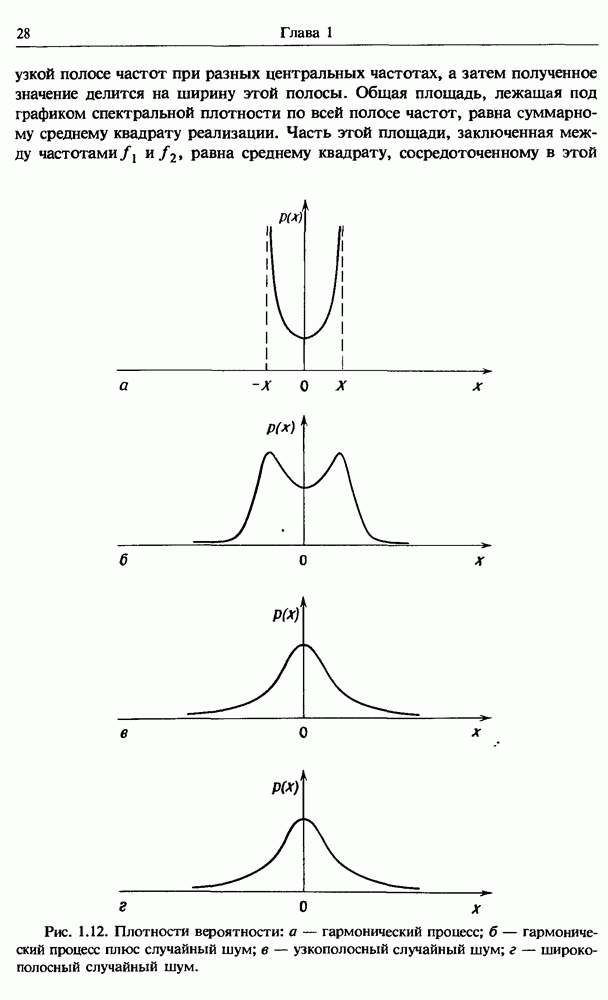
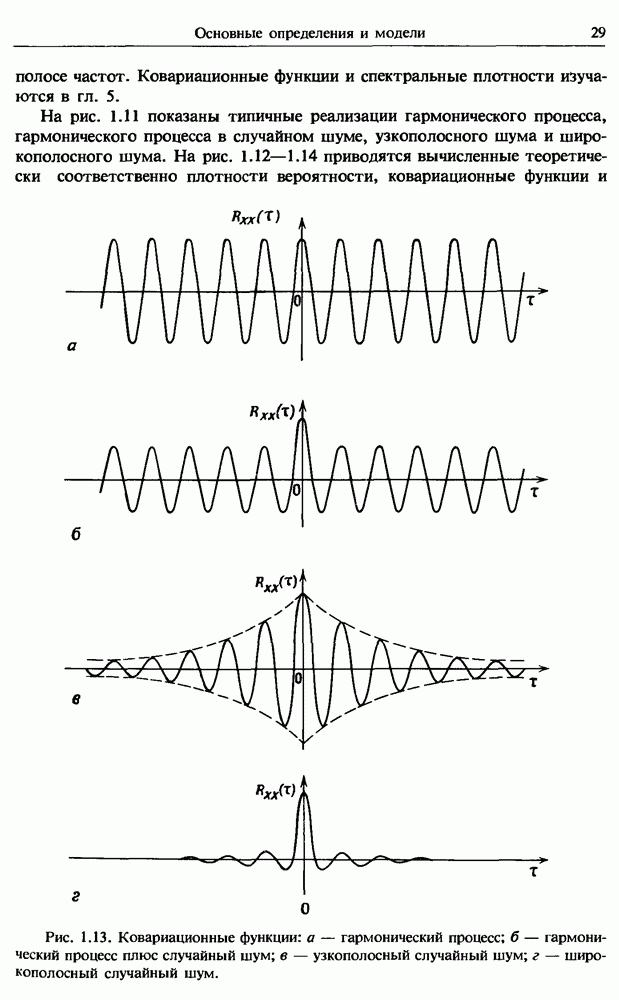
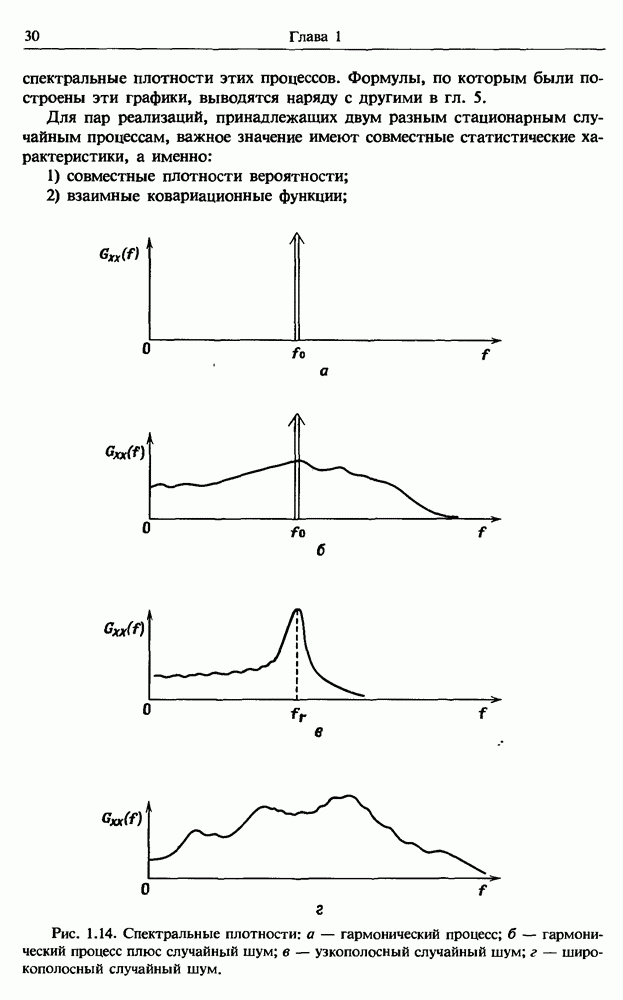
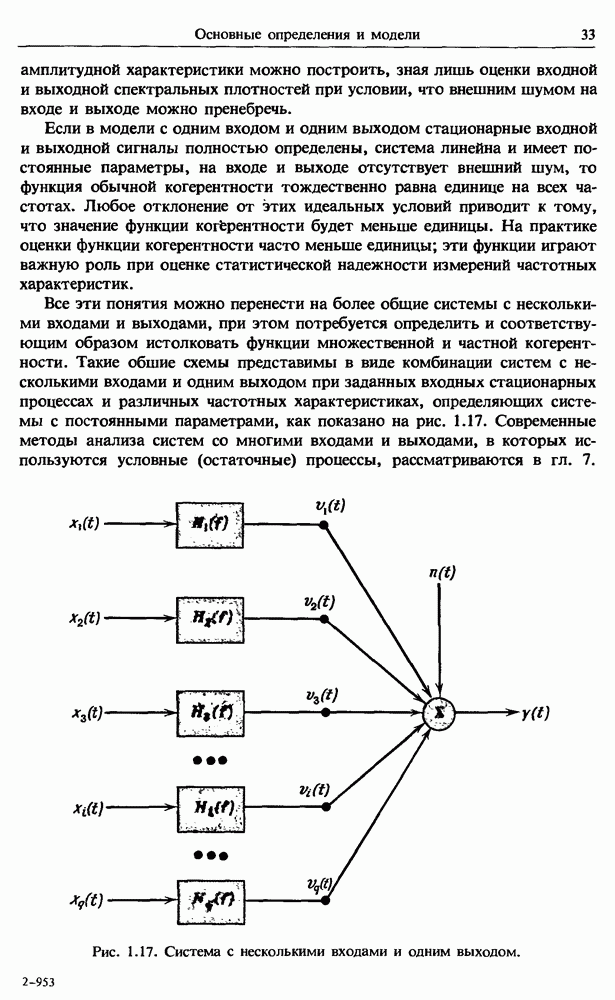
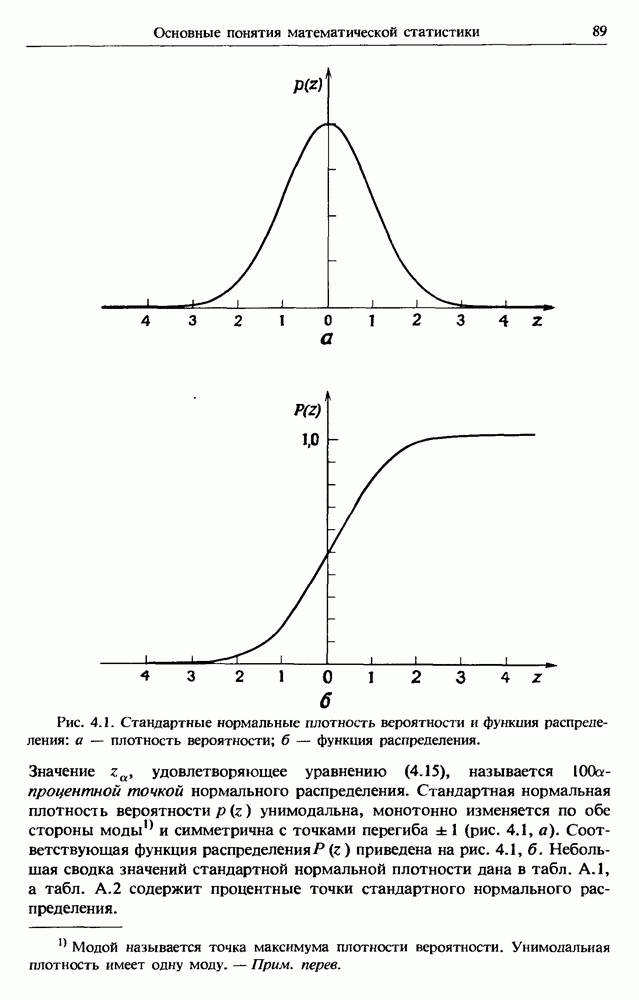
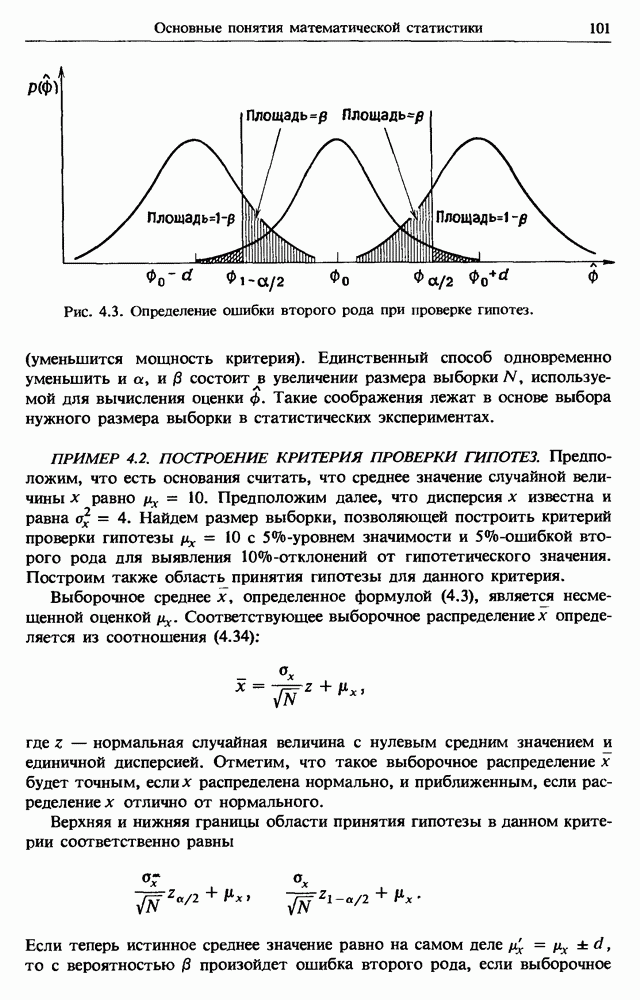
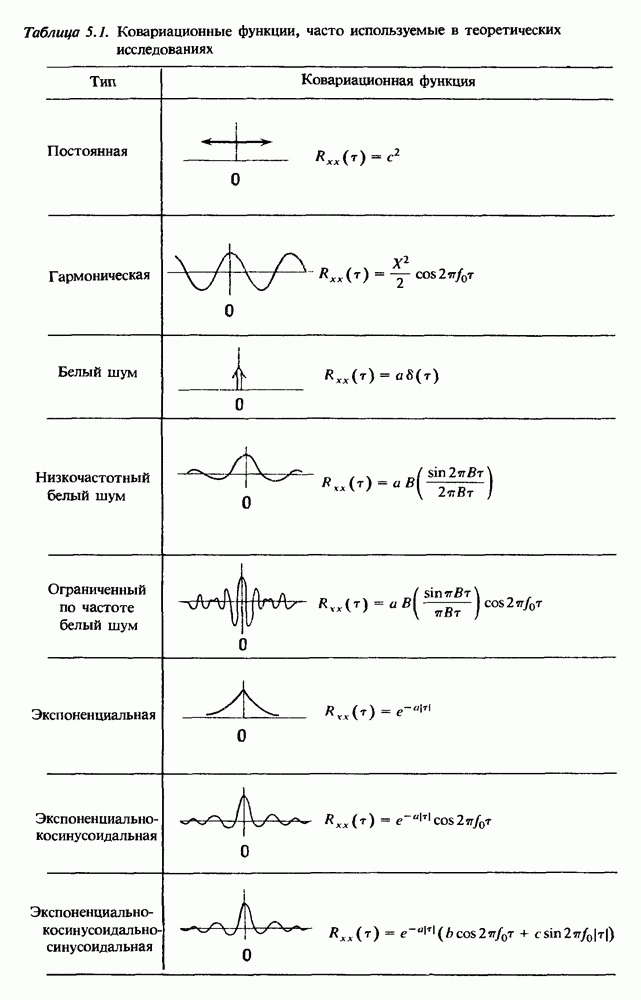
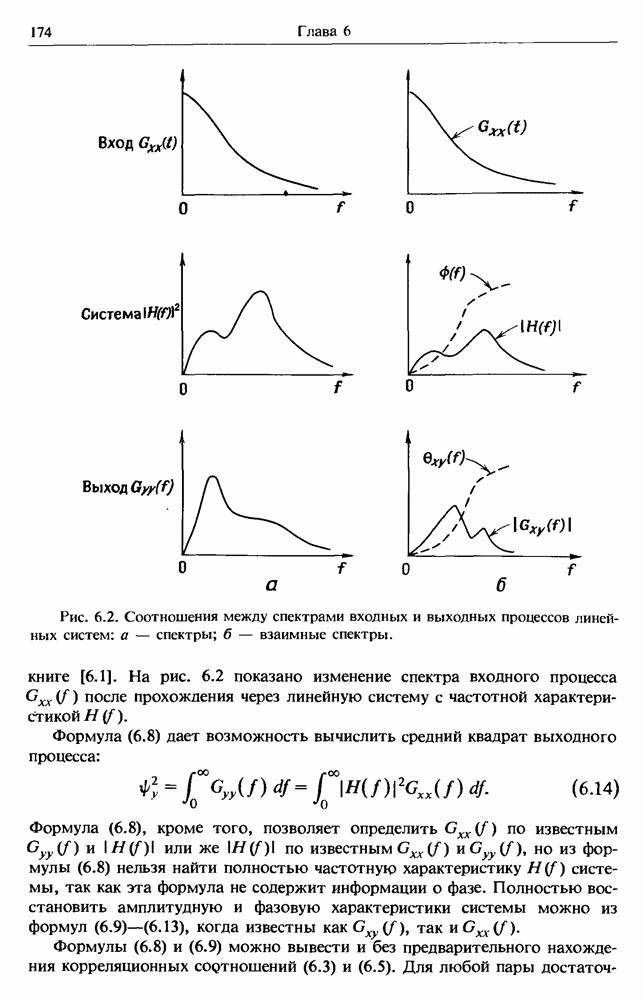
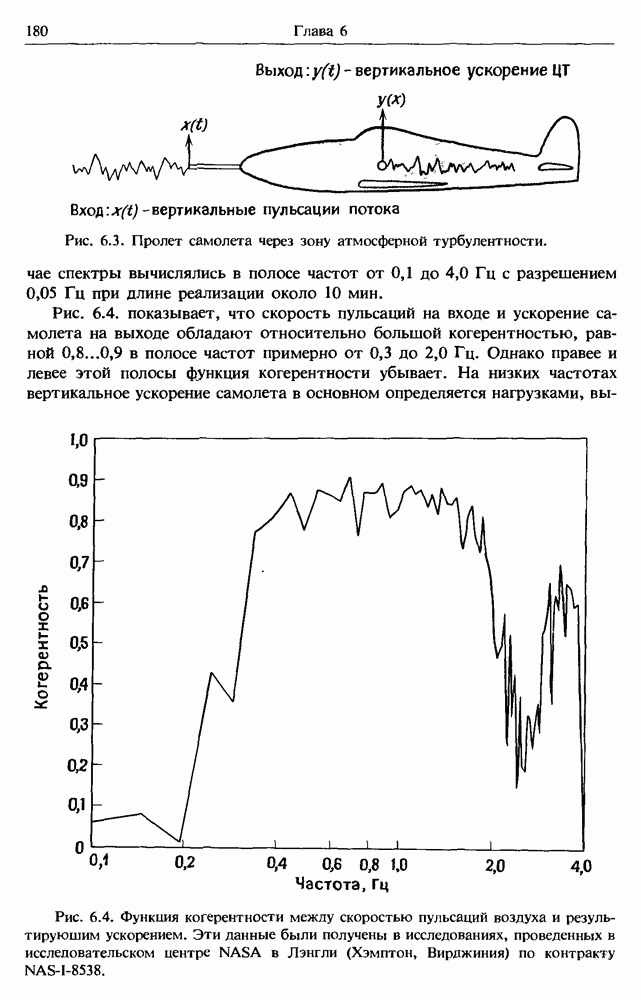
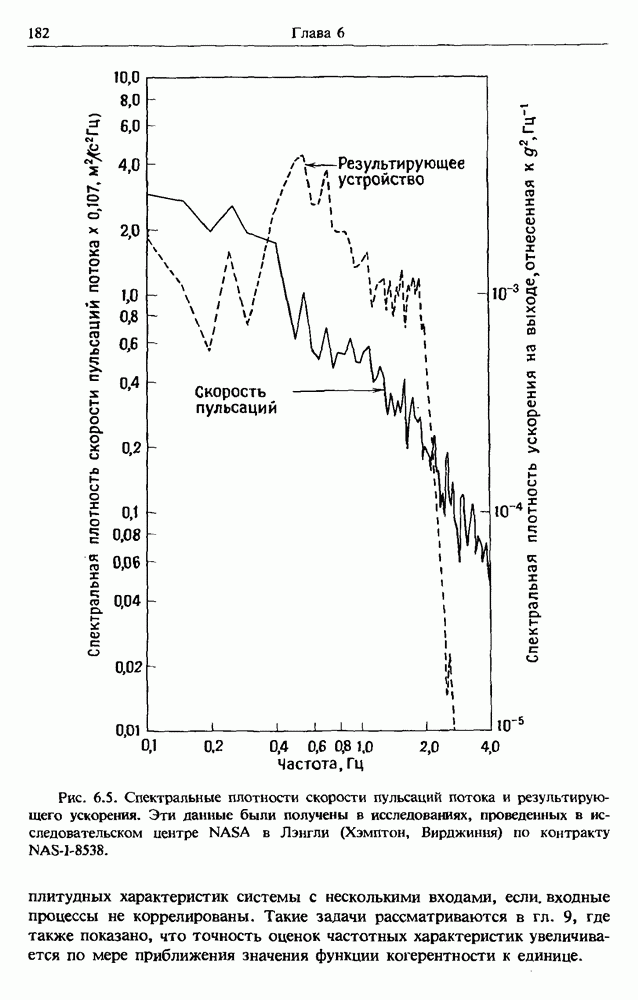
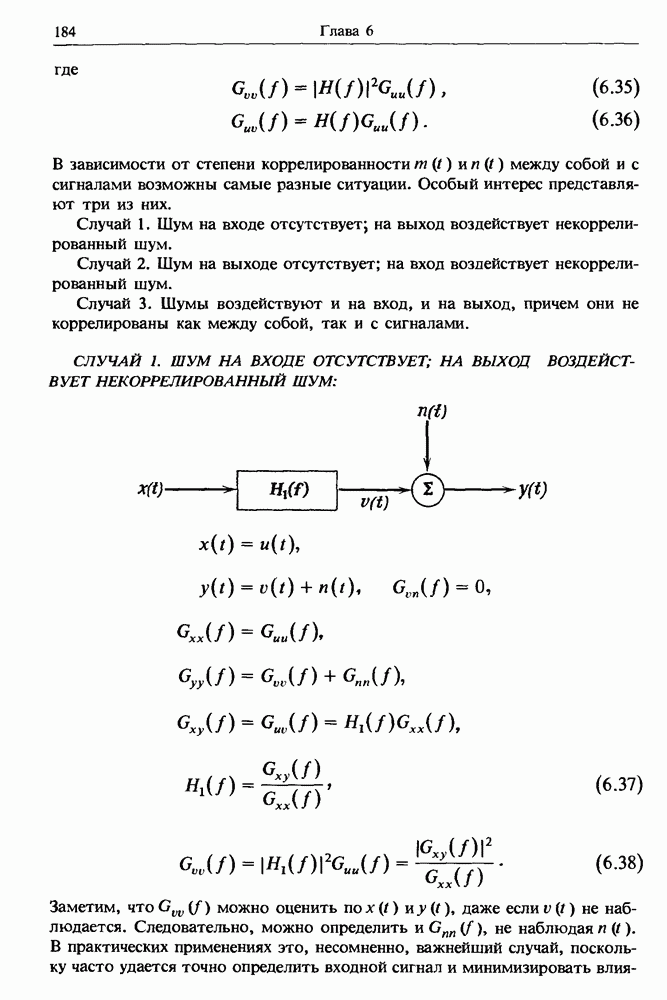
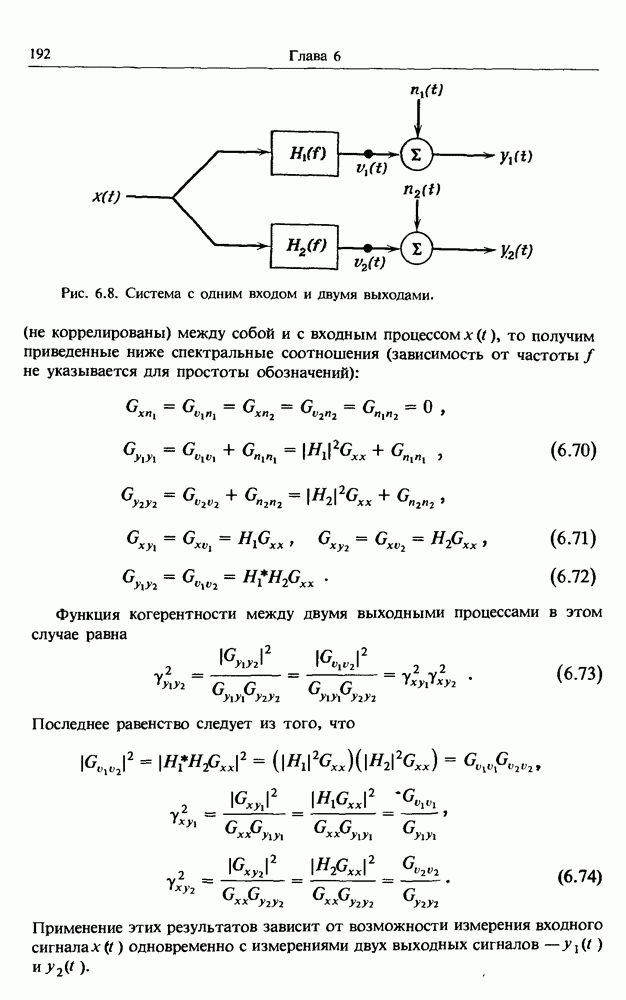
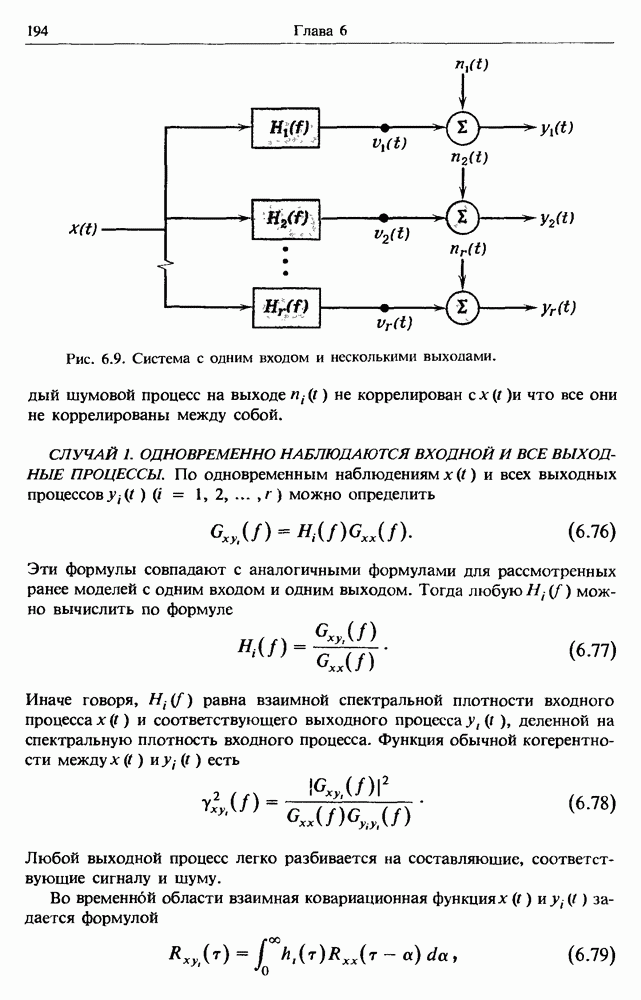
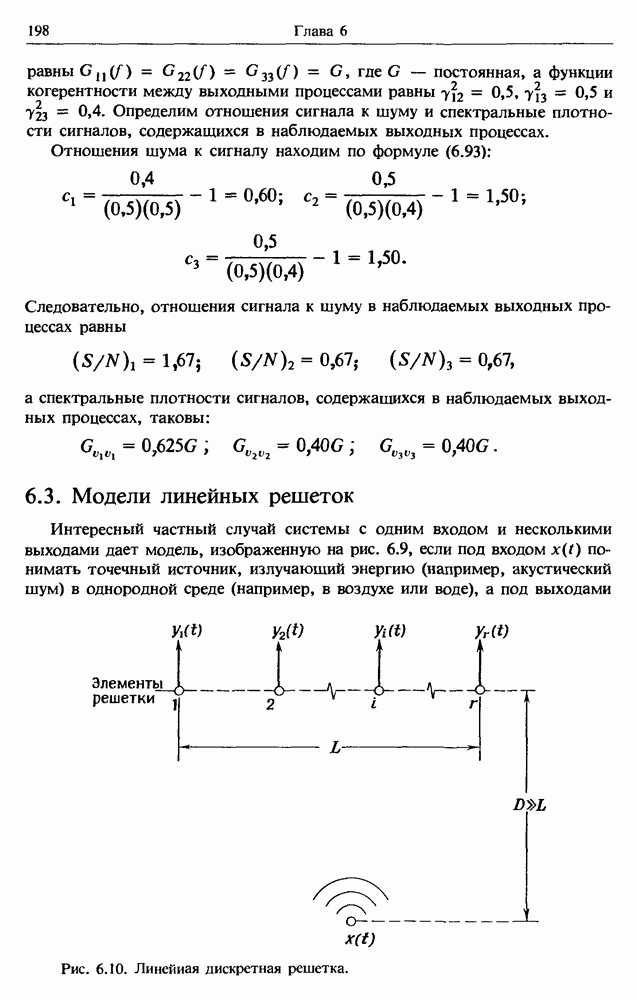
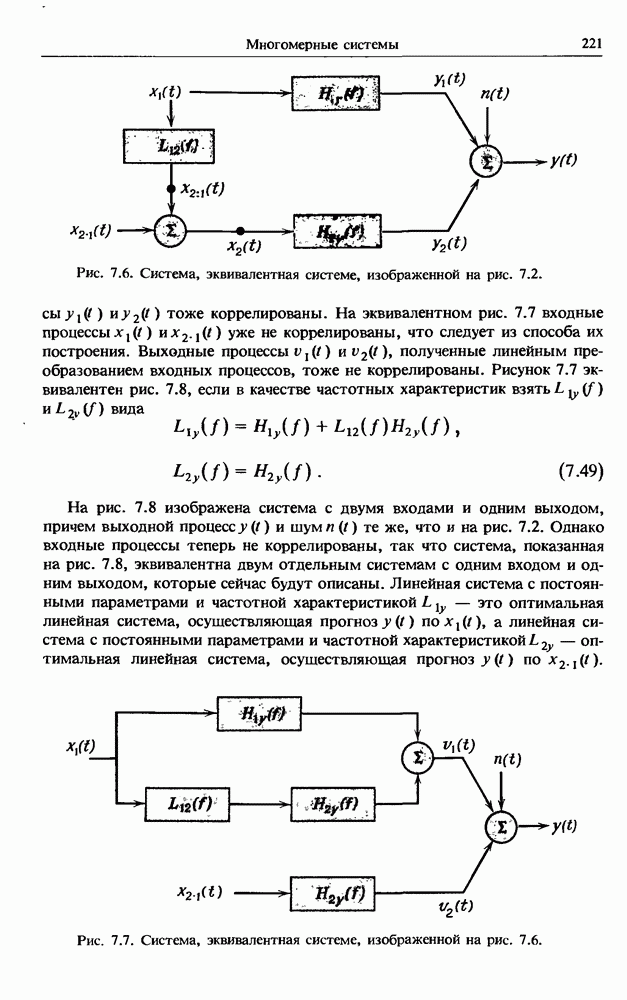
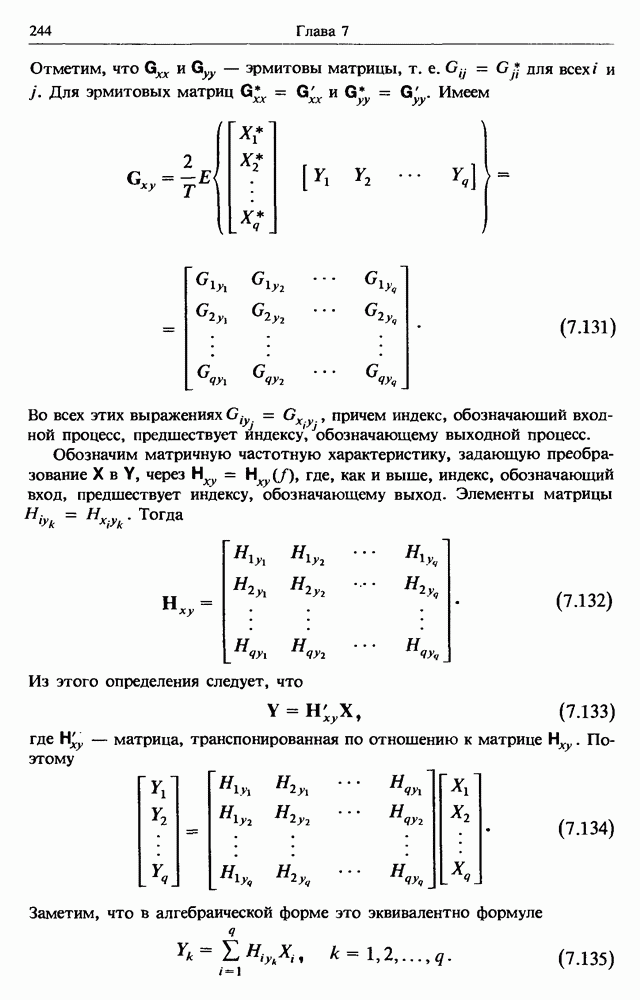
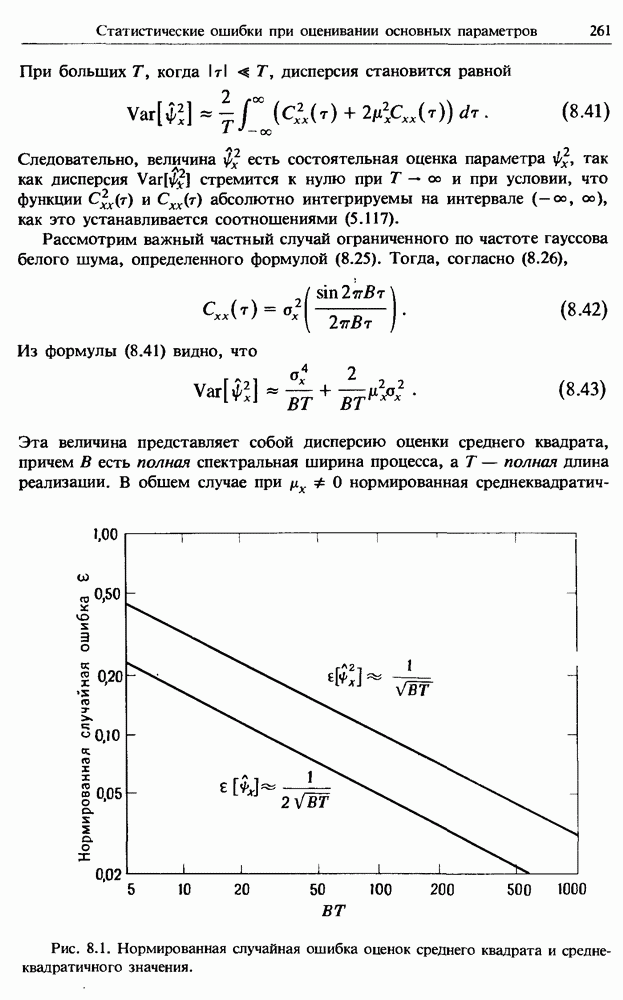
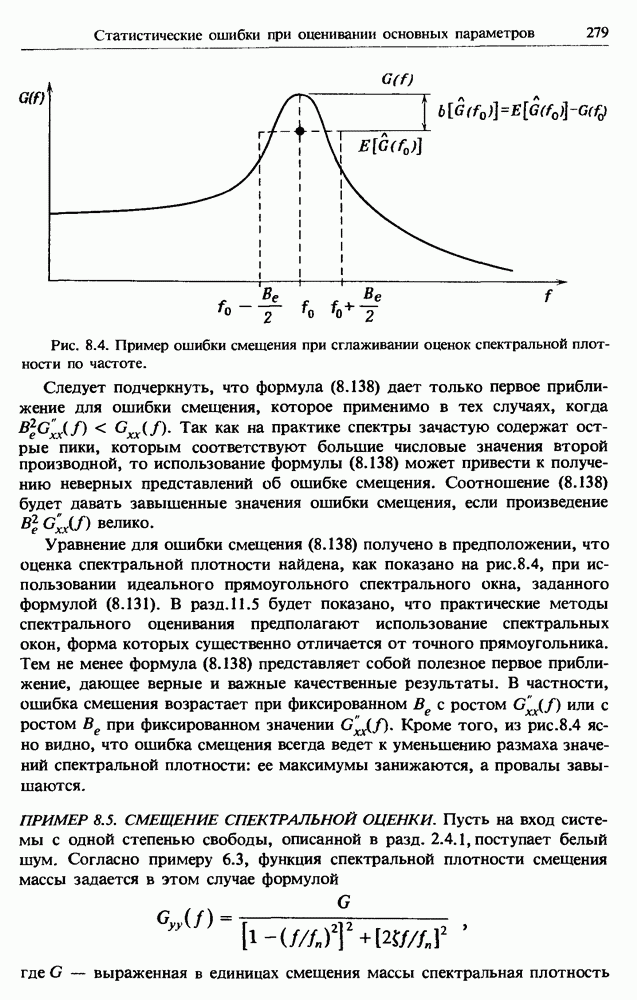
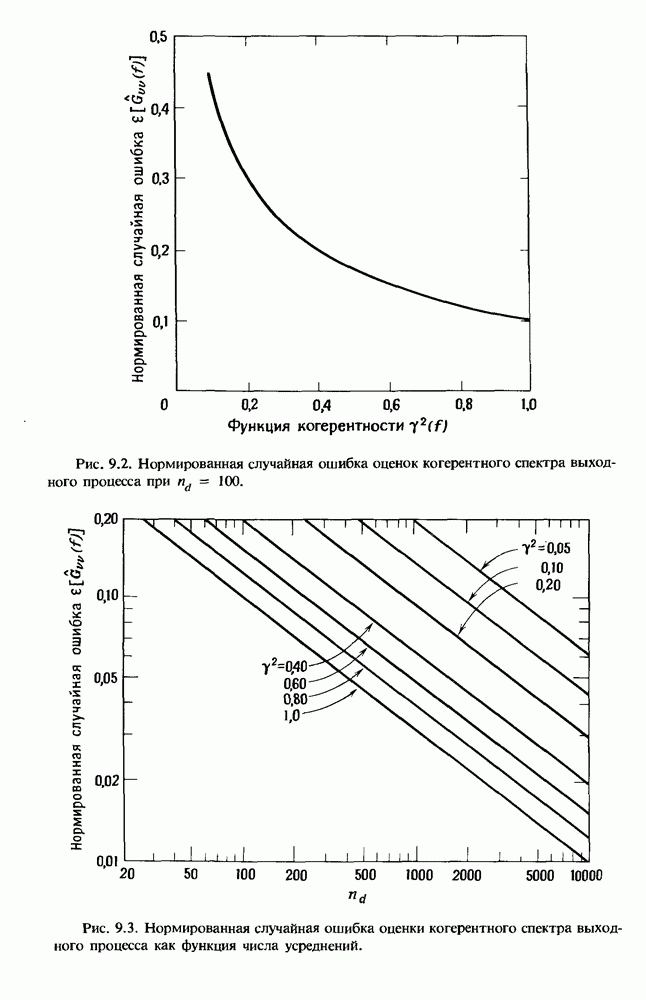
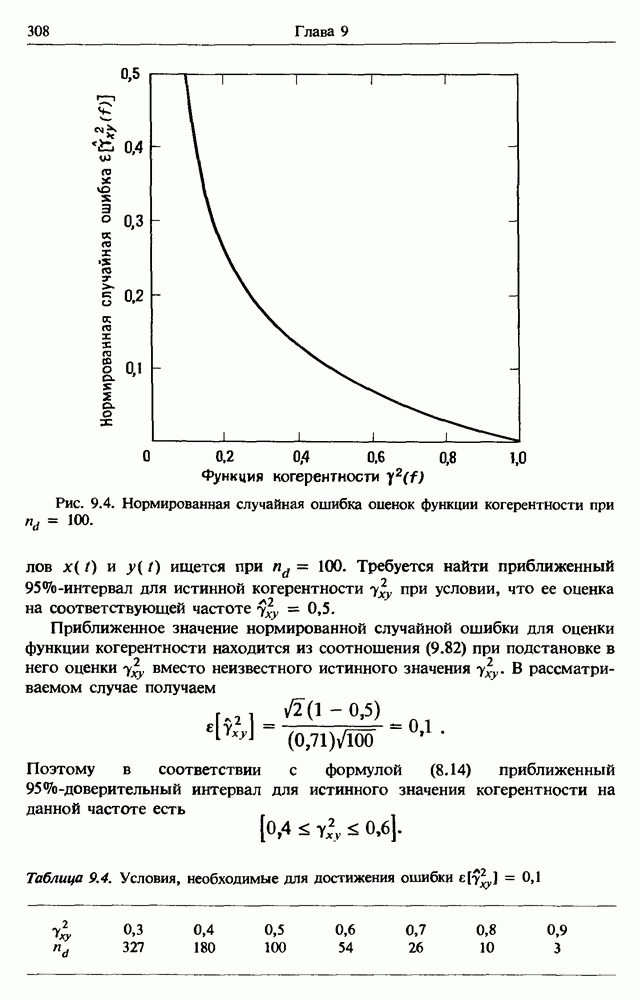
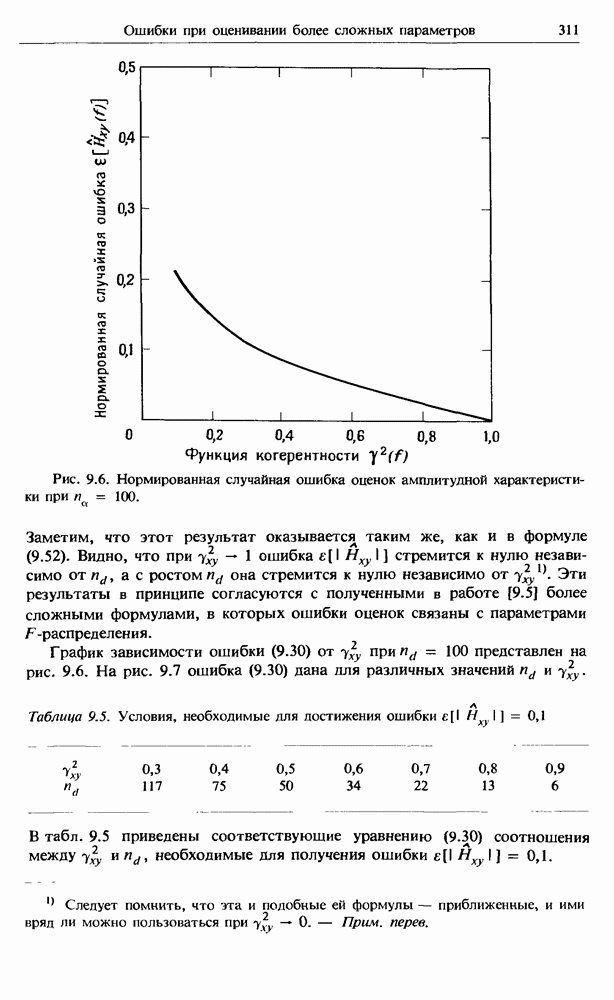
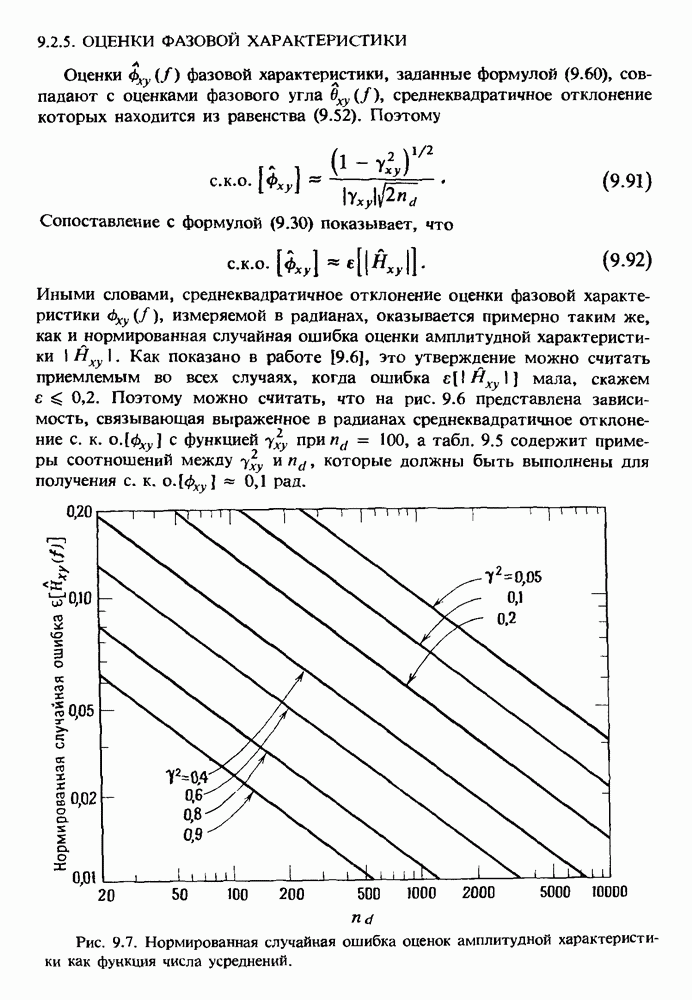
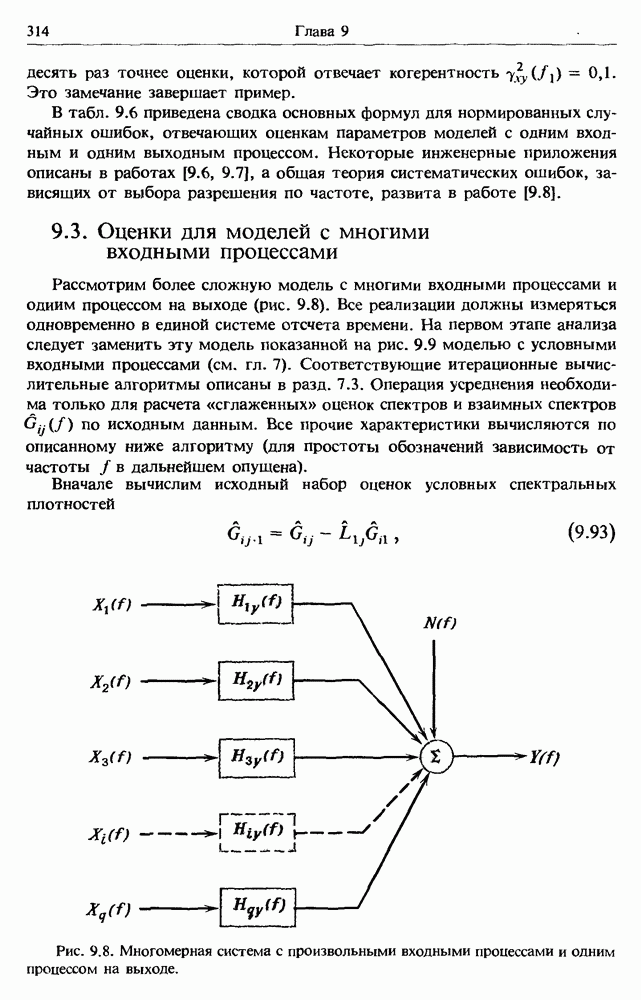
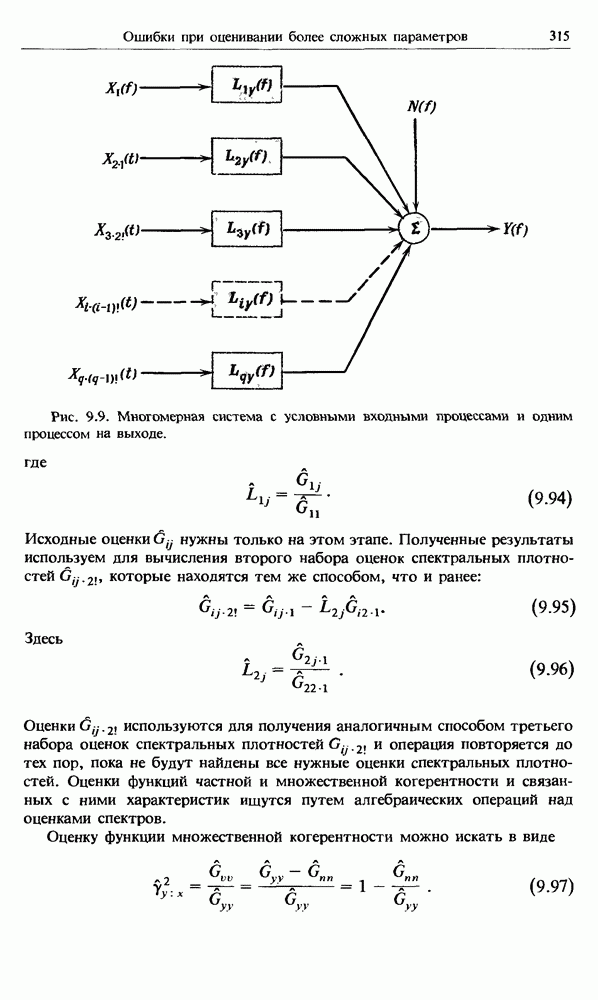
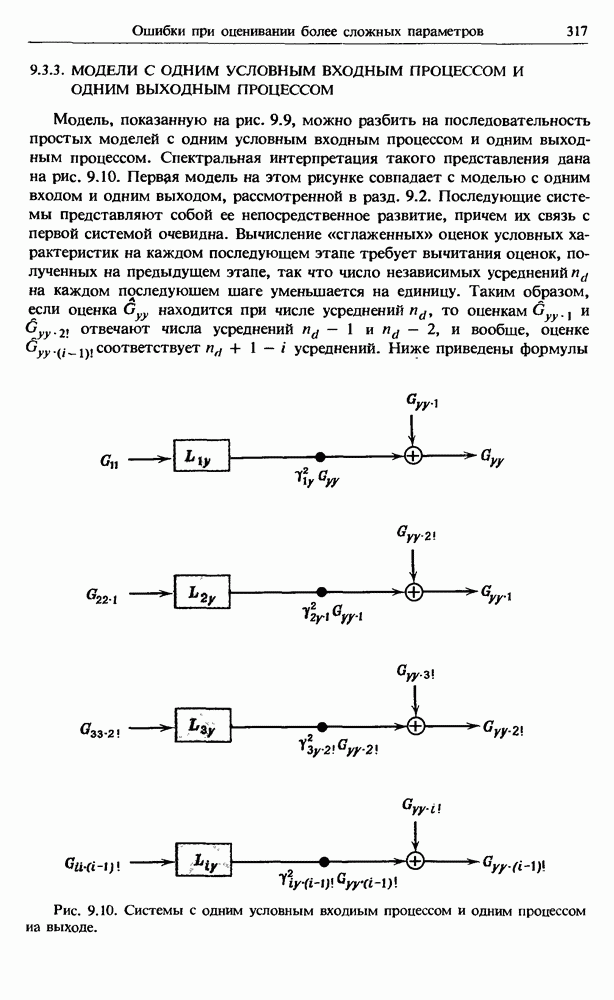
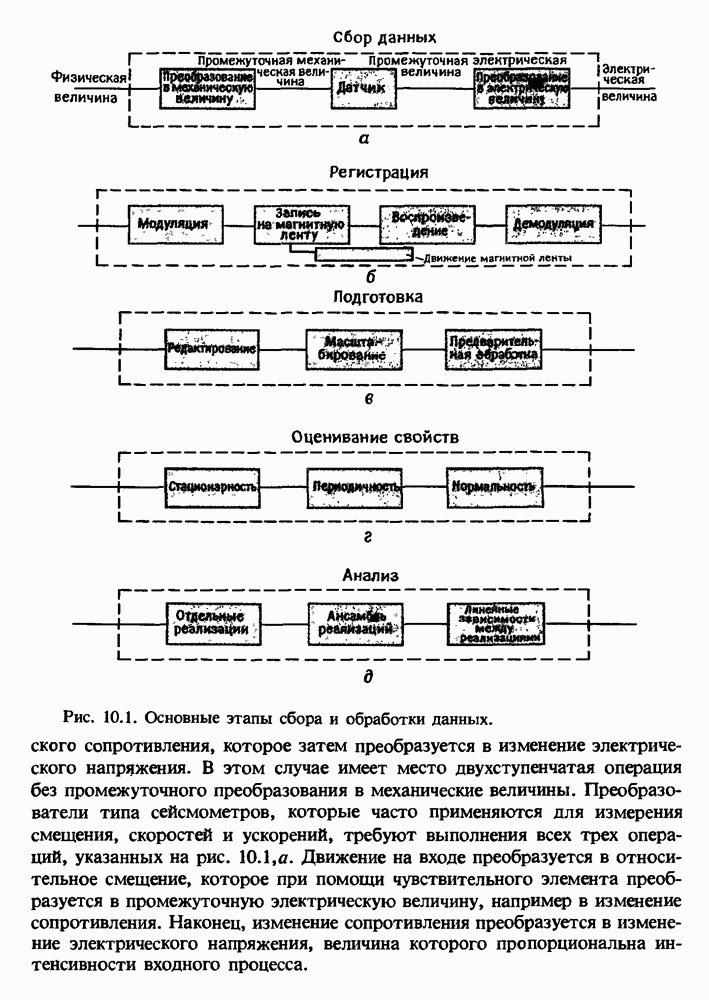
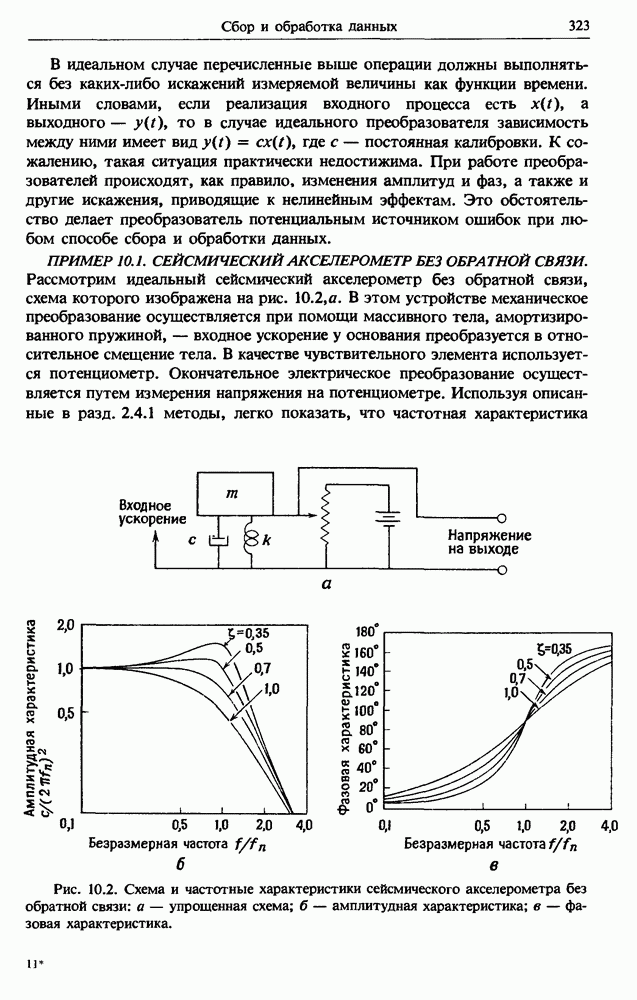
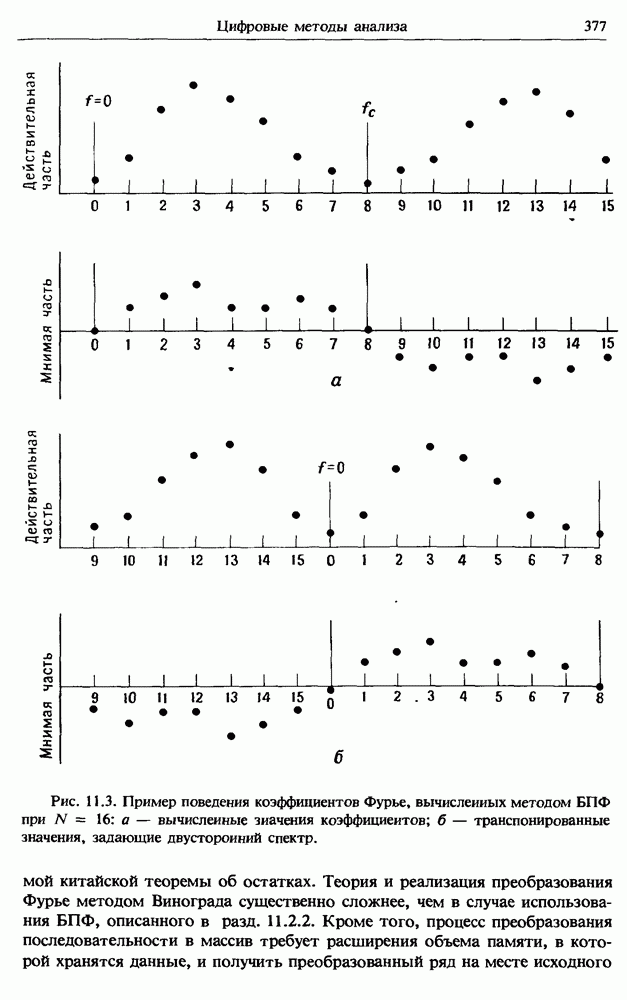
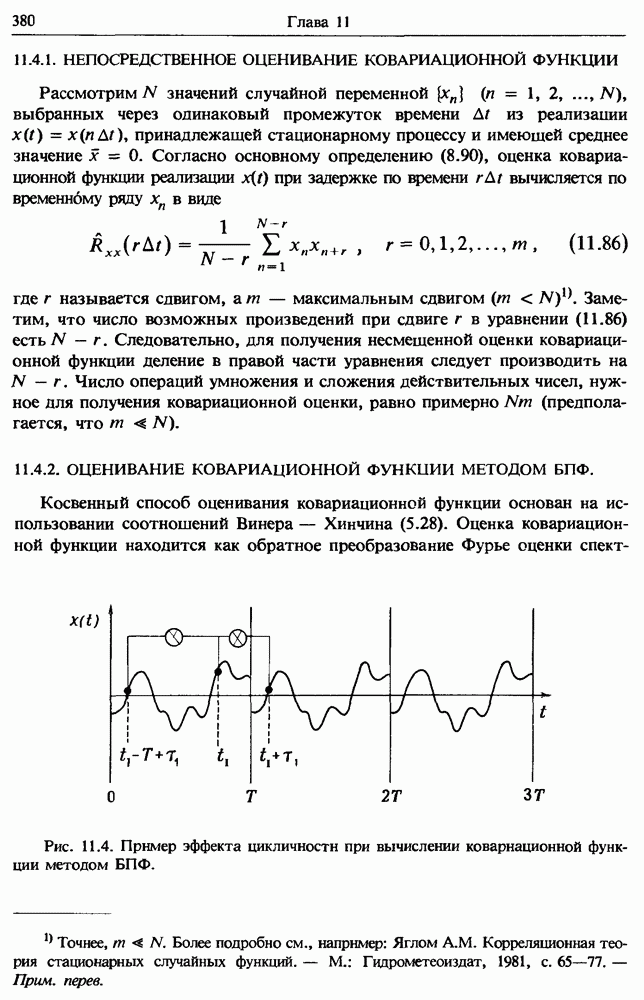
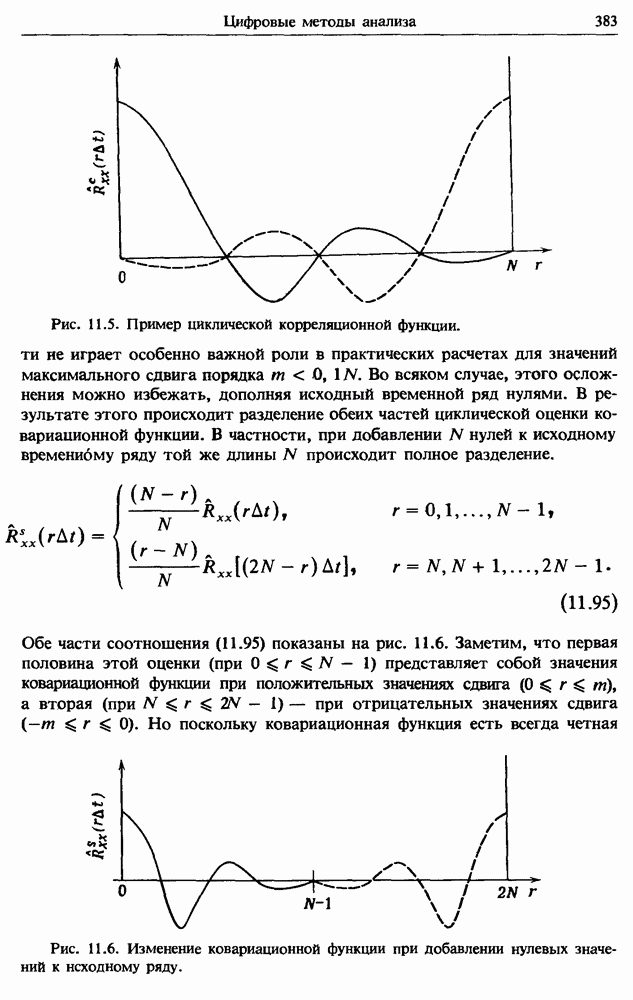
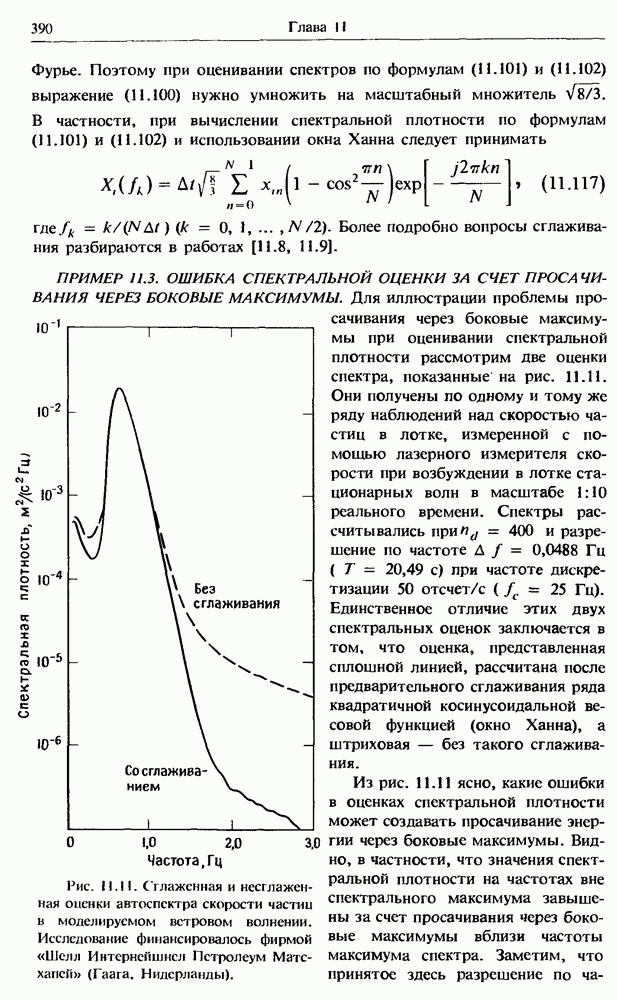
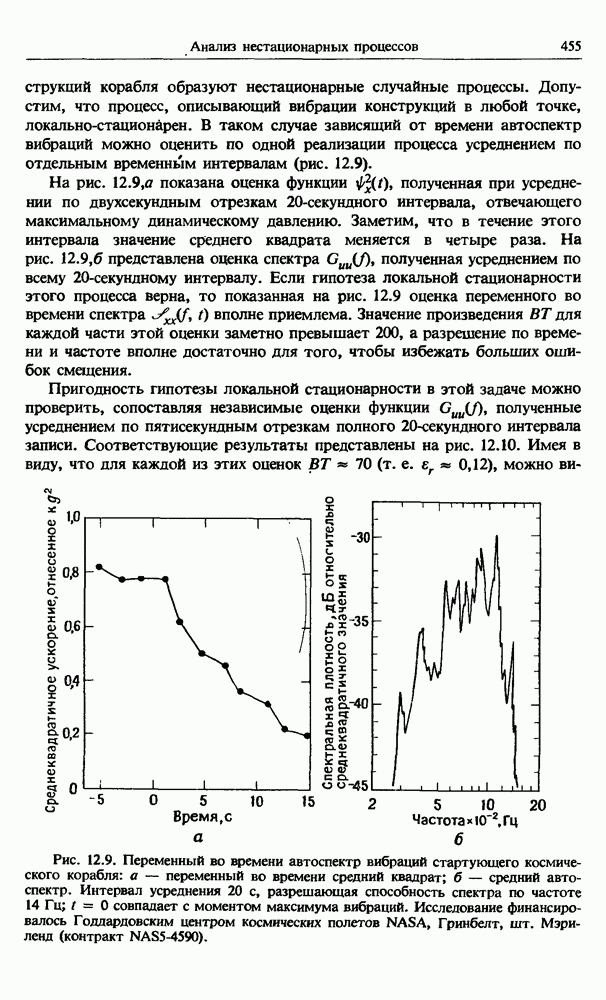
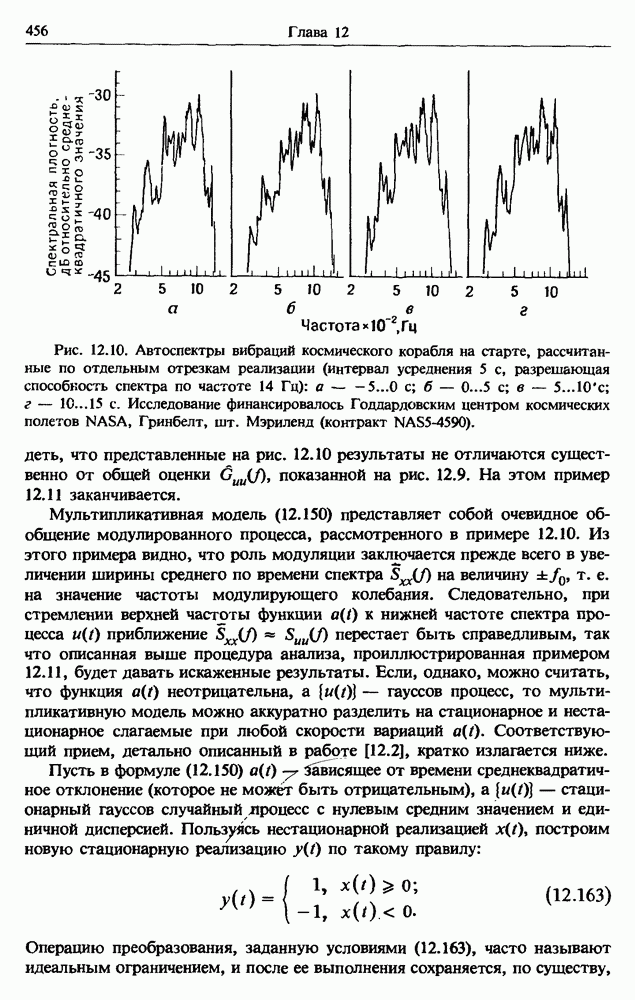
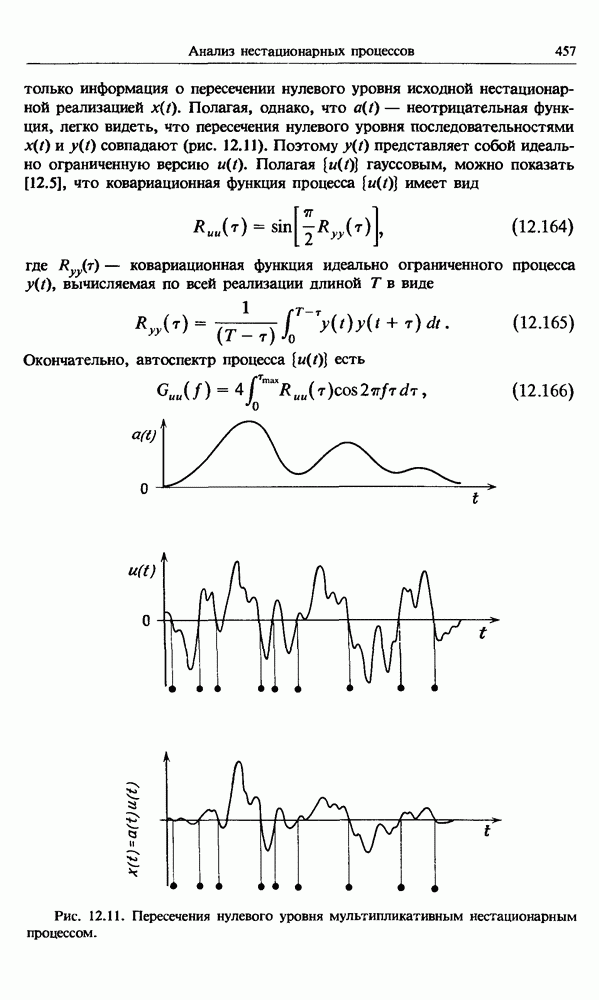
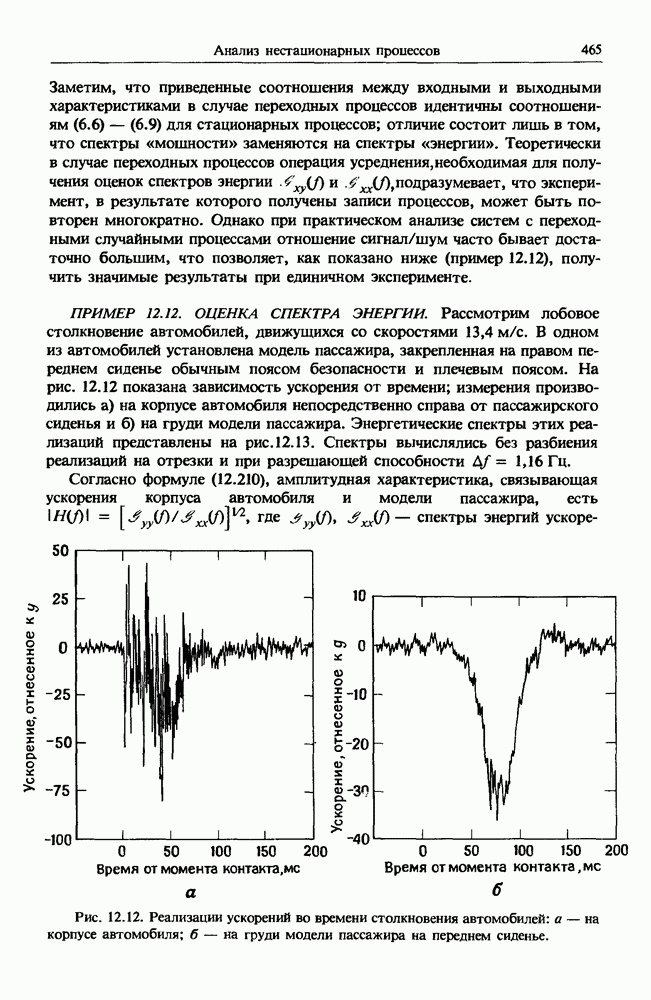
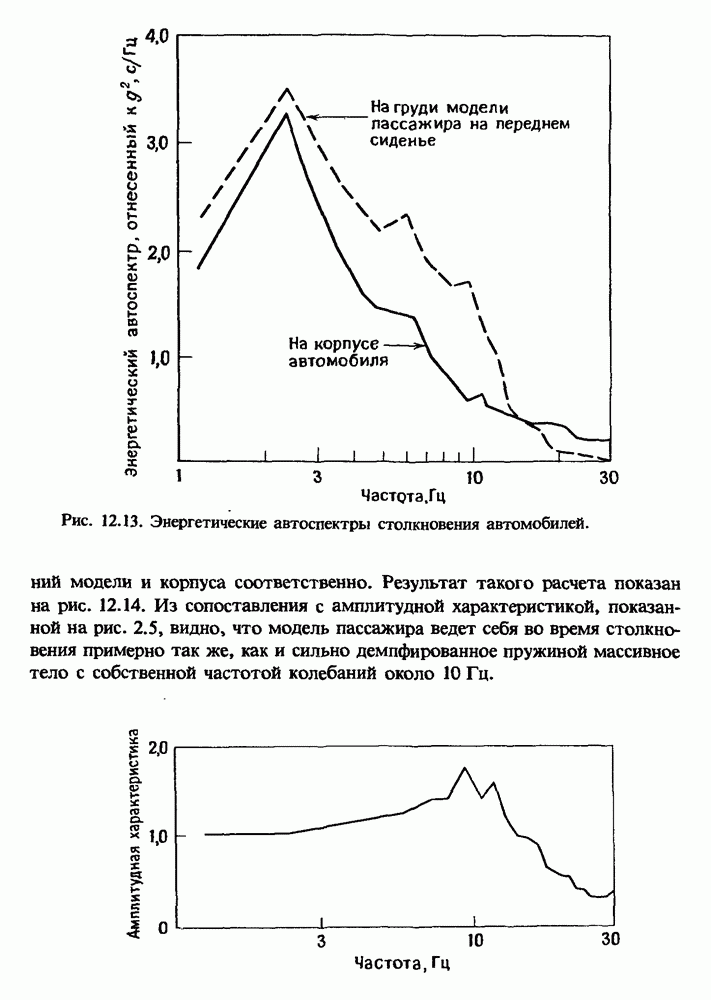
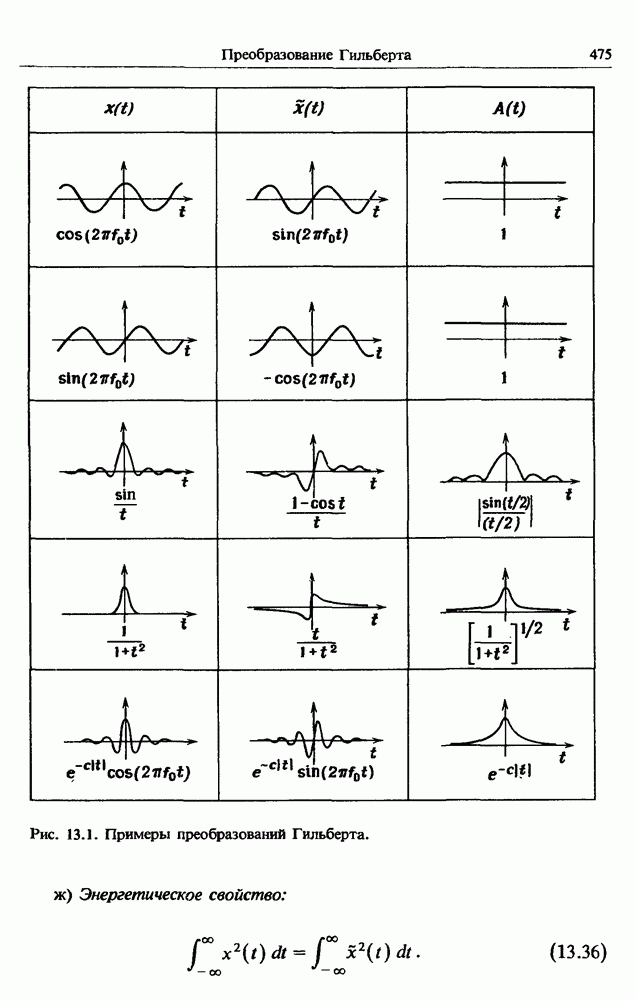
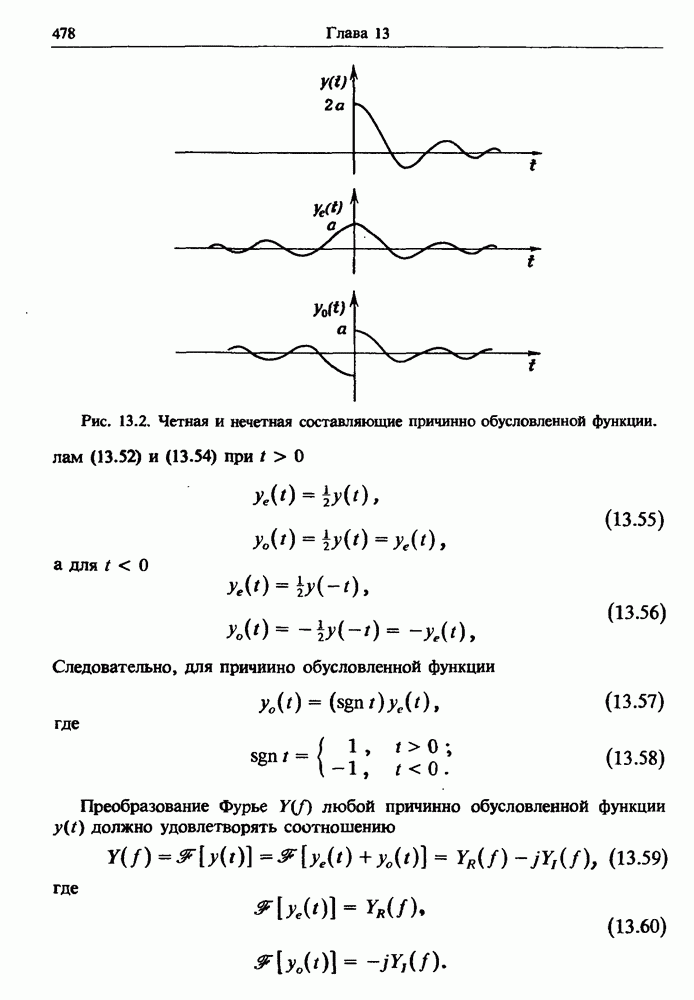
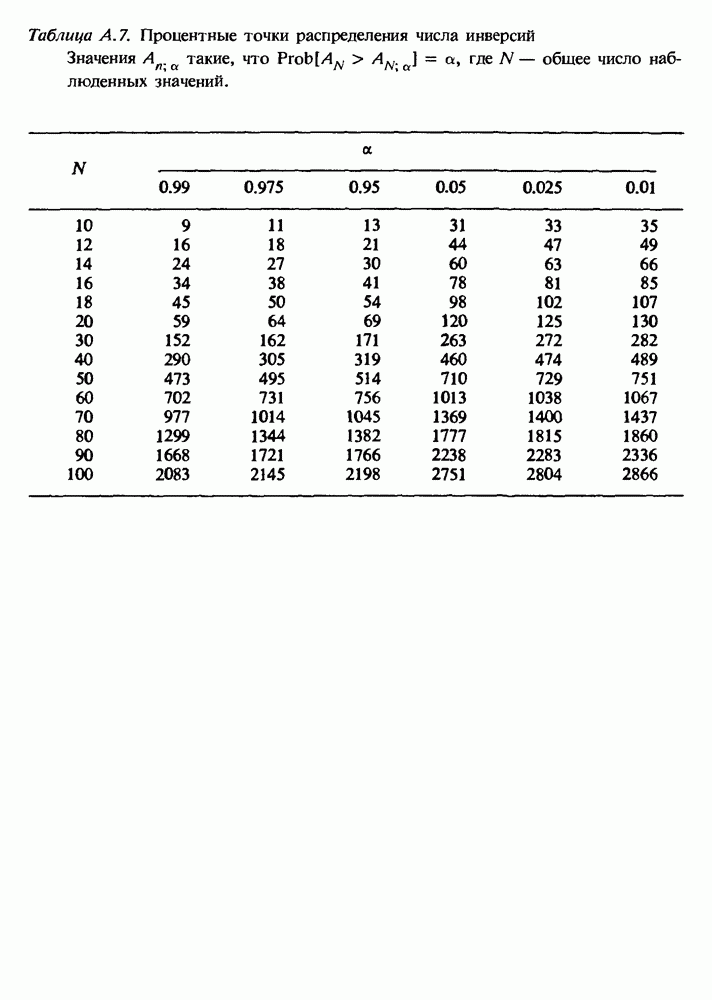
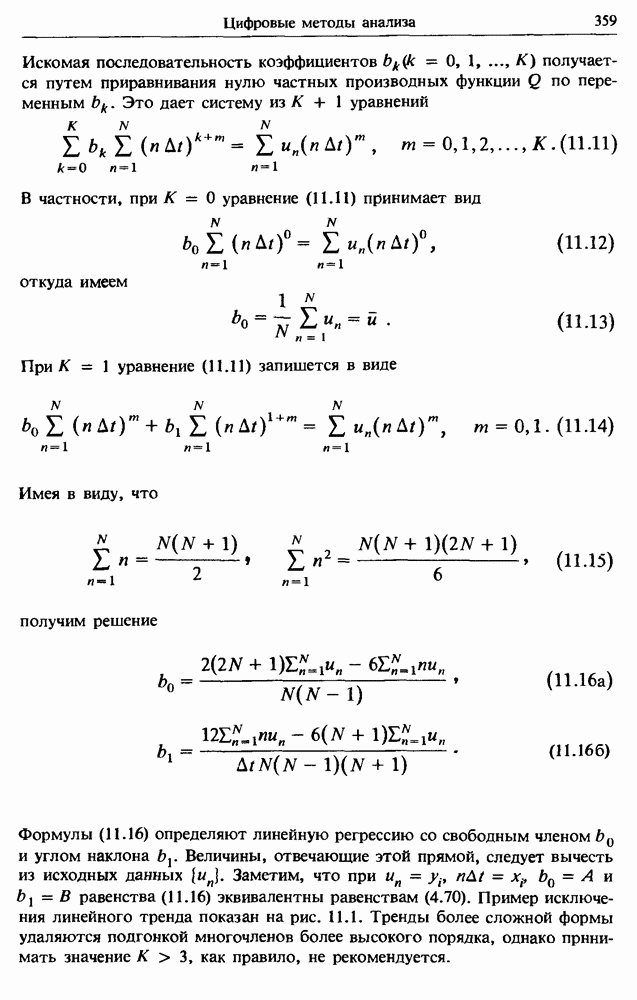Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
4.8.2. ЛИНЕЙНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
Корреляционный анализ позволяет установить степень взаимосвязи двух и более случайных величин. Однако наряду с этим желательно иметь модель этой связи, которая дала бы возможность предсказывать значения одной случайной величины по конкретным значениям другой. Например, корреляционный анализ данных из примера 4.6 установил значимую линейную связь между ростом и массой студентов. Логичен следующий шаг: конкретизировать эту связь так, чтобы по данному росту можно было бы предсказать массу студента. Методы решения подобных задач носят наименование «регрессионный анализ».
Рассмотрим простой случай двух коррелированных случайных величин  . В условиях примера 4.6 может быть ростом, а у — массой студента. Линейная связь между двумя случайными величинами означает, что прогноз значения величины по данному значению имеет вид
. В условиях примера 4.6 может быть ростом, а у — массой студента. Линейная связь между двумя случайными величинами означает, что прогноз значения величины по данному значению имеет вид

где  это соответственно отрезок оси ординат, отсекаемый прямой, и ее наклон. Если данные связаны идеальной линейной зависимостью
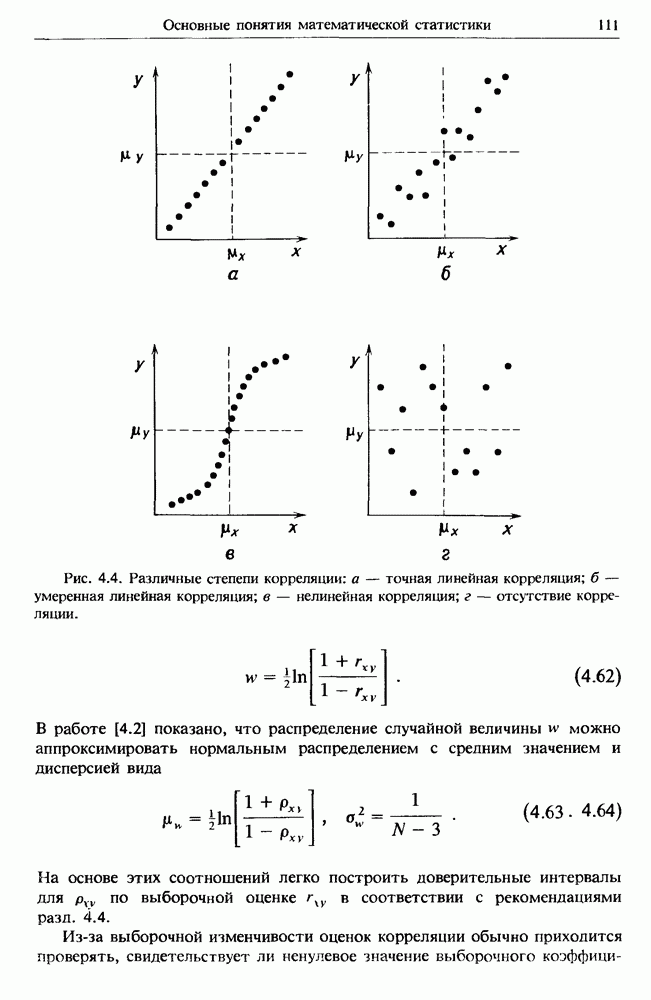
это соответственно отрезок оси ординат, отсекаемый прямой, и ее наклон. Если данные связаны идеальной линейной зависимостью  то предсказанное значение у, будет в точности равняться наблюденному значению у, при любом данном. Однако на практике обычно отсутствует идеальная линейная зависимость между данными. Как правило, внешние случайные воздействия приводят к разбросу данных, и, кроме того, возможны искажения за счет присутствия нелинейных эффектов (см. рис. 4.4). Тем не менее, если все же предположить существование линейной связи и наличие неограниченной выборки, то можно подобрать такие значения
то предсказанное значение у, будет в точности равняться наблюденному значению у, при любом данном. Однако на практике обычно отсутствует идеальная линейная зависимость между данными. Как правило, внешние случайные воздействия приводят к разбросу данных, и, кроме того, возможны искажения за счет присутствия нелинейных эффектов (см. рис. 4.4). Тем не менее, если все же предположить существование линейной связи и наличие неограниченной выборки, то можно подобрать такие значения  которые дадут возможность предсказать ожидаемое значение у, для любого данного. Это означает, что у, не обязательно совпадает с наблюденным значением
которые дадут возможность предсказать ожидаемое значение у, для любого данного. Это означает, что у, не обязательно совпадает с наблюденным значением  соответствующим данному, однако оно будет равно среднему значению всех таких наблюденных значений.
соответствующим данному, однако оно будет равно среднему значению всех таких наблюденных значений.
Общепринятая процедура определения коэффициентов уравнения (4.66) состоит в выборе таких значений  которые минимизируют сумму квадратов отклонений наблюденных значений от предсказанного значения
которые минимизируют сумму квадратов отклонений наблюденных значений от предсказанного значения
у. Эта процедура называется методом наименьших квадратов. Точнее, поскольку отклонения наблюденных значений от предсказанных равны

то сумма квадратов отклонений имеет вид

Следовательно, наилучшее согласие в смысле наименьших квадратов обеспечивают значения  для которых
для которых

На практике обычно имеется ограниченная выборка из  пар наблюденных значений и у. Это означает, что уравнение (4.69) даст всего лишь оценки
пар наблюденных значений и у. Это означает, что уравнение (4.69) даст всего лишь оценки  обозначим их через а и b соответственно. Подставляя (4.68) в уравнение (4.69) и решая его относительно оценок величин
обозначим их через а и b соответственно. Подставляя (4.68) в уравнение (4.69) и решая его относительно оценок величин  получим
получим

Эти оценки можно теперь использовать для построения модели, позволяющей предсказывать  по данному:
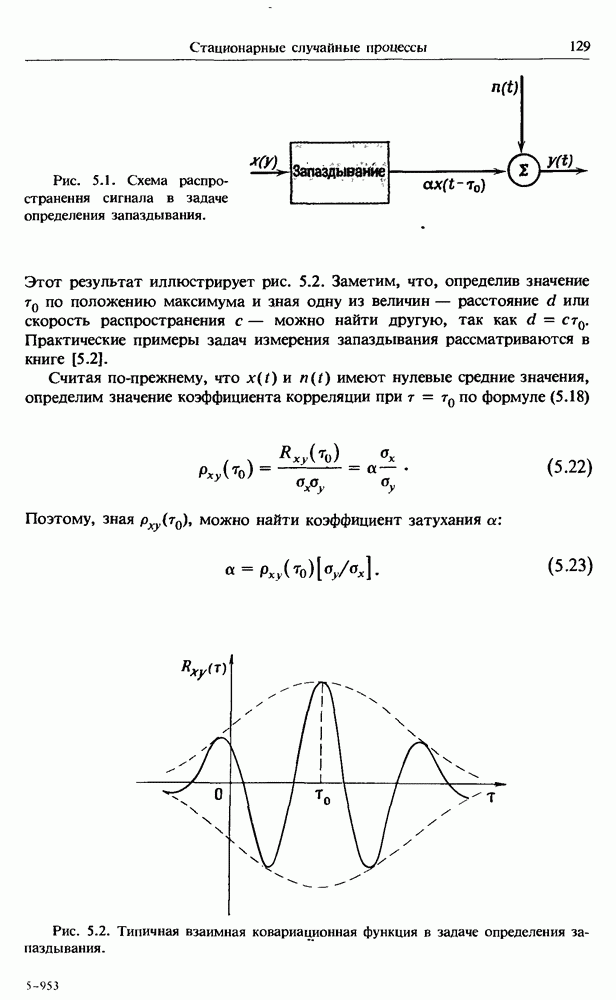
по данному:

Прямая линия, задаваемая уравнением (4.71), называется прямой линейной регрессии у на х. Поменяв ролями зависимую и независимую переменные в уравнении (4.70), получим прямую регрессии на у:

Сравнение произведения формул (4.706) и (4.73) с формулой (4.61) показывает, что наклоны прямых регрессии  на и на у связаны с выборочным
на и на у связаны с выборочным
коэффициентом корреляции соотношением

Займемся теперь точностью оценок а и  определенных формулами (4.70). Как показано в книге [4.2], в предположении нормальности распределения у при данном х оценки а и
определенных формулами (4.70). Как показано в книге [4.2], в предположении нормальности распределения у при данном х оценки а и  являются несмещенными оценками
являются несмещенными оценками  соответственно. Их выборочные распределения связаны с
соответственно. Их выборочные распределения связаны с  -распределением соотношениями
-распределением соотношениями

Особый интерес представляет выборочное распределение у при конкретном значении  Оно имеет вид
Оно имеет вид

В формулах  величина
величина  это выборочное стандартное отклонение наблюденного значения
это выборочное стандартное отклонение наблюденного значения  от предсказанного
от предсказанного  равное
равное

Приведенные выше соотношения дают возможность построить доверительные интервалы для  по оценкам
по оценкам 
ПРИМЕР 4.7. ЛИНЕЙНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ. Определим по данным, содержащимся в табл. 4.3 из примера 4.6, прямую регрессии, задающую линейный прогноз средней массы студента по его росту. Найдем также 95%-доверительный интервал для средней массы студентов, имеющих рост 178 см.
Пусть, как и в примере 4.6, х обозначает рост, а у — массу. Величины,
необходимые для определения наклона и отрезка, отсекаемого прямой на оси ординат, уже были вычислены в примере 4.6. Подставив  в формулы (4.70), найдем
в формулы (4.70), найдем

Следовательно, прямая регрессии, оценивающая среднюю массу студента по его росту, имеет вид

откуда для роста  см получаем массу
см получаем массу 
Для построения доверительного интервала для средней массы у по оценке  следует вычислить
следует вычислить  по формуле (4.78). С вычислительной точки зрения удобнее воспользоваться формулой
по формуле (4.78). С вычислительной точки зрения удобнее воспользоваться формулой

расчеты по которой можно упростить еще больше, заметив, что 

Подставив нужные значения в эти выражения, получим 

Тогда по формуле (4.77) 95%-доверительный интервал для средней массы студента, имеющего рост 178 см, имеет следующий вид:

На этом пример 4.7 заканчивается.
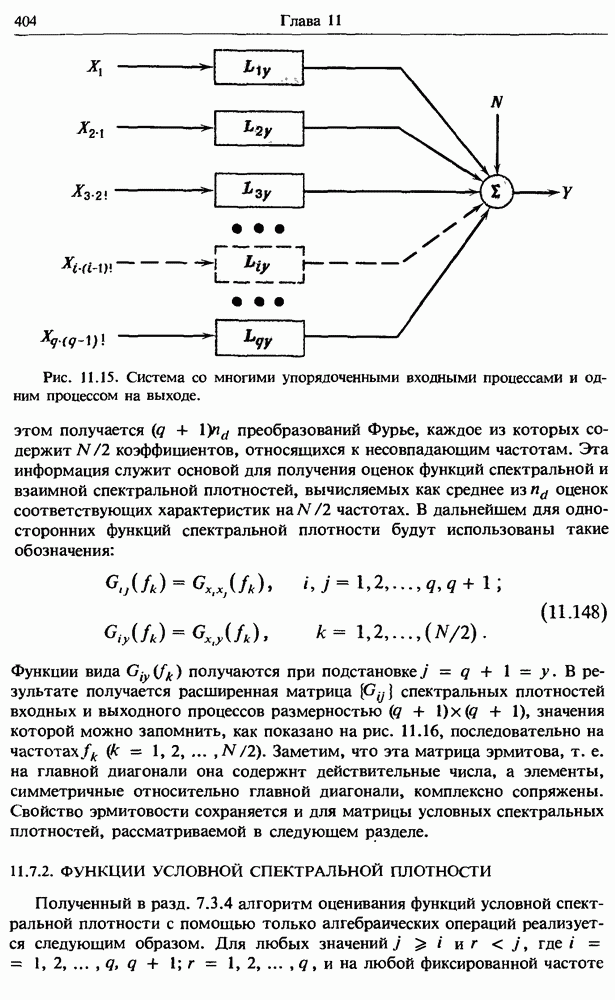
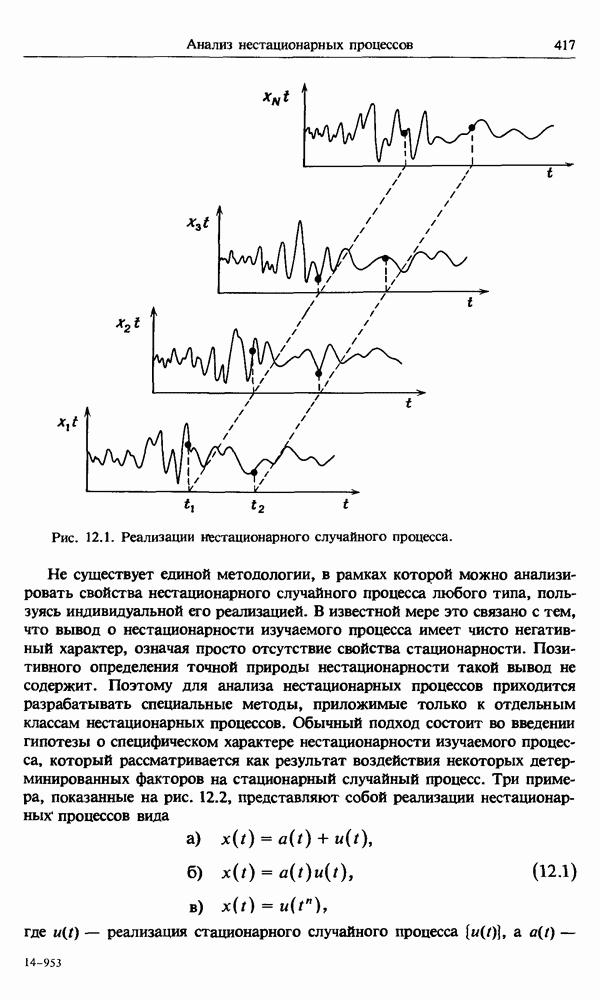
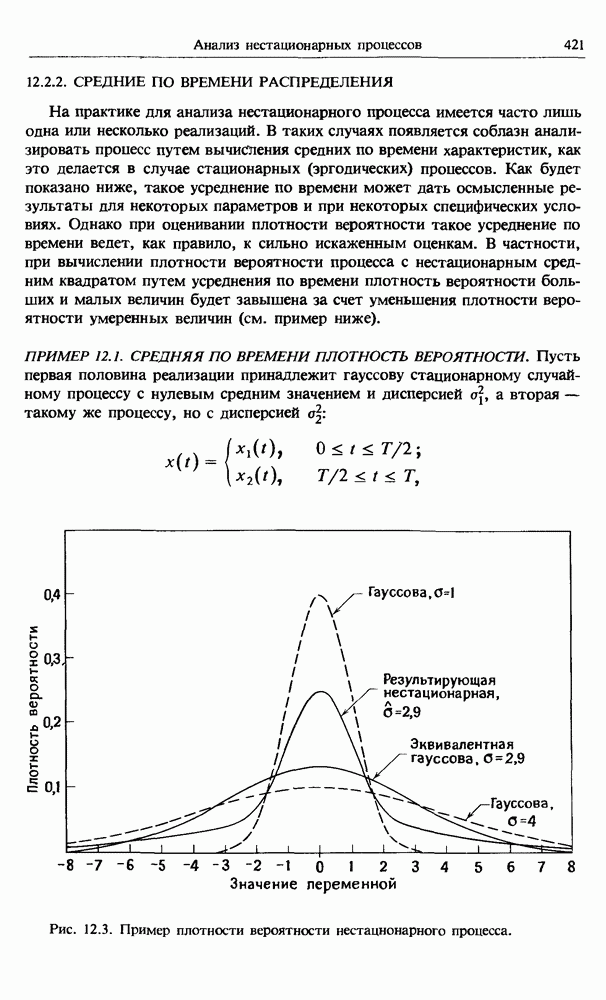
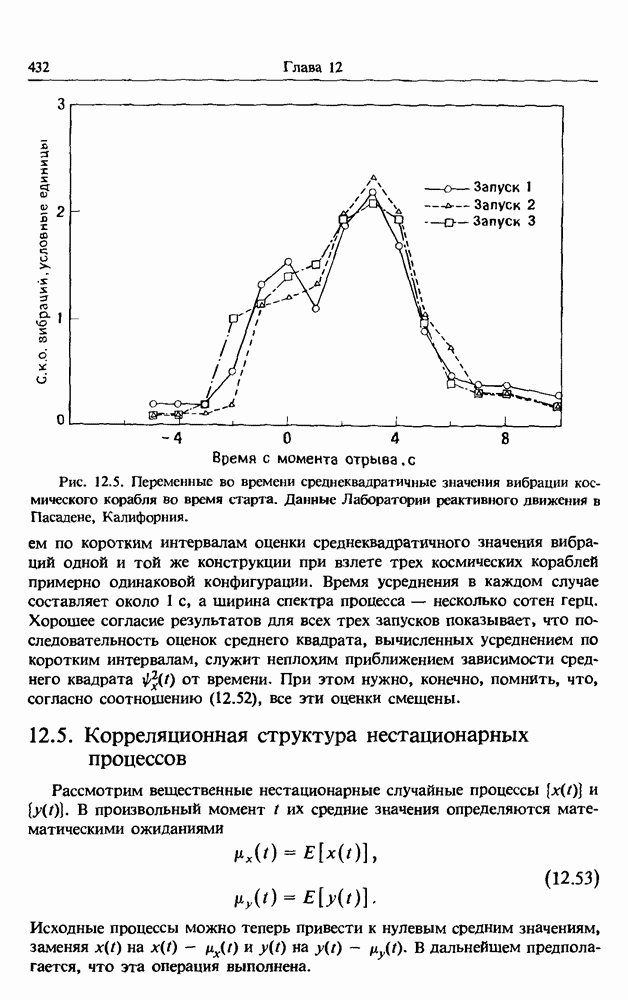
Описанные выше методы корреляционного и регрессионного анализа легко обобщаются на случай более двух случайных величин. Как указывалось ранее, такие обобщения играют фундаментальную роль в задачах анализа систем со многими входными и выходными процессами, изучаемых в
гл. 7. Поэтому дальнейшее обсуждение этого предмета откладывается до этой главы.
Задачи
(см. скан)