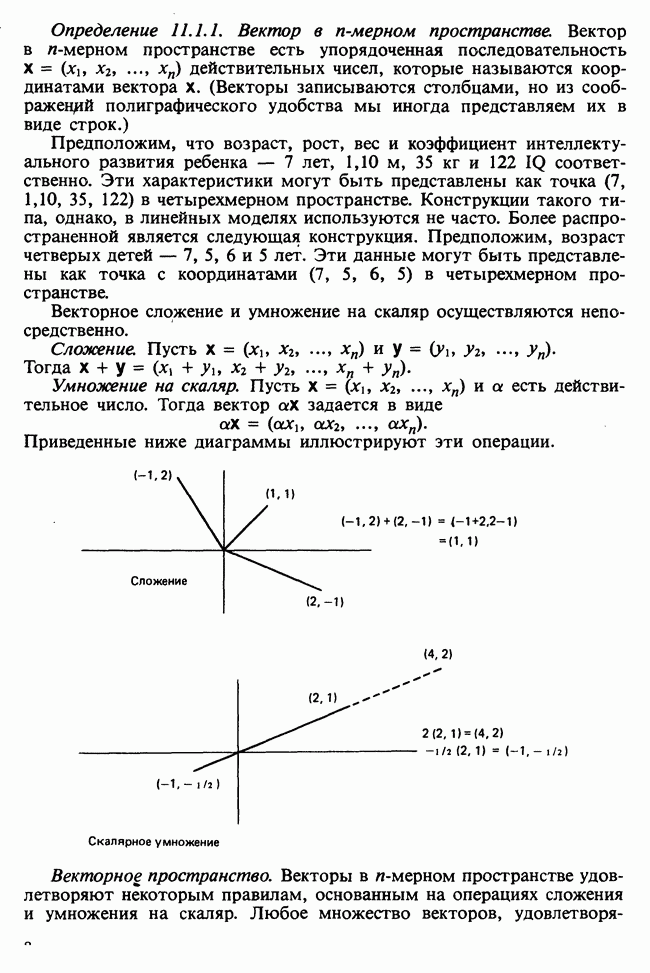
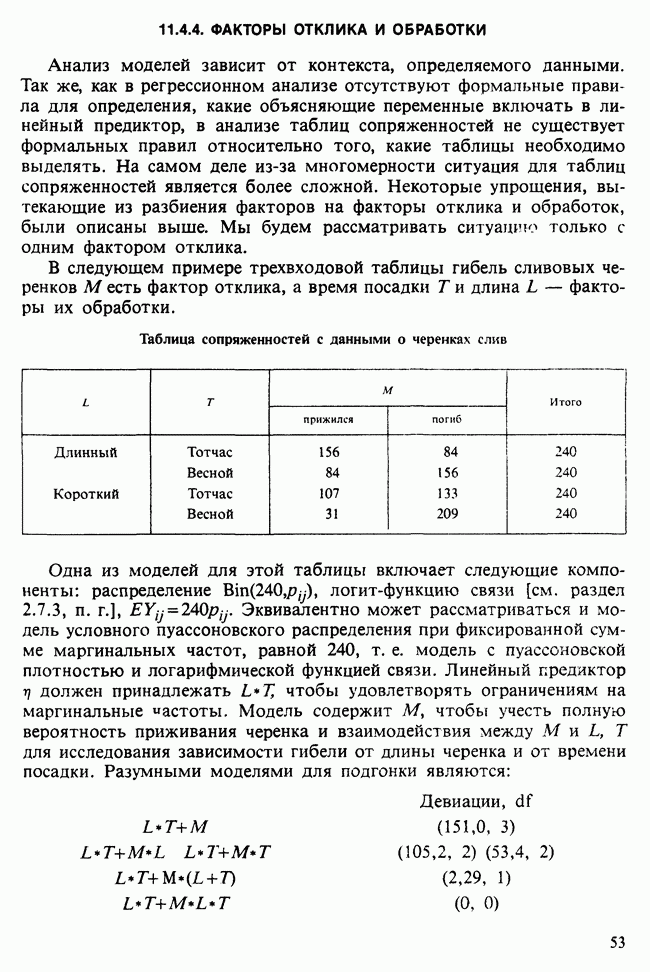
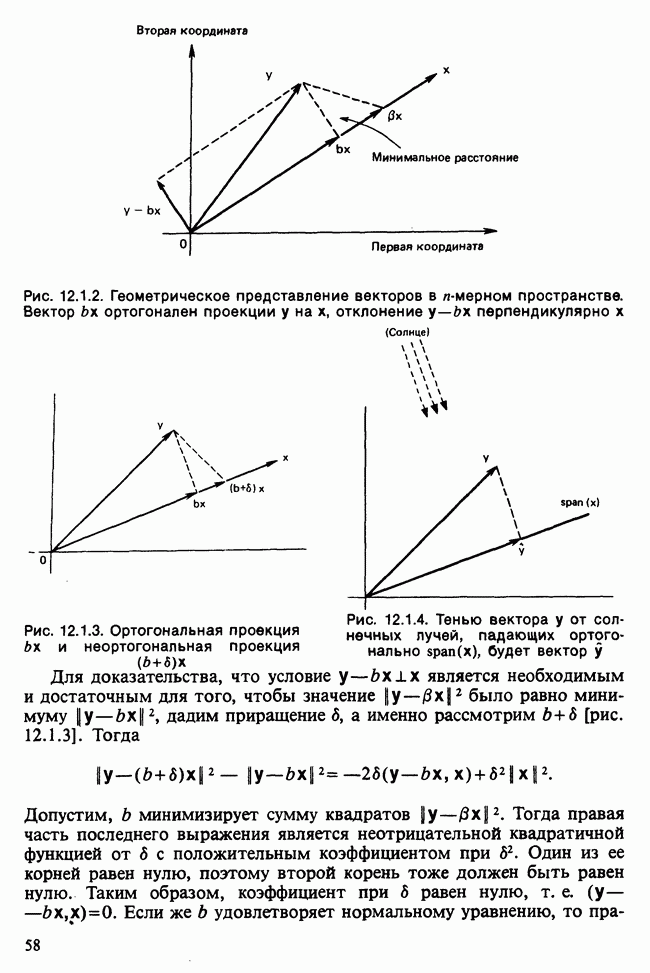
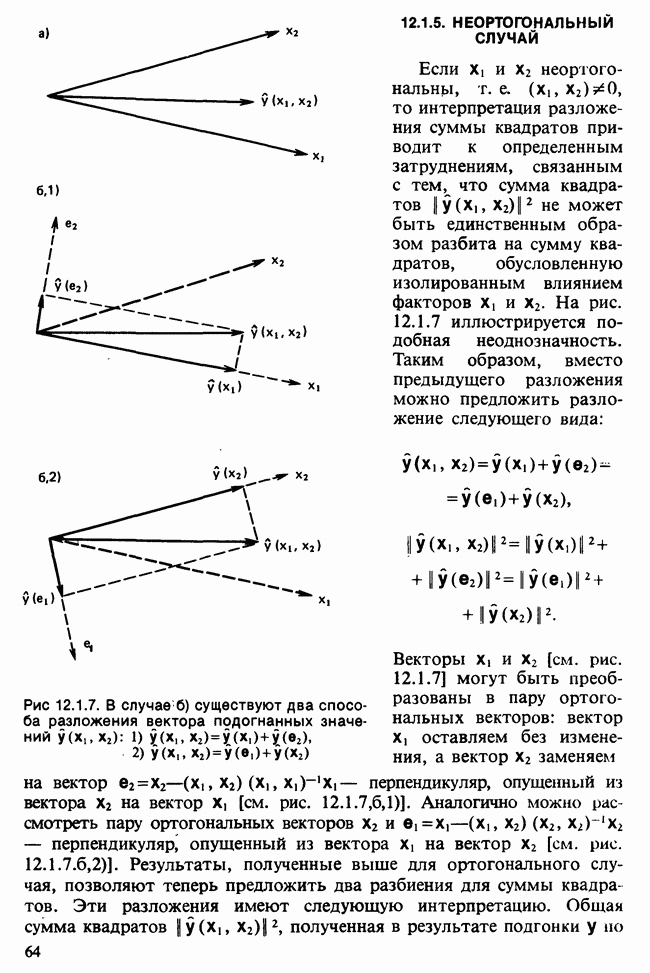
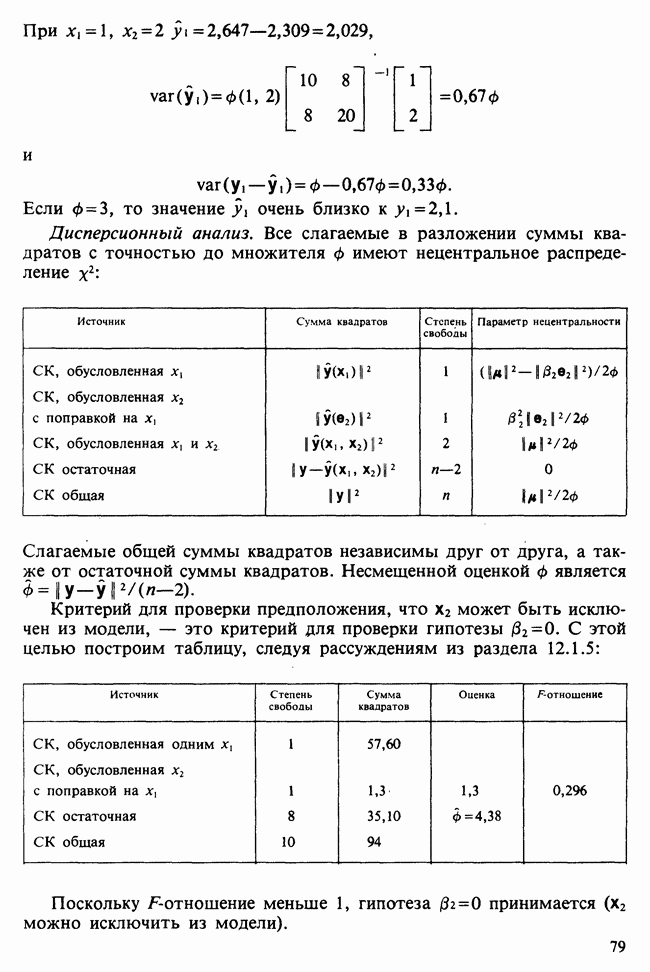
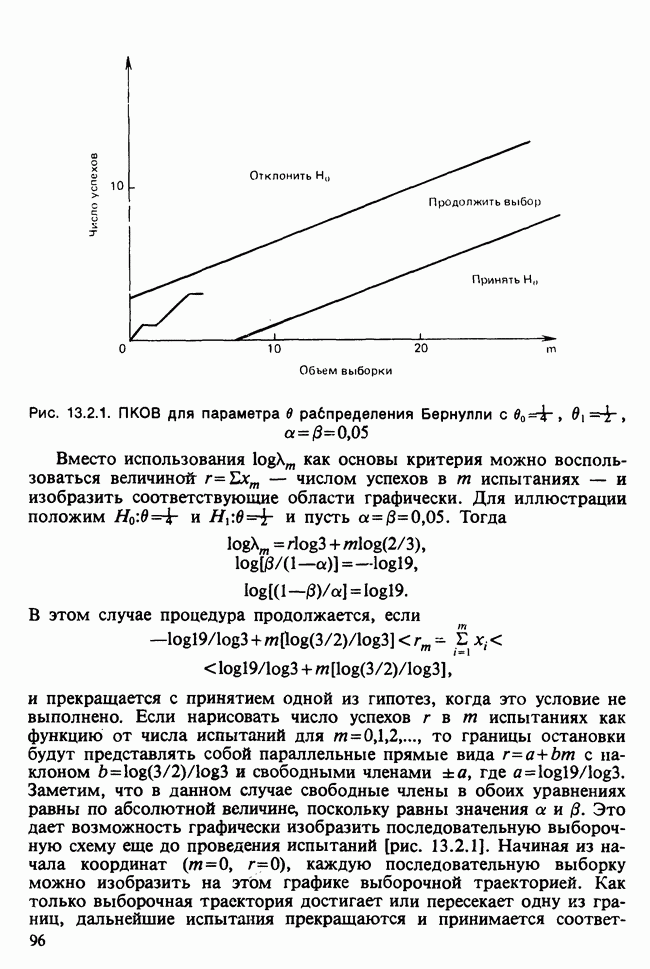
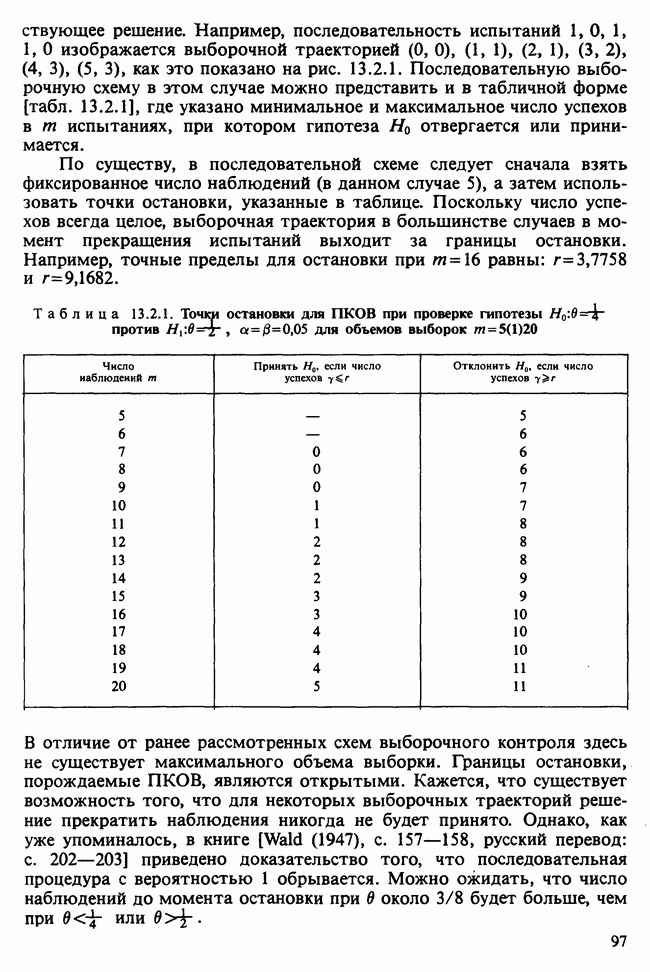
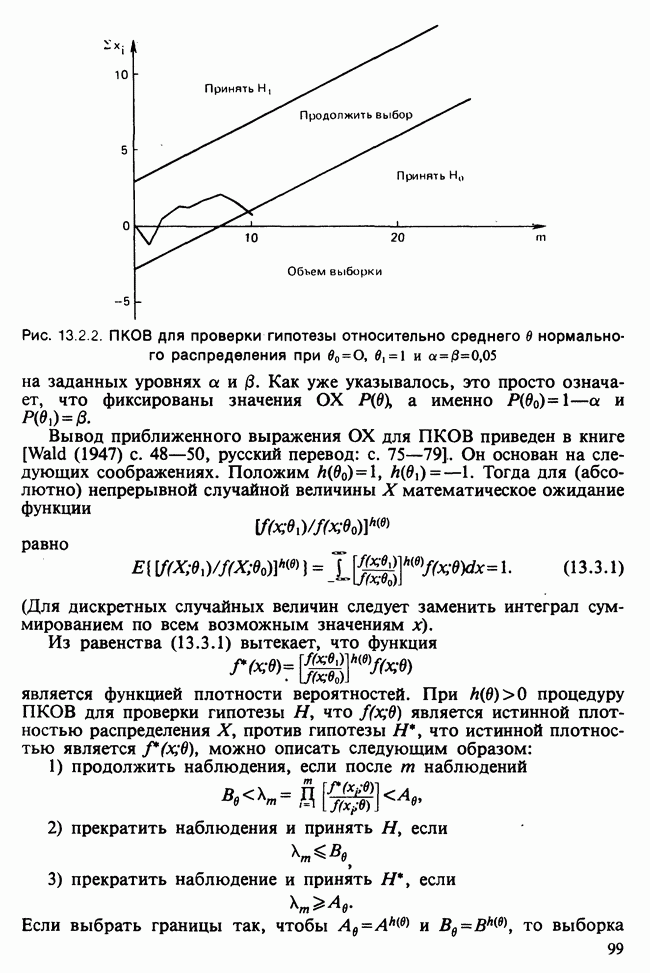
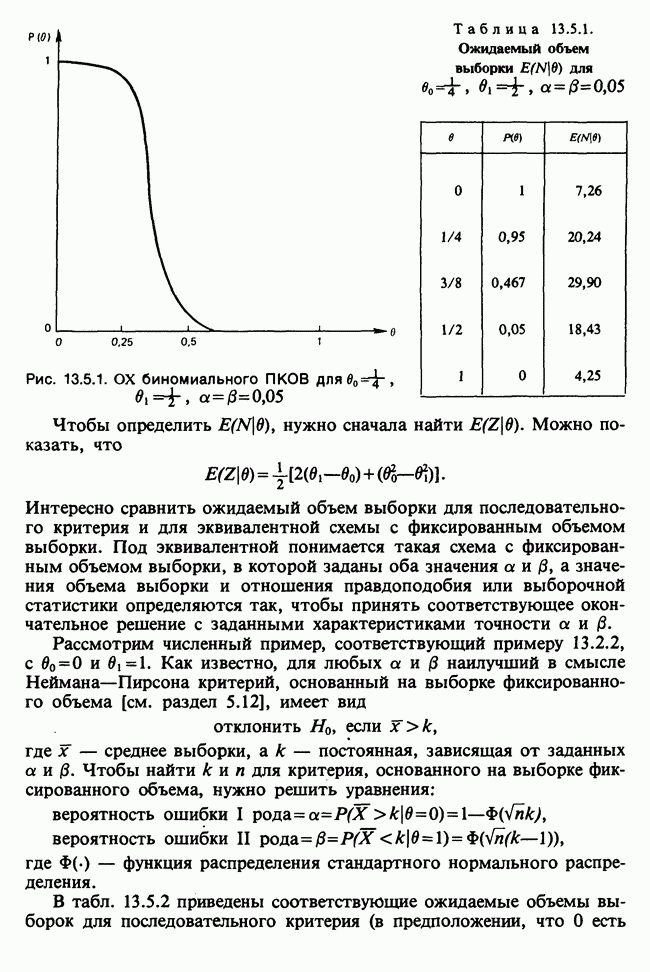
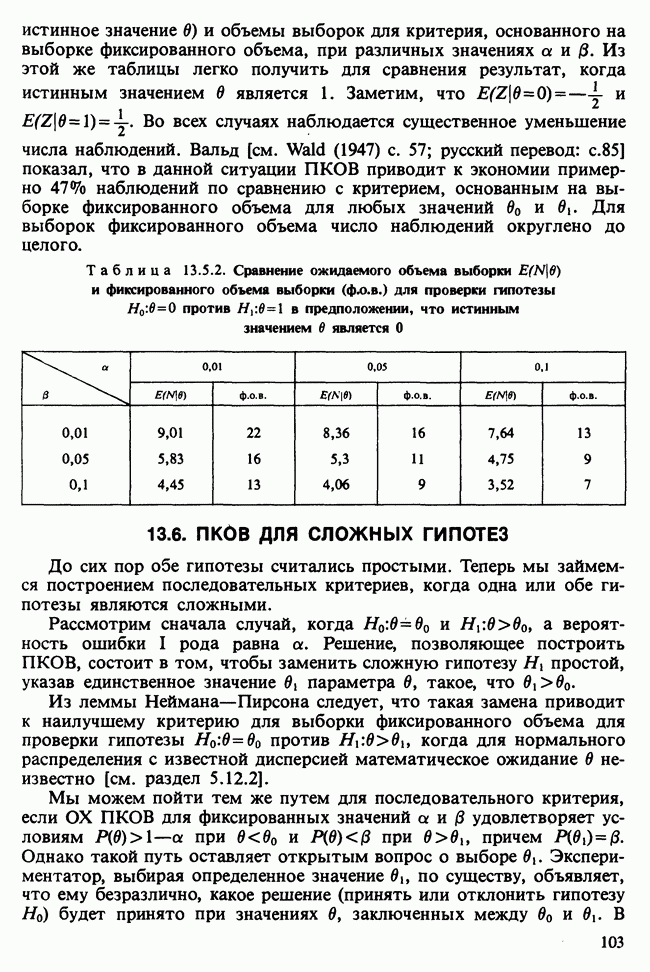
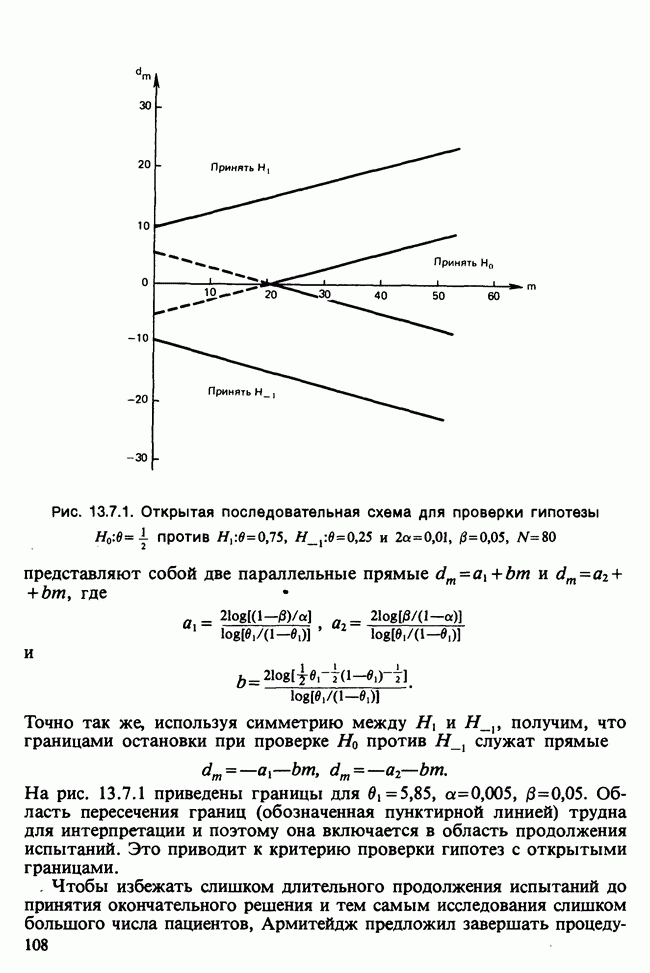
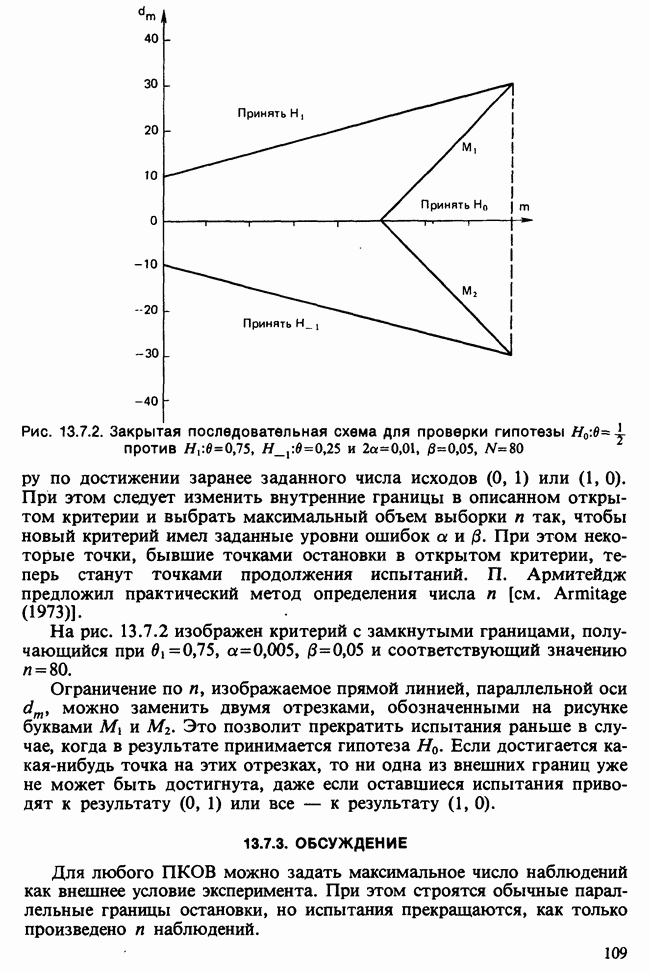
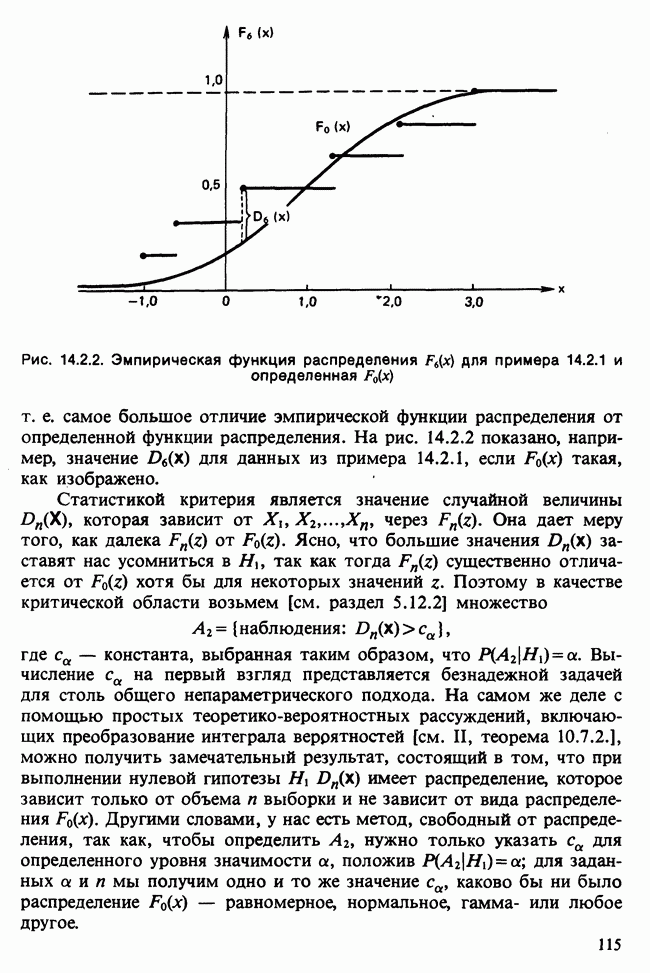
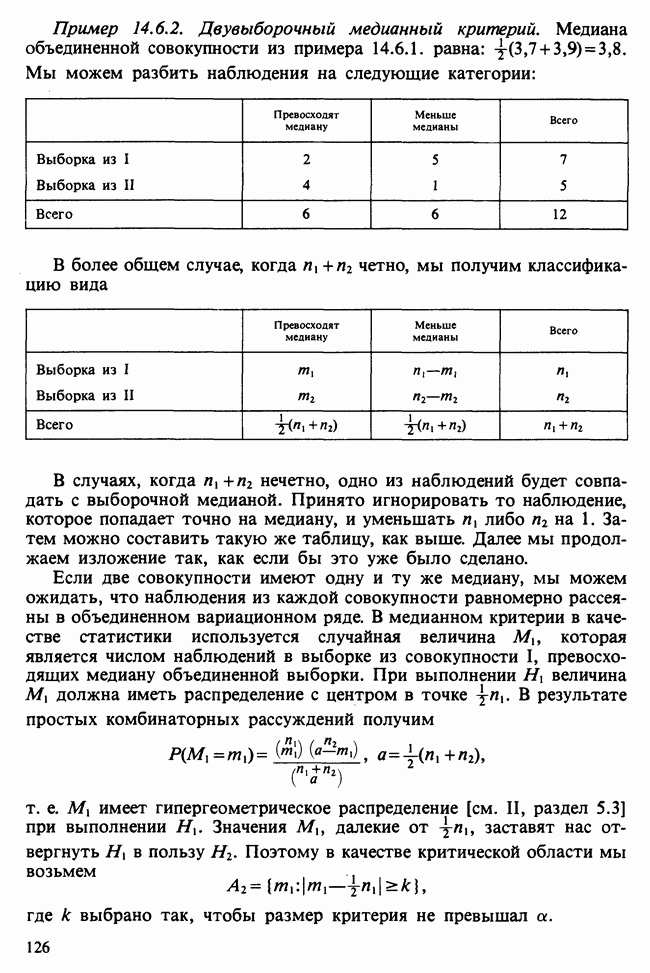
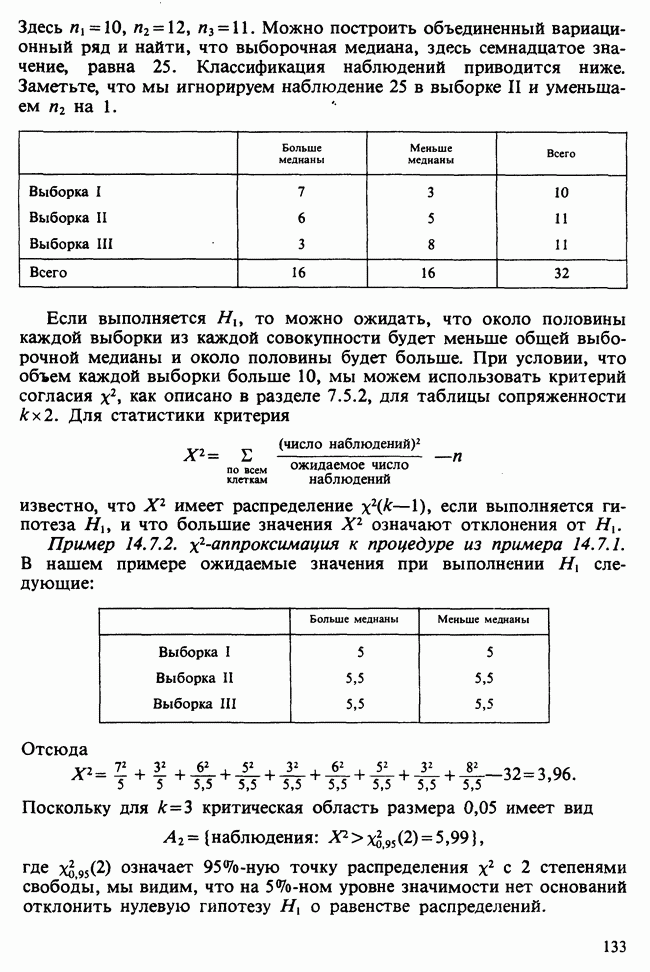
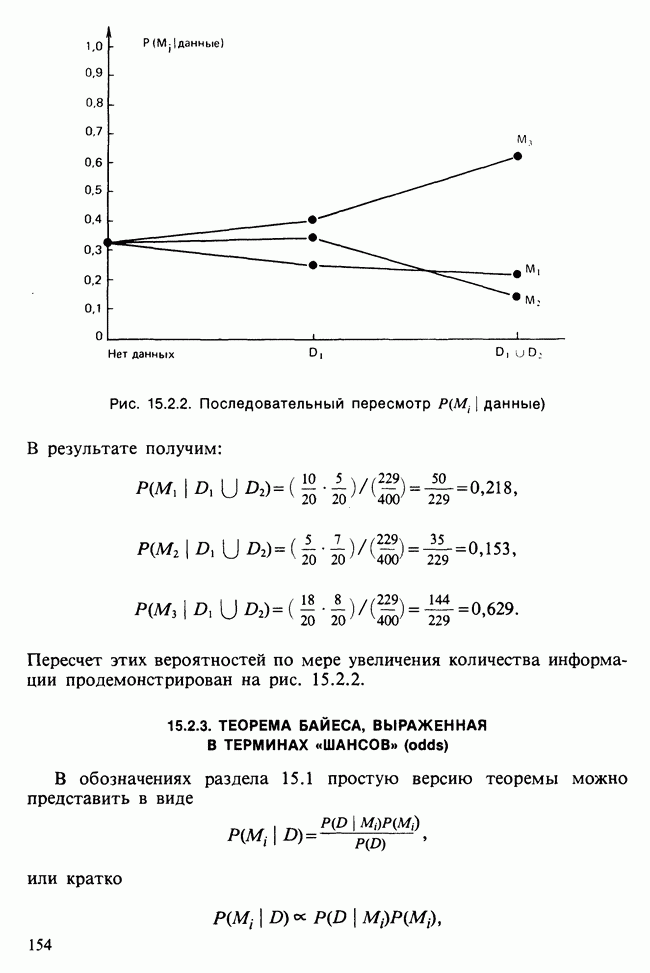
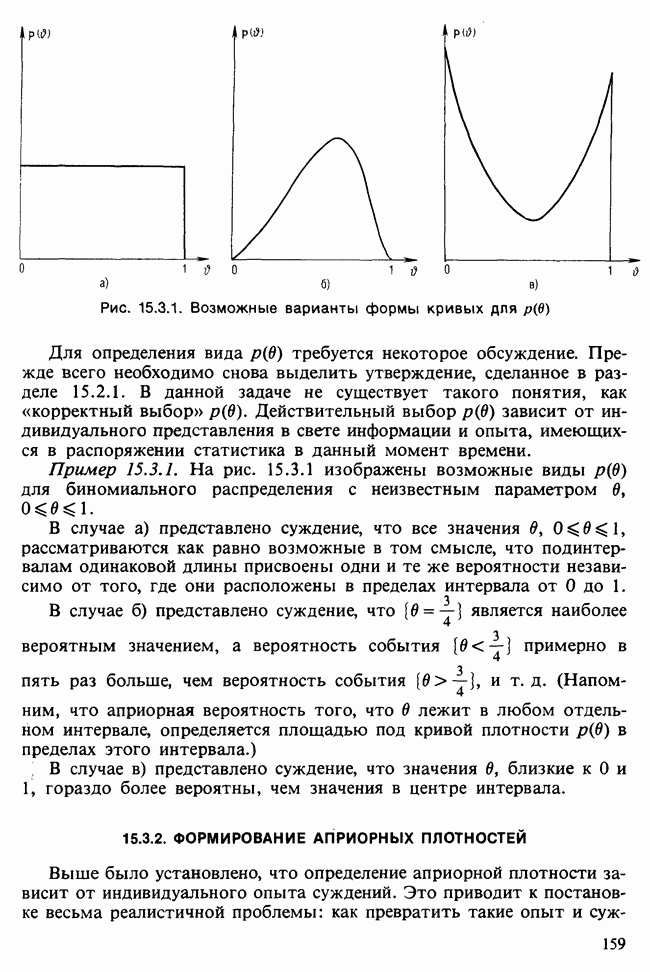
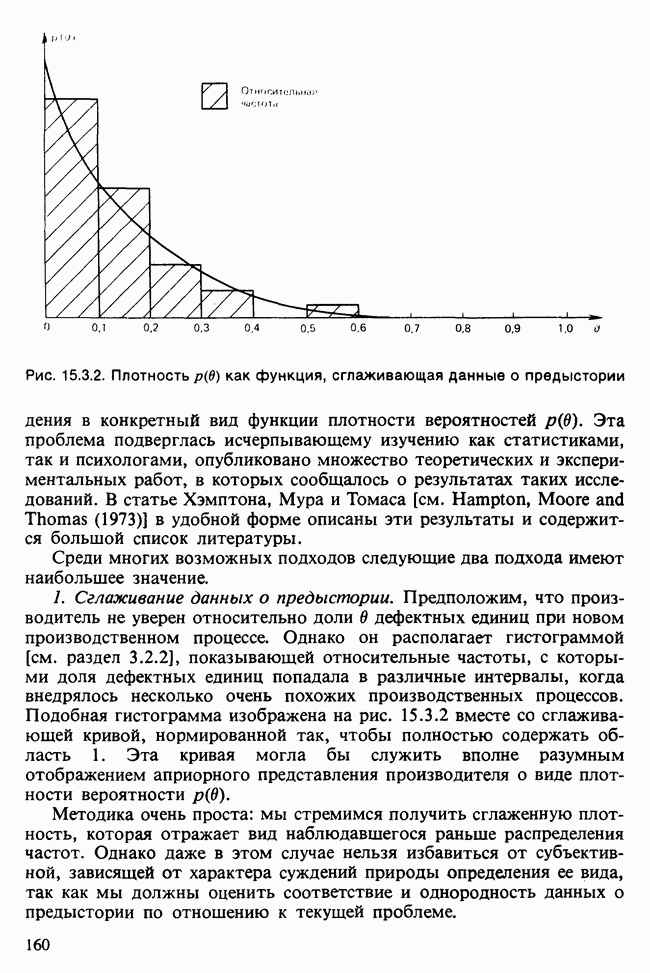
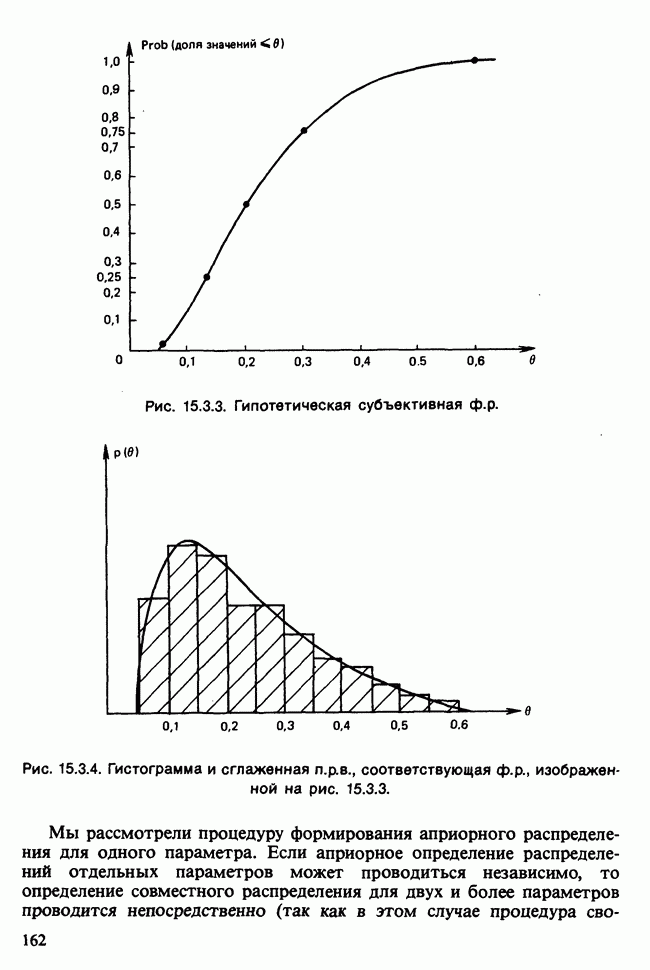
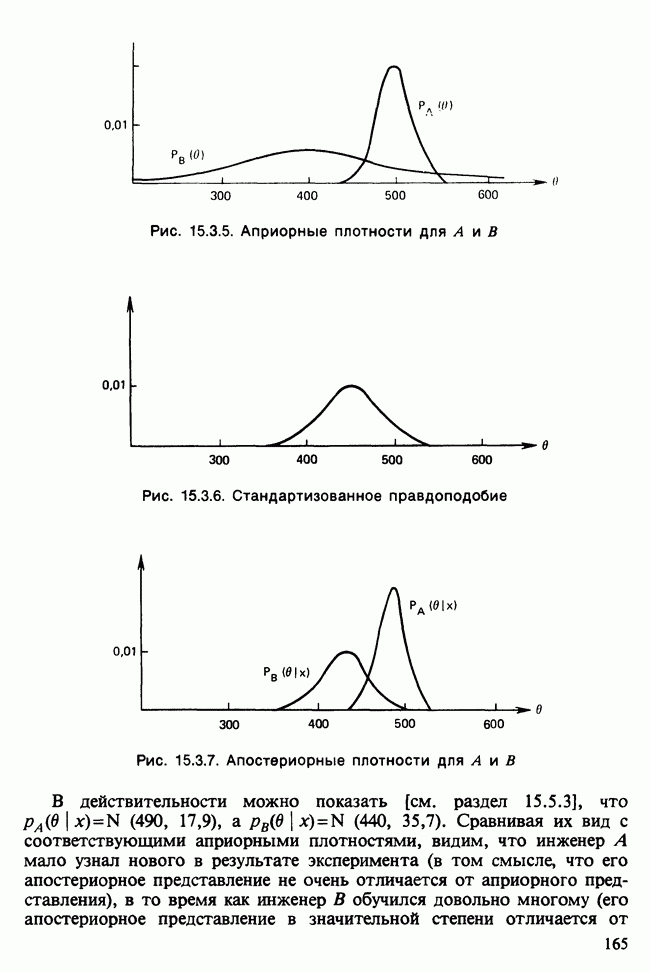
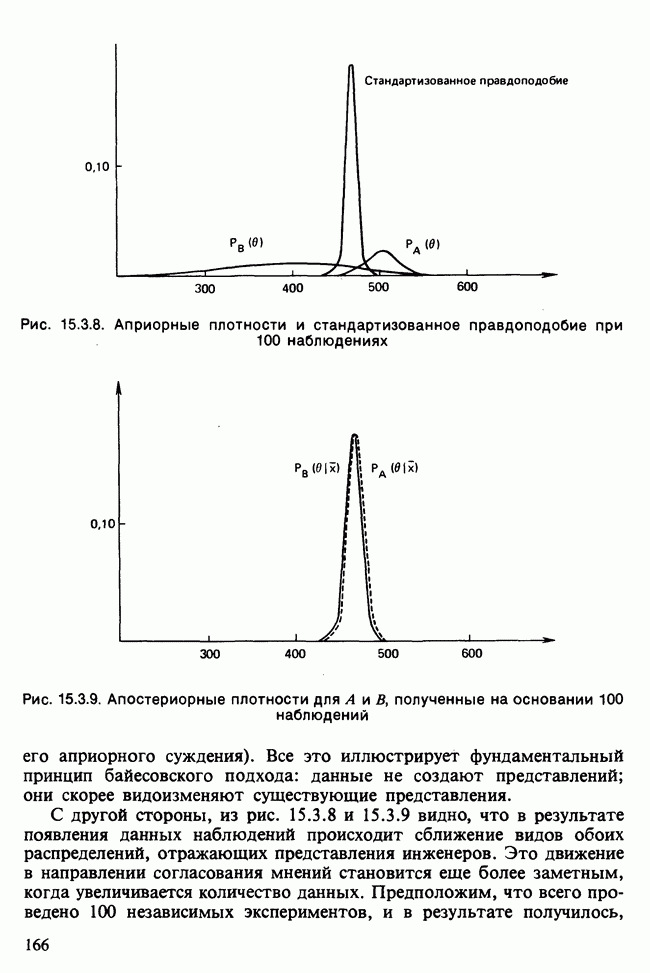
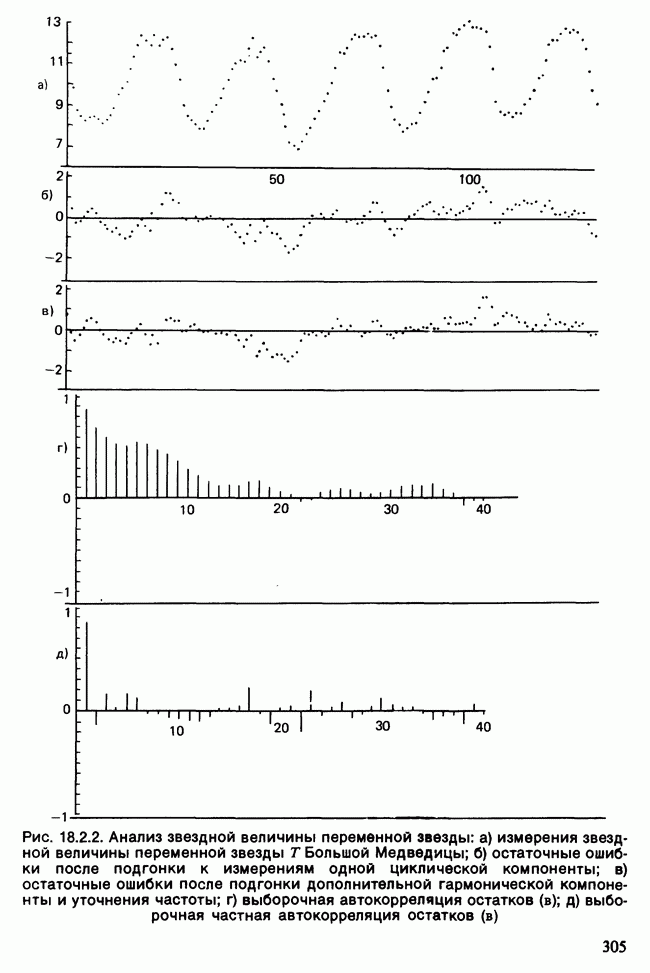
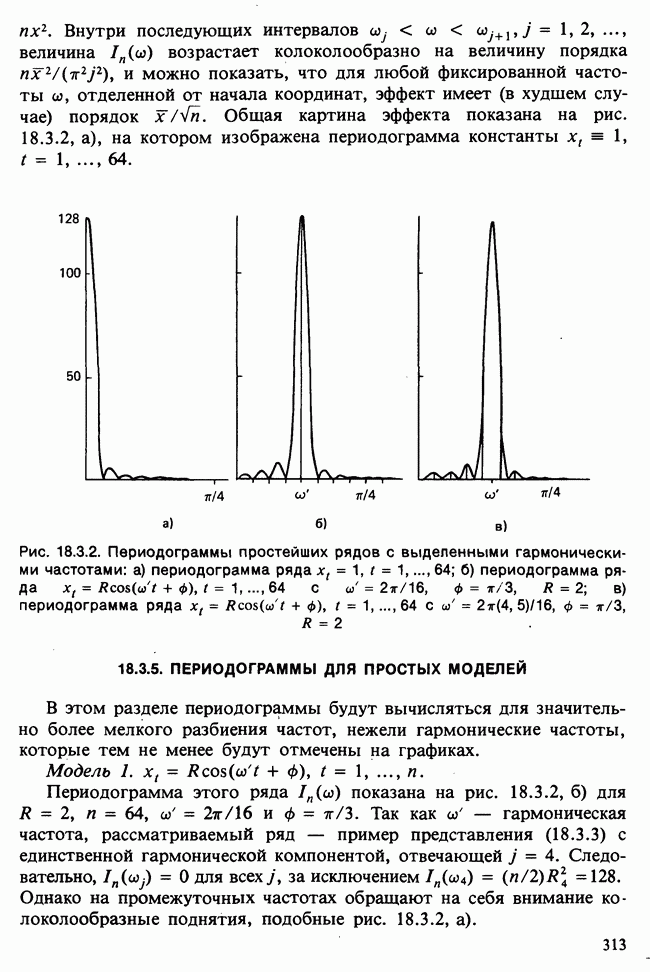
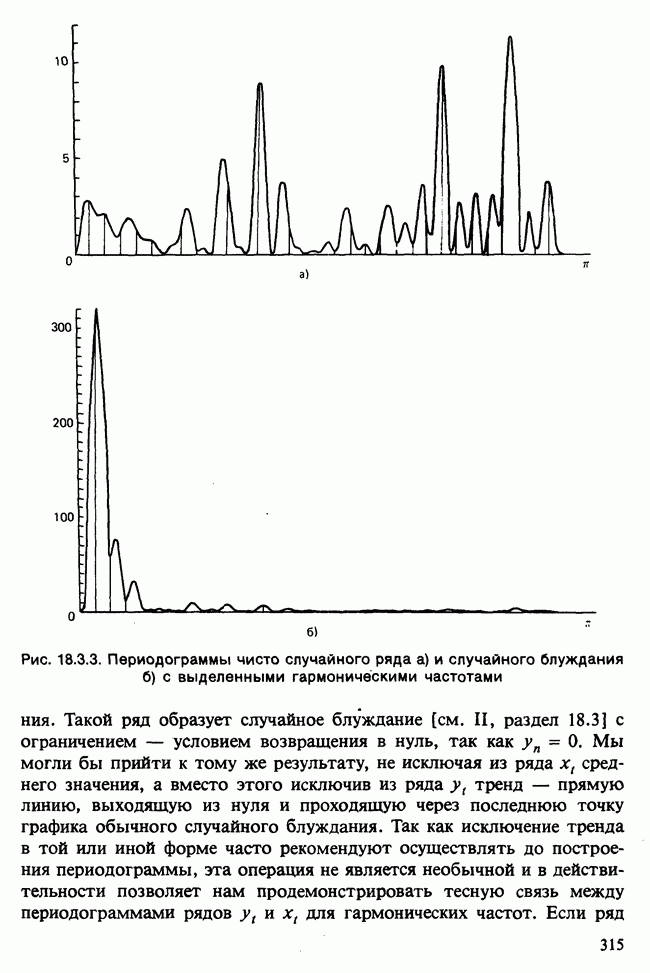
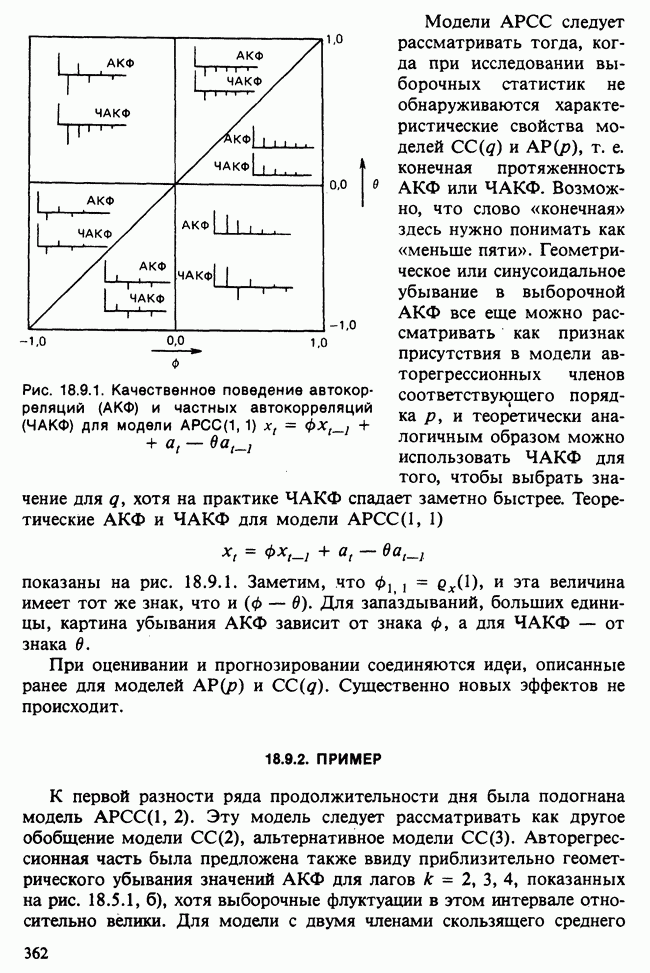
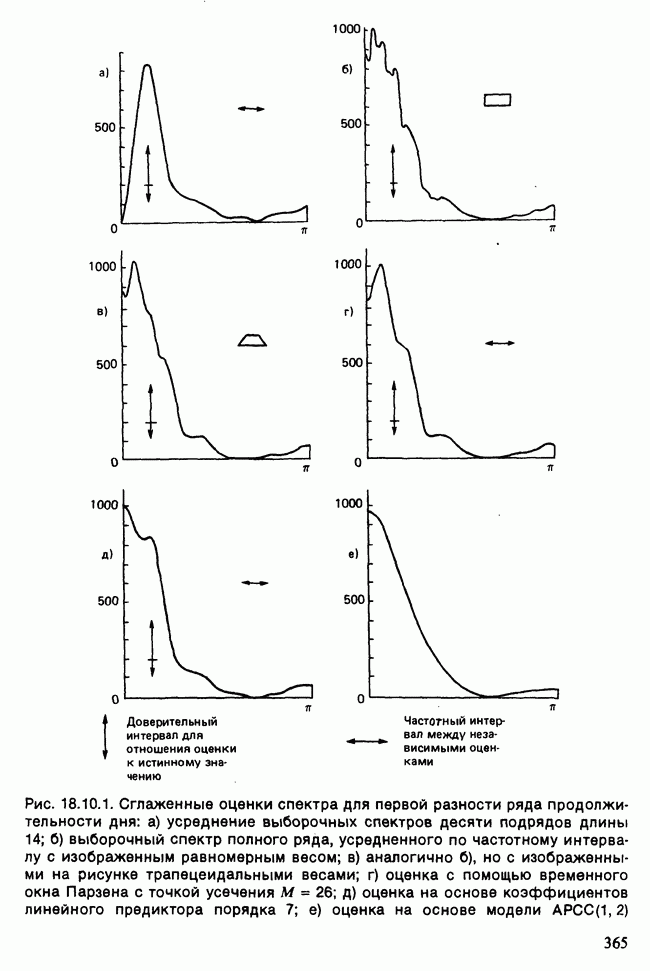
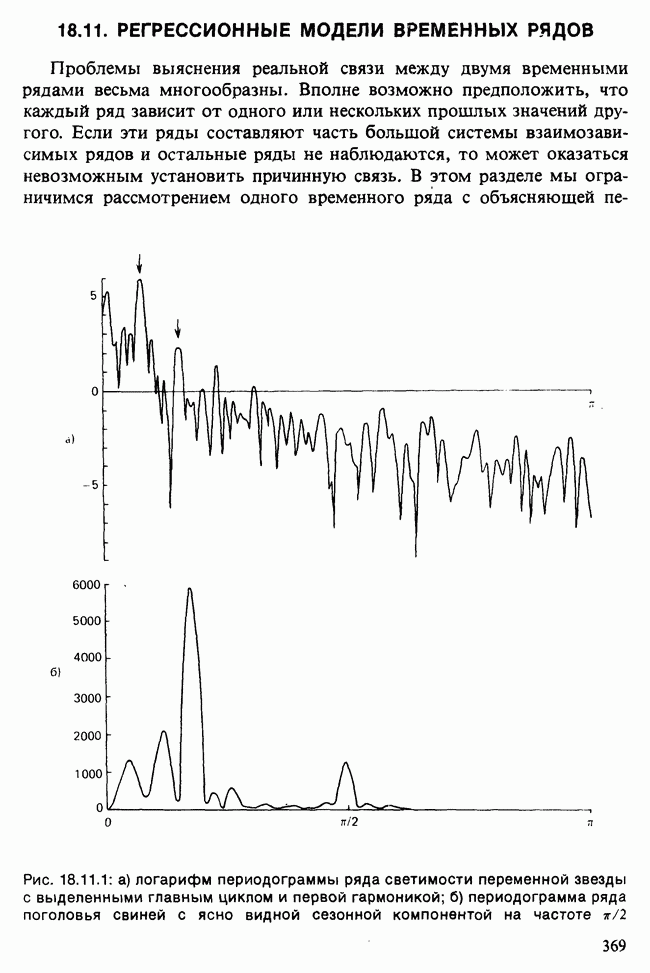
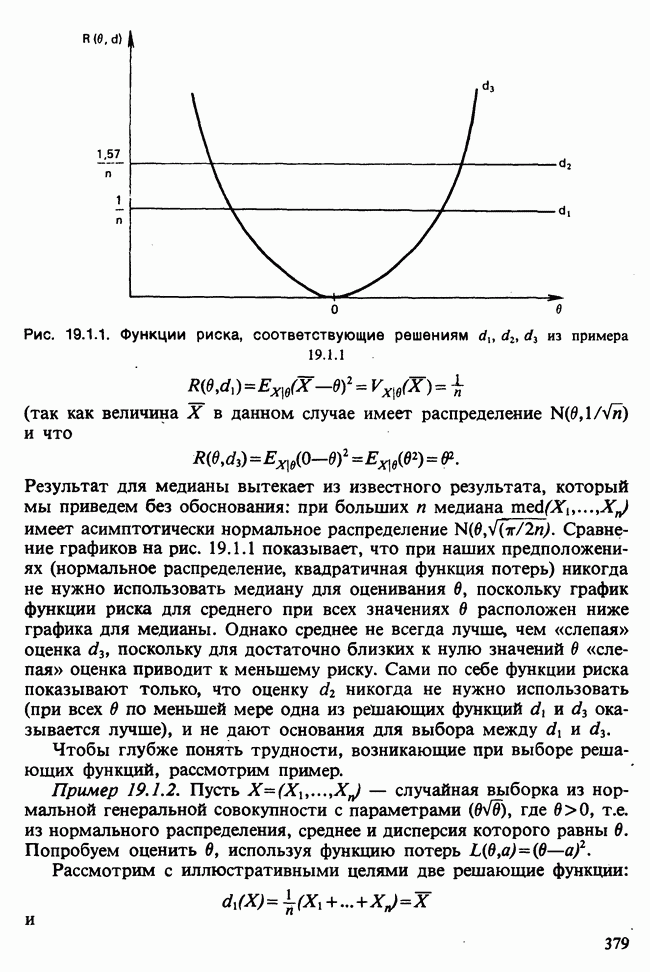
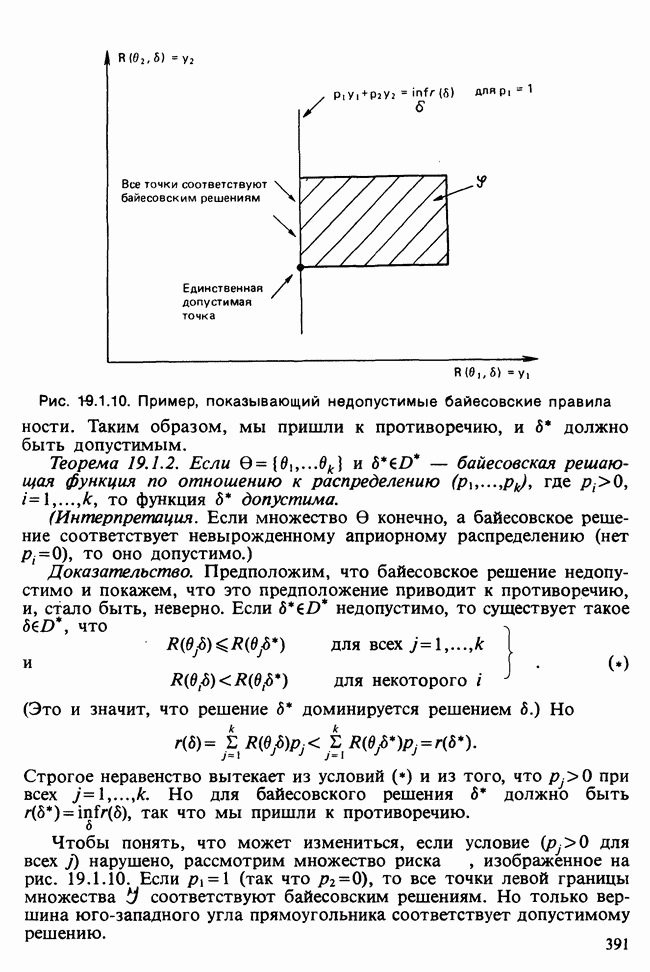
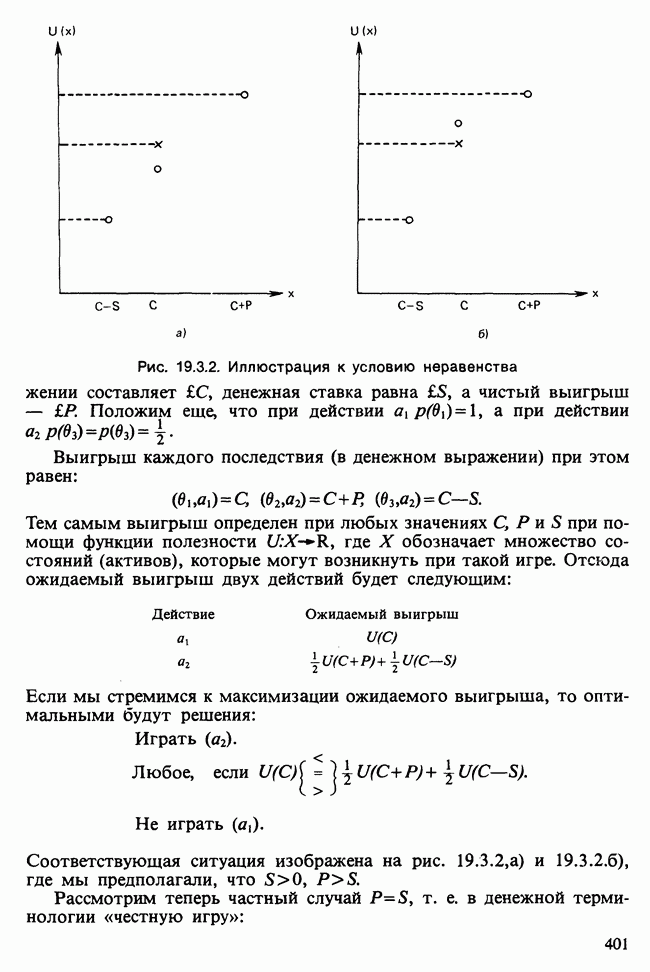
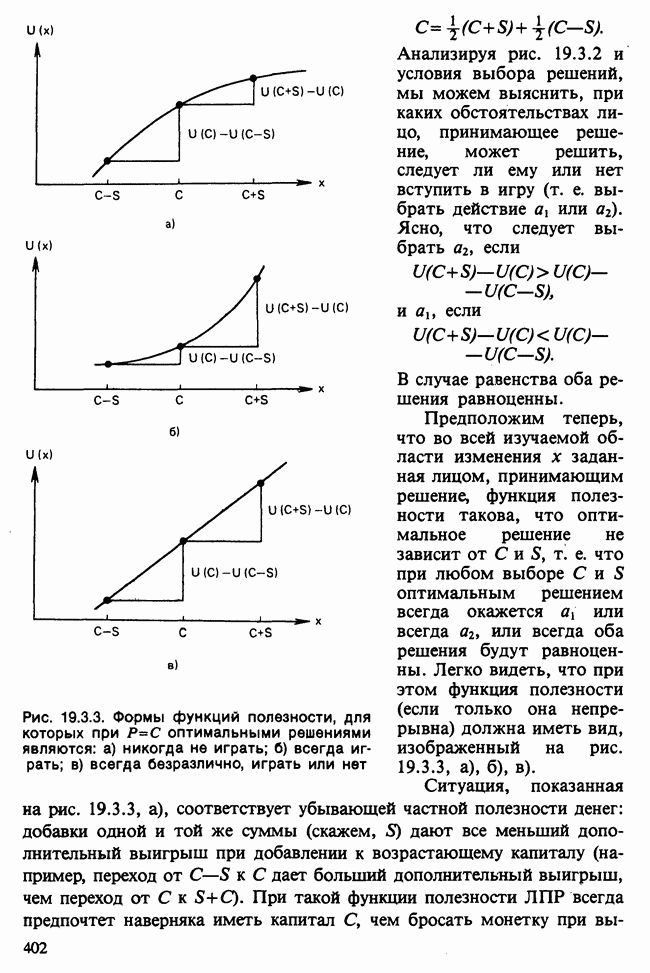
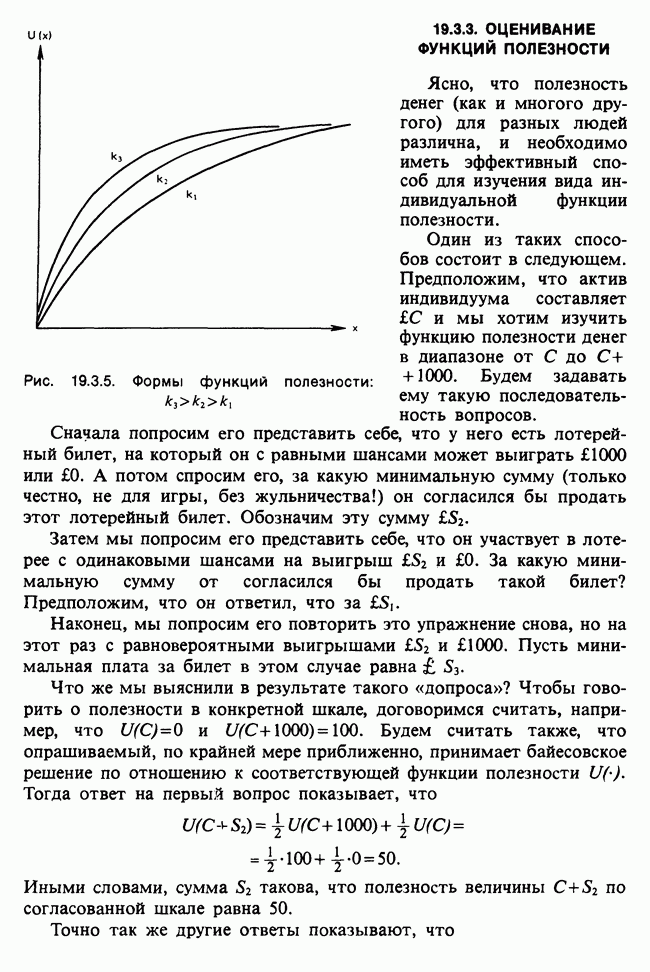
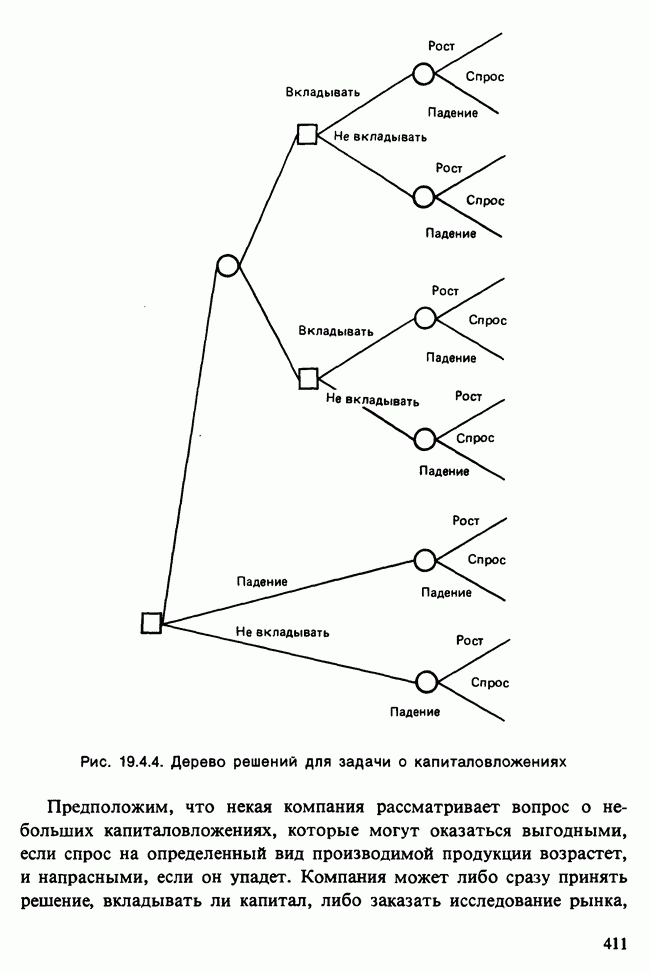
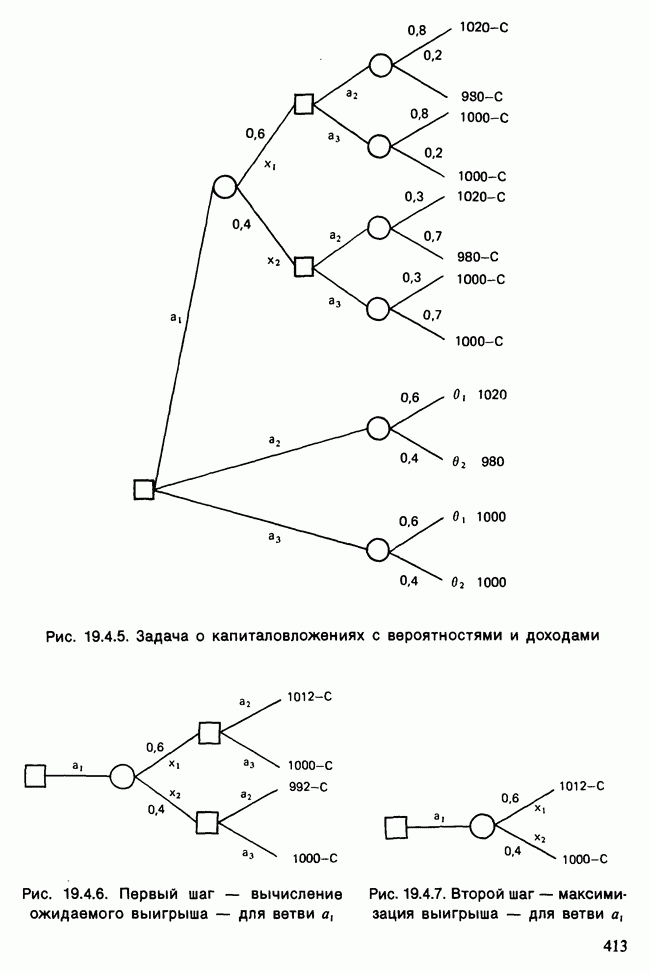
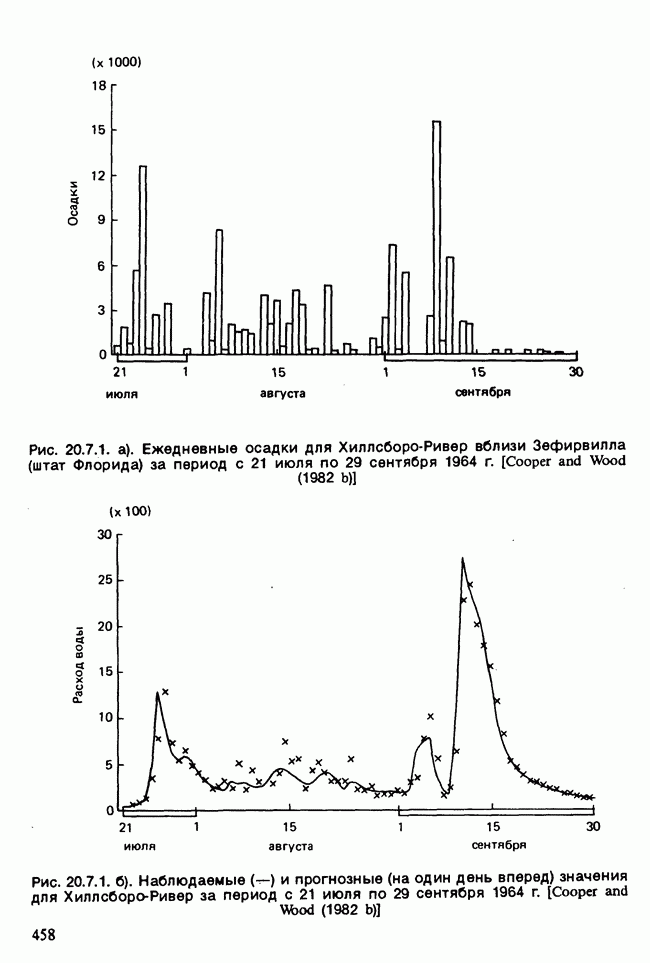
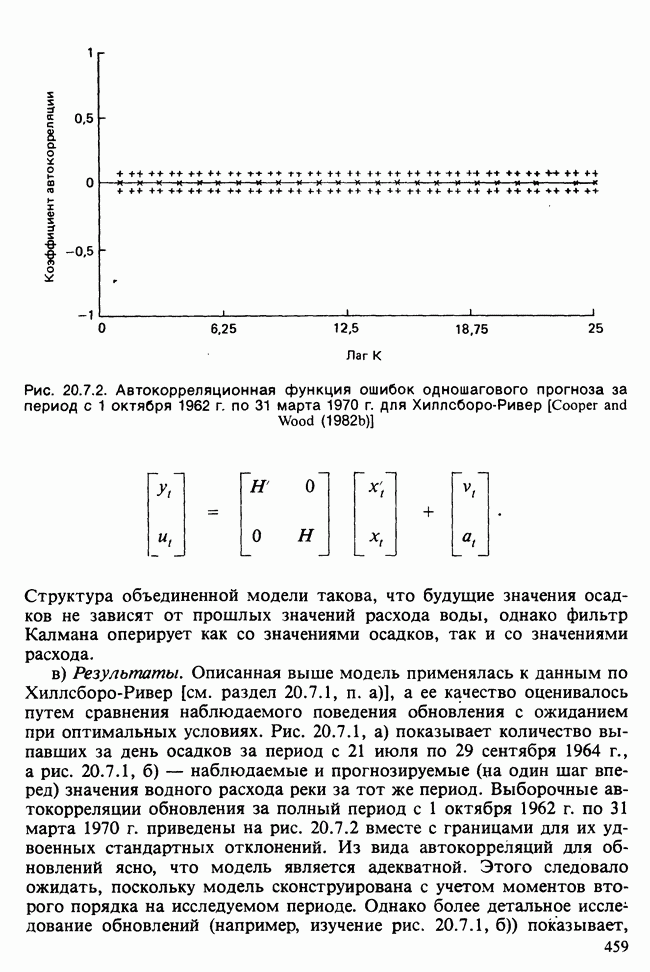
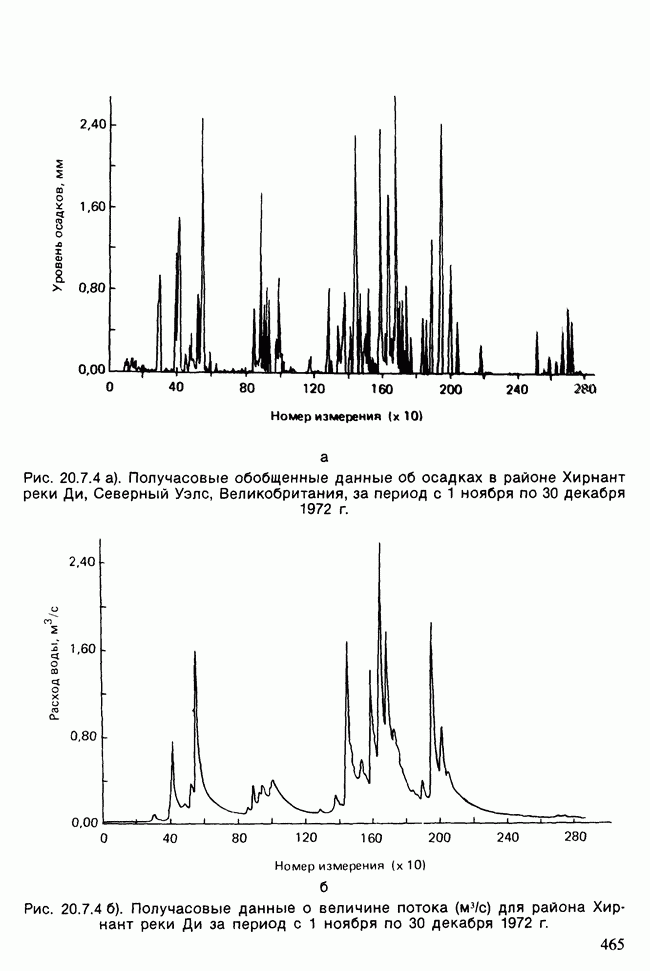
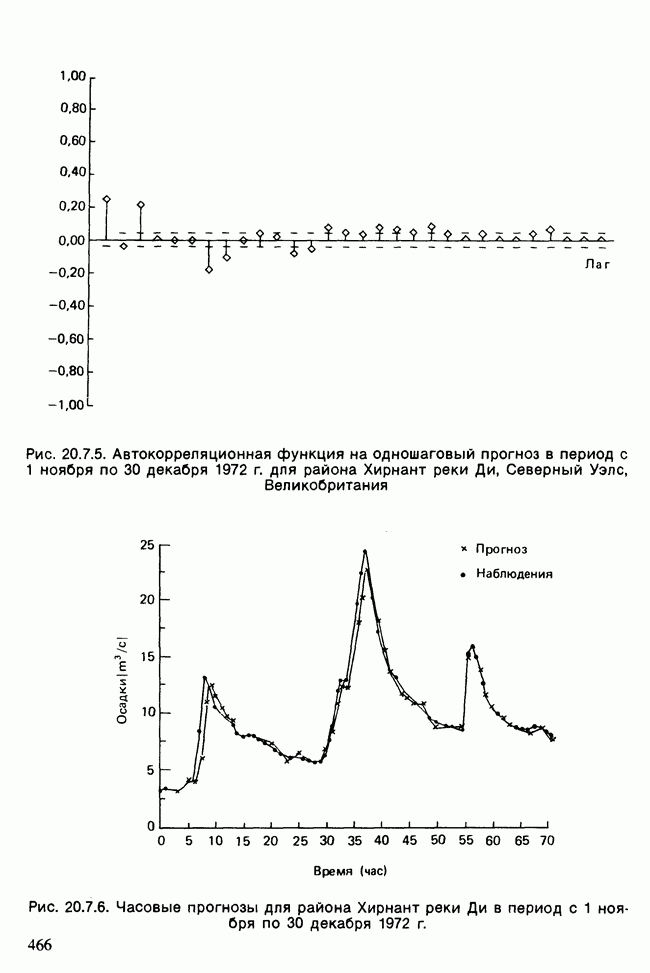
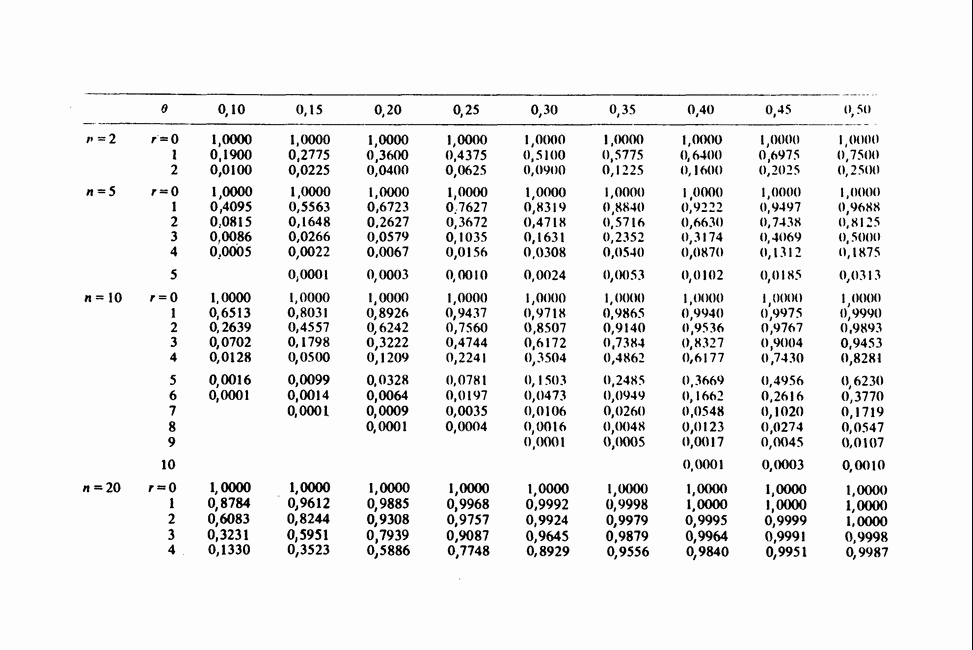
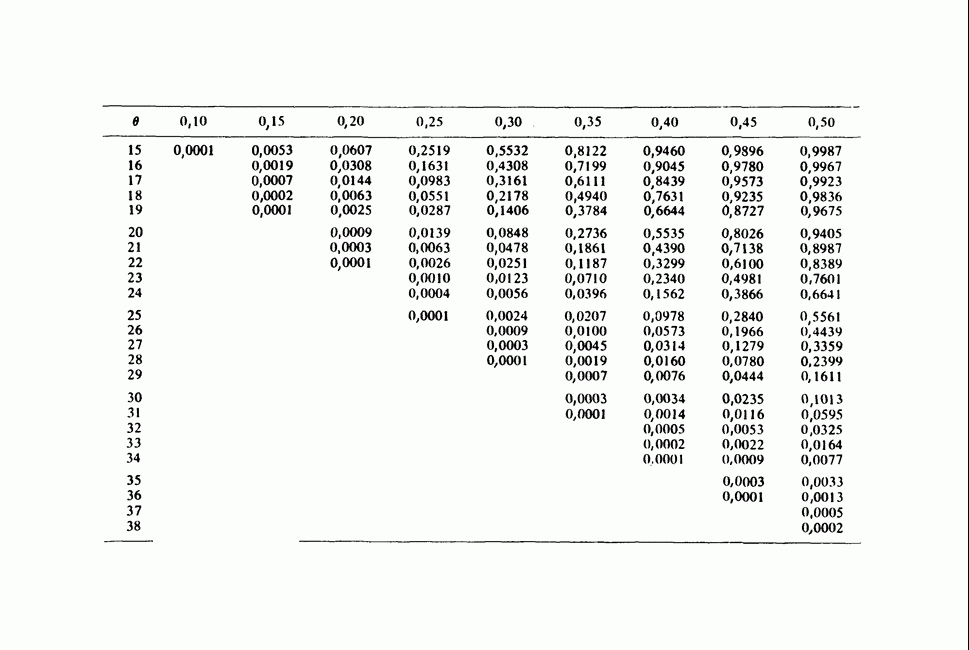
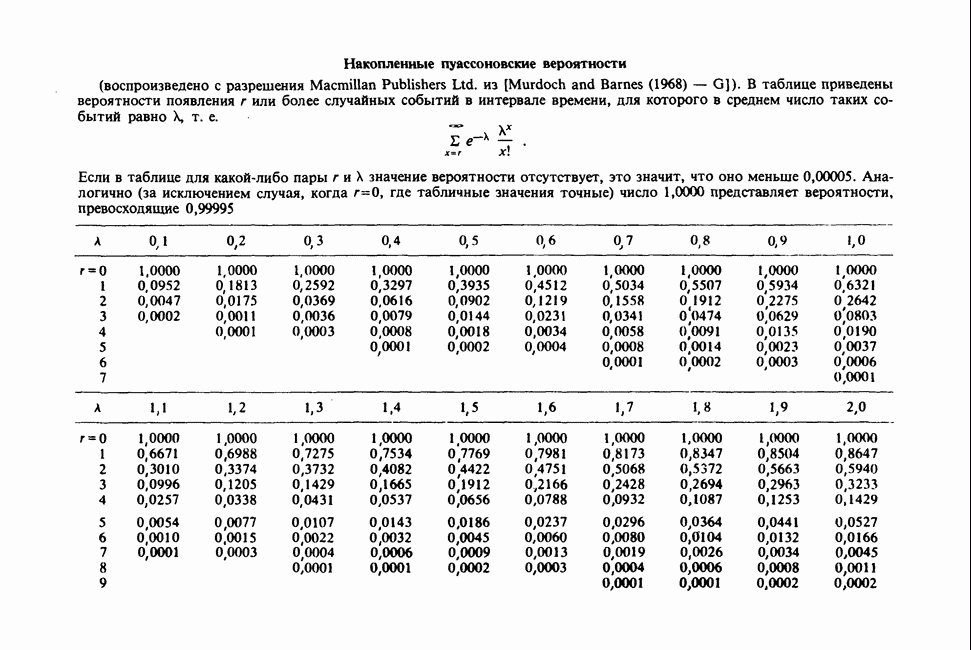
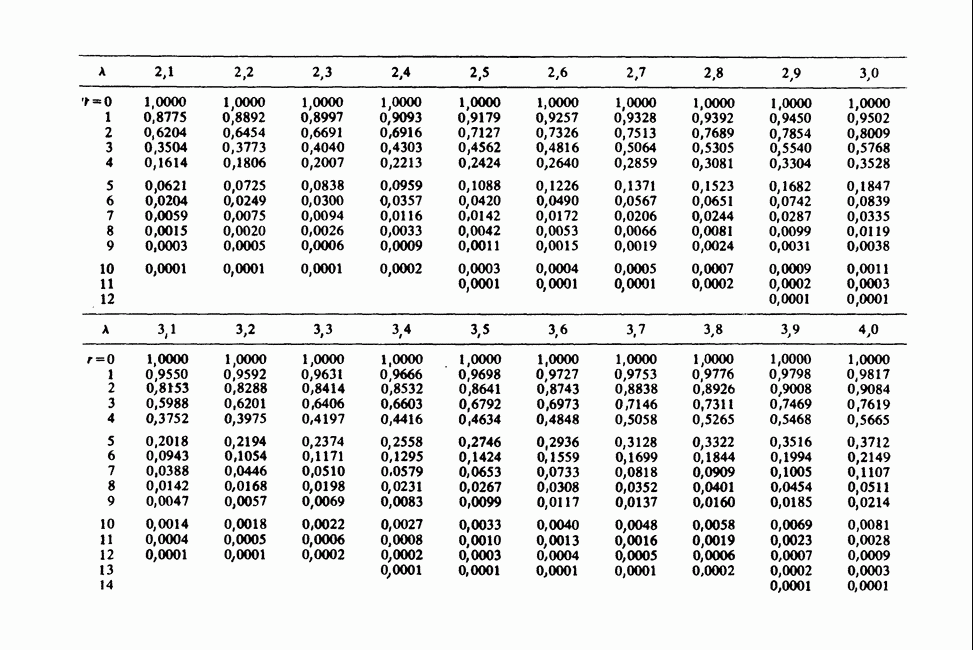
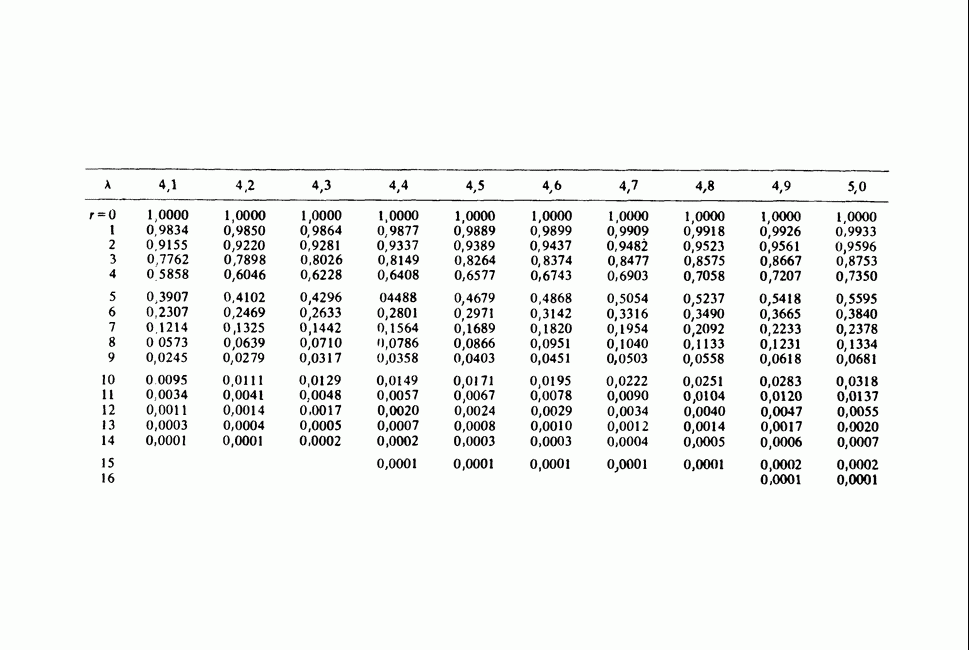
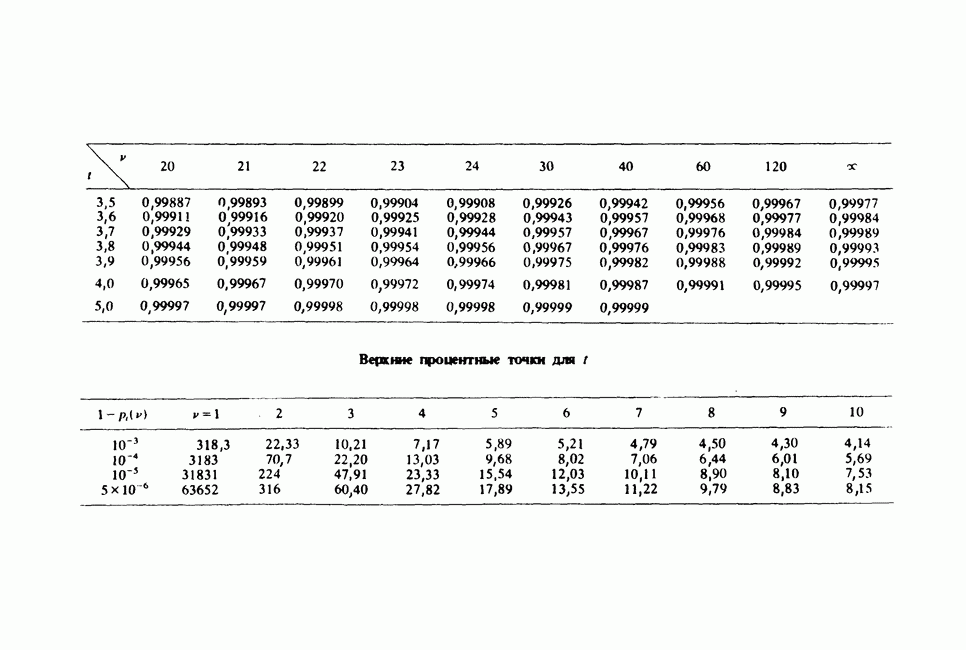
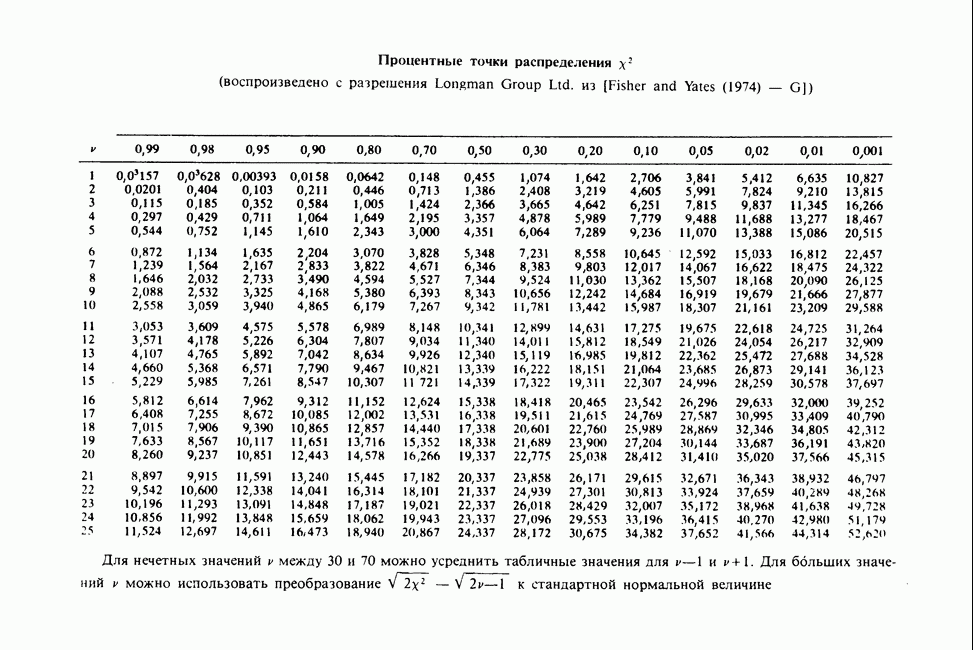
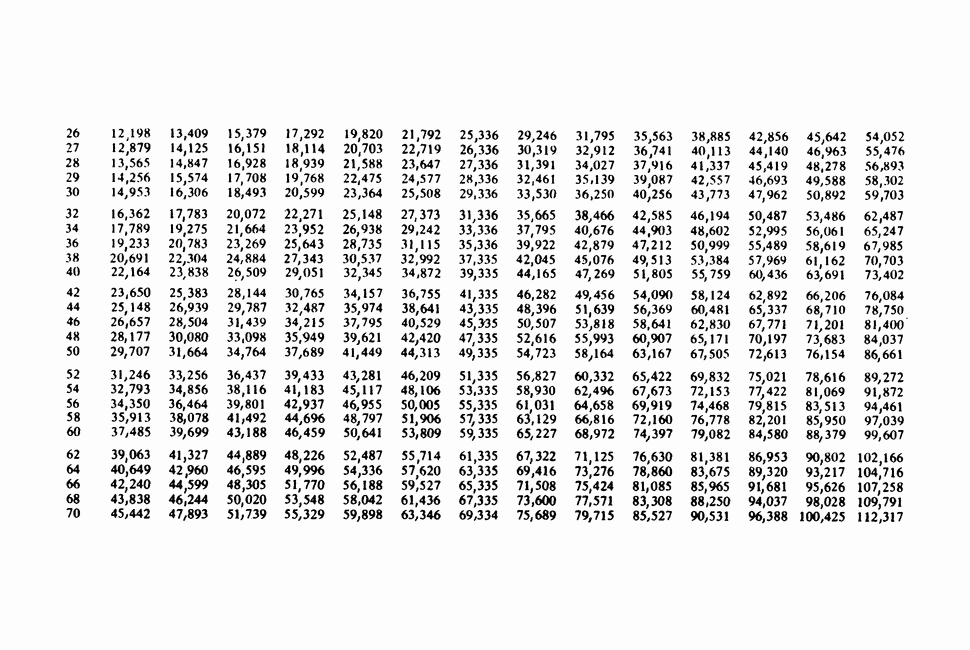
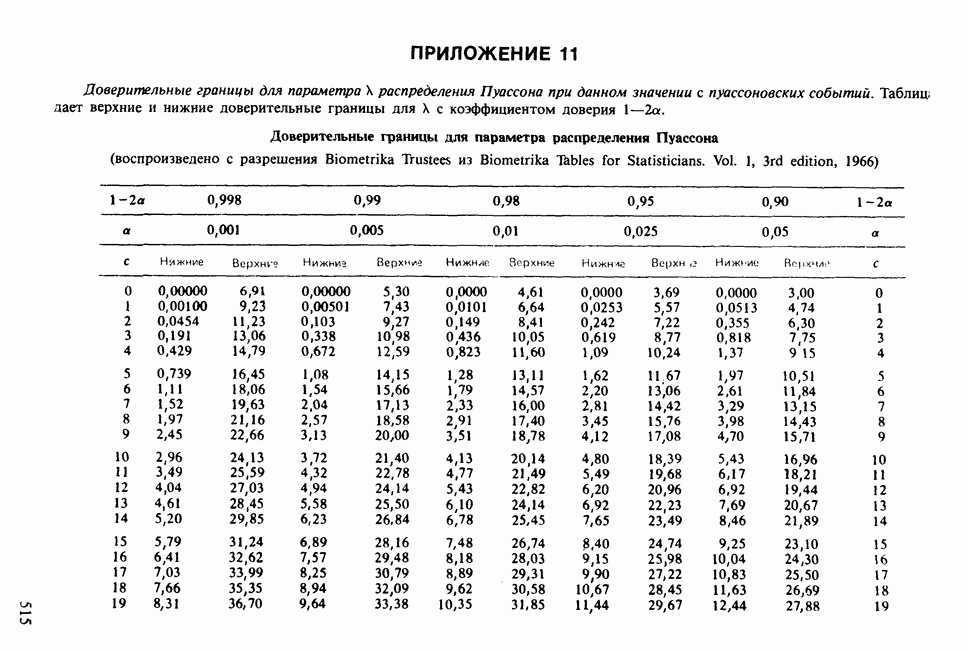
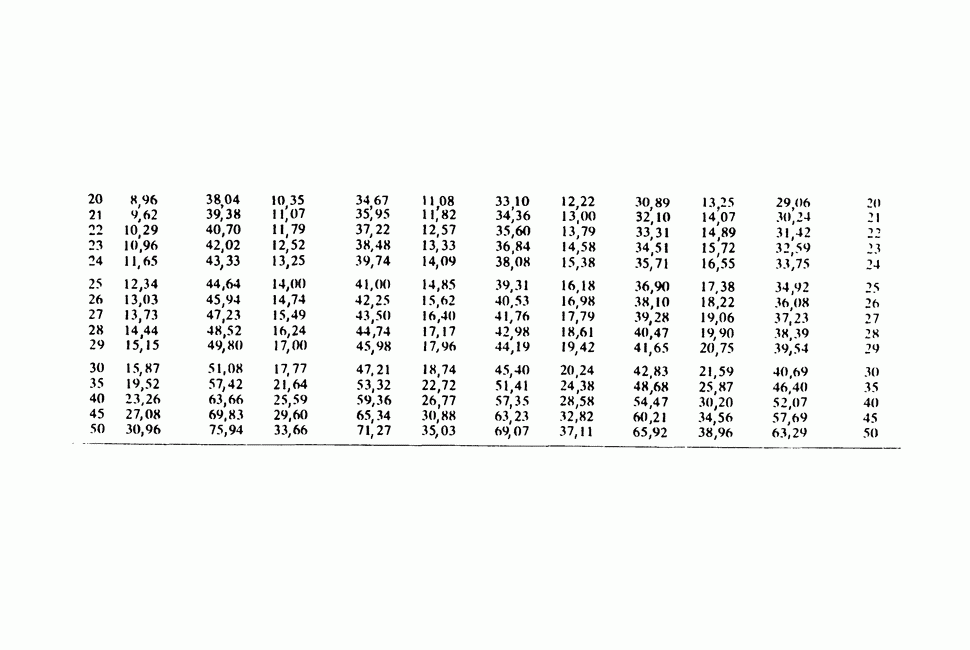Глава 11. ЛИНЕЙНЫЕ МОДЕЛИ I
11.1. ОПИСАНИЕ МОДЕЛИ
Одна из задач науки состоит в изучении отношений между переменными. Простейшим из отношений является линейное, которое состоит в том, что возрастание значения одной из переменных на единицу измерения обязательно влечет за собой изменение другой переменной на соответствующую постоянную величину. Если бы измерения переменных были абсолютно точными и вполне доступными, в статистическом анализе не было бы особой необходимости. Но так как измерения подвержены ошибкам и обладают определенной стоимостью, то изучение отношений между переменными проводится в условиях неопределенности и приближенности. Статистическая теория линейных моделей — область прикладной математики, развитие которой стимулировалось потребностями ученых, работающих в области экономики, биологии и во многих других областях. Начало теории линейной регрессии было положено Гальтоном в процессе изучения проблем наследственности. Методы дисперсионного анализа [см. гл. 8] появились в 20-х годах нашего столетия в связи с исследованиями, направленными на повышение урожайности сельскохозяйственных культур. Лог-линейные модели, применяемые в количественном анализе и для обработки качественных данных медицинской и социальной статистики, были развиты в 60-х годах. Все перечисленные виды анализа основаны на теории обобщенных линейных моделей.
Конструкция линейной модели есть некоторая попытка описать линейные отношения в условиях неопределенности. Эта конструкция включает несколько компонентов.
Обозначим переменные через  и пусть мы хотим выбрать оптимальную линейную комбинацию переменных
и пусть мы хотим выбрать оптимальную линейную комбинацию переменных  (объясняющих переменных) для наилучшей аппроксимации
(объясняющих переменных) для наилучшей аппроксимации 
Спецификация линейной модели включает:
1) функцию плотности вероятности для У;
2) параметр этой функции плотности, который линейно зависит от  (линейный предиктор);
(линейный предиктор);
3) набор наблюдений над переменными (данные);
4) выборочную модель для наблюдения.
Спецификация функции плотности и линейный предиктор определяют вероятностную модель для  Если бы оптимальная линейная комбинация объясняющих переменных стала известной, то статистическая работа была бы завершена, а модель оказалась бы готовой для использования. Однако обычно данные 3) и способ, которым они были собраны, предоставляют только возможность сформулировать 4), средство оценить линейный предиктор и проверить предположения, сделанные относительно функции плотности и ее связи с линейным предиктором.
Если бы оптимальная линейная комбинация объясняющих переменных стала известной, то статистическая работа была бы завершена, а модель оказалась бы готовой для использования. Однако обычно данные 3) и способ, которым они были собраны, предоставляют только возможность сформулировать 4), средство оценить линейный предиктор и проверить предположения, сделанные относительно функции плотности и ее связи с линейным предиктором.
Когда вероятностная модель полностью известна, она может быть применена для нескольких целей: для предсказания наиболее вероятного значения или интервалов значений для  при заданных значениях
при заданных значениях  для оценки относительного влияния одной из этих переменных, скажем
для оценки относительного влияния одной из этих переменных, скажем  на
на  для определения комбинаций значений объясняющих переменных, которые дают возрастание величины
для определения комбинаций значений объясняющих переменных, которые дают возрастание величины  на некоторое фиксированное значение по отношению к среднему значению
на некоторое фиксированное значение по отношению к среднему значению  для сравнения отношения между
для сравнения отношения между  и некоторым подмножеством объясняющих переменных с отношением для другого подмножества объясняющих переменных.
и некоторым подмножеством объясняющих переменных с отношением для другого подмножества объясняющих переменных.
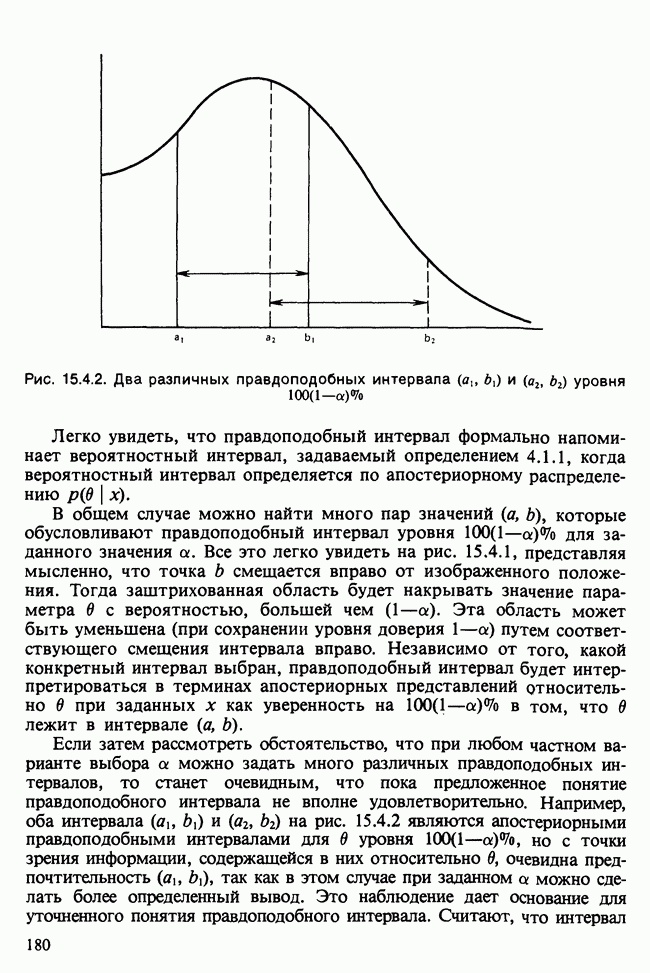
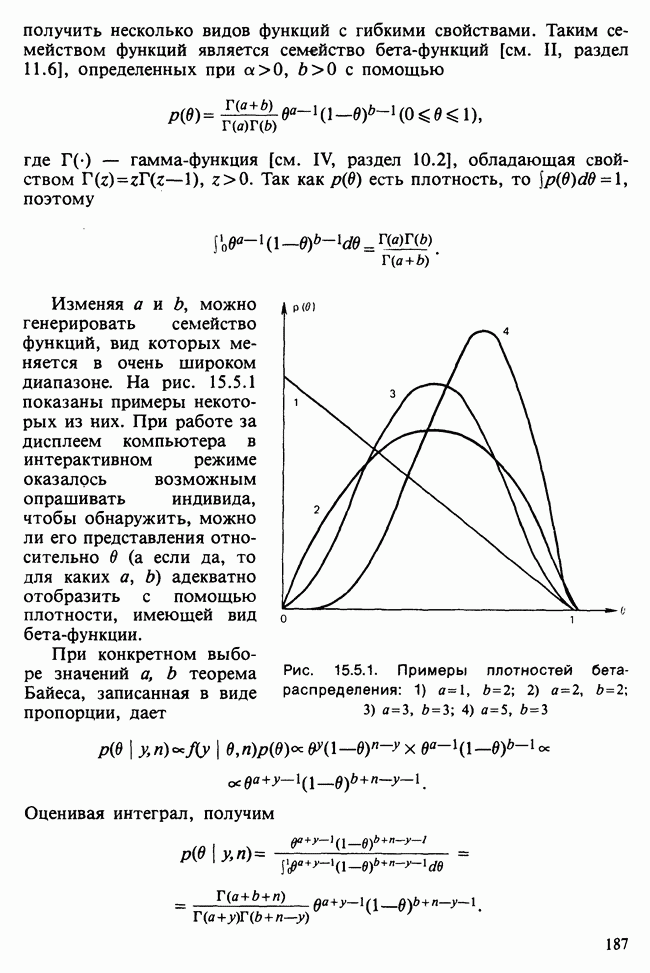
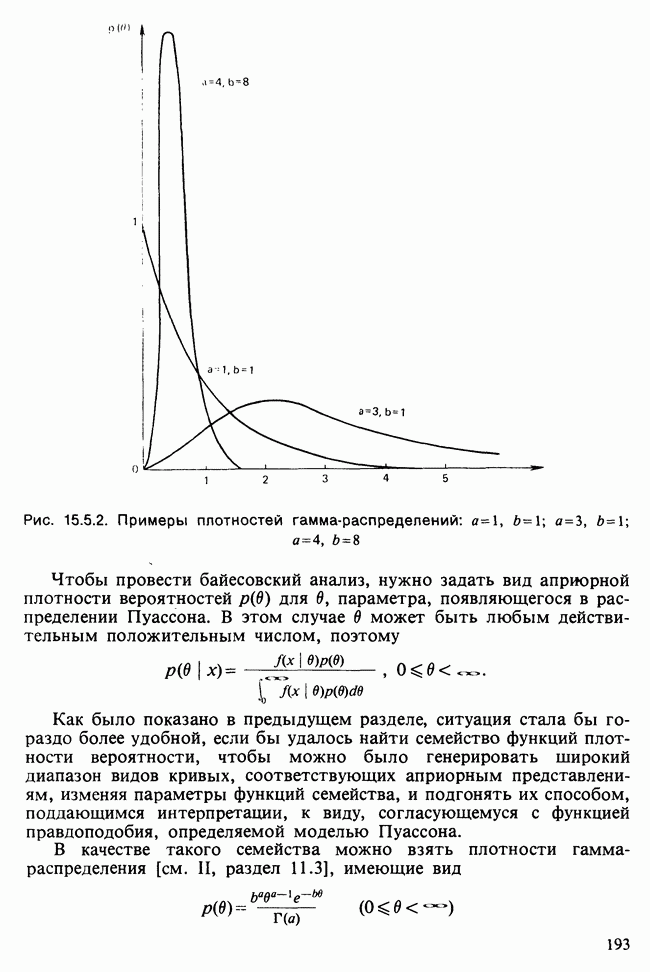
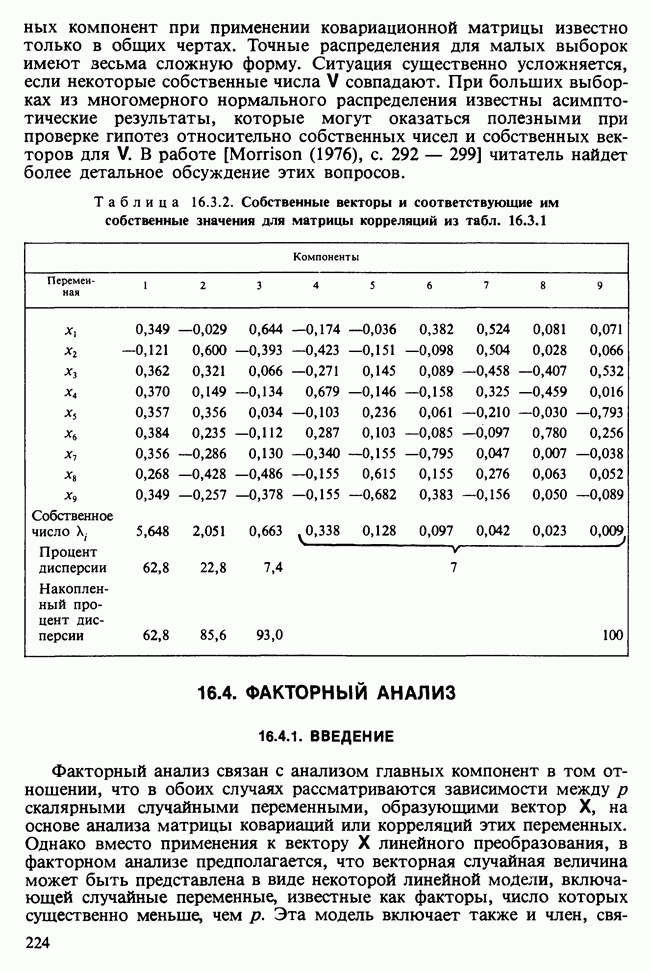
Когда модель определена по наблюдаемым данным посредством предположений, оценок, тестирований и проверок [см. гл. 1], она может служить также сжатым описанием данных и сглаженной их версией, где случайные выбросы подавлены.
Вероятностная модель описана в разделе 11.1, а ее база данных — в разделе 11.2. Дальнейшее рассмотрение моделей для регрессионного, дисперсионного и ковариационного анализа содержится в разделе 11.3, а таблицы сопряженности обсуждаются в разделе 11.4. Методы статистического вывода, основанные на функции правдоподобия [см. раздел 6.2.1], и аналогичные методы анализа обобщенных моделей являются наиболее распространенными. К методу наименьших квадратов, описанному в гл. 8, мы снова вернемся в разделе 12.1, а выборочные свойства оценок будут обсуждаться в разделе 12.2. Изучение этих проблем нам поможет в разделе 12.3 при анализе функции правдоподобия для линейной модели. Основная направленность гл. 11
— приложения, в то время как гл. 12 посвящена в основном теории.
В настоящей главе сделана попытка сконцентрировать внимание на запросах и возможностях ученого-практика. Абстрактные математические рассуждения представлены в сокращенном виде, а численные примеры служат для пояснений. Понятия вектора и векторного пространства введены в анализ линейных моделей, что обеспечивает достаточно мощный подход. Преимущество этого подхода состоит в том, что он позволяет унифицировать работу с моделями регрессионного, дисперсионного и ковариационного анализа, а также анализа таблиц сопряженностей, кратко описать модели в терминах векторных подпространств, избежать сложных формул, основанных на координатных обозначениях. Этот подход связывает линейные модели с многомерным анализом [см. гл. 16, 17], анализом временных рядов [см. гл. 18], планированием экспериментов [см. гл. 9].
Необходимые сведения из линейной алгебры содержатся в разделах 11.1.1 и 11.3.1.
Приведенные численные примеры иллюстрируют доказательства. Они не претендуют служить рецептами. Поскольку многие методы приводят к итеративным вычислительным процедурам, ожидается, что читатель имеет доступ к соответствующему программному обеспечению. Многие обозначения и выбор материала о линейных моделях связаны со статистическим пакетом GLIM [см. Baker and Nelder (1978)].