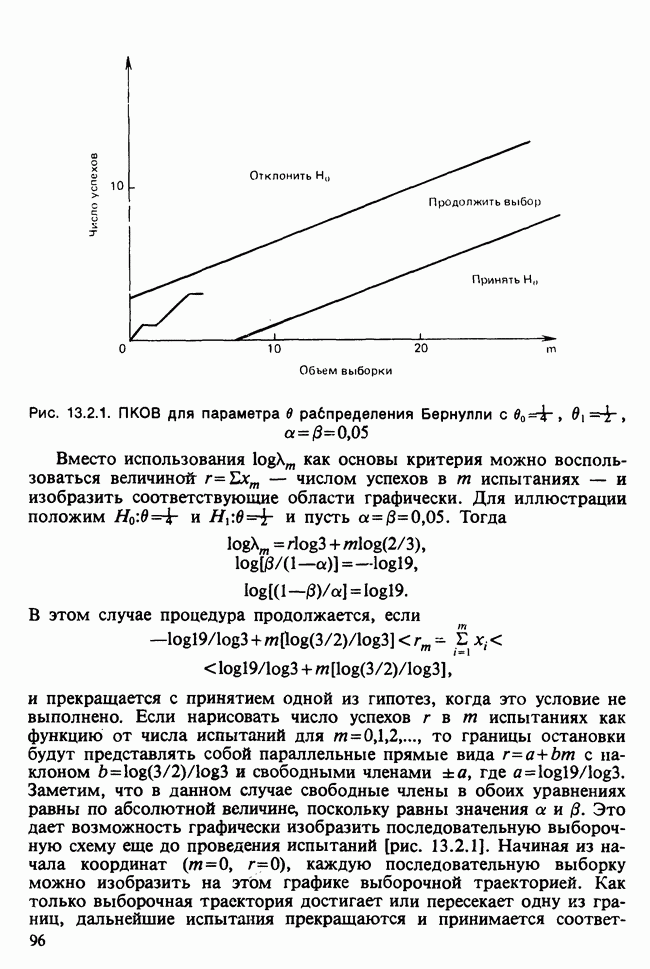
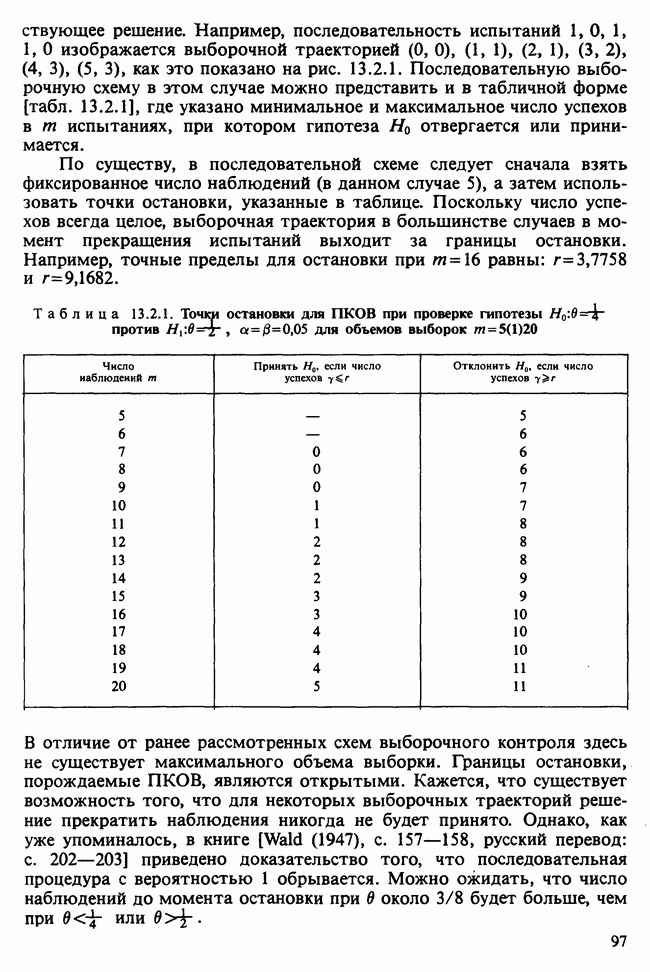
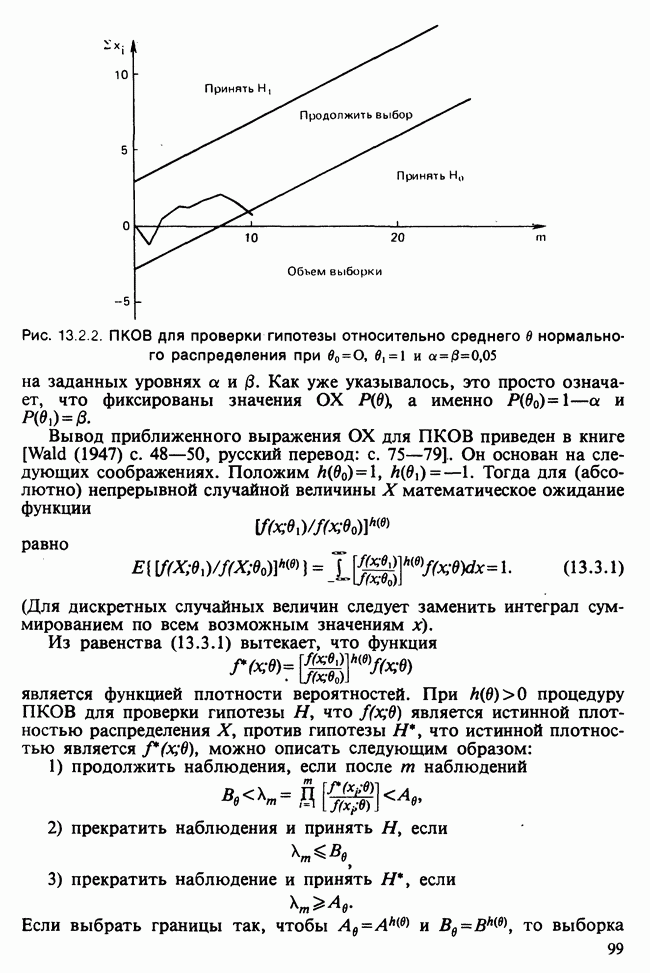
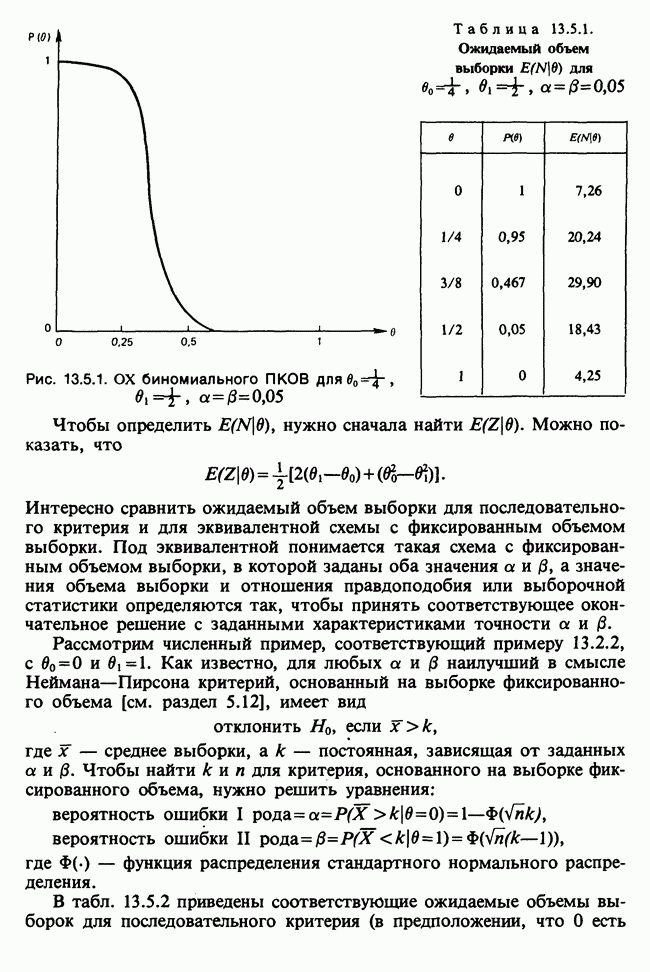
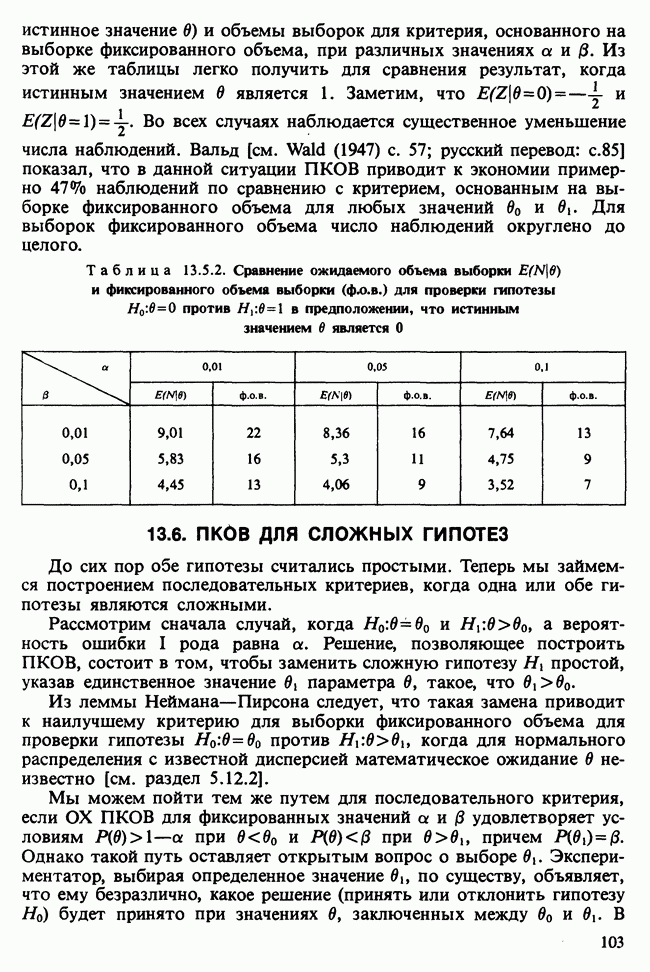
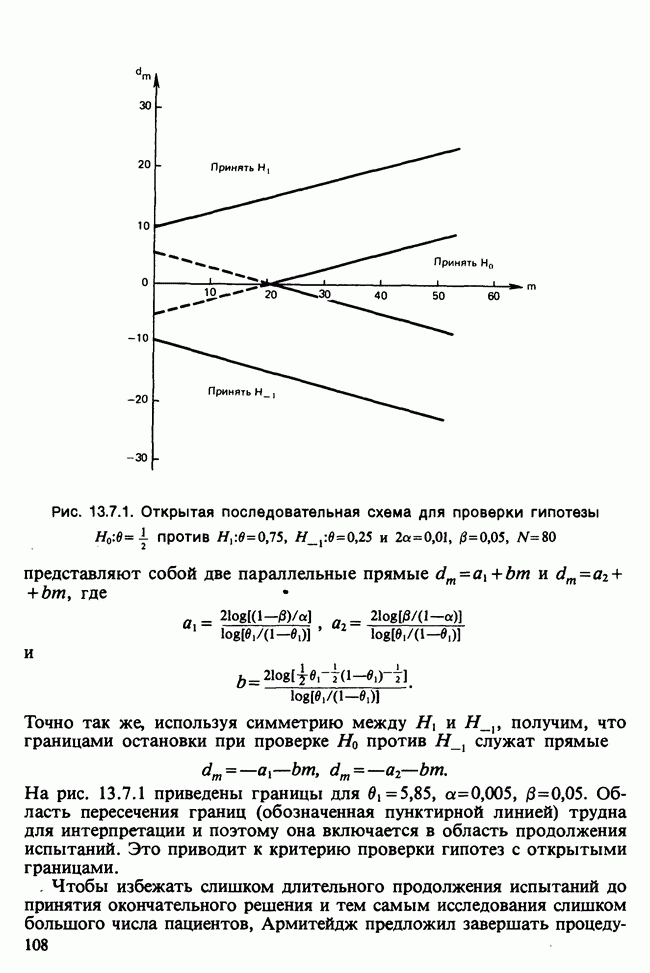
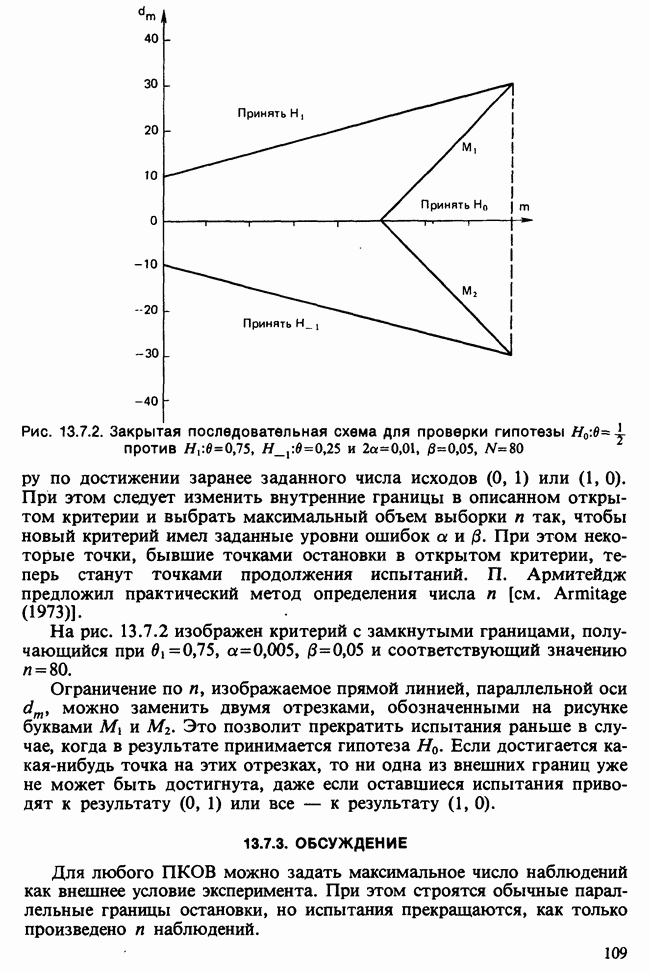
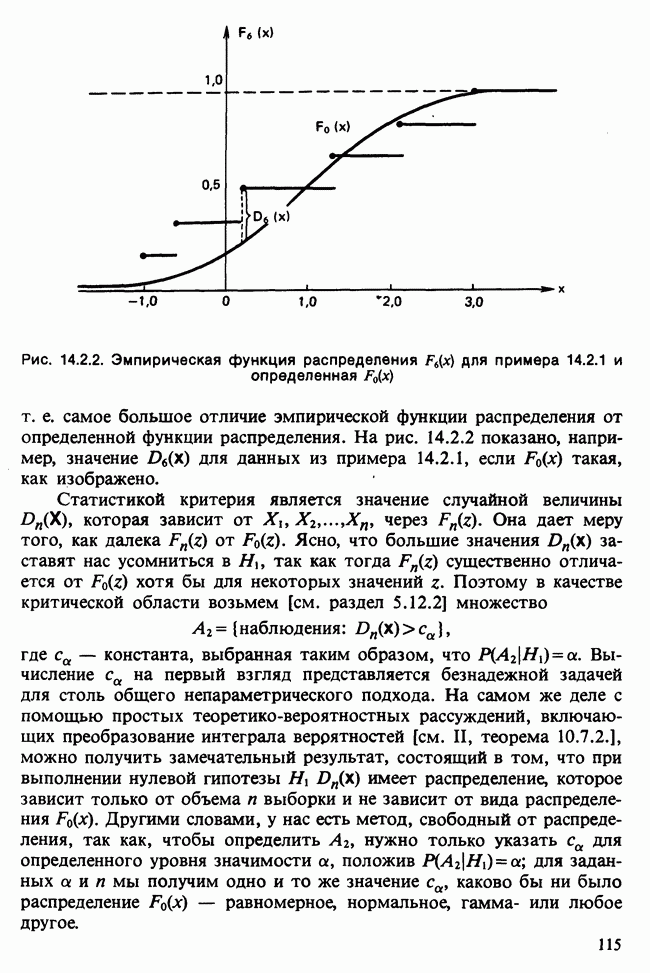
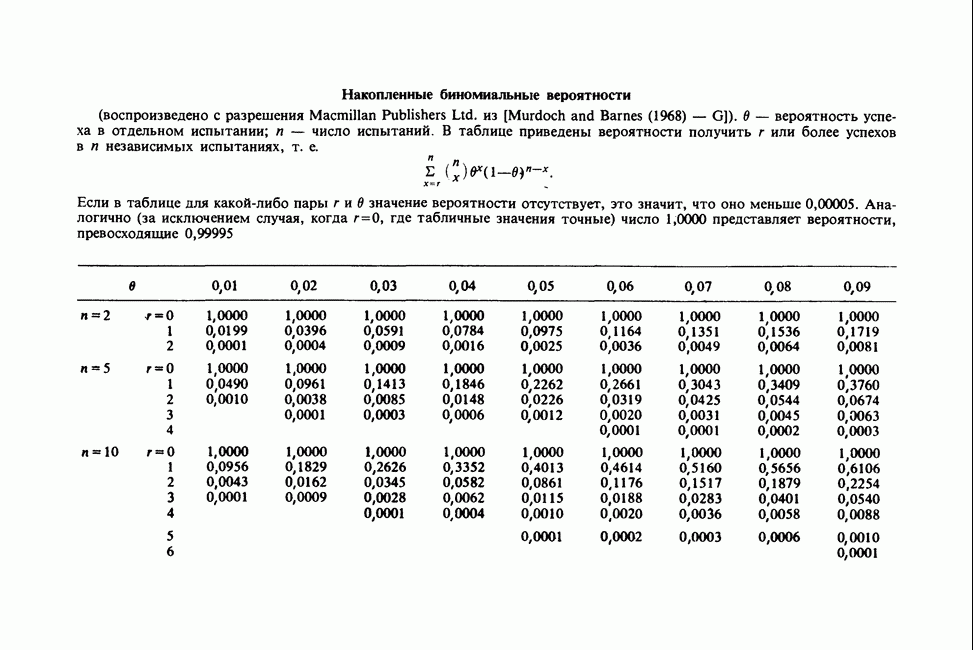
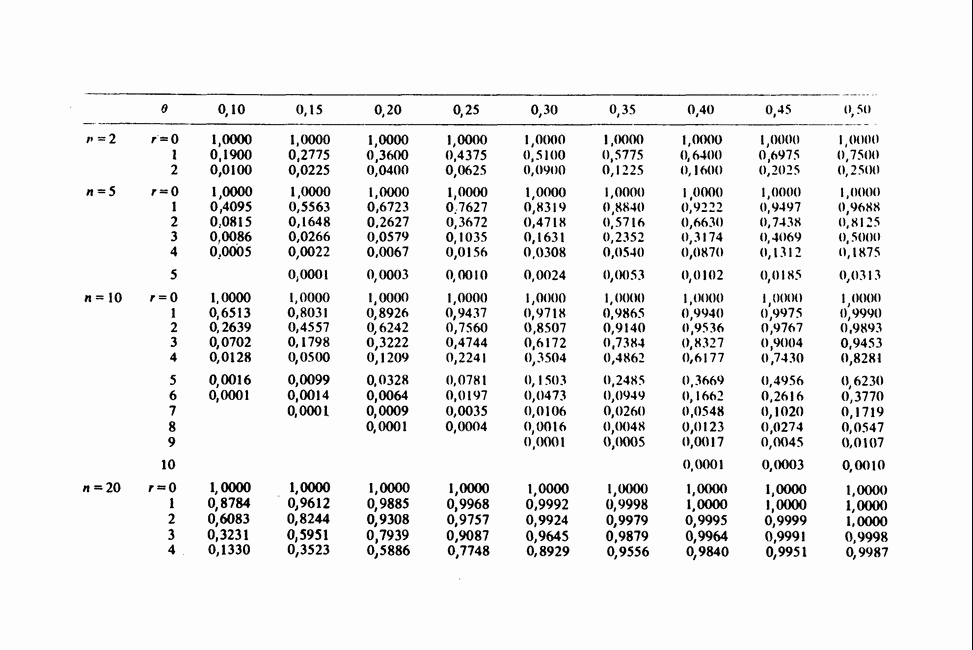
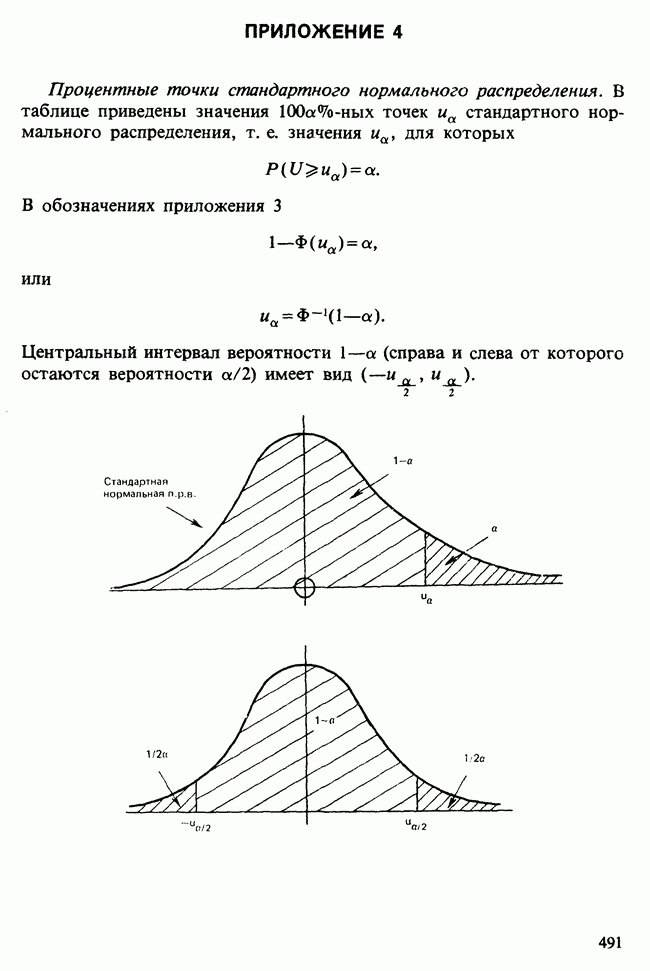
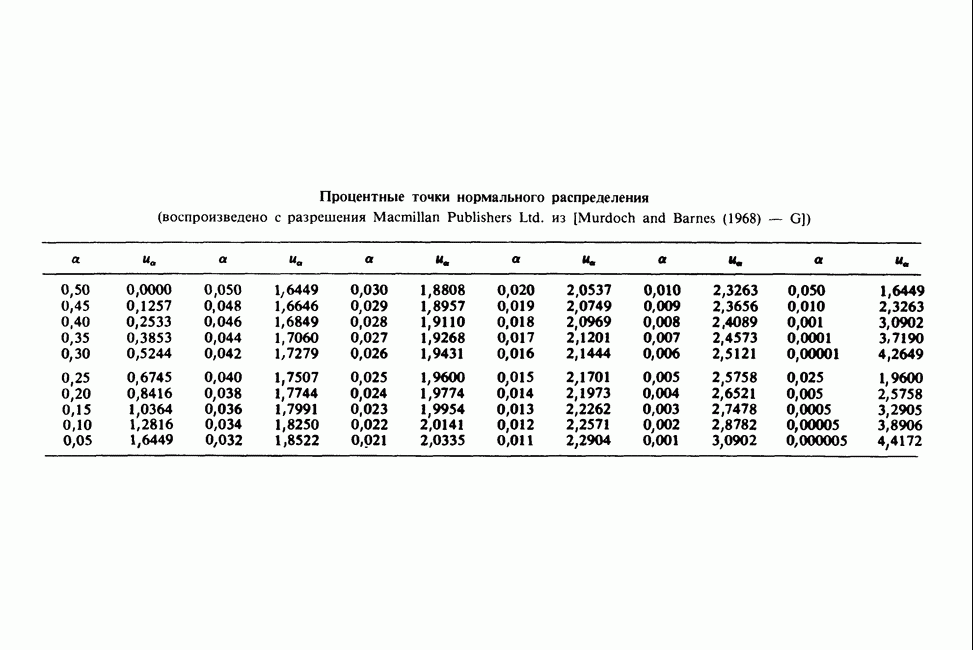
Пред.
След.
Макеты страниц
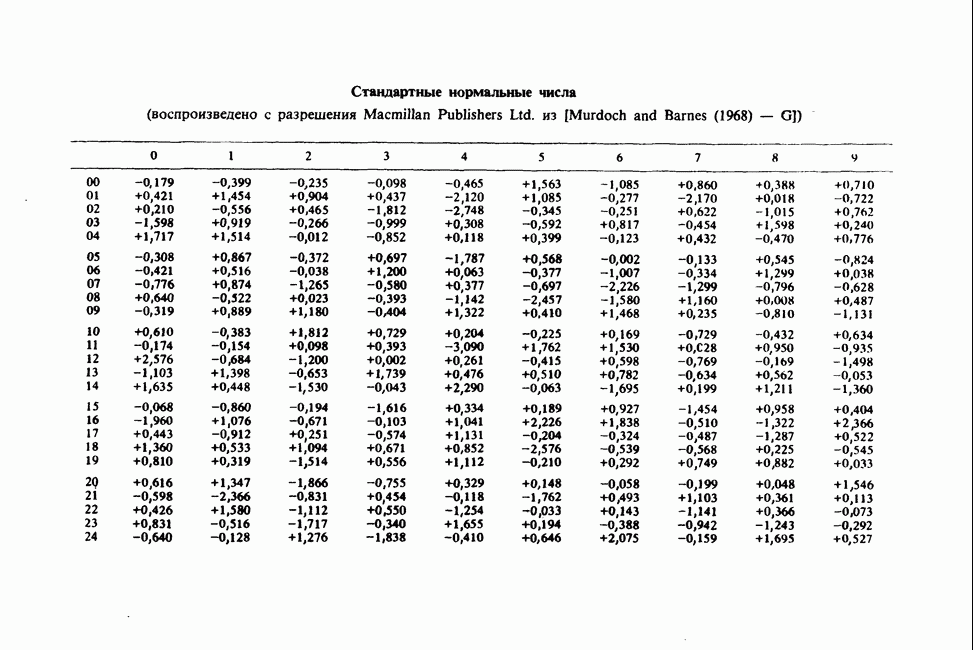
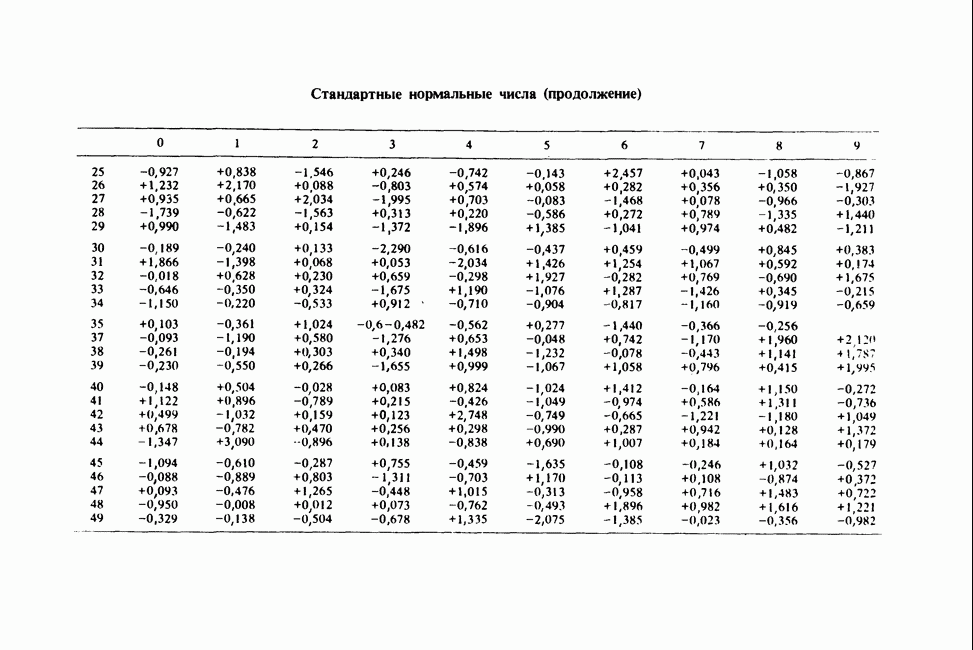
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
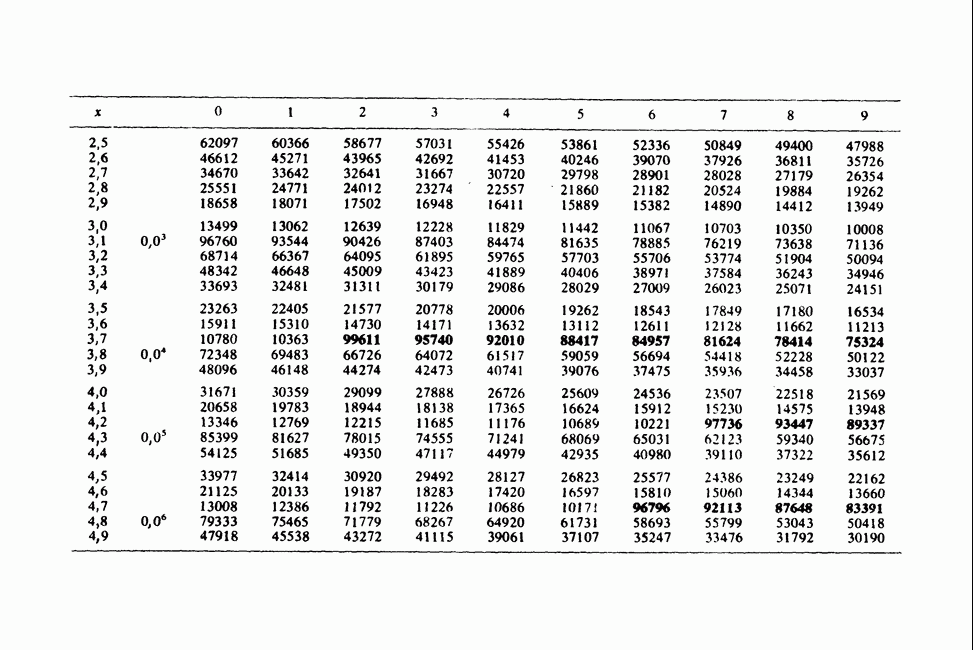
16.3. ГЛАВНЫЕ КОМПОНЕНТЫ16.3.1. ВВЕДЕНИЕВ этом разделе для упрощения изложения мы будем предполагать, что Главные компоненты представляют собой ортогональные линейные преобразования (т. е. некоррелированные случайные переменные) [см. раздел 2.5.3, п. е)] векторной случайной величины X, такие, что первая из них имеет наибольшую дисперсию, дисперсия убывает с ростом номера переменной, так что Анализ главных компонент направлен на сокращение числа переменных для анализа с использованием небольшого числа первых главных компонент и исключением линейных комбинаций (главных компонент) с минимальной дисперсией. 16.3.2. ГЛАВНЫЕ КОМПОНЕНТЫ СОВОКУПНОСТИПусть
Ясно, что
и
Вектор коэффициентов
Таким образом мы приходим к проблеме максимизации при наличии ограничений, которая может быть решена с применением множителей Лагранжа [см. IV, раздел 5.15]. Тогда задача сводится к нахождению вектора
где
где I — единичная матрица. Поскольку нас интересуют только решения, когда
Следовательно, Выражение (16.3.2) может быть переписано в виде
Умножая слева на
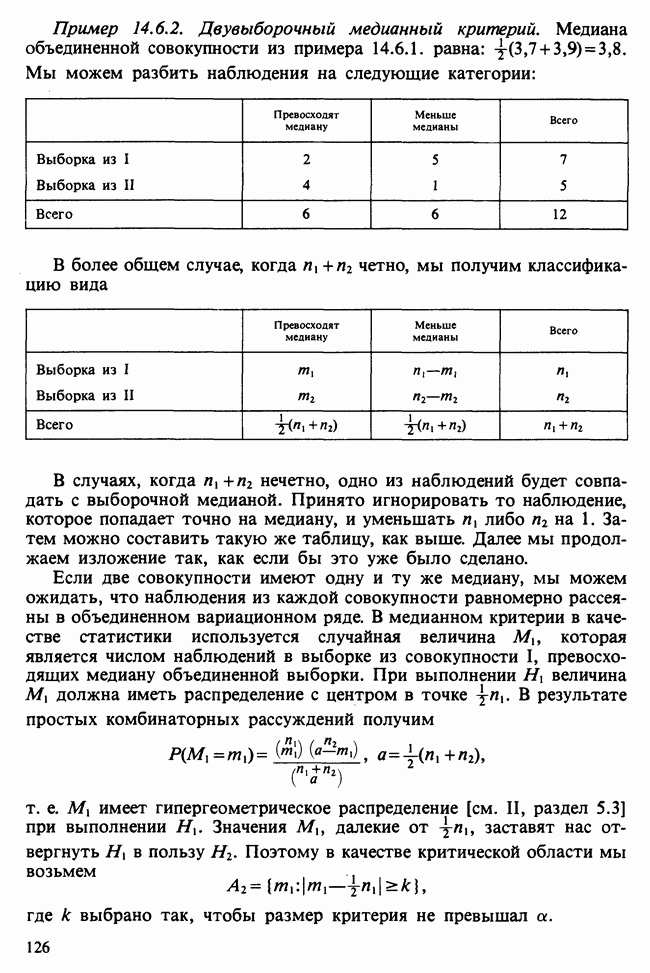
Но левая часть равенства (16.3.4) есть Чтобы найти вторую главную компоненту
потребуем выполнения двух условий — условия нормировки:
и условия ортогональности:
Вектор при выполнении двух указанных условий. Эта задача требует использования двух множителей Лагранжа
Взяв производную от (16.3.7) и приравняв ее к Процесс повторяется до тех пор, пока все собственные числа и собственные векторы не окажутся дисперсиями и коэффициентами линейных комбинаций главных компонент. Чтобы доказать этот результат для
и К сожалению, свойства главных компонент зависят от шкал измерений исходных переменных, т. е. они не являются масштабноинвариантными. Например, переход при измерении некоторого размера от футов к дюймам и при измерении времени от часов к секундам приведет, вообще говоря, к другим собственным числам и векторам. По этой причине, возможно, наиболее оптимальной будет работа со стандартизованными переменными
которые имеют нулевые средние значения и единичные дисперсии. В этом случае ковариационная матрица для Ранее мы не делали никаких предположений относительно ранга [см. I, раздел 5.6] матрицы V. Если матрица V не является матрицей полного ранга, то несколько наименьших ее собственных чисел будут нулевыми и вектор X может быть преобразован в меньшее, чем Поскольку
сумма собственных чисел может рассматриваться как полная дисперсия совокупности, а о первых
Если эта доля достаточно велика, то компоненты с дисперсиями
Если используется корреляционная матрица
На практике должен быть сделан выбор, получать ли главные компоненты на основе ковариационной матрицы или на основе корреляционной. Доля дисперсии, объясненная первыми главными компонентами, в обоих случаях будет различной. С помощью ковариационной матрицы можно получить компоненты с большими дисперсиями просто в силу выбора шкалы измерений одного их 16.3.3. ВЫБОРОЧНЫЕ ГЛАВНЫЕ КОМПОНЕНТЫВ предыдущем разделе обсуждалась проблема получения главных компонент для совокупности, когда параметры совокупности известны. На практике же параметры совокупности оцениваются по выборке, например, объема к. Матрица данных может быть центрирована, и выборочные главные компоненты оценены на основе выборочной ковариационной матрицы или выборочной корреляционной матрицы с помощью тех же методов, что описаны в предыдущем разделе. Необходимо иметь в виду, что имеется различие в вычисляемых значениях главных компонент для 16.3.4. ЧИСЛЕННЫЙ ПРИМЕРОценивались главные компоненты девяти характеристик, измеренных для шести клонов тополей. Дж. Джефферс [см. Jeffers (1965)] в этой задаче с помощью главных компонент попытался определить линейные комбинации девяти переменных, представляющих собой измерения на листьях шести клонов тополей. Эти комбинации должны были наилучшим образом разделять эти шесть клонов. Эти девять переменных следующие:
Для каждого из шести клонов было сделано пять наблюдений Таблица 16.3.1. Корреляции между девятью переменными [см. Jeffers (1965)]
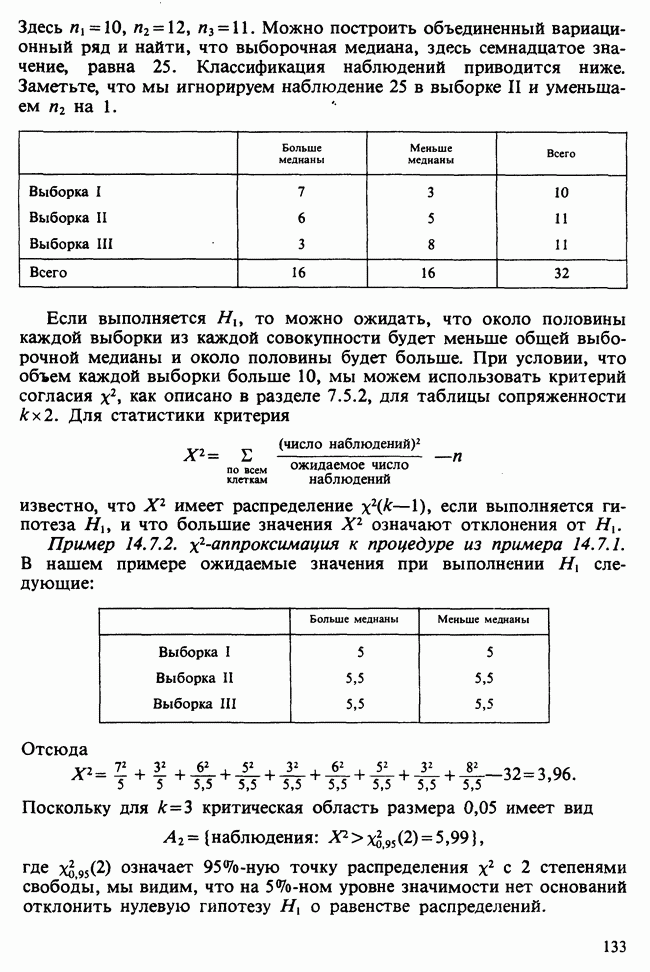
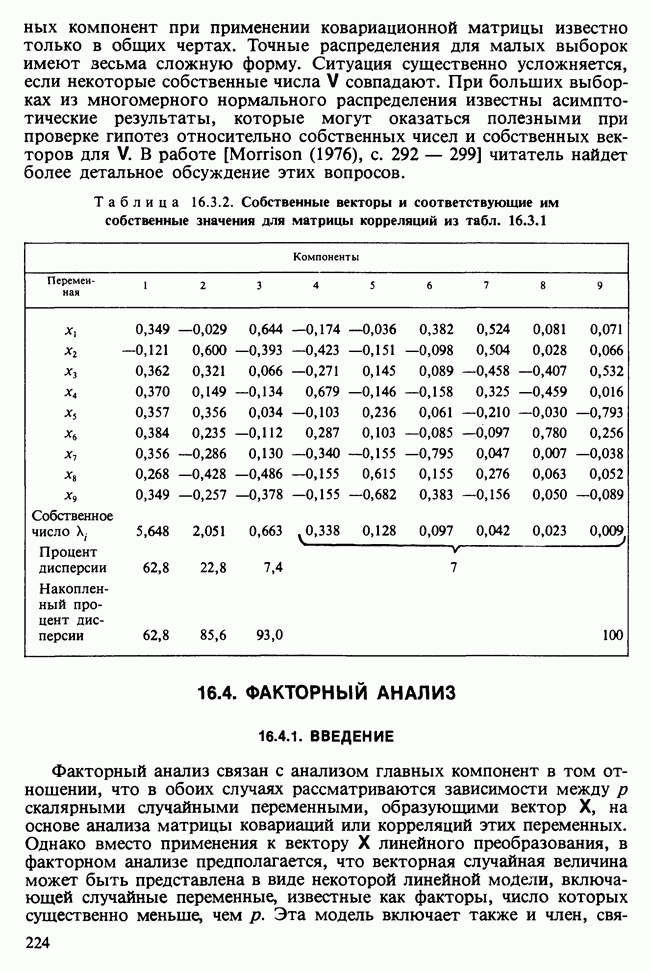
Из табл. 16.3.2 видно, что большая часть дисперсии объясняется с помощью первых двух главных компонент. Чтобы попытаться дать содержательную интерпретацию главных компонент, полезно разделить коэффициенты каждого собственного вектора на его наибольший по абсолютной величине коэффициент и обосновать интерпретацию на тех коэффициентах, абсолютная величина которых после такого деления больше или равна 0,7 [см. Например, в табл. 16.3.2 компоненты 1 и 2 вместе дают некоторую суммаризацию размерам листа, а компонента 5, напротив, связана с углами 16.3.5. НЕКОТОРЫЕ ВЫБОРОЧНЫЕ РАСПРЕДЕЛЕНИЯВ случае, когда X подчиняется многомерному нормальному распределению с вектором средних 0 и ковариационной матрицей V, главные компоненты совокупности будут распределены нормально, так как они являются линейными функциями случайных величин Распределение собственных чисел и векторов для выборочных главных компонент при применении ковариационной матрицы известно только в общих чертах. Точные распределения для малых выборок имеют весьма сложную форму. Ситуация существенно усложняется, если некоторые собственные числа V совпадают. При больших выборках из многомерного нормального распределения известны асимптотические результаты, которые могут оказаться полезными при проверке гипотез относительно собственных чисел и собственных векторов для V. В работе [Morrison (1976), с. 292 — 299] читатель найдет более детальное обсуждение этих вопросов. Таблица 16.3.2. (см. скан) Собственные векторы и соответствующие им собственные значения для матрицы корреляций из табл. 16.3.1
|
 |
Оглавление
|


























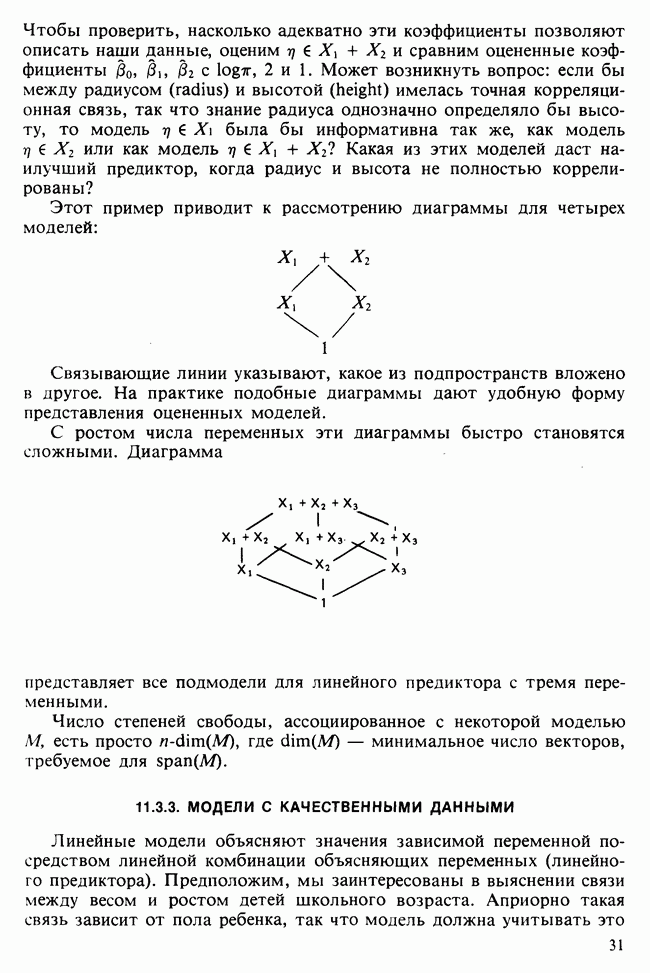











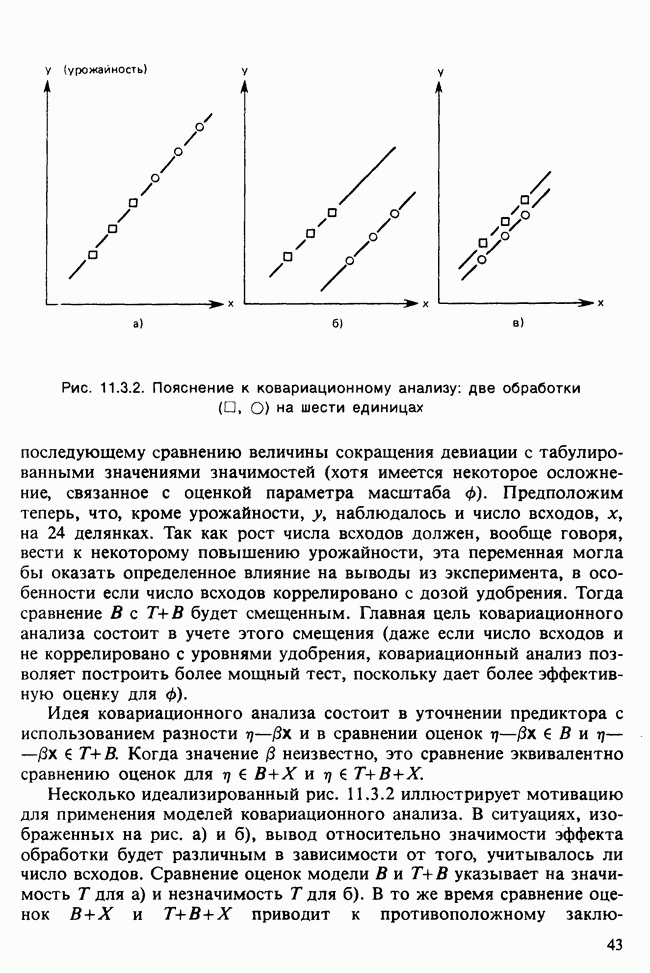








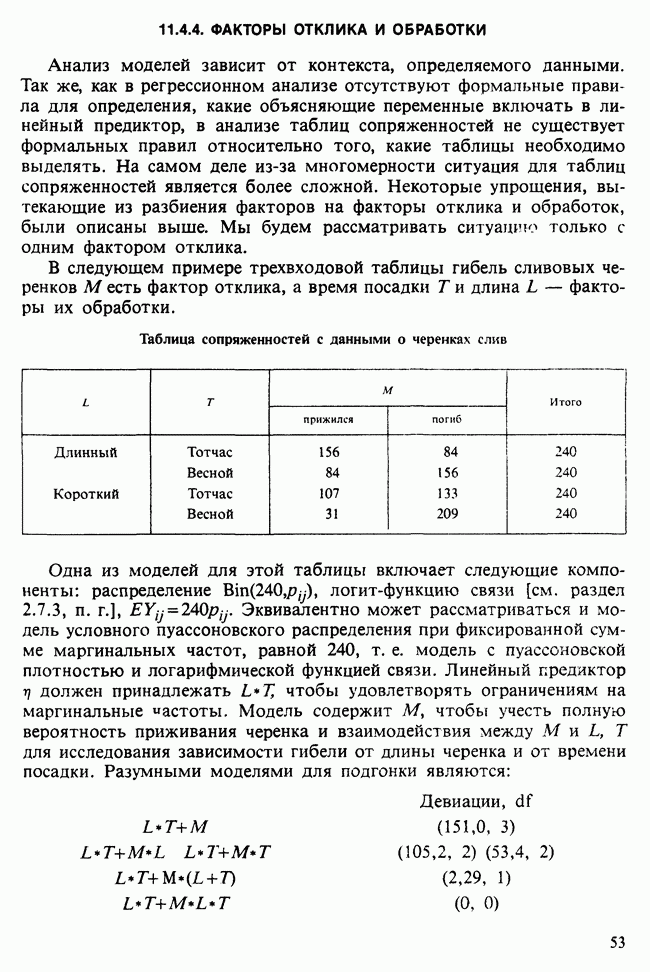




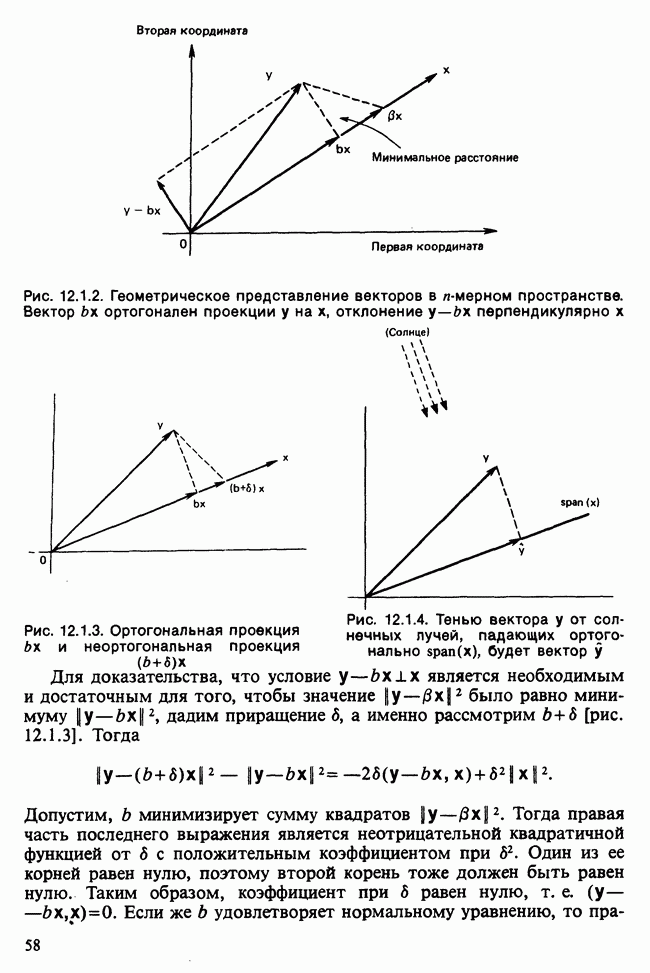





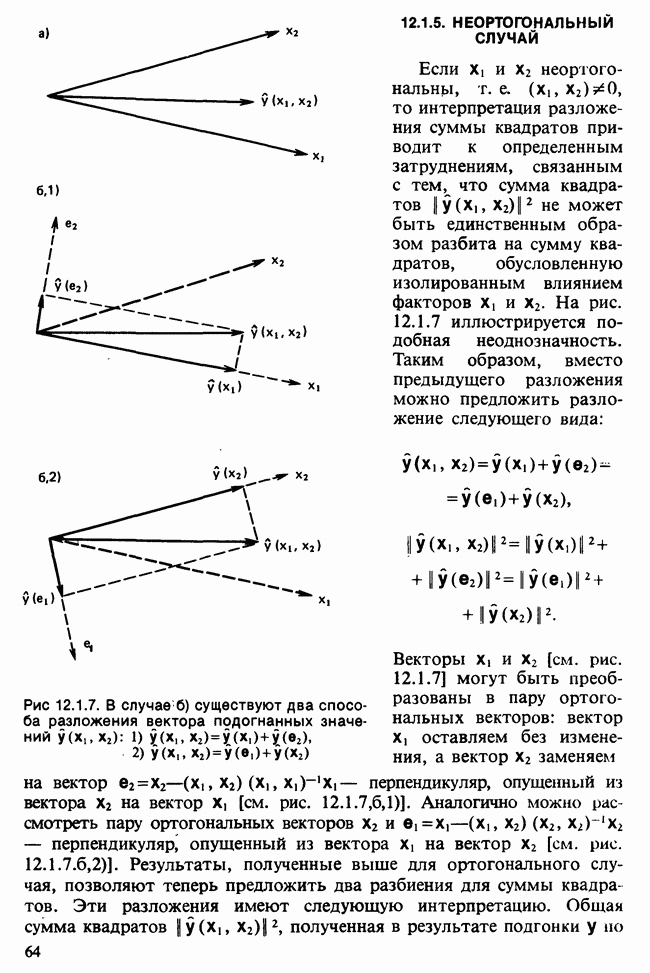


















































































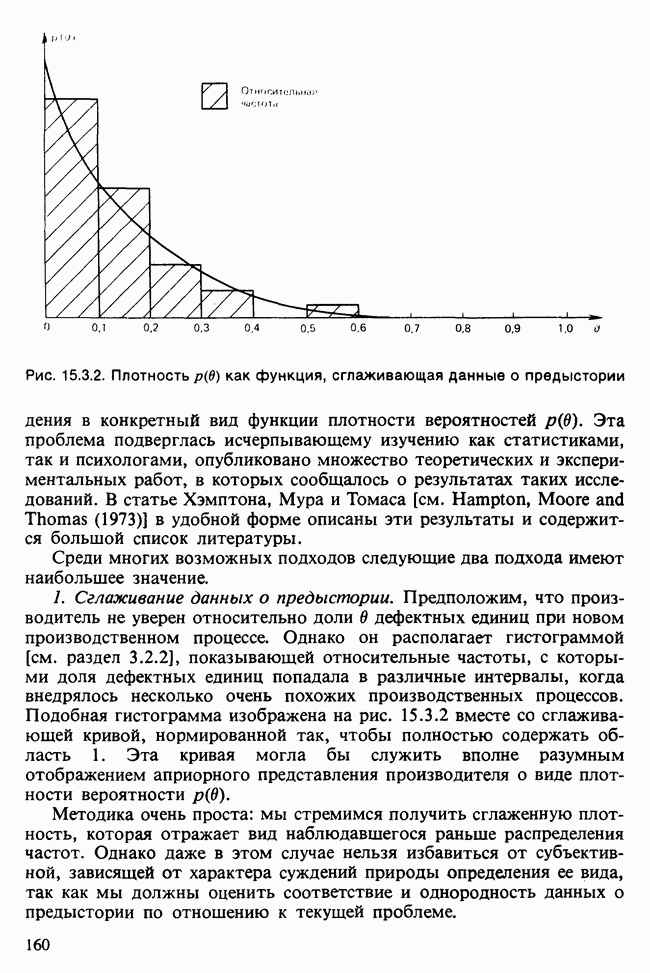

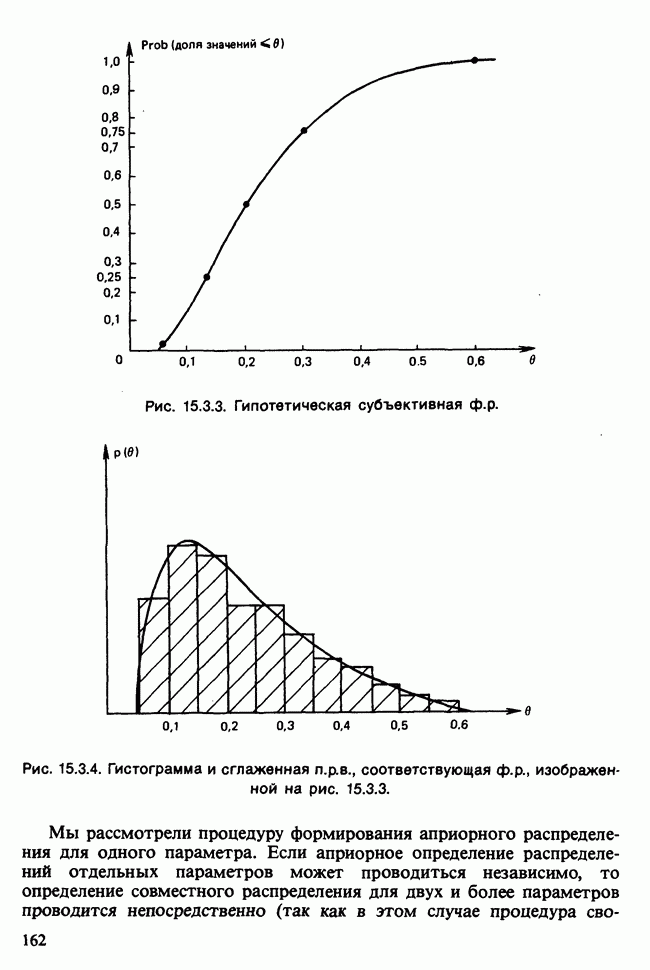


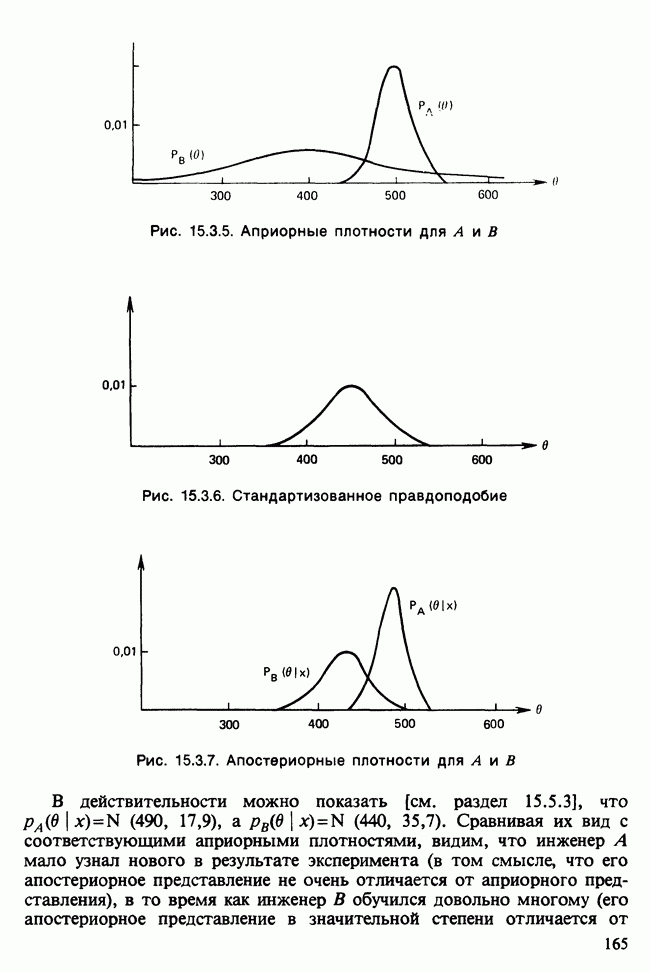
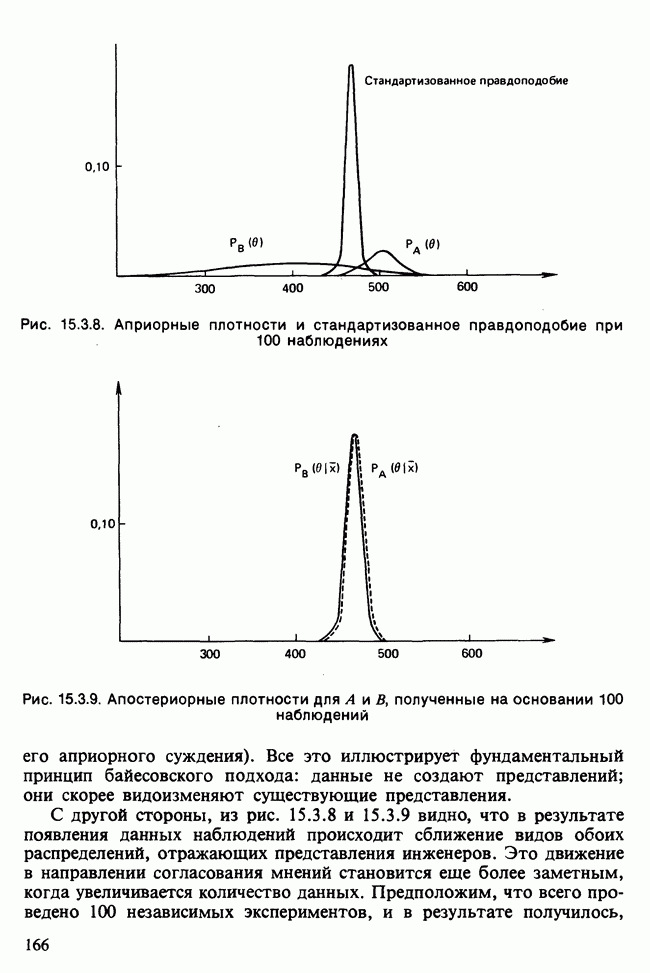


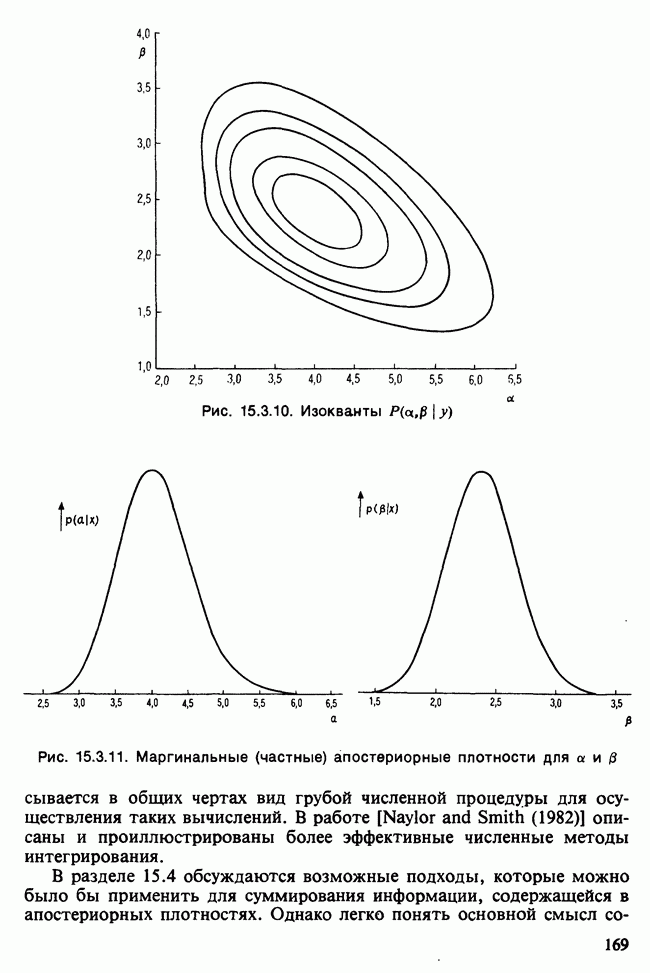
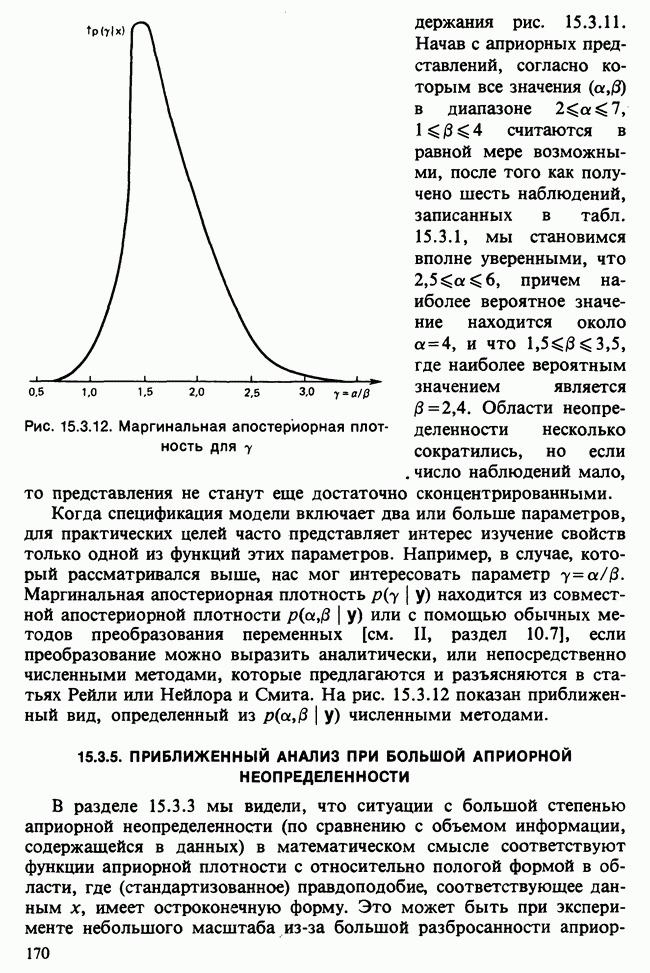
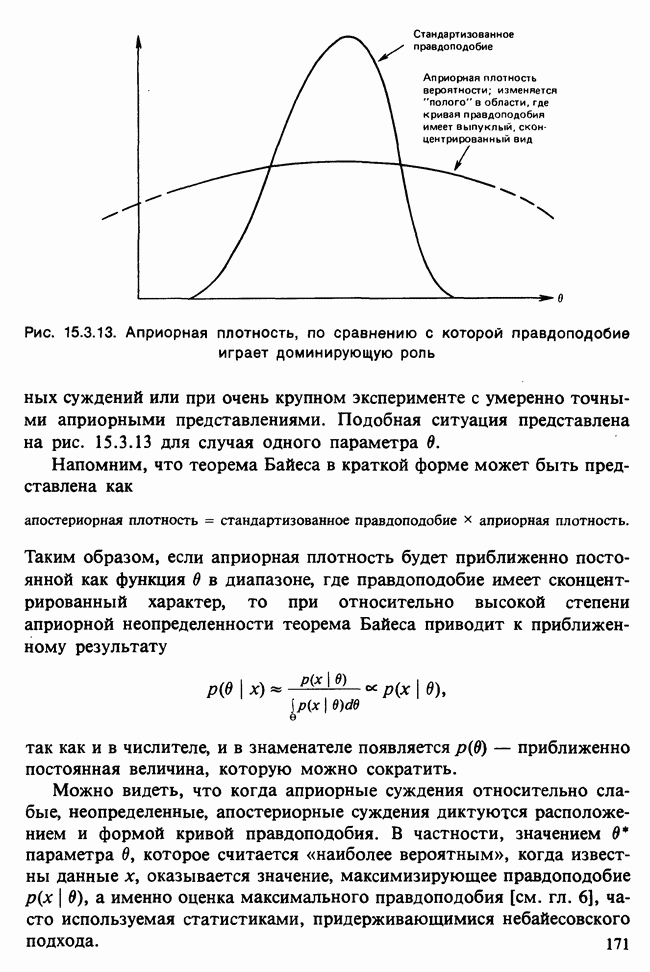




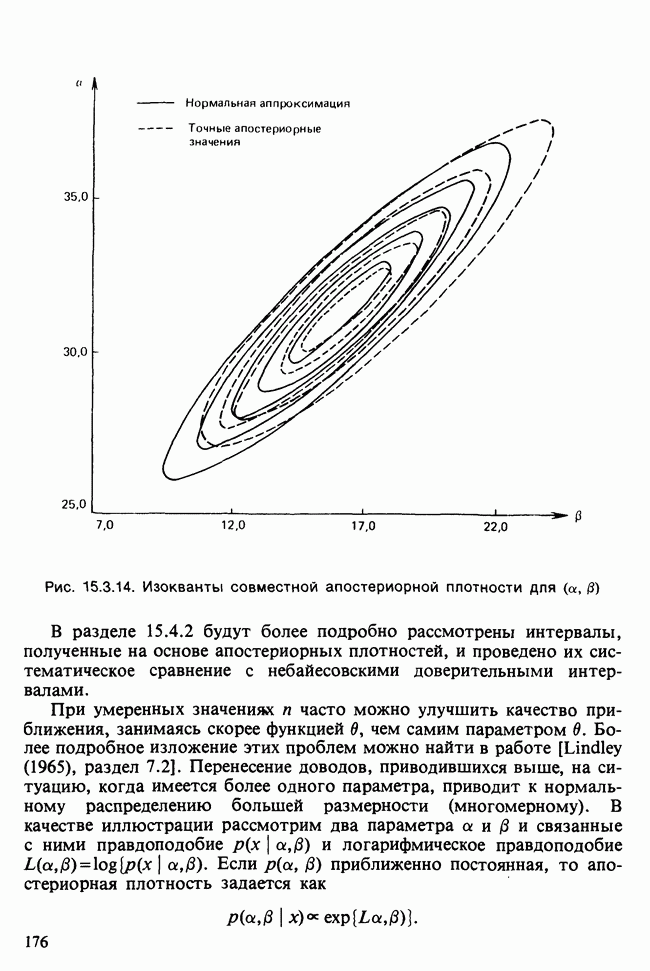



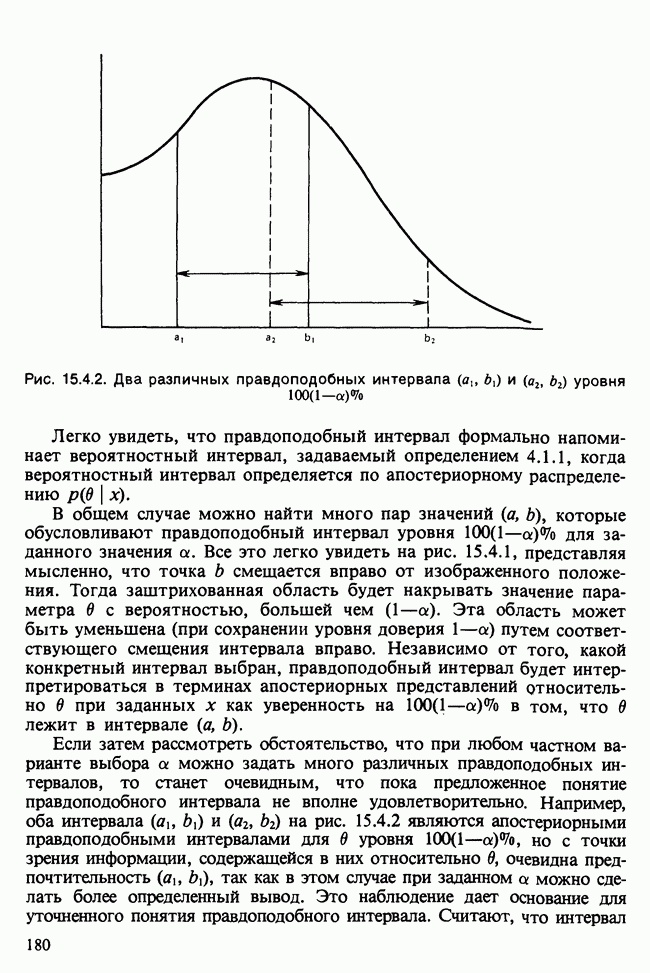






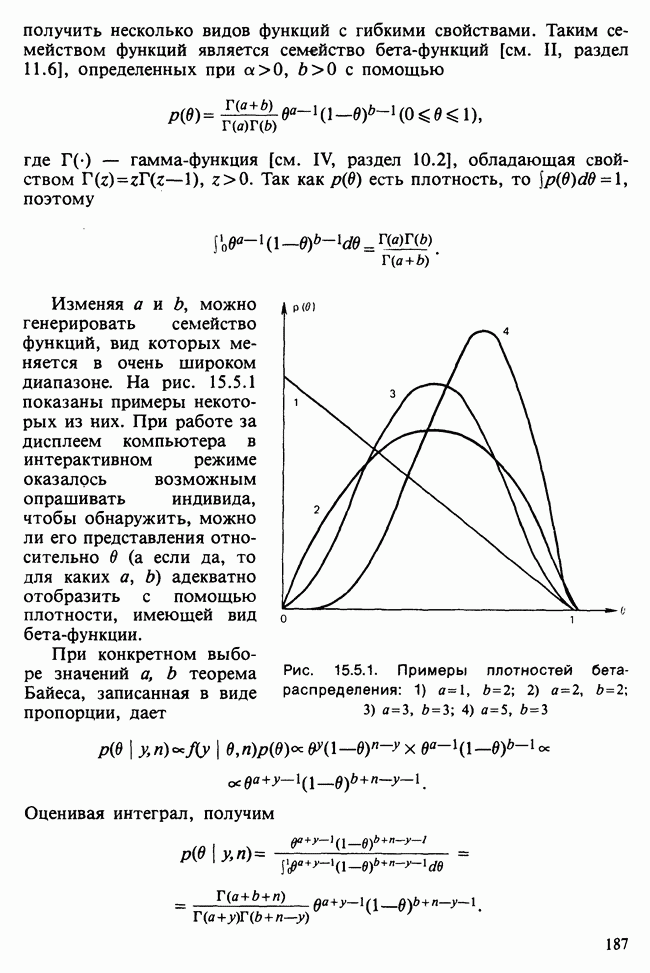





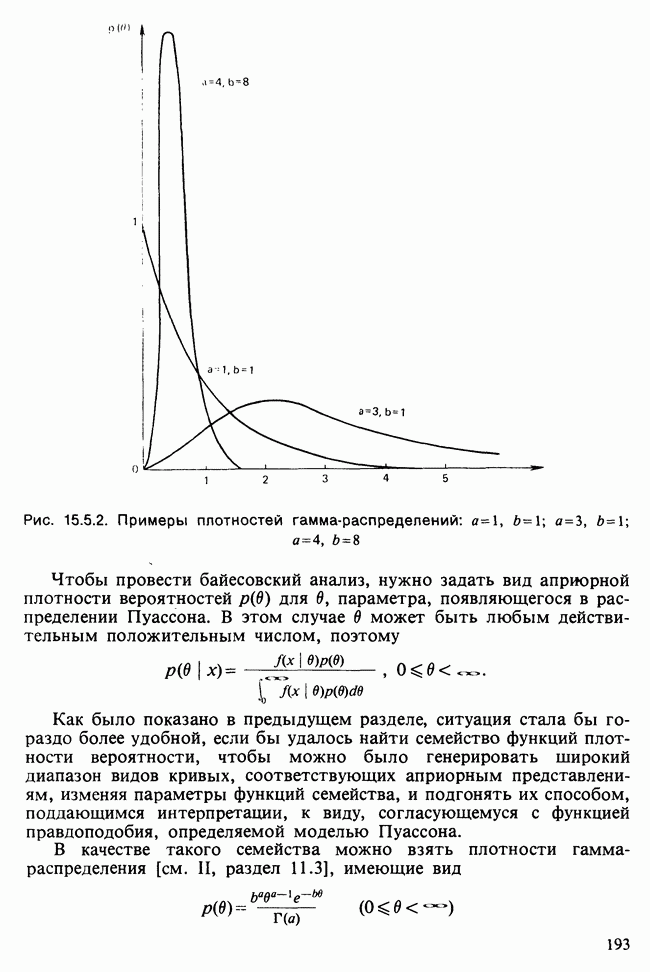






















































































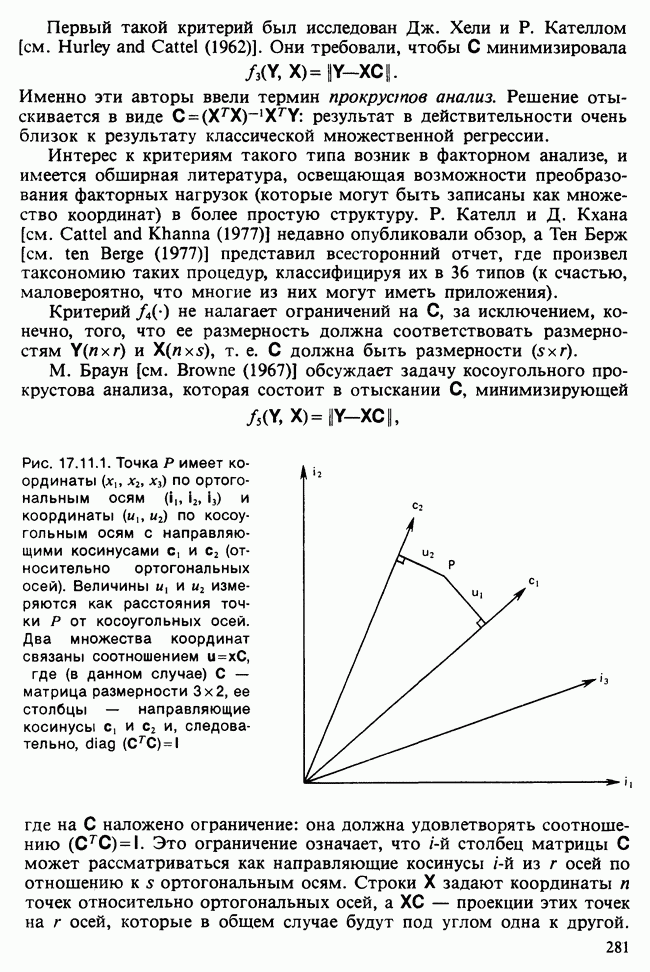







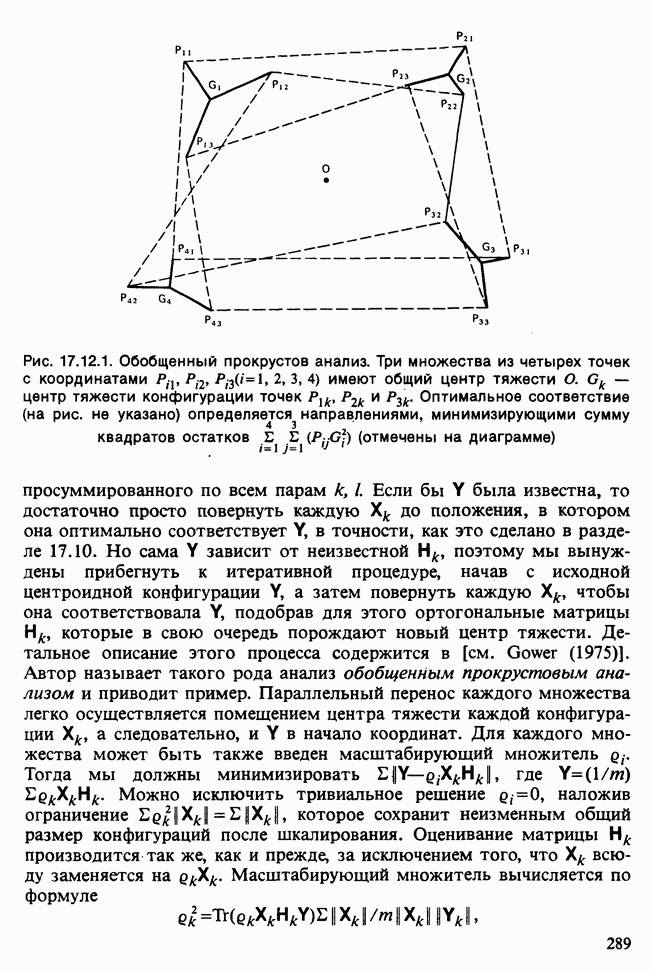











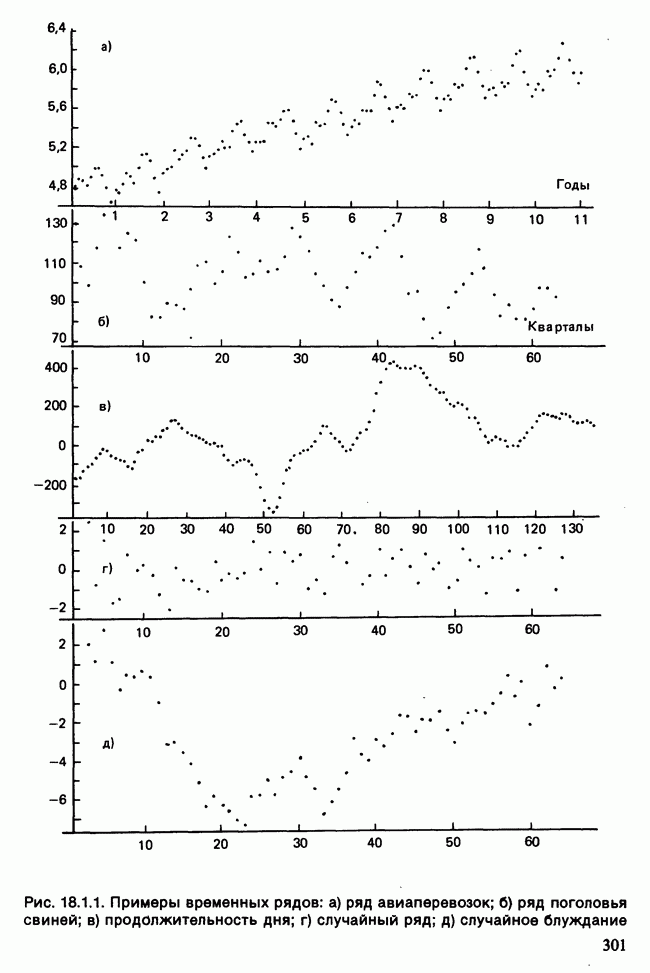

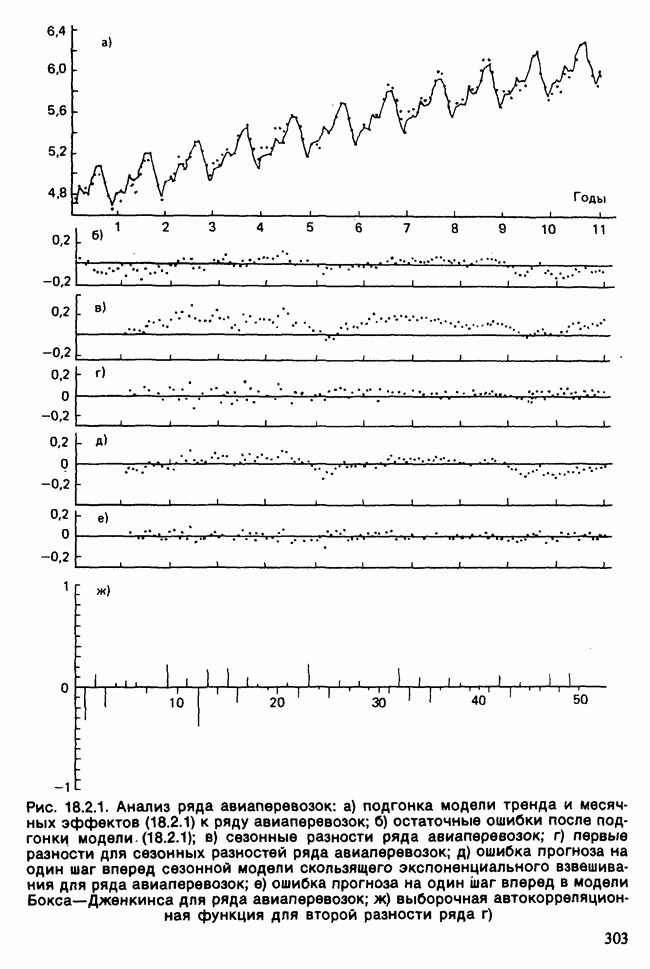

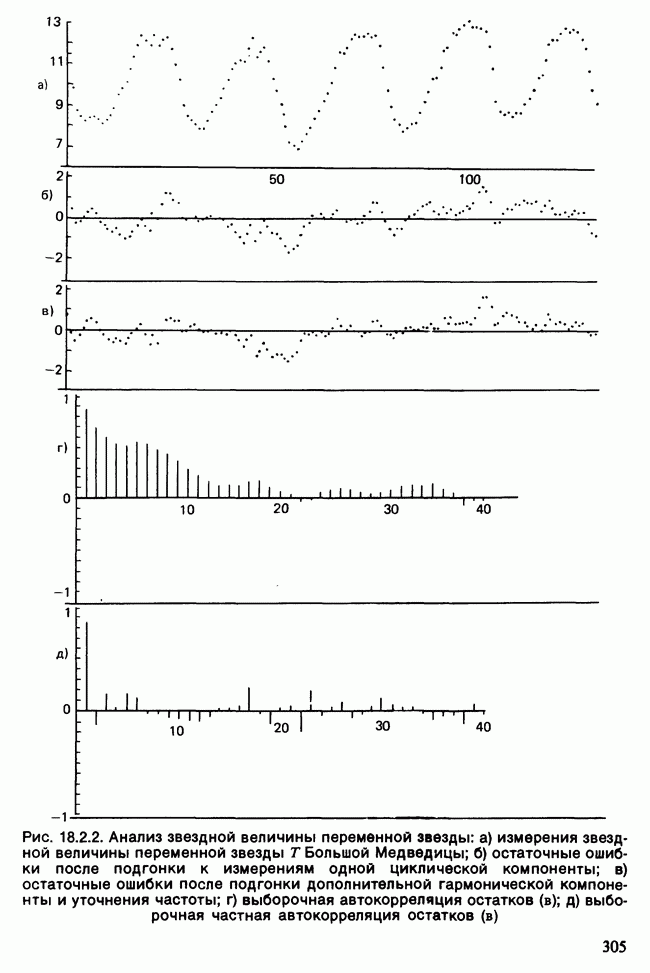



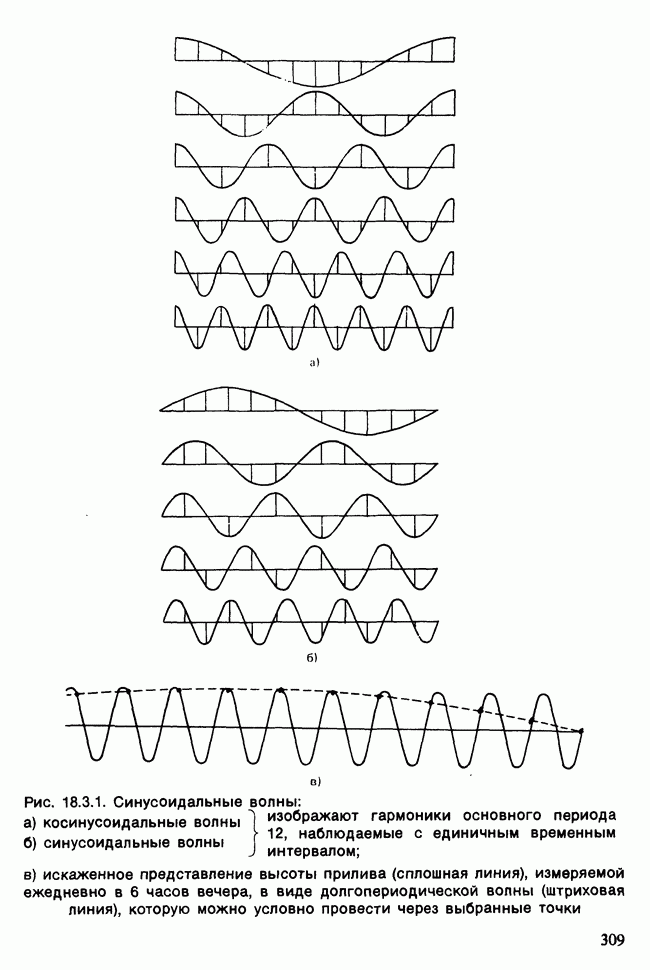



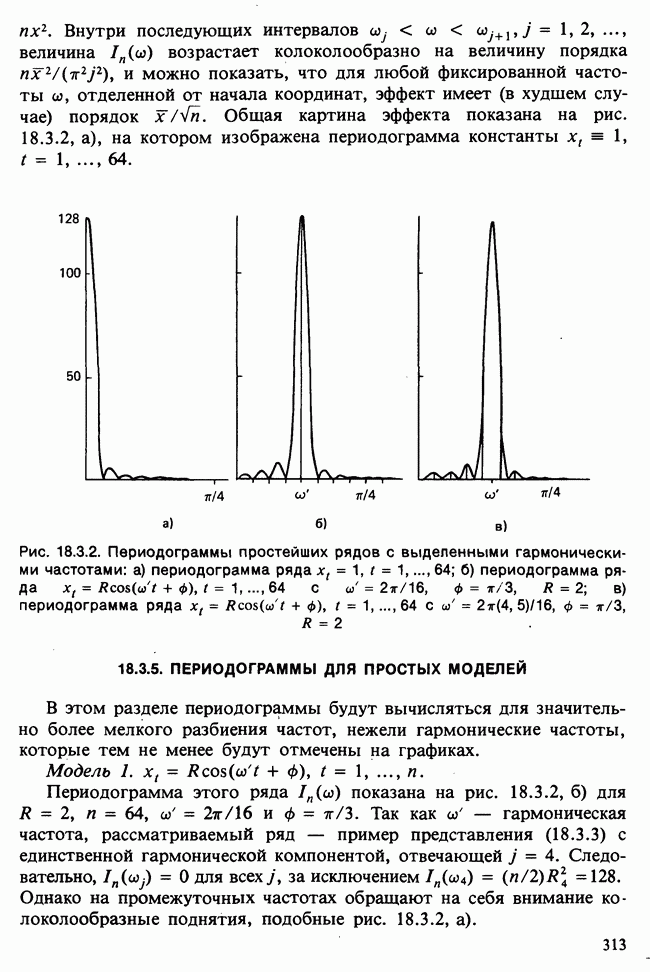

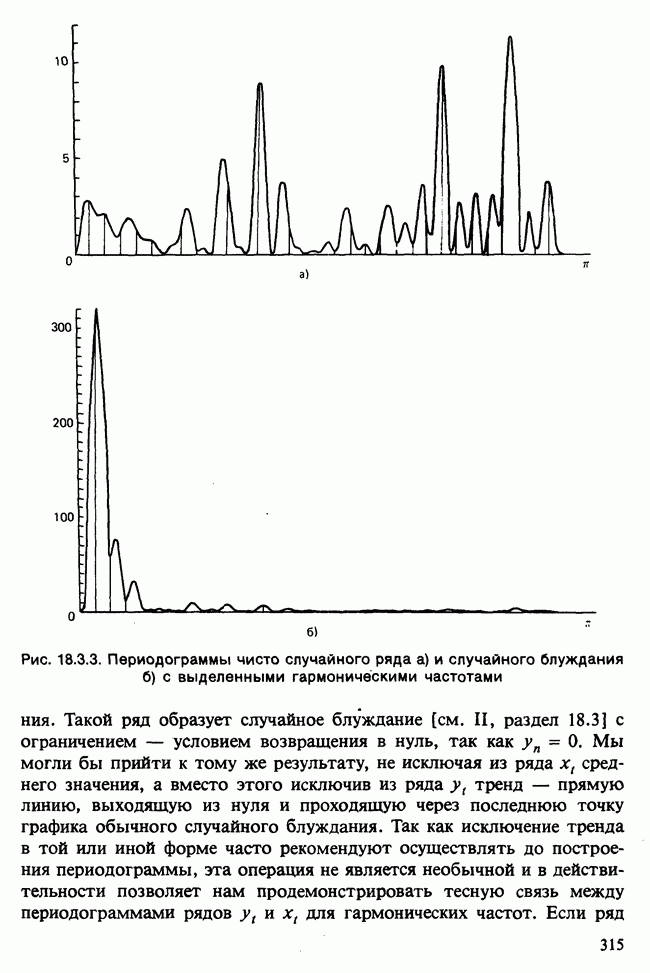

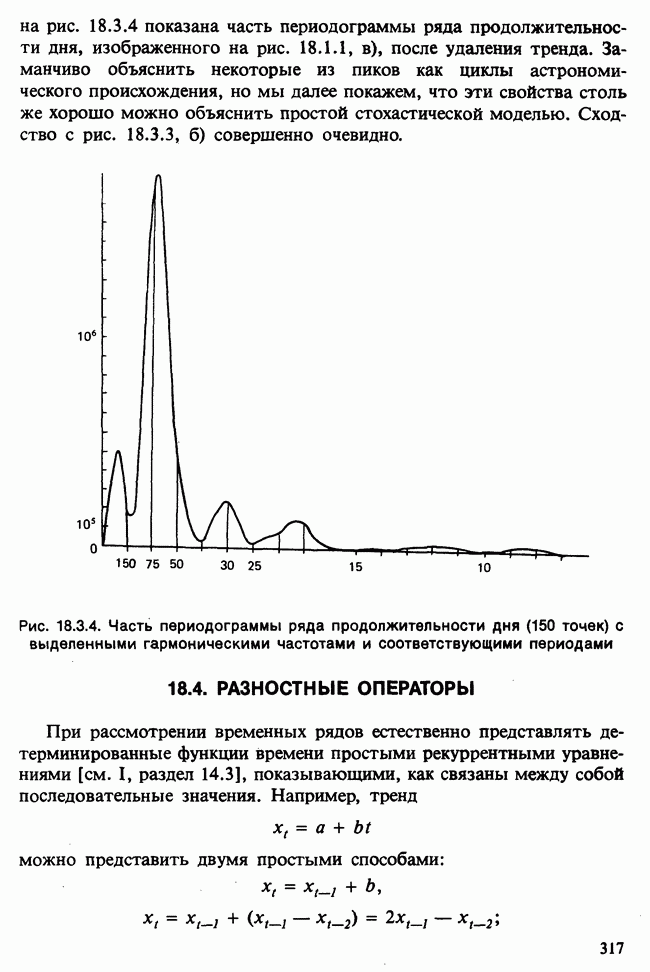













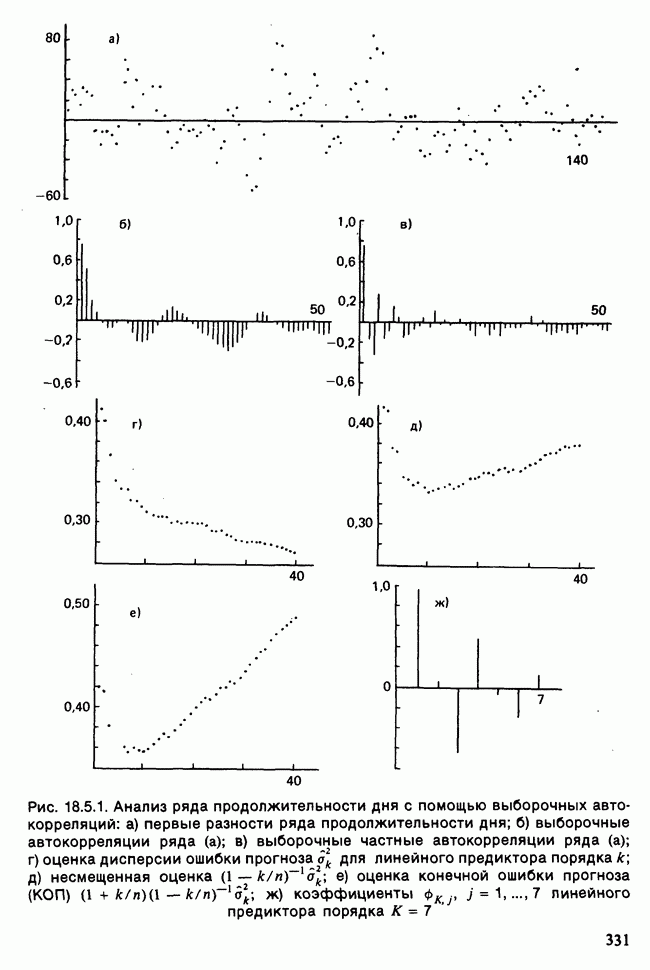
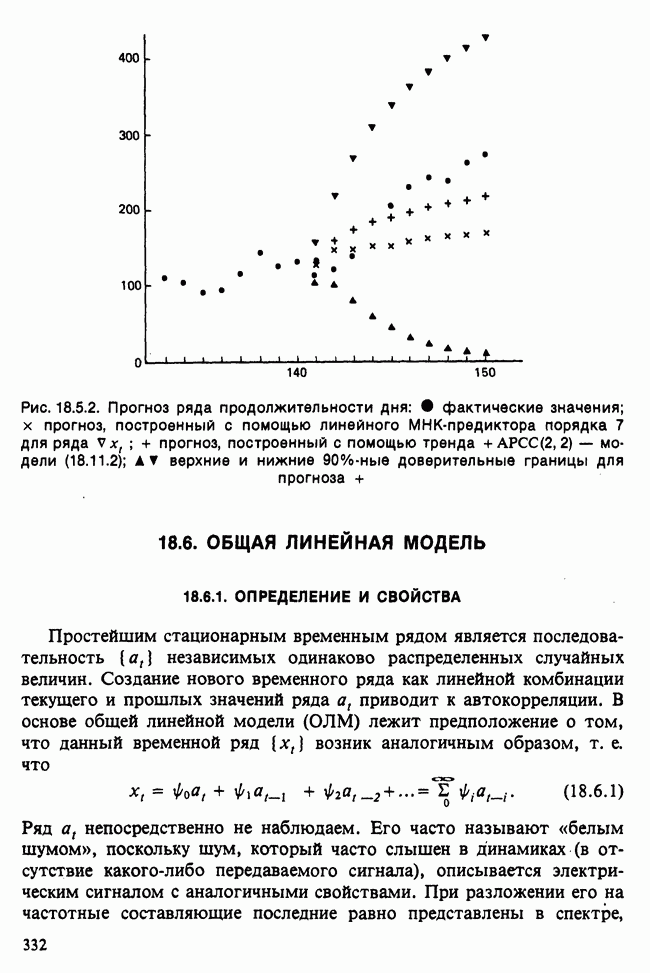





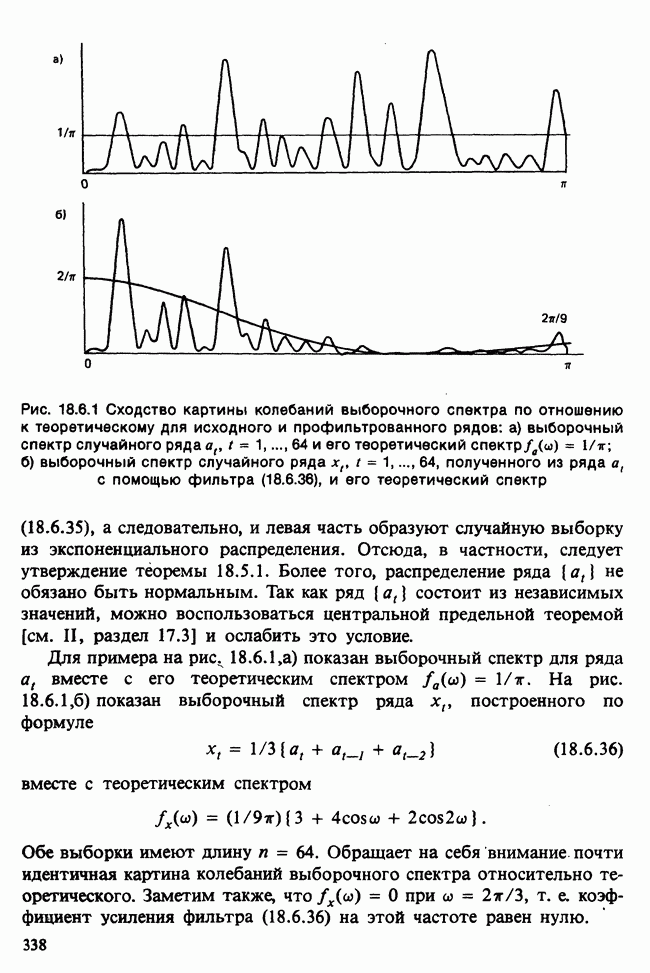























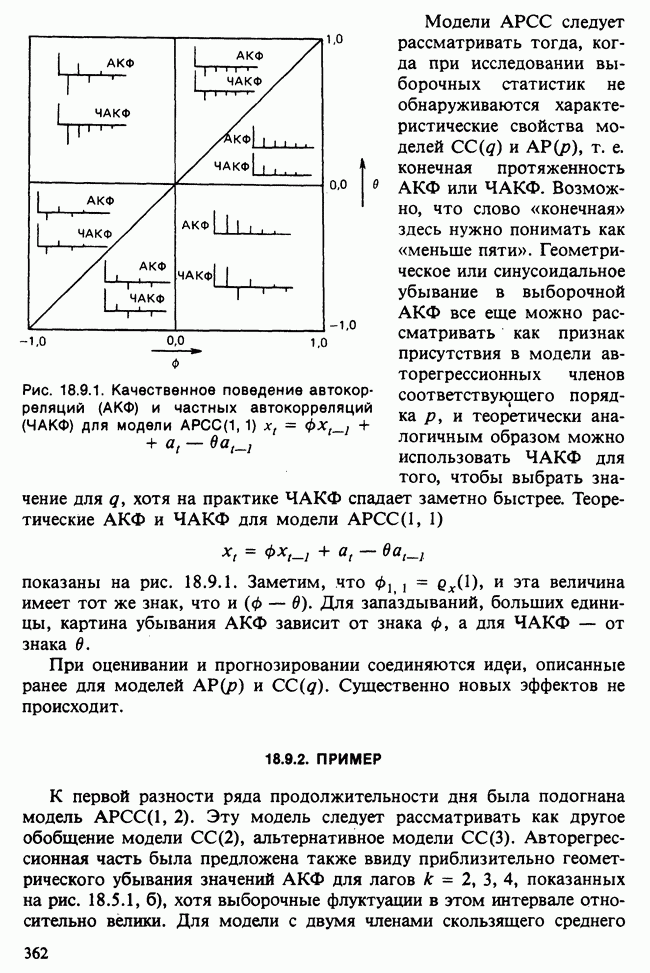


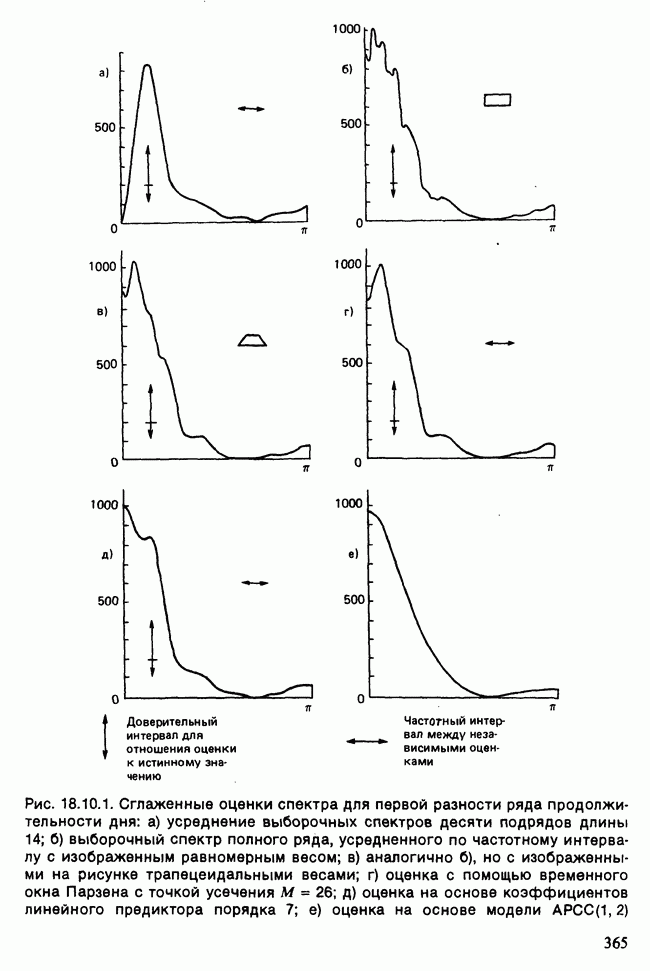












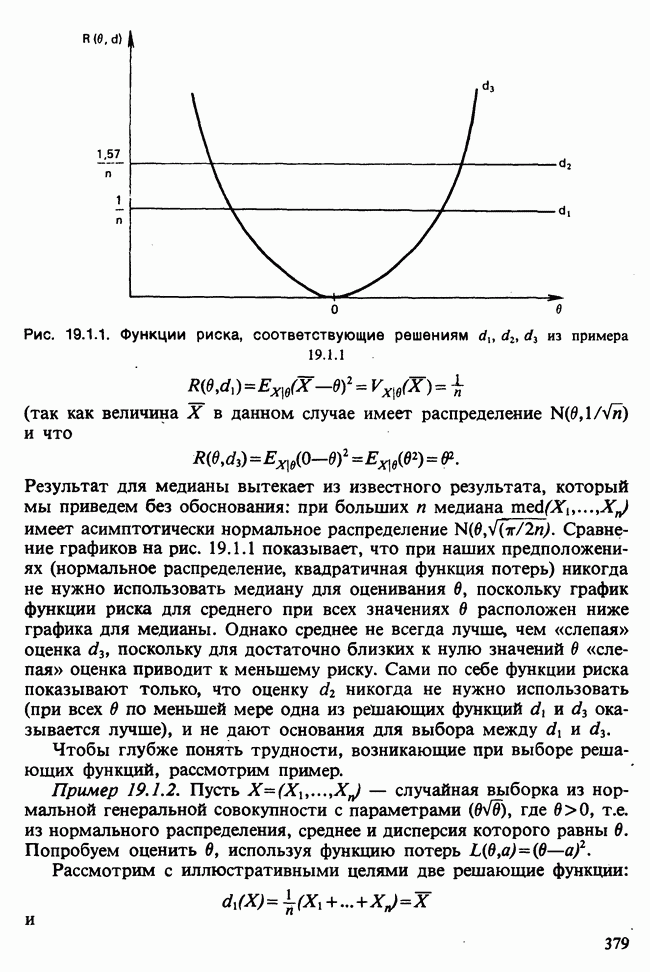
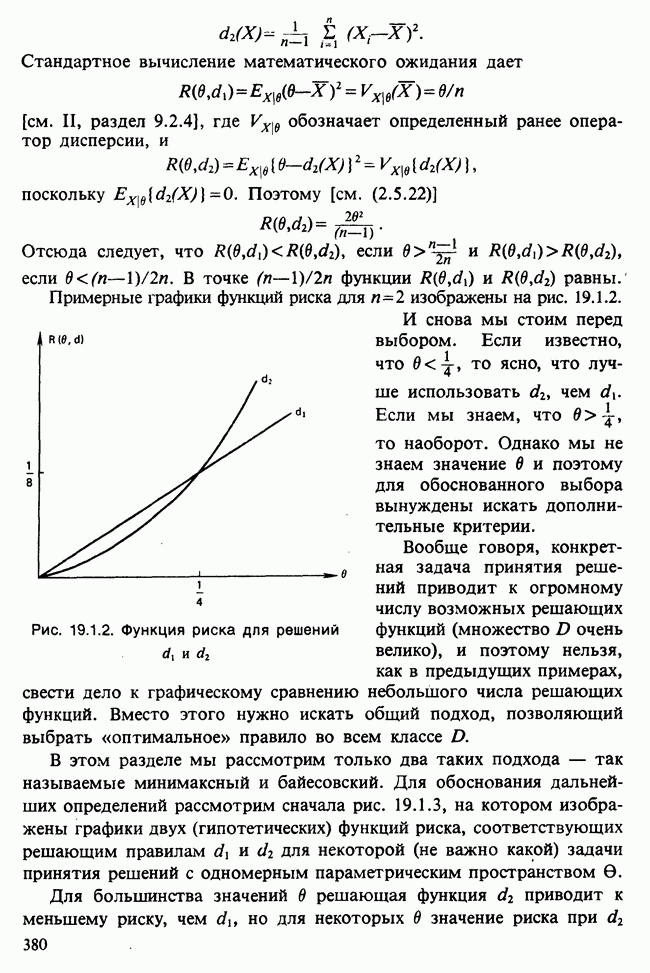

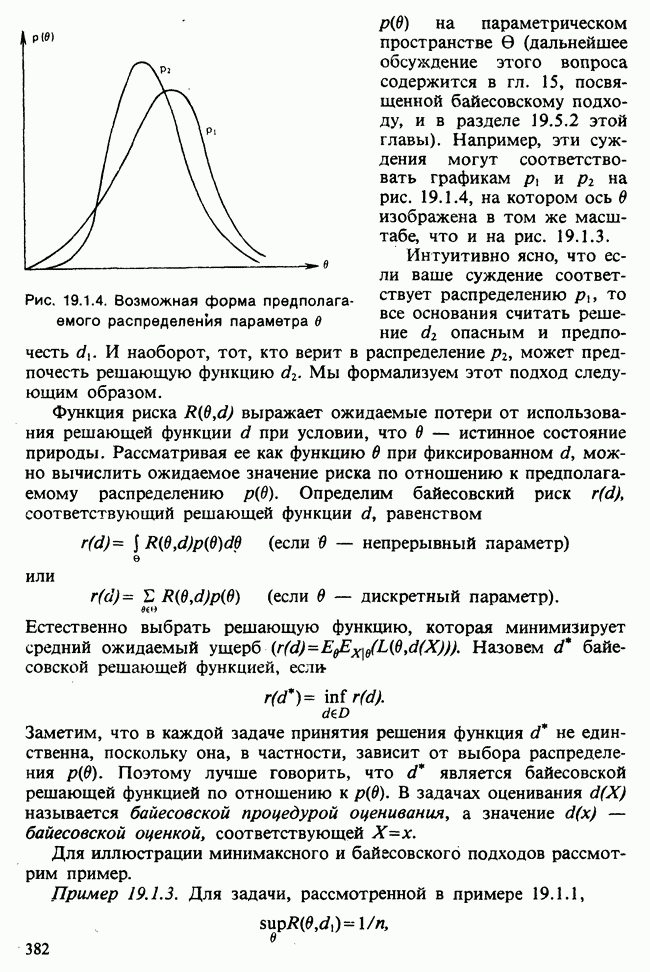




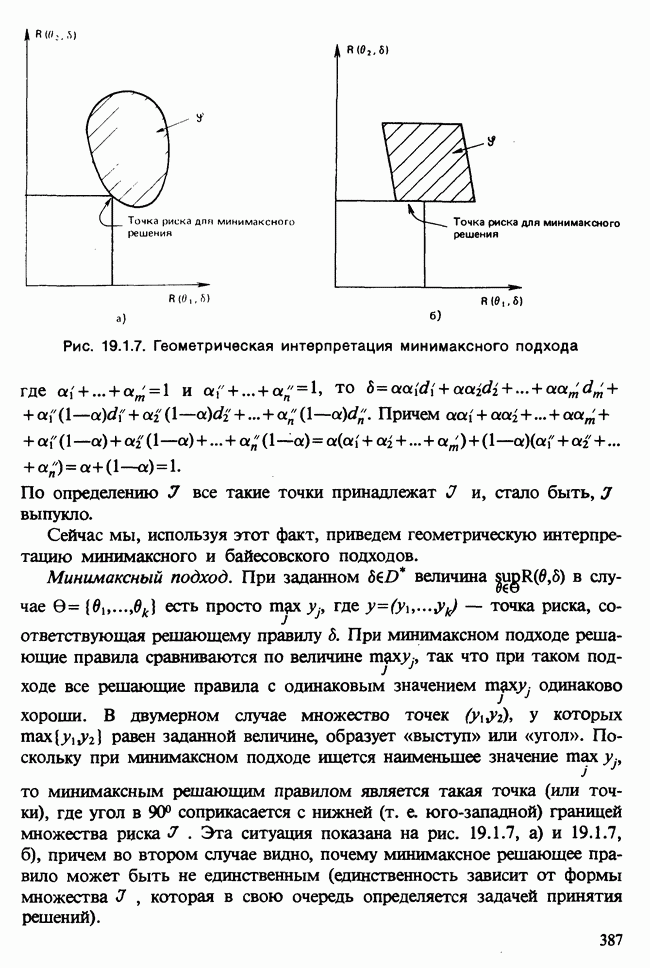

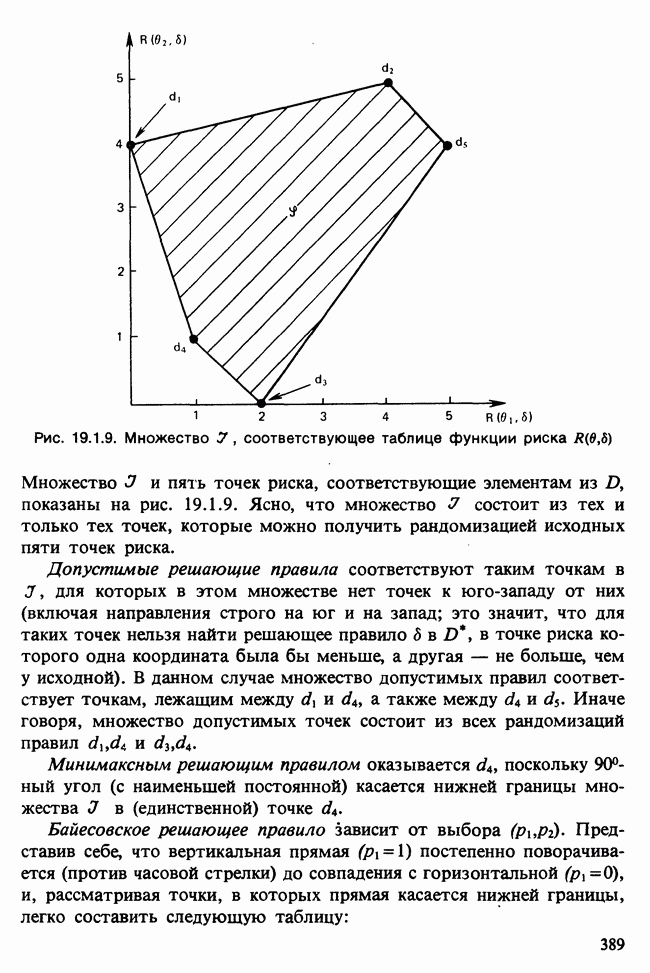

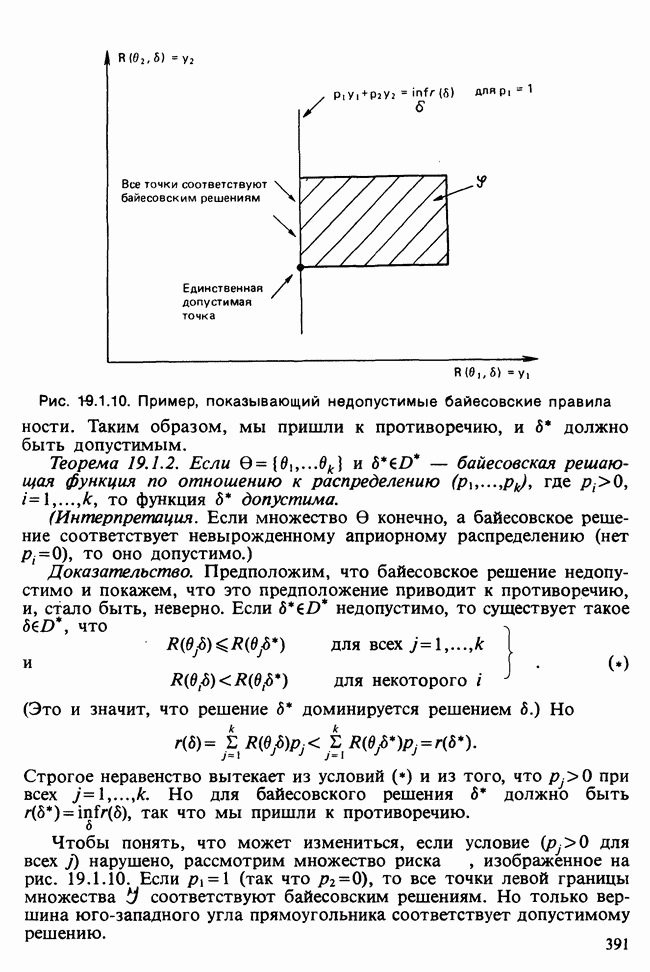









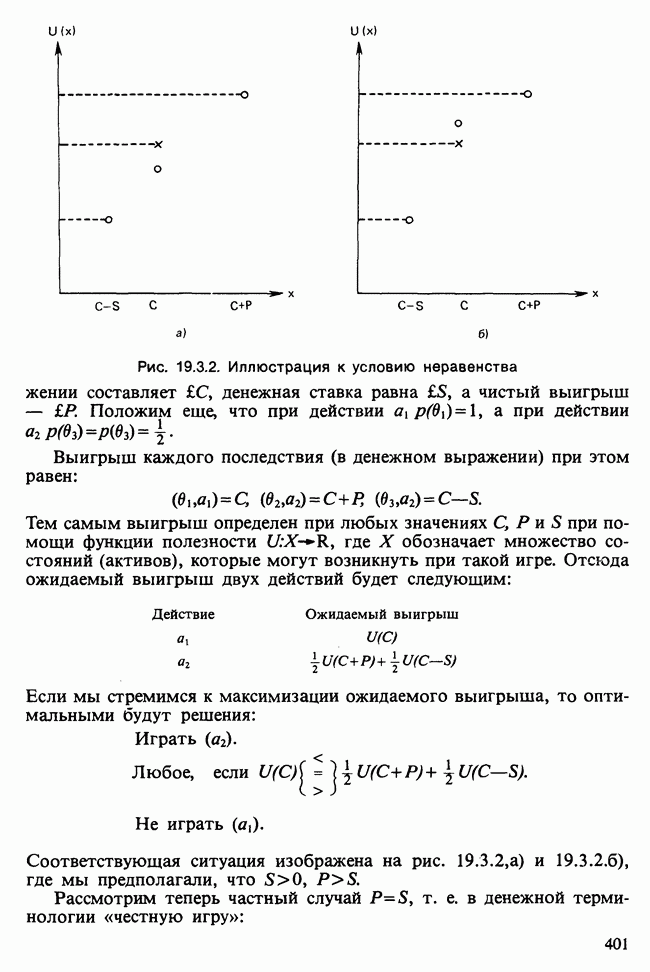
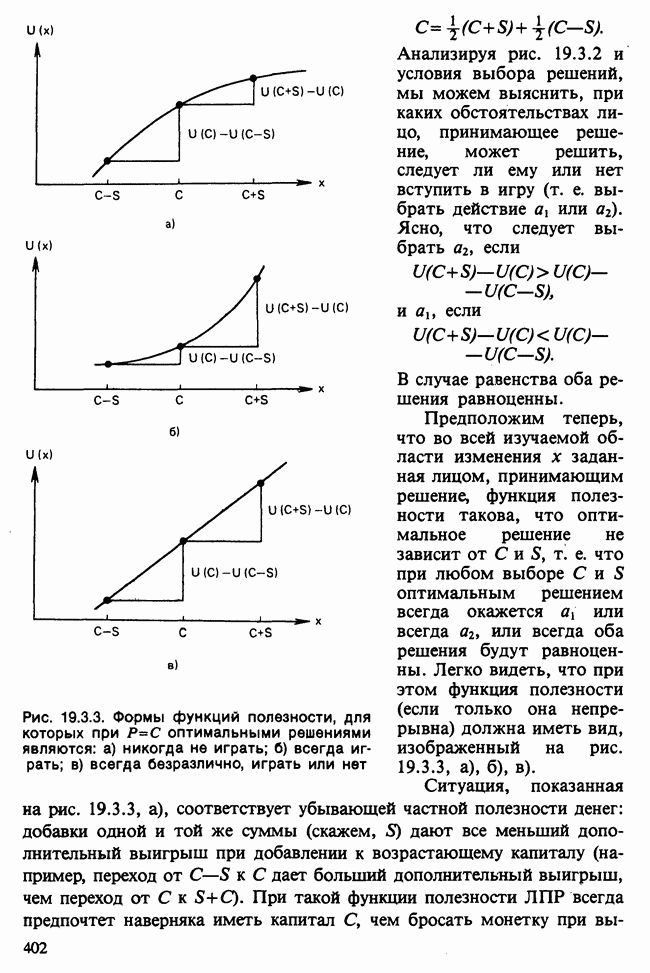



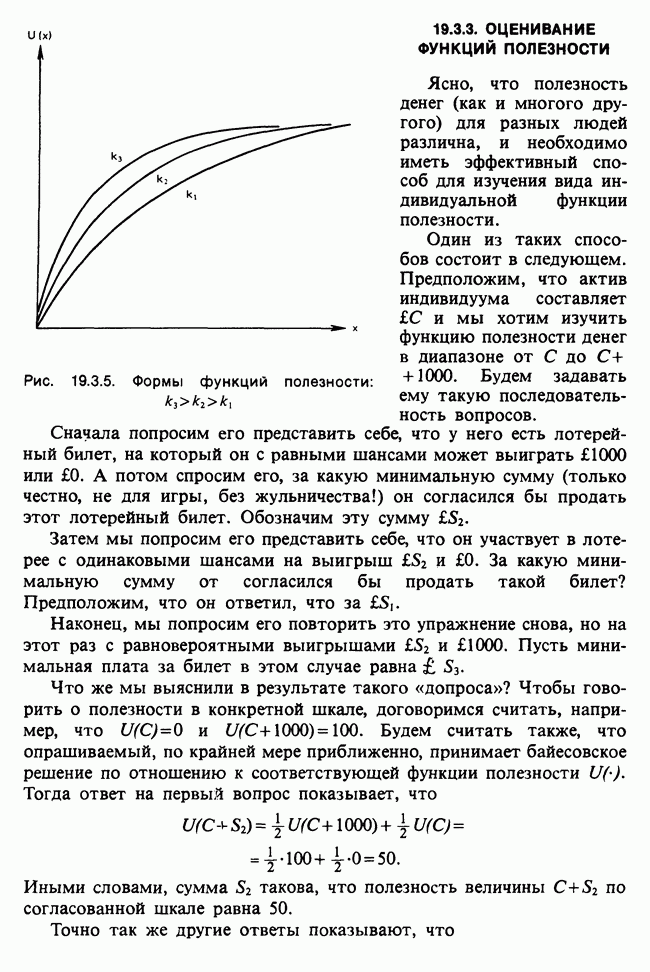




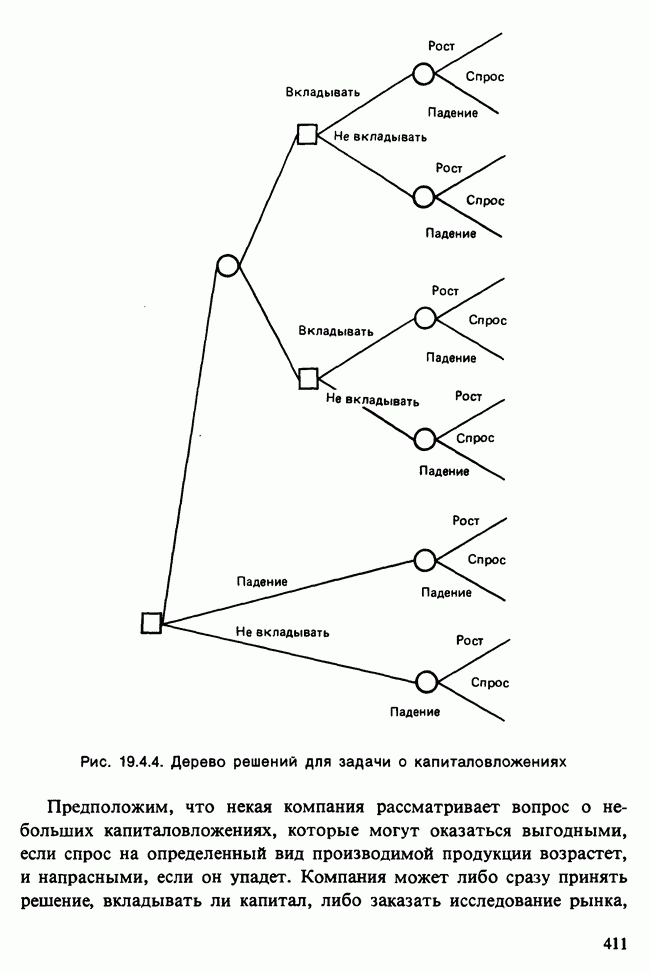

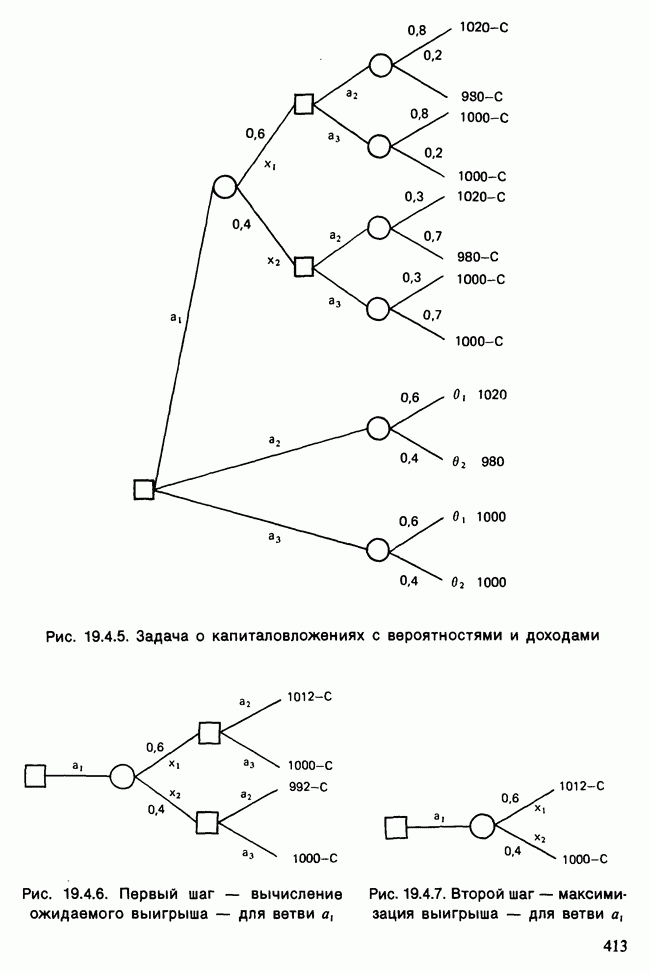












































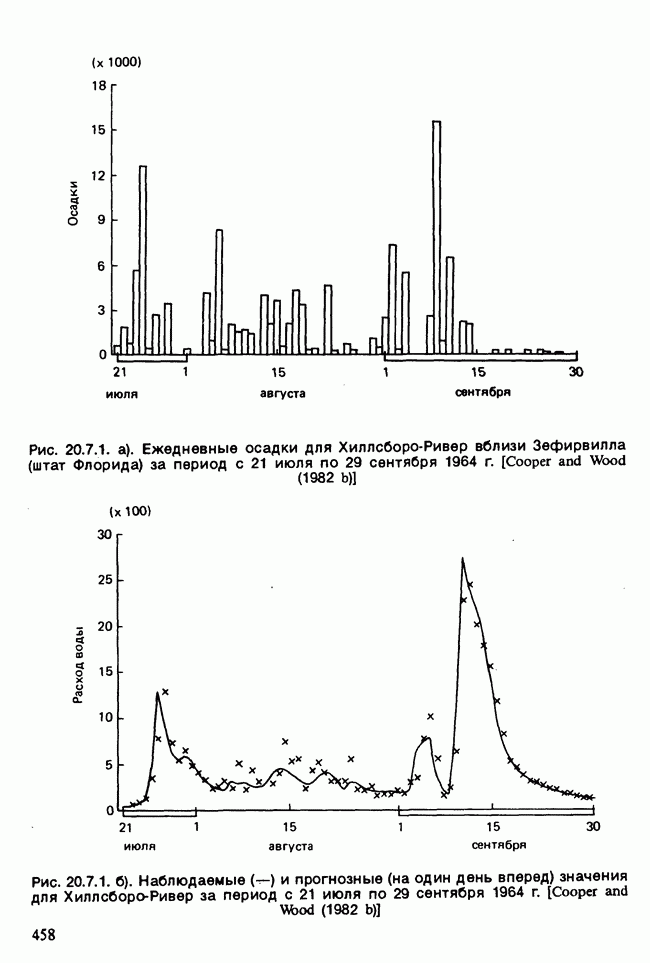
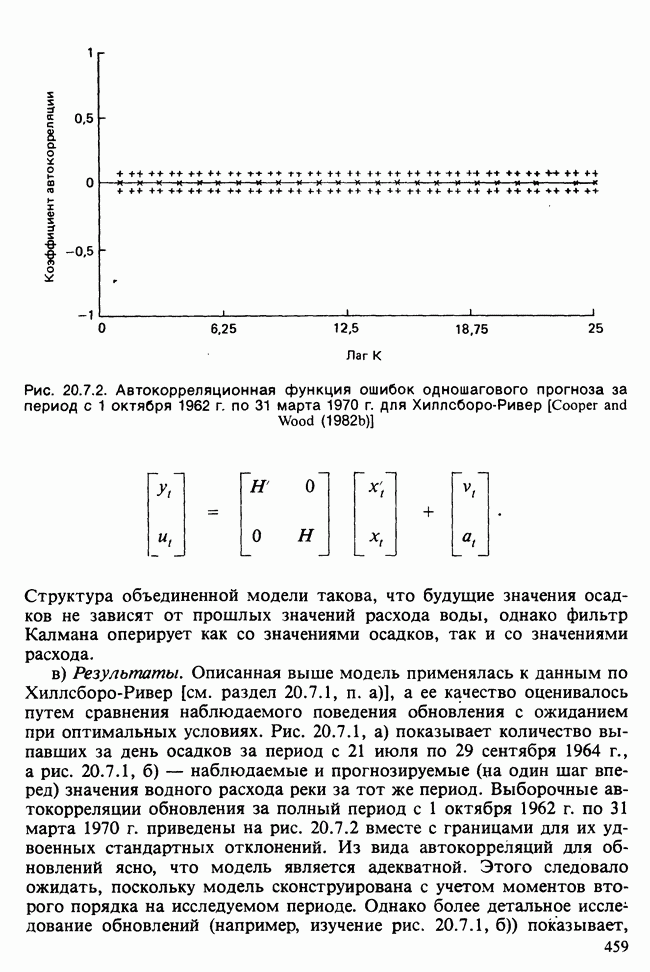





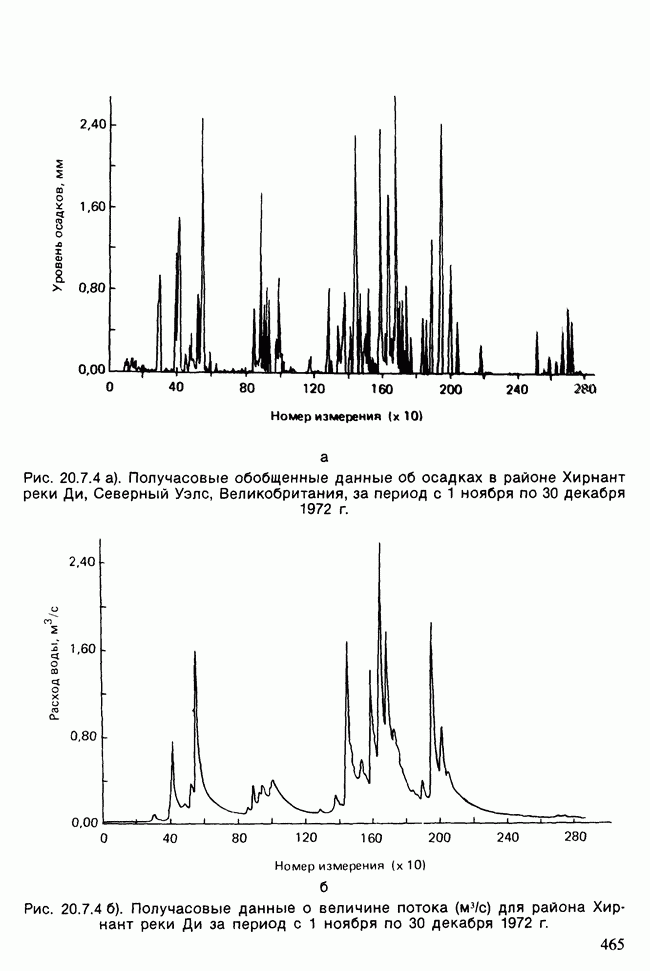
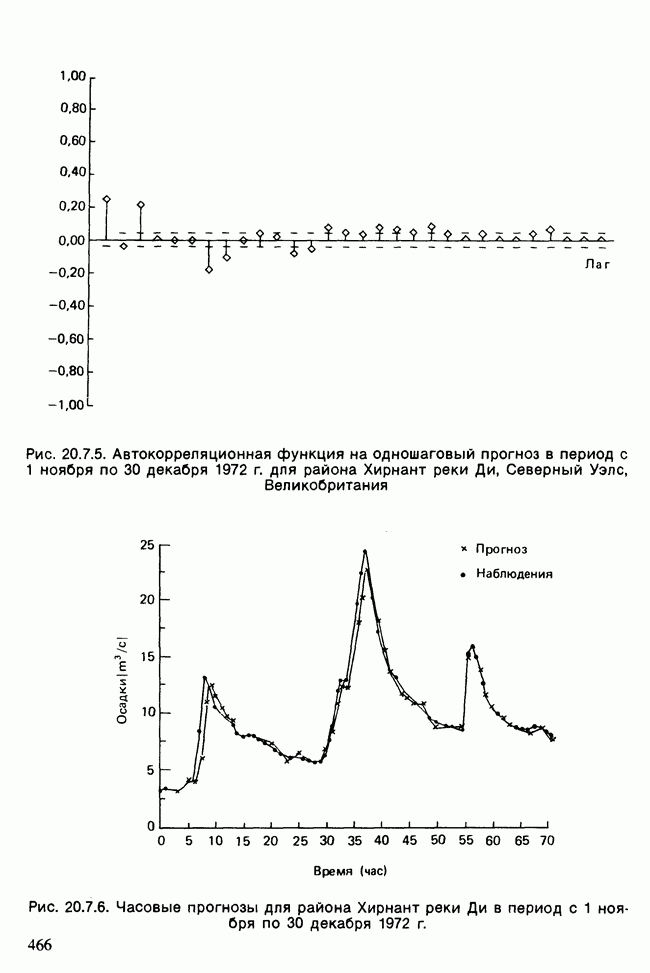











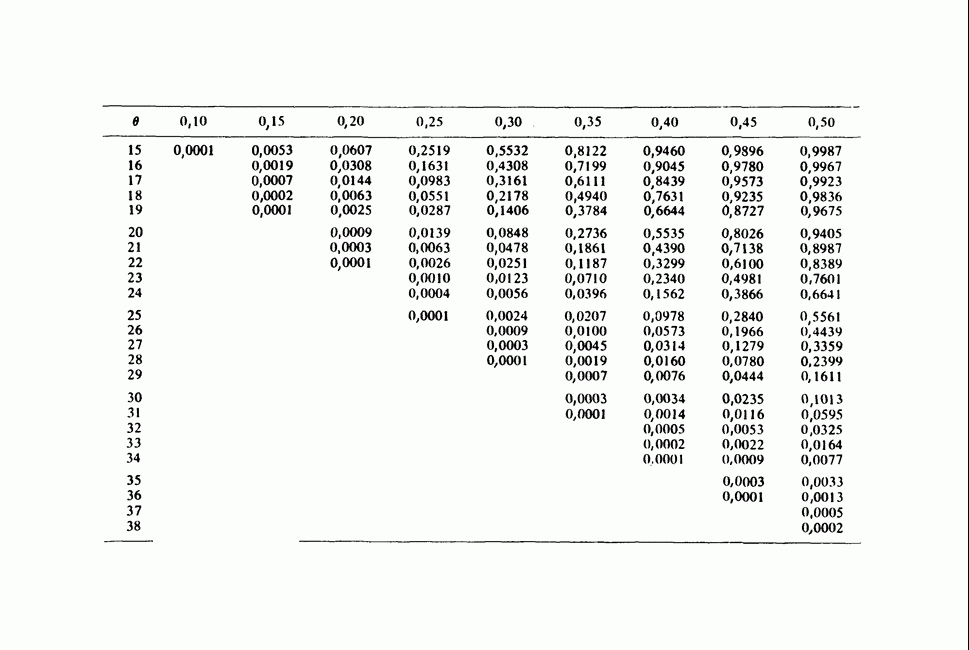

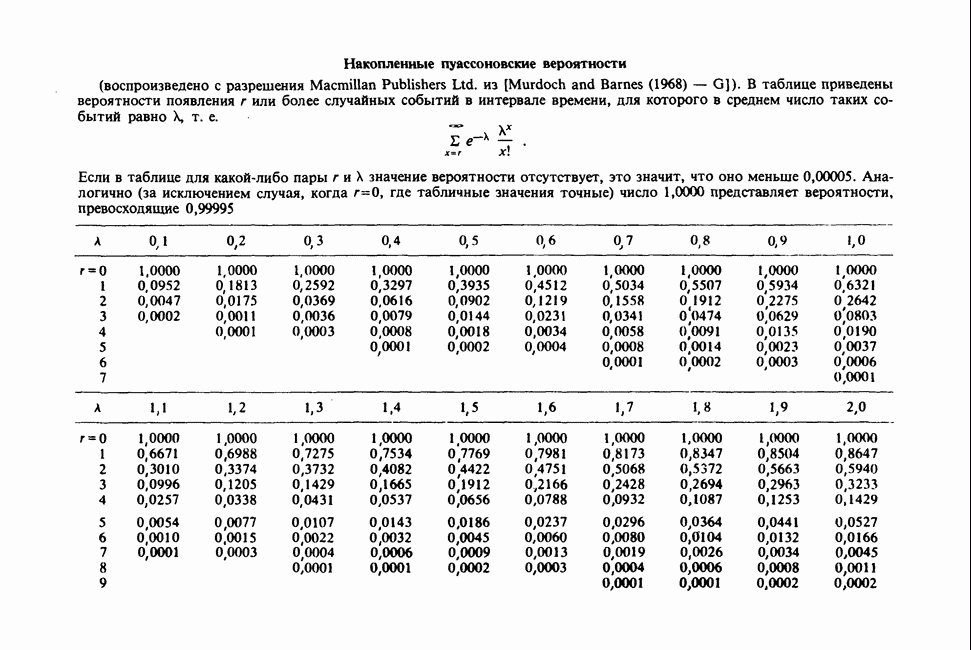
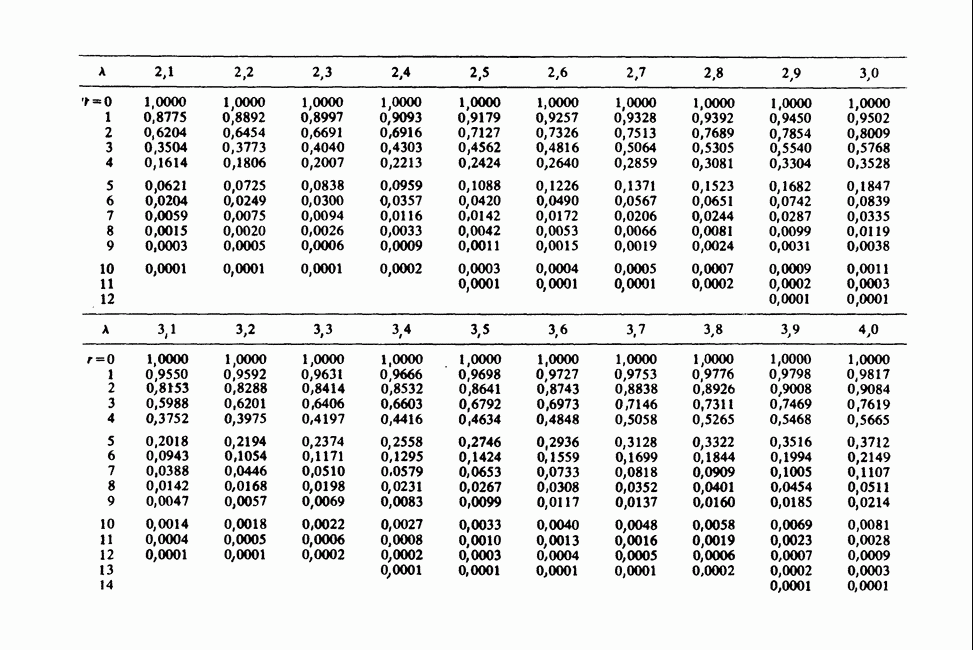
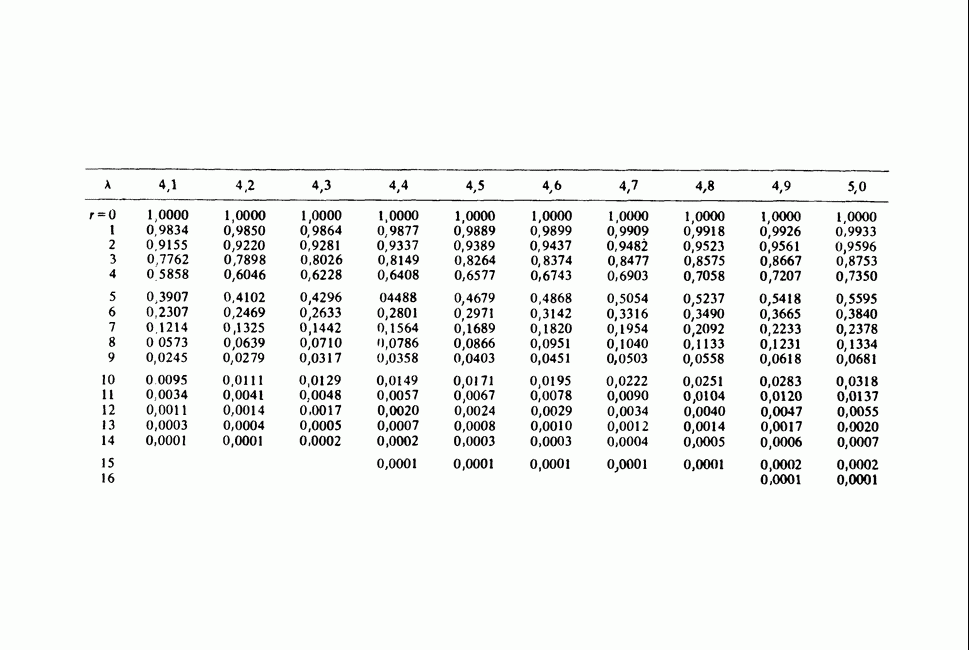
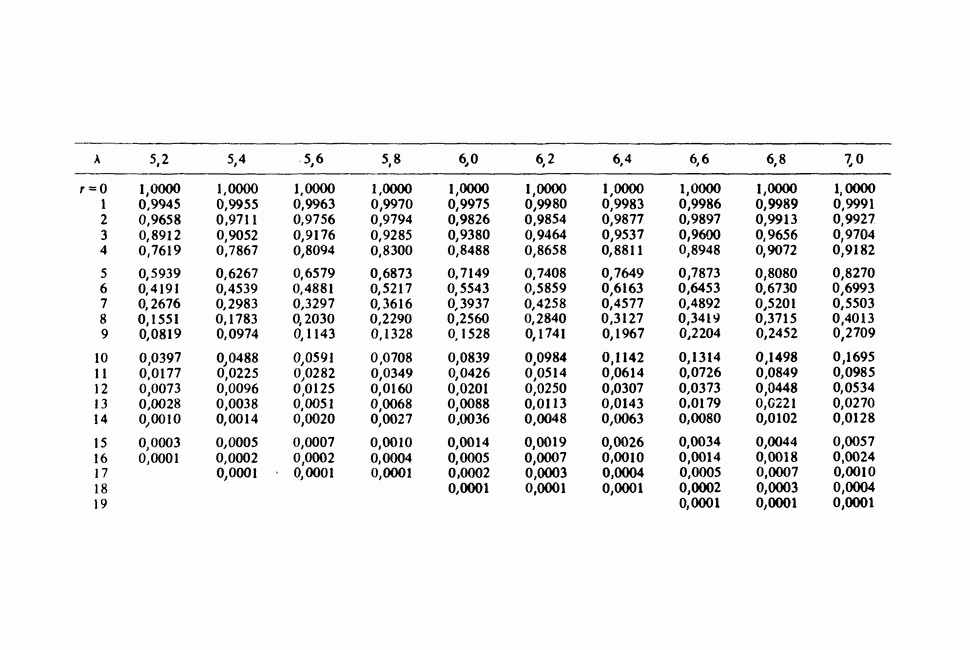
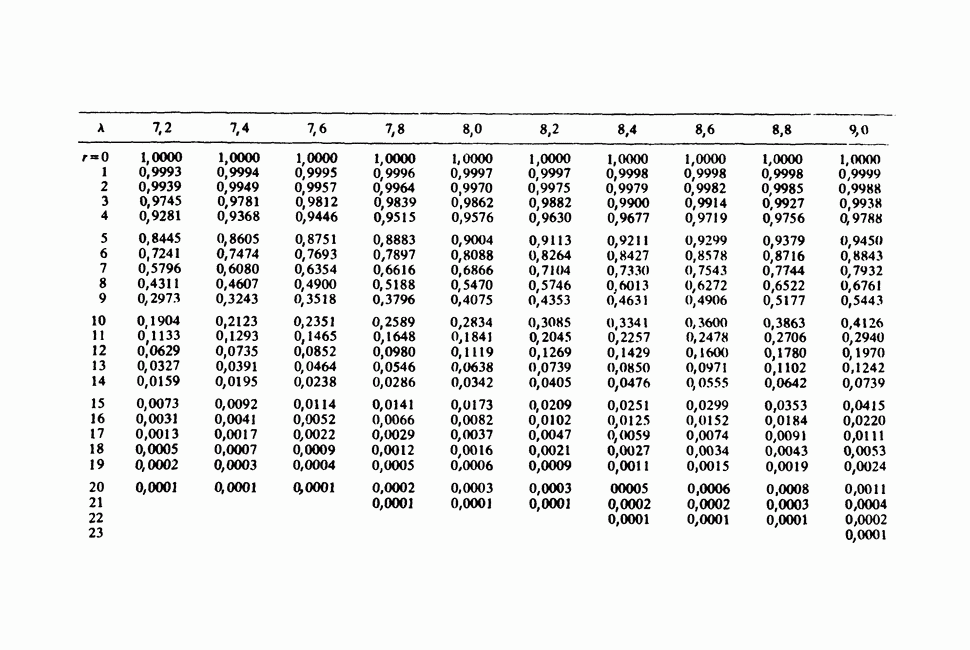
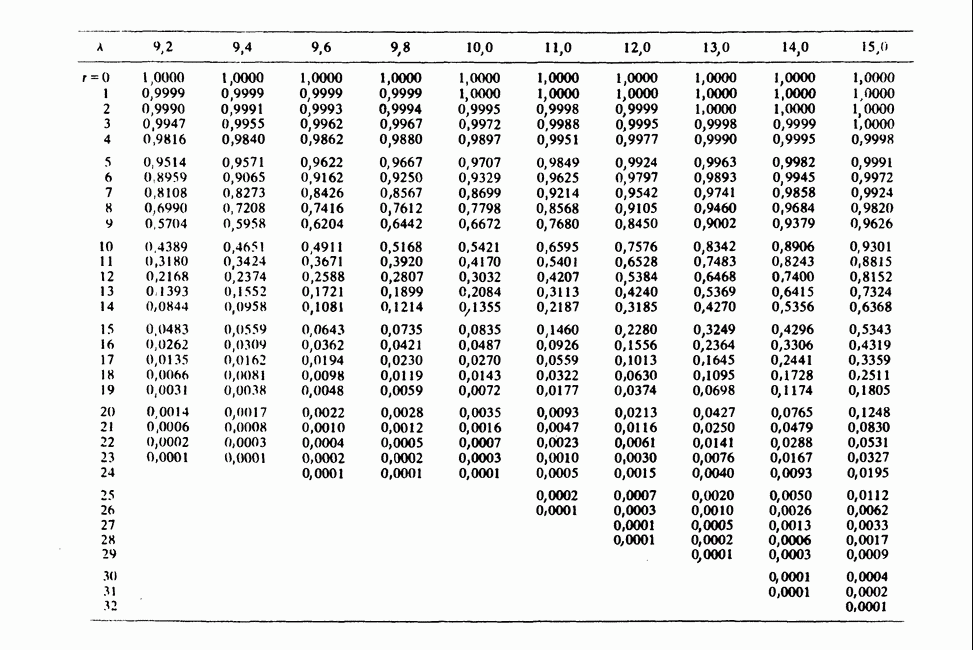

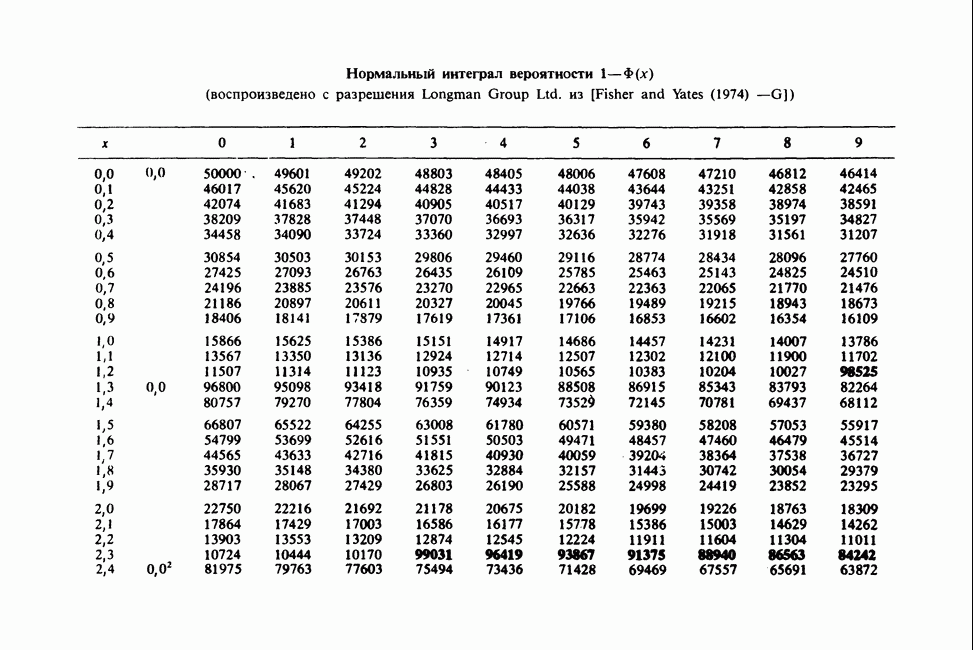
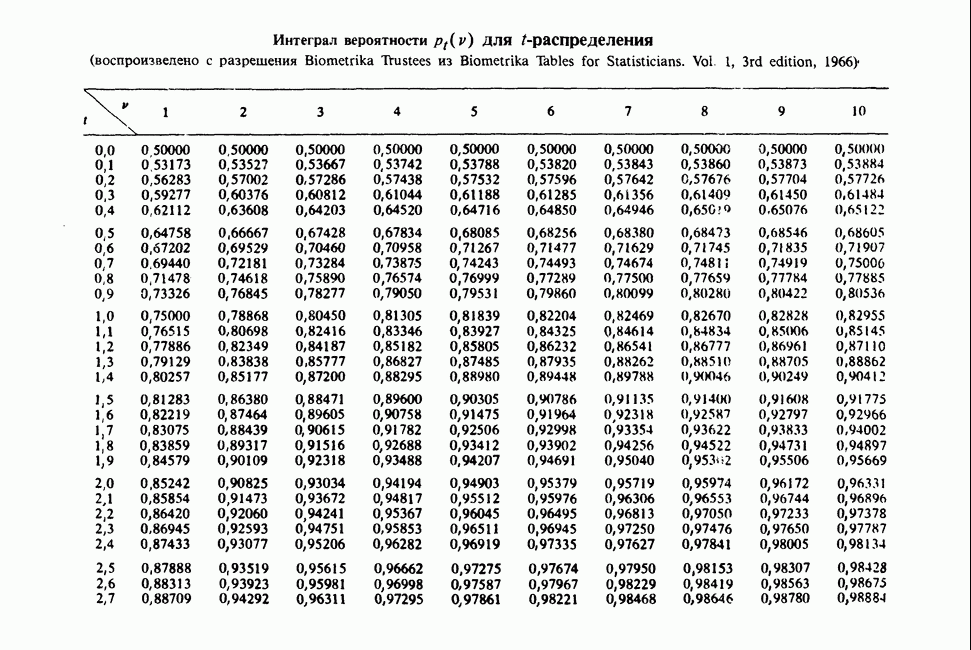

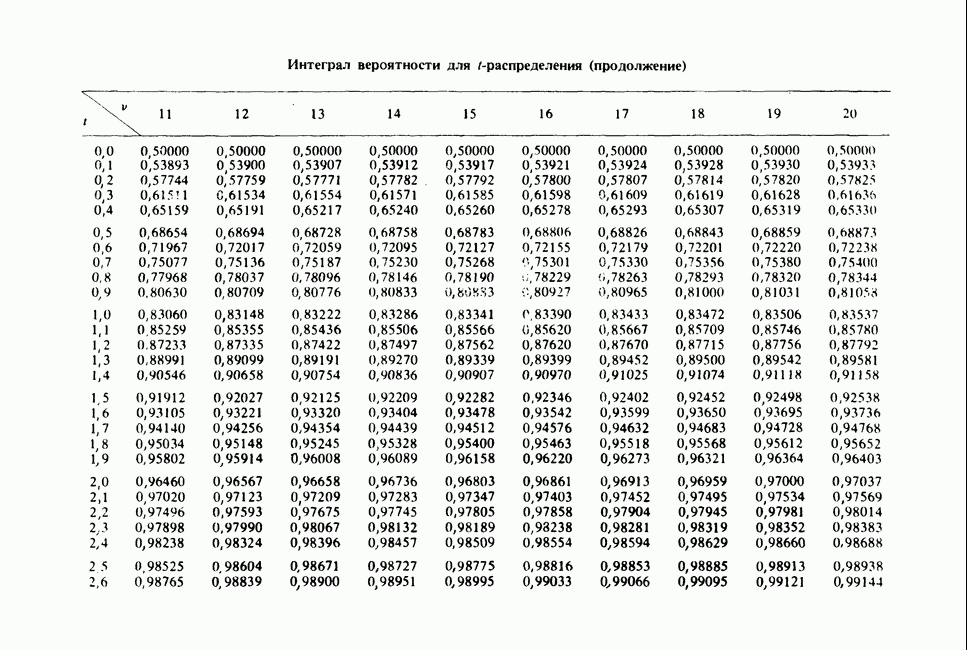

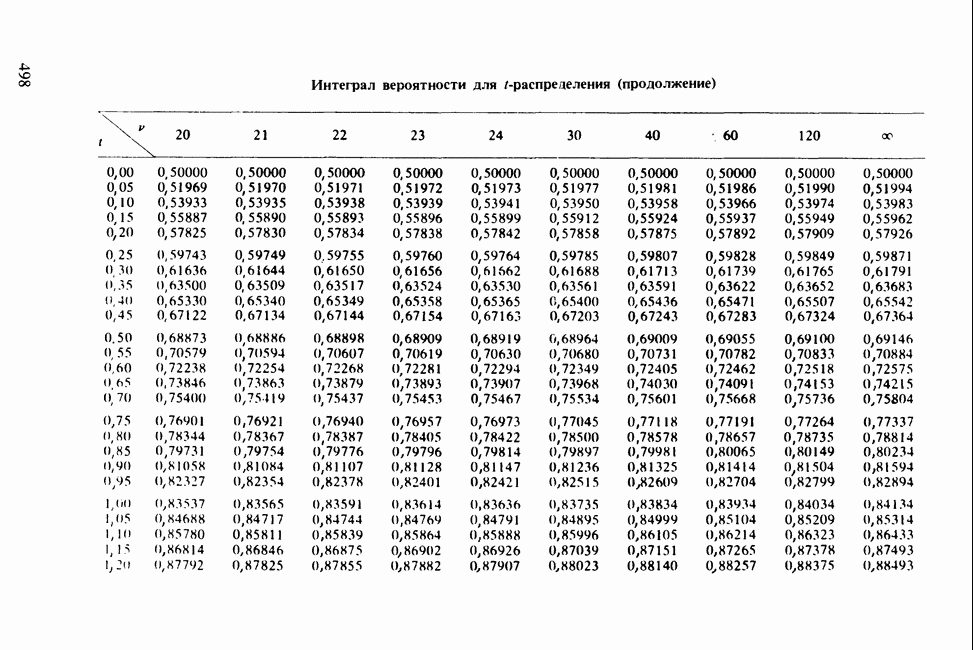
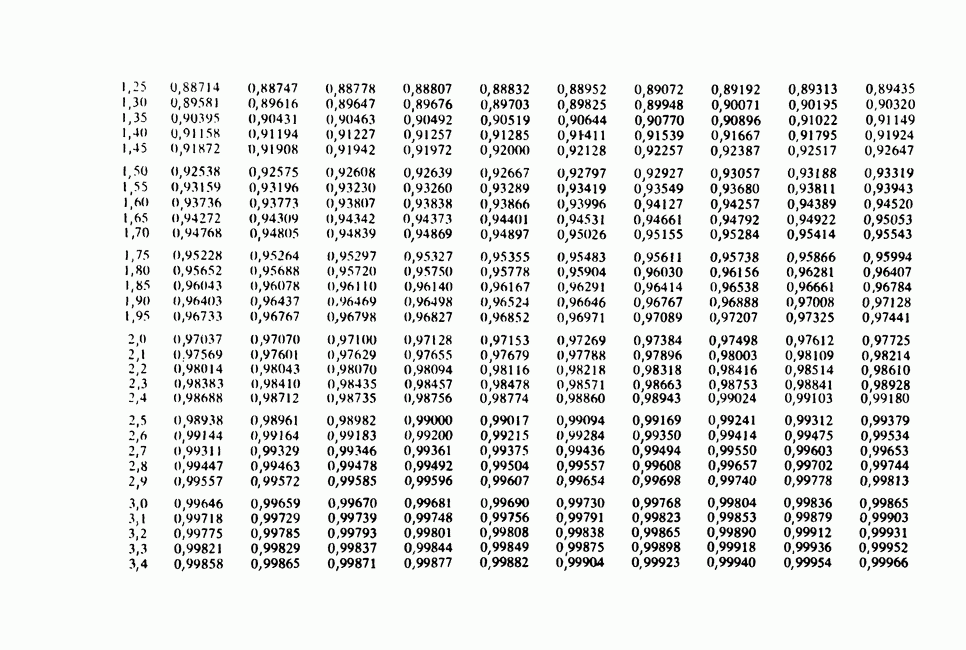
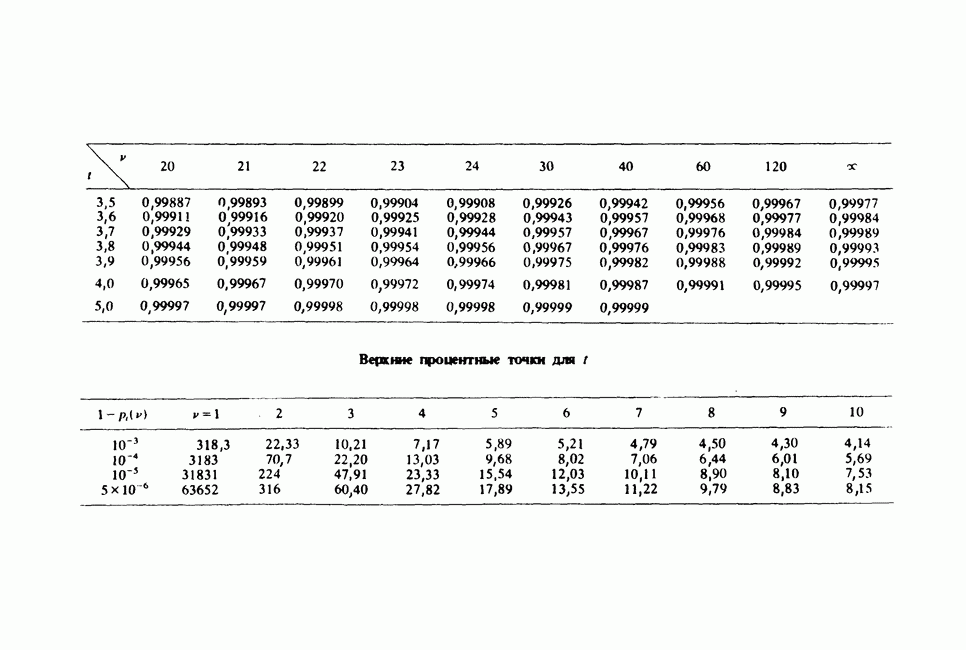
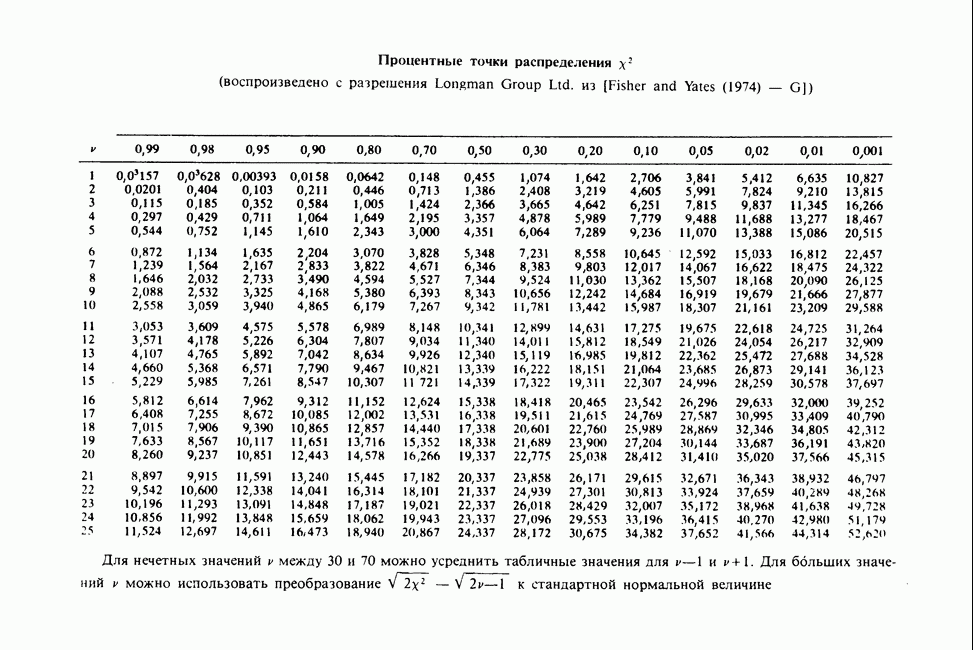
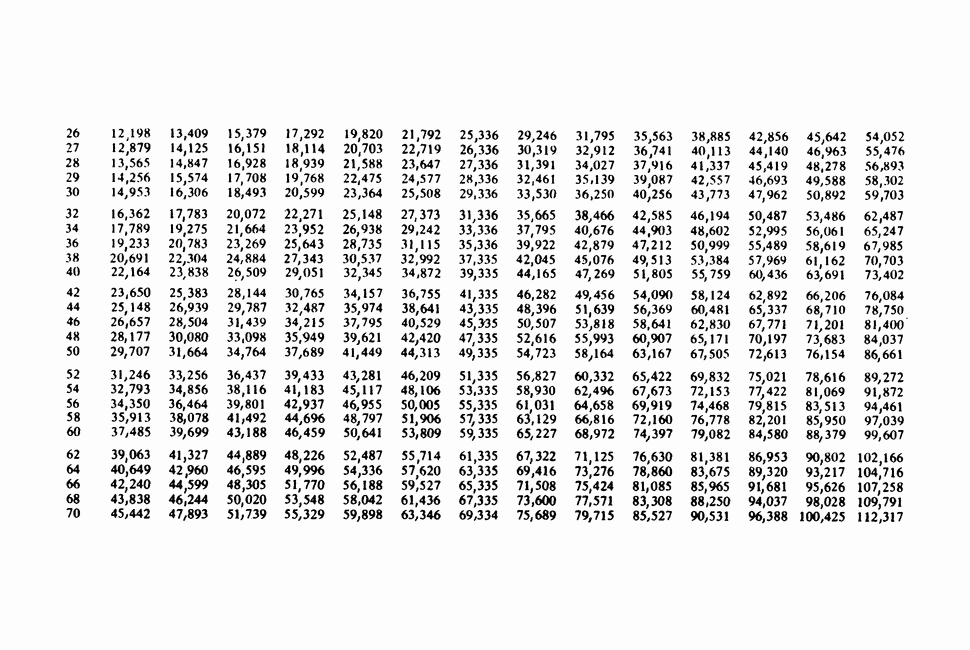
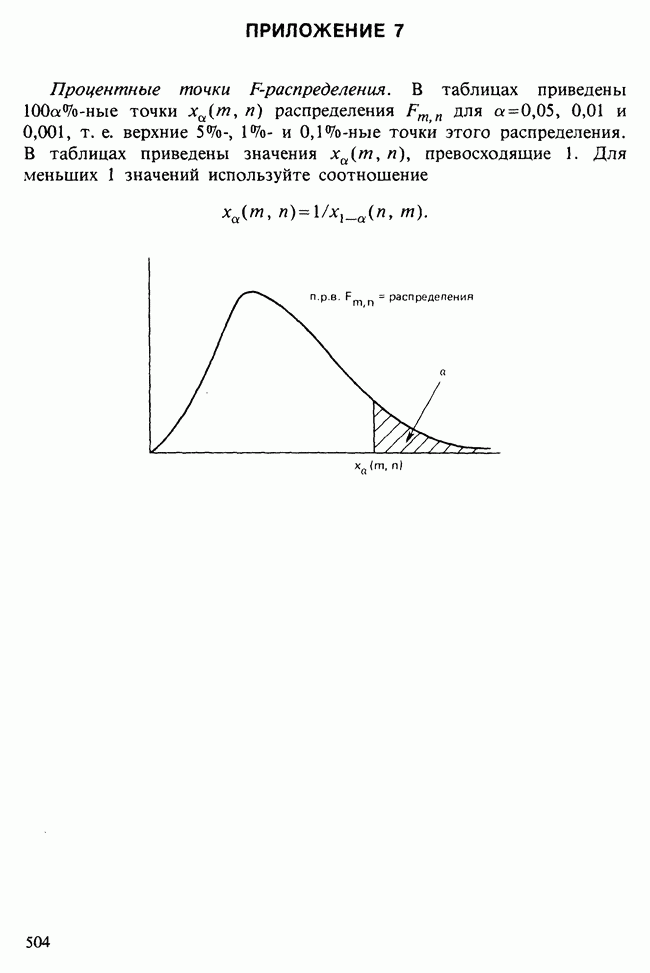
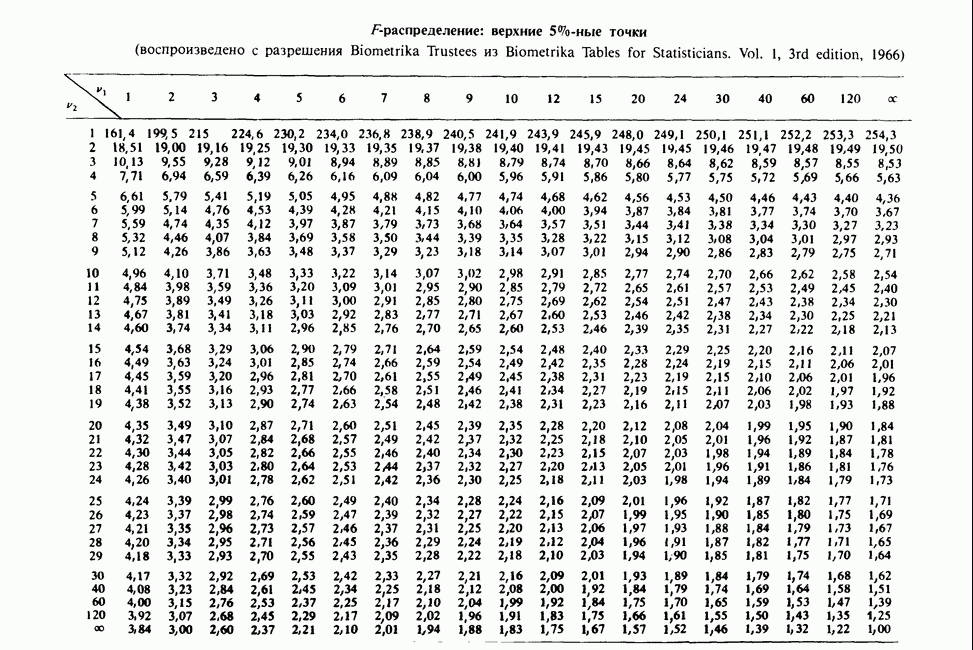
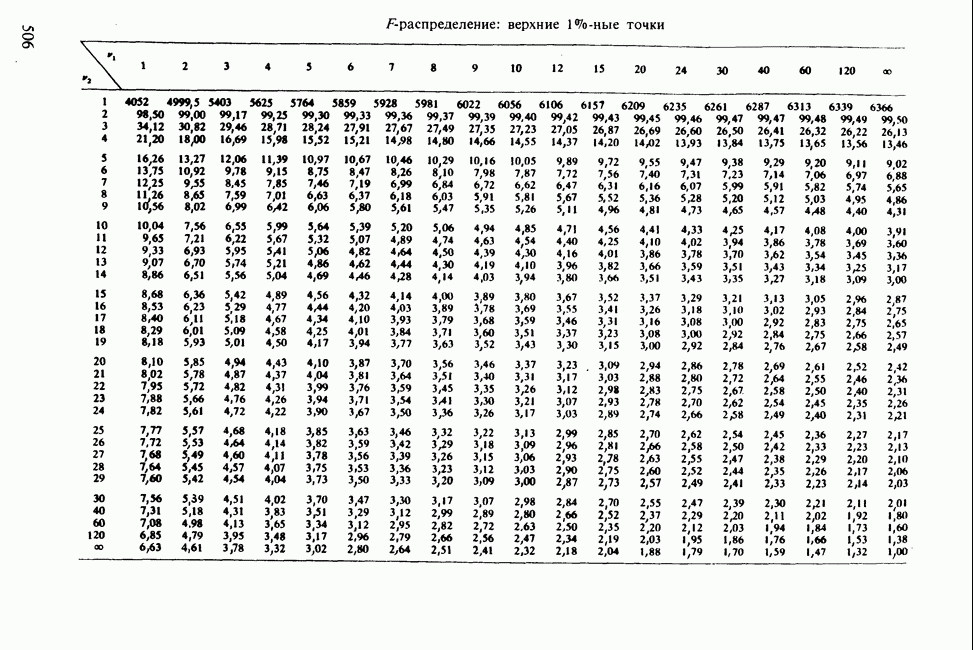
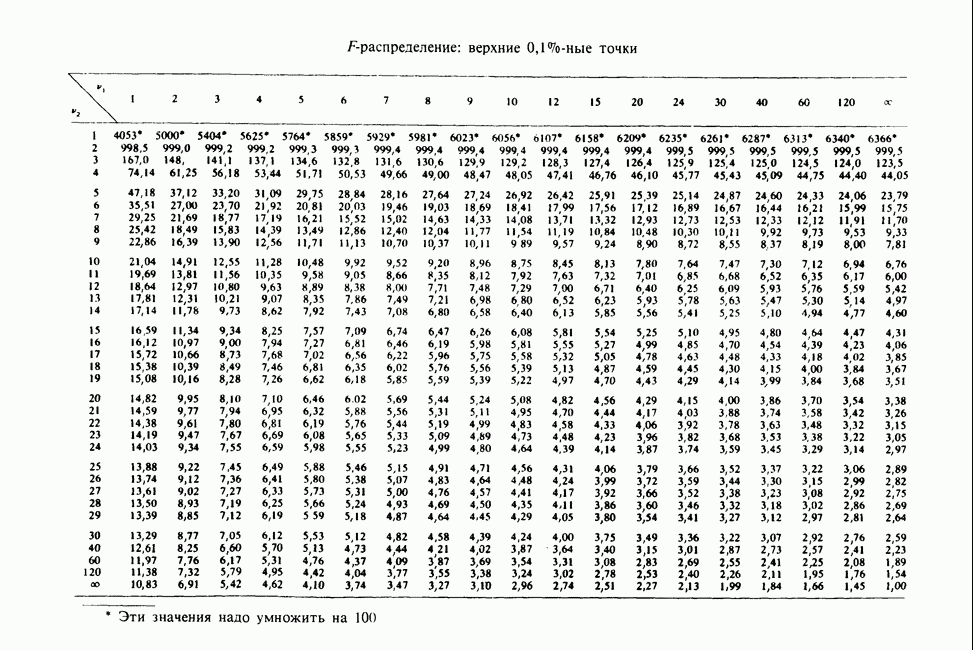



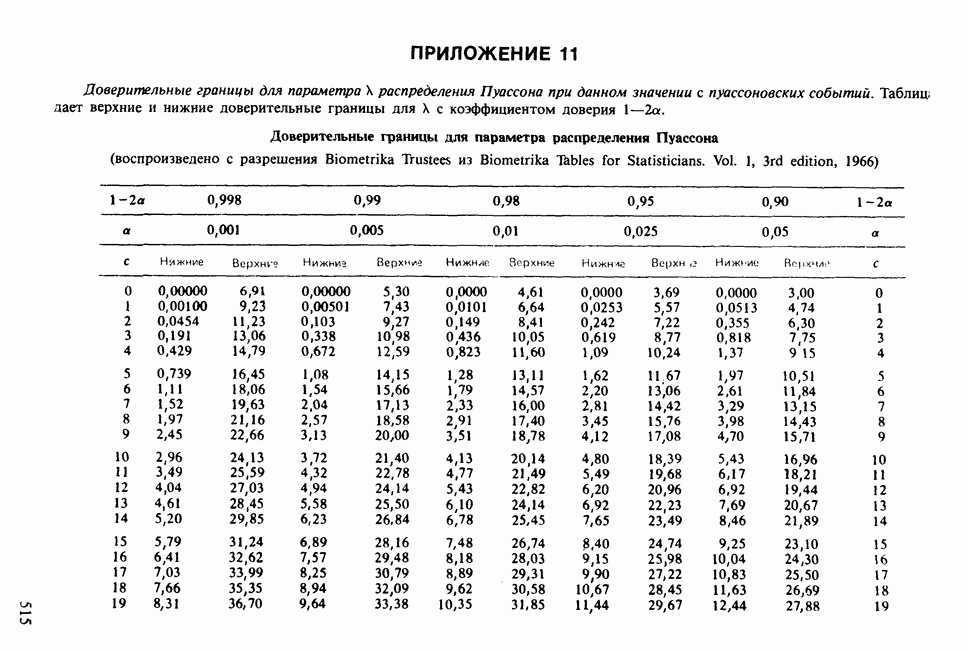
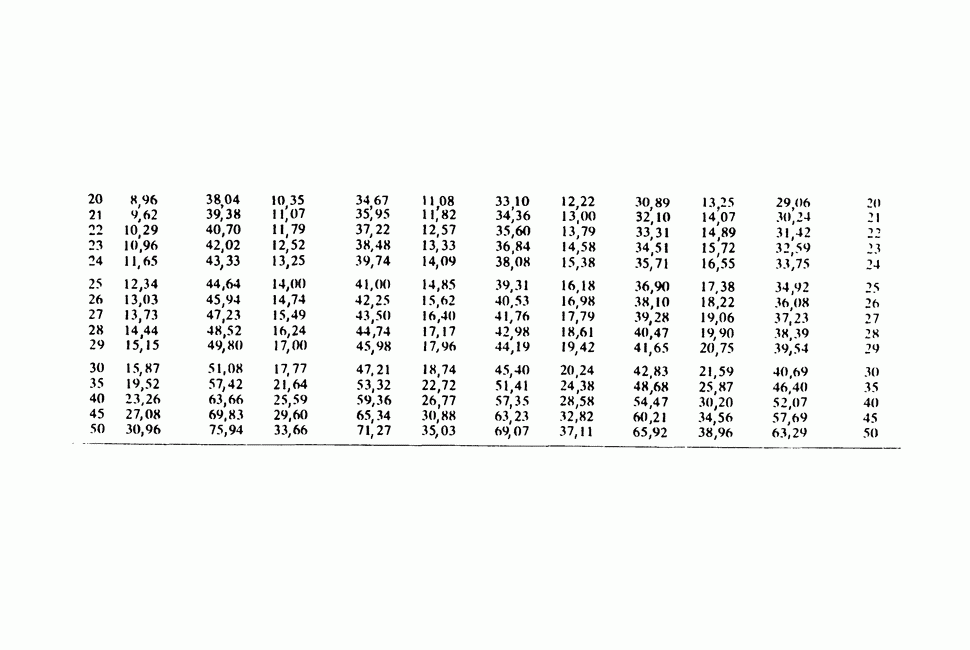
 -компонентная случайная переменная X имеет вектор средних 0 и положительно определенную [см. определение 16.1.1] дисперсионноковариационную матрицу V [см. (16.1.13)]. Другими словами, мы переходим к векторной случайной величине
-компонентная случайная переменная X имеет вектор средних 0 и положительно определенную [см. определение 16.1.1] дисперсионноковариационную матрицу V [см. (16.1.13)]. Другими словами, мы переходим к векторной случайной величине  где X — исходная случайная величина с вектором средних д. Заметим, что пока нет необходимости делать каких-либо предположений относительно формы распределения.
где X — исходная случайная величина с вектором средних д. Заметим, что пока нет необходимости делать каких-либо предположений относительно формы распределения.
 имеет минимальную дисперсию. При некоторых предположениях относительно шкал можно показать, что дисперсии главных компонент являются собственными числами матрицы V, а коэффициенты при компонентах X в линейных преобразованиях являются компонентами соответствующих собственных векторов.
имеет минимальную дисперсию. При некоторых предположениях относительно шкал можно показать, что дисперсии главных компонент являются собственными числами матрицы V, а коэффициенты при компонентах X в линейных преобразованиях являются компонентами соответствующих собственных векторов.
 — первая главная компонента случайного вектора X:
— первая главная компонента случайного вектора X:



 выбран таким образом, чтобы дисперсия
выбран таким образом, чтобы дисперсия  имела максимальное значение при условии, что
имела максимальное значение при условии, что

 максимизирующего
максимизирующего

 — множитель Лагранжа. Взяв производную по
— множитель Лагранжа. Взяв производную по  и приравняв ее к
и приравняв ее к  , получаем уравнение
, получаем уравнение

 должно удовлетворяться условие на определитель [см. I, раздел 5.9], а именно
должно удовлетворяться условие на определитель [см. I, раздел 5.9], а именно

 — собственное число матрицы
— собственное число матрицы  — соответствующий собственный вектор.
— соответствующий собственный вектор.

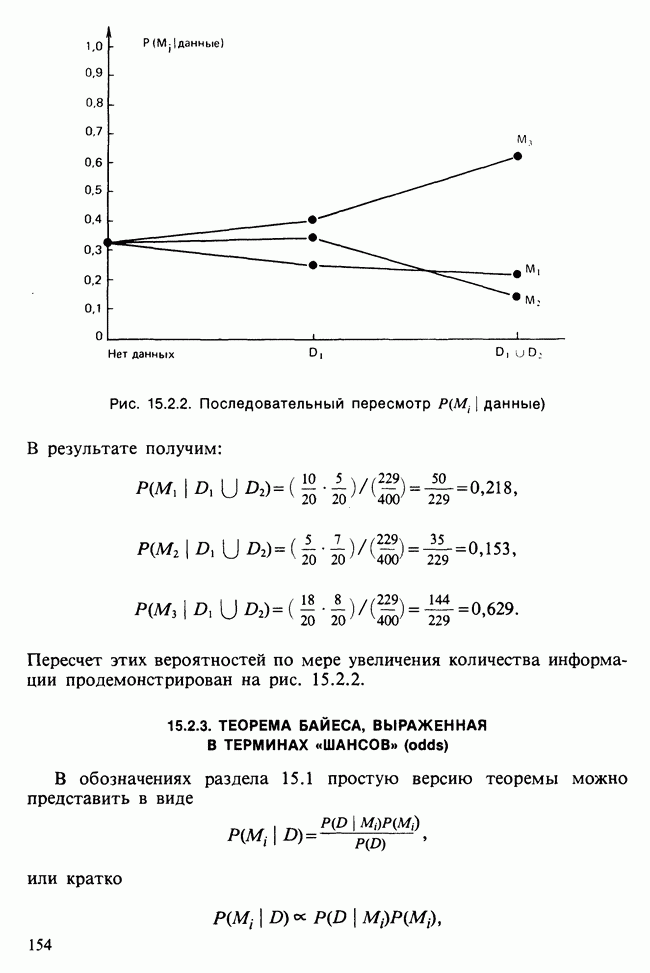
 получаем
получаем

 а поскольку решалась задача максимизации
а поскольку решалась задача максимизации  следовательно,
следовательно,  есть максимальное собственное число матрицы V.
есть максимальное собственное число матрицы V.



 определяется теперь так, чтобы
определяется теперь так, чтобы  была максимальна
была максимальна
 Мы должны максимизировать выражение
Мы должны максимизировать выражение

 , находим в соответствии с условием ортогональности (16.3.6), что
, находим в соответствии с условием ортогональности (16.3.6), что  . А в силу условия нормировки (16.3.5) получаем, что
. А в силу условия нормировки (16.3.5) получаем, что  есть второе по величине собственное число матрицы
есть второе по величине собственное число матрицы  — соответствующий собственный вектор.
— соответствующий собственный вектор.
 главной компоненты, мы должны максимизировать
главной компоненты, мы должны максимизировать  с учетом к условий, включающих условие нормировки
с учетом к условий, включающих условие нормировки

 условий ортогональности:
условий ортогональности: 

 будет корреляционной матрицей для X, скажем
будет корреляционной матрицей для X, скажем  после такого преобразования. Главные компоненты могут быть получены как собственные векторы матрицы
после такого преобразования. Главные компоненты могут быть получены как собственные векторы матрицы  а их дисперсии — как соответствующие им ее собственные числа.
а их дисперсии — как соответствующие им ее собственные числа.
 число главных компонент. Требуется только, чтобы V была неотрицательно-определенной матрицей [см. определение 16.1.3].
число главных компонент. Требуется только, чтобы V была неотрицательно-определенной матрицей [см. определение 16.1.3].

 главных компонентах с
главных компонентах с  наибольшими дисперсиями можно сказать, что они учитывают долю полной дисперсии, определяющуюся как
наибольшими дисперсиями можно сказать, что они учитывают долю полной дисперсии, определяющуюся как

 могут не учитываться и совокупность будет адекватно представлена с помощью
могут не учитываться и совокупность будет адекватно представлена с помощью  первых главных компонент.
первых главных компонент.
 то (предполагается, что V полного ранга)
то (предполагается, что V полного ранга)


 -мерных наблюдений при использовании этих двух матриц. Когда применяется ковариационная матрица, эти значения представляют собой просто линейные функции исходных переменных (предварительно центрированных). Для корреляционной матрицы — это линейные комбинации нормированных переменных.
-мерных наблюдений при использовании этих двух матриц. Когда применяется ковариационная матрица, эти значения представляют собой просто линейные функции исходных переменных (предварительно центрированных). Для корреляционной матрицы — это линейные комбинации нормированных переменных.
 — длина черешка;
— длина черешка;
 — длина листа;
— длина листа;
 — наибольшая ширина листа;
— наибольшая ширина листа;
 — ширина листа на середине длины;
— ширина листа на середине длины;
 — ширина листа на одной трети длины;
— ширина листа на одной трети длины;
 — ширина листа на двух третях длины;
— ширина листа на двух третях длины;
 — расстояние от основания листа до точки прикрепления черешка;
— расстояние от основания листа до точки прикрепления черешка;
 угол между первой главной прожилкой и средним ребром;
угол между первой главной прожилкой и средним ребром;
 — угол между первой второстепенной прожилкой и средним ребром.
— угол между первой второстепенной прожилкой и средним ребром.
 Выборочная матрица корреляций для девяти наблюдений приведена в табл. 16.3.1. Собственные числа и соответствующие им собственные векторы представлены в табл. 16.3.2.
Выборочная матрица корреляций для девяти наблюдений приведена в табл. 16.3.1. Собственные числа и соответствующие им собственные векторы представлены в табл. 16.3.2.


 Знаки коэффициентов не играют существенной роли, так как они все могут быть изменены на обратные, что не влияет на результат анализа. Они могут служить только для индикации противоположных тенденций на компоненте. В нашем примере стандартизованные значения наблюдений, соответствующие двум первым главным компонентам, могут быть графически отображены и использованы потом для дискриминации клонов.
Знаки коэффициентов не играют существенной роли, так как они все могут быть изменены на обратные, что не влияет на результат анализа. Они могут служить только для индикации противоположных тенденций на компоненте. В нашем примере стандартизованные значения наблюдений, соответствующие двум первым главным компонентам, могут быть графически отображены и использованы потом для дискриминации клонов.
 [см. II, раздел 13.4.7]. Не имеет значения, какая из матриц использовалась — ковариаций или корреляций.
[см. II, раздел 13.4.7]. Не имеет значения, какая из матриц использовалась — ковариаций или корреляций.