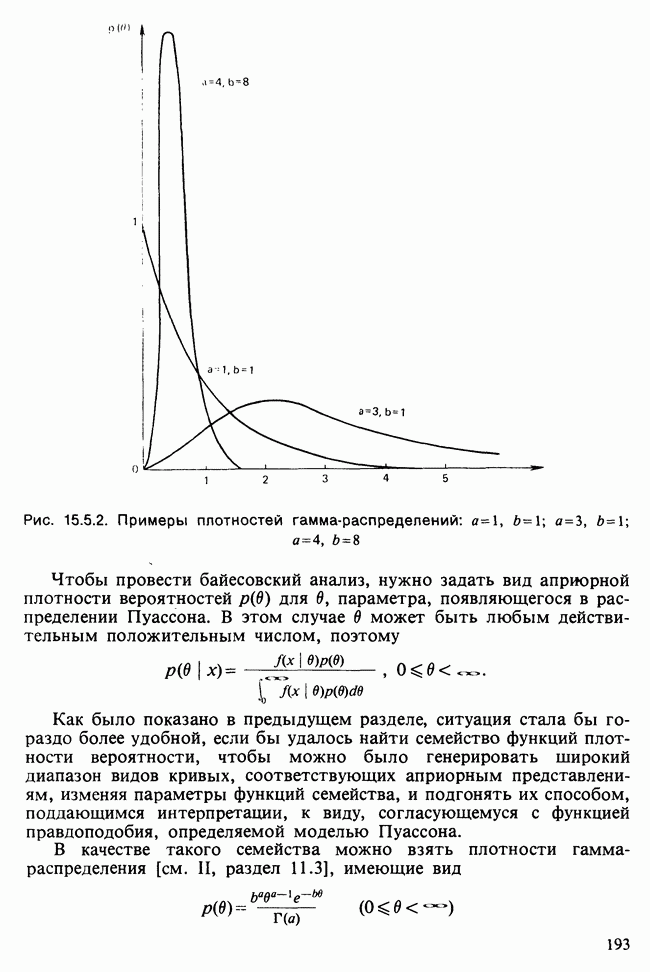
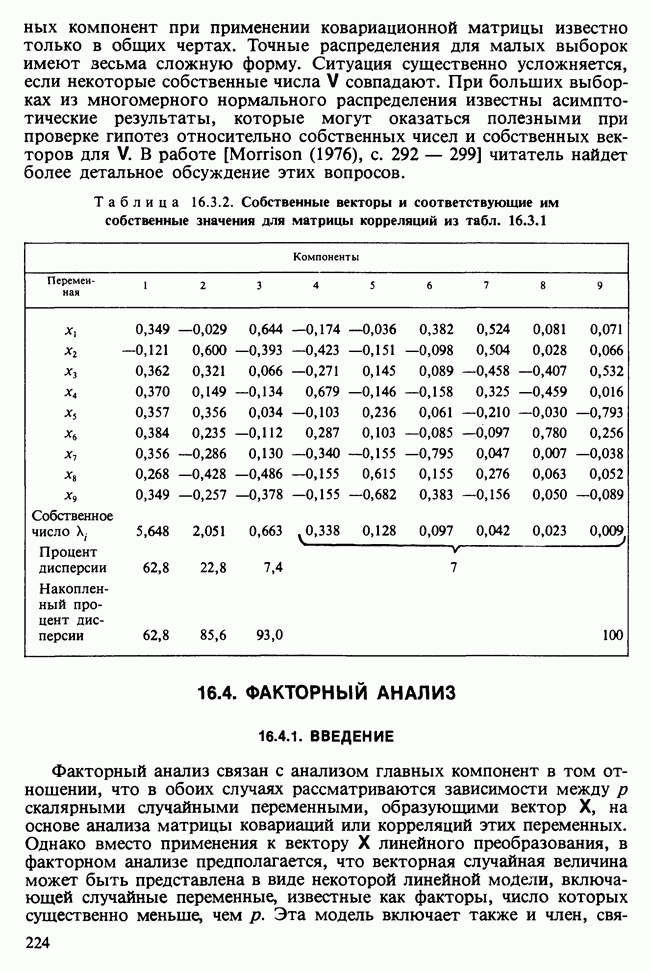
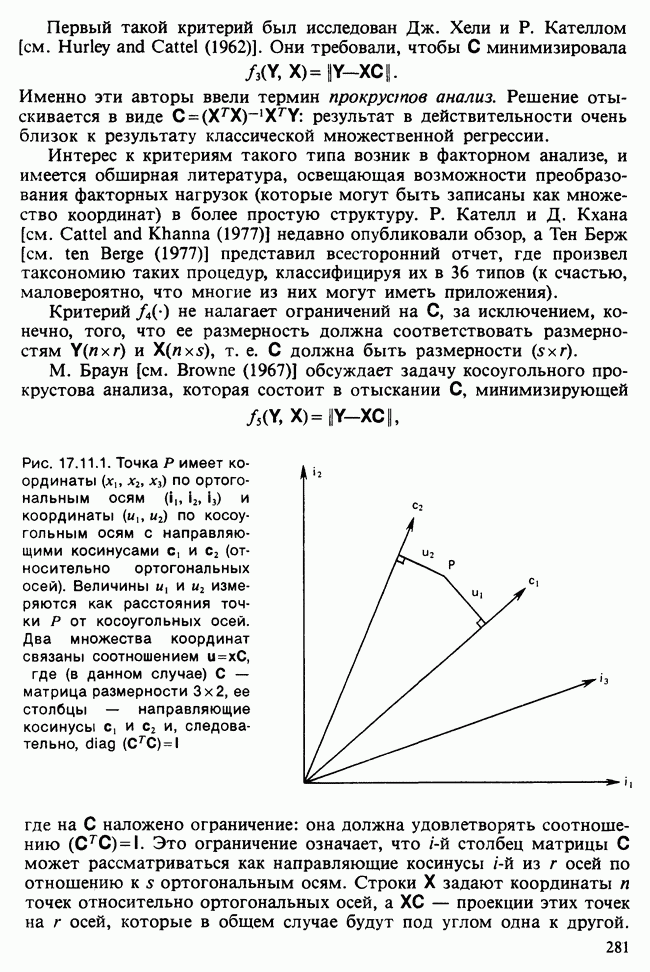
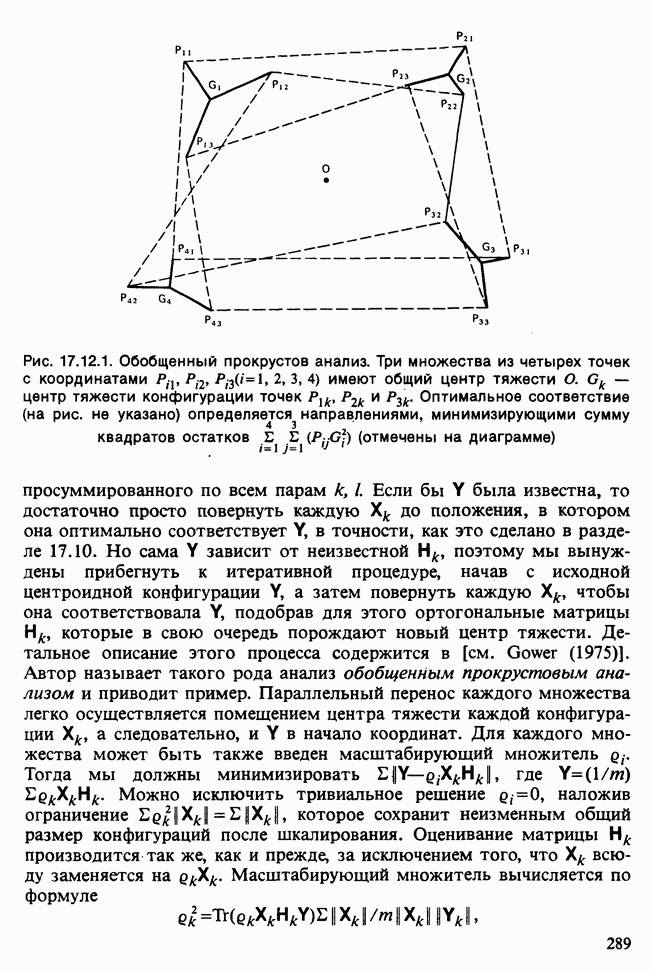
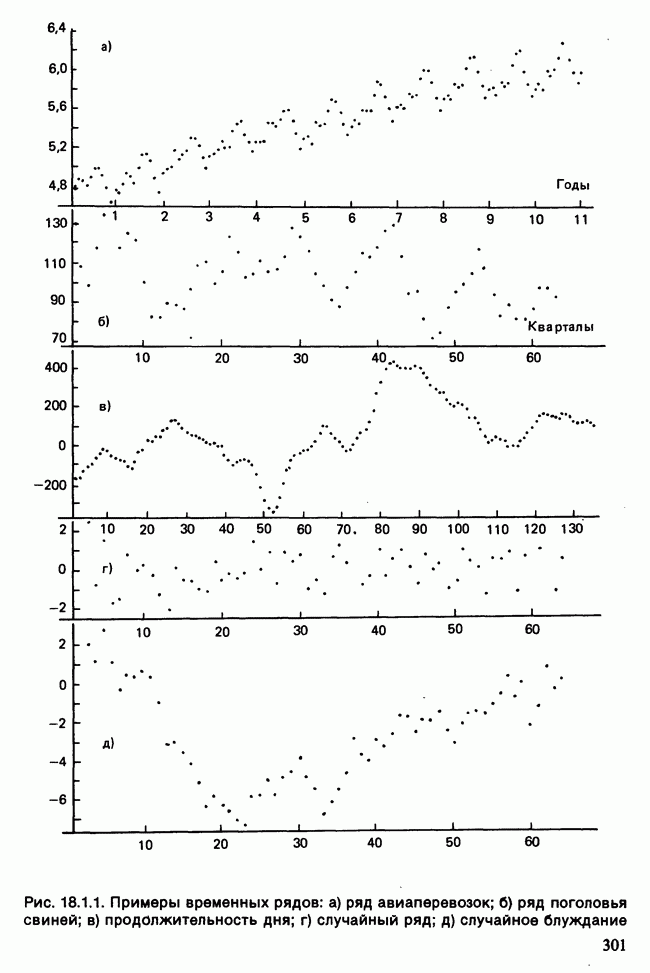
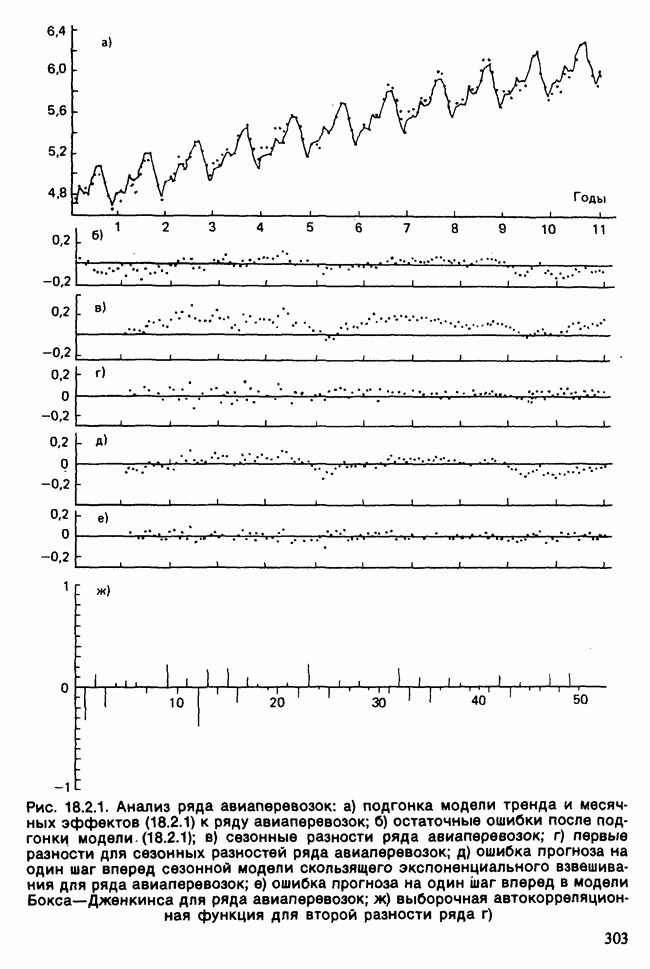
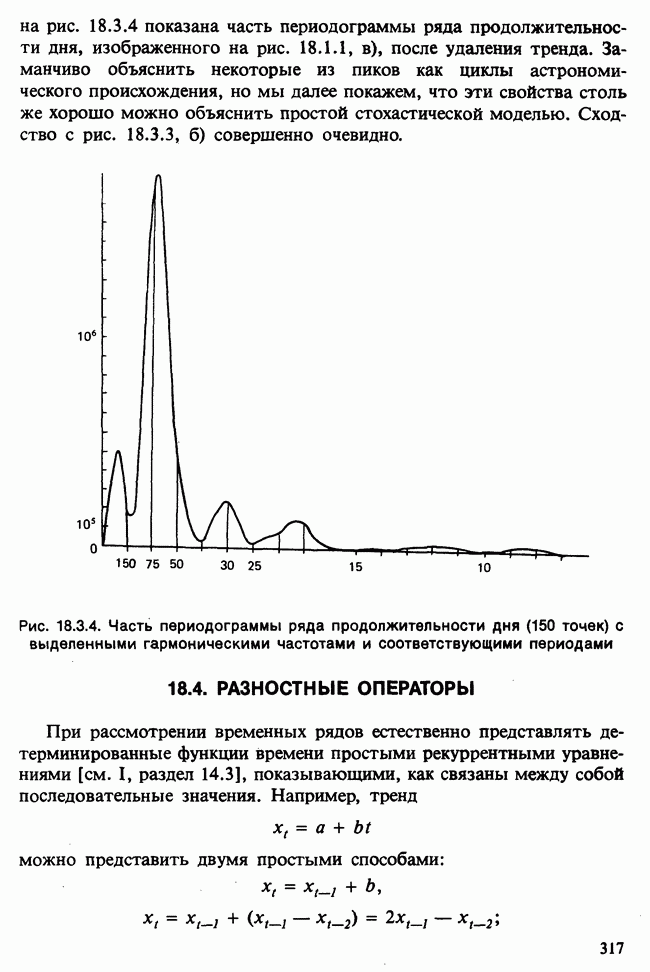
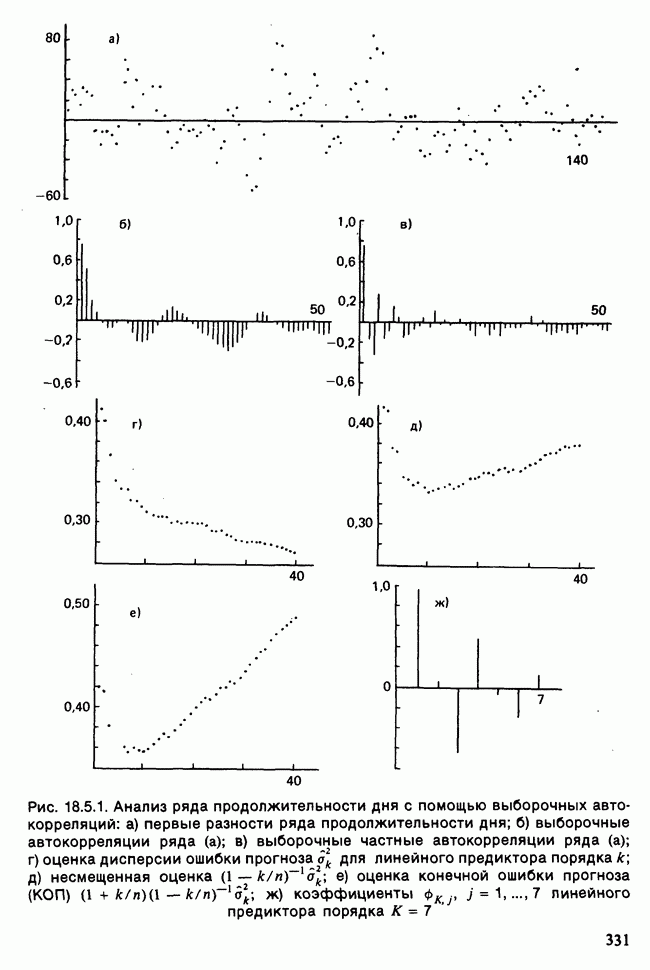
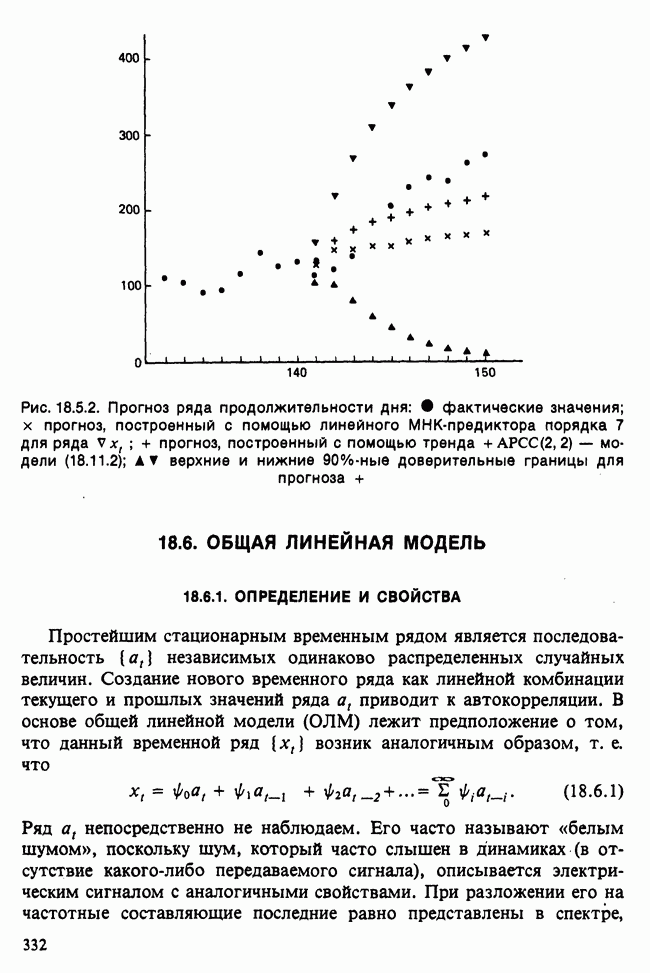
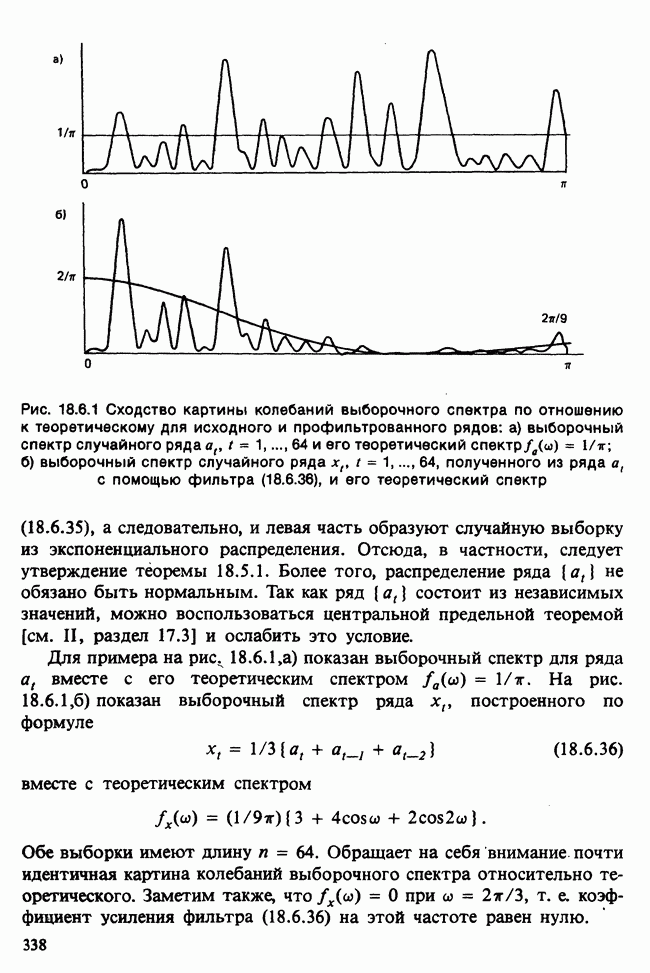
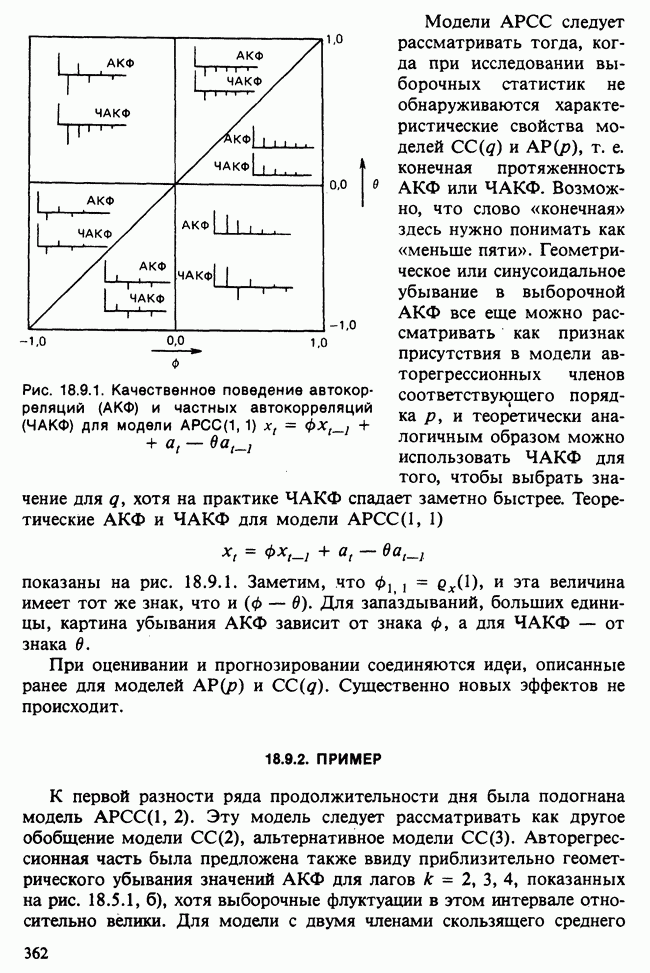
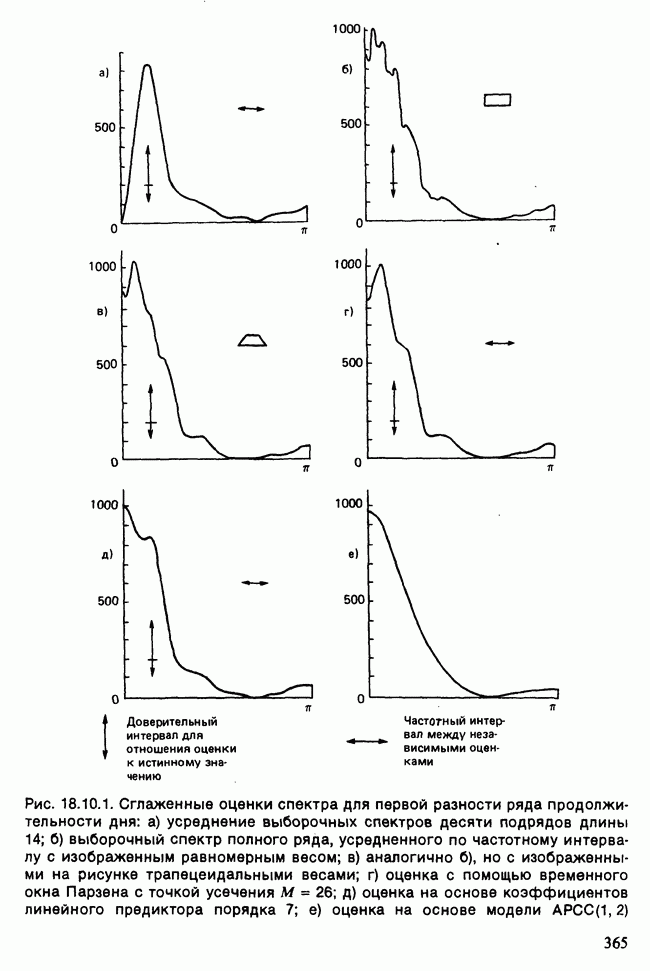
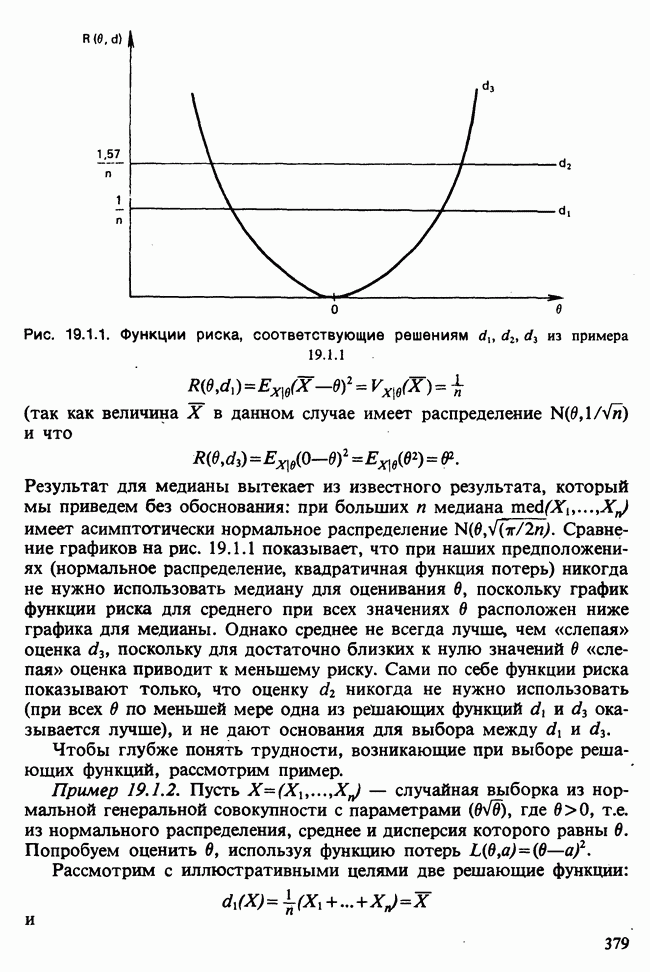
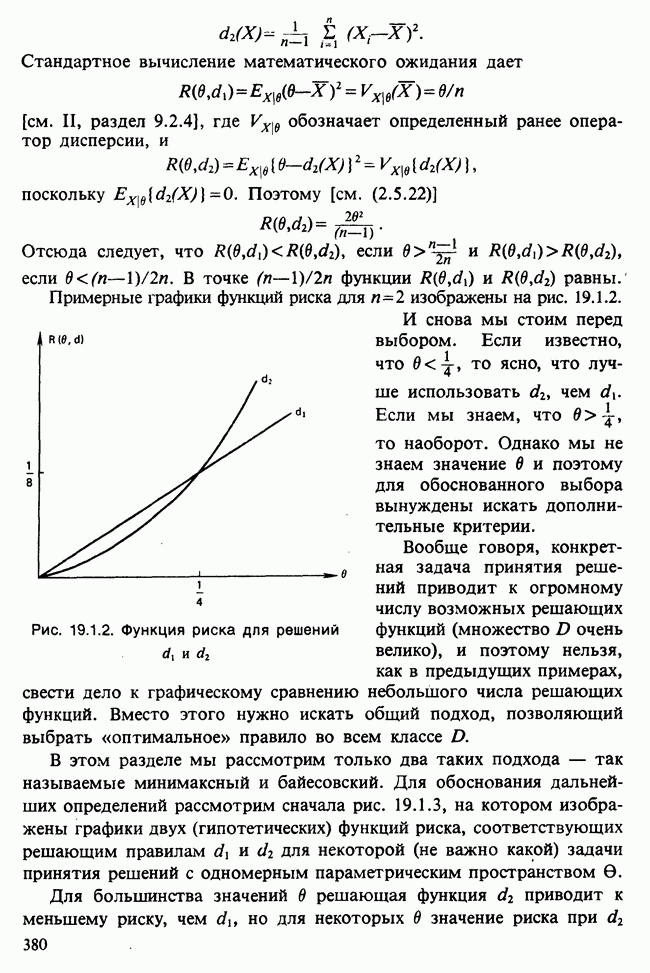
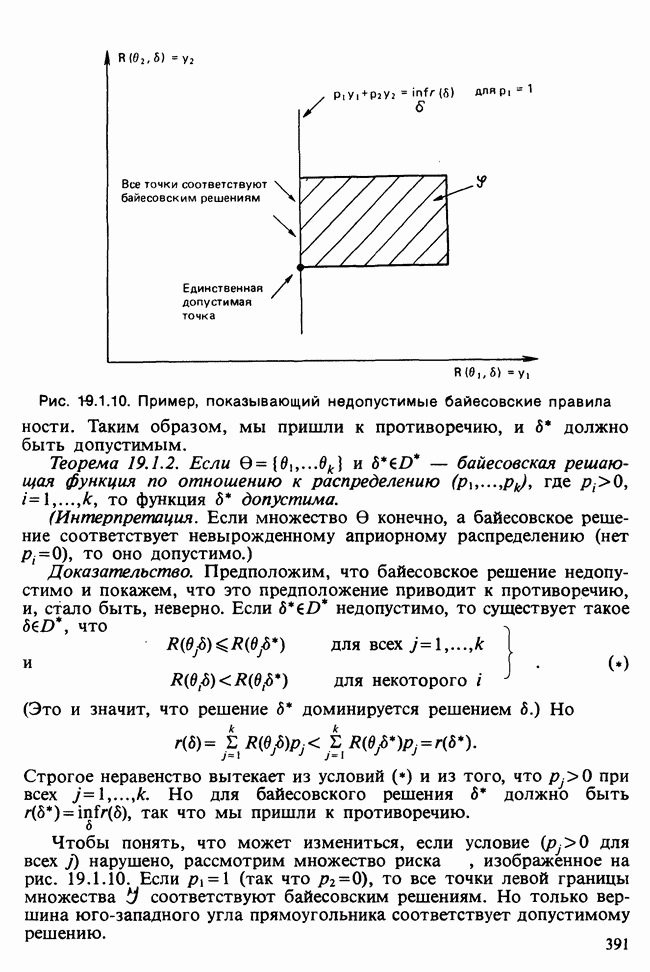
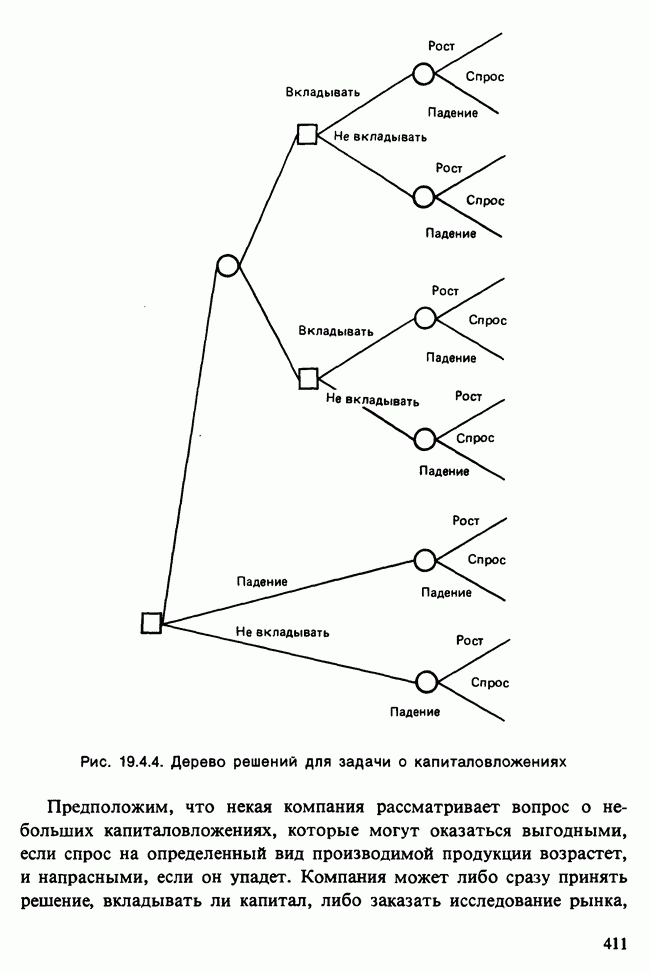
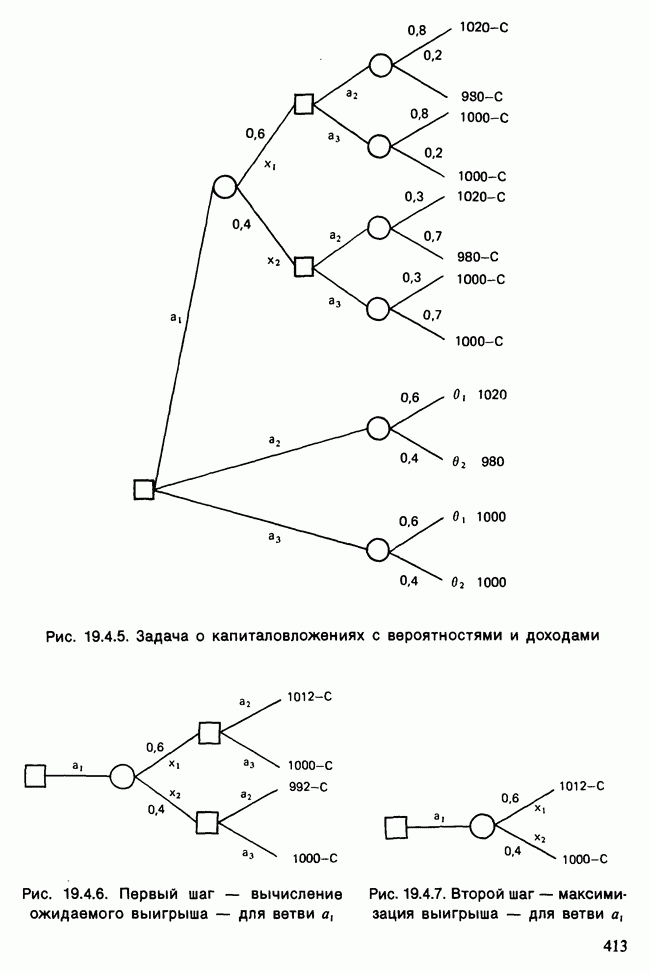
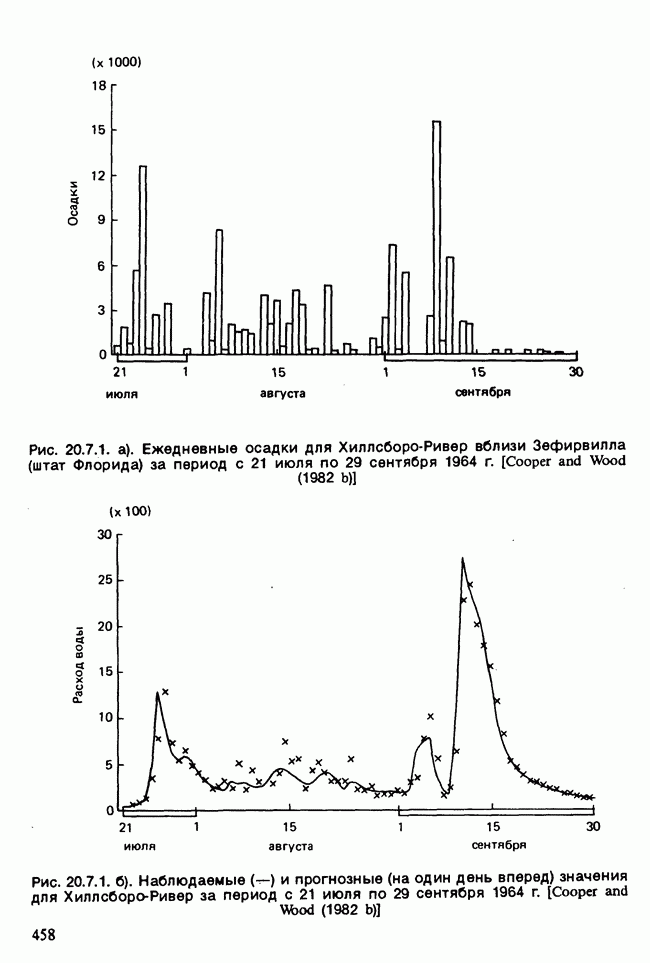
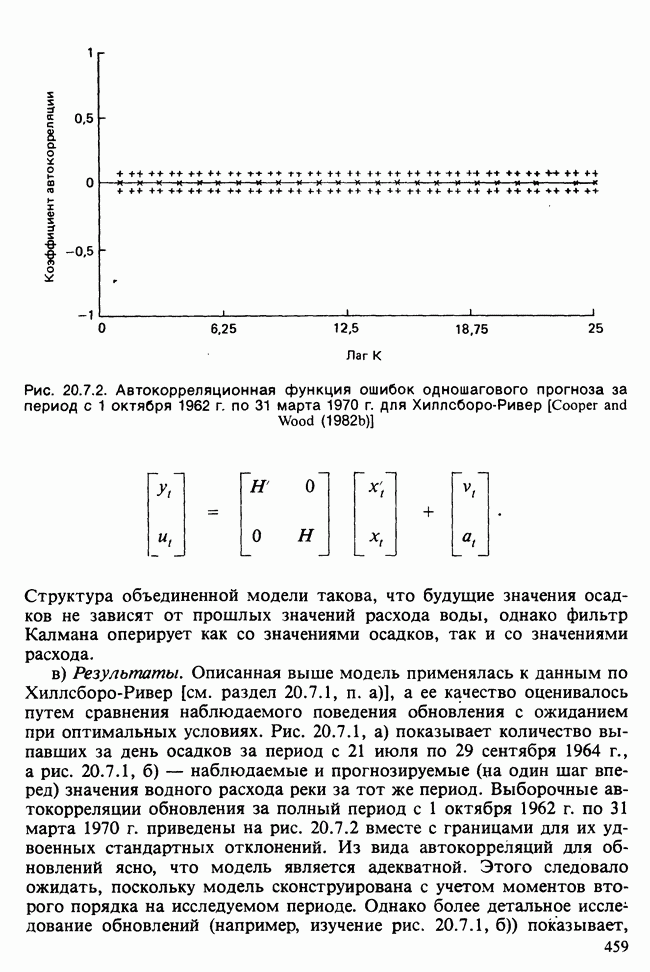
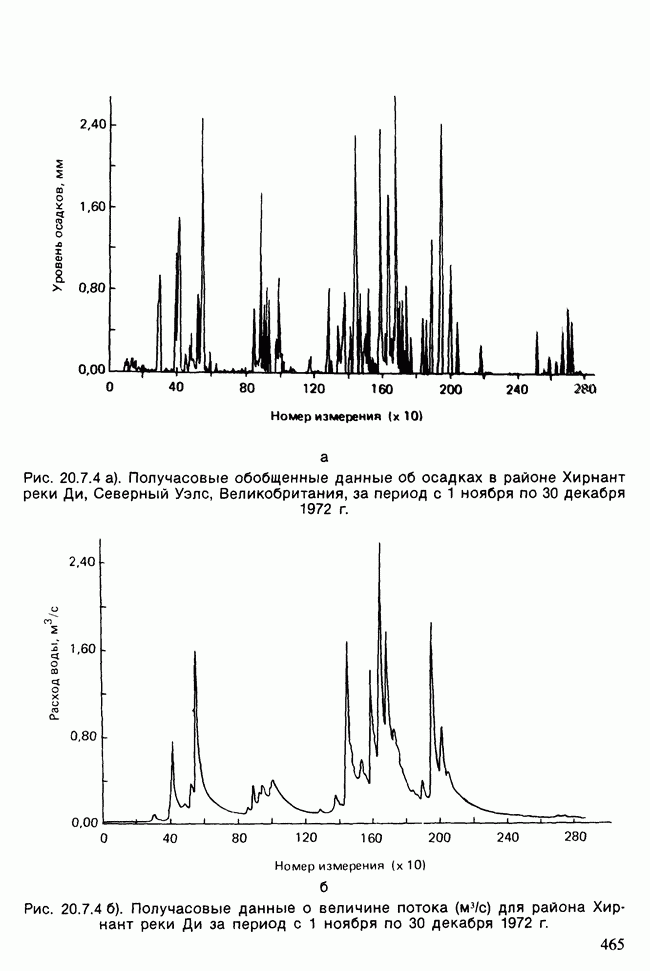
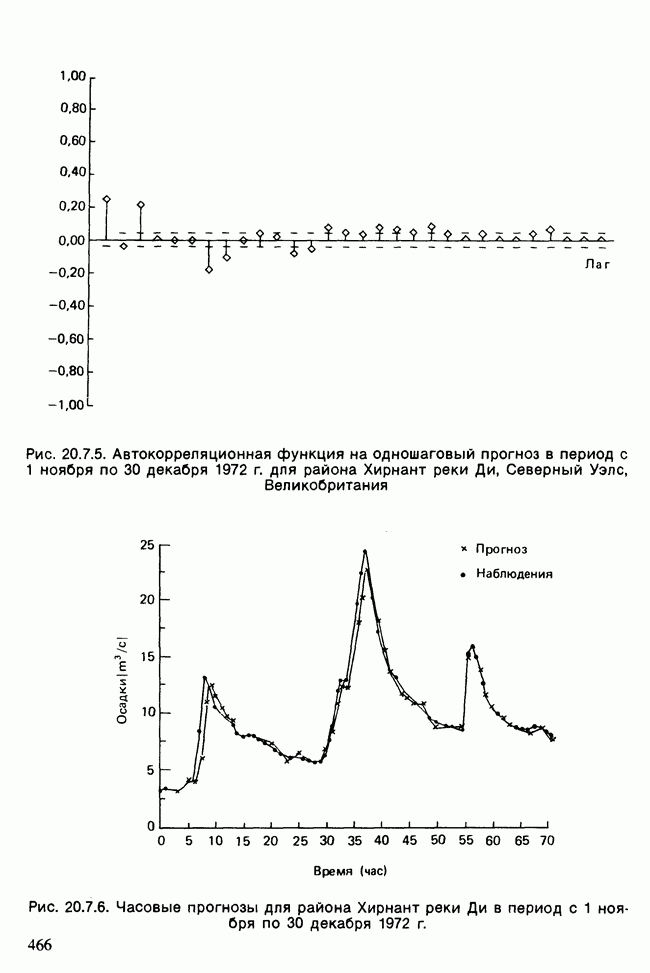
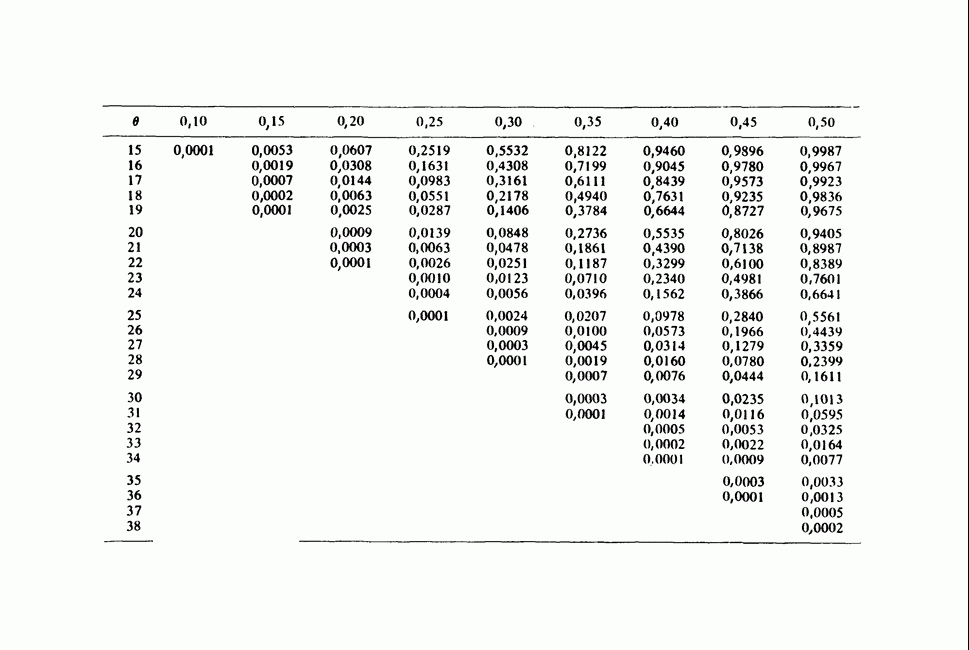
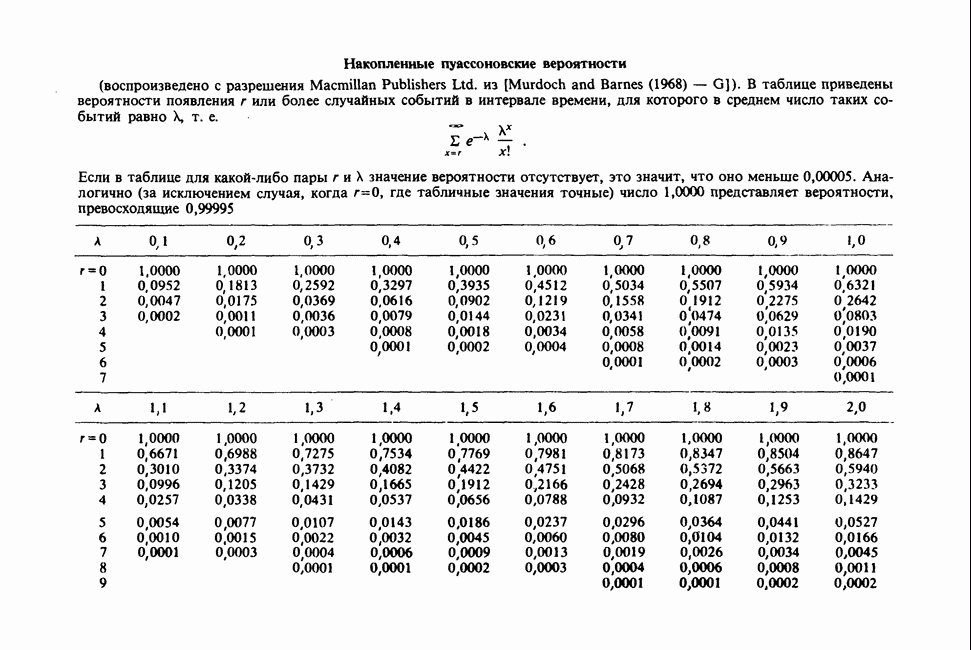
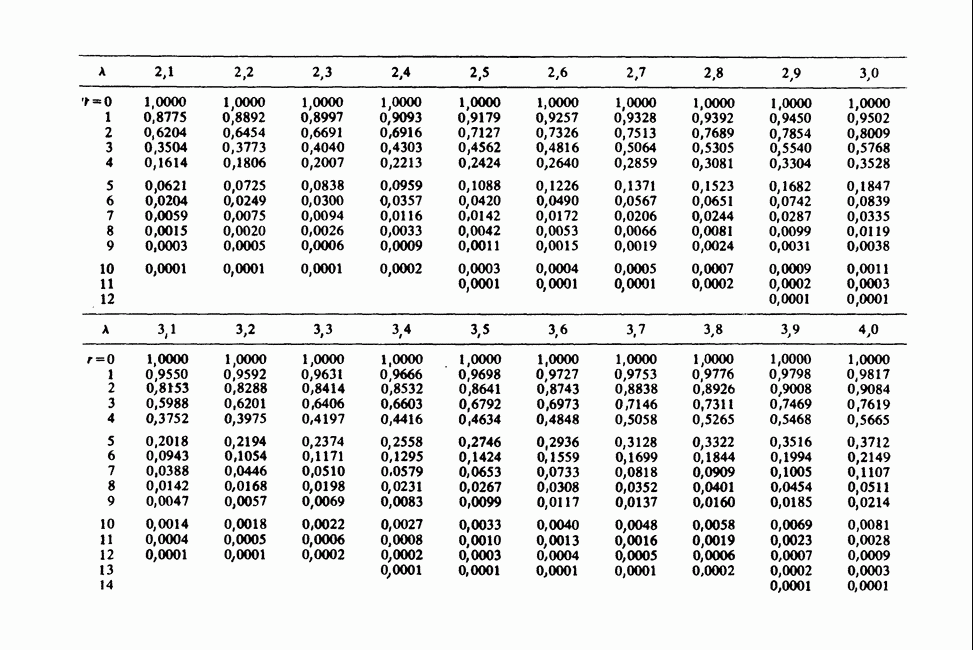
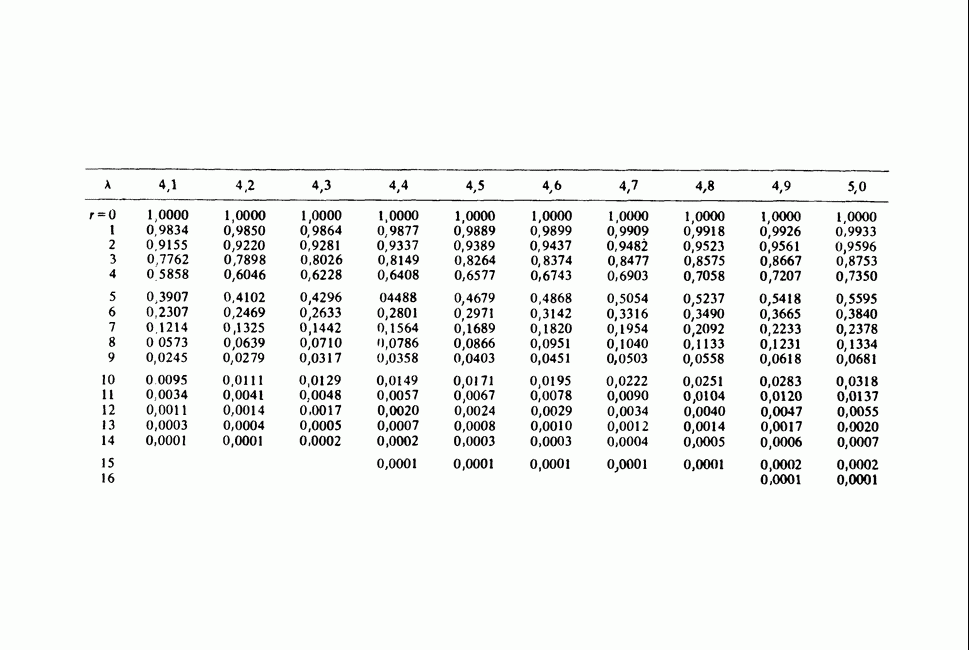
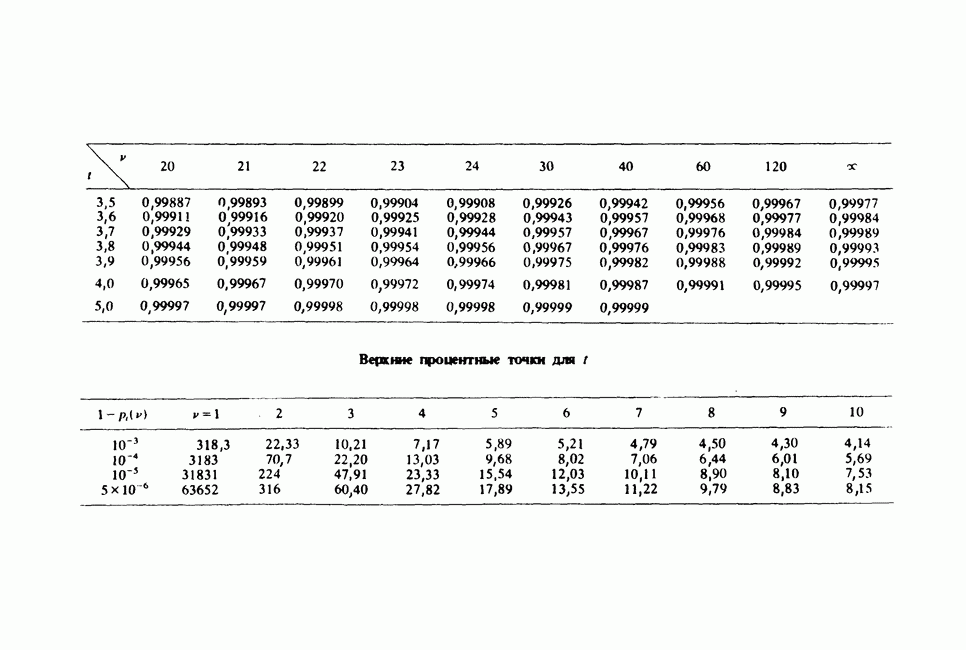
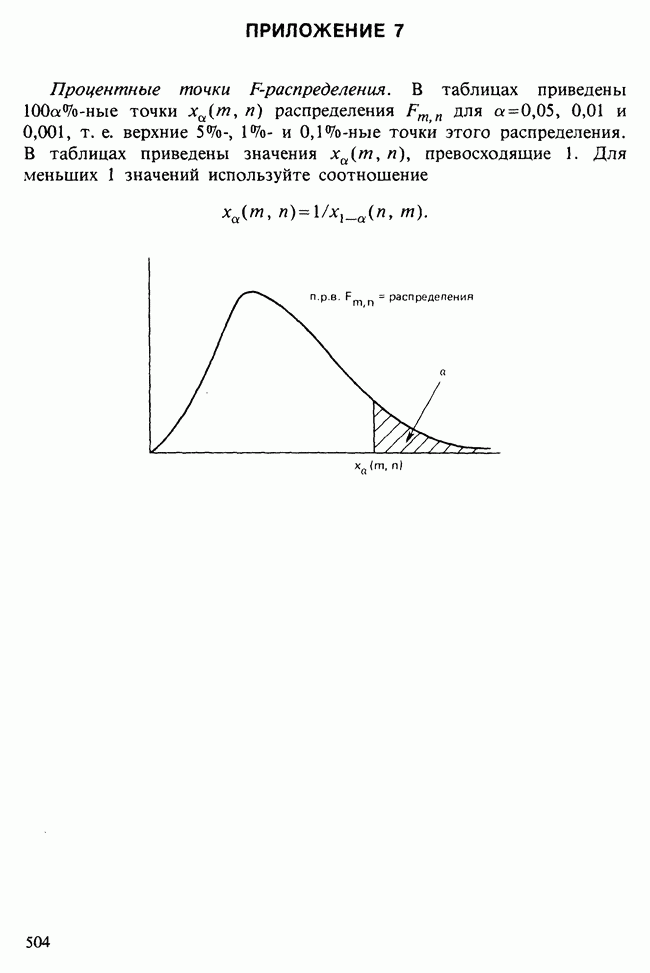
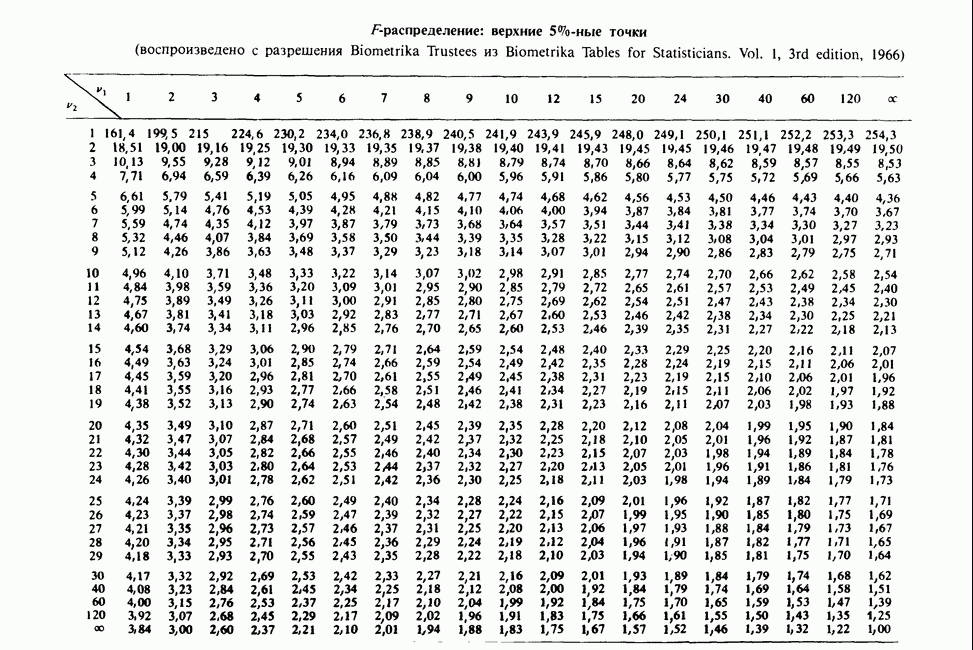
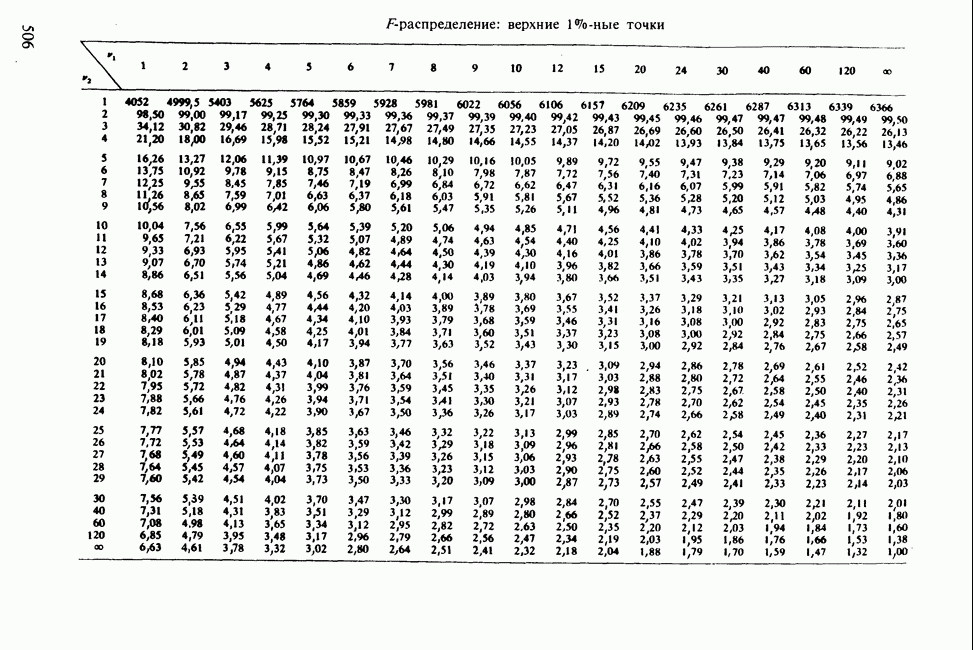
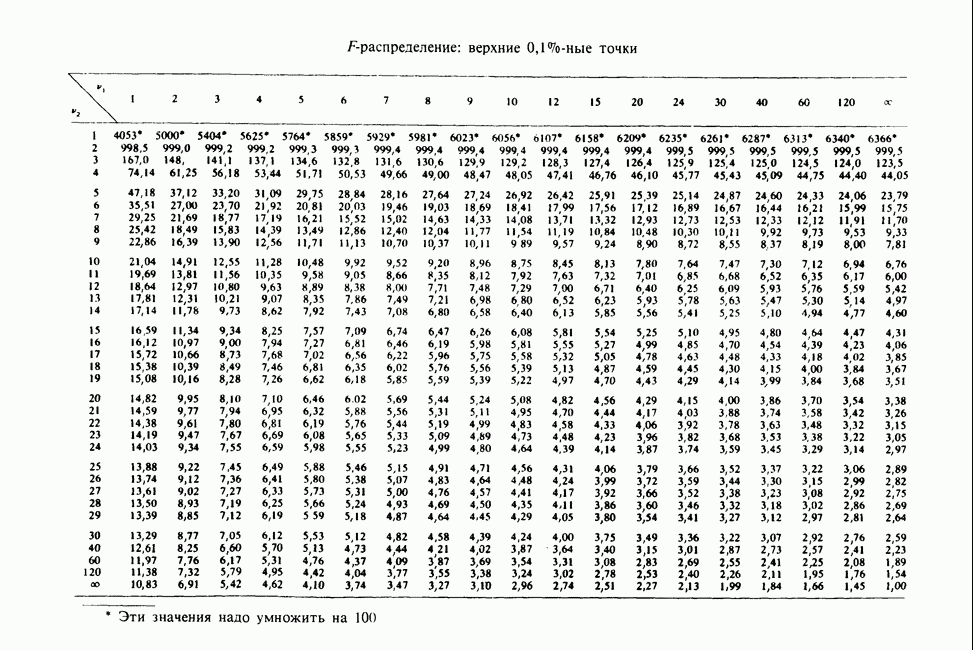
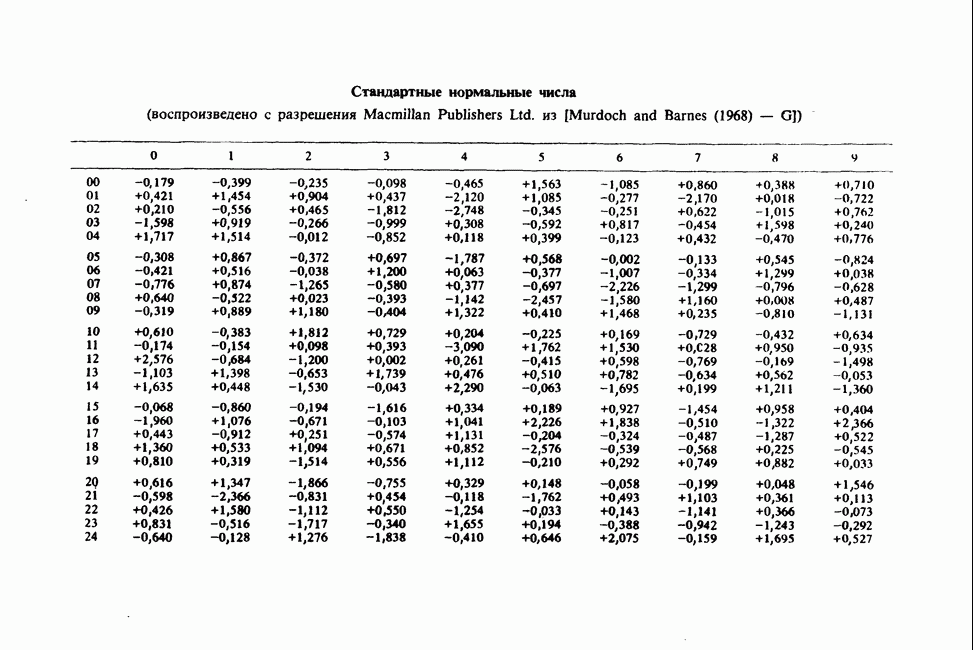
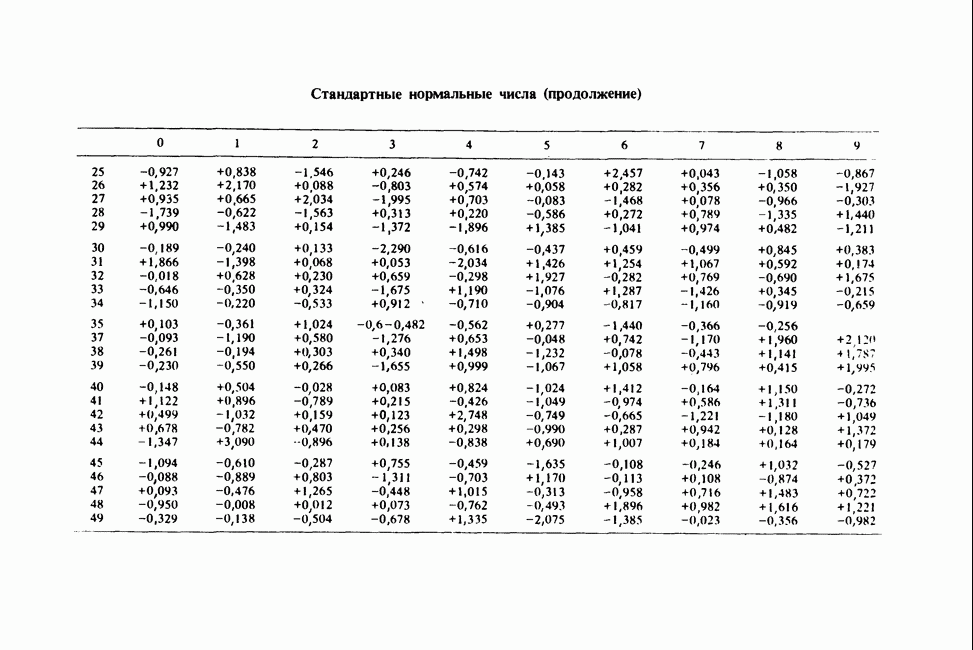
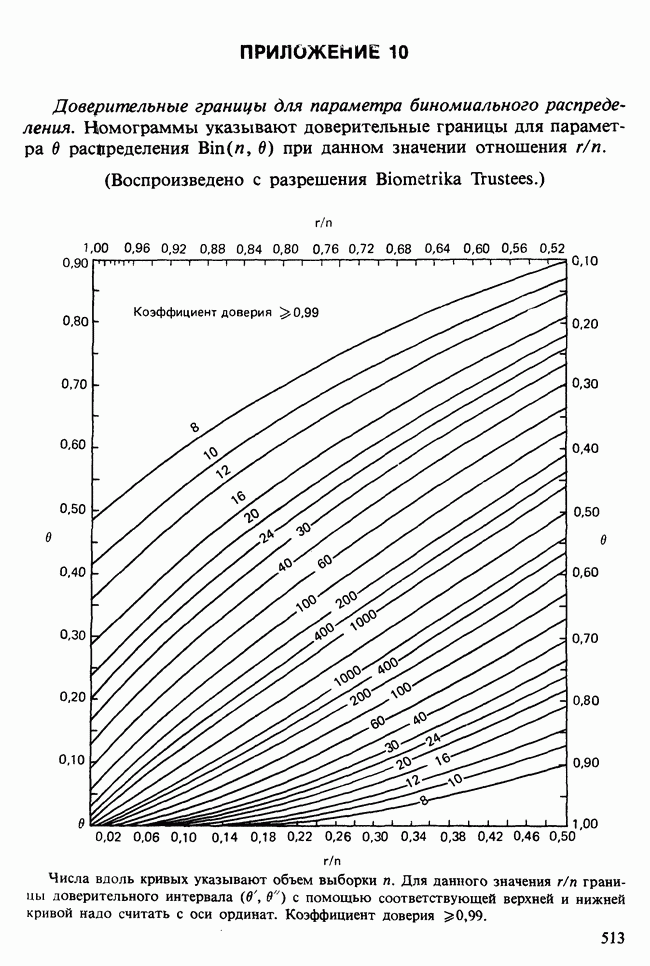
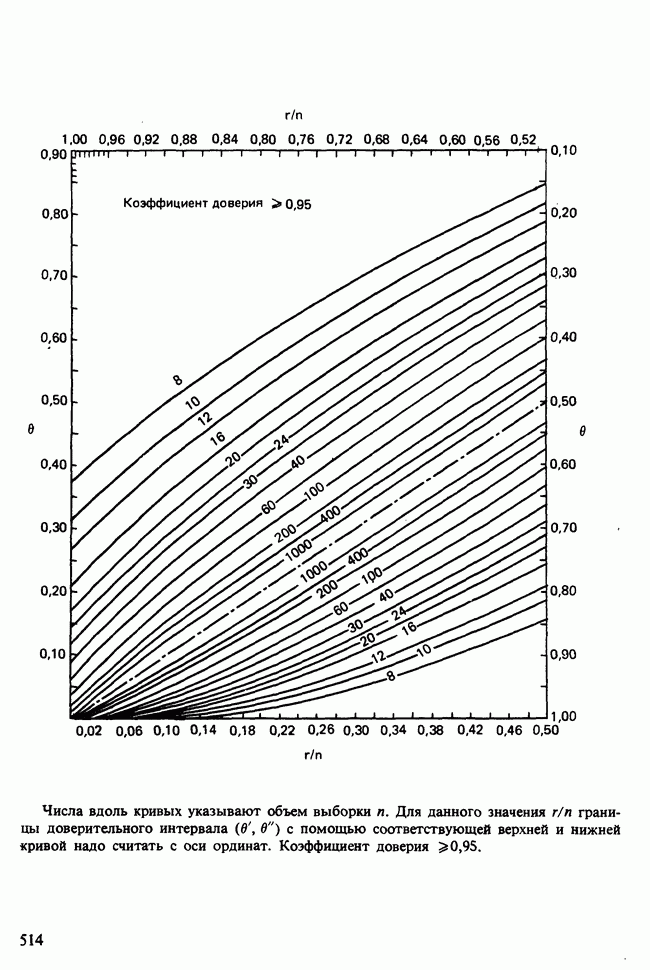
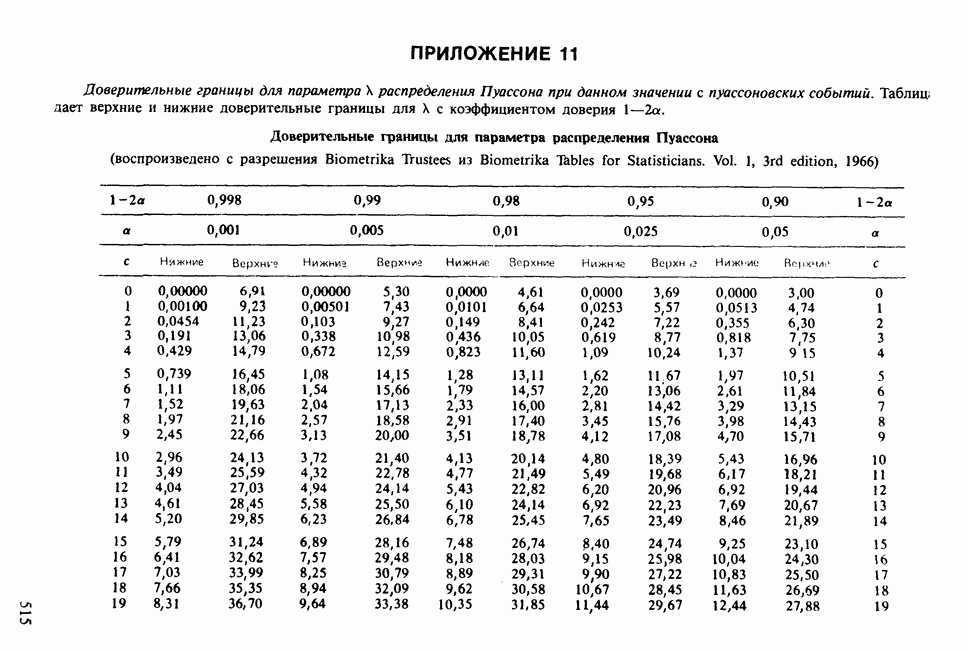
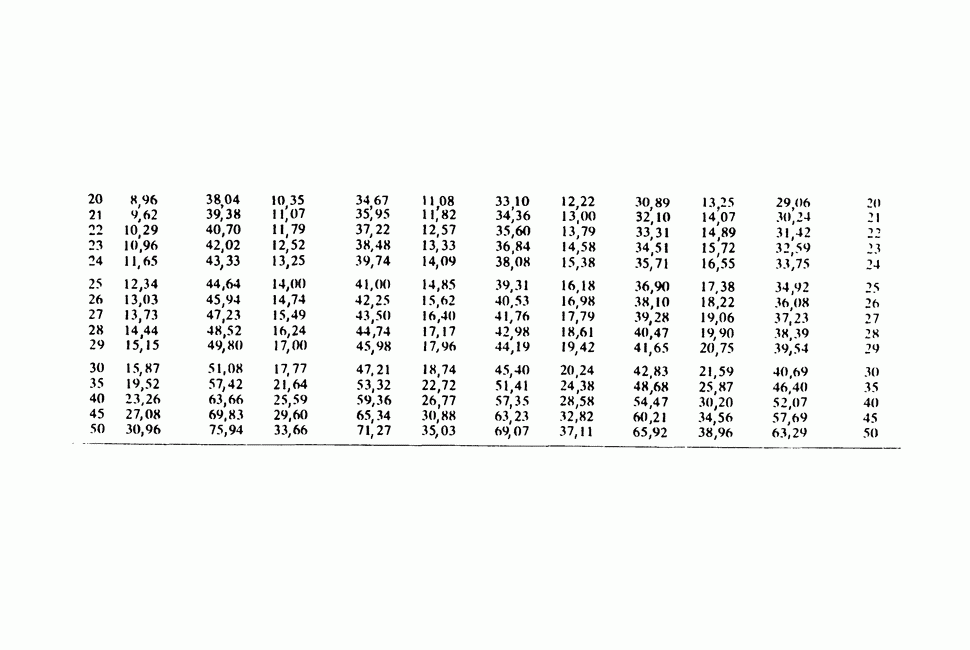17.2. АНАЛИЗ ГЛАВНЫХ КОМПОНЕНТ
Пусть  — матрица данных, содержащая значения
— матрица данных, содержащая значения  наблюдений
наблюдений  -мерного признака. Версия метода главных компонент для ситуации, когда
-мерного признака. Версия метода главных компонент для ситуации, когда  наблюдений могут рассматриваться как случайная выборка мультинормального (многомерного нормального) распределения [см. II, раздел 13.4], изложена в разделе 16.3. Этот подход обычно можно найти в учебниках. В настоящей главе рассматривается другой подход, который сам по себе представляет интерес и, кроме того, служит введением в более общие проблемы ординации. При данном подходе, который связывают со статьей К. Пирсона [см. Pearson (1901)], удобно считать, что
наблюдений могут рассматриваться как случайная выборка мультинормального (многомерного нормального) распределения [см. II, раздел 13.4], изложена в разделе 16.3. Этот подход обычно можно найти в учебниках. В настоящей главе рассматривается другой подход, который сам по себе представляет интерес и, кроме того, служит введением в более общие проблемы ординации. При данном подходе, который связывают со статьей К. Пирсона [см. Pearson (1901)], удобно считать, что  наблюдений представляют различные группы, а связанные с ними
наблюдений представляют различные группы, а связанные с ними  переменных задают типичные или средние значения количественных переменных для каждой группы.
переменных задают типичные или средние значения количественных переменных для каждой группы.
Геометрически можно считать, что значения  наблюдения
наблюдения  представляют точку в
представляют точку в  -мерном пространстве, натянутом на ортогональные координатные оси. Поскольку мы рассматриваем межгрупповой разброс, не имеет смысла ожидать эллипсоидального рассеяния точек в многомерном пространстве, как при мультинормальном распределении. Для обсуждаемого подхода допустим любой тип рассеяния, о типе распределения не требуется никаких предположений. Простая диаграмма рассеяния, скажем, для
-мерном пространстве, натянутом на ортогональные координатные оси. Поскольку мы рассматриваем межгрупповой разброс, не имеет смысла ожидать эллипсоидального рассеяния точек в многомерном пространстве, как при мультинормальном распределении. Для обсуждаемого подхода допустим любой тип рассеяния, о типе распределения не требуется никаких предположений. Простая диаграмма рассеяния, скажем, для  и 5-й переменных, представляет ортогональную проекцию выборки на плоскость, заданную
и 5-й переменных, представляет ортогональную проекцию выборки на плоскость, заданную  и 5-й осями. Правомерен вопрос: не может ли какая-либо другая плоскость дать в некотором смысле более репрезентативную проекцию? В методе главных компонент наилучшая аппроксимирующая плоскость определяется из условия минимизации суммы квадратов расстояний от анализируемых наблюдений до их проекций на эту плоскость. Вместо плоскости можно рассматривать проекции на любое
и 5-й осями. Правомерен вопрос: не может ли какая-либо другая плоскость дать в некотором смысле более репрезентативную проекцию? В методе главных компонент наилучшая аппроксимирующая плоскость определяется из условия минимизации суммы квадратов расстояний от анализируемых наблюдений до их проекций на эту плоскость. Вместо плоскости можно рассматривать проекции на любое  -мерное линейное подпространство полного
-мерное линейное подпространство полного  -мерного пространства.
-мерного пространства.
Пусть  -мерное подпространство образовано любыми к линейнонезависимыми векторами — столбцами матрицы
-мерное подпространство образовано любыми к линейнонезависимыми векторами — столбцами матрицы  Тогда стандартный результат линейной алгебры состоит в том, что координаты точек
Тогда стандартный результат линейной алгебры состоит в том, что координаты точек  спроецированных на это подпространство, задаются преобразованием
спроецированных на это подпространство, задаются преобразованием  (Здесь и далее в главе — обозначение для матрицы
(Здесь и далее в главе — обозначение для матрицы  строками и к столбцами, Н — обозначение для транспонированной матрицы.) Не теряя общности, можно наложить требование ортогональности линейно-независимых векторов [см. I, раздел 10.2]. Тогда координаты проекций будут определяться как
строками и к столбцами, Н — обозначение для транспонированной матрицы.) Не теряя общности, можно наложить требование ортогональности линейно-независимых векторов [см. I, раздел 10.2]. Тогда координаты проекций будут определяться как  где
где  Остатки [см. раздел 8.2.4] задаются координатами, ортогональными к подпространству, и могут быть вычислены как
Остатки [см. раздел 8.2.4] задаются координатами, ортогональными к подпространству, и могут быть вычислены как  Отсюда остаточная сумма квадратов равна
Отсюда остаточная сумма квадратов равна

Это выражение должно быть минимизировано по Н. Минимизация может быть заменена на максимизацию

что можно переписать в виде  , где
, где  — матрица сумм квадратов и произведений. Записав
— матрица сумм квадратов и произведений. Записав  в спектральной форме
в спектральной форме  [см. I, раздел 7.10], где
[см. I, раздел 7.10], где  — ортогональная матрица,
— ортогональная матрица,  получаем
получаем 

где  — элементы ортонормированной матрицы
— элементы ортонормированной матрицы  Обозначим
Обозначим

тогда

поскольку сумма квадратов элементов в строке ортонормированной матрицы  не превосходит единицы; единичное значение достигается, когда
не превосходит единицы; единичное значение достигается, когда  и
и  становится ортогональной.
становится ортогональной.

поскольку это выражение соответствует сумме квадратов всех элементов матрицы  каждый из к столбцов которой сам имеет единичную сумму квадратов элементов. Таким образом, необходимо максимизировать
каждый из к столбцов которой сам имеет единичную сумму квадратов элементов. Таким образом, необходимо максимизировать

при ограничениях (17.2.1) и (17.2.2). Это задача линейного программирования [см. I, гл. 11], максимум должен достигаться, когда  и
и  вершина допустимой области, заданной уравнениями (17.2.1) и (17.2.2). Все вершины обходятся, когда к значений
вершина допустимой области, заданной уравнениями (17.2.1) и (17.2.2). Все вершины обходятся, когда к значений  равны единице, а остальные
равны единице, а остальные  — нулю. Упорядочим собственные значения [см. I, гл. 7]
— нулю. Упорядочим собственные значения [см. I, гл. 7]  Ясно, что максимум равен
Ясно, что максимум равен  и достигается при
и достигается при  для
для  Если
Если  то максимум достигается и при других условиях. До сих пор мы не использовали дополнительные ограничения, состоящие в том, что столбцы матрицы
то максимум достигается и при других условиях. До сих пор мы не использовали дополнительные ограничения, состоящие в том, что столбцы матрицы  ортогональны. Однако решение, полученное при отсутствии этого ограничения, дает матрицу
ортогональны. Однако решение, полученное при отсутствии этого ограничения, дает матрицу  которая в действительности ортонормирована и поэтому должна максимизировать след по всем ортонормированным матрицам. Таким образом, мы показали, что в точке максимума ортонормированная матрица
которая в действительности ортонормирована и поэтому должна максимизировать след по всем ортонормированным матрицам. Таким образом, мы показали, что в точке максимума ортонормированная матрица  превращается в матрицу, строки и столбцы которой имеют единичную длину. В свою очередь это означает, что матрица
превращается в матрицу, строки и столбцы которой имеют единичную длину. В свою очередь это означает, что матрица  может быть разбита в виде
может быть разбита в виде 

где  — ортогональная матрица порядка к. Итак,
— ортогональная матрица порядка к. Итак,  — матрица с ортогональными столбцами, которые являются линейными комбинациями к первых собственных векторов матрицы
— матрица с ортогональными столбцами, которые являются линейными комбинациями к первых собственных векторов матрицы 
Из изложенного следует, что наилучшая аппроксимация в виде  -мерного линейного подпространства, содержащего начало координат, совпадает с пространством, образованным к (ортогональными) единичными векторами, соответствующими к наибольшим собственным значениям матрицы
-мерного линейного подпространства, содержащего начало координат, совпадает с пространством, образованным к (ортогональными) единичными векторами, соответствующими к наибольшим собственным значениям матрицы  Остаточная сумма квадратов, подлежащая минимизации, равна
Остаточная сумма квадратов, подлежащая минимизации, равна

это — сумма  наименьших собственных значений матрицы
наименьших собственных значений матрицы 
Если опустить требование, чтобы  -мерное подпространство содержало начало координат, то можно добиться меньшей остаточной суммы квадратов. Хорошо известно, и это легко доказывается, что суммы квадратов отклонений от центра тяжести (т. е. среднего) меньше, чем суммы квадратов отклонений от любой другой точки. Отсюда следует, что наилучшее аппроксимирующее
-мерное подпространство содержало начало координат, то можно добиться меньшей остаточной суммы квадратов. Хорошо известно, и это легко доказывается, что суммы квадратов отклонений от центра тяжести (т. е. среднего) меньше, чем суммы квадратов отклонений от любой другой точки. Отсюда следует, что наилучшее аппроксимирующее  -мерное подпространство должно содержать среднее. Это означает, что X следует заменить на матрицу отклонений от среднего
-мерное подпространство должно содержать среднее. Это означает, что X следует заменить на матрицу отклонений от среднего  где все элементы матрицы
где все элементы матрицы  равны
равны  Тогда матрица
Тогда матрица  заменяется на
заменяется на  — скорректированную матрицу сумм квадратов и произведений для
— скорректированную матрицу сумм квадратов и произведений для  наблюдений на
наблюдений на  случайных переменных. В дальнейшем будем предполагать, что столбцы матрицы X содержат отклонения от своих средних, так что суммы элементов по столбцам равны нулю и матрицу
случайных переменных. В дальнейшем будем предполагать, что столбцы матрицы X содержат отклонения от своих средних, так что суммы элементов по столбцам равны нулю и матрицу  можно отбросить.
можно отбросить.
Основной результат анализа главных компонент, изложенный выше, отличается от того, как это обычно описывается в учебниках. Как правило, используя дифференцирование с множителями Лагранжа, показывают, что при  матрица Н (которая в данном случае является вектором) определяется собственным вектором матрицы
матрица Н (которая в данном случае является вектором) определяется собственным вектором матрицы  соответствующим наибольшему собственному значению Аналогично если
соответствующим наибольшему собственному значению Аналогично если  направлений определяются
направлений определяются  первыми собственными векторами матрицы
первыми собственными векторами матрицы  то направление, ортогональное этому подпространству и минимизирующее остаточную сумму квадратов, определяется
то направление, ортогональное этому подпространству и минимизирующее остаточную сумму квадратов, определяется  собственным вектором матрицы
собственным вектором матрицы  Эта процедура приводит к условным оптимумам на уже определенных размерностях [см. раздел 16.3]. Описанный подход показывает, что эти условные оптимумы являются глобальными.
Эта процедура приводит к условным оптимумам на уже определенных размерностях [см. раздел 16.3]. Описанный подход показывает, что эти условные оптимумы являются глобальными.
Для ординации необходимы координаты  спроецированных точек. Такая форма не пригодна для графического представления, и даже при
спроецированных точек. Такая форма не пригодна для графического представления, и даже при  одномерное множество координат выражается в
одномерное множество координат выражается в  -мерном виде. Удобнее выбрать в подпространстве к ортогональных осей; наиболее простой способ — взять в качестве координат
-мерном виде. Удобнее выбрать в подпространстве к ортогональных осей; наиболее простой способ — взять в качестве координат  Любой другой набор ортогональных осей в подпространстве также допустим, но
Любой другой набор ортогональных осей в подпространстве также допустим, но  обладает преимуществом: ее первые с столбцов задают координаты, соответствующие наилучшему приближению в пространстве с измерений.
обладает преимуществом: ее первые с столбцов задают координаты, соответствующие наилучшему приближению в пространстве с измерений.
В терминологии компонентного анализа собственные векторы, задаваемые столбцами матрицы Н, являются главными компонентами или главными осями, а координаты  — значениями по главным компонентам. Коэффициенты
— значениями по главным компонентам. Коэффициенты  матрицы Н называются нагрузками
матрицы Н называются нагрузками  наблюдения на
наблюдения на  случайную переменную. Положив
случайную переменную. Положив  мы получим все главные оси, и Н превращается в ортогональную матрицу, содержащую все собственные векторы матрицы
мы получим все главные оси, и Н превращается в ортогональную матрицу, содержащую все собственные векторы матрицы  Поскольку евклидовы расстояния инвариантны относительно ортогональных преобразований, главные оси задают переход от первоначальных координатных осей к новым осям, обладающим обсуждаемыми выше оптимальными свойствами. При таких преобразованиях взаимное расположение точек не меняется. Можно также в качестве преобразования рассматривать такое, в котором исходные переменные становятся главными и их значения — значениями по главным компонентам.
Поскольку евклидовы расстояния инвариантны относительно ортогональных преобразований, главные оси задают переход от первоначальных координатных осей к новым осям, обладающим обсуждаемыми выше оптимальными свойствами. При таких преобразованиях взаимное расположение точек не меняется. Можно также в качестве преобразования рассматривать такое, в котором исходные переменные становятся главными и их значения — значениями по главным компонентам.
Нередко новые переменные отождествляются со скрытыми свойствами изучаемой выборки; такая процедура соответствует описанию объектов через обнаруженные свойства. В некоторых случаях такая идентификация весьма убедительна, но к описанию объектов через обнаруженные свойства, как и к идентификации факторов в факторном анализе [см. раздел 16.4], следует подходить с осторожностью. Как и в факторном анализе,  -мерное пространство определяется с помощью компонентного анализа, и любое множество линейно-независимых направлений в этом пространстве может быть выбрано в качестве координатных осей. Причина, по которой математически определенные главные оси должны иметь интерпретации лучше, чем любые другие координатные оси в том же пространстве, не очевидна.
-мерное пространство определяется с помощью компонентного анализа, и любое множество линейно-независимых направлений в этом пространстве может быть выбрано в качестве координатных осей. Причина, по которой математически определенные главные оси должны иметь интерпретации лучше, чем любые другие координатные оси в том же пространстве, не очевидна.
Поэтому для получения интерпретируемых осей в компонентном анализе имеется целый арсенал вспомогательных средств ортогонального и косоугольного вращения факторов. Нельзя забывать и о таящихся в них опасностях. К счастью, процедура описания объектов через обнаруженные свойства менее важна, когда компонентный анализ применяется для ординации, и более важна, когда анализируются выборки из единственного многомерного распределения. При ординации акцент делается на графическом изображении множества точек, представляющих выборки.
Переход от  -мерного пространства к хорошей аппроксимации в пространстве размерности
-мерного пространства к хорошей аппроксимации в пространстве размерности  — ключевой момент всех ординаций. Простая мера качества отображения —
— ключевой момент всех ординаций. Простая мера качества отображения —  обычно она задается в процентах и представляет собой отношение суммы квадратов расстояний всех спроецированных точек до начала координат (обычно центра тяжести) к общей сумме квадратов расстояний до проецирования. Это то же самое, что отношение суммы квадратов всех попарных расстояний между спроецированным: чками к той же сумме для исходных точек. Высокое значение этого коэффициента при малом к означает хорошее соответствие в пространстве нескольких осей. Итак, при компонентном анализе неявно выражена надежда, что
обычно она задается в процентах и представляет собой отношение суммы квадратов расстояний всех спроецированных точек до начала координат (обычно центра тяжести) к общей сумме квадратов расстояний до проецирования. Это то же самое, что отношение суммы квадратов всех попарных расстояний между спроецированным: чками к той же сумме для исходных точек. Высокое значение этого коэффициента при малом к означает хорошее соответствие в пространстве нескольких осей. Итак, при компонентном анализе неявно выражена надежда, что  -мерное облако точек представляет собой (хотя бы приближенно)
-мерное облако точек представляет собой (хотя бы приближенно)  -мерный линейный образ, где
-мерный линейный образ, где  Если множество точек имеет простую структуру, но лежит на нелинейном образе, то маловероятно, что компонентный анализ окажется успешным. Например, множество точек, лежащих на сфере, не допускает простого отображения в пространстве менее трех осей, если только не допустить для полярных областей отображение, подобное представлению глобуса на карте в виде двух полушарий.
Если множество точек имеет простую структуру, но лежит на нелинейном образе, то маловероятно, что компонентный анализ окажется успешным. Например, множество точек, лежащих на сфере, не допускает простого отображения в пространстве менее трех осей, если только не допустить для полярных областей отображение, подобное представлению глобуса на карте в виде двух полушарий.
Чаще всего нагрузки первой компоненты все положительны и нередко имеют близкие значения. В таком случае первая компонента часто идентифицируется как объемная. В биологических задачах, где измерения производятся на развивающихся организмах, такая ситуация традиционна, поскольку разные части организма развиваются с одинаковой скоростью (аллометрический рост). В такой ситуации корреляции между всеми парами признаков будут положительны и матрица  будет содержать неотрицательные элементы. Теорема Фробениуса—Перрона [см. I, теорема 7.11.1] утверждает, что максимальное собственное значение матрицы
будет содержать неотрицательные элементы. Теорема Фробениуса—Перрона [см. I, теорема 7.11.1] утверждает, что максимальное собственное значение матрицы  соответствует собственному вектору неотрицательных нагрузок. Таким образом, присутствие объемной компоненты связано с феноменом, наблюдаемым на практике. Если объемная компонента не представляет первостепенного интереса, обычно изображают проекции на координатные оси начиная со второй, поскольку, вообще говоря, считается, что представление должно подчеркивать различия в форме. При более формальном подходе XI рассматривают как объемную переменную. Исключение объемной
соответствует собственному вектору неотрицательных нагрузок. Таким образом, присутствие объемной компоненты связано с феноменом, наблюдаемым на практике. Если объемная компонента не представляет первостепенного интереса, обычно изображают проекции на координатные оси начиная со второй, поскольку, вообще говоря, считается, что представление должно подчеркивать различия в форме. При более формальном подходе XI рассматривают как объемную переменную. Исключение объемной
компоненты при проецировании приводит к «переменным формы»  и модифицированной матрице сумм квадратов и попарных произведений
и модифицированной матрице сумм квадратов и попарных произведений  , где
, где  Матрица имеет нулевое собственное значение, соответствующее вектору 1. Ее ненулевые собственные значения используются для анализа переменных формы методом главных компонент.
Матрица имеет нулевое собственное значение, соответствующее вектору 1. Ее ненулевые собственные значения используются для анализа переменных формы методом главных компонент.
Замечания, приведенные в разделе 17.1, относительно чувствительности некоторых видов многомерного анализа к изменениям шкалы относятся в полной мере и к методу главных компонент. В случае, когда шкалы для измерения переменных не совпадают, обычно первое, что необходимо сделать, это стандартизовать X так, чтобы обратить  в матрицу корреляций. В исследованиях объемных переменных (или переменных формы) наиболее общим является логарифмическое преобразование матрицы X. Поскольку под «формой» часто подразумевают отношение двух переменных, на это отношение не влияет аллометрический рост. Исключение объемной компоненты, о котором говорилось выше, приводит к переменным формы
в матрицу корреляций. В исследованиях объемных переменных (или переменных формы) наиболее общим является логарифмическое преобразование матрицы X. Поскольку под «формой» часто подразумевают отношение двух переменных, на это отношение не влияет аллометрический рост. Исключение объемной компоненты, о котором говорилось выше, приводит к переменным формы  что дает
что дает  объемную переменную
объемную переменную  с требуемым видом отношения. Заметим, что две выборки, в одной из которых все значения переменных кратны значениям другой, после преобразования имеют одну и ту же форму.
с требуемым видом отношения. Заметим, что две выборки, в одной из которых все значения переменных кратны значениям другой, после преобразования имеют одну и ту же форму.