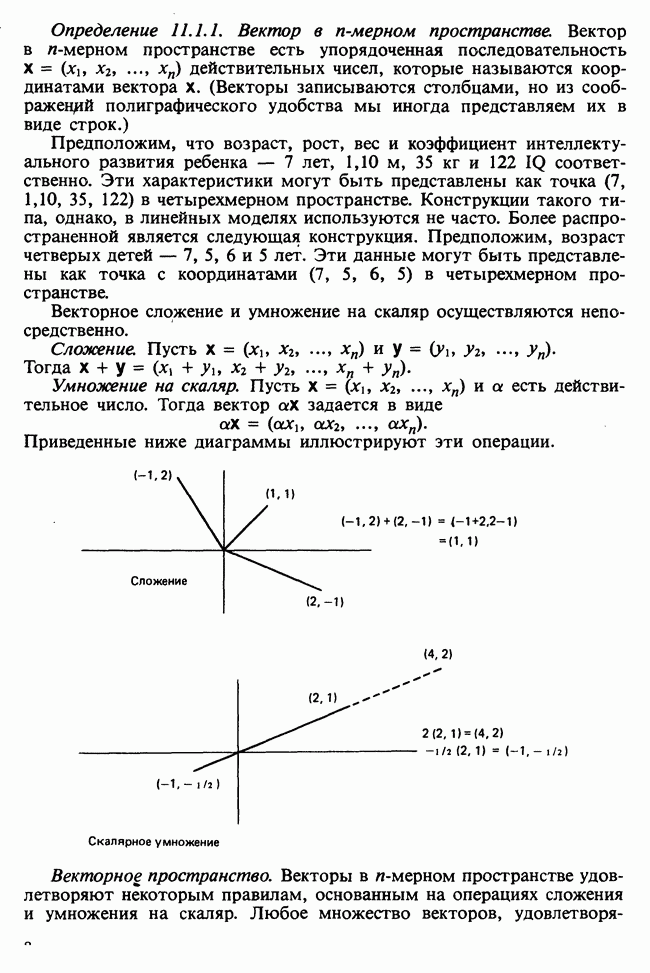
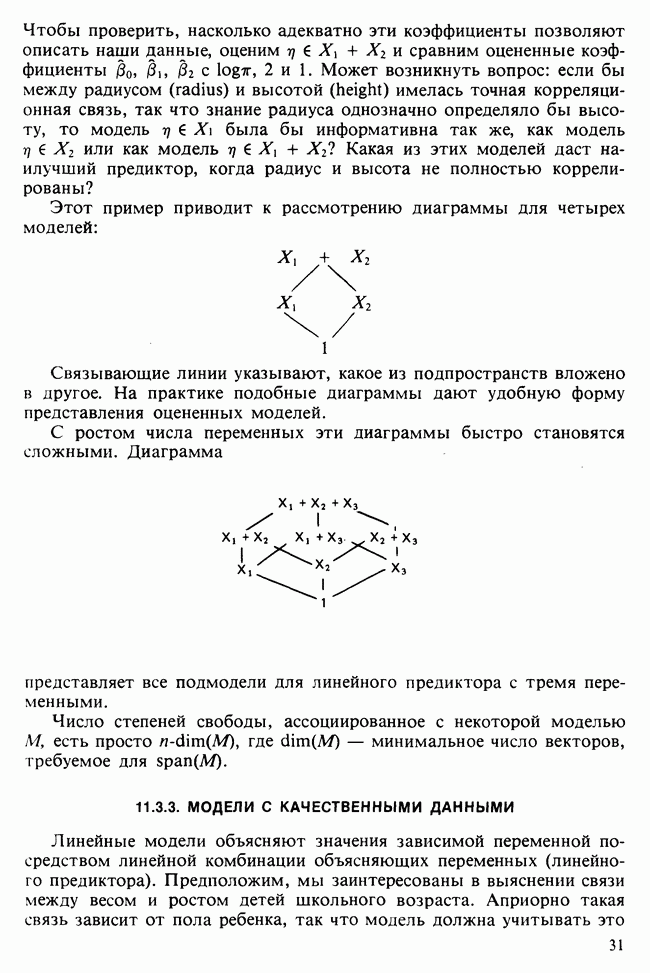
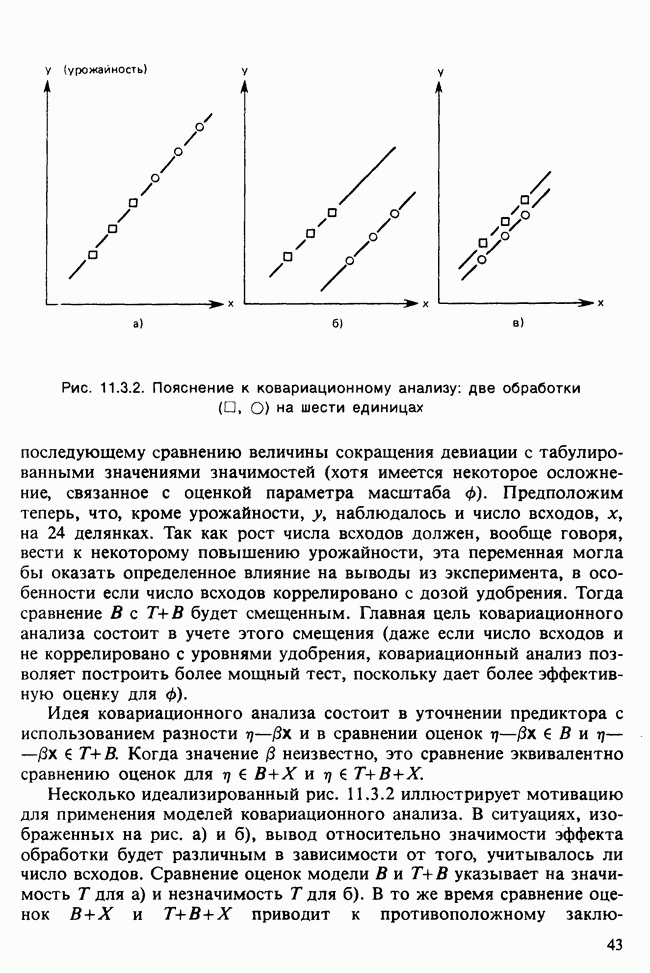
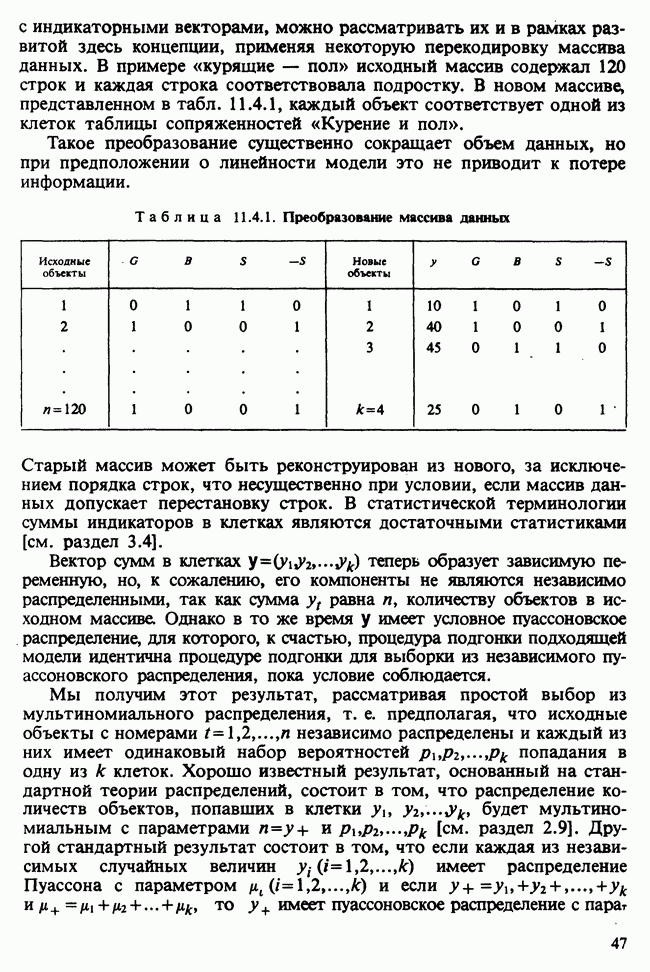
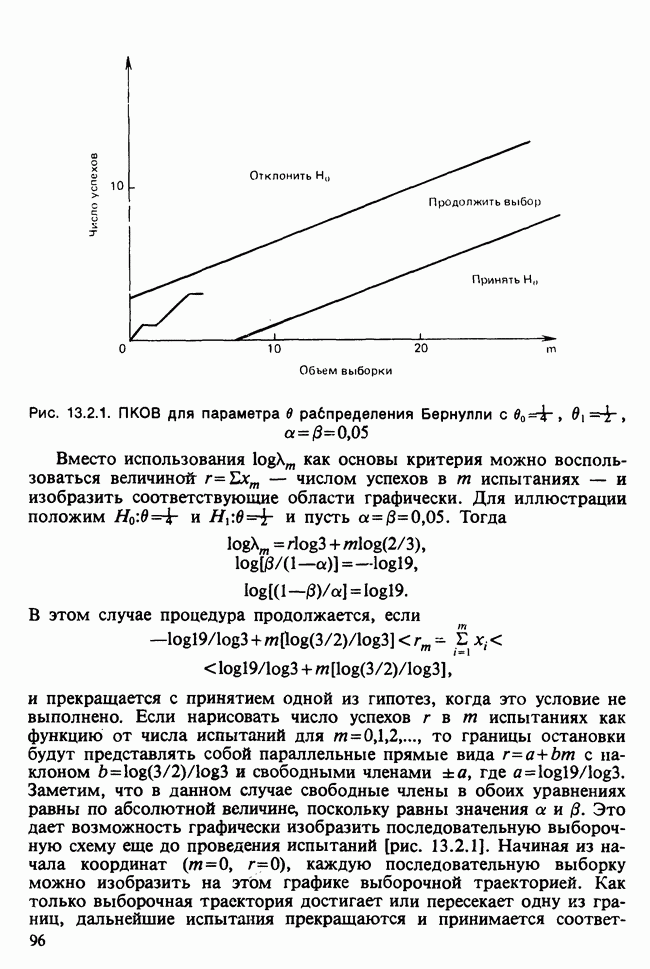
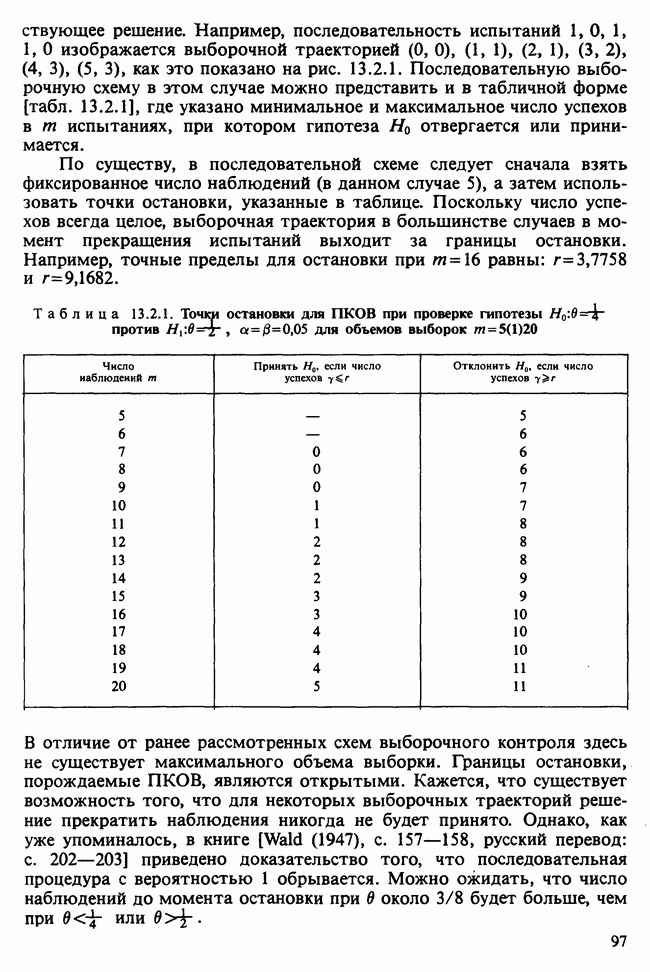
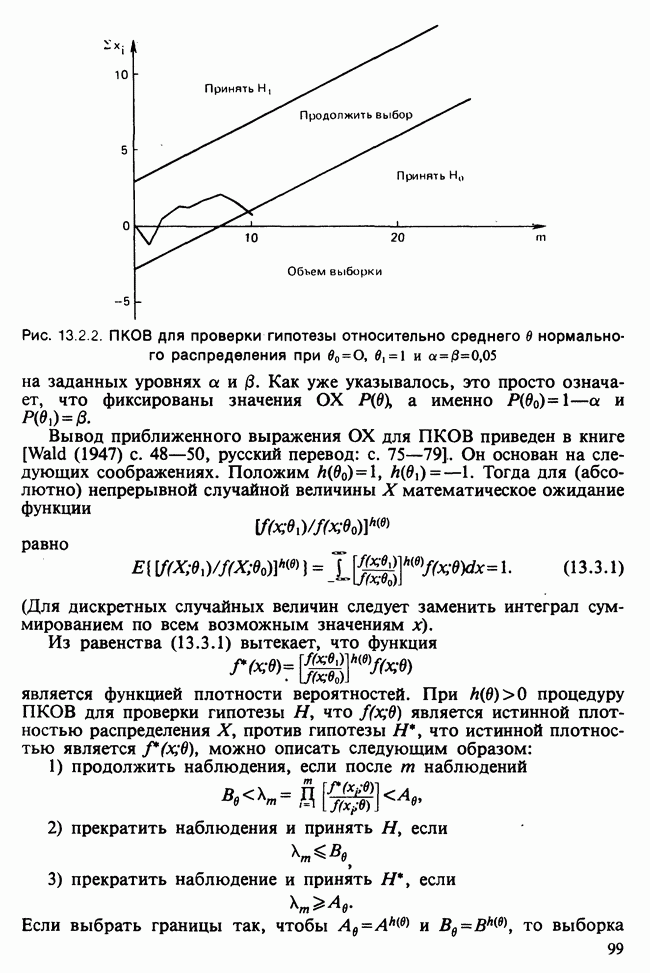
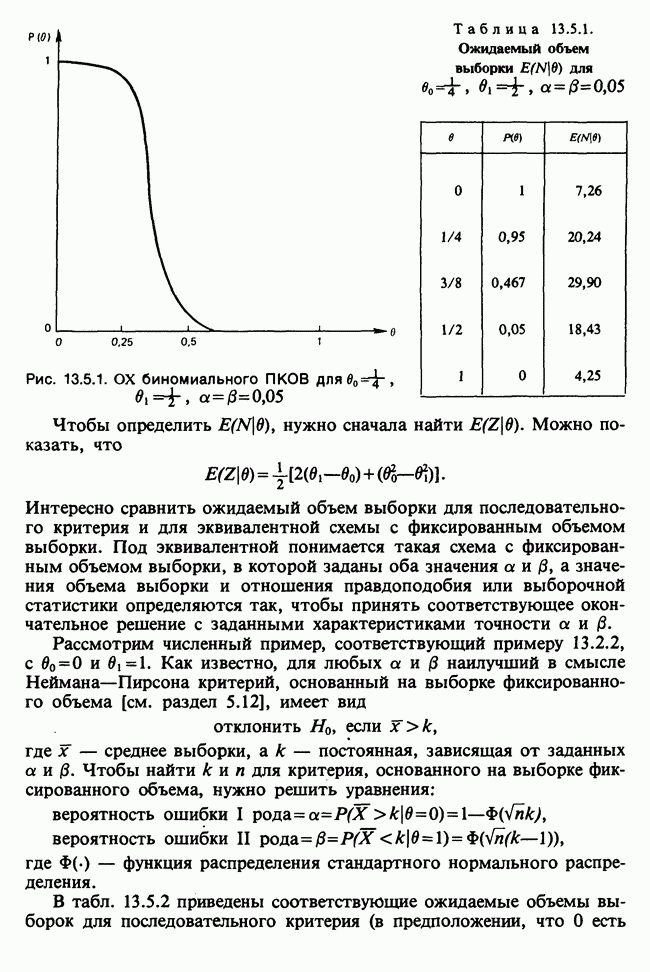
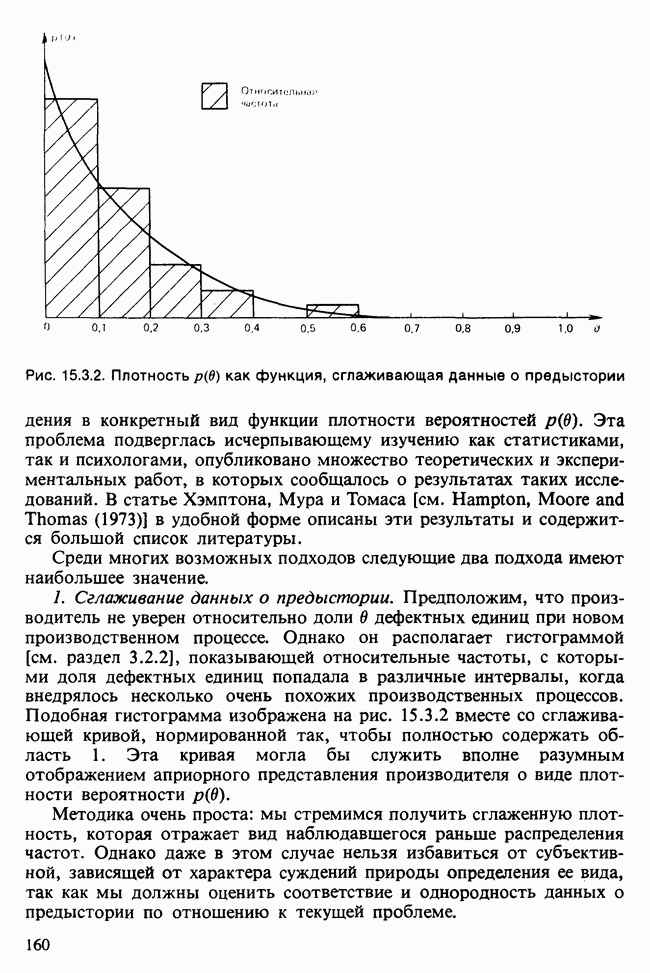
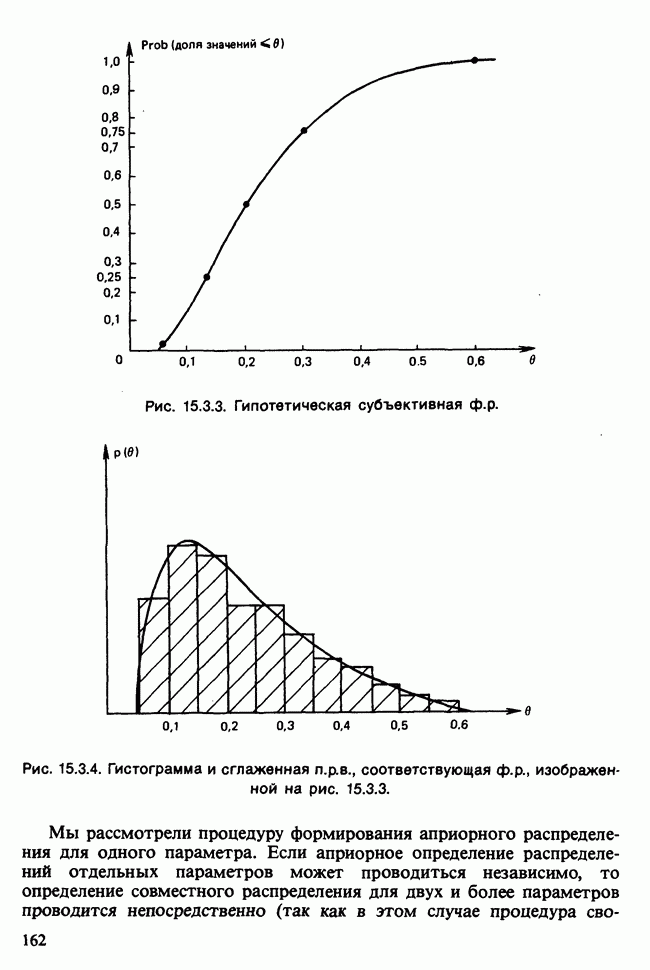
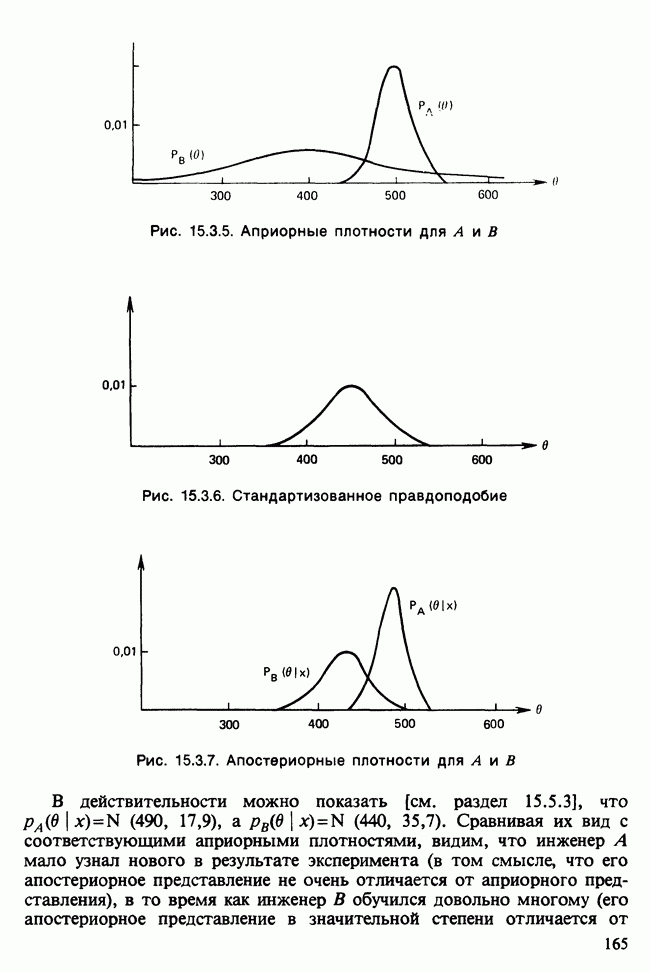
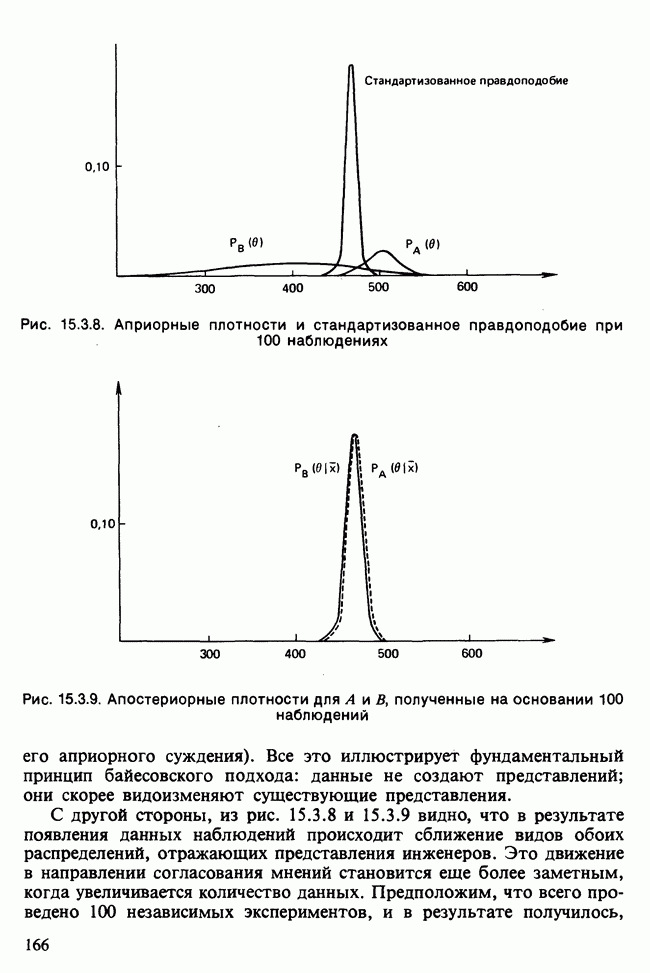
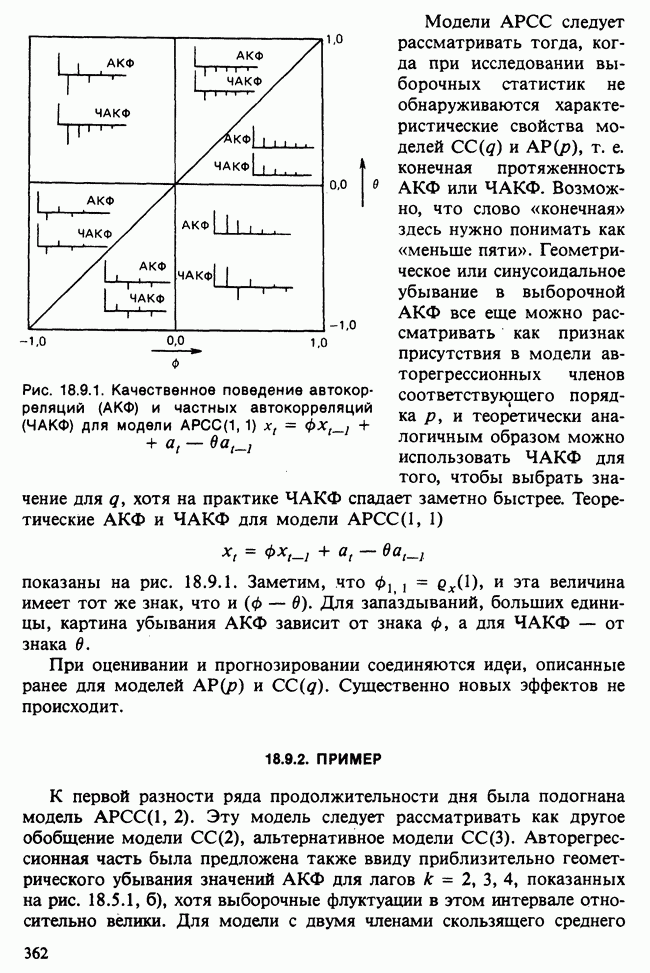
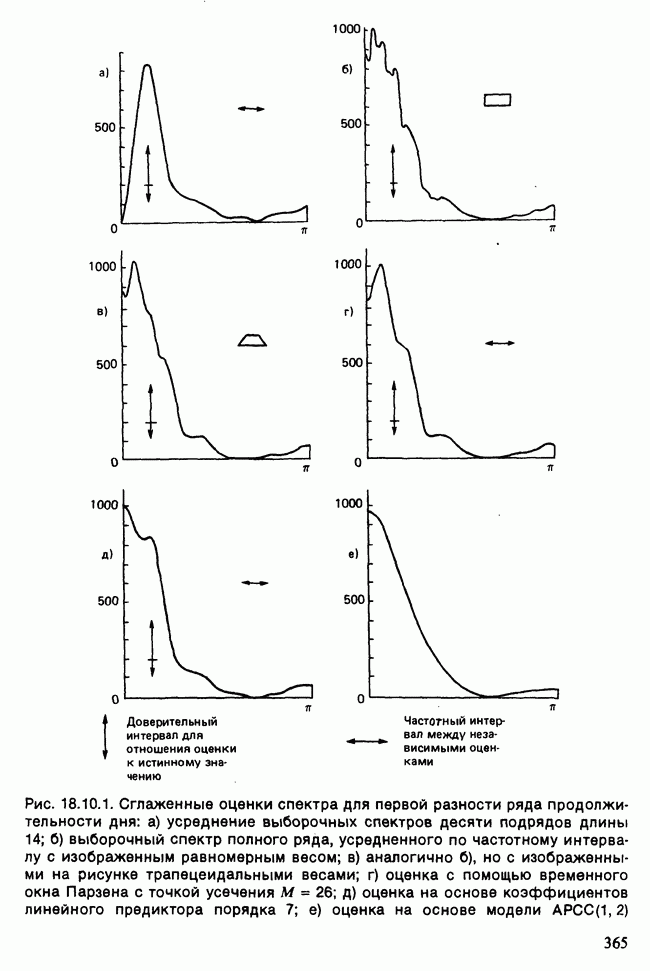
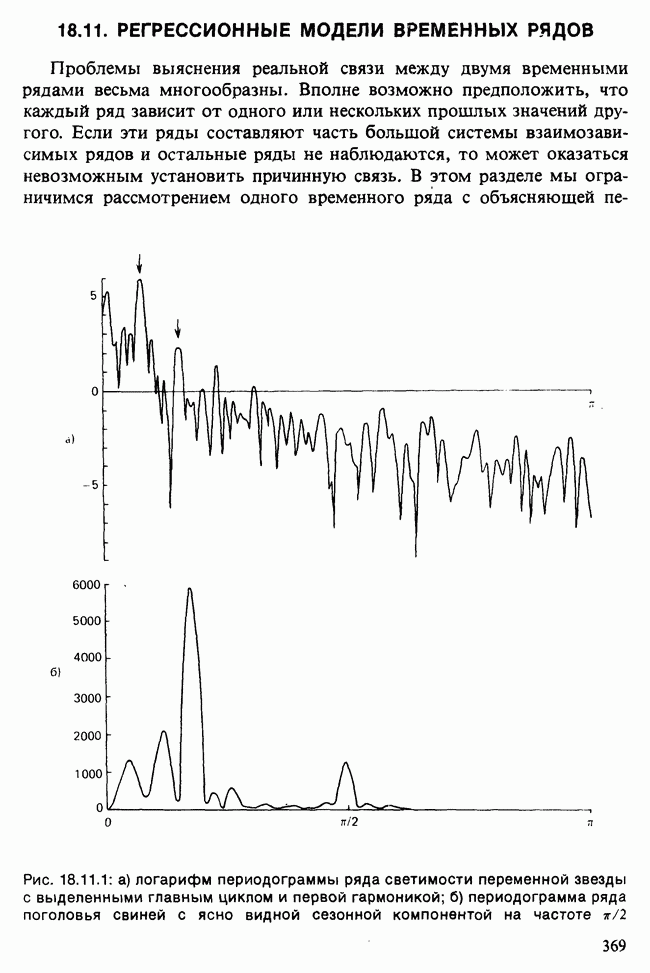
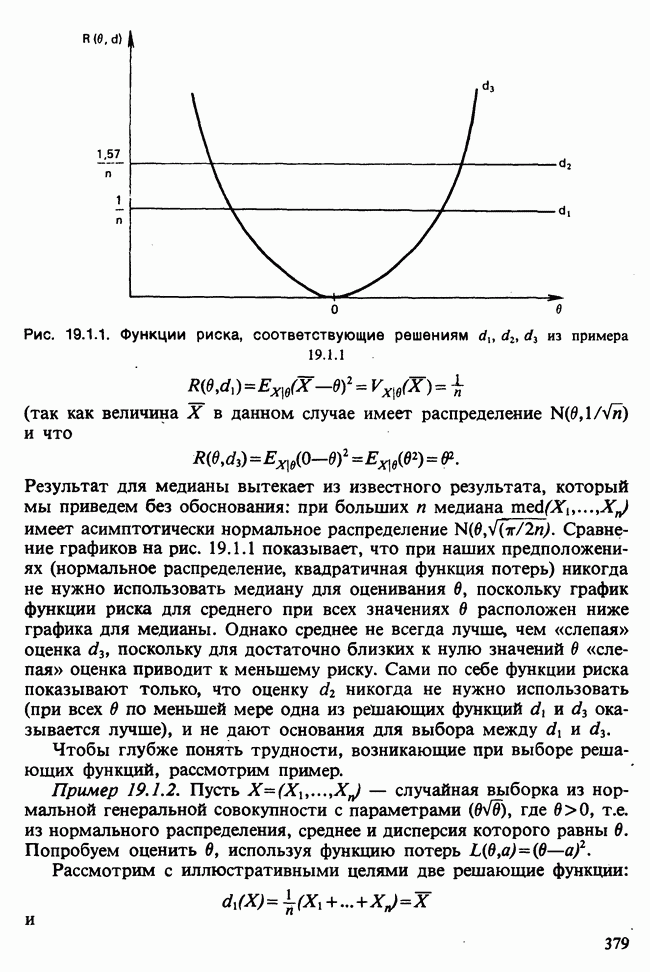
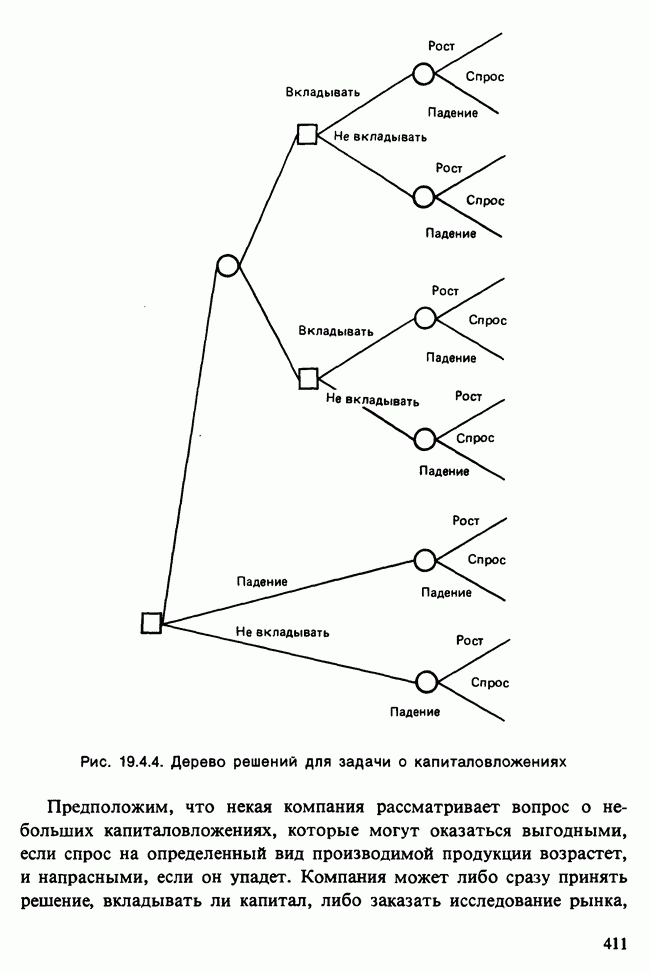
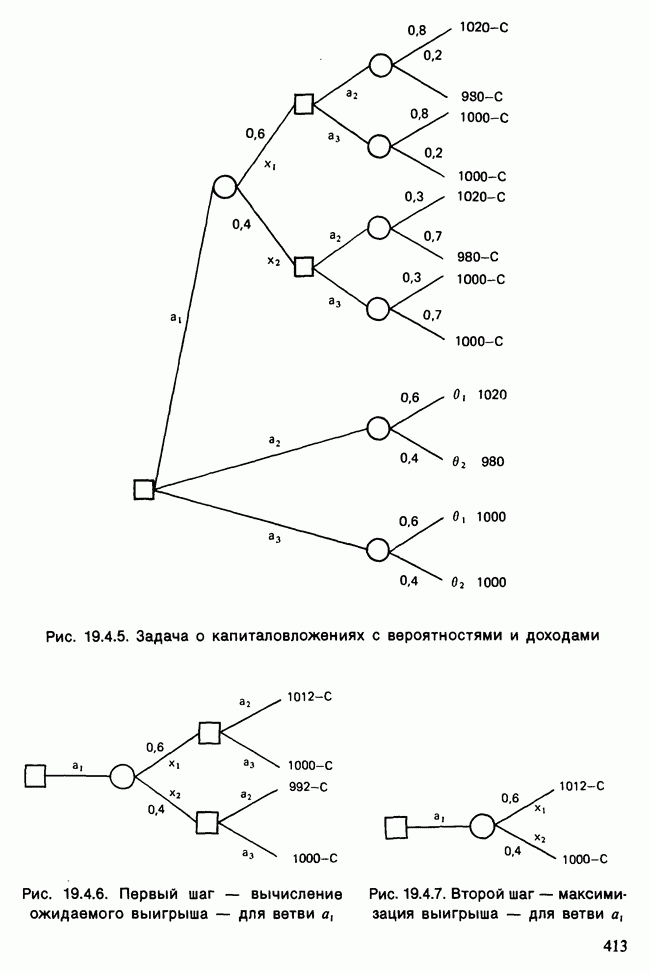
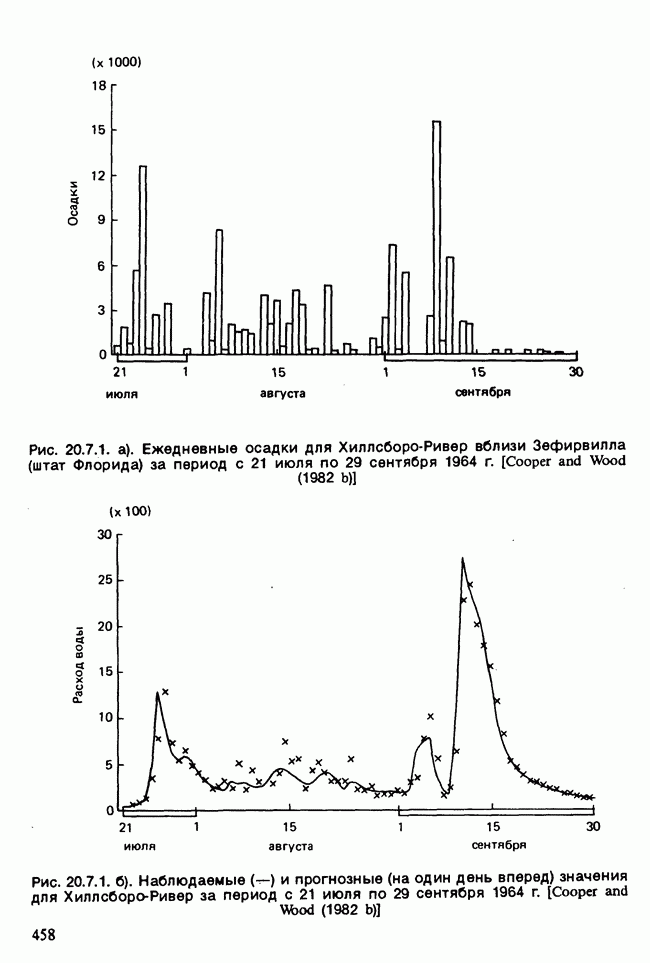
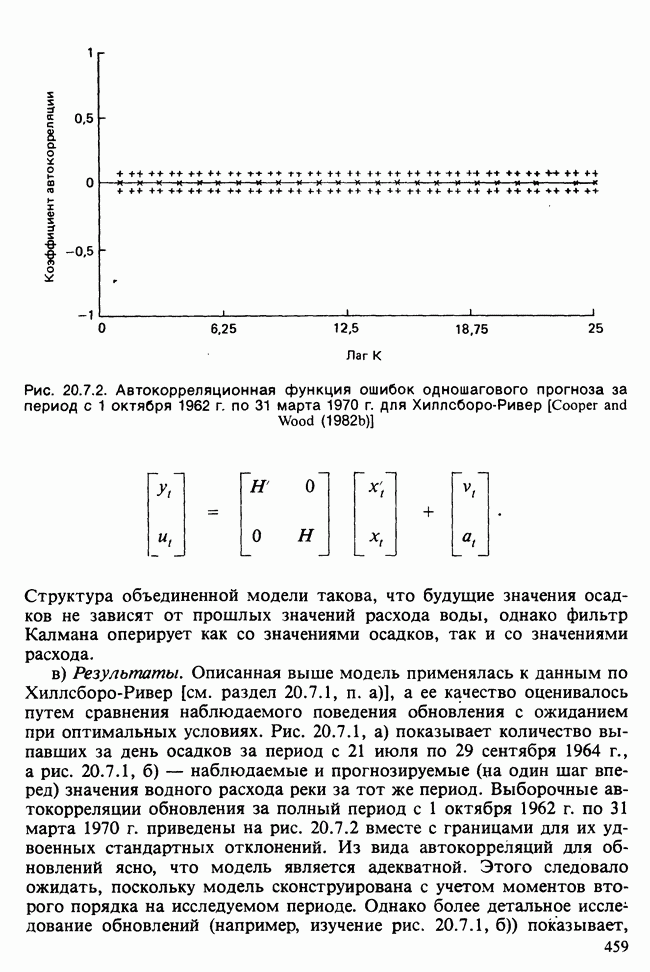
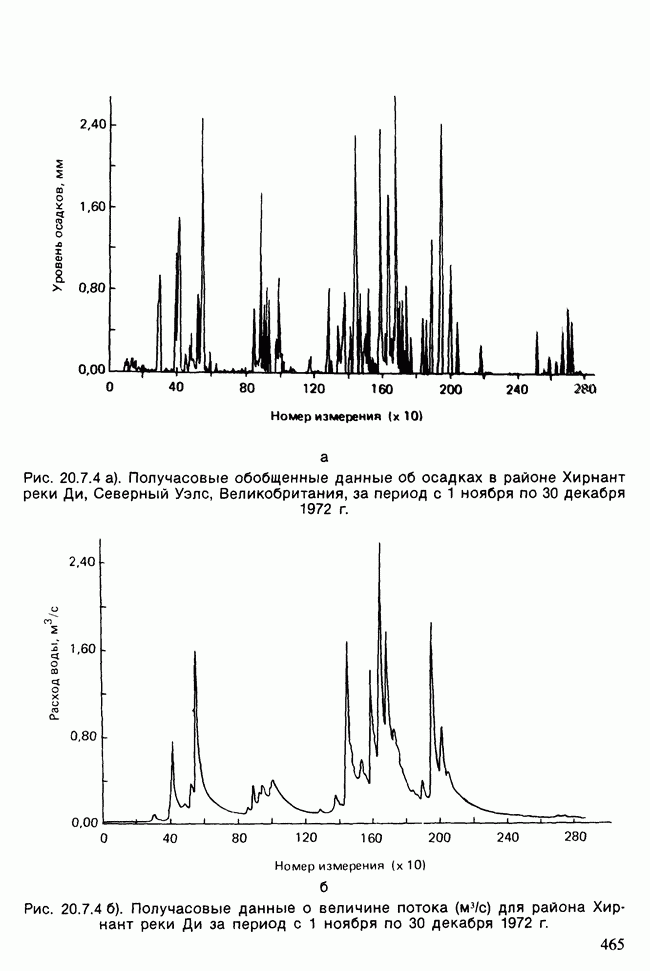
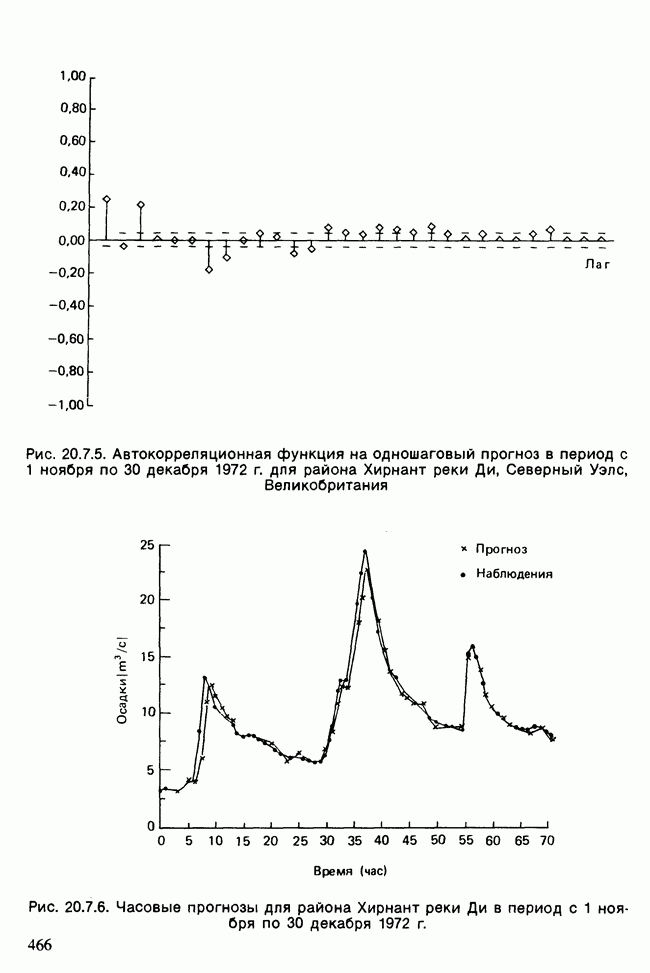
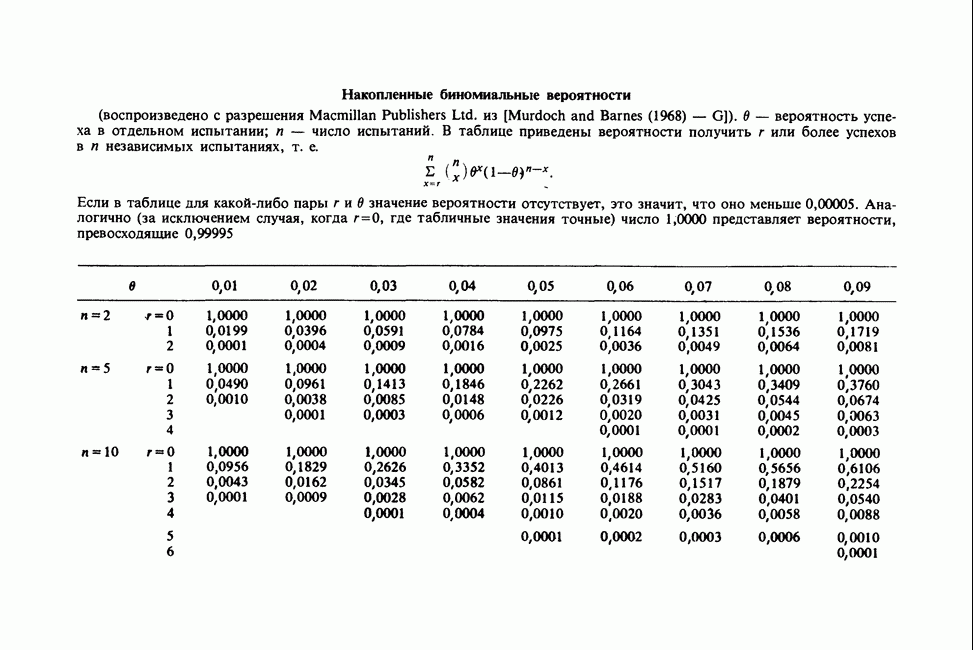
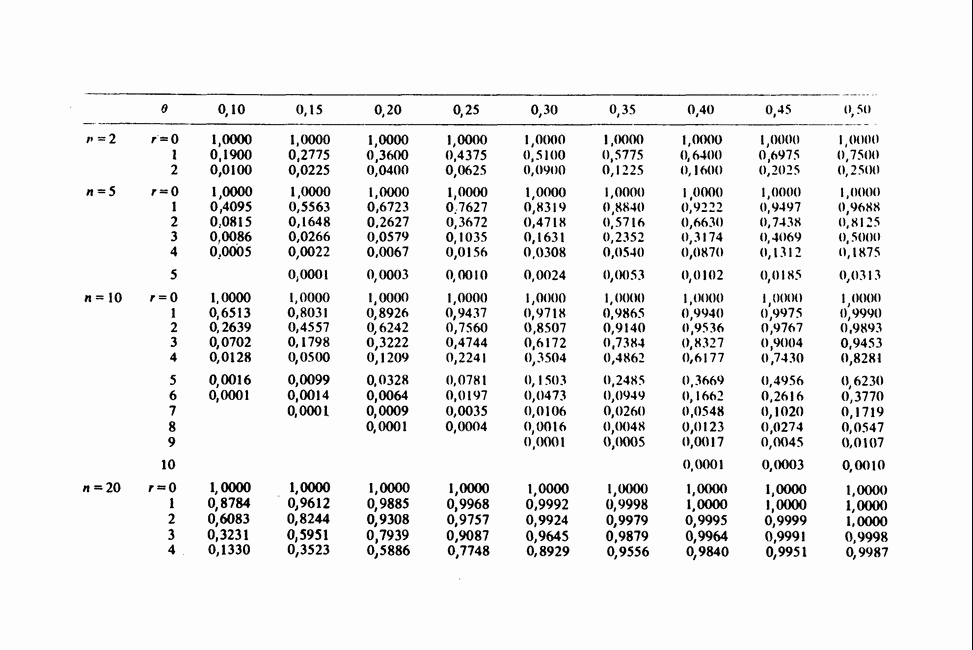
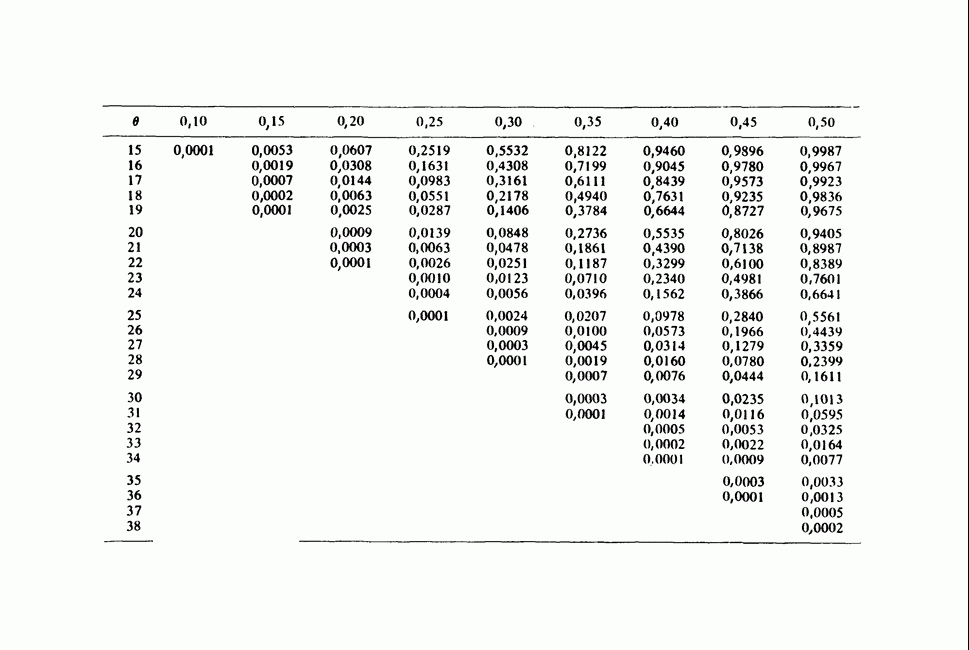
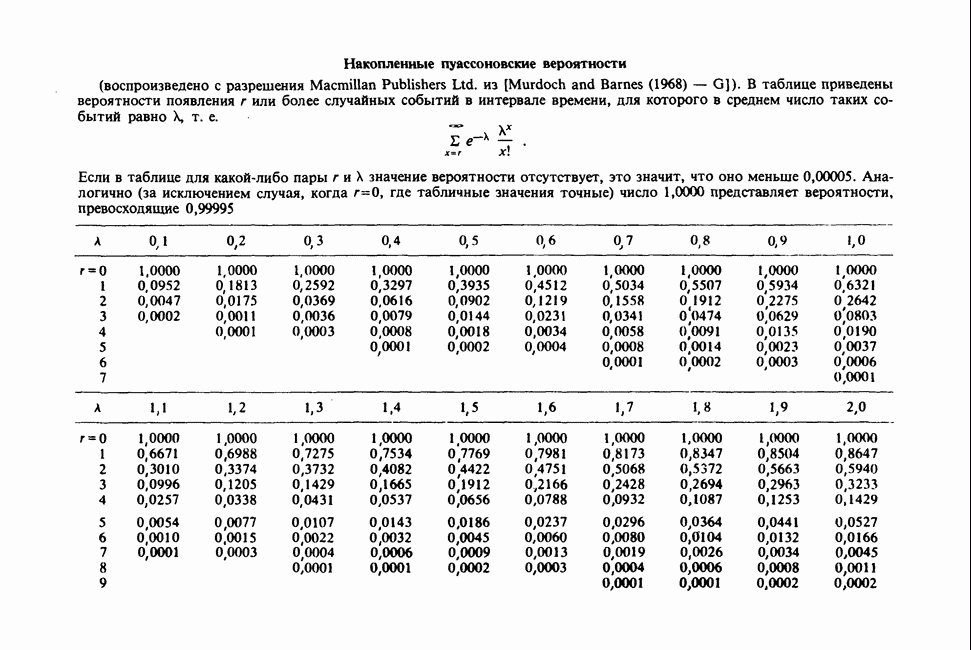
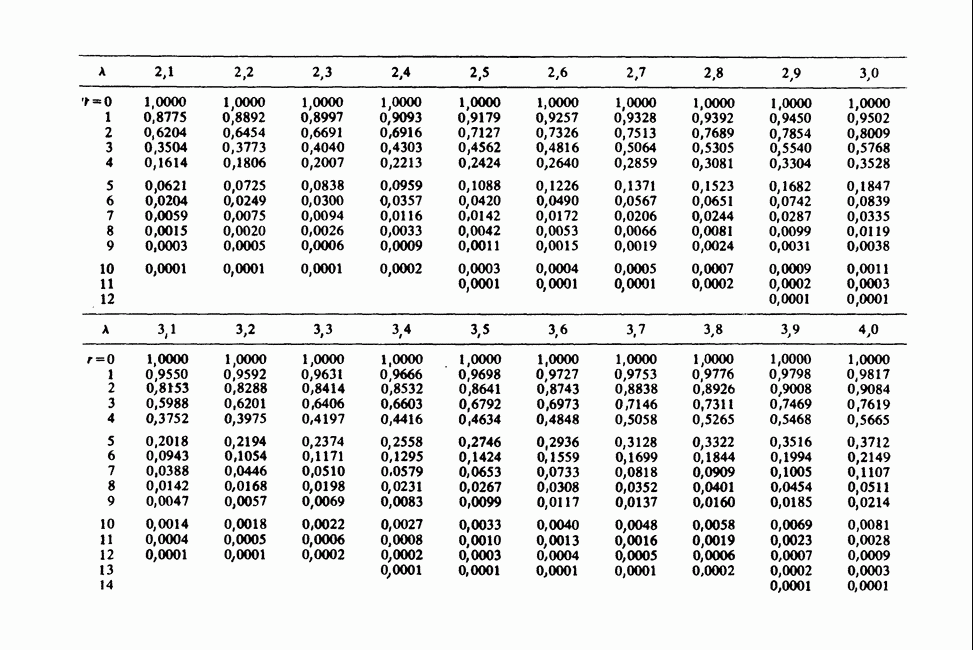
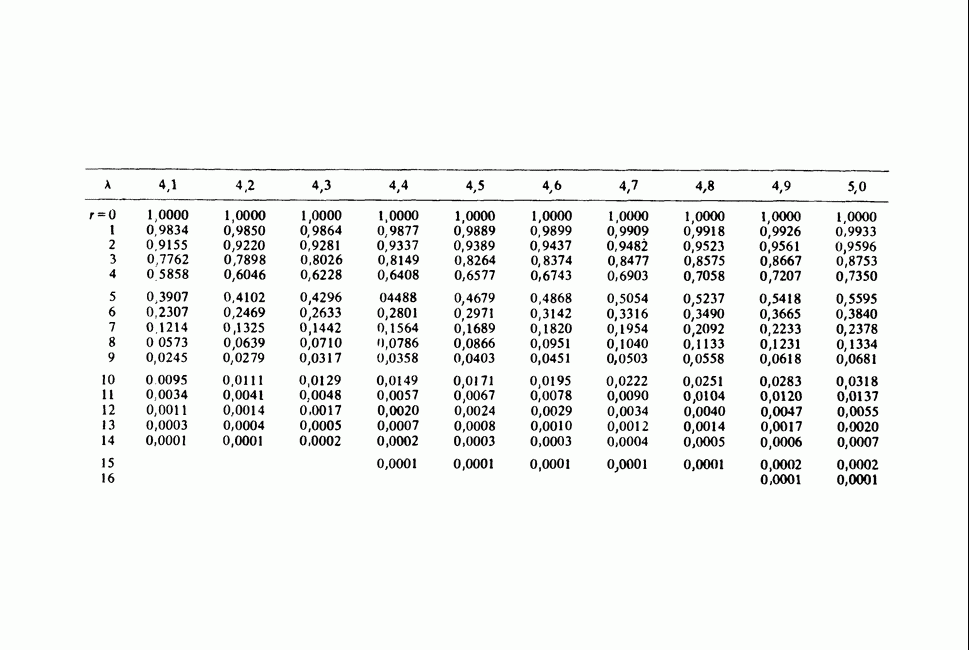
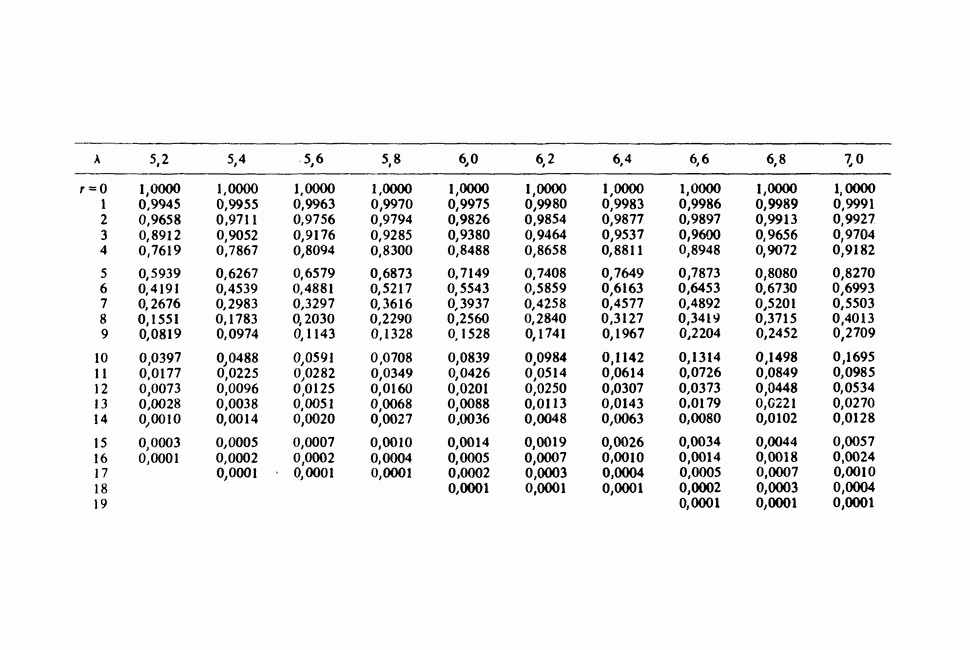
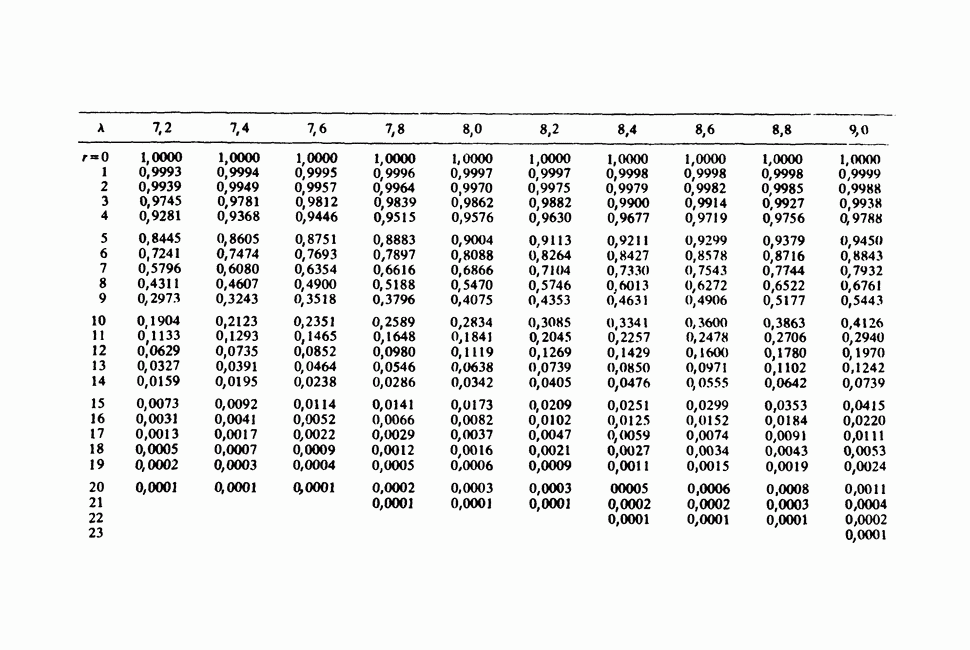
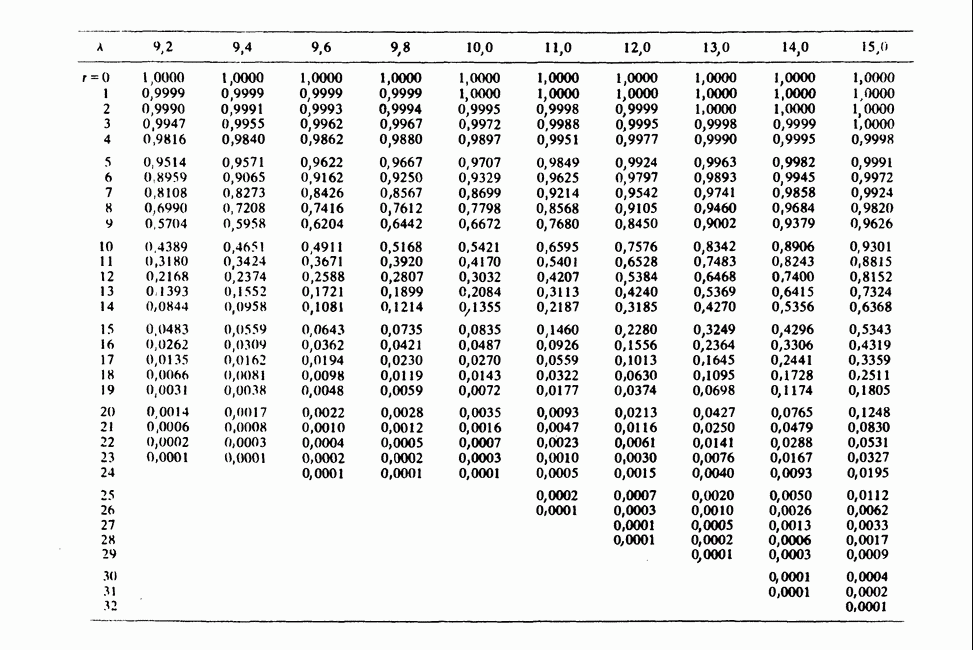
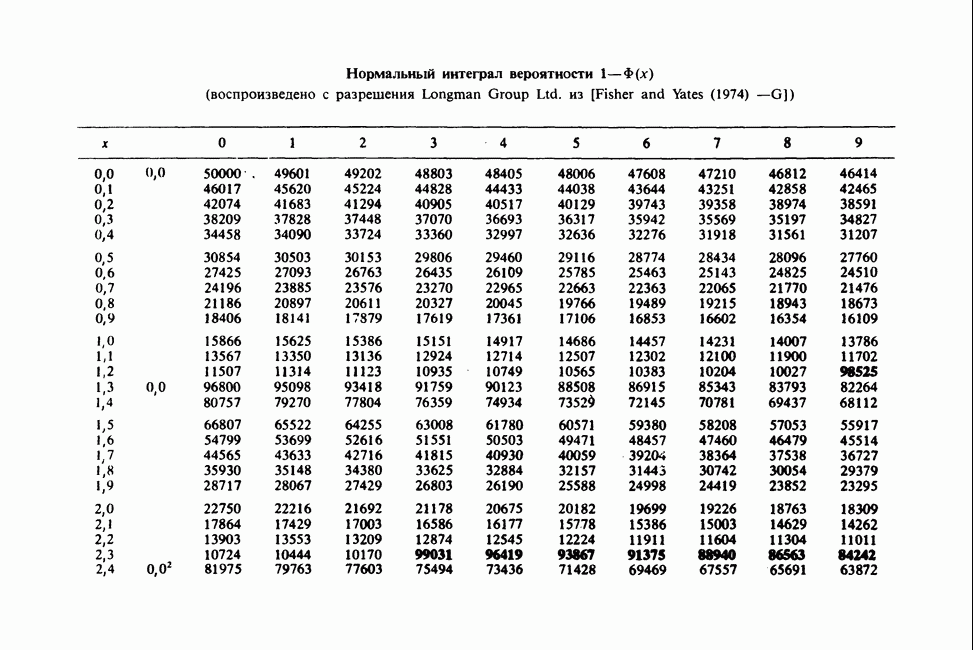
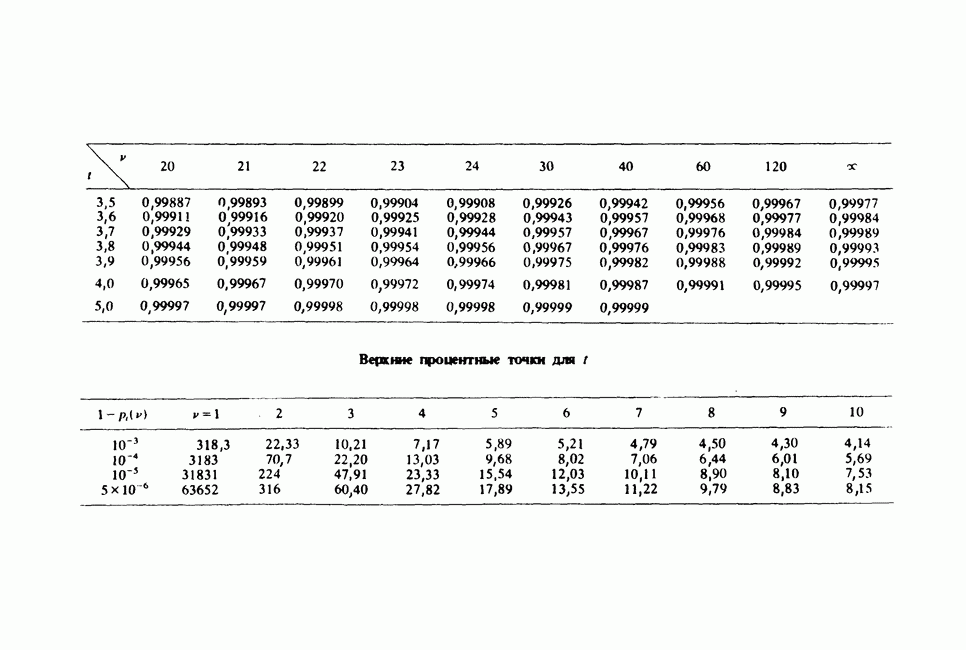
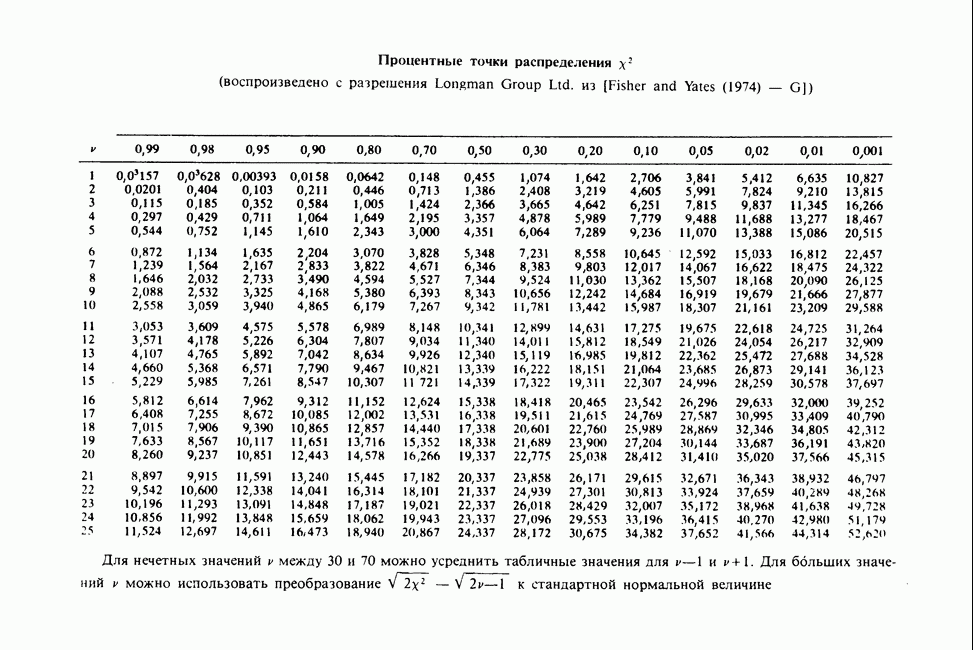
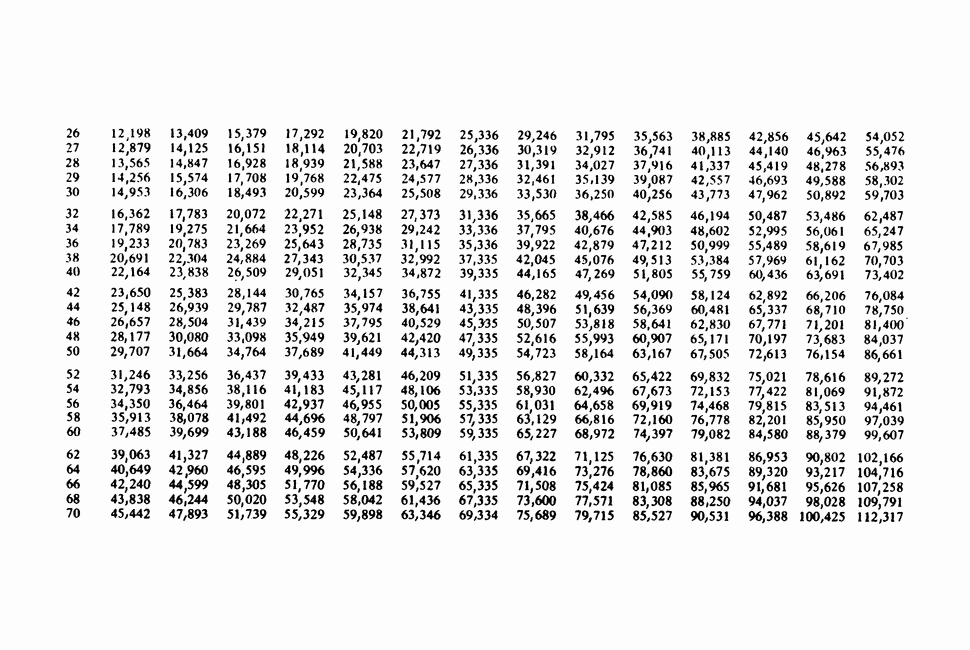
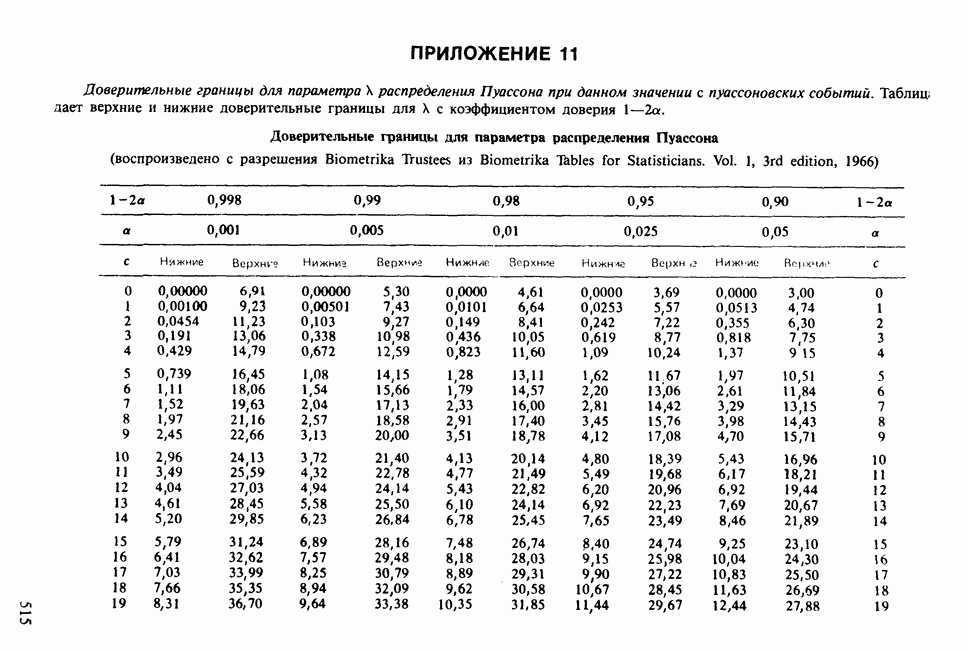
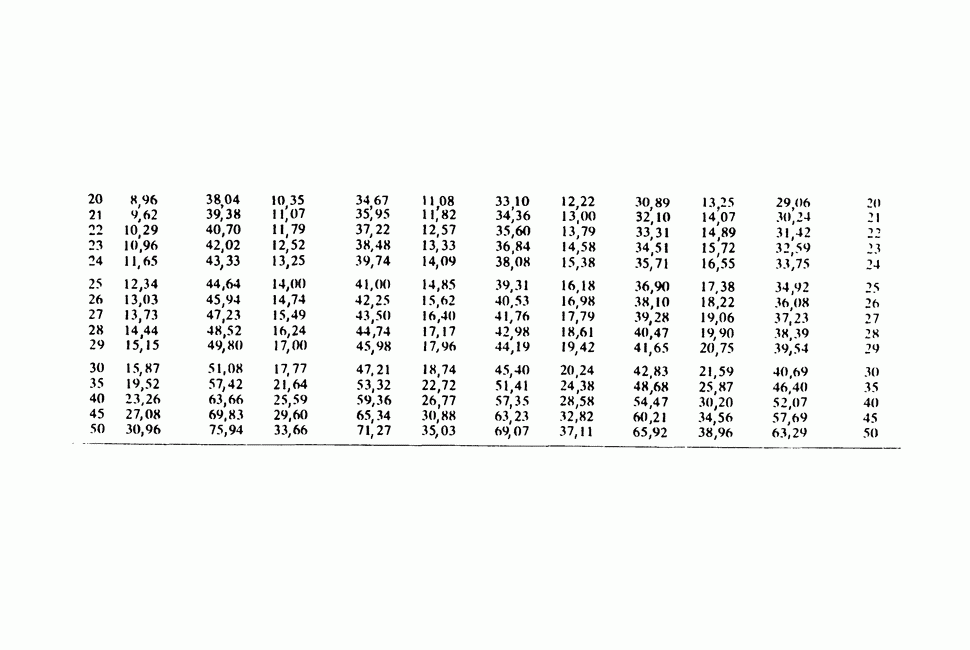11.2.3. ДЕВИАЦИЯ
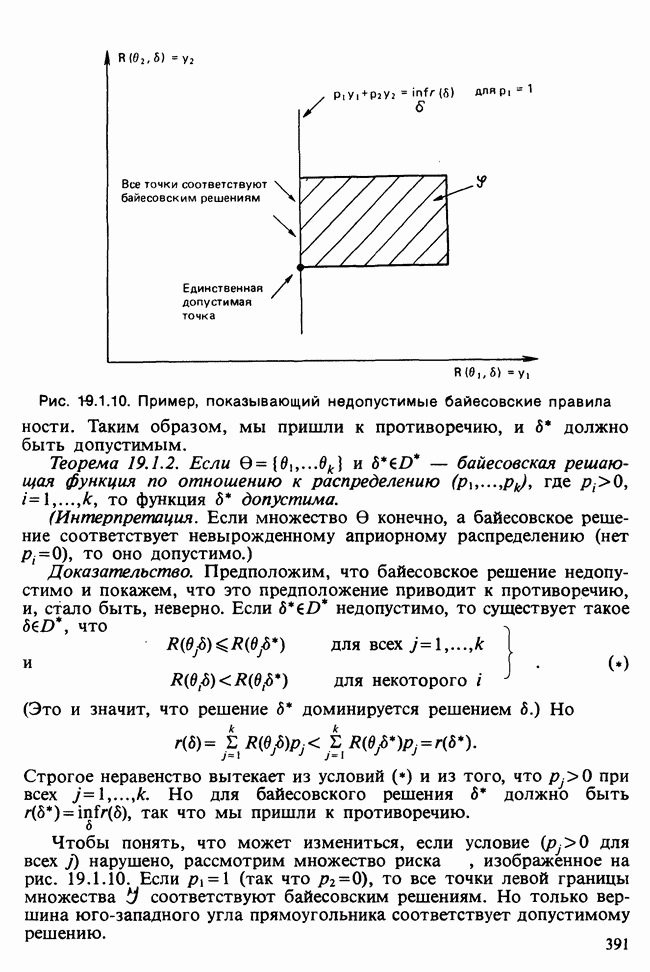
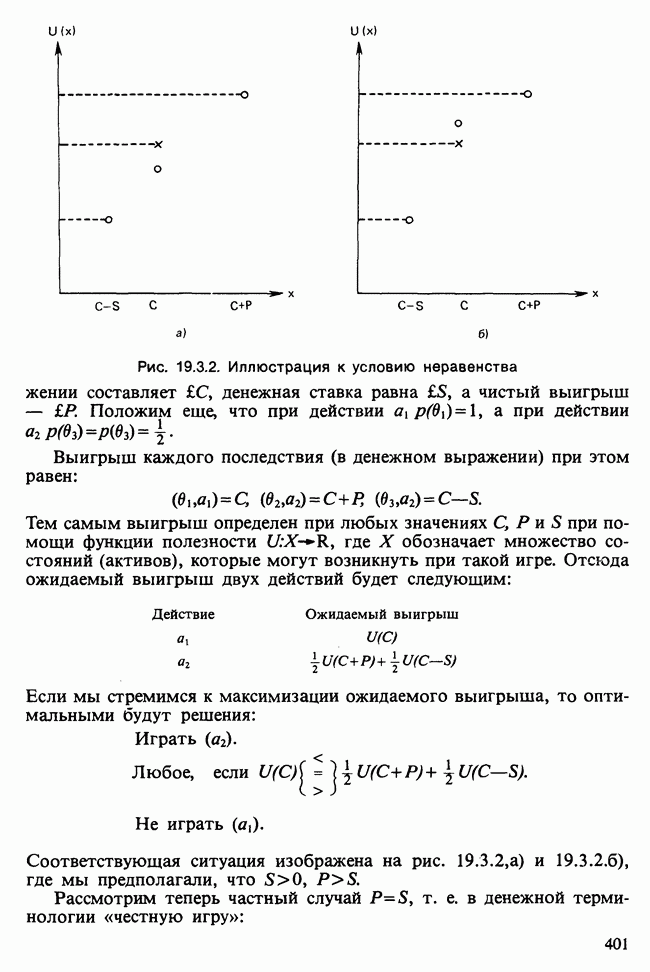
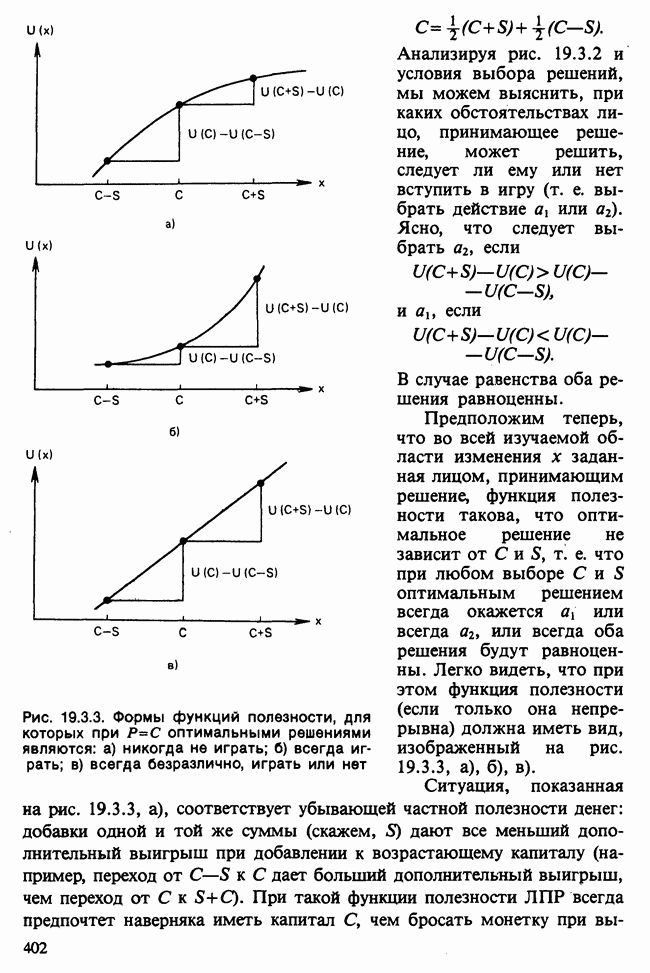
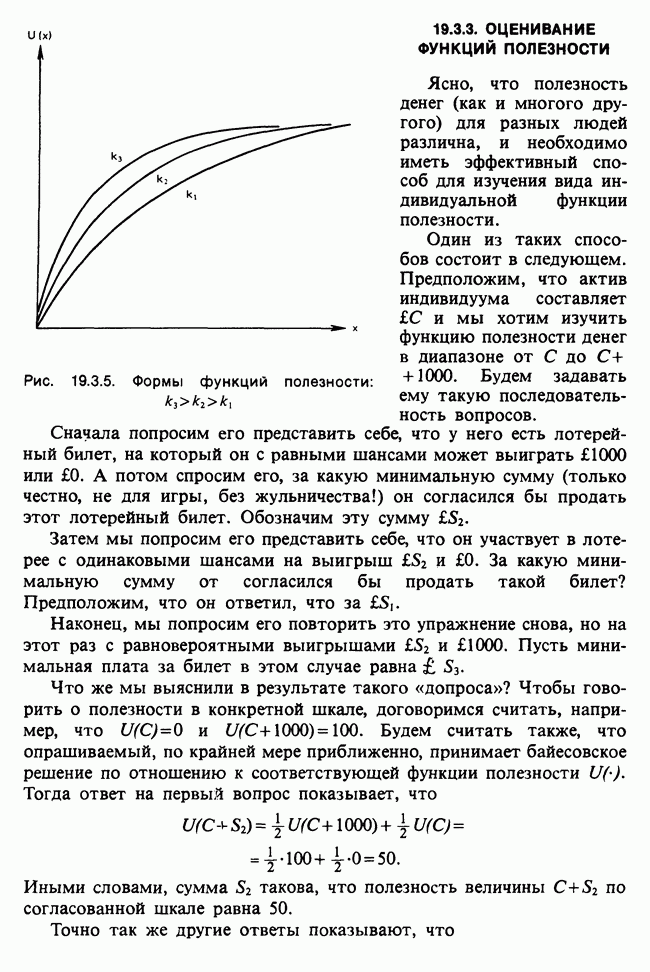
О том, насколько хорошо модель описывает данные, можно судить по расхождению между вектором наблюдаемых значений у и вектором подогнанных значений  Существуют различные способы измерить это расхождение. Поскольку мы используем метод максимального правдоподобия, подходящей для нас мерой является максимизированная тест-статистика логарифма отношения правдоподобия
Существуют различные способы измерить это расхождение. Поскольку мы используем метод максимального правдоподобия, подходящей для нас мерой является максимизированная тест-статистика логарифма отношения правдоподобия  сконструированная на основе следующих соображений [см. раздел 5.5].
сконструированная на основе следующих соображений [см. раздел 5.5].
Модели с большим количеством объясняющих переменных должны дать подогнанные значения, которые лучше аппроксимируют исходные данные. В экстремальном случае, включая в линейный предиктор столько переменных, сколько имеется объектов, получим линейную модель, точно воспроизводящую данные. Эта так называемая насыщенная модель,  имеет свойство
имеет свойство

Обозначим модель, включающую только часть объясняющих переменных, через М, а соответствующее ей подогнанное значение — через 
Девиация модели М определяется как

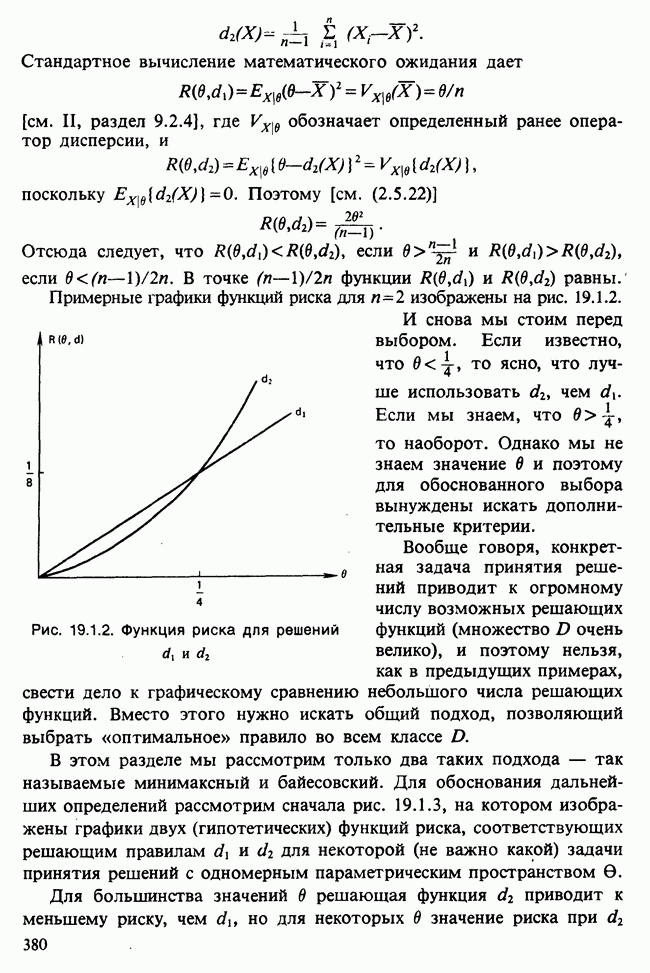
Максимизированное значение лог-максимума правдоподобия X может только возрастать с ростом числа переменных, включенных в М из  Чем ближе девиация к нулю, тем ближе
Чем ближе девиация к нулю, тем ближе  к у.
к у.

Для данных о смертности мышей с использованием биномиальнологистической модели имеем:

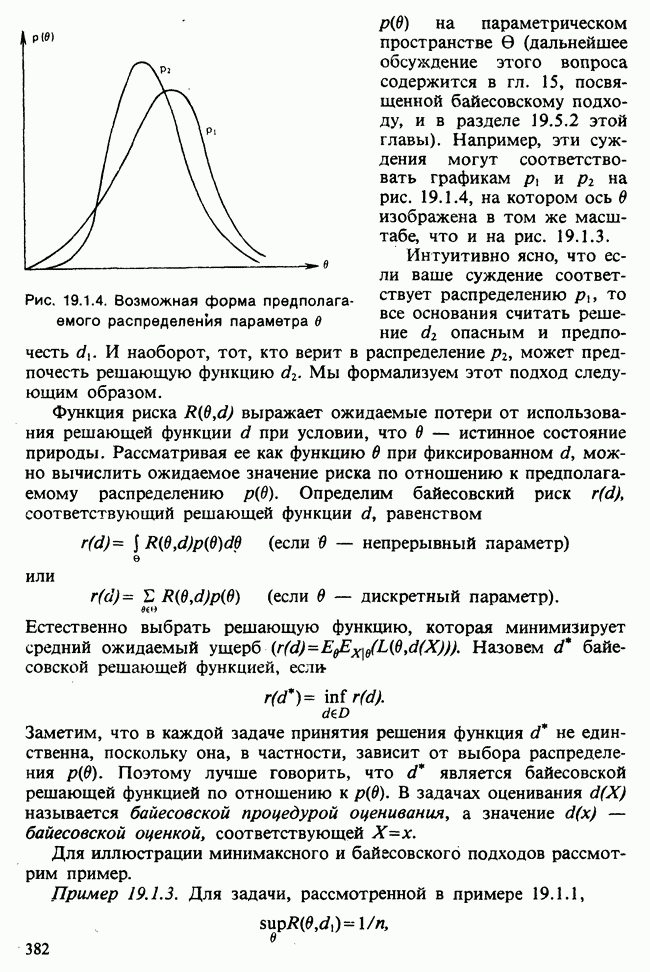
В примере с нормальной плотностью девиация есть сумма квадратов, и анализ девиации является обобщением техники дисперсионного анализа. Этот пример показывает также, что в том случае, когда имеется параметр  его роль не совпадает с ролью
его роль не совпадает с ролью  . В этом случае девиация может быть использована для оценки
. В этом случае девиация может быть использована для оценки 
Девиация играет большую роль в процедурах подгонки моделей.
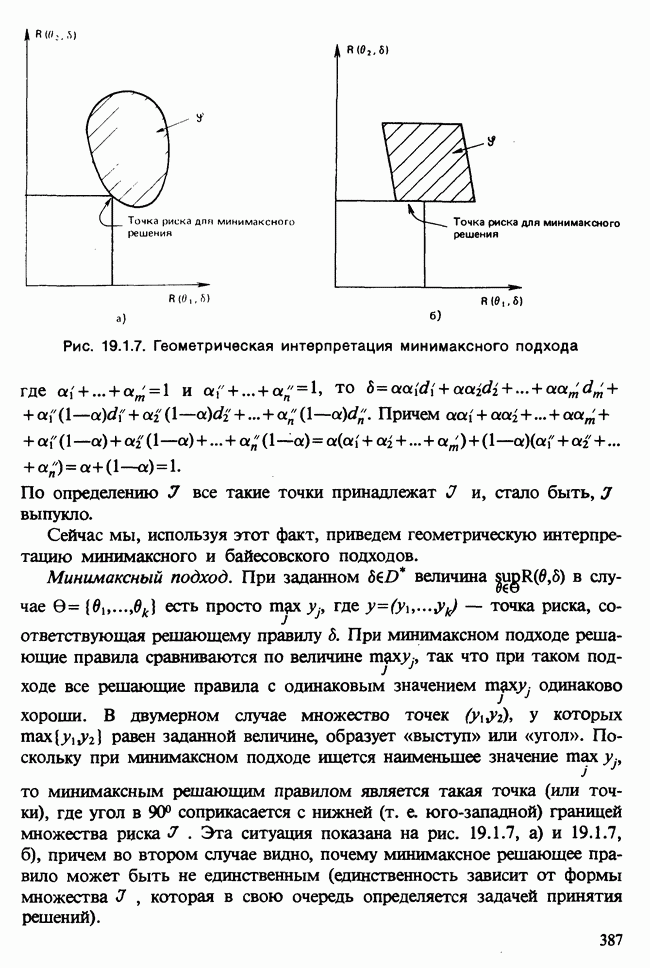
а) Она является суммирующей статистикой для суждения об адекватности подгонки частной (ненасыщенной) модели, а ее выборочное распределение позволяет построить тест для проверки качества подгонки.
б) С другой стороны, приравнивание девиации к ее ожидаемому значению может быть использовано для получения оценки мешающего параметра  Конечно, невозможно обеспечить а) и б) одновременно.
Конечно, невозможно обеспечить а) и б) одновременно.
в) Сравнение девиаций — основа теста отношения правдоподобия для проверки гипотезы, может ли быть включена в набор или исключена из него одна или несколько объясняющих переменных.
г) Этот тест может применяться для подбора наилучшего подмножества объясняющих переменных из некоторого исходного.
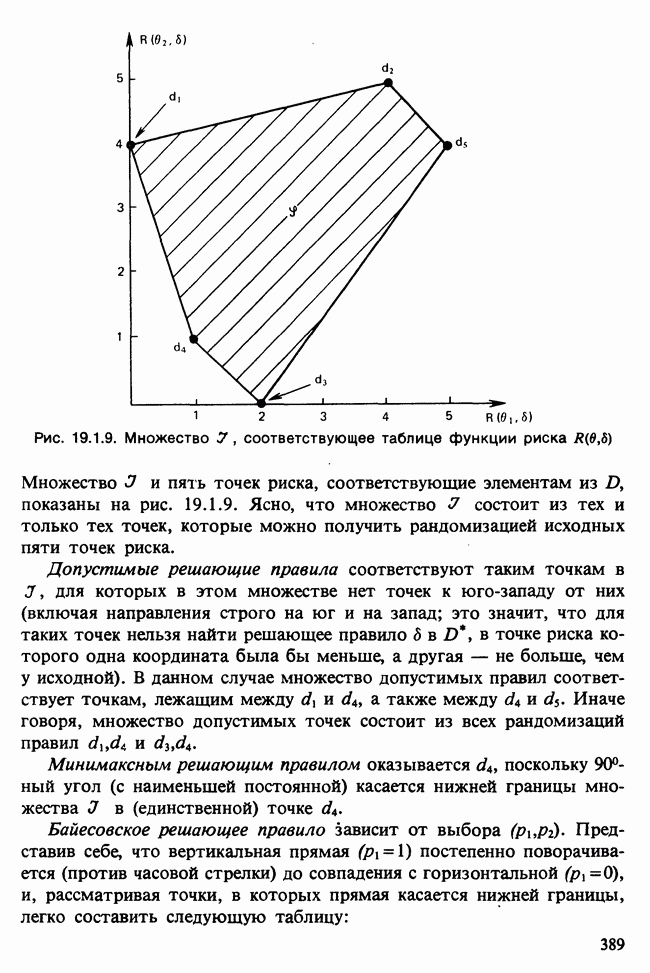
В предположении, что М — истинная модель, выборочное распределение девиации  есть хи-квадрат [см. раздел 2.5.4, п. а)] с числом степеней свободы
есть хи-квадрат [см. раздел 2.5.4, п. а)] с числом степеней свободы  число объясняющих переменных в М.
число объясняющих переменных в М.
Для примера о смертности мышей

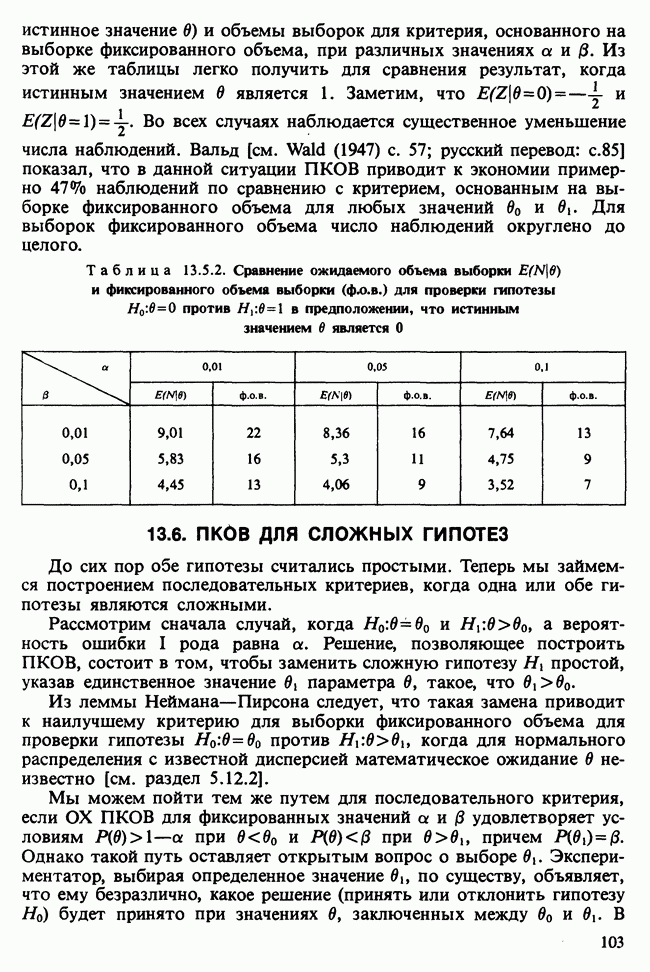
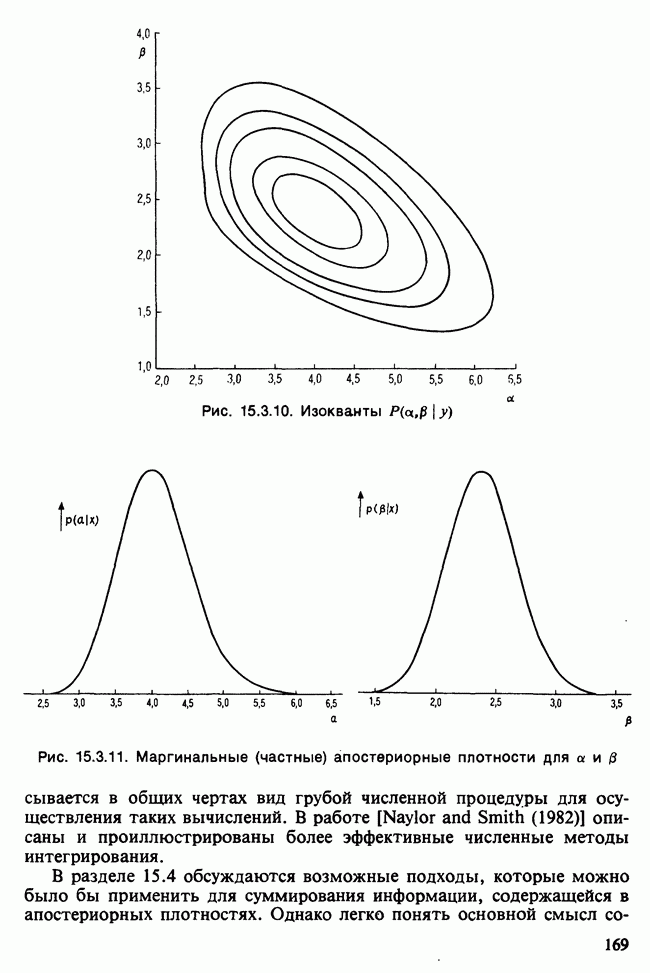
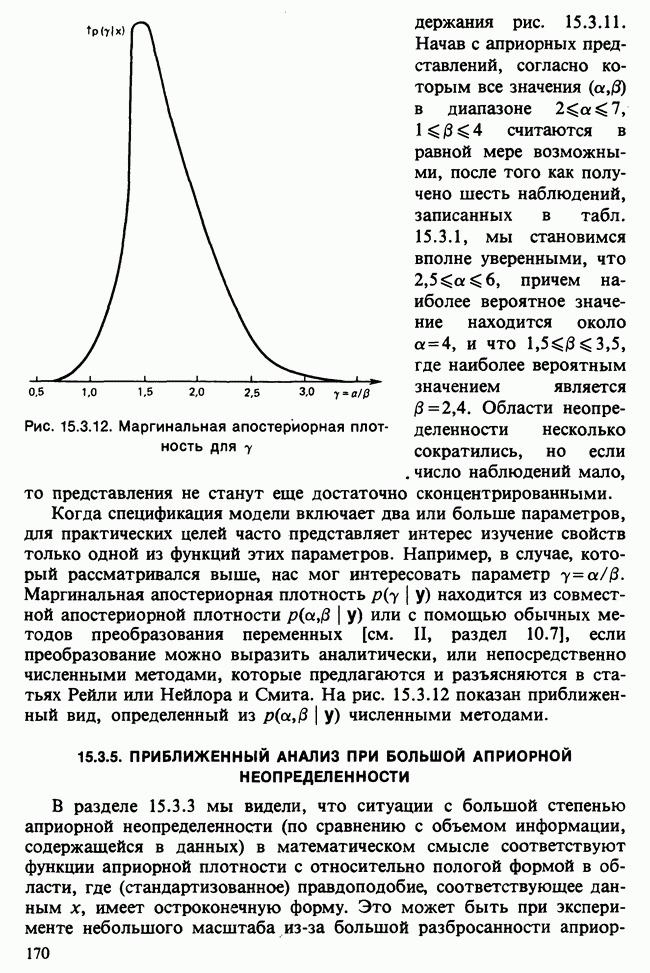
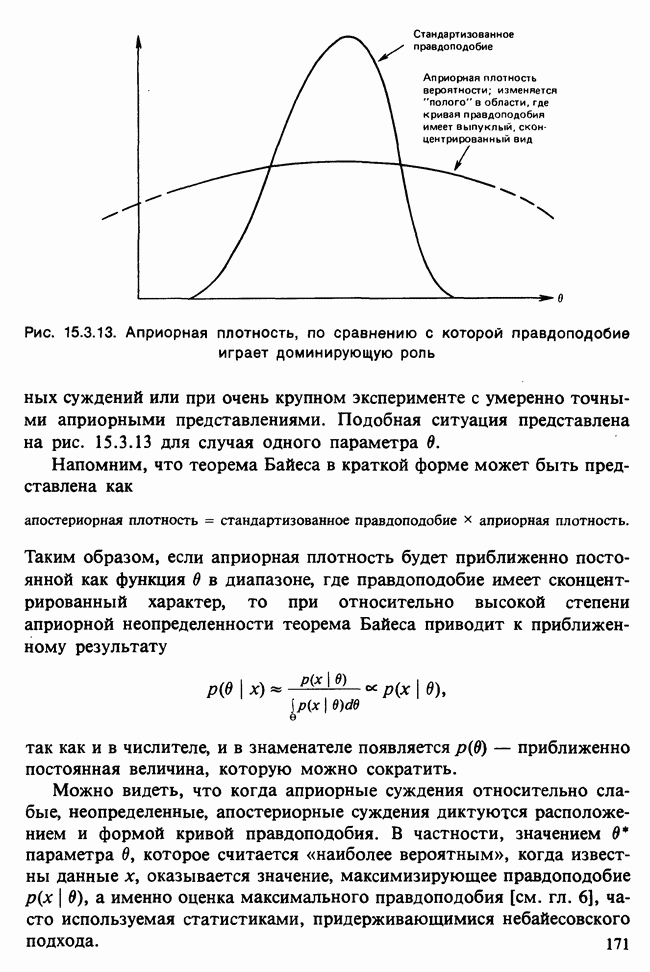
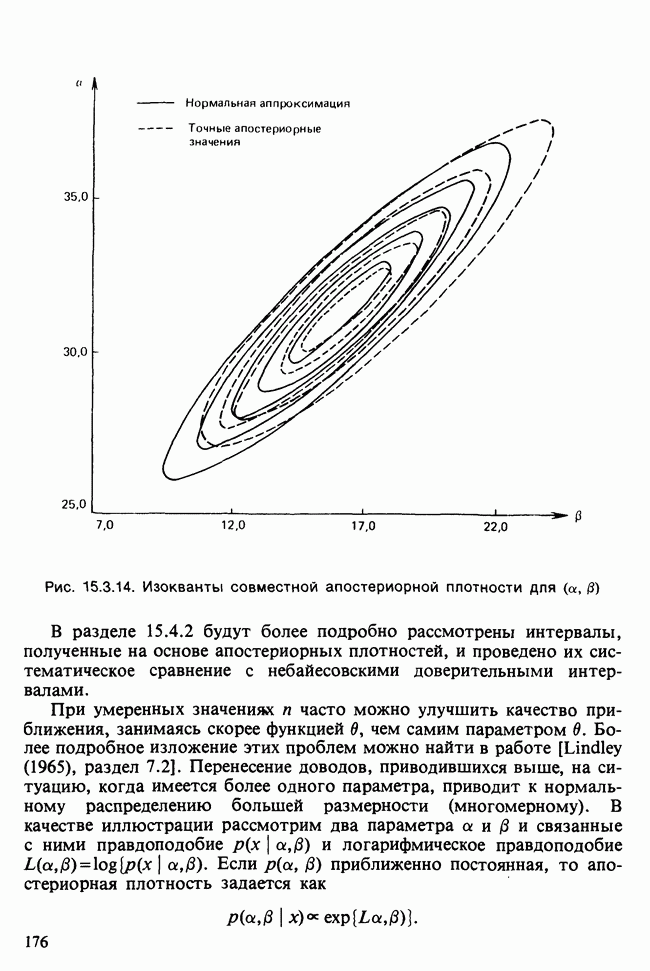
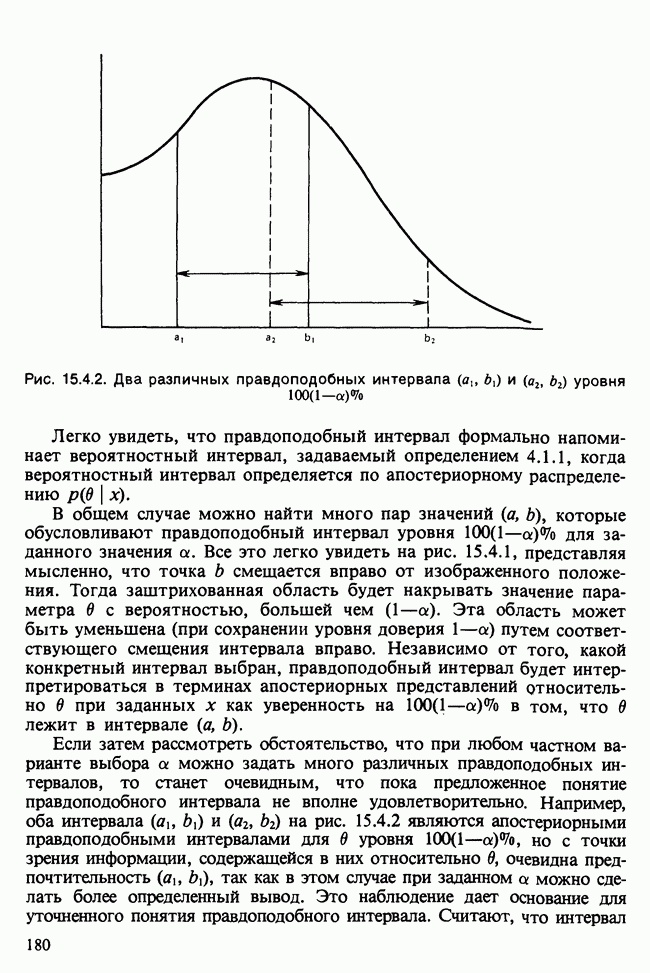
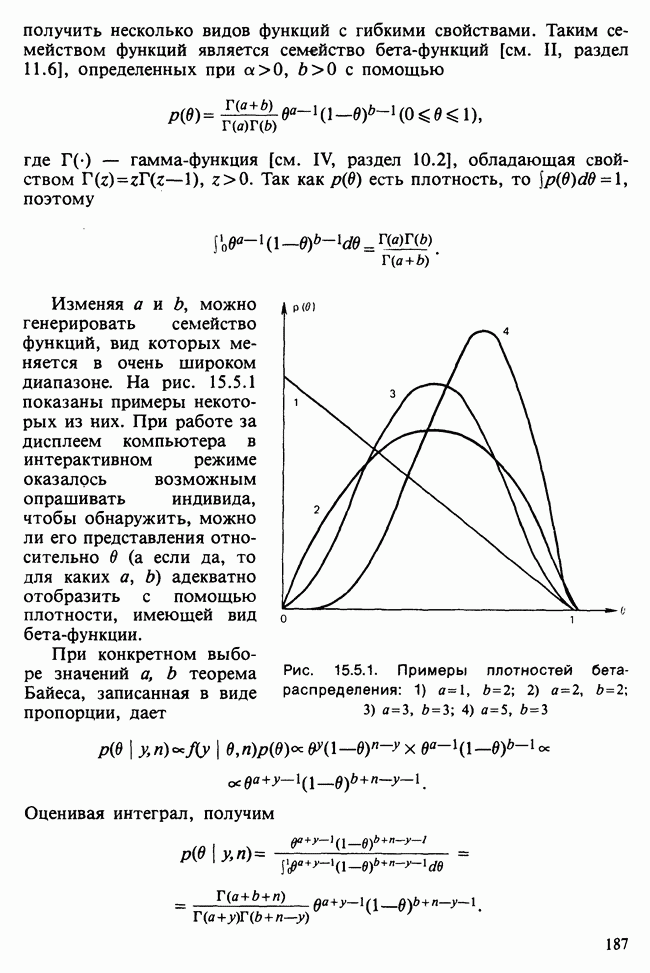
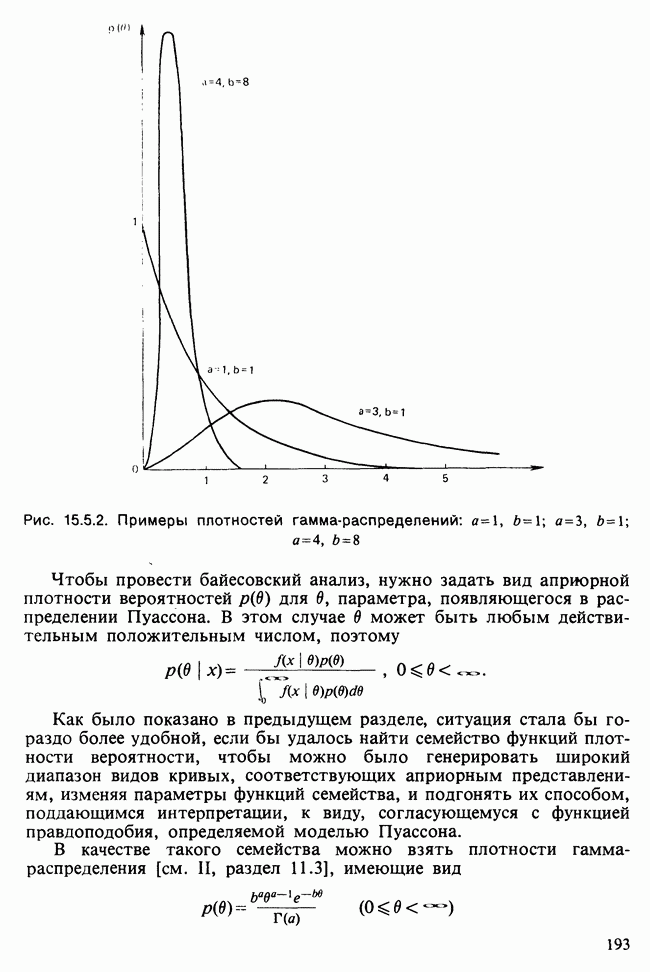
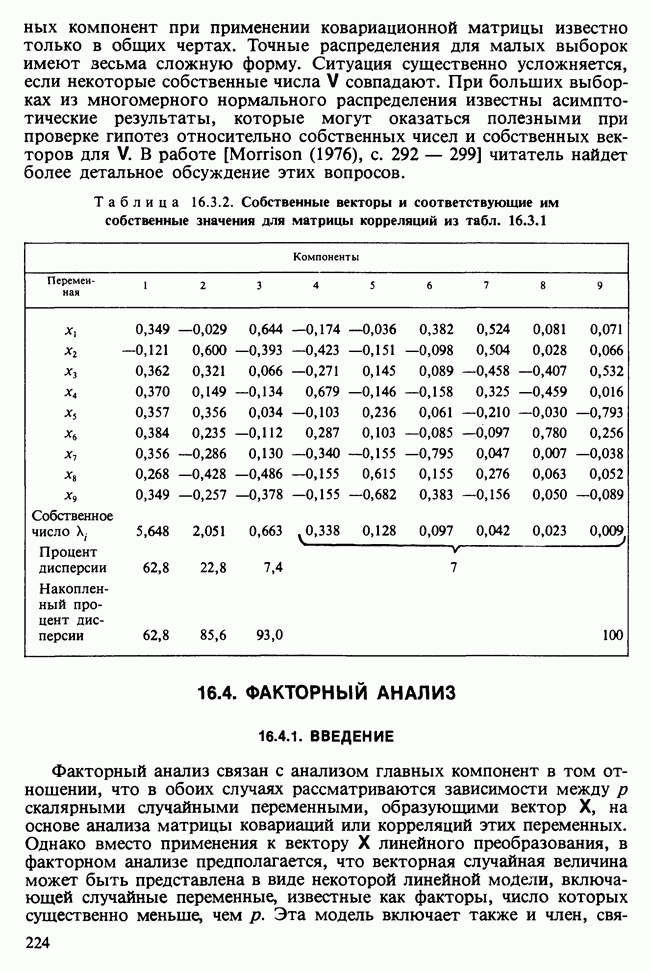
и наблюдаемое значение 4,52 незначимо на 5%-ном уровне, что указывает на осмысленность подгонки.