Глава 11. ЦИФРОВЫЕ МЕТОДЫ АНАЛИЗА
В этой главе дано подробное описание методов, необходимых для вычисления различного рода характеристик при анализе временных рядов. При этом предполагается, что анализируемые данные представляют собой дискретные по времени выборки из стационарных (эргодических) случайных процессов. Методы анализа нестационарных процессов рассмотрены в гл. 12, а преобразование Гильберта — в гл. 13.
11.1. Подготовка данных
В ряде случаев изучаемое физическое явление имеет дискретное время по самой своей природе. Примерами могут служить эмиссия нейтронов или многие типы экономических данных. Однако в большинстве случаев процесс имеет непрерывное время, и его следует вначале преобразовать во временной ряд, сделав это с учетом соображений относительно дискретизации и маскировки частот, детально рассмотренных в разд. 10.3. Во всяком случае, предполагается, что дискретные данные состоят из  равноотстоящих отсчетов с интервалом дискретности
равноотстоящих отсчетов с интервалом дискретности  секунд, как было показано ранее на рис. 10.5. Пусть величины
секунд, как было показано ранее на рис. 10.5. Пусть величины

отвечают моментам времени

причем момент  выбирается произвольно и в случае стационарного процесса в дальнейшие формулы не входит. Таким образом
выбирается произвольно и в случае стационарного процесса в дальнейшие формулы не входит. Таким образом

Общая длина реализации есть, очевидно,  Согласно разд. 10.3, частота Найквиста, отвечающая этой выборке, есть
Согласно разд. 10.3, частота Найквиста, отвечающая этой выборке, есть

Как указано в разд. 10.3, исходные данные должны быть подвергнуты различного рода предварительной обработке. При этом наиболее часто выполняются следующие операции: а) приведение к нулевому среднему значению и единичной дисперсии; б) удаление тренда; в) фильтрация.
11.1.1. ПРИВЕДЕНИЕ К НУЛЕВОМУ СРЕДНЕМУ ЗНАЧЕНИЮ И ЕДИНИЧНОЙ ДИСПЕРСИИ
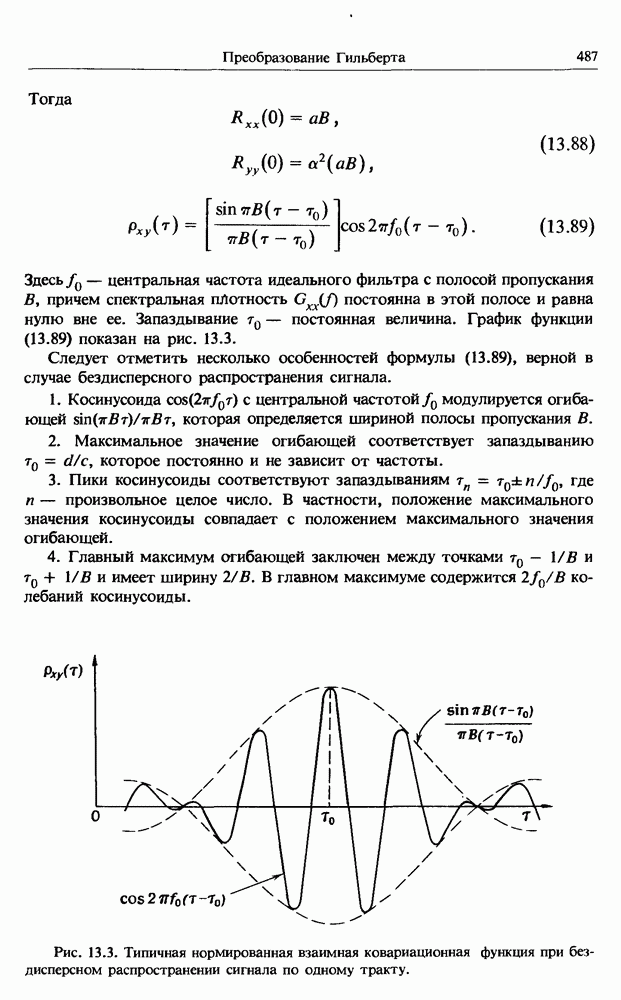
Выборочное среднее значение последовательности отсчетов  определяется в виде
определяется в виде

Искомая последовательность коэффициентов  получается путем приравнивания нулю частных производных функции
получается путем приравнивания нулю частных производных функции  по переменным
по переменным  Это дает систему из К
Это дает систему из К  уравнений
уравнений

В частности, при  уравнение (11.11) принимает вид
уравнение (11.11) принимает вид

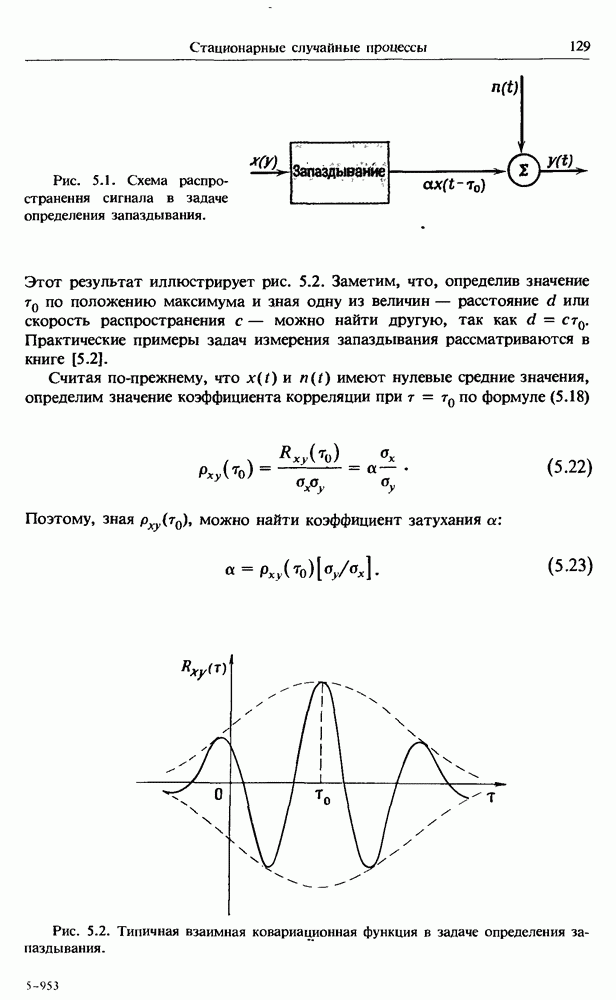
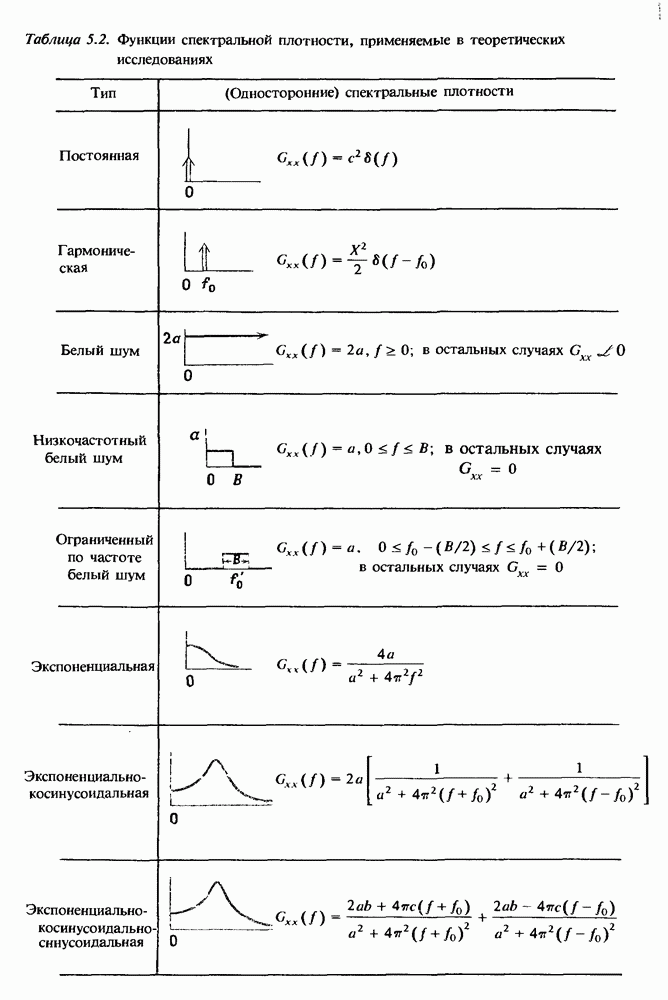
откуда имеем

При  уравнение (11.11) запишется в виде
уравнение (11.11) запишется в виде

Имея в виду, что

получим решение

Формулы (11.16) определяют линейную регрессию со свободным членом  и углом наклона
и углом наклона  Величины, отвечающие этой прямой, следует вычесть из исходных данных
Величины, отвечающие этой прямой, следует вычесть из исходных данных  Заметим, что при
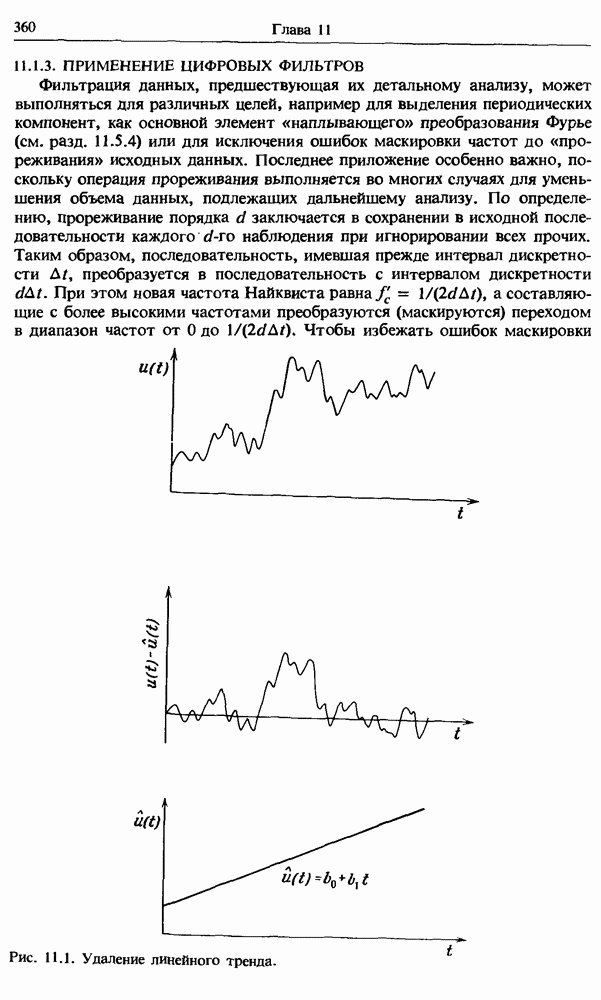
Заметим, что при  равенства (11.16) эквивалентны равенствам (4.70). Пример исключения линейного тренда показан на рис. 11.1. Тренды более сложной формы удаляются подгонкой многочленов более высокого порядка, однако принимать значение
равенства (11.16) эквивалентны равенствам (4.70). Пример исключения линейного тренда показан на рис. 11.1. Тренды более сложной формы удаляются подгонкой многочленов более высокого порядка, однако принимать значение  как правило, не рекомендуется.
как правило, не рекомендуется.
















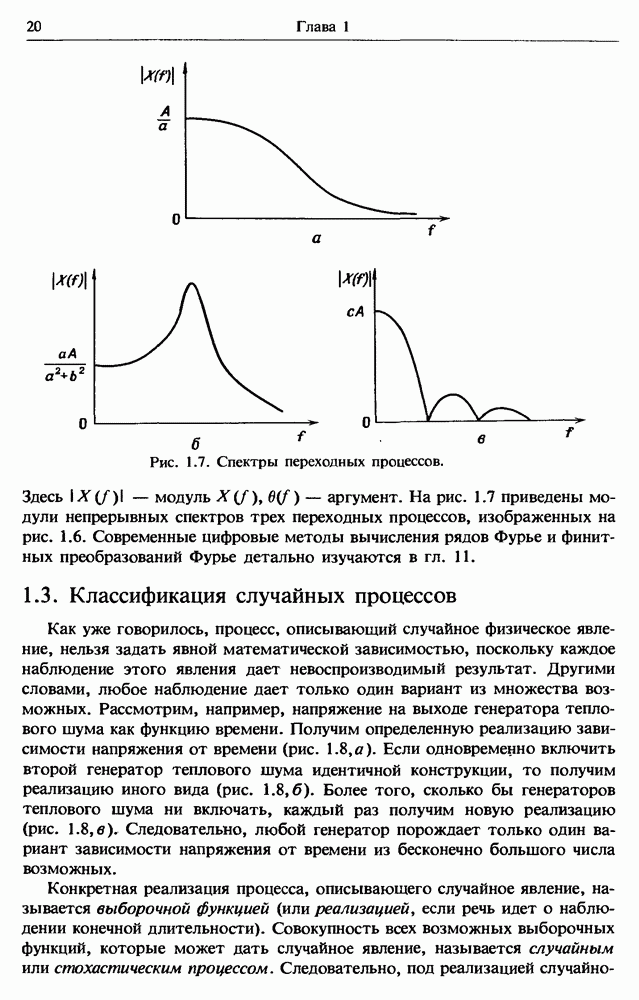
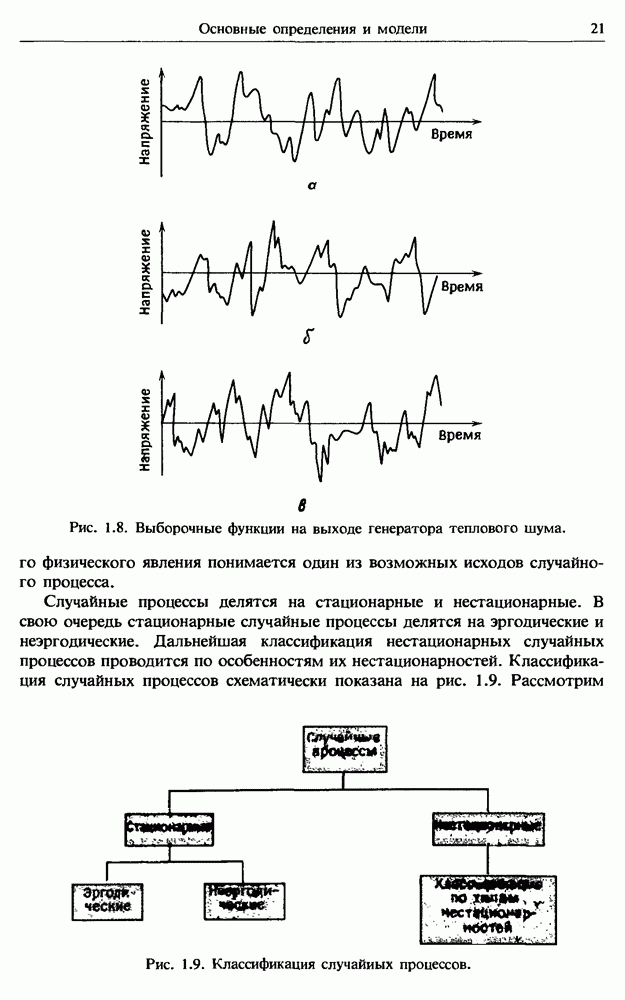

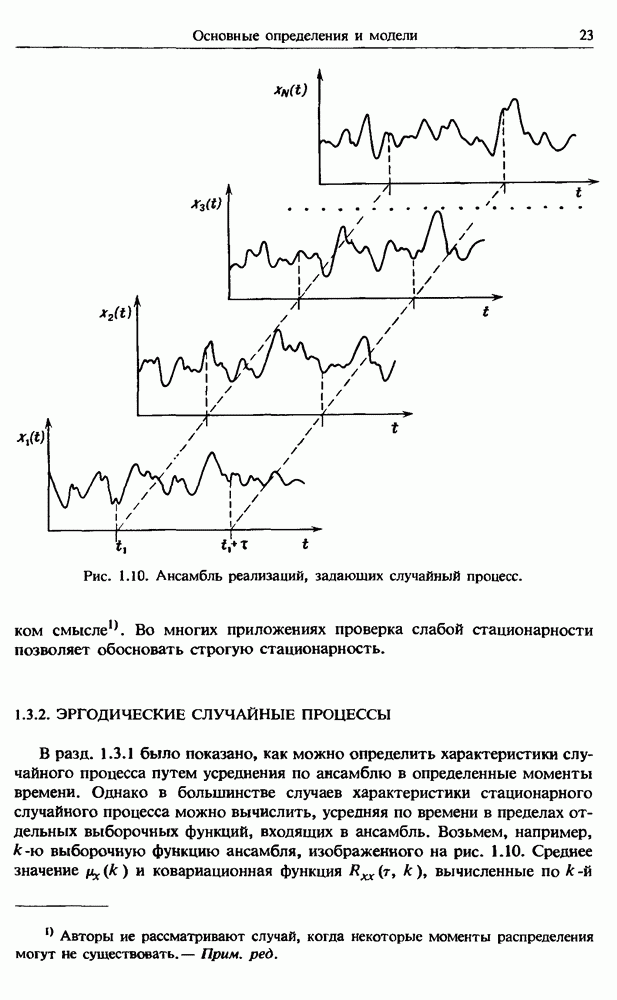



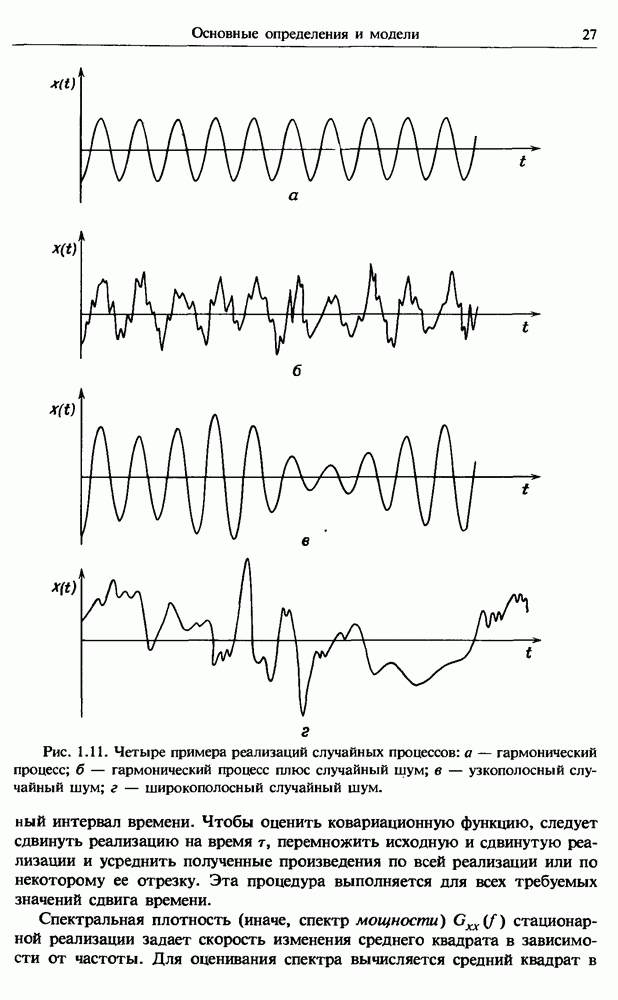
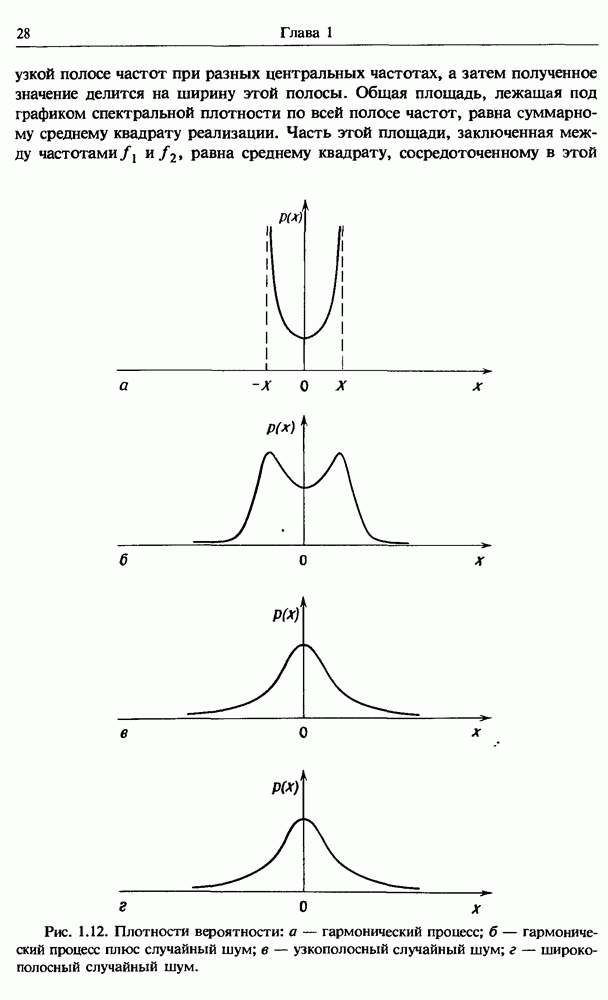
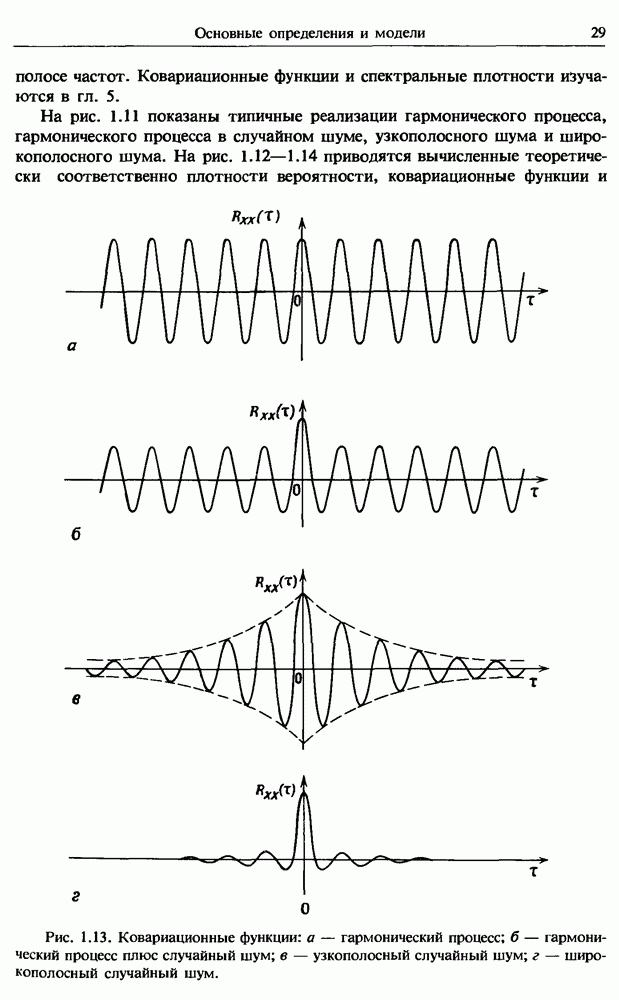
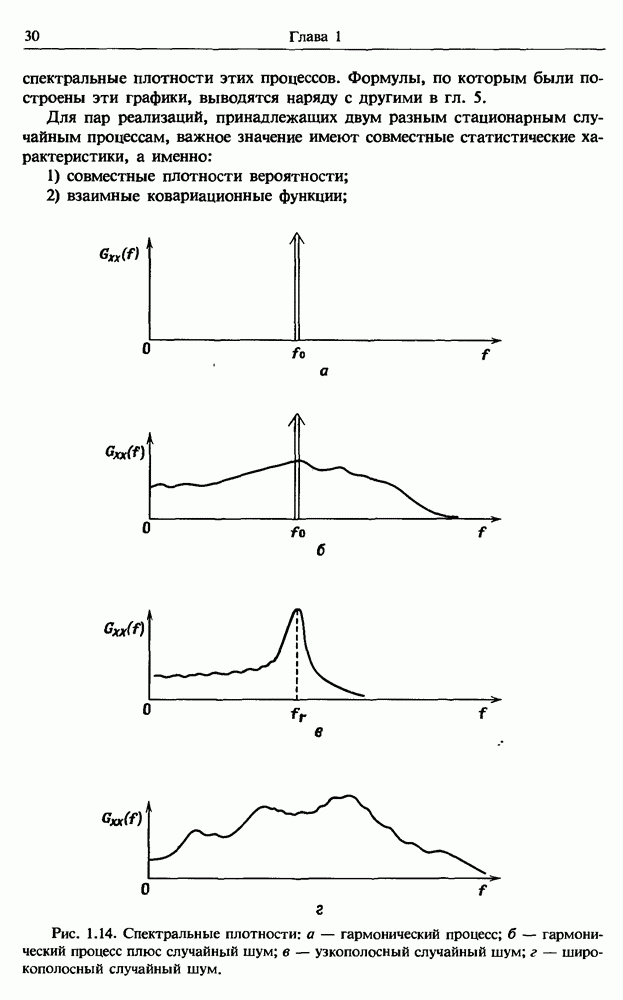


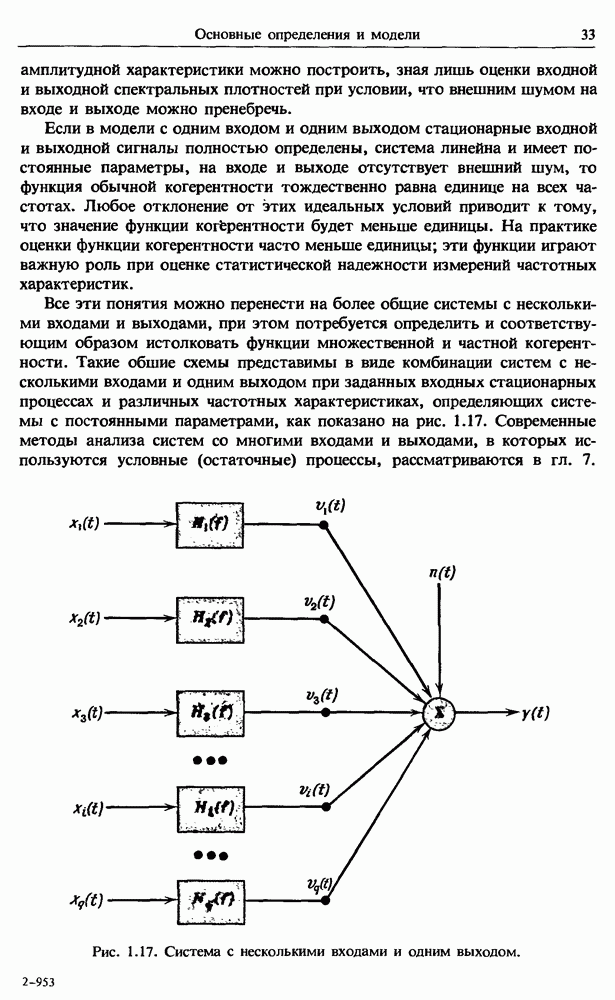
































































































































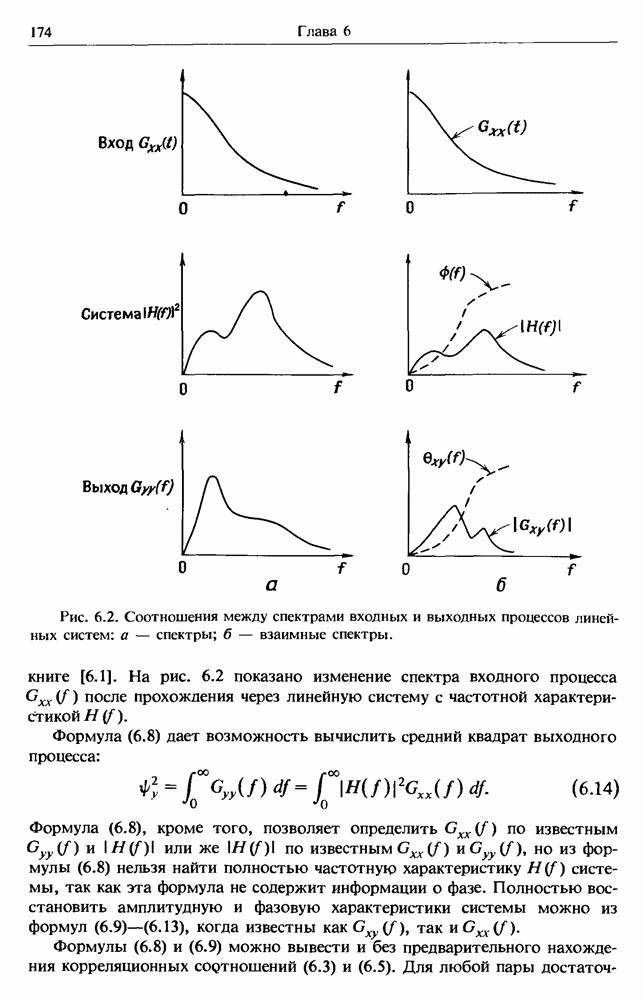





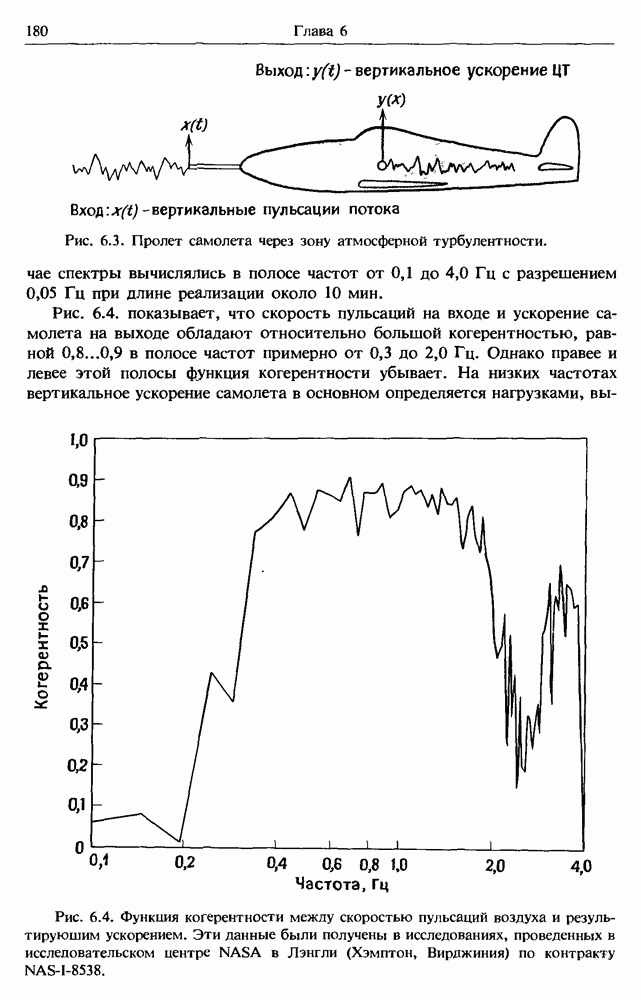

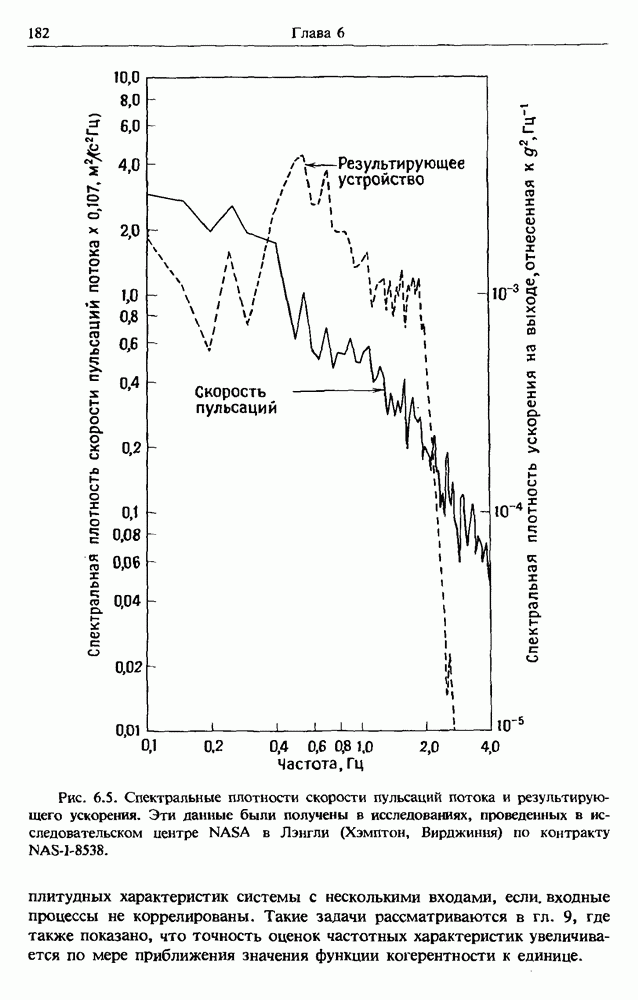

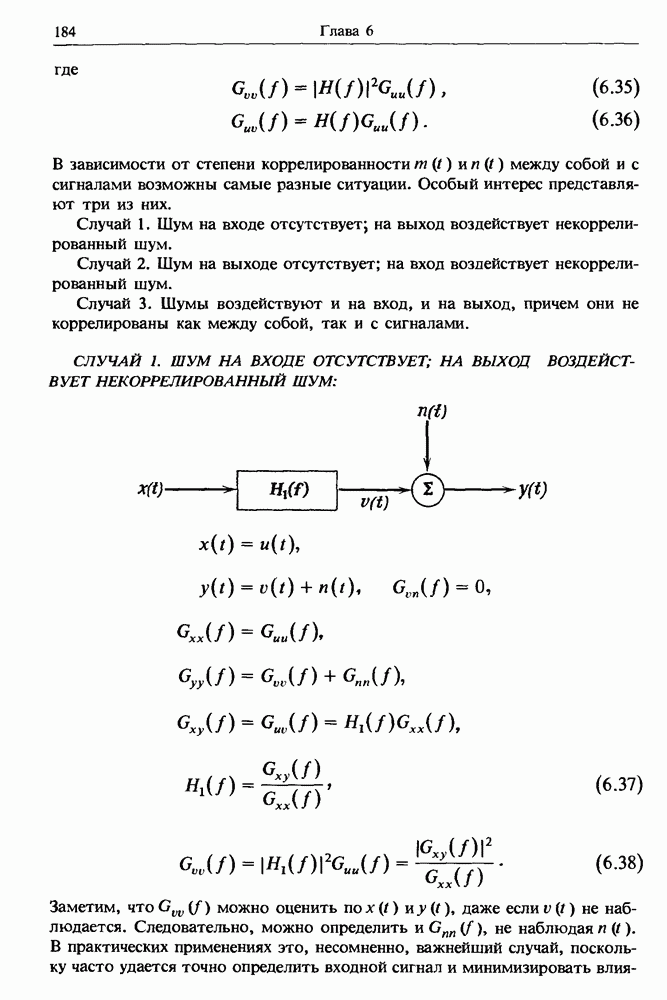







































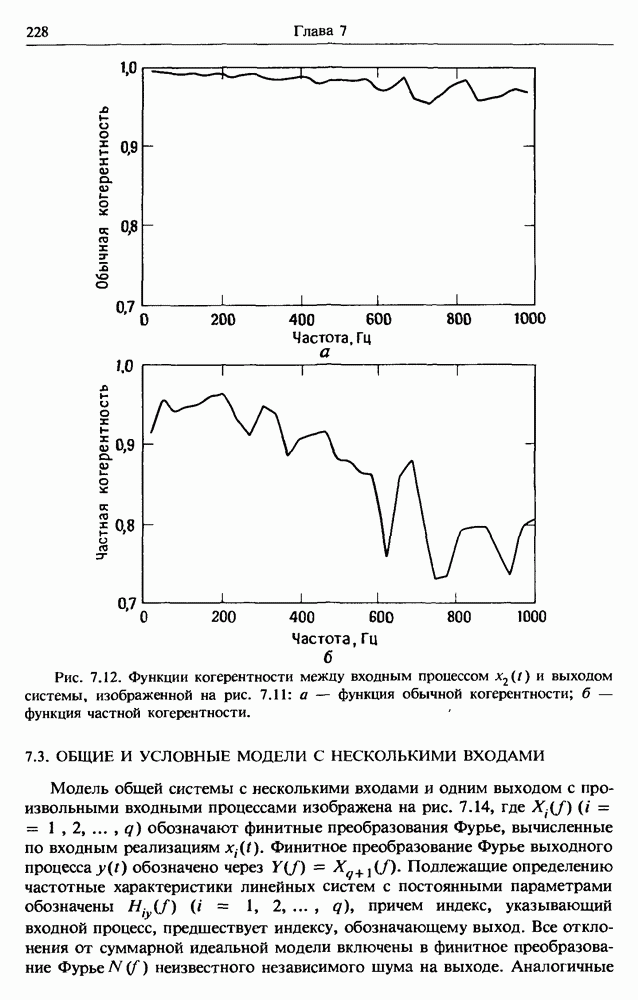
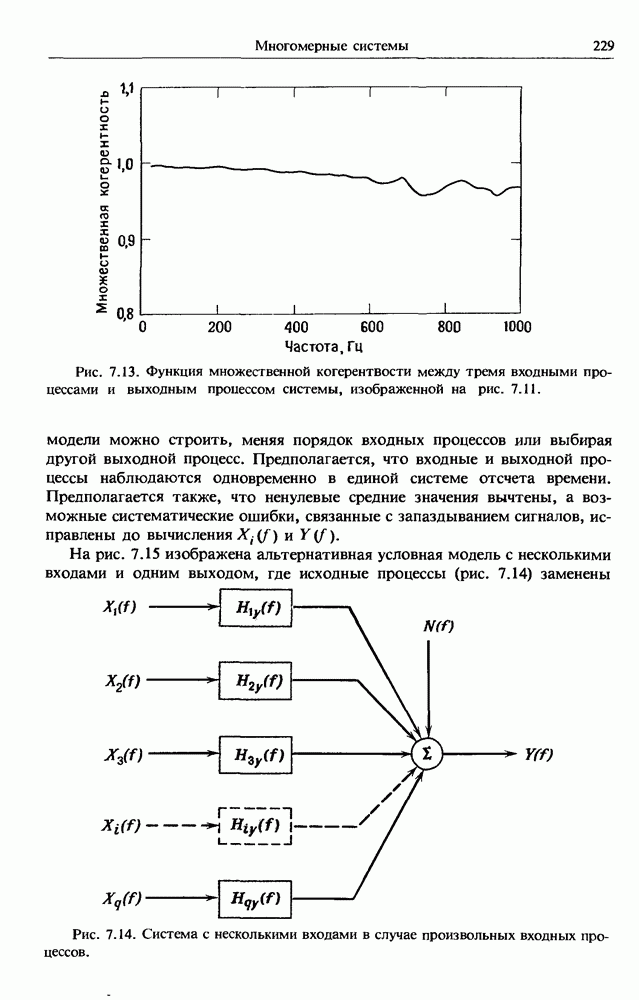





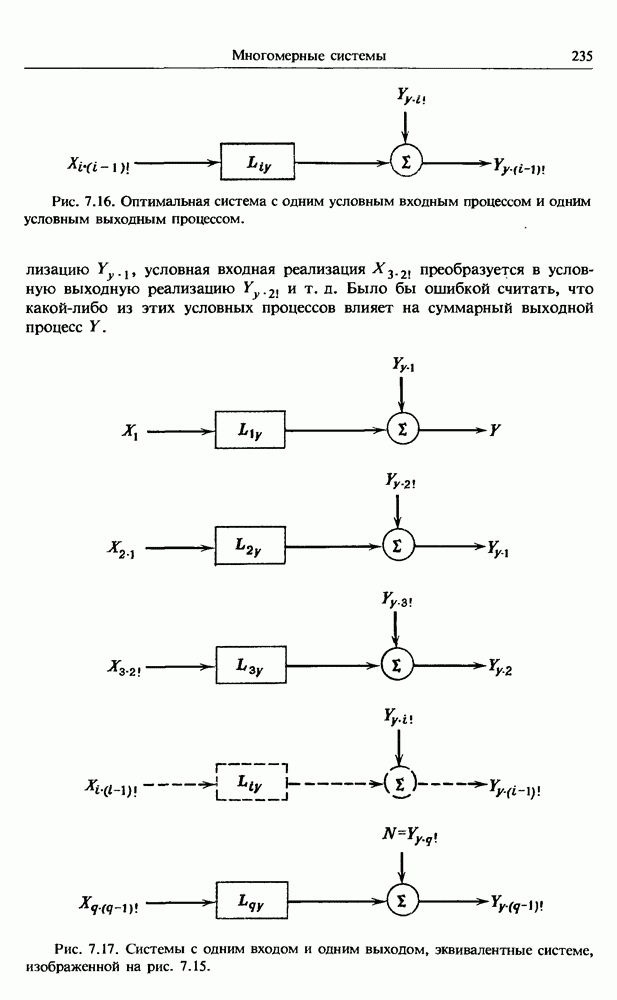


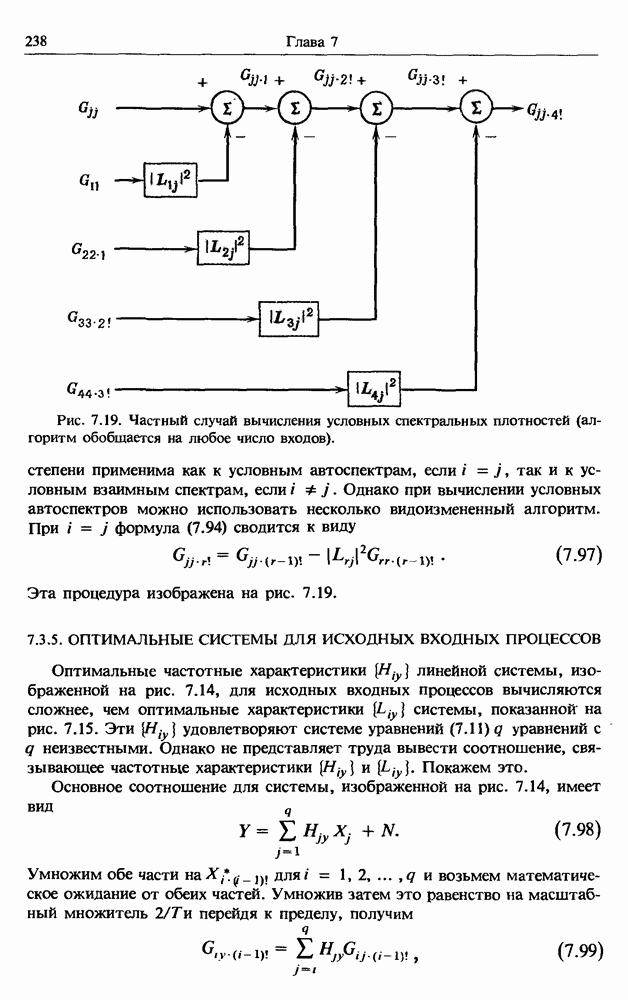





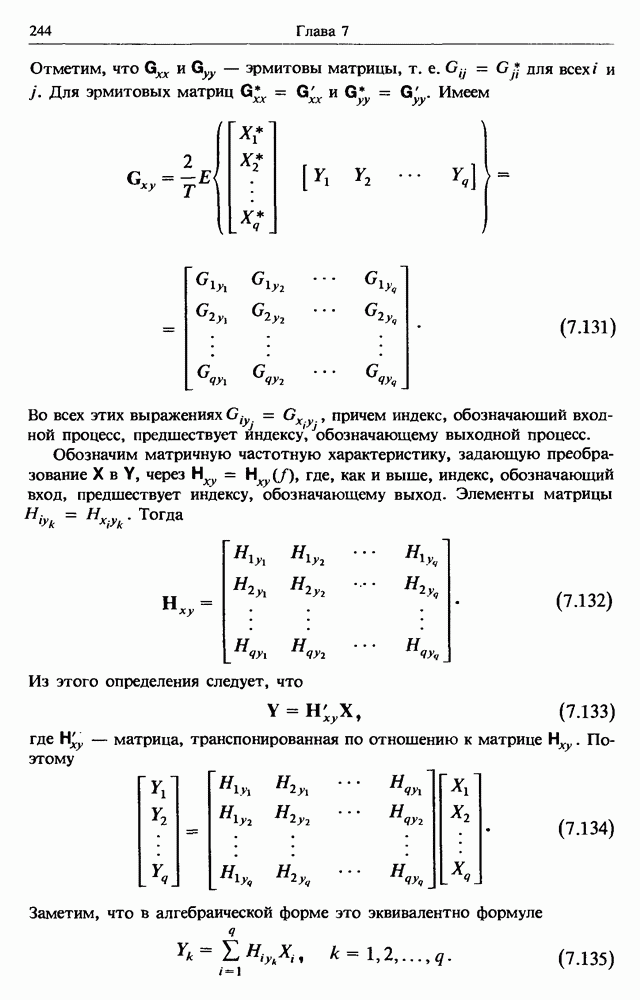
















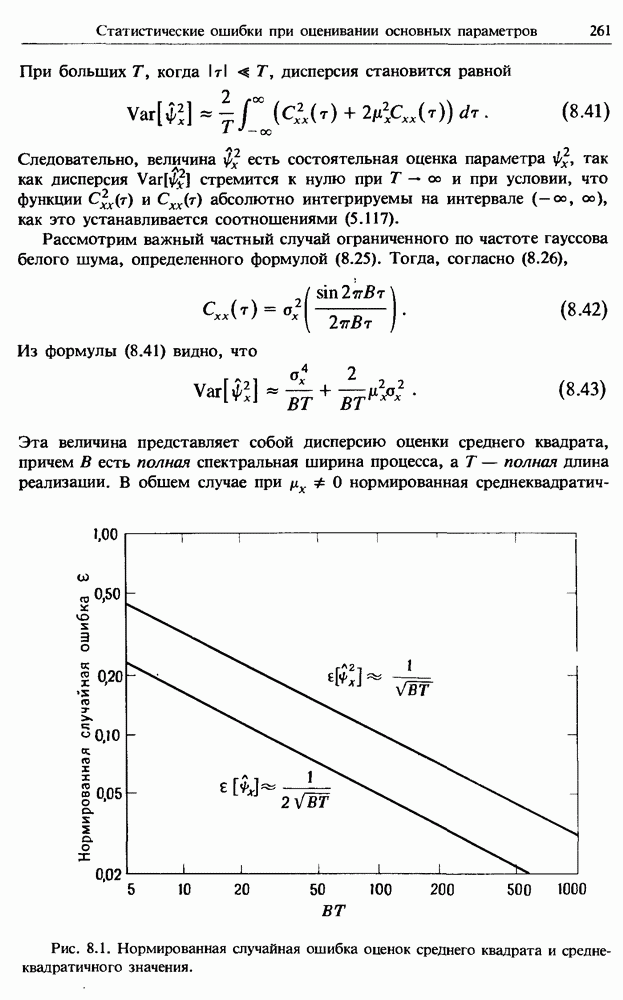

















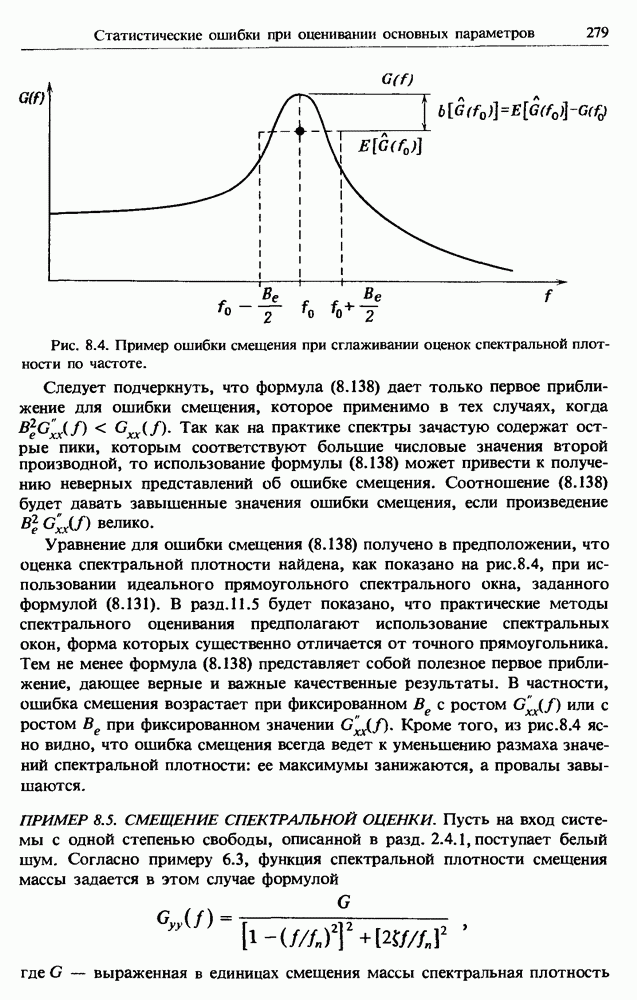

























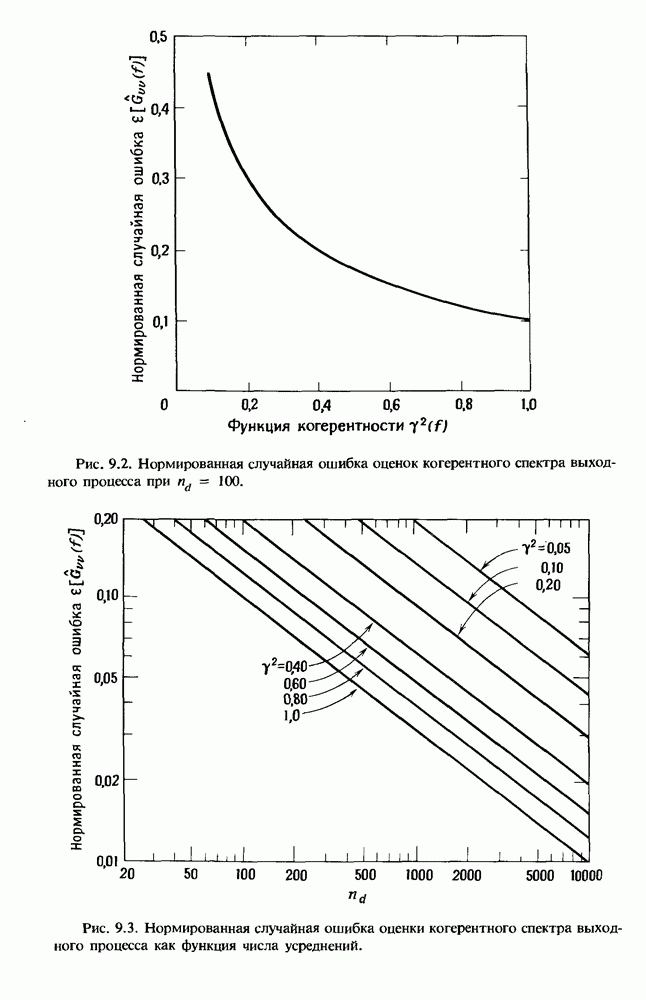


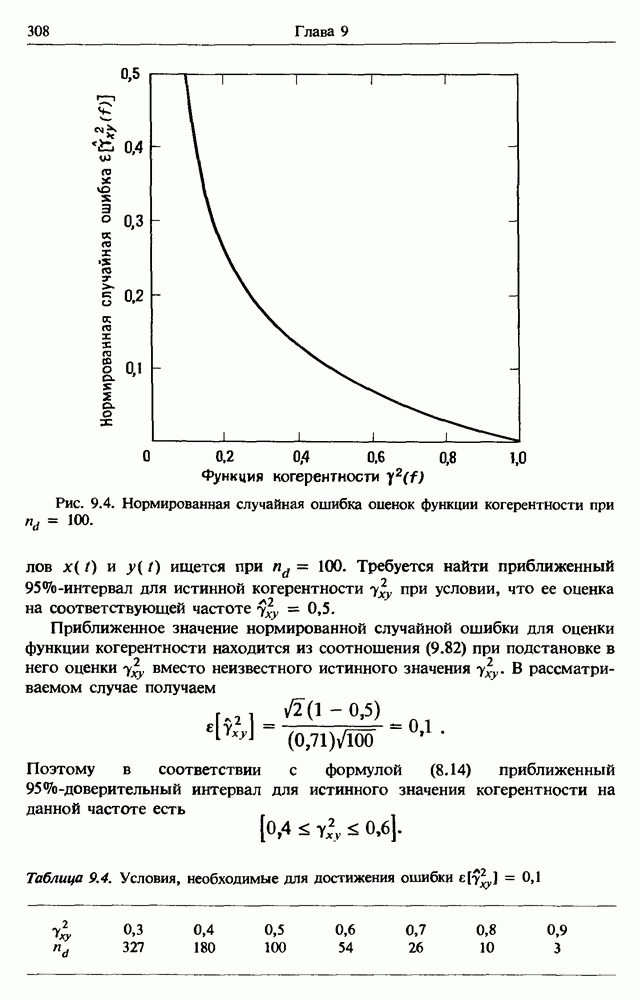


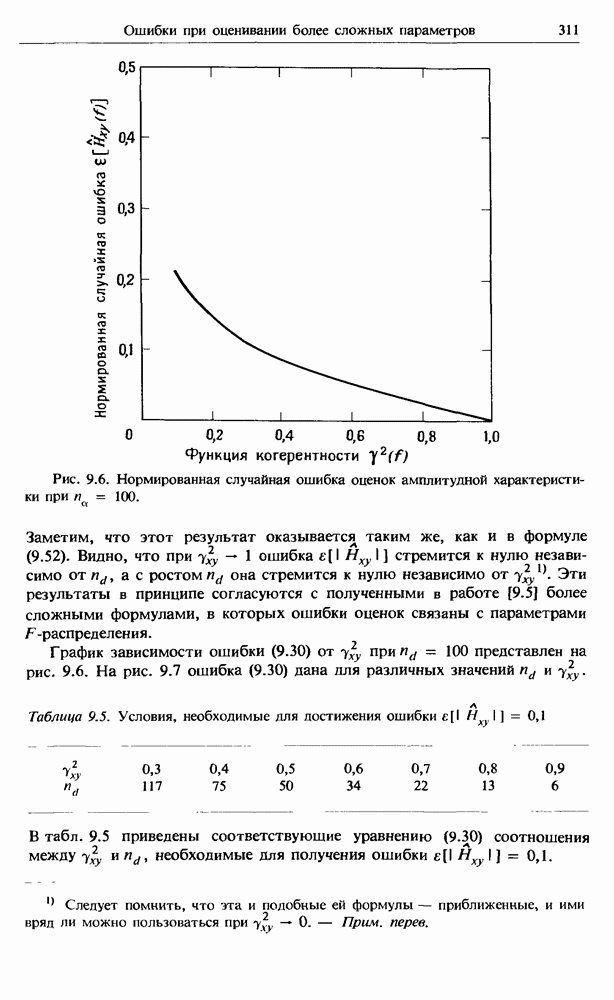
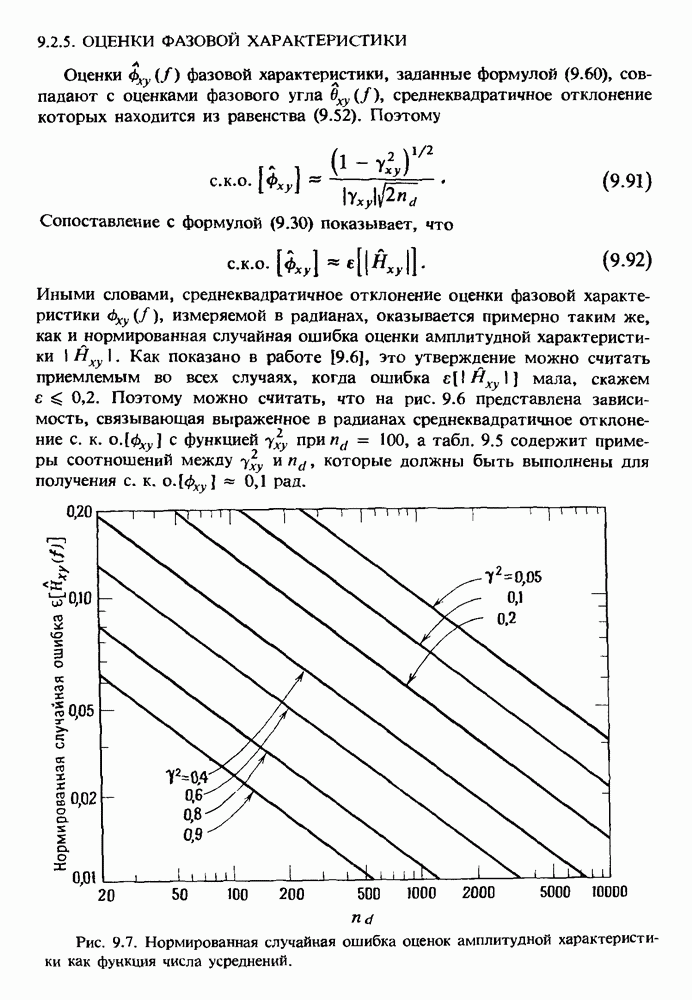

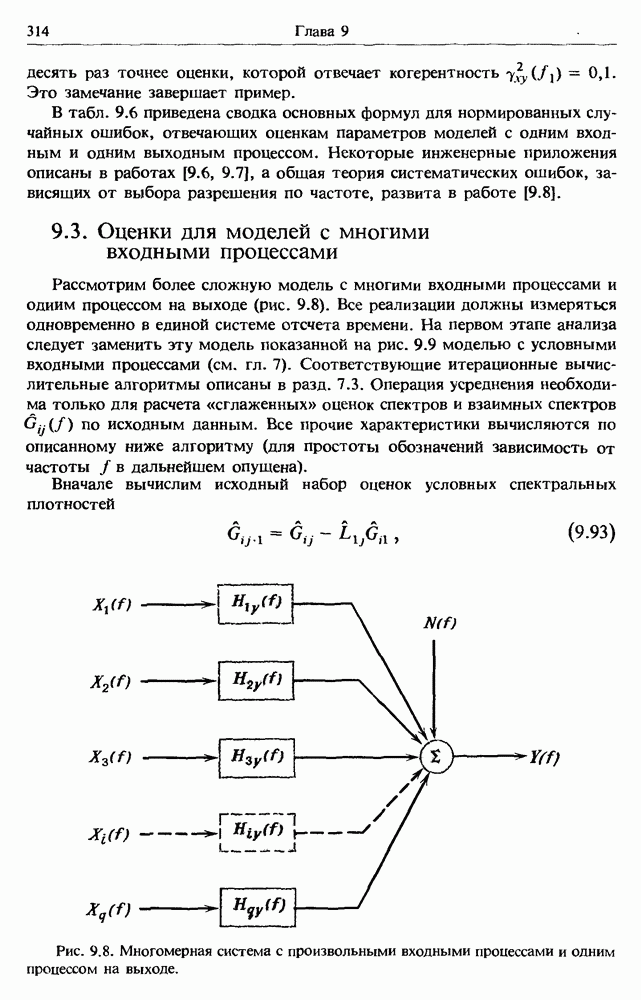


































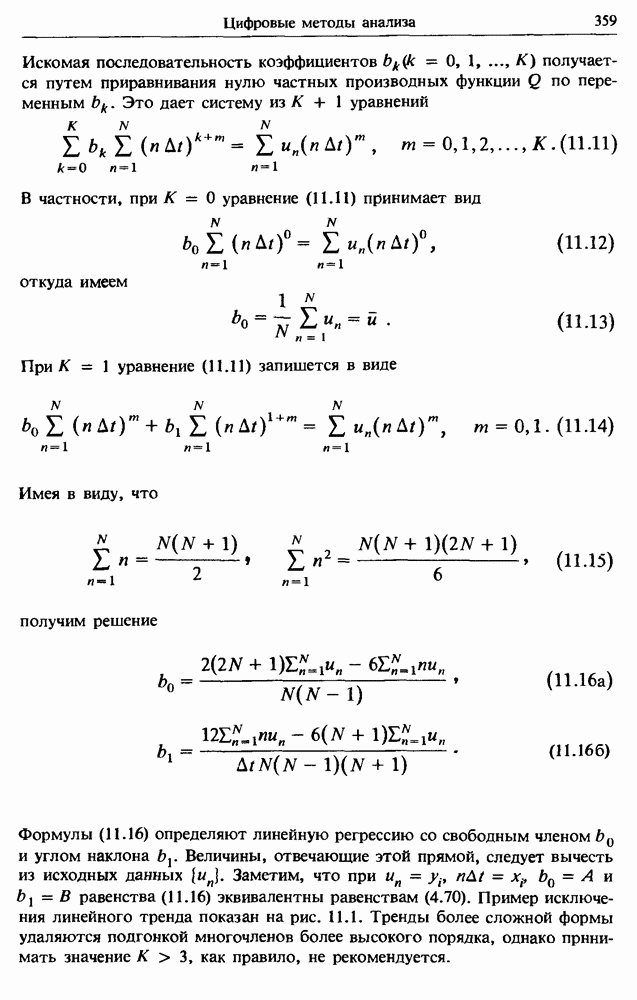






















































































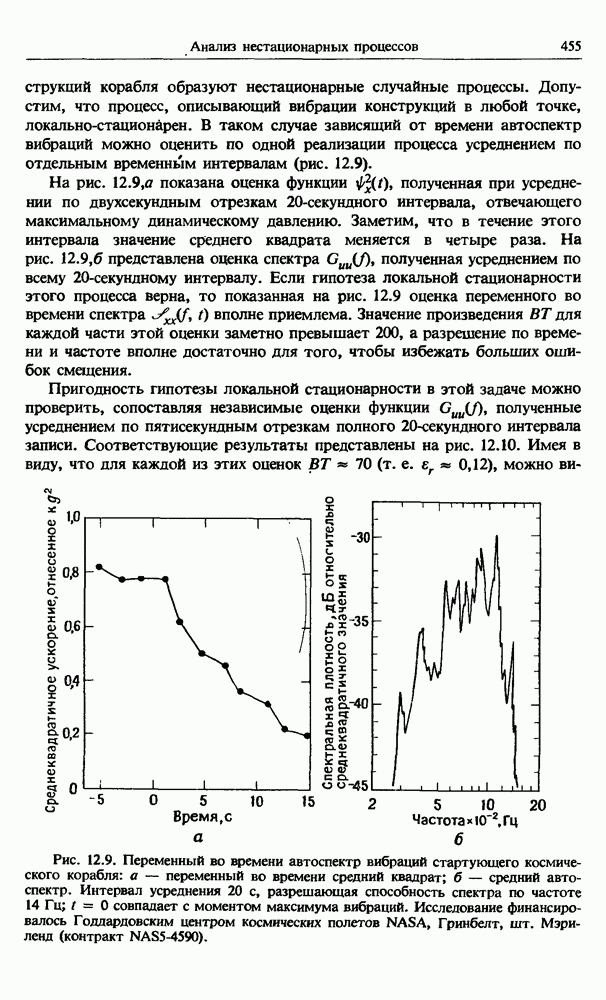
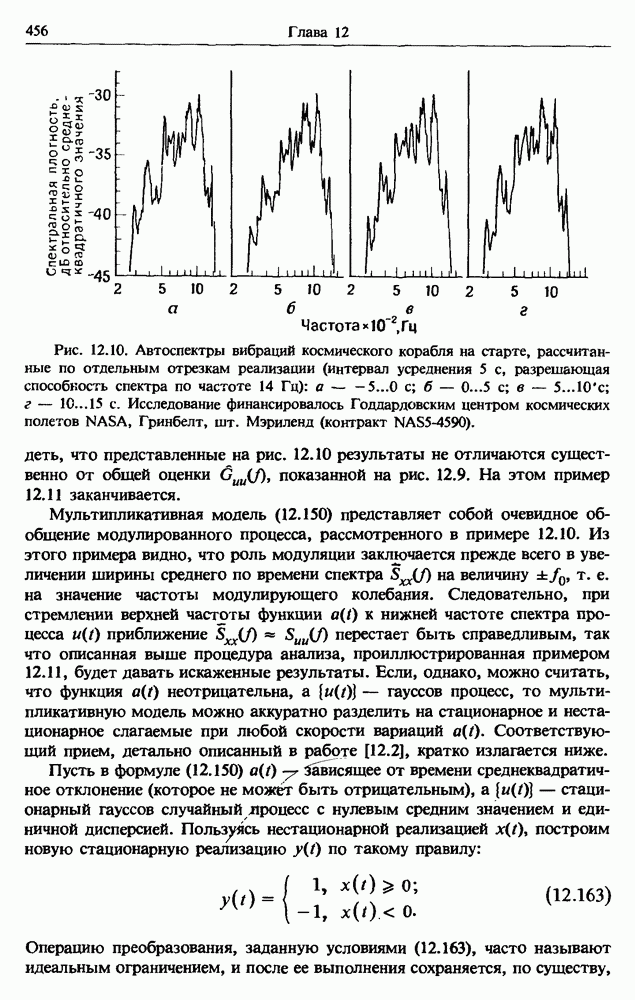
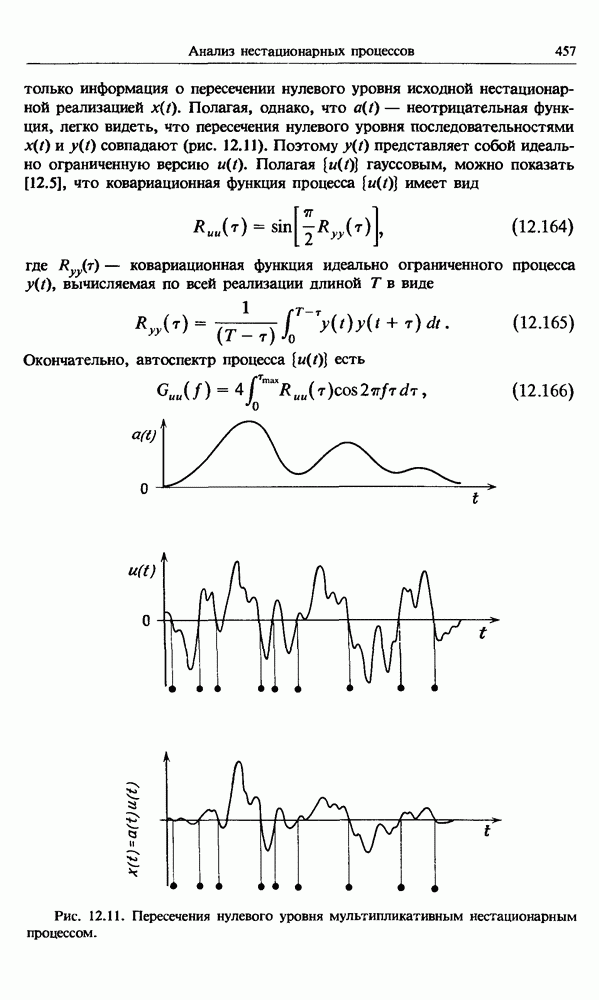







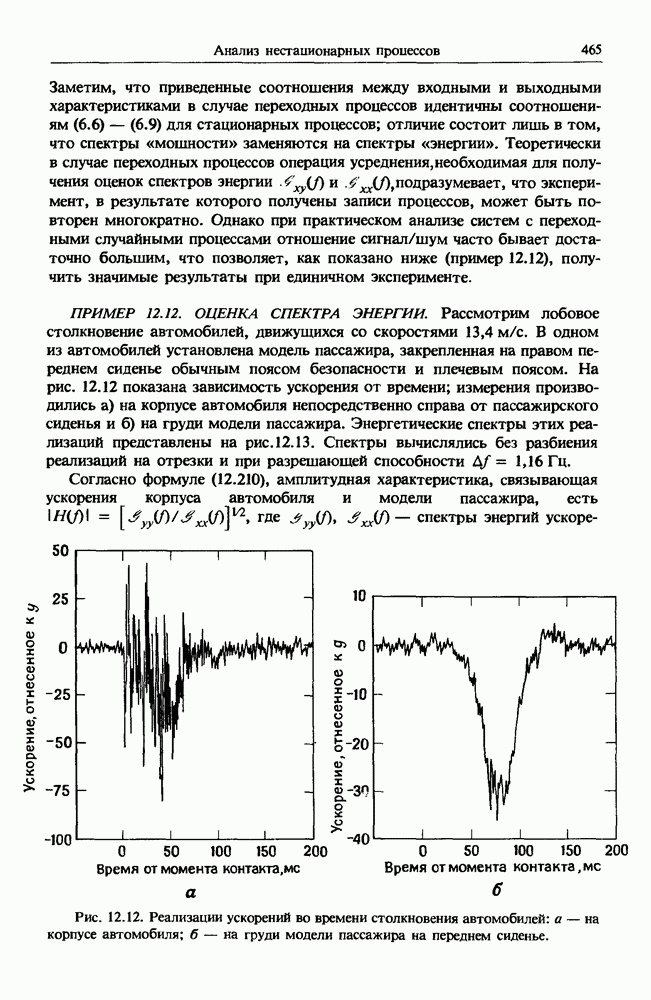


















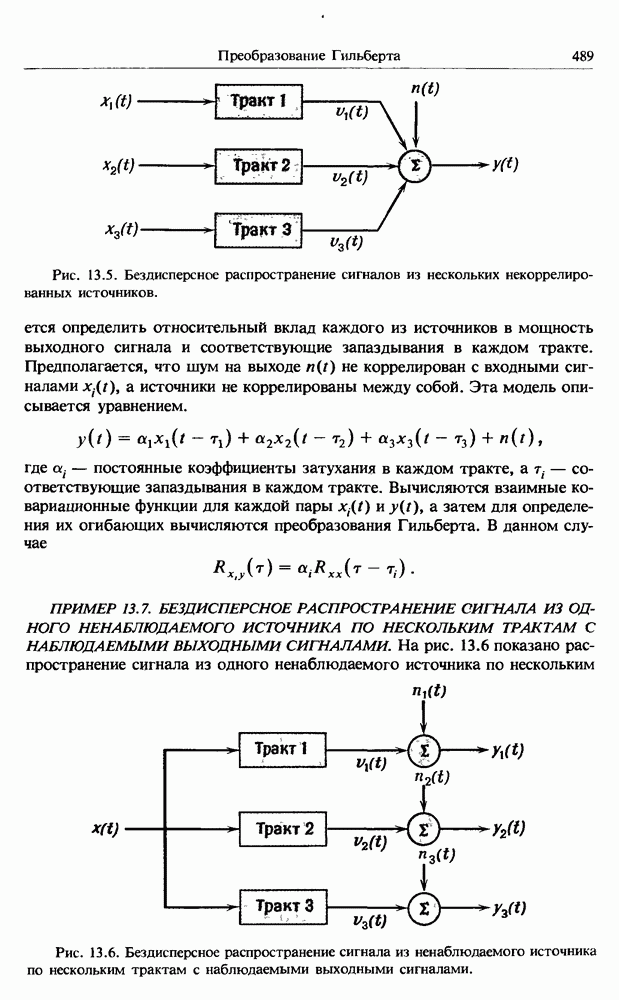

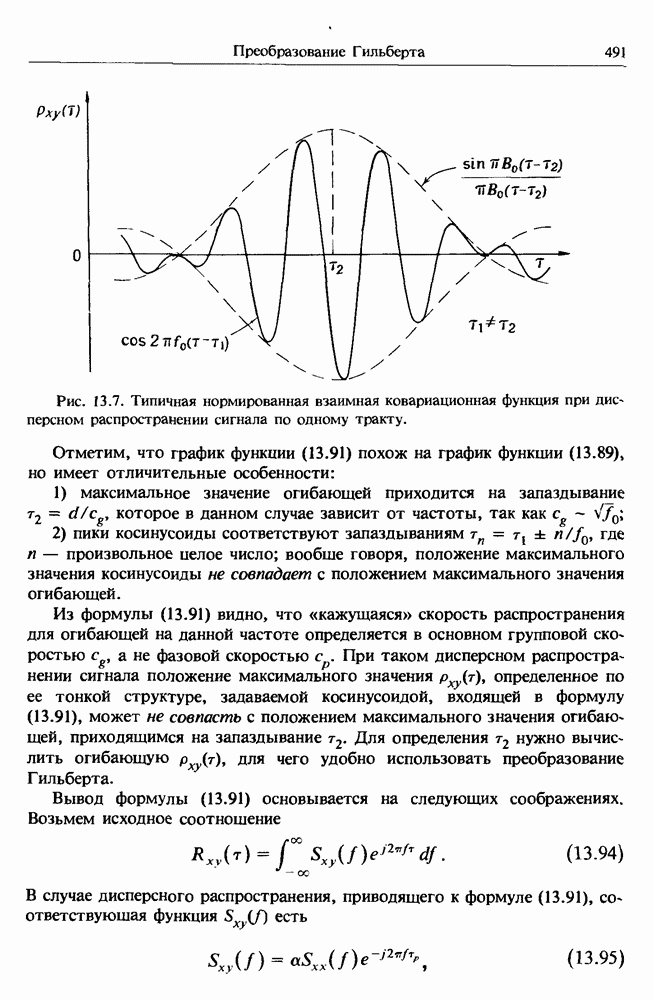
























 представляет собой несмещенную оценку среднего значения
представляет собой несмещенную оценку среднего значения  (см. разд. 4.1). Для последующих расчетов удобно преобразовать последовательность
(см. разд. 4.1). Для последующих расчетов удобно преобразовать последовательность  в новую последовательность
в новую последовательность  имеющую нулевое выборочное среднее заначение:
имеющую нулевое выборочное среднее заначение:

 для которых
для которых 
 имеет вид
имеет вид

 представляют собой несмещенные оценки среднеквадратичного отклонения
представляют собой несмещенные оценки среднеквадратичного отклонения  и дисперсии
и дисперсии  соответственно (см. разд. 4.1). Если дальнейшие расчеты предполагается вести на ЭВМ с фиксированной, а не плавающей запятой, то
соответственно (см. разд. 4.1). Если дальнейшие расчеты предполагается вести на ЭВМ с фиксированной, а не плавающей запятой, то  следует преобразовать в новую последовательность
следует преобразовать в новую последовательность  определенную в виде
определенную в виде

 Обычными источниками таких случайных трендов служат дрейф нуля регистрирующей аппаратуры и операции интегрирования сигнала. Если такие тренды не исключить из исходных данных, то при их последующем анализе могут возникнуть значительные искажения оценок плотности вероятности, ковариационных и спектральных характеристик. Однако здесь нужно проявлять известную осторожность и удалять тренд лишь в том случае, если его присутствие очевидно или следует из априорных физических соображений.
Обычными источниками таких случайных трендов служат дрейф нуля регистрирующей аппаратуры и операции интегрирования сигнала. Если такие тренды не исключить из исходных данных, то при их последующем анализе могут возникнуть значительные искажения оценок плотности вероятности, ковариационных и спектральных характеристик. Однако здесь нужно проявлять известную осторожность и удалять тренд лишь в том случае, если его присутствие очевидно или следует из априорных физических соображений.
 приближается многочленом степени К:
приближается многочленом степени К:


